
Про модели со смешанными эффектами (mixed models)
Рассмотрим ситуацию, в которой исследователи изучают эффективность нового препарата для снижения артериального давления. Для этого препарат назначается пациентам в десяти различных больницах, после чего фиксируется изменение уровня их артериального давления. Однако на полученные результаты могут влиять не только характеристики самого лечения, но и условия, в которых оно проводится.
Во-первых, имеются фиксированные эффекты — это факторы, которые напрямую интересуют исследователей. К ним относятся наличие терапевтического эффекта у препарата, индивидуальные особенности пациентов (например, возраст и пол), а также дозировка лекарства. Эти переменные считаются постоянными и одинаково важными для всех участников исследования, независимо от места проведения лечения.
Во-вторых, существуют случайные эффекты, связанные с различиями между больницами. Например, в некоторых учреждениях может использоваться более современное медицинское оборудование, врачи могут иметь разный уровень опыта, а профиль пациентов может отличаться по степени тяжести заболевания. Все эти особенности могут влиять на результаты лечения и вносить систематические отклонения, не связанные с самим препаратом. Пациенты, находящиеся в одной и той же больнице, нередко показывают схожие результаты именно из-за общих условий, а не из-за действия лекарства.
Именно здесь на помощь приходят модели со смешанными эффектами, которые позволяют исследователям одновременно учитывать как фиксированные, так и случайные эффекты. С их помощью можно, с одной стороны, оценить влияние препарата на уровень артериального давления в целом, а с другой — скорректировать результаты с учётом различий между больницами. Это особенно важно, чтобы не допустить искажения выводов, например, не считать препарат неэффективным только потому, что в одной из больниц наблюдались необычно плохие результаты, или, наоборот, не переоценить его пользу из-за особенно благоприятных условий в другой.
Таким образом, модели со смешанными эффектами позволяют отделить влияние самого лечения от влияния внешних факторов, связанных с местом его проведения. Это делает выводы исследования более точными, надёжными и научно обоснованными.
Рассмотрим ситуацию, в которой исследователи изучают эффективность нового препарата для снижения артериального давления. Для этого препарат назначается пациентам в десяти различных больницах, после чего фиксируется изменение уровня их артериального давления. Однако на полученные результаты могут влиять не только характеристики самого лечения, но и условия, в которых оно проводится.
Во-первых, имеются фиксированные эффекты — это факторы, которые напрямую интересуют исследователей. К ним относятся наличие терапевтического эффекта у препарата, индивидуальные особенности пациентов (например, возраст и пол), а также дозировка лекарства. Эти переменные считаются постоянными и одинаково важными для всех участников исследования, независимо от места проведения лечения.
Во-вторых, существуют случайные эффекты, связанные с различиями между больницами. Например, в некоторых учреждениях может использоваться более современное медицинское оборудование, врачи могут иметь разный уровень опыта, а профиль пациентов может отличаться по степени тяжести заболевания. Все эти особенности могут влиять на результаты лечения и вносить систематические отклонения, не связанные с самим препаратом. Пациенты, находящиеся в одной и той же больнице, нередко показывают схожие результаты именно из-за общих условий, а не из-за действия лекарства.
Именно здесь на помощь приходят модели со смешанными эффектами, которые позволяют исследователям одновременно учитывать как фиксированные, так и случайные эффекты. С их помощью можно, с одной стороны, оценить влияние препарата на уровень артериального давления в целом, а с другой — скорректировать результаты с учётом различий между больницами. Это особенно важно, чтобы не допустить искажения выводов, например, не считать препарат неэффективным только потому, что в одной из больниц наблюдались необычно плохие результаты, или, наоборот, не переоценить его пользу из-за особенно благоприятных условий в другой.
Таким образом, модели со смешанными эффектами позволяют отделить влияние самого лечения от влияния внешних факторов, связанных с местом его проведения. Это делает выводы исследования более точными, надёжными и научно обоснованными.
{kind=link}
👍1
Про непрерывные переменные
В медицинских исследованиях непрерывные переменные — такие как возраст, давление, концентрации биомаркеров — являются ключевыми предикторами, однако способы их обработки зачастую методологически некорректны. Наиболее распространенные ошибки включают в себя категоризацию и необоснованное предположение о линейной связи между независимой и зависимой переменными. Категоризация, например деление переменной по медиане или на группы с произвольными порогами, приводит к потере информации, снижению статистической мощности и искажению выводов. Линейное моделирование, в свою очередь, предполагает, что эффект изменения предиктора одинаков по всей шкале его значений, что редко соответствует биологической реальности.
Нелинейные зависимости — правило, а не исключение. Именно поэтому современные рекомендации подчеркивают необходимость гибкого моделирования непрерывных переменных. Наиболее надежными и широко применимыми методами являются фракционные полиномы и ограниченные кубические сплайны (restricted cubic splines). Эти подходы позволяют выявлять сложные формы зависимости, избегая произвольного выбора порогов и сохраняя всю доступную информацию. Более того, они улучшают предсказательную способность моделей, корректность выводов о связи и возможность адекватной визуализации эффектов на шкале значений переменной.
Новая публикация в BMJ подчеркивает, что, несмотря на наличие этих методов и их доступность в статистических пакетах (R, Stata), неправильная обработка непрерывных переменных остается повсеместной проблемой — от прогностических моделей до рандомизированных исследований. Авторы настаивают, что категоризация и предположение линейности должны быть исключением, а не стандартом. Использование гибкого моделирования должно стать обязательной частью аналитического процесса при работе с медицинскими данными.
В медицинских исследованиях непрерывные переменные — такие как возраст, давление, концентрации биомаркеров — являются ключевыми предикторами, однако способы их обработки зачастую методологически некорректны. Наиболее распространенные ошибки включают в себя категоризацию и необоснованное предположение о линейной связи между независимой и зависимой переменными. Категоризация, например деление переменной по медиане или на группы с произвольными порогами, приводит к потере информации, снижению статистической мощности и искажению выводов. Линейное моделирование, в свою очередь, предполагает, что эффект изменения предиктора одинаков по всей шкале его значений, что редко соответствует биологической реальности.
Нелинейные зависимости — правило, а не исключение. Именно поэтому современные рекомендации подчеркивают необходимость гибкого моделирования непрерывных переменных. Наиболее надежными и широко применимыми методами являются фракционные полиномы и ограниченные кубические сплайны (restricted cubic splines). Эти подходы позволяют выявлять сложные формы зависимости, избегая произвольного выбора порогов и сохраняя всю доступную информацию. Более того, они улучшают предсказательную способность моделей, корректность выводов о связи и возможность адекватной визуализации эффектов на шкале значений переменной.
Новая публикация в BMJ подчеркивает, что, несмотря на наличие этих методов и их доступность в статистических пакетах (R, Stata), неправильная обработка непрерывных переменных остается повсеместной проблемой — от прогностических моделей до рандомизированных исследований. Авторы настаивают, что категоризация и предположение линейности должны быть исключением, а не стандартом. Использование гибкого моделирования должно стать обязательной частью аналитического процесса при работе с медицинскими данными.
👍1🔥1
Вот конкретные пошаговые рекомендации для корректной работы с непрерывными переменными в медицинских исследованиях. Эти шаги помогут избежать методологических ошибок, повысить достоверность выводов и улучшить клиническую применимость статистических моделей:
🔹 1. Не категоризируйте непрерывные переменные!
Избегайте деления переменных на группы (например, «высокий/низкий», «<60 / ≥60»).
Особенно избегайте дихотомизации — она приводит к максимальной потере информации.
🔹 2. Не предполагаете линейность по умолчанию без проверки
Проверьте форму зависимости визуально и статистически.
🔹 3. Используйте гибкое моделирование
Применяйте ограниченные кубические сплайны (restricted cubic splines) или фракционные полиномы (fractional polynomials):
В R: библиотеки rms::rcs(), splines::ns(), mfp::mfp().
В Stata: функции mkspline, fp.
🔹 4. Выбирайте количество узлов (knots) с учетом объема выборки
Обычно 3–5 узлов достаточно.
Расположение узлов можно задать по квантилям (например, 10%, 50%, 90%).
🔹 5. Визуализируйте модель
Стройте partial effect plots и dose-response plots для наглядной интерпретации результатов.
Не полагайтесь только на коэффициенты регрессии — они неинтерпретируемы при сплайнах!
🔹 6. При ограниченных степенях свободы (когда у вас небольшая выборка) расставляйте приоритеты эмпирически
Моделируйте (модифицируйте с помощью сплайнов) только наиболее важные переменные (например, по клиническому значению).
Менее важные можно оставить в линейной форме, чтобы не расходовать лишние степени свободы.
🔹 7. Для прогностических моделей избегайте упрощения ради интерпретируемости
Даже если коэффициенты сложны, графики обеспечат нужную клиническую наглядность.
Точная модель важнее простоты при прогнозировании.
🔹 9. Протоколируйте выбор модели заранее
Фиксируйте способ трансформации переменных в SAP (Statistical Analysis Plan).
Если сравниваете модели — используйте AIC/BIC или кросс-валидацию, но избегайте data-driven подгонки. Data-driven подгонка — выбор модели или параметров (например, точки отсечения, количества узлов, формы зависимости) на основе анализа самих данных, а не заранее заданного плана. Она повышает риск переобучения, занижает p-значения и делает результаты ненадёжными и трудновоспроизводимыми.
🔹 1. Не категоризируйте непрерывные переменные!
Избегайте деления переменных на группы (например, «высокий/низкий», «<60 / ≥60»).
Особенно избегайте дихотомизации — она приводит к максимальной потере информации.
🔹 2. Не предполагаете линейность по умолчанию без проверки
Проверьте форму зависимости визуально и статистически.
🔹 3. Используйте гибкое моделирование
Применяйте ограниченные кубические сплайны (restricted cubic splines) или фракционные полиномы (fractional polynomials):
В R: библиотеки rms::rcs(), splines::ns(), mfp::mfp().
В Stata: функции mkspline, fp.
🔹 4. Выбирайте количество узлов (knots) с учетом объема выборки
Обычно 3–5 узлов достаточно.
Расположение узлов можно задать по квантилям (например, 10%, 50%, 90%).
🔹 5. Визуализируйте модель
Стройте partial effect plots и dose-response plots для наглядной интерпретации результатов.
Не полагайтесь только на коэффициенты регрессии — они неинтерпретируемы при сплайнах!
🔹 6. При ограниченных степенях свободы (когда у вас небольшая выборка) расставляйте приоритеты эмпирически
Моделируйте (модифицируйте с помощью сплайнов) только наиболее важные переменные (например, по клиническому значению).
Менее важные можно оставить в линейной форме, чтобы не расходовать лишние степени свободы.
🔹 7. Для прогностических моделей избегайте упрощения ради интерпретируемости
Даже если коэффициенты сложны, графики обеспечат нужную клиническую наглядность.
Точная модель важнее простоты при прогнозировании.
🔹 9. Протоколируйте выбор модели заранее
Фиксируйте способ трансформации переменных в SAP (Statistical Analysis Plan).
Если сравниваете модели — используйте AIC/BIC или кросс-валидацию, но избегайте data-driven подгонки. Data-driven подгонка — выбор модели или параметров (например, точки отсечения, количества узлов, формы зависимости) на основе анализа самих данных, а не заранее заданного плана. Она повышает риск переобучения, занижает p-значения и делает результаты ненадёжными и трудновоспроизводимыми.
👍1🔥1
Про стандартное отклонение и стандартную ошибку
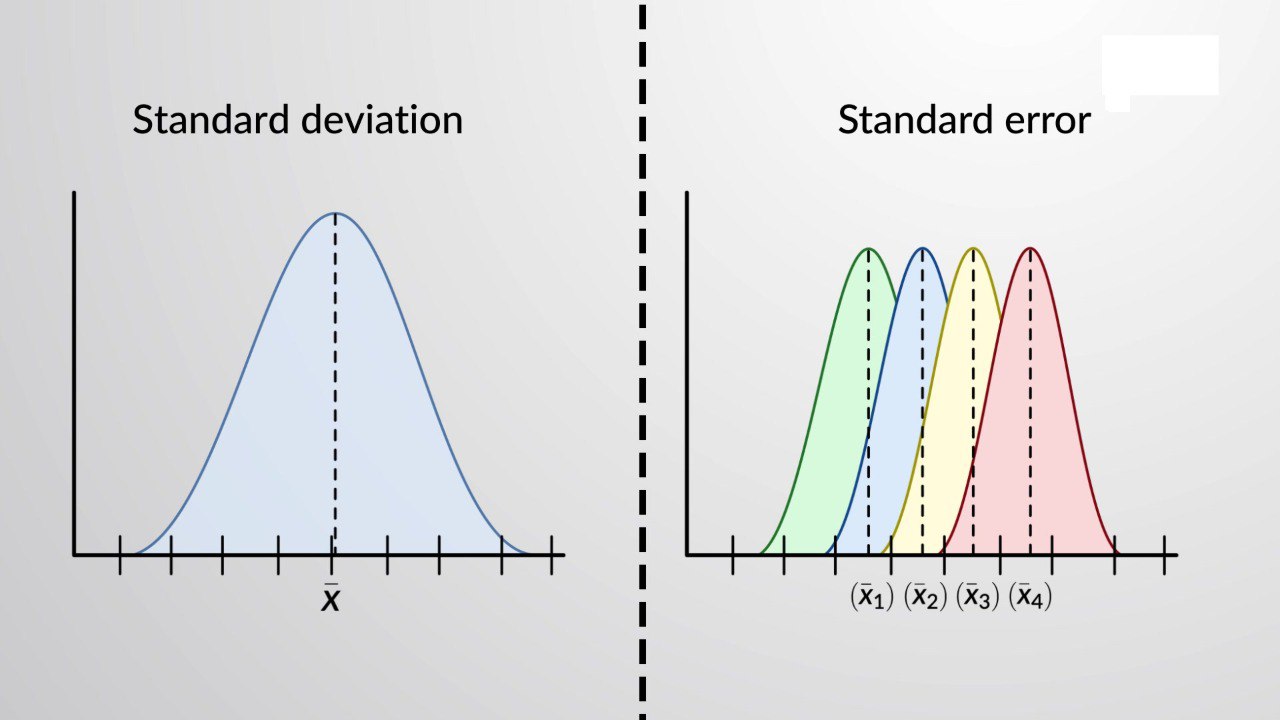
Понимание различий между стандартным отклонением (SD) и стандартной ошибкой (SE) имеет принципиальное значение для корректной интерпретации статистических данных. Стандартное отклонение характеризует степень вариативности в выборке, демонстрируя, насколько индивидуальные значения отклоняются от выборочного среднего. В противоположность этому, стандартная ошибка отражает степень неопределенности, связанной с оценкой среднего значения генеральной совокупности на основе выборки. Она показывает точность оценки среднего: с увеличением объема выборки SE уменьшается, что свидетельствует о большей надежности полученного результата. Математическая связь между SD и SE выражается формулой: SE = SD / √n, где n — размер выборки. В то время как стандартное отклонение остается относительно стабильным при изменении объема выборки, стандартная ошибка убывает, указывая на снижение неопределенности оценки среднего значения.
Одной из распространенных методологических ошибок в научных публикациях является использование обозначения «±» без уточнения, идет ли речь о стандартном отклонении или стандартной ошибке. Такое упущение может привести к неверному толкованию результатов. Для обеспечения точности и прозрачности представления данных крайне важно всегда ясно указывать, какой показатель используется.
Ключевые рекомендации:
🔹 Применяйте SD, когда описываете вариативность данных.
🔹 Используйте SE для обозначения точности оценки среднего значения.
🔹 Всегда явно указывайте, о каком показателе идет речь (SD или SE).
📖 Источник: https://www.bmj.com/content/331/7521/903
Понимание различий между стандартным отклонением (SD) и стандартной ошибкой (SE) имеет принципиальное значение для корректной интерпретации статистических данных. Стандартное отклонение характеризует степень вариативности в выборке, демонстрируя, насколько индивидуальные значения отклоняются от выборочного среднего. В противоположность этому, стандартная ошибка отражает степень неопределенности, связанной с оценкой среднего значения генеральной совокупности на основе выборки. Она показывает точность оценки среднего: с увеличением объема выборки SE уменьшается, что свидетельствует о большей надежности полученного результата. Математическая связь между SD и SE выражается формулой: SE = SD / √n, где n — размер выборки. В то время как стандартное отклонение остается относительно стабильным при изменении объема выборки, стандартная ошибка убывает, указывая на снижение неопределенности оценки среднего значения.
Одной из распространенных методологических ошибок в научных публикациях является использование обозначения «±» без уточнения, идет ли речь о стандартном отклонении или стандартной ошибке. Такое упущение может привести к неверному толкованию результатов. Для обеспечения точности и прозрачности представления данных крайне важно всегда ясно указывать, какой показатель используется.
Ключевые рекомендации:
🔹 Применяйте SD, когда описываете вариативность данных.
🔹 Используйте SE для обозначения точности оценки среднего значения.
🔹 Всегда явно указывайте, о каком показателе идет речь (SD или SE).
📖 Источник: https://www.bmj.com/content/331/7521/903
{kind=link}
🔥3
В последние годы исследования в области интенсивной терапии сталкиваются с нарастающей проблемой: рандомизированные контролируемые испытания (РКИ) все чаще оказываются нерезультативными, особенно в таких критически важных направлениях, как сепсис и острый респираторный дистресс-синдром (ОРДС). Несмотря на масштабные попытки, включая крупные многоцентровые и платформенные исследования, положительные результаты остаются редкостью и плохо воспроизводятся. В ответ на это со стороны научного сообщества выдвигались различные объяснения: от недостаточной мощности до чрезмерной гетерогенности пациентов. Однако в блогерской статье реаниматолога Рафаэля Оливе Лейте, предлагается более фундаментальное объяснение этой проблемы — предвзятость, обусловленная определениями на основе физиологических порогов.
В своей работе автор утверждает, что сами определения заболеваний, таких как сепсис и ОРДС, сформулированные через фиксированные пороговые значения (например, по показателям qSOFA > 2 баллов), представляют собой источник систематического смещения. Эти пороги не указывают на конкретную причину болезни и могут соответствовать множеству различных патофизиологических состояний. Таким образом, включение пациентов в РКИ по таким критериям приводит к формированию неоднородных и неповторяемых выборок. Один и тот же порог может быть обусловлен разными заболеваниями, что делает каждое исследование уникальным по составу пациентов и подрывает возможность воспроизведения результатов.
Используя инструмент причинно-следственного анализа — прямые ациклические графы (DAG) — Лейте наглядно демонстрирует, как пороговое значение становится так называемым «коллайдером»: переменной, зависящей от разных причин и одновременно определяющей доступ к лечению. Это создает селекционное смещение и разрушает логическую причинно-следственную цепочку, необходимую для интерпретации результатов РКИ. Более того, в ряде современных определений, как в случае с qSOFA, пороговый показатель одновременно служит и диагностическим критерием, и прогностическим фактором тяжести заболевания, что дополнительно усиливает смешивающее смещение и делает интерпретацию результатов еще более уязвимой.
Таким образом, автор делает категоричный вывод: пока клинические исследования в интенсивной терапии продолжают опираться на пороговые определения, они неизбежно будут оставаться предвзятыми по своей природе. Для выхода из этого методологического тупика автор призывает к отказу от таких определений и переходу к более индивидуализированным, фенотипически ориентированным стратегиям включения пациентов, что особенно актуально в рамках прецизионной медицины.
В своей работе автор утверждает, что сами определения заболеваний, таких как сепсис и ОРДС, сформулированные через фиксированные пороговые значения (например, по показателям qSOFA > 2 баллов), представляют собой источник систематического смещения. Эти пороги не указывают на конкретную причину болезни и могут соответствовать множеству различных патофизиологических состояний. Таким образом, включение пациентов в РКИ по таким критериям приводит к формированию неоднородных и неповторяемых выборок. Один и тот же порог может быть обусловлен разными заболеваниями, что делает каждое исследование уникальным по составу пациентов и подрывает возможность воспроизведения результатов.
Используя инструмент причинно-следственного анализа — прямые ациклические графы (DAG) — Лейте наглядно демонстрирует, как пороговое значение становится так называемым «коллайдером»: переменной, зависящей от разных причин и одновременно определяющей доступ к лечению. Это создает селекционное смещение и разрушает логическую причинно-следственную цепочку, необходимую для интерпретации результатов РКИ. Более того, в ряде современных определений, как в случае с qSOFA, пороговый показатель одновременно служит и диагностическим критерием, и прогностическим фактором тяжести заболевания, что дополнительно усиливает смешивающее смещение и делает интерпретацию результатов еще более уязвимой.
Таким образом, автор делает категоричный вывод: пока клинические исследования в интенсивной терапии продолжают опираться на пороговые определения, они неизбежно будут оставаться предвзятыми по своей природе. Для выхода из этого методологического тупика автор призывает к отказу от таких определений и переходу к более индивидуализированным, фенотипически ориентированным стратегиям включения пациентов, что особенно актуально в рамках прецизионной медицины.
Substack
Thresholds-based definitions introduced bias into critical care research
A short paper
🔥4
Разработка и валидация прогностической модели для прогнозирования риска тяжелых кожных побочных реакций, вызванных аллопуринолом: ретроспективное когортное исследование
Когда в соавторах профессор Richard D. Riley, а сама публикация в журнале The Lancet, это знак большого доверия. Но самое важное — то, как была построена прогностическая модель. В свежем исследовании авторы оценили риск тяжелых кожных реакций на аллопуринол и сделали это как это нужно делать! Поэтому эта работа важна для всех, кто занимается моделированием в медицине.
🔹 Во-первых, масштаб. Почти 174 000 пациентов в тренировочной выборке и 42 000 — для валидации. Без больших данных надежную модель, особенно для редких событий, не построишь. Модель должна «видеть» тысячи случаев, чтобы делать уверенные прогнозы.
🔹 Во-вторых, калибровка. Это не просто одна из метрик модели — это ее основа. Важно не только "угадывать", у кого будет исход, но и точно предсказывать вероятность. Модель должна говорить: «у этого пациента риск 0.3%» и это действительно должно быть 3 случая из 1000, а не 10 из 1000.
🔹 В модель включили 7 предикторов (14 параметров). Так как первоначальная калибровка модели даже на такой огромной выборке оказалась не очень хорошей в связи низкой частотой исхода, авторы применили рекалибровку с помощью псевдо-значений и генерализованных линейных моделей. А чтобы минимизировать переобучение коэффициенты модели после первичной калибровки дополнительно уменьшили (shrinked), используя бутстрап-оценку оптимизма, и затем пересчитали интерсепт. Это повысило надежность прогноза на новых пациентах. Это современный, точный и честный подход к построению прогностических моделей.
💡 В результате получилась надежная модель, которую можно применять в клинической практике, а не просто публиковать. Это и есть цель любой медицинской модели: быть полезной и точной, особенно когда речь идет о редких исходах.
Когда в соавторах профессор Richard D. Riley, а сама публикация в журнале The Lancet, это знак большого доверия. Но самое важное — то, как была построена прогностическая модель. В свежем исследовании авторы оценили риск тяжелых кожных реакций на аллопуринол и сделали это как это нужно делать! Поэтому эта работа важна для всех, кто занимается моделированием в медицине.
🔹 Во-первых, масштаб. Почти 174 000 пациентов в тренировочной выборке и 42 000 — для валидации. Без больших данных надежную модель, особенно для редких событий, не построишь. Модель должна «видеть» тысячи случаев, чтобы делать уверенные прогнозы.
🔹 Во-вторых, калибровка. Это не просто одна из метрик модели — это ее основа. Важно не только "угадывать", у кого будет исход, но и точно предсказывать вероятность. Модель должна говорить: «у этого пациента риск 0.3%» и это действительно должно быть 3 случая из 1000, а не 10 из 1000.
🔹 В модель включили 7 предикторов (14 параметров). Так как первоначальная калибровка модели даже на такой огромной выборке оказалась не очень хорошей в связи низкой частотой исхода, авторы применили рекалибровку с помощью псевдо-значений и генерализованных линейных моделей. А чтобы минимизировать переобучение коэффициенты модели после первичной калибровки дополнительно уменьшили (shrinked), используя бутстрап-оценку оптимизма, и затем пересчитали интерсепт. Это повысило надежность прогноза на новых пациентах. Это современный, точный и честный подход к построению прогностических моделей.
💡 В результате получилась надежная модель, которую можно применять в клинической практике, а не просто публиковать. Это и есть цель любой медицинской модели: быть полезной и точной, особенно когда речь идет о редких исходах.
The Lancet Rheumatology
Development and validation of a prognostic model for predicting the risk of allopurinol-induced severe cutaneous adverse reactions:…
We developed and validated a prognostic model for the 100-day risk of an allopurinol-induced
severe cutaneous adverse reaction with good predictive performance and clinical utility.
This model could be used to inform the choice of urate-lowering drugs.
severe cutaneous adverse reaction with good predictive performance and clinical utility.
This model could be used to inform the choice of urate-lowering drugs.
Новая статья «Second-generation p-values» посвящена проблемам классических p-уровней значимости (p-value) и предлагает концептуальное обновление. Классический p-value показывает лишь вероятность наблюдать данные столь же или более экстремальные данные, если нулевая гипотеза верна. Но такая формулировка имеет несколько принципиальных слабых мест. Во-первых, статистическая значимость не означает научной или клинической значимости: очень маленькие эффекты могут стать «значимыми» при больших выборках, но не иметь никакой практической ценности. Во-вторых, точечная нулевая гипотеза нереалистична и в реальной жизни чаще речь идет о диапазоне значений, которые можно считать неотличимыми от нуля. В-третьих, множественные сравнения создают лавину ложноположительных находок, требующих искусственных и часто чрезмерно жестких поправок. В-четвертых, классический p-value никогда не «поддерживает» нулевую гипотезу — большие значения лишь показывают, что нет оснований отвергнуть ее, что приводит к знаменитой путанице «отсутствие доказательств не есть доказательство отсутствия».
Тем не менее, более чем столетний опыт показывает, что использование p-значений, несмотря на их недостатки, видимо сохранится. Наука стремится к легкоусвояемому и достоверному выводу о совместимости данных с нулевыми или альтернативными гипотезами. Авторы статьи предлагают альтернативу — p-value второго поколения (pδ). В основе этой идеи лежит интервал нулевой гипотезы. Исследователь заранее определяет, какой диапазон эффектов считается практически (клинически) незначимым. Это может быть предел клинической значимости, нижняя граница измеряемости или научно обоснованный минимум эффекта. Например, в исследовании по выживаемости при раке легкого исследователи решили, что различия меньше 5% не имеют клинической ценности. Тогда интервал нуля был задан двумя способами. В терминах различий вероятности выживания он составил от –0,05 до +0,05, что отражает клинически незначимые отклонения менее 5%. На графиках Каплана–Майера видно, что кривые мужчин и женщин расходятся более чем на 5% в периоде от 300 до 600 дней, выходя за пределы этой зоны. При анализе модели Кокса нулевой интервал задавали вокруг значения hazard ratio = 1, считая клинически несущественными отклонения в пределах 0,9–1,1. Полученный доверительный интервал HR равен 1,23–2,36 и полностью лежит выше данной нулевой зоны, поэтому пересечения нет и pδ = 0. Интерпретация проста: данные подтверждают альтернативную гипотезу, различие в риске смерти не тольско статистически, но и клинически значимо и не может быть объяснено случайными эффектами. Если бы доверительный интервал целиком лежал внутри нулевого интервала, мы бы получили pδ = 1 и заключили, что данные подтверждают только нулевые гипотезы, то есть эффект незначим. А если доверительный интервал частично пересекался бы с нулевой зоной, pδ оказался бы между 0 и 1, показывая, что результат неопределенный: данные поддерживают и нулевые, и альтернативные гипотезы в разных степенях.
Такой способ формализации сразу решает несколько проблем. Во-первых, он четко разделяет случаи «данные подтверждают отсутствие эффекта» и «данные не дают ясного ответа», чего классический p-value не делает. Во-вторых, pδ естественным образом контролирует ошибку I рода: вероятность получить pδ = 0 при истинной нулевой гипотезе стремится к нулю по мере роста выборки. В-третьих, при множественных сравнениях pδ существенно снижает частоту ложных открытий, так как отсеивает тривиальные эффекты. В-четвертых, он повышает прозрачность исследований, так как исследователь обязан заранее определить минимальный значимый эффект, вместо того чтобы подгонять интерпретацию постфактум.
Тем не менее, более чем столетний опыт показывает, что использование p-значений, несмотря на их недостатки, видимо сохранится. Наука стремится к легкоусвояемому и достоверному выводу о совместимости данных с нулевыми или альтернативными гипотезами. Авторы статьи предлагают альтернативу — p-value второго поколения (pδ). В основе этой идеи лежит интервал нулевой гипотезы. Исследователь заранее определяет, какой диапазон эффектов считается практически (клинически) незначимым. Это может быть предел клинической значимости, нижняя граница измеряемости или научно обоснованный минимум эффекта. Например, в исследовании по выживаемости при раке легкого исследователи решили, что различия меньше 5% не имеют клинической ценности. Тогда интервал нуля был задан двумя способами. В терминах различий вероятности выживания он составил от –0,05 до +0,05, что отражает клинически незначимые отклонения менее 5%. На графиках Каплана–Майера видно, что кривые мужчин и женщин расходятся более чем на 5% в периоде от 300 до 600 дней, выходя за пределы этой зоны. При анализе модели Кокса нулевой интервал задавали вокруг значения hazard ratio = 1, считая клинически несущественными отклонения в пределах 0,9–1,1. Полученный доверительный интервал HR равен 1,23–2,36 и полностью лежит выше данной нулевой зоны, поэтому пересечения нет и pδ = 0. Интерпретация проста: данные подтверждают альтернативную гипотезу, различие в риске смерти не тольско статистически, но и клинически значимо и не может быть объяснено случайными эффектами. Если бы доверительный интервал целиком лежал внутри нулевого интервала, мы бы получили pδ = 1 и заключили, что данные подтверждают только нулевые гипотезы, то есть эффект незначим. А если доверительный интервал частично пересекался бы с нулевой зоной, pδ оказался бы между 0 и 1, показывая, что результат неопределенный: данные поддерживают и нулевые, и альтернативные гипотезы в разных степенях.
Такой способ формализации сразу решает несколько проблем. Во-первых, он четко разделяет случаи «данные подтверждают отсутствие эффекта» и «данные не дают ясного ответа», чего классический p-value не делает. Во-вторых, pδ естественным образом контролирует ошибку I рода: вероятность получить pδ = 0 при истинной нулевой гипотезе стремится к нулю по мере роста выборки. В-третьих, при множественных сравнениях pδ существенно снижает частоту ложных открытий, так как отсеивает тривиальные эффекты. В-четвертых, он повышает прозрачность исследований, так как исследователь обязан заранее определить минимальный значимый эффект, вместо того чтобы подгонять интерпретацию постфактум.
journals.plos.org
Second-generation p-values: Improved rigor, reproducibility, & transparency in statistical analyses
Verifying that a statistically significant result is scientifically meaningful is not only good scientific practice, it is a natural way to control the Type I error rate. Here we introduce a novel extension of the p-value—a second-generation p-value (pδ)–that…
👍2🔥1
В новом препринте "Sequential sample size calculations and learning curves safeguard the robust development of a clinical prediction model for individuals" от известных авторов западной школы современной статистики поднимается крайне важный вопрос, посвященный тому, как правильно рассчитывать объем выборки при разработке клинических предсказательных моделей, если данные собираются проспективно.
В классическом подходе исследователь заранее делает фиксированный расчет выборки (например, «нужно 350 пациентов»), исходя из предположений о характеристиках модели (c-статистика, риск события и т.п.). Но эти предположения могут оказаться неверными, и тогда либо модель переобучается и плохо работает, либо наоборот — тратится неоправданно много ресурсов. Авторы предлагают последовательный (sequential) подход. Суть в том, что каждые, например, 100 новых пациентов модель пересчитывается заново, проводится бутстреп-валидация и строятся кривые обучения (learning curves). На этих кривых видно, как меняются показатели качества модели (калибровка, дискриминация, стабильность индивидуальных прогнозов, вероятность ошибочной классификации) по мере роста выборки. Набор данных продолжают увеличивать до тех пор, пока не выполняются заранее установленные правила остановки — например, калибровка ≥ 0.9, малая неопределенность индивидуальных прогнозов или вероятность ошибки классификации ≤ 10%.
Пример: при разработке модели риска острого повреждения почек по базе MIMIC-III предварительный фиксированный расчет выборки показал, что нужно 342 пациента. Но последовательный анализ показал: чтобы добиться устойчивой калибровки, нужно минимум 1100 пациентов, а чтобы снизить нестабильность индивидуальных прогнозов и вероятность ошибочной классификации, уже около 1800. То есть фиксированный метод сильно недооценил необходимый размер выборки.
Главная мысль публикации — размер выборки нельзя надежно оценить один раз «до начала исследования», особенно если исходные предположения о модели оказываются слишком оптимистичными или пессимистичными. Последовательный подход с кривыми обучения позволяет динамически проверять, насколько модель стабилизировалась, и вовремя остановить или продолжить набор данных. Это снижает риск переобучения, дает более надежные индивидуальные прогнозы и защищает от неверных расчетов.
В классическом подходе исследователь заранее делает фиксированный расчет выборки (например, «нужно 350 пациентов»), исходя из предположений о характеристиках модели (c-статистика, риск события и т.п.). Но эти предположения могут оказаться неверными, и тогда либо модель переобучается и плохо работает, либо наоборот — тратится неоправданно много ресурсов. Авторы предлагают последовательный (sequential) подход. Суть в том, что каждые, например, 100 новых пациентов модель пересчитывается заново, проводится бутстреп-валидация и строятся кривые обучения (learning curves). На этих кривых видно, как меняются показатели качества модели (калибровка, дискриминация, стабильность индивидуальных прогнозов, вероятность ошибочной классификации) по мере роста выборки. Набор данных продолжают увеличивать до тех пор, пока не выполняются заранее установленные правила остановки — например, калибровка ≥ 0.9, малая неопределенность индивидуальных прогнозов или вероятность ошибки классификации ≤ 10%.
Пример: при разработке модели риска острого повреждения почек по базе MIMIC-III предварительный фиксированный расчет выборки показал, что нужно 342 пациента. Но последовательный анализ показал: чтобы добиться устойчивой калибровки, нужно минимум 1100 пациентов, а чтобы снизить нестабильность индивидуальных прогнозов и вероятность ошибочной классификации, уже около 1800. То есть фиксированный метод сильно недооценил необходимый размер выборки.
Главная мысль публикации — размер выборки нельзя надежно оценить один раз «до начала исследования», особенно если исходные предположения о модели оказываются слишком оптимистичными или пессимистичными. Последовательный подход с кривыми обучения позволяет динамически проверять, насколько модель стабилизировалась, и вовремя остановить или продолжить набор данных. Это снижает риск переобучения, дает более надежные индивидуальные прогнозы и защищает от неверных расчетов.
arXiv.org
Sequential sample size calculations and learning curves safeguard...
When prospectively developing a new clinical prediction model (CPM), fixed sample size calculations are typically conducted before data collection based on sensible assumptions. But if the...
👍2🔥1
В BMJ вышла новая статья "Hidden risks of predictive models in healthcare", авторы которой еще раз заставляют задуматься о проблеме прогностических моделей в медицине.
Предиктивные модели в здравоохранении широко используются для оценки рисков и прогноза исходов у пациентов, однако их применение зачастую опережает качество научного обоснования. Несмотря на тысячи ежегодно разрабатываемых инструментов — от простых расчетных правил (калькуляторов) до сложных моделей машинного обучения, лишь немногие из них проходят тщательную проверку на точность и клиническую ценность. В результате это может приводить к ошибочным диагнозам, неверному выбору терапии и усилению неравенства в здравоохранении.
Серьезной проблемой является недостаток надежных доказательств, методологические ошибки и высокая вероятность смещения. Многие модели оцениваются только по способности различать исходы, но не по влиянию на качество медицинской помощи. Кроме того, часть моделей разрабатывалась десятилетия назад и больше не отражает современные реалии: изменились заболеваемость, смертность, подходы к лечению и понимание социальных факторов. Отсутствие регулярного обновления приводит к снижению их эффективности и надежности.
Система контроля и регулирования предиктивных моделей фрагментарна и ограничивается, как правило, стадией публикации в научных журналах. Механизмы выявления плохо работающих моделей и их исключения из практики фактически отсутствуют. Часть моделей может подпадать под определение «программного обеспечения как медицинского изделия», что требует соблюдения нормативных требований, однако далеко не все инструменты регистрируются и проходят соответствующие проверки. Это создает риск неконтролируемого использования моделей с недоказанной безопасностью и эффективностью.
Такая ситуация имеет прямые последствия для пациентов. Ошибочные прогнозы могут влиять на врачебные решения и долгосрочное здоровье, подрывать процесс информированного согласия и усиливать дискриминацию. Необходимо двигаться к более целостной системе управления и контроля. Это включает прозрачность при разработке и публикации моделей, использование репрезентативных данных, соответствие международным стандартам и нормативным требованиям, регулярное обновление и мониторинг работы моделей в реальных условиях. Клиницисты должны учитывать не только точность моделей, но и их влияние на качество ухода и лечения, а также обсуждать результаты с пациентами в рамках совместного принятия решений. Для регуляторов важно находить баланс между недостаточной и чрезмерной регуляцией, поскольку чрезмерное ужесточение может затормозить инновации.
Главный вывод работы заключается в том, что отсутствие четких механизмов контроля делает использование предиктивных моделей в медицине потенциально опасным. Для минимизации рисков и повышения пользы для пациентов необходим комплексный подход к регулированию, внедрение лучших методологических практик и постоянный надзор за этими инструментами.
Предиктивные модели в здравоохранении широко используются для оценки рисков и прогноза исходов у пациентов, однако их применение зачастую опережает качество научного обоснования. Несмотря на тысячи ежегодно разрабатываемых инструментов — от простых расчетных правил (калькуляторов) до сложных моделей машинного обучения, лишь немногие из них проходят тщательную проверку на точность и клиническую ценность. В результате это может приводить к ошибочным диагнозам, неверному выбору терапии и усилению неравенства в здравоохранении.
Серьезной проблемой является недостаток надежных доказательств, методологические ошибки и высокая вероятность смещения. Многие модели оцениваются только по способности различать исходы, но не по влиянию на качество медицинской помощи. Кроме того, часть моделей разрабатывалась десятилетия назад и больше не отражает современные реалии: изменились заболеваемость, смертность, подходы к лечению и понимание социальных факторов. Отсутствие регулярного обновления приводит к снижению их эффективности и надежности.
Система контроля и регулирования предиктивных моделей фрагментарна и ограничивается, как правило, стадией публикации в научных журналах. Механизмы выявления плохо работающих моделей и их исключения из практики фактически отсутствуют. Часть моделей может подпадать под определение «программного обеспечения как медицинского изделия», что требует соблюдения нормативных требований, однако далеко не все инструменты регистрируются и проходят соответствующие проверки. Это создает риск неконтролируемого использования моделей с недоказанной безопасностью и эффективностью.
Такая ситуация имеет прямые последствия для пациентов. Ошибочные прогнозы могут влиять на врачебные решения и долгосрочное здоровье, подрывать процесс информированного согласия и усиливать дискриминацию. Необходимо двигаться к более целостной системе управления и контроля. Это включает прозрачность при разработке и публикации моделей, использование репрезентативных данных, соответствие международным стандартам и нормативным требованиям, регулярное обновление и мониторинг работы моделей в реальных условиях. Клиницисты должны учитывать не только точность моделей, но и их влияние на качество ухода и лечения, а также обсуждать результаты с пациентами в рамках совместного принятия решений. Для регуляторов важно находить баланс между недостаточной и чрезмерной регуляцией, поскольку чрезмерное ужесточение может затормозить инновации.
Главный вывод работы заключается в том, что отсутствие четких механизмов контроля делает использование предиктивных моделей в медицине потенциально опасным. Для минимизации рисков и повышения пользы для пациентов необходим комплексный подход к регулированию, внедрение лучших методологических практик и постоянный надзор за этими инструментами.
👍1🔥1
Про WebPlotDigitizer и распределение Вейбулла
Графики с кривыми выживаемости — один из важнейших источников информации в клинических исследованиях, особенно если исходные индивидуальные данные недоступны. Однако сами по себе изображения имеют ограниченную аналитическую ценность, и для проведения более глубоких оценок их необходимо переводить в числовой формат. Проблема в том, что исходные данные почти всегда недоступны, так как не предоставляются авторами исследований и статей.
Графики с кривыми выживаемости — один из важнейших источников информации в клинических исследованиях, особенно если исходные индивидуальные данные недоступны. Однако сами по себе изображения имеют ограниченную аналитическую ценность, и для проведения более глубоких оценок их необходимо переводить в числовой формат. Проблема в том, что исходные данные почти всегда недоступны, так как не предоставляются авторами исследований и статей.
👍1🔥1
Тем не менее, мы можем получить данные прямо из графиков. Для этого применяются специальные инструменты, например WebPlotDigitizer, которые позволяют оцифровать кривые Каплана-Мэйера, получив значения вероятности выживаемости во времени для каждой исследуемой группы.
После оцифровки можно перейти к следующему шагу — аппроксимации полученных точек с помощью математических распределений, чаще всего Вейбулла или экспоненциального распределения. Такая аппроксимация обеспечивает гладкое описание кривых и позволяет не только воспроизвести имеющиеся данные, но и экстраполировать их за пределы наблюдаемого периода. Кроме того, аппроксимированные кривые дают возможность вычислять вероятность событий в любой момент времени и формировать таблицы переходов для дальнейшего моделирования.
Когда кривые преобразованы в числовую форму, появляется возможность провести статистический анализ, например построить модель пропорциональных рисков Кокса. На основе времени до события (прогрессия или смерть) и информации о цензурировании модель Кокса позволяет рассчитать отношение рисков (hazard ratio) между двумя группами и доверительные интервалы для этой оценки. Таким образом можно количественно сравнить эффективность двух стратегий даже без доступа к исходным данным пациентов.
Наконец, такие аппроксимированные и оцифрованные кривые становятся базой для проведения более сложных исследований, в том числе фармакоэкономических. Именно они позволяют моделировать виртуальные когорты пациентов, рассчитывать время до прогрессии, задавать сценарии лечения и оценивать их экономические последствия в условиях ограниченного горизонта.
В моем недавнем проекте я использовал кривые выживаемости из исследования AQUILA (по множественной миеломе). На картинках показаны оригинальные и оцифрованные и апроксимированные кривые выживаемости. Мой расчетный HR составил 0.51 (0.35-0.82), что близко к оригиналу - 0.49 (0.36-0.67).
После оцифровки можно перейти к следующему шагу — аппроксимации полученных точек с помощью математических распределений, чаще всего Вейбулла или экспоненциального распределения. Такая аппроксимация обеспечивает гладкое описание кривых и позволяет не только воспроизвести имеющиеся данные, но и экстраполировать их за пределы наблюдаемого периода. Кроме того, аппроксимированные кривые дают возможность вычислять вероятность событий в любой момент времени и формировать таблицы переходов для дальнейшего моделирования.
Когда кривые преобразованы в числовую форму, появляется возможность провести статистический анализ, например построить модель пропорциональных рисков Кокса. На основе времени до события (прогрессия или смерть) и информации о цензурировании модель Кокса позволяет рассчитать отношение рисков (hazard ratio) между двумя группами и доверительные интервалы для этой оценки. Таким образом можно количественно сравнить эффективность двух стратегий даже без доступа к исходным данным пациентов.
Наконец, такие аппроксимированные и оцифрованные кривые становятся базой для проведения более сложных исследований, в том числе фармакоэкономических. Именно они позволяют моделировать виртуальные когорты пациентов, рассчитывать время до прогрессии, задавать сценарии лечения и оценивать их экономические последствия в условиях ограниченного горизонта.
В моем недавнем проекте я использовал кривые выживаемости из исследования AQUILA (по множественной миеломе). На картинках показаны оригинальные и оцифрованные и апроксимированные кривые выживаемости. Мой расчетный HR составил 0.51 (0.35-0.82), что близко к оригиналу - 0.49 (0.36-0.67).
automeris.io
automeris.io: Computer vision assisted data extraction from charts using WebPlotDigitizer
Web based software to extract data from plots, charts, bar charts etc.
🔥1
Будьте осторожны с ROC-кривой!
Если вы создаете прогностическую модель на несбалансированных данных, где "положительный исход" (например, летальный исход) встречается значительно реже, чем отрицательный, не стоит полагаться исключительно на ROC-кривую при оценке качества модели. Бинарные классификаторы традиционно оцениваются с помощью таких метрик, как чувствительность и специфичность, а их производительность часто визуализируется с помощью ROC-кривых. Альтернативные метрики, такие как положительная прогностическая ценность (PPV) и связанные с ней графики точности и полноты (PRC-кривые), используются реже, несмотря на их важность в задачах с выраженным дисбалансом классов.
Во многих прикладных исследованиях, включая биомедицинские задачи, классификаторы обучаются и тестируются на выборках, в которых число отрицательных случаев существенно превышает количество положительных. Хотя ROC-кривые дают общее представление о работе модели по всей шкале специфичности, в условиях дисбаланса они могут вводить в заблуждение. Это связано с тем, что высокая специфичность при малом числе положительных случаев может быть достигнута даже при неэффективной идентификации положительного класса — за счет большого числа верно классифицированных отрицательных примеров.
В новом исследовании показано, что ROC-кривые в таких ситуациях могут создавать иллюзию высокой точности, поскольку специфичность, входящая в их расчет, сохраняется высокой даже при минимальной чувствительности. В отличие от них, PRC-кривые более чувствительны к качеству распознавания редкого положительного класса, так как фокусируются на доле истинно положительных результатов среди всех положительных предсказаний.
Допустим, вы прогнозируете летальный исход у пациентов по выборке из 100 человек, из которых только 10 действительно умерли. ROC-кривая может демонстрировать высокое качество модели за счет правильной классификации 90 выживших пациентов (отрицательных случаев), даже если модель почти не определяет умерших. То есть, даже при низкой чувствительности, специфичность остается высокой, и ROC-кривая выглядит убедительно. Однако такая модель практически бесполезна в реальном прогнозировании летальности, поскольку не выполняет свою основную функцию — выявление редких, но критически важных положительных исходов. В этом случае PRC-кривая даст более реалистичную оценку, поскольку она акцентирует внимание на том, насколько точны положительные предсказания и какова доля среди них действительно верных.
Если вы создаете прогностическую модель на несбалансированных данных, где "положительный исход" (например, летальный исход) встречается значительно реже, чем отрицательный, не стоит полагаться исключительно на ROC-кривую при оценке качества модели. Бинарные классификаторы традиционно оцениваются с помощью таких метрик, как чувствительность и специфичность, а их производительность часто визуализируется с помощью ROC-кривых. Альтернативные метрики, такие как положительная прогностическая ценность (PPV) и связанные с ней графики точности и полноты (PRC-кривые), используются реже, несмотря на их важность в задачах с выраженным дисбалансом классов.
Во многих прикладных исследованиях, включая биомедицинские задачи, классификаторы обучаются и тестируются на выборках, в которых число отрицательных случаев существенно превышает количество положительных. Хотя ROC-кривые дают общее представление о работе модели по всей шкале специфичности, в условиях дисбаланса они могут вводить в заблуждение. Это связано с тем, что высокая специфичность при малом числе положительных случаев может быть достигнута даже при неэффективной идентификации положительного класса — за счет большого числа верно классифицированных отрицательных примеров.
В новом исследовании показано, что ROC-кривые в таких ситуациях могут создавать иллюзию высокой точности, поскольку специфичность, входящая в их расчет, сохраняется высокой даже при минимальной чувствительности. В отличие от них, PRC-кривые более чувствительны к качеству распознавания редкого положительного класса, так как фокусируются на доле истинно положительных результатов среди всех положительных предсказаний.
Допустим, вы прогнозируете летальный исход у пациентов по выборке из 100 человек, из которых только 10 действительно умерли. ROC-кривая может демонстрировать высокое качество модели за счет правильной классификации 90 выживших пациентов (отрицательных случаев), даже если модель почти не определяет умерших. То есть, даже при низкой чувствительности, специфичность остается высокой, и ROC-кривая выглядит убедительно. Однако такая модель практически бесполезна в реальном прогнозировании летальности, поскольку не выполняет свою основную функцию — выявление редких, но критически важных положительных исходов. В этом случае PRC-кривая даст более реалистичную оценку, поскольку она акцентирует внимание на том, насколько точны положительные предсказания и какова доля среди них действительно верных.
journals.plos.org
The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets
Binary classifiers are routinely evaluated with performance measures such as sensitivity and specificity, and performance is frequently illustrated with Receiver Operating Characteristics (ROC) plots. Alternative measures such as positive predictive value…
👍3
Как фундаментальная неопределенность мешает принимать решения в медицине
Медицина — постоянное принятие решений в условиях неопределенности. Врачи привыкли к тому, что реальность сложнее, чем результаты клинических исследований, и что даже статистически значимые выводы не гарантируют точного прогноза для конкретного пациента. Но откуда берется эта фундаментальная неопределенность и почему она так мешает клиническому мышлению?
Возьмем простой пример. В исследовании показано, что наличие фактора А ухудшает прогноз выживаемости. Мы встречаем пациента, у которого этот фактор присутствует, и по логике «однофакторного анализа» ожидаем худший исход. Все вроде бы очевидно. Но затем мы замечаем фактор B, который тоже ассоциируется с неблагоприятным исходом. Возникает вопрос: если у пациента есть оба фактора, насколько именно его прогноз хуже? Нужно ли складывать их эффекты, умножать, или один из них «доминирует»?
А потом появляется фактор C, который в другом исследовании, наоборот, улучшал выживаемость. Значит ли это, что он частично компенсирует действие факторов А и B? Или его эффект будет нивелирован их присутствием? На практике это не так просто: взаимодействия между факторами могут быть нелинейными, зависеть от контекста, коморбидности и десятков других скрытых переменных.
Вот в этот момент простая логика однофакторного анализа перестает работать. Она полезная отправная точка, но не инструмент для индивидуального прогноза. Реальный пациент — не средний участник исследования, а уникальная комбинация признаков, каждый из которых может менять значение другого. Именно поэтому многомерные модели, машинное обучение и нейросетевые подходы стремятся уловить эти сложные взаимосвязи. Но даже они не устраняют неопределенность, а лишь немного сокращают ее.
Фундаментальная неопределенность — это не недостаток науки, а ее постоянный спутник. Любая статистическая модель основана на вероятностях, а не на детерминизме. Она может подсказать, что «пациенты с профилем, похожим на вашего, имели худший исход в 68% случаев», но не ответит, что произойдет именно с ним. Поэтому байесовские подходы выигрывают, поэтому однофакторный анализ это только разминка для ума, но не способ принятия решений, поэтому ИИ для многофакторного анализа — текущая необходимость.
Также здесь важно помнить, что цель статистики — не дать окончательный ответ, а помочь врачу принять более информированное решение, осознавая границы предсказаний. Искусство медицины — умение жить внутри этой неопределенности, не отрицая ее, но используя данные максимально рационально.
Медицина — постоянное принятие решений в условиях неопределенности. Врачи привыкли к тому, что реальность сложнее, чем результаты клинических исследований, и что даже статистически значимые выводы не гарантируют точного прогноза для конкретного пациента. Но откуда берется эта фундаментальная неопределенность и почему она так мешает клиническому мышлению?
Возьмем простой пример. В исследовании показано, что наличие фактора А ухудшает прогноз выживаемости. Мы встречаем пациента, у которого этот фактор присутствует, и по логике «однофакторного анализа» ожидаем худший исход. Все вроде бы очевидно. Но затем мы замечаем фактор B, который тоже ассоциируется с неблагоприятным исходом. Возникает вопрос: если у пациента есть оба фактора, насколько именно его прогноз хуже? Нужно ли складывать их эффекты, умножать, или один из них «доминирует»?
А потом появляется фактор C, который в другом исследовании, наоборот, улучшал выживаемость. Значит ли это, что он частично компенсирует действие факторов А и B? Или его эффект будет нивелирован их присутствием? На практике это не так просто: взаимодействия между факторами могут быть нелинейными, зависеть от контекста, коморбидности и десятков других скрытых переменных.
Вот в этот момент простая логика однофакторного анализа перестает работать. Она полезная отправная точка, но не инструмент для индивидуального прогноза. Реальный пациент — не средний участник исследования, а уникальная комбинация признаков, каждый из которых может менять значение другого. Именно поэтому многомерные модели, машинное обучение и нейросетевые подходы стремятся уловить эти сложные взаимосвязи. Но даже они не устраняют неопределенность, а лишь немного сокращают ее.
Фундаментальная неопределенность — это не недостаток науки, а ее постоянный спутник. Любая статистическая модель основана на вероятностях, а не на детерминизме. Она может подсказать, что «пациенты с профилем, похожим на вашего, имели худший исход в 68% случаев», но не ответит, что произойдет именно с ним. Поэтому байесовские подходы выигрывают, поэтому однофакторный анализ это только разминка для ума, но не способ принятия решений, поэтому ИИ для многофакторного анализа — текущая необходимость.
Также здесь важно помнить, что цель статистики — не дать окончательный ответ, а помочь врачу принять более информированное решение, осознавая границы предсказаний. Искусство медицины — умение жить внутри этой неопределенности, не отрицая ее, но используя данные максимально рационально.
Давайте я еще раз скажу, что такое доверительный интервал
ДИ — интервал, который говорит нам, что если бы мы повторяли одно и то же исследование бесконечное число раз и каждый раз вычисляли 95% ДИ одним и тем же способом, то около 95% этих интервалов содержали бы истинный эффект.
Представим что Hazard ratio = 0.72 (95% CI 0.55–0.94). Истинное значение HR мы не знаем и не узнаем никогда! 0.72 — не истинное значение, а значение, вычисленное на основе конкретных данных одной выборки (нашего исследования) и при повторении исследования оно изменится. Другими словами 0.72 — случайная величина, зависящая от выборки. Если бы мы провели бесконечно много таких исследований и каждый раз строили интервал тем же способом, то примерно в 95% случаев полученные интервалы включали бы истинное HR. Мы же имеем только один из таких интервалов — (0.55–0.94). Мы не знаем, попал ли в него истинный HR, но говорим, что в 95% случаев "попадает".
Это рассуждение относится к любым другим статистическим методам в частотной статистике.
ДИ — интервал, который говорит нам, что если бы мы повторяли одно и то же исследование бесконечное число раз и каждый раз вычисляли 95% ДИ одним и тем же способом, то около 95% этих интервалов содержали бы истинный эффект.
Представим что Hazard ratio = 0.72 (95% CI 0.55–0.94). Истинное значение HR мы не знаем и не узнаем никогда! 0.72 — не истинное значение, а значение, вычисленное на основе конкретных данных одной выборки (нашего исследования) и при повторении исследования оно изменится. Другими словами 0.72 — случайная величина, зависящая от выборки. Если бы мы провели бесконечно много таких исследований и каждый раз строили интервал тем же способом, то примерно в 95% случаев полученные интервалы включали бы истинное HR. Мы же имеем только один из таких интервалов — (0.55–0.94). Мы не знаем, попал ли в него истинный HR, но говорим, что в 95% случаев "попадает".
Это рассуждение относится к любым другим статистическим методам в частотной статистике.
👍1
Вот еще одно хорошее объяснение ДИ 👇
Частотный доверительный интервал (ДИ) — интервал, который рассчитывается на основе выборочных данных с целью приблизительной оценки неизвестного истинного значения некоторого параметра (например, среднего значения или эффекта). Однако такой интервал не является утверждением о вероятности самого истинного значения.
Предположим, вы хотите оценить средний рост взрослых жителей города. Измерить рост каждого жителя невозможно, поэтому вы выбираете случайную выборку и строите ДИ. Допустим, результатом оказывается интервал от 170 до 180 см с уровнем доверия 95%.
Это означает следующее:
Если бы вы многократно повторяли весь процесс, каждый раз отбирая новую случайную выборку и рассчитывая аналогичный ДИ, то примерно в 95% случаев полученные интервалы охватывали бы истинное среднее значение роста всей популяции. Однако для конкретного рассчитанного интервала (170–180 см) истинное значение либо попадает в него, либо нет — после получения данных понятие вероятности к самому интервалу более не применяется.
Наиболее распространенная ошибка — утверждать, что «с вероятностью 95% истинное среднее находится между 170 и 180 см». С точки зрения частотной интерпретации это неверно. Указанный уровень доверия относится к долгосрочной частоте успеха процедуры построения интервала, а не к вероятности для конкретного результата. На практике ДИ от 170 до 180 см указывает на диапазон вполне возможных значений среднего роста в популяции на основании ваших данных.
Хотя вы не знаете истинное среднее, ДИ предоставляет количественную оценку точности и неопределенности:
🔹 Ширина интервала (в данном случае 10 см) отражает степень неопределенности: чем уже интервал, тем более точной считается оценка; чем шире, тем выше неопределенность.
🔹 Сам интервал (170–180 см) представляет собой оценку того, в каком диапазоне, согласно вашей выборке и методике, может находиться истинное среднее значение.
Частотный доверительный интервал (ДИ) — интервал, который рассчитывается на основе выборочных данных с целью приблизительной оценки неизвестного истинного значения некоторого параметра (например, среднего значения или эффекта). Однако такой интервал не является утверждением о вероятности самого истинного значения.
Предположим, вы хотите оценить средний рост взрослых жителей города. Измерить рост каждого жителя невозможно, поэтому вы выбираете случайную выборку и строите ДИ. Допустим, результатом оказывается интервал от 170 до 180 см с уровнем доверия 95%.
Это означает следующее:
Если бы вы многократно повторяли весь процесс, каждый раз отбирая новую случайную выборку и рассчитывая аналогичный ДИ, то примерно в 95% случаев полученные интервалы охватывали бы истинное среднее значение роста всей популяции. Однако для конкретного рассчитанного интервала (170–180 см) истинное значение либо попадает в него, либо нет — после получения данных понятие вероятности к самому интервалу более не применяется.
Наиболее распространенная ошибка — утверждать, что «с вероятностью 95% истинное среднее находится между 170 и 180 см». С точки зрения частотной интерпретации это неверно. Указанный уровень доверия относится к долгосрочной частоте успеха процедуры построения интервала, а не к вероятности для конкретного результата. На практике ДИ от 170 до 180 см указывает на диапазон вполне возможных значений среднего роста в популяции на основании ваших данных.
Хотя вы не знаете истинное среднее, ДИ предоставляет количественную оценку точности и неопределенности:
🔹 Ширина интервала (в данном случае 10 см) отражает степень неопределенности: чем уже интервал, тем более точной считается оценка; чем шире, тем выше неопределенность.
🔹 Сам интервал (170–180 см) представляет собой оценку того, в каком диапазоне, согласно вашей выборке и методике, может находиться истинное среднее значение.
Порог — артефакт контекста анализа данных, а не свойство прогностической модели
В анализе данных и особенно в медицинской статистике продолжается странное недоразумение. Некоторые преподаватели по-прежнему внушают студентам и исследователям идею, будто можно «найти оптимальный порог вероятности» и на его основе делать выводы о качестве модели. Ах, да, они еще берут за это деньги 🤥. Эта практика не просто методологически устарела — она логически ошибочна.
Порог не является свойством модели! Он — функция конкретной выборки, распределения классов и критериев, которые выбрал исследователь.
Стоит изменить выборку, изменится и оптимальный порог, и вслед за ним чувствительность, специфичность, индекс Юдена и другие метрики. Это не дефект статистики, а ее природа. Данные всегда контекстуальны, и характеристики модели на одной выборке не переносятся на другую без переоценки. Когда мы вычисляем «лучший порог» по ROC-кривой, мы всего лишь подгоняем модель под эмпирические особенности конкретного набора наблюдений. В другой клинике, в другом городе, при иной распространенности исхода этот порог потеряет смысл, он будет другой. Это не то, что легко проверяется, это просто элементарно понятно. Поэтому попытки искать «универсальный» порог не просто бесполезны, а вредны! Они создают иллюзию точности там, где нужно говорить о вероятности и неопределенности.
Калибруйте модели! Хорошо калиброванная модель не нуждается в пороге. Она сообщает вероятность события — например, риск осложнения 0.82, и этим исчерпывает задачу предсказания. Решение (лечить, госпитализировать, наблюдать) должно приниматься не статистикой, а клиническим контекстом и ценой ошибки. Порог в этом смысле это не сакральное знание, а договор между вероятностью и вашим действием, зависящий от многих условий, которые вы не контролируете.
Представьте, что метеорологическая модель говорит: «Завтра дождь с вероятностью 80%.» Все, это и есть результат. Информация исчерпывающая. С вероятностью 80% дождь будет, с вероятностью 20% — нет. Вы, человек, принимаете решение — взять зонт или рискнуть и оставить его дома. Это и есть суть вероятностного мышления.
Но вместо этого вас учат придумать порог, например 60%. Если прогноз выше порога — значит, «дождь». Если ниже — «солнце». Дальше вычисляют чувствительность и специфичность прогноза дождя при этом пороге, а потом обсуждают, насколько «точна» модель. Это абсурд, ведь сам порог — не часть модели, а человеческая условность! Завтра вы выберете порог 70% и получите другие метрики. Модель не изменилась, изменилась ваша интерпретация.
Использовать «оптимальный порог» из одной выборки — все равно что измерить температуру в одной комнате и объявить ее нормой для всей планеты. Это не наука, а методологический самообман, маскирующий неопределенность под цифры.
В анализе данных и особенно в медицинской статистике продолжается странное недоразумение. Некоторые преподаватели по-прежнему внушают студентам и исследователям идею, будто можно «найти оптимальный порог вероятности» и на его основе делать выводы о качестве модели. Ах, да, они еще берут за это деньги 🤥. Эта практика не просто методологически устарела — она логически ошибочна.
Порог не является свойством модели! Он — функция конкретной выборки, распределения классов и критериев, которые выбрал исследователь.
Стоит изменить выборку, изменится и оптимальный порог, и вслед за ним чувствительность, специфичность, индекс Юдена и другие метрики. Это не дефект статистики, а ее природа. Данные всегда контекстуальны, и характеристики модели на одной выборке не переносятся на другую без переоценки. Когда мы вычисляем «лучший порог» по ROC-кривой, мы всего лишь подгоняем модель под эмпирические особенности конкретного набора наблюдений. В другой клинике, в другом городе, при иной распространенности исхода этот порог потеряет смысл, он будет другой. Это не то, что легко проверяется, это просто элементарно понятно. Поэтому попытки искать «универсальный» порог не просто бесполезны, а вредны! Они создают иллюзию точности там, где нужно говорить о вероятности и неопределенности.
Калибруйте модели! Хорошо калиброванная модель не нуждается в пороге. Она сообщает вероятность события — например, риск осложнения 0.82, и этим исчерпывает задачу предсказания. Решение (лечить, госпитализировать, наблюдать) должно приниматься не статистикой, а клиническим контекстом и ценой ошибки. Порог в этом смысле это не сакральное знание, а договор между вероятностью и вашим действием, зависящий от многих условий, которые вы не контролируете.
Представьте, что метеорологическая модель говорит: «Завтра дождь с вероятностью 80%.» Все, это и есть результат. Информация исчерпывающая. С вероятностью 80% дождь будет, с вероятностью 20% — нет. Вы, человек, принимаете решение — взять зонт или рискнуть и оставить его дома. Это и есть суть вероятностного мышления.
Но вместо этого вас учат придумать порог, например 60%. Если прогноз выше порога — значит, «дождь». Если ниже — «солнце». Дальше вычисляют чувствительность и специфичность прогноза дождя при этом пороге, а потом обсуждают, насколько «точна» модель. Это абсурд, ведь сам порог — не часть модели, а человеческая условность! Завтра вы выберете порог 70% и получите другие метрики. Модель не изменилась, изменилась ваша интерпретация.
Использовать «оптимальный порог» из одной выборки — все равно что измерить температуру в одной комнате и объявить ее нормой для всей планеты. Это не наука, а методологический самообман, маскирующий неопределенность под цифры.
🔥2
Про относительный риск, абсолютный риск и NNT
Мы частенько можем слышать с трибун, видеть в презентацих и читать в публикациях заявления об эффективности того или иного лечения в виде снижения риска, например прогрессии или рецидива. Но заявления о снижении риска, например на 50%, часто вводят в заблуждение. Когда цифры большие - задумайтесь! За такими громкими цифрами обычно стоит снижение относительного риска (RRR), которое способно произвести впечатление, но не отражает реальной клинической пользы. Чтобы понять истинное значение результата, необходимо рассматривать его вместе с абсолютным снижением риска (ARR) и числом пациентов, которых нужно пролечить для предотвращения одного события (NNT).
Представим клиническое исследование нового адъювантного препарата при раке молочной железы. В отчете указано, что применение препарата снижает риск рецидива на 50%. На первый взгляд, это кажется значительным успехом. Однако при более внимательном рассмотрении становится ясно, что речь идет об относительном показателе. Если в контрольной группе рецидив наблюдался у 20 из 100 пациенток, а в группе лечения — у 10, относительное снижение риска действительно составляет 50%. Но абсолютное снижение риска в этом случае равно лишь 10% (20% минус 10%). Именно этот показатель отражает реальную клиническую выгоду. Для более практической оценки используется показатель NNT (number needed to treat). В данном примере он равен 1 / 0,10 = 10. Это означает, что для предотвращения одного рецидива необходимо пролечить десять пациенток. Такой результат нельзя назвать незначительным, однако он демонстрирует, насколько важно различать статистический эффект и клиническую значимость.
Относительное снижение риска часто используется в публикациях и маркетинговых материалах для усиления восприятия эффективности терапии. Абсолютное снижение риска дает более точное представление о реальном влиянии лечения на исходы. Показатель NNT, в свою очередь, помогает врачу оценить практическую ценность вмешательства и объяснить пациенту ожидаемую пользу в понятной форме. Таким образом, интерпретируя результаты клинических исследований, необходимо выходить за рамки эффектных формулировок и анализировать их с учетом абсолютных показателей. Только так можно объективно оценить клиническую значимость терапии и принять взвешенное решение в интересах пациента.
Мы частенько можем слышать с трибун, видеть в презентацих и читать в публикациях заявления об эффективности того или иного лечения в виде снижения риска, например прогрессии или рецидива. Но заявления о снижении риска, например на 50%, часто вводят в заблуждение. Когда цифры большие - задумайтесь! За такими громкими цифрами обычно стоит снижение относительного риска (RRR), которое способно произвести впечатление, но не отражает реальной клинической пользы. Чтобы понять истинное значение результата, необходимо рассматривать его вместе с абсолютным снижением риска (ARR) и числом пациентов, которых нужно пролечить для предотвращения одного события (NNT).
Представим клиническое исследование нового адъювантного препарата при раке молочной железы. В отчете указано, что применение препарата снижает риск рецидива на 50%. На первый взгляд, это кажется значительным успехом. Однако при более внимательном рассмотрении становится ясно, что речь идет об относительном показателе. Если в контрольной группе рецидив наблюдался у 20 из 100 пациенток, а в группе лечения — у 10, относительное снижение риска действительно составляет 50%. Но абсолютное снижение риска в этом случае равно лишь 10% (20% минус 10%). Именно этот показатель отражает реальную клиническую выгоду. Для более практической оценки используется показатель NNT (number needed to treat). В данном примере он равен 1 / 0,10 = 10. Это означает, что для предотвращения одного рецидива необходимо пролечить десять пациенток. Такой результат нельзя назвать незначительным, однако он демонстрирует, насколько важно различать статистический эффект и клиническую значимость.
Относительное снижение риска часто используется в публикациях и маркетинговых материалах для усиления восприятия эффективности терапии. Абсолютное снижение риска дает более точное представление о реальном влиянии лечения на исходы. Показатель NNT, в свою очередь, помогает врачу оценить практическую ценность вмешательства и объяснить пациенту ожидаемую пользу в понятной форме. Таким образом, интерпретируя результаты клинических исследований, необходимо выходить за рамки эффектных формулировок и анализировать их с учетом абсолютных показателей. Только так можно объективно оценить клиническую значимость терапии и принять взвешенное решение в интересах пациента.
👍2
Клинические прогностические модели в онкологии: вызовы и рекомендации
Мир сегодня буквально переполнен моделями машинного обучения в онкологии, но реальное их применение в клинике по-прежнему остается редкостью. Проблема не в недостатке нейросетей. Их как раз с избытком. Настоящий дефицит — методологическая строгость, честные и репрезентативные данные, участие клиницистов и, если уж на то пошло, банальный здравый смысл. Модели множатся, как клетки при опухоли, но большинство так и остаются «в пробирке», в виде публикаций и демонстраций на конференциях. Вместо того чтобы делать очередную «революционную» модель, стоит задать себе простой вопрос: а нельзя ли доработать уже существующее? Ведь если инструмент есть, логичнее его улучшить, чем изобретать новый, пренебрегая уже проделанной работой.
Огромный пробел — вовлечение тех, кто будет с этими моделями реально работать. Без врачей и пациентов алгоритм превращается в игрушку исследователя. Модель может блестяще предсказывать выживаемость на тестовой выборке, но что она реально меняет у постели больного? Как ее предсказания влияют на клиническое решение? Без понимания этого любая модель — как магнитно-резонансный томограф, включенный в пустой комнате; технология есть, пациента нет.
Другой важный момент — протокол исследования. Без четко зафиксированного публичного протокола разработку легко подогнать под желаемый результат, исключить неудобные случаи, выбрать метрики задним числом. Машинное обучение - гибкая технология, но гибкость требует дисциплины. То же самое касается дизайна исследования. ML-модели «жадны» до данных, и попытки строить их на малых выборках — путь к переобучению и обманчивой уверенности. А потом в публикации начинается хрестоматийное: «размер выборки был ограничен…», хотя должен был быть рассчитан заранее, как это делается в клинических испытаниях.
Имеет значение и то, чьи данные используются. Модель, обученная на однородной когорте, часто не работает в реальной многоликой популяции. Она может показывать великолепные метрики в рамках ретроспективного исследования, но окажется абсолютно бесполезной в отделении интенсивной терапии районной больницы. Методы балансировки классов, такие как SMOTE, это не панацея и нередко дают ложное ощущение контроля над ситуацией. Репрезентативность — не технический параметр, а этический вопрос. Это же касается и прозрачности происхождения данных. Если источник неизвестен, если процесс очистки и подготовки не описан, перед нами не медицинский инструмент, а черный ящик. И да, пропущенные значения — не повод исключать пациентов. Реальные клинические данные всегда неполные, и модель должна уметь с этим работать. Множественная иммутация и другие методы — не украшения, а необходимость.
А еще — валидация. Внутренняя — только разминка. Настоящая проверка — внешний тест на новых пациентах в других учреждениях. Часто именно на этом этапе модель проявляет свои слабости словно ребенок, впервые вышедший из дома. А дальше вопрос пользы. ROC-AUC — всего лишь цифра. Она ничего не говорит о калибровке, о полезности для врача, о том, станет ли пациенту лучше. Если модель не помогает принимать решения, улучшающие исход, то кому она вообще нужна?
Наконец, реализация. Даже лучшая модель — не конец пути, а его начало. Ее нужно внедрить, объяснить, как с ней работать, обучить персонал, отслеживать эффективность, понимать, как она «стареет» со временем и требует обновления. Медицина — живой организм, а не статичная лаборатория.
Машинное обучение в онкологии — не волшебная таблетка. Это инструмент. И как любой инструмент, он требует дисциплины, этики, статистического мастерства и глубокого понимания клинического контекста. Без этого он — не помощник, а цифровая иллюзия, красивая снаружи, но бесполезная внутри.
Источник ...
Мир сегодня буквально переполнен моделями машинного обучения в онкологии, но реальное их применение в клинике по-прежнему остается редкостью. Проблема не в недостатке нейросетей. Их как раз с избытком. Настоящий дефицит — методологическая строгость, честные и репрезентативные данные, участие клиницистов и, если уж на то пошло, банальный здравый смысл. Модели множатся, как клетки при опухоли, но большинство так и остаются «в пробирке», в виде публикаций и демонстраций на конференциях. Вместо того чтобы делать очередную «революционную» модель, стоит задать себе простой вопрос: а нельзя ли доработать уже существующее? Ведь если инструмент есть, логичнее его улучшить, чем изобретать новый, пренебрегая уже проделанной работой.
Огромный пробел — вовлечение тех, кто будет с этими моделями реально работать. Без врачей и пациентов алгоритм превращается в игрушку исследователя. Модель может блестяще предсказывать выживаемость на тестовой выборке, но что она реально меняет у постели больного? Как ее предсказания влияют на клиническое решение? Без понимания этого любая модель — как магнитно-резонансный томограф, включенный в пустой комнате; технология есть, пациента нет.
Другой важный момент — протокол исследования. Без четко зафиксированного публичного протокола разработку легко подогнать под желаемый результат, исключить неудобные случаи, выбрать метрики задним числом. Машинное обучение - гибкая технология, но гибкость требует дисциплины. То же самое касается дизайна исследования. ML-модели «жадны» до данных, и попытки строить их на малых выборках — путь к переобучению и обманчивой уверенности. А потом в публикации начинается хрестоматийное: «размер выборки был ограничен…», хотя должен был быть рассчитан заранее, как это делается в клинических испытаниях.
Имеет значение и то, чьи данные используются. Модель, обученная на однородной когорте, часто не работает в реальной многоликой популяции. Она может показывать великолепные метрики в рамках ретроспективного исследования, но окажется абсолютно бесполезной в отделении интенсивной терапии районной больницы. Методы балансировки классов, такие как SMOTE, это не панацея и нередко дают ложное ощущение контроля над ситуацией. Репрезентативность — не технический параметр, а этический вопрос. Это же касается и прозрачности происхождения данных. Если источник неизвестен, если процесс очистки и подготовки не описан, перед нами не медицинский инструмент, а черный ящик. И да, пропущенные значения — не повод исключать пациентов. Реальные клинические данные всегда неполные, и модель должна уметь с этим работать. Множественная иммутация и другие методы — не украшения, а необходимость.
А еще — валидация. Внутренняя — только разминка. Настоящая проверка — внешний тест на новых пациентах в других учреждениях. Часто именно на этом этапе модель проявляет свои слабости словно ребенок, впервые вышедший из дома. А дальше вопрос пользы. ROC-AUC — всего лишь цифра. Она ничего не говорит о калибровке, о полезности для врача, о том, станет ли пациенту лучше. Если модель не помогает принимать решения, улучшающие исход, то кому она вообще нужна?
Наконец, реализация. Даже лучшая модель — не конец пути, а его начало. Ее нужно внедрить, объяснить, как с ней работать, обучить персонал, отслеживать эффективность, понимать, как она «стареет» со временем и требует обновления. Медицина — живой организм, а не статичная лаборатория.
Машинное обучение в онкологии — не волшебная таблетка. Это инструмент. И как любой инструмент, он требует дисциплины, этики, статистического мастерства и глубокого понимания клинического контекста. Без этого он — не помощник, а цифровая иллюзия, красивая снаружи, но бесполезная внутри.
Источник ...
Про медиаторный (медиационный) анализ (дочитайте до конца, чтобы было понятно)
Медиаторный анализ — метод количественной оценки, который позволяет понять, через какие другие факторы изучаемый фактор (экспозиция) оказывает влияние на исход. Другими словами это расширение классического регрессионого анализа. Он особенно полезен в исследованиях, где важно не только установить наличие ассоциации между переменными, но и понять, каким путем реализуется эта связь. В классической регрессионной модели мы просто фиксируем общее влияние фактора на исход, однако медиаторный анализ дает возможность разложить это влияние на прямое и опосредованное — через другой фактор или факторы, так называемый медиатор(ы). Далее я буду описывать этот статистический метод на собственных данных (пациенты в отделении реанимации), которые я уже использовал ранее при построении AFT-модели выживаемости здесь.
Классическая структура медиаторного анализа включает три переменные: экспозицию (например, гипоксемию), медиатор (например, уровень сознания по шкале Глазго) и исход (например, летальность в отделении реанимации). Экспозиция может влиять на медиатор, медиатор также влияет на исход, и экспозиция может также действовать на исход напрямую, минуя медиатор. С помощью медиаторного анализа можно количественно оценить, какая часть общего влияния экспозиции (в нашем случае гипоксемии) на исход проходит через медиатор, а какая остается прямой. Эти компоненты называют соответственно ACME (Average Causal Mediation Effect — средний опосредованный эффект) и ADE (Average Direct Effect — средний прямой эффект). Другими словами мы можем количественно оценить степень влияния гипоксемии на летальность как в виде прямого эффекта, так и в виде опосредованного через угнетение сознания.
Медиаторный анализ — метод количественной оценки, который позволяет понять, через какие другие факторы изучаемый фактор (экспозиция) оказывает влияние на исход. Другими словами это расширение классического регрессионого анализа. Он особенно полезен в исследованиях, где важно не только установить наличие ассоциации между переменными, но и понять, каким путем реализуется эта связь. В классической регрессионной модели мы просто фиксируем общее влияние фактора на исход, однако медиаторный анализ дает возможность разложить это влияние на прямое и опосредованное — через другой фактор или факторы, так называемый медиатор(ы). Далее я буду описывать этот статистический метод на собственных данных (пациенты в отделении реанимации), которые я уже использовал ранее при построении AFT-модели выживаемости здесь.
Классическая структура медиаторного анализа включает три переменные: экспозицию (например, гипоксемию), медиатор (например, уровень сознания по шкале Глазго) и исход (например, летальность в отделении реанимации). Экспозиция может влиять на медиатор, медиатор также влияет на исход, и экспозиция может также действовать на исход напрямую, минуя медиатор. С помощью медиаторного анализа можно количественно оценить, какая часть общего влияния экспозиции (в нашем случае гипоксемии) на исход проходит через медиатор, а какая остается прямой. Эти компоненты называют соответственно ACME (Average Causal Mediation Effect — средний опосредованный эффект) и ADE (Average Direct Effect — средний прямой эффект). Другими словами мы можем количественно оценить степень влияния гипоксемии на летальность как в виде прямого эффекта, так и в виде опосредованного через угнетение сознания.
В своем исследовании я проанализировал, каким образом гипоксемия влияет на летальность у пациентов в отделении реанимации, и может ли уровень сознания быть промежуточным звеном в этой связи. В качестве экспозиции использовалась переменная «гипоксемия», как бинарный показатель нарушения оксигенации (да/нет). В качестве медиатора — уровень сознания, выраженный тоже бинарно как снижение по шкале Глазго ниже 15 баллов. Исходом была внутрибольничная летальность. Согласно патофизиологической логике, гипоксемия может вызывать гипоксическое поражение головного мозга, что приводит к снижению уровня сознания. Угнетение сознания, в свою очередь, увеличивает риск неблагоприятного исхода, в том числе за счет развития дыхательной недостаточности, аспирации, нарушения витальных функций.
Сначала была построена обычная регрессионная модель медиатора (модель1), в которой анализировалась связь гипоксемии (X) с нарушением сознания (Y) с учетом возраста и пола. Гипоксемия оказалась статистически значимым предиктором снижения по шкале Глазго, с отношением шансов 1.61, что подтверждает первую предпосылку медиаторного анализа (гипоксемия повышает риск угнетения сознания). Затем была построена модель2 исхода (летальность), в которую входили гипоксемия, шкала Глазго, возраст и пол. И гипоксемия, и снижение сознания продемонстрировали независимую статистически значимую связь с летальностью. На это подготовительные регрессионные модели завершены.
Следующим этапом стал собственно сам медиаторный анализ, выполненный с использованием бутстрэп-метода с 1000 симуляциями.
Его результаты показали, что 41% общего влияния гипоксемии на риск летального исхода опосредовано через снижение уровня сознания. Остальные 59% приходятся на прямой эффект гипоксемии, не зависящий от уровня сознания. Все оценки — прямого, опосредованного и общего эффектов были статистически значимыми с доверительными интервалами, не включающими ноль.
Таким образом, проведенный анализ продемонстрировал, что гипоксемия повышает риск смерти у пациентов в реанимации как напрямую, так и через угнетение сознания. Шкала Глазго в данном контексте выступает как важный патофизиологический и прогностический индикатор, отражающий один из ключевых механизмов, через который гипоксия ведет к летальному исходу. Возможно, это очевидный пример, но он прост для понимания медиаторного анализа. Часто далеко не всегда можно понять причинно-следственную связь между факторами в регрессионных моделях и медиаторный анализ может помочь вам в этом разобраться.
Сначала была построена обычная регрессионная модель медиатора (модель1), в которой анализировалась связь гипоксемии (X) с нарушением сознания (Y) с учетом возраста и пола. Гипоксемия оказалась статистически значимым предиктором снижения по шкале Глазго, с отношением шансов 1.61, что подтверждает первую предпосылку медиаторного анализа (гипоксемия повышает риск угнетения сознания). Затем была построена модель2 исхода (летальность), в которую входили гипоксемия, шкала Глазго, возраст и пол. И гипоксемия, и снижение сознания продемонстрировали независимую статистически значимую связь с летальностью. На это подготовительные регрессионные модели завершены.
Следующим этапом стал собственно сам медиаторный анализ, выполненный с использованием бутстрэп-метода с 1000 симуляциями.
mediate(модель1, модель2, treat = "Гипоксемия", mediator = "кома Глазго", boot = TRUE, sims = 1000)Его результаты показали, что 41% общего влияния гипоксемии на риск летального исхода опосредовано через снижение уровня сознания. Остальные 59% приходятся на прямой эффект гипоксемии, не зависящий от уровня сознания. Все оценки — прямого, опосредованного и общего эффектов были статистически значимыми с доверительными интервалами, не включающими ноль.
Таким образом, проведенный анализ продемонстрировал, что гипоксемия повышает риск смерти у пациентов в реанимации как напрямую, так и через угнетение сознания. Шкала Глазго в данном контексте выступает как важный патофизиологический и прогностический индикатор, отражающий один из ключевых механизмов, через который гипоксия ведет к летальному исходу. Возможно, это очевидный пример, но он прост для понимания медиаторного анализа. Часто далеко не всегда можно понять причинно-следственную связь между факторами в регрессионных моделях и медиаторный анализ может помочь вам в этом разобраться.
🔥3
Когда можно получить ну очень маленькие p-уровни значимости
В одной из статей Связь уровней циркулирующих липидов крови с частотой ишемической болезни сердца я наткнулся на расчет HR у различного рода предикторов ИБС и очень маленькие p-уровни значимости. Минимальный из них равнялся менее 1e-300 (1 в минус 300 степени). Это не ошибка.Такие сверхмалые p-значения абсолютно реальны и возникают в ситуациях, когда одновременно присутствуют очень большая выборка (в исследовании более 300 тыс. участников), высокая точность оценки эффекта и использование некоторых статистических тестов. В Cox-модели p-уровень обычно основано на статистике Вальда, лог-ранковом тесте или тесте отношения правдоподобия; все они сводятся к вычислению отношения b/SE(b), где b — логарифм отношения рисков, а SE — его стандартная ошибка. В выборке из сотен тысяч участников стандартная ошибка становится исключительно маленькой, поэтому даже умеренный эффект, например HR=1.59, приводит к огромной Z-статистике и как следствие к настолько малым p-уровням занчимости, что компьютер просто не может их представить и выводит как менее 1e-300 или даже 0. Это не свидетельствует о силе ассоциации — это лишь отражение колоссальной мощности исследования и очень высокой точности оценок. В эпидемиологии, особенно в крупных когортах обследованных, подобные значения p-уровней являются нормой и встречаются регулярно.
В одной из статей Связь уровней циркулирующих липидов крови с частотой ишемической болезни сердца я наткнулся на расчет HR у различного рода предикторов ИБС и очень маленькие p-уровни значимости. Минимальный из них равнялся менее 1e-300 (1 в минус 300 степени). Это не ошибка.Такие сверхмалые p-значения абсолютно реальны и возникают в ситуациях, когда одновременно присутствуют очень большая выборка (в исследовании более 300 тыс. участников), высокая точность оценки эффекта и использование некоторых статистических тестов. В Cox-модели p-уровень обычно основано на статистике Вальда, лог-ранковом тесте или тесте отношения правдоподобия; все они сводятся к вычислению отношения b/SE(b), где b — логарифм отношения рисков, а SE — его стандартная ошибка. В выборке из сотен тысяч участников стандартная ошибка становится исключительно маленькой, поэтому даже умеренный эффект, например HR=1.59, приводит к огромной Z-статистике и как следствие к настолько малым p-уровням занчимости, что компьютер просто не может их представить и выводит как менее 1e-300 или даже 0. Это не свидетельствует о силе ассоциации — это лишь отражение колоссальной мощности исследования и очень высокой точности оценок. В эпидемиологии, особенно в крупных когортах обследованных, подобные значения p-уровней являются нормой и встречаются регулярно.
🔥1