
Как оценивать качество?
У каждого агрегатора такси есть несколько типов машин — эконом, комфорт, комфорт+, бизнес, VIP. Самые дорогие тоже отличаются — это Мерседес E-класса / BMW 5-серии или S-класс / 7-серия, а в максимальном варианте — Maybach.
На парковке стояло несколько таких авто и мне задали вопрос — а чем они отличаются? У меня не нашлось вразумительного ответа. Попытался сформулировать сам, не подглядывая в интернет, и в голову шли какие-то очень поверхностные вещи: Майбах больше, материалы отделки богаче, ход тише, опции навороченнее etc.
Это маркетинг высшего уровня!
:: Я не знаю, сколько стоят эти авто в конкретной комплектации, но с первого взгляда чувствую 'класс' автомобиля, его принадлежность к очень понятному слою общества.
:: И E-класс и S-класс будут удовлетворять необходимость в передвижении из точки А в точку Б, необходимость в комфорте, но они созданы не для этого, а для сигнализации об определённом статусе.
:: Этот маркетинг стоит очень дорого и выстраивается годами, десятилетиями. В высшую лигу брендов нельзя попасть, запустив пару рекламных флайтов на ТВ и заполнив всё медиапространство. Для начала нужно по-крупицам выстроить сообщение и затем долго и тщательно его коммуницировать.
Также интересно, что
:: Я не смог сразу оценить ситуацию из первых принципов и объяснить разницу человеку далёкому от автомобильной тематики. Просто круче и всё. Просто в 3 раза дороже.
:: У каждого из нас масса подобных установок в отношении брендов, которые мы не можем разглядеть и доверяемся прошлому выбору.
У каждого агрегатора такси есть несколько типов машин — эконом, комфорт, комфорт+, бизнес, VIP. Самые дорогие тоже отличаются — это Мерседес E-класса / BMW 5-серии или S-класс / 7-серия, а в максимальном варианте — Maybach.
На парковке стояло несколько таких авто и мне задали вопрос — а чем они отличаются? У меня не нашлось вразумительного ответа. Попытался сформулировать сам, не подглядывая в интернет, и в голову шли какие-то очень поверхностные вещи: Майбах больше, материалы отделки богаче, ход тише, опции навороченнее etc.
Это маркетинг высшего уровня!
:: Я не знаю, сколько стоят эти авто в конкретной комплектации, но с первого взгляда чувствую 'класс' автомобиля, его принадлежность к очень понятному слою общества.
:: И E-класс и S-класс будут удовлетворять необходимость в передвижении из точки А в точку Б, необходимость в комфорте, но они созданы не для этого, а для сигнализации об определённом статусе.
:: Этот маркетинг стоит очень дорого и выстраивается годами, десятилетиями. В высшую лигу брендов нельзя попасть, запустив пару рекламных флайтов на ТВ и заполнив всё медиапространство. Для начала нужно по-крупицам выстроить сообщение и затем долго и тщательно его коммуницировать.
Также интересно, что
:: Я не смог сразу оценить ситуацию из первых принципов и объяснить разницу человеку далёкому от автомобильной тематики. Просто круче и всё. Просто в 3 раза дороже.
:: У каждого из нас масса подобных установок в отношении брендов, которые мы не можем разглядеть и доверяемся прошлому выбору.
Анализируя аккаунты некоторых российских брендов в TikTok на практическом примере почувствовал принцип Shit-in — Shit-out. Нет цели оскорблять кого-то, лишь делюсь наблюдениями:
:: Крупные бренды = строгие полиси. Много чего нельзя, очень высокие риски в случае скандалов и неодназначных публикаций. Это сразу зажимает сверху — без мата, без острых тем. "Как бы чего не вышло".
:: Специфика площадки. В TikTok не зайдёт то, что хорошо показывает себя в инсте, фейсбуке или VK. Здесь свой контент и принципы его подачи. Есть большой соблазн не разбираться, а адаптировать готовое.
:: Не всё решается деньгами. Качество картинки, звук и монтаж менее важны и могут быть выполнены буквально на коленке. Большие бренды не готовы делать контент низкого качества, потому что это нарушение tone of voice.
:: Не те люди. (1) Несколько людей, ответственных за креатив в компании скорее старше 25 лет, с меньшей восприимчивостью к новому. (2) Они занимают достаточно высокую должность, чтобы единолично принимать решения по контенту. (3) Они достаточно долго в диджитале, чтобы уверовать в то, что "понимают как тут всё работает" (люди искренне веруют в эту иллюзию, truss me!). (4) Они считают себя креативными, не являясь таковыми. (5) Самое важное — они год назад плевались от тиктокеров, показушно коверкали название платформы, считали, что там нет платёжеспосоьной аудитории. И подсознательно продолжают так думать, не понимая сути площадки. (6) Поэтому главная причина идти в TikTok — наличие там всех конкурентов.
Так и получаются унылые, номинальные аккаунты брендов, работающие по принципу "чтобы было". Можно залить рекламу через Spark Ads (инструмент позводяет продвигать в рекламе посты из аккаунта), но сотни тысяч и даже миллионы купленных просмотров не заменят искреннего органического роста, не подменят живых подписчиков.
Выход? Принять правила площадки и действовать сообразно им. Об этом как-нибудь позже.
:: Крупные бренды = строгие полиси. Много чего нельзя, очень высокие риски в случае скандалов и неодназначных публикаций. Это сразу зажимает сверху — без мата, без острых тем. "Как бы чего не вышло".
:: Специфика площадки. В TikTok не зайдёт то, что хорошо показывает себя в инсте, фейсбуке или VK. Здесь свой контент и принципы его подачи. Есть большой соблазн не разбираться, а адаптировать готовое.
:: Не всё решается деньгами. Качество картинки, звук и монтаж менее важны и могут быть выполнены буквально на коленке. Большие бренды не готовы делать контент низкого качества, потому что это нарушение tone of voice.
:: Не те люди. (1) Несколько людей, ответственных за креатив в компании скорее старше 25 лет, с меньшей восприимчивостью к новому. (2) Они занимают достаточно высокую должность, чтобы единолично принимать решения по контенту. (3) Они достаточно долго в диджитале, чтобы уверовать в то, что "понимают как тут всё работает" (люди искренне веруют в эту иллюзию, truss me!). (4) Они считают себя креативными, не являясь таковыми. (5) Самое важное — они год назад плевались от тиктокеров, показушно коверкали название платформы, считали, что там нет платёжеспосоьной аудитории. И подсознательно продолжают так думать, не понимая сути площадки. (6) Поэтому главная причина идти в TikTok — наличие там всех конкурентов.
Так и получаются унылые, номинальные аккаунты брендов, работающие по принципу "чтобы было". Можно залить рекламу через Spark Ads (инструмент позводяет продвигать в рекламе посты из аккаунта), но сотни тысяч и даже миллионы купленных просмотров не заменят искреннего органического роста, не подменят живых подписчиков.
Выход? Принять правила площадки и действовать сообразно им. Об этом как-нибудь позже.
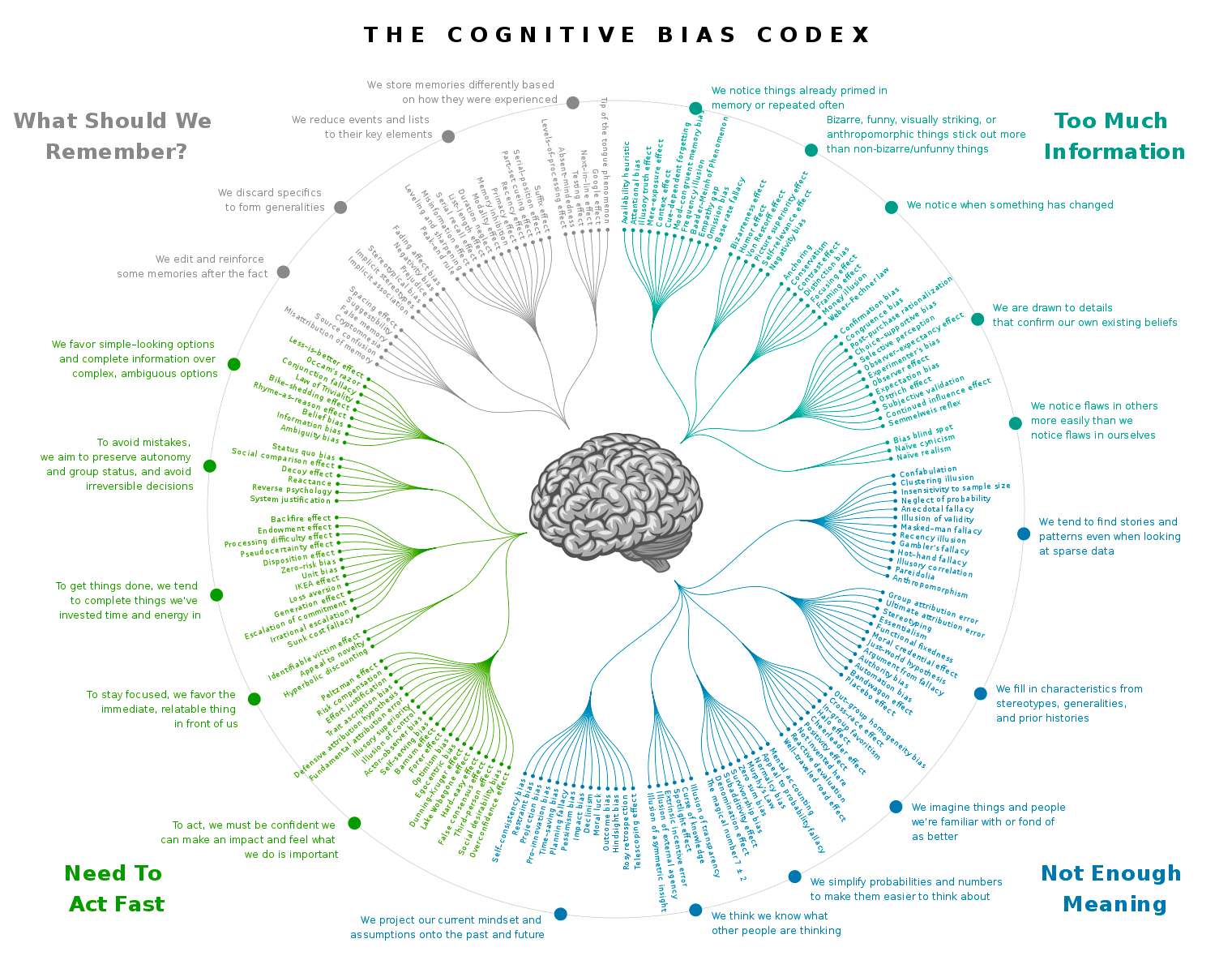
Психологические искажения при принятии решений: почему мы совершаем ошибки
У каждого из нас есть искажения, которые мы не выбирали. Они защищают нас от жизненных реалий, иногда слишком бережно. Собрал несколько сумбурных заметок на полях о предубеждениях, которые мне кажутся занимательными:
Иллюзия контроля
Самое фундаментальное предубеждение, которое есть у каждого: иллюзия контроля.
Большинство людей и не подозревают, что плохо принимают решения; скорее, мы верим, что сами управляем собственной судьбой. Однако профессор биологии Роберт Сапольски думает, что это не так, никогда так не было и неизвестно, будет ли — у нас на самом деле нет свободы выбора. Единственный контроль = выбор пути из лабиринта. Неправильный выбор = наибольший уровень страданий.
Я настроен менее скептически: кажется, мы лишь частично жертвы внешних обстоятельств. Часть из нас являются сторонниками фатализма, но не стоит зацикливаться на этом. Лучше задаться вопросом: «Почему я делаю тот выбор, который делаю?». Именно так можно дойти к множеству замечательных открытий ;)
Искажение подтверждения
Мы склонны обращать внимание на доказательства, подтверждающие то, во что мы верим, а не наоборот. Чаще всего мы воспринимаем информацию и окружающий мир примерно однородно и одинаково. Мы не признаем сознательно своих искажений. Но более показательно то, что люди делают, а не то, о чём говорят.
Чем больше человек видит нечто — тем больше в это верит = это и есть сила внушения. Когда нас спрашивают что-либо, мы бессознательно выбираем тот ответ, который усиливает наши собственные предубеждения.
Эффект ореола
Эффект ореола — хорошо известное когнитивное искажение. Это иллюзия знания, когда испытуемые склонны верить в то, с чем они заранее согласны.
Чтобы продемонстрировать эффект ореола, участникам исследования сообщили, что недавно разработанный крем хорошо защищает кожу. Затем испытуемых поделили на три группы и сказали, что либо: А) крем действует; Б) он вызывает гиперпигментацию в 1 случае из 1000; или В) он не защищает в 30% случаев.
Когда участникам дали опробовать крем, они оценили его по пятибалльной шкале, а затем им предложили приобрести крем за доступную сумму. Участники в когорте А оценили крем гораздо выше, чем в прочих.
Люди принимают больше решений в гипотетическом будущем, чем на данных из прошлого. Поэтому мы часто делаем поспешные выводы и опираются на факты, подтверждающие эти выводы.
У каждого из нас есть искажения, которые мы не выбирали. Они защищают нас от жизненных реалий, иногда слишком бережно. Собрал несколько сумбурных заметок на полях о предубеждениях, которые мне кажутся занимательными:
Иллюзия контроля
Самое фундаментальное предубеждение, которое есть у каждого: иллюзия контроля.
Большинство людей и не подозревают, что плохо принимают решения; скорее, мы верим, что сами управляем собственной судьбой. Однако профессор биологии Роберт Сапольски думает, что это не так, никогда так не было и неизвестно, будет ли — у нас на самом деле нет свободы выбора. Единственный контроль = выбор пути из лабиринта. Неправильный выбор = наибольший уровень страданий.
Я настроен менее скептически: кажется, мы лишь частично жертвы внешних обстоятельств. Часть из нас являются сторонниками фатализма, но не стоит зацикливаться на этом. Лучше задаться вопросом: «Почему я делаю тот выбор, который делаю?». Именно так можно дойти к множеству замечательных открытий ;)
Искажение подтверждения
Мы склонны обращать внимание на доказательства, подтверждающие то, во что мы верим, а не наоборот. Чаще всего мы воспринимаем информацию и окружающий мир примерно однородно и одинаково. Мы не признаем сознательно своих искажений. Но более показательно то, что люди делают, а не то, о чём говорят.
Чем больше человек видит нечто — тем больше в это верит = это и есть сила внушения. Когда нас спрашивают что-либо, мы бессознательно выбираем тот ответ, который усиливает наши собственные предубеждения.
Эффект ореола
Эффект ореола — хорошо известное когнитивное искажение. Это иллюзия знания, когда испытуемые склонны верить в то, с чем они заранее согласны.
Чтобы продемонстрировать эффект ореола, участникам исследования сообщили, что недавно разработанный крем хорошо защищает кожу. Затем испытуемых поделили на три группы и сказали, что либо: А) крем действует; Б) он вызывает гиперпигментацию в 1 случае из 1000; или В) он не защищает в 30% случаев.
Когда участникам дали опробовать крем, они оценили его по пятибалльной шкале, а затем им предложили приобрести крем за доступную сумму. Участники в когорте А оценили крем гораздо выше, чем в прочих.
Люди принимают больше решений в гипотетическом будущем, чем на данных из прошлого. Поэтому мы часто делаем поспешные выводы и опираются на факты, подтверждающие эти выводы.
{kind=link}
Как мы получаем и передаём информацию?
Мозг взаимодействует с миром посредством каналов ввода / вывода информации.
Из чего состоит ввод?
:: Восприятие внешнего сигнала. Пример: водитель видит пешехода, перебегающего дорогу — визуальный раздражитель доходит до мозга в среднем со скоростью 250 миллисекунд (четверть секунды).
:: Выбор способа обработки исходя из контекста — автоматически / с вмешательством 'сознания'. Пример: если опыт вождения велик, незачем тратить ресурс мозга на осознанное решение.
:: Принятие решения — о действии / бездействии. Пример: нажать на тормоз, или человек успеет перебежать?
У каналов ввода есть понятные ограничения — например скорость восприятия информации, неумение видеть в темноте или слышать на дальних расстояниях. Мозг тратит 20-60% ресурсов на декодирование только визуального сигнала +дальнейшая обработка и принятие решений, которые проходят через сложную систему установок, искажающих полученные данные.
Каналы вывода информации тоже довольно ограничены.
:: Мы кодируем данные с помощью языка — составляем слоги в слова, в предложения и обороты, чтобы передавать комплексные и даже абстрактные идеи. Но если для чего-то нет подходящего названия — это выпадает из нашей области внимания и становится «ничем» для нашего мозга, как у Древних Греков (и других «древних» культур), которые не знали голубого цвета.
:: Другой канал вывода = тело. Жесты и мимика мало полезны при удалённом общении и сильно варьируются в зависимости от контекста и культурных особенностей.
Итого: получая информацию человек видит не полную картину, обрабатывает её через свои предубеждения и на выход выдаёт сжатый условностями результат.
Мозг взаимодействует с миром посредством каналов ввода / вывода информации.
Из чего состоит ввод?
:: Восприятие внешнего сигнала. Пример: водитель видит пешехода, перебегающего дорогу — визуальный раздражитель доходит до мозга в среднем со скоростью 250 миллисекунд (четверть секунды).
:: Выбор способа обработки исходя из контекста — автоматически / с вмешательством 'сознания'. Пример: если опыт вождения велик, незачем тратить ресурс мозга на осознанное решение.
:: Принятие решения — о действии / бездействии. Пример: нажать на тормоз, или человек успеет перебежать?
У каналов ввода есть понятные ограничения — например скорость восприятия информации, неумение видеть в темноте или слышать на дальних расстояниях. Мозг тратит 20-60% ресурсов на декодирование только визуального сигнала +дальнейшая обработка и принятие решений, которые проходят через сложную систему установок, искажающих полученные данные.
Каналы вывода информации тоже довольно ограничены.
:: Мы кодируем данные с помощью языка — составляем слоги в слова, в предложения и обороты, чтобы передавать комплексные и даже абстрактные идеи. Но если для чего-то нет подходящего названия — это выпадает из нашей области внимания и становится «ничем» для нашего мозга, как у Древних Греков (и других «древних» культур), которые не знали голубого цвета.
:: Другой канал вывода = тело. Жесты и мимика мало полезны при удалённом общении и сильно варьируются в зависимости от контекста и культурных особенностей.
Итого: получая информацию человек видит не полную картину, обрабатывает её через свои предубеждения и на выход выдаёт сжатый условностями результат.
{kind=link}
Как преодолеть ограничения на ввод/вывод информации?
Brain–computer interface (BCI) — это прямой канал связи между мозгом и внешним интерфейсом. Первые опыты начались в 1920-х с обнаружения электрической активности мозга, а активные исследования ведутся с 70-х годов. Такие устройства чаще используют для узких целей — для восстановления отдельных функций организма или для их дополнения. В продаже есть и потребительские приборы, но пока из того что видел — это игрушки (зажечь лампу / включить YouTube).
Как могут помочь BCI в части передачи информации:
:: Получаем больше данных. Видим, ощущаем, слышим то, что приносят внешние сенсоры.
:: Лучше понимаем себя. Датчики, считывающие состояние организма дают информацию об усталости, стрессе, возросшем сердечном ритме, узнаём о необходимости сделать полный чекап.
:: Интерпретируем информацию, не подвергая искажениям. Задача не для BCI напрямую, но если пофантазировать — собираем данные о проблеме, просчитываем варианты на облаке, даём человеку оптимальный выбор.
:: Проще передаём информацию. Без необходимости кодировать её в язык, кратно быстрее — как в US Army, где ведется внедрение (?) телепатии между солдатами.
Brain–computer interface (BCI) — это прямой канал связи между мозгом и внешним интерфейсом. Первые опыты начались в 1920-х с обнаружения электрической активности мозга, а активные исследования ведутся с 70-х годов. Такие устройства чаще используют для узких целей — для восстановления отдельных функций организма или для их дополнения. В продаже есть и потребительские приборы, но пока из того что видел — это игрушки (зажечь лампу / включить YouTube).
Как могут помочь BCI в части передачи информации:
:: Получаем больше данных. Видим, ощущаем, слышим то, что приносят внешние сенсоры.
:: Лучше понимаем себя. Датчики, считывающие состояние организма дают информацию об усталости, стрессе, возросшем сердечном ритме, узнаём о необходимости сделать полный чекап.
:: Интерпретируем информацию, не подвергая искажениям. Задача не для BCI напрямую, но если пофантазировать — собираем данные о проблеме, просчитываем варианты на облаке, даём человеку оптимальный выбор.
:: Проще передаём информацию. Без необходимости кодировать её в язык, кратно быстрее — как в US Army, где ведется внедрение (?) телепатии между солдатами.
{kind=link}
Facebook разрабатывает AI-систему, которая потенциально может слышать / видеть и помнить всё что делает пользователь. Компания активно инвестирует в AR, и Ego4D станет частью усилий по захвату дополненной реальности.
Суть разработки — анализ окружения через видео / звук от первого лица (с AR-очков) для:
:: Эпизодической памяти — поможет «вспомнить», где лежат бабушкины часы;
:: Аудио-визуального запоминания — «напомнить» кто, где и что сказал;
:: Предсказания — куда повернуть ручку на духовке, чтобы выбрать температуру под рецепт и когда закидывать лук;
:: Движения объектов и рук — как играть на ударных или держать теннисную ракетку;
:: Социальные взаимодействия — перевод собеседника, который говорит на незнакомом языке, усиление его/её голоса.
Честно говоря — никогда не смотрел с такой стороны. AR всегда представлялся такой вещью-в-себе, где у меня появляется аватар собеседника в зум-колле или можно ловить покемонов.
С этой новостью же что-то щёлкнуло
:: Если у сервиса есть полный доступ к видео и аудио, то появляется возможность аналитить происходящее вокруг и в real-time отдавать данные, как у фантастов, где у каждого человека рядом с головой висят «социальные кредиты», а просканировав кроссовки взглядом можно купить такие же в пару кликов.
:: До этого основная область анализа видео — от третьего лица, и будто никто не пробовал посмотреть на распознавание объектов со стороны человека, хотя в конечном счёте всё ради этого и делается — расширить наши возможности, ускорить работу. Эта разработка Facebook будто убирает невидимое лишнее звено.
:: Машины думают лучше и выполняют некоторые операции лучше людей, но всё ещё хуже проявляют себя в движении. Если Facebook пропушат свои очки и будут собирать с них информацию — это потенциально даст также толчок к тому, чтобы научить роботов координации, тому как люди взаимодействуют с окружением, объектами и другими людьми.
:: Отдельный странный момент — система сможет напомнить, что говорил человек, который сейчас вне поля зрения. И это хорошо в моменте, чтобы не искажать воспоминания, но также кажется не совсем этичным. Пока непонятно, как правильно обходить «воспоминания» об умерших.
Пока это только зачатки технологии — если я верно понимаю, очень сложно и ресурсозатратно анализировать картинку и тут же выдавать какой-то результат. А ещё нужны массивные датасеты видео от первого лица, но компания как раз занята их сбором, и зная их жёсткую политику — это только вопрос времени.
Суть разработки — анализ окружения через видео / звук от первого лица (с AR-очков) для:
:: Эпизодической памяти — поможет «вспомнить», где лежат бабушкины часы;
:: Аудио-визуального запоминания — «напомнить» кто, где и что сказал;
:: Предсказания — куда повернуть ручку на духовке, чтобы выбрать температуру под рецепт и когда закидывать лук;
:: Движения объектов и рук — как играть на ударных или держать теннисную ракетку;
:: Социальные взаимодействия — перевод собеседника, который говорит на незнакомом языке, усиление его/её голоса.
Честно говоря — никогда не смотрел с такой стороны. AR всегда представлялся такой вещью-в-себе, где у меня появляется аватар собеседника в зум-колле или можно ловить покемонов.
С этой новостью же что-то щёлкнуло
:: Если у сервиса есть полный доступ к видео и аудио, то появляется возможность аналитить происходящее вокруг и в real-time отдавать данные, как у фантастов, где у каждого человека рядом с головой висят «социальные кредиты», а просканировав кроссовки взглядом можно купить такие же в пару кликов.
:: До этого основная область анализа видео — от третьего лица, и будто никто не пробовал посмотреть на распознавание объектов со стороны человека, хотя в конечном счёте всё ради этого и делается — расширить наши возможности, ускорить работу. Эта разработка Facebook будто убирает невидимое лишнее звено.
:: Машины думают лучше и выполняют некоторые операции лучше людей, но всё ещё хуже проявляют себя в движении. Если Facebook пропушат свои очки и будут собирать с них информацию — это потенциально даст также толчок к тому, чтобы научить роботов координации, тому как люди взаимодействуют с окружением, объектами и другими людьми.
:: Отдельный странный момент — система сможет напомнить, что говорил человек, который сейчас вне поля зрения. И это хорошо в моменте, чтобы не искажать воспоминания, но также кажется не совсем этичным. Пока непонятно, как правильно обходить «воспоминания» об умерших.
Пока это только зачатки технологии — если я верно понимаю, очень сложно и ресурсозатратно анализировать картинку и тут же выдавать какой-то результат. А ещё нужны массивные датасеты видео от первого лица, но компания как раз занята их сбором, и зная их жёсткую политику — это только вопрос времени.
Facebook
Teaching AI to perceive the world through your eyes
We’re announcing Ego4D, an ambitious long-term project we’ve embarked on with 13 universities in 9 countries to advance first-person perception. This work will catalyze research to build more useful AI assistants, robots, and other future innovation.
Повёлся на броский заголовок — новость — Facebook планирует нанять 10 000 человек в Европе для работы над метавселенной. Попытался разобраться и оказалось, что на декабрь 2020 года в ФБ на фулл-тайме работало 58 604 человек, значит наймут около +17%. Теперь цифра кажется не такой гигантской, особенно учитывая сложность работы над целой VR-вселенной. Продолжаю наблюдения ;)
BBC News
Facebook to hire 10,000 in EU to work on metaverse
Mark Zuckerberg is a leading voice on the metaverse - a virtual reality version of the internet.
Наткнулся на интересное исследование MIT. Проанализировали то, как люди идут из точки A в точку B на выборке 14 000 человек и 550 000 их пеших походов. Оказалось, что мы выбираем не самый кратчайший путь, но дорогу, которая (1) требует меньшей нагрузки на мозг и (2) уменьшает «угловое смещение», т.е. как можно меньше отклоняется от заданного направления, даже если прямыми углами идти было бы быстрее.
Что подумал:
:: Очевидно, путь также выбирается из привычки, либо из тех мест, что уже знакомы. Человек менее вероятно пойдёт улицей, которой никогда не ходил; выбор будет определяться ещё и всем прошлым опытом, например «не пойду больше через тёмную арку».
:: По моим наблюдениям — люди склонны «не замечать» альтернативные пути и обходы, даже если потенциально они могут помочь сэкономить время. В моей голове это работает так: «Я сегодня пойду через этот овраг, потому что кажется я видел там тропу. В худшем случае я опоздаю и пройдусь по грязи, в лучшем — сокращу все будущие походы по этому маршруту на N-минут».
Я очень люблю ходить незнакомыми маршрутами, воспринимаю это как изучение карты местности в древних RPG, где можно рассеять темноту, только побывав на неизведанном клочке земли.
А какими маршрутами ходите вы?
Что подумал:
:: Очевидно, путь также выбирается из привычки, либо из тех мест, что уже знакомы. Человек менее вероятно пойдёт улицей, которой никогда не ходил; выбор будет определяться ещё и всем прошлым опытом, например «не пойду больше через тёмную арку».
:: По моим наблюдениям — люди склонны «не замечать» альтернативные пути и обходы, даже если потенциально они могут помочь сэкономить время. В моей голове это работает так: «Я сегодня пойду через этот овраг, потому что кажется я видел там тропу. В худшем случае я опоздаю и пройдусь по грязи, в лучшем — сокращу все будущие походы по этому маршруту на N-минут».
Я очень люблю ходить незнакомыми маршрутами, воспринимаю это как изучение карты местности в древних RPG, где можно рассеять темноту, только побывав на неизведанном клочке земли.
А какими маршрутами ходите вы?
MIT News
How the brain navigates cities
An MIT study suggests our brains are not optimized to calculate the shortest possible route when navigating on foot. Instead, pedestrians use vector-based navigation, choosing “pointiest” paths that point most directly toward their destination, even if the…
Куда пропал Марк?
В начале октября я перестал писать — нужно было сделать перерыв, потому что:
:: Потерял нить — зачем пишу, для кого, упустил единую идею, которая начала проклевываться в начале
:: Не осталось заземлённых тем, о которых хотелось бы подумать
:: Из-за специфики процесса написания и публикации было мало времени нормально осмыслить текст, прожарить его
:: Тексты получались скучными, плоскими, неинтересными, начали ходить вокруг да около, не давая добавленной ценности, не объединяясь в единую повестку
:: Начал чувствовать неопределенность, тревожность, неудовлетворение текстами и поэтому старался избегать их написания
Всё это вылилось в необходимость остановиться, перезагрузиться и с новыми силами вернуться к каналу. Сперва я обдумал каждый из этих негативных пунктов, прилежно обработал каждый, но потом ко мне пришло осознание того, что стало основной блокирующей точкой проекта:
:: Множество занятных для меня штук лежит во внешнем мире. Я хочу изучать их и погружаться, знание представлено в книгах, лекциях, подкастах и т.п.
:: При этом я пишу 99% времени про внутреннее — переживания и наблюдения, оторванные от внешнего мира
:: Почему так? Потому что этому способствует процесс написания. Если я пишу с телефона в дороге, я не могу найти несколько статей по теме, переработать их и выдать заметку за 20 минут (именно столько ~ я тратил на канал в день)
:: Поэтому я в прямом смысле пишу о том, что вижу, мне недостаёт качественных внешних сигналов и на выходе у меня получаются однообразные тексты. Нет, ну я получаю какую-то полезную информацию, но её мало и недостает для того, чтобы это выливалось в тексты
И тут у меня родилась стройная концепция:
:: У человека есть цели. Чтобы к ним прийти нужно топливо: в том числе знания и навыки. Навыки лучше усваиваются в практике, знания можно получить извне. Информационное поле вокруг — это неструктурированное знание. Чтобы получать качественное знание и избавиться от шума (насколько это возможно) нужно самостоятельно формировать это поле
:: Есть инпут, в который вкидываются разговоры, прочитанные книги, впечатления от поездок и трендовые тиктоки; есть алгоритм (мозг), пережевывающий эти входные данные; есть аутпут — текст, который пригоден для чтения
:: Для чего это нужно? Чтобы перейти «интереса» к «пониманию» новой сферы — чтобы объединять с другими блоками знаний в голове и применять на практике под неожиданными углами
:: Результат — погрузиться и разобраться так сильно, что это становится преимуществом в игре «заработать больше денег» / «дать больше ценности» / любой другой игре, в какую вам хочется поиграть
:: Помимо непосредственно работы по переработке мыслей в тексты система вырабатывает энергию, от которой идёт подзарядка, чтобы бежать эти марафоны. Т.е. локальная метрика = полученная от каждой публикации энергия
Теперь я пишу вечерами — выделил себе время на сёрфинг и обработку мыслей. Как оказалось — непросто сформировать правда качественный пул источников, из которых можно вдохновляться. И пока это выглядит так, что я рассеянно листаю Hacker News в поисках чего-то, что зацепит взгляд 🤖
В начале октября я перестал писать — нужно было сделать перерыв, потому что:
:: Потерял нить — зачем пишу, для кого, упустил единую идею, которая начала проклевываться в начале
:: Не осталось заземлённых тем, о которых хотелось бы подумать
:: Из-за специфики процесса написания и публикации было мало времени нормально осмыслить текст, прожарить его
:: Тексты получались скучными, плоскими, неинтересными, начали ходить вокруг да около, не давая добавленной ценности, не объединяясь в единую повестку
:: Начал чувствовать неопределенность, тревожность, неудовлетворение текстами и поэтому старался избегать их написания
Всё это вылилось в необходимость остановиться, перезагрузиться и с новыми силами вернуться к каналу. Сперва я обдумал каждый из этих негативных пунктов, прилежно обработал каждый, но потом ко мне пришло осознание того, что стало основной блокирующей точкой проекта:
:: Множество занятных для меня штук лежит во внешнем мире. Я хочу изучать их и погружаться, знание представлено в книгах, лекциях, подкастах и т.п.
:: При этом я пишу 99% времени про внутреннее — переживания и наблюдения, оторванные от внешнего мира
:: Почему так? Потому что этому способствует процесс написания. Если я пишу с телефона в дороге, я не могу найти несколько статей по теме, переработать их и выдать заметку за 20 минут (именно столько ~ я тратил на канал в день)
:: Поэтому я в прямом смысле пишу о том, что вижу, мне недостаёт качественных внешних сигналов и на выходе у меня получаются однообразные тексты. Нет, ну я получаю какую-то полезную информацию, но её мало и недостает для того, чтобы это выливалось в тексты
И тут у меня родилась стройная концепция:
:: У человека есть цели. Чтобы к ним прийти нужно топливо: в том числе знания и навыки. Навыки лучше усваиваются в практике, знания можно получить извне. Информационное поле вокруг — это неструктурированное знание. Чтобы получать качественное знание и избавиться от шума (насколько это возможно) нужно самостоятельно формировать это поле
:: Есть инпут, в который вкидываются разговоры, прочитанные книги, впечатления от поездок и трендовые тиктоки; есть алгоритм (мозг), пережевывающий эти входные данные; есть аутпут — текст, который пригоден для чтения
:: Для чего это нужно? Чтобы перейти «интереса» к «пониманию» новой сферы — чтобы объединять с другими блоками знаний в голове и применять на практике под неожиданными углами
:: Результат — погрузиться и разобраться так сильно, что это становится преимуществом в игре «заработать больше денег» / «дать больше ценности» / любой другой игре, в какую вам хочется поиграть
:: Помимо непосредственно работы по переработке мыслей в тексты система вырабатывает энергию, от которой идёт подзарядка, чтобы бежать эти марафоны. Т.е. локальная метрика = полученная от каждой публикации энергия
Теперь я пишу вечерами — выделил себе время на сёрфинг и обработку мыслей. Как оказалось — непросто сформировать правда качественный пул источников, из которых можно вдохновляться. И пока это выглядит так, что я рассеянно листаю Hacker News в поисках чего-то, что зацепит взгляд 🤖
Прислали пост — официальная рекламная площадка Телеграма наконец запущена! Подробнее например здесь: https://t.me/durov\_russia/35
Побежал тестировать — хотел залить рекламы для Учитесь думать, пока ставки не взлетели из-за больших брендов и криптобаронов, но уже на моменте запуска столкнулся с вот такой штукой:
«To ensure and maintain high quality of ad content, a minimum advance payment of €2,000,000 is required to launch ads on the Telegram Ad Platform».
Выводы: ждём, пока выкатят на простых смертных; не все русскоязычные каналы про маркетинг корректно указали требования по бюджету — зато прыгнули на хайповую новость ;)
Побежал тестировать — хотел залить рекламы для Учитесь думать, пока ставки не взлетели из-за больших брендов и криптобаронов, но уже на моменте запуска столкнулся с вот такой штукой:
«To ensure and maintain high quality of ad content, a minimum advance payment of €2,000,000 is required to launch ads on the Telegram Ad Platform».
Выводы: ждём, пока выкатят на простых смертных; не все русскоязычные каналы про маркетинг корректно указали требования по бюджету — зато прыгнули на хайповую новость ;)
Telegram
Павел Дуров
Скоро в каналах Telegram впервые появятся официальные рекламные сообщения. Большинство пользователей едва ли заметит это изменение — по трем причинам:
1. Telegram не будет показывать рекламные сообщения в списке чатов, личных беседах или группах. Реклама…
1. Telegram не будет показывать рекламные сообщения в списке чатов, личных беседах или группах. Реклама…
Заинтересовался платформой Shopify. Компания хочет давать продукт из коробки, где пользователю легко построить свой онлайн-магазин, не выходя из экосистемы. Для этого у них есть магазин приложений — приложения расширяют дефолтную функциональность.
:: Магазин даёт сторонним девелоперам возможность сопровождать процесс на всём пути — помогать мерчантам с маркетингом / доставкой / рекомендациями / whatever. Каждое из таких направлений — самостоятельная и очень большая возможность
:: Девелоперы могут хорошо зарабатывать — есть понятная модель, а с недавних пор на первый $1M прибыли нет комиссии, на всё что сверху — всего 15% (всего, потому что в App Store — 30%)
:: Есть целый ряд инвестиций в проекты на платформе, хороший сигнал
Почему экосистема Shopify удобна для запуска продуктов?
:: Дружелюбные API для разработчиков. Обучающие программы и внятная документация. Уменьшает боль от входа на площадку
:: Обновленные алгоритмы рекомендаций и поиска. Твой продукт найдут, он не потеряется на последних страницах поиска
:: Возможность запускать рекламу. Понятно, откуда можно привлечь трафик в своё приложение
:: Коммьюнити вокруг экосистемы. Легко найти ответы, потому что ранее уже кто-то сталкивался с подобным (+ Shopify проводит мероприятия для девелоперов). Это серьёзное отличие от подхода App Store или Google Play
:: Прямая монетизация. Можно собирать деньги как угодно и бустануть за счёт отсутствия комиссий на первый миллион прибыли
:: В среднем один мерчант юзает ~6 приложений из стора Shopify для своего магазина. На платформе около 2 млн. мерчантов, можно добавить цифр и прикинуть total addressable market. И это много — на BigCommerce и Magneto (конкуренты Shopify) — 60k и 250k соответственно
Продолжаю наблюдения
Почитать
:: ‘Developers have what they need’: How Shopify’s app ecosystem boosted its core business
:: How to Build a Shopify App: The Complete Guide
:: Магазин даёт сторонним девелоперам возможность сопровождать процесс на всём пути — помогать мерчантам с маркетингом / доставкой / рекомендациями / whatever. Каждое из таких направлений — самостоятельная и очень большая возможность
:: Девелоперы могут хорошо зарабатывать — есть понятная модель, а с недавних пор на первый $1M прибыли нет комиссии, на всё что сверху — всего 15% (всего, потому что в App Store — 30%)
:: Есть целый ряд инвестиций в проекты на платформе, хороший сигнал
Почему экосистема Shopify удобна для запуска продуктов?
:: Дружелюбные API для разработчиков. Обучающие программы и внятная документация. Уменьшает боль от входа на площадку
:: Обновленные алгоритмы рекомендаций и поиска. Твой продукт найдут, он не потеряется на последних страницах поиска
:: Возможность запускать рекламу. Понятно, откуда можно привлечь трафик в своё приложение
:: Коммьюнити вокруг экосистемы. Легко найти ответы, потому что ранее уже кто-то сталкивался с подобным (+ Shopify проводит мероприятия для девелоперов). Это серьёзное отличие от подхода App Store или Google Play
:: Прямая монетизация. Можно собирать деньги как угодно и бустануть за счёт отсутствия комиссий на первый миллион прибыли
:: В среднем один мерчант юзает ~6 приложений из стора Shopify для своего магазина. На платформе около 2 млн. мерчантов, можно добавить цифр и прикинуть total addressable market. И это много — на BigCommerce и Magneto (конкуренты Shopify) — 60k и 250k соответственно
Продолжаю наблюдения
Почитать
:: ‘Developers have what they need’: How Shopify’s app ecosystem boosted its core business
:: How to Build a Shopify App: The Complete Guide
Shopify
Shopify App Store
Shopify App Store: customize your online store and grow your business with Shopify-approved apps for marketing, store design, fulfillment, and more.
На The Verge вышел материал с заголовком «Facebook’s lost generation», ключевые поинты:
:: С 2019 года в США тинейджеры используют приложение Facebook на 13% меньше, в прогнозе следующих двух лет — снижение ещё на 45%.
:: Страггл начался ещё в 2012, но только в последнее время вызов стал существенным под натиском TikTok и Snapchat.
:: С 2017 года компания пытается выйти на целевую аудиторию. Были попытки создать Messenger for Kids, отдельный Instagram; Facebook не постеснялся добавить Reels как полную копию конкурента.
:: Facebook был сконцентрирован на тексте и не смог вовремя прыгнуть на видео-тренды. Даже добавление stories — удачная копия основного функционала Snapchat.
:: Хотят удержать аудиторию продуктами в области mental health (sic!), менторства для молодёжи и вовлечения в локальные инициативы и обсуждения.
:: В том числе рассматривали возможности: расширить алгоритмы ленты, чтобы они показывали свежую информацию вне контент-пузыря, сделать новый News Feed, позволить пользователям делать разные профили под разные Facebook Groups, сделать новую версию групп, Groups+, с более тесными взаимодействиями.
:: Между Instagram / Facebook есть разница в использовании — первая площадка медленнее теряет молодую базу. Молодые люди на западе воспринимают Facebook как место для людей возрастом 40-50+, а контент как скучный, негативный и вводящий в заблуждение; о площадке только негативные ассоциации в связи со скандалами по поводу приватности и отсутствием релевантных сервисов. Около 7% подростков подвергались буллингу в инстаграме (только то, что сами подростки репортили).
Мои мысли:
Проблема «стареющей» базы пользователей в том, что процесс накладывает ограничения на будущий рост компании
:: Не будет притока молодёжи — не откуда взяться и росту, потому что существенная масса населения старшего возраста уже в сети. Всего в Facebook более 2 млрд пользователей.
:: Не будет роста базы — не будет и роста доходов, потому что Facebook зависим от рекламной модели продажи внимания своих пользователей. Отсюда попытки выйти в AR/VR — захватить как можно больше пространства в жизни человека, т.к. это конечный ресурс.
Думается, что Facebook проспали момент перехода в новую реальность. Почему так?
:: Слишком закрутили ленту. Листать Facebook / Instagram невозможно — ничего интересного, релевантного пользователю — сплошь мусор и реклама. TikTok очень хорошо сыграл на этом, дав людям в руки управление собственной лентой.
:: Слишком много функционала. Facebook выглядит монстром с кучей непонятных кнопок, морально устаревшими «группами».
:: Незаметно потеряли авторитет. Для подростков важно социальное одобрение, если кто-то в твоей группе считает, что Facebook — зло — мнение распространяется мгновенно. Скандалы последних лет серьёзно подогрели этот настрой.
:: Отсутствие вижена. Судя по тому, что утекает в сеть, внутри компании сами не знают, куда движутся, прыгают с тренда на тренд, не получают нужных метрик и от этого паникуют. Это только моё внешнее впечатление, интересно будет посмотреть на их metaverse.
С большой долей вероятности в прогнозе 10-20 лет Facebook серьёзно упустит первенство в социальных взаимодействиях, но вариант полного краха маловероятен. Также маловероятен вариант нового рассвета площадки в VR — времена и люди поменялись, а Facebook трансформируется с трудом.
:: С 2019 года в США тинейджеры используют приложение Facebook на 13% меньше, в прогнозе следующих двух лет — снижение ещё на 45%.
:: Страггл начался ещё в 2012, но только в последнее время вызов стал существенным под натиском TikTok и Snapchat.
:: С 2017 года компания пытается выйти на целевую аудиторию. Были попытки создать Messenger for Kids, отдельный Instagram; Facebook не постеснялся добавить Reels как полную копию конкурента.
:: Facebook был сконцентрирован на тексте и не смог вовремя прыгнуть на видео-тренды. Даже добавление stories — удачная копия основного функционала Snapchat.
:: Хотят удержать аудиторию продуктами в области mental health (sic!), менторства для молодёжи и вовлечения в локальные инициативы и обсуждения.
:: В том числе рассматривали возможности: расширить алгоритмы ленты, чтобы они показывали свежую информацию вне контент-пузыря, сделать новый News Feed, позволить пользователям делать разные профили под разные Facebook Groups, сделать новую версию групп, Groups+, с более тесными взаимодействиями.
:: Между Instagram / Facebook есть разница в использовании — первая площадка медленнее теряет молодую базу. Молодые люди на западе воспринимают Facebook как место для людей возрастом 40-50+, а контент как скучный, негативный и вводящий в заблуждение; о площадке только негативные ассоциации в связи со скандалами по поводу приватности и отсутствием релевантных сервисов. Около 7% подростков подвергались буллингу в инстаграме (только то, что сами подростки репортили).
Мои мысли:
Проблема «стареющей» базы пользователей в том, что процесс накладывает ограничения на будущий рост компании
:: Не будет притока молодёжи — не откуда взяться и росту, потому что существенная масса населения старшего возраста уже в сети. Всего в Facebook более 2 млрд пользователей.
:: Не будет роста базы — не будет и роста доходов, потому что Facebook зависим от рекламной модели продажи внимания своих пользователей. Отсюда попытки выйти в AR/VR — захватить как можно больше пространства в жизни человека, т.к. это конечный ресурс.
Думается, что Facebook проспали момент перехода в новую реальность. Почему так?
:: Слишком закрутили ленту. Листать Facebook / Instagram невозможно — ничего интересного, релевантного пользователю — сплошь мусор и реклама. TikTok очень хорошо сыграл на этом, дав людям в руки управление собственной лентой.
:: Слишком много функционала. Facebook выглядит монстром с кучей непонятных кнопок, морально устаревшими «группами».
:: Незаметно потеряли авторитет. Для подростков важно социальное одобрение, если кто-то в твоей группе считает, что Facebook — зло — мнение распространяется мгновенно. Скандалы последних лет серьёзно подогрели этот настрой.
:: Отсутствие вижена. Судя по тому, что утекает в сеть, внутри компании сами не знают, куда движутся, прыгают с тренда на тренд, не получают нужных метрик и от этого паникуют. Это только моё внешнее впечатление, интересно будет посмотреть на их metaverse.
С большой долей вероятности в прогнозе 10-20 лет Facebook серьёзно упустит первенство в социальных взаимодействиях, но вариант полного краха маловероятен. Также маловероятен вариант нового рассвета площадки в VR — времена и люди поменялись, а Facebook трансформируется с трудом.
The Verge
Facebook’s lost generation
Facebook is in crisis mode over losing young people on its main app and Instagram, according to leaked documents.
Один из крупнейших игроков на рынке венчурного инвестирования, Sequoia — меняют модель. С 1972 года они концентрировались на десятилетних циклах, на которые собирались и реализовывались деньги. В этих циклах было важно поскорее вывести компанию на IPO чтобы продать акции и получить деньги вспять, но сейчас многие компании остаются частными, рост занимает больше, чем пару лет, а продажа долей часто преждевременно сворачивает хорошие отношения между VC и фаундерами — традиционная модель устаревает.
Поэтому компания реструктурирует Sequoia Fund, где фокус смещается на долгосрочные вложения, минуя основное ограничение VC — короткое время инвестиций. В подчинении головного фонда будут суб-фонды для всех стадий инвестирования. Что думаю:
:: Смещение на долгий срок позволяет отказаться от парадигмы инвестиций только в самые быстрорастущие проекты. Значит можно кардинально изменить принципы отбора проектов под инвестиции.
:: Изменение принципов отбора позволяет собирать те проекты, на которые не смотрят другие фонды, которые ограничены десятилетним циклом и берут только самое хайповое, быстрое и, как следствие, очевидное.
:: Отказ от инвестиций только в быстрорастущие проекты позволяет смотреть шире и дальше. Вне привычных индустрий и на декады вперёд.
:: Меньше привязки к факту IPO и к результатам размещения — не нужно продавать акции / доли. Следствие — можно делать частную компанию, не светиться публично.
Как новый подход влияет на рискованность? Традиционная модель — около 90% стартапов, в которые вкладываются VC либо прогорят совсем, либо вернут 1X, и только 10% в лучшем случае дадут прибыль. Новый подход:
:: Отсутствие спешки позволяет расширить внимание на проекты с меньшим сегодняшним ростом, но большим потенциалом в будущем.
:: Соотношение риска сместится в меньшую сторону. Потому что есть возможность дать "слабым" стартапам больше времени и ресурса на рост.
:: Появится возможность заработать ещё больше на лучших ставках. Потому что нет необходимости возвращать деньги, сложенные фонд, можно придержать доли, пока они не вырастут кратно.
Интересно будет следить за развитием — как фонд будет оперировать, в кого инвестировать и какой будет результат по доходности.
Поэтому компания реструктурирует Sequoia Fund, где фокус смещается на долгосрочные вложения, минуя основное ограничение VC — короткое время инвестиций. В подчинении головного фонда будут суб-фонды для всех стадий инвестирования. Что думаю:
:: Смещение на долгий срок позволяет отказаться от парадигмы инвестиций только в самые быстрорастущие проекты. Значит можно кардинально изменить принципы отбора проектов под инвестиции.
:: Изменение принципов отбора позволяет собирать те проекты, на которые не смотрят другие фонды, которые ограничены десятилетним циклом и берут только самое хайповое, быстрое и, как следствие, очевидное.
:: Отказ от инвестиций только в быстрорастущие проекты позволяет смотреть шире и дальше. Вне привычных индустрий и на декады вперёд.
:: Меньше привязки к факту IPO и к результатам размещения — не нужно продавать акции / доли. Следствие — можно делать частную компанию, не светиться публично.
Как новый подход влияет на рискованность? Традиционная модель — около 90% стартапов, в которые вкладываются VC либо прогорят совсем, либо вернут 1X, и только 10% в лучшем случае дадут прибыль. Новый подход:
:: Отсутствие спешки позволяет расширить внимание на проекты с меньшим сегодняшним ростом, но большим потенциалом в будущем.
:: Соотношение риска сместится в меньшую сторону. Потому что есть возможность дать "слабым" стартапам больше времени и ресурса на рост.
:: Появится возможность заработать ещё больше на лучших ставках. Потому что нет необходимости возвращать деньги, сложенные фонд, можно придержать доли, пока они не вырастут кратно.
Интересно будет следить за развитием — как фонд будет оперировать, в кого инвестировать и какой будет результат по доходности.
Medium
The Sequoia Capital Fund: Patient Capital for Building Enduring Companies
By Roelof Botha for Team Sequoia
Microsoft и NVIDIA представили Megatron-Turing NLG 530B — самую большую генеративную языковую модель, натренированную на 530 млрд параметрах. Почему в последние 3-4 года происходит быстрый рост и улучшение таких моделей?
:: Стало проще делать расчёты из-за роста производительности GPU и увеличения скорости их соединения.
:: Получается собрать всё более крупные датасеты для тренировки.
:: С течением времени тренировки модели прогрессируют.
Основные сложности
:: Параметры этих моделей не выйдет уместить в памяти даже самого большого GPU. Для тренировки этой модели например использовали 280 чипов NVIDIA A100 Tensor Core.
:: Возрастающая сложность вычислений предполагает нереалистичное время тренировки, если не прикладывать отдельные усилия к оптимизации. Как раз этим и занялись Microsoft / NVIDIA.
:: Использовали суперкомпьютеры Azure NDv4 / Selene чтобы иметь достаточно мощности для расчёта и триллионов параметров. Важна связка GPU, computing power и софта, который всем этим управляет.
:: Предубеждения / стереотипы. Модель учится на живых текстах и проникает в места, которые люди привыкли прятать. Поэтому сгенерированные вещи могут быть неприятными и даже токсичными.
Что умеет / чем хороша модель (без указания конкретных тестов и бенчмарков)
:: Прогноз завершения текста. Предугадывает последнее слово в параграфе.
:: Понимание прочитанного текста. Создаёт ответ на вопрос, основываясь на тексте.
:: Логические связи. Проходит тесты на построение рассуждений вне статистических знаний языка.
:: Естественный язык. Обходит типичные ошибки предшественников!
:: Разбор смысла слов. Понимает значение из контекста.
Прочитал также материал в противовес позитивному настрою официального источника:
:: У модели GPT-4 будет (может быть) 100 триллионов параметров против человеческого мозга с 86 миллиардами нейронов и 100 триллионами нейронных связей между ними. До мозга все ещё далеко.
:: Оборудование для эксперимента стоит около $100M. Кто, какой бизнес может себе позволить это и зачем?
:: Непрозрачны экологические последствия. Как пример: каждый из DGX-серверов в компьютере Selene потребляет 6,5 киловатт — это много, а их для модели используется 560 штук.
Итого автор считает, что цена за небольшое улучшение бенчмарков слишком высока, и эта новая модель никак не поможет бизнесу адаптировать ML в своей работе. Мне пока сложно согласиться или опровергнуть, скорее завораживает прогресс и большие цифры. Stay tuned!
:: Стало проще делать расчёты из-за роста производительности GPU и увеличения скорости их соединения.
:: Получается собрать всё более крупные датасеты для тренировки.
:: С течением времени тренировки модели прогрессируют.
Основные сложности
:: Параметры этих моделей не выйдет уместить в памяти даже самого большого GPU. Для тренировки этой модели например использовали 280 чипов NVIDIA A100 Tensor Core.
:: Возрастающая сложность вычислений предполагает нереалистичное время тренировки, если не прикладывать отдельные усилия к оптимизации. Как раз этим и занялись Microsoft / NVIDIA.
:: Использовали суперкомпьютеры Azure NDv4 / Selene чтобы иметь достаточно мощности для расчёта и триллионов параметров. Важна связка GPU, computing power и софта, который всем этим управляет.
:: Предубеждения / стереотипы. Модель учится на живых текстах и проникает в места, которые люди привыкли прятать. Поэтому сгенерированные вещи могут быть неприятными и даже токсичными.
Что умеет / чем хороша модель (без указания конкретных тестов и бенчмарков)
:: Прогноз завершения текста. Предугадывает последнее слово в параграфе.
:: Понимание прочитанного текста. Создаёт ответ на вопрос, основываясь на тексте.
:: Логические связи. Проходит тесты на построение рассуждений вне статистических знаний языка.
:: Естественный язык. Обходит типичные ошибки предшественников!
:: Разбор смысла слов. Понимает значение из контекста.
Прочитал также материал в противовес позитивному настрою официального источника:
:: У модели GPT-4 будет (может быть) 100 триллионов параметров против человеческого мозга с 86 миллиардами нейронов и 100 триллионами нейронных связей между ними. До мозга все ещё далеко.
:: Оборудование для эксперимента стоит около $100M. Кто, какой бизнес может себе позволить это и зачем?
:: Непрозрачны экологические последствия. Как пример: каждый из DGX-серверов в компьютере Selene потребляет 6,5 киловатт — это много, а их для модели используется 560 штук.
Итого автор считает, что цена за небольшое улучшение бенчмарков слишком высока, и эта новая модель никак не поможет бизнесу адаптировать ML в своей работе. Мне пока сложно согласиться или опровергнуть, скорее завораживает прогресс и большие цифры. Stay tuned!
Microsoft Research
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model…
We are excited to introduce the DeepSpeed- and Megatron-powered Megatron-Turing Natural Language Generation model (MT-NLG), the largest and the most powerful monolithic transformer language model trained to date, with 530 billion parameters. It is the result…
Как шум влияет на продуктивность?
:: Он забирает на себя фокус. Разговор коллег рядом невольно вовлекает в обсуждение, фоновая музыка увлекает в ритм или в смысл текста
:: В просторных опенспейсах без перегородок отсутствие шума — роскошь. С переходом на удалённую работу люди думали о том, что продуктивность вырастет из-за того что нет мешающих внешних звуков, но изменился лишь формат шума
:: Мозгу нужен баланс — отсутствие звуков также губительно, как и слишком громкие / постоянные / резкие / и т.д. шумы
:: Можно условно разделить шум на два вида — отвлекающий и увеличивающий продуктивность. Отвлекающий можно конвертировать в полезный за счёт лишения шума зацепок для внимания: например контекста разговоров или знакомых уху мелодий
Что я думаю?
:: От шума не спрятаться. Никаких звуков нет только в специально оборудованных комнатах; мы не привыкли к такому опыту, в нормальных условиях звуки есть всегда. Поэтому бежать от звуков — проигрышный вариант, лучше влиять на их качество и отслеживать свою продуктивность в разных звуковых средах
:: Существует понятие розового шума — это такой звук, который «равномерен в логарифмической шкале частот». Честно говоря не знаю, что это значит, но если на пальцах: довольно интенсивный сигнал на низких частотах, линейно снижается к более высоким. Чем интересен? Он повторяет «природные» звуки — шелест листьев, звук водопада, ветер, дождь и т.д. Такой шум воспринимается человеком, как очень естественный и успокаивающий. Его даже используют при сведении музыки для того, чтобы выявлять, какие частоты на дорожке выбиваются и будут резать слух — это важно, потому что ухо быстро замыливается и перестаёт слышать разницу
:: Спрос на личный дизайн звукового пространства будет расти — здесь поможет распространение наушников с активным шумоподавлением, mindfulness приложения с медитациями и записями леса. Распространившаяся работа из дома не решила проблемы — думаю, что появится запрос на смену звуковых локаций, следом за запросом выбраться из визуального плена небольшой жилплощади
А вас отвлекают посторонние звуки?
:: Он забирает на себя фокус. Разговор коллег рядом невольно вовлекает в обсуждение, фоновая музыка увлекает в ритм или в смысл текста
:: В просторных опенспейсах без перегородок отсутствие шума — роскошь. С переходом на удалённую работу люди думали о том, что продуктивность вырастет из-за того что нет мешающих внешних звуков, но изменился лишь формат шума
:: Мозгу нужен баланс — отсутствие звуков также губительно, как и слишком громкие / постоянные / резкие / и т.д. шумы
:: Можно условно разделить шум на два вида — отвлекающий и увеличивающий продуктивность. Отвлекающий можно конвертировать в полезный за счёт лишения шума зацепок для внимания: например контекста разговоров или знакомых уху мелодий
Что я думаю?
:: От шума не спрятаться. Никаких звуков нет только в специально оборудованных комнатах; мы не привыкли к такому опыту, в нормальных условиях звуки есть всегда. Поэтому бежать от звуков — проигрышный вариант, лучше влиять на их качество и отслеживать свою продуктивность в разных звуковых средах
:: Существует понятие розового шума — это такой звук, который «равномерен в логарифмической шкале частот». Честно говоря не знаю, что это значит, но если на пальцах: довольно интенсивный сигнал на низких частотах, линейно снижается к более высоким. Чем интересен? Он повторяет «природные» звуки — шелест листьев, звук водопада, ветер, дождь и т.д. Такой шум воспринимается человеком, как очень естественный и успокаивающий. Его даже используют при сведении музыки для того, чтобы выявлять, какие частоты на дорожке выбиваются и будут резать слух — это важно, потому что ухо быстро замыливается и перестаёт слышать разницу
:: Спрос на личный дизайн звукового пространства будет расти — здесь поможет распространение наушников с активным шумоподавлением, mindfulness приложения с медитациями и записями леса. Распространившаяся работа из дома не решила проблемы — думаю, что появится запрос на смену звуковых локаций, следом за запросом выбраться из визуального плена небольшой жилплощади
А вас отвлекают посторонние звуки?
Sustainable Productivity
Noise
Why noise is necessary for our brains to perform at a high-level
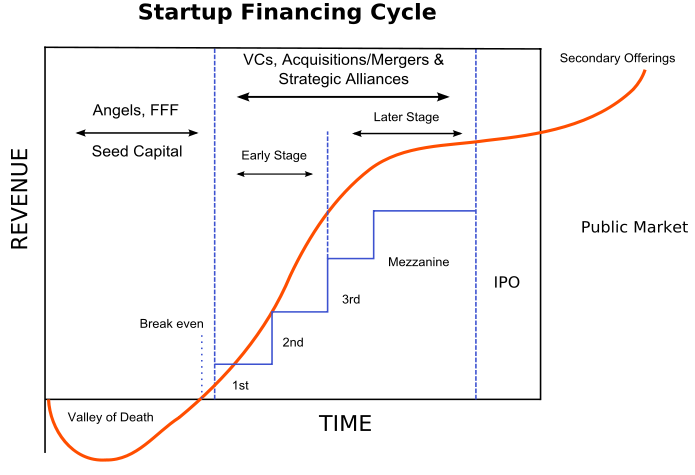
Погружаемся в удивительный мир раундов инвестиций в стартапы
Pre-seed
:: Цель компании: найти product/market fit
:: Оценка: $10k — $100k
:: Чек: ~$50k
:: Длительность: 12-18 месяцев
:: Кто инвестирует: ангелы / акселлераторы / инкубаторы / VC-фонды ранних стадий
Seed
:: Цель компании: получить первичный трекшен
:: Оценка: $100k — $6M
:: Чек: ~$50k — $3M
:: Длительность:
:: Кто инвестирует: ангелы / VC-фонды ранних стадий
Series A
:: Цель: Выход на рынок / Первичный рост
:: Оценка: $10M — $30M
:: Чек: ~$15M
:: Длительность: 6-18 месяцев
:: Кто инвестирует: ангелы / традиционные VC-фонды
:: Доля для инвестора: 10-30%
Что важно:
:: Необходима оценка стоимости. Нужна, чтобы понимать, сколько денег брать относительно доли в компании.
:: Смотрят прошлые заслуги, если их нет то на ARR (Annual Recurring Revenue), рост MoM (Month-over-Month) 15-20%.
Series B
:: Цель: Рост бизнеса / Стабилизация
:: Оценка: $30M — $60M
:: Чек: ~$30M
:: Кто инвестирует: прошлые инвесторы / институциональные инвесторы / VC
Series C
:: Цель: Расширение
:: Оценка: $100M — $120M
:: Чек: ~$50M
:: Кто инвестирует: VC поздних стадий / частные фонды / банки
IPO
:: Цель: Получить доступ к дополнительным средствам, став публичной компанией
:: Оценка: $100M+ в Revenue
:: Чек: ~$50M — $500M+
Что интересно
:: Чеки растут. Например средний чек Seed вырос в 2-3 (?) раза за последние 10 лет.
:: Есть дополнительные раунды. После Series C идёт D/E/F/G — если не хватило денег добежать до цели, но это часто паршивый знак — компания тратит деньги (много денег) и не выходит на прибыль. Хотя есть и положительные примеры таких кейсов (Uber?).
:: Важен трекшен. Деньги сейчас дают легко, НО либо за личности фаундеров / команду, либо за классные показатели. Если нет в списке заслуг пары экзитов — только второй путь :)
Pre-seed
:: Цель компании: найти product/market fit
:: Оценка: $10k — $100k
:: Чек: ~$50k
:: Длительность: 12-18 месяцев
:: Кто инвестирует: ангелы / акселлераторы / инкубаторы / VC-фонды ранних стадий
Seed
:: Цель компании: получить первичный трекшен
:: Оценка: $100k — $6M
:: Чек: ~$50k — $3M
:: Длительность:
:: Кто инвестирует: ангелы / VC-фонды ранних стадий
Series A
:: Цель: Выход на рынок / Первичный рост
:: Оценка: $10M — $30M
:: Чек: ~$15M
:: Длительность: 6-18 месяцев
:: Кто инвестирует: ангелы / традиционные VC-фонды
:: Доля для инвестора: 10-30%
Что важно:
:: Необходима оценка стоимости. Нужна, чтобы понимать, сколько денег брать относительно доли в компании.
:: Смотрят прошлые заслуги, если их нет то на ARR (Annual Recurring Revenue), рост MoM (Month-over-Month) 15-20%.
Series B
:: Цель: Рост бизнеса / Стабилизация
:: Оценка: $30M — $60M
:: Чек: ~$30M
:: Кто инвестирует: прошлые инвесторы / институциональные инвесторы / VC
Series C
:: Цель: Расширение
:: Оценка: $100M — $120M
:: Чек: ~$50M
:: Кто инвестирует: VC поздних стадий / частные фонды / банки
IPO
:: Цель: Получить доступ к дополнительным средствам, став публичной компанией
:: Оценка: $100M+ в Revenue
:: Чек: ~$50M — $500M+
Что интересно
:: Чеки растут. Например средний чек Seed вырос в 2-3 (?) раза за последние 10 лет.
:: Есть дополнительные раунды. После Series C идёт D/E/F/G — если не хватило денег добежать до цели, но это часто паршивый знак — компания тратит деньги (много денег) и не выходит на прибыль. Хотя есть и положительные примеры таких кейсов (Uber?).
:: Важен трекшен. Деньги сейчас дают легко, НО либо за личности фаундеров / команду, либо за классные показатели. Если нет в списке заслуг пары экзитов — только второй путь :)
{kind=link}
Саммари: Kai-Fu Lee — «AI Superpowers»
Кайфу Ли — один из ведущих AI-визионеров. Работает области более 40 лет, участвовал в создании Google China. Книга построена на противопоставлении двух подходов к технологическому прогрессу — китайского и американского, а также на размышлениях о нашем будущем, управляемом ИИ.
Очень грамотно про разницу Китая / США — наконец сложилась единая картинка, но очень сонно во второй части книги про будущее. Много воды про то, как AI заменит белых воротничков и как человечество должно сплотиться во имя любви. Ещё важно, что книга вышла в 2018 году, а по меркам области это эпоха динозавров, что не мешает насладиться легким слогом и классными инсайдами, чек ит!
Ссылка на саммари:
https://themarko.org/101think/tpost/791lksz5t1-sammari-kai-fu-lee-ai-superpowers
Кайфу Ли — один из ведущих AI-визионеров. Работает области более 40 лет, участвовал в создании Google China. Книга построена на противопоставлении двух подходов к технологическому прогрессу — китайского и американского, а также на размышлениях о нашем будущем, управляемом ИИ.
Очень грамотно про разницу Китая / США — наконец сложилась единая картинка, но очень сонно во второй части книги про будущее. Много воды про то, как AI заменит белых воротничков и как человечество должно сплотиться во имя любви. Ещё важно, что книга вышла в 2018 году, а по меркам области это эпоха динозавров, что не мешает насладиться легким слогом и классными инсайдами, чек ит!
Ссылка на саммари:
https://themarko.org/101think/tpost/791lksz5t1-sammari-kai-fu-lee-ai-superpowers
{kind=link}
Как собрать питч дек?
Питч дек — это презентация стартапа, которую показывают, чтобы поднять раунд инвестиций. Деньги становятся доступнее, но и компаний в поисках финансирования тоже становится больше. Например, в топовый фонд Andreessen Horowitz в год (данные 2014 года) приходит 4 000 стартапов, а финансируют они ~20 штук (0,07%). Задумался и решил покопать, на чём строится хороший питч дек, а в интернете миллион статей — начиная от серьёзных Forbes, заканчивая эзотерическими, с забавными, но абсурдными рекомендациями.
Итак, что делать:
:: 10 минут на презентацию (максимум 20)
:: 10 слайдов = идеальная длительность, не более 15-20
:: Важно хорошо подсветить цифры визуально
:: При возможности включить демо продукта в структуру
:: Нужна запоминающаяся история, чтобы выделиться. Потому что похожих проектов у VC десятки-сотни
:: Стоит включать пометку “Confidential and Proprietary" ;)
Структура:
:: Овервью. Несколько основных поинтов о компании
:: Цель / миссия / вижен. Для чего мы это делаем?
:: Команда / эдвайзоры. Особенно важно на ранних стадиях
:: Проблема. Насколько большая и больная, для кого это важно
:: Решение. Как отвечаем на указанную проблему
:: Продукт / Демо. Из чего состоит продукт и в чём уникальность
:: Технология. На чём строим проект
:: Клиенты. Кто-то уже купил это?
:: Размер рынка. Деньги, TAM
:: Конкуренты. Кто, почему мы можем быть лучше
:: Почему сейчас. Что изменилось, что стало важно сделать продукт
:: Трекшен. Первые продажи, сделки, скачивания приложения etc.
:: Бизнес-модель. На чём зарабатываем, какая цена у продукта
:: Маркетинг. откуда будем брать клиентов, какая ёмкость у каналов
:: Финансирование. Юнит-экономика проекта, burn-rate и метрики
:: Роадмап. Когда выйдем на N и заработаем X
:: Предложение. Сколько денег просим, на что и на сколько, какие вехи
Пока собирал отметил, что подход не сильно отличается от того, что я выработал, собирая маркетинговые стратегии — интересно наблюдать, как множество несвязанных с собой навыков / мыслей / знаний постепенно пересекаются
Материалы:
:: A Guide To Investor Pitch Decks For Startup Fundraising — https://www.forbes.com/sites/allbusiness/2020/06/20/guide-to-investor-pitch-decks-for-startup-fundraising/
:: 30 Legendary Startup Pitch Decks — https://piktochart.com/blog/startup-pitch-decks-what-you-can-learn/
:: How to Create a Winning Series A Pitch Deck — https://piktochart.com/blog/startup-pitch-decks-what-you-can-learn/
:: Guy Kawasaki 10 20 30 Rule — https://www.youtube.com/watch?v=-M13SObffog
Питч дек — это презентация стартапа, которую показывают, чтобы поднять раунд инвестиций. Деньги становятся доступнее, но и компаний в поисках финансирования тоже становится больше. Например, в топовый фонд Andreessen Horowitz в год (данные 2014 года) приходит 4 000 стартапов, а финансируют они ~20 штук (0,07%). Задумался и решил покопать, на чём строится хороший питч дек, а в интернете миллион статей — начиная от серьёзных Forbes, заканчивая эзотерическими, с забавными, но абсурдными рекомендациями.
Итак, что делать:
:: 10 минут на презентацию (максимум 20)
:: 10 слайдов = идеальная длительность, не более 15-20
:: Важно хорошо подсветить цифры визуально
:: При возможности включить демо продукта в структуру
:: Нужна запоминающаяся история, чтобы выделиться. Потому что похожих проектов у VC десятки-сотни
:: Стоит включать пометку “Confidential and Proprietary" ;)
Структура:
:: Овервью. Несколько основных поинтов о компании
:: Цель / миссия / вижен. Для чего мы это делаем?
:: Команда / эдвайзоры. Особенно важно на ранних стадиях
:: Проблема. Насколько большая и больная, для кого это важно
:: Решение. Как отвечаем на указанную проблему
:: Продукт / Демо. Из чего состоит продукт и в чём уникальность
:: Технология. На чём строим проект
:: Клиенты. Кто-то уже купил это?
:: Размер рынка. Деньги, TAM
:: Конкуренты. Кто, почему мы можем быть лучше
:: Почему сейчас. Что изменилось, что стало важно сделать продукт
:: Трекшен. Первые продажи, сделки, скачивания приложения etc.
:: Бизнес-модель. На чём зарабатываем, какая цена у продукта
:: Маркетинг. откуда будем брать клиентов, какая ёмкость у каналов
:: Финансирование. Юнит-экономика проекта, burn-rate и метрики
:: Роадмап. Когда выйдем на N и заработаем X
:: Предложение. Сколько денег просим, на что и на сколько, какие вехи
Пока собирал отметил, что подход не сильно отличается от того, что я выработал, собирая маркетинговые стратегии — интересно наблюдать, как множество несвязанных с собой навыков / мыслей / знаний постепенно пересекаются
Материалы:
:: A Guide To Investor Pitch Decks For Startup Fundraising — https://www.forbes.com/sites/allbusiness/2020/06/20/guide-to-investor-pitch-decks-for-startup-fundraising/
:: 30 Legendary Startup Pitch Decks — https://piktochart.com/blog/startup-pitch-decks-what-you-can-learn/
:: How to Create a Winning Series A Pitch Deck — https://piktochart.com/blog/startup-pitch-decks-what-you-can-learn/
:: Guy Kawasaki 10 20 30 Rule — https://www.youtube.com/watch?v=-M13SObffog
TechCrunch
Startups have never had it so good
The venture capital market is racing ahead, foot on the gas, middle finger out the window, hair on fire. That’s our read of the Q2 2021 data released thus far.
Два месяца назад встал на путь отказа от продуктов Google. Дело непростое конечно, я ещё в процессе, делюсь промежуточными результатами.
Заменил часть сервисов:
:: Maps — MAPS.ME. Не лучшие карты, иногда страдаю, особенно с маршрутами.
:: Translate — DeepL. Отлично переводит слова и целые предложения, лучше чем Google. Из минусов — нет приложения в телефон, только на мак, поэтому с телефона приходится заходить на сайт :-/
:: Meet — Zoom. Уже довольно давно и успешно, хотя конечно часто заставляет понервничать ;)
:: Docs — Notion. В личных целях перешёл полностью, в рабочих продолжаю постоянно юзать спредшиты гугла — альтернатив пока мало.
:: Drive — предстоит переезд, пока не горит.
:: Chrome — Firefox. Сам браузер поменять легко, но очень сложно перенести все аккаунты! Я перебегаю по одному, чтобы не тратить на это время, поэтому пока иногда скачу между браузерами.
:: Search — DuckDuckGo. После гугла очень паршиво ищет. Но это плата за то, что у них минимум данных обо мне, нет контекста поиска. Если нужно найти что-то конкретное, приходится идти в гугл (ну не в яндекс же!)
:: Gmail — Ctemplar. Почта — самая больная проблема. Оказалось, что у меня только личных, только на гугле 4 штуки, на них завязаны все возможные логины. Но труднее всего оказалось найти адекватную почту — все приватные сервисы платные, но некоторые не работают, а остальные выглядят, будто скоро закроются.
Что прикольно — пробую другие сервисы, это выдёргивает меня из экосистемы гугла, к которой я прирос
Заменил часть сервисов:
:: Maps — MAPS.ME. Не лучшие карты, иногда страдаю, особенно с маршрутами.
:: Translate — DeepL. Отлично переводит слова и целые предложения, лучше чем Google. Из минусов — нет приложения в телефон, только на мак, поэтому с телефона приходится заходить на сайт :-/
:: Meet — Zoom. Уже довольно давно и успешно, хотя конечно часто заставляет понервничать ;)
:: Docs — Notion. В личных целях перешёл полностью, в рабочих продолжаю постоянно юзать спредшиты гугла — альтернатив пока мало.
:: Drive — предстоит переезд, пока не горит.
:: Chrome — Firefox. Сам браузер поменять легко, но очень сложно перенести все аккаунты! Я перебегаю по одному, чтобы не тратить на это время, поэтому пока иногда скачу между браузерами.
:: Search — DuckDuckGo. После гугла очень паршиво ищет. Но это плата за то, что у них минимум данных обо мне, нет контекста поиска. Если нужно найти что-то конкретное, приходится идти в гугл (ну не в яндекс же!)
:: Gmail — Ctemplar. Почта — самая больная проблема. Оказалось, что у меня только личных, только на гугле 4 штуки, на них завязаны все возможные логины. Но труднее всего оказалось найти адекватную почту — все приватные сервисы платные, но некоторые не работают, а остальные выглядят, будто скоро закроются.
Что прикольно — пробую другие сервисы, это выдёргивает меня из экосистемы гугла, к которой я прирос
Telegram
Учитесь думать
Многократно задумывался о том, что хочу снизить зависимость от сервисов крупных компаний, в частности Google. Я пользуюсь множеством их массовых продуктов (Chrome, Gmail, Translate, Maps, Drive, Meet, Android, Play, YouTube, Docs и др.), и в один момент почувствовал…