
Forwarded from Мониторим ИТ
Kubeshark — мониторинг и анализ Kubernetes
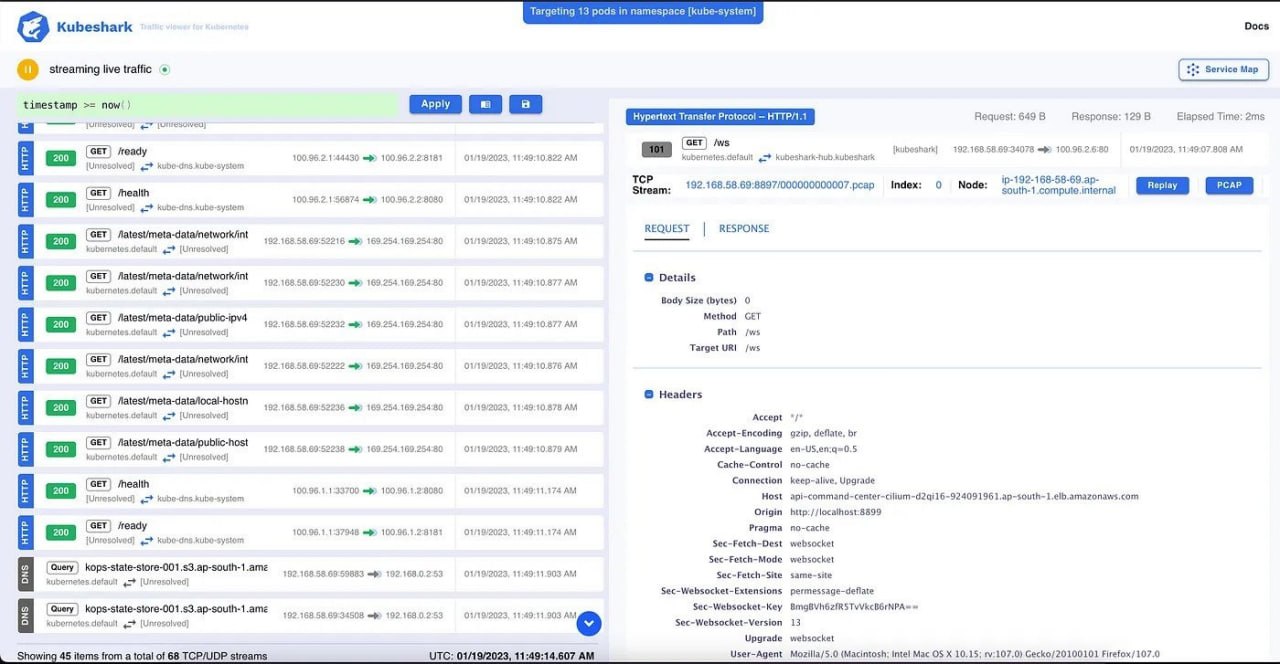
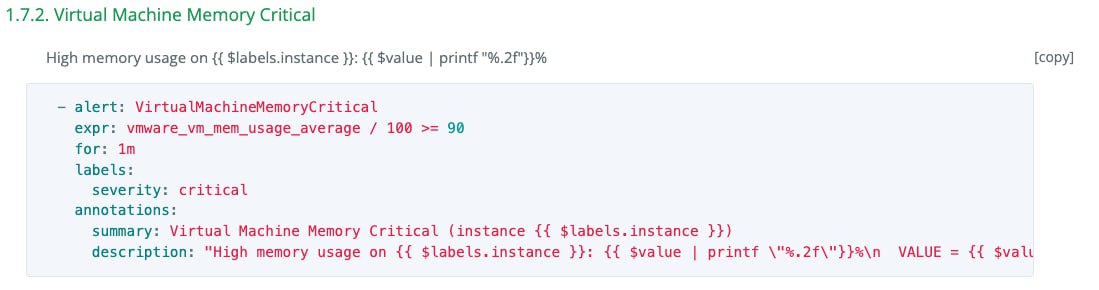
Kubeshark захватывает пакеты на уровнях L3 и L7. В результате, можно создать дашборд мониторинга для визуализации данных Kubernetes по аналогии того же самого Wireshark. Читать статью.
Kubeshark захватывает пакеты на уровнях L3 и L7. В результате, можно создать дашборд мониторинга для визуализации данных Kubernetes по аналогии того же самого Wireshark. Читать статью.
{kind=link}
Forwarded from Мониторим ИТ
{kind=link}
Forwarded from Мониторим ИТ
MaaS, или мониторинг как сервис
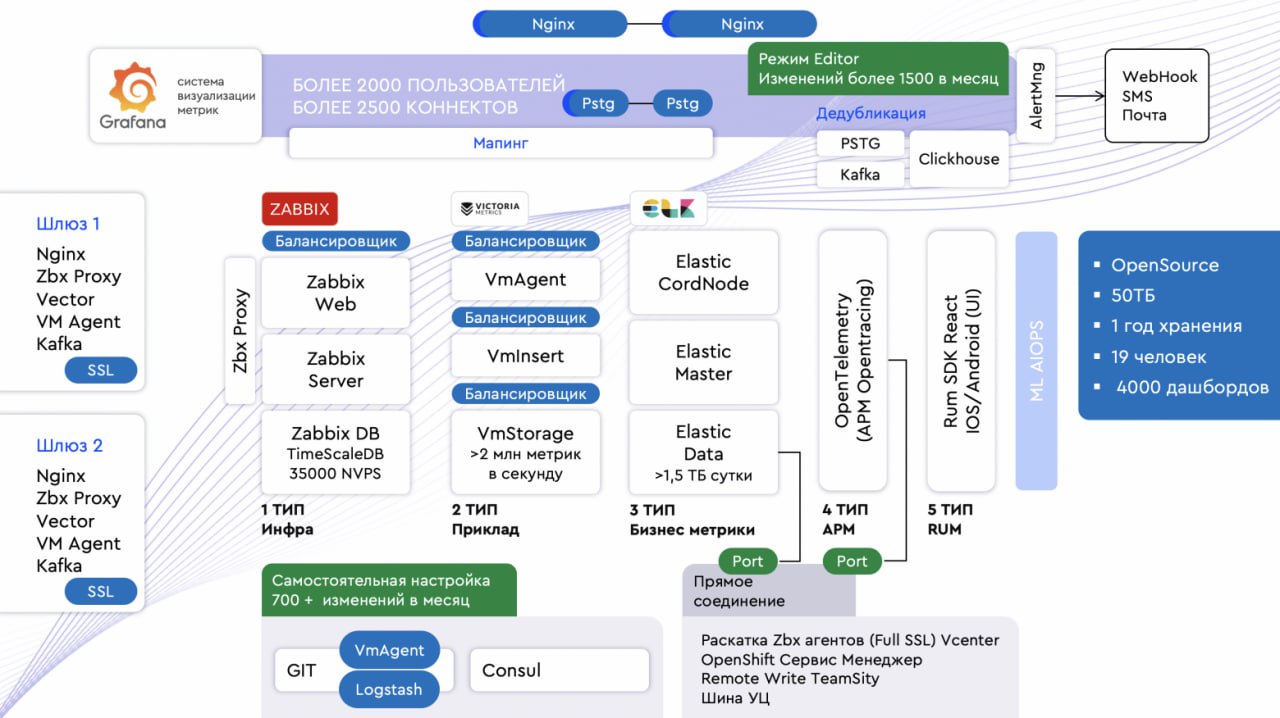
В статье о том, как устроен мониторинг в Газпромбанке. Читать статью.
В статье о том, как устроен мониторинг в Газпромбанке. Читать статью.
{kind=link}
Media is too big
VIEW IN TELEGRAM
Если у вас нет денег на новый модный проц, то обязательно посмотрите эту инструкцию из интернета!
И даже если есть, все равно посмотрите 😅
И даже если есть, все равно посмотрите 😅
https://www.redhat.com/en/blog/global-load-balancer-approaches
#openshift #k8s #kuber #network #loadbalancing #anycast #bgp #gslb #dns
#openshift #k8s #kuber #network #loadbalancing #anycast #bgp #gslb #dns
Redhat
Global Load Balancer Approaches
When working with Kubernetes or OpenShift in a multicluster (possibly hybrid cloud) deployment, one of the considerations that comes up is how to direct traffic to the applications deployed across these clusters. To solve this problem, we need a global load…
Forwarded from Мониторим ИТ
SREcon24
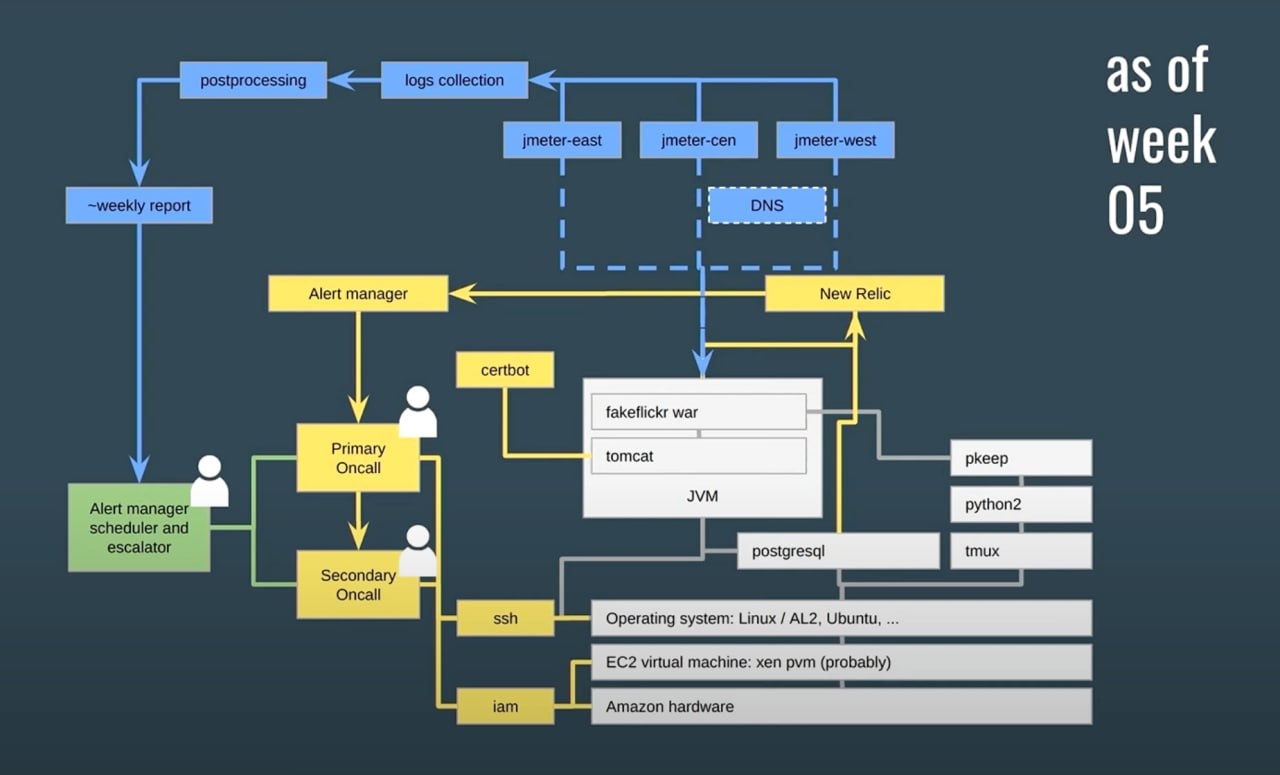
18-20 марта этого года в Сан-Франциско прошла конференция SREcon24. Полную программу можно увидеть по ссылке. Было много интересных выступлений.
Ниже приведу те, которые показались наиболее полезными:
99.99% of Your Traces Are (Probably) Trash
The Sins of High Cardinality
"Logs Told Us It Was Kernel – It Wasn't"
Resilience in Action
What Is Incident Severity, but a Lie Agreed Upon?
Teaching SRE
Cross-System Interaction Failures: Don't Fail through the Cracks
Automating Disaster Recovery: The Ultimate Reliability Challenge
Taming the Linux Distribution Sprawl: A Journey to Standardization and Efficiency
The Ticking Time Bomb of Observability Expectations
18-20 марта этого года в Сан-Франциско прошла конференция SREcon24. Полную программу можно увидеть по ссылке. Было много интересных выступлений.
Ниже приведу те, которые показались наиболее полезными:
99.99% of Your Traces Are (Probably) Trash
The Sins of High Cardinality
"Logs Told Us It Was Kernel – It Wasn't"
Resilience in Action
What Is Incident Severity, but a Lie Agreed Upon?
Teaching SRE
Cross-System Interaction Failures: Don't Fail through the Cracks
Automating Disaster Recovery: The Ultimate Reliability Challenge
Taming the Linux Distribution Sprawl: A Journey to Standardization and Efficiency
The Ticking Time Bomb of Observability Expectations
{kind=link}
Forwarded from Мониторим ИТ
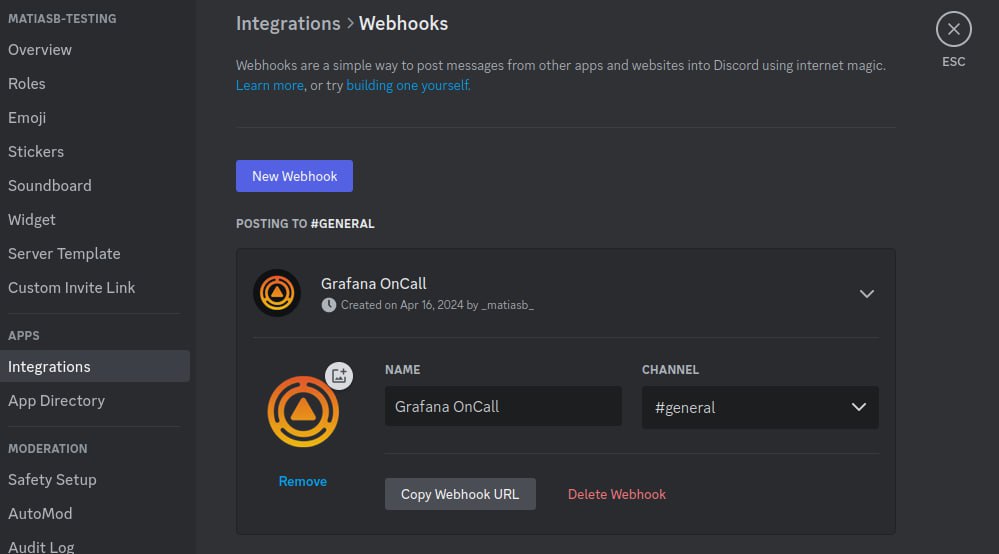
Grafana OnCall: Connect to Discord, Mattermost, and more with webhooks
Цель статьи — показать примеры подключения Grafana OnCall к стороннему API, устанавливая простую одностороннюю синхронизацию (OnCall -> внешний сервис), чтобы поддерживать актуальность информации о состоянии проблем без написания какого-либо кода. Рассмотрен процесс для каждого приложения ChatOps из заголовка статьи. Читать в блоге Grafana.
Цель статьи — показать примеры подключения Grafana OnCall к стороннему API, устанавливая простую одностороннюю синхронизацию (OnCall -> внешний сервис), чтобы поддерживать актуальность информации о состоянии проблем без написания какого-либо кода. Рассмотрен процесс для каждого приложения ChatOps из заголовка статьи. Читать в блоге Grafana.
{kind=link}
Forwarded from Мониторим ИТ
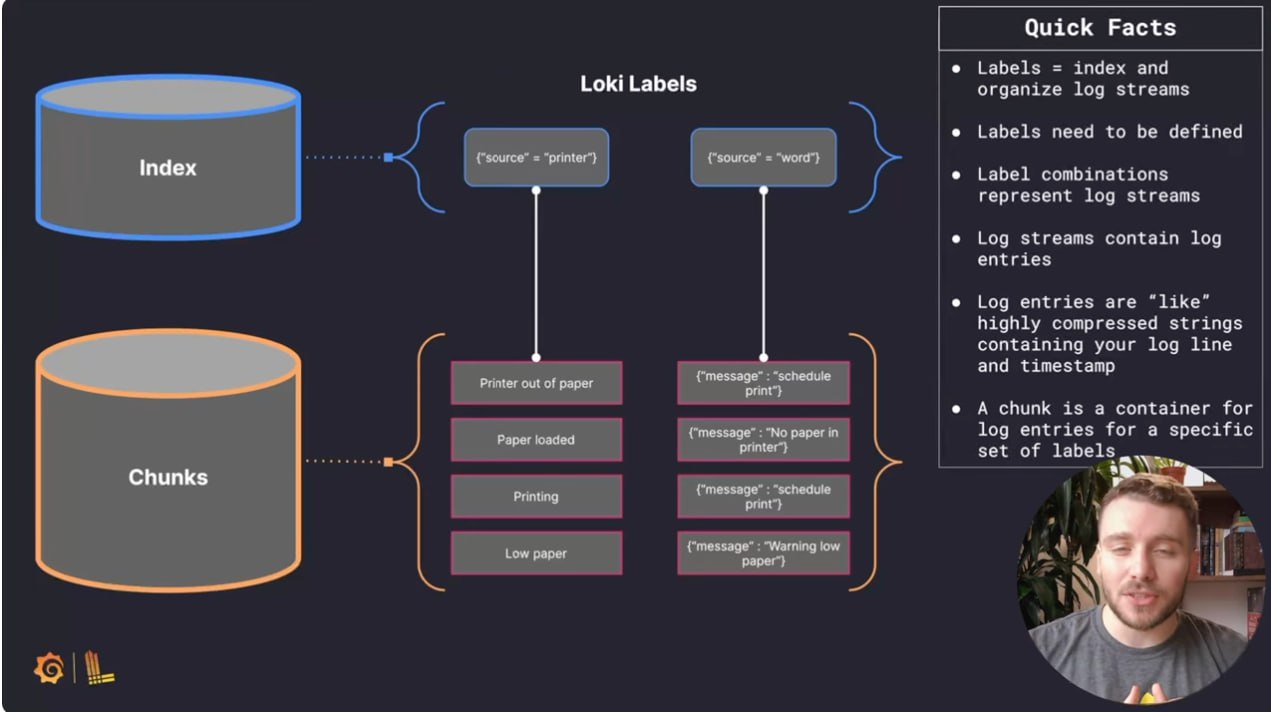
Zero to Hero: Loki | Grafana
Если вы ищете простую систему логирования — почему бы не обратить внимание на Loki? В этой серии видео команда Grafana рассказывает начиная с самых азов.
Intro to Logging | Zero to Hero: Loki | Grafana
Structure of Logs (Part 1) | Zero to Hero: Loki | Grafana
Structure of Logs (Part 2) | Zero to Hero: Loki | Grafana
How to Get Started with Loki | Zero to Hero: Loki | Grafana
Introduction to Ingesting logs with Loki | Zero to Hero: Loki | Grafana
Если вы ищете простую систему логирования — почему бы не обратить внимание на Loki? В этой серии видео команда Grafana рассказывает начиная с самых азов.
Intro to Logging | Zero to Hero: Loki | Grafana
Structure of Logs (Part 1) | Zero to Hero: Loki | Grafana
Structure of Logs (Part 2) | Zero to Hero: Loki | Grafana
How to Get Started with Loki | Zero to Hero: Loki | Grafana
Introduction to Ingesting logs with Loki | Zero to Hero: Loki | Grafana
{kind=link}
Forwarded from SRE/OPS | RUS
Всем привет у кого-то сегодня могли сломаться пайплайны для Docker, а все потому-что https://hub.docker.com теперь не доступен из России. Вот такой вот он свободный мир)))
Есть несколько вариантов сейчас, это настроить в конфиге Docker дополнительные зеркала. Так что настраивайте заранее сегодня, всем удачи)
sudo nano /etc/docker/daemon.json
P.S. Есть еще более забавный проект https://huecker.io/
Есть несколько вариантов сейчас, это настроить в конфиге Docker дополнительные зеркала. Так что настраивайте заранее сегодня, всем удачи)
sudo nano /etc/docker/daemon.json
{
"registry-mirrors": [
"https://mirror.gcr.io",
"https://daocloud.io",
"https://c.163.com/",
"https://registry.docker-cn.com"
]
}
P.S. Есть еще более забавный проект https://huecker.io/
Началась infa.conf 24, на главной доступна online трансляция
https://infraevents.yandex.ru/event/infraconf2024
#event #yandex #infra #2024
https://infraevents.yandex.ru/event/infraconf2024
#event #yandex #infra #2024
Мероприятия | Yandex Infrastructure
infra.conf 2024. Инженерные истории со смыслом.
Всё про создание инфраструктуры и эксплуатацию высоконагруженных систем.
Forwarded from Лукьян Излучина
Меня долгое время занимало почему у btrfs есть конфигурируемый параметр flushonocommit — какие последствия могут быть от его включения/выключения и почему вообще пользователю этот параметр дали конфигурировать — из документации это мне было не очевидно.
Сегодня я нашёл, что его переключение это выбор между возможностью наступления двух маловероятных событий:
1. В значении по умолчанию (noflushoncommit) возможно появление дырок в файлах, если пользовательский процесс что-то писал в файл, когда система или диск вдруг аварийно остановились.
2. При установке flushoncommit, возможна другая ситуация — если у вас есть процесс который записывает данные быстрее, чем они успевают быть перенесены на диск из очереди в памяти, то fsync никогда не завершится, а диск заполнится на 100%. При этом, набор данных, с точки зрения пользовательских программ, может быть и небольшим (просто постоянно обновляемым) — диск же заполнят, созданные в рамках работы CoW, метаданные и копии данных.
https://www.spinics.net/lists/linux-btrfs/msg109823.html
https://github.com/Zygo/bees/issues/68
Сегодня я нашёл, что его переключение это выбор между возможностью наступления двух маловероятных событий:
1. В значении по умолчанию (noflushoncommit) возможно появление дырок в файлах, если пользовательский процесс что-то писал в файл, когда система или диск вдруг аварийно остановились.
2. При установке flushoncommit, возможна другая ситуация — если у вас есть процесс который записывает данные быстрее, чем они успевают быть перенесены на диск из очереди в памяти, то fsync никогда не завершится, а диск заполнится на 100%. При этом, набор данных, с точки зрения пользовательских программ, может быть и небольшим (просто постоянно обновляемым) — диск же заполнят, созданные в рамках работы CoW, метаданные и копии данных.
https://www.spinics.net/lists/linux-btrfs/msg109823.html
https://github.com/Zygo/bees/issues/68
Forwarded from Мониторим ИТ
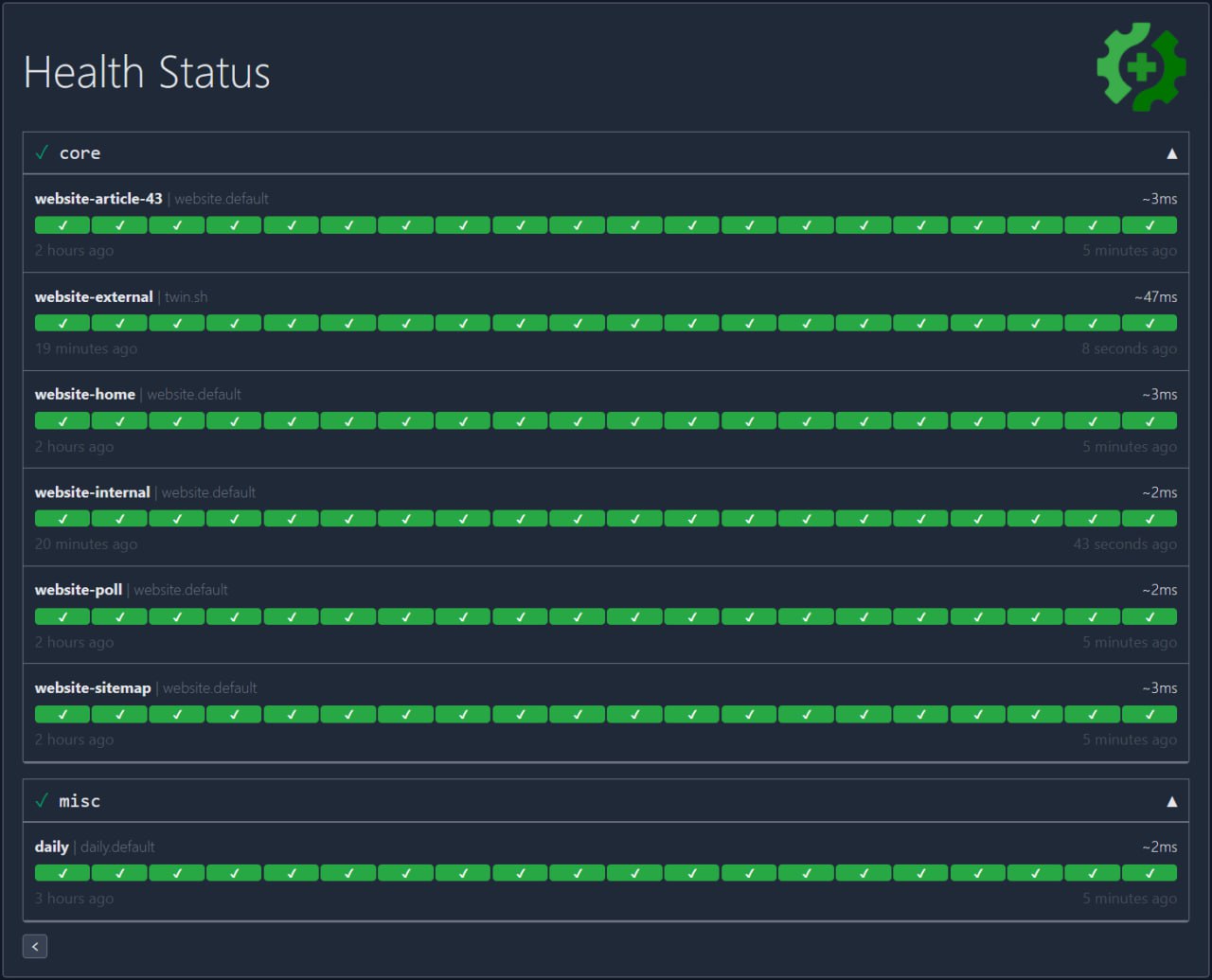
gatus
Утилита мониторинга состояния, ориентированная на разработчиков, которая дает вам возможность отслеживать службы с помощью HTTP, ICMP, TCP и DNS-запросов, а также анализировать результат запросов, используя список условий для значений, таких как код и время ответа, срок действия сертификата, тело ответа и многие другие. Каждую из этих проверок работоспособности можно сочетать с оповещениями через Slack, Teams, PagerDuty, Discord, Twilio и другие.
Репыч на гитхабе
Утилита мониторинга состояния, ориентированная на разработчиков, которая дает вам возможность отслеживать службы с помощью HTTP, ICMP, TCP и DNS-запросов, а также анализировать результат запросов, используя список условий для значений, таких как код и время ответа, срок действия сертификата, тело ответа и многие другие. Каждую из этих проверок работоспособности можно сочетать с оповещениями через Slack, Teams, PagerDuty, Discord, Twilio и другие.
Репыч на гитхабе
{kind=link}
Forwarded from Книжный куб (Alexander Polomodov)
CNCF Platforms White Paper - I
Ну и в продолжение поста про Kubecon я решил рассказать про whitepaper от CNCF на тему платформ. Документ состоит из 7 пунктов
1. Why platforms?
Собственно документ начинается со списка преимуществ платформ и того, какие проблемы они решают:
- уменьшают когнитивную нагрузку на продуктовые команды
- улучшают надежность и устойчивость продуктов, развернутых поверх платформ
- ускоряют разработку и доставку продуктов за счет переиспользования платформенных инструментов
- уменьшают риски: безопасности, регуляторные, функциональных багов
- помогают использовать эффективно сервисы и мощности публичных облаков
2. What is a platform
Здесь дается определение платформы в виде коллекции возможностей, что определены и представлены в соотоветствии с потребностями пользователей платформы. Здесь важно, что все эти возможности интегрированы вместе и предоставляют возможность выполнять типичные сценарии пользователей платформы. Критически важно, что не все возможности платформенные команды должны реализовывать сами (их могут предоставлять облачные провайдеры или внутренние команды в организации). Так как эти платформе направлены на внутренних разработчиков, то их называют internal developer platform. Дальше авторы отдельно разбирают уровни зрелости платформ
Platform maturity
- продуктовые разработчики могут получать возможности платформы on-demand и сразу использовать их для запуска своих приложений
- продуктовые разработчики могут получать пространство для сервисов и сразу использовать их для запуска пайплайнов и задач для хранения артефактов, конфигурации и сбора телеметрии
- администраторы стороннего софта могут получать свои зависимости по требованию, например, баззы данных, а дальше использовать их в своих решениях
- продуктовые разработчики могут получать полное окружение с темплейтами вместе с run-time и development-time сервисами для специфичных сценарием (Web, ML, ...)
- продуктовые разработчики и менеджеры могут наблюдать за функциональностью, производительностью и костами развернутых сервисов через стандартные инструменты и дашборды
3. Attributes of successful platforms
В этом пункте авторы рассказывают про свойства платформ, которые
- platform as a product - к созданию платформ надо подходит как к созданию продукта
- user experience - надо ориентироваться на опыт разработчиков (DexEx, про него я недавно разбирал white paper)
- documentation and onboarding - здесь приводится пример того что могут предлагать платформы "the platform could offer a reusable supply chain workflow for building, scanning, testing, deploying, and observing a web application on Kubernetes. Such a workflow could be offered with an initial project template and documentation, a bundle often described as a golden path"
- self-service - возможность самостоятельно использовать сервисы
- reduced cognitive load for users - платформа должна уменьшать нагрузку
- optional and composable - продукты должны иметь возможность использовать нужные части платформ, а нехватающие части закрывать самостоятельно
- secure by default - безопасность должна быть встроена в платформы по умолчанию
4. Attributes of successful platform teams
Платформенные команды отвечают за следующие зоны
- исследование требований пользователей и создание роадмапа фичей
- маркетинг, евангелирование и адвокатство ценностей, которые предлагает платформы
- управление и разработка интерфейсов для использования и изучение возможностей и сервисов, включая портал, API, документацию, шаблоны и CI инструменты
Самое важное в том, что платформенные команды должны изучать потребности платформенных пользователей и дальше информировать и постоянно улучшать возможности и интерфейсы, что предоставляют платформы. Для этого можно использовать стандартные продуктовые инструменты, например, описанные в книге Мартина Кагана "Inspired", про которую я писал раньше.
Продолжение в постах 2 и 3.
#Kubernetes #SRE #DistributedSystems #PlatformEngineering #SoftwareDevelopment #Software #ProductManagement
Ну и в продолжение поста про Kubecon я решил рассказать про whitepaper от CNCF на тему платформ. Документ состоит из 7 пунктов
1. Why platforms?
Собственно документ начинается со списка преимуществ платформ и того, какие проблемы они решают:
- уменьшают когнитивную нагрузку на продуктовые команды
- улучшают надежность и устойчивость продуктов, развернутых поверх платформ
- ускоряют разработку и доставку продуктов за счет переиспользования платформенных инструментов
- уменьшают риски: безопасности, регуляторные, функциональных багов
- помогают использовать эффективно сервисы и мощности публичных облаков
2. What is a platform
Здесь дается определение платформы в виде коллекции возможностей, что определены и представлены в соотоветствии с потребностями пользователей платформы. Здесь важно, что все эти возможности интегрированы вместе и предоставляют возможность выполнять типичные сценарии пользователей платформы. Критически важно, что не все возможности платформенные команды должны реализовывать сами (их могут предоставлять облачные провайдеры или внутренние команды в организации). Так как эти платформе направлены на внутренних разработчиков, то их называют internal developer platform. Дальше авторы отдельно разбирают уровни зрелости платформ
Platform maturity
- продуктовые разработчики могут получать возможности платформы on-demand и сразу использовать их для запуска своих приложений
- продуктовые разработчики могут получать пространство для сервисов и сразу использовать их для запуска пайплайнов и задач для хранения артефактов, конфигурации и сбора телеметрии
- администраторы стороннего софта могут получать свои зависимости по требованию, например, баззы данных, а дальше использовать их в своих решениях
- продуктовые разработчики могут получать полное окружение с темплейтами вместе с run-time и development-time сервисами для специфичных сценарием (Web, ML, ...)
- продуктовые разработчики и менеджеры могут наблюдать за функциональностью, производительностью и костами развернутых сервисов через стандартные инструменты и дашборды
3. Attributes of successful platforms
В этом пункте авторы рассказывают про свойства платформ, которые
- platform as a product - к созданию платформ надо подходит как к созданию продукта
- user experience - надо ориентироваться на опыт разработчиков (DexEx, про него я недавно разбирал white paper)
- documentation and onboarding - здесь приводится пример того что могут предлагать платформы "the platform could offer a reusable supply chain workflow for building, scanning, testing, deploying, and observing a web application on Kubernetes. Such a workflow could be offered with an initial project template and documentation, a bundle often described as a golden path"
- self-service - возможность самостоятельно использовать сервисы
- reduced cognitive load for users - платформа должна уменьшать нагрузку
- optional and composable - продукты должны иметь возможность использовать нужные части платформ, а нехватающие части закрывать самостоятельно
- secure by default - безопасность должна быть встроена в платформы по умолчанию
4. Attributes of successful platform teams
Платформенные команды отвечают за следующие зоны
- исследование требований пользователей и создание роадмапа фичей
- маркетинг, евангелирование и адвокатство ценностей, которые предлагает платформы
- управление и разработка интерфейсов для использования и изучение возможностей и сервисов, включая портал, API, документацию, шаблоны и CI инструменты
Самое важное в том, что платформенные команды должны изучать потребности платформенных пользователей и дальше информировать и постоянно улучшать возможности и интерфейсы, что предоставляют платформы. Для этого можно использовать стандартные продуктовые инструменты, например, описанные в книге Мартина Кагана "Inspired", про которую я писал раньше.
Продолжение в постах 2 и 3.
#Kubernetes #SRE #DistributedSystems #PlatformEngineering #SoftwareDevelopment #Software #ProductManagement
tag-app-delivery.cncf.io
CNCF Platforms White Paper
This paper intends to support enterprise leaders, enterprise architects and platform team leaders to advocate for, investigate and plan internal platforms for cloud computing. We believe platforms significantly impact enterprises' actual value streams, but…
Forwarded from Админим с Буквой (Aleksandr Kondratev | Hiring)
Инструмент для проведения собесов
Решил, что в целом уже можно поделиться своим инструментом который я сделал для проведения собесов. Я обкатал его на порядка 50 собесах и кажется что он готов для публики. Этот гугл таблица, в которой можно натыкать вопросы разных категорий, разных уровней сложности и содержащие несколько ключевых точек.
Главные фишки документа - решить следующие задачи:
1) получить одинаковый результат оценивания кандидатов, при проведении собеседования разными людьми. вопросы унифицированы, разбиты на ключевые точки, которые показывают глубину знаний человека.
2) наличие артифакта, который уменьшает субъективное мнение рекрутёра, ведь при наличии ключевых точек видно что именно кандидат знает про тот или иной вопрос. т.е. можно после собеса посоветоваться с коллегами
3) приведение субъективного мнения к математическому. Документ автоматически рассчитывает баллы и говорит какой уровень у кандидата - жун\мид\сеньёр. Чаще всего математически подсчитанный результат совпадает с моим субъективным мнением.
4) Разные вопросы под разные вакансии. Можно сформировать вопросы под конкретную вакансию в зависимости от необходимостей конкретного отдела. Так, вы можете определить core технологии, без которых существование инженера невозможно в команде. Добавить опциональные знания и знания расширенного кругозора.
5) Добавление баллов на лету. если человек раскрывает вопрос очень круто можно накинуть баллов на каждый вопрос в отдельности (или отнять)
Более подробно - в ридми документа. (Точка входа - где собес проводить - страничка Sheet1 - исторически сложилось, лень переименовывать)
Предполагаемый флоу работы - вы копируете документ-шаблон, именуете его фио кандидата, натыкиваете ответы, получившийся документ прикрепляете с комментарием в хантфлоу или что-то иное.
З.Ы. Вопросы и ключевые точки - моё субъективное мнение. Вы можете писать в доку свои вопросы, если хотите использовать док для себя. Но холиварить о вопросах и ключевых точках я не очень готов. Документ не идеален, некоторые ключевые точки плохо прописаны, я уже это не меняю - в любом случае и вопросы и ключевые точки - помогаторы при оценке человека, а не идеальный "тест"
З.З.Ы. "математика" сделана немного кривовато, т.к. не все можно сделать "чисто" с функционалом гугл таблиц. Если будете что-то менять в своей копии -делайте аккуратно.
З.З.З.Ы - дополнения и улучшения принимаются. лучше через ЛС.
https://docs.google.com/spreadsheets/d/1D2B6Xzse3fYtrTD0RcbNAeK9N7ORPHzhMGTOvaEtbCA/edit?usp=sharing
Решил, что в целом уже можно поделиться своим инструментом который я сделал для проведения собесов. Я обкатал его на порядка 50 собесах и кажется что он готов для публики. Этот гугл таблица, в которой можно натыкать вопросы разных категорий, разных уровней сложности и содержащие несколько ключевых точек.
Главные фишки документа - решить следующие задачи:
1) получить одинаковый результат оценивания кандидатов, при проведении собеседования разными людьми. вопросы унифицированы, разбиты на ключевые точки, которые показывают глубину знаний человека.
2) наличие артифакта, который уменьшает субъективное мнение рекрутёра, ведь при наличии ключевых точек видно что именно кандидат знает про тот или иной вопрос. т.е. можно после собеса посоветоваться с коллегами
3) приведение субъективного мнения к математическому. Документ автоматически рассчитывает баллы и говорит какой уровень у кандидата - жун\мид\сеньёр. Чаще всего математически подсчитанный результат совпадает с моим субъективным мнением.
4) Разные вопросы под разные вакансии. Можно сформировать вопросы под конкретную вакансию в зависимости от необходимостей конкретного отдела. Так, вы можете определить core технологии, без которых существование инженера невозможно в команде. Добавить опциональные знания и знания расширенного кругозора.
5) Добавление баллов на лету. если человек раскрывает вопрос очень круто можно накинуть баллов на каждый вопрос в отдельности (или отнять)
Более подробно - в ридми документа. (Точка входа - где собес проводить - страничка Sheet1 - исторически сложилось, лень переименовывать)
Предполагаемый флоу работы - вы копируете документ-шаблон, именуете его фио кандидата, натыкиваете ответы, получившийся документ прикрепляете с комментарием в хантфлоу или что-то иное.
З.Ы. Вопросы и ключевые точки - моё субъективное мнение. Вы можете писать в доку свои вопросы, если хотите использовать док для себя. Но холиварить о вопросах и ключевых точках я не очень готов. Документ не идеален, некоторые ключевые точки плохо прописаны, я уже это не меняю - в любом случае и вопросы и ключевые точки - помогаторы при оценке человека, а не идеальный "тест"
З.З.Ы. "математика" сделана немного кривовато, т.к. не все можно сделать "чисто" с функционалом гугл таблиц. Если будете что-то менять в своей копии -делайте аккуратно.
З.З.З.Ы - дополнения и улучшения принимаются. лучше через ЛС.
https://docs.google.com/spreadsheets/d/1D2B6Xzse3fYtrTD0RcbNAeK9N7ORPHzhMGTOvaEtbCA/edit?usp=sharing
Google Docs
Шаблон оценки компетенции (публикация)
Логическая репликация в PostgreSQL. Репликационные идентификаторы и популярные ошибки
https://habr.com/ru/companies/postgrespro/articles/489308/
#postgresql #replication
https://habr.com/ru/companies/postgrespro/articles/489308/
#postgresql #replication
Хабр
Логическая репликация в PostgreSQL. Репликационные идентификаторы и популярные ошибки
Начиная с 10 версии, перенести данные с одной базы PostgreSQL на другую несложно, с обновлением, без обновления — неважно. Об этом немало сказано и сказанное сводится к следующему: на мастере, 10...
Forwarded from k8s (in)security (Дмитрий Евдокимов)
"Advanced Linux Detection and Forensics Cheatsheet" - полезный систематизирующий документ по моментам связанным с обнаружением и расследованием инцидентов в
Linux. Вы определенно можете отметить как много всего есть и как много куда надо смотреть в Linux (и от этого даже может заболеть голова). В документе упоминается и ряд моментов связанных с контейнерами и K8s. Но если прям специализироваться и затачиваться под последнее, то на их специфике можно сделать много всего интересного и очень полезного. Об этом мы как раз расскажем и покажем на будущем вебинаре «Ловим злоумышленников и собираем улики в контейнерах Kubernetes».