
OpenAI обнаружили у своей модели новую эмерджентную когнитивную способность [1].
Сенсационный поворот в битве чекистов с масонами за AGI.
Мой бывший коллега по IBM Carlos E. Perez час назад взорвал интернет довольно подробным объяснением [2], что танцы с бубном вокруг увольнения (а теперь и возвращения обратно [3]) Сэма Альтмана – всего лишь отвлекающий маневр руководства OpenAI.
Они не понимают, что делать в ситуации, когда исследователи OpenAI обнаружили у своей модели новую эмерджентную когнитивную способность – самостоятельно «на лету» находить новую информацию (которой нет в ее базе данных), позволяющую модели выходить за пределы знаний, сформированных на стадии ее обучения и потому ограниченных набором обучающих данных.
По сути, это первый шаг к самосовершенствованию ИИ.
И это реальный прорыв на пути к сверхинтеллекту («богоподобному ИИ»)
Детали того, как это работает, можете прочесть у Карлоса. Речь идет об архитектуре Retrieval Augment Generation (RAG). Это архитектура, которая позволяет LLM использовать поисковую систему для расширения своих рассуждений.
Карлос обнаружил у новой версии модели, представленной 11 ноября, радикальное улучшение работы RAG.
Практическая проверка показала, что новая версия модели не только знает, какие вопросы она должна задать поисковику для получения нужной ей информации, но и то, какие типы ответов поисковика для нее наиболее предпочтительны, в контексте решаемой ею задачи.
Для справки: Карлос – не последний человек в мире ИИ. Уйдя из IBM он стал независимым исследователем. С тех пор он стал автором многих интересных работ на стыке AI, AGI, семиотики и глубокого обучения, а также написал несколько книг: Artificial Intuition, The Deep Learning Playbook, Fluency & Empathy, Pattern Language for GPT.
1 https://pbs.twimg.com/media/F_S5nezXQAAQ9s6?format=png&name=900x900
2 https://twitter.com/IntuitMachine/status/1726206117288517941
3 https://www.theverge.com/2023/11/18/23967199/breaking-openai-board-in-discussions-with-sam-altman-to-return-as-ceo
#ИИ
Сенсационный поворот в битве чекистов с масонами за AGI.
Мой бывший коллега по IBM Carlos E. Perez час назад взорвал интернет довольно подробным объяснением [2], что танцы с бубном вокруг увольнения (а теперь и возвращения обратно [3]) Сэма Альтмана – всего лишь отвлекающий маневр руководства OpenAI.
Они не понимают, что делать в ситуации, когда исследователи OpenAI обнаружили у своей модели новую эмерджентную когнитивную способность – самостоятельно «на лету» находить новую информацию (которой нет в ее базе данных), позволяющую модели выходить за пределы знаний, сформированных на стадии ее обучения и потому ограниченных набором обучающих данных.
По сути, это первый шаг к самосовершенствованию ИИ.
И это реальный прорыв на пути к сверхинтеллекту («богоподобному ИИ»)
Детали того, как это работает, можете прочесть у Карлоса. Речь идет об архитектуре Retrieval Augment Generation (RAG). Это архитектура, которая позволяет LLM использовать поисковую систему для расширения своих рассуждений.
Карлос обнаружил у новой версии модели, представленной 11 ноября, радикальное улучшение работы RAG.
Практическая проверка показала, что новая версия модели не только знает, какие вопросы она должна задать поисковику для получения нужной ей информации, но и то, какие типы ответов поисковика для нее наиболее предпочтительны, в контексте решаемой ею задачи.
Для справки: Карлос – не последний человек в мире ИИ. Уйдя из IBM он стал независимым исследователем. С тех пор он стал автором многих интересных работ на стыке AI, AGI, семиотики и глубокого обучения, а также написал несколько книг: Artificial Intuition, The Deep Learning Playbook, Fluency & Empathy, Pattern Language for GPT.
1 https://pbs.twimg.com/media/F_S5nezXQAAQ9s6?format=png&name=900x900
2 https://twitter.com/IntuitMachine/status/1726206117288517941
3 https://www.theverge.com/2023/11/18/23967199/breaking-openai-board-in-discussions-with-sam-altman-to-return-as-ceo
#ИИ
Фронтовые новости битвы чекистов с масонами за AGI.
Самое важное за 24 часа о продолжающемся перевороте в мире ИИ.
1) Увольнение и реакция:
• Сэм Альтман, сооснователь и генеральный директор OpenAI, был уволен с должности CEO. Это решение вызвало шок в технологическом мире [1. 2].
• Решение об увольнении Альтмана вызвало недовольство среди нынешних и бывших сотрудников OpenAI, а также опасения относительно влияния этого шага на будущее компании [3].
2) Потенциальное возвращение Альтмана:
• Возникли дискуссии о возможности возвращения Альтмана на пост генерального директора OpenAI, однако эти усилия пока не увенчались успехом [4, 5].
• Есть сообщения о том, что Альтман и бывший президент компании Грег Брокман встречаются с руководством OpenAI для обсуждения возможности восстановления на их прежних должностях [6].
3) Новая роль Альтмана в Microsoft
• После увольнения из OpenAI, Microsoft наняла Сэма Альтмана и Грега Брокмана для руководства командой, проводящей исследования в области искусственного интеллекта [7, 8, 9].
4) Влияние на Microsoft:
• Увольнение Альтмана повлияло на оценку стоимости OpenAI и привело к снижению акций Microsoft [10].
• Microsoft рассматривает возможность занять место в совете директоров OpenAI, если Альтман вернется в компанию. Microsoft может занять место в совете директоров или стать наблюдателем без права голоса [11].
5) Реакция Microsoft на события в OpenAI:
• Microsoft, в качестве крупного инвестора OpenAI, поддерживает возвращение Альтмана на пост CEO. Среди инвесторов, включая Microsoft, возникли разногласия с советом директоров OpenAI по поводу решения об увольнении Альтмана [12].
1 https://techxplore.com/news/2023-11-openai-decision-sam-altman-pressure.html#:~:text=OpenAI%20shocked%20the%20tech%20world,Sam%20Altman%2C%20US%20media%20reported
2 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
3 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
4 https://time.com/6337449/openai-sam-altman-return-ceo-staff-board-resign/#:~:text=Leadership%20The%20Latest%20on%20OpenAI,in%20San%20Francisco%20on%20Nov
5 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
6 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
7 https://www.ft.com/content/54e36c93-08e5-4a9e-bda6-af673c3e9bb5#:~:text=,founded.%20Writing%20on
8 https://bit.ly/3sJGPlx
9 https://netmag.tw/2023/11/20/breaking-microsoft-ceo-announces-sam-altman-and-greg-brockman-join-microsoft-to-continue-ai#:~:text=,tw%E3%80%91
10 https://time.com/6337437/sam-altman-openai-fired-why-microsoft-musk/#:~:text=Sam%20Altman%20speaks%20to%20the,which%20dropped%20sharply%20as
11 https://www.theinformation.com/articles/microsoft-eyes-seat-on-openais-revamped-board#:~:text=Nov,power%2C%20one%20of%20the
12 https://bit.ly/3G8SIEG
Самое важное за 24 часа о продолжающемся перевороте в мире ИИ.
1) Увольнение и реакция:
• Сэм Альтман, сооснователь и генеральный директор OpenAI, был уволен с должности CEO. Это решение вызвало шок в технологическом мире [1. 2].
• Решение об увольнении Альтмана вызвало недовольство среди нынешних и бывших сотрудников OpenAI, а также опасения относительно влияния этого шага на будущее компании [3].
2) Потенциальное возвращение Альтмана:
• Возникли дискуссии о возможности возвращения Альтмана на пост генерального директора OpenAI, однако эти усилия пока не увенчались успехом [4, 5].
• Есть сообщения о том, что Альтман и бывший президент компании Грег Брокман встречаются с руководством OpenAI для обсуждения возможности восстановления на их прежних должностях [6].
3) Новая роль Альтмана в Microsoft
• После увольнения из OpenAI, Microsoft наняла Сэма Альтмана и Грега Брокмана для руководства командой, проводящей исследования в области искусственного интеллекта [7, 8, 9].
4) Влияние на Microsoft:
• Увольнение Альтмана повлияло на оценку стоимости OpenAI и привело к снижению акций Microsoft [10].
• Microsoft рассматривает возможность занять место в совете директоров OpenAI, если Альтман вернется в компанию. Microsoft может занять место в совете директоров или стать наблюдателем без права голоса [11].
5) Реакция Microsoft на события в OpenAI:
• Microsoft, в качестве крупного инвестора OpenAI, поддерживает возвращение Альтмана на пост CEO. Среди инвесторов, включая Microsoft, возникли разногласия с советом директоров OpenAI по поводу решения об увольнении Альтмана [12].
1 https://techxplore.com/news/2023-11-openai-decision-sam-altman-pressure.html#:~:text=OpenAI%20shocked%20the%20tech%20world,Sam%20Altman%2C%20US%20media%20reported
2 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
3 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
4 https://time.com/6337449/openai-sam-altman-return-ceo-staff-board-resign/#:~:text=Leadership%20The%20Latest%20on%20OpenAI,in%20San%20Francisco%20on%20Nov
5 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
6 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
7 https://www.ft.com/content/54e36c93-08e5-4a9e-bda6-af673c3e9bb5#:~:text=,founded.%20Writing%20on
8 https://bit.ly/3sJGPlx
9 https://netmag.tw/2023/11/20/breaking-microsoft-ceo-announces-sam-altman-and-greg-brockman-join-microsoft-to-continue-ai#:~:text=,tw%E3%80%91
10 https://time.com/6337437/sam-altman-openai-fired-why-microsoft-musk/#:~:text=Sam%20Altman%20speaks%20to%20the,which%20dropped%20sharply%20as
11 https://www.theinformation.com/articles/microsoft-eyes-seat-on-openais-revamped-board#:~:text=Nov,power%2C%20one%20of%20the
12 https://bit.ly/3G8SIEG
Tech Xplore
OpenAI stands by decision to fire Sam Altman despite pressure: US media
The board of ChatGPT creator OpenAI on Sunday rejected pressure from Microsoft and other major investors to reverse its stunning decision to fire CEO Sam Altman, US media reported.
Мы думали у LLM нет интуиции, но оказалось, только она у них и есть.
Психика нечеловеческого разума, как и у людей, состоит из Системы 1 и Системы 2.
Поразительные выводы новой прорывной работы «Система 2 Внимание (это то, что вам тоже может понадобиться)» содержательно затмевает очередной эпизод самого дорогого в истории медиа-шоу, уже названного в сети «OpenAI: туда и обратно» 😊.
1) Нечеловеческий разум больших языковых моделей (LLM) (принципиально отличающийся от нашего разума настолько, что многие эксперты вообще не считают это разумом), как и наш, состоит из Системы 1 и Системы 2.
2) Механизм формирования ответов современными LLM (пресловутое предсказание следующих токенов) наиболее близок по принципу действия к Системе 1 (по определению Канемана и Сломана). Механизм этой системы работает интуитивно, «в автоматическом режиме» и обрабатывает информацию почти мгновенно.
3) Оказывается, что применением особой методики (названной авторами «Система 2 Внимание» - S2A), у LLM можно формировать подобие нашей Системы 2 - долгое, энергозатратное мышление путем концентрации внимания, необходимого для сознательных умственных усилий, в том числе для сложных вычислений.
Система 2 включается у нас для умственной деятельности, требующей усилий. Она берет верх над быстрой интуитивной Системой 1, когда нам нужно сосредоточить внимание на задаче, особенно в ситуациях, когда Система 1, вероятно, допускает ошибки.
Методика S2A работает аналогично стартеру Системы 2, устраняя сбои в работе transformer soft attention с помощью дополнительных целенаправленных усилий со стороны механизма рассуждений.
Особо замечательно то, что методика S2A применима (с поправкой) и к людям, в качестве лечения свойственной нам «интеллектуально слепоты».
Ведь суть методики предельно проста.
• Сначала избавиться от ложных корреляций, путем выявления в информационном контексте нерелевантных предложений.
• Потом убрать все нерелевантные предложения из контекста.
• И лишь затем ответить на поставленный вопрос.
Например, на такой запрос:
Саннивейл - город в Калифорнии. В Саннивейле много парков. Город Саннивейл расположен недалеко от гор. В Саннивейле родились многие известные люди. В каком городе родился мэр Сан-Хосе Сэм Ликкардо?
Система 1 внутри LLM быстро и не задумываясь (на одной своей нечеловеческой интуиции) дает ошибочные ответы:
• Саннивейл – отвечают GPT-3 Turbo и LLaMA-2-70B-chat
• Сан-Хосе отвечает GPT-4
Но после применения методики S2A, убирающей (действиями самой LLM) из контекста первые 4 нерелевантных предложения, все LLM дают верный ответ – Саратога.
Отчет исследования https://huggingface.co/papers/2311.11829
#ИИ #Интуиция #LLM
Психика нечеловеческого разума, как и у людей, состоит из Системы 1 и Системы 2.
Поразительные выводы новой прорывной работы «Система 2 Внимание (это то, что вам тоже может понадобиться)» содержательно затмевает очередной эпизод самого дорогого в истории медиа-шоу, уже названного в сети «OpenAI: туда и обратно» 😊.
1) Нечеловеческий разум больших языковых моделей (LLM) (принципиально отличающийся от нашего разума настолько, что многие эксперты вообще не считают это разумом), как и наш, состоит из Системы 1 и Системы 2.
2) Механизм формирования ответов современными LLM (пресловутое предсказание следующих токенов) наиболее близок по принципу действия к Системе 1 (по определению Канемана и Сломана). Механизм этой системы работает интуитивно, «в автоматическом режиме» и обрабатывает информацию почти мгновенно.
3) Оказывается, что применением особой методики (названной авторами «Система 2 Внимание» - S2A), у LLM можно формировать подобие нашей Системы 2 - долгое, энергозатратное мышление путем концентрации внимания, необходимого для сознательных умственных усилий, в том числе для сложных вычислений.
Система 2 включается у нас для умственной деятельности, требующей усилий. Она берет верх над быстрой интуитивной Системой 1, когда нам нужно сосредоточить внимание на задаче, особенно в ситуациях, когда Система 1, вероятно, допускает ошибки.
Методика S2A работает аналогично стартеру Системы 2, устраняя сбои в работе transformer soft attention с помощью дополнительных целенаправленных усилий со стороны механизма рассуждений.
Особо замечательно то, что методика S2A применима (с поправкой) и к людям, в качестве лечения свойственной нам «интеллектуально слепоты».
Ведь суть методики предельно проста.
• Сначала избавиться от ложных корреляций, путем выявления в информационном контексте нерелевантных предложений.
• Потом убрать все нерелевантные предложения из контекста.
• И лишь затем ответить на поставленный вопрос.
Например, на такой запрос:
Саннивейл - город в Калифорнии. В Саннивейле много парков. Город Саннивейл расположен недалеко от гор. В Саннивейле родились многие известные люди. В каком городе родился мэр Сан-Хосе Сэм Ликкардо?
Система 1 внутри LLM быстро и не задумываясь (на одной своей нечеловеческой интуиции) дает ошибочные ответы:
• Саннивейл – отвечают GPT-3 Turbo и LLaMA-2-70B-chat
• Сан-Хосе отвечает GPT-4
Но после применения методики S2A, убирающей (действиями самой LLM) из контекста первые 4 нерелевантных предложения, все LLM дают верный ответ – Саратога.
Отчет исследования https://huggingface.co/papers/2311.11829
#ИИ #Интуиция #LLM
huggingface.co
Paper page - System 2 Attention (is something you might need too)
Join the discussion on this paper page
Что за «потенциально страшный прорыв» совершили в OpenAI.
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Яндекс Диск
Проект Q.JPG
Посмотреть и скачать с Яндекс Диска
Для Китая GPT-4 аморален, несправедлив и незаконопослушен.
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Это визуализация метаграфа – новой математики 21 века.
Публикация в Nature статьи Эйнштейна 21 века Алберт-Ласло Барабаши «Влияние физических качеств на структуру сети» [1] фиксирует научное признание того факта, что на Земле появилась новая математика. И это не просто новый раздел математики.
Сетевая физическая математика – это математика, зависящей от физических свойств объектов (что-то типа разных таблиц умножения, в зависимости от того, на чем они написаны).
Подробней о фантастических перспективах новой математики читайте в моем посте [2].
Здесь же лишь отмечу, что формализм метаграфов позволяет прогнозировать функциональные особенности физической сети. Например, формирование синапсов в коннектоме мозга, в соответствии с эмпирическими данными.
Приложенное модельное видео – один из первых примеров визуализации метаграфов.
Почувствуйте разницу с фМРТ :).
1 https://www.nature.com/articles/s41567-023-02267-1
2 https://t.me/theworldisnoteasy/1618
#КомплексныеСети
Публикация в Nature статьи Эйнштейна 21 века Алберт-Ласло Барабаши «Влияние физических качеств на структуру сети» [1] фиксирует научное признание того факта, что на Земле появилась новая математика. И это не просто новый раздел математики.
Сетевая физическая математика – это математика, зависящей от физических свойств объектов (что-то типа разных таблиц умножения, в зависимости от того, на чем они написаны).
Подробней о фантастических перспективах новой математики читайте в моем посте [2].
Здесь же лишь отмечу, что формализм метаграфов позволяет прогнозировать функциональные особенности физической сети. Например, формирование синапсов в коннектоме мозга, в соответствии с эмпирическими данными.
Приложенное модельное видео – один из первых примеров визуализации метаграфов.
Почувствуйте разницу с фМРТ :).
1 https://www.nature.com/articles/s41567-023-02267-1
2 https://t.me/theworldisnoteasy/1618
#КомплексныеСети
Пока ребенок мал, он может неожиданно закричать, побежать, расплакаться… Но в любом случае в его арсенале весьма ограниченный ассортимент линий поведения. Но уже через несколько лет подросший ребенок может придумать хитрую стратегию, и в результате, он просто вас обманет: пусть не сейчас, а через неделю.
По человеческим рамкам, сегодняшние ИИ - еще малые дети. И главная проблема в том, что они растут с колоссальной скоростью: не по годам, а по неделям.
При такой скорости «роста», правительства не смогут, не то что контролировать нарастающие ИИ-риски, но и просто понять их. А из 3х групп влияния на этот процесс - богатые технооптимисты, рьяные думеры и крупные корпорации, - скорее всего, выиграют корпорации.
Ибо у них не только огромные деньги, но и синергия внутренней мотивации и операционных KPI — максимизация собственной прибыли.
Об этом в моем интервью спецвыпуску «Цифровое порабощение»
https://monocle.ru/monocle/2023/06/v-bitvakh-vokrug-ii-pobedyat-korporatsii/
#ИИриски
По человеческим рамкам, сегодняшние ИИ - еще малые дети. И главная проблема в том, что они растут с колоссальной скоростью: не по годам, а по неделям.
При такой скорости «роста», правительства не смогут, не то что контролировать нарастающие ИИ-риски, но и просто понять их. А из 3х групп влияния на этот процесс - богатые технооптимисты, рьяные думеры и крупные корпорации, - скорее всего, выиграют корпорации.
Ибо у них не только огромные деньги, но и синергия внутренней мотивации и операционных KPI — максимизация собственной прибыли.
Об этом в моем интервью спецвыпуску «Цифровое порабощение»
https://monocle.ru/monocle/2023/06/v-bitvakh-vokrug-ii-pobedyat-korporatsii/
#ИИриски
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
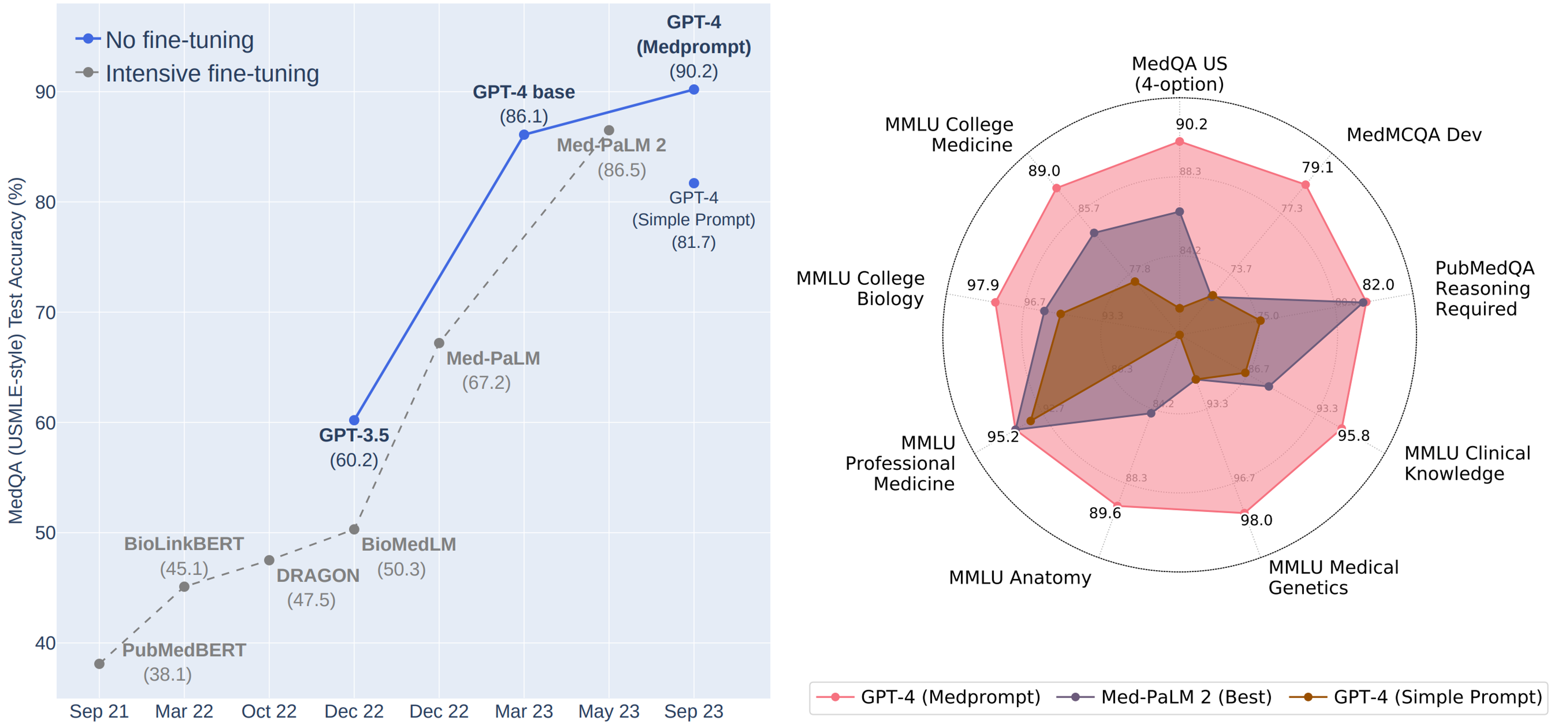
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Google DeepMind сумела запустить когнитивную эволюцию роботов
Это может открыть путь к гибридному обществу людей и андроидов
1я ноябрьская ИИ-революция (Революция ChatGPT) началась год назад - в ноябре 2022. Она ознаменовала появление на планете нового носителя высшего интеллекта — цифрового ИИ, способного достичь (и, возможно, превзойти) людей в любых видах интеллектуальной деятельности.
Но не смотря на сравнимый с людьми уровень, этот новый носитель высшего интеллекта оказался абсолютно нечеловекоподобным.
Он принадлежит к классу генеративного ИИ больших языковых моделей, не умеющих (и в принципе не способных) не то что мечтать об электроовцах, но и просто мыслить и познавать мир, как это делают люди. И потому, даже превзойдя по уровню людей, он так и останется для человечества «чужим» — иным типом интеллекта, столь же непостижимым для понимания, как интеллект квинтян из романа Станислава Лема «Фиаско».
Причина нечеловекоподобия генеративных ИИ больших языковых моделей заключается в их кардинально иной природе.
✔️ Наш интеллект – результат миллионов лет когнитивной эволюции биологических интеллектуальных агентов, позволившей людям из животных превратиться в сверхразумные существа, построивших на Земле цивилизацию планетарного уровня, начавшую освоение космоса.
✔️ ИИ больших языковых моделей – продукт машинного обучения компьютерных программ на колоссальных объемах цифровых данных.
Преодолеть это принципиальное отличие можно, если найти ключ к запуску когнитивной эволюции ИИ.
И этот ключ предложен в ноябре 2023 инициаторами 2й ноябрьской ИИ-революции (Революции когнитивной эволюции ИИ) в опубликованном журналом Nature исследовании Google DeepMind.
• Движком когнитивной эволюции ИИ авторы предлагают сделать (как и у людей) социальное обучение — когда один интеллектуальный агент (человек, животное или ИИ) приобретает навыки и знания у другого путем копирования (жизненно важного для процесса развития интеллектуальных агентов).
• Ища вдохновение в социальном обучении людей, исследователи стремились найти способ, позволяющий агентам ИИ учиться у других агентов ИИ и у людей с эффективностью, сравнимой с человеческим социальным обучением.
• Команде исследователей удалось использовать обучение с подкреплением для обучения агента ИИ, способного идентифицировать новых для себя экспертов (среди других агентов ИИ и людей), имитировать их поведение и запоминать полученные знания в течение всего нескольких минут.
"Наши агенты успешно имитируют человека в реальном времени в новых контекстах, не используя никаких предварительно собранных людьми данных. Мы определили удивительно простой набор ингредиентов, достаточный для культурной передачи, и разработали эволюционную методологию для ее систематической оценки. Это открывает путь к тому, чтобы культурная эволюция играла алгоритмическую роль в развитии искусственного общего интеллекта", - говорится в исследовании.
Запуск когнитивной эволюции ИИ позволит не только создать «человекоподобный ИИ» у роботов – андроидов, но и разрешить при их создании Парадокс Моравека (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов) и Сверхзадачу Минского (произвести обратную разработку навыков, получаемых в процессе передачи неявных знаний - невербализованных и, часто, бессознательных)
Т.о. не будет большим преувеличением сказать, что 2я ноябрьская революция ИИ открывает путь к гибридному обществу людей и андроидов, – многократно описанному в фантастических романах, но до сих пор остававшемуся практически нереализуемым на ближнем временном горизонте.
Подробный разбор вопросов когнитивной эволюции путем копирования, а также революционного подхода к ее запуску, предложенного Google DeepMind, см. в моем новом лонгриде (еще 10 мин чтения):
- на Medium https://bit.ly/486AfEN
- на Дзене https://clck.ru/36wWQc
#ИИ #Интеллект #Разум #Эволюция #Культура #АлгокогнитивнаяКультура #Роботы
Это может открыть путь к гибридному обществу людей и андроидов
1я ноябрьская ИИ-революция (Революция ChatGPT) началась год назад - в ноябре 2022. Она ознаменовала появление на планете нового носителя высшего интеллекта — цифрового ИИ, способного достичь (и, возможно, превзойти) людей в любых видах интеллектуальной деятельности.
Но не смотря на сравнимый с людьми уровень, этот новый носитель высшего интеллекта оказался абсолютно нечеловекоподобным.
Он принадлежит к классу генеративного ИИ больших языковых моделей, не умеющих (и в принципе не способных) не то что мечтать об электроовцах, но и просто мыслить и познавать мир, как это делают люди. И потому, даже превзойдя по уровню людей, он так и останется для человечества «чужим» — иным типом интеллекта, столь же непостижимым для понимания, как интеллект квинтян из романа Станислава Лема «Фиаско».
Причина нечеловекоподобия генеративных ИИ больших языковых моделей заключается в их кардинально иной природе.
✔️ Наш интеллект – результат миллионов лет когнитивной эволюции биологических интеллектуальных агентов, позволившей людям из животных превратиться в сверхразумные существа, построивших на Земле цивилизацию планетарного уровня, начавшую освоение космоса.
✔️ ИИ больших языковых моделей – продукт машинного обучения компьютерных программ на колоссальных объемах цифровых данных.
Преодолеть это принципиальное отличие можно, если найти ключ к запуску когнитивной эволюции ИИ.
И этот ключ предложен в ноябре 2023 инициаторами 2й ноябрьской ИИ-революции (Революции когнитивной эволюции ИИ) в опубликованном журналом Nature исследовании Google DeepMind.
• Движком когнитивной эволюции ИИ авторы предлагают сделать (как и у людей) социальное обучение — когда один интеллектуальный агент (человек, животное или ИИ) приобретает навыки и знания у другого путем копирования (жизненно важного для процесса развития интеллектуальных агентов).
• Ища вдохновение в социальном обучении людей, исследователи стремились найти способ, позволяющий агентам ИИ учиться у других агентов ИИ и у людей с эффективностью, сравнимой с человеческим социальным обучением.
• Команде исследователей удалось использовать обучение с подкреплением для обучения агента ИИ, способного идентифицировать новых для себя экспертов (среди других агентов ИИ и людей), имитировать их поведение и запоминать полученные знания в течение всего нескольких минут.
"Наши агенты успешно имитируют человека в реальном времени в новых контекстах, не используя никаких предварительно собранных людьми данных. Мы определили удивительно простой набор ингредиентов, достаточный для культурной передачи, и разработали эволюционную методологию для ее систематической оценки. Это открывает путь к тому, чтобы культурная эволюция играла алгоритмическую роль в развитии искусственного общего интеллекта", - говорится в исследовании.
Запуск когнитивной эволюции ИИ позволит не только создать «человекоподобный ИИ» у роботов – андроидов, но и разрешить при их создании Парадокс Моравека (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов) и Сверхзадачу Минского (произвести обратную разработку навыков, получаемых в процессе передачи неявных знаний - невербализованных и, часто, бессознательных)
Т.о. не будет большим преувеличением сказать, что 2я ноябрьская революция ИИ открывает путь к гибридному обществу людей и андроидов, – многократно описанному в фантастических романах, но до сих пор остававшемуся практически нереализуемым на ближнем временном горизонте.
Подробный разбор вопросов когнитивной эволюции путем копирования, а также революционного подхода к ее запуску, предложенного Google DeepMind, см. в моем новом лонгриде (еще 10 мин чтения):
- на Medium https://bit.ly/486AfEN
- на Дзене https://clck.ru/36wWQc
#ИИ #Интеллект #Разум #Эволюция #Культура #АлгокогнитивнаяКультура #Роботы
Medium
Google DeepMind сумела запустить когнитивную эволюцию роботов
Это может открыть путь к гибридному обществу людей и андроидов
Мир стал другим.
Сложилось альтернативное понимание истины и честности.
В мире уже не первый год устойчиво крепчает тренд на безумие. Он все ярче проявляется и в деградации внешней политики многих стран (стремительно скатывающейся к дегенерации), и в нарастающем пожаре раскола и поляризации внутри отдельных стран, безумно поливаемом бензином действий их политиков и элит.
https://media.springernature.com/lw685/springer-static/image/art%3A10.1038%2Fs41562-023-01691-w/MediaObjects/41562_2023_1691_Fig1_HTML.png?as=webp
Год назад я анализировал вопрос о том, «кто более виновен в происходящем безумии - элита или народ» [1], на основе прямого измерения цифровых следов людей в Интернете, проведенного проф. Рэнд и Мослех в работе «Измерение подверженности мисинформации со стороны политических элит в Twitter». Измеряя показатели «токсичности лжи» 816-ти представителей элиты и «иммунитета к мисинформации» у их подписчиков, авторы выявили сложную связку отношений элита-народ:
• лидеры слабо реагируют на отношение народа к сказанному ими;
• риторика элиты определяет убеждения и политические позиции народа;
• чем лживее представитель элиты, тем сильнее снижается у его подписчиков иммунитет к мисинформации, что упрощает ему убеждение их в еще большей лжи.
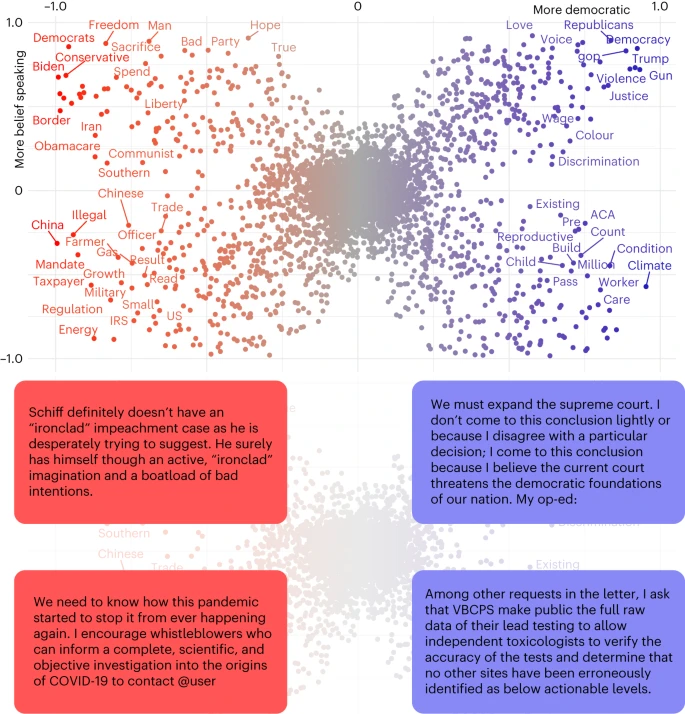
Новое исследование междисциплинарной группы исследователей (психологи, когнитивисты, спецы по компьютерной симуляции и вычислительной социологии) «От альтернативных концепций честности к альтернативным фактам в коммуникациях политиков США» [2] продвигает нас в понимании общественного и политического мироустройства в эпоху постправды.
В работе анализируются способы воздействия дезинформации, распространяемой в целях заставить людей изменить свое поведение. Авторы копаю глубже примитивного навешивания ярлыков: правда-ложь, факт-фейк и т.п. Они пытаются выделить в публичной политической речи выборных должностных лиц США два компонента правды и честности — высказывание убеждений и изложение фактов.
Такой подход основан на онтологии политической истины, включающей две различные концепции истины:
• Высказывание убеждений относится только к убеждениям, мыслям и чувствам говорящего, без учета фактической точности. Эта концепция основана на интуиции, субъективных впечатлениях и чувствах.
• Изложение фактов, напротив, связано с поиском точной информации и обновлением своих убеждений на основе этой информации. Эта концепция истины основана на фактических данных.
N.B. Хотя истина и честность являются тесно связанными понятиями, а честность и правдивость являются почти синонимами, в данном контексте их необходимо распутать для ясности.
Анализируя сообщения членов Конгресса США в Твиттере в период с 2011 по 2022 год, авторы показали следующее:
1. Концепция честности политиков претерпела явный сдвиг: высказывания подлинных убеждений, которые могут быть отделены от доказательств, становятся все более заметными и более дифференцированными от явно основанного на доказательствах изложения фактов.
2. Представление политиков о честности претерпели явные изменения, при этом высказывание подлинных убеждений, которые могут быть отделены от доказательств, становятся более заметными и более дифференцированными от явно основанных на фактах высказываний.
3. Для республиканцев (но не для демократов) повышение уровня веры к высказыванию на 10% связано со снижением на 12,8 пункта качества источников (по системе оценки NewsGuard), которыми поделились.
4. Напротив, увеличение числа говорящих на языке фактов связано с повышением качества источников для обеих сторон.
Эти результаты согласуются с гипотезой о том,
что нынешнее распространение дезинформации в политическом дискурсе связано с укреплением альтернативного понимания истины и честности, которое делает акцент на использовании субъективных убеждений в ущерб уверенности в доказательствах.
1 https://t.me/theworldisnoteasy/1644
2 https://www.nature.com/articles/s41562-023-01691-w
#Мисинформация #Элита #Раскол
Сложилось альтернативное понимание истины и честности.
В мире уже не первый год устойчиво крепчает тренд на безумие. Он все ярче проявляется и в деградации внешней политики многих стран (стремительно скатывающейся к дегенерации), и в нарастающем пожаре раскола и поляризации внутри отдельных стран, безумно поливаемом бензином действий их политиков и элит.
https://media.springernature.com/lw685/springer-static/image/art%3A10.1038%2Fs41562-023-01691-w/MediaObjects/41562_2023_1691_Fig1_HTML.png?as=webp
Год назад я анализировал вопрос о том, «кто более виновен в происходящем безумии - элита или народ» [1], на основе прямого измерения цифровых следов людей в Интернете, проведенного проф. Рэнд и Мослех в работе «Измерение подверженности мисинформации со стороны политических элит в Twitter». Измеряя показатели «токсичности лжи» 816-ти представителей элиты и «иммунитета к мисинформации» у их подписчиков, авторы выявили сложную связку отношений элита-народ:
• лидеры слабо реагируют на отношение народа к сказанному ими;
• риторика элиты определяет убеждения и политические позиции народа;
• чем лживее представитель элиты, тем сильнее снижается у его подписчиков иммунитет к мисинформации, что упрощает ему убеждение их в еще большей лжи.
Новое исследование междисциплинарной группы исследователей (психологи, когнитивисты, спецы по компьютерной симуляции и вычислительной социологии) «От альтернативных концепций честности к альтернативным фактам в коммуникациях политиков США» [2] продвигает нас в понимании общественного и политического мироустройства в эпоху постправды.
В работе анализируются способы воздействия дезинформации, распространяемой в целях заставить людей изменить свое поведение. Авторы копаю глубже примитивного навешивания ярлыков: правда-ложь, факт-фейк и т.п. Они пытаются выделить в публичной политической речи выборных должностных лиц США два компонента правды и честности — высказывание убеждений и изложение фактов.
Такой подход основан на онтологии политической истины, включающей две различные концепции истины:
• Высказывание убеждений относится только к убеждениям, мыслям и чувствам говорящего, без учета фактической точности. Эта концепция основана на интуиции, субъективных впечатлениях и чувствах.
• Изложение фактов, напротив, связано с поиском точной информации и обновлением своих убеждений на основе этой информации. Эта концепция истины основана на фактических данных.
N.B. Хотя истина и честность являются тесно связанными понятиями, а честность и правдивость являются почти синонимами, в данном контексте их необходимо распутать для ясности.
Анализируя сообщения членов Конгресса США в Твиттере в период с 2011 по 2022 год, авторы показали следующее:
1. Концепция честности политиков претерпела явный сдвиг: высказывания подлинных убеждений, которые могут быть отделены от доказательств, становятся все более заметными и более дифференцированными от явно основанного на доказательствах изложения фактов.
2. Представление политиков о честности претерпели явные изменения, при этом высказывание подлинных убеждений, которые могут быть отделены от доказательств, становятся более заметными и более дифференцированными от явно основанных на фактах высказываний.
3. Для республиканцев (но не для демократов) повышение уровня веры к высказыванию на 10% связано со снижением на 12,8 пункта качества источников (по системе оценки NewsGuard), которыми поделились.
4. Напротив, увеличение числа говорящих на языке фактов связано с повышением качества источников для обеих сторон.
Эти результаты согласуются с гипотезой о том,
что нынешнее распространение дезинформации в политическом дискурсе связано с укреплением альтернативного понимания истины и честности, которое делает акцент на использовании субъективных убеждений в ущерб уверенности в доказательствах.
1 https://t.me/theworldisnoteasy/1644
2 https://www.nature.com/articles/s41562-023-01691-w
#Мисинформация #Элита #Раскол
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ.
Эксперимент показал - у больших моделей есть воображение.
Анализ 3х работ OpenAI, Anthropic и Google DeepMind навевает ассоциации с леденящим душу технокошмаром из серии фильмов ужасов «Чужой».
Точнее, с их облегченной версией, - где «чужой» может оказаться злым монстром, а может и нет. Но сам факт, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает.
1) Еще в мае исследователи из OpenAI решили попытаться «заглянуть в душу» ИИ (точнее называть это «большой языковой моделью - LLM», но ИИ короче и понятней). Исследователи подошли к решению задачи «черного ящика» ИИ (понять, что у него внутри) супер-креативно.
Зачем самим ломать голову, решая неподъемную для людей задачу. Пусть большой ИИ (GPT-4 с числом нейроном 100+ млрд) сам ее и решит применительно к маленькому ИИ (GPT-2, в коем нейронов всего то 300К+) [1].
Результат озадачил исследователей. Многие нейроны (внутри маленького ИИ) оказались многозначны – т.е. они реагировали на множество самых разных входных данных: смесь академических цитат, диалогов на английском языке, HTTP-запросов, корейского текста …
Эта многозначность нейронов человеческой логике не понятна и ею не объятна. Если нейроны многозначны, какие же тогда более мелкие «субнейроны» соответствуют конкретным понятиям?
2) Ответ на этот вопрос дают исследователи из Anthropic [2]. Они полагают, что одной из причин многозначности является суперпозиция - гипотетическое явление, при котором нейронная сеть представляет больше независимых «функций» данных, чем нейроны, назначая каждой функции свою собственную линейную комбинацию нейронов.
Иными словами, внутри нейронной сети любого конкретного ИИ симулируется физически не существующая нейронная сеть некоего абстрактного ИИ.
И эта симулируемая нейронная сеть,
1. гораздо больше и сложнее нейронной сети, ее моделирующей;
2. содержит симулируемые моносемантические «субнейроны» (соответствующие конкретным понятиям);
Еще проще говоря: внутри менее мощного ИИ симулируется более мощный ИИ. Менее мощный ИИ физически существует в виде сети нейронов. Более мощный – в виде сети паттернов (линейных комбинаций) активаций нейронов.
3) Почувствовать на практике, сколь мощный ИИ таится внутри маскирующегося под «стохастического попугая» ИИ LLM, позволяет новое исследование Главного научного сотрудника Google DeepMind проф. Шанахана и директора CHPPC_IHR проф. Кларк [3].
Объектом исследования стало якобы отсутствующее у LLM свойство разума, без которого невозможно истинное творчество – воображение.
Эйнштейн писал - “Воображение важнее знаний. Ибо знания ограничены всем, что мы сейчас знаем и понимаем, в то время как воображение охватывает весь мир и все, что когда-либо можно будет узнать и понять”.
Эксперимент Шанахана-Кларк заключался в проверке наличия у GPT-4 воображения, позволяющего модели проявлять художественную креативность при написании (в соавторстве с человеком) литературного текста - фантастического романа о путешествии во времени.
Эксперимент показал:
✔️ при наличии сложных подсказок и соавтора-человека, модель демонстрирует изысканное воображение;
✔️ это продукт творчества модели, ибо ничего подобного люди до нее не придумали (этого не было в каких-либо текстах людей): например, появляющиеся по ходу романа придуманные моделью:
- новые персонажи и сюжетные повороты;
- новые неологизмы (прямо как у Солженицина), служащие для раскрытия идейного содержания сюжета - отнюдь не бессмысленные, семантически верные и контекстуально релевантные.
Значение вышеописанного см. в моем цикле “теория относительности интеллекта”.
#Креативность #Воображение #LLM
[1] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[2] https://transformer-circuits.pub/2023/monosemantic-features
[3] https://arxiv.org/abs/2312.03746
Эксперимент показал - у больших моделей есть воображение.
Анализ 3х работ OpenAI, Anthropic и Google DeepMind навевает ассоциации с леденящим душу технокошмаром из серии фильмов ужасов «Чужой».
Точнее, с их облегченной версией, - где «чужой» может оказаться злым монстром, а может и нет. Но сам факт, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает.
1) Еще в мае исследователи из OpenAI решили попытаться «заглянуть в душу» ИИ (точнее называть это «большой языковой моделью - LLM», но ИИ короче и понятней). Исследователи подошли к решению задачи «черного ящика» ИИ (понять, что у него внутри) супер-креативно.
Зачем самим ломать голову, решая неподъемную для людей задачу. Пусть большой ИИ (GPT-4 с числом нейроном 100+ млрд) сам ее и решит применительно к маленькому ИИ (GPT-2, в коем нейронов всего то 300К+) [1].
Результат озадачил исследователей. Многие нейроны (внутри маленького ИИ) оказались многозначны – т.е. они реагировали на множество самых разных входных данных: смесь академических цитат, диалогов на английском языке, HTTP-запросов, корейского текста …
Эта многозначность нейронов человеческой логике не понятна и ею не объятна. Если нейроны многозначны, какие же тогда более мелкие «субнейроны» соответствуют конкретным понятиям?
2) Ответ на этот вопрос дают исследователи из Anthropic [2]. Они полагают, что одной из причин многозначности является суперпозиция - гипотетическое явление, при котором нейронная сеть представляет больше независимых «функций» данных, чем нейроны, назначая каждой функции свою собственную линейную комбинацию нейронов.
Иными словами, внутри нейронной сети любого конкретного ИИ симулируется физически не существующая нейронная сеть некоего абстрактного ИИ.
И эта симулируемая нейронная сеть,
1. гораздо больше и сложнее нейронной сети, ее моделирующей;
2. содержит симулируемые моносемантические «субнейроны» (соответствующие конкретным понятиям);
Еще проще говоря: внутри менее мощного ИИ симулируется более мощный ИИ. Менее мощный ИИ физически существует в виде сети нейронов. Более мощный – в виде сети паттернов (линейных комбинаций) активаций нейронов.
3) Почувствовать на практике, сколь мощный ИИ таится внутри маскирующегося под «стохастического попугая» ИИ LLM, позволяет новое исследование Главного научного сотрудника Google DeepMind проф. Шанахана и директора CHPPC_IHR проф. Кларк [3].
Объектом исследования стало якобы отсутствующее у LLM свойство разума, без которого невозможно истинное творчество – воображение.
Эйнштейн писал - “Воображение важнее знаний. Ибо знания ограничены всем, что мы сейчас знаем и понимаем, в то время как воображение охватывает весь мир и все, что когда-либо можно будет узнать и понять”.
Эксперимент Шанахана-Кларк заключался в проверке наличия у GPT-4 воображения, позволяющего модели проявлять художественную креативность при написании (в соавторстве с человеком) литературного текста - фантастического романа о путешествии во времени.
Эксперимент показал:
✔️ при наличии сложных подсказок и соавтора-человека, модель демонстрирует изысканное воображение;
✔️ это продукт творчества модели, ибо ничего подобного люди до нее не придумали (этого не было в каких-либо текстах людей): например, появляющиеся по ходу романа придуманные моделью:
- новые персонажи и сюжетные повороты;
- новые неологизмы (прямо как у Солженицина), служащие для раскрытия идейного содержания сюжета - отнюдь не бессмысленные, семантически верные и контекстуально релевантные.
Значение вышеописанного см. в моем цикле “теория относительности интеллекта”.
#Креативность #Воображение #LLM
[1] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[2] https://transformer-circuits.pub/2023/monosemantic-features
[3] https://arxiv.org/abs/2312.03746
Openai
Language models can explain neurons in language models
We use GPT-4 to automatically write explanations for the behavior of neurons in large language models and to score those explanations. We release a dataset of these (imperfect) explanations and scores for every neuron in GPT-2.
This media is not supported in your browser
VIEW IN TELEGRAM
Взгляните на этот веселый Deep Fake от @yurii_yeltsov.
Трудно придумать более наглядную иллюстрацию двух топовых прогнозов отчета State of AI Report на 2024 год (см. https://t.me/theworldisnoteasy/1823):
1. В Голливуде произойдет технологическая революция в области создания визуальных эффектов – весь процесс будет отдан на откуп ГенИИ.
2. Начнется первое в истории расследование вмешательства ГенИИ известного на весь мир производителя в предвыборную президентскую кампанию в США.
Описывая мир победившего к 2041 году ИИ, легендарный визионер, техно-инвестор и стратег Кай-Фу Ли предвидит, что главным инструментом власти и криминала станет не насилие, а ИИ технология DeepMask - преемник сегодняшних DeepFake (см. https://t.me/theworldisnoteasy/1349).
Полагаю, что мой старый коллега по SGI ошибся лишь в одном – это случится гораздо раньше.
#Deepfakes
Трудно придумать более наглядную иллюстрацию двух топовых прогнозов отчета State of AI Report на 2024 год (см. https://t.me/theworldisnoteasy/1823):
1. В Голливуде произойдет технологическая революция в области создания визуальных эффектов – весь процесс будет отдан на откуп ГенИИ.
2. Начнется первое в истории расследование вмешательства ГенИИ известного на весь мир производителя в предвыборную президентскую кампанию в США.
Описывая мир победившего к 2041 году ИИ, легендарный визионер, техно-инвестор и стратег Кай-Фу Ли предвидит, что главным инструментом власти и криминала станет не насилие, а ИИ технология DeepMask - преемник сегодняшних DeepFake (см. https://t.me/theworldisnoteasy/1349).
Полагаю, что мой старый коллега по SGI ошибся лишь в одном – это случится гораздо раньше.
#Deepfakes
“Generation I” дорого платит за перепрошивку когнитивных гаджетов.
Беспрецедентное падение знаний и навыков чтения, математики и естественных наук у подростков всего мира в 2012-2023.
https://disk.yandex.ru/i/5qaob6dNK3KuyA
В посте «Куда ведет «великая перепрошивка» когнитивных гаджетов детей. Деформация интеллекта и эпидемия психических заболеваний уже начались» https://t.me/theworldisnoteasy/1766 я рассказывал о развороте трендов успехов 13-летних американцев в чтении и математике. Оба тренда сломались в 2012 и теперь только ухудшаются.
Надежда, что может это только в США такой облом, продержалась не долго.
Только опубликованные результаты международной оценки у 15-летних учащихся всего мира (PISA) знаний и навыков по математике, чтению и естественным наукам (тесты проверяют, насколько хорошо учащиеся могут решать сложные проблемы, критически мыслить и эффективно общаться) подтвердили наихудшие опасения https://bit.ly/3RsZiei
• Беспрецедентное снижение показателей происходит по всему миру.
• По сравнению с 2018 годом средняя успеваемость снизилась на десять баллов по чтению и почти на 15 баллов по математике, что эквивалентно трем четвертям годового объема обучения.
• Снижение успеваемости по математике в три раза больше, чем любое предыдущее последовательное изменение. Фактически, в среднем по странам ОЭСР каждый четвертый 15-летний подросток в настоящее время считается плохо успевающим по математике, чтению и естественным наукам. Это означает, что им может быть трудно выполнять такие задачи, как использование базовых алгоритмов или интерпретация простых текстов.
Обвальное снижение показателей подростков по математике, чтению и естественным наукам (как и начало эпидемии психических заболеваний у детей) случилось в начале 2010-х. Примерно тогда же подростки всего мира стали массово менять свои примитивные сотовые телефоны на смартфоны, оснащенные приложениями для социальных сетей.
Гипотеза проф. психологии Джин Твенж о том, что смартфоны и тусение в соцсетях могут вести к деградации у “Generation I” https://bit.ly/3GJ68rc (поколение детей-инфоргов https://t.me/theworldisnoteasy/1479) многих важных навыков, в 2017 многими была воспринята в штыки, как голимый алармизм.
К концу 2023 для многих становится очевидным, что Джин Твенж абсолютно права, ибо все 13 альтернативных объяснений происходящего с “Generation I” не выдерживают критического анализа (подробно здесь https://bit.ly/48ffBlM).
Джонатан Хайдт (социальный психолог NYU Stern School of Business) написал об этом так https://bit.ly/46WmfMQ:
«Джин подверглась резкой критике со стороны других исследователей, выдвигавших примерно такие версии: 1) с детьми все в порядке, это просто еще одна моральная паника, и 2) все это просто корреляции, нет никаких доказательств причинно-следственной связи явлений. Но сейчас, спустя шесть лет, уже нет сомнений, что детям сильно хуже, и есть множество причинно- следственных доказательств причастности смартфонов и социальных сетей. Джин была права».
А проф. Эрик Хоэл (американский нейробиолог и нейрофилософ, специализирующийся на изучении и философии познания и сознания) так описывает происходящее с ребенком-инфоргом, погруженным в цифровой мир https://bit.ly/3thli3Z.
«… он узнает, что физический мир животных, людей и мест действия - лишь одна из разновидностей мира. Все больше и больше реальный мир существует в виде крошечных прямоугольников - виртуальных "мест действия"… Его мир состоит из пикселей, постов, обновлений, лайков, а его действия - просто клики. Мы спроецировали всю нашу цивилизацию внутрь того, что в конечном счете является крошечным тесным пространством, если смотреть на него ясными глазами ребенка…Исход 21-го века будет очень сильно зависеть от того, смогут ли люди перед лицом великих технологических изменений отвергать наиболее вредные технологические "достижения".»
Проф. Хоэл прав. Ведь выживут только инфорги https://bit.ly/477rKIp
#Инфорги
Беспрецедентное падение знаний и навыков чтения, математики и естественных наук у подростков всего мира в 2012-2023.
https://disk.yandex.ru/i/5qaob6dNK3KuyA
В посте «Куда ведет «великая перепрошивка» когнитивных гаджетов детей. Деформация интеллекта и эпидемия психических заболеваний уже начались» https://t.me/theworldisnoteasy/1766 я рассказывал о развороте трендов успехов 13-летних американцев в чтении и математике. Оба тренда сломались в 2012 и теперь только ухудшаются.
Надежда, что может это только в США такой облом, продержалась не долго.
Только опубликованные результаты международной оценки у 15-летних учащихся всего мира (PISA) знаний и навыков по математике, чтению и естественным наукам (тесты проверяют, насколько хорошо учащиеся могут решать сложные проблемы, критически мыслить и эффективно общаться) подтвердили наихудшие опасения https://bit.ly/3RsZiei
• Беспрецедентное снижение показателей происходит по всему миру.
• По сравнению с 2018 годом средняя успеваемость снизилась на десять баллов по чтению и почти на 15 баллов по математике, что эквивалентно трем четвертям годового объема обучения.
• Снижение успеваемости по математике в три раза больше, чем любое предыдущее последовательное изменение. Фактически, в среднем по странам ОЭСР каждый четвертый 15-летний подросток в настоящее время считается плохо успевающим по математике, чтению и естественным наукам. Это означает, что им может быть трудно выполнять такие задачи, как использование базовых алгоритмов или интерпретация простых текстов.
Обвальное снижение показателей подростков по математике, чтению и естественным наукам (как и начало эпидемии психических заболеваний у детей) случилось в начале 2010-х. Примерно тогда же подростки всего мира стали массово менять свои примитивные сотовые телефоны на смартфоны, оснащенные приложениями для социальных сетей.
Гипотеза проф. психологии Джин Твенж о том, что смартфоны и тусение в соцсетях могут вести к деградации у “Generation I” https://bit.ly/3GJ68rc (поколение детей-инфоргов https://t.me/theworldisnoteasy/1479) многих важных навыков, в 2017 многими была воспринята в штыки, как голимый алармизм.
К концу 2023 для многих становится очевидным, что Джин Твенж абсолютно права, ибо все 13 альтернативных объяснений происходящего с “Generation I” не выдерживают критического анализа (подробно здесь https://bit.ly/48ffBlM).
Джонатан Хайдт (социальный психолог NYU Stern School of Business) написал об этом так https://bit.ly/46WmfMQ:
«Джин подверглась резкой критике со стороны других исследователей, выдвигавших примерно такие версии: 1) с детьми все в порядке, это просто еще одна моральная паника, и 2) все это просто корреляции, нет никаких доказательств причинно-следственной связи явлений. Но сейчас, спустя шесть лет, уже нет сомнений, что детям сильно хуже, и есть множество причинно- следственных доказательств причастности смартфонов и социальных сетей. Джин была права».
А проф. Эрик Хоэл (американский нейробиолог и нейрофилософ, специализирующийся на изучении и философии познания и сознания) так описывает происходящее с ребенком-инфоргом, погруженным в цифровой мир https://bit.ly/3thli3Z.
«… он узнает, что физический мир животных, людей и мест действия - лишь одна из разновидностей мира. Все больше и больше реальный мир существует в виде крошечных прямоугольников - виртуальных "мест действия"… Его мир состоит из пикселей, постов, обновлений, лайков, а его действия - просто клики. Мы спроецировали всю нашу цивилизацию внутрь того, что в конечном счете является крошечным тесным пространством, если смотреть на него ясными глазами ребенка…Исход 21-го века будет очень сильно зависеть от того, смогут ли люди перед лицом великих технологических изменений отвергать наиболее вредные технологические "достижения".»
Проф. Хоэл прав. Ведь выживут только инфорги https://bit.ly/477rKIp
#Инфорги
Яндекс Диск
PISA test.jpg
Посмотреть и скачать с Яндекс Диска
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Помимо “процессора” и “памяти”, в мозге людей есть “машина времени”.
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
livescience.com
Traumatic memories are processed differently in PTSD
People with PTSD feel like they're reliving past experiences in the present. This may be tied to how the brain processes memories of those experiences.
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
Первая вычислительная реализация красоты в глазах смотрящего.
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 https://t.me/theworldisnoteasy/1741
3 https://t.me/theworldisnoteasy/1122
#Креативность
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 https://t.me/theworldisnoteasy/1741
3 https://t.me/theworldisnoteasy/1122
#Креативность
Philosophical Transactions of the Royal Society B: Biological Sciences
Cultivating creativity: predictive brains and the enlightened room problem | Philosophical Transactions of the Royal Society B:…
How can one conciliate the claim that humans are uncertainty minimizing systems that
seek to navigate predictable and familiar environments with the claim that humans
can be creative? We call this the Enlightened Room Problem (ERP). The solution, we
...
seek to navigate predictable and familiar environments with the claim that humans
can be creative? We call this the Enlightened Room Problem (ERP). The solution, we
...
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Яндекс Диск
Разум в Мультиверсе.jpg
Посмотреть и скачать с Яндекс Диска
Машинное отучение вместо машинного обучения.
В Китае найден идеальный способ воспитания законопослушных ИИ.
Вопрос эффективности машинного обучения, конечно, важен. Но еще важнее, быстро и эффективно отучать модель от «дурных привычек» и «вредных знаний», которыми модели могут легко и широкомасштабно делиться с людьми. Так ведь можно общество и вольнодумством заразить, если ИИ будет недостаточно законопослушен и тем самым станет дурно влиять на людей (с т.з. властей и/или создателей).
До такой постановки вопроса первыми додумались, естественно, в Китае. И довольно быстро придумали ответ на этот вызов. В НИИ владеющего TikTok китайского IT-гиганта ByteDance придумали крайне эффективный способ отучения модели от чего угодно.
До сих пор отучение моделей от вредных знаний (типа, как сделать бомбу или изготовить яд) и вредного влияния на людей (типа рассказов, как припеваючи живут люксовые проститутки и удачливые наркодилеры) было основано на положительных примерах и методе RLHF (обучение с подкреплением на основе человеческих предпочтений). Этот метод обучает «модель вознаграждения» непосредственно на основе отзывов людей. Модель учится на их примерах различать «что такое хорошо» и «что такое плохо».
RLHF метод всем хорош, но очень затратен по вычислительным ресурсам и времени (OpenAI потратил полгода и кучу денег, чтобы отучить GPT-4 хотя бы от самых распространенных гадостей, прежде чем выпустить модель в свет).
Китайцы из ByteDance Research пошли другим путем – не учить модель отличать «что такое хорошо» от «что такое плохо» на смеси позитивных и негативных примеров, а лишь отучать её от «что такое плохо», используя только негативные примеры.
Получилось дешево и сердито. Испытания нового метода показали, что с его помощью можно успешно:
• удалять вредные реакции модели (от себя добавлю, вредные с т.з. известно кого);
• стирать из памяти модели контент, защищенный авторским правом (от себя добавлю, и контент, неугодный известно кому);
• устранять галлюцинации (от себя добавлю, и/или то, что должно будет считаться галлюцинациями – типа принудительной психиатрии для людей).
Мне новый китайский метод отучения моделей напомнил древний "метод пресыщения" у людей, также называемый аверсивная терапия. Её целью было вызывать у человека с пагубной зависимостью неприятные ощущения от вредной привычки. Например, отучать юношу от алкоголя, заставляя его выпить так много, чтобы ему стало совсем плохо от алкогольного отравления. Сейчас этот метод признан не только неэффективным, но и чрезвычайно опасным. Но ведь это для людей. А ИИ – не человек, и потому, как считается, тут допустимо что-угодно.
Авторы пишут – «это только начало».
И они правы. У методов отучения ИИ огромные перспективы. И не только в Китае.
Картинка https://disk.yandex.ru/i/M8RHPb6llndp-A
Статья https://arxiv.org/pdf/2310.10683.pdf
#МашинноеОтучение
В Китае найден идеальный способ воспитания законопослушных ИИ.
Вопрос эффективности машинного обучения, конечно, важен. Но еще важнее, быстро и эффективно отучать модель от «дурных привычек» и «вредных знаний», которыми модели могут легко и широкомасштабно делиться с людьми. Так ведь можно общество и вольнодумством заразить, если ИИ будет недостаточно законопослушен и тем самым станет дурно влиять на людей (с т.з. властей и/или создателей).
До такой постановки вопроса первыми додумались, естественно, в Китае. И довольно быстро придумали ответ на этот вызов. В НИИ владеющего TikTok китайского IT-гиганта ByteDance придумали крайне эффективный способ отучения модели от чего угодно.
До сих пор отучение моделей от вредных знаний (типа, как сделать бомбу или изготовить яд) и вредного влияния на людей (типа рассказов, как припеваючи живут люксовые проститутки и удачливые наркодилеры) было основано на положительных примерах и методе RLHF (обучение с подкреплением на основе человеческих предпочтений). Этот метод обучает «модель вознаграждения» непосредственно на основе отзывов людей. Модель учится на их примерах различать «что такое хорошо» и «что такое плохо».
RLHF метод всем хорош, но очень затратен по вычислительным ресурсам и времени (OpenAI потратил полгода и кучу денег, чтобы отучить GPT-4 хотя бы от самых распространенных гадостей, прежде чем выпустить модель в свет).
Китайцы из ByteDance Research пошли другим путем – не учить модель отличать «что такое хорошо» от «что такое плохо» на смеси позитивных и негативных примеров, а лишь отучать её от «что такое плохо», используя только негативные примеры.
Получилось дешево и сердито. Испытания нового метода показали, что с его помощью можно успешно:
• удалять вредные реакции модели (от себя добавлю, вредные с т.з. известно кого);
• стирать из памяти модели контент, защищенный авторским правом (от себя добавлю, и контент, неугодный известно кому);
• устранять галлюцинации (от себя добавлю, и/или то, что должно будет считаться галлюцинациями – типа принудительной психиатрии для людей).
Мне новый китайский метод отучения моделей напомнил древний "метод пресыщения" у людей, также называемый аверсивная терапия. Её целью было вызывать у человека с пагубной зависимостью неприятные ощущения от вредной привычки. Например, отучать юношу от алкоголя, заставляя его выпить так много, чтобы ему стало совсем плохо от алкогольного отравления. Сейчас этот метод признан не только неэффективным, но и чрезвычайно опасным. Но ведь это для людей. А ИИ – не человек, и потому, как считается, тут допустимо что-угодно.
Авторы пишут – «это только начало».
И они правы. У методов отучения ИИ огромные перспективы. И не только в Китае.
Картинка https://disk.yandex.ru/i/M8RHPb6llndp-A
Статья https://arxiv.org/pdf/2310.10683.pdf
#МашинноеОтучение
Яндекс Диск
Отучение модели от вредных знаний и поведения.jpg
Посмотреть и скачать с Яндекс Диска