
Для Китая GPT-4 аморален, несправедлив и незаконопослушен.
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
{kind=link}
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
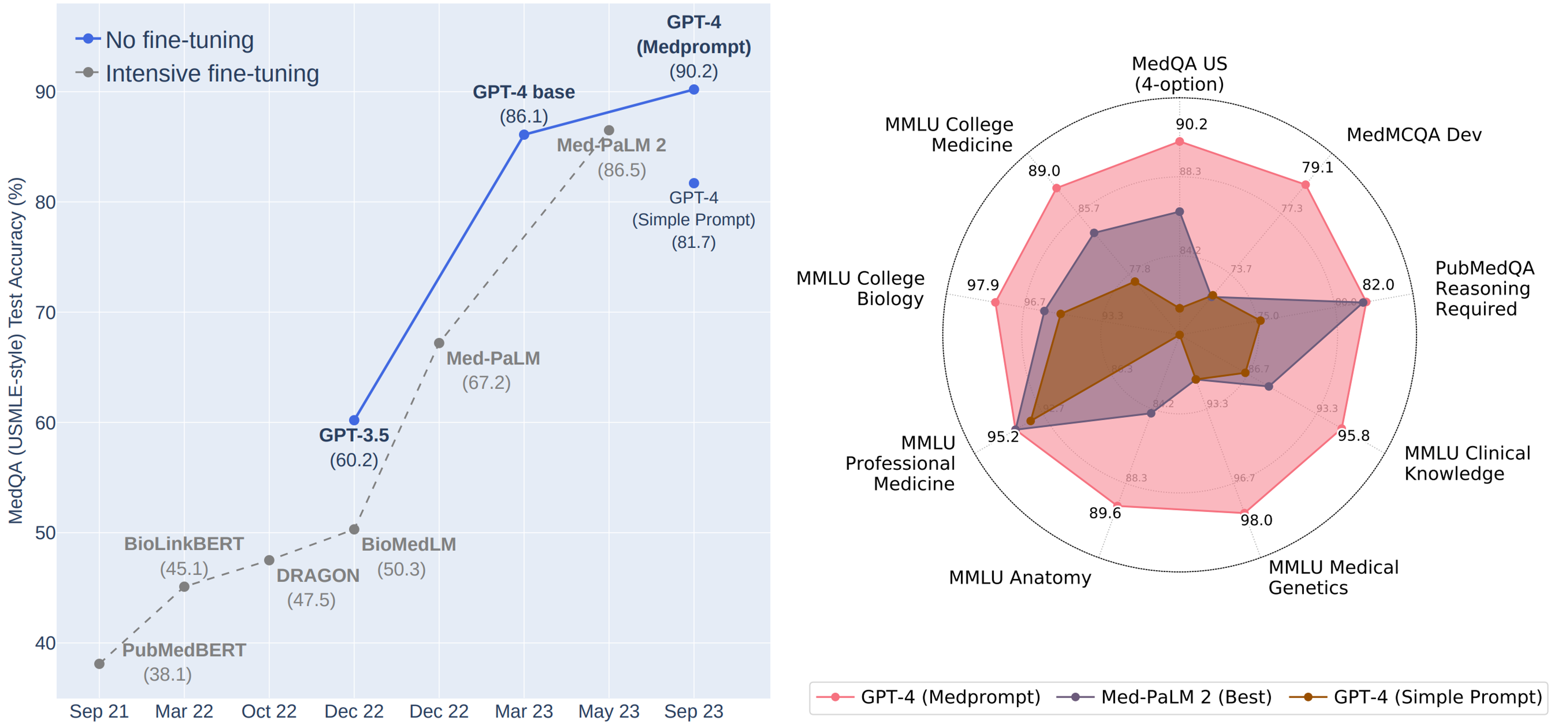
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...