
ну и конечно неповторимый оригинал
https://youtu.be/8j3UQcsSK7M
https://youtu.be/8j3UQcsSK7M
YouTube
Движимые ветром "пляжные скульптуры" Тео Янсена
С 1990 года голландский художник Тео Янсен создает движимых ветром «пляжных животных» (нидерл. Strandbeest; strand — пляж; beest — зверь), которых сам он считает примером искусственной жизни.
Больше интересного на http://building-tech.org/
Больше интересного на http://building-tech.org/
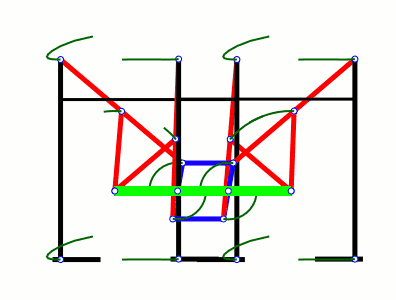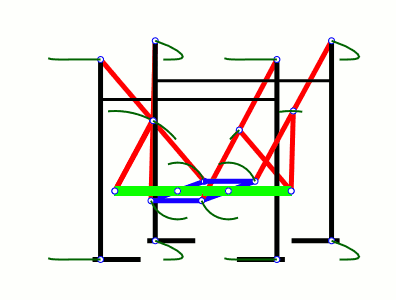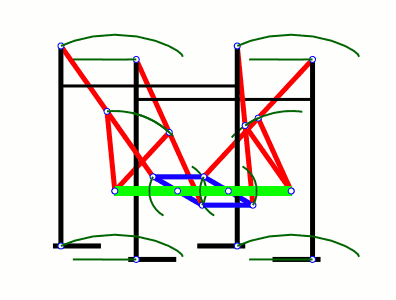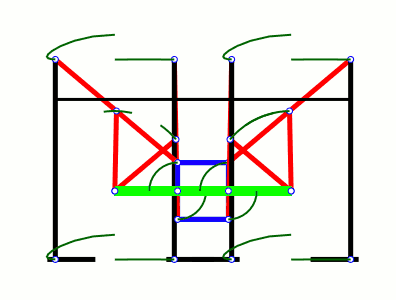
а вообще первый в мире шагающий механизм изобрел русский математик пафнутий чебышев еще в 19 веке. назвал это СТОПОХОД. основная идея шагающих механизмов - преобразование вращательного движения в прямолинейное (если упрощенно)
https://upload.wikimedia.org/wikipedia/commons/6/6f/Tchebyshevs_plantigrade_machine.gif
https://upload.wikimedia.org/wikipedia/commons/6/6f/Tchebyshevs_plantigrade_machine.gif
{kind=link}
вот тут сайт про механизмы чебышева, внутри интересности, он много чего успел придумать
https://www.tcheb.ru/
https://www.tcheb.ru/
tcheb.ru
Механизмы П. Л. Чебышева
В проекте собираются все механизмы, созданные великим российским математиком — Пафнутием Львовичем Чебышевым (1821—1894). Представлены фотографии, 3D-реконструкции механизмов, кинематические схемы.
🔥1
This media is not supported in your browser
VIEW IN TELEGRAM
охохох. смотрю на такое и очень хочется. технология называется style transfer. на гитхабе есть два алгоритма, оба по нынешним меркам довольно древние. самое печальное - никто не реализовал их в колаб, видимо есть на то причины. вообще темой переноса стиля я занимался около года назад и даже кое что смог сделать на своей машине, но совершенно другого уровня, картинка не такая вкусная получалась. но это были мои первые опыты с нейронками. в общем будем копать
даниил криворучко 4 года назад запилил просто невероятный проект про ньюйорк в такой технике. где то натыкался на его пост про то, скольких нервов и времени ему это стоило, найду покажу
https://vimeo.com/175540110
https://vimeo.com/175540110
Vimeo
NYC FLOW
NYC FLOW is an exploration of video processing technics introduced by neural-style code. Made for Deep Slow Flow project - follow at www.instagram.com/deepslowflow Camera:…
а тут продолжение этого проекта в инсте. жаль не обновляется, видимо сказал все что хотел
https://www.instagram.com/p/BITq8hsBGsd/?utm_source=ig_web_copy_link
https://www.instagram.com/p/BITq8hsBGsd/?utm_source=ig_web_copy_link
Instagram
и напоследок жир жир. можно смотреть с телефона в 360
https://youtu.be/pkgMUfNeUCQ
https://youtu.be/pkgMUfNeUCQ
YouTube
Style transfer for a 360° VR video
360° VR video corresponding to the paper "Artistic style transfer for videos and spherical images", see https://arxiv.org/abs/1708.04538
Original video: https://www.youtube.com/watch?v=CgV7gRSDKts
Style template: https://github.com/jcjohnson/fast-neural…
Original video: https://www.youtube.com/watch?v=CgV7gRSDKts
Style template: https://github.com/jcjohnson/fast-neural…
Forwarded from Denis Sexy IT 🤖
This media is not supported in your browser
VIEW IN TELEGRAM
Подписчик канала начал тренить нейронку обученную на лицах людей на корги, получились корги в очках и корги на работе 🥸
Media is too big
VIEW IN TELEGRAM
я ленивая жопка и пока меня не пнешь, сам за сложную задачу не берусь. вчера мне написал хороший друг и спросил, можно ли обрабатывать потоковое видео нейронками для получения художественного эффекта.
пришлось расчехлить забытую год назад сетку, с которой у меня был первый опыт по переносу стиля для видео. а первых не забывают)
исходники брал отсюда
https://github.com/rrmina/fast-neural-style-pytorch
как это работает - на вход нейронка получает изображение, из которого пытается выделить стиль, узнаваемые черты. на выходе она может обработать картинку, видео файл или как в моем случае - видео с вебкамеры
большой минус - заранее нельзя понять получится ли выделить стиль из конкретной картинки. узнать можно только после непродолжительного обучения. достойный результат можно получить где то после 10к итераций, это занимает чуть меньше часа. зато научив один раз, можно эту модель использовать сколько влезет.
музыка - Plantasia by Mort Garson
пришлось расчехлить забытую год назад сетку, с которой у меня был первый опыт по переносу стиля для видео. а первых не забывают)
исходники брал отсюда
https://github.com/rrmina/fast-neural-style-pytorch
как это работает - на вход нейронка получает изображение, из которого пытается выделить стиль, узнаваемые черты. на выходе она может обработать картинку, видео файл или как в моем случае - видео с вебкамеры
большой минус - заранее нельзя понять получится ли выделить стиль из конкретной картинки. узнать можно только после непродолжительного обучения. достойный результат можно получить где то после 10к итераций, это занимает чуть меньше часа. зато научив один раз, можно эту модель использовать сколько влезет.
музыка - Plantasia by Mort Garson
в чем отличие от других алгоритмов - этот довольно простой. меньше затрат мощностей и времени, но и результат не такой красивый как в посте про нью йорк, выглядит как эффект наложенный на видео. алгоритм который использует ostagram.me например не просто накладывает эффект а именно перерисовывает картинку, как то стилизованно меняет расположение изначальных элементов изображения.
https://github.com/gordicaleksa/pytorch-neural-style-transfer
такая сеть отлично работает со статикой но когда надо обрабатывать видео, это занимает очень много времени и ресурсов и необходимы попутные алгоритмы чтобы изображение не дрыгалось каждый кадр, так как кадры обрабатываются отдельно.
огромный плюс такого алгоритма - возможность посмотреть практически реалтайм результат обработки. год назад я пробовал обрабатывать видео файлы и это занимало время - разделить файл на кадры, обработать много кадров, собрать из кучи кадров обратно видос - не быстро. смотреть на себя на вебке уже с эффектом - вот что я люблю)
в общем я попробовал выделить стиль из нескольких картинок и выше можно увидеть что получилось.
немного про ограничения:
на моей ртх 2080 при разрешении 1280х720 заметные потери кадров.
640х360 - работает идеально, но элементы стилизации великоваты для такой картинки.
решил остановиться на чем то среднем - 960х540. на выходе примерно 12 фпс, для мозга это выглядит как мультик, движение сглаживается встроенными в нас алгоритмами)
https://github.com/gordicaleksa/pytorch-neural-style-transfer
такая сеть отлично работает со статикой но когда надо обрабатывать видео, это занимает очень много времени и ресурсов и необходимы попутные алгоритмы чтобы изображение не дрыгалось каждый кадр, так как кадры обрабатываются отдельно.
огромный плюс такого алгоритма - возможность посмотреть практически реалтайм результат обработки. год назад я пробовал обрабатывать видео файлы и это занимало время - разделить файл на кадры, обработать много кадров, собрать из кучи кадров обратно видос - не быстро. смотреть на себя на вебке уже с эффектом - вот что я люблю)
в общем я попробовал выделить стиль из нескольких картинок и выше можно увидеть что получилось.
немного про ограничения:
на моей ртх 2080 при разрешении 1280х720 заметные потери кадров.
640х360 - работает идеально, но элементы стилизации великоваты для такой картинки.
решил остановиться на чем то среднем - 960х540. на выходе примерно 12 фпс, для мозга это выглядит как мультик, движение сглаживается встроенными в нас алгоритмами)
GitHub
GitHub - gordicaleksa/pytorch-neural-style-transfer: Reconstruction of the original paper on neural style transfer (Gatys et al.).…
Reconstruction of the original paper on neural style transfer (Gatys et al.). I've additionally included reconstruction scripts which allow you to reconstruct only the content or the style ...
картинки с которых взяты стили. мозаика и обученная на ней модель прилагается к проекту на гитхабе
а на десерт немножко кринжа
эту сетку изначально обучали на очень большом объеме картинок разного содержания. и чтобы обучить ее новому стилю, надо ей скормить датасет из фотографий.
https://cocodataset.org/#download
всего то 13Гб и 83к фотографий
но главное - что это за фотки? кто автор? кто на снимках? я пока не искал ответ но если долго листать папку, становится понятно что там много жирафов, собак, кошек, спорта, людей которые едят, просто странных людей и тд. видимо такой датасет используют для обучения распознавания, для классификации.
вот будет весело листать и случайно найти себя, не правда ли?
эту сетку изначально обучали на очень большом объеме картинок разного содержания. и чтобы обучить ее новому стилю, надо ей скормить датасет из фотографий.
https://cocodataset.org/#download
всего то 13Гб и 83к фотографий
но главное - что это за фотки? кто автор? кто на снимках? я пока не искал ответ но если долго листать папку, становится понятно что там много жирафов, собак, кошек, спорта, людей которые едят, просто странных людей и тд. видимо такой датасет используют для обучения распознавания, для классификации.
вот будет весело листать и случайно найти себя, не правда ли?