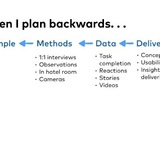
Я тут благородаря Саше (спасибо, Саша) задумался, как я вижу идеальную организацию UX research в компании.
Это ретроградная реакционная самотерапевтическая заметка, сори заранее.
Первое, что приходит в голову, когда думаешь про идеальную организацию исследований - посмотреть, как делают известные команды - Facebook, Airbnb, Lyft, Atlassian, кто ещё светится на рынке? Я немного писал об этом, и вот собрал всё в кучу https://bit.ly/2MraQjV (но сейчас не о ней).
Тренды понятны - ресёч опс, дизайн мышление и уход в сторону придумывания решений, обучение дизайнеров и распределение исследовательских компетенций, база инсайтов, совмещение quantitative и qualitative research, исследования в необычных контекстах/с экстремальными сегментами и т.д.
Но я думаю вот о чём, на ранних этапах развития исследований важно всё это выкинуть из головы. Забить на базы знаний в airtable, экспириенс семплинг, кано, гомс, и экстремальных пользователей. Проводить много-много юзабилити-тестирований и интервью, звать побольше людей в наблюдатели, и не заморачиваться.
Это кажется очевидной идеей, но я думаю, есть большая группа исследователей вроде меня, которым кажется, что просто проводить юзабилити-тестирования это не комильфо, не для того мы университеты кончали и работали в агенствах с дикими проектами. Надо всё время придумывать что-то заковыристое, изощрённое. Сложно свыкнуться с тем, что для 90% задач достаточно интервью (можно даже без слова "глубинное") и экселя.
Но это так.
Мне тут кажется уместной аналогия с примером Егора Данилова о машин лёрнинг для маленьких стартапов https://t.me/betternotworse/22. Сначала сделайте простую рабочую систему, а потом оптимизируйте её. (Знаю, многовато ссылок не по теме, но я только дочитал "Бесконечную шутку" и отыгрываюсь на вас).
В большинстве случаев простая рабочая система состоит из кучи интервью, юзабилити-тестирований и наблюдений.
А простая метрика для процесса исследований в начале - трафик исследований - количество участников команды (менеджеров, дизайнеров, разработчиков), которые побывали на сессиях и лично посмотрели на то, как люди работают с продуктом. Метрика набивается очень просто - нужно больше сессий и больше людей на каждой. Набьёте трафик, можно будет оптимизировать конверсию в продуктовые изменения, думать про хранение инсайтов, расширение методического репертуара и вот это всё. А пока забейте.
Это ретроградная реакционная самотерапевтическая заметка, сори заранее.
Первое, что приходит в голову, когда думаешь про идеальную организацию исследований - посмотреть, как делают известные команды - Facebook, Airbnb, Lyft, Atlassian, кто ещё светится на рынке? Я немного писал об этом, и вот собрал всё в кучу https://bit.ly/2MraQjV (но сейчас не о ней).
Тренды понятны - ресёч опс, дизайн мышление и уход в сторону придумывания решений, обучение дизайнеров и распределение исследовательских компетенций, база инсайтов, совмещение quantitative и qualitative research, исследования в необычных контекстах/с экстремальными сегментами и т.д.
Но я думаю вот о чём, на ранних этапах развития исследований важно всё это выкинуть из головы. Забить на базы знаний в airtable, экспириенс семплинг, кано, гомс, и экстремальных пользователей. Проводить много-много юзабилити-тестирований и интервью, звать побольше людей в наблюдатели, и не заморачиваться.
Это кажется очевидной идеей, но я думаю, есть большая группа исследователей вроде меня, которым кажется, что просто проводить юзабилити-тестирования это не комильфо, не для того мы университеты кончали и работали в агенствах с дикими проектами. Надо всё время придумывать что-то заковыристое, изощрённое. Сложно свыкнуться с тем, что для 90% задач достаточно интервью (можно даже без слова "глубинное") и экселя.
Но это так.
Мне тут кажется уместной аналогия с примером Егора Данилова о машин лёрнинг для маленьких стартапов https://t.me/betternotworse/22. Сначала сделайте простую рабочую систему, а потом оптимизируйте её. (Знаю, многовато ссылок не по теме, но я только дочитал "Бесконечную шутку" и отыгрываюсь на вас).
В большинстве случаев простая рабочая система состоит из кучи интервью, юзабилити-тестирований и наблюдений.
А простая метрика для процесса исследований в начале - трафик исследований - количество участников команды (менеджеров, дизайнеров, разработчиков), которые побывали на сессиях и лично посмотрели на то, как люди работают с продуктом. Метрика набивается очень просто - нужно больше сессий и больше людей на каждой. Набьёте трафик, можно будет оптимизировать конверсию в продуктовые изменения, думать про хранение инсайтов, расширение методического репертуара и вот это всё. А пока забейте.
Telegraph
UX исследования в разных компаниях
Вот как в Фейсбуке https://t.me/uxread/71 В Airbnb https://t.me/uxread/35 В Atlassian https://t.me/uxread/39 Ещё классное: У Airbnb выделеные research ops, survey sience и marketing research отделы. У Shopify 55 человек в research team. Есть система peer…
Я немного злюсь, когда обсуждают игру про страшную онлайн-форму, потому что с одной стороны да, наглядная иллюстрация UX проблем, а с другой, ну блин, давайте ещё пять раз проговорим, что правильная семантика элементов важна, что главный CTA надо выделять, что подписи к полям должны быть хорошо видны и лучше делать их снаружи, а потом ещё посмеёмся над сайтом федерации настольного тенниса Башкоторстана.
А злит меня это потому, что это опять топтание на базовом уровне форм и кнопок. Ну камон, ребята, ну хватит уже, для нормальной формы уже даже не нужны ни исследования, ни изобретательность, достаточно прочитать книжку по web form design, взять готовый движок с нормальными паттернами, и немного думать при проектировании. Да, есть жуткие примеры настоящих сайтов с лютыми паттернами, но обычно проблема там не в том, что все идиоты и не в курсе, как подписывать поля, а немного глубже (тех долг, организационные проблемы, просто всем плевать на канал, который не приносит денег ит.д.).
Но большая часть людей пройдут тест, подумают "вот это треш, боже, слава богу, у нас в 10 раз лучше" и пойдут дальше аккуратненько рисовать форму, которой вообще не должно быть, но которая существует, потому что процесс кривой и непродуманный. Или будут считать, что работа дизайнера и исследователя заключается в том, чтобы догадаться подчеркнуть ссылочку. Отсюда начинается моё любимое "у нас дизайн уже очень хороший, нам над смыслом надо поработать, над тем, как это устроено", под которым подразумевается "у нас хорошо работают маски в полях и в целом всё красивенько".
(я зануда, но как-то очень уж в лоб, ну правда)
А злит меня это потому, что это опять топтание на базовом уровне форм и кнопок. Ну камон, ребята, ну хватит уже, для нормальной формы уже даже не нужны ни исследования, ни изобретательность, достаточно прочитать книжку по web form design, взять готовый движок с нормальными паттернами, и немного думать при проектировании. Да, есть жуткие примеры настоящих сайтов с лютыми паттернами, но обычно проблема там не в том, что все идиоты и не в курсе, как подписывать поля, а немного глубже (тех долг, организационные проблемы, просто всем плевать на канал, который не приносит денег ит.д.).
Но большая часть людей пройдут тест, подумают "вот это треш, боже, слава богу, у нас в 10 раз лучше" и пойдут дальше аккуратненько рисовать форму, которой вообще не должно быть, но которая существует, потому что процесс кривой и непродуманный. Или будут считать, что работа дизайнера и исследователя заключается в том, чтобы догадаться подчеркнуть ссылочку. Отсюда начинается моё любимое "у нас дизайн уже очень хороший, нам над смыслом надо поработать, над тем, как это устроено", под которым подразумевается "у нас хорошо работают маски в полях и в целом всё красивенько".
(я зануда, но как-то очень уж в лоб, ну правда)
Канеман про работу памяти, дневниковые исследования и оптимальное время для опросов
Ну ладно, зато вот немного о том, как работа памяти влияет на дневниковые исследования, я почему-то не задумывался об этом раньше.
Часть данных из Канемана, часть отсюда https://academic.oup.com/iwc/article/23/5/473/660020 (Паша, спасибо за статью)
1) Опыт человека и воспоминания об этом опыте различаются. Люди обычно лучше всего запоминают пиковый момент и финал события (в нашем случае - взаимодействия с сервисом). Поэтому, если мы хотим в деталях узнать, как люди что-то делают, как часто у них возникает какая-то потребность и вообще получить подробное представление об их опыте, то лучше делать experience sampling и просить зафиксировать опыт по ходу, потом респонденты не вспомнят половину деталей.
2) Но тут самое интересное: выбор человека строится не на основе реального опыта, а на основе воспоминаний об этом опыте и о принятых ранее решениях. Условно, мы идём в Старбакс не потому что нам в прошлый раз там понравилось, а потому что помним, что в прошлый раз зашли (пример то ли из Канемана, то ли из Ариэли).
3) Более того, впечатления, которыми мы поделились с другими, влияют на наше будущее поведение больше, чем реальный опыт, потому что реальный опыт мы не очень-то помним. И поэтому ретроспективная оценка опыта предсказывает последующее поведение человека лучше, чем рейтинг сразу "на месте", мой рассказал о Старбаксе спустя пару дней предсказывает моё следующее посещение лучше, чем оценка НПС сразу выходе (НЕУЖЕЛИ НПС БУДЕТ ЛУЧШЕ ПРЕДСКАЗЫВАТЬ ОТТОК, ЕСЛИ ЗАМЕРЯТЬ ЕГО НА СЛЕДУЮЩИЙ ДЕНЬ? ШОК!).
4) То есть если нам нужно узнать больше о самом опыте, лучше просить людей давать самоотчёты сразу (эксприенс семплинг и дёргаем всех через приложение/мессенджер), а если мы хотим оценить возможный ретешн, то ретроспективно, спустя день/в конце недели (классический дневничок).
___
Ещё по теме:
https://t.me/uxread/68 Head of behavior science в Google
https://t.me/uxread/137 как имплицитное чувство вины за потребление мешает покупать красивые вещи (связка anticipatory guilt и hedonic consumption) (линк на там и атенахелз, потому что атенахелз становятся красивыми)
https://t.me/uxread/130 UX curve как опыт исследования опыт в динамике, дешёвая замена дневников
https://t.me/uxread/138 спекуляции на тему "как в разных культурах могут относиться к hedonic systems"
Больше "околонаучных" заметок по тегу
#Science
Ну ладно, зато вот немного о том, как работа памяти влияет на дневниковые исследования, я почему-то не задумывался об этом раньше.
Часть данных из Канемана, часть отсюда https://academic.oup.com/iwc/article/23/5/473/660020 (Паша, спасибо за статью)
1) Опыт человека и воспоминания об этом опыте различаются. Люди обычно лучше всего запоминают пиковый момент и финал события (в нашем случае - взаимодействия с сервисом). Поэтому, если мы хотим в деталях узнать, как люди что-то делают, как часто у них возникает какая-то потребность и вообще получить подробное представление об их опыте, то лучше делать experience sampling и просить зафиксировать опыт по ходу, потом респонденты не вспомнят половину деталей.
2) Но тут самое интересное: выбор человека строится не на основе реального опыта, а на основе воспоминаний об этом опыте и о принятых ранее решениях. Условно, мы идём в Старбакс не потому что нам в прошлый раз там понравилось, а потому что помним, что в прошлый раз зашли (пример то ли из Канемана, то ли из Ариэли).
3) Более того, впечатления, которыми мы поделились с другими, влияют на наше будущее поведение больше, чем реальный опыт, потому что реальный опыт мы не очень-то помним. И поэтому ретроспективная оценка опыта предсказывает последующее поведение человека лучше, чем рейтинг сразу "на месте", мой рассказал о Старбаксе спустя пару дней предсказывает моё следующее посещение лучше, чем оценка НПС сразу выходе (НЕУЖЕЛИ НПС БУДЕТ ЛУЧШЕ ПРЕДСКАЗЫВАТЬ ОТТОК, ЕСЛИ ЗАМЕРЯТЬ ЕГО НА СЛЕДУЮЩИЙ ДЕНЬ? ШОК!).
4) То есть если нам нужно узнать больше о самом опыте, лучше просить людей давать самоотчёты сразу (эксприенс семплинг и дёргаем всех через приложение/мессенджер), а если мы хотим оценить возможный ретешн, то ретроспективно, спустя день/в конце недели (классический дневничок).
___
Ещё по теме:
https://t.me/uxread/68 Head of behavior science в Google
https://t.me/uxread/137 как имплицитное чувство вины за потребление мешает покупать красивые вещи (связка anticipatory guilt и hedonic consumption) (линк на там и атенахелз, потому что атенахелз становятся красивыми)
https://t.me/uxread/130 UX curve как опыт исследования опыт в динамике, дешёвая замена дневников
https://t.me/uxread/138 спекуляции на тему "как в разных культурах могут относиться к hedonic systems"
Больше "околонаучных" заметок по тегу
#Science
OUP Academic
UX Curve: A method for evaluating long-term user experience Free
Abstract. The goal of user experience design in industry is to improve customer satisfaction and loyalty through the utility, ease of use, and pleasure pro
И теперь понятно, что инстаграмность места влияет не только на привлечение новых людей, но и на возврат побывавших: "если я оттуда постил, что мне понравилось, значит мне понравилось".
А ещё из этих ограничений следует два забавных дневниковых метода, которые я раньше не видел и не использовал.
1) Если важен всё-таки опыт и детали деятельности, а не впечатление, то Канеман с командой (и видимо он правда приложился, указан первым автором) разработали супер протокол "Day Reconstruction Method", который вроде как экспириенс семплинг, но показывает "lower respondent burden than typical for experience sampling methods, more complete coverage of the day than typical for experience sampling methods, lower susceptibility to retrospective reporting biases than typical for global reports of daily experiences". Я его не применял, и он кажется тяжеловесным для коммерческих исследований в моей области, но может и нет. http://www.midss.org/content/day-reconstruction-method-drc
2) А если важно оценить ретроспективное впечатление и понять, какие эпизоды вспоминаются как неприятные (и влияют на ретешн), то есть супер простой и симпатичный метод - UX curve, такой CJM на коленке. Пользователю дают шаблон (он ниже) и инструкцию "Вспомните, как вы начали использовать наш продукт. Нарисуйте график, который показывает, как ваше отношение к продукту менялось, начиная с первого использования и до текущего момента". В рамках одного шаблона можно попросить нарисовать несколько кривых относительно разных шкал - просторы использования, привлекательности, полезности итд. https://www.researchgate.net/figure/The-UX-Curve-template-used-in-the-study-Translated-from-Finnish_fig1_268049461, или вот пересказ на медиуме https://medium.com/@rajulsingh/ux-curve-a-method-for-evaluating-long-term-user-experience-cc5e0e146c6d
А ещё из этих ограничений следует два забавных дневниковых метода, которые я раньше не видел и не использовал.
1) Если важен всё-таки опыт и детали деятельности, а не впечатление, то Канеман с командой (и видимо он правда приложился, указан первым автором) разработали супер протокол "Day Reconstruction Method", который вроде как экспириенс семплинг, но показывает "lower respondent burden than typical for experience sampling methods, more complete coverage of the day than typical for experience sampling methods, lower susceptibility to retrospective reporting biases than typical for global reports of daily experiences". Я его не применял, и он кажется тяжеловесным для коммерческих исследований в моей области, но может и нет. http://www.midss.org/content/day-reconstruction-method-drc
2) А если важно оценить ретроспективное впечатление и понять, какие эпизоды вспоминаются как неприятные (и влияют на ретешн), то есть супер простой и симпатичный метод - UX curve, такой CJM на коленке. Пользователю дают шаблон (он ниже) и инструкцию "Вспомните, как вы начали использовать наш продукт. Нарисуйте график, который показывает, как ваше отношение к продукту менялось, начиная с первого использования и до текущего момента". В рамках одного шаблона можно попросить нарисовать несколько кривых относительно разных шкал - просторы использования, привлекательности, полезности итд. https://www.researchgate.net/figure/The-UX-Curve-template-used-in-the-study-Translated-from-Finnish_fig1_268049461, или вот пересказ на медиуме https://medium.com/@rajulsingh/ux-curve-a-method-for-evaluating-long-term-user-experience-cc5e0e146c6d
www.midss.org
The Day Reconstruction Method (DRC) | Measurement Instrument Database for the Social Sciences
The Day Reconstruction Method (DRM) assesses how people spend their time and how they experience the various activities and settings of their lives, combining features of time-budget measurement and experience sampling.
База инсайтов Майкрософт
Про библиотеку инсайтов Microsoft - the Human Insights System (HITS)
https://medium.com/microsoft-design/how-microsofts-human-insights-library-creates-a-living-body-of-knowledge-fff54e53f5ec
Сначала про процессы вокруг, потом про саму базу.
Про культуру, смысл и процессы:
- Ценность базы в том, что результаты исследований перестают быть одноразовыми и превращаются в timeless knowlege, их можно использовать на следующих проектах. Это повышает качество продукта, и увеличивает долговременный ROI исследований.
- Сценарий использования выглядит так: дизайнер спрашивает у исследователя "слушай, а пуши в таком контексте не будут раздражать пользователя?", исследователь смотрит в базу, видит, что что-то подобное два года назад уже проверяли, и выдаёт ответ через две минуты.
- вносить результаты в базу после исследования всех бесит, поэтому придумали фокус - её заполняют сразу по ходу исследования, сценарий и протокол сразу ведут в ней. Т.е. в начале исследования ресёчер вносит в базу знаний гипотезы, а потом по ходу сессий помечает, какие появились данные, подтверждающие или опровергающие их. У WeWork тоже была похожая попытка затянуть в библиотеку инсайтов все стадии процесса исследования, потому что иначе на отдельное хранилище все забивают. Я в своей работе пришёл к тому же.
- Так как протокол ведут там же, то в базе остаются и подтверждённые, и опровергнутые гипотезы.
- За хранилище отвечает выделенный человек. Пересекается с рассказом Якубенкова о том, что в Facebook есть отдельная группа людей, которая следит за порядком в датасетах.
- Нигде больше не встречал - очень много кросс-ссылок между инсайтами. Он пишет, что это ссылки, которые делают сами исследователи, когда подкрепляют свои инсайты другими: "When someone pulls up an insight through a search, they can see how much evidence supports it and trace that insight back to its source.", но я пока не понял, как это работает у них (иллюстрация ниже).
Как устроена сама база:
- Внизу скрин системы и схема того, как она выглядит. Структурирование через фильтры по темам, по продукту, по дате, исследователю, типу контента + есть поиск. Может ещё сделают рекомендательные подборки, было бы норм :)
- Судя по картинке ниже, это не просто база атомарных инсайтов, как у WeWork в airtable, там в перемешку лежат исследования, рекомендации, инсайты, коллекции и сами гипотезы (выглядит довольно разнопланово, но ок)
Коллекции - судя по всему, это коллекции высокоуровневых знаний о поведении пользователей (условно, о том, как люди в целом строят графики в экселе)
(Тут хочется вставить ремарку, что люди меняются, паттерны меняются, и старые инсайты на складе протухают, поэтому важно сначала научиться быстро отгружать свеженькие открытия менеджерам, сделать continuous и lean research, запустить рассылочки с результатами на всех и вовлекать команду в исследования, а потом уже делать крутое хранилище результатов и строить fundamental knowledge (если только вы не Норман). Я когда-то пытался сделать наоборот и пожалел :))
___
Ещё про базы инсайтов
https://t.me/uxread/38 Мейлчимп сделали базу инсайтов о пользователях в Evernote в 2013-м году
https://t.me/uxread/44 Tomer Sharon из WeWork первым сделал базу инсайтов на Airtable, на которую мы все теперь равняемся
https://t.me/uxread/127 как мы в Acronis вели базу 2 года, и почему разочаровались
https://t.me/uxread/118 что класть в базу инсайтов, а что - нет
https://t.me/uxread/148 полнотекстовые транскрипты интервью через связку zoom+otter как замена базе инсайтов
#Bases
Про библиотеку инсайтов Microsoft - the Human Insights System (HITS)
https://medium.com/microsoft-design/how-microsofts-human-insights-library-creates-a-living-body-of-knowledge-fff54e53f5ec
Сначала про процессы вокруг, потом про саму базу.
Про культуру, смысл и процессы:
- Ценность базы в том, что результаты исследований перестают быть одноразовыми и превращаются в timeless knowlege, их можно использовать на следующих проектах. Это повышает качество продукта, и увеличивает долговременный ROI исследований.
- Сценарий использования выглядит так: дизайнер спрашивает у исследователя "слушай, а пуши в таком контексте не будут раздражать пользователя?", исследователь смотрит в базу, видит, что что-то подобное два года назад уже проверяли, и выдаёт ответ через две минуты.
- вносить результаты в базу после исследования всех бесит, поэтому придумали фокус - её заполняют сразу по ходу исследования, сценарий и протокол сразу ведут в ней. Т.е. в начале исследования ресёчер вносит в базу знаний гипотезы, а потом по ходу сессий помечает, какие появились данные, подтверждающие или опровергающие их. У WeWork тоже была похожая попытка затянуть в библиотеку инсайтов все стадии процесса исследования, потому что иначе на отдельное хранилище все забивают. Я в своей работе пришёл к тому же.
- Так как протокол ведут там же, то в базе остаются и подтверждённые, и опровергнутые гипотезы.
- За хранилище отвечает выделенный человек. Пересекается с рассказом Якубенкова о том, что в Facebook есть отдельная группа людей, которая следит за порядком в датасетах.
- Нигде больше не встречал - очень много кросс-ссылок между инсайтами. Он пишет, что это ссылки, которые делают сами исследователи, когда подкрепляют свои инсайты другими: "When someone pulls up an insight through a search, they can see how much evidence supports it and trace that insight back to its source.", но я пока не понял, как это работает у них (иллюстрация ниже).
Как устроена сама база:
- Внизу скрин системы и схема того, как она выглядит. Структурирование через фильтры по темам, по продукту, по дате, исследователю, типу контента + есть поиск. Может ещё сделают рекомендательные подборки, было бы норм :)
- Судя по картинке ниже, это не просто база атомарных инсайтов, как у WeWork в airtable, там в перемешку лежат исследования, рекомендации, инсайты, коллекции и сами гипотезы (выглядит довольно разнопланово, но ок)
Коллекции - судя по всему, это коллекции высокоуровневых знаний о поведении пользователей (условно, о том, как люди в целом строят графики в экселе)
(Тут хочется вставить ремарку, что люди меняются, паттерны меняются, и старые инсайты на складе протухают, поэтому важно сначала научиться быстро отгружать свеженькие открытия менеджерам, сделать continuous и lean research, запустить рассылочки с результатами на всех и вовлекать команду в исследования, а потом уже делать крутое хранилище результатов и строить fundamental knowledge (если только вы не Норман). Я когда-то пытался сделать наоборот и пожалел :))
___
Ещё про базы инсайтов
https://t.me/uxread/38 Мейлчимп сделали базу инсайтов о пользователях в Evernote в 2013-м году
https://t.me/uxread/44 Tomer Sharon из WeWork первым сделал базу инсайтов на Airtable, на которую мы все теперь равняемся
https://t.me/uxread/127 как мы в Acronis вели базу 2 года, и почему разочаровались
https://t.me/uxread/118 что класть в базу инсайтов, а что - нет
https://t.me/uxread/148 полнотекстовые транскрипты интервью через связку zoom+otter как замена базе инсайтов
#Bases
Medium
How Microsoft’s Human Insights Library Creates a Living Body of Knowledge
HITS enables researchers and product teams to unlock their collective UX power
Внезапно понял, что персоны пользователей это мемы.
Именно поэтому они такие живучие, и именно поэтому хочется вставлять в описание персон дурацкие подробности - иначе мем не разойдётся.
Соответственно в хорошем (есть и такие, ещё напишу об этом) описании персоны есть часть с полезной информацией, которая помогает при принятии решений, и есть виральная часть, которая позволяет информации распространяться.
А у плохих персон репликационная часть большая, а в информационной ничего нет.
И поэтому придумывать персон всем нравится больше, чем очень полезные, но не особо виральные jtbd, это же как коубы нарезать.
___
Ещё про презентацию инсайтов
https://t.me/uxread/40 Uber Eats сняли 360 видео про работу курьера чтобы вовлечь команду
https://t.me/uxread/71 - Facebook рассказывают про другие способы презентации результатов
#Presentation
Именно поэтому они такие живучие, и именно поэтому хочется вставлять в описание персон дурацкие подробности - иначе мем не разойдётся.
Соответственно в хорошем (есть и такие, ещё напишу об этом) описании персоны есть часть с полезной информацией, которая помогает при принятии решений, и есть виральная часть, которая позволяет информации распространяться.
А у плохих персон репликационная часть большая, а в информационной ничего нет.
И поэтому придумывать персон всем нравится больше, чем очень полезные, но не особо виральные jtbd, это же как коубы нарезать.
___
Ещё про презентацию инсайтов
https://t.me/uxread/40 Uber Eats сняли 360 видео про работу курьера чтобы вовлечь команду
https://t.me/uxread/71 - Facebook рассказывают про другие способы презентации результатов
#Presentation
Telegram
UX Research
Uber Eats сняли 360 видео про работу курьера чтобы вовлечь команду
Во-вторых, статья от исследователя из Uber Eats под громким названием "Using virtual reality to build empathy in distributed organizations".
Ron Goldin исследовал работу курьера Uber Eats…
Во-вторых, статья от исследователя из Uber Eats под громким названием "Using virtual reality to build empathy in distributed organizations".
Ron Goldin исследовал работу курьера Uber Eats…
Друзья, я ищу участников на 15-минутое исследование (онлайн, сегодня или завтра утром). Мне нужны люди, которые сидят в огромных групповых чатиках (рабочих, дружеских, родительских - не важно), отправляет или получает голосовые сообщения, а также слушает музыку в ВК.
С меня приятная беседа и какой-нибудь совет по ресёчу, могу помочь спланировать исследование, выбрать метод или подсказать статью на нужную тему (я не гуру юзабилити, но немного шарю).
Записываться тут https://calendly.com/maxim-korolev/chatsandvoices
С меня приятная беседа и какой-нибудь совет по ресёчу, могу помочь спланировать исследование, выбрать метод или подсказать статью на нужную тему (я не гуру юзабилити, но немного шарю).
Записываться тут https://calendly.com/maxim-korolev/chatsandvoices
Да, оказывается в calendly по-умолчанию стоит настройка, которая не позволяет записываться на сейчас (Minimum Scheduling Notice в Advanced Settings), так что если вы готовы сегодня, но не нашли свободного таймслота, то теперь они есть)
Написал статью о том, как планирую сложные исследования http://bit.ly/2XOXdvt
____
Другие фреймворки для мышления об исследованиях
https://t.me/uxread/145 как структурированно продумывать гипотезы для аналитики
https://t.me/uxread/87 feature canvas для планирования работы над фичей
#Frameworks
____
Другие фреймворки для мышления об исследованиях
https://t.me/uxread/145 как структурированно продумывать гипотезы для аналитики
https://t.me/uxread/87 feature canvas для планирования работы над фичей
#Frameworks
Medium
Фреймворки для планирования продуктовых и UX исследований.
Задача исследователя — отвечать на вопросы бизнеса.
ИКЕА классно спрашивают про human experience
IKEA регулярно проводит исследования на темы, связанные с домом. В 2018-м это был опрос "where the feeling of home really comes from" - откуда появляется чувство дома, как оно создаётся?
Они опросили 22 тысячи человек на 22 разных рынках, и сделали отчёт.
Узнали, что 35% людей чувствуют себя дома не там, где живут, а где-то ещё (и эта цифра выросла с 2016-го), и ещё много интересного.
В этом году спрашивают про privacy, пройти опрос и посмотреть результаты можно здесь https://lifeathome.ikea.com/tool/
Так во всей серии опросов, каждый год вместо "как мы могли бы улучшить магазины и стул ПОЭНГ" спрашивают про человека (cheloveka, хаха) и его опыт. Это немного напоминает кейс Google с experience sampling (https://t.me/uxread/47), где тоже смотрели не на сам поиск, а на людей и их потребности в информации.
Мне нравятся проекты такого рода, где фокус внимания выносится из продукта на людей.
Сама идея общеизвестна, все знают, что надо спрашивать не про решение а про проблемы и т.д., но элегантных примеров мало (ну и IKEA ещё немного дальше/глубже пошли, в сторону semiotical research, в которых я ничего не понимаю, и которые мне издалека нравятся).
И ещё, это хороший кейс о том, как превратить исследование в PR проект.
Все отчёты, начиная с 2014-го https://lifeathome.ikea.com/reports/previous-reports/
___
Другие забавные исследования
https://t.me/uxread/41 как парные юзабилити-тестирования (с двумя респондентами одновременно) позволяют глубже понять ментальную модель пользователя
https://t.me/uxread/16 - Интерком про точечные интервью с пользователями, совершившим определенное действие на сайте
https://t.me/uxread/47 Как Google в 2011 делали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
Другие кейсы: #Cases
Другие методы: #Methods
IKEA регулярно проводит исследования на темы, связанные с домом. В 2018-м это был опрос "where the feeling of home really comes from" - откуда появляется чувство дома, как оно создаётся?
Они опросили 22 тысячи человек на 22 разных рынках, и сделали отчёт.
Узнали, что 35% людей чувствуют себя дома не там, где живут, а где-то ещё (и эта цифра выросла с 2016-го), и ещё много интересного.
В этом году спрашивают про privacy, пройти опрос и посмотреть результаты можно здесь https://lifeathome.ikea.com/tool/
Так во всей серии опросов, каждый год вместо "как мы могли бы улучшить магазины и стул ПОЭНГ" спрашивают про человека (cheloveka, хаха) и его опыт. Это немного напоминает кейс Google с experience sampling (https://t.me/uxread/47), где тоже смотрели не на сам поиск, а на людей и их потребности в информации.
Мне нравятся проекты такого рода, где фокус внимания выносится из продукта на людей.
Сама идея общеизвестна, все знают, что надо спрашивать не про решение а про проблемы и т.д., но элегантных примеров мало (ну и IKEA ещё немного дальше/глубже пошли, в сторону semiotical research, в которых я ничего не понимаю, и которые мне издалека нравятся).
И ещё, это хороший кейс о том, как превратить исследование в PR проект.
Все отчёты, начиная с 2014-го https://lifeathome.ikea.com/reports/previous-reports/
___
Другие забавные исследования
https://t.me/uxread/41 как парные юзабилити-тестирования (с двумя респондентами одновременно) позволяют глубже понять ментальную модель пользователя
https://t.me/uxread/16 - Интерком про точечные интервью с пользователями, совершившим определенное действие на сайте
https://t.me/uxread/47 Как Google в 2011 делали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
Другие кейсы: #Cases
Другие методы: #Methods
🔥1
Исследования в Spotify - mixed research и смешанный департамент product insights
https://spotify.design/articles/2018-12-05/cross-disciplinary-insights-teams-integrating-data-scientists-and-user-researchers-at-spotify/
(новая ссылка https://www.epicpeople.org/cross-disciplinary-insights-teams-integrating-data-scientists-and-user-researchers-at-spotify/)
Spotify в первую очередь про фоновый опыт, плейлист является фоном для контекста, поэтому исследуют не "каково пользователю работать в спотифае", а "каково жить с включенным в наушниках плейлистом", упор не только на интерфейс плеера, но и на то, как музыка воспринимается в разном окружении.
Отсюда большая любовь к глубинным исследованиям: они изучают, почему вообще люди слушают музыку, как они ощущают "good listening experience", как контекст влияет на восприятие плейлиста и как это понимание переводить в ML модели, которые генерят плейлисты. Прямо пишут, что стараются перейти from a core focus of understanding explicit user interactions to understanding implicit motivation and contextual expectations (как Икея и Гугл в прошлом посте). Звучит здорово, но не хватает примеров.
Всем этим занимается объединенная команда "product insights" из исследователей и аналитиков (data scientists). Кроме исследования глубинной мотивации есть и более типичные проекты: исследователи на интервью сужают поле гипотез для AB-тестов и задают вектор для exploratory analysis, аналитики ищут странненькие по поведению сегменты и выгружают их для опросов и интервью, батарея количественных и качественных методов позволяет уточнять гипотезы друг-друга.
Как и у Фейсбука (https://t.me/uxread/71), очень большой акцент на презентации результататов, донесение знаний также важно, как и сами исследования: "we invest in mixed media storytelling, interactive insights, and employ typologies and illustrations that attempt to encapsulate knowledge beyond isolated findings".
Команды стараются доносить не отдельные инсайты, а целостное представление о пользователях, которое, среди прочего, поможет команде ощутить эмпатию. Так и пишут: We aspire to form a comprehensive narrative of what we know about the current and future users of our products rather than methodologically siloed insights.
___
Процессы в других компаниях:
Mesosphere https://t.me/uxread/8, Atlassian https://t.me/uxread/39, LinkedIn https://t.me/uxread/121, Facebook https://t.me/uxread/71, Ableton https://t.me/uxread/123, Lyft https://t.me/uxread/11 и IBM https://t.me/uxread/13,
https://t.me/uxread/77 матрица зрелости UX исследований
#Companies
https://spotify.design/articles/2018-12-05/cross-disciplinary-insights-teams-integrating-data-scientists-and-user-researchers-at-spotify/
(новая ссылка https://www.epicpeople.org/cross-disciplinary-insights-teams-integrating-data-scientists-and-user-researchers-at-spotify/)
Spotify в первую очередь про фоновый опыт, плейлист является фоном для контекста, поэтому исследуют не "каково пользователю работать в спотифае", а "каково жить с включенным в наушниках плейлистом", упор не только на интерфейс плеера, но и на то, как музыка воспринимается в разном окружении.
Отсюда большая любовь к глубинным исследованиям: они изучают, почему вообще люди слушают музыку, как они ощущают "good listening experience", как контекст влияет на восприятие плейлиста и как это понимание переводить в ML модели, которые генерят плейлисты. Прямо пишут, что стараются перейти from a core focus of understanding explicit user interactions to understanding implicit motivation and contextual expectations (как Икея и Гугл в прошлом посте). Звучит здорово, но не хватает примеров.
Всем этим занимается объединенная команда "product insights" из исследователей и аналитиков (data scientists). Кроме исследования глубинной мотивации есть и более типичные проекты: исследователи на интервью сужают поле гипотез для AB-тестов и задают вектор для exploratory analysis, аналитики ищут странненькие по поведению сегменты и выгружают их для опросов и интервью, батарея количественных и качественных методов позволяет уточнять гипотезы друг-друга.
Как и у Фейсбука (https://t.me/uxread/71), очень большой акцент на презентации результататов, донесение знаний также важно, как и сами исследования: "we invest in mixed media storytelling, interactive insights, and employ typologies and illustrations that attempt to encapsulate knowledge beyond isolated findings".
Команды стараются доносить не отдельные инсайты, а целостное представление о пользователях, которое, среди прочего, поможет команде ощутить эмпатию. Так и пишут: We aspire to form a comprehensive narrative of what we know about the current and future users of our products rather than methodologically siloed insights.
___
Процессы в других компаниях:
Mesosphere https://t.me/uxread/8, Atlassian https://t.me/uxread/39, LinkedIn https://t.me/uxread/121, Facebook https://t.me/uxread/71, Ableton https://t.me/uxread/123, Lyft https://t.me/uxread/11 и IBM https://t.me/uxread/13,
https://t.me/uxread/77 матрица зрелости UX исследований
#Companies
EPIC
Cross-disciplinary Insights Teams: Integrating Data Scientists and User Researchers at Spotify - EPIC
Spotify researchers describe how data scientists and UX researchers work together on insights teams to create richer data, analysis, and value.
Amazon Turk для быстрого рекрута
Написал пост о том, как использовать Amazon Mechanical Turk (аналог Яндекс.Толоки в США) для очень быстрых и дешёвых опросов аудитории, и почему это норм http://bit.ly/2XpMaug
____
Ещё про рекрут
https://t.me/uxread/4 Как рекрутить респондентов через фейсбук
https://t.me/uxread/8 Mesosphere про автоматизированный рекрут
https://t.me/uxread/15 - IBM про рекрут sponsor users для кодизайна в b2b
https://t.me/uxread/37 Светлана Ратнер из Контура про рекрут b2b пользователей по конкретным темам через почту для обратной связи
https://t.me/uxread/46 Томер Шарон про автоматизированный рекрут в WeWork
#Recruitment
Написал пост о том, как использовать Amazon Mechanical Turk (аналог Яндекс.Толоки в США) для очень быстрых и дешёвых опросов аудитории, и почему это норм http://bit.ly/2XpMaug
____
Ещё про рекрут
https://t.me/uxread/4 Как рекрутить респондентов через фейсбук
https://t.me/uxread/8 Mesosphere про автоматизированный рекрут
https://t.me/uxread/15 - IBM про рекрут sponsor users для кодизайна в b2b
https://t.me/uxread/37 Светлана Ратнер из Контура про рекрут b2b пользователей по конкретным темам через почту для обратной связи
https://t.me/uxread/46 Томер Шарон про автоматизированный рекрут в WeWork
#Recruitment
Medium
Как использовать Amazon Turk для быстрых исследований аудитории
Amazon Mechanical Turk — краудсорсинговая платформа, на которой люди могут выполнять небольшие задания за деньги. Обычно задания связаны с…
Люк Вроблевски (продакт директор в Гугле, и чел, который придумал термин "mobile first" и написал о нём книжку) за минуту показывает, как устроен дизайн в больших компаниях. Простите, что не про исследования, но это лучшее вообще https://youtu.be/mAiNdU1go1A?t=1340
По смыслу ничего нового - видео о том, что хороший дизайн не сделать, не залезая по уши в лигал, маркетинг, и разработку, но рассказывает очень хорошо.
По смыслу ничего нового - видео о том, что хороший дизайн не сделать, не залезая по уши в лигал, маркетинг, и разработку, но рассказывает очень хорошо.
Навигация по заметкам:
#Cases - кейсы исследований от Headspace, Google и Mozilla
#b2bResearch - кейсы, рекрут и процессы в b2b
#Methods - необычные методы
#Process - способы организации исследований (FAST, Research Sprint и т.д.)
#Companies - процессы в компаниях от Facebook до Ableton
#Frameworks - фреймворки для структурированного планирования исследований
#Bases - базы инсайтов и хранение результатов
#Recruitment - рекрут
#Science - behavioural science и "психология в UX"
#ResearchNocode, #Operations - автоматизация процессов исследований
#ResearchROI - ROI исследований
#Cases - кейсы исследований от Headspace, Google и Mozilla
#b2bResearch - кейсы, рекрут и процессы в b2b
#Methods - необычные методы
#Process - способы организации исследований (FAST, Research Sprint и т.д.)
#Companies - процессы в компаниях от Facebook до Ableton
#Frameworks - фреймворки для структурированного планирования исследований
#Bases - базы инсайтов и хранение результатов
#Recruitment - рекрут
#Science - behavioural science и "психология в UX"
#ResearchNocode, #Operations - автоматизация процессов исследований
#ResearchROI - ROI исследований
❤1
Королёв про всё остальное (ex UX Research) pinned «Навигация по заметкам: #Cases - кейсы исследований от Headspace, Google и Mozilla #b2bResearch - кейсы, рекрут и процессы в b2b #Methods - необычные методы #Process - способы организации исследований (FAST, Research Sprint и т.д.) #Companies - процессы в компаниях…»
Как рекрутят респондентов в Salesforce
Как у команды Salesforce устроен процесс рекрута на исследования, и про их панель респондентов:
1) Есть рекрутинговая страничка https://design.secure.force.com/ux/
2) При заполнении опросника спрашивают подтверждение, чтобы GDPR
3) Внутри команд оперируют персонами, и фичи делают для конкретных персон/сегментов. Поэтому они сделали так, чтобы после заполнения скринингового опроса участнику автоматически присваивалась нужная персона.
4) Вознаграждают подарочными карточками, трекают в сейлзфорсе (к слову, atlassian вознаграждают виртуальными картами, используют https://www.tremendous.com/)
5) Выбор времени через self-scheduling (у них там какой-то свой модуль в сейлзфорсе)
6) База помогает планировать загрузку и бюджет команды: "We know how many studies we’ve conducted, how much we’ve spent on incentives, the percentage breakdown of personas on any given panel, our busiest research season, our recruitment throughput, and much more."
7) Им важно чистить базу от неактивных участников, поэтому автоматический скрипт в годовщину регистрации отправляет каждому участнику письмо с просьбой обновить информацию о себе. Если пользователь не отвечает два года подряд, его удаляют (что позволяет держать актуальную базу, актуальную информацию об участниках, и избегать проблем из-за того, что соглашение об обработке персональных данных истекло)
8) О, ещё у каждого участника есть реферальная ссылка, через которую он может приглашать новых участников. Никогда такого не видел, и жаль, что они не описывают, как работает реферальная программа - платят ли они деньгами/карточками за привлечение новых респондентов.
https://medium.com/salesforce-ux/scaling-user-research-operations-infrastructure-with-salesforce-a095054b41ac
___
Ещё про рекрут:
https://t.me/uxread/15 - IBM про рекрут sponsor users для кодизайна в b2b
https://t.me/uxread/60 Как Athenahealth (b2b, it системы для больниц) перекроили весь процесс дизайна
https://t.me/uxread/39 - процессы исследований в Atlassian
https://t.me/uxread/50 Как Светлана Ратнер из Контура превратила менеджеров по продажам в исследователей
#b2bResearch
#Recruitment
Как у команды Salesforce устроен процесс рекрута на исследования, и про их панель респондентов:
1) Есть рекрутинговая страничка https://design.secure.force.com/ux/
2) При заполнении опросника спрашивают подтверждение, чтобы GDPR
3) Внутри команд оперируют персонами, и фичи делают для конкретных персон/сегментов. Поэтому они сделали так, чтобы после заполнения скринингового опроса участнику автоматически присваивалась нужная персона.
4) Вознаграждают подарочными карточками, трекают в сейлзфорсе (к слову, atlassian вознаграждают виртуальными картами, используют https://www.tremendous.com/)
5) Выбор времени через self-scheduling (у них там какой-то свой модуль в сейлзфорсе)
6) База помогает планировать загрузку и бюджет команды: "We know how many studies we’ve conducted, how much we’ve spent on incentives, the percentage breakdown of personas on any given panel, our busiest research season, our recruitment throughput, and much more."
7) Им важно чистить базу от неактивных участников, поэтому автоматический скрипт в годовщину регистрации отправляет каждому участнику письмо с просьбой обновить информацию о себе. Если пользователь не отвечает два года подряд, его удаляют (что позволяет держать актуальную базу, актуальную информацию об участниках, и избегать проблем из-за того, что соглашение об обработке персональных данных истекло)
8) О, ещё у каждого участника есть реферальная ссылка, через которую он может приглашать новых участников. Никогда такого не видел, и жаль, что они не описывают, как работает реферальная программа - платят ли они деньгами/карточками за привлечение новых респондентов.
https://medium.com/salesforce-ux/scaling-user-research-operations-infrastructure-with-salesforce-a095054b41ac
___
Ещё про рекрут:
https://t.me/uxread/15 - IBM про рекрут sponsor users для кодизайна в b2b
https://t.me/uxread/60 Как Athenahealth (b2b, it системы для больниц) перекроили весь процесс дизайна
https://t.me/uxread/39 - процессы исследований в Atlassian
https://t.me/uxread/50 Как Светлана Ратнер из Контура превратила менеджеров по продажам в исследователей
#b2bResearch
#Recruitment
Tremendous
Gift Card & Rewards Platform for Businesses
20K+ businesses use Tremendous to send gift cards and money instantly to their employees, prospects, customers, and more. Start sending for free today.
Ещё Люк Вроблевски рассказывает, как они в Google RITE методом 10 раз переделывали онбординг и first-time flow для одного из приложений, чтобы сдвинуть пользователей в сторону нужной им ментальной модели (не видел раньше, чтобы связывали ментальную модель и метрики)
https://youtu.be/mAiNdU1go1A?t=4034
Смотреть всего минут 7, но я перескажу, опустив несколько деталей:
1) Тестировали приложение Space - изначально оно позволяло собирать/хранить и делиться небольшими заметками. Тестировали его RITE методом.
2) RITE - быстрые итеративные исследования, которые придумали в Майкрософт. Вот описание в вики, и небольшая статья с кейсом. Если кратко, то "The schedule was 3 tests per day, every other day. Each test was one hour in duration. The non-testing days were design days where I worked with the product team to revise and adapt the prototype based on the findings."
3) Так вот, они быстро итеративно переделывали приложение на основе обратной связи, и попутно замеряли субъективные метрики. И заметили, что часть людей воспринимает приложение как ценное, красивое и классное, а часть - как не очень. Почему?
4) Выяснилось, что у людей во время первой сессии возникают разные ментальные модели использования сервиса. Часть воспринимает его как private space, сервис для создания небольших групп, где можно делиться информацией с друзьями. Часть, как public space, с открытыми группами по интересам, как Пинтерест. На деле в сервисе были обе функции: и public, и private.
5) Те, кто воспринимал как private, оценивали его значимо выше. Поэтому у дизайнеров была задача - сделать такой онбординг, чтобы у людей сложилась модель, что сервис в первую очередь про private space, потому что это делало его более ценным. И им пришлось кучу раз переделать starting flow, чтобы подчёркнуть это в достаточной степени.
6) В итоге переделали, процент private space mental model ребят вырос, оценки дизайна подросли.
Только сервис, как я понимаю, закрыли почти сразу после запуска :(
___
Другие форматы быстрых исследований:
https://t.me/uxread/27 FAST фреймворк (реализация на тему ресёрч спринта) на примере хардкорного b2g проекта
https://t.me/uxread/17 Google Ventures про свой Research Sprint фреймворк (тоже тестирования без исследователя, тоже за неделю)
https://t.me/uxread/35 Airbnb реализуют FAST - вовлекают команду в исследования, заставляя наблюдателей писать протокол самостоятельно (модерация backroom)
#Processes
#Methods
https://youtu.be/mAiNdU1go1A?t=4034
Смотреть всего минут 7, но я перескажу, опустив несколько деталей:
1) Тестировали приложение Space - изначально оно позволяло собирать/хранить и делиться небольшими заметками. Тестировали его RITE методом.
2) RITE - быстрые итеративные исследования, которые придумали в Майкрософт. Вот описание в вики, и небольшая статья с кейсом. Если кратко, то "The schedule was 3 tests per day, every other day. Each test was one hour in duration. The non-testing days were design days where I worked with the product team to revise and adapt the prototype based on the findings."
3) Так вот, они быстро итеративно переделывали приложение на основе обратной связи, и попутно замеряли субъективные метрики. И заметили, что часть людей воспринимает приложение как ценное, красивое и классное, а часть - как не очень. Почему?
4) Выяснилось, что у людей во время первой сессии возникают разные ментальные модели использования сервиса. Часть воспринимает его как private space, сервис для создания небольших групп, где можно делиться информацией с друзьями. Часть, как public space, с открытыми группами по интересам, как Пинтерест. На деле в сервисе были обе функции: и public, и private.
5) Те, кто воспринимал как private, оценивали его значимо выше. Поэтому у дизайнеров была задача - сделать такой онбординг, чтобы у людей сложилась модель, что сервис в первую очередь про private space, потому что это делало его более ценным. И им пришлось кучу раз переделать starting flow, чтобы подчёркнуть это в достаточной степени.
6) В итоге переделали, процент private space mental model ребят вырос, оценки дизайна подросли.
Только сервис, как я понимаю, закрыли почти сразу после запуска :(
___
Другие форматы быстрых исследований:
https://t.me/uxread/27 FAST фреймворк (реализация на тему ресёрч спринта) на примере хардкорного b2g проекта
https://t.me/uxread/17 Google Ventures про свой Research Sprint фреймворк (тоже тестирования без исследователя, тоже за неделю)
https://t.me/uxread/35 Airbnb реализуют FAST - вовлекают команду в исследования, заставляя наблюдателей писать протокол самостоятельно (модерация backroom)
#Processes
#Methods
YouTube
Mind the gap, user centered design in large organizations with Luke Wroblewski
Mind the gap, user centered design in large organizations with Luke Wroblewski
https://twitter.com/lukew
https://www.lukew.com
https://twitter.com/lukew
https://www.lukew.com