
Про ограниченное среднее время выживания (Restricted Mean Survival Time, RMST) в анализе выживаемости
✅ RMST - площадь под кривой выживаемости за ограниченный промежуток времени. Более конкретно, если S(t) - функция выживаемости (кумулятивная доля выживших) во времени t:
RMST за время t - интеграл S(t) от 0 до t. То есть это математическая площадь под кривой выживаемости S(t) от начала наблюдения до фиксированного момента времени t.
✅ RMST предлагается в качестве новой альтернативной меры в анализе выживаемости, которая может быть полезна, когда невозможно сделать предположение о пропорциональных рисках (опасностях) или когда частота событий низка.
✅ RMST определяется как площадь под кривой выживаемости до определённой временной точки и, как правило, оценивается более надёжно, чем медиана выживания.
✅ Для получения клинически значимого RMST необходимо чётко выбрать временной горизонт для оценки, например, за 1-, 2-, 5-лет.
✅ В случае пересечения кривых выживаемости, что может указывать на нарушение пропорциональности рисков, эффективность вмешательства, например, терапии, можно продемонстрировать, показав разность в RMST между кривыми, несмотря на то, что log-rank тест будет статистически незначим, а HR не применим.
✅ Разница между RMST двух групп - разность между площадями под кривыми выживаемости этих групп за один и тот же период t.
✅ RMST - площадь под кривой выживаемости за ограниченный промежуток времени. Более конкретно, если S(t) - функция выживаемости (кумулятивная доля выживших) во времени t:
RMST за время t - интеграл S(t) от 0 до t. То есть это математическая площадь под кривой выживаемости S(t) от начала наблюдения до фиксированного момента времени t.
✅ RMST предлагается в качестве новой альтернативной меры в анализе выживаемости, которая может быть полезна, когда невозможно сделать предположение о пропорциональных рисках (опасностях) или когда частота событий низка.
✅ RMST определяется как площадь под кривой выживаемости до определённой временной точки и, как правило, оценивается более надёжно, чем медиана выживания.
✅ Для получения клинически значимого RMST необходимо чётко выбрать временной горизонт для оценки, например, за 1-, 2-, 5-лет.
✅ В случае пересечения кривых выживаемости, что может указывать на нарушение пропорциональности рисков, эффективность вмешательства, например, терапии, можно продемонстрировать, показав разность в RMST между кривыми, несмотря на то, что log-rank тест будет статистически незначим, а HR не применим.
✅ Разница между RMST двух групп - разность между площадями под кривыми выживаемости этих групп за один и тот же период t.
🔥1
Про проблемы таблицы 1
В различных клинически исследованиях часто можно видеть, как базовые характеристики пациентов подвергаются описательной сравнительной статистике, при этом каждая базовая характеристика в таблице №1 (чаще всего) имеет соответствующее p-значение. Например, группы пациентов сравниваются по стадиям, полу, возрасту и т.д. Мы хотим узнать, повлияли ли различия в исходных характеристиках пациентов на конечный наблюдаемый результат, например, на эффективность терапии. Чтобы ответить на этот вопрос нам необходимо точно знать, каковы были различия в исходных характеристиках. Поскольку у нас есть исходные характеристики для всех участников выборки исследования, нам нужна лишь простая описательная статистика (на- или во сколько раз они отличаются и могут ли полученные различия иметь клинический эффект). Вопрос не в том, являются ли различия статистически значимыми. Вопрос заключается в том, достаточно ли велики абсолютные различия между группами по исходным характеристикам, чтобы повлиять на результат. На него можно ответить, изучив описательную статистику и используя клиническое суждение, а не p-уровень значимости, который лишь помогает предположить, что наблюдаемая разница была обусловлена исключительно случайностью, и просто дает нам оценку вероятности такого развития событий при множестве возможных повторений исследования. Нет смысла использовать различные статистические тесты для сравнения пациентов по базовым характеристикам, достаточно представить и описать их как есть.
Не нужно проверять статистическую значимость различий между группами по базовым характеристикам (пол, возраст и т.п.) в следующих случаях:
✅ Если характеристики (например, пол) не являются результатом вмешательства (например, лечения). Различия по ним могут быть случайными.
✅ Даже если различия статистически значимы, они не несут информации о причинно-следственных связях между базовыми характеристиками и изучаемым исходом.
✅ Интерпретация статистически значимых различий между признаками может привести к ложноположительным выводам об их влиянии на результаты изучаемого исхода.
Можно проверять значимость различий по базовым характеристикам пациентов в следующих случаях:
✅ Если пациенты подвергались рандомизации, тогда различия могут указывать на проблемы с ее проведением - оценка качества рандомизации. Обоснованность такого подхода является спорным и называется "заблуждение" таблицы 1 (the table 1 fallacy).
✅ Существует предварительная гипотеза о влиянии конкретного признака на результат.
Краткий вывод: не стоит заморачиваться поиском статистически значимых различий базовых характеристик в группах (через тесты Хи2, тест Манна-Уитни и др.) только ради формального сравнения, если это не является целью исследования.
В различных клинически исследованиях часто можно видеть, как базовые характеристики пациентов подвергаются описательной сравнительной статистике, при этом каждая базовая характеристика в таблице №1 (чаще всего) имеет соответствующее p-значение. Например, группы пациентов сравниваются по стадиям, полу, возрасту и т.д. Мы хотим узнать, повлияли ли различия в исходных характеристиках пациентов на конечный наблюдаемый результат, например, на эффективность терапии. Чтобы ответить на этот вопрос нам необходимо точно знать, каковы были различия в исходных характеристиках. Поскольку у нас есть исходные характеристики для всех участников выборки исследования, нам нужна лишь простая описательная статистика (на- или во сколько раз они отличаются и могут ли полученные различия иметь клинический эффект). Вопрос не в том, являются ли различия статистически значимыми. Вопрос заключается в том, достаточно ли велики абсолютные различия между группами по исходным характеристикам, чтобы повлиять на результат. На него можно ответить, изучив описательную статистику и используя клиническое суждение, а не p-уровень значимости, который лишь помогает предположить, что наблюдаемая разница была обусловлена исключительно случайностью, и просто дает нам оценку вероятности такого развития событий при множестве возможных повторений исследования. Нет смысла использовать различные статистические тесты для сравнения пациентов по базовым характеристикам, достаточно представить и описать их как есть.
Не нужно проверять статистическую значимость различий между группами по базовым характеристикам (пол, возраст и т.п.) в следующих случаях:
✅ Если характеристики (например, пол) не являются результатом вмешательства (например, лечения). Различия по ним могут быть случайными.
✅ Даже если различия статистически значимы, они не несут информации о причинно-следственных связях между базовыми характеристиками и изучаемым исходом.
✅ Интерпретация статистически значимых различий между признаками может привести к ложноположительным выводам об их влиянии на результаты изучаемого исхода.
Можно проверять значимость различий по базовым характеристикам пациентов в следующих случаях:
✅ Если пациенты подвергались рандомизации, тогда различия могут указывать на проблемы с ее проведением - оценка качества рандомизации. Обоснованность такого подхода является спорным и называется "заблуждение" таблицы 1 (the table 1 fallacy).
✅ Существует предварительная гипотеза о влиянии конкретного признака на результат.
Краткий вывод: не стоит заморачиваться поиском статистически значимых различий базовых характеристик в группах (через тесты Хи2, тест Манна-Уитни и др.) только ради формального сравнения, если это не является целью исследования.
Про категоризацию количественных переменных в прогностических моделях
✅ Категоризация непрерывных предикторов в прогностических моделях приводит к созданию моделей с более слабыми прогностическими характеристиками.
✅ Дихотомия по медиане предиктора является неадекватным подходом, так как навязывает нереалистичную и неверную взаимосвязь предиктора и исхода.
✅ Категоризация приводит к значительным затратам на создание прогностических моделей, которые контрпродуктивны.
✅ Рекомендуется оставлять предикторы непрерывными во время моделирования и упростить конечную модель с помощью балльной системы.
✅ Моделирование нелинейной зависимости с помощью дробных полиномов или ограниченных кубических сплайнов приводит к незначительным различиям в производительности модели (вполне допустимо).
✅ Меньшие размеры выборки приводят к большей вариабельности результативности модели (нестабильности).
✅ Необходимо следовать методологии построения прогностических моделей, которая не допускает категоризации количественных переменных.
✅ Категоризация непрерывных предикторов в прогностических моделях приводит к созданию моделей с более слабыми прогностическими характеристиками.
✅ Дихотомия по медиане предиктора является неадекватным подходом, так как навязывает нереалистичную и неверную взаимосвязь предиктора и исхода.
✅ Категоризация приводит к значительным затратам на создание прогностических моделей, которые контрпродуктивны.
✅ Рекомендуется оставлять предикторы непрерывными во время моделирования и упростить конечную модель с помощью балльной системы.
✅ Моделирование нелинейной зависимости с помощью дробных полиномов или ограниченных кубических сплайнов приводит к незначительным различиям в производительности модели (вполне допустимо).
✅ Меньшие размеры выборки приводят к большей вариабельности результативности модели (нестабильности).
✅ Необходимо следовать методологии построения прогностических моделей, которая не допускает категоризации количественных переменных.
👍1🔥1
Представим, что вы исследуете препарат для снижения артериального давления (АД) по сравнению с плацебо. Тогда вывод традицинной частотной статистики будет звучать примерно так: АД в среднем снизилось на 10 мм рт.ст. (p=0.02). Это означает, что вероятность получить такой или более экстремальный результат, при условии, что исследуемый препарат не отличается от плацебо, составляет 2%.
Если же использовать методы байесовской статистики, то можно получить следующие выводы: при использовании исследуемого препарата вероятность снижения АД более, чем на 0 мм рт. ст. равняется N% или вероятность снижения АД более чем на 5 мм рт. ст. равняется N% или вероятность, что снижение АД будет между 5 и 10 мм рт. ст. равняется N%. И т.д., ну вы поняли...
Если же использовать методы байесовской статистики, то можно получить следующие выводы: при использовании исследуемого препарата вероятность снижения АД более, чем на 0 мм рт. ст. равняется N% или вероятность снижения АД более чем на 5 мм рт. ст. равняется N% или вероятность, что снижение АД будет между 5 и 10 мм рт. ст. равняется N%. И т.д., ну вы поняли...
Какие выводы более интересны для вас с точки зрения практического использования данного препарата?
Anonymous Poll
50%
Вывод частотной статистики
50%
Выводы байесовской статистики
Про активное обучение прогностических моделей
🤖 Активное обучение - semi-supervised метод машинного обучения (отчасти с учителем, отчасти без учителя). При создании прогностической модели часто нужно много размеченных данных. Размеченные (маркированные) наборы данных в реальном мире не встречаются, а получить доступ к уже маркированным данным обычно не получается, особенно в медицине. Представим, что у нас есть 10 тысяч не размеченных данных для создания некой диагностической модели. Данные могут быть любые - структурированные, текстовые или медицинские изображения. Идеально - разметить их все перед началом построения модели, если этого не было сделать (supervised learning) - отнести каждый образец к тому или иному диагнозу или группе. Но это трудозатратно для эксперта (ов) в данной предметной области.
Вот общий план того, как можно поступить:
1. Разметьте только 1000 (10%) образцов данных и постройте модель
2. Используйте эту модель для разметки 9000 оставшихся образцов
3. Выделите, например, 10% образцов, на которых модель показывает наибольшую неуверенность в предсказаниях*
4. Проведите ручную разметку только этих "худших" образов. Образцы с наибольшей уверенностью можно оставить размеченными моделью как есть
5. Постройте новую модель на новых размеченных данных (их станет уже больше) и повторите шаги выше пока не промаркируете весь датасет
* Для определения качества предсказания можно использовать, например, коэффициент уверенности (КУ): 1 - (N*(1-Pmax)/(N-1)), где N - число прогнозируемых исходов (классов), Pmax - максимальная вероятность того, что образец относится к тому или иному классу, посчитанная моделью. КУ при этом будет колебаться от 0 до 1. Образцы с КУ ниже 0.1, 0.2, 0.5 (порог может быть любым на усмотрение) можно отнести к "худшим" образцам, а с КУ более 0.8 или 0.9 - к "наилучшим".
🤖 Активное обучение - semi-supervised метод машинного обучения (отчасти с учителем, отчасти без учителя). При создании прогностической модели часто нужно много размеченных данных. Размеченные (маркированные) наборы данных в реальном мире не встречаются, а получить доступ к уже маркированным данным обычно не получается, особенно в медицине. Представим, что у нас есть 10 тысяч не размеченных данных для создания некой диагностической модели. Данные могут быть любые - структурированные, текстовые или медицинские изображения. Идеально - разметить их все перед началом построения модели, если этого не было сделать (supervised learning) - отнести каждый образец к тому или иному диагнозу или группе. Но это трудозатратно для эксперта (ов) в данной предметной области.
Вот общий план того, как можно поступить:
1. Разметьте только 1000 (10%) образцов данных и постройте модель
2. Используйте эту модель для разметки 9000 оставшихся образцов
3. Выделите, например, 10% образцов, на которых модель показывает наибольшую неуверенность в предсказаниях*
4. Проведите ручную разметку только этих "худших" образов. Образцы с наибольшей уверенностью можно оставить размеченными моделью как есть
5. Постройте новую модель на новых размеченных данных (их станет уже больше) и повторите шаги выше пока не промаркируете весь датасет
* Для определения качества предсказания можно использовать, например, коэффициент уверенности (КУ): 1 - (N*(1-Pmax)/(N-1)), где N - число прогнозируемых исходов (классов), Pmax - максимальная вероятность того, что образец относится к тому или иному классу, посчитанная моделью. КУ при этом будет колебаться от 0 до 1. Образцы с КУ ниже 0.1, 0.2, 0.5 (порог может быть любым на усмотрение) можно отнести к "худшим" образцам, а с КУ более 0.8 или 0.9 - к "наилучшим".
🔥1
В исследовании изучалась эффективность терапии Х по сравнению с плацебо. Получен результат с p=0.07.
❌ Неправильный вывод: терапия X не эффективна или терапия Х не лучше, чем плацебо.
✅ Правильный вывод: не получено (не представлено) доказательств того, что терапия Х эффективнее, чем плацебо в контексте данного исследования и используемого статистического метода.
❌ Неправильный вывод: терапия X не эффективна или терапия Х не лучше, чем плацебо.
✅ Правильный вывод: не получено (не представлено) доказательств того, что терапия Х эффективнее, чем плацебо в контексте данного исследования и используемого статистического метода.
👍3🔥1
Какой должна быть хорошая медицинская прогностическая модель
1. Модель должна иметь практическую пользу!
✳️ помогать в принятии конкретных решений в диагностике или лечении
✳️ решать принципиально новые задачи или старые, но лучше, чем существующие модели
✳️ не давать прогнозов, с которыми неясно, что делать
2. Модель должна быть создана методологически правильно
✳️ обучающая выборка достаточно велика и репрезентативна, иначе модель будет нестабильной
✳️ модель хорошо откалибрована и позволяет получать результат в виде вероятности прогнозируемого события
✳️ модель должна быть провалидирована
3. Моделью легко пользоваться в реальной клинической практике
✳️ она максимально простая и не включает в себя трудно доступные для оценки факторы
✳️ представлена в виде медицинского калькулятора и/или цифрового приложения для расчета вероятности
Прогностические модели "под ключ" с вашими данными (дизайн, разработка модели, создание цифрового приложения-калькулятора) ➡️ @glivec
1. Модель должна иметь практическую пользу!
✳️ помогать в принятии конкретных решений в диагностике или лечении
✳️ решать принципиально новые задачи или старые, но лучше, чем существующие модели
✳️ не давать прогнозов, с которыми неясно, что делать
2. Модель должна быть создана методологически правильно
✳️ обучающая выборка достаточно велика и репрезентативна, иначе модель будет нестабильной
✳️ модель хорошо откалибрована и позволяет получать результат в виде вероятности прогнозируемого события
✳️ модель должна быть провалидирована
3. Моделью легко пользоваться в реальной клинической практике
✳️ она максимально простая и не включает в себя трудно доступные для оценки факторы
✳️ представлена в виде медицинского калькулятора и/или цифрового приложения для расчета вероятности
Прогностические модели "под ключ" с вашими данными (дизайн, разработка модели, создание цифрового приложения-калькулятора) ➡️ @glivec
This media is not supported in your browser
VIEW IN TELEGRAM
Парадокс Симпсона - статистический феномен, когда связь между двумя переменными может полностью измениться, если учесть третью переменную. При отсутствии тщательного анализа это часто приводит к противоречивым выводам.
Например, в наборе данных вы можете увидеть положительную тенденцию между переменными X и Y. Однако если разделить данные на подгруппы на основе третьей переменной, Z, тенденция может измениться или исчезнуть. Всегда учитывайте потенциальные скрытые переменные, которые могут повлиять на результаты. Будьте осторожны с агрегированными данными; иногда истинные знания кроются в подгруппах. Используйте визуализацию, чтобы лучше понять характер взаимосвязей в ваших данных. Подробнее здесь.
Например, в наборе данных вы можете увидеть положительную тенденцию между переменными X и Y. Однако если разделить данные на подгруппы на основе третьей переменной, Z, тенденция может измениться или исчезнуть. Всегда учитывайте потенциальные скрытые переменные, которые могут повлиять на результаты. Будьте осторожны с агрегированными данными; иногда истинные знания кроются в подгруппах. Используйте визуализацию, чтобы лучше понять характер взаимосвязей в ваших данных. Подробнее здесь.
👍1🔥1
Про бинарную (биномиальную) логистическую регрессиию
Бинарная логистическая регрессия (БЛР) - статистический метод прогнозирования бинарных исходов. Она оценивает вероятность того, что наблюдение принадлежит к определенной категории (1/0). В основе лежит сигмоидная функция (S-образная кривая на картинке) для получения вероятностей, по порогу которых (обычно 0.5) определяется нужный класс. БЛР применяется для решения задач бинарной классификации, для вычисления вероятностей, когда нужны интерпретируемые результаты и когда связи между признаками и результатом в основном линейны.
Плюсы:
- Легко понять и реализовать
- Быстрое обучение
- Предоставляет оценки вероятности
- По коэффициентам БЛР можно определить важность признаков
Минусы:
- Предполагает линейные взаимосвязи между логитом исхода и ковариатами
- Может не справляться со сложными паттернами
- Чувствительна к выбросам
- Может не справляться с несбалансированными данными
Бинарная логистическая регрессия (БЛР) - статистический метод прогнозирования бинарных исходов. Она оценивает вероятность того, что наблюдение принадлежит к определенной категории (1/0). В основе лежит сигмоидная функция (S-образная кривая на картинке) для получения вероятностей, по порогу которых (обычно 0.5) определяется нужный класс. БЛР применяется для решения задач бинарной классификации, для вычисления вероятностей, когда нужны интерпретируемые результаты и когда связи между признаками и результатом в основном линейны.
Плюсы:
- Легко понять и реализовать
- Быстрое обучение
- Предоставляет оценки вероятности
- По коэффициентам БЛР можно определить важность признаков
Минусы:
- Предполагает линейные взаимосвязи между логитом исхода и ковариатами
- Может не справляться со сложными паттернами
- Чувствительна к выбросам
- Может не справляться с несбалансированными данными
👍3🔥1
Про линейную регрессию
Линейная регрессия - статистический метод прогнозирования значения постоянной зависимой количественной переменной на основе одной или нескольких независимых переменных. Он оценивает взаимосвязь с помощью линейного уравнения. Линейное уравнение - прямая линия, которая моделирует связь между зависимой и независимой переменными, показывая, как изменения входящих характеристик влияют на целевое значение.
Когда использовать:
- Прогнозирование непрерывных (количественных) результатов
- Когда связь между признаками и результатом линейна
- Когда вам нужны интерпретируемые результаты
- Когда у вас есть простые или умеренно сложные данные
Плюсы:
- Легко понять и реализовать
- Быстрое обучение
- По коэффициентам уравнения линейной регрессии можно определить важность признаков
Минусы:
- Предполагает линейные взаимосвязи между исходом и ковариатами
- Может не справляться со сложными закономерностями
- Чувствительна к выбросам
- Может иметь проблемы с мультиколлинеарностью
Линейная регрессия - статистический метод прогнозирования значения постоянной зависимой количественной переменной на основе одной или нескольких независимых переменных. Он оценивает взаимосвязь с помощью линейного уравнения. Линейное уравнение - прямая линия, которая моделирует связь между зависимой и независимой переменными, показывая, как изменения входящих характеристик влияют на целевое значение.
Когда использовать:
- Прогнозирование непрерывных (количественных) результатов
- Когда связь между признаками и результатом линейна
- Когда вам нужны интерпретируемые результаты
- Когда у вас есть простые или умеренно сложные данные
Плюсы:
- Легко понять и реализовать
- Быстрое обучение
- По коэффициентам уравнения линейной регрессии можно определить важность признаков
Минусы:
- Предполагает линейные взаимосвязи между исходом и ковариатами
- Может не справляться со сложными закономерностями
- Чувствительна к выбросам
- Может иметь проблемы с мультиколлинеарностью
🔥2
Еще раз, важно помнить, что корреляция не означает причинно-следственную связь. Если две переменные коррелируют между собой, это не значит, что одна из них является причиной другой. Корреляция просто указывает на связь, но для установления причинно-следственной связи необходимы дополнительные доказательства. На них не следует полагаться при составлении прогнозов или формулировании окончательных выводов. При интерпретации корреляций необходимо учитывать: контекст, характер переменных, потенциальные факторы, сбивающие с толку, чтобы избежать ошибочных выводов. Корреляции могут быть рассчитаны с помощью различных методов, таких как: корреляция Пирсона, корреляция Спирмена и Кендалла.
🔥6
Про фиктивные (dummy) переменные
Фиктивные переменные - бинарные (0/1) переменные, которые используются для представления категориальных данных в регрессионном анализе и других статистических моделях.
Например, у нас есть 4 стадии заболевания и наша переменная "стадия" имеет 4 категории (k): стадия 1, стадия 2, стадия 3 и стадия 4. Для переменной с k категориями создается k-1 фиктивных переменных, чтобы избежать проблемы мультиколлинеарности. Значение каждой фиктивной переменной показывает разницу в эффекте по сравнению с базовой категорией. В нашем примере, если за базовую категорию принять стадию 1, то вместо переменной "стадия" новыми dummy переменными станут "стадия 2 (1/0)", "стадия 3(1/0)" и "стадия 4(1/0)" (3 новых столбика вместо 1). Фиктивные переменные взаимоисключают друг друга. Если значения всех фиктивных переменных у одного наблюдения (пациента) равны 0, то это означает, что пациент принадлежит к базовой категории, в нашем примере это "стадия 1". В противном случае, одна из фиктивных переменных принимает значение 1, остальные - 0.
Выбор базовой категории при создании фиктивных переменных действительно важен и может существенно повлиять на интерпретацию результатов. Вот несколько рекомендаций по выбору базовой категории в медицинских исследованиях:
✅ Контрольная группа. Если в исследовании есть контрольная группа (например, пациенты, получающие плацебо или стандартное лечение), логично выбрать ее в качестве базовой категории. Это позволит легко интерпретировать эффекты других групп относительно контроля.
✅ Наиболее распространенная категория. Выбор наиболее часто встречающейся категории в качестве базовой может улучшить статистическую мощность и стабильность оценок.
✅ Наименьший риск. В исследованиях, связанных с оценкой риска, можно выбрать категорию с наименьшим ожидаемым риском в качестве базовой. Это позволит интерпретировать коэффициенты как увеличение риска относительно базового уровня.
✅ Естественное "нулевое" состояние. Например, при оценке влияния курения можно выбрать "некурящих" в качестве базовой категории.
✅ Клиническая значимость. Выбирайте категорию, которая имеет наибольший клинический смысл в контексте вашего исследования.
✅ Традиция. Если в вашей области есть устоявшаяся практика выбора определенной категории в качестве базовой, следование ей облегчит сравнение результатов с другими исследованиями.
✅ Избегайте крайних значений. Старайтесь не выбирать слишком редкие или экстремальные категории в качестве базовых, так как это может привести к нестабильным оценкам.
✅ Учет пропущенных данных. Если в одной из категорий много пропущенных значений, возможно, стоит выбрать ее в качестве базовой, чтобы минимизировать влияние этих пропусков на анализ.
Важно помнить, что выбор базовой категории не влияет на общую пригодность модели, но может существенно повлиять на интерпретацию коэффициентов модели. Поэтому рекомендуется обосновать свой выбор в методологии исследования и учитывать его при интерпретации результатов.
Фиктивные переменные - бинарные (0/1) переменные, которые используются для представления категориальных данных в регрессионном анализе и других статистических моделях.
Например, у нас есть 4 стадии заболевания и наша переменная "стадия" имеет 4 категории (k): стадия 1, стадия 2, стадия 3 и стадия 4. Для переменной с k категориями создается k-1 фиктивных переменных, чтобы избежать проблемы мультиколлинеарности. Значение каждой фиктивной переменной показывает разницу в эффекте по сравнению с базовой категорией. В нашем примере, если за базовую категорию принять стадию 1, то вместо переменной "стадия" новыми dummy переменными станут "стадия 2 (1/0)", "стадия 3(1/0)" и "стадия 4(1/0)" (3 новых столбика вместо 1). Фиктивные переменные взаимоисключают друг друга. Если значения всех фиктивных переменных у одного наблюдения (пациента) равны 0, то это означает, что пациент принадлежит к базовой категории, в нашем примере это "стадия 1". В противном случае, одна из фиктивных переменных принимает значение 1, остальные - 0.
Выбор базовой категории при создании фиктивных переменных действительно важен и может существенно повлиять на интерпретацию результатов. Вот несколько рекомендаций по выбору базовой категории в медицинских исследованиях:
✅ Контрольная группа. Если в исследовании есть контрольная группа (например, пациенты, получающие плацебо или стандартное лечение), логично выбрать ее в качестве базовой категории. Это позволит легко интерпретировать эффекты других групп относительно контроля.
✅ Наиболее распространенная категория. Выбор наиболее часто встречающейся категории в качестве базовой может улучшить статистическую мощность и стабильность оценок.
✅ Наименьший риск. В исследованиях, связанных с оценкой риска, можно выбрать категорию с наименьшим ожидаемым риском в качестве базовой. Это позволит интерпретировать коэффициенты как увеличение риска относительно базового уровня.
✅ Естественное "нулевое" состояние. Например, при оценке влияния курения можно выбрать "некурящих" в качестве базовой категории.
✅ Клиническая значимость. Выбирайте категорию, которая имеет наибольший клинический смысл в контексте вашего исследования.
✅ Традиция. Если в вашей области есть устоявшаяся практика выбора определенной категории в качестве базовой, следование ей облегчит сравнение результатов с другими исследованиями.
✅ Избегайте крайних значений. Старайтесь не выбирать слишком редкие или экстремальные категории в качестве базовых, так как это может привести к нестабильным оценкам.
✅ Учет пропущенных данных. Если в одной из категорий много пропущенных значений, возможно, стоит выбрать ее в качестве базовой, чтобы минимизировать влияние этих пропусков на анализ.
Важно помнить, что выбор базовой категории не влияет на общую пригодность модели, но может существенно повлиять на интерпретацию коэффициентов модели. Поэтому рекомендуется обосновать свой выбор в методологии исследования и учитывать его при интерпретации результатов.
Про разведочный (эксплораторный) анализ данных
Эксплораторный анализ данных (EDA) - процесс исследования данных с целью выявления закономерностей, аномалий, взаимосвязей или тенденций с помощью статистических и визуальных методов. Это необходимо для понимания базовой структуры и характеристик данных, прежде чем применять более формальные статистические методы или методы машинного обучения.
EDA должен всегда выполняться на самом первом этапе статистического анализа и может включать в себя:
✅ Оценка типов данных (числовые, категориальные, порядковые) для их правильной обработки при последующем анализе.
✅ Оценка качества данных для выявления ошибок и несоответствий, которые могут потребовать исправления.
✅ Оценка распределения данных (например, нормальное, асимметричное распределение) с помощью гистограмм, графиков и сводных статистик помогает интуитивно понять общую тенденцию, изменчивость и сложные взаимосвязи в данных.
✅ Оценка пропущенных значений: выявление и устранение недостающих данных крайне важно, поскольку это может существенно повлиять на результаты анализа. Методы включают в себя импутацию (вменение), удаление отсутствующих данных, а также понимание причин их отсутствия.
✅ Оценка выбросов: обнаружение и изучение выбросов, чтобы понять их влияние на набор данных и решить, как с ними справиться (например, удалить, преобразовать).
✅ Анализ корреляций между переменными с помощью коэффициентов корреляции и диаграмм рассеяния для выявления взаимосвязей и потенциальных зависимостей.
✅ Оценка закономерностей, тенденций или аномалий в данных, которые могут быть визуализированы с помощью линейных графиков, гистограмм или анализа временных рядов.
✅ Сравнение показателей в разных группах для выявления существенных различий или сходств.
Эксплораторный анализ данных (EDA) - процесс исследования данных с целью выявления закономерностей, аномалий, взаимосвязей или тенденций с помощью статистических и визуальных методов. Это необходимо для понимания базовой структуры и характеристик данных, прежде чем применять более формальные статистические методы или методы машинного обучения.
EDA должен всегда выполняться на самом первом этапе статистического анализа и может включать в себя:
✅ Оценка типов данных (числовые, категориальные, порядковые) для их правильной обработки при последующем анализе.
✅ Оценка качества данных для выявления ошибок и несоответствий, которые могут потребовать исправления.
✅ Оценка распределения данных (например, нормальное, асимметричное распределение) с помощью гистограмм, графиков и сводных статистик помогает интуитивно понять общую тенденцию, изменчивость и сложные взаимосвязи в данных.
✅ Оценка пропущенных значений: выявление и устранение недостающих данных крайне важно, поскольку это может существенно повлиять на результаты анализа. Методы включают в себя импутацию (вменение), удаление отсутствующих данных, а также понимание причин их отсутствия.
✅ Оценка выбросов: обнаружение и изучение выбросов, чтобы понять их влияние на набор данных и решить, как с ними справиться (например, удалить, преобразовать).
✅ Анализ корреляций между переменными с помощью коэффициентов корреляции и диаграмм рассеяния для выявления взаимосвязей и потенциальных зависимостей.
✅ Оценка закономерностей, тенденций или аномалий в данных, которые могут быть визуализированы с помощью линейных графиков, гистограмм или анализа временных рядов.
✅ Сравнение показателей в разных группах для выявления существенных различий или сходств.
{kind=link}
🔥1
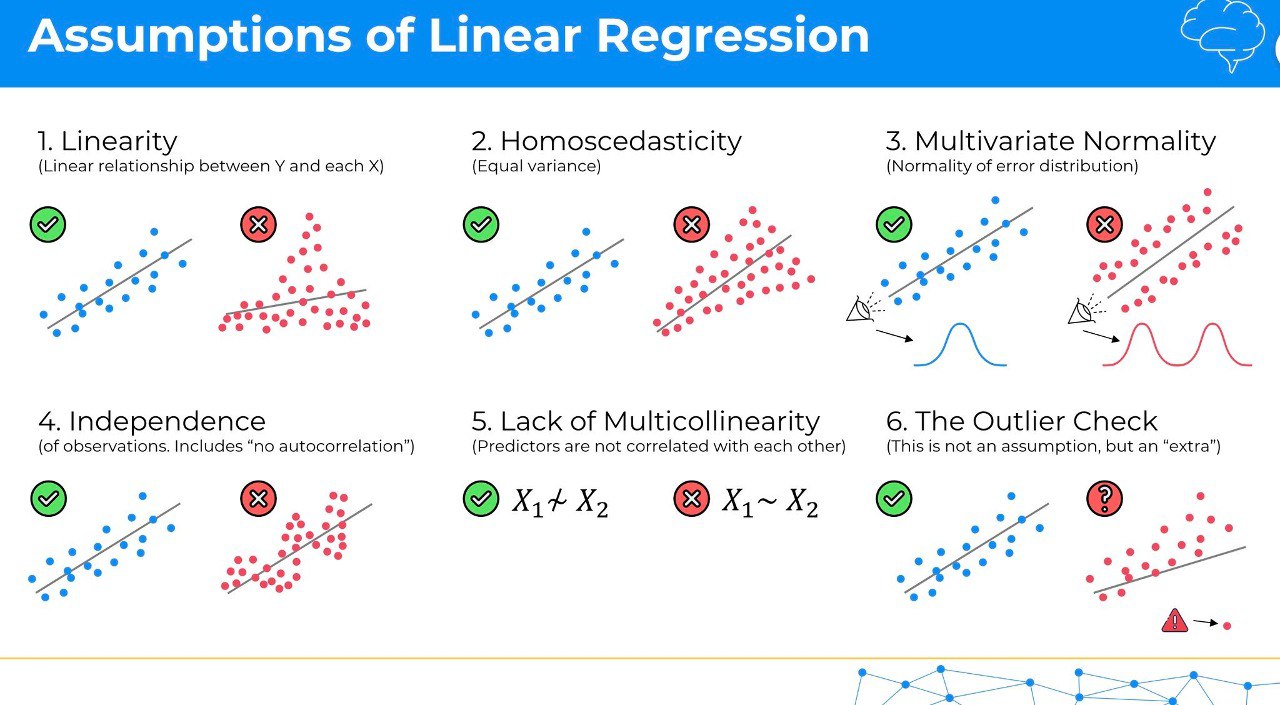
Проверка пригодности модели линейной регрессии в медицинских исследованиях (про допущения метода)
Применение метода линейной регрессии в статистике требует выполнения обязательного набора допущений, без которых итоговый результат может быть некорректным. Каждое из допущенией проверяется другими статистическими или графическими методами.
✅ Линейность: связь между предикторами (например, возраст пациента, уровень сахара в крови) и откликом (например, риск развития диабета) должна быть линейной. Это означает, что изменение предиктора приводит к пропорциональному изменению отклика.
✅ Независимость: остатки или ошибки (разница между фактическим и предсказанным значением отклика) должны быть независимы друг от друга. Например, результат анализа одного пациента не должен зависеть от результатов других пациентов.
✅ Гомоскедастичность против гетероскедастичности: остатки должны иметь постоянное распределение на всех уровнях независимой переменной. Например, разброс уровней артериального давления должен быть одинаковым для разных возрастных групп.
✅ Нормальность остатков (многомерная нормальность): остатки должны следовать нормальному распределению, подобному колоколообразной кривой распределения роста в популяции.
✅ Отсутствие мультиколлинеарности: предикторы (например, возраст и масса тела) не должны быть сильно коррелированы друг с другом, чтобы можно было оценить их независимое влияние на отклик.
✅ Отсутствие выбросов. Выбросы нарушают линейность взаимосвязей и приводят к другим проблемам с допущениями линейной регрессии.
Дополнительно читайте здесь.
Применение метода линейной регрессии в статистике требует выполнения обязательного набора допущений, без которых итоговый результат может быть некорректным. Каждое из допущенией проверяется другими статистическими или графическими методами.
✅ Линейность: связь между предикторами (например, возраст пациента, уровень сахара в крови) и откликом (например, риск развития диабета) должна быть линейной. Это означает, что изменение предиктора приводит к пропорциональному изменению отклика.
✅ Независимость: остатки или ошибки (разница между фактическим и предсказанным значением отклика) должны быть независимы друг от друга. Например, результат анализа одного пациента не должен зависеть от результатов других пациентов.
✅ Гомоскедастичность против гетероскедастичности: остатки должны иметь постоянное распределение на всех уровнях независимой переменной. Например, разброс уровней артериального давления должен быть одинаковым для разных возрастных групп.
✅ Нормальность остатков (многомерная нормальность): остатки должны следовать нормальному распределению, подобному колоколообразной кривой распределения роста в популяции.
✅ Отсутствие мультиколлинеарности: предикторы (например, возраст и масса тела) не должны быть сильно коррелированы друг с другом, чтобы можно было оценить их независимое влияние на отклик.
✅ Отсутствие выбросов. Выбросы нарушают линейность взаимосвязей и приводят к другим проблемам с допущениями линейной регрессии.
Дополнительно читайте здесь.
{kind=link}
🔥1
Про тест Cochran-Armitage (Кохрейна-Армитажа)
Тест Cochran-Armitage на тренд (также известный как тест на линейный тренд в пропорциях) - статистический метод, используемый для выявления наличия линейной тенденции между бинарным исходом и порядковой или непрерывной независимой переменной. Используется для определения, существует ли линейная связь между долей (частотой) некоего исхода и уровнями упорядоченного предиктора. Часто применяется в медицинских исследованиях, эпидемиологии, где нужно оценить тренд.
✅ Тест проверяет следующие гипотезы:
Нулевая гипотеза (H0): Нет линейного тренда.
Альтернативная гипотеза (H1): Существует линейный тренд.
✅ Тест предполагает линейную связь, если тренд нелинейный (например, U-образный), тест может не обнаружить его или дать неверный результат.
Тест Cochran-Armitage на тренд (также известный как тест на линейный тренд в пропорциях) - статистический метод, используемый для выявления наличия линейной тенденции между бинарным исходом и порядковой или непрерывной независимой переменной. Используется для определения, существует ли линейная связь между долей (частотой) некоего исхода и уровнями упорядоченного предиктора. Часто применяется в медицинских исследованиях, эпидемиологии, где нужно оценить тренд.
✅ Тест проверяет следующие гипотезы:
Нулевая гипотеза (H0): Нет линейного тренда.
Альтернативная гипотеза (H1): Существует линейный тренд.
✅ Тест предполагает линейную связь, если тренд нелинейный (например, U-образный), тест может не обнаружить его или дать неверный результат.
✅ Пример. Предположим, вы изучаете заболеваемость или летальность за N-летний период. Тогда тест Cochran-Armitage поможет определить, существует ли статистически значимый возрастающий тренд в частоте заболевания с течением времени. Если тест покажет значимый результат, это будет свидетельствовать о наличии линейного тренда в частоте события во времени. Положительный тренд будет указывать на увеличение частоты события со временем, отрицательный - на уменьшение.
This media is not supported in your browser
VIEW IN TELEGRAM
Прогностические модели в медицине: точность имеет значение
Главная задача прогностической модели в медицине - предоставить врачу и пациенту точную оценку вероятности определенного исхода. Будь то риск развития заболевания, вероятность осложнений или прогноз выживаемости - модель должна давать надежный прогноз, основанный на индивидуальных характеристиках пациента.
Продемонстрируем два примера широко используемых прогностических моделей:
✅ Модель пропорциональных рисков Кокса позволяет оценить влияние различных факторов на время до наступления определенного события (например, рецидива заболевания).
Главная задача прогностической модели в медицине - предоставить врачу и пациенту точную оценку вероятности определенного исхода. Будь то риск развития заболевания, вероятность осложнений или прогноз выживаемости - модель должна давать надежный прогноз, основанный на индивидуальных характеристиках пациента.
Продемонстрируем два примера широко используемых прогностических моделей:
✅ Модель пропорциональных рисков Кокса позволяет оценить влияние различных факторов на время до наступления определенного события (например, рецидива заболевания).
This media is not supported in your browser
VIEW IN TELEGRAM
✅ Бинарная логистическая регрессия используется для прогнозирования вероятности наступления события, имеющего два возможных исхода (например, наличие или отсутствие заболевания или осложнения).
Разработка точных и надежных прогностических моделей требует глубокого понимания как статистических методов, так и специфики медицинской области. Создание индивидуальных прогностических моделей "под ключ" для различных медицинских задач включает в себя:
✅ Анализ ваших данных и выбор оптимального метода моделирования;
✅ Разработку и валидацию модели;
✅ Создание удобных интерфейсов и калькуляторов для практического применения модели;
✅ Полное сопровождение описания модели в вашей научной работе и внедрение модели в клиническую практику.
Пишите: @glivec
Разработка точных и надежных прогностических моделей требует глубокого понимания как статистических методов, так и специфики медицинской области. Создание индивидуальных прогностических моделей "под ключ" для различных медицинских задач включает в себя:
✅ Анализ ваших данных и выбор оптимального метода моделирования;
✅ Разработку и валидацию модели;
✅ Создание удобных интерфейсов и калькуляторов для практического применения модели;
✅ Полное сопровождение описания модели в вашей научной работе и внедрение модели в клиническую практику.
Пишите: @glivec
Еще раз про центральную предельную теорему
Центральная предельная теорема (ЦПТ) является фундаментальной концепцией в статистике, имеющей широкие приложения. Она утверждает, что распределение выборочных средних приближается к нормальному распределению (гауссовскому распределению) по мере увеличения размера выборки, независимо от исходного распределения популяции. Это имеет решающее значение для проведения выводов о популяциях на основе выборочных данных.
Понимание ЦПТ значительно улучшает навыки анализа данных, предоставляя надежную основу для проверки гипотез и оценки доверительных интервалов. Однако у нее есть некоторые ограничения:
❌ Размер выборки: для эффективного применения ЦПТ требуется достаточно большой размер выборки. Небольшие выборки могут не давать точных результатов.
❌ Независимость: выборки должны быть независимыми. Зависимости между данными могут исказить результаты.
❌ Одинаковое распределение: выборки должны происходить из одного и того же распределения.
Несмотря на эти недостатки, ЦПТ остается чрезвычайно полезной. Вот почему:
✔️ Универсальность: она применима к широкому диапазону распределений, что делает ее универсальной для различных наборов данных.
✔️ Предсказуемость: при достаточно большом размере выборки прогнозы о параметрах популяции становятся более точными.
✔️ Простота: она упрощает сложные задачи, позволяя статистикам и аналитикам данных использовать свойства нормального распределения для анализа.
Центральная предельная теорема (ЦПТ) является фундаментальной концепцией в статистике, имеющей широкие приложения. Она утверждает, что распределение выборочных средних приближается к нормальному распределению (гауссовскому распределению) по мере увеличения размера выборки, независимо от исходного распределения популяции. Это имеет решающее значение для проведения выводов о популяциях на основе выборочных данных.
Понимание ЦПТ значительно улучшает навыки анализа данных, предоставляя надежную основу для проверки гипотез и оценки доверительных интервалов. Однако у нее есть некоторые ограничения:
❌ Размер выборки: для эффективного применения ЦПТ требуется достаточно большой размер выборки. Небольшие выборки могут не давать точных результатов.
❌ Независимость: выборки должны быть независимыми. Зависимости между данными могут исказить результаты.
❌ Одинаковое распределение: выборки должны происходить из одного и того же распределения.
Несмотря на эти недостатки, ЦПТ остается чрезвычайно полезной. Вот почему:
✔️ Универсальность: она применима к широкому диапазону распределений, что делает ее универсальной для различных наборов данных.
✔️ Предсказуемость: при достаточно большом размере выборки прогнозы о параметрах популяции становятся более точными.
✔️ Простота: она упрощает сложные задачи, позволяя статистикам и аналитикам данных использовать свойства нормального распределения для анализа.
{kind=link}