
Forwarded from ISPsystem — облака, инфраструктура, хостинг
Как переехать с VMware и ничего не потерять
Как известно, события прошлого года привели к тому, что многие иностранные компании прервали или полностью остановили свою работу над инфраструктурными проектами в России. Компания VMware не стала исключением, и многие участники российского ИТ-рынка оказались вынуждены менять платформу виртуализации и искать равноценную отечественную альтернативу для миграции.
VMmanager позволяет стать эффективным инструментом для создания масштабируемой и отказоустойчивой среды виртуализации. А произвести перенос виртуальных машин на отечественную платформу с VMware можно самостоятельно с помощью универсальных утилит qemu-img и virt-v2v.
О том, как пошагово справиться с переездом с ESXi на KVM и не проколоть колеса на граблях – рассказываем в нашем новом материале на сайте.
📎ЧИТАТЬ
#ispsystem #ispsystem
Как известно, события прошлого года привели к тому, что многие иностранные компании прервали или полностью остановили свою работу над инфраструктурными проектами в России. Компания VMware не стала исключением, и многие участники российского ИТ-рынка оказались вынуждены менять платформу виртуализации и искать равноценную отечественную альтернативу для миграции.
VMmanager позволяет стать эффективным инструментом для создания масштабируемой и отказоустойчивой среды виртуализации. А произвести перенос виртуальных машин на отечественную платформу с VMware можно самостоятельно с помощью универсальных утилит qemu-img и virt-v2v.
О том, как пошагово справиться с переездом с ESXi на KVM и не проколоть колеса на граблях – рассказываем в нашем новом материале на сайте.
📎ЧИТАТЬ
#ispsystem #ispsystem
www.ispsystem.ru
Как мигрировать с VMware на VMmanager — Блог ISPsystem
Как перенести ваши виртуальные машины с VMware ESXi на платформу виртуализации VMmanager
Forwarded from opennet.ru
Рейтинг из 20 самых эксплуатируемых узязвимостей https://opennet.ru/59718/
www.opennet.ru
Рейтинг из 20 самых эксплуатируемых уязвимостей
Компания Qualys опубликовала рейтинг уязвимостей, наиболее часто используемых для совершения атак и для распространения вредоносного или вымогательского ПО. 15 из представленных в рейтинге уязвимостей затрагивают продукты Microsoft. Получившийся рейтинг:
Forwarded from Официальный канал Труконф
Труконф в городах России этой осенью:
Приглашаем вас присоединиться к команде Труконф и нашим технологическим партнёрам! Поговорим о рынке видеосвязи, глобальных обновлениях в нашем мессенджере и ВКС-платформе, проведём мастер-класс по настройке и управлению продуктами TrueConf, а также поделимся опытом замещения иностранных сервисов и расскажем о планах на будущее.
В каждом городе мы совместно с другими ИТ-компаниями проведем обучающие выступления, организуем демозону для тестирования представленных решений и с удовольствием ответим на все ваши вопросы.
Будем рады вас видеть!
@trueconf
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from ServerAdmin.ru
Для Linux есть замечательный локальный веб сервер, который можно запустить с помощью python:
Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
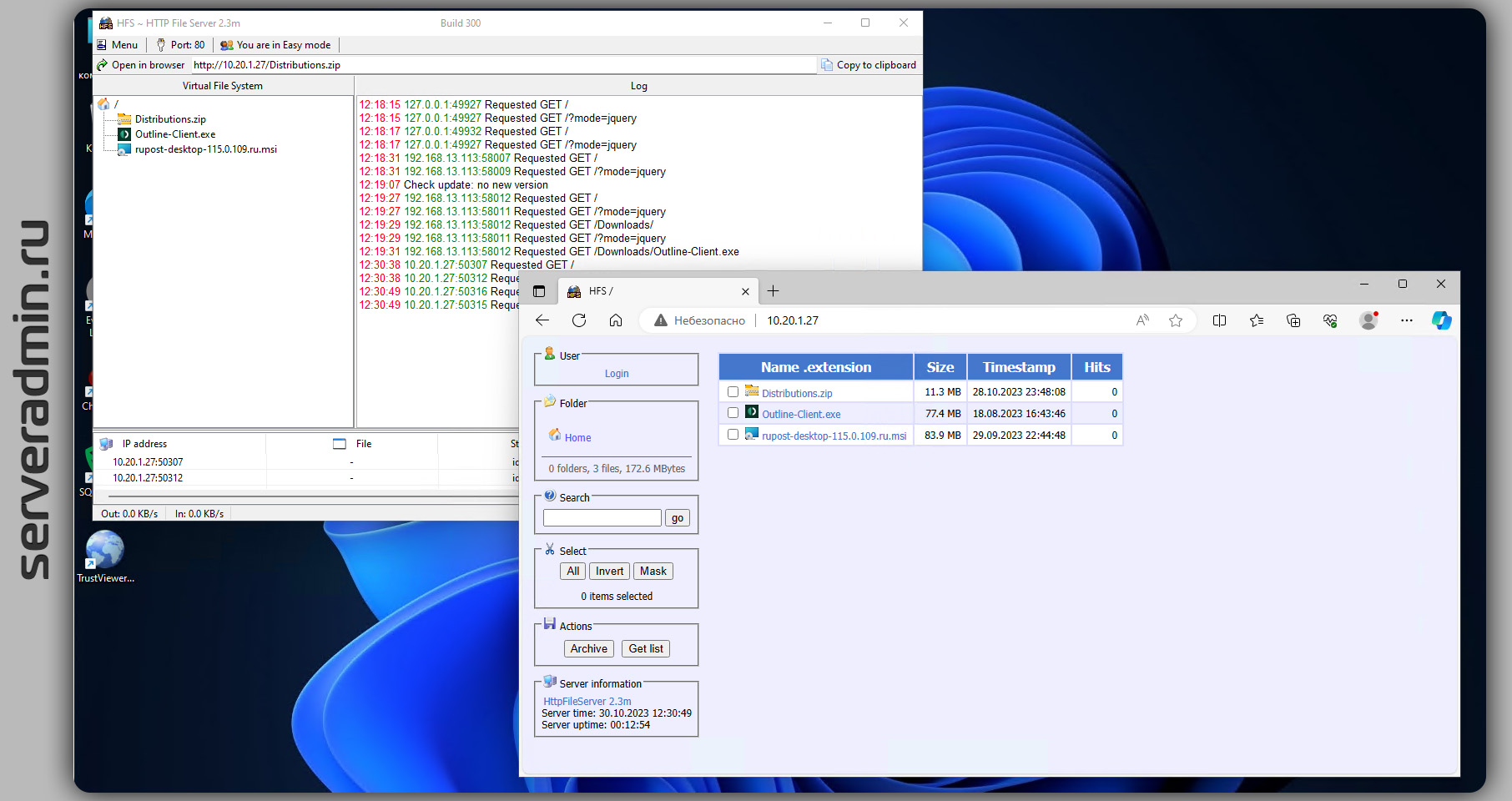
Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
# cd /var/log# python3 -m http.server 8181Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
/var/log. Когда скачали, завершаем работу. Это очень простой способ быстро передать файлы, когда не хочется ничего настраивать. Я регулярно им пользуюсь. Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
{kind=link}
Forwarded from opennet.ru
Изменение IP-адреса корневого DNS-сервера "B" https://opennet.ru/60191/
www.opennet.ru
Изменение IP-адреса корневого DNS-сервера "B"
27 ноября 2023 года состоялось плановое изменение IPv4 и IPv6 адресов одного из 13-ти корневых серверов DNS, обеспечивающих работу корневой зоны DNS. Для сервера B.ROOT-SERVERS.NET вместо IP-адреса 199.9.14.201 отныне задействован 170.247.170.2, а вместо…
Forwarded from opennet.ru
Проект OpenWrt развивает собственную аппаратную платформу https://opennet.ru/60414/
www.opennet.ru
Проект OpenWrt развивает собственную аппаратную платформу
В канун 20-летия проекта разработчики дистрибутива OpenWrt выступили с инициативой создания развиваемого сообществом беспроводного маршрутизатора OpenWrt One (AP-24.X). В качестве основы OpenWrt One предлагается использовать начинку, схожую с платами Banana…
Forwarded from ServerAdmin.ru
Сейчас в большинстве популярных дистрибутивов на базе Linux в качестве файрвола по умолчанию используется nftables. Конкретно в Debian начиная с Debian 10 Buster. Я обычно делаю вот так в нём:
Но это не может продолжаться вечно. Для какого-нибудь одиночного сервера эти действия просто не нужны. Проще сразу настроить nftables. К тому же у него есть и явные преимущества, про которые я знаю:
◽️ единый конфиг для ipv4 и ipv6;
◽️ более короткий и наглядный синтаксис;
◽️ nftables умеет быстро работать с огромными списками, не нужен ipset;
◽️ экспорт правил в json, удобно для мониторинга.
Я точно помню, что когда-то писал набор стандартных правил для nftables, но благополучно его потерял. Пришлось заново составлять, поэтому и пишу сразу заметку, чтобы не потерять ещё раз. Правила будут для условного веб сервера, где разрешены на вход все соединения на 80 и 443 порты, на порт 10050 zabbix агента разрешены только с zabbix сервера, а на 22-й порт SSH только для списка IP адресов. Всё остальное закрыто на вход. Исходящие соединения сервера разрешены.
Начну с базы, нужной для управления правилами. Смотрим существующий список правил и таблиц:
Очистка правил:
Дальше сразу привожу готовый набор правил. Отдельно отмечу, что в nftables привычные таблицы и цепочки нужно создать отдельно. В iptables они были по умолчанию.
Вот и всё. Мы создали таблицу filter, добавили цепочку input, закинули туда нужные нам разрешающие правила и в конце изменили политику по умолчанию на drop. Так как никаких других правил нам сейчас не надо, остальные таблицы и цепочки можно не создавать. Осталось только сохранить эти правила и применить их после загрузки сервера.
У nftables есть служба, которая при запуске читает файл конфигурации
Можно перезагружаться и проверять автозагрузку правил. Ещё полезная команда, которая пригодится в процессе настройки. Удаление правила по номеру:
Добавление правила в конкретное место с номером в списке:
В целом, ничего сложного. Подобным образом настраиваются остальные цепочки output или forward, если нужно. Синтаксис удобнее, чем у iptables. Как-то более наглядно и логично, особенно со списками ip адресов и портов, если они небольшие.
Единственное, что не нашёл пока как делать - как подгружать очень большие списки с ip адресами. Вываливать их в список правил - плохая идея. Надо как-то подключать извне. По идее это описано в sets, но я пока не разбирался.
⇨ Документация
#nftables
# apt remove --auto-remove nftables# apt purge nftables# apt update# apt install iptablesНо это не может продолжаться вечно. Для какого-нибудь одиночного сервера эти действия просто не нужны. Проще сразу настроить nftables. К тому же у него есть и явные преимущества, про которые я знаю:
◽️ единый конфиг для ipv4 и ipv6;
◽️ более короткий и наглядный синтаксис;
◽️ nftables умеет быстро работать с огромными списками, не нужен ipset;
◽️ экспорт правил в json, удобно для мониторинга.
Я точно помню, что когда-то писал набор стандартных правил для nftables, но благополучно его потерял. Пришлось заново составлять, поэтому и пишу сразу заметку, чтобы не потерять ещё раз. Правила будут для условного веб сервера, где разрешены на вход все соединения на 80 и 443 порты, на порт 10050 zabbix агента разрешены только с zabbix сервера, а на 22-й порт SSH только для списка IP адресов. Всё остальное закрыто на вход. Исходящие соединения сервера разрешены.
Начну с базы, нужной для управления правилами. Смотрим существующий список правил и таблиц:
# nft -a list ruleset# nft list tablesОчистка правил:
# nft flush rulesetДальше сразу привожу готовый набор правил. Отдельно отмечу, что в nftables привычные таблицы и цепочки нужно создать отдельно. В iptables они были по умолчанию.
nft add table inet filternft add chain inet filter input { type filter hook input priority 0\; }nft add rule inet filter input ct state related,established counter acceptnft add rule inet filter input iifname "lo" counter acceptnft add rule inet filter input ip protocol icmp counter acceptnft add rule inet filter input tcp dport {80, 443} counter acceptnft add rule inet filter input ip saddr { 192.168.100.0/24, 172.20.0.0/24, 1.1.1.1/32 } tcp dport 22 counter acceptnft add rule inet filter input ip saddr 2.2.2.2/32 tcp dport 10050 counter acceptnft chain inet filter input { policy drop \; }Вот и всё. Мы создали таблицу filter, добавили цепочку input, закинули туда нужные нам разрешающие правила и в конце изменили политику по умолчанию на drop. Так как никаких других правил нам сейчас не надо, остальные таблицы и цепочки можно не создавать. Осталось только сохранить эти правила и применить их после загрузки сервера.
У nftables есть служба, которая при запуске читает файл конфигурации
/etc/nftables.conf. Запишем туда наш набор правил. Так как мы перезапишем существующую конфигурацию, где в начале стоит очистка всех правил, нам надо отдельно добавить её туда:# echo "flush ruleset" > /etc/nftables.conf# nft -s list ruleset >> /etc/nftables.conf# systemctl enable nftables.serviceМожно перезагружаться и проверять автозагрузку правил. Ещё полезная команда, которая пригодится в процессе настройки. Удаление правила по номеру:
# nft delete rule inet filter input handle 9Добавление правила в конкретное место с номером в списке:
# nft add rule inet filter input position 8 tcp dport 22 counter acceptВ целом, ничего сложного. Подобным образом настраиваются остальные цепочки output или forward, если нужно. Синтаксис удобнее, чем у iptables. Как-то более наглядно и логично, особенно со списками ip адресов и портов, если они небольшие.
Единственное, что не нашёл пока как делать - как подгружать очень большие списки с ip адресами. Вываливать их в список правил - плохая идея. Надо как-то подключать извне. По идее это описано в sets, но я пока не разбирался.
⇨ Документация
#nftables
{kind=link}
Forwarded from НеКасперский
Wake up
Полистали ленту новостей за последнюю неделю и не сдержались не сделать конспирологический пост про большого брата.
Windows 11 ОС теперь автоматически включает резервное копирование ваших данных в OneDrive, предварительно выделив для вас место в облаке. Естественно, никакого разрешения Microsoft спрашивать у вас не собираются. Для этого они даже изменили свою политику конфиденциальности.
Ну и ладно, казалось бы, что плохого в резервной копии. Дело в том, что в корпорации весьма специфично относятся к данным пользователей на фоне своего отставания в сфере ИИ. Так, руководитель отдела AI в Microsoft заявил, что использовать пользовательский контент для обучения ИИ — это ок. Более того, он пользовательский контент называет «бесплатным». Кроме того, Мустафа Сулейман считает бесплатным и весь остальной контент, который можно найти в сети. Для его использования, по его мнению, не должно быть ограничений.
Есть загвоздка: резервное копирование включается при подключении устройства к сети. Видимо, чтобы минимизировать количество офлайн-устройств Microsoft убрали со своего сайта инструкцию по настройке локальной учётной записи, заменив её на противоположную, повествующую о том, как выйти из локальной учётки.
Полагаем, что незазорно обучать ИИ и на логах в роде Recall, баги в котором серьёзно беспокоят общественность.
Вроде ничего нового — Microsoft крадёт ваши данные. Но удивляет то, как открыто они сейчас это делают.
НеКасперский
Полистали ленту новостей за последнюю неделю и не сдержались не сделать конспирологический пост про большого брата.
Windows 11 ОС теперь автоматически включает резервное копирование ваших данных в OneDrive, предварительно выделив для вас место в облаке. Естественно, никакого разрешения Microsoft спрашивать у вас не собираются. Для этого они даже изменили свою политику конфиденциальности.
Ну и ладно, казалось бы, что плохого в резервной копии. Дело в том, что в корпорации весьма специфично относятся к данным пользователей на фоне своего отставания в сфере ИИ. Так, руководитель отдела AI в Microsoft заявил, что использовать пользовательский контент для обучения ИИ — это ок. Более того, он пользовательский контент называет «бесплатным». Кроме того, Мустафа Сулейман считает бесплатным и весь остальной контент, который можно найти в сети. Для его использования, по его мнению, не должно быть ограничений.
Есть загвоздка: резервное копирование включается при подключении устройства к сети. Видимо, чтобы минимизировать количество офлайн-устройств Microsoft убрали со своего сайта инструкцию по настройке локальной учётной записи, заменив её на противоположную, повествующую о том, как выйти из локальной учётки.
Полагаем, что незазорно обучать ИИ и на логах в роде Recall, баги в котором серьёзно беспокоят общественность.
Вроде ничего нового — Microsoft крадёт ваши данные. Но удивляет то, как открыто они сейчас это делают.
НеКасперский
Полезные сайты о кибербезопасности
киберзож.рф — о способах защиты себя и близких от киберугроз
кибер-буллинг.рф — об умении противостоять интернет-травле
выучисвоюроль.рф — о том, как распознавать телефонных мошенников и правильно действовать при их звонках
прокачайскиллзащиты.рф — о создании защищённых паролей и определении фишинга
киберзож.рф — о способах защиты себя и близких от киберугроз
кибер-буллинг.рф — об умении противостоять интернет-травле
выучисвоюроль.рф — о том, как распознавать телефонных мошенников и правильно действовать при их звонках
прокачайскиллзащиты.рф — о создании защищённых паролей и определении фишинга
Forwarded from Максим Горшенин | imaxai
#cpu
Копипаста с Хабр: Крупица истины в безумном заявлении «в России нет и не может быть чипов» и что из нее следует
Тут был диспут пару дней назад на фейсбуке с социологом Алексеем Рощиным, в котором он сделал совершенно безумное заявление "в России нет и не может быть чипов, а если что-то и есть, то оно на два поколения устарело"
Понятно, что в России чипы есть, например микроконтроллер MIK32 АМУР, выпущенный в Зеленограде на основе процессорного ядра от питерской компании Syntacore. Причем если сравнивать Амур с STM32 U0 2024 года (низкопотребляющий микроконтроллер от мирового лидера на 90 нм, 56 MHz), то нельзя сказать что российское "на два поколения устарело"
У микроконтроллеров крутость не в нанометрах (чип на 3 нм все равно не выдержит рядом с горячим автомобильным двигателем), а в системных и микроархитектурных решениях (трюки для экономии динамического энергопотребления, эффективный DMA, даже AI расширения в стиле ARM Ethos-U55)
Учитывая, что Рощин - человек не безумный, я попытался понять, что он имеет в виду, и кажется понял. Мира микроконтроллеров и встроенных процессоров для него не существует (гуманитарии-социологи не задумываются что микроконтроллеры с RTOS ныне есть и в утюгах), а чипы для него - это компьютеры с Windows, которые используют "все"
И вот если смотреть с такой дефиницией, то я с Рощиным совершенно соглашусь. В России нет, не было и никогда не будет конкурентоспособных процессоров архитектуры x86-64 на которых можно нормально (то бишь без медленной симуляции с QEMU и без бинарной трансляции) пускать Microsoft Windows. Неудачные бенчмарки Эльбруса в Сбербанке - это наглядная демонстрация тупиковости такой идеи
Но тут главная фишка не в недостатке экспертизы по проектированию процессоров в России (хотя и в ней тоже), а в том, что паровоз технологии x86-64 вкупе с Windows очень давно ушел. У Windows 30 лет назад, у x86 - 40 лет назад. Хотя x86 немного омолодили в 1990-е годы - за счет внедрения динамического конвейера в PentiumPro в 1996 году и 64-битности от AMD потом
Но попытки повторить все тупиковые решения и недокументированные совместимости, которые скопились в x86 с 1978 года / Intel 8086/8088 (который в свою очередь содержит бессмысленные сейчас совместимости с 8080 от 1974-го года, например H/L регистром) - это даже при наличии идеально подготовленных инженеров означало бы ковыряние тысяч инженеров во всякой ерунде многие годы и все равно бы не привело к успеху. То же самое ядро и приложения Windows
Путь России, Китая и другой зарождающейся мировой альтернативы - это линуксные компьютеры на RISC-V. Там можно легально, конструктивно и эффективно использовать открытые решения со всего мира, на основе которых строить свои
А x86-64 с Windows - это умирающие технологии, несмотря на миллиарды пользователей в мире и несмотря на то, что они умирать будут еще сто лет. Поднимать глаза к потолку что этого у России нет и не будет - это как ругать Нигерию, что та не может скопировать компьютеры на процессоре IBM Z
Не слышали о таком? Это современное продолжение IBM 360, которые СССР скопировал как ЕС ЭВМ в 1960-е годы. Да, оно еще живо!!! Работает в банках, которые не сошли c этого паровоза за 80 лет. Но повторять его не нужно
UPD: Самые дотошные могут спросить "а почему вы не вспоминаете про советские клоны 8086/186/286 на которых можно было запускать MS-DOS?" Я думал всунуть упоминание о них в какой-то форме в свою заметку, но потом решил что эта ветка дискуссии не способствует просветлению (последовательные, не конвейерные, 16-битные, не хочу даже углубляться в protected-mode versus real mode и можно ли было запустить Windows 2.1 aka Windows/286 на малоиспользуемом советском клоне 286-го)
@imaxairu Подписаться
Копипаста с Хабр: Крупица истины в безумном заявлении «в России нет и не может быть чипов» и что из нее следует
Тут был диспут пару дней назад на фейсбуке с социологом Алексеем Рощиным, в котором он сделал совершенно безумное заявление "в России нет и не может быть чипов, а если что-то и есть, то оно на два поколения устарело"
Понятно, что в России чипы есть, например микроконтроллер MIK32 АМУР, выпущенный в Зеленограде на основе процессорного ядра от питерской компании Syntacore. Причем если сравнивать Амур с STM32 U0 2024 года (низкопотребляющий микроконтроллер от мирового лидера на 90 нм, 56 MHz), то нельзя сказать что российское "на два поколения устарело"
У микроконтроллеров крутость не в нанометрах (чип на 3 нм все равно не выдержит рядом с горячим автомобильным двигателем), а в системных и микроархитектурных решениях (трюки для экономии динамического энергопотребления, эффективный DMA, даже AI расширения в стиле ARM Ethos-U55)
Учитывая, что Рощин - человек не безумный, я попытался понять, что он имеет в виду, и кажется понял. Мира микроконтроллеров и встроенных процессоров для него не существует (гуманитарии-социологи не задумываются что микроконтроллеры с RTOS ныне есть и в утюгах), а чипы для него - это компьютеры с Windows, которые используют "все"
И вот если смотреть с такой дефиницией, то я с Рощиным совершенно соглашусь. В России нет, не было и никогда не будет конкурентоспособных процессоров архитектуры x86-64 на которых можно нормально (то бишь без медленной симуляции с QEMU и без бинарной трансляции) пускать Microsoft Windows. Неудачные бенчмарки Эльбруса в Сбербанке - это наглядная демонстрация тупиковости такой идеи
Но тут главная фишка не в недостатке экспертизы по проектированию процессоров в России (хотя и в ней тоже), а в том, что паровоз технологии x86-64 вкупе с Windows очень давно ушел. У Windows 30 лет назад, у x86 - 40 лет назад. Хотя x86 немного омолодили в 1990-е годы - за счет внедрения динамического конвейера в PentiumPro в 1996 году и 64-битности от AMD потом
Но попытки повторить все тупиковые решения и недокументированные совместимости, которые скопились в x86 с 1978 года / Intel 8086/8088 (который в свою очередь содержит бессмысленные сейчас совместимости с 8080 от 1974-го года, например H/L регистром) - это даже при наличии идеально подготовленных инженеров означало бы ковыряние тысяч инженеров во всякой ерунде многие годы и все равно бы не привело к успеху. То же самое ядро и приложения Windows
Путь России, Китая и другой зарождающейся мировой альтернативы - это линуксные компьютеры на RISC-V. Там можно легально, конструктивно и эффективно использовать открытые решения со всего мира, на основе которых строить свои
А x86-64 с Windows - это умирающие технологии, несмотря на миллиарды пользователей в мире и несмотря на то, что они умирать будут еще сто лет. Поднимать глаза к потолку что этого у России нет и не будет - это как ругать Нигерию, что та не может скопировать компьютеры на процессоре IBM Z
Не слышали о таком? Это современное продолжение IBM 360, которые СССР скопировал как ЕС ЭВМ в 1960-е годы. Да, оно еще живо!!! Работает в банках, которые не сошли c этого паровоза за 80 лет. Но повторять его не нужно
UPD: Самые дотошные могут спросить "а почему вы не вспоминаете про советские клоны 8086/186/286 на которых можно было запускать MS-DOS?" Я думал всунуть упоминание о них в какой-то форме в свою заметку, но потом решил что эта ветка дискуссии не способствует просветлению (последовательные, не конвейерные, 16-битные, не хочу даже углубляться в protected-mode versus real mode и можно ли было запустить Windows 2.1 aka Windows/286 на малоиспользуемом советском клоне 286-го)
@imaxairu Подписаться
Forwarded from ServerAdmin.ru
Я уже давно использую заметки с канала как свои шпаргалки. Всё полезное из личных заметок перенёс сюда, плюс оформил всё это аккуратно и дополнил. Когда ищу какую-то информацию, в первую очередь иду сюда, ищу по тегам или содержимому.
Обнаружил, что тут нет заметки про tcpdump, хотя личная шпаргалка по этой программе у меня есть. Переношу сюда. По tcpdump можно много всего написать, материала море. Я напишу кратко, только те команды, что использую сам. Их немного. Tcpdump использую редко, если есть острая необходимость.
Я ко всем командам добавляю ключ
📌 Список сетевых интерфейсов, с которых tcpdump может смотреть пакеты:
Если запустить программу без ключей, то трафик будет захвачен с первого активного интерфейса из списка выше.
📌 Слушаем все интерфейсы:
Или только конкретный:
📌 Исключаем SSH протокол. Если в трафике, на который мы смотрим, будет SSH соединение, то оно забивает весь вывод своей активностью. Глазами уже не разобрать. Исключаю его по номеру порта:
По аналогии исключается любой другой трафик по портам. Если убираем слово not, то слушаем трафик только указанного порта.
📌 Пакеты к определённому адресату или адресатам:
Комбинация порта и адресата:
Подобным образом можно комбинировать любые параметры: src, dst, port и т.д. с помощью операторов and, or, not,
📌 Смотрим конкретный протокол или исключаем его и не только:
На этом всё. Лично мне этих команд в повседневной деятельности достаточно. Не припоминаю, чтобы хоть раз использовал что-то ещё. Если надо проанализировать большой список, то просто направляю вывод в файл:
На основе приведённых выше примеров можно посмотреть, к примеру, на SIP трафик по VPN туннелю от конкретного пользователя к VOIP серверу:
Если не знакомы с tcpdump, рекомендую обязательно познакомиться и научиться пользоваться. Это не трудно, хоть на первый взгляд вывод выглядит жутковато и запутанно. Сильно в нём разбираться чаще всего не нужно, а важно увидеть какие пакеты и куда направляются. Это очень помогает в отладке. Чаще всего достаточно вот этого в выводе:
Протокол IP, адрес источника и порт > адрес получателя и его порт.
#network
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
Обнаружил, что тут нет заметки про tcpdump, хотя личная шпаргалка по этой программе у меня есть. Переношу сюда. По tcpdump можно много всего написать, материала море. Я напишу кратко, только те команды, что использую сам. Их немного. Tcpdump использую редко, если есть острая необходимость.
Я ко всем командам добавляю ключ
-nn, чтобы не резолвить IP адреса в домены и не заменять номера портов именем протокола. Мне это мешает. 📌 Список сетевых интерфейсов, с которых tcpdump может смотреть пакеты:
# tcpdump -DЕсли запустить программу без ключей, то трафик будет захвачен с первого активного интерфейса из списка выше.
📌 Слушаем все интерфейсы:
# tcpdump -nn -i anyИли только конкретный:
# tcpdump -nn -i ens3📌 Исключаем SSH протокол. Если в трафике, на который мы смотрим, будет SSH соединение, то оно забивает весь вывод своей активностью. Глазами уже не разобрать. Исключаю его по номеру порта:
# tcpdump -nn -i any port not 22По аналогии исключается любой другой трафик по портам. Если убираем слово not, то слушаем трафик только указанного порта.
📌 Пакеты к определённому адресату или адресатам:
# tcpdump -nn dst 8.8.8.8# tcpdump -nn dst 8.8.8.8 or dst 8.8.4.4Комбинация порта и адресата:
# tcpdump -nn dst 8.8.8.8 and port 53Подобным образом можно комбинировать любые параметры: src, dst, port и т.д. с помощью операторов and, or, not,
📌 Смотрим конкретный протокол или исключаем его и не только:
# tcpdump arp -nn -i any# tcpdump not arp -nn -i any# tcpdump not arp and not icmp -nn -i anyНа этом всё. Лично мне этих команд в повседневной деятельности достаточно. Не припоминаю, чтобы хоть раз использовал что-то ещё. Если надо проанализировать большой список, то просто направляю вывод в файл:
# tcpdump -nn -i any > ~/tcpdump.txtНа основе приведённых выше примеров можно посмотреть, к примеру, на SIP трафик по VPN туннелю от конкретного пользователя к VOIP серверу:
# tcpdump -nn -i tun4 src 10.1.4.23 and dst 10.1.3.205 and port 5060Если не знакомы с tcpdump, рекомендую обязательно познакомиться и научиться пользоваться. Это не трудно, хоть на первый взгляд вывод выглядит жутковато и запутанно. Сильно в нём разбираться чаще всего не нужно, а важно увидеть какие пакеты и куда направляются. Это очень помогает в отладке. Чаще всего достаточно вот этого в выводе:
IP 10.8.2.2.13083 > 10.8.2.3.8118Протокол IP, адрес источника и порт > адрес получателя и его порт.
#network
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
Forwarded from opennet.ru
Релиз Proxmox VE 8.3, дистрибутива для организации работы виртуальных серверов https://opennet.ru/62273/
www.opennet.ru
Релиз Proxmox VE 8.3, дистрибутива для организации работы виртуальных серверов
Опубликован релиз Proxmox Virtual Environment 8.3, специализированного Linux-дистрибутива на базе Debian GNU/Linux, нацеленного на развертывание и обслуживание виртуальных серверов с использованием LXC и KVM, и способного выступить в роли замены таких продуктов…
Сервис VK Видео теперь доступен на отдельном домене vkvideo.ru.
Forwarded from ServerAdmin.ru
В недавнем цикле статей по LVM в комментариях всплывали вопросы так называемого Bit Rot или битового гниения. Это когда на носитель записан бит 1 или 0, а со временем по разным причинам он поменял своё значение. В конечном счёте эти изменения ведут к тому, что нужный файл хоть и нормально прочитается, но окажется "битым". Причём подвержены этим ошибкам все типы устройств хранения - от лент и CD до современных SSD. Я проверял свои старые записанные CD диски. Многие из них хоть и прочитались, но часть данных была безвозвратно утеряна или повреждена.
Защита от этого явления начинается с того, что данные у вас должны храниться в нескольких экземплярах. Если экземпляр один, то даже если вы узнаете о том, что файл побился, вам это никак не поможет.
Проще всего следить за целостностью файлов с помощью подсчёта контрольных сумм по тем или иным алгоритмам (CRC, MD5, SHA1 и т.д.) Есть много бесплатного софта, который автоматически может это выполнять и сравнивать по расписанию. В Linux такой софт обычно используется для контроля за системными файлами, чтобы определять несанкционированное изменение. Пример - Afick, Tripwire. Если у вас лежат файлы, с ними никто не работает, но изменилась контрольная сумма, значит возникли проблемы. Необходимо то же самое проверить на другом хранилище этих же файлов и если там контрольная сумма не менялась, значит тот файл оригинальный и стоит его восстановить из этой копии.
Некоторые файловые системы выполняют такие проверки в автоматическом режиме. Это заложено в их архитектуру. Пример - ZFS, Btrfs, ReiserFS, Ceph. Все эти файловые системы могут не только контролировать изменения, но и выполнять автоматическое восстановление повреждённых файлов, если хранилища на их основе собраны с избыточностью данных. То есть каждый файл хранится как минимум в двух или более копиях, для каждой из которых посчитана и сохранена контрольная сумма.
Важно понимать, что подобный контроль - не бесплатная операция. Она занимает системные ресурсы, как процессора, так и диска. И чем больше нагрузка на диск, тем больше ресурсов нужно. Перечисленные выше ФС обладают не только функциональностью контроля хэшей, но и многими другими, которые не обязательно будут нужны, но ресурсы они потребляют. Плюс, в них могут быть свои ошибки с вероятностью возникновения выше, чем Bit Rot. И стоит не забывать, что даже если вы возьмёте хранилище с ZFS или Ceph с контролем целостности файлов, это не освобождает вас от хранения этих же файлов где-то ещё.
Есть и другой механизм защиты файлов в Linux на основе контроля целостности - DM-integrity. С его помощью можно блочное устройство превратить в устройство с контролем целостности. А дальше с ним можно работать как с обычным диском - создавать разделы, тома Mdadm или Lvm. В случае нарушения целостности файла такое устройство будет возвращать Input/output error. Mdadm или LVM будут пытаться автоматически восстановить файл из копии, если хранилище обладает избыточностью данных, то есть собран рейд соответствующего уровня.
Таким образом мне не понятны претензии к Mdadm, Lvm или обычным файловым системам типа Ext4 или Xfs. Следить за целостностью файлов - не их задача. Где-то это будет слишком накладно, а где-то вообще не нужно. Если вам это необходимо, возьмите отдельный инструмент. В основном это актуально для долговременных хранилищ с холодными архивами.
☝️ Самая надёжная защита от Bit Rot - множественные копии. И тут очень важно соблюдать один принцип. Делать копию надо не от копии, а от оригинала данных. У вас есть исходное хранилище с данными, где они регулярно меняются. С него вы снимаете первый бэкап. Второй бэкап для другого хранилища надо снимать не с первого бэкапа, а тоже с исходного сервера. Иначе вы на все зависимые сервера принесёте битые файлы с первого бэкапа.
❓Для меня остался открытым другой вопрос. А как вообще понять, что у нас в хранилище файлы исправны, откроются и прочитаются? Как проверить изначальный источник правды для всех остальных копий?
#backup
Защита от этого явления начинается с того, что данные у вас должны храниться в нескольких экземплярах. Если экземпляр один, то даже если вы узнаете о том, что файл побился, вам это никак не поможет.
Проще всего следить за целостностью файлов с помощью подсчёта контрольных сумм по тем или иным алгоритмам (CRC, MD5, SHA1 и т.д.) Есть много бесплатного софта, который автоматически может это выполнять и сравнивать по расписанию. В Linux такой софт обычно используется для контроля за системными файлами, чтобы определять несанкционированное изменение. Пример - Afick, Tripwire. Если у вас лежат файлы, с ними никто не работает, но изменилась контрольная сумма, значит возникли проблемы. Необходимо то же самое проверить на другом хранилище этих же файлов и если там контрольная сумма не менялась, значит тот файл оригинальный и стоит его восстановить из этой копии.
Некоторые файловые системы выполняют такие проверки в автоматическом режиме. Это заложено в их архитектуру. Пример - ZFS, Btrfs, ReiserFS, Ceph. Все эти файловые системы могут не только контролировать изменения, но и выполнять автоматическое восстановление повреждённых файлов, если хранилища на их основе собраны с избыточностью данных. То есть каждый файл хранится как минимум в двух или более копиях, для каждой из которых посчитана и сохранена контрольная сумма.
Важно понимать, что подобный контроль - не бесплатная операция. Она занимает системные ресурсы, как процессора, так и диска. И чем больше нагрузка на диск, тем больше ресурсов нужно. Перечисленные выше ФС обладают не только функциональностью контроля хэшей, но и многими другими, которые не обязательно будут нужны, но ресурсы они потребляют. Плюс, в них могут быть свои ошибки с вероятностью возникновения выше, чем Bit Rot. И стоит не забывать, что даже если вы возьмёте хранилище с ZFS или Ceph с контролем целостности файлов, это не освобождает вас от хранения этих же файлов где-то ещё.
Есть и другой механизм защиты файлов в Linux на основе контроля целостности - DM-integrity. С его помощью можно блочное устройство превратить в устройство с контролем целостности. А дальше с ним можно работать как с обычным диском - создавать разделы, тома Mdadm или Lvm. В случае нарушения целостности файла такое устройство будет возвращать Input/output error. Mdadm или LVM будут пытаться автоматически восстановить файл из копии, если хранилище обладает избыточностью данных, то есть собран рейд соответствующего уровня.
Таким образом мне не понятны претензии к Mdadm, Lvm или обычным файловым системам типа Ext4 или Xfs. Следить за целостностью файлов - не их задача. Где-то это будет слишком накладно, а где-то вообще не нужно. Если вам это необходимо, возьмите отдельный инструмент. В основном это актуально для долговременных хранилищ с холодными архивами.
☝️ Самая надёжная защита от Bit Rot - множественные копии. И тут очень важно соблюдать один принцип. Делать копию надо не от копии, а от оригинала данных. У вас есть исходное хранилище с данными, где они регулярно меняются. С него вы снимаете первый бэкап. Второй бэкап для другого хранилища надо снимать не с первого бэкапа, а тоже с исходного сервера. Иначе вы на все зависимые сервера принесёте битые файлы с первого бэкапа.
❓Для меня остался открытым другой вопрос. А как вообще понять, что у нас в хранилище файлы исправны, откроются и прочитаются? Как проверить изначальный источник правды для всех остальных копий?
#backup
Forwarded from opennet.ru
Состоялась встреча Билла Гейтса, Дэйва Катлера и Линуса Торвальдса https://opennet.ru/63440/
www.opennet.ru
Состоялась встреча Билла Гейтса, Дэйва Катлера и Линуса Торвальдса
Марк Руссинович, автор драйвера NTFS для DOS и технический директор Microsoft Azure, устроил совместный ужин Билла Гейтса, Дэйва Катлера и Линуса Торвальдса. Это была первая встреча Линуса с основателем компании Microsoft и создателем операционных систем…
Forwarded from opennet.ru
В завтрашнем обновлении Windows Server будет нарушена совместимость с Samba https://opennet.ru/63540/
www.opennet.ru
В завтрашнем обновлении Windows Server будет нарушена совместимость с Samba
Сформированы внеплановые обновления Samba 4.22.3 и 4.21.7, решающие проблему с нарушением совместимости серверов Samba с завтрашним обновлением Windows Server. В случае, если не установить предложенные корректирующие обновления, серверы Samba не смогут функционировать…