
Проверка пригодности модели линейной регрессии в медицинских исследованиях (про допущения метода)
Применение метода линейной регрессии в статистике требует выполнения обязательного набора допущений, без которых итоговый результат может быть некорректным. Каждое из допущенией проверяется другими статистическими или графическими методами.
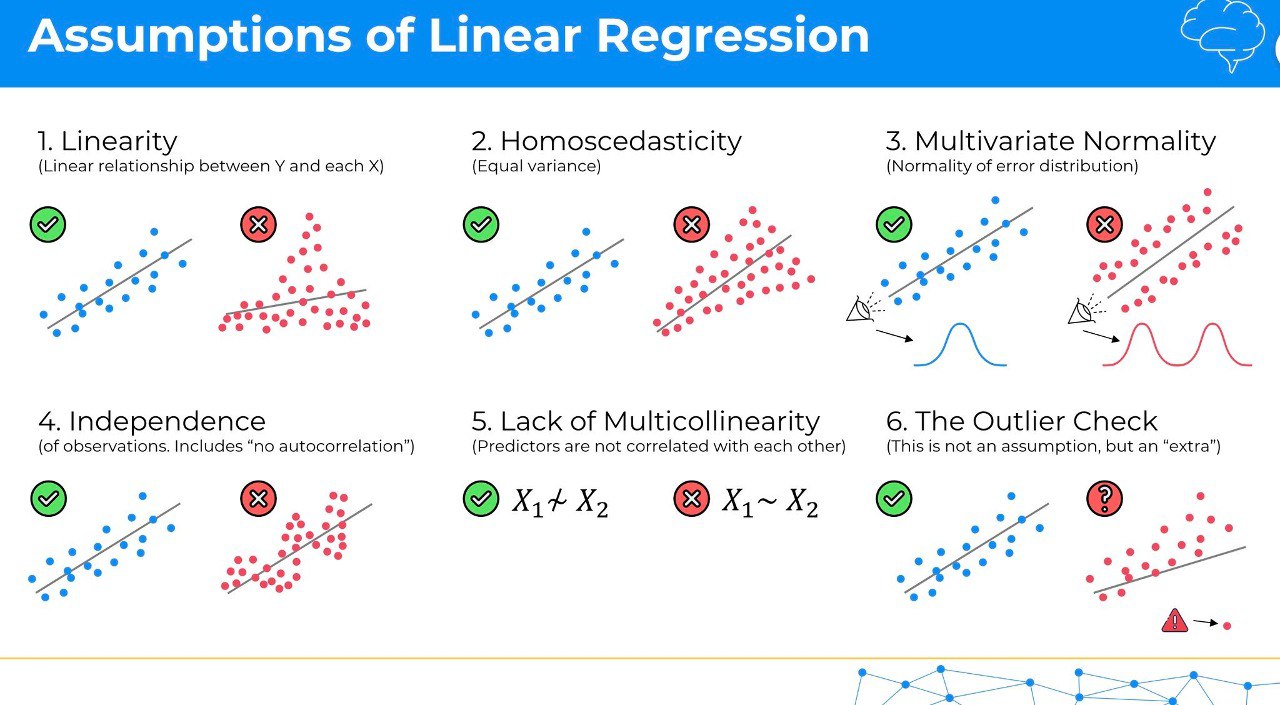
✅ Линейность: связь между предикторами (например, возраст пациента, уровень сахара в крови) и откликом (например, риск развития диабета) должна быть линейной. Это означает, что изменение предиктора приводит к пропорциональному изменению отклика.
✅ Независимость: остатки или ошибки (разница между фактическим и предсказанным значением отклика) должны быть независимы друг от друга. Например, результат анализа одного пациента не должен зависеть от результатов других пациентов.
✅ Гомоскедастичность против гетероскедастичности: остатки должны иметь постоянное распределение на всех уровнях независимой переменной. Например, разброс уровней артериального давления должен быть одинаковым для разных возрастных групп.
✅ Нормальность остатков (многомерная нормальность): остатки должны следовать нормальному распределению, подобному колоколообразной кривой распределения роста в популяции.
✅ Отсутствие мультиколлинеарности: предикторы (например, возраст и масса тела) не должны быть сильно коррелированы друг с другом, чтобы можно было оценить их независимое влияние на отклик.
✅ Отсутствие выбросов. Выбросы нарушают линейность взаимосвязей и приводят к другим проблемам с допущениями линейной регрессии.
Дополнительно читайте здесь.
Применение метода линейной регрессии в статистике требует выполнения обязательного набора допущений, без которых итоговый результат может быть некорректным. Каждое из допущенией проверяется другими статистическими или графическими методами.
✅ Линейность: связь между предикторами (например, возраст пациента, уровень сахара в крови) и откликом (например, риск развития диабета) должна быть линейной. Это означает, что изменение предиктора приводит к пропорциональному изменению отклика.
✅ Независимость: остатки или ошибки (разница между фактическим и предсказанным значением отклика) должны быть независимы друг от друга. Например, результат анализа одного пациента не должен зависеть от результатов других пациентов.
✅ Гомоскедастичность против гетероскедастичности: остатки должны иметь постоянное распределение на всех уровнях независимой переменной. Например, разброс уровней артериального давления должен быть одинаковым для разных возрастных групп.
✅ Нормальность остатков (многомерная нормальность): остатки должны следовать нормальному распределению, подобному колоколообразной кривой распределения роста в популяции.
✅ Отсутствие мультиколлинеарности: предикторы (например, возраст и масса тела) не должны быть сильно коррелированы друг с другом, чтобы можно было оценить их независимое влияние на отклик.
✅ Отсутствие выбросов. Выбросы нарушают линейность взаимосвязей и приводят к другим проблемам с допущениями линейной регрессии.
Дополнительно читайте здесь.
{kind=link}
🔥1
Про тест Cochran-Armitage (Кохрейна-Армитажа)
Тест Cochran-Armitage на тренд (также известный как тест на линейный тренд в пропорциях) - статистический метод, используемый для выявления наличия линейной тенденции между бинарным исходом и порядковой или непрерывной независимой переменной. Используется для определения, существует ли линейная связь между долей (частотой) некоего исхода и уровнями упорядоченного предиктора. Часто применяется в медицинских исследованиях, эпидемиологии, где нужно оценить тренд.
✅ Тест проверяет следующие гипотезы:
Нулевая гипотеза (H0): Нет линейного тренда.
Альтернативная гипотеза (H1): Существует линейный тренд.
✅ Тест предполагает линейную связь, если тренд нелинейный (например, U-образный), тест может не обнаружить его или дать неверный результат.
Тест Cochran-Armitage на тренд (также известный как тест на линейный тренд в пропорциях) - статистический метод, используемый для выявления наличия линейной тенденции между бинарным исходом и порядковой или непрерывной независимой переменной. Используется для определения, существует ли линейная связь между долей (частотой) некоего исхода и уровнями упорядоченного предиктора. Часто применяется в медицинских исследованиях, эпидемиологии, где нужно оценить тренд.
✅ Тест проверяет следующие гипотезы:
Нулевая гипотеза (H0): Нет линейного тренда.
Альтернативная гипотеза (H1): Существует линейный тренд.
✅ Тест предполагает линейную связь, если тренд нелинейный (например, U-образный), тест может не обнаружить его или дать неверный результат.
✅ Пример. Предположим, вы изучаете заболеваемость или летальность за N-летний период. Тогда тест Cochran-Armitage поможет определить, существует ли статистически значимый возрастающий тренд в частоте заболевания с течением времени. Если тест покажет значимый результат, это будет свидетельствовать о наличии линейного тренда в частоте события во времени. Положительный тренд будет указывать на увеличение частоты события со временем, отрицательный - на уменьшение.
This media is not supported in your browser
VIEW IN TELEGRAM
Прогностические модели в медицине: точность имеет значение
Главная задача прогностической модели в медицине - предоставить врачу и пациенту точную оценку вероятности определенного исхода. Будь то риск развития заболевания, вероятность осложнений или прогноз выживаемости - модель должна давать надежный прогноз, основанный на индивидуальных характеристиках пациента.
Продемонстрируем два примера широко используемых прогностических моделей:
✅ Модель пропорциональных рисков Кокса позволяет оценить влияние различных факторов на время до наступления определенного события (например, рецидива заболевания).
Главная задача прогностической модели в медицине - предоставить врачу и пациенту точную оценку вероятности определенного исхода. Будь то риск развития заболевания, вероятность осложнений или прогноз выживаемости - модель должна давать надежный прогноз, основанный на индивидуальных характеристиках пациента.
Продемонстрируем два примера широко используемых прогностических моделей:
✅ Модель пропорциональных рисков Кокса позволяет оценить влияние различных факторов на время до наступления определенного события (например, рецидива заболевания).
This media is not supported in your browser
VIEW IN TELEGRAM
✅ Бинарная логистическая регрессия используется для прогнозирования вероятности наступления события, имеющего два возможных исхода (например, наличие или отсутствие заболевания или осложнения).
Разработка точных и надежных прогностических моделей требует глубокого понимания как статистических методов, так и специфики медицинской области. Создание индивидуальных прогностических моделей "под ключ" для различных медицинских задач включает в себя:
✅ Анализ ваших данных и выбор оптимального метода моделирования;
✅ Разработку и валидацию модели;
✅ Создание удобных интерфейсов и калькуляторов для практического применения модели;
✅ Полное сопровождение описания модели в вашей научной работе и внедрение модели в клиническую практику.
Пишите: @glivec
Разработка точных и надежных прогностических моделей требует глубокого понимания как статистических методов, так и специфики медицинской области. Создание индивидуальных прогностических моделей "под ключ" для различных медицинских задач включает в себя:
✅ Анализ ваших данных и выбор оптимального метода моделирования;
✅ Разработку и валидацию модели;
✅ Создание удобных интерфейсов и калькуляторов для практического применения модели;
✅ Полное сопровождение описания модели в вашей научной работе и внедрение модели в клиническую практику.
Пишите: @glivec
Еще раз про центральную предельную теорему
Центральная предельная теорема (ЦПТ) является фундаментальной концепцией в статистике, имеющей широкие приложения. Она утверждает, что распределение выборочных средних приближается к нормальному распределению (гауссовскому распределению) по мере увеличения размера выборки, независимо от исходного распределения популяции. Это имеет решающее значение для проведения выводов о популяциях на основе выборочных данных.
Понимание ЦПТ значительно улучшает навыки анализа данных, предоставляя надежную основу для проверки гипотез и оценки доверительных интервалов. Однако у нее есть некоторые ограничения:
❌ Размер выборки: для эффективного применения ЦПТ требуется достаточно большой размер выборки. Небольшие выборки могут не давать точных результатов.
❌ Независимость: выборки должны быть независимыми. Зависимости между данными могут исказить результаты.
❌ Одинаковое распределение: выборки должны происходить из одного и того же распределения.
Несмотря на эти недостатки, ЦПТ остается чрезвычайно полезной. Вот почему:
✔️ Универсальность: она применима к широкому диапазону распределений, что делает ее универсальной для различных наборов данных.
✔️ Предсказуемость: при достаточно большом размере выборки прогнозы о параметрах популяции становятся более точными.
✔️ Простота: она упрощает сложные задачи, позволяя статистикам и аналитикам данных использовать свойства нормального распределения для анализа.
Центральная предельная теорема (ЦПТ) является фундаментальной концепцией в статистике, имеющей широкие приложения. Она утверждает, что распределение выборочных средних приближается к нормальному распределению (гауссовскому распределению) по мере увеличения размера выборки, независимо от исходного распределения популяции. Это имеет решающее значение для проведения выводов о популяциях на основе выборочных данных.
Понимание ЦПТ значительно улучшает навыки анализа данных, предоставляя надежную основу для проверки гипотез и оценки доверительных интервалов. Однако у нее есть некоторые ограничения:
❌ Размер выборки: для эффективного применения ЦПТ требуется достаточно большой размер выборки. Небольшие выборки могут не давать точных результатов.
❌ Независимость: выборки должны быть независимыми. Зависимости между данными могут исказить результаты.
❌ Одинаковое распределение: выборки должны происходить из одного и того же распределения.
Несмотря на эти недостатки, ЦПТ остается чрезвычайно полезной. Вот почему:
✔️ Универсальность: она применима к широкому диапазону распределений, что делает ее универсальной для различных наборов данных.
✔️ Предсказуемость: при достаточно большом размере выборки прогнозы о параметрах популяции становятся более точными.
✔️ Простота: она упрощает сложные задачи, позволяя статистикам и аналитикам данных использовать свойства нормального распределения для анализа.
{kind=link}
🗣️ Каждые 1.5 часа в мире создается новая клиническая прогностическая модель. 99% из них бесполезны (никогда не будут использованы в практике)!
🔥3👍2
🗣️ И в классической (фриквентисткой) и в байесовской статистике ключевым понятием является понятие вероятности. В классической статистике это p-уровень значимости, который является вероятностью наблюдать данные, которые вы наблюдаете, но не является вероятностью верности вашей гипотезы! Низкая вероятность (менее 5%) наблюдать то, что вы наблюдаете при гипотезе, что такого не должно быть (нулевая гипотеза), дает вам основания принять вашу гипотезу, как верную, с большой долей уверенности. Вероятность же в байесовской статистике, которая лежит в пределах от 0 до 1, это именно вероятность того, что ваша гипотеза верна.
Читая чаты по медицинской статистике ...
Просить порекомендовать метод статистического анализа для своих данных, а потом наблюдать спор, что лучше Спирмен или Пирсон, Стьюдент или Манн-Уитни, Фридман или кто-то еще, что часто видишь в чатах по статистике, это как лечить анализы, а не диагноз у пациента. Да, все мы учимся и нет предела совершенства, и тем, кто еще в самом начале своего научного пути позволено задавать разные вопросы подобного рода, но всегда есть НО! Есть немало экспертов в тех же чатах, которые учат, советуют и даже преподают за деньги. Но все сводится к лечению анализов, а не пациента. Где формулировки научных гипотез и рассуждения в контексте их доказательств? Их нет. Спрашивайте и советуйте не как купировать симптом, а как вылечить болезнь! Купирование симптомов - не чем не лучше, чем p-хакинг, напротив, лечение первопричины этих сиптомов равно доказательству научной гипотезы. Да и симптоматическое лечение, которое рекомендуют многие, зачастую малоэффективно. Но люди склоны верить и доверять, не проверяя так ли хорошо на самом деле работает лекарство (совет), который им дал тот или иной "гуру". Совет из ряда "используйте ROC-анализ, чтобы найти порог для вашей прогностической модели или превращения количественной переменной в категориальную" равноценен совету выпить яд, чтобы долго не мучаться.
Начинайте с дизайна своего исследования, формулируйте научные гипотезы, каждую из которых можно проверять разными методами статистического анализа, также как для разного диагноза может существовать несколько видов лекарств. Не спрашивайте про симптоматическое лечение, ищите возможность решения проблемы целиком. Не занимайтесь наукой для галочки, потому что для этого вам не нужно ничего спрашивать, вам нужно просто уметь сочинять (ИИ в помощь). Познание истины - единственная возможная цель, но она не всегда достижима, это тоже нужно понимать. Поэтому ставьте только те задачи, которые реально решить. Что реально, а что нет, определяет правильный дизайн вашего исследования и методы статистического анализа для каждой и сформулированных научных гипотез.
@glivec
Просить порекомендовать метод статистического анализа для своих данных, а потом наблюдать спор, что лучше Спирмен или Пирсон, Стьюдент или Манн-Уитни, Фридман или кто-то еще, что часто видишь в чатах по статистике, это как лечить анализы, а не диагноз у пациента. Да, все мы учимся и нет предела совершенства, и тем, кто еще в самом начале своего научного пути позволено задавать разные вопросы подобного рода, но всегда есть НО! Есть немало экспертов в тех же чатах, которые учат, советуют и даже преподают за деньги. Но все сводится к лечению анализов, а не пациента. Где формулировки научных гипотез и рассуждения в контексте их доказательств? Их нет. Спрашивайте и советуйте не как купировать симптом, а как вылечить болезнь! Купирование симптомов - не чем не лучше, чем p-хакинг, напротив, лечение первопричины этих сиптомов равно доказательству научной гипотезы. Да и симптоматическое лечение, которое рекомендуют многие, зачастую малоэффективно. Но люди склоны верить и доверять, не проверяя так ли хорошо на самом деле работает лекарство (совет), который им дал тот или иной "гуру". Совет из ряда "используйте ROC-анализ, чтобы найти порог для вашей прогностической модели или превращения количественной переменной в категориальную" равноценен совету выпить яд, чтобы долго не мучаться.
Начинайте с дизайна своего исследования, формулируйте научные гипотезы, каждую из которых можно проверять разными методами статистического анализа, также как для разного диагноза может существовать несколько видов лекарств. Не спрашивайте про симптоматическое лечение, ищите возможность решения проблемы целиком. Не занимайтесь наукой для галочки, потому что для этого вам не нужно ничего спрашивать, вам нужно просто уметь сочинять (ИИ в помощь). Познание истины - единственная возможная цель, но она не всегда достижима, это тоже нужно понимать. Поэтому ставьте только те задачи, которые реально решить. Что реально, а что нет, определяет правильный дизайн вашего исследования и методы статистического анализа для каждой и сформулированных научных гипотез.
@glivec
👍1
🗣️ Причинно-следственный вывод больше зависит от дизайна исследования, нежели от метода статистического анализа или машинного обучения.
Луи Доминик Жюль Гаварре (28 января 1809 - 30 августа 1890) - пионер "статистического метода" в медицине, его книга "Principes de Statistique Médicale" (1840) одна из первых, в которой изложены статистические принципы для тщательного проведения клинических исследований.
Впервые он слышит о "вычислении вероятностей" в октябре 1835 года во время дебатов в Академии наук, где Навье - автор уравнения Навье-Стокса, описывает, как можно применить свое уравнение в терапевтических исследованиях (и побеждает в дебатах).
Лаплас и Пуассон уже предполагали, что расчеты вероятностей могут быть применены к количественным медицинским данным, чтобы помочь в принятии клинических решений. Гаварре ссылается на них в своей работе "Probabilité des Jugements.’".
Гаварре вычисляет прототип доверительного интервала ("limites d'oscillation") для данных Пьера-Шарля Луи об эффективности кровопускания как метода лечения пневмонии. Луи сообщил о 52 смертях из 140 пациентов (37%). Аргументируя против принятия точечной оценки Луи за чистую монету, он говорит: "Все, что мы узнали... в действительности, это то, что под влиянием лечебных средств, использованных в его 140 наблюдениях, количество смертей должно колебаться... приблизительно между 49 и 26 случаев смерти на 100 пациентов".
Его 5 советов по проведению клинических испытаний по-прежнему актуальны:
1. "Пациенты должны быть взяты исключительно в одном населенном пункте и из одних и тех же слоев населения"
2. "У пережитого заболевание пациента должен быть точный диагноз и идеальное его определение. Оно должно быть нозологически четко очерчено и отделено от болезней, наиболее похожих на него в данной группе"
3. "Статистические данные по заболеванию должны содержать точное указание числа случаев в рамках каждой из его разновидностей"
4. "Необходимо четко формулировать применяемое лекарство, а также его основные модификации для каждой из разновидностей заболевания"
5. "Медицинский статистик должен быть компетентным".
Впервые он слышит о "вычислении вероятностей" в октябре 1835 года во время дебатов в Академии наук, где Навье - автор уравнения Навье-Стокса, описывает, как можно применить свое уравнение в терапевтических исследованиях (и побеждает в дебатах).
Лаплас и Пуассон уже предполагали, что расчеты вероятностей могут быть применены к количественным медицинским данным, чтобы помочь в принятии клинических решений. Гаварре ссылается на них в своей работе "Probabilité des Jugements.’".
Гаварре вычисляет прототип доверительного интервала ("limites d'oscillation") для данных Пьера-Шарля Луи об эффективности кровопускания как метода лечения пневмонии. Луи сообщил о 52 смертях из 140 пациентов (37%). Аргументируя против принятия точечной оценки Луи за чистую монету, он говорит: "Все, что мы узнали... в действительности, это то, что под влиянием лечебных средств, использованных в его 140 наблюдениях, количество смертей должно колебаться... приблизительно между 49 и 26 случаев смерти на 100 пациентов".
Его 5 советов по проведению клинических испытаний по-прежнему актуальны:
1. "Пациенты должны быть взяты исключительно в одном населенном пункте и из одних и тех же слоев населения"
2. "У пережитого заболевание пациента должен быть точный диагноз и идеальное его определение. Оно должно быть нозологически четко очерчено и отделено от болезней, наиболее похожих на него в данной группе"
3. "Статистические данные по заболеванию должны содержать точное указание числа случаев в рамках каждой из его разновидностей"
4. "Необходимо четко формулировать применяемое лекарство, а также его основные модификации для каждой из разновидностей заболевания"
5. "Медицинский статистик должен быть компетентным".
Ежегодно публикуется множество медицинских прогностических моделей, но зачастую они имеют методологические недостатки, которые ограничивают их валидность и применимость. Представлено руководство из 13 шагов, которое поможет медицинским работникам и исследователям разрабатывать и проверять модели прогнозирования, избегая распространенных "подводных камней". На первом этапе необходимо определить цель модели прогнозирования, включая целевую популяцию, прогнозируемый исход, медицинскую среду, в которой будет использоваться модель и предполагаемых пользователей. Прогнозное моделирование требует совместных и междисциплинарных усилий в рамках команды, которая в идеале включает клиницистов с опытом работы, методистов и пользователей. К числу распространенных ошибок относятся неправильная категоризация непрерывных исходов или предикторов, точки отсечения (пороги), основанные на данных, одномерные методы выбора предикторов, чрезмерная подгонка, недостаточное внимание к отсутствующим данным и неверная оценка эффективности и клинической пользы модели.
Помощь в создании прогностических моделей на statshots.ru
Помощь в создании прогностических моделей на statshots.ru
{kind=link}
Машинное обучение играет важнейшую роль во многих современных областях науки и инновациях. Все методы МО можно разделить на несколько главных групп, которые могут пересекаться между собой в решении тех или иных практических задач:
✅ Регрессия
✅ Классификация
✅ Кластеризация
✅ Оптимизация
✅ Компьютерное зрение
✅ Прогнозирование
✅ Рекомендательные системы
✅ Обработка естественного языка (NLP)
Изучение 1-3 ключевых алгоритмов в каждой из этих областей может значительно повысить вашу универсальность как специалиста по анализу данных.
✅ Регрессия
✅ Классификация
✅ Кластеризация
✅ Оптимизация
✅ Компьютерное зрение
✅ Прогнозирование
✅ Рекомендательные системы
✅ Обработка естественного языка (NLP)
Изучение 1-3 ключевых алгоритмов в каждой из этих областей может значительно повысить вашу универсальность как специалиста по анализу данных.
This media is not supported in your browser
VIEW IN TELEGRAM
Как работает нейронная сеть: входные данные, активация нейронов в промежуточных слоях, выходной слой с наиболее вероятным результатом.
This media is not supported in your browser
VIEW IN TELEGRAM
Алгоритм Дейкстры — алгоритм для поиска кратчайшего пути от одной вершины (пункта отправки) до всех других вершин (пунктов назначения) в графе с ненулевыми и неотрицательными весами рёбер. Может использоваться в контексте поддержки принятия решений в медицинских информационных системах. Подробнее на statshots.ru
В 2019 году была опубликована статья Американской статистической ассоциации (ASA) "Статистический вывод в 21 веке: мир за пределами p < 0.05"
В ней авторы рассказывают историю появления статистического вывода и роли p-уровня значимости в нем. P-значение впервые введено в статистику Рональдом Фишером в 1920-х годах, как способ оценки значимости результатов экспериментов. Однако со временем p-уровень значимости стали использоваться как единственный критерий для оценки значимости результатов, что привело к ряду проблем.
Одной из основных проблем является то, что p-уровень значимости часто интерпретируются неправильно. Многие исследователи считают, что p-значение представляет собой вероятность того, что нулевая гипотеза верна или что результат обусловлен случайностью. Однако это не так. P-значение представляет собой только вероятность получения наблюдаемого результата или более экстремального результата, если нулевая гипотеза верна.
Авторы также обсуждают проблему множественных сравнений. Когда исследователи проводят множество тестов, они часто используют p-уровень значимости для оценки значимости каждого теста. Однако это может привести к тому, что некоторые из результатов будут признаны значимыми просто по случайности.
Другой проблемой, обсуждаемой в статье, является то, что p-уровень значимости не учитывают размер эффекта. Даже если результат статистически значим, он может быть практически незначимым, если размер эффекта мал.
Предлагается несколько альтернативных подходов к статистическому выводу, которые могут помочь решить эти проблемы. Одним из них является использование доверительных интервалов. Это может помочь исследователям оценить размер эффекта и понять, насколько результаты могут быть обобщены на другие ситуации.
Другим подходом является использование байесовских методов. Байесовские методы позволяют исследователям обновлять свои убеждения о вероятности того или иного события на основе новых данных. Это может помочь исследователям оценить вероятность того, что нулевая гипотеза верна или что результат обусловлен случайностью.
Статистический вывод должен быть более детальным и информативным. При интерпретации результатов исследователи должны учитывать множество факторов, включая научный вопрос (гипотезу), дизайн исследования и качество данных. P-уровень значимости не должны быть единственным критерием для оценки важности полученных результатов.
В ней авторы рассказывают историю появления статистического вывода и роли p-уровня значимости в нем. P-значение впервые введено в статистику Рональдом Фишером в 1920-х годах, как способ оценки значимости результатов экспериментов. Однако со временем p-уровень значимости стали использоваться как единственный критерий для оценки значимости результатов, что привело к ряду проблем.
Одной из основных проблем является то, что p-уровень значимости часто интерпретируются неправильно. Многие исследователи считают, что p-значение представляет собой вероятность того, что нулевая гипотеза верна или что результат обусловлен случайностью. Однако это не так. P-значение представляет собой только вероятность получения наблюдаемого результата или более экстремального результата, если нулевая гипотеза верна.
Авторы также обсуждают проблему множественных сравнений. Когда исследователи проводят множество тестов, они часто используют p-уровень значимости для оценки значимости каждого теста. Однако это может привести к тому, что некоторые из результатов будут признаны значимыми просто по случайности.
Другой проблемой, обсуждаемой в статье, является то, что p-уровень значимости не учитывают размер эффекта. Даже если результат статистически значим, он может быть практически незначимым, если размер эффекта мал.
Предлагается несколько альтернативных подходов к статистическому выводу, которые могут помочь решить эти проблемы. Одним из них является использование доверительных интервалов. Это может помочь исследователям оценить размер эффекта и понять, насколько результаты могут быть обобщены на другие ситуации.
Другим подходом является использование байесовских методов. Байесовские методы позволяют исследователям обновлять свои убеждения о вероятности того или иного события на основе новых данных. Это может помочь исследователям оценить вероятность того, что нулевая гипотеза верна или что результат обусловлен случайностью.
Статистический вывод должен быть более детальным и информативным. При интерпретации результатов исследователи должны учитывать множество факторов, включая научный вопрос (гипотезу), дизайн исследования и качество данных. P-уровень значимости не должны быть единственным критерием для оценки важности полученных результатов.
Taylor & Francis
Moving to a World Beyond “p < 0.05”
EDITORIAL: The editorial was written by the three editors acting as individuals and reflects their scientific views not an endorsed position of the American Statistical Association.
🚀 ПРОФЕССИОНАЛЬНЫЙ АНАЛИЗ ДАННЫХ: ОТ ОПИСАТЕЛЬНОЙ СТАТИСТИКИ ДО МАШИННОГО ОБУЧЕНИЯ
Помогу превратить ваши данные в качественные проекты!
📊 ЧТО Я ДЕЛАЮ:
• Разрабатываю дизайн исследований
• Провожу глубокий статистический анализ
• Создаю прогностические модели по западным стандартам
• Разрабатываю интерактивные визуализации и калькуляторы
• Внедряю решения на базе машинного обучения
• Обучаю статистике
💡 МОЙ ПОДХОД:
✓ Современная методология
✓ Полное погружение в проект
✓ Решения "под ключ"
🎯 Посмотреть примеры моих проектов: https://sites.google.com/view/luchinin
📩 СВЯЗАТЬСЯ СО МНОЙ:
Email: glivec@mail.ru
Телеграм: @glivec
Готов обсудить ваш проект и предложить оптимальное решение!
Помогу превратить ваши данные в качественные проекты!
📊 ЧТО Я ДЕЛАЮ:
• Разрабатываю дизайн исследований
• Провожу глубокий статистический анализ
• Создаю прогностические модели по западным стандартам
• Разрабатываю интерактивные визуализации и калькуляторы
• Внедряю решения на базе машинного обучения
• Обучаю статистике
💡 МОЙ ПОДХОД:
✓ Современная методология
✓ Полное погружение в проект
✓ Решения "под ключ"
🎯 Посмотреть примеры моих проектов: https://sites.google.com/view/luchinin
📩 СВЯЗАТЬСЯ СО МНОЙ:
Email: glivec@mail.ru
Телеграм: @glivec
Готов обсудить ваш проект и предложить оптимальное решение!
Google
Лучинин А.С.
Мои проекты
статИИстик pinned «🚀 ПРОФЕССИОНАЛЬНЫЙ АНАЛИЗ ДАННЫХ: ОТ ОПИСАТЕЛЬНОЙ СТАТИСТИКИ ДО МАШИННОГО ОБУЧЕНИЯ Помогу превратить ваши данные в качественные проекты! 📊 ЧТО Я ДЕЛАЮ: • Разрабатываю дизайн исследований • Провожу глубокий статистический анализ • Создаю прогностические модели…»
Про синтетические данные в медицине
Синтетические данные в медицине – искусственно созданные данные, которые имитируют реальные, сохраняя статистические характеристики и паттерны, но без раскрытия персональной информации о пациентах. Они играют важную роль в развитии ИИ в здравоохранении, особенно для задач, требующих больших и разнообразных наборов данных.
Применение синтетических данных охватывает разные направления: от улучшения диагностики и прогнозирования заболеваний до ускорения клинических исследований. Например, для разработки алгоритмов, работающих с редкими заболеваниями, где реальных данных может быть мало, синтетические данные позволяют восполнить имеющиеся пробелы. Современные технологии позволяют искусственно создавать практически любые типы данных (табличные, геномные, текстовые, медицинские изображения ...) для проведения различных типов исследований.
Гибридные данные — сочетание реальных и синтетических данных, позволяющее, например, улучшить качество прогностических моделей (точность и стабильность), обучая их на расширенном и разнообразном датасете.
Пара последних исследований в данной области:
☑️ Synthetic data in machine learning for medicine and healthcare ...
☑️ Generation of Multimodal Longitudinal Synthetic Data By Artificial Intelligence to Improve Personalized Medicine in Hematology ...
✅ Для синтеза или устранения пропущенных значений в табличных числовых данных вы можете воспользоваться сервисом DataClone, ссылка на который также есть на statshots.ru.
Синтетические данные в медицине – искусственно созданные данные, которые имитируют реальные, сохраняя статистические характеристики и паттерны, но без раскрытия персональной информации о пациентах. Они играют важную роль в развитии ИИ в здравоохранении, особенно для задач, требующих больших и разнообразных наборов данных.
Применение синтетических данных охватывает разные направления: от улучшения диагностики и прогнозирования заболеваний до ускорения клинических исследований. Например, для разработки алгоритмов, работающих с редкими заболеваниями, где реальных данных может быть мало, синтетические данные позволяют восполнить имеющиеся пробелы. Современные технологии позволяют искусственно создавать практически любые типы данных (табличные, геномные, текстовые, медицинские изображения ...) для проведения различных типов исследований.
Гибридные данные — сочетание реальных и синтетических данных, позволяющее, например, улучшить качество прогностических моделей (точность и стабильность), обучая их на расширенном и разнообразном датасете.
Пара последних исследований в данной области:
☑️ Synthetic data in machine learning for medicine and healthcare ...
☑️ Generation of Multimodal Longitudinal Synthetic Data By Artificial Intelligence to Improve Personalized Medicine in Hematology ...
✅ Для синтеза или устранения пропущенных значений в табличных числовых данных вы можете воспользоваться сервисом DataClone, ссылка на который также есть на statshots.ru.
PubMed Central (PMC)
Synthetic data in machine learning for medicine and healthcare
The proliferation of synthetic data in artificial intelligence for medicine and healthcare raises concerns about the vulnerabilities of the software and the challenges of current policy.