
Робастное масштабирование (Robust Scaling) - способ борьбы с выбросами в данных.
В этом методе для масштабирования используются медиана и интерквартильный размах. Используйте этот метод, когда данные содержат много выбросов и необходимо обеспечить устойчивость к ним. Из значений вариационного ряда проводится вычитание медианы этого ряда и выполняется деление на межквартильных размах (IQR).
В этом методе для масштабирования используются медиана и интерквартильный размах. Используйте этот метод, когда данные содержат много выбросов и необходимо обеспечить устойчивость к ним. Из значений вариационного ряда проводится вычитание медианы этого ряда и выполняется деление на межквартильных размах (IQR).
{kind=link}
👍1
Про информационные критерии AIC и BIC
Когда строится прогностическая модель возникает вопрос, делает ли добавление дополнительных переменных ее действительно лучше? Или просто более сложной? AIC и BIC - инструменты, помогающие найти баланс между хорошей подгонкой и простотой! Выбор "лучшей" модели заключается не только в том, что она наиболее точно соответствует данным, но и в том, что она использует наименьшее количество ненужных переменных. Это компромисс между соответствием и простотой.
AIC (информационный критерий Акаике) был предложенн Хиротугу Акаике в 1970-х годах. AIC оценивает соответствие модели данным, а затем добавляет штраф за каждый используемый параметр (или переменную). Идея в том, чтобы предотвратить излишнее усложнение модели.
BIC (Байесовский информационный критерий) введен Гидеоном Шварцем в 1970-х годах. BIC также балансирует между пригодностью и простотой. Но он более строгий! Его штраф растет более существенно с добавлением параметров, особенно при увеличении размера выборки.
Оба показателя штрафуют за сложность, но если AIC более нацелен на качество прогнозирования, то BIC - на выявление более простой модели среди множества кандидатов. На больших выборках BIC, как правило, предпочитает более простые модели, чем AIC. Ни один критерий не является идеальным! AIC и BIC иногда могут выбирать слишком сложные или слишком упрощенные модели. Это все лишь рекомендательные критерии. Всегда используйте их в сочетании со знанием предметной области и другими диагностическими методами. При сравнении нескольких моделей лучшей считается модель с наименьшим AIC или BIC. Однако следует помнить, что небольшие различия между моделями (особенно по AIC) не всегда могут быть значимыми. Помимо AIC и BIC существует много других критериев: скорректированный AIC, DIC и др. Каждый из них обладает своими уникальными преимуществами и возможностями.
Когда строится прогностическая модель возникает вопрос, делает ли добавление дополнительных переменных ее действительно лучше? Или просто более сложной? AIC и BIC - инструменты, помогающие найти баланс между хорошей подгонкой и простотой! Выбор "лучшей" модели заключается не только в том, что она наиболее точно соответствует данным, но и в том, что она использует наименьшее количество ненужных переменных. Это компромисс между соответствием и простотой.
AIC (информационный критерий Акаике) был предложенн Хиротугу Акаике в 1970-х годах. AIC оценивает соответствие модели данным, а затем добавляет штраф за каждый используемый параметр (или переменную). Идея в том, чтобы предотвратить излишнее усложнение модели.
BIC (Байесовский информационный критерий) введен Гидеоном Шварцем в 1970-х годах. BIC также балансирует между пригодностью и простотой. Но он более строгий! Его штраф растет более существенно с добавлением параметров, особенно при увеличении размера выборки.
Оба показателя штрафуют за сложность, но если AIC более нацелен на качество прогнозирования, то BIC - на выявление более простой модели среди множества кандидатов. На больших выборках BIC, как правило, предпочитает более простые модели, чем AIC. Ни один критерий не является идеальным! AIC и BIC иногда могут выбирать слишком сложные или слишком упрощенные модели. Это все лишь рекомендательные критерии. Всегда используйте их в сочетании со знанием предметной области и другими диагностическими методами. При сравнении нескольких моделей лучшей считается модель с наименьшим AIC или BIC. Однако следует помнить, что небольшие различия между моделями (особенно по AIC) не всегда могут быть значимыми. Помимо AIC и BIC существует много других критериев: скорректированный AIC, DIC и др. Каждый из них обладает своими уникальными преимуществами и возможностями.
{kind=link}
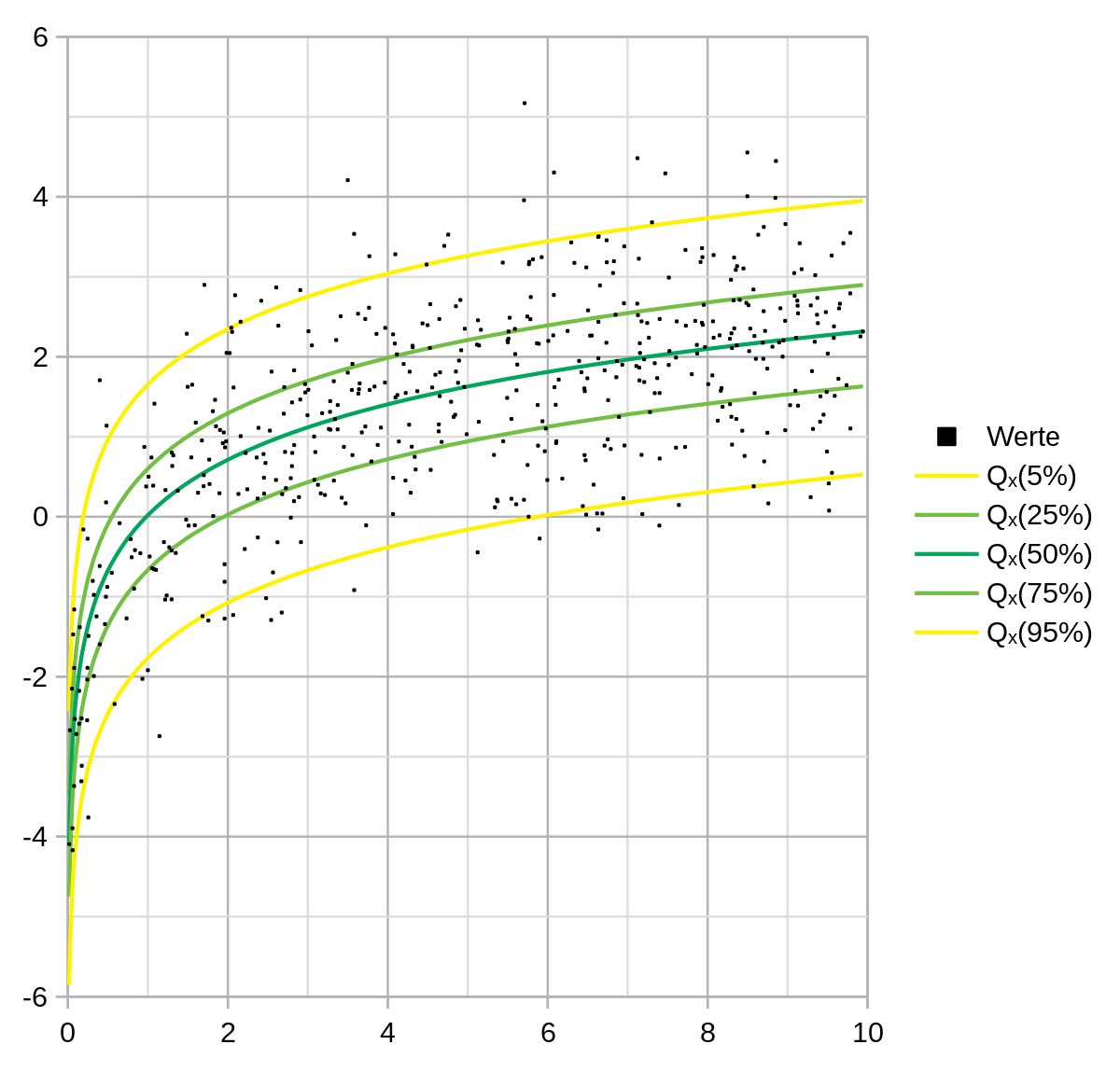
Про квантильную регрессию
Средние значения далеко не всегда хорошо отражают данные. Традиционная линейная регрессия предсказывает среднее значение зависимой переменной. Но что, если нас интересует, скажем, медиана? Или 90-й процентиль? Квантильная регрессия (КР) - рассматривает различные квантили (процентили) в качестве переменной ответа (отклика) и позволяет моделировать эти специфические квантили, давая более полное представление о распределении данных. КР минимизирует сумму взвешенных абсолютных остатков, в отличие от регрессии по методу наименьших квадратов, которая минимизирует квадратичные остатки. Изменяя весовые коэффициенты, мы ориентируемся на различные квантили. КР является универсальным инструментом для понимания взаимосвязей в данных, выходящих за рамки среднего значения. Она освещает все распределение, позволяя получить более глубокие выводы, однако интерпретация может быть менее интуитивной, чем при использовании методов, ориентированных на средние значения.
Преимущества КР:
✅ Дает понимание взаимосвязи между независимыми переменным с зависимой в различных ее точках (квантилях)
✅ Высокая устойчивость к выбросам
✅ Полезна, когда остатки линейной модели не являются гомоскедастичными (т.е. имеют непостоянную дисперсию).
✅ Совместное визуальное построение нескольких квантильных регрессий может дать более целостное представление о взаимосвязи данных. Например, можно увидеть, как меняется влияние лечения на уровень сахара в крови в зависимости от распределения пациентов с изначально разным уровнем сахара.
Показания к использованию КР:
✅ При подозрении на гетероскедастичность
✅ При интересе к высоким или низким экстремумам (например, какие факторы влияют на 10% пациентов с самым высоким уровнем сахара в крови).
Средние значения далеко не всегда хорошо отражают данные. Традиционная линейная регрессия предсказывает среднее значение зависимой переменной. Но что, если нас интересует, скажем, медиана? Или 90-й процентиль? Квантильная регрессия (КР) - рассматривает различные квантили (процентили) в качестве переменной ответа (отклика) и позволяет моделировать эти специфические квантили, давая более полное представление о распределении данных. КР минимизирует сумму взвешенных абсолютных остатков, в отличие от регрессии по методу наименьших квадратов, которая минимизирует квадратичные остатки. Изменяя весовые коэффициенты, мы ориентируемся на различные квантили. КР является универсальным инструментом для понимания взаимосвязей в данных, выходящих за рамки среднего значения. Она освещает все распределение, позволяя получить более глубокие выводы, однако интерпретация может быть менее интуитивной, чем при использовании методов, ориентированных на средние значения.
Преимущества КР:
✅ Дает понимание взаимосвязи между независимыми переменным с зависимой в различных ее точках (квантилях)
✅ Высокая устойчивость к выбросам
✅ Полезна, когда остатки линейной модели не являются гомоскедастичными (т.е. имеют непостоянную дисперсию).
✅ Совместное визуальное построение нескольких квантильных регрессий может дать более целостное представление о взаимосвязи данных. Например, можно увидеть, как меняется влияние лечения на уровень сахара в крови в зависимости от распределения пациентов с изначально разным уровнем сахара.
Показания к использованию КР:
✅ При подозрении на гетероскедастичность
✅ При интересе к высоким или низким экстремумам (например, какие факторы влияют на 10% пациентов с самым высоким уровнем сахара в крови).
{kind=link}
👍1
Три мифа о пороговых значениях риска для медицинских прогностических моделей
Миф 1: группы риска более полезны, чем прогнозы риска в виде непрерывного расчета вероятности прогнозируемого события - нет, конкретное значение вероятности события позволяет принимать более точные решения на индивидуальном уровне. Например, гораздо полезнее знать, что риск рака составляет 83%, чем то, что он просто выше 50%.
Миф 2: оптимальный порог высчитывается статистическими методами непосредственно по данным - нет, хороший порог тот, который отражает клинический контекст.
Например, порог высчитанный при помощий ROC-кривой не имеет никакой пользы, по сравнению с пороговым значением той же вероятности, когда врач в данной конкретной клинической ситуации считает необходимым предпринять какие-то действия из-за высокого риска прогнозируемого моделью события.
Миф 3: порог является частью прогностической модели - нет, это лишь частный случай модели, точность которой может быть проверена для разных порогов риска. Например, показатели чувствительности, специфичности и точности модели, полученные при использовании порога, не отражают истинные метрики модели, а лишь характеризуют частный случай ее применения.
Медицинские прогностические модели полезны для принятия решений в клинической практике. Для этой цели ключевое значение имеют надежные непрерывные оценки риска. Если для выявления пациентов с высоким риском необходимы пороговые значения, оптимальные пороговые значения не могут быть рассчитаны только на основании каких-либо статистических методов. Вместо этого выбор порога должен отражать вред от ложноположительных результатов и пользу от истинно положительных, что зависит от клинического контекста. Следует сосредоточиться на методах, которые оценивают прогностическую эффективность модели независимо от порога (например, AUC и калибровочные графики) или включают диапазон порогов риска (например, анализ кривой принятия решений).
Миф 1: группы риска более полезны, чем прогнозы риска в виде непрерывного расчета вероятности прогнозируемого события - нет, конкретное значение вероятности события позволяет принимать более точные решения на индивидуальном уровне. Например, гораздо полезнее знать, что риск рака составляет 83%, чем то, что он просто выше 50%.
Миф 2: оптимальный порог высчитывается статистическими методами непосредственно по данным - нет, хороший порог тот, который отражает клинический контекст.
Например, порог высчитанный при помощий ROC-кривой не имеет никакой пользы, по сравнению с пороговым значением той же вероятности, когда врач в данной конкретной клинической ситуации считает необходимым предпринять какие-то действия из-за высокого риска прогнозируемого моделью события.
Миф 3: порог является частью прогностической модели - нет, это лишь частный случай модели, точность которой может быть проверена для разных порогов риска. Например, показатели чувствительности, специфичности и точности модели, полученные при использовании порога, не отражают истинные метрики модели, а лишь характеризуют частный случай ее применения.
Медицинские прогностические модели полезны для принятия решений в клинической практике. Для этой цели ключевое значение имеют надежные непрерывные оценки риска. Если для выявления пациентов с высоким риском необходимы пороговые значения, оптимальные пороговые значения не могут быть рассчитаны только на основании каких-либо статистических методов. Вместо этого выбор порога должен отражать вред от ложноположительных результатов и пользу от истинно положительных, что зависит от клинического контекста. Следует сосредоточиться на методах, которые оценивают прогностическую эффективность модели независимо от порога (например, AUC и калибровочные графики) или включают диапазон порогов риска (например, анализ кривой принятия решений).
👍3
Использование бутстрэппинга для внутренней валидации прогностической модели
Одним из этапов создания медицинских прогностических моделей является внутренняя валидация. Чтобы не терять данные, которых как правило никогда не хватает, не стоит делить датасет на тренировочную и валидационную (тестовую) выборки. Делайте модель на всем наборе данных, а для внутренней валидации используйте бутстрэпп.
Чтобы рассчитать оптимизм модели, скорректированный с помощью бутстрэппинга, необходимо выполнить следующие шаги:
1. Сделайте модель прогнозирования, используя все исходные данные, и рассчитайте ее эффективность (например, по значению С-индекса или AUC-ROC)
2. Создайте бутстрэпп-выборку (того же размера, что и исходные данные), выбрав наблюдения с заменой из исходных данных. Подробнее здесь
3. Создайте бутстрэпп-модель на основе бутстрэпп-выборки (применяя все те же методы моделирования и выбора предикторов, что и на шаге 1):
3.1 Определите эффективность (например, по значению С-индекса или AUC-ROC) этой бутстрэпп-модели.
3.2. Определите эффективность бутстрэпп-модели на исходных данных.
4. Рассчитайте оптимизм как разницу между эффективностью модели, протестированной на бутстрэпп-выборке и на исходных данных.
5. Повторите шаги 2-4 много раз (не менее 500 раз).
6. Усредните оценки оптимизма на шаге 5.
7. Вычтите среднее значение оптимизма (на шаге 6) из кажущейся эффективности первоначальной модели, полученной на шаге 1, чтобы получить оценку производительности с поправкой на оптимизм.
Поздравляю! Вы провели внутреннюю валидацию своей модели и скорректировали метрики ее эффективности.
Одним из этапов создания медицинских прогностических моделей является внутренняя валидация. Чтобы не терять данные, которых как правило никогда не хватает, не стоит делить датасет на тренировочную и валидационную (тестовую) выборки. Делайте модель на всем наборе данных, а для внутренней валидации используйте бутстрэпп.
Чтобы рассчитать оптимизм модели, скорректированный с помощью бутстрэппинга, необходимо выполнить следующие шаги:
1. Сделайте модель прогнозирования, используя все исходные данные, и рассчитайте ее эффективность (например, по значению С-индекса или AUC-ROC)
2. Создайте бутстрэпп-выборку (того же размера, что и исходные данные), выбрав наблюдения с заменой из исходных данных. Подробнее здесь
3. Создайте бутстрэпп-модель на основе бутстрэпп-выборки (применяя все те же методы моделирования и выбора предикторов, что и на шаге 1):
3.1 Определите эффективность (например, по значению С-индекса или AUC-ROC) этой бутстрэпп-модели.
3.2. Определите эффективность бутстрэпп-модели на исходных данных.
4. Рассчитайте оптимизм как разницу между эффективностью модели, протестированной на бутстрэпп-выборке и на исходных данных.
5. Повторите шаги 2-4 много раз (не менее 500 раз).
6. Усредните оценки оптимизма на шаге 5.
7. Вычтите среднее значение оптимизма (на шаге 6) из кажущейся эффективности первоначальной модели, полученной на шаге 1, чтобы получить оценку производительности с поправкой на оптимизм.
Поздравляю! Вы провели внутреннюю валидацию своей модели и скорректировали метрики ее эффективности.
👍4
статИИстик
🤔 Немного терминологии в медицинском прогнозировании ✅ Прогностический фактор или предиктор - переменная, которая помогает прогнозировать (расчитывать вероятность) изучаемого исхода в конкретной прогностической модели. ✅ Фактор риска - переменная, определенное…
🤨 На дворе 2024 год, а в медицинской литературе до сих пор принято подставлять кучу ковариат в регрессионную модель для какого-нибудь плохого исхода и объявлять значимые ассоциации "факторами риска", о которых следует беспокоиться. Псевдонаука!
👍2🤔1
Матрица ошибок (Confusion matrix) – таблица, помогающая проанализировать эффективность модели классификации на наборе данных, для которых известны истинные значения классов. Матрица позволяет вычислить частоты истинно положительных (TP), истинно отрицательных (TN), ложно положительных (FP, ошибка 1 рода) и ложно отрицательных (FN, ошибка 2 рода) результатов. Размерность таблицы соответствует числу прогнозируемых классов. Матрица ошибок – простой способ визуализировать ошибки, которые допускает модель по каждому из классов.
❤1
По матрице ошибок можно высчитать другие метрики модели классификации:
🟢 Точность (Accuracy) – показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен (нет классового дисбаланса). Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Точность = (TP+TN)/(TP+TN+FP+FN).
🟢 Положительная прогностическая ценность (PPV, Precision) – частота правильно предсказанных TP результатов из общего числа истинно и ложно предсказанных положительных результатов.
PPV = TP/(TP+FP).
🟢 Отрицательная прогностическая ценность (NPV) – частота правильно предсказанных TN результатов из общего числа истинно и ложно предсказанных отрицательных результатов.
NPV = TN/(FN+TN).
🟢 Чувствительность (Recall) – частота правильно предсказанных TP результатов из их общего числа.
Чувствительность = TP/(TP+FN).
🟢 Специфичность – частота правильно предсказанных TN результатов из их общего числа.
Специфичность = TN/(TN+FP)
🟢 F-мера (F-score, F1) – показатель, который помогает комплексно оценивать Recall и Precision, используя среднее гармоническое вместо среднего арифметического.
F1 = (2*Recall*Precision)/(Recall+Precision).
🟢 Точность (Accuracy) – показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен (нет классового дисбаланса). Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Точность = (TP+TN)/(TP+TN+FP+FN).
🟢 Положительная прогностическая ценность (PPV, Precision) – частота правильно предсказанных TP результатов из общего числа истинно и ложно предсказанных положительных результатов.
PPV = TP/(TP+FP).
🟢 Отрицательная прогностическая ценность (NPV) – частота правильно предсказанных TN результатов из общего числа истинно и ложно предсказанных отрицательных результатов.
NPV = TN/(FN+TN).
🟢 Чувствительность (Recall) – частота правильно предсказанных TP результатов из их общего числа.
Чувствительность = TP/(TP+FN).
🟢 Специфичность – частота правильно предсказанных TN результатов из их общего числа.
Специфичность = TN/(TN+FP)
🟢 F-мера (F-score, F1) – показатель, который помогает комплексно оценивать Recall и Precision, используя среднее гармоническое вместо среднего арифметического.
F1 = (2*Recall*Precision)/(Recall+Precision).
❤1
Классовый дисбаланс - одна из тех проблем, которые обычно оказываются не проблемами, но превращаются в настоящие проблемы только тогда, когда вы начинаете их "исправлять".
Пояснение: дисбаланс классов при маленькой выборке может проблемой при создании моделей прогнозирования, подробнее здесь. Но методы исправления дисбаланаса могут привести еще к большим проблемам, в частности к увеличению ошибки калибровки модели и риску предвзятости полученных результатов. Что делать? Варианты: ничего и строить модель как есть, увеличить выборку (собрать больше данных), использовать методы устранения дисбаланса, но очень осторожно.
Пояснение: дисбаланс классов при маленькой выборке может проблемой при создании моделей прогнозирования, подробнее здесь. Но методы исправления дисбаланаса могут привести еще к большим проблемам, в частности к увеличению ошибки калибровки модели и риску предвзятости полученных результатов. Что делать? Варианты: ничего и строить модель как есть, увеличить выборку (собрать больше данных), использовать методы устранения дисбаланса, но очень осторожно.
PubMed Central (PMC)
The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression
Methods to correct class imbalance (imbalance between the frequency of outcome events and nonevents) are receiving increasing interest for developing prediction models. We examined the effect of imbalance correction on the performance of logistic regression…
🔥1
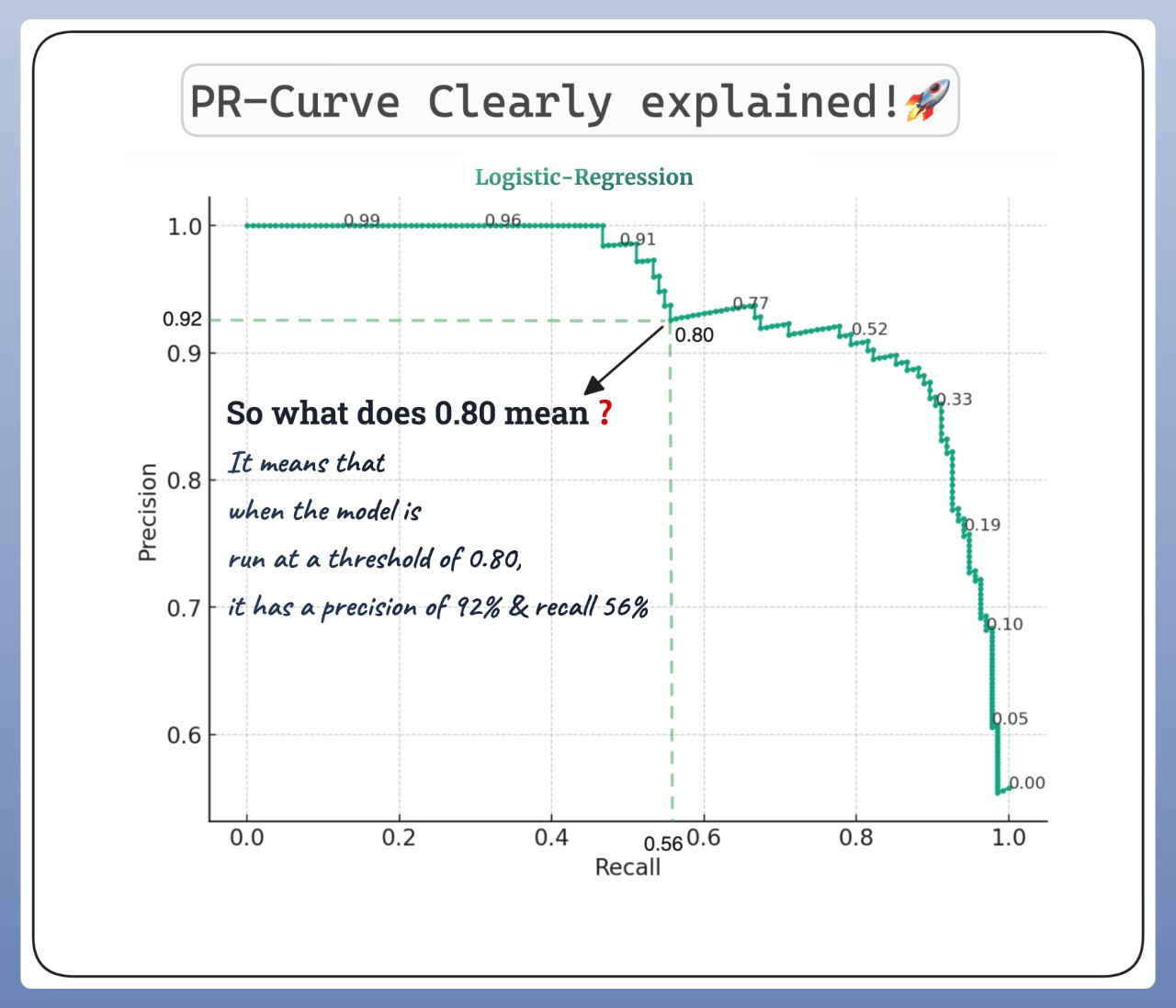
Про Precision-Recall curve
Метрики прогностической модели Precision и Recall (см. пост) являются конкурирующими, поэтому часто приходится искать баланс между ними. На помощь приходит PRC (PR-кривая, по аналогии с ROC кривой) и оценка площади под кривой AUPRC (по аналогии с AUC-ROC).
PR-кривая - график, который показывает компромисс между Precision и Recall для различных пороговых значений. Он также является способом оценки и сравнения различных моделей друг с другом. Модель с идеальной точностью будет иметь кривую PR, которая стремится к правому верхнему углу графика, а также AUPRC, стремящуюся к 1.
Метрики прогностической модели Precision и Recall (см. пост) являются конкурирующими, поэтому часто приходится искать баланс между ними. На помощь приходит PRC (PR-кривая, по аналогии с ROC кривой) и оценка площади под кривой AUPRC (по аналогии с AUC-ROC).
PR-кривая - график, который показывает компромисс между Precision и Recall для различных пороговых значений. Он также является способом оценки и сравнения различных моделей друг с другом. Модель с идеальной точностью будет иметь кривую PR, которая стремится к правому верхнему углу графика, а также AUPRC, стремящуюся к 1.
{kind=link}
❤1
Про SMOTE - один из методов борьбы с несбалансированными данными
Спойлер: метод существует, использовать не рекомендуется, если есть другие варианты.
Несбалансированные наборы данных могут представлять собой проблему, потому что более редкий класс (меньшинство) затмевается доминирующим классом (большинством), что приводит к перекосам в работе модели. Модель хорошо предсказывает большинство, но игнорирует меньшинство. SMOTE расшифровывается как Synthetic Minority Over-sampling Technique. В основе метода лежит создание новых синтетических примеров меньшего класса данных путем интерполяции (способ нахождения промежуточных значений величины по имеющемуся дискретному набору известных значений) между существующими их значениями. SMOTE выбирает экземпляр меньшинства, затем выбирает k его ближайших соседей, случайным образом выбирает одного соседа, вычисляет разницу между ними и создает синтетические экземпляры данных по этой разнице. Таким образом, происходит выравнивание данных между двумя классами. SMOTE - мощный инструмент, но им нельзя злоупотреблять! Генерирование слишком большого количества синтетических данных может привести к появлению избыточного шума. Нахождение правильного баланса - ключевой момент. Кроме того, не все статистические методы моделирования чувстительны к дисбалансу данных и не требуют предварительного использования подоходов, подобных SMOTE.
И еще один важный момент! Если вы хотите разделить выборку на тренировочную и тестовую, то это ВСЕГДА нужно делать до каких-либо манипуляций с данными, в том числе до устранения дисбаланса.
Спойлер: метод существует, использовать не рекомендуется, если есть другие варианты.
Несбалансированные наборы данных могут представлять собой проблему, потому что более редкий класс (меньшинство) затмевается доминирующим классом (большинством), что приводит к перекосам в работе модели. Модель хорошо предсказывает большинство, но игнорирует меньшинство. SMOTE расшифровывается как Synthetic Minority Over-sampling Technique. В основе метода лежит создание новых синтетических примеров меньшего класса данных путем интерполяции (способ нахождения промежуточных значений величины по имеющемуся дискретному набору известных значений) между существующими их значениями. SMOTE выбирает экземпляр меньшинства, затем выбирает k его ближайших соседей, случайным образом выбирает одного соседа, вычисляет разницу между ними и создает синтетические экземпляры данных по этой разнице. Таким образом, происходит выравнивание данных между двумя классами. SMOTE - мощный инструмент, но им нельзя злоупотреблять! Генерирование слишком большого количества синтетических данных может привести к появлению избыточного шума. Нахождение правильного баланса - ключевой момент. Кроме того, не все статистические методы моделирования чувстительны к дисбалансу данных и не требуют предварительного использования подоходов, подобных SMOTE.
И еще один важный момент! Если вы хотите разделить выборку на тренировочную и тестовую, то это ВСЕГДА нужно делать до каких-либо манипуляций с данными, в том числе до устранения дисбаланса.
{kind=link}
❤1
Решение проблемы P-хакинга в науке
P-хакинг - явление, когда исследователи манипулируют данными, чтобы получить статистически значимый результат. P-хакинг является проблемой, потому что такие исследователи и исследования вводят в заблуждение - преувеличивают доказательства конкретной гипотезы. Результаты p-хакинга часто не воспроизводятся. P-хакинг ставит под угрозу надежность научных исследований и целостность науки.
Решения проблемы:
✅ Предварительная регистрация. Исследователи должны зарегистрировать план (дизайн) исследования, гипотезу и способы ее проверки до сбора данных. Это снижает соблазн "взлома".
✅ Прозрачная отчетность. Необходимо сообщать обо всех проведенных анализах и результатах, а не только о значимых. Следует быть открытым в отношении исключения данных из анализа или их преобразования с обоснованием таких действий.
✅ Понимание необходимости и поправки на многократное тестирование. Каждый дополнительный анализ тех же данных увеличивает вероятность ложноположительного результата. Корректируйте это с помощью таких методов, как поправка Бонферрони или Холма-Бонферрони.
✅ Избегайте предвзятого выбора временных интервалов для своих данных. Не сообщайте выборочно о результатах, полученных в определенные периоды времени, чтобы получить значимость. Заранее определите временные рамки своего исследования и анализа данных.
✅ Скептически относитесь к post-hoc гипотезам. Если гипотеза не была заранее сформулирована, анализ может нести в себе элементы предвзятости, чтобы реабилитировать первичные неудачи. Результаты post-hoc нуждаются в более тщательной проверке.
✅ Репликация исследований. Поощрение повторных исследований. Результат, совпадающий в нескольких исследованиях, снижает вероятность того, что он получен в результате p-хакинга.
✅ Открытое рецензирование. Исследователи должны позволять рецензентам видеть весь процесс анализа данных, а не только конечный результат. Прозрачное рецензирование поможет выявить случаи p-хакинга.
✅ Поощрение отчетности о размере эффекта. Вместо того чтобы ограничиваться p-значениями, сосредоточьтесь на величине эффекта. Это дает больше контекста. Результаты о размере эффекта в виде p менее 0,05 могут вызвать подозрения.
✅ Открытые данные. Необходимо поощрять обмен данными. Это позволит другим проверить результаты анализа. Внешние проверки могут выявить непреднамеренный p-хакинг.
✅ Обучение и тренировки. Знания статистического анализа и понимание статистических ошибок снижает вероятность намеренного и преднамеренного p-хакинга.
✅ Байесовские методы. Рассмотрите возможность использования байесовской статистики, которая менее подверженна p-хакингу. В ее основе провекра вероятности гипотез, а не жесткое сравнение нулевой и альтернативной гипотезы через расчет статистической значимости по порогу в виде p-уровень.
✅ Культура работы с данными. В науке приоритет должен отдаваться поиске истины, а не количеству публикаций.
P-хакинг - явление, когда исследователи манипулируют данными, чтобы получить статистически значимый результат. P-хакинг является проблемой, потому что такие исследователи и исследования вводят в заблуждение - преувеличивают доказательства конкретной гипотезы. Результаты p-хакинга часто не воспроизводятся. P-хакинг ставит под угрозу надежность научных исследований и целостность науки.
Решения проблемы:
✅ Предварительная регистрация. Исследователи должны зарегистрировать план (дизайн) исследования, гипотезу и способы ее проверки до сбора данных. Это снижает соблазн "взлома".
✅ Прозрачная отчетность. Необходимо сообщать обо всех проведенных анализах и результатах, а не только о значимых. Следует быть открытым в отношении исключения данных из анализа или их преобразования с обоснованием таких действий.
✅ Понимание необходимости и поправки на многократное тестирование. Каждый дополнительный анализ тех же данных увеличивает вероятность ложноположительного результата. Корректируйте это с помощью таких методов, как поправка Бонферрони или Холма-Бонферрони.
✅ Избегайте предвзятого выбора временных интервалов для своих данных. Не сообщайте выборочно о результатах, полученных в определенные периоды времени, чтобы получить значимость. Заранее определите временные рамки своего исследования и анализа данных.
✅ Скептически относитесь к post-hoc гипотезам. Если гипотеза не была заранее сформулирована, анализ может нести в себе элементы предвзятости, чтобы реабилитировать первичные неудачи. Результаты post-hoc нуждаются в более тщательной проверке.
✅ Репликация исследований. Поощрение повторных исследований. Результат, совпадающий в нескольких исследованиях, снижает вероятность того, что он получен в результате p-хакинга.
✅ Открытое рецензирование. Исследователи должны позволять рецензентам видеть весь процесс анализа данных, а не только конечный результат. Прозрачное рецензирование поможет выявить случаи p-хакинга.
✅ Поощрение отчетности о размере эффекта. Вместо того чтобы ограничиваться p-значениями, сосредоточьтесь на величине эффекта. Это дает больше контекста. Результаты о размере эффекта в виде p менее 0,05 могут вызвать подозрения.
✅ Открытые данные. Необходимо поощрять обмен данными. Это позволит другим проверить результаты анализа. Внешние проверки могут выявить непреднамеренный p-хакинг.
✅ Обучение и тренировки. Знания статистического анализа и понимание статистических ошибок снижает вероятность намеренного и преднамеренного p-хакинга.
✅ Байесовские методы. Рассмотрите возможность использования байесовской статистики, которая менее подверженна p-хакингу. В ее основе провекра вероятности гипотез, а не жесткое сравнение нулевой и альтернативной гипотезы через расчет статистической значимости по порогу в виде p-уровень.
✅ Культура работы с данными. В науке приоритет должен отдаваться поиске истины, а не количеству публикаций.
{kind=link}
👍3
Как осуществлять внешнюю валидацию (проверку) прогностической модели
✅ Внешняя валидация — оценка характеристик модели на другом (но актуальном) наборе данных, который не использовался в процессе разработки.
✅ Внешнее валидирующее исследование включает в себя пять ключевых этапов (каждый из них - отдельная тема для дискуссии и разные методы статистического анализа):
- получение подходящего набора данных нужного размера
- прогнозирование результатов
- оценка прогнозируемой эффективности
- оценка клинической полезности
- качественное представление результатов (отчет о внешей валидации).
✅ Набор данных для проверки должен представлять целевую группу населения и соответствовать условиям, в которых модель планируется реализовать на практике.
✅ Как минимум, набор проверочных данных должен содержать информацию, необходимую для применения модели (т. е. для прогнозирования) и ее сравнения с наблюдаемыми результатами.
✅ Прогностическая эффективность модели должна быть проверена с точки зрения ее соответствия данным, калибровки и дискриминативности (точности прогноза).
✅ Калибровку следует проверять во всем диапазоне прогнозируемых значений с использованием калибровочного графика, представляющего собой сглаженную гибкую калибровочную кривую (отдельная большая тема для разговора).
✅ Если цель модели состоит в том, чтобы выдаваемые ею прогнозы помогали принимать конкретные решения, модель также следует оценить на предмет ее клинической полезности, например, путем построения кривых чистой выгоды и принятия решений.
✅ Хорошо откалиброванная модель (прогнозы модели совпадают с наблюдаемыми прогнозами изучаемого явления/события) является идеальной для применения, но недостаточно хорошо откалиброванная модель все равно может иметь клиническую ценность при определенных условиях.
✅ Стандарт TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis) включает контрольный список из 22 пунктов, который призван улучшить отчетность исследований, разрабатывающих и проверяющих медицинские модели прогнозирования.
✅ Внешняя валидация — оценка характеристик модели на другом (но актуальном) наборе данных, который не использовался в процессе разработки.
✅ Внешнее валидирующее исследование включает в себя пять ключевых этапов (каждый из них - отдельная тема для дискуссии и разные методы статистического анализа):
- получение подходящего набора данных нужного размера
- прогнозирование результатов
- оценка прогнозируемой эффективности
- оценка клинической полезности
- качественное представление результатов (отчет о внешей валидации).
✅ Набор данных для проверки должен представлять целевую группу населения и соответствовать условиям, в которых модель планируется реализовать на практике.
✅ Как минимум, набор проверочных данных должен содержать информацию, необходимую для применения модели (т. е. для прогнозирования) и ее сравнения с наблюдаемыми результатами.
✅ Прогностическая эффективность модели должна быть проверена с точки зрения ее соответствия данным, калибровки и дискриминативности (точности прогноза).
✅ Калибровку следует проверять во всем диапазоне прогнозируемых значений с использованием калибровочного графика, представляющего собой сглаженную гибкую калибровочную кривую (отдельная большая тема для разговора).
✅ Если цель модели состоит в том, чтобы выдаваемые ею прогнозы помогали принимать конкретные решения, модель также следует оценить на предмет ее клинической полезности, например, путем построения кривых чистой выгоды и принятия решений.
✅ Хорошо откалиброванная модель (прогнозы модели совпадают с наблюдаемыми прогнозами изучаемого явления/события) является идеальной для применения, но недостаточно хорошо откалиброванная модель все равно может иметь клиническую ценность при определенных условиях.
✅ Стандарт TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis) включает контрольный список из 22 пунктов, который призван улучшить отчетность исследований, разрабатывающих и проверяющих медицинские модели прогнозирования.
Telegram
Статистические шоты
Про C-индекс и коэффициент корреляции Сомерса
Обе характеристики являются метриками дискриминативности прогностической модели, по которым определяется ее потенциальная прогностическая точность.
Коэффициент корреляции Сомерса Dxy – корреляция оценочных истинных…
Обе характеристики являются метриками дискриминативности прогностической модели, по которым определяется ее потенциальная прогностическая точность.
Коэффициент корреляции Сомерса Dxy – корреляция оценочных истинных…
🤨 Прежде чем пригласить (нанять) статистика помочь с исследованием, подумайте! Существует множество доказательств того, что статистики очень эффективно замедляют исследования, делают их более трудными для понимания для нестатистиков, превращают анализ данных в более дорогой и трудоемкий процесс, а результаты становятся менее впечатляющими и более скучными.
😁4👍1
🤔 Цель любого научного исследования или анализа, а статистика - лишь инструмент для того и другого, - получить новые, истинные знания. Научное исследование - не только проведение эксперимента и проверка гипотез, но и убеждение других людей - остальных ученых - в истинности того, что вы обнаружили. Истинность подтверждается через воспроизводимость результатов.
К сожалению, в настоящее время, огромные ресурсы, вливаемые в науку в надежде на полезную отдачу, растрачиваются на исследования, абсолютно не несущие новых знаний. Ошибки и ляпы, во многом совершенные в ходе статистического анализа, регулярно прорываются через системы рецензирования даже авторитетных научных журналов. Наши головы наполняются «фактами», которые неверны, преувеличены или заведомо ложны. И в самых худших случаях, особенно когда дело касается медицинской науки, гибнут люди.
К сожалению, в настоящее время, огромные ресурсы, вливаемые в науку в надежде на полезную отдачу, растрачиваются на исследования, абсолютно не несущие новых знаний. Ошибки и ляпы, во многом совершенные в ходе статистического анализа, регулярно прорываются через системы рецензирования даже авторитетных научных журналов. Наши головы наполняются «фактами», которые неверны, преувеличены или заведомо ложны. И в самых худших случаях, особенно когда дело касается медицинской науки, гибнут люди.
💯2
«Харкинг» (HARKing, Hypothesising After the Results are Known) - разновидность p-хакинга, когда берется имеющийся набор данных, прогоняется через кучу разных статистических тестов без какой-либо определенной гипотезы в голове, а потом просто докладывается о каких угодно эффектах, которым случилось получить p-значения ниже 0.05. Затем исследовать может заявить, в том числе убеждая самого себя, что изначально и ждал этих результатов.
Такую разновидность p-хакинга наглядно демонстрирует аналогия «техасского стрелка», который выхватил револьвер, наугад изрешетил стену амбара, а потом нарисовав мишень вокруг пулевых отверстий, оказавшихся рядом друг с другом, заявил, что, мол, туда и целился.
Такую разновидность p-хакинга наглядно демонстрирует аналогия «техасского стрелка», который выхватил револьвер, наугад изрешетил стену амбара, а потом нарисовав мишень вокруг пулевых отверстий, оказавшихся рядом друг с другом, заявил, что, мол, туда и целился.
👍2
Про причинный вывод (Causal Inference)
В научных медицинских публикациях очень часто наблюдается проблема, связанная с формулировкой причинных выводов. Точнее сказать исследователи слишком спекулируют подобного рода формулировками, не имея на то достаточных оснований в ходе обсуждения полученных результатов. Причинный вывод подразумевает доказательство и/или логическое обоснование причинно-следственной связи.
Понятие причинности можно сформулировать так: будет ли результат другим, если мы изменим то, что мы называем причинным фактором? Например, мы говорим, что курение вызывает рак легких, потому что, если мы сократим курение, мы уменьшим заболеваемость раком. И наоборот, хотя продажи мороженого сильно коррелируют с нападением акул, мы избегаем говорить о причинно-следственной связи, поскольку запрет мороженого не сделает плавание в океане в жаркую погоду более безопасным. Основная проблема заключается в том, что авторы слишком часто избегают каких-либо явных рассуждений и предоставления доказательств причинно-следственных связей, но затем все же пытаются сделать причинные выводы, хотя могут даже этого не замечать. Статистическая взаимосвязь (корреляционная, регрессионная или др.) не равно причинно-следственная связь!
Например, такие формулировки как лекарство «снижает риск», а метод лечения «улучшает результаты», или когда даются рекомендации пациентам или врачам к изменению их поведения, чтобы улучшить результаты, явно подразумевается причинно-следственную связь. Оценить статистическую связь легко, а определить причинно-следственную связь сложно!
Что и как делать:
1. Сформулировать научную гипотезу и заранее продумать причинно-следственные связи, если такие планируется обнаружить. Они должны быть логически объяснимы и понятны! В разделе «Введение» должна быть явная ссылка на причинно-следственную связь, если вы формулируете причинно-следственную гипотезу. Не для всех исследований это требуется, если вы не ставите таких целей.
2. Опишите возможные причинно-следственные связи в разделе «Методы». Хотя это можно сделать формально, например, с помощью ориентированных ациклических графов (DAG), но причинно-следственные связи разумно описывать и обычным языком в основном тексте.
3. Подберите и выполните статистический анализ для поиска статистических взаимосвязей. Помните, что Correlation is not Causation!
3.1 Факторы, которые могут влиять и нарушать причинно-следственные связи следует оценивать в качестве конфаундеров в многомерных моделях.
3.2 Можно применять анализ взаимосвязей скорректированный по различным переменным.
3.3 Существуют отдельные статистические и графические методы для оценки причинно-следственных взаимосвязей.
В научных медицинских публикациях очень часто наблюдается проблема, связанная с формулировкой причинных выводов. Точнее сказать исследователи слишком спекулируют подобного рода формулировками, не имея на то достаточных оснований в ходе обсуждения полученных результатов. Причинный вывод подразумевает доказательство и/или логическое обоснование причинно-следственной связи.
Понятие причинности можно сформулировать так: будет ли результат другим, если мы изменим то, что мы называем причинным фактором? Например, мы говорим, что курение вызывает рак легких, потому что, если мы сократим курение, мы уменьшим заболеваемость раком. И наоборот, хотя продажи мороженого сильно коррелируют с нападением акул, мы избегаем говорить о причинно-следственной связи, поскольку запрет мороженого не сделает плавание в океане в жаркую погоду более безопасным. Основная проблема заключается в том, что авторы слишком часто избегают каких-либо явных рассуждений и предоставления доказательств причинно-следственных связей, но затем все же пытаются сделать причинные выводы, хотя могут даже этого не замечать. Статистическая взаимосвязь (корреляционная, регрессионная или др.) не равно причинно-следственная связь!
Например, такие формулировки как лекарство «снижает риск», а метод лечения «улучшает результаты», или когда даются рекомендации пациентам или врачам к изменению их поведения, чтобы улучшить результаты, явно подразумевается причинно-следственную связь. Оценить статистическую связь легко, а определить причинно-следственную связь сложно!
Что и как делать:
1. Сформулировать научную гипотезу и заранее продумать причинно-следственные связи, если такие планируется обнаружить. Они должны быть логически объяснимы и понятны! В разделе «Введение» должна быть явная ссылка на причинно-следственную связь, если вы формулируете причинно-следственную гипотезу. Не для всех исследований это требуется, если вы не ставите таких целей.
2. Опишите возможные причинно-следственные связи в разделе «Методы». Хотя это можно сделать формально, например, с помощью ориентированных ациклических графов (DAG), но причинно-следственные связи разумно описывать и обычным языком в основном тексте.
3. Подберите и выполните статистический анализ для поиска статистических взаимосвязей. Помните, что Correlation is not Causation!
3.1 Факторы, которые могут влиять и нарушать причинно-следственные связи следует оценивать в качестве конфаундеров в многомерных моделях.
3.2 Можно применять анализ взаимосвязей скорректированный по различным переменным.
3.3 Существуют отдельные статистические и графические методы для оценки причинно-следственных взаимосвязей.
Telegram
статИИстик
Что такое конфаундеры (спутывающие/сбивающие факторы в исследованиях)
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
❤2
4. В разделе "Обсуждение" подробно опишите полученные результаты и логически объясните найденные причинно-следственные связи с отсылкой на результаты статистического анализа.
4.1 Следует осторожно применять язык причинного вывода, если у вас нет оснований для этого. Это относится не только к словам «причина» и «причинная связь», но также к словам, которые подразумевают причинную связь, например «следствие», «уменьшение», «увеличение» и «воздействие», а также к рекомендациям, которые зависят от причинно-следственной связи. Например, «пациенты должны избегать», «врачи должны использовать» и т.д. При этом следует избегать термина «фактор риска», поскольку он имеет неопределенное значение.
4.2 Причинно-следственную связь следует обсуждать в контексте практических действий. Например, мы знаем, что курение вызывает рак легких (помимо других заболеваний), поэтому мы советуем пациентам бросить курить.
4.3 Важно оценить все возможные риски предвзятости (bias)
4.4 Необходимо сообщить о размере причинно-следственной оценки (величне эффекта). Например, в одном исследовании высокое потребление кофе было связано со снижением риска летального рака простаты более чем на 50%. Это намного выше, чем химиопрофилактическое действие лекарств, воздействующих на определенные пути канцерогенного воздействия (например, тамоксифен и ралоксифен снижают риск рака молочной железы примерно на 40%), и поэтому и выглядит неправдоподобно.
5. Сделайте выводы для других исследователей и/или клинической практики в свете причинно-следственных связей. Рекомендации должны быть четкими, а последствия решений - конкретными. Следует избегать расплывчатых призывов к дальнейшим исследованиям и вместо этого подробно рассказывать о том, как такие исследования следует проводить, учитывая конкретные, полученные вами результаты.
4.1 Следует осторожно применять язык причинного вывода, если у вас нет оснований для этого. Это относится не только к словам «причина» и «причинная связь», но также к словам, которые подразумевают причинную связь, например «следствие», «уменьшение», «увеличение» и «воздействие», а также к рекомендациям, которые зависят от причинно-следственной связи. Например, «пациенты должны избегать», «врачи должны использовать» и т.д. При этом следует избегать термина «фактор риска», поскольку он имеет неопределенное значение.
4.2 Причинно-следственную связь следует обсуждать в контексте практических действий. Например, мы знаем, что курение вызывает рак легких (помимо других заболеваний), поэтому мы советуем пациентам бросить курить.
4.3 Важно оценить все возможные риски предвзятости (bias)
4.4 Необходимо сообщить о размере причинно-следственной оценки (величне эффекта). Например, в одном исследовании высокое потребление кофе было связано со снижением риска летального рака простаты более чем на 50%. Это намного выше, чем химиопрофилактическое действие лекарств, воздействующих на определенные пути канцерогенного воздействия (например, тамоксифен и ралоксифен снижают риск рака молочной железы примерно на 40%), и поэтому и выглядит неправдоподобно.
5. Сделайте выводы для других исследователей и/или клинической практики в свете причинно-следственных связей. Рекомендации должны быть четкими, а последствия решений - конкретными. Следует избегать расплывчатых призывов к дальнейшим исследованиям и вместо этого подробно рассказывать о том, как такие исследования следует проводить, учитывая конкретные, полученные вами результаты.
Telegram
Статистические шоты
Про bias (предвзятость / смещенность)
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать…
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать…
❤2
В этом исследовании, на которое можно ссылаться, в ходе статистических экспериментов показано, что минимальный размер выборки для построения модели логистической регрессии должен включать 20-50 изучаемых событий на одну переменную (Events per variable, EPV), в то время как при использовании методов машинного обучения (CART, SVM, NN, RF) модели оказывались нестабильными даже при EPV>200. Под стабильностью здесь понималась стабильность AUC при моделировании на разных по размеру выборках.
BioMed Central
Modern modelling techniques are data hungry: a simulation study for predicting dichotomous endpoints - BMC Medical Research Methodology
Background Modern modelling techniques may potentially provide more accurate predictions of binary outcomes than classical techniques. We aimed to study the predictive performance of different modelling techniques in relation to the effective sample size…
🔥2❤1👍1
🧠 "Физики не существует" - эта фраза присутствует в фантастическом романе Лю Цысиня "Задача трех тел" и связана с кризисом воспроизводимости научных экспериментов в области фундаментальной физики, который повлек за собой череду самоубийств известных ученых.
Кризис воспроизводимости - невозможность воспроизвести ранее поставленные эксперименты, и это серьезная проблема современной науки. Причин тому множество, от нарушений условий проведения повторных исследований, до октровенной фальсификации первоначальных результатов. Есть еще одна причина, которая неподвластна какому-либо контролю. Это фундаментальная неопределенность.
Как бы хорошо вы не спланировали свое исследование, всегда присутствует элемент некотролируемой случайности, который может повлиять на ваши результаты. В свое время Рональд Фишер ввел понятие порогового значения p-уровня значимости = 0.05, чтобы минимизировать эффект случайности. Это правда сыграло злую шутку, и теперь большое число исследователей занимаются p-хакингом, а не поиском истины.
Представим ситуацию. Вы хотите понять честная ли у вас монетка. Если да, то при ее подбрасывании количество орлов и решек будет примерно поровну. Будем подбрасывать монетку 5 раз. Можно больше, но сейчас это сути не меняет. Итак вы проводите первый эксперимент, подбросили монетку 5 раз и получили 5 орлов! Первая мысль - монетка нечестная, так как вероятность пяти подряд орлов крайне мала. В биномиальном тесте вы получите статистическую значимость. Если бы за этим экспериментом скрывалась проверка какой-либо реальной гипотезы, которую хотелось бы подтвердить, вы, как и большинство исследователей, закончили бы исследование, радостно потирая ладоши. Но проблема в том, что это могло быть всего лишь случайностью, которая бы не подтвердилась, если воспроизвести эксперимент снова. Другой вариант - вы подбросили монетку 100 раз и везде получили примерно равное распределение орлов и решек, но при 101 попытке выпало пять орлов. Скорее всего в этом случае большинство исследователей склонилось к бы версии случайности, ведь, если долго мучиться, то что-нибудь получится. Те, кто сочтут данный результат истиной, скорее всего являются p-хакерами, не учитывающими поправки на множественные сравнения.
Итак, в обоих описанных вариантах могла быть случайность! А главная проблема заключается в том, что у нас нет критериев и предсказательных возможностей, чтобы понять когда она наступит - сразу или после нескольких попыток. Статистическая значимость полученного результата не исключает случайность или ошибку 1 рода, возникшую по иным причинам.
Мораль этого поста заключается в том, что все результаты исследования, начиная со сбора данных и заканчивая расчетами, могут оказаться случайным эффектом, произошедшим в данный конкретный момент жизни вселенной. Вы не можете вернуться в прошлое, повторить эксперимент и убедиться в обратном. Один из вариантов подтверждения того, что вы подтвердили свою гипотезу - повторные эксперименты других исследователей. Именно поэтому вы должны максимально подробно описать в публикации дизайн и ход вашего исследования. Из-за того, что это не делается, в том числе существует кризис воспроизводимости в науке. Вы можете сами повторить свой эксперимент через какое-то время, вновь собрав другие данные, но этим вряд ли кто будет заниматься. Еще есть технология бутсрэппа, которая может помочь понять стабильность ваших результатов, что повысит вероятность их неслучайности.
Кризис воспроизводимости - невозможность воспроизвести ранее поставленные эксперименты, и это серьезная проблема современной науки. Причин тому множество, от нарушений условий проведения повторных исследований, до октровенной фальсификации первоначальных результатов. Есть еще одна причина, которая неподвластна какому-либо контролю. Это фундаментальная неопределенность.
Как бы хорошо вы не спланировали свое исследование, всегда присутствует элемент некотролируемой случайности, который может повлиять на ваши результаты. В свое время Рональд Фишер ввел понятие порогового значения p-уровня значимости = 0.05, чтобы минимизировать эффект случайности. Это правда сыграло злую шутку, и теперь большое число исследователей занимаются p-хакингом, а не поиском истины.
Представим ситуацию. Вы хотите понять честная ли у вас монетка. Если да, то при ее подбрасывании количество орлов и решек будет примерно поровну. Будем подбрасывать монетку 5 раз. Можно больше, но сейчас это сути не меняет. Итак вы проводите первый эксперимент, подбросили монетку 5 раз и получили 5 орлов! Первая мысль - монетка нечестная, так как вероятность пяти подряд орлов крайне мала. В биномиальном тесте вы получите статистическую значимость. Если бы за этим экспериментом скрывалась проверка какой-либо реальной гипотезы, которую хотелось бы подтвердить, вы, как и большинство исследователей, закончили бы исследование, радостно потирая ладоши. Но проблема в том, что это могло быть всего лишь случайностью, которая бы не подтвердилась, если воспроизвести эксперимент снова. Другой вариант - вы подбросили монетку 100 раз и везде получили примерно равное распределение орлов и решек, но при 101 попытке выпало пять орлов. Скорее всего в этом случае большинство исследователей склонилось к бы версии случайности, ведь, если долго мучиться, то что-нибудь получится. Те, кто сочтут данный результат истиной, скорее всего являются p-хакерами, не учитывающими поправки на множественные сравнения.
Итак, в обоих описанных вариантах могла быть случайность! А главная проблема заключается в том, что у нас нет критериев и предсказательных возможностей, чтобы понять когда она наступит - сразу или после нескольких попыток. Статистическая значимость полученного результата не исключает случайность или ошибку 1 рода, возникшую по иным причинам.
Мораль этого поста заключается в том, что все результаты исследования, начиная со сбора данных и заканчивая расчетами, могут оказаться случайным эффектом, произошедшим в данный конкретный момент жизни вселенной. Вы не можете вернуться в прошлое, повторить эксперимент и убедиться в обратном. Один из вариантов подтверждения того, что вы подтвердили свою гипотезу - повторные эксперименты других исследователей. Именно поэтому вы должны максимально подробно описать в публикации дизайн и ход вашего исследования. Из-за того, что это не делается, в том числе существует кризис воспроизводимости в науке. Вы можете сами повторить свой эксперимент через какое-то время, вновь собрав другие данные, но этим вряд ли кто будет заниматься. Еще есть технология бутсрэппа, которая может помочь понять стабильность ваших результатов, что повысит вероятность их неслучайности.
🔥4
🗣️ Если вы интерпретируете статические данные, исходя из ваших ожиданий, а не фактических результатов… Если вы принимаете и публикуете только значимые результаты, а о незначимых предпочитаете умолчать… Если вы избирательно презентуете результаты так, чтобы они подтверждали ваши аргументы и прерываете свое исследование, как только достигли p-уровня значимости менее 0.05… Вы на темной стороне науки!
❤1🌚1