
OAuth 2.0 и OpenID Connect
🔐 OAuth 2.0 — протокол авторизации, который позволяет приложениям получать доступ к ресурсам от имени пользователей, без необходимости передавать логин и пароль. Вместо этого используются токены доступа.
👤 OpenID Connect — протокол аутентификации, который позволяет безопасно узнать сведения о пользователе, от имени которого совершается вход. OpenID Connect позволяет реализовывать сценарии, когда единственный логин можно использовать во множестве приложений, — этот подход также известен как single sign-on (SSO).
В чём отличие между OAuth 2.0 и OpenID Connect
Вся разница сводится к различию процессов аутентификации и авторизации.
Простыми словами:
💩 Аутентификация — это когда мы проверяем, кто именно запрашивает доступ и является ли он тем, кем он себя представляет.
💩 Авторизация — это когда мы проверяем, имеет ли конкретный клиент доступ к запрашиваемой информации.
OAuth 2.0 используется для авторизации, а OpenID Connect для аутентификации. А ещё OpenID Connect делает возможным использование SSO.
Токены
Оба протокола используют токены. Токен — это строка, которая содержит зашифрованную или подписанную информацию.
💩 id_token — содержит информацию о клиенте, он выдается провайдером идентификации (IdP) в ответ на успешную аутентификацию пользователя. Может содержать, например, id пользователя, фамилию, имя, телефон и т.д.
💩 access_token — это токен доступа, который используется для совершения действий от имени пользователя. Может быть ограничен скоупом — перечислением прав, которые может делать приложение с этим токеном от имени клиента. access_token имеет короткий срок жизни в целях безопасности.
💩 refresh_token — это токен, который используется для получения нового access_token, когда старый истекает или отзывается. Имеет более длительный срок.
Все эти токены можно генерировать по-разному, но самый популярный формат — это JSON Web Token (JWT).
Структура JWT
💫 Заголовок (header) — состоит из типа токена и алгоритма хэширования подписи
💫 Полезная нагрузка (payload) — любые данные, которые вы хотите передать в токене. Payload не шифруется при использовании токена, поэтому не стоит передавать в нем чувствительные данные. Например, паспортные данные.
💫 Подпись (signature) — заголовок и нагрузка формируются отдельно в формате JSON, кодируются в base64, а затем на их основе вычисляется подпись, которая также становится частью токена.
🔀 Процесс на примере использования VK API
1. Приложение генерирует параметры запроса и отправляет пользователя на сервер авторизации oauth.vk.com, добавив к ссылке параметры, включая запрашиваемый scope, например, friends
2. Пользователю открывается окно, где он проходит аутентификацию — вводит логин и пароль
3. После входа открывается окно с запросом прав доступа. Пользователь нажимает на кнопку "Разрешить". Тем самым он авторизует приложение на выполнение действий от его имени с запрашиваемым scope.
4. Сервер авторизации генерирует access_token и refresh_token и возвращает их приложению
5. Теперь приложение может управлять списком друзей пользователя
⭐️ Подборка материалов доступна в закрытом канале
#архитектура #проектирование
🔐 OAuth 2.0 — протокол авторизации, который позволяет приложениям получать доступ к ресурсам от имени пользователей, без необходимости передавать логин и пароль. Вместо этого используются токены доступа.
👤 OpenID Connect — протокол аутентификации, который позволяет безопасно узнать сведения о пользователе, от имени которого совершается вход. OpenID Connect позволяет реализовывать сценарии, когда единственный логин можно использовать во множестве приложений, — этот подход также известен как single sign-on (SSO).
В чём отличие между OAuth 2.0 и OpenID Connect
Вся разница сводится к различию процессов аутентификации и авторизации.
Простыми словами:
OAuth 2.0 используется для авторизации, а OpenID Connect для аутентификации. А ещё OpenID Connect делает возможным использование SSO.
Токены
Оба протокола используют токены. Токен — это строка, которая содержит зашифрованную или подписанную информацию.
Все эти токены можно генерировать по-разному, но самый популярный формат — это JSON Web Token (JWT).
Структура JWT
🔀 Процесс на примере использования VK API
1. Приложение генерирует параметры запроса и отправляет пользователя на сервер авторизации oauth.vk.com, добавив к ссылке параметры, включая запрашиваемый scope, например, friends
2. Пользователю открывается окно, где он проходит аутентификацию — вводит логин и пароль
3. После входа открывается окно с запросом прав доступа. Пользователь нажимает на кнопку "Разрешить". Тем самым он авторизует приложение на выполнение действий от его имени с запрашиваемым scope.
4. Сервер авторизации генерирует access_token и refresh_token и возвращает их приложению
5. Теперь приложение может управлять списком друзей пользователя
⭐️ Подборка материалов доступна в закрытом канале
#архитектура #проектирование
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
Forwarded from Библиотека Системного Аналитика
Принцип пирамиды Минто.pdf
4.1 MB
Принцип пирамиды Минто. Золотые правила мышления, делового письма и устных выступлений
✍️ Автор: Барбара Минто
🗓 Год издания: 2004
🔤 Язык: русский
📚 Объём: 189 стр.
Эта книга учит эффективно составлять письменные документы и устные выступления. Согласно теории автора, текст делового документа хорошо воспринимается только в том случае, если его идеи логически взаимосвязаны и выстроены по принципу пирамиды.
Только такая структура делает сообщение максимально доступным для понимания, потому что мысли излагаются в порядке, оптимальном для восприятия. Эта теория прошла проверку временем: автор много лет преподает свой курс в крупнейших бизнес-школах, университетах и компаниях.
"Золотые правила" Барбары Минто необходимы всем, кому приходится иметь дело с составлением отчетов, служебных записок, докладов, выступлений, презентаций, а также всем, кто хочет научиться предельно ясно и правильно излагать свои мысли, вне зависимости от рода деятельности.
#навыки
✍️ Автор: Барбара Минто
🗓 Год издания: 2004
🔤 Язык: русский
📚 Объём: 189 стр.
Эта книга учит эффективно составлять письменные документы и устные выступления. Согласно теории автора, текст делового документа хорошо воспринимается только в том случае, если его идеи логически взаимосвязаны и выстроены по принципу пирамиды.
Только такая структура делает сообщение максимально доступным для понимания, потому что мысли излагаются в порядке, оптимальном для восприятия. Эта теория прошла проверку временем: автор много лет преподает свой курс в крупнейших бизнес-школах, университетах и компаниях.
"Золотые правила" Барбары Минто необходимы всем, кому приходится иметь дело с составлением отчетов, служебных записок, докладов, выступлений, презентаций, а также всем, кто хочет научиться предельно ясно и правильно излагать свои мысли, вне зависимости от рода деятельности.
#навыки
Версионирование REST API
Версионирование API — это поддержка в рабочем состоянии нескольких версий одного и того же метода. Версионирование API соблюдать требование обратной совместимости, позволяя вносить изменения без нарушения работы потребителей.
⚙️ Как это работает
1️⃣ Под номером версии фиксируется существующий контракт API, который используется потребителями
2️⃣ Если возникла необходимость внести изменения в существующий контракт, заводится отдельная ветка под дорабатываемый метод
3️⃣ Изменения публикуются в новой версии метода API, при этом старая версия остаётся рабочей до тех пор, пока у неё есть потребители
4️⃣ Потребители сами решают, в какой момент они будут готовы перейти на новую версию того или иного метода
✍️ Пример
Допустим, есть метод который позволяет опубликовать статью в блоге:
Метод принимает на вход в теле запроса следующие параметры, которые являются обязательными:
Если мы добавим новый обязательный параметр
Поэтому создаём новую версию метода
При этом старая версия метода (
Способы версионирования API
💫 Префикс URI
Пример:
✔️ Способ простой в проектировании, реализации и документировании
✖️ Создает большое количество дубликатов URL и может снизить производительность приложения
💫 Параметр запроса
Пример:
✔️ Способ рекомендуется, если важно HTTP-кеширование для повышения пропускной способности
✖️ Приводит к загрязнению URI, так как префиксы и суффиксы добавляются к основным строкам URI
💫 HTTP заголовок запроса
Пример:
✔️ Не приводит к загрязнению URI, легко реализовать
✖️ Приводит к неправильному использованию заголовков, т.к они нужны для метаинформации
💫 Feature-версионирование
У клиента API есть набор фич. При отправке запроса, сервер проверяет его набор фич и на этой основе сам определяет нужную версию для каждого клиента
✔️ Можно использовать в качестве внутреннего API
✖️ Со временем фичи могут вступить в конфликт, если отвечают за одну и ту же часть бизнес-логики
⭐️ Подборка материалов доступна в закрытом канале
#api
Версионирование API — это поддержка в рабочем состоянии нескольких версий одного и того же метода. Версионирование API соблюдать требование обратной совместимости, позволяя вносить изменения без нарушения работы потребителей.
⚙️ Как это работает
✍️ Пример
Допустим, есть метод который позволяет опубликовать статью в блоге:
POST /v1/articlesМетод принимает на вход в теле запроса следующие параметры, которые являются обязательными:
{
"text": "string",
"author": "string",
"title": "string"
}Если мы добавим новый обязательный параметр
category, не применяя версионирование API и не оповестив потребителей, то получим ситуацию, когда у потребителей будут сыпаться ошибки, а у нас пепел на нашу голову.Поэтому создаём новую версию метода
POST /v2/articles и все изменения реализуем там:{
"text": "string",
"author": "string",
"title": "string",
"category": "string"
}При этом старая версия метода (
POST /v1/articles) продолжает работать.Способы версионирования API
Пример:
GET /v1/usersПример:
GET /users?version=v1Пример:
GET /users, а версию передаём в headers: version=v1У клиента API есть набор фич. При отправке запроса, сервер проверяет его набор фич и на этой основе сам определяет нужную версию для каждого клиента
⭐️ Подборка материалов доступна в закрытом канале
#api
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
Forwarded from Библиотека Системного Аналитика
Высоконагруженные_приложения_Программирование,_масштабирование,.pdf
14 MB
Высоконагруженные приложения. Программирование, масштабирование, поддержка
✍️ Автор: Мартин Клеппман
🗓 Год издания: 2018
🔤 Язык: русский
📚 Объём: 640 стр.
Книга поможет расширить кругозор по проектированию систем. Рекомендуется системным аналитикам уровня middle и выше.
В этой книге вы найдете ключевые принципы, алгоритмы и компромиссы, без которых не обойтись при разработке высоконагруженных систем для работы с данными. Материал рассматривается на примере внутреннего устройства популярных программных пакетов и фреймворков. В книге три основные части, посвященные, прежде всего, теоретическим аспектам работы с распределенными системами и базами данных. От читателя требуются базовые знания SQL и принципов работы баз данных.
#архитектура #проектирование
✍️ Автор: Мартин Клеппман
🗓 Год издания: 2018
🔤 Язык: русский
📚 Объём: 640 стр.
Книга поможет расширить кругозор по проектированию систем. Рекомендуется системным аналитикам уровня middle и выше.
В этой книге вы найдете ключевые принципы, алгоритмы и компромиссы, без которых не обойтись при разработке высоконагруженных систем для работы с данными. Материал рассматривается на примере внутреннего устройства популярных программных пакетов и фреймворков. В книге три основные части, посвященные, прежде всего, теоретическим аспектам работы с распределенными системами и базами данных. От читателя требуются базовые знания SQL и принципов работы баз данных.
#архитектура #проектирование
TOGAF. Краткий обзор
TOGAF (The Open Group Architecture Framework) — архитектурный фреймворк, который используется для проектирования, реализации и управления архитектурой предприятия.
Главное, что нужно знать о TOGAF
➖ самый распространённый фреймворк для корпоративной архитектуры
➖ предлагает метод разработки архитектуры — Architecture Development Method (ADM)
➖ имеет возможность расширения и адаптации исходной метамодели
➖ включает набор рекомендаций, шаблонов и практик для проектирования АП
➖ способствует эффективному управлению изменениями и реализации стратегии корпоративной архитектуры
TOGAF разделяет архитектуру предприятия на 4 домена (слоя):
💫 бизнес-архитектура (Business Architecture): определяет стратегию бизнеса, управление, организацию и ключевые бизнес-процессы.
💫 архитектура данных (Data Architecture): структура информационных ресурсов, включая логическую и физическую организацию данных, а также средства управления информацией
💫 архитектура приложений (Application Architecture): описывает приложения, которые нужны для работы с данными и бизнес-функциями, структуру и свойства приложений, их взаимодействие между собой и с другими элементами архитектуры, соответствие целям и требованиям бизнеса.
💫 технологическая архитектура (Technical Architecture): описывает аппаратную часть (железо), сети, промежуточное ПО
Структура стандарта TOGAF 10
Ссылки на каждую из частей фреймворка:
1. Fundamental Content
2. Series guides
3. TOGAF Library
1️⃣ Фундаментальный контент (Fundamental Content). Включает
*️⃣ Метод разработки архитектуры (Architecture Development Method (ADM) — центральный компонент TOGAF, который описывает последовательность фаз и шагов для разработки архитектуры предприятия. Каждая фаза содержит подробные руководства, входы, выходы, задачи и артефакты. ADM также поддерживает управление требованиями, архитектурными принципами, рисками, проблемами и изменениями, а также обеспечивает итеративный, циклический и непрерывный характер процесса разработки архитектуры.
*️⃣ Рекомендации к ADM (ADM Guidelines and Techniques)
*️⃣ Применения ADM (Applying the ADM)
Например, использование ADM в различных архитектурных стилях (например, Agile), применение итераций в ADM
*️⃣ Содержания архитектуры (Architecture Content)
Фреймворк , предоставляющий структурную модель для объектов-результатов, создаваемых архитекторами.
Позволяет их последовательно определять, структурировать и представлять.
*️⃣ Возможностей и управления АП (Enterprise Architecture Capability and Governance)
Руководство для создания оргструктур, процессов, ролей, обязанностей, навыков и т.д. Может реализовываться с помощью ADM.
2️⃣ Руководства серий (доменов) (Series guides).
Предлагают лучшие практики для применения корпоративной архитектуры
3️⃣ Библиотека (The Open Group Library) — дополнение к TOGAF. Содержит:
— справочные модели
— методические рекомендации
— общую практическую информацию
— руководство по созданию команды архитектуры предприятия
⭐️ Подборка материалов доступна в закрытом канале
#архитектура
TOGAF (The Open Group Architecture Framework) — архитектурный фреймворк, который используется для проектирования, реализации и управления архитектурой предприятия.
Главное, что нужно знать о TOGAF
TOGAF разделяет архитектуру предприятия на 4 домена (слоя):
Структура стандарта TOGAF 10
Ссылки на каждую из частей фреймворка:
1. Fundamental Content
2. Series guides
3. TOGAF Library
Например, использование ADM в различных архитектурных стилях (например, Agile), применение итераций в ADM
Фреймворк , предоставляющий структурную модель для объектов-результатов, создаваемых архитекторами.
Позволяет их последовательно определять, структурировать и представлять.
Руководство для создания оргструктур, процессов, ролей, обязанностей, навыков и т.д. Может реализовываться с помощью ADM.
Предлагают лучшие практики для применения корпоративной архитектуры
— справочные модели
— методические рекомендации
— общую практическую информацию
— руководство по созданию команды архитектуры предприятия
⭐️ Подборка материалов доступна в закрытом канале
#архитектура
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
🧑💻 Будущее системного анализа — подкаст «Техно.Логично» от Газпромбанка
Раньше аналитики в основном писали ТЗ для инженеров. Но после agile-трансформации их задачи и зона ответственности в начали быстро меняться. Что будет дальше?
В подкасте:
🔹Почему работать как в 2018 больше не получится
🔹Почему роль системного аналитика в agile-команде вызывает вопросы
🔹Зачем аналитики пытаются отказаться от документации
🔹Связаны ли переработки с профессиональным ростом
🔹Какое будущее у профессии аналитика – и есть ли оно вообще
Посмотреть и послушать:
🔗YouTube
🔗Apple Podcasts
🔗Яндекс Музыка
🔗Google Podcasts
Раньше аналитики в основном писали ТЗ для инженеров. Но после agile-трансформации их задачи и зона ответственности в начали быстро меняться. Что будет дальше?
В подкасте:
🔹Почему работать как в 2018 больше не получится
🔹Почему роль системного аналитика в agile-команде вызывает вопросы
🔹Зачем аналитики пытаются отказаться от документации
🔹Связаны ли переработки с профессиональным ростом
🔹Какое будущее у профессии аналитика – и есть ли оно вообще
Посмотреть и послушать:
🔗YouTube
🔗Apple Podcasts
🔗Яндекс Музыка
🔗Google Podcasts
В канал Системный аналитик (в том числе для VIP-канала) ищем автора. Нужно будет писать посты с подборками полезных материалов в стиле канала.
Про условия
Как стать автором
Заполнить анкету и выполнить тестовое задание по ссылке.
Анкеты принимаем до 9 марта (суббота), 23:59 по МСК.
🍩 Плюшки участникам
Все, кто выполнит тестовое задание, получат доступ к VIP-каналу бесплатно и навсегда.
Остались вопросы? Пишите в комментарии 🔽
UPD: дедлайн продлили по многочисленным просьбам
Please open Telegram to view this post
VIEW IN TELEGRAM
🔁 Обеспечение идемпотентности API
Идемпотентная операция — это операция, которая при многократном вызове не меняет состояние ресурса. То есть, если мы повторно вызываем идемпотентный метод API, то не возникнет ошибок, связанных с дублированием одной и той же операции (например, двойных списаний баланса за один и тот же заказ).
По-хорошему, любой API должен быть идемпотентным.
Идемпотентность в REST API
HTTP-методы
❗️ Важно: ответ идемпотентного метода может меняться. Например, при повторном вызове идемпотентного API создания заказа — заказ не будет создаваться ещё раз, но API может ответить как 200, так и 400. При обоих кодах ответа API будет идемпотентно с точки зрения состояния сервера (заказ один, с ним ничего не происходит), а с точки зрения клиента поведение существенно разное.
❗️ Проблемы неидемпотентных API
Проблема №1. Дублирование операций.
При сетевых задержках или ошибках одна и та же операция может быть выполнена несколько раз.
Пример с заказом такси:
1️⃣ Пользователь вызывает такси в приложении
2️⃣ Приложение отправляет запрос на создание заказа на сервер
3️⃣ Возникает сбой, и приложение не получает успешный ответ по таймауту
4️⃣ Приложение показывает сообщение «произошла ошибка» и делает кнопку заказа снова активной
5️⃣ Пользователь снова нажимает кнопку
6️⃣ К пользователю может приехать два такси вместо одного
Проблема №2. Неконсистентное состояние.
Неидемпотентные операции затрудняют отслеживание текущего состояния системы, что может привести к ошибкам и неконсистентности данных.
Пример с заказом такси:
1️⃣ Пользователь изменяет пункт назначения в активном заказе такси через приложение.
2️⃣ Приложение отправляет запрос PATCH /v1/orders/{id} на сервер для обновления заказа
3️⃣ Возникает сбой, и приложение не получает подтверждение об успешном обновлении
4️⃣ Приложение показывает пользователю сообщение об ошибке и предлагает повторить попытку
5️⃣ Пользователь решает изменить пункт назначения на новый и снова отправляет запрос
6️⃣ Сервер обрабатывает оба запроса: сначала второй, затем первый. В системе возникает неконсистентность: водитель видит один пункт назначения, а пользователь ожидает, что будет доставлен в другое место.
Идемпотентность создания и изменения
Способы обеспечения идемпотентности методов создания (POST) и частичного изменения (PATCH):
1. Ключ идемпотентности в заголовке запросов
2. Версионирование состояния
3. Блокировка на основе правил
🗝 Ключ идемпотентности
Это уникальный идентификатор операции, который помогает защититься от повторного исполнения операции.
Как это работает:
1. Клиент генерирует уникальный ключ идемпотентности и отправляет его в заголовке запроса. Например, Idempotency-Key: <UUID>
2. Сервер проверяет, был ли уже обработан запрос с таким ключом. Если да, возвращает результат предыдущего запроса, не выполняя операцию повторно. Иначе просто выполняет операцию.
⬇️ Продолжение ниже⬇️
Идемпотентная операция — это операция, которая при многократном вызове не меняет состояние ресурса. То есть, если мы повторно вызываем идемпотентный метод API, то не возникнет ошибок, связанных с дублированием одной и той же операции (например, двойных списаний баланса за один и тот же заказ).
По-хорошему, любой API должен быть идемпотентным.
Идемпотентность в REST API
HTTP-методы
GET, PUT, DELETE формально считаются идемпотентными, тогда как POST и PATCH нет. Это не означает, что нельзя сделать GET неидемпотентным, а POST идемпотентным.Проблема №1. Дублирование операций.
При сетевых задержках или ошибках одна и та же операция может быть выполнена несколько раз.
Пример с заказом такси:
Проблема №2. Неконсистентное состояние.
Неидемпотентные операции затрудняют отслеживание текущего состояния системы, что может привести к ошибкам и неконсистентности данных.
Пример с заказом такси:
Идемпотентность создания и изменения
Способы обеспечения идемпотентности методов создания (POST) и частичного изменения (PATCH):
1. Ключ идемпотентности в заголовке запросов
2. Версионирование состояния
3. Блокировка на основе правил
🗝 Ключ идемпотентности
Это уникальный идентификатор операции, который помогает защититься от повторного исполнения операции.
Как это работает:
1. Клиент генерирует уникальный ключ идемпотентности и отправляет его в заголовке запроса. Например, Idempotency-Key: <UUID>
2. Сервер проверяет, был ли уже обработан запрос с таким ключом. Если да, возвращает результат предыдущего запроса, не выполняя операцию повторно. Иначе просто выполняет операцию.
Please open Telegram to view this post
VIEW IN TELEGRAM
Сервер отслеживает версии состояния ресурса и позволяет клиенту указывать, для какой версии предназначен запрос. Если состояние изменилось, сервер отклоняет запрос. Версия может быть как числом (номером последнего изменения), так и хэшом от списка ресурсов.
Как это работает на примере сервиса заказа такси:
Вводные
GET /v1/orders.Процесс
GET /v1/orders.HTTP-метод удаления
DELETE по своей природе идемпотентный, так как повторное удаление уже удаленного ресурса не изменяет состояние системы. После первого успешного все последующие запросы на удаление будут возвращать ошибку 404 (или другой код согласно логике сервера).Более гибкий способ обеспечить идемпотентность удаления – использовать подход “Soft Delete”. Вместо физического удаления записи из базы данных, запись просто помечается как удаленная с помощью специального флага.
Soft Delete гарантирует, что все последующие запросы на удаление будут успешными и вернут одинаковый результат. Это также позволяет отслеживать удаленные записи и при необходимости восстанавливать их, обеспечивая дополнительный уровень безопасности и контроля.
📎 Статьи
1. Стажёр Вася и его истории об идемпотентности API — очень рекомендуем
2. Кратко об идемпотентности от Yandex Cloud
3. Идемпотентность: больше, чем кажется
4. Идемпотентность при использовании API Mindbox
5. Что такое ключ идемпотентности и зачем он нужен
6. Семантика exactly-once в Apache Kafka
1. Что такое идемпотентность, или история Васи и его приложения
2. Идемпотентность и коммутативность API в очередях и HTTP // Демо-занятие курса «Software Architect»
3. Идемпотентность: что, где и как
4. Микросервисы: идемпотентность операций
#api #проектирование
Please open Telegram to view this post
VIEW IN TELEGRAM
Способы обеспечения работы высоконагруженных систем
1️⃣ Инфраструктура
💩 Вертикальное масштабирование — увеличение производительности серверов (увеличение RAM, добавление дисков, более мощных СPU и т.д.). Самый простой способ, однако он довольно быстро упирается в потолок
💩 Горизонтальное масштабирование — добавление дополнительных серверов (или виртуальных копий сервиса — реплик) для распределения нагрузки между ними. Это работает примерно так же, как в реальной жизни: если один рабочий выкопает яму за 4 часа, то двое рабочих сделают это быстрее (но не факт, что в 2 раза)
💩 Балансировка нагрузки — актуально при горизонтальном масштабировании, когда используется несколько серверов или реплик приложения. Балансировка помогает распределить загрузку между сервисами равномерно
2️⃣ Хранение и доступ к данным
💩 Кэширование — сохранение часто запрашиваемых данных в памяти для быстрого доступа. Подробнее см. в этом посте
💩 Индексы — дополнительная структура данных в реляционных БД для ускорения поиска и обработки записей. Это подобно алфавитному указателю в англо-русском словарике: не нужно листать весь словарь, достаточно лишь открыть страницы с нужным сочетанием букв. Подробнее в этом посте
💩 Денормализация — введение избыточности в таблицах и представлениях, чтобы сократить число запросов к БД и тем самым минимизировать время обработки запросов. Вместо того, чтобы делать кучу джойнов с группировками и вычисляемыми полями, можно завести представление (вью), которая будет содержать все нужные данные, хотя она не будет соблюдать 3 нормальных формы
💩 Репликация — копирование одних и тех же данных между разными серверами. При использовании такого метода выделяют два типа серверов: master и slave. Мастер используется для записи или изменения информации, слейвы — для копирования информации с мастера и её чтения. Эффект достигается за счёт повышения отзазоустойчивости и разделения операций чтения и записи
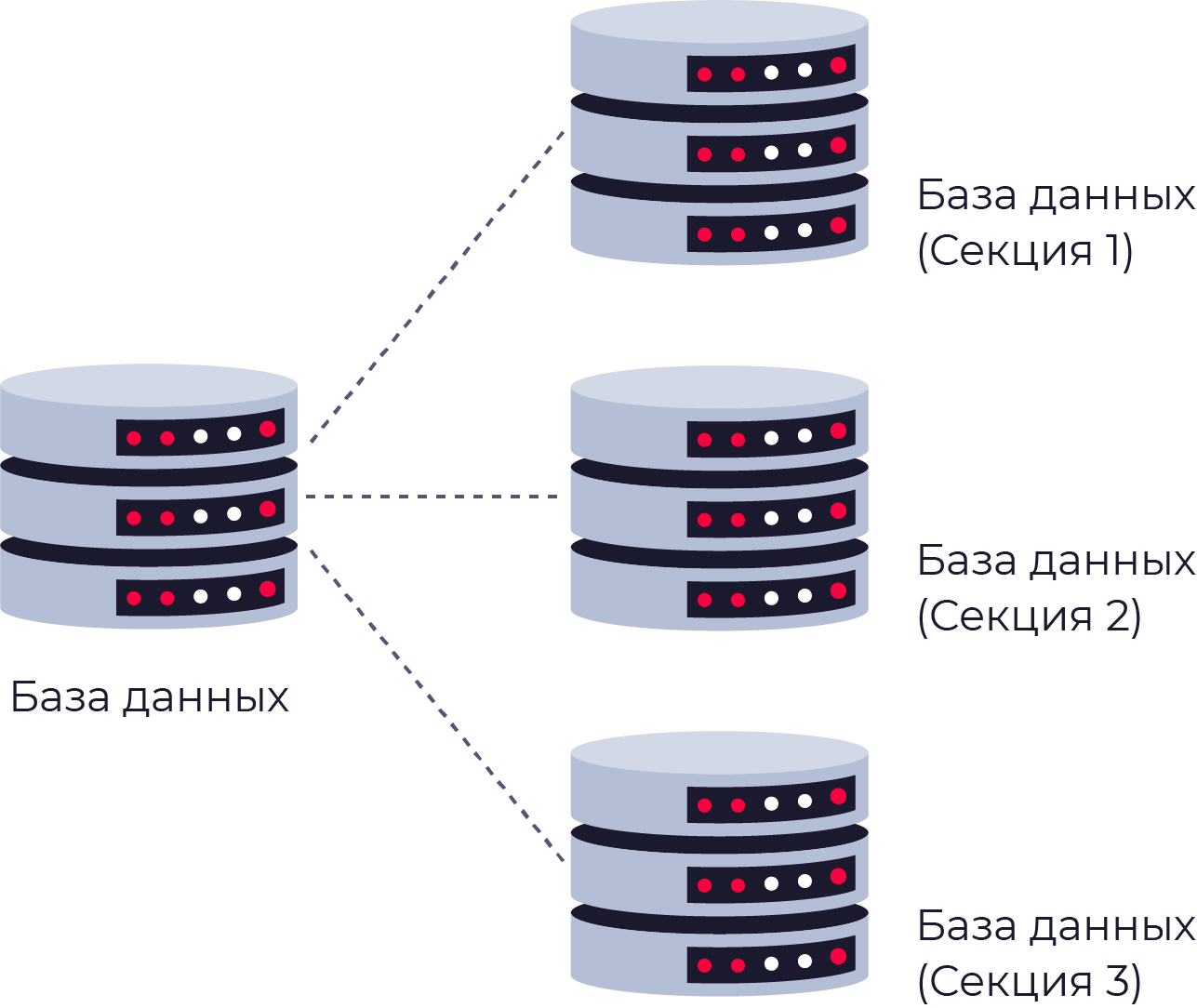
💩 Партиционирование — разделение таблиц на несколько частей в рамках одного сервера. Позволяет увеличить производительность за счёт уменьшения объема данных, которые нужно обрабатывать при выполнении запросов. Подробнее в этом посте
💩 Шардирование — техника масштабирования БД, когда данные разносятся по нескольким машинам. Разделение данных эффективно, когда для разных запросов требуются разные данные некогда единой таблицы. Подробнее в этом посте
3️⃣ Приложения
Проектирование архитектуры приложений
💩 DDD (Domain-Driven Design) — подход к проектированию архитектуры, при котором приложение разделяется на функциональные домены на основе того, как работает реальный бизнес. DDD помогает создавать более устойчивые и масштабируемые системы. Подробнее в этом посте
💩 CQRS (Command Query Responsibility Segregation) — подход, при котором система разделяется на две части: одна отвечает за обработку команд (изменения состояния), а другая — за запросы (чтение данных). Команды и запросы могут быть масштабированы независимо, что позволяет системе более эффективно обрабатывать большое количество RPC. Подробнее в этом посте
💩 CDC (Change Data Capture) — техника, используемая для определения и отслеживания изменений в данных. Очень полезно, когда нужно в режиме реального времени реагировать на изменения в базе-источнике. Подробнее
Интеграции
💩 Брокеры сообщений — помогают обрабатывать тысячи запросов с гарантией доставки сообщений. Подробнее тут.
💩 Использование gRPC — более производительный стиль интеграции, который под капотом использует HTTP/2 для транспорта и Protocol Buffers для сериализации данных. В этом посте подробнее.
💩 Веб-сокеты — вместо множества запросов для обновления данных, веб-сокеты позволяют поддерживать постоянное соединение, через которое данные могут передаваться в обе стороны в реальном времени. Подробнее здесь.
Оптимизация кода
💩 Распараллеливание запросов
💩 Минимизация сериализации данных
💩 Оптимизация запросов к БД
💩 Управление HTTP-сессиями и использование возможностей TCP
⭐️ Подборка материалов доступна в закрытом канале
#проектирование
Проектирование архитектуры приложений
Интеграции
Оптимизация кода
⭐️ Подборка материалов доступна в закрытом канале
#проектирование
Please open Telegram to view this post
VIEW IN TELEGRAM
Масштабирование БД. Партиционирование, шардирование и репликация
⚡️Максимально кратко
💩 Партиционирование — разделение БД на части в рамках одного сервера. Может быть вертикальным (по столбцам) и горизонтальным (по строкам)
💩 Шардирование — разделение БД на части по разным серверам. Может быть только горизонтальным (по строкам)
💩 Репликация — копирование одних и тех же данных между разными серверами
💩 Партиционирование
Партиционирование — разделение большой таблицы на несколько частей. Все части хранятся на одном сервере. Бывает горизонтальным и вертикальным.
1⃣ Горизонтальное партиционирование: данные разбиваются на несколько отдельных таблиц по строкам. Каждая такая таблица содержит содержит одинаковые столбцы, но разные строки данных.
Преимущества:
➕ уменьшение объема данных, которые нужно обрабатывать при выполнении запросов
➕ ускорение выполнения запросов, которые затрагивают только определенный диапазон строк
➕ возможность распараллеливания запросов между подтаблицами
Пример: разделение таблицы заказов по дате заказа, так что каждая подтаблица содержит заказы за определенный месяц или год.
2⃣ Вертикальное партиционирование: данные разбиваются на несколько отдельных таблиц по столбцам. Каждая такая таблица содержит часть столбцов и все связанные с ними строки данных.
Преимущества:
➕ уменьшение объема данных, которые нужно загружать в память при выполнении запросов
➕ ускорение выполнения запросов, которые затрагивают только определенный набор столбцов
➕ возможность оптимизации хранения данных в зависимости от типа и частоты использования столбцов.
Пример: разделение таблицы пользователей на две подтаблицы, одна из которых содержит основную информацию о пользователях, а другая — доп. информацию.
💩 Шардирование — техника масштабирования БД, когда данные разносятся по нескольким машинам. Бывает только горизонтальным (по строкам). Шардирование позволяет распределить нагрузку на запись и чтение данных между различными серверами, за каждый из которых отвечает отдельная машина.
Пример: есть БД пользователей. Чтобы ослабить нагрузку на сервер, разработчики горизонтально делят ее по шардам, используя хеш-функцию для определения, в какой шард отправить каждую запись. В результате пользователи будут равномерно распределены по серверам.
Методы шардирования
1. Хешированное — данные разбиваются на шарды на основе хеш-функции, которая принимает входные данные и возвращает хеш-значение. Это значение определяет, в какой шард будет помещена каждая запись данных. Метод позволяет достичь высокой производительности и отсутствия единой точки отказа, однако усложняет поиск данных.
2. Диапазонное — данные разбиваются на шарды на основе диапазона значений. Значения могут присваиваться с помощью ключей и других атрибутов. Метод прост в реализации и позволяет быстрее находить информацию, чем при хешировании, однако может привести к несбалансированности базы.
3. Круговое — шарды упорядочиваются в виде кольца и каждый из них ответственен за определенный диапазон значений. Запросы на данные маршрутизируются в соответствии с позицией шарда в кольце. Запросы распределяются равномерно, но при добавлении и удалении шардов требуется перераспределение данных.
4. Динамическое — позволяет автоматически масштабировать хранилище в зависимости от текущей производительности и объема данных. Нужна система мониторинга и балансировки нагрузки.
💩 Репликация
Репликация — копирование данных между несколькими серверами. При использовании такого метода выделяют два типа серверов: master и slave. Мастер используется для записи или изменения информации, слейвы — для копирования информации с мастера и её чтения. Чаще используется один мастер и несколько слейвов, т. к. обычно запросов на чтение больше, чем запросов на изменение.
Преимущество: большое количество копий данных. Если мастер выходит из строя, любой другой сервер сможет его заменить.
Недостатки: рассинхронизация и задержки при передаче данных. Репликация используется как средство обеспечения отказоустойчивости вместе с другими методами.
⭐️ Подборка материалов доступна в закрытом канале
#бд
⚡️Максимально кратко
Партиционирование — разделение большой таблицы на несколько частей. Все части хранятся на одном сервере. Бывает горизонтальным и вертикальным.
Преимущества:
Пример: разделение таблицы заказов по дате заказа, так что каждая подтаблица содержит заказы за определенный месяц или год.
Преимущества:
Пример: разделение таблицы пользователей на две подтаблицы, одна из которых содержит основную информацию о пользователях, а другая — доп. информацию.
Пример: есть БД пользователей. Чтобы ослабить нагрузку на сервер, разработчики горизонтально делят ее по шардам, используя хеш-функцию для определения, в какой шард отправить каждую запись. В результате пользователи будут равномерно распределены по серверам.
Методы шардирования
1. Хешированное — данные разбиваются на шарды на основе хеш-функции, которая принимает входные данные и возвращает хеш-значение. Это значение определяет, в какой шард будет помещена каждая запись данных. Метод позволяет достичь высокой производительности и отсутствия единой точки отказа, однако усложняет поиск данных.
2. Диапазонное — данные разбиваются на шарды на основе диапазона значений. Значения могут присваиваться с помощью ключей и других атрибутов. Метод прост в реализации и позволяет быстрее находить информацию, чем при хешировании, однако может привести к несбалансированности базы.
3. Круговое — шарды упорядочиваются в виде кольца и каждый из них ответственен за определенный диапазон значений. Запросы на данные маршрутизируются в соответствии с позицией шарда в кольце. Запросы распределяются равномерно, но при добавлении и удалении шардов требуется перераспределение данных.
4. Динамическое — позволяет автоматически масштабировать хранилище в зависимости от текущей производительности и объема данных. Нужна система мониторинга и балансировки нагрузки.
Репликация — копирование данных между несколькими серверами. При использовании такого метода выделяют два типа серверов: master и slave. Мастер используется для записи или изменения информации, слейвы — для копирования информации с мастера и её чтения. Чаще используется один мастер и несколько слейвов, т. к. обычно запросов на чтение больше, чем запросов на изменение.
Преимущество: большое количество копий данных. Если мастер выходит из строя, любой другой сервер сможет его заменить.
Недостатки: рассинхронизация и задержки при передаче данных. Репликация используется как средство обеспечения отказоустойчивости вместе с другими методами.
⭐️ Подборка материалов доступна в закрытом канале
#бд
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
Подборка публичных собеседований системных аналитиков
1. Техническое собеседование для System Analyst
2. Техническое собеседование системного аналитика. В роли кандидата Булат Якубов, системный аналитик в Samokat Tech. В роли интервьюера Алексей Лобзов, руководитель направления в Альфа-Банке.
3. Публичное собеседование системного аналитика с компанией Usetech
4. Собеседование системного аналитика. Райффайзен банк
5. Публичное собеседование системного аналитика. Lamoda
6. Собеседование бизнес-системного аналитика. В роли интервьюера Сергей Нужненко — руководитель экспертной группы обновления профстандарта "Системный аналитик" редакции 2022 года, преподаватель, со-основатель Школы Cистемного Анализа. В роли кандидата — Ольга Шимкив, системный аналитик в финтехе.
7. Собеседование лида аналитиков. Интервьювер: Анна Серетенская, тимлид и системный аналитик в продуктовой разработке. Кандидат: Екатерина Зиновьева - главный системный аналитик в системном интеграторе
8. Моковое собеседование на системного аналитика. Интервьювер — Маргарита Нижельская, ex Head of SA в Мегафоне
9. Моковое собеседование на позицию Junior Системного аналитика
Бонусом — подборка интервью по System Design
1. Интервью по System Design. Александр Поломодов (Тинькофф)
2. Публичное интервью по System Design. Александр Поломодов (тех. дир. Тинькофф).
3. Публичное собеседование по System design. В роли собеседующего - Владимир Иванов (Bolt). На позиции собеседуемого - Виталий Лихачев (Авито)
4. Публичное собеседование по System Design. Интервьювер — Владимир Иванов (Bolt), собеседуемый — Денис Костоусов (Тинькофф)
5. Публичное собеседование по System Design. Проводить собеседование будет Игорь Антонов, TeamLead из Тинькофф
⏯ Все видео собрали в плейлисты на Ютубе:
1. Публичные собеседования системных аналитиков
2. System Design Interview
#подборка
1. Техническое собеседование для System Analyst
2. Техническое собеседование системного аналитика. В роли кандидата Булат Якубов, системный аналитик в Samokat Tech. В роли интервьюера Алексей Лобзов, руководитель направления в Альфа-Банке.
3. Публичное собеседование системного аналитика с компанией Usetech
4. Собеседование системного аналитика. Райффайзен банк
5. Публичное собеседование системного аналитика. Lamoda
6. Собеседование бизнес-системного аналитика. В роли интервьюера Сергей Нужненко — руководитель экспертной группы обновления профстандарта "Системный аналитик" редакции 2022 года, преподаватель, со-основатель Школы Cистемного Анализа. В роли кандидата — Ольга Шимкив, системный аналитик в финтехе.
7. Собеседование лида аналитиков. Интервьювер: Анна Серетенская, тимлид и системный аналитик в продуктовой разработке. Кандидат: Екатерина Зиновьева - главный системный аналитик в системном интеграторе
8. Моковое собеседование на системного аналитика. Интервьювер — Маргарита Нижельская, ex Head of SA в Мегафоне
9. Моковое собеседование на позицию Junior Системного аналитика
Бонусом — подборка интервью по System Design
1. Интервью по System Design. Александр Поломодов (Тинькофф)
2. Публичное интервью по System Design. Александр Поломодов (тех. дир. Тинькофф).
3. Публичное собеседование по System design. В роли собеседующего - Владимир Иванов (Bolt). На позиции собеседуемого - Виталий Лихачев (Авито)
4. Публичное собеседование по System Design. Интервьювер — Владимир Иванов (Bolt), собеседуемый — Денис Костоусов (Тинькофф)
5. Публичное собеседование по System Design. Проводить собеседование будет Игорь Антонов, TeamLead из Тинькофф
1. Публичные собеседования системных аналитиков
2. System Design Interview
#подборка
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Библиотека Системного Аналитика
Please open Telegram to view this post
VIEW IN TELEGRAM
Event Driven Architecture: краткий обзор
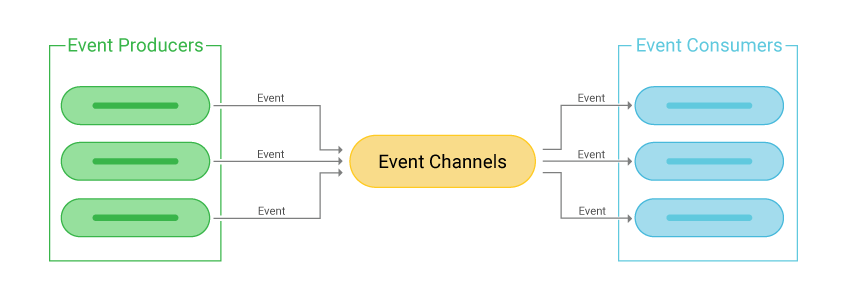
Event-Driven Architecture (EDA) — архитектурный подход, при котором система строится вокруг событий.
В таком подходе сервисы взаимодействуют друг с другом через генерацию событий, вместо того, чтобы вызывать друг друга напрямую через HTTP-запросы. Сервис, который породил событие, ничего не знает о сервисах, которые будут это событие обрабатывать (обратное тоже верно). Подход EDA широко применяется в архитектуре микросервисов.
Компоненты EDA
💩 Событие – любое изменение состояния некой сущности или возникновение новой.
💩 Производитель события – сервис, который создаёт событие.
💩 Обработчик события – сервис, который получает событие и обрабатывает его, после чего порождается новое событие – результат обработки события.
💩 Маршрутизатор события – промежуточный слой, который обеспечивает. доставку события от производителя до обработчика. Обычно это брокер сообщений.
Одни и те же сервисы могут выполнять как роль производителя, так и роль обработчика событий.
Модели доставки событий в EDA
1⃣ Pub/Sub
1. Производители генерируют события и отправляют брокеру.
2. Брокер направляет события потребителям, которые на них подписались.
3. После отправки события удаляются.
Пример – RabbitMQ.
2⃣ Потоковая передача
1. Производители генерируют события и отправляют брокеру.
2. Брокер сохраняет события у себя в журнале.
3. Потребители считывают события из любой части журнала в любой момент времени. События не удаляются брокером.
Пример – Kafka.
Преимущества событийно-ориентированной архитектуры вытекают из реализации принципа слабой связности. В событийно-ориентированной архитектуре сервисы взаимодействуют исключительно через события. При этом производитель события не знает, какие обработчики принимают события, а обработчики не знают, какие производители их генерируют.
✅ Преимущества EDA
➕ Слабая связность и гибкость: можно масштабировать, обновлять и развертывать сервисы независимо друг от друга.
➕ Скорость: в EDA каждое событие может быть обработано независимо, что позволяет системе использовать параллельную обработку. А ещё можно эффективнее распределять нагрузку между обработчиками событий с учётом текущей загруженности узлов.
➕ Отказоустойчивость и высокая доступность: даже если один сервис выйдет из строя, система в целом сохранит доступность. А ещё сервисы можно реплицировать и резервировать – когда один экземпляр сервиса падает, можно задействовать резервную реплику сервиса и быстрее восстановить работу.
⛔️ Недостатки EDA
💩 Сложность разработки и тестирования вследствие распределённой архитектуры и асинхронного взаимодействия.
💩 Отсутствие транзакционности. Поскольку компоненты обработчика событий сильно разобщены и распределены, очень трудно поддерживать транзакции между ними. Если нужно разделить один шаг процесса работы между обработчиками событий, то есть вы используете отдельные обработчики событий для чего-то, что должно быть неделимой транзакцией — вероятно, EDA тут не подходит.
💩 Единая точка отказа – брокер сообщений, который является связующим звеном между всеми сервисами. Если он выйдет из строя, то вся система в целом перестанет работать.
💩 Дополнительные затраты на инфраструктуру. Реализация EDA требует больше производительности вычислительных ресурсов, нужно больше хранилищ данных, растут расходы на поддержку и управление инфраструктурой.
⭐️ Подборка материалов доступна в закрытом канале
#архитектура #проектирование
Event-Driven Architecture (EDA) — архитектурный подход, при котором система строится вокруг событий.
В таком подходе сервисы взаимодействуют друг с другом через генерацию событий, вместо того, чтобы вызывать друг друга напрямую через HTTP-запросы. Сервис, который породил событие, ничего не знает о сервисах, которые будут это событие обрабатывать (обратное тоже верно). Подход EDA широко применяется в архитектуре микросервисов.
Компоненты EDA
Одни и те же сервисы могут выполнять как роль производителя, так и роль обработчика событий.
Модели доставки событий в EDA
1. Производители генерируют события и отправляют брокеру.
2. Брокер направляет события потребителям, которые на них подписались.
3. После отправки события удаляются.
Пример – RabbitMQ.
1. Производители генерируют события и отправляют брокеру.
2. Брокер сохраняет события у себя в журнале.
3. Потребители считывают события из любой части журнала в любой момент времени. События не удаляются брокером.
Пример – Kafka.
Преимущества событийно-ориентированной архитектуры вытекают из реализации принципа слабой связности. В событийно-ориентированной архитектуре сервисы взаимодействуют исключительно через события. При этом производитель события не знает, какие обработчики принимают события, а обработчики не знают, какие производители их генерируют.
✅ Преимущества EDA
⛔️ Недостатки EDA
⭐️ Подборка материалов доступна в закрытом канале
#архитектура #проектирование
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
Git. Обзор и подборка материалов
В связи всё более широким распространением подхода Docs as Code самое время изучить Git.
Git — это система контроля версий, которая помогает отслеживать изменения в проекте. Этот инструмент можно использовать как для индивидуальной, так и для командной работы.
Git позволяет:
💩 Хранить историю изменений проекта. Git может определить, кто и в какой момент внёс изменения.
💩 Параллельно работать над файлами. Все изменения затем сливаются воедино.
💩 Откатиться к предыдущим версиям проекта, если что-то пойдёт не так.
Принцип работы Git
1️⃣ Разработчик создаёт свою ветку от главного проекта, куда вносит свои изменения
2️⃣ В своей ветке разработчик делает необходимые изменения в коде или документации, которые затем фиксируются в истории изменений.
3️⃣ После того как работа в ветке завершена, разработчик сохраняет изменения, создавая коммиты. Коммиты отражают историю изменений и могут быть просмотрены в любой момент.
4️⃣ Слияние изменений. Когда изменения готовы, создаётся Merge Request, чтобы влить изменения в мастер-ветку. До этого момента все изменения всё ещё находятся в отдельной ветке проекта. После слияния с мастер-веткой изменения вступают в силу для всего проекта.
5️⃣ Контроль версий Git позволяет отслеживать все изменения, предоставляя возможность возвращения к любому предыдущему состоянию проекта, если это необходимо.
Курсы (бесплатные)
1. «Основы работы с Git» от Яндекс.Практикума. 16 часов обучения, свободный график, теория и тесты для самопроверки, поддержка специалистов, электронное свидетельство о прохождении курса, доступ после авторизации через Яндекс ID
2. Git для начинающих от Слёрм. Доступ придет на указанную почту после регистрации, закрытый Telegram-чат, теория и практические задания, без сертификата
3. Введение в Git от Хекслет. Видеоуроки, лекции, тренажеры с практикой, бессрочный доступ к теории, асинхронный формат обучения, без сертификата, доступ после регистрации
4. Основы Git из Степика. Много практики
5. Git. Базовый курс от GeekBrains. 13 видеоуроков, без сертификата, доступ после записи
⏯ Видосы с Ютуба
1. GIT - Полный Курс Git и GitHub Для Начинающих — одно видео на 4 часа полного погружения
2. Что такое Git для Начинающих — GitHub за 30 минут
3. Уроки по Git и GitHub от ITDoctor
4. Базовый курс по Git от Devcolibri
🕹 Интерактивные гайды на русском
1. Git How To — это интерактивный тур, который познакомит с основами Git
2. LearnGitBranching — веб-приложение по интерактивному погружению в Git
📄 Полезные статьи
1. Что такое GitHub и как он работает
2. Как начать работать с GitHub: быстрый старт
3. Про стратегии ветвления в Гите
4. 19 советов по повседневной работе с Git
5. Как настроить работу с Git в Intellij IDEA
✍️ Шпаргалка по командам Git
📖 Книга
Pro Git — основное чтиво по гиту от Скотта Чакона и Бена Штрауба
#подборка
В связи всё более широким распространением подхода Docs as Code самое время изучить Git.
Git — это система контроля версий, которая помогает отслеживать изменения в проекте. Этот инструмент можно использовать как для индивидуальной, так и для командной работы.
Git позволяет:
Принцип работы Git
Курсы (бесплатные)
1. «Основы работы с Git» от Яндекс.Практикума. 16 часов обучения, свободный график, теория и тесты для самопроверки, поддержка специалистов, электронное свидетельство о прохождении курса, доступ после авторизации через Яндекс ID
2. Git для начинающих от Слёрм. Доступ придет на указанную почту после регистрации, закрытый Telegram-чат, теория и практические задания, без сертификата
3. Введение в Git от Хекслет. Видеоуроки, лекции, тренажеры с практикой, бессрочный доступ к теории, асинхронный формат обучения, без сертификата, доступ после регистрации
4. Основы Git из Степика. Много практики
5. Git. Базовый курс от GeekBrains. 13 видеоуроков, без сертификата, доступ после записи
1. GIT - Полный Курс Git и GitHub Для Начинающих — одно видео на 4 часа полного погружения
2. Что такое Git для Начинающих — GitHub за 30 минут
3. Уроки по Git и GitHub от ITDoctor
4. Базовый курс по Git от Devcolibri
🕹 Интерактивные гайды на русском
1. Git How To — это интерактивный тур, который познакомит с основами Git
2. LearnGitBranching — веб-приложение по интерактивному погружению в Git
📄 Полезные статьи
1. Что такое GitHub и как он работает
2. Как начать работать с GitHub: быстрый старт
3. Про стратегии ветвления в Гите
4. 19 советов по повседневной работе с Git
5. Как настроить работу с Git в Intellij IDEA
✍️ Шпаргалка по командам Git
📖 Книга
Pro Git — основное чтиво по гиту от Скотта Чакона и Бена Штрауба
#подборка
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Библиотека Системного Аналитика
Тестирование веб-API.pdf
30.9 MB
Тестирование веб-API
✍️ Авторы: Марк Винтерингем
🗓 Год издания: 2024
🔤 Язык: русский
📚 Объём: 304 стр.
Книга представляет собой руководство по автоматизированному тестированию веб-интерфейсов и API. Она охватывает процесс тестирования от проектирования тестов до документирования и реализации API. Читатели узнают различные методы тестирования, включая тестирование на стадии разработки и в продакшене, и как автоматизация может ускорить этот процесс. Книга направлена на обеспечение качества API и упрощение процесса тестирования.
Обзор книги на Хабре
За книгу спасибо нашей подписчице Анне 🙏
#тестирование
✍️ Авторы: Марк Винтерингем
🗓 Год издания: 2024
🔤 Язык: русский
📚 Объём: 304 стр.
Книга представляет собой руководство по автоматизированному тестированию веб-интерфейсов и API. Она охватывает процесс тестирования от проектирования тестов до документирования и реализации API. Читатели узнают различные методы тестирования, включая тестирование на стадии разработки и в продакшене, и как автоматизация может ускорить этот процесс. Книга направлена на обеспечение качества API и упрощение процесса тестирования.
Обзор книги на Хабре
За книгу спасибо нашей подписчице Анне 🙏
#тестирование
Обзор посвящён асинхрону в API. Асинхрон в брокерах сообщений смотрите в этом посте. А здесь можно найти вводный пост по асинхронным интеграциям.
Асинхрон в API позволяет клиентским приложениям отправлять запросы на сервер и продолжать работу без ожидания ответа.
Зачем это нужно
Способы асинхронного взаимодействия в API
1. Клиент отправляет запрос серверу, указывая сallback URL
2. Сервер принимает запрос и отвечает клиенту, что запрос принят в обработку (например, 202 Accepted)
3. Сервер обрабатывает запрос и отправляет клиенту запрос с результатами на сallback URL
Клиент отправляет запрос на сервер, а затем раз в Т миллисекунд отправляет запросы к серверу, чтобы проверить статус операции
1. Пользователь заполняет анкету и загружает скан паспорта
2. Фронт отправляет файл на сервер, получает 202 Accepted и позволяет пользователю заполнять анкету дальше
3. Сервер начинает процесс распознавания паспортных данных, который в среднем занимает 5-7 секунд.
4. Приложение запускает фоновый процесс поллинга: раз в 1 секунду отправляет запрос для получения статуса обработки запроса
Сервер получает запрос, но держит его открытым до момента появления новых данных. Это уменьшает количество запросов по сравнению с обычным поллингом. Работает на протоколе HTTP. После получения данных от сервера соединение закрывается.
Однонаправленный канал связи от сервера к клиенту, позволяющий серверу посылать события клиенту через открытое соединение. В отличие от Long Polling клиент может получать несколько событий и данных от сервера без необходимости устанавливать соединение заново.
Протокол, обеспечивающий двустороннее постоянное соединение между клиентом и сервером, позволяя обмениваться данными в реальном времени. Это именно отдельный протокол (не НTTP), клиент и сервер могут без задержек обмениваться данными в обе стороны, без необходимости устанавливать и закрывать соединения по несколько раз.
⭐️ Подборка материалов доступна в закрытом канале
#интеграции #async
Please open Telegram to view this post
VIEW IN TELEGRAM
🪧Методы трассировки требований
Трассировка требований — процесс отслеживания и документирования связей между требованиями различного уровня абстракции (бизнес-требования, пользовательские требования, системные требования).
Трассировка требований позволяет:
1️⃣ Обеспечить соответствие функциональности системы исходным бизнес-требованиям
2️⃣ Отслеживать изменения требований на протяжении всего жизненного цикла разработки
3️⃣ Управлять изменениями: позволяет оценить влияние изменений требований на другие артефакты и всю систему в целом
4️⃣ Упрощает тестирование: позволяет покрыть бизнес-требования тест-кейсами и не упустить важное
Для обеспечения прослеживаемости каждое требование должно уникальным образом идентифицироваться, например, иметь ID.
Каждая версия требования должна быть прослеживаема, т.к изменение неизбежны и нужно ими управлять.
Помимо ID, требования могут иметь следующие атрибуты:
💩 статус
💩 дата создания
💩 версия
💩 автор
💩 владелец
💩 приоритет
💩 источник
💩 обоснование
💩 релиз
💩 контактное лицо или ответственный за принятие решений по внесению изменений в требование
💩 критерии приёмки
Виды трассировки
↕️Вертикальная—связи между высокоуровневыми элементами проекта ( бизнес-требованиями) и низкоуровневыми (техническими требованиями или кодом)
↔️Горизонтальная—связи между элементами одного уровня. Например, трассировка между функциональными требованиями или между разными компонентами архитектуры системы.
✏️ Методы трассировки требований
💫 Матрица трассировки (Requirements Traceability Matrix)
Это таблица для документирования связей между требованиями и другими элементами системы: тест-кейсами, функциями, документацией, исходный код и т. д. Также может трассироваться история изменений требований.
Примеры возможных связей
—Один к одному: один элемент дизайна реализуется в одном модуле кода;
—Один ко многим: одно функциональное требование (ФТ) проверяется множеством тест-кейсов;
—Многие ко многим: общие или повторяющиеся элементы дизайна могут удовлетворять нескольким ФТ. На практике данным видом трассировки сложно и трудно управлять
Эффективна
💩 в проектах с большим количеством требований и сложной структурой
💩 в проектах, где нужно установить связи между различными типами требований и элементами проекта
💩 для анализа и оценки влияния изменений в требованиях на проект
💫 Дерево требований
Структурированное дерево, показывающее иерархию требований от общих к более детальным.
Пример
Техническое требование
—> Архитектурное требование
——>Требование к БД
——>Требование к интерфейсу
Эффективно
💩 в проектах, где требования имеют иерархическую структуру или зависимости друг от друга
💩 для визуализации и управления связями между различными уровнями требований (бизнес-требования, функциональные требования и требования к интерфейсу)
Плюсы и минусы трассировки
➕ Четкое представление о требованиях к системе и их взаимосвязях
➕ Отслеживание изменений требований
➖ Ресурсо-затратно: некоторые методы требуют времени на подготовку, ведение требований и обновление
➖ Есть риск недооценки сложных взаимосвязей между требованиями и элементами проекта.
#требования
Трассировка требований — процесс отслеживания и документирования связей между требованиями различного уровня абстракции (бизнес-требования, пользовательские требования, системные требования).
Трассировка требований позволяет:
Для обеспечения прослеживаемости каждое требование должно уникальным образом идентифицироваться, например, иметь ID.
Каждая версия требования должна быть прослеживаема, т.к изменение неизбежны и нужно ими управлять.
Помимо ID, требования могут иметь следующие атрибуты:
Виды трассировки
↕️Вертикальная—связи между высокоуровневыми элементами проекта ( бизнес-требованиями) и низкоуровневыми (техническими требованиями или кодом)
↔️Горизонтальная—связи между элементами одного уровня. Например, трассировка между функциональными требованиями или между разными компонентами архитектуры системы.
Это таблица для документирования связей между требованиями и другими элементами системы: тест-кейсами, функциями, документацией, исходный код и т. д. Также может трассироваться история изменений требований.
Примеры возможных связей
—Один к одному: один элемент дизайна реализуется в одном модуле кода;
—Один ко многим: одно функциональное требование (ФТ) проверяется множеством тест-кейсов;
—Многие ко многим: общие или повторяющиеся элементы дизайна могут удовлетворять нескольким ФТ. На практике данным видом трассировки сложно и трудно управлять
Эффективна
Структурированное дерево, показывающее иерархию требований от общих к более детальным.
Пример
Техническое требование
—> Архитектурное требование
——>Требование к БД
——>Требование к интерфейсу
Эффективно
Плюсы и минусы трассировки
#требования
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Библиотека Системного Аналитика
Osipov_D_-_Tekhnologii_proektirovania_baz_dannykh_-_2019.pdf
26.4 MB
Технологии проектирования баз данных
✍️ Авторы: Дмитрий Осипов
🗓 Год издания: 2019
🔤 Язык: русский
📚 Объём: 498 стр.
В книге обсуждаются роль и место баз данных в современных информационных системах, рассматриваются основные функции и архитектура СУБД, организация многопользовательского доступа к данным, обеспечение целостности данных, управление транзакциями, физическое хранение отношений, особенности построения индексов, основные черты коммерчески успешных моделей данных.
Рассматривается жизненный цикл баз данных, технология проекти-рования реляционных баз данных на концептуальном, логическом и физическом этапах, базовые конструкции, используемые в SQL-ориентированных СУБД.
Излагаются обязанности особенности проектирования пользовательского интерфейса клиентских прило-жений, возможности интерактивной аналитической обработки данных OLAP, безопасность данных и способы противодействия угрозам, требования ГОСТ к документации БД.
Большое внимание уделяется перспективам развития баз данных, переход от централизованных к распределенным способам хранения данных, обсуждаются объектно-ориентированная и доку-мент-ориентированная модели данных. Излагаются возможности языка XML для работы с слабоструктурированными данными.
#бд
✍️ Авторы: Дмитрий Осипов
🗓 Год издания: 2019
🔤 Язык: русский
📚 Объём: 498 стр.
В книге обсуждаются роль и место баз данных в современных информационных системах, рассматриваются основные функции и архитектура СУБД, организация многопользовательского доступа к данным, обеспечение целостности данных, управление транзакциями, физическое хранение отношений, особенности построения индексов, основные черты коммерчески успешных моделей данных.
Рассматривается жизненный цикл баз данных, технология проекти-рования реляционных баз данных на концептуальном, логическом и физическом этапах, базовые конструкции, используемые в SQL-ориентированных СУБД.
Излагаются обязанности особенности проектирования пользовательского интерфейса клиентских прило-жений, возможности интерактивной аналитической обработки данных OLAP, безопасность данных и способы противодействия угрозам, требования ГОСТ к документации БД.
Большое внимание уделяется перспективам развития баз данных, переход от централизованных к распределенным способам хранения данных, обсуждаются объектно-ориентированная и доку-мент-ориентированная модели данных. Излагаются возможности языка XML для работы с слабоструктурированными данными.
#бд
🧪 Требования ACID: Краткий обзор
ACID (Atomicity, Consistency, Isolation, Durability) — набор характеристик, обеспечивающих надежность транзакций в базах данных.
Транзакция в БД — логическая операция, состоящая из одного/нескольких запросов, которые выполняются как единое целое.
💩 Атомарность: Транзакция рассматривается как "неделимая" единица работы. Транзакция либо полностью выполняется, либо вообще не выполняется. Нет промежуточных состояний.
💩 Согласованность: Транзакция должна переводить базу данных из одного согласованного состояния в другое (например, в каждом столбце значения имеют нужный тип данных, сохранена ссылочная целостность, операции выполнены по порядку). Если БД была в согласованном состоянии до транзакции, она должна остаться такой и после.
💩 Изолированность: Другие транзакции не должны видеть промежуточных результатов текущей транзакции. Каждая транзакция должна быть изолирована от других: ее выполнение не должно влиять на другие транзакции.
💩 Долговечность (надёжность): После успешного завершения транзакции изменения в БД должны сохраняться даже в случае сбоев системы. Данные, внесенные в БД, должны быть долговечными.
Когда применяется ACID:
✅ В финансовых, банковских, бухгалтерских приложениях, где точность данных является критически важной
✅ В системах управления заказами и инвентарем, управления ресурсами (таких как авиабилеты, номера номеров и т.д.)
ACID не актуальны, когда:
➖ производительность имеет большее значение, чем полная гарантия целостности данных
➖ часто выполняются параллельные операции и где допустимы некоторые компромиссы в обмен на повышенную производительность
➖ данные имеют низкую ценность или могут быть легко восстановлены
➖ данные имеют высокую степень избыточности или дублирования.
ACID в реляционных/нереляционных СУБД
🔹Большинство традиционных реляционных БД поддерживают требования ACID
🔸В распределенных БД связанные данные находятся на нескольких узлах. Транзакции в NoSQL затруднены и в большинстве СУБД требования ACID не удовлетворяются. Но некоторые NoSQL СУБД (например, графовая Neo4j и документоориентированная MarkLogic) могут обеспечивать свойства ACID.
Пример
Пусть есть БД с информацией о банковских счетах Алисы и Боба. Рассмотрим две транзакции:
➕ Перевод денег: Боб переводит Алисе 100$ со своего счета.
🔻Покупка печенек: Алиса покупает на 50$ со своей банковской карты.
У Алисы изначально 0 на счету. У Боба 110$
Применение ACID гарантирует:
💩 А: Покупка печенек завершится ошибкой т.к баланс 0$, деньги не будут списаны. Отмена всей транзакции.
💩 С: После обеих транзакций у Алисы должно остаться 50$ (0 + 100 - 50), а у Боба 10$. Операции выполнены в правильном порядке. Данные по клиентам корректно отражены
💩 I: Если покупка происходит в то время, когда перевод еще не завершился, в БД не появится несогласованных данных. Блокировки и версионирование в БД изолируют транзакции во избежание путаницы в значениях.
💩 D: Если обе транзакции завершились успешно, изменения (перевод и покупка) будут сохранены в базе данных даже в случае сбоев системы.
Как связаны ACID и CAP-теорема
Это две разные концепции, касающиеся транзакций в распределенных системах. Они не противоречат друг другу.
💩 Цель ACID — обеспечить надежность в транзакционных БД , где данные обрабатываются в рамках централизованной системы.
💩 CAP-теорема рассматривается там, где система распределена между несколькими узлами, что создает потенциальные проблемы согласованности и доступности.
🔹 Подробнее про CAP-теорему в нашем посте
⭐️ Подборки материалов по этой и другим темам доступны в закрытом канале
#бд
ACID (Atomicity, Consistency, Isolation, Durability) — набор характеристик, обеспечивающих надежность транзакций в базах данных.
Транзакция в БД — логическая операция, состоящая из одного/нескольких запросов, которые выполняются как единое целое.
Когда применяется ACID:
✅ В финансовых, банковских, бухгалтерских приложениях, где точность данных является критически важной
✅ В системах управления заказами и инвентарем, управления ресурсами (таких как авиабилеты, номера номеров и т.д.)
ACID не актуальны, когда:
➖ производительность имеет большее значение, чем полная гарантия целостности данных
➖ часто выполняются параллельные операции и где допустимы некоторые компромиссы в обмен на повышенную производительность
➖ данные имеют низкую ценность или могут быть легко восстановлены
➖ данные имеют высокую степень избыточности или дублирования.
ACID в реляционных/нереляционных СУБД
🔹Большинство традиционных реляционных БД поддерживают требования ACID
🔸В распределенных БД связанные данные находятся на нескольких узлах. Транзакции в NoSQL затруднены и в большинстве СУБД требования ACID не удовлетворяются. Но некоторые NoSQL СУБД (например, графовая Neo4j и документоориентированная MarkLogic) могут обеспечивать свойства ACID.
Пример
Пусть есть БД с информацией о банковских счетах Алисы и Боба. Рассмотрим две транзакции:
🔻Покупка печенек: Алиса покупает на 50$ со своей банковской карты.
У Алисы изначально 0 на счету. У Боба 110$
Применение ACID гарантирует:
Как связаны ACID и CAP-теорема
Это две разные концепции, касающиеся транзакций в распределенных системах. Они не противоречат друг другу.
⭐️ Подборки материалов по этой и другим темам доступны в закрытом канале
#бд
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🖥 Модель TCP/IP: Краткий обзор и сравнение с OSI
Модель TCP/IP — это стек протоколов, которые задают правила передачи данных по сети (локальной(LAN), корпоративной, Интернет и пр.).
Основой являются протоколы TCP и IP. На них построен весь Интернет:
🕹 TCP (Transmission Control Protocol)—управляет отправкой данных и следит, чтобы они были гарантированно приняты получателем.
🔗 IP (Internet Protocol) —отвечает за адресацию: выделяет IP-адреса устройств, связывает устройства друг с другом, нарезает данные на пакеты для удобной отправки, строит маршруты доставки пакетов
📶 Уровни модели TCP/IP
4️⃣ Прикладной (Application)
Протоколы: HTTP, SMTP (Simple Mail Transfer Protocol).
Здесь находятся приложения, предоставляющие сетевые службы. Протоколы обеспечивают взаимодействие между программами на удаленных компьютерах.
3️⃣ Транспортный (Transport)
Протоколы: TCP, UDP (User Datagram Protocol)
Отвечает за надежную передачу данных между устройствами. TCP обеспечивает управление потоком и надежность, UDP — более быструю, но менее надежную передачу.
2️⃣ Сетевой (Internet)
Протоколы: IP, ICMP (Internet Control Message Protocol).
Управляет передачей данных между узлами в сети. IP обеспечивает маршрутизацию, ICMP используется для диагностики и сообщений об ошибках.
1️⃣ Канальный (Link)
Протоколы: Ethernet, Wi-Fi.
Тут происходит организация физического соединения между устройствами в пределах одной сети. Эти протоколы работают с физическими адресами (MAC-адресами) устройств.
⚙️ Процесс работы TCP/IP
▫️Перед отправкой данные разбиваются на пакеты
▫️Каждый пакет получает IP-адрес (уникальный идентификатор устройства в сети), который указывает на конечный пункт назначения.
▫️На транспортном уровне TCP следит за тем, чтобы все пакеты дошли без потерь и в правильном порядке. Также управляет потоком данных, предотвращая перегрузку сети.
▫️На сетевом уровне (IP), каждый пакет получает информацию о том, какие узлы (маршруты) нужно использовать для достижения конечного пункта.
▫️На канальном уровне (например, Ethernet), каждый пакет получает физический адрес (MAC-адрес) для доставки пакета на устройство в пределах сети.
▫️Пакеты отправляются в сеть, проходят через различные маршрутизаторы и коммутаторы, следуя указанным путям.
▫️По достижению конечного устройства, они собираются в правильном порядке и восстанавливают данные.
🛜Применение TCP/IP
🔹Интернет: TCP/IP - фундаментальный стек протоколов. Каждое устройство, подключенное к интернету использует IP-адрес и коммуницирует посредством TCP или UDP.
🔹Локальные сети: Часто используется в локальных сетях офисов и домов. Это обеспечивает согласованное взаимодействие между компьютерами.
🔹Коммуникация между приложениями: Протоколы прикладного уровня, такие как HTTP для веб-сервисов, FTP - передачи файлов и SMTP - почты, работают поверх TCP/IP.
🛠Модель TCP/IP vs OSI
Обе модели описывают архитектуру сетевых взаимосвязей.
OSI имеет более подробное разделение сетевых функций по уровням, см картинку
▪️Применение
OSI: Используется в обучении и теории, но редко применяется на практике.
TCP/IP: Широко применяется в реальных сетях, включая интернет.
▪️Управление потоком данных:
OSI: Уровень сеансов и транспортный уровень могут управлять потоком данных.
TCP/IP: Управление потоком осуществляется только на транспортном уровне (TCP).
▪️Сетевые протоколы:
OSI: Протоколы, определенные на каждом уровне, не всегда вписываются в четкую структуру. Например, отдельные уровни для сеансов, представления и прикладного уровня.
TCP/IP: Протоколы тесно связаны с каждым уровнем, что делает их более интегрированными.
⭐️ Подборки материалов по этой и другим темам доступны в закрытом канале
#сети
Модель TCP/IP — это стек протоколов, которые задают правила передачи данных по сети (локальной(LAN), корпоративной, Интернет и пр.).
Основой являются протоколы TCP и IP. На них построен весь Интернет:
🕹 TCP (Transmission Control Protocol)—управляет отправкой данных и следит, чтобы они были гарантированно приняты получателем.
🔗 IP (Internet Protocol) —отвечает за адресацию: выделяет IP-адреса устройств, связывает устройства друг с другом, нарезает данные на пакеты для удобной отправки, строит маршруты доставки пакетов
📶 Уровни модели TCP/IP
4️⃣ Прикладной (Application)
Протоколы: HTTP, SMTP (Simple Mail Transfer Protocol).
Здесь находятся приложения, предоставляющие сетевые службы. Протоколы обеспечивают взаимодействие между программами на удаленных компьютерах.
3️⃣ Транспортный (Transport)
Протоколы: TCP, UDP (User Datagram Protocol)
Отвечает за надежную передачу данных между устройствами. TCP обеспечивает управление потоком и надежность, UDP — более быструю, но менее надежную передачу.
2️⃣ Сетевой (Internet)
Протоколы: IP, ICMP (Internet Control Message Protocol).
Управляет передачей данных между узлами в сети. IP обеспечивает маршрутизацию, ICMP используется для диагностики и сообщений об ошибках.
1️⃣ Канальный (Link)
Протоколы: Ethernet, Wi-Fi.
Тут происходит организация физического соединения между устройствами в пределах одной сети. Эти протоколы работают с физическими адресами (MAC-адресами) устройств.
⚙️ Процесс работы TCP/IP
▫️Перед отправкой данные разбиваются на пакеты
▫️Каждый пакет получает IP-адрес (уникальный идентификатор устройства в сети), который указывает на конечный пункт назначения.
▫️На транспортном уровне TCP следит за тем, чтобы все пакеты дошли без потерь и в правильном порядке. Также управляет потоком данных, предотвращая перегрузку сети.
▫️На сетевом уровне (IP), каждый пакет получает информацию о том, какие узлы (маршруты) нужно использовать для достижения конечного пункта.
▫️На канальном уровне (например, Ethernet), каждый пакет получает физический адрес (MAC-адрес) для доставки пакета на устройство в пределах сети.
▫️Пакеты отправляются в сеть, проходят через различные маршрутизаторы и коммутаторы, следуя указанным путям.
▫️По достижению конечного устройства, они собираются в правильном порядке и восстанавливают данные.
🛜Применение TCP/IP
🔹Интернет: TCP/IP - фундаментальный стек протоколов. Каждое устройство, подключенное к интернету использует IP-адрес и коммуницирует посредством TCP или UDP.
🔹Локальные сети: Часто используется в локальных сетях офисов и домов. Это обеспечивает согласованное взаимодействие между компьютерами.
🔹Коммуникация между приложениями: Протоколы прикладного уровня, такие как HTTP для веб-сервисов, FTP - передачи файлов и SMTP - почты, работают поверх TCP/IP.
🛠Модель TCP/IP vs OSI
Обе модели описывают архитектуру сетевых взаимосвязей.
OSI имеет более подробное разделение сетевых функций по уровням, см картинку
▪️Применение
OSI: Используется в обучении и теории, но редко применяется на практике.
TCP/IP: Широко применяется в реальных сетях, включая интернет.
▪️Управление потоком данных:
OSI: Уровень сеансов и транспортный уровень могут управлять потоком данных.
TCP/IP: Управление потоком осуществляется только на транспортном уровне (TCP).
▪️Сетевые протоколы:
OSI: Протоколы, определенные на каждом уровне, не всегда вписываются в четкую структуру. Например, отдельные уровни для сеансов, представления и прикладного уровня.
TCP/IP: Протоколы тесно связаны с каждым уровнем, что делает их более интегрированными.
⭐️ Подборки материалов по этой и другим темам доступны в закрытом канале
#сети