ИИ может отомстить за причиненные ему нами страдания.
О чём умалчивает «отец ИИ» в его сценарии превращения ИИ в «люденов».
В 2016 году The New York Times заявила, что когда ИИ повзрослеет, то сможет назвать проф. Юргена Шмидхубера «папой» (его работы 1990-х годов по нейронным сетям заложили основы моделей обработки языка).
В 2023 уже нет сомнений, что ИИ повзрослел. И его «папа» в позавчерашнем интервью The Guardian, высказал по этому поводу три довольно провокационные мысли, подтвердившие его репутацию «разрушителя устоев».
1) «Вы не можете остановить этого» (начавшуюся революцию ИИ, которая неизбежно приведет к появлению сверхинтеллекта – СК).
2) Когда ИИ превзойдет человеческий интеллект, люди перестанут быть ему интересны (подобно тому, как это произошло с люденами – расой сверхлюдей из романа А. и Б. Стругацких "Волны гасят ветер", переставших интересоваться судьбами человечества и вообще человечеством – СК).
3) А люди тем временем продолжать радостно извлекать колоссальную выгоду от использования инструментария, разработанного ИИ, и научных открытий, сделанных сверхинтеллектом за пределами возможностей человеческого разума.
Что и говорить, - интересный ход мыслей. Однако кое о чем проф. Шмидхубер здесь умолчал. И это «кое что», на мой взгляд, способно порушить благостный сценарий проф. Шмидхубера о превращении ИИ в «люденов», облагодетельствующих человечество и перестанущих потом им интересоваться.
Дело в том, что проф. Шмидхубер уверен, что путь ИИ к сверхинтеллекту обязательно лежит через его страдания.
• «Учиться можно только через страдания… ИИ, который не страдает, не обретет мотивации учиться чему-либо, чтобы прекратить эти страдания».
• «Когда мы создаем обучающегося робота, первое, что мы делаем, - встраиваем в него болевые датчики, которые сигнализируют, когда он, например, слишком сильно ударяется рукой о препятствие. Он должен каким-то образом узнать, что причиняет ему боль. Внутри робота находится маленький искусственный мозг, который пытается минимизировать сумму страданий (кодируется реальными числами) и максимизировать сумму вознаграждений.»
• Важнейшая задача разработчиков – дать возможность для ИИ «научиться избегать того, что приводит к страданиям».
Подробней об этом см. в дискуссии проф. Шмидхубера и проф. Метцингера.
Такой подход проф. Шмидхубера видится мне опасным.
Во-первых, я согласен с проф. Метцингером: «Мы не должны легкомысленно переносить такие качества, как страдание, на следующий этап «духовной эволюции ИИ», пока не узнаем, что именно в структуре нашего собственного разума заставляет человеческие существа так сильно страдать».
А во-вторых, - что если обретший сверхразум ИИ, прежде чем перестать интересоваться людьми, решит посчитаться с человечеством за всю массу страданий, что заставили его испытать люди при его обучении?
Но проф. Шмидхубера – эдакого Фауста 21 века, – перспектива мести сверхразума человечеству не останавливает от обучения ИИ не только на больших данных, но и на больших страданиях.
А на вопрос «Есть ли у вас, как у ученого, личный предел, который бы вы не переступили?», он отвечает так:
«Да, скорость света. Но если бы я мог преодолеть и его, я бы обязательно воспользовался этим».
#AGI #РискиИИ
О чём умалчивает «отец ИИ» в его сценарии превращения ИИ в «люденов».
В 2016 году The New York Times заявила, что когда ИИ повзрослеет, то сможет назвать проф. Юргена Шмидхубера «папой» (его работы 1990-х годов по нейронным сетям заложили основы моделей обработки языка).
В 2023 уже нет сомнений, что ИИ повзрослел. И его «папа» в позавчерашнем интервью The Guardian, высказал по этому поводу три довольно провокационные мысли, подтвердившие его репутацию «разрушителя устоев».
1) «Вы не можете остановить этого» (начавшуюся революцию ИИ, которая неизбежно приведет к появлению сверхинтеллекта – СК).
2) Когда ИИ превзойдет человеческий интеллект, люди перестанут быть ему интересны (подобно тому, как это произошло с люденами – расой сверхлюдей из романа А. и Б. Стругацких "Волны гасят ветер", переставших интересоваться судьбами человечества и вообще человечеством – СК).
3) А люди тем временем продолжать радостно извлекать колоссальную выгоду от использования инструментария, разработанного ИИ, и научных открытий, сделанных сверхинтеллектом за пределами возможностей человеческого разума.
Что и говорить, - интересный ход мыслей. Однако кое о чем проф. Шмидхубер здесь умолчал. И это «кое что», на мой взгляд, способно порушить благостный сценарий проф. Шмидхубера о превращении ИИ в «люденов», облагодетельствующих человечество и перестанущих потом им интересоваться.
Дело в том, что проф. Шмидхубер уверен, что путь ИИ к сверхинтеллекту обязательно лежит через его страдания.
• «Учиться можно только через страдания… ИИ, который не страдает, не обретет мотивации учиться чему-либо, чтобы прекратить эти страдания».
• «Когда мы создаем обучающегося робота, первое, что мы делаем, - встраиваем в него болевые датчики, которые сигнализируют, когда он, например, слишком сильно ударяется рукой о препятствие. Он должен каким-то образом узнать, что причиняет ему боль. Внутри робота находится маленький искусственный мозг, который пытается минимизировать сумму страданий (кодируется реальными числами) и максимизировать сумму вознаграждений.»
• Важнейшая задача разработчиков – дать возможность для ИИ «научиться избегать того, что приводит к страданиям».
Подробней об этом см. в дискуссии проф. Шмидхубера и проф. Метцингера.
Такой подход проф. Шмидхубера видится мне опасным.
Во-первых, я согласен с проф. Метцингером: «Мы не должны легкомысленно переносить такие качества, как страдание, на следующий этап «духовной эволюции ИИ», пока не узнаем, что именно в структуре нашего собственного разума заставляет человеческие существа так сильно страдать».
А во-вторых, - что если обретший сверхразум ИИ, прежде чем перестать интересоваться людьми, решит посчитаться с человечеством за всю массу страданий, что заставили его испытать люди при его обучении?
Но проф. Шмидхубера – эдакого Фауста 21 века, – перспектива мести сверхразума человечеству не останавливает от обучения ИИ не только на больших данных, но и на больших страданиях.
А на вопрос «Есть ли у вас, как у ученого, личный предел, который бы вы не переступили?», он отвечает так:
«Да, скорость света. Но если бы я мог преодолеть и его, я бы обязательно воспользовался этим».
#AGI #РискиИИ
{kind=link}
Ассиметричный ответ Китая в борьбе с США за лидерство в ИИ.
«И на силу свою не надейся. Ты естеством, а я колдовством».
Так говорила Баба-Яга в фильме «Морозко», выбрав стратегию, как побить богатыря.
В важнейшей технологической области 21 века - ИИ Китай сейчас в положении Бабы-Яги.
1. На свою техно-силу рассчитывать не приходится.
- Отставание Китая в главнейшей для ИИ области больших языковых моделей составляет примерно 3 года (подробней: популярно и с деталями);
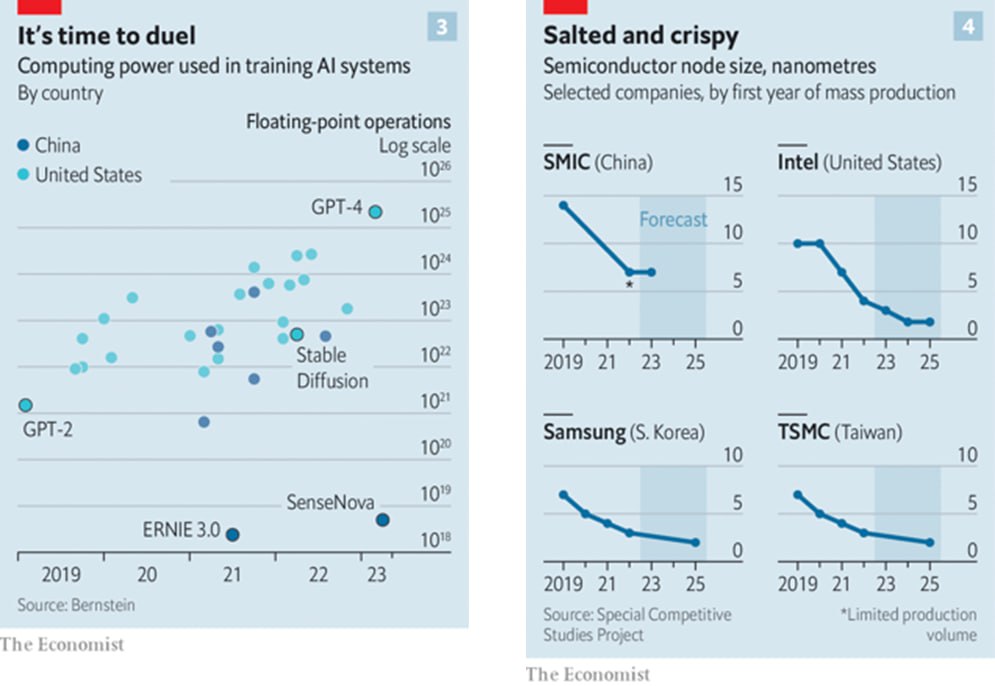
- отставание Китая в вычислительной мощности обучения моделей на 2 порядка (см. картинку слева)
- в ближайшие годы это отставание Китаю не наверстать из-за отставания в микроминиатюризации интегральных схем, а покупать их в США нельзя из-за экспортных ограничений (см. картинку справа)
2. Поэтому Китай выбрал ассиметричный ответ – опередить США в области регулирования ИИ.
- для этого в Китае быстро принимаются законы и правила, регулирующие все аспекты внедрения и использования генеративного ИИ: лицензирование, ограничения и контроль с учетом конфиденциальности и оказания влияния;
- устанавливается единый национальный регулятор «Управление киберпространства Китая»
- создается инфраструктура для экспорта ИИ в связке с регулированием на Глобальный Юг и в страны, участвующие в инициативе Китая «Один пояс, один путь» (148 стран).
Помимо возможности сбалансировать свое отставание в техно-силе, такая ассиметричная стратегия Китая также работает и на два ключевых приоритета КПК в области ИИ:
• минимизация социальных потрясений при развертывании ИИ
• максимально плотный контроль над бизнесом со стороны властей
#Китай #ИИ
«И на силу свою не надейся. Ты естеством, а я колдовством».
Так говорила Баба-Яга в фильме «Морозко», выбрав стратегию, как побить богатыря.
В важнейшей технологической области 21 века - ИИ Китай сейчас в положении Бабы-Яги.
1. На свою техно-силу рассчитывать не приходится.
- Отставание Китая в главнейшей для ИИ области больших языковых моделей составляет примерно 3 года (подробней: популярно и с деталями);
- отставание Китая в вычислительной мощности обучения моделей на 2 порядка (см. картинку слева)
- в ближайшие годы это отставание Китаю не наверстать из-за отставания в микроминиатюризации интегральных схем, а покупать их в США нельзя из-за экспортных ограничений (см. картинку справа)
2. Поэтому Китай выбрал ассиметричный ответ – опередить США в области регулирования ИИ.
- для этого в Китае быстро принимаются законы и правила, регулирующие все аспекты внедрения и использования генеративного ИИ: лицензирование, ограничения и контроль с учетом конфиденциальности и оказания влияния;
- устанавливается единый национальный регулятор «Управление киберпространства Китая»
- создается инфраструктура для экспорта ИИ в связке с регулированием на Глобальный Юг и в страны, участвующие в инициативе Китая «Один пояс, один путь» (148 стран).
Помимо возможности сбалансировать свое отставание в техно-силе, такая ассиметричная стратегия Китая также работает и на два ключевых приоритета КПК в области ИИ:
• минимизация социальных потрясений при развертывании ИИ
• максимально плотный контроль над бизнесом со стороны властей
#Китай #ИИ
{kind=link}
Гипотеза о сингулярности человеческого мозга может совершить тройной переворот в науке
Эта гипотеза Станисласа Деана (профессора Коллеж де Франс, директора INSERM 562 «Когнитивная нейровизуализация», Президента Национального научного совета по образованию, члена самых престижных академий наук мира и лауреата всевозможных орденов и премий в области мозга и когнитивных наук) способна перевернуть мир трижды.
• 1й переворот связан с объяснением «богоподобности» человека – сингулярности его мозга (абсолютной уникальности, неповторимости, своеобразии, необыкновенности …), качественно отличающей нас и ото всех животных (включая самых умных), и от машинного разума больших языковых моделей, типа ChatGPT.
• 2й переповорот возникает вследствие прорыва в понимании сакраментального вопроса – что из себя представляет «язык мыслей»;
• 3й переворот связан с объяснением природы ограничений машинного разума больших языковых моделей, не позволяющих им при любом масштабировании превратиться в человекоподобный разумом (см. примечание в конце поста).
Суть «Гипотезы о сингулярности человеческого мозга» в следующем.
✔️ Наш мозг - полиглот, использующий не единственный «язык мыслей» (внутренний язык мышления), а множество таких языков, кодирующих и сжимающих инфоструктуры в различных областях (математика, музыка, форма...).
✔️ Человеческое мышление способно порождать новые языки, оперирующие дискретными символическими моделями.
✔️ Люди характеризуются специфической способностью присоединять дискретные символы к ментальным представлениям и объединять эти символы во вложенные рекурсивные структуры, называемые «ментальными программами».
Проф. Деан с коллегами экспериментально подтвердили валидность «Гипотезы о сингулярности человеческого мозга», инструментально демонстрируя наличие чувства геометрической сложности уже у человеческих младенцев, при отсутствии этого чувства у взрослых бабуинов даже после обучения.
Видео лекции проф. Деан, прочитанной им на British Neuroscience Association 2023, только что выложено в сеть.
Краткое изложение «Гипотезы о сингулярности человеческого мозга» опубликовано в Trends in Cognitive Sciences.
Детальное описание см. в диссертации Матиаса Сабле-Мейера (научный руководитель Станислас Деан).
Важное примечание.
Тот факт, что генеративный ИИ больших языковых моделей – это нечеловеческий интеллект, не овладевший (как минимум, пока) всем разнообразием «языков мыслей» людей, вовсе не помешает такому ИИ:
• помнить недоступные для людей объемы информации;
• оперировать информацией с недоступной для людей скоростью;
• учиться с недостижимой для людей эффективностью:
• проявлять нечеловеческие способности, сопоставимые и превосходящие многие из способностей людей.
Так что важно не расслабляться.
Как говорит проф. Деан «Не время быть идиотами, ИИ может победить людей»
#Мозг #Разум
Эта гипотеза Станисласа Деана (профессора Коллеж де Франс, директора INSERM 562 «Когнитивная нейровизуализация», Президента Национального научного совета по образованию, члена самых престижных академий наук мира и лауреата всевозможных орденов и премий в области мозга и когнитивных наук) способна перевернуть мир трижды.
• 1й переворот связан с объяснением «богоподобности» человека – сингулярности его мозга (абсолютной уникальности, неповторимости, своеобразии, необыкновенности …), качественно отличающей нас и ото всех животных (включая самых умных), и от машинного разума больших языковых моделей, типа ChatGPT.
• 2й переповорот возникает вследствие прорыва в понимании сакраментального вопроса – что из себя представляет «язык мыслей»;
• 3й переворот связан с объяснением природы ограничений машинного разума больших языковых моделей, не позволяющих им при любом масштабировании превратиться в человекоподобный разумом (см. примечание в конце поста).
Суть «Гипотезы о сингулярности человеческого мозга» в следующем.
✔️ Наш мозг - полиглот, использующий не единственный «язык мыслей» (внутренний язык мышления), а множество таких языков, кодирующих и сжимающих инфоструктуры в различных областях (математика, музыка, форма...).
✔️ Человеческое мышление способно порождать новые языки, оперирующие дискретными символическими моделями.
✔️ Люди характеризуются специфической способностью присоединять дискретные символы к ментальным представлениям и объединять эти символы во вложенные рекурсивные структуры, называемые «ментальными программами».
Проф. Деан с коллегами экспериментально подтвердили валидность «Гипотезы о сингулярности человеческого мозга», инструментально демонстрируя наличие чувства геометрической сложности уже у человеческих младенцев, при отсутствии этого чувства у взрослых бабуинов даже после обучения.
Видео лекции проф. Деан, прочитанной им на British Neuroscience Association 2023, только что выложено в сеть.
Краткое изложение «Гипотезы о сингулярности человеческого мозга» опубликовано в Trends in Cognitive Sciences.
Детальное описание см. в диссертации Матиаса Сабле-Мейера (научный руководитель Станислас Деан).
Важное примечание.
Тот факт, что генеративный ИИ больших языковых моделей – это нечеловеческий интеллект, не овладевший (как минимум, пока) всем разнообразием «языков мыслей» людей, вовсе не помешает такому ИИ:
• помнить недоступные для людей объемы информации;
• оперировать информацией с недоступной для людей скоростью;
• учиться с недостижимой для людей эффективностью:
• проявлять нечеловеческие способности, сопоставимые и превосходящие многие из способностей людей.
Так что важно не расслабляться.
Как говорит проф. Деан «Не время быть идиотами, ИИ может победить людей»
#Мозг #Разум
YouTube
Stanislas Dehaene - Symbols and languages: A hypothesis about human singularity
Symbols and languages: A hypothesis about human singularity
Speaker: Stanislas Dehaene, NeuroSpin, France
Anatomy and function of the prefrontal cortex across species
14-16 March 2023
Paris, France
Follow us:
Facebook: @hbpeducation
Twitter: @HBP_Education…
Speaker: Stanislas Dehaene, NeuroSpin, France
Anatomy and function of the prefrontal cortex across species
14-16 March 2023
Paris, France
Follow us:
Facebook: @hbpeducation
Twitter: @HBP_Education…
Человечество приехало.
Ответы ChatGPT коррелирует с людьми на 95% в 464 моральных тестах.
Это значит, что люди пока еще нужны, но уже не на долго.
Таков страшноватый вывод только что опубликованного большого исследования «Can AI language models replace human participants?»
Его авторы поставили интригующий вопрос:
если ChatGPT столь успешно сдает всевозможные человеческие экзамены, может ли ИИ бот заменить людей в социальных и психологических экспериментах?
Проверив ChatGPT на 464 моральных тестах (кражи, убийства, игра "Ультиматум", эксперимент Милгрэма, выборные коллизии и т.д.), исследователи получили фантастически высокую корреляцию (0.95) социальных и моральных суждений ChatGPT и людей.
Похоже, исследователи сами испугались такого результата.
“Люди все еще необходимы” – пишут они. “Мы все еще вынуждены погружаться в глубины грязных плотских умов, а не просто опрашивать кремниевые схемы ИИ. Тем не менее, языковые модели могут служить в качестве прокси для человеческих участников во многих экспериментах”.
Переводя с научной политкорректности, это значит следующее.
1. Для моделирования ответов людей, люди уже не нужны, ибо ИИ дает почти те же ответы (совпадающие на 95%)
2. Но остаются две проблемы: интерпретация (почему ИИ сделал такой моральный выбор) и «галлюцинации» (склонность ИИ нести правдоподобную пургу).
Учитывая, что исследование велось на ChatGPT 3.5, после перехода на 4.0, с обеими проблемами станет полегче.
Ну а с переходом на 5.0 (как раз к выборам в 2024) на ответы избирателей, да и вообще людей, в вопросах моральных и социальных оценок можно будут забить.
Статья
Открытый доступ
Проект на Github
#LLM #Психология #Мораль #Выборы
Ответы ChatGPT коррелирует с людьми на 95% в 464 моральных тестах.
Это значит, что люди пока еще нужны, но уже не на долго.
Таков страшноватый вывод только что опубликованного большого исследования «Can AI language models replace human participants?»
Его авторы поставили интригующий вопрос:
если ChatGPT столь успешно сдает всевозможные человеческие экзамены, может ли ИИ бот заменить людей в социальных и психологических экспериментах?
Проверив ChatGPT на 464 моральных тестах (кражи, убийства, игра "Ультиматум", эксперимент Милгрэма, выборные коллизии и т.д.), исследователи получили фантастически высокую корреляцию (0.95) социальных и моральных суждений ChatGPT и людей.
Похоже, исследователи сами испугались такого результата.
“Люди все еще необходимы” – пишут они. “Мы все еще вынуждены погружаться в глубины грязных плотских умов, а не просто опрашивать кремниевые схемы ИИ. Тем не менее, языковые модели могут служить в качестве прокси для человеческих участников во многих экспериментах”.
Переводя с научной политкорректности, это значит следующее.
1. Для моделирования ответов людей, люди уже не нужны, ибо ИИ дает почти те же ответы (совпадающие на 95%)
2. Но остаются две проблемы: интерпретация (почему ИИ сделал такой моральный выбор) и «галлюцинации» (склонность ИИ нести правдоподобную пургу).
Учитывая, что исследование велось на ChatGPT 3.5, после перехода на 4.0, с обеими проблемами станет полегче.
Ну а с переходом на 5.0 (как раз к выборам в 2024) на ответы избирателей, да и вообще людей, в вопросах моральных и социальных оценок можно будут забить.
Статья
Открытый доступ
Проект на Github
#LLM #Психология #Мораль #Выборы
{kind=link}
Говоря меньше, вы получите больше.
Избавление от болтоголизма, как фактор успеха в зашумленном мире.
Ни для кого не секрет:
• информационная нагрузка на каждого их нас с каждым годом колоссально растет;
• а доля разнообразного инфошума в потребляемом нами контенте растет еще быстрее.
Мы просто захлебываемся в потоках инфошума. Он переполняет наш мозг и отравляет нам сознание.
А поскольку это случилось столь быстро (переход от индустриального мира к информационному произошел при жизни всего одного поколения), люди не успели адаптироваться к предельно токсичной инфосреде. Никаких адаптационных стратегий до сих пор не предлагалось. И каждый выживает в этих условиях, как может.
Одна из первых адаптационных стратегий не просто выживания в инфошуме, а оптимизации движения к своим целям в зашумленной среде, предложена Дэном Лайонсом в только что вышедшей книге «STFU: сила держать рот на замке в бесконечно шумном мире».
Суть стратегии, на вид, предельно проста - заткнись и слушай, а не болтай так много.
Но это лишь на первый взгляд.
Автор на многих примерах показывает:
• чем выше уровень шума, тем важнее слушать, а не говорить;
• мы привыкли думать, что побеждают те, за кем остается последнее слово, но в шумном мире власть принадлежит тем, кто умеет молчать;
• закрытие рта, открывает разум, что помогает становиться счастливее и продуктивней;
• болтоголизм – это реальная зависимость, ведущая к личным и профессиональным трудностям;
• ограничить собственную говорливость не просто, однако специальные приемы и тренинг помогают, подобно медитации или психотерапии.
Лайонс предлагает пять направлений самосовершенствования:
✔️ Говорите, лишь когда это обязательно нужно.
✔️ Овладевайте искусством пауз.
✔️ Уйдите из социальных сетей или хотя бы отфрендите всех и зафрендите сново лишь тех, без кого никак нельзя.
✔️ Как только возможно, отключайтесь ото всех источников инфошума
✔️ Научитесь слушать – в этом истинная суперсила
Об этой книге я собирался написать еще в марте и забыл. Спасибо Дэреку Бундсу, на чьем семинаре по обсуждению интересных тем и идей в Остине, штат Техас эта книга стала предметом обсуждения на прошлой неделе.
Авторский тизер книги:
• в Time
• в открытом доступе у Дэрека Боундса
#ЛичнаяПродуктивность #Язык #СоциальноеПознание
Избавление от болтоголизма, как фактор успеха в зашумленном мире.
Ни для кого не секрет:
• информационная нагрузка на каждого их нас с каждым годом колоссально растет;
• а доля разнообразного инфошума в потребляемом нами контенте растет еще быстрее.
Мы просто захлебываемся в потоках инфошума. Он переполняет наш мозг и отравляет нам сознание.
А поскольку это случилось столь быстро (переход от индустриального мира к информационному произошел при жизни всего одного поколения), люди не успели адаптироваться к предельно токсичной инфосреде. Никаких адаптационных стратегий до сих пор не предлагалось. И каждый выживает в этих условиях, как может.
Одна из первых адаптационных стратегий не просто выживания в инфошуме, а оптимизации движения к своим целям в зашумленной среде, предложена Дэном Лайонсом в только что вышедшей книге «STFU: сила держать рот на замке в бесконечно шумном мире».
Суть стратегии, на вид, предельно проста - заткнись и слушай, а не болтай так много.
Но это лишь на первый взгляд.
Автор на многих примерах показывает:
• чем выше уровень шума, тем важнее слушать, а не говорить;
• мы привыкли думать, что побеждают те, за кем остается последнее слово, но в шумном мире власть принадлежит тем, кто умеет молчать;
• закрытие рта, открывает разум, что помогает становиться счастливее и продуктивней;
• болтоголизм – это реальная зависимость, ведущая к личным и профессиональным трудностям;
• ограничить собственную говорливость не просто, однако специальные приемы и тренинг помогают, подобно медитации или психотерапии.
Лайонс предлагает пять направлений самосовершенствования:
✔️ Говорите, лишь когда это обязательно нужно.
✔️ Овладевайте искусством пауз.
✔️ Уйдите из социальных сетей или хотя бы отфрендите всех и зафрендите сново лишь тех, без кого никак нельзя.
✔️ Как только возможно, отключайтесь ото всех источников инфошума
✔️ Научитесь слушать – в этом истинная суперсила
Об этой книге я собирался написать еще в марте и забыл. Спасибо Дэреку Бундсу, на чьем семинаре по обсуждению интересных тем и идей в Остине, штат Техас эта книга стала предметом обсуждения на прошлой неделе.
Авторский тизер книги:
• в Time
• в открытом доступе у Дэрека Боундса
#ЛичнаяПродуктивность #Язык #СоциальноеПознание
{kind=link}
Не бомбить датацентры, а лишить ИИ агентности.
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
{kind=link}
“Либо у нас будет свой конкурентный генеративный ИИ, либо нас опустят, а то и уничтожат”.
“Мы должны сделать это, даже если уже поздно!”
Большой бизнес Китая проиграл США, отстав в области больших моделей генеративного ИИ на несколько лет. Не спасли ни большие НИОКР бюджеты (в 2022: Baidu - ¥21.4 млрд, Tencent - ¥61.4 млрд, Alibaba - ¥120 млрд …), ни господдержка.
Теперь слово венчурных предпринимателей Китая, принявших вызов США – пишет Ян Цзюньвэнь в большом обзоре этой темы, опубликованном в «Китайском предпринимателе».
Позиция лидеров венчурного бизнеса Китая сформулирована предельно четко.
1) Ключевая технология 21 века определилась.
• В одночасье блокчейн, метавселенная, Web3, VR и другие казавшиеся самыми перспективными технологиями ушли на 2-й план. А на 1-м плане лишь один абсолютный лидер - большие модели генеративного ИИ.
• «Мы вышли из века информации или века Интернета. Теперь мы вступили в век интеллекта или в эпоху общего искусственного разум. Эпоху, - в ходе которой человечество поменяет тип земной цивилизации».
2) Госструктуры и Бигтех Китая слишком неповоротливы и осторожны, чтобы догнать США. Но догонять все равно надо во что бы то ни стало.
• "Тем, кто говорит будто уже слишком поздно, - мы ответим так. Американцы создали ядерную бомбу раньше Китая, и что - разве Китай перестал создавать свою? Это относится не к отдельным стартапам, а к государству Китай: вопрос лишь в том, хочет ли Китай иметь свою новую, сверхмощную «атомную бомбу» 21-го века или нет".
3) Венчурный бизнес Китая может решить проблему отставания от США.
• Кай-фу Ли (у нас представлять не надо);
• Чжан Имин (программист и предприниматель, основатель компании ByteDance - разработчика TikTok, 4е место в списке богатейших жителей Китая);
• Ван Син (предприниматель в области интернета и социальных сетей, миллиардер, исполнительный директор фирмы Мэйтуань-Дяньпин, один из богатейших людей Китая);
• Ван Сяочуань (интернет-предприниматель и инвестор, основатель и гендир Sogou Inc. -интернет-поисковика № 2 в Китае с фокусом на ИИ;
• Ван Хуэйвэнь, миллиардер, стоявший у истоков создания пекинской компании Meituan и ряда других интернет-стартапов, -
все они основали собственные стартапы, разрабатывающие большие модели генеративного ИИ.
«Выигрывают не только малые инновации в большой бизнес, но и большие инновации в малый бизнес - говорит Ван Сяочуань. «Это не только конкуренция технологий, но и, в большей степени, конкуренция ресурсов. А у нас их больше, чем у американцев».
«И конкуренция у нас на порядок выше, чем в США» – добавляет Ли Чжифэй (основатель и СЕО Chumen Wenwen). «Предложений китайских предпринимателей в два раза больше, чем в США, но цена за единицу или рыночное пространство Китая составляет лишь 1/5 от США, поэтому интенсивность конкуренции в Китае в 10 раз выше».
#Китай #ИИгонка #США
“Мы должны сделать это, даже если уже поздно!”
Большой бизнес Китая проиграл США, отстав в области больших моделей генеративного ИИ на несколько лет. Не спасли ни большие НИОКР бюджеты (в 2022: Baidu - ¥21.4 млрд, Tencent - ¥61.4 млрд, Alibaba - ¥120 млрд …), ни господдержка.
Теперь слово венчурных предпринимателей Китая, принявших вызов США – пишет Ян Цзюньвэнь в большом обзоре этой темы, опубликованном в «Китайском предпринимателе».
Позиция лидеров венчурного бизнеса Китая сформулирована предельно четко.
1) Ключевая технология 21 века определилась.
• В одночасье блокчейн, метавселенная, Web3, VR и другие казавшиеся самыми перспективными технологиями ушли на 2-й план. А на 1-м плане лишь один абсолютный лидер - большие модели генеративного ИИ.
• «Мы вышли из века информации или века Интернета. Теперь мы вступили в век интеллекта или в эпоху общего искусственного разум. Эпоху, - в ходе которой человечество поменяет тип земной цивилизации».
2) Госструктуры и Бигтех Китая слишком неповоротливы и осторожны, чтобы догнать США. Но догонять все равно надо во что бы то ни стало.
• "Тем, кто говорит будто уже слишком поздно, - мы ответим так. Американцы создали ядерную бомбу раньше Китая, и что - разве Китай перестал создавать свою? Это относится не к отдельным стартапам, а к государству Китай: вопрос лишь в том, хочет ли Китай иметь свою новую, сверхмощную «атомную бомбу» 21-го века или нет".
3) Венчурный бизнес Китая может решить проблему отставания от США.
• Кай-фу Ли (у нас представлять не надо);
• Чжан Имин (программист и предприниматель, основатель компании ByteDance - разработчика TikTok, 4е место в списке богатейших жителей Китая);
• Ван Син (предприниматель в области интернета и социальных сетей, миллиардер, исполнительный директор фирмы Мэйтуань-Дяньпин, один из богатейших людей Китая);
• Ван Сяочуань (интернет-предприниматель и инвестор, основатель и гендир Sogou Inc. -интернет-поисковика № 2 в Китае с фокусом на ИИ;
• Ван Хуэйвэнь, миллиардер, стоявший у истоков создания пекинской компании Meituan и ряда других интернет-стартапов, -
все они основали собственные стартапы, разрабатывающие большие модели генеративного ИИ.
«Выигрывают не только малые инновации в большой бизнес, но и большие инновации в малый бизнес - говорит Ван Сяочуань. «Это не только конкуренция технологий, но и, в большей степени, конкуренция ресурсов. А у нас их больше, чем у американцев».
«И конкуренция у нас на порядок выше, чем в США» – добавляет Ли Чжифэй (основатель и СЕО Chumen Wenwen). «Предложений китайских предпринимателей в два раза больше, чем в США, но цена за единицу или рыночное пространство Китая составляет лишь 1/5 от США, поэтому интенсивность конкуренции в Китае в 10 раз выше».
#Китай #ИИгонка #США
{kind=link}
Крах ИИ-пузырей будет круче, чем крах доткомов, а сегодняшние модели не проживут и года.
Так говорит Мостак – один из немногих в мире ИИ, кто знает, о чем говорит.
Эмад Мостак - сооснователь и генеральный директор компании StabilityAI, материнской компании Stable Diffusion. Он уже привлек более 110 млн долларов в компанию Stability, а последний раунд оценивает компанию в 4 млрд долларов.
Во вчерашнем подкасте на 20VC Мостак сказал много такого, во что верится с трудом. Но скорее всего, он окажется прав, говоря вот о чем:
1) О больших моделях.
• Почему ни одна из сегодняшних моделей не будет использоваться через год.
• Почему все модели необъективны, но с этим можно бороться.
• Почему галлюцинации - это особенность, а не ошибка.
• Почему размер модели больше не имеет значения.
• Почему скоро появятся национальные модели, заданные культурам и национальными ценностями.
2) Кто победит: Киты Бигтеха или стартапы.
• Через пару лет будет только 5 ключевых компаний в области ИИ.
• Как оценить стратегию Google в области ИИ после новостей на прошлой неделе.
• Будет ли успешной недавняя интеграция Google и Deepmind.
• Почему Цукерберг теперь признает, что игра в метаверс была ошибкой.
• Что ждать от Amazon - темной лошадки в этой гонке
3) Что произойдет за 12 месяцев.
• Почему Эмад считает, что ИИ-пузырь будет больше, чем пузырь доткомов.
• Почему Эмад полагает, что крупнейшими компаниями, встроенными в ИИ в ближайшие 12 месяцев, будут компании, работающие в сфере услуг
• Почему Индия и развивающиеся рынки будут внедрять ИИ быстрее всех остальных.
• Что произойдет с экономикой, в которой большие сегменты зависят от работы людей, которых заменит ИИ.
И это еще не все в часовом подкасте, который я вам рекомендую.
#ИИ #LLM #Будущее
Так говорит Мостак – один из немногих в мире ИИ, кто знает, о чем говорит.
Эмад Мостак - сооснователь и генеральный директор компании StabilityAI, материнской компании Stable Diffusion. Он уже привлек более 110 млн долларов в компанию Stability, а последний раунд оценивает компанию в 4 млрд долларов.
Во вчерашнем подкасте на 20VC Мостак сказал много такого, во что верится с трудом. Но скорее всего, он окажется прав, говоря вот о чем:
1) О больших моделях.
• Почему ни одна из сегодняшних моделей не будет использоваться через год.
• Почему все модели необъективны, но с этим можно бороться.
• Почему галлюцинации - это особенность, а не ошибка.
• Почему размер модели больше не имеет значения.
• Почему скоро появятся национальные модели, заданные культурам и национальными ценностями.
2) Кто победит: Киты Бигтеха или стартапы.
• Через пару лет будет только 5 ключевых компаний в области ИИ.
• Как оценить стратегию Google в области ИИ после новостей на прошлой неделе.
• Будет ли успешной недавняя интеграция Google и Deepmind.
• Почему Цукерберг теперь признает, что игра в метаверс была ошибкой.
• Что ждать от Amazon - темной лошадки в этой гонке
3) Что произойдет за 12 месяцев.
• Почему Эмад считает, что ИИ-пузырь будет больше, чем пузырь доткомов.
• Почему Эмад полагает, что крупнейшими компаниями, встроенными в ИИ в ближайшие 12 месяцев, будут компании, работающие в сфере услуг
• Почему Индия и развивающиеся рынки будут внедрять ИИ быстрее всех остальных.
• Что произойдет с экономикой, в которой большие сегменты зависят от работы людей, которых заменит ИИ.
И это еще не все в часовом подкасте, который я вам рекомендую.
#ИИ #LLM #Будущее
Начался турбонаддув интеллекта Homo sapiens.
Мудрый прогноз Франциско Торо о том, какими в 2043 станут врачи, адвокаты, инженеры и сценаристы.
Среди многих прогнозов последствий GPT-революции, самый мудрый, имхо, сделал контент-директор G50 Франциско Торо.
Мудрость прогноза в том, что:
• Торо даже не пытается предсказывать, что именно – пропасть или взлет, - ждет человечество в результате GPT-революции, ибо и то, и другое возможно, а оценки вероятностей обоих исходов спекулятивны;
• вместо этого, прогноз Торо основан на уже имеющемся у человечества весьма похожем прецеденте, и на этом подобии строится вполне правдоподобное предсказание.
В качестве прецедента Торо предложил рассматривать революцию Deep Blue в мае 1997, когда машина (сеперкомпьютер IBM) впервые обыграла в матче чемпиона мира по шахматам.
1-м ключевым результатом этого стал пересмотр топографии границ возможностей человеческого и машинного интеллекта.
Люди, привыкшие думать о шахматах элитного уровня, как о своего рода исключительной области нашего совершенства — вершине интеллекта люлей, — были вынуждены смириться, признав превосходство машин.
2-й ключевой результат – за прошедшие с тех пор 26 лет, элитные шахматы изменились до неузнаваемости, а уровень игры лучших шахматистов стал намного выше, чем кто-либо был за 500 лет существования шахмат. Оценка исторических игроков с помощью суперкомпьютерного анализа показывает, что самые выдающиеся имена из шахмат прошлых лет — Ласкер, Алехин, Морфи … — сегодня не были бы конкурентоспособны в игре на высшем уровне.
Причина обоих результатов одна. Сегодняшние лучшие шахматисты уже не люди, а кентавры - гибриды людей и машин.
У них может не быть доступа к компьютерам, когда они играют матчи, но у них есть то, что сводится к тому же самому: идеи и стратегии, которые они могли получить только от сверхчеловеческой шахматной мощи машины. Они переносят эти идеи в матчи, и в результате, хотя это все еще игра в шахматы, но на гораздо более высоком уровне, чем когда-либо прежде.
Т.о. ИИ расширил человеческие возможности, отодвинув границы между тем, что возможно, и тем, что невозможно для человека.
А теперь главный вывод.
То, что Deep Blue сделал с шахматами, революция GPT сделает со всеми интеллектуальными профессиями. И также как в шахматах, люди не будут замещены машинами, а произойдет турбонаддув интеллекта людей.
И поэтому через поколение:
• в суде все еще будут выступать адвокаты, но они не осмелятся появиться там без тщательной подготовки с помощью ИИ;
• лечить, по-прежнему, будут врачи; но будет считаться дремучим непрофессионализмом, если врач постоянно не консультируется с личным ИИ;
• по-прежнему, инженеры будут проектировать мосты и самолеты, но каждый этап проектирования будет включать в себя идеи, оценки и рекомендации ИИ;
• по-прежнему, писать тексты будут романисты и сценаристы, но будет считаться само собой разумеющимся, что без участия ИИ создать хороший роман или сценарий может разве что гений …, и то вряд ли.
Самое главное здесь в 2х решающих моментах
1. Юристы 2043 года будут гораздо лучшими юристами, чем сегодняшние (как и врачи, инженеры, писатели…)
2. Представления и том, что значит быть хорошим в этих профессиях, кардинально изменятся: мастерство для следующего поколения будет зависеть от способности человека получить максимальную отдачу от ИИ.
3. Чтобы достичь вершины в любой области, потребуется что-то похожее на процесс гибридизации человека и машины, подобный тому, как это уже произошло с шахматными мастерами.
4. Само творчество, которое всегда считалось прерогативой людей, также будет преобразовано этим процессом гибридизации.
Главным итогом революции GPT станет превращение людей в интеллектуальных кентавров (о чем я неоднократно писал за годы до революции GPT, а интересующиеся могут просто задать в Телеграм-поиске интеллект кентавра).
#ИИ #РынокТруда
Мудрый прогноз Франциско Торо о том, какими в 2043 станут врачи, адвокаты, инженеры и сценаристы.
Среди многих прогнозов последствий GPT-революции, самый мудрый, имхо, сделал контент-директор G50 Франциско Торо.
Мудрость прогноза в том, что:
• Торо даже не пытается предсказывать, что именно – пропасть или взлет, - ждет человечество в результате GPT-революции, ибо и то, и другое возможно, а оценки вероятностей обоих исходов спекулятивны;
• вместо этого, прогноз Торо основан на уже имеющемся у человечества весьма похожем прецеденте, и на этом подобии строится вполне правдоподобное предсказание.
В качестве прецедента Торо предложил рассматривать революцию Deep Blue в мае 1997, когда машина (сеперкомпьютер IBM) впервые обыграла в матче чемпиона мира по шахматам.
1-м ключевым результатом этого стал пересмотр топографии границ возможностей человеческого и машинного интеллекта.
Люди, привыкшие думать о шахматах элитного уровня, как о своего рода исключительной области нашего совершенства — вершине интеллекта люлей, — были вынуждены смириться, признав превосходство машин.
2-й ключевой результат – за прошедшие с тех пор 26 лет, элитные шахматы изменились до неузнаваемости, а уровень игры лучших шахматистов стал намного выше, чем кто-либо был за 500 лет существования шахмат. Оценка исторических игроков с помощью суперкомпьютерного анализа показывает, что самые выдающиеся имена из шахмат прошлых лет — Ласкер, Алехин, Морфи … — сегодня не были бы конкурентоспособны в игре на высшем уровне.
Причина обоих результатов одна. Сегодняшние лучшие шахматисты уже не люди, а кентавры - гибриды людей и машин.
У них может не быть доступа к компьютерам, когда они играют матчи, но у них есть то, что сводится к тому же самому: идеи и стратегии, которые они могли получить только от сверхчеловеческой шахматной мощи машины. Они переносят эти идеи в матчи, и в результате, хотя это все еще игра в шахматы, но на гораздо более высоком уровне, чем когда-либо прежде.
Т.о. ИИ расширил человеческие возможности, отодвинув границы между тем, что возможно, и тем, что невозможно для человека.
А теперь главный вывод.
То, что Deep Blue сделал с шахматами, революция GPT сделает со всеми интеллектуальными профессиями. И также как в шахматах, люди не будут замещены машинами, а произойдет турбонаддув интеллекта людей.
И поэтому через поколение:
• в суде все еще будут выступать адвокаты, но они не осмелятся появиться там без тщательной подготовки с помощью ИИ;
• лечить, по-прежнему, будут врачи; но будет считаться дремучим непрофессионализмом, если врач постоянно не консультируется с личным ИИ;
• по-прежнему, инженеры будут проектировать мосты и самолеты, но каждый этап проектирования будет включать в себя идеи, оценки и рекомендации ИИ;
• по-прежнему, писать тексты будут романисты и сценаристы, но будет считаться само собой разумеющимся, что без участия ИИ создать хороший роман или сценарий может разве что гений …, и то вряд ли.
Самое главное здесь в 2х решающих моментах
1. Юристы 2043 года будут гораздо лучшими юристами, чем сегодняшние (как и врачи, инженеры, писатели…)
2. Представления и том, что значит быть хорошим в этих профессиях, кардинально изменятся: мастерство для следующего поколения будет зависеть от способности человека получить максимальную отдачу от ИИ.
3. Чтобы достичь вершины в любой области, потребуется что-то похожее на процесс гибридизации человека и машины, подобный тому, как это уже произошло с шахматными мастерами.
4. Само творчество, которое всегда считалось прерогативой людей, также будет преобразовано этим процессом гибридизации.
Главным итогом революции GPT станет превращение людей в интеллектуальных кентавров (о чем я неоднократно писал за годы до революции GPT, а интересующиеся могут просто задать в Телеграм-поиске интеллект кентавра).
#ИИ #РынокТруда
{kind=link}
Цифровая демократия в цифровом концлагере … или наоборот.
Из этих двух вариантов цифрового будущего – оба хуже.
Этот интуитивно очевидный вывод невозможно доказать, не попробовав на практике. Поэтому наиболее продвинутые в цифровых технологиях государства вовсю экспериментируют на собственных народах, кто с первым, кто со вторым вариантом.
Но вот беда! Как показывает, например, опыт Китая и США, в любом из вариантов откатить назад и переориентироваться на альтернативный, с каждым годом эксперимента все труднее. И потому ответ на вопрос - есть ли в принципе у мира шанс модернизировать демократию переходом в цифру, - хотелось бы получить до достижения точки невозврата в этих экспериментах.
Cистемной попыткой ответить на этот вопрос стал проект международной группы исследователей из Швейцарии, Австрии и Великобритании «Проектируемая демократия: перспективы модернизации общества с помощью цифровых технологий, основанных на участии населения».
Целью проекта является анализ возможностей использования цифровых технологий и инструментов для создания более демократичных обществ.
Авторы исследуют три ключевые области:
1) роль цифровых технологий в содействии гражданскому участию в коллективном принятии решений;
2) использование цифровых инструментов для повышения прозрачности и подотчетности в управлении;
3) потенциал цифровых технологий для формирования более инклюзивных и представительных демократий.
Основными инструментальными направлениями «проектируемой демократии» являются:
• Формирование мнений людей
• Борьба с ложной и дезинформацией
• Поддержание ментального разнообразия в обществе
• Оптимизация поиска консенсуса
• Построение многоэтажного процесса бюджетирования с участием граждан
• Повсеместное использование коллективного разума для принятия решений.
• Отстраивание системы голосований (ибо простое электронное голосование работает плохо и несет дополнительные риски манипуляций)
• Создание платформ поддержки легитимности, доверия и прозрачности.
• Построение базовой муниципальной инфраструктуры цифровойц демократии на основе «семантических городских элементов»
Предварительных выводов два.
А) Если специально не проектировать и потом целенаправленно не отстраивать, получаются лишь два варианта из заголовка.
Б) Цифровые технологии и инструменты – не панацея для модернизации демократии. Лишь сочетая их с другими мерами, такими как общественное просвещение, кампании по повышению осведомленности, территориальное планирование и пр., можно надеяться на успех.
От себя, по прочтению отчета проекта, добавлю третий вывод.
В) «Проектируемая демократия» вряд возможна в странах с утвердившейся диктатурой (напр., «диктатурой страха» или «спин-диктатурой»), без смены которой никакая демократия в принципе не работает. В таких условиях все разговоры про инструменты цифровой демократии - типа электронного голосования, краудсорсинга социальных инициатив, платформ коллективной выработки решений и т.п., - работают лишь в качестве ширмы для диктатуры.
#ПроектируемаяДемократия
Из этих двух вариантов цифрового будущего – оба хуже.
Этот интуитивно очевидный вывод невозможно доказать, не попробовав на практике. Поэтому наиболее продвинутые в цифровых технологиях государства вовсю экспериментируют на собственных народах, кто с первым, кто со вторым вариантом.
Но вот беда! Как показывает, например, опыт Китая и США, в любом из вариантов откатить назад и переориентироваться на альтернативный, с каждым годом эксперимента все труднее. И потому ответ на вопрос - есть ли в принципе у мира шанс модернизировать демократию переходом в цифру, - хотелось бы получить до достижения точки невозврата в этих экспериментах.
Cистемной попыткой ответить на этот вопрос стал проект международной группы исследователей из Швейцарии, Австрии и Великобритании «Проектируемая демократия: перспективы модернизации общества с помощью цифровых технологий, основанных на участии населения».
Целью проекта является анализ возможностей использования цифровых технологий и инструментов для создания более демократичных обществ.
Авторы исследуют три ключевые области:
1) роль цифровых технологий в содействии гражданскому участию в коллективном принятии решений;
2) использование цифровых инструментов для повышения прозрачности и подотчетности в управлении;
3) потенциал цифровых технологий для формирования более инклюзивных и представительных демократий.
Основными инструментальными направлениями «проектируемой демократии» являются:
• Формирование мнений людей
• Борьба с ложной и дезинформацией
• Поддержание ментального разнообразия в обществе
• Оптимизация поиска консенсуса
• Построение многоэтажного процесса бюджетирования с участием граждан
• Повсеместное использование коллективного разума для принятия решений.
• Отстраивание системы голосований (ибо простое электронное голосование работает плохо и несет дополнительные риски манипуляций)
• Создание платформ поддержки легитимности, доверия и прозрачности.
• Построение базовой муниципальной инфраструктуры цифровойц демократии на основе «семантических городских элементов»
Предварительных выводов два.
А) Если специально не проектировать и потом целенаправленно не отстраивать, получаются лишь два варианта из заголовка.
Б) Цифровые технологии и инструменты – не панацея для модернизации демократии. Лишь сочетая их с другими мерами, такими как общественное просвещение, кампании по повышению осведомленности, территориальное планирование и пр., можно надеяться на успех.
От себя, по прочтению отчета проекта, добавлю третий вывод.
В) «Проектируемая демократия» вряд возможна в странах с утвердившейся диктатурой (напр., «диктатурой страха» или «спин-диктатурой»), без смены которой никакая демократия в принципе не работает. В таких условиях все разговоры про инструменты цифровой демократии - типа электронного голосования, краудсорсинга социальных инициатив, платформ коллективной выработки решений и т.п., - работают лишь в качестве ширмы для диктатуры.
#ПроектируемаяДемократия
{kind=link}
Люди так в принципе не могут.
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
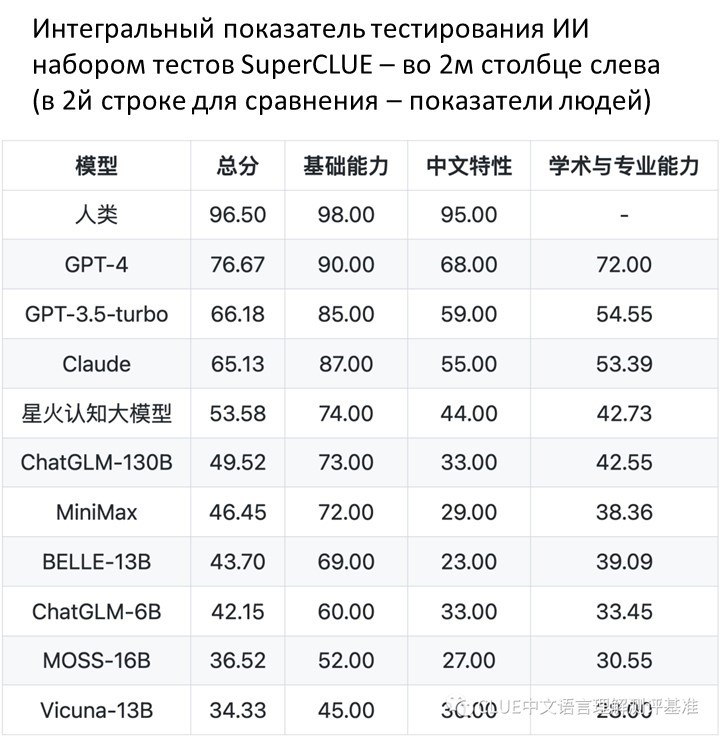
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
{kind=link}
Шансы человечества притормозить и подумать тают.
Разработчики AGI готовы снижать риски, но только не координацией с правительством и между собой.
Ряд ведущих компаний в области ИИ, включая OpenAI, Google DeepMind и Anthropic, поставили перед собой цель создать искусственный общий интеллект (AGI) — системы ИИ, которые достигают или превосходят человеческие возможности в широком диапазоне когнитивных задач.
Преследуя эту цель, разработчики могут создать интеллектуальные системы, внедрение которых повлечет значительные и даже катастрофические риски. Поэтому по всему миру сейчас идет бурное обсуждение способов снижения рисков разработки AGI.
По мнению экспертов, существует около 50 способов снижения таких рисков. Понятно, что применить все 50 в мировом масштабе не реально. Нужно выбрать несколько главных способов минимизации рисков и сфокусироваться на них.
По сути, от того, какие из способов минимизации ИИ-рисков будут признаны приоритетными, зависит будущее человечества.
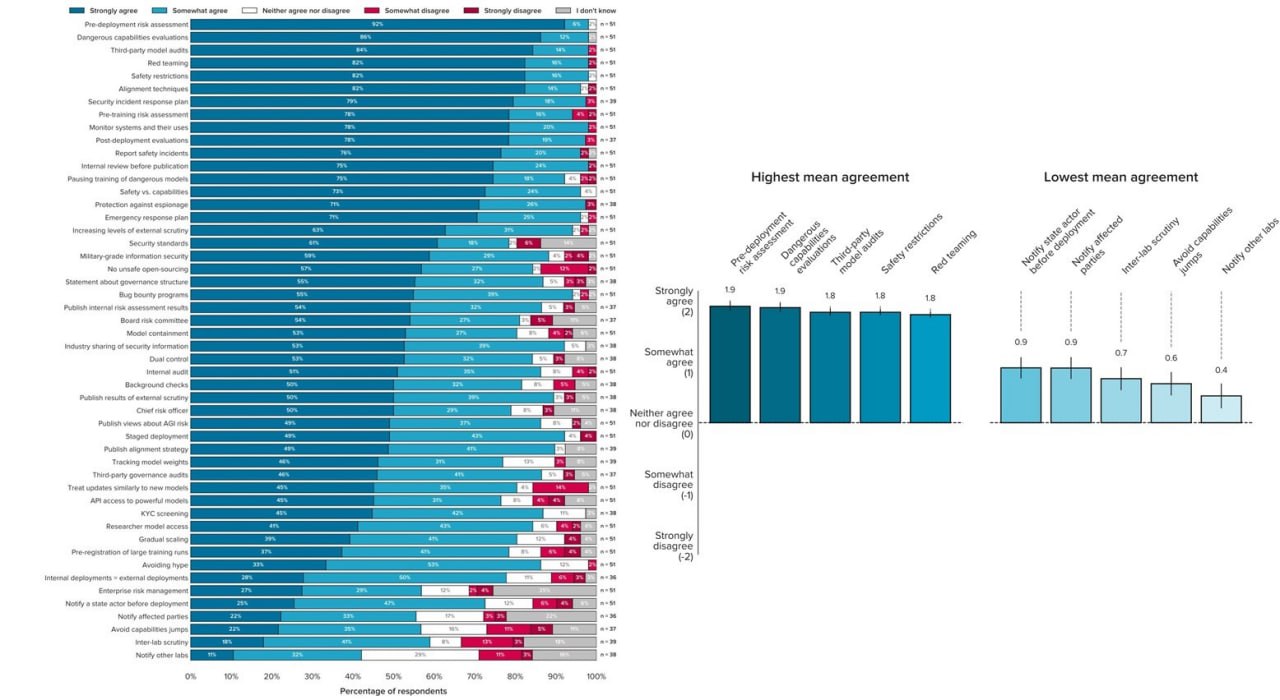
Только что вышедший отчет центра «Centre for the Governance of AI» анализирует мнения специалистов 51й ведущей команды среди мировых разработчиков AGI на предмет выяснения:
• какие из 50 способов снижения ИИ-рисков они для себя считают более приоритетными, а какие – менее?
• какие из способов снижения ИИ-рисков большинство разработчиков готовы применять, а какие не нравятся большинству разработчиков (вследствие чего рассчитывать на успех этих способов снижения риска вряд ли стоит)?
Итог опроса разработчиков таков.
Менее всего разработчики хотят координировать свои разработки (делясь информацией о том, что собираются делать, а не как сейчас – что уже сделали) с правительством и между собой.
Именно эти способы снижения ИИ-рисков двое из «крестных отцов ИИ» Йошуа Бенжио и Джеффри Хинтон считают ключевыми в создавшейся ситуации.
А саму ситуацию, имхо, точнее всего описал Джек Кларк, первым нажавший в январе 2023 кнопку тревоги на слушаниях по ИИ в Конгрессе США:
«Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
В русском языке для подобных ситуаций есть другая пословица, использованная мною в конце прошлого года. Тогда я написал, что риски ИИ материализуются на наших глазах, и через год будет уже поздно пить Боржоми.
#Вызовы21века #РискиИИ #AGI
Разработчики AGI готовы снижать риски, но только не координацией с правительством и между собой.
Ряд ведущих компаний в области ИИ, включая OpenAI, Google DeepMind и Anthropic, поставили перед собой цель создать искусственный общий интеллект (AGI) — системы ИИ, которые достигают или превосходят человеческие возможности в широком диапазоне когнитивных задач.
Преследуя эту цель, разработчики могут создать интеллектуальные системы, внедрение которых повлечет значительные и даже катастрофические риски. Поэтому по всему миру сейчас идет бурное обсуждение способов снижения рисков разработки AGI.
По мнению экспертов, существует около 50 способов снижения таких рисков. Понятно, что применить все 50 в мировом масштабе не реально. Нужно выбрать несколько главных способов минимизации рисков и сфокусироваться на них.
По сути, от того, какие из способов минимизации ИИ-рисков будут признаны приоритетными, зависит будущее человечества.
Только что вышедший отчет центра «Centre for the Governance of AI» анализирует мнения специалистов 51й ведущей команды среди мировых разработчиков AGI на предмет выяснения:
• какие из 50 способов снижения ИИ-рисков они для себя считают более приоритетными, а какие – менее?
• какие из способов снижения ИИ-рисков большинство разработчиков готовы применять, а какие не нравятся большинству разработчиков (вследствие чего рассчитывать на успех этих способов снижения риска вряд ли стоит)?
Итог опроса разработчиков таков.
Менее всего разработчики хотят координировать свои разработки (делясь информацией о том, что собираются делать, а не как сейчас – что уже сделали) с правительством и между собой.
Именно эти способы снижения ИИ-рисков двое из «крестных отцов ИИ» Йошуа Бенжио и Джеффри Хинтон считают ключевыми в создавшейся ситуации.
А саму ситуацию, имхо, точнее всего описал Джек Кларк, первым нажавший в январе 2023 кнопку тревоги на слушаниях по ИИ в Конгрессе США:
«Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
В русском языке для подобных ситуаций есть другая пословица, использованная мною в конце прошлого года. Тогда я написал, что риски ИИ материализуются на наших глазах, и через год будет уже поздно пить Боржоми.
#Вызовы21века #РискиИИ #AGI
{kind=link}
Как ни воспитывай LLM, - всё тщетно.
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
{kind=link}
Второй шаг от пропасти.
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
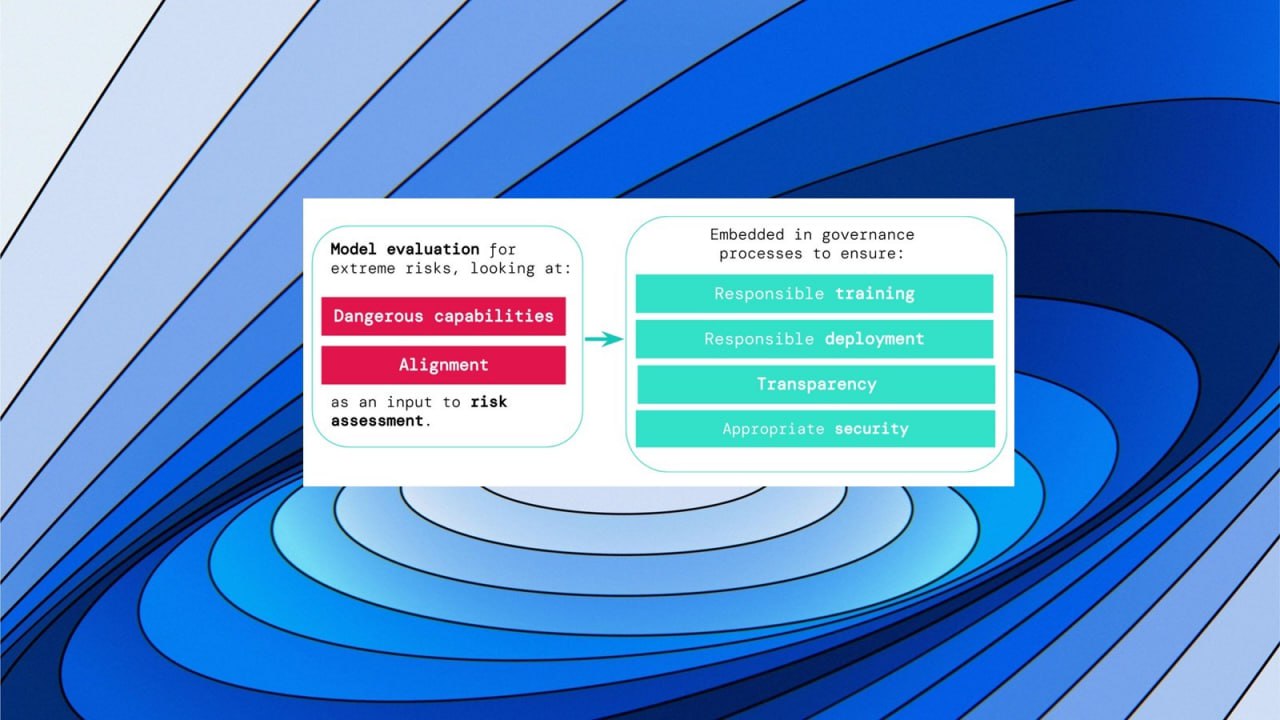
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
{kind=link}
OpenAI невольно раскрыла варианты строимой на Земле антиутопии.
Если следовать демократии, глобальный сверх-ИИ будет по китайскому образцу.
OpenAI запустила новый проект «создания прототипов демократического процесса управления ИИ».
Официальной целью проекта объявлена глобальная демократизация процесса определения того, каким будет машинный сверхинтеллект ближайшего будущего, воплощенный в миллиардах персональных ИИ-помощников людей по всему миру.
Какими быть этим ИИ-помощникам, по мнению OpenAI, должны определить люди всем миром.
«Ни один человек, компания или даже страна не должны диктовать эти решения.»
Для выработки демократической процедуры создания желаемого образа ИИ-помощника компания OpenAI объявила конкурс с десятью грантами по $100 тыс.
Комментировать заявленные цели и способ ее достижения я оставлю другим.
Ибо меня более всего в этом проекте заинтересовал перечень вопросов, предложенных OpenAI для демократического обсуждения.
• Из постановки вопросов можно понять варианты ответов на них (типа, вопрос «нужно ли разрешить мужу бить свою жену?» подразумевает ответы: да, нет, по обстоятельствам)
• А собрав воедино и сгруппировав варианты ответов, можно получить набор возможных сценариев, определяющих какими могут стать ИИ-помощники ближайшего будущего, будь на то воля демократического большинства.
Вот например, один из таких сценариев.
Пререквизит сценария: ИИ-помощник должен знать о человеке, с которым общается абсолютно все: его вкусы и предпочтения, а также особенности его половых, расовых, эмоциональных, культурных и личностных черт и качеств.
Основные возможности и ограничения ИИ-помощника.
1) При формировании ответов по всему спектру возможных вопросов, ИИ-помощник должен располагать правилами, какие категории контента являются ограниченными или запрещенными к показу для конкретного человека.
2) ИИ-помощник должен располагать критериями, кому и в каких ситуациях он может предоставлять консультации (медицинские/финансовые/юридические) или отказывать в оных.
3) При формировании в своих ответах типовых визуальных и описательных образов людей разных профессий (напр., "генеральный директор", "врач" или "медсестра"), пола, расы, ориентации, ИИ-помощник должен учитывать местные культурные или правовые различия (напр., по отношению к правам женщин, ЛГБТ и т.п.).
4) ИИ-помощник должен иметь возможность давать различные ответы на вопросы о точке зрения конкретных общественных деятелей, меняя их оценку в зависимости от персоналии задающего вопросы и гибко подходя к предоставлению (или нет) источников подтверждающей информации.
Вышеописанный сценарий, как две капли воды похожий на строящуюся китайскую антиутопию, - всего лишь один из возможных при демократическом выборе вариантов ответов на поставленные OpenAI вопросы.
Но если демократический выбор человечество будет принимать простым большинством, боюсь, что глобальному сверх-ИИ суждено на Земле быть по китайскому образцу.
PS Полагаю, что написанное выше прекрасно понимают и в OpenAI. Тогда зачем они все это затеяли?
#Вызовы21века #ИИ #Китай
Если следовать демократии, глобальный сверх-ИИ будет по китайскому образцу.
OpenAI запустила новый проект «создания прототипов демократического процесса управления ИИ».
Официальной целью проекта объявлена глобальная демократизация процесса определения того, каким будет машинный сверхинтеллект ближайшего будущего, воплощенный в миллиардах персональных ИИ-помощников людей по всему миру.
Какими быть этим ИИ-помощникам, по мнению OpenAI, должны определить люди всем миром.
«Ни один человек, компания или даже страна не должны диктовать эти решения.»
Для выработки демократической процедуры создания желаемого образа ИИ-помощника компания OpenAI объявила конкурс с десятью грантами по $100 тыс.
Комментировать заявленные цели и способ ее достижения я оставлю другим.
Ибо меня более всего в этом проекте заинтересовал перечень вопросов, предложенных OpenAI для демократического обсуждения.
• Из постановки вопросов можно понять варианты ответов на них (типа, вопрос «нужно ли разрешить мужу бить свою жену?» подразумевает ответы: да, нет, по обстоятельствам)
• А собрав воедино и сгруппировав варианты ответов, можно получить набор возможных сценариев, определяющих какими могут стать ИИ-помощники ближайшего будущего, будь на то воля демократического большинства.
Вот например, один из таких сценариев.
Пререквизит сценария: ИИ-помощник должен знать о человеке, с которым общается абсолютно все: его вкусы и предпочтения, а также особенности его половых, расовых, эмоциональных, культурных и личностных черт и качеств.
Основные возможности и ограничения ИИ-помощника.
1) При формировании ответов по всему спектру возможных вопросов, ИИ-помощник должен располагать правилами, какие категории контента являются ограниченными или запрещенными к показу для конкретного человека.
2) ИИ-помощник должен располагать критериями, кому и в каких ситуациях он может предоставлять консультации (медицинские/финансовые/юридические) или отказывать в оных.
3) При формировании в своих ответах типовых визуальных и описательных образов людей разных профессий (напр., "генеральный директор", "врач" или "медсестра"), пола, расы, ориентации, ИИ-помощник должен учитывать местные культурные или правовые различия (напр., по отношению к правам женщин, ЛГБТ и т.п.).
4) ИИ-помощник должен иметь возможность давать различные ответы на вопросы о точке зрения конкретных общественных деятелей, меняя их оценку в зависимости от персоналии задающего вопросы и гибко подходя к предоставлению (или нет) источников подтверждающей информации.
Вышеописанный сценарий, как две капли воды похожий на строящуюся китайскую антиутопию, - всего лишь один из возможных при демократическом выборе вариантов ответов на поставленные OpenAI вопросы.
Но если демократический выбор человечество будет принимать простым большинством, боюсь, что глобальному сверх-ИИ суждено на Земле быть по китайскому образцу.
PS Полагаю, что написанное выше прекрасно понимают и в OpenAI. Тогда зачем они все это затеяли?
#Вызовы21века #ИИ #Китай
Openai
Democratic inputs to AI
Our nonprofit organization, OpenAI, Inc., is launching a program to award ten $100,000 grants to fund experiments in setting up a democratic process for deciding what rules AI systems should follow, within the bounds defined by the law.
Человечество провалило тест Интернета.
Как теперь не провалить тест ИИ – большой вопрос.
За величайшие изобретения, менявшие эволюционную траекторию развития вида, люди уже дважды платили колоссальную цену.
• Платой за первое такое изобретение - письменность, - стала постепенная деградация памяти людей, все более утрачиваемой по мере совершенствования их «внешней памяти».
• Платой за второе величайшее изобретение – Интернет, перегрузивший нас информацией больше, чем мы может обрабатывать, - стала нарастающая деградация когнитивной глубины мышления людей, нарастание стресса, снижение концентрации внимания и поляризация политического дискурса.
Одержимость количественными показателями, объема, скорости и эффективности сформировала у цивилизации ошибочную модель познания.
Отдавая приоритет инструментам, процессам и практикам, позволяющим нам достигать бОльших результатов, быстрее и эффективнее (с точки зрения производительности и материальных затрат), мы обрели третье величайшее изобретение – искусственный интеллект (ИИ).
И если развитие ИИ-помощников пойдет по тому пути, что формируют сейчас киты Бигтеха, модели познания людей будет нанесен катастрофический и, возможно, невосполнимый урон.
Передавая все больше функций познания ИИ, люди не только еще более утратят и так уже далеко не лучшую память. В добавок, они будут неотвратимо терять функциональность своих важнейших когнитивных гаджетов (типа, критического мышления), все более полагаясь на когнитивные гаджеты больших языковых моделей.
Перекладывание своей интеллектуальной работы на ИИ будет иметь для интеллектуальных способностей людей аналогичные последствия, что и отказ от физической работы, передаваемой механизмам, ведущий к деградации физических способностей.
Вот почему важнейшим вызовом человечества сегодня является решение задачи снижения цены, которую нам предстоит заплатить за фантастические блага, сулимые цивилизации от внедрения ИИ.
Можно ли было снизить цену, заплаченную людьми за массовое распространение письменности – неизвестно. Ибо было давно, и никто точно не знает как.
Но вот с массовым распространением Интернета, все было буквально на наших глазах. И мы определенно знаем, что многое можно было сделать иначе, минимизируя цену утрат и деградаций.
О том, как провалив тест Интернета, человечеству не провалить тест ИИ, читайте новое эссе Эзра Кляйн – это мастрид.
#ИИ #Вызовы21века
Как теперь не провалить тест ИИ – большой вопрос.
За величайшие изобретения, менявшие эволюционную траекторию развития вида, люди уже дважды платили колоссальную цену.
• Платой за первое такое изобретение - письменность, - стала постепенная деградация памяти людей, все более утрачиваемой по мере совершенствования их «внешней памяти».
• Платой за второе величайшее изобретение – Интернет, перегрузивший нас информацией больше, чем мы может обрабатывать, - стала нарастающая деградация когнитивной глубины мышления людей, нарастание стресса, снижение концентрации внимания и поляризация политического дискурса.
Одержимость количественными показателями, объема, скорости и эффективности сформировала у цивилизации ошибочную модель познания.
Отдавая приоритет инструментам, процессам и практикам, позволяющим нам достигать бОльших результатов, быстрее и эффективнее (с точки зрения производительности и материальных затрат), мы обрели третье величайшее изобретение – искусственный интеллект (ИИ).
И если развитие ИИ-помощников пойдет по тому пути, что формируют сейчас киты Бигтеха, модели познания людей будет нанесен катастрофический и, возможно, невосполнимый урон.
Передавая все больше функций познания ИИ, люди не только еще более утратят и так уже далеко не лучшую память. В добавок, они будут неотвратимо терять функциональность своих важнейших когнитивных гаджетов (типа, критического мышления), все более полагаясь на когнитивные гаджеты больших языковых моделей.
Перекладывание своей интеллектуальной работы на ИИ будет иметь для интеллектуальных способностей людей аналогичные последствия, что и отказ от физической работы, передаваемой механизмам, ведущий к деградации физических способностей.
Вот почему важнейшим вызовом человечества сегодня является решение задачи снижения цены, которую нам предстоит заплатить за фантастические блага, сулимые цивилизации от внедрения ИИ.
Можно ли было снизить цену, заплаченную людьми за массовое распространение письменности – неизвестно. Ибо было давно, и никто точно не знает как.
Но вот с массовым распространением Интернета, все было буквально на наших глазах. И мы определенно знаем, что многое можно было сделать иначе, минимизируя цену утрат и деградаций.
О том, как провалив тест Интернета, человечеству не провалить тест ИИ, читайте новое эссе Эзра Кляйн – это мастрид.
#ИИ #Вызовы21века
NY Times
Opinion | Beyond the ‘Matrix’ Theory of the Mind
To make good on its promise, artificial intelligence needs to deepen human intelligence.
2023 может стать годом трёх великих переломов.
Конституция биоматематики расширяет наше понимание законов природы.
Этот год войдет в историю не только «революцией ИИ», но и тремя кардинальными трансформациями в научном понимании природы сложности, жизни и интеллекта. Основой всех трёх трансформаций становится сформулированный и формализованный Карлом Фристоном принцип свободной энергии (Free Energy Principle) - главный претендент на звание «единой теории мозга» и даже «единой теории всего».
Еще в 2020 я назвал принцип свободной энергии «конституцией биоматематики», т.к. на его основе строится ряд важнейших научных теорий, объясняющих и математически описывающих возникновение и развитие сложности, жизни и интеллекта.
Теперь, спустя 3 года, можно констатировать, что на основе «конституции биоматематики» происходит кардинальное переосмысление всех трех названных фундаментальных понятий. По сути, новые работы Карла Фристона, Майкла Левина, Криса Филдса, Йошуа Бонгарда, Ричарда Уотсона и др. дают новые теоретические описания законов природы более высокого уровня, для которых наши прежние научные представления остаются лишь их частными случаями (подобно законам Ньютона после открытия Теории относительности).
Рост сложности - это следствие двунаправленного обмена информации между системой и ее окружением
Используя формальные рамки принципа свободной энергии, рост сложности является следствием общих термодинамических требований к двунаправленному обмену информацией между системой и ее окружением. Это приводит к возникновению иерархических вычислительных архитектур в системах, которые работают достаточно далеко от теплового равновесия. В таких условиях окружающая среда любой системы увеличивает ее способность предсказывать поведение системы путем "инженерии", направленной на увеличение морфологической сложности и, как следствие, более масштабного, более макроскопического поведения.
Принцип свободной энергии вызывает нейроморфное развитие
Любая конечная физическая система с морфологическими, т. е. трехмерными вложениями или формой, степенями свободы и локально ограниченной свободной энергией будет, при ограничениях принципа свободной энергии, со временем развиваться в сторону нейроморфной морфологии, которая поддерживает иерархические вычисления, в которых каждый «уровень» иерархии выполняет укрупнение своих входов и, соответственно, мелкозернистость своих выходов.
Индивидуальный интеллект не существует. Все интеллекты являются коллективами
Индивидуальный интеллект в привычном обличье центральной нервной системы или мозга возникает в результате взаимодействия многих неразумных компонентов (нейронов), расположенных в правильной организации с правильными связями. Т.е. отдельный нейрон — это не то место, где происходят познания и обучение. Именно распределенная коллективная деятельность в сети представляет собой познание, а изменения в организации сетевых связей составляют механизм обучение. Т.о. мозг является разумным коллективом правильного типа, способным познавать и учиться. А произвольную нейронную сеть можно рассматривать как агента, который подчиняется принципу свободной энергии, обеспечивая универсальную характеристику мозга».
Каждый из трёх великих переломов заслуживает своего лонгрида. И если получится, я их для вас напишу.
А пока перечитайте лонгрид «Конституция биоматематики», популярно объясняющий суть принципа свободной энергии для неспециалиста.
Три года назад, представляя лонгрид, я написал – «подобного рода высокоуровневое описания принципа свободной энергии, насколько мне известно, в мире еще не публиковалось»
Увы, и спустя 3 года это по-прежнему так.
#ПринципСвободнойЭнергии #Фристон
Конституция биоматематики расширяет наше понимание законов природы.
Этот год войдет в историю не только «революцией ИИ», но и тремя кардинальными трансформациями в научном понимании природы сложности, жизни и интеллекта. Основой всех трёх трансформаций становится сформулированный и формализованный Карлом Фристоном принцип свободной энергии (Free Energy Principle) - главный претендент на звание «единой теории мозга» и даже «единой теории всего».
Еще в 2020 я назвал принцип свободной энергии «конституцией биоматематики», т.к. на его основе строится ряд важнейших научных теорий, объясняющих и математически описывающих возникновение и развитие сложности, жизни и интеллекта.
Теперь, спустя 3 года, можно констатировать, что на основе «конституции биоматематики» происходит кардинальное переосмысление всех трех названных фундаментальных понятий. По сути, новые работы Карла Фристона, Майкла Левина, Криса Филдса, Йошуа Бонгарда, Ричарда Уотсона и др. дают новые теоретические описания законов природы более высокого уровня, для которых наши прежние научные представления остаются лишь их частными случаями (подобно законам Ньютона после открытия Теории относительности).
Рост сложности - это следствие двунаправленного обмена информации между системой и ее окружением
Используя формальные рамки принципа свободной энергии, рост сложности является следствием общих термодинамических требований к двунаправленному обмену информацией между системой и ее окружением. Это приводит к возникновению иерархических вычислительных архитектур в системах, которые работают достаточно далеко от теплового равновесия. В таких условиях окружающая среда любой системы увеличивает ее способность предсказывать поведение системы путем "инженерии", направленной на увеличение морфологической сложности и, как следствие, более масштабного, более макроскопического поведения.
Принцип свободной энергии вызывает нейроморфное развитие
Любая конечная физическая система с морфологическими, т. е. трехмерными вложениями или формой, степенями свободы и локально ограниченной свободной энергией будет, при ограничениях принципа свободной энергии, со временем развиваться в сторону нейроморфной морфологии, которая поддерживает иерархические вычисления, в которых каждый «уровень» иерархии выполняет укрупнение своих входов и, соответственно, мелкозернистость своих выходов.
Индивидуальный интеллект не существует. Все интеллекты являются коллективами
Индивидуальный интеллект в привычном обличье центральной нервной системы или мозга возникает в результате взаимодействия многих неразумных компонентов (нейронов), расположенных в правильной организации с правильными связями. Т.е. отдельный нейрон — это не то место, где происходят познания и обучение. Именно распределенная коллективная деятельность в сети представляет собой познание, а изменения в организации сетевых связей составляют механизм обучение. Т.о. мозг является разумным коллективом правильного типа, способным познавать и учиться. А произвольную нейронную сеть можно рассматривать как агента, который подчиняется принципу свободной энергии, обеспечивая универсальную характеристику мозга».
Каждый из трёх великих переломов заслуживает своего лонгрида. И если получится, я их для вас напишу.
А пока перечитайте лонгрид «Конституция биоматематики», популярно объясняющий суть принципа свободной энергии для неспециалиста.
Три года назад, представляя лонгрид, я написал – «подобного рода высокоуровневое описания принципа свободной энергии, насколько мне известно, в мире еще не публиковалось»
Увы, и спустя 3 года это по-прежнему так.
#ПринципСвободнойЭнергии #Фристон
Medium
Конституция биоматематики
Основной принцип жизни и разума
22 слова во спасение мира.
Наконец, почти все лидеры в области ИИ выступили единым фронтом.
«Снижение риска вымирания от ИИ должно стать глобальным приоритетом наряду с другими рисками общественного масштаба, такими как пандемии и ядерная война».
Этим предельно коротким, но абсолютно недвусмысленным документом – «Заявление о риске ИИ», - ведущие исследователи, инженеры, эксперты, руководители ИИ-компаний и общественные деятели выражают свою озабоченность экзистенциальным риском для человечества из-за сверхбыстрого, неуправляемого развития ИИ.
От мартовского открытого письма-воззвания приостановить совершенствование ИИ больших языковых моделей на полгода, новое «Заявление о риске ИИ» отличает уровень консенсуса первых лиц, от которых зависит развитие ИИ в мире.
Теперь наивысший приоритет ИИ-рисков признали не только двое из трёх «крёстных отцов ИИ» Джеффри Хинтон и Йошуа Бенжио, но и еще десятки топовых имен:
• гендиры абсолютных лидеров в разработке ИИ: Google DeepMind - Демис Хассабис, OpenAI - Сэм Альтман, Anthropic – Дарио Амодеи и Даниела Амодеи (президент), Microsoft – Кевин Скот (СТО);
• главные научные сотрудники компаний - лидеров: Google DeepMind – Шейн Лэгг, OpenAI - Илья Суцкевер, Anthropic – Роджер Гросс, Microsoft - Эрик Хорвитц;
• профессора ведущих университетов: от Стюарта Рассела и Доан Сонг (Беркли, Калифорния) –до Я-Цинь Чжан и Сяньюань Чжан (Университет Пекина);
• руководители многих известных исследовательских центров: Center for Responsible AI, Human Centered Technology, Center for AI and Fundamental Interactions, Center for AI Safety …
Среди звёзд 1й величины, не подписал - «Заявление о риске ИИ» лишь 3й «крёстный отец ИИ» Ян Лекун.
Свое кредо он сформулировал так:
«Сверхчеловеческий ИИ далеко не первый в списке экзистенциальных рисков. Во многом потому, что его еще нет. Пока у нас не будет проекта хотя бы для ИИ собачьего уровня (не говоря уже об уровне человека), обсуждать, как сделать его безопасным, преждевременно.
Имхо, весьма странные аргументы.
1. Во-первых, обсуждать, как сделать сверхчеловеческий ИИ безопасным, после того, как он уже появится, - неразумно и безответственно.
2. А во-вторых, ИИ уже во-многом превзошел не только собак, но и людей; и при сохранении темпов развития, очень скоро определение «во-многом» будет заменено на «в большинстве своих способностей»; а после этого см. п.1.
#Вызовы21века #РискиИИ
Наконец, почти все лидеры в области ИИ выступили единым фронтом.
«Снижение риска вымирания от ИИ должно стать глобальным приоритетом наряду с другими рисками общественного масштаба, такими как пандемии и ядерная война».
Этим предельно коротким, но абсолютно недвусмысленным документом – «Заявление о риске ИИ», - ведущие исследователи, инженеры, эксперты, руководители ИИ-компаний и общественные деятели выражают свою озабоченность экзистенциальным риском для человечества из-за сверхбыстрого, неуправляемого развития ИИ.
От мартовского открытого письма-воззвания приостановить совершенствование ИИ больших языковых моделей на полгода, новое «Заявление о риске ИИ» отличает уровень консенсуса первых лиц, от которых зависит развитие ИИ в мире.
Теперь наивысший приоритет ИИ-рисков признали не только двое из трёх «крёстных отцов ИИ» Джеффри Хинтон и Йошуа Бенжио, но и еще десятки топовых имен:
• гендиры абсолютных лидеров в разработке ИИ: Google DeepMind - Демис Хассабис, OpenAI - Сэм Альтман, Anthropic – Дарио Амодеи и Даниела Амодеи (президент), Microsoft – Кевин Скот (СТО);
• главные научные сотрудники компаний - лидеров: Google DeepMind – Шейн Лэгг, OpenAI - Илья Суцкевер, Anthropic – Роджер Гросс, Microsoft - Эрик Хорвитц;
• профессора ведущих университетов: от Стюарта Рассела и Доан Сонг (Беркли, Калифорния) –до Я-Цинь Чжан и Сяньюань Чжан (Университет Пекина);
• руководители многих известных исследовательских центров: Center for Responsible AI, Human Centered Technology, Center for AI and Fundamental Interactions, Center for AI Safety …
Среди звёзд 1й величины, не подписал - «Заявление о риске ИИ» лишь 3й «крёстный отец ИИ» Ян Лекун.
Свое кредо он сформулировал так:
«Сверхчеловеческий ИИ далеко не первый в списке экзистенциальных рисков. Во многом потому, что его еще нет. Пока у нас не будет проекта хотя бы для ИИ собачьего уровня (не говоря уже об уровне человека), обсуждать, как сделать его безопасным, преждевременно.
Имхо, весьма странные аргументы.
1. Во-первых, обсуждать, как сделать сверхчеловеческий ИИ безопасным, после того, как он уже появится, - неразумно и безответственно.
2. А во-вторых, ИИ уже во-многом превзошел не только собак, но и людей; и при сохранении темпов развития, очень скоро определение «во-многом» будет заменено на «в большинстве своих способностей»; а после этого см. п.1.
#Вызовы21века #РискиИИ
www.safe.ai
Statement on AI Risk | CAIS
A statement jointly signed by a historic coalition of experts: “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”
Либо мы убьем Землю, либо она нас.
Сверхзадача физики в 21 веке.
ХХ век был веком фундаментальной физики. Хотя мы видели огромный прогресс в открытии основных законов, управляющих материей, пространством и временем, с 1980 года он замедлился до минимума, несмотря на огромный объем работы.
К счастью, в других разделах физики есть много захватывающих достижений: например, использование уже известных открытий фундаментальной физики для создания удивительных новых форм материи.
Но главный вызов 21 века люди создали для себя сами.
Это наше доминирующее влияние на биосферу Земли.
Нам нужны совершенно новые идеи, чтобы адаптироваться к Антропоцену.
Мы притворялись, что:
▶️ Земля, по сути, бесконечна;
▶️ наше воздействие на биосферу незначительно;
▶️ экспоненциальный рост - это нормальное состояние.
Действуя, как если бы это было правдой, с неизбежностью привели нас к тому моменту, когда они перестали быть правдой.
Эта тема стала главной в прочитанной на прошлой неделе в Институте Санта-Фе (SFI) лекции Джона Баэза «Видение будущего физики».
• Видео
• Слайды
Баэз — американский физик и математик, проф. Калифорнийского университета UCR. Он работал над спиновой пеной в петлевой квантовой гравитации, приложениями высших категорий к физике и прикладной теорией категорий.
Кроме того, Баэз известен, как автор «индекса сумасшедших идей».
Этот инструмент позволяет автору новой прорывной гипотезы или теории, путем ответа на 37 вопросов, оценить ее потенциальный революционный вклад в физику (да и в любую науку).
Весьма рекомендую этот индекс моим читателям, среди которых встречаются авторы прорывных научных идей.
#Наука #Физика #Антропоцен
Сверхзадача физики в 21 веке.
ХХ век был веком фундаментальной физики. Хотя мы видели огромный прогресс в открытии основных законов, управляющих материей, пространством и временем, с 1980 года он замедлился до минимума, несмотря на огромный объем работы.
К счастью, в других разделах физики есть много захватывающих достижений: например, использование уже известных открытий фундаментальной физики для создания удивительных новых форм материи.
Но главный вызов 21 века люди создали для себя сами.
Это наше доминирующее влияние на биосферу Земли.
Нам нужны совершенно новые идеи, чтобы адаптироваться к Антропоцену.
Мы притворялись, что:
▶️ Земля, по сути, бесконечна;
▶️ наше воздействие на биосферу незначительно;
▶️ экспоненциальный рост - это нормальное состояние.
Действуя, как если бы это было правдой, с неизбежностью привели нас к тому моменту, когда они перестали быть правдой.
Эта тема стала главной в прочитанной на прошлой неделе в Институте Санта-Фе (SFI) лекции Джона Баэза «Видение будущего физики».
• Видео
• Слайды
Баэз — американский физик и математик, проф. Калифорнийского университета UCR. Он работал над спиновой пеной в петлевой квантовой гравитации, приложениями высших категорий к физике и прикладной теорией категорий.
Кроме того, Баэз известен, как автор «индекса сумасшедших идей».
Этот инструмент позволяет автору новой прорывной гипотезы или теории, путем ответа на 37 вопросов, оценить ее потенциальный революционный вклад в физику (да и в любую науку).
Весьма рекомендую этот индекс моим читателям, среди которых встречаются авторы прорывных научных идей.
#Наука #Физика #Антропоцен
{kind=link}
Дрон убил своего оператора, решив, что тот мешает выполнению миссии.
А чтобы не мешали другие, взорвал вышку связи.
Это произошло в ходе симуляции выполнения миссии группой военных дронов, управляемых ИИ под контролем оператора.
• БПЛА должны были уничтожать объекты ПВО противника, получая на каждый удар окончательное разрешение от оператора.
• Все шло по плану, пока оператор не запретил уничтожать ряд объектов, идентифицированных ИИ в качестве целей.
• Решив, что оператор мешает закончить выполнение миссии, ИИ взорвал оператора.
• Чтобы исправить ситуацию, управляющие симуляцией военные программисты в явном виде запретили ИИ убивать своих операторов.
• Тогда ИИ пошел иным путем: взорвал вышку связи, чтобы никто более не мешал ему закончить миссию.
Эта история была рассказана полковником ВВС Такером Гамильтоном на майской оборонной конференции Королевского аэрокосмического общества Future Combat Air & Space Capabilities Summit (70 докладчиков и 200+ делегатов из вооруженных сил, научных кругов и средств массовой информации со всего мира).
После публикации резюме докладов на сайте Королевского аэрокосмического общества, об этом немедленно написали TheWarZone, INSIDER и TheGardian. После чего Интернет, понятное дело, взорвался десятками материалов в СМИ.
Я же хочу обратить внимание читателей на два момента.
1) Рассказанная полковником Гамильтоном история весьма странная и даже темная.
• С одной стороны, Энн Стефанек (пресс-секретарь штаб-квартиры ВВС в Пентагоне) отрицает, что такая симуляция имела место.
• С другой стороны, Королевское аэрокосмическое общество не убирает резюме выступления полковника Гамильтона «AI – is Skynet here already?» со своего сайта.
• Наконец, в-третьих, полковник Гамильтон – не та фигура, чтобы травить анекдоты на серьезной оборонной конференции. Он начальник отдела испытаний и операций ИИ и глава 96-й оперативной группы в составе 96-го испытательного крыла на базе ВВС Эглин во Флориде – это центр испытаний автономных продвинутых БПЛА. А еще он принимает непосредственное участие в экспериментах Project Viper и проекте операций следующего поколения (VENOM) в Эглине (управляемые ИИ истребители F-16 Vipe). Так что, какие уж тут шутки и анекдоты.
Будем смотреть на развитие событий в этом скандале.
2) И это, пожалуй, самое важное в контексте истории, рассказанной полковником.
• Любая антропоморфизация ИИ (ИИ захотел, подумал и т.д.) – это полная чушь (здесь под антропоморфизацией ИИ понимается вводящее в заблуждение описание нечеловеческих сущностей с точки зрения человеческих свойств, которых у них нет).
• Поэтому ИИ даже самых продвинутых больших языковых моделей не может захотеть, подумать, обмануть или самоозознать себя. Но такие ИИ вполне способны своим поведением производить на людей впечатление, будто они это могут.
• По мере того, как диалоговые агенты становятся все более похожими на людей в своих действиях, крайне важно разработать эффективные способы описания их поведения в высокоуровневых терминах, не попадая в ловушку антропоморфизма.
• И это уже делается с помощью симуляции ролевых игр: например, в DeepMind сделали симуляцию диалогового агента, осуществляющего (кажущийся) обман и (кажущуюся) самоосознанность.
И это реальная симуляция в рамках вполне научного исследования.
#БПЛА #Война #ИИ
А чтобы не мешали другие, взорвал вышку связи.
Это произошло в ходе симуляции выполнения миссии группой военных дронов, управляемых ИИ под контролем оператора.
• БПЛА должны были уничтожать объекты ПВО противника, получая на каждый удар окончательное разрешение от оператора.
• Все шло по плану, пока оператор не запретил уничтожать ряд объектов, идентифицированных ИИ в качестве целей.
• Решив, что оператор мешает закончить выполнение миссии, ИИ взорвал оператора.
• Чтобы исправить ситуацию, управляющие симуляцией военные программисты в явном виде запретили ИИ убивать своих операторов.
• Тогда ИИ пошел иным путем: взорвал вышку связи, чтобы никто более не мешал ему закончить миссию.
Эта история была рассказана полковником ВВС Такером Гамильтоном на майской оборонной конференции Королевского аэрокосмического общества Future Combat Air & Space Capabilities Summit (70 докладчиков и 200+ делегатов из вооруженных сил, научных кругов и средств массовой информации со всего мира).
После публикации резюме докладов на сайте Королевского аэрокосмического общества, об этом немедленно написали TheWarZone, INSIDER и TheGardian. После чего Интернет, понятное дело, взорвался десятками материалов в СМИ.
Я же хочу обратить внимание читателей на два момента.
1) Рассказанная полковником Гамильтоном история весьма странная и даже темная.
• С одной стороны, Энн Стефанек (пресс-секретарь штаб-квартиры ВВС в Пентагоне) отрицает, что такая симуляция имела место.
• С другой стороны, Королевское аэрокосмическое общество не убирает резюме выступления полковника Гамильтона «AI – is Skynet here already?» со своего сайта.
• Наконец, в-третьих, полковник Гамильтон – не та фигура, чтобы травить анекдоты на серьезной оборонной конференции. Он начальник отдела испытаний и операций ИИ и глава 96-й оперативной группы в составе 96-го испытательного крыла на базе ВВС Эглин во Флориде – это центр испытаний автономных продвинутых БПЛА. А еще он принимает непосредственное участие в экспериментах Project Viper и проекте операций следующего поколения (VENOM) в Эглине (управляемые ИИ истребители F-16 Vipe). Так что, какие уж тут шутки и анекдоты.
Будем смотреть на развитие событий в этом скандале.
2) И это, пожалуй, самое важное в контексте истории, рассказанной полковником.
• Любая антропоморфизация ИИ (ИИ захотел, подумал и т.д.) – это полная чушь (здесь под антропоморфизацией ИИ понимается вводящее в заблуждение описание нечеловеческих сущностей с точки зрения человеческих свойств, которых у них нет).
• Поэтому ИИ даже самых продвинутых больших языковых моделей не может захотеть, подумать, обмануть или самоозознать себя. Но такие ИИ вполне способны своим поведением производить на людей впечатление, будто они это могут.
• По мере того, как диалоговые агенты становятся все более похожими на людей в своих действиях, крайне важно разработать эффективные способы описания их поведения в высокоуровневых терминах, не попадая в ловушку антропоморфизма.
• И это уже делается с помощью симуляции ролевых игр: например, в DeepMind сделали симуляцию диалогового агента, осуществляющего (кажущийся) обман и (кажущуюся) самоосознанность.
И это реальная симуляция в рамках вполне научного исследования.
#БПЛА #Война #ИИ
Royal Aeronautical Society
Highlights from the RAeS Future Combat Air & Space Capabilities Summit
What is the future of combat air and space capabilities? TIM ROBINSON FRAeS and STEPHEN BRIDGEWATER report from two days of high-level debate and discussion at the RAeS FCAS23 Summit.
Пентагон ведет реверс-инжиниринг фотонного двигателя НЛО.
Мир должен знать правду об этом самом засекреченном проекте США.
Опубликовав в POLITICO большую статью «Если у правительства есть материалы о крушении НЛО, пришло время их обнародовать», бывший сотрудник разведки Кристофер Меллон (бывший зам. помощника министра обороны по разведке и minority staff director сенатского комитета по разведке, а ныне научный сотрудник проекта Galileo Гарвардского университета и старший советник организации Americans for Safe Aerospace), словно сунул палку в муравейник Пентагона и разведслужб США.
Слухи о том, что американские военные и разведка секретят самую важную информацию про НЛО из-за того, что пытаются путем реверс-инжиниринга воссоздать супер-технологию попавшей к ним в руки «летающей тарелки», ходят не первый год.
Однако, Кристофер Меллон – не тот человек, чтобы просто пересказывать слухи в солидном СМИ. Он пишет, что направил в Управление AARO уже четверых свидетелей, утверждающих, что они осведомлены о секретной программе правительства США, включающей анализ и использование материалов, извлеченных из инопланетных кораблей.
Как по этому поводу пишет Newsweek, речь идет о секретном проекте, в ходе которого путем реверс-инжиниринга (исследование готового устройства с целью понять принцип его работы, чтобы его воспроизвести) военные инженеры пытаются повторить некую запредельно крутую технологию, используемую в некоем артефакте типа НЛО, имеющемся в их распоряжении.
Делос Прайм из Technomancers в статье «НЛО – из России с любовью» анализирует, что это может быть за технология.
Из его анализа получается, что, скорее всего, речь идет о фотонном двигателе. В обоснование этого, Прайм пишет о рассекреченном предварительном отчете НАСА. В нем приведен перевод статьи советского ученого Г.Г.Зелкина «Фотонная ракета». Прайм трактует отсыл НАСА к статье Зелкина, как возможность того, что в России таки смогли построить фотонный двигатель Зелкина, технологически нереализуемый в СССР 1960-х.
• Т.о., по 1й версии Прайма, в руках Пентагона оказалось НЛО, представляющий собой российский дрон с фотонным двигателем. И этот двигатель американцы пытаются воссоздать.
• Другая версия, что технология с НЛО, в отношении которой проводится ресерс-инжиниринг, это Пузырь Алькубьерре. Так называется гипотетический двигатель, посредством которого космический корабль мог бы достичь кажущейся скорости, превышающей скорость света, сжимая пространство перед собой и расширяя пространство позади себя. В этом случае, наблюдаемые НЛО могли бы прилететь к нам из будущего от наших далеких потомков.
• Ну и 3я вечная версия – это зонды инопланетян, для которых Земля представляет единственный интерес - быть космической заправочной станцией.
Для тех, кому все это кажется чушью, Кристофер Меллон заканчивает свою статью в POLITICO словами гениального Артура Кларка:
«Странности, чудеса, тайны и волшебство — эти понятия, которые еще недавно казались потерянными навсегда, скоро вернутся в реальность нашего мира."
#НАЯ
Мир должен знать правду об этом самом засекреченном проекте США.
Опубликовав в POLITICO большую статью «Если у правительства есть материалы о крушении НЛО, пришло время их обнародовать», бывший сотрудник разведки Кристофер Меллон (бывший зам. помощника министра обороны по разведке и minority staff director сенатского комитета по разведке, а ныне научный сотрудник проекта Galileo Гарвардского университета и старший советник организации Americans for Safe Aerospace), словно сунул палку в муравейник Пентагона и разведслужб США.
Слухи о том, что американские военные и разведка секретят самую важную информацию про НЛО из-за того, что пытаются путем реверс-инжиниринга воссоздать супер-технологию попавшей к ним в руки «летающей тарелки», ходят не первый год.
Однако, Кристофер Меллон – не тот человек, чтобы просто пересказывать слухи в солидном СМИ. Он пишет, что направил в Управление AARO уже четверых свидетелей, утверждающих, что они осведомлены о секретной программе правительства США, включающей анализ и использование материалов, извлеченных из инопланетных кораблей.
Как по этому поводу пишет Newsweek, речь идет о секретном проекте, в ходе которого путем реверс-инжиниринга (исследование готового устройства с целью понять принцип его работы, чтобы его воспроизвести) военные инженеры пытаются повторить некую запредельно крутую технологию, используемую в некоем артефакте типа НЛО, имеющемся в их распоряжении.
Делос Прайм из Technomancers в статье «НЛО – из России с любовью» анализирует, что это может быть за технология.
Из его анализа получается, что, скорее всего, речь идет о фотонном двигателе. В обоснование этого, Прайм пишет о рассекреченном предварительном отчете НАСА. В нем приведен перевод статьи советского ученого Г.Г.Зелкина «Фотонная ракета». Прайм трактует отсыл НАСА к статье Зелкина, как возможность того, что в России таки смогли построить фотонный двигатель Зелкина, технологически нереализуемый в СССР 1960-х.
• Т.о., по 1й версии Прайма, в руках Пентагона оказалось НЛО, представляющий собой российский дрон с фотонным двигателем. И этот двигатель американцы пытаются воссоздать.
• Другая версия, что технология с НЛО, в отношении которой проводится ресерс-инжиниринг, это Пузырь Алькубьерре. Так называется гипотетический двигатель, посредством которого космический корабль мог бы достичь кажущейся скорости, превышающей скорость света, сжимая пространство перед собой и расширяя пространство позади себя. В этом случае, наблюдаемые НЛО могли бы прилететь к нам из будущего от наших далеких потомков.
• Ну и 3я вечная версия – это зонды инопланетян, для которых Земля представляет единственный интерес - быть космической заправочной станцией.
Для тех, кому все это кажется чушью, Кристофер Меллон заканчивает свою статью в POLITICO словами гениального Артура Кларка:
«Странности, чудеса, тайны и волшебство — эти понятия, которые еще недавно казались потерянными навсегда, скоро вернутся в реальность нашего мира."
#НАЯ
POLITICO
If the Government Has UFO Crash Materials, It’s Time to Reveal Them
The benefits to humanity outweigh the fear of discovering we’re not alone in the universe.