Неделя первой эвристики - видимость состояния системы
Про формат выше
Первая эвристика: The design should always keep users informed about what is going on, through appropriate feedback within a reasonable amount of time.
Вольный перевод - "пользователь может оперативно получить информацию о том, что происходит в системе, втч увидеть обратную связь на свои действия".
Трёхминутное видео Нильсена на тему, и хороший пример оттуда: при вызове лифта кнопка горит красным (фидбек, что мы вызвали его), а табло над лифтом показывает, что он начал движение, и находится на n-м этаже.
Накидывайте примеры)
Про формат выше
Первая эвристика: The design should always keep users informed about what is going on, through appropriate feedback within a reasonable amount of time.
Вольный перевод - "пользователь может оперативно получить информацию о том, что происходит в системе, втч увидеть обратную связь на свои действия".
Трёхминутное видео Нильсена на тему, и хороший пример оттуда: при вызове лифта кнопка горит красным (фидбек, что мы вызвали его), а табло над лифтом показывает, что он начал движение, и находится на n-м этаже.
Накидывайте примеры)
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
👍23❤8
Около месяца назад я анонсировал лето эвристик Нильсена, а потом пропал (спасибо тем 15 людям, что не отписались из чата за это время).
Я пропал, потому что тема показалась мне новичковой, и я застеснялся.
Как будто на литературной мастерской все обсуждают построение сюжетных арок и характера героев, а я вылез с историей про то, как новая клавиатура позволяет быстрее печатать. Здорово, конечно, но серьёзные специалисты обсуждают проблемы другого порядка.
Так что я застеснялся, что тема слишком базовая, и что в ней нет интеллектуальной претензии. Нет ни престижа новых областей (исследования в ML? Continuous research?) ни гордой бесполезности академических моделей.
Подзабытая, всем известная, пыльноватая тема.
Мне помог роман, который я сейчас читаю (рассечение Стоуна, хороший). В одном из эпизодов наставник главного героя, хирурга, заставляет его перевязывать узелки на хирургических швах. Узелки на швах - очень повседневная и всем известная вещь, но он прямо заморачивается над тем, как это важно.
Я не знаю, есть ли на самом деле прок в эвристиках, но давайте продолжим)
Я пропал, потому что тема показалась мне новичковой, и я застеснялся.
Как будто на литературной мастерской все обсуждают построение сюжетных арок и характера героев, а я вылез с историей про то, как новая клавиатура позволяет быстрее печатать. Здорово, конечно, но серьёзные специалисты обсуждают проблемы другого порядка.
Так что я застеснялся, что тема слишком базовая, и что в ней нет интеллектуальной претензии. Нет ни престижа новых областей (исследования в ML? Continuous research?) ни гордой бесполезности академических моделей.
Подзабытая, всем известная, пыльноватая тема.
Мне помог роман, который я сейчас читаю (рассечение Стоуна, хороший). В одном из эпизодов наставник главного героя, хирурга, заставляет его перевязывать узелки на хирургических швах. Узелки на швах - очень повседневная и всем известная вещь, но он прямо заморачивается над тем, как это важно.
Я не знаю, есть ли на самом деле прок в эвристиках, но давайте продолжим)
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
❤41🐳2
Вторая эвристика - соответствие между системой и реальным миром
Про формат выше
Как формулирует Нильсен: Systems should speak the users' language with familiar words, phrases, and concepts rather than system-oriented terms. Interfaces that follow real-world conventions and make information appear in a natural and logical order demonstrate empathy and acknowledgement for users.
Т.е.: система должна использовать понятный пользователью язык, и ещё должна использовать паттерны и конвенции реального мира.
Вот коротенькое видео на тему [Usability Heuristic 2: Match Between the System and the Real World (Video)](https://www.nngroup.com/videos/match-system-real-world/)
В изначальной статье Нильсена под "рельным миром" понимается "физический мир". И в такой трактовке эвристика кажется мне устаревшей, если честно. Немножко подробней в комментариях об этом напишу.
Про формат выше
Как формулирует Нильсен: Systems should speak the users' language with familiar words, phrases, and concepts rather than system-oriented terms. Interfaces that follow real-world conventions and make information appear in a natural and logical order demonstrate empathy and acknowledgement for users.
Т.е.: система должна использовать понятный пользователью язык, и ещё должна использовать паттерны и конвенции реального мира.
Вот коротенькое видео на тему [Usability Heuristic 2: Match Between the System and the Real World (Video)](https://www.nngroup.com/videos/match-system-real-world/)
В изначальной статье Нильсена под "рельным миром" понимается "физический мир". И в такой трактовке эвристика кажется мне устаревшей, если честно. Немножко подробней в комментариях об этом напишу.
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
❤13🔥5👍3
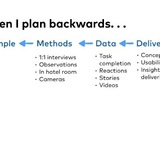
Как исследования экономят время разработки, и почему их лучше не разделять
Когда я только стал продактом, то думал, что будет примерно так: я буду исследовать клиентов и конкурентов, описывать требования, и отдавать разработке, а дальше оно всё будет разрабатываться само.
Короче, я буду отвечать за дискавери, а в деливери особо лезть не буду, там же уже есть проджект и тимлид. Так я на месяцы сорвал сроки запуска первых нескольких фичей.
Причин было несколько. Одна из них в том, что даже при хорошо описанных требованиях в процессе разработки возникает куча вопросов. Например:
- Как отрабатывать сообщения об ошибках? Допустим, какая-то форма может не работать по каким-то двум причинам. Вы можете вывести в тексте ошибки универсальный текст "не работает из-за причины x или y" или разработать штуку, коротая определяет, какая именно ошибка случилась, и выводит специфический текст (это доп. время разработки)
- Или если есть маловероятная ошибка, обрабатывать ли её? Например, "если новый пользователь является полным однофамильцем существующего, система не может его зарегистрировать". Мы хотим ли мы что-то с этим делать, или забиваем? (если хотим, то это доп. время разработки)
- А какую нужно закладывать гибкость на следующие итерации? Например, вы решили добавить пуш уведомления. А вы захотите потом историю пуш уведомлений, надо их хранить? А вдруг захотите потом кроме пушей сделать уведомления в вацап и смс, нужен какой-то единый центр нотификаций, и возможность добавлять каналы? (+время разработки)
- А вот вы хотите выводить список каких-нибудь сущностей. Надо сделать паджинацию списка на всякий случай? Вдруг сущностей будет больше ста? (+время разработки)
Часть таких вопросов можно продумать заранее, а часть нет - какие-то ограничения не видны до начала разработки, про какие-то технические возможности вы не знаете. Вопросы возникают по ходу.
Если их не отслеживать, можете оказаться в ситуации, когда в продукте закладывается ненужная гибкость, прорабатываются нерелевантные сценарии, и сроки съезжают. Так было у меня.
Спустя время я стал больше погружаться, и давать команде больше контекста по ходу работы, в том числе более явно подсвечивать, что важно делать, а куда погружаться не критично. И стал уточнять требования по ходу, по результатам исследований и аналитики.
Я сделал из этой истории несколько выводов (мб чуть тривиальных, но прожитых с опытом):
1. Что погружение продуктовой команды в сценарии и потребности пользователей позволяет экономить время в процессе разработки, отсекая неважные направления (раньше думал только с точки зрения ценности, а про сроки - нет).
2. Что погружение это нужно не только на старте (вот юзкейсы, вот сценарии, вот jtbd, поехали) а постоянно в процессе работы, т.к. всё время возникает много маленьких вопросов, о которых на берегу никто не подумал.
3. Что погружение должно быть push, а не pull, т.е. разработчик/дизайнер не всегда приходит с вопросом "не знаю, делать ли тут паджинацию, давайте в аналитике посмотрим, сколько тут может быть сущностей". Надо самому отлавливать такие точки принятия решений и закрывать их данным. Ну и учить команду замечать их, конечно.
4. Что из-за вот этих микровопросов и микроконтекстов очень важен быстрый доступ к знаниям о пользователе. В любом формате: продуктовая аналитика, continuous research, база инсайтов, user board, накопленная за счёт наблюдений экспертиза - нужен способ получить быстрый и относительно верный ответ на точечный вопрос.
5. Я сформулировал для себя идею сценарной/UX устойчивости напишу о ней чуть позже.
Когда я только стал продактом, то думал, что будет примерно так: я буду исследовать клиентов и конкурентов, описывать требования, и отдавать разработке, а дальше оно всё будет разрабатываться само.
Короче, я буду отвечать за дискавери, а в деливери особо лезть не буду, там же уже есть проджект и тимлид. Так я на месяцы сорвал сроки запуска первых нескольких фичей.
Причин было несколько. Одна из них в том, что даже при хорошо описанных требованиях в процессе разработки возникает куча вопросов. Например:
- Как отрабатывать сообщения об ошибках? Допустим, какая-то форма может не работать по каким-то двум причинам. Вы можете вывести в тексте ошибки универсальный текст "не работает из-за причины x или y" или разработать штуку, коротая определяет, какая именно ошибка случилась, и выводит специфический текст (это доп. время разработки)
- Или если есть маловероятная ошибка, обрабатывать ли её? Например, "если новый пользователь является полным однофамильцем существующего, система не может его зарегистрировать". Мы хотим ли мы что-то с этим делать, или забиваем? (если хотим, то это доп. время разработки)
- А какую нужно закладывать гибкость на следующие итерации? Например, вы решили добавить пуш уведомления. А вы захотите потом историю пуш уведомлений, надо их хранить? А вдруг захотите потом кроме пушей сделать уведомления в вацап и смс, нужен какой-то единый центр нотификаций, и возможность добавлять каналы? (+время разработки)
- А вот вы хотите выводить список каких-нибудь сущностей. Надо сделать паджинацию списка на всякий случай? Вдруг сущностей будет больше ста? (+время разработки)
Часть таких вопросов можно продумать заранее, а часть нет - какие-то ограничения не видны до начала разработки, про какие-то технические возможности вы не знаете. Вопросы возникают по ходу.
Если их не отслеживать, можете оказаться в ситуации, когда в продукте закладывается ненужная гибкость, прорабатываются нерелевантные сценарии, и сроки съезжают. Так было у меня.
Спустя время я стал больше погружаться, и давать команде больше контекста по ходу работы, в том числе более явно подсвечивать, что важно делать, а куда погружаться не критично. И стал уточнять требования по ходу, по результатам исследований и аналитики.
Я сделал из этой истории несколько выводов (мб чуть тривиальных, но прожитых с опытом):
1. Что погружение продуктовой команды в сценарии и потребности пользователей позволяет экономить время в процессе разработки, отсекая неважные направления (раньше думал только с точки зрения ценности, а про сроки - нет).
2. Что погружение это нужно не только на старте (вот юзкейсы, вот сценарии, вот jtbd, поехали) а постоянно в процессе работы, т.к. всё время возникает много маленьких вопросов, о которых на берегу никто не подумал.
3. Что погружение должно быть push, а не pull, т.е. разработчик/дизайнер не всегда приходит с вопросом "не знаю, делать ли тут паджинацию, давайте в аналитике посмотрим, сколько тут может быть сущностей". Надо самому отлавливать такие точки принятия решений и закрывать их данным. Ну и учить команду замечать их, конечно.
4. Что из-за вот этих микровопросов и микроконтекстов очень важен быстрый доступ к знаниям о пользователе. В любом формате: продуктовая аналитика, continuous research, база инсайтов, user board, накопленная за счёт наблюдений экспертиза - нужен способ получить быстрый и относительно верный ответ на точечный вопрос.
5. Я сформулировал для себя идею сценарной/UX устойчивости напишу о ней чуть позже.
👍32❤16
Всё встраивают ИИ (LLM) в свои продукты, и я тоже буду.
Интересно, что пространство решений +- понятно (даём пользователю в нужном контексте задать промпт и получить ответ), а вот пространство проблем (куда можно такое взаимодействие приткнуть) очень большое.
Составил для себя набор шагов, по которым пойду, поделюсь:
1. Составить список "работ", которые может закрывать LLM, не в моём продукте, а вообще. Этот список примерно понятен, соберу его из личного опыта и наблюдения за другими продуктами, погуглю.
2. Происследовать, в каких контекстах при взаимодействии с моим продуктом эти работы возникают (интервью, опрос, мб просто task analysis даже. Скорее на интервью остановлюсь)
3. Проскорить, какие из задач наиболее полезно упростить через LLM. Тут может быть любой подход для ранжирования: Кано, опросник TAM, всякие concept validation опросики. Вероятно, на входе буду давать либо описания на пару строк, либо статичные макеты (кажется, базовое взаимодействие с LLM уже понятно, и можно не прототипировать прямо жёстко, но будет понятней после интервью). Можно сделать дневниковое и попросить пользователей поиспользовать LLM для типичных задач недельку, и потом опросить про полезность. Ну не знаю.
4. Предсказательная сила у таких опросов низкая. Это способ отбросить очевидных аутсайдеров, или выявить лидеров настолько явных, что мы можем доверять их лидерству даже на метрике со слабой валидностью. Жду что отсеятся слабые варианты, а из сильных придётся выбирать финалиста самому :)
5. Можно ещё опросить, несколько часто и для каких задач пользователи уже используют LLM, и отскорить по этому признаку. Вроде идея норм, но не хочется почему-то, не интересно (ну и тут явный скос в early adopter-ов)
6. Вот и всё. Надеюсь, всё это позволит мне а)не делать совсем ерунду б)отойти от прямого копирования конкурентов
А есть, ещё два момента:
1. Это может быть эмоционально заряженной фичой, т.е. есть шанс, что кто-то из разработки будет готов запилить первую версию на коленке за выходные ради веселья. И в этом случае "давайте сначала поисследуем потребности" может обломать изначальный кураж, и бонус "фича бесплатно" я потеряю (мотивация команды разработки - отдельная большая тема. Я знаю, что интерес очень влияет и на сроки, и на качество разработки, и что исследованиями можно и разжигать этот интерес, показывая смысл и ценность продукта, и гасить, превращая всё в болото. Но пока я не очень хорош в этом, разберусь, напишу пост).
2. Это может быть политически заряженной фичой, т.е. может быть её нужно выпустить за две недели, чтобы получить PR повод "первая в мире штучка с ИИ", или получить доп инвестиции, или чтобы у продаж был классные слайд в презе для роста конверсии из первой встречи Это потёмкинские деревни, когда нужно быстро сделать для галочки, а уже потом союз будет сделать нормально. Я такое не очень люблю, но такой контекст случается. К счастью, у меня сейчас не так)
Интересно, что пространство решений +- понятно (даём пользователю в нужном контексте задать промпт и получить ответ), а вот пространство проблем (куда можно такое взаимодействие приткнуть) очень большое.
Составил для себя набор шагов, по которым пойду, поделюсь:
1. Составить список "работ", которые может закрывать LLM, не в моём продукте, а вообще. Этот список примерно понятен, соберу его из личного опыта и наблюдения за другими продуктами, погуглю.
2. Происследовать, в каких контекстах при взаимодействии с моим продуктом эти работы возникают (интервью, опрос, мб просто task analysis даже. Скорее на интервью остановлюсь)
3. Проскорить, какие из задач наиболее полезно упростить через LLM. Тут может быть любой подход для ранжирования: Кано, опросник TAM, всякие concept validation опросики. Вероятно, на входе буду давать либо описания на пару строк, либо статичные макеты (кажется, базовое взаимодействие с LLM уже понятно, и можно не прототипировать прямо жёстко, но будет понятней после интервью). Можно сделать дневниковое и попросить пользователей поиспользовать LLM для типичных задач недельку, и потом опросить про полезность. Ну не знаю.
4. Предсказательная сила у таких опросов низкая. Это способ отбросить очевидных аутсайдеров, или выявить лидеров настолько явных, что мы можем доверять их лидерству даже на метрике со слабой валидностью. Жду что отсеятся слабые варианты, а из сильных придётся выбирать финалиста самому :)
5. Можно ещё опросить, несколько часто и для каких задач пользователи уже используют LLM, и отскорить по этому признаку. Вроде идея норм, но не хочется почему-то, не интересно (ну и тут явный скос в early adopter-ов)
6. Вот и всё. Надеюсь, всё это позволит мне а)не делать совсем ерунду б)отойти от прямого копирования конкурентов
А есть, ещё два момента:
1. Это может быть эмоционально заряженной фичой, т.е. есть шанс, что кто-то из разработки будет готов запилить первую версию на коленке за выходные ради веселья. И в этом случае "давайте сначала поисследуем потребности" может обломать изначальный кураж, и бонус "фича бесплатно" я потеряю (мотивация команды разработки - отдельная большая тема. Я знаю, что интерес очень влияет и на сроки, и на качество разработки, и что исследованиями можно и разжигать этот интерес, показывая смысл и ценность продукта, и гасить, превращая всё в болото. Но пока я не очень хорош в этом, разберусь, напишу пост).
2. Это может быть политически заряженной фичой, т.е. может быть её нужно выпустить за две недели, чтобы получить PR повод "первая в мире штучка с ИИ", или получить доп инвестиции, или чтобы у продаж был классные слайд в презе для роста конверсии из первой встречи Это потёмкинские деревни, когда нужно быстро сделать для галочки, а уже потом союз будет сделать нормально. Я такое не очень люблю, но такой контекст случается. К счастью, у меня сейчас не так)
❤6🔥3
Что мы создаём? Что я создаю как продакт, как исследователь?
Один из ответов (скорее поэтический, чем практически применимый) - мы создаём поведение.
IT это способ создавать или масштабировать поведение людей - новые способы покупать, тратить, учиться, разговаривать, и запоминать.
(На самом деле не само поведение, а среду, которая делает определенное поведение более притягательным, снижая барьеры и подключая триггеры)
В целом это тривиально, можно так сказать про что угодно - "Макдональдс создаёт не бургеры, а поведение по их покупке" или "Найк создаёт культуру бега, а не кросы". Это схоластика, такая же, как и "мы создаём пользовательский опыт".
Отчасти да. Но разница в том, что Найк замеряет количество проданных кроссовок, а не количество километров, которые в них пробежали.
В противовес, IT продукты (SAAS особенно) отслеживают само поведение: количество транзакций в магазинах, сражений в играх, мэтчей и переписок в дэйтинге. Не количество отрисованных экранов или строчек кода.
Поведенческие метрики, а не приложенческие.
Это немного сдвигает фокус. Например, задача Хедспейса - сделать так, чтобы люди больше медитировали, и дольше платили за подписку, а Эйрбнб - увеличить количество путешествий с проживанием вне отелей. Хорошее приложение - возможный способ, но не обязательный.
Хорошо. Так какое поведение мы создаём?
У Влада Головача в одной из книг (золотой батон?) было разделение дизайна на "дизайн чтобы дороже" (упрощённо - дизайн для создания доп ценности) и "дизайн чтобы дешевле" (дизайн для удешевления текущей ценности).
По аналогии можно разделить наши продукты на "продукты, чтобы упростить поведение" и "продукты, чтобы создать поведение".
"Продукт чтобы упростить" облегчает действия, которые мы уже совершаем. Быстрее заказ, проще оплата, проще выбор, быстрее доставка. Один клик вместо десятка. Еком в большинстве случаев про это - упросить выбор, заказ, и получение товара. CRM облегчает ведение дел с клиентами.
"Продукт чтобы создать" - открывает для нас новые сценарии, что-то, что мы не могли делать раньше, а теперь можем.
Анализ текста математическими методами, планирование сложных путешествий, новые форматы групповой работы.
В большинстве случаев это одни и те же решения.
Убер упростил поездки на такси для одних, и сделал в принципе возможным/доступным для других.
Инструменты для разметки интервью (dovetail, considerly, и другие) меняют поведение исследователей, упрощая практику дотошного анализа интервью, тем самым создавая её для тех, кто раньше заморачивался, или облегчая для тех, кто раньше кодировал всё руками.
В таком ракурсе у работы появляется более социальное, гуманитарное измерение.
"Я создал такой продукт, что такие-то люди стали чаще вести себя таким-то образом, иначе делать свою работу, иначе планировать свой день".
Один из ответов (скорее поэтический, чем практически применимый) - мы создаём поведение.
IT это способ создавать или масштабировать поведение людей - новые способы покупать, тратить, учиться, разговаривать, и запоминать.
(На самом деле не само поведение, а среду, которая делает определенное поведение более притягательным, снижая барьеры и подключая триггеры)
В целом это тривиально, можно так сказать про что угодно - "Макдональдс создаёт не бургеры, а поведение по их покупке" или "Найк создаёт культуру бега, а не кросы". Это схоластика, такая же, как и "мы создаём пользовательский опыт".
Отчасти да. Но разница в том, что Найк замеряет количество проданных кроссовок, а не количество километров, которые в них пробежали.
В противовес, IT продукты (SAAS особенно) отслеживают само поведение: количество транзакций в магазинах, сражений в играх, мэтчей и переписок в дэйтинге. Не количество отрисованных экранов или строчек кода.
Поведенческие метрики, а не приложенческие.
Это немного сдвигает фокус. Например, задача Хедспейса - сделать так, чтобы люди больше медитировали, и дольше платили за подписку, а Эйрбнб - увеличить количество путешествий с проживанием вне отелей. Хорошее приложение - возможный способ, но не обязательный.
Хорошо. Так какое поведение мы создаём?
У Влада Головача в одной из книг (золотой батон?) было разделение дизайна на "дизайн чтобы дороже" (упрощённо - дизайн для создания доп ценности) и "дизайн чтобы дешевле" (дизайн для удешевления текущей ценности).
По аналогии можно разделить наши продукты на "продукты, чтобы упростить поведение" и "продукты, чтобы создать поведение".
"Продукт чтобы упростить" облегчает действия, которые мы уже совершаем. Быстрее заказ, проще оплата, проще выбор, быстрее доставка. Один клик вместо десятка. Еком в большинстве случаев про это - упросить выбор, заказ, и получение товара. CRM облегчает ведение дел с клиентами.
"Продукт чтобы создать" - открывает для нас новые сценарии, что-то, что мы не могли делать раньше, а теперь можем.
Анализ текста математическими методами, планирование сложных путешествий, новые форматы групповой работы.
В большинстве случаев это одни и те же решения.
Убер упростил поездки на такси для одних, и сделал в принципе возможным/доступным для других.
Инструменты для разметки интервью (dovetail, considerly, и другие) меняют поведение исследователей, упрощая практику дотошного анализа интервью, тем самым создавая её для тех, кто раньше заморачивался, или облегчая для тех, кто раньше кодировал всё руками.
В таком ракурсе у работы появляется более социальное, гуманитарное измерение.
"Я создал такой продукт, что такие-то люди стали чаще вести себя таким-то образом, иначе делать свою работу, иначе планировать свой день".
🔥30👍7❤5
Наткнулся на совершенно новый для меня способ думать об эффективности исследований (и в целом продуктовых подходов).
В медицинских исследованиях есть два способа оценивать эффективность лекарств.
Есть эффективность "per protocol" (PP), когда при оценке лекарства смотрят только на тех пациентов, которые строго следовали указанному протоколу лечения - частоте, дозировкам итд.
Есть эффективность "intention to treat" (ITT), когда эффективность оценивают по всем участникам исследования, в том числе по тем, кто путал дозировки или бросал на середине.
Эти две оценки различаются, так как люди часто не следуют протоколу - забивают, снижают дозы или перестают принимать лекарство совсем с появлением побочных эффектов, и т.д.
Если эффективность "per protocol" отличается от "intention to treat" очень сильно, это может значить, что лекарство в целом эффективно, но схеме лечения сложно следовать.
"Золотым стандартом" для оценки эффективности является "intention to treat", потому что она точнее отражает реальную клиническую практику. Нам важно, чтобы лекарство было эффективным не только в лаборатории, но и в обычной жизни, где за пациентом не следят.
Это разделение на PP и ITT легко переносится и на исследовательские, менеджерские, продуктовые подходы.
Например, я уверен, что подход Ульвика к созданию продуктов (с выделением сотен desired outcomes, выявлением underserved outcomes и их кластеризацией) имеет очень высокую PP эффективность. Но следовать этому "протоколу" очень сложно, поэтому ITT эффективность у него невысока.
Или условное включённое наблюдение имеет высокую PP эффективность, но относительно низкую ITT, потому что не все умеют проводить его хорошо.
Наконец, споры про "scrum это супер, вы просто неправильно его применяете" или "все неправильно понимают, что такое lean ux" обращаются к той же теме - зазору между теоретически достижимой "per-protocol" эффективностью подхода, и реальной "intention to treat" эффективностью, учитывающей сложность использования.
Интересно, что эффективность "intention to treat" явно зависит от выборки людей и их культуры (их способности следовать протоколу), может отличаться в разных сообществах, и, видимо, меняться со временем.
Например, процесс демократизации исследований явно снижает ITT части исследовательских методов, включая "в выборку" людей, которые к исследовательским "протоколам" непривычны.
Ну и мне конечно симпатична идея, что лекарства оценивают по ITT - т.е. что хорошее лекарство должно быть в том числе таким, чтобы средний пациент мог его +- нормально принимать (или чтобы оно работало даже несмотря на отклонения от протокола лечения).
Нам в исследованиях стоит поучиться, мне кажется.
__
Про саму идею прочитал у Скотта Александера, он использует её для обсуждения социальных практик и проблем (условно, можно ли утверждать, что у христианства высокая PP эффективность для построения счастливых сообществ, хотя и невысокая ITT, т.к. его практикуют неправильно).
Это тоже кажется очень интересным.
В медицинских исследованиях есть два способа оценивать эффективность лекарств.
Есть эффективность "per protocol" (PP), когда при оценке лекарства смотрят только на тех пациентов, которые строго следовали указанному протоколу лечения - частоте, дозировкам итд.
Есть эффективность "intention to treat" (ITT), когда эффективность оценивают по всем участникам исследования, в том числе по тем, кто путал дозировки или бросал на середине.
Эти две оценки различаются, так как люди часто не следуют протоколу - забивают, снижают дозы или перестают принимать лекарство совсем с появлением побочных эффектов, и т.д.
Если эффективность "per protocol" отличается от "intention to treat" очень сильно, это может значить, что лекарство в целом эффективно, но схеме лечения сложно следовать.
"Золотым стандартом" для оценки эффективности является "intention to treat", потому что она точнее отражает реальную клиническую практику. Нам важно, чтобы лекарство было эффективным не только в лаборатории, но и в обычной жизни, где за пациентом не следят.
Это разделение на PP и ITT легко переносится и на исследовательские, менеджерские, продуктовые подходы.
Например, я уверен, что подход Ульвика к созданию продуктов (с выделением сотен desired outcomes, выявлением underserved outcomes и их кластеризацией) имеет очень высокую PP эффективность. Но следовать этому "протоколу" очень сложно, поэтому ITT эффективность у него невысока.
Или условное включённое наблюдение имеет высокую PP эффективность, но относительно низкую ITT, потому что не все умеют проводить его хорошо.
Наконец, споры про "scrum это супер, вы просто неправильно его применяете" или "все неправильно понимают, что такое lean ux" обращаются к той же теме - зазору между теоретически достижимой "per-protocol" эффективностью подхода, и реальной "intention to treat" эффективностью, учитывающей сложность использования.
Интересно, что эффективность "intention to treat" явно зависит от выборки людей и их культуры (их способности следовать протоколу), может отличаться в разных сообществах, и, видимо, меняться со временем.
Например, процесс демократизации исследований явно снижает ITT части исследовательских методов, включая "в выборку" людей, которые к исследовательским "протоколам" непривычны.
Ну и мне конечно симпатична идея, что лекарства оценивают по ITT - т.е. что хорошее лекарство должно быть в том числе таким, чтобы средний пациент мог его +- нормально принимать (или чтобы оно работало даже несмотря на отклонения от протокола лечения).
Нам в исследованиях стоит поучиться, мне кажется.
__
Про саму идею прочитал у Скотта Александера, он использует её для обсуждения социальных практик и проблем (условно, можно ли утверждать, что у христианства высокая PP эффективность для построения счастливых сообществ, хотя и невысокая ITT, т.к. его практикуют неправильно).
Это тоже кажется очень интересным.
👍59❤20🤔6🔥1🤨1
Хорошая история неожиданна, но реалистична.
Это относится к любой форме: в хороших стихах, романе и мелодии сложно предсказать следующий поворот, но когда он случается, то кажется логичным. В этом удовольствие.
В плохих все рифмы, повороты и развязки понятны с первого кадра.
(Не всегда так, но часто срабатывает)
Можем ли мы сказать то же самое про результаты исследований?
Должны ли хорошие исследования быть неожиданными и удивлять?
Вопрос в таком виде не имеет смысла, я заменю его тремя другими: имеют ли ценность тривиальные исследования, как эту ценность обосновывать, и как получать неожиданные результаты.
Имеют ли ценность исследования, которые не удивляют?
Да. Конечно да. Безусловно.
Исследование - источник данных. Большинство данных не удивляют нас, но они нужны.
Если вы закроете глаза и подойдёте а другую комнату, то, вероятно, наткнётесь на что-то, или заденете плечом косяк двери. Без зрительных данных сложно.
Значит ли это, что, открыв глаза я вы удивитесь обстановке в комнате и положению дверного проёма? Едва ли.
Зрение помогает, хотя его результаты ожидаемы.
Как обосновывать ценность исследования, если результаты тривиальны?
Обосновать себе сложно - мне кажется, это зависит от характера и опыта. Если вам важно удивлять, то убедить себя "ну и что, что не вышло, я же делаю полезное дело" в моменте тяжело.
Но вот обосновать заказчику проще, потому что важна (часто) не неожиданность результатов, а эффект.
"Мы на тестировании обнаружили, что люди не жмут кнопку, потому что опасаются, что сразу спишут деньги. Текст на кнопке поменяли, и конверсия выросла" - что может быть банальней?
Но такие результаты ценны, и не требуют дополнительного обоснования.
Тривиальные результаты в ключевых точках важнее, чем неожиданные результаты в неважных.
Чтобы выбирать эти важные точки, нужно понимать контекст - знать, где сейчас самая большая проблема, как выглядит цепочка создания ценности, где режется воронка, где есть запрос на данные, даже ожидаемые.
Как всё-таки получать неожиданные результаты?
Иногда это важно.
Есть плохой способ, средний, и хороший.
Плохой - "натягивать" данные, и раздувать анекдотичные свидетельства в тренд, преувеличивать проблемы. Он очевидно плох, но соблазнителен и доступен особенно в качественных методах. Мало кто так не делал.
Средний - смотреть на данные под неожиданным углом, осмыслять с другого ракурса, вписывать в исторический контекст и тренды.
Этот способ лучше, и производит впечатление, но у него есть проблема - результаты сложно применить.
То, что результаты вашего исследования рифмуются с отчётом Deloitte за прошлый год и статьями по behavioral science не делает их более полезными.
(Сам я этот способ нежно люблю, что видно по каналу).
Хороший - пойти "в другие комнаты", если неожиданность результатов для вас или заказчика важна.
В странную предметную область, в странные сегменты, странные сценарии. Найти заказчиков, которым это важно.
Это относится к любой форме: в хороших стихах, романе и мелодии сложно предсказать следующий поворот, но когда он случается, то кажется логичным. В этом удовольствие.
В плохих все рифмы, повороты и развязки понятны с первого кадра.
(Не всегда так, но часто срабатывает)
Можем ли мы сказать то же самое про результаты исследований?
Должны ли хорошие исследования быть неожиданными и удивлять?
Вопрос в таком виде не имеет смысла, я заменю его тремя другими: имеют ли ценность тривиальные исследования, как эту ценность обосновывать, и как получать неожиданные результаты.
Имеют ли ценность исследования, которые не удивляют?
Да. Конечно да. Безусловно.
Исследование - источник данных. Большинство данных не удивляют нас, но они нужны.
Если вы закроете глаза и подойдёте а другую комнату, то, вероятно, наткнётесь на что-то, или заденете плечом косяк двери. Без зрительных данных сложно.
Значит ли это, что, открыв глаза я вы удивитесь обстановке в комнате и положению дверного проёма? Едва ли.
Зрение помогает, хотя его результаты ожидаемы.
Как обосновывать ценность исследования, если результаты тривиальны?
Обосновать себе сложно - мне кажется, это зависит от характера и опыта. Если вам важно удивлять, то убедить себя "ну и что, что не вышло, я же делаю полезное дело" в моменте тяжело.
Но вот обосновать заказчику проще, потому что важна (часто) не неожиданность результатов, а эффект.
"Мы на тестировании обнаружили, что люди не жмут кнопку, потому что опасаются, что сразу спишут деньги. Текст на кнопке поменяли, и конверсия выросла" - что может быть банальней?
Но такие результаты ценны, и не требуют дополнительного обоснования.
Тривиальные результаты в ключевых точках важнее, чем неожиданные результаты в неважных.
Чтобы выбирать эти важные точки, нужно понимать контекст - знать, где сейчас самая большая проблема, как выглядит цепочка создания ценности, где режется воронка, где есть запрос на данные, даже ожидаемые.
Как всё-таки получать неожиданные результаты?
Иногда это важно.
Есть плохой способ, средний, и хороший.
Плохой - "натягивать" данные, и раздувать анекдотичные свидетельства в тренд, преувеличивать проблемы. Он очевидно плох, но соблазнителен и доступен особенно в качественных методах. Мало кто так не делал.
Средний - смотреть на данные под неожиданным углом, осмыслять с другого ракурса, вписывать в исторический контекст и тренды.
Этот способ лучше, и производит впечатление, но у него есть проблема - результаты сложно применить.
То, что результаты вашего исследования рифмуются с отчётом Deloitte за прошлый год и статьями по behavioral science не делает их более полезными.
(Сам я этот способ нежно люблю, что видно по каналу).
Хороший - пойти "в другие комнаты", если неожиданность результатов для вас или заказчика важна.
В странную предметную область, в странные сегменты, странные сценарии. Найти заказчиков, которым это важно.
🔥18👍4❤3
Channel name was changed to «Королёв про всё остальное (ex UX Research)»
Привет)
Этот канал начался шесть лет назад с пересказа англоязычных статей про UX исследования (кажется, я просто пересказывал статьи из дайджеста Ветрова).
Я писал про исследования в mozilla, операционализацию сложных запросов, RITE подход, влияние Канемана на дневниковые исследования, и другие смежные темы.
С тех пор мои интересы поменялись - исследую я мало, а думаю про другое: про то, как распространяются идеи, про науку как медиа, про то, что каждый хороший продукт что-то экстериоризирует (а GPT, возможно, экстериоризирует эмпатию), и про другие бесполезные вещи. Хочу писать про них.
Страшновато отказываться от родной идентичности исследователя, но пора)
Этот канал начался шесть лет назад с пересказа англоязычных статей про UX исследования (кажется, я просто пересказывал статьи из дайджеста Ветрова).
Я писал про исследования в mozilla, операционализацию сложных запросов, RITE подход, влияние Канемана на дневниковые исследования, и другие смежные темы.
С тех пор мои интересы поменялись - исследую я мало, а думаю про другое: про то, как распространяются идеи, про науку как медиа, про то, что каждый хороший продукт что-то экстериоризирует (а GPT, возможно, экстериоризирует эмпатию), и про другие бесполезные вещи. Хочу писать про них.
Страшновато отказываться от родной идентичности исследователя, но пора)
❤36🔥10😱2
И ещё, я знаю, что многие из вас ведут каналы про UX и продуктовые исследования более актуальные, бодрые и бойкие, чем этот, накидайте пожалуйста, ссылок в комментариях)
❤18👍1
Как маленькие интерфейсные решения влияют на мотивацию пользователей
Когда вы заходите в канал, почти первое, что вы видите - количество подписчиков. Оно сразу же под названием, вверху экрана.
Я, как автор, тоже вижу его. Как это влияет на моё поведение?
Когда вы постоянно отслеживаете метрику, вы начинаете воспринимать её как значимую, и хотите её оптимизировать.
В случае с авторами это побуждает больше думать "а будет ли мой пост востребован", "а не оттекут ли"? Косвенно это подталкивает к написанию охватных постов, или к внутреннему конфликту, если писать охватные посты не хочется.
Это прямо противоречит рекомендациям для начинающих авторов, основная из которых "просто пишите каждый день, не оглядывайтесь, вы не знаете, что выстрелит".
Пофантазирую, какие метрики можно было бы выводить вместо количества подписчиков, и как это повлияло бы на поведение авторов.
Количество постов за всё время: может помочь не забрасывать новые посты (можно ставить себе цели вроде "просто напишу сто постов, не оглядываясь), но провоцировать больше мусора.
"Страйк", количество дней с постами подряд (как дуолингво или контент хиро): может помочь выработать привычку писать регулярно. Про Долгосрочные эффекты не знаю.
Лингвистическое разнообразие в постах: может провоцировать использование смешных низкочастотных слов и сленга. Самая симпатичная мне метрика, но для продукта, наверное, бесполезная)
Среднее количество расшаривания постов: будет провоцировать дайджесты, потому что подборки сохраняют в сохранёнки чаще всего
Доля шерингов без сохранёнок: больше мемов и картинок? Не знаю
Индекс хирша для постов: а может быть неплохо, да? Вроде и на количество, и на качество мотивирует.
Какое ещё поведение можно было бы поощрять у авторов телеграма с помощью этого маленького кусочка интерфейса?
Какие ещё метрики или набор метрик можно было бы вывести вместо этой?
Когда вы заходите в канал, почти первое, что вы видите - количество подписчиков. Оно сразу же под названием, вверху экрана.
Я, как автор, тоже вижу его. Как это влияет на моё поведение?
Когда вы постоянно отслеживаете метрику, вы начинаете воспринимать её как значимую, и хотите её оптимизировать.
В случае с авторами это побуждает больше думать "а будет ли мой пост востребован", "а не оттекут ли"? Косвенно это подталкивает к написанию охватных постов, или к внутреннему конфликту, если писать охватные посты не хочется.
Это прямо противоречит рекомендациям для начинающих авторов, основная из которых "просто пишите каждый день, не оглядывайтесь, вы не знаете, что выстрелит".
Пофантазирую, какие метрики можно было бы выводить вместо количества подписчиков, и как это повлияло бы на поведение авторов.
Количество постов за всё время: может помочь не забрасывать новые посты (можно ставить себе цели вроде "просто напишу сто постов, не оглядываясь), но провоцировать больше мусора.
"Страйк", количество дней с постами подряд (как дуолингво или контент хиро): может помочь выработать привычку писать регулярно. Про Долгосрочные эффекты не знаю.
Лингвистическое разнообразие в постах: может провоцировать использование смешных низкочастотных слов и сленга. Самая симпатичная мне метрика, но для продукта, наверное, бесполезная)
Среднее количество расшаривания постов: будет провоцировать дайджесты, потому что подборки сохраняют в сохранёнки чаще всего
Доля шерингов без сохранёнок: больше мемов и картинок? Не знаю
Индекс хирша для постов: а может быть неплохо, да? Вроде и на количество, и на качество мотивирует.
Какое ещё поведение можно было бы поощрять у авторов телеграма с помощью этого маленького кусочка интерфейса?
Какие ещё метрики или набор метрик можно было бы вывести вместо этой?
❤37🔥6
Немота моя связана с тем, что gpt, когнитивное обесценивание, и в целом местами уже не понятно, кто вторичен относительно кого - мы относительно ИИ, или наоборот.
Имеет ли смысл текст, если его версия могла быть написана клодом/gpt быстрее и местами не хуже (как следующий пост)? Вот такие загоны
И конечно сразу думаешь, ну gpt не сможет написать трщщщщщлнк, или плнктрпс, не будет этого делать. Не напишет тилькропс лямпреньк
Не обгонит меня в бесполезных абсурдных словоформах.
Вот моё творческое убежище, креплидор глурпомц!
Это выводит нас на общее поле с футуристами, от Хармса до Хлебникова, от "боэоби пелись губы", до, ну в общем, понятно, до всех "йанкались златоноткие коэни", и прочего такого.
Да и вне футуристов это старая идея, глитч против автоматизации, абсурд против обыденности, вечное наше спасение
Короче, есть ощущение, что "быть умным" постепенно обесценивается, но быть блаженным ещё вполне имеет смысл, потому что быть блаженными llm пока умеют не так хорошо.
Как писать в этой ситуации про ux, продакт менеджмент, b2b продажи, и в целом про креативно-офисную работу, как оставаться автором канала с интеллектуальной претензией - ну пока не ясно.
Клёклё, локпомпом
(Да, ну я понимаю, что это странный пост, совершенно не в тематике и аудитории, извините, я помечу́сь и найду какой-то нормальный формат наверное)
Имеет ли смысл текст, если его версия могла быть написана клодом/gpt быстрее и местами не хуже (как следующий пост)? Вот такие загоны
И конечно сразу думаешь, ну gpt не сможет написать трщщщщщлнк, или плнктрпс, не будет этого делать. Не напишет тилькропс лямпреньк
Не обгонит меня в бесполезных абсурдных словоформах.
Вот моё творческое убежище, креплидор глурпомц!
Это выводит нас на общее поле с футуристами, от Хармса до Хлебникова, от "боэоби пелись губы", до, ну в общем, понятно, до всех "йанкались златоноткие коэни", и прочего такого.
Да и вне футуристов это старая идея, глитч против автоматизации, абсурд против обыденности, вечное наше спасение
Короче, есть ощущение, что "быть умным" постепенно обесценивается, но быть блаженным ещё вполне имеет смысл, потому что быть блаженными llm пока умеют не так хорошо.
Как писать в этой ситуации про ux, продакт менеджмент, b2b продажи, и в целом про креативно-офисную работу, как оставаться автором канала с интеллектуальной претензией - ну пока не ясно.
Клёклё, локпомпом
(Да, ну я понимаю, что это странный пост, совершенно не в тематике и аудитории, извините, я помечу́сь и найду какой-то нормальный формат наверное)
❤35💔11🔥2
Есть и нормальный пост конечно. Давайте подумаем над юзабилити эвристиками для агентов?
Есть эвристики Нильсена, но они для людей.
А люди постепенно начинают рутинные штуки автоматизировать агентами - кто-то Клод код себе настроил, кто-то опенкло, кто-то у Яндекс Браузера просит пересказать содержание страницы.
Так будет и дальше, я думаю, в ближайших версиях os появятся встроенные инструменты вроде Claude cowork, только нормальные.
У агентов свои особенности взаимодействия - хорошо понимают json, не очень хорошо работают с интерфейсом, могут не знать контекста итд.
Давайте соберём тут свои эвристики для них?
Что заметил я:
- Нужно нормальное API для загрузки/выгрузки информации, и для настроек (в идеале всё, что можно сделать в интерфейсе, должно быть можно сделать через условно публичное API)
- Нужна дока к апи, и возможность ограничивать доступы (api scopes, авторизация конечно)
- Загрузка/выгрузка всех настроек и сущностей через json/xml конфиг (если что-то настраивается, должна быть возможность описать настойки json файлом)
- для аналитики: денормализованные таблички с ключевыми метриками, или явное описание, как эти метрики считаются
Что ещё? Как сделать систему удобной для агентов?
Есть эвристики Нильсена, но они для людей.
А люди постепенно начинают рутинные штуки автоматизировать агентами - кто-то Клод код себе настроил, кто-то опенкло, кто-то у Яндекс Браузера просит пересказать содержание страницы.
Так будет и дальше, я думаю, в ближайших версиях os появятся встроенные инструменты вроде Claude cowork, только нормальные.
У агентов свои особенности взаимодействия - хорошо понимают json, не очень хорошо работают с интерфейсом, могут не знать контекста итд.
Давайте соберём тут свои эвристики для них?
Что заметил я:
- Нужно нормальное API для загрузки/выгрузки информации, и для настроек (в идеале всё, что можно сделать в интерфейсе, должно быть можно сделать через условно публичное API)
- Нужна дока к апи, и возможность ограничивать доступы (api scopes, авторизация конечно)
- Загрузка/выгрузка всех настроек и сущностей через json/xml конфиг (если что-то настраивается, должна быть возможность описать настойки json файлом)
- для аналитики: денормализованные таблички с ключевыми метриками, или явное описание, как эти метрики считаются
Что ещё? Как сделать систему удобной для агентов?
❤6
Мне всегда интересно, как внешние инструменты могут становится экзоскелетами для наших психических функций, расширять наши способности мыслить и творить.
Это и практики (письмо как расширение памяти), и способы представления (таблицы как способ иначе думать о данных), и инструменты (напр. шаблоны в Миро могут задавать, через какие метафоры мы думаем в групповой работате).
Сюда же корпоративное целеполагание (OKR, KPI, итд) как экзоскелет для мотивации, культура как внешняя опора для морали. Короче, тема широка и для меня увлекательна.
Другая важная для меня тема это отношения, и в целом способность лучше видеть, понимать, и любить людей. И я попробовал использовать ИИ для этого.
Схема проста: мои встречи на работе записываются (с разрешения, конечно), транскрипты прогоняются через ллм, и сразу после встречи получаю саммари о том, насколько я был внимателен, кого слышал, а кого нет, в чём была мотивация участников, как на встрече распределились роли, и всё это с точки зрения близких мне менеджерских и лидерских подходов (всё собрано на коленке клодом за пол часа).
Фактически, я получаю небольшую менеджерскую супервизию каждой встречи, плюс сводку в конце недели.
Ожидал, что эта петелька мгновенной обратной связи вознесёт меня до небес, и я за пару недель стану просветлённым и всепонимающим, смесью Будды и Карла Роджерса
Не сработало
Я действительно получил много полезной, развивающей, и точечной обратной связи. Буквально цитаты из десятков встреч, которые иллюстрируют, что я поддерживающий котик с западающими в конкретных ситуациях скилами регулярного менеджмента. Я настолько подробный разбор своего поведения получал только через КБТ дневник, а тут вот, на тебе, всё само.
Но это плохо конвертируется в изменения.
Я научился лучше обращать внимание на отдельные детали, но в целом стал менее внимательным, менее чутким. Как часто бывает, внешняя опора атрофирует внутренние, экзоскелет ослабляет собственные мышцы. Видимо, КБТ дневник, собранный за вас, стоит гораздо меньше, даёт знания о себе, но не тренирует сам навык замечать.
Поэтому я эту штуку отключил, и теперь думаю, как построить иначе. Мне всё ещё близка идея быстрой точечной обратной связи (в конце концов, сам идея тренерства в спорте и музыке построена на ней), но пока не понимаю, как не загасить внешней обратной связью внутреннее чутьё и готовность быть внимательным.
Что касается внешних инструментов, я вернулся к небольшим заметкам. Для меня письмо - один способ структурированно мыслить, и когда я хочу лучше понять кого-то, я пишу про себе маленькие эссе, где размышляю о человеке. Материала и фактуры в них часто меньше, чем в разборах ллм, но понимание как будто глубже.
Это и практики (письмо как расширение памяти), и способы представления (таблицы как способ иначе думать о данных), и инструменты (напр. шаблоны в Миро могут задавать, через какие метафоры мы думаем в групповой работате).
Сюда же корпоративное целеполагание (OKR, KPI, итд) как экзоскелет для мотивации, культура как внешняя опора для морали. Короче, тема широка и для меня увлекательна.
Другая важная для меня тема это отношения, и в целом способность лучше видеть, понимать, и любить людей. И я попробовал использовать ИИ для этого.
Схема проста: мои встречи на работе записываются (с разрешения, конечно), транскрипты прогоняются через ллм, и сразу после встречи получаю саммари о том, насколько я был внимателен, кого слышал, а кого нет, в чём была мотивация участников, как на встрече распределились роли, и всё это с точки зрения близких мне менеджерских и лидерских подходов (всё собрано на коленке клодом за пол часа).
Фактически, я получаю небольшую менеджерскую супервизию каждой встречи, плюс сводку в конце недели.
Ожидал, что эта петелька мгновенной обратной связи вознесёт меня до небес, и я за пару недель стану просветлённым и всепонимающим, смесью Будды и Карла Роджерса
Не сработало
Я действительно получил много полезной, развивающей, и точечной обратной связи. Буквально цитаты из десятков встреч, которые иллюстрируют, что я поддерживающий котик с западающими в конкретных ситуациях скилами регулярного менеджмента. Я настолько подробный разбор своего поведения получал только через КБТ дневник, а тут вот, на тебе, всё само.
Но это плохо конвертируется в изменения.
Я научился лучше обращать внимание на отдельные детали, но в целом стал менее внимательным, менее чутким. Как часто бывает, внешняя опора атрофирует внутренние, экзоскелет ослабляет собственные мышцы. Видимо, КБТ дневник, собранный за вас, стоит гораздо меньше, даёт знания о себе, но не тренирует сам навык замечать.
Поэтому я эту штуку отключил, и теперь думаю, как построить иначе. Мне всё ещё близка идея быстрой точечной обратной связи (в конце концов, сам идея тренерства в спорте и музыке построена на ней), но пока не понимаю, как не загасить внешней обратной связью внутреннее чутьё и готовность быть внимательным.
Что касается внешних инструментов, я вернулся к небольшим заметкам. Для меня письмо - один способ структурированно мыслить, и когда я хочу лучше понять кого-то, я пишу про себе маленькие эссе, где размышляю о человеке. Материала и фактуры в них часто меньше, чем в разборах ллм, но понимание как будто глубже.
❤27🔥9🤔4👍3