Наткнулся на манифест онтологического дизайна.
https://medium.datadriveninvestor.com/the-manifesto-of-ontological-design-7fdb19169107
Давайте сразу признаюсь, что он тут не ради пользы, а потому что в нём встречаются подлинно поэтические куски вроде: "Chairs deny certain possibilities for how bodies exist in space, and enable others". "Стул отсекает некоторые способы существования тела в пространстве", ну не чудо ли, а? Чистое искусство.
Всё-таки вытащу два вида тезисов - поэтические/философские (для души), и условно-практические (в качестве оправдания)
Для души:
- tools as prothesis - орудия труда можно воспринимать как расширения тела и сознания (extended mind и extended cognition, хорошо гуглится). Это известные красивые идеи - мы можем воспринимать ручку с бумагой, Figma, Miro и Obsidian как протезы/расширения нашей памяти и мышления -> создавая инструменты мы создаём человека - создание новых нотаций, фреймворков и вообще способов мыслить продвигает человечество к светлому будущему наравне с техническими достижениями.
- we design our tools, and then they design us in return - инструменты, которыми мы пользуемся, влияют на нас самих (we design our tools, and then they design us in return). Стул, на которым вы сидите, влияет на осанку, а используемые вами инструменты - на то, как вы мыслите, на ваши ментальные модели итд, формируют вас. Т.е. инструменты не только являются "внешними расширеними" сознания, но и влияют на него в ответ.
- Т.е. проектируя внешние объекты, мы конструируем это "расширенное" сознание. Через создание предметов быта и инструментов и проектируем сознание, mindware. Письмо сформировало нового человека, интернет - следующего, IDE формирует разработчиков, фигма - дизайнеров, музыкальные инструменты (и музыкальные традиции, лады) - музыкантов итд.
Условно-практические:
- "we design our tools, and then they design us in return" - каскадируется в более применимое "используемые инструменты влияют на ментальную модель пользователя и то, как он воспринимает интерфейсы", и мы можем учитывать при проектировании и исследованиях, какими ещё интерфейсами пользуются наши конкуренты -> какие паттерны им знакомы (немного тривиально, сори)
- Внешние инструменты влияют на то, как мы мыслим -> граница между внешними инструментами и привычными схемами мышления размывается -> можно воспринимать эти схемы мышления как части продукта и "проектировать" их через внешние коммуникации/вебинары/обучающие материалы сейлзов/рассылки/транслируемые ценности в принципе.
Напоследок вверну цитату из Лотмана:
"Дело в том, что предметы старинного быта производились вручную, форма их отрабатывалась десятилетиями, а иногда и веками, секреты производства передавались от мастера к мастеру. Это не только вырабатывало наиболее удобную форму, но и неизбежно превращало вещь в историю вещи, в память о связанных с нею жестах. Вещь, с одной стороны, придавала телу человека новые возможности, а с другой – включала человека в традицию, то есть и развивала, и ограничивала его индивидуальность."
https://medium.datadriveninvestor.com/the-manifesto-of-ontological-design-7fdb19169107
Давайте сразу признаюсь, что он тут не ради пользы, а потому что в нём встречаются подлинно поэтические куски вроде: "Chairs deny certain possibilities for how bodies exist in space, and enable others". "Стул отсекает некоторые способы существования тела в пространстве", ну не чудо ли, а? Чистое искусство.
Всё-таки вытащу два вида тезисов - поэтические/философские (для души), и условно-практические (в качестве оправдания)
Для души:
- tools as prothesis - орудия труда можно воспринимать как расширения тела и сознания (extended mind и extended cognition, хорошо гуглится). Это известные красивые идеи - мы можем воспринимать ручку с бумагой, Figma, Miro и Obsidian как протезы/расширения нашей памяти и мышления -> создавая инструменты мы создаём человека - создание новых нотаций, фреймворков и вообще способов мыслить продвигает человечество к светлому будущему наравне с техническими достижениями.
- we design our tools, and then they design us in return - инструменты, которыми мы пользуемся, влияют на нас самих (we design our tools, and then they design us in return). Стул, на которым вы сидите, влияет на осанку, а используемые вами инструменты - на то, как вы мыслите, на ваши ментальные модели итд, формируют вас. Т.е. инструменты не только являются "внешними расширеними" сознания, но и влияют на него в ответ.
- Т.е. проектируя внешние объекты, мы конструируем это "расширенное" сознание. Через создание предметов быта и инструментов и проектируем сознание, mindware. Письмо сформировало нового человека, интернет - следующего, IDE формирует разработчиков, фигма - дизайнеров, музыкальные инструменты (и музыкальные традиции, лады) - музыкантов итд.
Условно-практические:
- "we design our tools, and then they design us in return" - каскадируется в более применимое "используемые инструменты влияют на ментальную модель пользователя и то, как он воспринимает интерфейсы", и мы можем учитывать при проектировании и исследованиях, какими ещё интерфейсами пользуются наши конкуренты -> какие паттерны им знакомы (немного тривиально, сори)
- Внешние инструменты влияют на то, как мы мыслим -> граница между внешними инструментами и привычными схемами мышления размывается -> можно воспринимать эти схемы мышления как части продукта и "проектировать" их через внешние коммуникации/вебинары/обучающие материалы сейлзов/рассылки/транслируемые ценности в принципе.
Напоследок вверну цитату из Лотмана:
"Дело в том, что предметы старинного быта производились вручную, форма их отрабатывалась десятилетиями, а иногда и веками, секреты производства передавались от мастера к мастеру. Это не только вырабатывало наиболее удобную форму, но и неизбежно превращало вещь в историю вещи, в память о связанных с нею жестах. Вещь, с одной стороны, придавала телу человека новые возможности, а с другой – включала человека в традицию, то есть и развивала, и ограничивала его индивидуальность."
Medium
The Manifesto of Ontological Design
Ontological design is the design discipline concerned with designing human experience. It does so by operating under one essential…
Последнее время меня занимает, как можно улучшить качество дизайна (и исследований), вовлекая недизайнерские подразделения.
Вот Iris Sprague (сейчас product designer в Google, но в статье описан опыт работы в абстрактном "fast growing startup") рассказывает, как работа с другими подразделениями помогла ей улучшить качество дизайна:
https://uxplanet.org/ux-team-of-one-building-relationships-with-other-departments-to-ensure-your-success-105cce510d15
- Заманила разработчиков на ежемесячные дизайн-ретроспективы с помощью домашних печенек и расспрашивала о возможных улучшениях продукта. После 4-5 встреч все привыкли, разработчики стали засыпать ценным фидбеком, особенно про микровзаимодействия в дизайне, про которые они, в ходе создания кода, много думают.
- В первую очередь важно вовлечь фронтенд разработку, но вот при создании API важно и бекенд тоже, потому что "Your mental models of the product and corresponding APIs need to match.". Очевидно, но не думал об этом так.
- Организовала публичные демо дизайна для ребят из сейлз и customer care команд, чтобы собрать с них обратную связь. Первые несколько сессий прошли болезненно для обеих сторон, потом пошло легче - сейлзы лучше поняли, информация какого рода важна.
- Вовлекала customer success team для рекрута участников на исследования и для ведения заметок на самом интервью. Для сustomer success и команды поддержки задача дизайнера очень понятна и близка - сделать продукт понятней для пользователей и снизить нагрузку на сustomer success, поэтому обычно они охотно помогают.
Поделюсь своим личным опытом по теме:
- Полезно делиться с сейлзами и аккаунт-менеджерами результатами исследований. Мы довольно давно привлекаем их для рекрута клиентов и сбора обратной связи по макетам, но только недавно я додумался присылать в конце проекта результаты исследований. Формат очень сжатый: "Ребята, спасибо, что помогли с интервью. Вот о каких проблемах мы узнали, часть поправим в ближайшем релизе, а другие попозже, пока они лежат в бэклоге в таком-то эпике". Стало работать лучше - всем понятней, что мы делаем, и зачем нам клиенты.
- Саппорт подразделения всегда очень, очень сильно помогают в исследованиях - делятся аналитикой, помогают рекрутировать клиентов, готовы настроить нужные отчёты и морально поддерживают, так было везде, где я работал. Более того, из customer care и support специалистов получаются хорошие исследователи - всю часть про диджитал и HCD приходится объяснять с нуля, зато модерируют они почти сразу очень хорошо.
- С данными от фронт подразделений (сейлз, аккаунты, саппорт) можно работать как с данными исследований и аналитики. Их можно использовать для поиска и проверки гипотез, для триангуляции данных от других методов, замешивать в mixed research вместе с данными аналитики и интервью, обогащать ими job stories и CJM. CRM с деревом тематик для кейсов помогает с количественными данными, полнотекстовый поиск (в случае поддержки по чату, или автотранскрибаторов для расшифровки разговоров) с поиском узких кейсов в конкретных сценариях.
- Фронт подразделения - часть клиентского сценария. Если думать в терминах клиентского пути, то питчи и презентации сейлзов, такая же часть опыта, как лендинг, пуши и цепочка писем. Их тоже можно тестировать, компенсировать ими временные недоработки интерфейсов, или, как минимум, учитывать при описании контекста на тестировании.
___
Ещё по теме:
https://t.me/uxread/50 - как Света Ратнер из контура вовлекла сейлз менеджеров в исследования
https://medium.com/acronis-design/how-to-improve-the-ux-research-process-in-b2b-12b7475ef2cf - чуть подробней о том, как мы вовлекаем саппорт и аккаунт-менеджеров в Акронисе.
#b2bResearch
#Process
Вот Iris Sprague (сейчас product designer в Google, но в статье описан опыт работы в абстрактном "fast growing startup") рассказывает, как работа с другими подразделениями помогла ей улучшить качество дизайна:
https://uxplanet.org/ux-team-of-one-building-relationships-with-other-departments-to-ensure-your-success-105cce510d15
- Заманила разработчиков на ежемесячные дизайн-ретроспективы с помощью домашних печенек и расспрашивала о возможных улучшениях продукта. После 4-5 встреч все привыкли, разработчики стали засыпать ценным фидбеком, особенно про микровзаимодействия в дизайне, про которые они, в ходе создания кода, много думают.
- В первую очередь важно вовлечь фронтенд разработку, но вот при создании API важно и бекенд тоже, потому что "Your mental models of the product and corresponding APIs need to match.". Очевидно, но не думал об этом так.
- Организовала публичные демо дизайна для ребят из сейлз и customer care команд, чтобы собрать с них обратную связь. Первые несколько сессий прошли болезненно для обеих сторон, потом пошло легче - сейлзы лучше поняли, информация какого рода важна.
- Вовлекала customer success team для рекрута участников на исследования и для ведения заметок на самом интервью. Для сustomer success и команды поддержки задача дизайнера очень понятна и близка - сделать продукт понятней для пользователей и снизить нагрузку на сustomer success, поэтому обычно они охотно помогают.
Поделюсь своим личным опытом по теме:
- Полезно делиться с сейлзами и аккаунт-менеджерами результатами исследований. Мы довольно давно привлекаем их для рекрута клиентов и сбора обратной связи по макетам, но только недавно я додумался присылать в конце проекта результаты исследований. Формат очень сжатый: "Ребята, спасибо, что помогли с интервью. Вот о каких проблемах мы узнали, часть поправим в ближайшем релизе, а другие попозже, пока они лежат в бэклоге в таком-то эпике". Стало работать лучше - всем понятней, что мы делаем, и зачем нам клиенты.
- Саппорт подразделения всегда очень, очень сильно помогают в исследованиях - делятся аналитикой, помогают рекрутировать клиентов, готовы настроить нужные отчёты и морально поддерживают, так было везде, где я работал. Более того, из customer care и support специалистов получаются хорошие исследователи - всю часть про диджитал и HCD приходится объяснять с нуля, зато модерируют они почти сразу очень хорошо.
- С данными от фронт подразделений (сейлз, аккаунты, саппорт) можно работать как с данными исследований и аналитики. Их можно использовать для поиска и проверки гипотез, для триангуляции данных от других методов, замешивать в mixed research вместе с данными аналитики и интервью, обогащать ими job stories и CJM. CRM с деревом тематик для кейсов помогает с количественными данными, полнотекстовый поиск (в случае поддержки по чату, или автотранскрибаторов для расшифровки разговоров) с поиском узких кейсов в конкретных сценариях.
- Фронт подразделения - часть клиентского сценария. Если думать в терминах клиентского пути, то питчи и презентации сейлзов, такая же часть опыта, как лендинг, пуши и цепочка писем. Их тоже можно тестировать, компенсировать ими временные недоработки интерфейсов, или, как минимум, учитывать при описании контекста на тестировании.
___
Ещё по теме:
https://t.me/uxread/50 - как Света Ратнер из контура вовлекла сейлз менеджеров в исследования
https://medium.com/acronis-design/how-to-improve-the-ux-research-process-in-b2b-12b7475ef2cf - чуть подробней о том, как мы вовлекаем саппорт и аккаунт-менеджеров в Акронисе.
#b2bResearch
#Process
Medium
UX Team of One
Building relationships with other departments to ensure your success
❤2👍1
Umux-lite, Supr-q, NPS это, конечно, хорошо, но давайте поговорим про кроссовочность, круглоту и вопросы на основе эмодзи.
Речь о чём: когда мы говорим об измерении субъективных характеристик - удобстве, красоте, инновационности (я мешаю тут в кучу метрики удовлетворённости и бренд дискрипторы), мы:
- либо делаем это, подразумевая, что эти субъективные характеристики влияют на поведение пользователей: отток, количество рефералов, количество саппорт кейсов (метрики удовлетворённости обычно рассматриваются как предикторы лояльности и LTV)
- либо хотим быть консистентными в том, какие эмоции мы вызываем, и транслировать, что мы инновационные/семейные/дерзкие во всех каналах и продуктах.
Но непонятно, почему в качестве предикторов лояльности или эмоциональных дескрипторов должны быть привычные всем прилагательные. Почему нельзя "оцените, насколько наш продукт круглый?"
Если задача - быть консистентным и предсказывать поведение, то я, могу измерять для продукта любую характеристику, вроде кроссовочности или русалочности, если покажу что она предсказывает нужное мне поведение, и что люди могут консистентно её оценивать в разных точках касания с брендом.
И могу измерять эту характеристику вопросами типа "оцените, насколько новый сайт похож на 🧜♀️ по семибалльной шкале.
Или "насколько комфортно было бы нашему продукту жить в воде" от "абсолютно некомфортно" до "абсолютно комфортно".
Даже можно не заморачиваться с валидностью опроса: раз русалочность я придумал только, что, значит она, по определению, идеально измеряется придуманным мной же и единственным существующим опросником русалочности, всё как с NPS. Ну а надёжность можно быстро проверить, прогнав опрос.
Или это не так работает?
Речь о чём: когда мы говорим об измерении субъективных характеристик - удобстве, красоте, инновационности (я мешаю тут в кучу метрики удовлетворённости и бренд дискрипторы), мы:
- либо делаем это, подразумевая, что эти субъективные характеристики влияют на поведение пользователей: отток, количество рефералов, количество саппорт кейсов (метрики удовлетворённости обычно рассматриваются как предикторы лояльности и LTV)
- либо хотим быть консистентными в том, какие эмоции мы вызываем, и транслировать, что мы инновационные/семейные/дерзкие во всех каналах и продуктах.
Но непонятно, почему в качестве предикторов лояльности или эмоциональных дескрипторов должны быть привычные всем прилагательные. Почему нельзя "оцените, насколько наш продукт круглый?"
Если задача - быть консистентным и предсказывать поведение, то я, могу измерять для продукта любую характеристику, вроде кроссовочности или русалочности, если покажу что она предсказывает нужное мне поведение, и что люди могут консистентно её оценивать в разных точках касания с брендом.
И могу измерять эту характеристику вопросами типа "оцените, насколько новый сайт похож на 🧜♀️ по семибалльной шкале.
Или "насколько комфортно было бы нашему продукту жить в воде" от "абсолютно некомфортно" до "абсолютно комфортно".
Даже можно не заморачиваться с валидностью опроса: раз русалочность я придумал только, что, значит она, по определению, идеально измеряется придуманным мной же и единственным существующим опросником русалочности, всё как с NPS. Ну а надёжность можно быстро проверить, прогнав опрос.
Или это не так работает?
После перерыва сложно писать практичные посты, позволю себе поспекулировать про схожесть естественного и интерфейсного языков.
Понятно, что интерфейс можно воспринимать как текст, а паттерны проектирования как язык - мы используем общепринятые обозначения (дропдаун, кнопка, табы, формы), чтобы передать другим людям информацию о том, как взаимодействовать с системой.
Этот язык очень молодой, мы почти застали его создание (языки программирования тоже, но речь не о них, там мы реже говорим с другим человеком), и видим, как он развивается.
Развивается он похоже на обычную письменность.
Письмо началось с картинок и пиктограмм, похожих на реальные объекты.
Скевоморфические иконки, интерфейсные текстуры в первом айфоне, метафоры папки, файла и рабочего стола тоже максимально повторяют физический мир.
Современные иероглифы на реальные объекты похожи уже меньше, современные поколения иконок и паттернов тоже более схематичны, прямой смысл старых иконок выветривается.
Иконка дискеты для части пользователей - абстрактная морфема сохранения, не связанная с реальным объектом (тут вообще подходит слово "морфема"? Слишком увлекся, чтобы проверять).
Наконец, уже есть иероглифы для абстрактных понятий, у которых нет физической оболочки. Паттерны такие тоже появились - ничего, похожего на сториз в физическом мире нет - это не папка, и не лента/свиток контента.
Интерфейсный паттерн без соответствия в реальном мире ~ иероглиф абстрактного понятия.
Станут ли интерфейсные обозначения атомарными, как буквы, будут ли у нас свои финикийцы? Не понятно.
Дальше, и у языков, и у интерфейсов есть региональная специфика. Азиатские интернет-магазины выглядят непривычно для нас - несмотря на глобализацию, визуальный язык уже успел разделиться на разные визуальные диалекты. Нам сложно работать с китайским визуальным диалектом и сложно понимать его. Поэтому копировать WeChat 1в1 для аудитории США нельзя, хотя заимствовать отдельные слова можно.
В моделях распространения языков и интерфейсов тоже много общего.
И в языках и в интерфейсах распространение визуального/разговорного диалекта чаще всего зависит не от удобства/качества, а от дистрибуции и маркетинга.
Эсперанто создавали супер юзабельным, но на нём говорит в 500 раз меньше людей, чем на английском или китайском.
Ранний захват рынка и влиятельные последователи решают всё, простота и виральность - не всегда.
В интерфейсах все переиспользуют паттерны faang, не потому что они удобней всего, а потому что они на виду/под рукой для дизайнера, и потому что у них автоматически много носителей, они быстро становятся общепринятыми.
Интересно, что в некоторых случаях язык распространяется по модели b2c - когда толпа влиятельных последователей постепенно переводит всех своих друзей и детей на ваш язык, а иногда по b2b, когда новый язык внедряется в колониях сверху и централизованно, как сап.
А ещё иногда официальный язык для богослужений и официальных отчётов один (Скайп для бизнеса), а дома и в неформальной обстановке все говорят на втором (Телеграм удобней). А иногда комплаенс преследует использование "домашнего" языка и искореняет его.
Но интересно, что у языков прирост происходит в основном за счёт детей последователей, а в продуктах - за счёт пока ещё бессловесных. Почему мы не закладываем в модели роста продукта коэффициенты рождаемости наших клиентов? Бессмысленный вопрос.
Немного трендвотчинга напоследок: массовое распространение VR ненадолго откатит нас к нативным/консервативным интерфейсам (но уже привычные сториз никуда не денутся), но лет через 5 там тоже начнут появляться метафоры, которых в реальном мире нет.
Понятно, что интерфейс можно воспринимать как текст, а паттерны проектирования как язык - мы используем общепринятые обозначения (дропдаун, кнопка, табы, формы), чтобы передать другим людям информацию о том, как взаимодействовать с системой.
Этот язык очень молодой, мы почти застали его создание (языки программирования тоже, но речь не о них, там мы реже говорим с другим человеком), и видим, как он развивается.
Развивается он похоже на обычную письменность.
Письмо началось с картинок и пиктограмм, похожих на реальные объекты.
Скевоморфические иконки, интерфейсные текстуры в первом айфоне, метафоры папки, файла и рабочего стола тоже максимально повторяют физический мир.
Современные иероглифы на реальные объекты похожи уже меньше, современные поколения иконок и паттернов тоже более схематичны, прямой смысл старых иконок выветривается.
Иконка дискеты для части пользователей - абстрактная морфема сохранения, не связанная с реальным объектом (тут вообще подходит слово "морфема"? Слишком увлекся, чтобы проверять).
Наконец, уже есть иероглифы для абстрактных понятий, у которых нет физической оболочки. Паттерны такие тоже появились - ничего, похожего на сториз в физическом мире нет - это не папка, и не лента/свиток контента.
Интерфейсный паттерн без соответствия в реальном мире ~ иероглиф абстрактного понятия.
Станут ли интерфейсные обозначения атомарными, как буквы, будут ли у нас свои финикийцы? Не понятно.
Дальше, и у языков, и у интерфейсов есть региональная специфика. Азиатские интернет-магазины выглядят непривычно для нас - несмотря на глобализацию, визуальный язык уже успел разделиться на разные визуальные диалекты. Нам сложно работать с китайским визуальным диалектом и сложно понимать его. Поэтому копировать WeChat 1в1 для аудитории США нельзя, хотя заимствовать отдельные слова можно.
В моделях распространения языков и интерфейсов тоже много общего.
И в языках и в интерфейсах распространение визуального/разговорного диалекта чаще всего зависит не от удобства/качества, а от дистрибуции и маркетинга.
Эсперанто создавали супер юзабельным, но на нём говорит в 500 раз меньше людей, чем на английском или китайском.
Ранний захват рынка и влиятельные последователи решают всё, простота и виральность - не всегда.
В интерфейсах все переиспользуют паттерны faang, не потому что они удобней всего, а потому что они на виду/под рукой для дизайнера, и потому что у них автоматически много носителей, они быстро становятся общепринятыми.
Интересно, что в некоторых случаях язык распространяется по модели b2c - когда толпа влиятельных последователей постепенно переводит всех своих друзей и детей на ваш язык, а иногда по b2b, когда новый язык внедряется в колониях сверху и централизованно, как сап.
А ещё иногда официальный язык для богослужений и официальных отчётов один (Скайп для бизнеса), а дома и в неформальной обстановке все говорят на втором (Телеграм удобней). А иногда комплаенс преследует использование "домашнего" языка и искореняет его.
Но интересно, что у языков прирост происходит в основном за счёт детей последователей, а в продуктах - за счёт пока ещё бессловесных. Почему мы не закладываем в модели роста продукта коэффициенты рождаемости наших клиентов? Бессмысленный вопрос.
Немного трендвотчинга напоследок: массовое распространение VR ненадолго откатит нас к нативным/консервативным интерфейсам (но уже привычные сториз никуда не денутся), но лет через 5 там тоже начнут появляться метафоры, которых в реальном мире нет.
Интересно, что части продукта, сервиса и бренда редко сравнивают в одном исследовании.
Сравнительные исследования обычно сфокусированы на чем-то одном за раз, их вопрос звучит как "что важнее, сделать гибкие фильтры, или обновленный календарь", или "мы позиционируемся как супер надёжные, или как супер инновационные"?
Но редко звучит вопрос "Что важнее, гибкие фильтры, или репутация инновационной компании, или вообще чтобы поддержка быстрее отвечала"?
Но клиент то сравнивает всё это в куче.
Известность бренда, качество поддержки, наличие знакомого сейлза внутри компании, наличие известных клиентов - это части ценностного предложения, такие же, как функции самого продукта, клиент учитывает их все сразу.
Например, есть красивый хипстерский сервис, но в нём есть риск, что через пол года всё закроется и перестанет обновляться, есть медленный сутулый корпоративный софт, но с гарантиями поддержки и обратной совместимости на десять лет вперёд. Вы выбираете сразу и по функциональности, и по удобству, и по надёжности/репутации, всё это в одном котле принятия решений.
Следствие 1: делаете сравнительные исследования - конжоинты, внутренние бэттлкардс, анализ по Ульвику, строите Кано - учитывайте внепродуктовые качества тоже.
(Знаю, что Ульвик и Кано создавали свои фреймворки для оценки свойств продукта, но кажется, их можно использовать и шире. Требования к репутации нормально формулируются в виде desired outcome).
Звучит контринтуитивно - запихнуть в одну диаграмму Кано признак "у нас есть фича n" и признак "нашу рекламу крутят по ТВ", но кажется, чтоб выбор так и работает.
Да, в рамках классического продукта вы выбираете, на что потратить ресурсы разработки, поэтому взвешиваете продуктовые фичи, но в рамках компании вы уже выбираете, нанять ли вам вообще больше разработчиков, или влить деньги в рекламу, или вообще потратить их на лоббиста и войти в реестр импортозамещающего софта.
Или, если вы продаете контент (ЛитРес, Яндекс.Музыка), вы выбираете потратить вам деньги на машин лернинг спецов, чтобы улучшить длинный хвост рекомендаций, или купить прав на новые книги и треки.
Поэтому имеет смысл сравнивать качества разного рода в одном списке, или хотя бы понимать, что это сравнимые и сравниваемые вещи - и для бизнеса, и для пользователя/покупателя.
Следствие 2: Продукт может хорошо продаваться, будучи функционально плохим, потому что есть сегменты покупателей и (реже) пользователей), которым удобство или даже набор функций не так важны, как репутация, стоимость, идеальный саппорт, наличие сертификации или что-то ещё.
Стратегия это то, что вы не делаете (не "сделать всё хорошо", а "забить на x, чтобы сфокусироваться на y"), и в этих случаях хорошая (с точки зрения прибыли) стратегия может звучать как "не развивать продукт или какую-то из его частей, чтобы больше уделить внимания внепродуктовому кусочку ценности".
И кажется, исследовать имеет смысл те зоны, ценность которых верхнеуровнево уже доказана, и это не всегда удобство продукта, и даже не всегда функциональность.
И вопрос: про продуктовые подходы к приоритезации я знаю довольно много, а вот про надпродуктовые - почти нет.
Кажется, что логика та же - есть рынок, есть сегменты которым важны разные аспекты, от "быстро развиваются и всё первыми внедряют", до "самые дешёвые", важно этот рынок понять, найти свой сегмент, сформулировать ценность и захватывать свой кусочек рынка.
Можете накидать мне на @Node_of_Ranvier примеров, где исследования помогали решить, на чём сфокусироваться не только в рамках продукта, а вообще?
Сравнительные исследования обычно сфокусированы на чем-то одном за раз, их вопрос звучит как "что важнее, сделать гибкие фильтры, или обновленный календарь", или "мы позиционируемся как супер надёжные, или как супер инновационные"?
Но редко звучит вопрос "Что важнее, гибкие фильтры, или репутация инновационной компании, или вообще чтобы поддержка быстрее отвечала"?
Но клиент то сравнивает всё это в куче.
Известность бренда, качество поддержки, наличие знакомого сейлза внутри компании, наличие известных клиентов - это части ценностного предложения, такие же, как функции самого продукта, клиент учитывает их все сразу.
Например, есть красивый хипстерский сервис, но в нём есть риск, что через пол года всё закроется и перестанет обновляться, есть медленный сутулый корпоративный софт, но с гарантиями поддержки и обратной совместимости на десять лет вперёд. Вы выбираете сразу и по функциональности, и по удобству, и по надёжности/репутации, всё это в одном котле принятия решений.
Следствие 1: делаете сравнительные исследования - конжоинты, внутренние бэттлкардс, анализ по Ульвику, строите Кано - учитывайте внепродуктовые качества тоже.
(Знаю, что Ульвик и Кано создавали свои фреймворки для оценки свойств продукта, но кажется, их можно использовать и шире. Требования к репутации нормально формулируются в виде desired outcome).
Звучит контринтуитивно - запихнуть в одну диаграмму Кано признак "у нас есть фича n" и признак "нашу рекламу крутят по ТВ", но кажется, чтоб выбор так и работает.
Да, в рамках классического продукта вы выбираете, на что потратить ресурсы разработки, поэтому взвешиваете продуктовые фичи, но в рамках компании вы уже выбираете, нанять ли вам вообще больше разработчиков, или влить деньги в рекламу, или вообще потратить их на лоббиста и войти в реестр импортозамещающего софта.
Или, если вы продаете контент (ЛитРес, Яндекс.Музыка), вы выбираете потратить вам деньги на машин лернинг спецов, чтобы улучшить длинный хвост рекомендаций, или купить прав на новые книги и треки.
Поэтому имеет смысл сравнивать качества разного рода в одном списке, или хотя бы понимать, что это сравнимые и сравниваемые вещи - и для бизнеса, и для пользователя/покупателя.
Следствие 2: Продукт может хорошо продаваться, будучи функционально плохим, потому что есть сегменты покупателей и (реже) пользователей), которым удобство или даже набор функций не так важны, как репутация, стоимость, идеальный саппорт, наличие сертификации или что-то ещё.
Стратегия это то, что вы не делаете (не "сделать всё хорошо", а "забить на x, чтобы сфокусироваться на y"), и в этих случаях хорошая (с точки зрения прибыли) стратегия может звучать как "не развивать продукт или какую-то из его частей, чтобы больше уделить внимания внепродуктовому кусочку ценности".
И кажется, исследовать имеет смысл те зоны, ценность которых верхнеуровнево уже доказана, и это не всегда удобство продукта, и даже не всегда функциональность.
И вопрос: про продуктовые подходы к приоритезации я знаю довольно много, а вот про надпродуктовые - почти нет.
Кажется, что логика та же - есть рынок, есть сегменты которым важны разные аспекты, от "быстро развиваются и всё первыми внедряют", до "самые дешёвые", важно этот рынок понять, найти свой сегмент, сформулировать ценность и захватывать свой кусочек рынка.
Можете накидать мне на @Node_of_Ranvier примеров, где исследования помогали решить, на чём сфокусироваться не только в рамках продукта, а вообще?
А вот тред по книге continuous discovery habits, буду понемногу читать и закидывать сюда заметки (continuous discovery книги по continuous discovery, хаха).
Книга про то, как строить customer-centered продуктовый процесс (авторка часто ссылается на HCD (училась в Стэнфорде), и desired outcomes)*, основана на 12-недельной программе коучинга продуктовых команд.
Насколько я понял, книга не про "как сделать всё классно", а про "как сделать всё классно, с учётом того, что вы уже про это читали, но почему-то не получилось" т.е. учитывает то, как меняются команды на самом деле.
И книгу и программу очень рекомендует Марти Кэган (который Inspired), а ещё у авторки, Терезы Торрес, толковый блог https://www.producttalk.org/ (нравится не только за название)
Книга про то, как строить customer-centered продуктовый процесс (авторка часто ссылается на HCD (училась в Стэнфорде), и desired outcomes)*, основана на 12-недельной программе коучинга продуктовых команд.
Насколько я понял, книга не про "как сделать всё классно", а про "как сделать всё классно, с учётом того, что вы уже про это читали, но почему-то не получилось" т.е. учитывает то, как меняются команды на самом деле.
И книгу и программу очень рекомендует Марти Кэган (который Inspired), а ещё у авторки, Терезы Торрес, толковый блог https://www.producttalk.org/ (нравится не только за название)
❤1
4 режима поиска информации, и как проектировать для них
https://boxesandarrows.com/four-modes-of-seeking-information-and-how-to-design-for-them/
Модель Донны Спенсер не устарела за 15 лет (статья написана в 2006-м), она простая и практичная, и я часто использую её, когда продумываю сценарии продукта или исследования. Даже разок где-то ссылался (а, вот здесь), сейчас расскажу:
Донна выделяет 4 ситуации, в которых находятся люди, когда ищут что-либо:
1. Я не знаю, чего именно хочу (Don’t know what you need to know), например, зашёл на медиум посмотреть, чего бы почитать про UX.
2. Знаю, чего хочу в целом, но без конкретного объекта (Exploratory), хочу статью про то, как лучше презентовать результаты, но не знаю, какую.
3. Точно знаю, какой объект, информация или операция мне нужна (Known-item), мне рекомендовали статью конкретного автора, ищу её.
4. Хочу найти что-то, что уже находил ранее (Re-finding), хочу найти то, что уже читал.
Для каждого паттерна поиска нужны свои интерфейсные паттерны:
- Поиск полезен known-item, но бесполезен для don’t know what you need to know.
- Exploratory и Don’t know what you need требуют витрины, пушей, рассылок, и других способов рассказать пользователю о том, чего он ещё не очень ищет.
- Для re-finding помогут закладки/недавно посещённые страницы.
Хотя изначально это список сценариев поиска информации, он легко адаптируется для проектирования интерфейсов. Вот 4 состояния пользователя относительно функции в продукте:
1. Пользователь не знает, что в вашем продукте есть функция, надо донести (продакт маркетинг и онбординг в широком смысле)
2. Знает про функцию, но не понимает, как именно ей пользоваться, надо объяснить (онбординг фичи, эмпти стейты, стартовые сценарии)
3. Знает, понимает, нужно, чтобы было удобно (ежедневное взаимодействие)
4. Пользуется часто, нужно, чтобы продукт можно было адаптировать, нужная конфигурация настраивалась и сохранялась (настройка под пользователя)
https://boxesandarrows.com/four-modes-of-seeking-information-and-how-to-design-for-them/
Модель Донны Спенсер не устарела за 15 лет (статья написана в 2006-м), она простая и практичная, и я часто использую её, когда продумываю сценарии продукта или исследования. Даже разок где-то ссылался (а, вот здесь), сейчас расскажу:
Донна выделяет 4 ситуации, в которых находятся люди, когда ищут что-либо:
1. Я не знаю, чего именно хочу (Don’t know what you need to know), например, зашёл на медиум посмотреть, чего бы почитать про UX.
2. Знаю, чего хочу в целом, но без конкретного объекта (Exploratory), хочу статью про то, как лучше презентовать результаты, но не знаю, какую.
3. Точно знаю, какой объект, информация или операция мне нужна (Known-item), мне рекомендовали статью конкретного автора, ищу её.
4. Хочу найти что-то, что уже находил ранее (Re-finding), хочу найти то, что уже читал.
Для каждого паттерна поиска нужны свои интерфейсные паттерны:
- Поиск полезен known-item, но бесполезен для don’t know what you need to know.
- Exploratory и Don’t know what you need требуют витрины, пушей, рассылок, и других способов рассказать пользователю о том, чего он ещё не очень ищет.
- Для re-finding помогут закладки/недавно посещённые страницы.
Хотя изначально это список сценариев поиска информации, он легко адаптируется для проектирования интерфейсов. Вот 4 состояния пользователя относительно функции в продукте:
1. Пользователь не знает, что в вашем продукте есть функция, надо донести (продакт маркетинг и онбординг в широком смысле)
2. Знает про функцию, но не понимает, как именно ей пользоваться, надо объяснить (онбординг фичи, эмпти стейты, стартовые сценарии)
3. Знает, понимает, нужно, чтобы было удобно (ежедневное взаимодействие)
4. Пользуется часто, нужно, чтобы продукт можно было адаптировать, нужная конфигурация настраивалась и сохранялась (настройка под пользователя)
Boxes and Arrows
Four Modes of Seeking Information and How to Design for Them - Boxes and Arrows
Information-seeking behavior varies from situation to situation. Donna Maurer explores different ways in which users look for information and offers tactics for accommodating them.
👍3❤1
Придумался забавный критерий удобного продукта - его много используют не по назначению.
Планируют задачи в миро, ведут бюджеты в трелло, ремонтируют что угодно с помощью изоленты, ведут дневники в телеграме, про эксель даже начинать не буду - во всех этих случаях продукт очевидно создан для другого, но настолько привычен(?)/ удобен(?)/очарователен(?), что его используют вместо целевых.
Вот теперь думаю, во-первых, можно ли "% пользователей со странными сценариями" выкрутить в симпатичную метрику - показатель хорошего ux или всенародной любви (очень амбивалентную метрику, потому что её приятно видеть высокой, и при этом всё время надо снижать, делая популярные сценарии частью позиционирования).
И во-вторых, какие есть в b2b софте (в энтерпрайз сегменте даже) примеры таких инструментов? Какой-то рабочий инструмент, который людям нравится настолько, что его используют не по назначению.
Среды разработки, наверняка, а что ещё?
___
Сразу ещё хочется поспекулировать про способность инструментов (физических и цифровых) становиться частью нас, про условия, в которых это происходит, но это отдельно, потом)
Планируют задачи в миро, ведут бюджеты в трелло, ремонтируют что угодно с помощью изоленты, ведут дневники в телеграме, про эксель даже начинать не буду - во всех этих случаях продукт очевидно создан для другого, но настолько привычен(?)/ удобен(?)/очарователен(?), что его используют вместо целевых.
Вот теперь думаю, во-первых, можно ли "% пользователей со странными сценариями" выкрутить в симпатичную метрику - показатель хорошего ux или всенародной любви (очень амбивалентную метрику, потому что её приятно видеть высокой, и при этом всё время надо снижать, делая популярные сценарии частью позиционирования).
И во-вторых, какие есть в b2b софте (в энтерпрайз сегменте даже) примеры таких инструментов? Какой-то рабочий инструмент, который людям нравится настолько, что его используют не по назначению.
Среды разработки, наверняка, а что ещё?
___
Сразу ещё хочется поспекулировать про способность инструментов (физических и цифровых) становиться частью нас, про условия, в которых это происходит, но это отдельно, потом)
👍2
Метрики продукта и рынок труда
На рынке сейчас не хватает курьеров, официантов, вообще работников из сфер сервиса и обслуживания, дефицит огромный. Как это повлияет на метрики продуктов в этой сфере?
Вернёмся на шаг назад - в b2b и внутренних продуктах метрики вроде LTV и оттока работают плохо. Они запаздывают и их нельзя измерить на маленькой выборке b2b клиентов.
Поэтому качество продукта пытаются измерить другими способами - через объективные показатели (время на операцию, кол-во кликов, GOMS), или субъективные (NPS, CSI, SUS, UMIX итд).
Если выбираете, фокусироваться на количестве кликов или на NPS, есть простая эвристика - чем важнее итоговый пользователь, тем важнее субъективные метрики.
Если в отрасли избыток кандидатов на вакансию, то бизнесу не так важно обеспечивать хорошие условия труда. В числе прочего - можно не так заморачиваться по удобству внутренних систем.
В таких ситуациях эффективность (т.е. время на операцию) условной crm-ки для колл-центра важнее субъективного удобства, хорошая система - та, которая позволяет снизить время на задачи и сократить штат операторов.
Но если потенциальных кандидатов в отрасли не хватает и конкуренция за них велика, роль субъективных метрик растёт. Работадатель улучшает условия, в том числе удобство рабочих инструментов, а итоговые пользователи становятся достаточно влиятельными, чтобы выбирать. Это верно и для SMB (где пользователь=покупателю) и для энтерпрайз продуктов для дефицитных специалистов - например, разработчиков или врачей.
Atlassian (Jira, Confluence) сделали ключевой метрикой NPS в том числе потому, что разработчиков на рынке настолько не хватает, что они (разработчики) могут навязывать работодателям удобную для них систему, даже более дорогую.
Salesforce с NPS не торопится, т.к. дефицит сейлзов на рынке меньше.
Системы IP телефонии торопятся ещё меньше. Они стараются, очевидно, делать удобные продукты, но это не так приоритетно для них, т.к. итоговые пользователи менее дефицитны и влиятельны.
Вернёмся к курьерам. Их не хватает, компании начинают повышать зарплаты, чтобы удержать людей. Повышать зарплаты дорого, чтобы удерживать не только зарплатой, улучшают условия труда и employee experience (EX, по аналогии с CX) - страховки, больничные, принимают людей в штат. Удобное приложение в этом же ряду, оно гораздо менее важно для курьера, чем программа страхования, но и стоит оно для компании потенциально десятки раз меньше, поэтому роль субъективных метрик в продуктах для сервисных работников, как я ожидаю, возрастёт.
Соотношение спроса/предложения на рынке труда для пользователей в вашей отрасли можно найти на https://stats.hh.ru/ (для США такого же удобного пока не нашёл).
___
Ещё по теме - роль hedonic qualities в b2b продуктах в целом растёт https://t.me/uxread/138.
На рынке сейчас не хватает курьеров, официантов, вообще работников из сфер сервиса и обслуживания, дефицит огромный. Как это повлияет на метрики продуктов в этой сфере?
Вернёмся на шаг назад - в b2b и внутренних продуктах метрики вроде LTV и оттока работают плохо. Они запаздывают и их нельзя измерить на маленькой выборке b2b клиентов.
Поэтому качество продукта пытаются измерить другими способами - через объективные показатели (время на операцию, кол-во кликов, GOMS), или субъективные (NPS, CSI, SUS, UMIX итд).
Если выбираете, фокусироваться на количестве кликов или на NPS, есть простая эвристика - чем важнее итоговый пользователь, тем важнее субъективные метрики.
Если в отрасли избыток кандидатов на вакансию, то бизнесу не так важно обеспечивать хорошие условия труда. В числе прочего - можно не так заморачиваться по удобству внутренних систем.
В таких ситуациях эффективность (т.е. время на операцию) условной crm-ки для колл-центра важнее субъективного удобства, хорошая система - та, которая позволяет снизить время на задачи и сократить штат операторов.
Но если потенциальных кандидатов в отрасли не хватает и конкуренция за них велика, роль субъективных метрик растёт. Работадатель улучшает условия, в том числе удобство рабочих инструментов, а итоговые пользователи становятся достаточно влиятельными, чтобы выбирать. Это верно и для SMB (где пользователь=покупателю) и для энтерпрайз продуктов для дефицитных специалистов - например, разработчиков или врачей.
Atlassian (Jira, Confluence) сделали ключевой метрикой NPS в том числе потому, что разработчиков на рынке настолько не хватает, что они (разработчики) могут навязывать работодателям удобную для них систему, даже более дорогую.
Salesforce с NPS не торопится, т.к. дефицит сейлзов на рынке меньше.
Системы IP телефонии торопятся ещё меньше. Они стараются, очевидно, делать удобные продукты, но это не так приоритетно для них, т.к. итоговые пользователи менее дефицитны и влиятельны.
Вернёмся к курьерам. Их не хватает, компании начинают повышать зарплаты, чтобы удержать людей. Повышать зарплаты дорого, чтобы удерживать не только зарплатой, улучшают условия труда и employee experience (EX, по аналогии с CX) - страховки, больничные, принимают людей в штат. Удобное приложение в этом же ряду, оно гораздо менее важно для курьера, чем программа страхования, но и стоит оно для компании потенциально десятки раз меньше, поэтому роль субъективных метрик в продуктах для сервисных работников, как я ожидаю, возрастёт.
Соотношение спроса/предложения на рынке труда для пользователей в вашей отрасли можно найти на https://stats.hh.ru/ (для США такого же удобного пока не нашёл).
___
Ещё по теме - роль hedonic qualities в b2b продуктах в целом растёт https://t.me/uxread/138.
stats.hh.ru
hh Статистика: сервис открытой аналитики рынка труда
Уровень конкуренции, ожидаемые и предлагаемые зарплаты, количество вакансий и резюме по регионам и профобластям. Смотрите данные в динамике и сравнивайте нужные вам показатели.
👍2
Как считать окупаемость исследований
Обычно UX исследователя просят посчитать ROI не для того, чтобы получить точную выверенную модель (иногда да, но обычно нет), а чтобы проверить, что она/он не блаженные и мыслят с бизнес-заказчиком в одних категориях.
Формально верный ответ на просьбу оценить окупаемость ресерча такой: "давайте сделаем a/b тест, выпустим часть фичей с исследованием, часть без, по 100 на группу, только надо уравновесить фичи по всем параметрам", или "давайте сделаем регрессионный анализ и оценим влияние исследований и дизайна" или "давайте посмотрим на Service-Profit Chain model и посчитаем всё как там". Всё это прекрасно, правильно, и в среднем проекте нереализуемо. При формально верном ответе вы проваливаете тест на адекватность, вас запишут в категорию умниц-эрудитов, с которыми полезно посоветоваться, но каши не сваришь.
Ответ получше (повторюсь, не всегда так, иногда нужна "Service-Profit model" нужно уточнять контекст задачи итд итп, но часто именно так) - приблизительно прикинуть ценность исследований в деньгах. Она оценивается в рамках ценности всей доработки продукта, в том же кейсе. Сейчас объясню.
Когда продакт берёт в работу фичу, он делает мысленную или реальную прикидку по её рентабельности.
Примерно так:
Затраты: запилить блок рекомендаций стоит спринт продуктовой команды, это где-то 1.2млн, если считать по текущим ставкам.
Доходы: я предполагаю, что конверсия вырастет на 0.1% (из бенчмарков, из сравнения с похожими фичами, из опыта, ещё как-то). С учётом текущей конверсии, среднего чека, и маржи, это + 40к в день
Итог: 1.2 млн/40 тысяч - фича отобьётся за 30 дней. Неплохо.
Это супер сжатый формат, иногда обоснование каждого из пунктов (и затрат и возможного влияния на метрики) декомпозируется и требует десяти табличек, но категории такие.
Исследования можно посчитать по схожей схеме:
Расходы: время исследователя + время дизайнера на прототип + время команды на переделки + рекрут ~ 300к.
Доходы: мы на 10% увеличим эффективность фичи, будет не 0.1%, а 0.11%, ещё +4к в день.
Итог: 300/4 - окупится за 2.5 месяцев примерно
Доходную часть можно прикинуть на основе прошлого опыта, или поискать бенчмарки, или спросить у коллег из других компаний, или предположить.
В начале оценка будет не точная, это ок, потом итеративно подкрутите.
Дальше можно обсуждать и детализировать - а сколько стоит сдвиг фичи на неделю (ещё почти 300к), а есть ли ещё упущенная выгода от сдвига сроков, а как получили +10% эффективности и т.д. Ещё можно думать, можем ли мы сделать дешевле (немодерируемое тестирование сократит стоимость раза в два) или повлиять больше.
Это всё обсуждаемо, но важно, что вы в принципе попробовали прикинуть, за счёт чего исследования могут окупаться, в терминах, понятных для бизнес-заказчиков, и с вами можно иметь дело.
Со стратегическими исследованиями так работает хуже, они дороже и их сложнее обосновать. Тут важнее культура компании и ваше влияние.
Ну и понятно, что фундаментальные исследования по HCI и UX обосновываются иначе.
Обычно UX исследователя просят посчитать ROI не для того, чтобы получить точную выверенную модель (иногда да, но обычно нет), а чтобы проверить, что она/он не блаженные и мыслят с бизнес-заказчиком в одних категориях.
Формально верный ответ на просьбу оценить окупаемость ресерча такой: "давайте сделаем a/b тест, выпустим часть фичей с исследованием, часть без, по 100 на группу, только надо уравновесить фичи по всем параметрам", или "давайте сделаем регрессионный анализ и оценим влияние исследований и дизайна" или "давайте посмотрим на Service-Profit Chain model и посчитаем всё как там". Всё это прекрасно, правильно, и в среднем проекте нереализуемо. При формально верном ответе вы проваливаете тест на адекватность, вас запишут в категорию умниц-эрудитов, с которыми полезно посоветоваться, но каши не сваришь.
Ответ получше (повторюсь, не всегда так, иногда нужна "Service-Profit model" нужно уточнять контекст задачи итд итп, но часто именно так) - приблизительно прикинуть ценность исследований в деньгах. Она оценивается в рамках ценности всей доработки продукта, в том же кейсе. Сейчас объясню.
Когда продакт берёт в работу фичу, он делает мысленную или реальную прикидку по её рентабельности.
Примерно так:
Затраты: запилить блок рекомендаций стоит спринт продуктовой команды, это где-то 1.2млн, если считать по текущим ставкам.
Доходы: я предполагаю, что конверсия вырастет на 0.1% (из бенчмарков, из сравнения с похожими фичами, из опыта, ещё как-то). С учётом текущей конверсии, среднего чека, и маржи, это + 40к в день
Итог: 1.2 млн/40 тысяч - фича отобьётся за 30 дней. Неплохо.
Это супер сжатый формат, иногда обоснование каждого из пунктов (и затрат и возможного влияния на метрики) декомпозируется и требует десяти табличек, но категории такие.
Исследования можно посчитать по схожей схеме:
Расходы: время исследователя + время дизайнера на прототип + время команды на переделки + рекрут ~ 300к.
Доходы: мы на 10% увеличим эффективность фичи, будет не 0.1%, а 0.11%, ещё +4к в день.
Итог: 300/4 - окупится за 2.5 месяцев примерно
Доходную часть можно прикинуть на основе прошлого опыта, или поискать бенчмарки, или спросить у коллег из других компаний, или предположить.
В начале оценка будет не точная, это ок, потом итеративно подкрутите.
Дальше можно обсуждать и детализировать - а сколько стоит сдвиг фичи на неделю (ещё почти 300к), а есть ли ещё упущенная выгода от сдвига сроков, а как получили +10% эффективности и т.д. Ещё можно думать, можем ли мы сделать дешевле (немодерируемое тестирование сократит стоимость раза в два) или повлиять больше.
Это всё обсуждаемо, но важно, что вы в принципе попробовали прикинуть, за счёт чего исследования могут окупаться, в терминах, понятных для бизнес-заказчиков, и с вами можно иметь дело.
Со стратегическими исследованиями так работает хуже, они дороже и их сложнее обосновать. Тут важнее культура компании и ваше влияние.
Ну и понятно, что фундаментальные исследования по HCI и UX обосновываются иначе.
🔥15👍7❤3🥰1
Ну и оговорюсь, что хотя прошло почти полгода, я так и не придумал, как писать в канал, чтобы это ощущалось этичным и уместным на фоне происходящего. Извините
❤31
(Простите за back to basics нужен пост, чтобы на него ссылаться)
Когда пишете что-то по работе (тестовое, резюме, отчёт, письмо, план проекта) прогоняйте это через внутренний 5-second test (это метод исследования, при котором человеку показывают экран на пять секунд, а потом просят пересказать основное содержание. Проверяют первое впечатление и заметность главных элементов).
Это сильно повысит конверсию ваших резюме, тестовых заданий, презентаций, отчётов, фолоуапов и любых других письменных сообщений. Это особенно важно в случаях, когда у получателя такого рода сообщений десятки (для резюме и тестовых).
Реальный тест делать не нужно, достаточно воображаемого. Обычно и так понятно, считывается основная идея и структура при беглом сканировании, или нет.
(И избегайте бесконечных уточнений в скобочках, как у меня, это, конечно, мешает)
Когда пишете что-то по работе (тестовое, резюме, отчёт, письмо, план проекта) прогоняйте это через внутренний 5-second test (это метод исследования, при котором человеку показывают экран на пять секунд, а потом просят пересказать основное содержание. Проверяют первое впечатление и заметность главных элементов).
Это сильно повысит конверсию ваших резюме, тестовых заданий, презентаций, отчётов, фолоуапов и любых других письменных сообщений. Это особенно важно в случаях, когда у получателя такого рода сообщений десятки (для резюме и тестовых).
Реальный тест делать не нужно, достаточно воображаемого. Обычно и так понятно, считывается основная идея и структура при беглом сканировании, или нет.
(И избегайте бесконечных уточнений в скобочках, как у меня, это, конечно, мешает)
Fivesecondtest
Five Second Test
The five second test is a simple usability test to optimize the clarity of your designs and improve conversion rates by measuring people's first impressions.
❤27👍6
Зачем нужны фреймворки, почему нельзя просто голову включить.
В психологии есть понятие "пустое усилие". Пустое усилие - попытка произвольно делать что-то, что мы на самом деле намеренно делать не можем: не волноваться, включить голову, быть уверенней, замедлить сердцебиение, пошевелить левой почкой.
Обычно ничего не выходит, потому что эти процессы непроизвольны. Мы контролируем (или чувствуем, что контролируем), движение и внимание - можем задержать дыхание, пошевелить ногой, пробежать километр.
Но мы не можем произвольно перестать волноваться, у нас нет мышц волнения. Не можем включить голову, нет произвольного контроля количества глюкозы в мозгу. Не можем усилием воли почувствовать себя уверенно, не можем произвольно не грустить.
Мышление тоже не всегда подконтрольно. Остановитесь и попробуйте минуты две как следует подумать про зелёный.
Это, вероятно, будет сложно, не только из-за скачков внимания, но ещё и потому, что не до конца понятно, а что именно делать. Ок, вы подумали "зелёный", а дальше что? Ощущается не как сложность "почему так трудно" а скорее как замешательство "а как это вообще". Что значит "глубоко, структурированно и долго думать о чём-то?"
Но мы можем контролировать эти процессы - мышление, волнение, уверенность - через привязку к конкретным физическим действиям или результатам.
- Не волнуйся -> сделай 20 медленных вдохов и выдохов, сделай мышечную релаксацию
- Подумай про зелёный -> придумай пять способов органично встроить зелёный в интерьер вокруг, а ещё напиши эссе на пару страниц про роль зелёного в древних сообществах
- Будь дальновиднее, включи голову -> распиши заранее табличку вариантов и последствия второго порядка, составь матрицу рисков.
Во всех этих случаях мы сводим задачу к более конкретному действию по заполнению артефакта. Мыслить физически проще.
Профессиональные фреймворки работают по такому же принципу:
- Подумай про клиентский опыт -> построй cjm
- Прикинь, ок ли бизнес-модель -> заполни лин канвас и pnl вот по таким-то шагам
- Придумай остроумное решение -> напиши список из 50 решений
- Подумай про клиентов -> опиши персону
Мы снижаем скорость и гибкость, зато становится понятно, что именно надо делать.
Есть универсальные фреймворки для мышления о чём-то - записать это в математической форме, написать эссе, разложить на майндмап, сделать issue tree, подготовить лекцию на тему. Все они - про перевод мышления в физическую форму и создание внешнего артефакта.
Есть частные тематические фреймворки - jtbd, юзкейсы, swot анализ, диаграмма Исикавы, и т.д. Но их идея в том же самом - перевести "подумайте о конкурентах" в понятное действие "заполните матричку 2*2"
Со временем нужда в таких опорах пропадает, мы учимся делать что-то непосредственно, и мышление снова становится более гибким и быстрым, но в начале внешние опоры нужны.
Наверное практический совет тут такой: если у вас не получается придумать решение какой-то проблемы, можно попробовать перевести процесс решения в физическую форму. Написать письмо, составить список, нарисовать картину, не знаю.
И второй: если вам нужно масштабировать на группу людей свою экспертизу, интуицию, навык думать про что-то, попробуйте перевести этот навык в физическое действие по заполнению фреймворка. Это работает гораздо грубее, чем непосредственное понимание, но помогает в освоении новой темы.
___
Пара смежных идей:
- Extended mind, тоже про внешние инструменты мышления и физическое мышление
- общий тезис - экстериоризация повышает качество чего угодно. Это работает на уровне отдельных идей (подготовка поста заставляет глубже обдумать тему, чтение лекций упорядочить собственный опыт, проговаривание выступления помогает ощутить нестыковки и слабые места), так и на уровне сервисов/продуктов (внешние интерфейсы обычно аккуратней внутренних, public API обычно согласованней и стройней внутренних)
В психологии есть понятие "пустое усилие". Пустое усилие - попытка произвольно делать что-то, что мы на самом деле намеренно делать не можем: не волноваться, включить голову, быть уверенней, замедлить сердцебиение, пошевелить левой почкой.
Обычно ничего не выходит, потому что эти процессы непроизвольны. Мы контролируем (или чувствуем, что контролируем), движение и внимание - можем задержать дыхание, пошевелить ногой, пробежать километр.
Но мы не можем произвольно перестать волноваться, у нас нет мышц волнения. Не можем включить голову, нет произвольного контроля количества глюкозы в мозгу. Не можем усилием воли почувствовать себя уверенно, не можем произвольно не грустить.
Мышление тоже не всегда подконтрольно. Остановитесь и попробуйте минуты две как следует подумать про зелёный.
Это, вероятно, будет сложно, не только из-за скачков внимания, но ещё и потому, что не до конца понятно, а что именно делать. Ок, вы подумали "зелёный", а дальше что? Ощущается не как сложность "почему так трудно" а скорее как замешательство "а как это вообще". Что значит "глубоко, структурированно и долго думать о чём-то?"
Но мы можем контролировать эти процессы - мышление, волнение, уверенность - через привязку к конкретным физическим действиям или результатам.
- Не волнуйся -> сделай 20 медленных вдохов и выдохов, сделай мышечную релаксацию
- Подумай про зелёный -> придумай пять способов органично встроить зелёный в интерьер вокруг, а ещё напиши эссе на пару страниц про роль зелёного в древних сообществах
- Будь дальновиднее, включи голову -> распиши заранее табличку вариантов и последствия второго порядка, составь матрицу рисков.
Во всех этих случаях мы сводим задачу к более конкретному действию по заполнению артефакта. Мыслить физически проще.
Профессиональные фреймворки работают по такому же принципу:
- Подумай про клиентский опыт -> построй cjm
- Прикинь, ок ли бизнес-модель -> заполни лин канвас и pnl вот по таким-то шагам
- Придумай остроумное решение -> напиши список из 50 решений
- Подумай про клиентов -> опиши персону
Мы снижаем скорость и гибкость, зато становится понятно, что именно надо делать.
Есть универсальные фреймворки для мышления о чём-то - записать это в математической форме, написать эссе, разложить на майндмап, сделать issue tree, подготовить лекцию на тему. Все они - про перевод мышления в физическую форму и создание внешнего артефакта.
Есть частные тематические фреймворки - jtbd, юзкейсы, swot анализ, диаграмма Исикавы, и т.д. Но их идея в том же самом - перевести "подумайте о конкурентах" в понятное действие "заполните матричку 2*2"
Со временем нужда в таких опорах пропадает, мы учимся делать что-то непосредственно, и мышление снова становится более гибким и быстрым, но в начале внешние опоры нужны.
Наверное практический совет тут такой: если у вас не получается придумать решение какой-то проблемы, можно попробовать перевести процесс решения в физическую форму. Написать письмо, составить список, нарисовать картину, не знаю.
И второй: если вам нужно масштабировать на группу людей свою экспертизу, интуицию, навык думать про что-то, попробуйте перевести этот навык в физическое действие по заполнению фреймворка. Это работает гораздо грубее, чем непосредственное понимание, но помогает в освоении новой темы.
___
Пара смежных идей:
- Extended mind, тоже про внешние инструменты мышления и физическое мышление
- общий тезис - экстериоризация повышает качество чего угодно. Это работает на уровне отдельных идей (подготовка поста заставляет глубже обдумать тему, чтение лекций упорядочить собственный опыт, проговаривание выступления помогает ощутить нестыковки и слабые места), так и на уровне сервисов/продуктов (внешние интерфейсы обычно аккуратней внутренних, public API обычно согласованней и стройней внутренних)
❤23👍15🔥11🤔1
Можно делать количественные выводы на маленьких выборках, если привязываться к причинам с изученной частотой.
Допустим, вы исследуете банковское приложение для физлиц. 3 из 10 респондентов не понимают, как посмотреть историю платежей.
Считаете доверительный интервал, и оказывается, что 3 из 10 это от 1 до 59% популяции (p 0.95), т.е. проблема может быть супер редкой или супер частой. Это почти бесполезное знание.
Вы копаете глубже и оказывается, что эти трое - единственные из всей тестовой выборки, кто не пользовался другими банковскими приложениями до этого.
Добираете ещё четверых таких новичков, и да, оказывается, что из 7 новичков 6 не поняли, как смотреть историю операций (а из 7 опытных 7 поняли).
Смотрим дальше: какова доля таких новичков в вашей аудитории? Гуглите, что аудитория банковских приложений на вашем рынке растёт на 5% в год, т.е похоже, что вы нашли частую (46-99% при p 0.95) проблему для 5% аудитории.
Но потом вспоминаете, что стратегия вашего банка сейчас в том, чтобы привлекать больше подростков, 80% роста аудитории в этом году заложено на них. А аудитория среди подростков растёт на 20% в год, т.е. каждый пятый - новичок.
Итог: ~15% (80% подростков*20% новичков среди них) аудитории вашего приложения в этом году - новички, и минимум половине из них скорее всего будет сложно найти историю платежей.
Или ещё пример: вы делаете систему документооборота, и у одного из опрошенных клиентов специфическое требование - выгружать документы в каком-нибудь странном формате с водяными знаками на фоне.
Выясняется, что нужно это потому, что клиент участвует в гос тендерах, а там при подаче обязательны документы в таком формате.
Ищите инфу (иногда по косвенным данным), какая доля компаний вообще участвует в гос. тендерах, хоп, понимаете примерный размер аудитории, для которой требования релевантны.
Или (это последний): вы делаете приложение для покупки ЖД билетов, и 4 из 10 людей сказали, что им важна модель вагона, хотят видеть её в поисковой выдаче при покупке билета.
Копаете, выясняется, что все четверо состоят в клубе "побывай в вагонах всех существующих моделей". В нём всего три тысячи человек (вы нашли группу в ВК и форум), и это 0.001% вашей аудитории. Но четверо из них пришли к вам на интервью, т.к. они все друг с другом знакомы.
Логика проста: наблюдения на маленькой выборке->огромный доверительный интервал->причины с изученной частотой->маленький доверительный интервал.
На словах звучит красиво, а на деле так складно не получается - явные причины встречаются редко, обычно поведение обусловлено десятками факторов. Но всё часто находятся причины, которые позволяют сузить вероятную частоту с 1-56% до более практичной.
Особенно в b2b продуктах - процессы клиента диктуют требования к продуктам, и маленькие выборки часто получается компенсировать типизацией клиентов и открытыми данными по ним.
Допустим, вы исследуете банковское приложение для физлиц. 3 из 10 респондентов не понимают, как посмотреть историю платежей.
Считаете доверительный интервал, и оказывается, что 3 из 10 это от 1 до 59% популяции (p 0.95), т.е. проблема может быть супер редкой или супер частой. Это почти бесполезное знание.
Вы копаете глубже и оказывается, что эти трое - единственные из всей тестовой выборки, кто не пользовался другими банковскими приложениями до этого.
Добираете ещё четверых таких новичков, и да, оказывается, что из 7 новичков 6 не поняли, как смотреть историю операций (а из 7 опытных 7 поняли).
Смотрим дальше: какова доля таких новичков в вашей аудитории? Гуглите, что аудитория банковских приложений на вашем рынке растёт на 5% в год, т.е похоже, что вы нашли частую (46-99% при p 0.95) проблему для 5% аудитории.
Но потом вспоминаете, что стратегия вашего банка сейчас в том, чтобы привлекать больше подростков, 80% роста аудитории в этом году заложено на них. А аудитория среди подростков растёт на 20% в год, т.е. каждый пятый - новичок.
Итог: ~15% (80% подростков*20% новичков среди них) аудитории вашего приложения в этом году - новички, и минимум половине из них скорее всего будет сложно найти историю платежей.
Или ещё пример: вы делаете систему документооборота, и у одного из опрошенных клиентов специфическое требование - выгружать документы в каком-нибудь странном формате с водяными знаками на фоне.
Выясняется, что нужно это потому, что клиент участвует в гос тендерах, а там при подаче обязательны документы в таком формате.
Ищите инфу (иногда по косвенным данным), какая доля компаний вообще участвует в гос. тендерах, хоп, понимаете примерный размер аудитории, для которой требования релевантны.
Или (это последний): вы делаете приложение для покупки ЖД билетов, и 4 из 10 людей сказали, что им важна модель вагона, хотят видеть её в поисковой выдаче при покупке билета.
Копаете, выясняется, что все четверо состоят в клубе "побывай в вагонах всех существующих моделей". В нём всего три тысячи человек (вы нашли группу в ВК и форум), и это 0.001% вашей аудитории. Но четверо из них пришли к вам на интервью, т.к. они все друг с другом знакомы.
Логика проста: наблюдения на маленькой выборке->огромный доверительный интервал->причины с изученной частотой->маленький доверительный интервал.
На словах звучит красиво, а на деле так складно не получается - явные причины встречаются редко, обычно поведение обусловлено десятками факторов. Но всё часто находятся причины, которые позволяют сузить вероятную частоту с 1-56% до более практичной.
Особенно в b2b продуктах - процессы клиента диктуют требования к продуктам, и маленькие выборки часто получается компенсировать типизацией клиентов и открытыми данными по ним.
👍33🔥11🤔1
Привет) Я попал в подборку каналов про продуктовые исследования (Костя, спасибо!)
Подборка хороша, здорово видеть в ней небольшие каналы, которые заслуживают больше читателей (аналитику на кубах, Улитина, и другие).
Представлюсь для новичков.
Я Макс Королёв, руководил исследованиями в Билайне и Акронисе, маркетингом в Genotek, сейчас продакт лид в TalentTech.
Про что я пишу:
1. Про редкие способы исследований: highlighter testing для контента, UX Curve для оценки длительного опыта
2. Исследовательские кейсы: headspace чинят онбординг дневниками, mozilla перепридумывают закладки, запрещая их
3. Связь UX и бизнеса: как дефицит курьеров повышает важность CX, как снижение госрегуляций повышает важность дизайна (на примере Athenahealth)
4. Процессы исследований в компаниях: Ableton, LinkedIn, Spotify, Atlassian и других.
5. Про странненькое: русалочность, манифест онтологического дизайна,
костыльное использование продукта как признак удобства.
Рад вопросам здесь, или в личке @Node_of_Ranvier
Подборка хороша, здорово видеть в ней небольшие каналы, которые заслуживают больше читателей (аналитику на кубах, Улитина, и другие).
Представлюсь для новичков.
Я Макс Королёв, руководил исследованиями в Билайне и Акронисе, маркетингом в Genotek, сейчас продакт лид в TalentTech.
Про что я пишу:
1. Про редкие способы исследований: highlighter testing для контента, UX Curve для оценки длительного опыта
2. Исследовательские кейсы: headspace чинят онбординг дневниками, mozilla перепридумывают закладки, запрещая их
3. Связь UX и бизнеса: как дефицит курьеров повышает важность CX, как снижение госрегуляций повышает важность дизайна (на примере Athenahealth)
4. Процессы исследований в компаниях: Ableton, LinkedIn, Spotify, Atlassian и других.
5. Про странненькое: русалочность, манифест онтологического дизайна,
костыльное использование продукта как признак удобства.
Рад вопросам здесь, или в личке @Node_of_Ranvier
Telegram
Research
Konstantin Efimov invites you to add the folder “Research”, which includes 15 chats.
❤36👍8🐳2
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать проблемы на автомате (не задумывался раньше, что схемы Найсера это же почти аугментации)
Ну так вот. Придумал формат - каждую неделю беру эвристику, и пытаюсь замечать её везде где можно - в цифровых продуктах, физических продуктах, и сервисах. Удачные и неудачные примеры кидаю в комменты или в чат.
Буду рад, если вы присоединитесь)
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать проблемы на автомате (не задумывался раньше, что схемы Найсера это же почти аугментации)
Ну так вот. Придумал формат - каждую неделю беру эвристику, и пытаюсь замечать её везде где можно - в цифровых продуктах, физических продуктах, и сервисах. Удачные и неудачные примеры кидаю в комменты или в чат.
Буду рад, если вы присоединитесь)
👍35🔥13
Неделя первой эвристики - видимость состояния системы
Про формат выше
Первая эвристика: The design should always keep users informed about what is going on, through appropriate feedback within a reasonable amount of time.
Вольный перевод - "пользователь может оперативно получить информацию о том, что происходит в системе, втч увидеть обратную связь на свои действия".
Трёхминутное видео Нильсена на тему, и хороший пример оттуда: при вызове лифта кнопка горит красным (фидбек, что мы вызвали его), а табло над лифтом показывает, что он начал движение, и находится на n-м этаже.
Накидывайте примеры)
Про формат выше
Первая эвристика: The design should always keep users informed about what is going on, through appropriate feedback within a reasonable amount of time.
Вольный перевод - "пользователь может оперативно получить информацию о том, что происходит в системе, втч увидеть обратную связь на свои действия".
Трёхминутное видео Нильсена на тему, и хороший пример оттуда: при вызове лифта кнопка горит красным (фидбек, что мы вызвали его), а табло над лифтом показывает, что он начал движение, и находится на n-м этаже.
Накидывайте примеры)
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
👍23❤8
Около месяца назад я анонсировал лето эвристик Нильсена, а потом пропал (спасибо тем 15 людям, что не отписались из чата за это время).
Я пропал, потому что тема показалась мне новичковой, и я застеснялся.
Как будто на литературной мастерской все обсуждают построение сюжетных арок и характера героев, а я вылез с историей про то, как новая клавиатура позволяет быстрее печатать. Здорово, конечно, но серьёзные специалисты обсуждают проблемы другого порядка.
Так что я застеснялся, что тема слишком базовая, и что в ней нет интеллектуальной претензии. Нет ни престижа новых областей (исследования в ML? Continuous research?) ни гордой бесполезности академических моделей.
Подзабытая, всем известная, пыльноватая тема.
Мне помог роман, который я сейчас читаю (рассечение Стоуна, хороший). В одном из эпизодов наставник главного героя, хирурга, заставляет его перевязывать узелки на хирургических швах. Узелки на швах - очень повседневная и всем известная вещь, но он прямо заморачивается над тем, как это важно.
Я не знаю, есть ли на самом деле прок в эвристиках, но давайте продолжим)
Я пропал, потому что тема показалась мне новичковой, и я застеснялся.
Как будто на литературной мастерской все обсуждают построение сюжетных арок и характера героев, а я вылез с историей про то, как новая клавиатура позволяет быстрее печатать. Здорово, конечно, но серьёзные специалисты обсуждают проблемы другого порядка.
Так что я застеснялся, что тема слишком базовая, и что в ней нет интеллектуальной претензии. Нет ни престижа новых областей (исследования в ML? Continuous research?) ни гордой бесполезности академических моделей.
Подзабытая, всем известная, пыльноватая тема.
Мне помог роман, который я сейчас читаю (рассечение Стоуна, хороший). В одном из эпизодов наставник главного героя, хирурга, заставляет его перевязывать узелки на хирургических швах. Узелки на швах - очень повседневная и всем известная вещь, но он прямо заморачивается над тем, как это важно.
Я не знаю, есть ли на самом деле прок в эвристиках, но давайте продолжим)
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
❤41🐳2
Вторая эвристика - соответствие между системой и реальным миром
Про формат выше
Как формулирует Нильсен: Systems should speak the users' language with familiar words, phrases, and concepts rather than system-oriented terms. Interfaces that follow real-world conventions and make information appear in a natural and logical order demonstrate empathy and acknowledgement for users.
Т.е.: система должна использовать понятный пользователью язык, и ещё должна использовать паттерны и конвенции реального мира.
Вот коротенькое видео на тему [Usability Heuristic 2: Match Between the System and the Real World (Video)](https://www.nngroup.com/videos/match-system-real-world/)
В изначальной статье Нильсена под "рельным миром" понимается "физический мир". И в такой трактовке эвристика кажется мне устаревшей, если честно. Немножко подробней в комментариях об этом напишу.
Про формат выше
Как формулирует Нильсен: Systems should speak the users' language with familiar words, phrases, and concepts rather than system-oriented terms. Interfaces that follow real-world conventions and make information appear in a natural and logical order demonstrate empathy and acknowledgement for users.
Т.е.: система должна использовать понятный пользователью язык, и ещё должна использовать паттерны и конвенции реального мира.
Вот коротенькое видео на тему [Usability Heuristic 2: Match Between the System and the Real World (Video)](https://www.nngroup.com/videos/match-system-real-world/)
В изначальной статье Нильсена под "рельным миром" понимается "физический мир". И в такой трактовке эвристика кажется мне устаревшей, если честно. Немножко подробней в комментариях об этом напишу.
Telegram
UX Research
Лето эвристик Нильсена
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
У меня проблема с эвристиками Нильсена.
Они мне нравятся, но я помню их очень приблизительно, и у меня нет привычки их применять.
А хочется прямо встроить их в перцептивный цикл, чтобы можно было "видеть через эвристики", и замечать…
❤13🔥5👍3
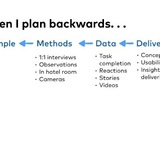
Как исследования экономят время разработки, и почему их лучше не разделять
Когда я только стал продактом, то думал, что будет примерно так: я буду исследовать клиентов и конкурентов, описывать требования, и отдавать разработке, а дальше оно всё будет разрабатываться само.
Короче, я буду отвечать за дискавери, а в деливери особо лезть не буду, там же уже есть проджект и тимлид. Так я на месяцы сорвал сроки запуска первых нескольких фичей.
Причин было несколько. Одна из них в том, что даже при хорошо описанных требованиях в процессе разработки возникает куча вопросов. Например:
- Как отрабатывать сообщения об ошибках? Допустим, какая-то форма может не работать по каким-то двум причинам. Вы можете вывести в тексте ошибки универсальный текст "не работает из-за причины x или y" или разработать штуку, коротая определяет, какая именно ошибка случилась, и выводит специфический текст (это доп. время разработки)
- Или если есть маловероятная ошибка, обрабатывать ли её? Например, "если новый пользователь является полным однофамильцем существующего, система не может его зарегистрировать". Мы хотим ли мы что-то с этим делать, или забиваем? (если хотим, то это доп. время разработки)
- А какую нужно закладывать гибкость на следующие итерации? Например, вы решили добавить пуш уведомления. А вы захотите потом историю пуш уведомлений, надо их хранить? А вдруг захотите потом кроме пушей сделать уведомления в вацап и смс, нужен какой-то единый центр нотификаций, и возможность добавлять каналы? (+время разработки)
- А вот вы хотите выводить список каких-нибудь сущностей. Надо сделать паджинацию списка на всякий случай? Вдруг сущностей будет больше ста? (+время разработки)
Часть таких вопросов можно продумать заранее, а часть нет - какие-то ограничения не видны до начала разработки, про какие-то технические возможности вы не знаете. Вопросы возникают по ходу.
Если их не отслеживать, можете оказаться в ситуации, когда в продукте закладывается ненужная гибкость, прорабатываются нерелевантные сценарии, и сроки съезжают. Так было у меня.
Спустя время я стал больше погружаться, и давать команде больше контекста по ходу работы, в том числе более явно подсвечивать, что важно делать, а куда погружаться не критично. И стал уточнять требования по ходу, по результатам исследований и аналитики.
Я сделал из этой истории несколько выводов (мб чуть тривиальных, но прожитых с опытом):
1. Что погружение продуктовой команды в сценарии и потребности пользователей позволяет экономить время в процессе разработки, отсекая неважные направления (раньше думал только с точки зрения ценности, а про сроки - нет).
2. Что погружение это нужно не только на старте (вот юзкейсы, вот сценарии, вот jtbd, поехали) а постоянно в процессе работы, т.к. всё время возникает много маленьких вопросов, о которых на берегу никто не подумал.
3. Что погружение должно быть push, а не pull, т.е. разработчик/дизайнер не всегда приходит с вопросом "не знаю, делать ли тут паджинацию, давайте в аналитике посмотрим, сколько тут может быть сущностей". Надо самому отлавливать такие точки принятия решений и закрывать их данным. Ну и учить команду замечать их, конечно.
4. Что из-за вот этих микровопросов и микроконтекстов очень важен быстрый доступ к знаниям о пользователе. В любом формате: продуктовая аналитика, continuous research, база инсайтов, user board, накопленная за счёт наблюдений экспертиза - нужен способ получить быстрый и относительно верный ответ на точечный вопрос.
5. Я сформулировал для себя идею сценарной/UX устойчивости напишу о ней чуть позже.
Когда я только стал продактом, то думал, что будет примерно так: я буду исследовать клиентов и конкурентов, описывать требования, и отдавать разработке, а дальше оно всё будет разрабатываться само.
Короче, я буду отвечать за дискавери, а в деливери особо лезть не буду, там же уже есть проджект и тимлид. Так я на месяцы сорвал сроки запуска первых нескольких фичей.
Причин было несколько. Одна из них в том, что даже при хорошо описанных требованиях в процессе разработки возникает куча вопросов. Например:
- Как отрабатывать сообщения об ошибках? Допустим, какая-то форма может не работать по каким-то двум причинам. Вы можете вывести в тексте ошибки универсальный текст "не работает из-за причины x или y" или разработать штуку, коротая определяет, какая именно ошибка случилась, и выводит специфический текст (это доп. время разработки)
- Или если есть маловероятная ошибка, обрабатывать ли её? Например, "если новый пользователь является полным однофамильцем существующего, система не может его зарегистрировать". Мы хотим ли мы что-то с этим делать, или забиваем? (если хотим, то это доп. время разработки)
- А какую нужно закладывать гибкость на следующие итерации? Например, вы решили добавить пуш уведомления. А вы захотите потом историю пуш уведомлений, надо их хранить? А вдруг захотите потом кроме пушей сделать уведомления в вацап и смс, нужен какой-то единый центр нотификаций, и возможность добавлять каналы? (+время разработки)
- А вот вы хотите выводить список каких-нибудь сущностей. Надо сделать паджинацию списка на всякий случай? Вдруг сущностей будет больше ста? (+время разработки)
Часть таких вопросов можно продумать заранее, а часть нет - какие-то ограничения не видны до начала разработки, про какие-то технические возможности вы не знаете. Вопросы возникают по ходу.
Если их не отслеживать, можете оказаться в ситуации, когда в продукте закладывается ненужная гибкость, прорабатываются нерелевантные сценарии, и сроки съезжают. Так было у меня.
Спустя время я стал больше погружаться, и давать команде больше контекста по ходу работы, в том числе более явно подсвечивать, что важно делать, а куда погружаться не критично. И стал уточнять требования по ходу, по результатам исследований и аналитики.
Я сделал из этой истории несколько выводов (мб чуть тривиальных, но прожитых с опытом):
1. Что погружение продуктовой команды в сценарии и потребности пользователей позволяет экономить время в процессе разработки, отсекая неважные направления (раньше думал только с точки зрения ценности, а про сроки - нет).
2. Что погружение это нужно не только на старте (вот юзкейсы, вот сценарии, вот jtbd, поехали) а постоянно в процессе работы, т.к. всё время возникает много маленьких вопросов, о которых на берегу никто не подумал.
3. Что погружение должно быть push, а не pull, т.е. разработчик/дизайнер не всегда приходит с вопросом "не знаю, делать ли тут паджинацию, давайте в аналитике посмотрим, сколько тут может быть сущностей". Надо самому отлавливать такие точки принятия решений и закрывать их данным. Ну и учить команду замечать их, конечно.
4. Что из-за вот этих микровопросов и микроконтекстов очень важен быстрый доступ к знаниям о пользователе. В любом формате: продуктовая аналитика, continuous research, база инсайтов, user board, накопленная за счёт наблюдений экспертиза - нужен способ получить быстрый и относительно верный ответ на точечный вопрос.
5. Я сформулировал для себя идею сценарной/UX устойчивости напишу о ней чуть позже.
👍32❤16
Всё встраивают ИИ (LLM) в свои продукты, и я тоже буду.
Интересно, что пространство решений +- понятно (даём пользователю в нужном контексте задать промпт и получить ответ), а вот пространство проблем (куда можно такое взаимодействие приткнуть) очень большое.
Составил для себя набор шагов, по которым пойду, поделюсь:
1. Составить список "работ", которые может закрывать LLM, не в моём продукте, а вообще. Этот список примерно понятен, соберу его из личного опыта и наблюдения за другими продуктами, погуглю.
2. Происследовать, в каких контекстах при взаимодействии с моим продуктом эти работы возникают (интервью, опрос, мб просто task analysis даже. Скорее на интервью остановлюсь)
3. Проскорить, какие из задач наиболее полезно упростить через LLM. Тут может быть любой подход для ранжирования: Кано, опросник TAM, всякие concept validation опросики. Вероятно, на входе буду давать либо описания на пару строк, либо статичные макеты (кажется, базовое взаимодействие с LLM уже понятно, и можно не прототипировать прямо жёстко, но будет понятней после интервью). Можно сделать дневниковое и попросить пользователей поиспользовать LLM для типичных задач недельку, и потом опросить про полезность. Ну не знаю.
4. Предсказательная сила у таких опросов низкая. Это способ отбросить очевидных аутсайдеров, или выявить лидеров настолько явных, что мы можем доверять их лидерству даже на метрике со слабой валидностью. Жду что отсеятся слабые варианты, а из сильных придётся выбирать финалиста самому :)
5. Можно ещё опросить, несколько часто и для каких задач пользователи уже используют LLM, и отскорить по этому признаку. Вроде идея норм, но не хочется почему-то, не интересно (ну и тут явный скос в early adopter-ов)
6. Вот и всё. Надеюсь, всё это позволит мне а)не делать совсем ерунду б)отойти от прямого копирования конкурентов
А есть, ещё два момента:
1. Это может быть эмоционально заряженной фичой, т.е. есть шанс, что кто-то из разработки будет готов запилить первую версию на коленке за выходные ради веселья. И в этом случае "давайте сначала поисследуем потребности" может обломать изначальный кураж, и бонус "фича бесплатно" я потеряю (мотивация команды разработки - отдельная большая тема. Я знаю, что интерес очень влияет и на сроки, и на качество разработки, и что исследованиями можно и разжигать этот интерес, показывая смысл и ценность продукта, и гасить, превращая всё в болото. Но пока я не очень хорош в этом, разберусь, напишу пост).
2. Это может быть политически заряженной фичой, т.е. может быть её нужно выпустить за две недели, чтобы получить PR повод "первая в мире штучка с ИИ", или получить доп инвестиции, или чтобы у продаж был классные слайд в презе для роста конверсии из первой встречи Это потёмкинские деревни, когда нужно быстро сделать для галочки, а уже потом союз будет сделать нормально. Я такое не очень люблю, но такой контекст случается. К счастью, у меня сейчас не так)
Интересно, что пространство решений +- понятно (даём пользователю в нужном контексте задать промпт и получить ответ), а вот пространство проблем (куда можно такое взаимодействие приткнуть) очень большое.
Составил для себя набор шагов, по которым пойду, поделюсь:
1. Составить список "работ", которые может закрывать LLM, не в моём продукте, а вообще. Этот список примерно понятен, соберу его из личного опыта и наблюдения за другими продуктами, погуглю.
2. Происследовать, в каких контекстах при взаимодействии с моим продуктом эти работы возникают (интервью, опрос, мб просто task analysis даже. Скорее на интервью остановлюсь)
3. Проскорить, какие из задач наиболее полезно упростить через LLM. Тут может быть любой подход для ранжирования: Кано, опросник TAM, всякие concept validation опросики. Вероятно, на входе буду давать либо описания на пару строк, либо статичные макеты (кажется, базовое взаимодействие с LLM уже понятно, и можно не прототипировать прямо жёстко, но будет понятней после интервью). Можно сделать дневниковое и попросить пользователей поиспользовать LLM для типичных задач недельку, и потом опросить про полезность. Ну не знаю.
4. Предсказательная сила у таких опросов низкая. Это способ отбросить очевидных аутсайдеров, или выявить лидеров настолько явных, что мы можем доверять их лидерству даже на метрике со слабой валидностью. Жду что отсеятся слабые варианты, а из сильных придётся выбирать финалиста самому :)
5. Можно ещё опросить, несколько часто и для каких задач пользователи уже используют LLM, и отскорить по этому признаку. Вроде идея норм, но не хочется почему-то, не интересно (ну и тут явный скос в early adopter-ов)
6. Вот и всё. Надеюсь, всё это позволит мне а)не делать совсем ерунду б)отойти от прямого копирования конкурентов
А есть, ещё два момента:
1. Это может быть эмоционально заряженной фичой, т.е. есть шанс, что кто-то из разработки будет готов запилить первую версию на коленке за выходные ради веселья. И в этом случае "давайте сначала поисследуем потребности" может обломать изначальный кураж, и бонус "фича бесплатно" я потеряю (мотивация команды разработки - отдельная большая тема. Я знаю, что интерес очень влияет и на сроки, и на качество разработки, и что исследованиями можно и разжигать этот интерес, показывая смысл и ценность продукта, и гасить, превращая всё в болото. Но пока я не очень хорош в этом, разберусь, напишу пост).
2. Это может быть политически заряженной фичой, т.е. может быть её нужно выпустить за две недели, чтобы получить PR повод "первая в мире штучка с ИИ", или получить доп инвестиции, или чтобы у продаж был классные слайд в презе для роста конверсии из первой встречи Это потёмкинские деревни, когда нужно быстро сделать для галочки, а уже потом союз будет сделать нормально. Я такое не очень люблю, но такой контекст случается. К счастью, у меня сейчас не так)
❤6🔥3