
Про доверительные интервалы
Представьте, что врач хочет определить среднее артериальное давление для всех взрослых. Измерить всех пациентов не представляется возможным, поэтому он берет выборку из 100 взрослых и рассчитывает, что среднее артериальное давление составляет 120 мм рт.ст. Врач знает, что это всего лишь оценка, и если он возьмет другую выборку, то может получить другое среднее значение. Чтобы количественно выразить данную неопределенность и существует доверительный интервал (ДИ). ДИ - диапазон значений, полученный на основе данных выборки, который, скорее всего, содержит истинное значение неизвестного параметра популяции. Например, врач может сказать, что он на 95% уверен в том, что среднее артериальное давление у всех взрослых находится в диапазоне от 118 до 122 мм рт.ст. Это и есть 95%-ный доверительный интервал.
Для расчета 95%-ного доверительного интервала используется среднее значение выборки (среднее) +|- 1.96 x (стандартное отклонение / √(размер выборки)). Величина 1.96 обусловлена тем, что 95% площади под кривой нормального распределения лежит в пределах 1.96 стандартных отклонений от среднего значения. Таким образом, если в выборке нашего врача стандартное отклонение составляет 10 мм рт.ст., то 95%-ный ДИ будет равен 120 +|- 1.96 x (10/√(100)) = от 118 до 122 мм рт.ст.
Интерпретация является ключевым моментом. Выражение "Я на 95% уверен, что среднее артериальное давление находится в диапазоне от 118 до 122 мм рт.ст." НЕ означает, что вероятность того, что истинное среднее значение находится в этом диапазоне, составляет 95%. Напротив, это означает, что если взять множество выборок и рассчитать 95% ДИ для каждой из них, то около 95% этих интервалов будут содержать истинное среднее артериальное давление в диапазоне от 118 до 122 мм рт.ст. А в 5% экспериментов среднее АД в популяции будет выходить за данные лимиты. Однако мы не знаем точного значения среднего АД, поскольку работаем с выборочными данными, а интервал дает нам возможность предположить, в каком диапазоне может находиться среднее АД. Также мы не знаем истинной вероятности того, что среднее АД будет находиться в данном интервале.
Обычно используется 95% ДИ, но в некоторых случаях может потребоваться более высокий или более низкий уровень. Например, если последствия ошибки очень серьезны, можно выбрать более высокий уровень доверия, например 99%.
✅ Расчет ДИ для оценки дает полезную информацию, даже если он не сообщает прямой информации о вероятности того, что истинное значение попадает в этот интервал. Это лучше, чем просто точечная оценка, поскольку дает диапазон значений, которые согласуются с данными.
✅ ДИ позволяет сравнивать различные оценки. Например, если ДИ эффективности двух методов лечения не пересекаются, это говорит о том, что один метод лечения может быть лучше другого.
✅ ДИ могут использоваться для проверки гипотез. Если 95%-ный ДИ для разницы между двумя группами не включает ноль, это говорит о наличии статистически значимой разницы при уровне 0.05.
✅ Практическая значимость. Малый ДИ предполагает наличие точной оценки, которая может быть очень ценной в процессе принятия решений.
✅ Зная максимальное и минимальное значения выборки, можно получить диапазон всех наблюдаемых данных, но этот диапазон может оказаться не очень хорошей оценкой истинного параметра популяции. Например, если вы измеряете артериальное давление у 100 взрослых, то наименьшее и наибольшее значения дадут вам диапазон артериального давления в вашей выборке, но это мало что скажет вам о среднем артериальном давлении в популяции в целом. ДИ, напротив, дают диапазон правдоподобных значений популяционного параметра, основанный на данных выборки. Это может быть гораздо более информативным для принятия решений или выводов о популяции.
Представьте, что врач хочет определить среднее артериальное давление для всех взрослых. Измерить всех пациентов не представляется возможным, поэтому он берет выборку из 100 взрослых и рассчитывает, что среднее артериальное давление составляет 120 мм рт.ст. Врач знает, что это всего лишь оценка, и если он возьмет другую выборку, то может получить другое среднее значение. Чтобы количественно выразить данную неопределенность и существует доверительный интервал (ДИ). ДИ - диапазон значений, полученный на основе данных выборки, который, скорее всего, содержит истинное значение неизвестного параметра популяции. Например, врач может сказать, что он на 95% уверен в том, что среднее артериальное давление у всех взрослых находится в диапазоне от 118 до 122 мм рт.ст. Это и есть 95%-ный доверительный интервал.
Для расчета 95%-ного доверительного интервала используется среднее значение выборки (среднее) +|- 1.96 x (стандартное отклонение / √(размер выборки)). Величина 1.96 обусловлена тем, что 95% площади под кривой нормального распределения лежит в пределах 1.96 стандартных отклонений от среднего значения. Таким образом, если в выборке нашего врача стандартное отклонение составляет 10 мм рт.ст., то 95%-ный ДИ будет равен 120 +|- 1.96 x (10/√(100)) = от 118 до 122 мм рт.ст.
Интерпретация является ключевым моментом. Выражение "Я на 95% уверен, что среднее артериальное давление находится в диапазоне от 118 до 122 мм рт.ст." НЕ означает, что вероятность того, что истинное среднее значение находится в этом диапазоне, составляет 95%. Напротив, это означает, что если взять множество выборок и рассчитать 95% ДИ для каждой из них, то около 95% этих интервалов будут содержать истинное среднее артериальное давление в диапазоне от 118 до 122 мм рт.ст. А в 5% экспериментов среднее АД в популяции будет выходить за данные лимиты. Однако мы не знаем точного значения среднего АД, поскольку работаем с выборочными данными, а интервал дает нам возможность предположить, в каком диапазоне может находиться среднее АД. Также мы не знаем истинной вероятности того, что среднее АД будет находиться в данном интервале.
Обычно используется 95% ДИ, но в некоторых случаях может потребоваться более высокий или более низкий уровень. Например, если последствия ошибки очень серьезны, можно выбрать более высокий уровень доверия, например 99%.
✅ Расчет ДИ для оценки дает полезную информацию, даже если он не сообщает прямой информации о вероятности того, что истинное значение попадает в этот интервал. Это лучше, чем просто точечная оценка, поскольку дает диапазон значений, которые согласуются с данными.
✅ ДИ позволяет сравнивать различные оценки. Например, если ДИ эффективности двух методов лечения не пересекаются, это говорит о том, что один метод лечения может быть лучше другого.
✅ ДИ могут использоваться для проверки гипотез. Если 95%-ный ДИ для разницы между двумя группами не включает ноль, это говорит о наличии статистически значимой разницы при уровне 0.05.
✅ Практическая значимость. Малый ДИ предполагает наличие точной оценки, которая может быть очень ценной в процессе принятия решений.
✅ Зная максимальное и минимальное значения выборки, можно получить диапазон всех наблюдаемых данных, но этот диапазон может оказаться не очень хорошей оценкой истинного параметра популяции. Например, если вы измеряете артериальное давление у 100 взрослых, то наименьшее и наибольшее значения дадут вам диапазон артериального давления в вашей выборке, но это мало что скажет вам о среднем артериальном давлении в популяции в целом. ДИ, напротив, дают диапазон правдоподобных значений популяционного параметра, основанный на данных выборки. Это может быть гораздо более информативным для принятия решений или выводов о популяции.
{kind=link}
❤1
Про многофакторный анализ
Большинство реальных проблем включает в себя несколько переменных, влияющих на результат. В однофакторном анализе рассматривается одна переменная, в многофакторном - две или более переменных одновременно. В реальной жизни переменные часто взаимодействуют друг с другом сложным образом. Многофакторный анализ помогает выявить эти взаимодействия и понять взаимосвязь между ними. Например, у любого пациента кроме изучаемого вами фактора как минимум есть еще пол и возраст, которые могут влиять на изучаемый исход.
Преимущества многофакторного анализа
✅ Многофакторный анализ позволяет контролировать сбивающие переменные, т.е. внешние переменные, которые могут влиять как на другие факторы, так и на зависимые переменные, что приводит к неверным выводам.
✅ Благодаря учету нескольких переменных многофакторный анализ часто приводит к созданию моделей с большей предсказательной силой и точностью по сравнению с однофакторными моделями.
✅ Выполнение нескольких однофакторных тестов повышает риск ошибки первого типа (ложноположительных результатов).
✅ Многофакторный анализ учитывает все переменные одновременно, что снижает этот риск.
✅ Многофакторный анализ позволяет получить более полное представление о взаимосвязях между переменными, что очень важно для принятия обоснованных решений и разработки эффективных стратегий.
Большинство реальных проблем включает в себя несколько переменных, влияющих на результат. В однофакторном анализе рассматривается одна переменная, в многофакторном - две или более переменных одновременно. В реальной жизни переменные часто взаимодействуют друг с другом сложным образом. Многофакторный анализ помогает выявить эти взаимодействия и понять взаимосвязь между ними. Например, у любого пациента кроме изучаемого вами фактора как минимум есть еще пол и возраст, которые могут влиять на изучаемый исход.
Преимущества многофакторного анализа
✅ Многофакторный анализ позволяет контролировать сбивающие переменные, т.е. внешние переменные, которые могут влиять как на другие факторы, так и на зависимые переменные, что приводит к неверным выводам.
✅ Благодаря учету нескольких переменных многофакторный анализ часто приводит к созданию моделей с большей предсказательной силой и точностью по сравнению с однофакторными моделями.
✅ Выполнение нескольких однофакторных тестов повышает риск ошибки первого типа (ложноположительных результатов).
✅ Многофакторный анализ учитывает все переменные одновременно, что снижает этот риск.
✅ Многофакторный анализ позволяет получить более полное представление о взаимосвязях между переменными, что очень важно для принятия обоснованных решений и разработки эффективных стратегий.
Telegram
статИИстик
Что такое конфаундеры (спутывающие/сбивающие факторы в исследованиях)
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
Про центральную предельную теорему
Центральная предельная теорема (ЦПТ) утверждает, что распределение среднего значения достаточно большой выборки, независимо от распределения самой генеральной совокупности, будет стремиться к нормальному распределению. В результате, даже если базовая совокупность не является нормально распределенной, распределение выборочных средних будет становиться приблизительно нормальным по мере увеличения объема выборки. Другими словами, если мы будем формировать случайные выборки из общей совокупности данных и находить в них средние значения, то по мере роста числа таких выборок их средние будут нормально распределяться. При этом распределение генеральной совокупности может быть любым.
ЦПТ позволяет делать выводы о параметрах популяции на основе выборочных данных. Поскольку многие статистические тесты предполагают нормальность, ЦПТ дает нам основу для применения этих тестов даже в тех случаях, когда базовая совокупность не является нормально распределенной. Например, это относится к t-тесту Стьюдента. t-тест можно использовать и без предположения об абсолютно нормальном распределении, особенно если объем выборки достаточно велик. Благодаря ЦПТ t-тест устойчив к отклонениям от нормальности, особенно при достаточно большом объеме выборки, обычно около 30 или более наблюдений в каждой группе. Однако это эмпирическое правило, а не абсолютная граница. В некоторых случаях даже меньший объем выборки может дать приемлемые результаты, в то время как в других случаях может потребоваться больший объем выборки.
Центральная предельная теорема (ЦПТ) утверждает, что распределение среднего значения достаточно большой выборки, независимо от распределения самой генеральной совокупности, будет стремиться к нормальному распределению. В результате, даже если базовая совокупность не является нормально распределенной, распределение выборочных средних будет становиться приблизительно нормальным по мере увеличения объема выборки. Другими словами, если мы будем формировать случайные выборки из общей совокупности данных и находить в них средние значения, то по мере роста числа таких выборок их средние будут нормально распределяться. При этом распределение генеральной совокупности может быть любым.
ЦПТ позволяет делать выводы о параметрах популяции на основе выборочных данных. Поскольку многие статистические тесты предполагают нормальность, ЦПТ дает нам основу для применения этих тестов даже в тех случаях, когда базовая совокупность не является нормально распределенной. Например, это относится к t-тесту Стьюдента. t-тест можно использовать и без предположения об абсолютно нормальном распределении, особенно если объем выборки достаточно велик. Благодаря ЦПТ t-тест устойчив к отклонениям от нормальности, особенно при достаточно большом объеме выборки, обычно около 30 или более наблюдений в каждой группе. Однако это эмпирическое правило, а не абсолютная граница. В некоторых случаях даже меньший объем выборки может дать приемлемые результаты, в то время как в других случаях может потребоваться больший объем выборки.
{kind=link}
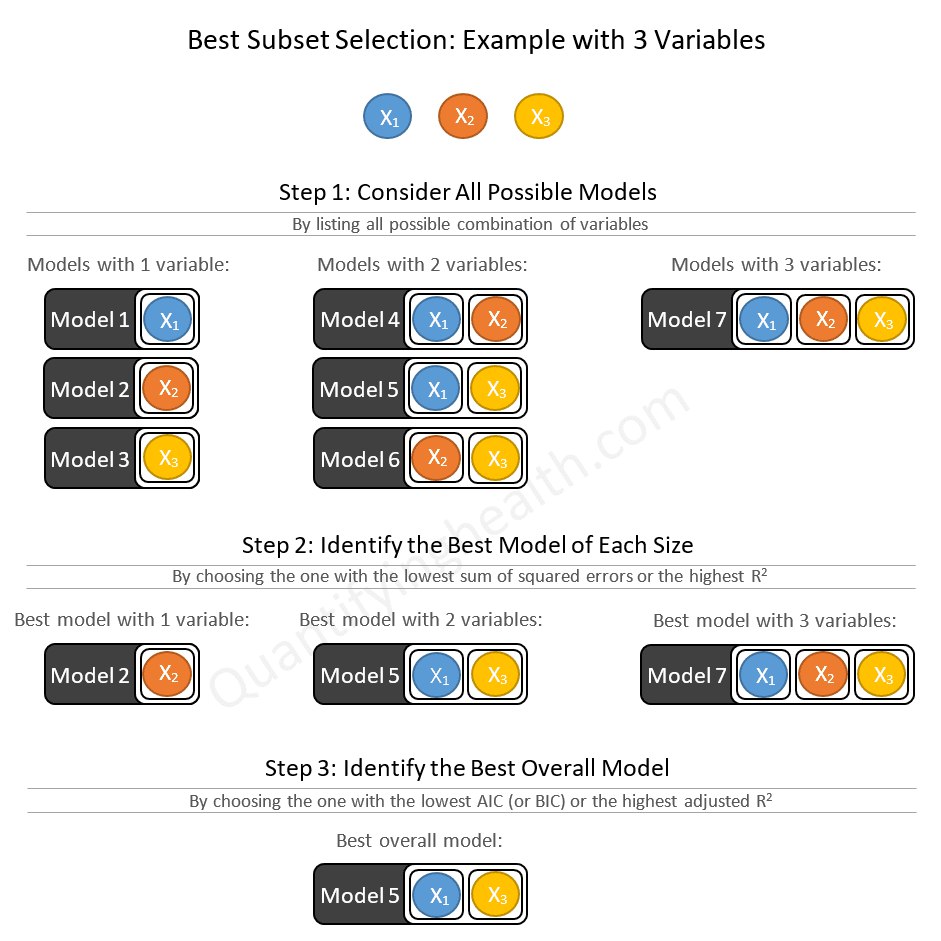
Про выбор наилучшего подмножества (Best Subset Selection, BSS)
BSS - метод, целью которого является найти подмножество независимых переменных (X), которые лучше всего предсказывают результат (Y), и он делает это путем рассмотрения всех возможных комбинаций независимых переменных. Другими словами это перебор всех возможных комбинаций предикторов, для поиска наиболее оптимальной из них с целью получения наиболее эффективной прогностической модели.
Этапы BSS при k независимых переменных:
1. Анализ эффективности всех возможных моделей с 1 переменной, 2 переменными,..., k переменными.
2. Выбираем лучшую модель размера 1, лучшую модель размера 2, ..., лучшую модель размера k методом перекрестной проверки.
3. Наконец , из этих финалистов выбираем лучшую модель в целом.
📌 Выбор наилучшей модели осуществляется из 2 в степени k возможных моделей.
📌 Выбор лучшей модели осуществляется по известным метрикам, например, по AIC, BIC и скорректированному R2.
📌 Выбор лучшей модели по показателям RSS (сумма квадратов остатков) и нескорректированному R2 возможно только на шаге 1, так как модель с бОльшим числом переменных всегда будет иметь наименьший показатель RSS и самый высокий R2.
Преимущества метода:
📌 "Золотой стандарт" выбора предикторов в модель, который позволяет нам определить наилучшую возможную модель, поскольку мы рассматриваем все комбинации переменных-предикторов.
Недостатки метода:
📌 Вычислительное ограничение: количество возможных моделей, которые должен учитывать алгоритм подмножества, растет экспоненциально с количеством рассматриваемых предикторов. Для 20 предикторов 2^20 = 1 048 576 моделей!
📌 Выбор из тысяч, даже миллионов моделей можно рассматривать как р-хакинг, поскольку одна модель может случайно выглядеть лучше и в конечном итоге оказаться неэффективной, когда мы попытаемся проверить ее на новых данных.
BSS - метод, целью которого является найти подмножество независимых переменных (X), которые лучше всего предсказывают результат (Y), и он делает это путем рассмотрения всех возможных комбинаций независимых переменных. Другими словами это перебор всех возможных комбинаций предикторов, для поиска наиболее оптимальной из них с целью получения наиболее эффективной прогностической модели.
Этапы BSS при k независимых переменных:
1. Анализ эффективности всех возможных моделей с 1 переменной, 2 переменными,..., k переменными.
2. Выбираем лучшую модель размера 1, лучшую модель размера 2, ..., лучшую модель размера k методом перекрестной проверки.
3. Наконец , из этих финалистов выбираем лучшую модель в целом.
📌 Выбор наилучшей модели осуществляется из 2 в степени k возможных моделей.
📌 Выбор лучшей модели осуществляется по известным метрикам, например, по AIC, BIC и скорректированному R2.
📌 Выбор лучшей модели по показателям RSS (сумма квадратов остатков) и нескорректированному R2 возможно только на шаге 1, так как модель с бОльшим числом переменных всегда будет иметь наименьший показатель RSS и самый высокий R2.
Преимущества метода:
📌 "Золотой стандарт" выбора предикторов в модель, который позволяет нам определить наилучшую возможную модель, поскольку мы рассматриваем все комбинации переменных-предикторов.
Недостатки метода:
📌 Вычислительное ограничение: количество возможных моделей, которые должен учитывать алгоритм подмножества, растет экспоненциально с количеством рассматриваемых предикторов. Для 20 предикторов 2^20 = 1 048 576 моделей!
📌 Выбор из тысяч, даже миллионов моделей можно рассматривать как р-хакинг, поскольку одна модель может случайно выглядеть лучше и в конечном итоге оказаться неэффективной, когда мы попытаемся проверить ее на новых данных.
{kind=link}
Вредные советы в статистике. Выполните однофакторный анализ перед многофакторным, чтобы выбрать предикторы
Данный подход на сегодняшний день считается устаревшим и неэффективным потому что:
📌 Выбор предикторов осуществляется на основании множества однофакторных тестов с риском случайной ошибки при выполнении каждого из них, величина которой накапливается.
📌 Присутствует риск ошибки 1 рода.
📌 В однофакторном анализе не учитывается как прогностически значимое, так и спутывающее влияние одних переменных на другие, не учитываются нелинейные взаимосвязи между предикторами.
В итоге во многофакторный анализ не попадают нужные или попадают ненужные переменные, в том числе конфаундеры. Многофакторная модель необязательно должна
включать в себя только статистически значимые предикторы, поэтому стремление выбрать только их лишено смысла.
Как следует решать проблему большого числа предикторов при построении модели
✅ Проблема возникает в случае одновременно недостаточного количества данных и/или при желании сделать модель более простой. При достаточном количестве данных в изначальную модель следует включать все возможные предикторы, по которым собрана информация. Селекцию нужно начинать с ручного удаления тех из них, которые являются лишними с позиции логических рассуждений и знаний в данной предметной области. Машинные методы используются в том случае, когда эмпирического подхода становится недостаточно.
✅ Используйте метод выбора наилучшего подмножества (BSS)
✅ Используйте метод пошаговой регрессии (forward|backward)
✅ Используйте регрессии со штрафными коэффициентами (LASSO, Enet и др.)
✅ Используйте методы снижения размерности данных (например, метод главных компонент). В этом случае модель скорее всего станет "черным ящиком", но нам же главное результат ее эффективности.
Данный подход на сегодняшний день считается устаревшим и неэффективным потому что:
📌 Выбор предикторов осуществляется на основании множества однофакторных тестов с риском случайной ошибки при выполнении каждого из них, величина которой накапливается.
📌 Присутствует риск ошибки 1 рода.
📌 В однофакторном анализе не учитывается как прогностически значимое, так и спутывающее влияние одних переменных на другие, не учитываются нелинейные взаимосвязи между предикторами.
В итоге во многофакторный анализ не попадают нужные или попадают ненужные переменные, в том числе конфаундеры. Многофакторная модель необязательно должна
включать в себя только статистически значимые предикторы, поэтому стремление выбрать только их лишено смысла.
Как следует решать проблему большого числа предикторов при построении модели
✅ Проблема возникает в случае одновременно недостаточного количества данных и/или при желании сделать модель более простой. При достаточном количестве данных в изначальную модель следует включать все возможные предикторы, по которым собрана информация. Селекцию нужно начинать с ручного удаления тех из них, которые являются лишними с позиции логических рассуждений и знаний в данной предметной области. Машинные методы используются в том случае, когда эмпирического подхода становится недостаточно.
✅ Используйте метод выбора наилучшего подмножества (BSS)
✅ Используйте метод пошаговой регрессии (forward|backward)
✅ Используйте регрессии со штрафными коэффициентами (LASSO, Enet и др.)
✅ Используйте методы снижения размерности данных (например, метод главных компонент). В этом случае модель скорее всего станет "черным ящиком", но нам же главное результат ее эффективности.
Вы сделали прогностическую модель и определили порог вероятности, на основании которого принимаете решение. Почему это крайне плохое решение?!
Некоторые преподаватели статистики рекомендуют использовать порог (cut-off point), например, Индекс Юдена, для того, чтобы найти некую границу для принятия решений в контексте максимальной чувствительности и специфичности вашей прогностической модели. В чем проблема:
1. Проблема дихотомии. Допустим пороговая вероятность по индексу Юдена = 0.4. Перед вами 2 реальных пациента. Согласно вашей модели вероятность интересующего вас исхода у пациента №1 = 0.42, у пациента №2 = 0.39. Тогда пациент №1 попадет в группу высокого риска, а пациента №2 - в группу низкого. Пациенту №1 будет назначено лечение, а пациенту №2 - нет. Но на самом деле вероятность исхода у этих двух пациентов отличается только на 3%, они практически равнозначны между собой в контексте прямого понимания вероятности, неговоря уже о том, что прогнозируемая вероятность имеет свой доверительный интервал. Подумайте, сильно ли изменится ваше намерение взять зонт с собой если вероятность дождя увеличится с 39% до 42%?
2. Представим, что индекс Юдена = 0.2 или 0.8. В первом случае пациент с вероятностью исхода 0.21 попадает в группу высокого риска, а во втором случае пациент с вероятностью 0.79 - в группу низкого риска. В разве вероятность 21% это много или вероятность 79% это мало в контексте прямого понимания вероятности? Если вам скажут, что риск осложения от операции равен 79%, но мы считаем что он низкий, вы согласитесь?
3. Любая модель априори нестабильна, если она построена на маленьких по размерам выборках. Маленькие - это меньше 10-20 тысяч наблюдений, а то и больше при большом количестве предикторов. Под нестабильностью здесь понимается следующее. Если мы будем многократно повторять все шаги построения модели на других случайных выборках, модели будут отличаться между собой как по видам, входящих в них параметров, так и по настройкам данных параметров (например, величинам коэффциентов регрессии). Как следствие, результат прогноза для одного и того же пациента будет сильно отличаться. Ваша конкретная модель - лишь одна из множества возможных, которая получилась на данной случайной выборке. Модель тем более нестабильна, чем меньше размер выборки, на которой она создавалась. Любой порог будет также нестабильной величиной, который не будет работать в реальных условиях.
4. Даже при стабильной модели с неизменными параметрами и настройками определение порога на разных случайных выборках приведет к формированию доверительного интервала для величины порога. Любой интервал неопределенности лишает смысла существование единого порогового значения.
5. Мало кто занимается калибровкой модели. Ваша модель может, а скорее всего, выдает вероятности, которые не соответствуют истинным значениям прогнозируемого исхода для пациентов, то есть "псевдовероятности". Для понимания соответствия вероятностей модели и истинных вероятностей изучаемого исхода строится калибровочная кривая. Плохо откалиброванные модели не будут работать в реальности сами по себе и это намного более важно, чем поиск искусственных пороговых значений для принятия решений на таких "псевдомоделях".
6. Любое решение в реальной жизни зависит не столько от некоего универсального вероятностного порога, сколько от контекста ситуации. Например, если речь идет об операции, без которой пациент может умереть, взвешиваемые риски обычно очень высокие, чтобы уверенность в выбранном решении была максимальной. При индексе Юдена 90% вероятность 80% будет считаться низким риском и операция будет отложена. В реальности же вряд ли кто-то будет пренебрегать 80% вероятностью плохого исхода. Таким образом, важна сама персональная истинная вероятность, рассчитанная моделью в диапазоне от 0 до 1. Принятие конкретных решений на основе данной вероятности будет происходить в контексте текущей клинической ситуации, когда ясны последствия верно и неверно принятого решения. Здесь также могут помочь кривые принятия решений, но никак не пороговые значения ROC-кривых.
Некоторые преподаватели статистики рекомендуют использовать порог (cut-off point), например, Индекс Юдена, для того, чтобы найти некую границу для принятия решений в контексте максимальной чувствительности и специфичности вашей прогностической модели. В чем проблема:
1. Проблема дихотомии. Допустим пороговая вероятность по индексу Юдена = 0.4. Перед вами 2 реальных пациента. Согласно вашей модели вероятность интересующего вас исхода у пациента №1 = 0.42, у пациента №2 = 0.39. Тогда пациент №1 попадет в группу высокого риска, а пациента №2 - в группу низкого. Пациенту №1 будет назначено лечение, а пациенту №2 - нет. Но на самом деле вероятность исхода у этих двух пациентов отличается только на 3%, они практически равнозначны между собой в контексте прямого понимания вероятности, неговоря уже о том, что прогнозируемая вероятность имеет свой доверительный интервал. Подумайте, сильно ли изменится ваше намерение взять зонт с собой если вероятность дождя увеличится с 39% до 42%?
2. Представим, что индекс Юдена = 0.2 или 0.8. В первом случае пациент с вероятностью исхода 0.21 попадает в группу высокого риска, а во втором случае пациент с вероятностью 0.79 - в группу низкого риска. В разве вероятность 21% это много или вероятность 79% это мало в контексте прямого понимания вероятности? Если вам скажут, что риск осложения от операции равен 79%, но мы считаем что он низкий, вы согласитесь?
3. Любая модель априори нестабильна, если она построена на маленьких по размерам выборках. Маленькие - это меньше 10-20 тысяч наблюдений, а то и больше при большом количестве предикторов. Под нестабильностью здесь понимается следующее. Если мы будем многократно повторять все шаги построения модели на других случайных выборках, модели будут отличаться между собой как по видам, входящих в них параметров, так и по настройкам данных параметров (например, величинам коэффциентов регрессии). Как следствие, результат прогноза для одного и того же пациента будет сильно отличаться. Ваша конкретная модель - лишь одна из множества возможных, которая получилась на данной случайной выборке. Модель тем более нестабильна, чем меньше размер выборки, на которой она создавалась. Любой порог будет также нестабильной величиной, который не будет работать в реальных условиях.
4. Даже при стабильной модели с неизменными параметрами и настройками определение порога на разных случайных выборках приведет к формированию доверительного интервала для величины порога. Любой интервал неопределенности лишает смысла существование единого порогового значения.
5. Мало кто занимается калибровкой модели. Ваша модель может, а скорее всего, выдает вероятности, которые не соответствуют истинным значениям прогнозируемого исхода для пациентов, то есть "псевдовероятности". Для понимания соответствия вероятностей модели и истинных вероятностей изучаемого исхода строится калибровочная кривая. Плохо откалиброванные модели не будут работать в реальности сами по себе и это намного более важно, чем поиск искусственных пороговых значений для принятия решений на таких "псевдомоделях".
6. Любое решение в реальной жизни зависит не столько от некоего универсального вероятностного порога, сколько от контекста ситуации. Например, если речь идет об операции, без которой пациент может умереть, взвешиваемые риски обычно очень высокие, чтобы уверенность в выбранном решении была максимальной. При индексе Юдена 90% вероятность 80% будет считаться низким риском и операция будет отложена. В реальности же вряд ли кто-то будет пренебрегать 80% вероятностью плохого исхода. Таким образом, важна сама персональная истинная вероятность, рассчитанная моделью в диапазоне от 0 до 1. Принятие конкретных решений на основе данной вероятности будет происходить в контексте текущей клинической ситуации, когда ясны последствия верно и неверно принятого решения. Здесь также могут помочь кривые принятия решений, но никак не пороговые значения ROC-кривых.
👍1🔥1
Про число пациентов, необходимое для лечения (Number Needed to Treat, NNT) и число пациентов, необходимое для нанесения вреда (Number Needed to Harm, NNH) в клинических исследованиях
При оценке нового лечения часто анализируются два ключевых показателя NNT и NNH.
📌 NNT
Представьте себе 100 человек с головной болью. Если 80 стало лучше с новой таблеткой, а 70 - без нее, то 10 получили пользу от таблетки. Таким образом, для того чтобы один человек получил пользу, необходимо вылечить 10 человек. Это и есть NNT, равный 10. Формула: NNT = 1/ARR, где ARR (Absolute Risk Reduction) - разница в показателях исходов между контрольной и леченной группами.
Допустим, у 20% нелеченых пациентов происходит событие (например, сердечный приступ). При лечении это событие происходит только у 10%. ARR = 0.2-0.1 = 0.1, тогда NNT = 1/0.1 = 10. Таким образом, для предотвращения одного события нам необходимо пролечить 10 человек. Более низкий показатель NNT, как правило, лучше. Если NNT препарата равен 2, это означает, что на каждые 2 человека, прошедших лечение, приходится 1 человек, которому наше лечение помогло. Если NNT равен 50, то для того, чтобы 1 человек получил пользу, необходимо пролечить 50 человек. Чем меньше это число, тем эффективнее лечение.
📌 NNH
Предположим, что из 100 человек у 5 возникли побочные эффекты от приема лекарства. Это означает, что на каждые 20 человек, прошедших курс лечения, приходится 1 человек, которому наносится вред. Таким образом, NNH = 20. Допустим, у 5% пациентов, не получавших лечения, возникает побочный эффект. При лечении побочный эффект возникает у 10%. Absolute Risk Increase (ARI) = 0.1 - 0.05 = 0.05, тогда NNH = 1/0.05 = 20. Таким образом, для того чтобы 1 человек испытал вред, необходимо, чтобы 20 человек получили лечение. Чем больше показатель NNH, тем лучше, тем безопаснее лечение (с точки зрения конкретного вреда).
✅ Нужен баланс! Оценка как NNT, так и NNH нужна, чтобы решить, перевешивает ли польза риск от лечения. Препарат может иметь NNT, равный 5 (хорошо), но NNH, равный 6 (плохо). Таким образом, несмотря на его эффективность, существует и заметный риск. Например, аспирин может быть рекомендован для профилактики сердечных приступов. NNT показывает, сколько человек должны принимать его, чтобы предотвратить один инфаркт. Но он также может вызвать кровотечение, поэтому NNH показывает, сколько человек могут принимать его, прежде чем один человек пострадает от данного побочного эффекта.
При оценке нового лечения часто анализируются два ключевых показателя NNT и NNH.
📌 NNT
Представьте себе 100 человек с головной болью. Если 80 стало лучше с новой таблеткой, а 70 - без нее, то 10 получили пользу от таблетки. Таким образом, для того чтобы один человек получил пользу, необходимо вылечить 10 человек. Это и есть NNT, равный 10. Формула: NNT = 1/ARR, где ARR (Absolute Risk Reduction) - разница в показателях исходов между контрольной и леченной группами.
Допустим, у 20% нелеченых пациентов происходит событие (например, сердечный приступ). При лечении это событие происходит только у 10%. ARR = 0.2-0.1 = 0.1, тогда NNT = 1/0.1 = 10. Таким образом, для предотвращения одного события нам необходимо пролечить 10 человек. Более низкий показатель NNT, как правило, лучше. Если NNT препарата равен 2, это означает, что на каждые 2 человека, прошедших лечение, приходится 1 человек, которому наше лечение помогло. Если NNT равен 50, то для того, чтобы 1 человек получил пользу, необходимо пролечить 50 человек. Чем меньше это число, тем эффективнее лечение.
📌 NNH
Предположим, что из 100 человек у 5 возникли побочные эффекты от приема лекарства. Это означает, что на каждые 20 человек, прошедших курс лечения, приходится 1 человек, которому наносится вред. Таким образом, NNH = 20. Допустим, у 5% пациентов, не получавших лечения, возникает побочный эффект. При лечении побочный эффект возникает у 10%. Absolute Risk Increase (ARI) = 0.1 - 0.05 = 0.05, тогда NNH = 1/0.05 = 20. Таким образом, для того чтобы 1 человек испытал вред, необходимо, чтобы 20 человек получили лечение. Чем больше показатель NNH, тем лучше, тем безопаснее лечение (с точки зрения конкретного вреда).
✅ Нужен баланс! Оценка как NNT, так и NNH нужна, чтобы решить, перевешивает ли польза риск от лечения. Препарат может иметь NNT, равный 5 (хорошо), но NNH, равный 6 (плохо). Таким образом, несмотря на его эффективность, существует и заметный риск. Например, аспирин может быть рекомендован для профилактики сердечных приступов. NNT показывает, сколько человек должны принимать его, чтобы предотвратить один инфаркт. Но он также может вызвать кровотечение, поэтому NNH показывает, сколько человек могут принимать его, прежде чем один человек пострадает от данного побочного эффекта.
{kind=link}
❤1👍1
Про проверку статистических гипотез
Проверка статистической гипотезы - фундаментальное понятие статистики, играющее важнейшую роль в научных исследованиях. Она помогает нам принимать решения на основе полученных данных. Гипотеза - утверждение или предположение о каком-либо параметре (явлении) в популяции. В калссической статистике существует два типа гипотез: нулевая гипотеза (H0) и альтернативная гипотеза (H1 или Ha).
Нулевая гипотеза (H0) - утверждение об отсутствии эффекта или различий. Это то, что мы принимаем за истину до сбора данных. Альтернативная гипотеза (H1 или Ha) противоположна нулевой, это то, что мы хотим проверить или доказать. Вся идея проверки гипотез состоит в том, чтобы предоставить доказательства, позволяющие либо принять, либо отвергнуть нулевую гипотезу в пользу альтернативной гипотезы. Научный процесс начинается с выдвижения гипотез, как нулевой, так и альтернативной. Затем мы собираем и анализируем выборочные данные. Далее рассчитывается тестовая статистика, которая поможет принять решение.
Решение о том, отвергать или не отвергать нулевую гипотезу, принимается путем сравнения тестовой статистики с критическим значением, которое определяется выбранным нами уровнем значимости (α, альфа). Обычно используются значения α 0.05 или 0.01. Если тестовая статистика попадает в критическую область, мы отвергаем нулевую гипотезу в пользу альтернативной гипотезы. Если нет, то нулевая гипотеза не отвергается. Важно отметить, что отказ от нулевой гипотезы не означает, что мы принимаем ее как истинную. Это означает лишь то, что у нас недостаточно доказательств для подтверждения альтернативной гипотезы.
Также следует помнить, что проверка гипотез основана на вероятности. Даже если мы пришли к выводу о наличии значимого эффекта (или различия), всегда есть вероятность того, что мы допустили ошибку. Существует два типа ошибок при проверке гипотез: ошибка первого типа и ошибка второго типа. Ошибка первого типа возникает, когда мы отвергаем нулевую гипотезу, хотя на самом деле она верна. Ошибка второго типа возникает, когда мы не отвергаем нулевую гипотезу, когда альтернативная гипотеза верна. Выбранный нами уровень значимости (α) определяет вероятность ошибки первого типа. Мощность теста (1-β) - вероятность правильно отвергнуть нулевую гипотезу, если альтернативная гипотеза верна.
P-уровень значимости является важнейшей частью проверки гипотез. Это вероятность того, что если предположить, что нулевая гипотеза верна, наблюдаемая статистика (например, среднее значение, доля) будет такой же или более экстремальной, чем наблюдаемая статистика. Малое значение р-уровня, например меньше 0.05 указывает на то, что наблюдаемая статистика была бы очень маловероятной при нулевой гипотезе, и, следовательно, приводит к отклонению нулевой гипотезы.
Если результат статистически значим, это не означает, что он практически важен. Статистическая значимость относится к вероятности того, что результат является случайным, а практическая значимость - к величине эффекта и его потенциальному влиянию в реальном мире. Всегда важно учитывать как статистическую значимость, так и практическую важность результатов.
Проверка статистической гипотезы - фундаментальное понятие статистики, играющее важнейшую роль в научных исследованиях. Она помогает нам принимать решения на основе полученных данных. Гипотеза - утверждение или предположение о каком-либо параметре (явлении) в популяции. В калссической статистике существует два типа гипотез: нулевая гипотеза (H0) и альтернативная гипотеза (H1 или Ha).
Нулевая гипотеза (H0) - утверждение об отсутствии эффекта или различий. Это то, что мы принимаем за истину до сбора данных. Альтернативная гипотеза (H1 или Ha) противоположна нулевой, это то, что мы хотим проверить или доказать. Вся идея проверки гипотез состоит в том, чтобы предоставить доказательства, позволяющие либо принять, либо отвергнуть нулевую гипотезу в пользу альтернативной гипотезы. Научный процесс начинается с выдвижения гипотез, как нулевой, так и альтернативной. Затем мы собираем и анализируем выборочные данные. Далее рассчитывается тестовая статистика, которая поможет принять решение.
Решение о том, отвергать или не отвергать нулевую гипотезу, принимается путем сравнения тестовой статистики с критическим значением, которое определяется выбранным нами уровнем значимости (α, альфа). Обычно используются значения α 0.05 или 0.01. Если тестовая статистика попадает в критическую область, мы отвергаем нулевую гипотезу в пользу альтернативной гипотезы. Если нет, то нулевая гипотеза не отвергается. Важно отметить, что отказ от нулевой гипотезы не означает, что мы принимаем ее как истинную. Это означает лишь то, что у нас недостаточно доказательств для подтверждения альтернативной гипотезы.
Также следует помнить, что проверка гипотез основана на вероятности. Даже если мы пришли к выводу о наличии значимого эффекта (или различия), всегда есть вероятность того, что мы допустили ошибку. Существует два типа ошибок при проверке гипотез: ошибка первого типа и ошибка второго типа. Ошибка первого типа возникает, когда мы отвергаем нулевую гипотезу, хотя на самом деле она верна. Ошибка второго типа возникает, когда мы не отвергаем нулевую гипотезу, когда альтернативная гипотеза верна. Выбранный нами уровень значимости (α) определяет вероятность ошибки первого типа. Мощность теста (1-β) - вероятность правильно отвергнуть нулевую гипотезу, если альтернативная гипотеза верна.
P-уровень значимости является важнейшей частью проверки гипотез. Это вероятность того, что если предположить, что нулевая гипотеза верна, наблюдаемая статистика (например, среднее значение, доля) будет такой же или более экстремальной, чем наблюдаемая статистика. Малое значение р-уровня, например меньше 0.05 указывает на то, что наблюдаемая статистика была бы очень маловероятной при нулевой гипотезе, и, следовательно, приводит к отклонению нулевой гипотезы.
Если результат статистически значим, это не означает, что он практически важен. Статистическая значимость относится к вероятности того, что результат является случайным, а практическая значимость - к величине эффекта и его потенциальному влиянию в реальном мире. Всегда важно учитывать как статистическую значимость, так и практическую важность результатов.
{kind=link}
👍1
Про непараметрические тесты в медицинских исследованиях
Непараметрические тесты, также известны как тесты без распределения, представляют собой статистические методы, используемые для анализа данных, которые не предполагают какого-либо определенного распределения. Эти тесты особенно полезны, когда данные не удовлетворяют предположениям параметрических тестов, таким как, например, нормальность. Непараметрические тесты более пригодны для малых выборок, асимметричных данных или порядковых данных. Эти тесты могут быть ценным инструментом в медицинских исследованиях когда данные не удовлетворяют предположениям параметрических тестов, таким как нормальность, равенство дисперсий или линейность. Эти тесты также подходят для порядковых данных или небольших объемов выборки.
К числу часто используемых непараметрических тестов относятся:
✅ Ранговый тест Уилкоксона. Этот тест используется для сравнения двух связанных выборок с целью оценки того, различаются ли их средние популяционные ранги. Он представляет собой непараметрический эквивалент парного t-теста и подходит для небольших объемов выборок и ненормально распределенных данных.
✅ U-тест Манна-Уитни. Этот тест используется для сравнения двух независимых выборок с целью определения различий в распределениях их рангов. Он является непараметрической альтернативой независимому t-тесту и используется в тех случаях, когда предположения t-теста не выполняются.
✅ Тест Крускала-Уоллиса. Это непараметрическая альтернатива одностороннему ANOVA. Он используется для сравнения более двух независимых выборок, чтобы определить, есть ли разница в их распределениях. Он подходит для данных с ненормальным распределением и неравными дисперсиями.
✅ Ранговая корреляция Спирмена. Этот тест измеряет силу и направление связи между двумя порядковыми или непрерывными переменными. Он является непараметрической альтернативой коэффициенту корреляции Пирсона и подходит для нелинейных отношений.
Хотя непараметрические тесты более устойчивы к нарушениям предположений о данных, они, как правило, менее эффективны (маломощные), чем параметрические тесты, когда предположения выполняются. Это означает, что для обнаружения заданного эффекта может потребоваться больший объем выборки.
Непараметрические тесты, также известны как тесты без распределения, представляют собой статистические методы, используемые для анализа данных, которые не предполагают какого-либо определенного распределения. Эти тесты особенно полезны, когда данные не удовлетворяют предположениям параметрических тестов, таким как, например, нормальность. Непараметрические тесты более пригодны для малых выборок, асимметричных данных или порядковых данных. Эти тесты могут быть ценным инструментом в медицинских исследованиях когда данные не удовлетворяют предположениям параметрических тестов, таким как нормальность, равенство дисперсий или линейность. Эти тесты также подходят для порядковых данных или небольших объемов выборки.
К числу часто используемых непараметрических тестов относятся:
✅ Ранговый тест Уилкоксона. Этот тест используется для сравнения двух связанных выборок с целью оценки того, различаются ли их средние популяционные ранги. Он представляет собой непараметрический эквивалент парного t-теста и подходит для небольших объемов выборок и ненормально распределенных данных.
✅ U-тест Манна-Уитни. Этот тест используется для сравнения двух независимых выборок с целью определения различий в распределениях их рангов. Он является непараметрической альтернативой независимому t-тесту и используется в тех случаях, когда предположения t-теста не выполняются.
✅ Тест Крускала-Уоллиса. Это непараметрическая альтернатива одностороннему ANOVA. Он используется для сравнения более двух независимых выборок, чтобы определить, есть ли разница в их распределениях. Он подходит для данных с ненормальным распределением и неравными дисперсиями.
✅ Ранговая корреляция Спирмена. Этот тест измеряет силу и направление связи между двумя порядковыми или непрерывными переменными. Он является непараметрической альтернативой коэффициенту корреляции Пирсона и подходит для нелинейных отношений.
Хотя непараметрические тесты более устойчивы к нарушениям предположений о данных, они, как правило, менее эффективны (маломощные), чем параметрические тесты, когда предположения выполняются. Это означает, что для обнаружения заданного эффекта может потребоваться больший объем выборки.
🔥1
Про клиническую и статистическую значимость
Рассмотрим два важнейших термина в медицинских исследованиях: клиническая и статистическая значимость - две стороны одной медали в медицинских исследованиях.
Статистическая значимость. Концептуально термин относится к вероятности того, что наблюдаемый эффект в исследовании не является результатом случайного стечения обстоятельств. Если p менее 0.05, то принято говорить о статистической значимости результата. Речь идет только о математике, а не о медицинском воздействии!
Клиническая значимость. Здесь задается другой вопрос, достаточно ли велик наблюдаемый эффект, чтобы оказать значимое влияние на пациентов в реальном мире? Результат может быть статистически значимым, но не иметь клинического значения. Представьте, что новый препарат снижает артериальное давление на 1 мм рт.ст. при p менее 0.05. Статистически значимо? Да. Клинически значимо? Скорее всего, нет. Это крошечное снижение может не оказать существенного влияния на состояние здоровья пациента.
Вот здесь и возникают проблемы. Опора только на статистическую значимость может ввести в заблуждение. Большой объем выборки в исследованиях может выявить небольшие различия, которые могут не иметь клинического значения, что приводит к чрезмерному акцентированию внимания на тривиальных результатах. С другой стороны, игнорирование статистической значимости также может быть проблематичным. Без нее мы не можем быть уверены, являются ли наблюдаемые различия истинными или просто результатом случайных колебаний данных.
Таким образом, при принятии обоснованных медицинских решений необходимо учитывать оба типа значимости. Это все равно, что при вождении автомобиля использовать и GPS, и собственные суждения. Полагаясь только на одно, можно сбиться с пути.Читая результаты медицинских исследований, задавайте себе вопрос является ли этот результат статистически значимым? Если да, то достаточно ли велика величина этого эффекта, чтобы иметь значение в реальных сценариях? Это обеспечит наилучшие результаты для пациентов.
Рассмотрим два важнейших термина в медицинских исследованиях: клиническая и статистическая значимость - две стороны одной медали в медицинских исследованиях.
Статистическая значимость. Концептуально термин относится к вероятности того, что наблюдаемый эффект в исследовании не является результатом случайного стечения обстоятельств. Если p менее 0.05, то принято говорить о статистической значимости результата. Речь идет только о математике, а не о медицинском воздействии!
Клиническая значимость. Здесь задается другой вопрос, достаточно ли велик наблюдаемый эффект, чтобы оказать значимое влияние на пациентов в реальном мире? Результат может быть статистически значимым, но не иметь клинического значения. Представьте, что новый препарат снижает артериальное давление на 1 мм рт.ст. при p менее 0.05. Статистически значимо? Да. Клинически значимо? Скорее всего, нет. Это крошечное снижение может не оказать существенного влияния на состояние здоровья пациента.
Вот здесь и возникают проблемы. Опора только на статистическую значимость может ввести в заблуждение. Большой объем выборки в исследованиях может выявить небольшие различия, которые могут не иметь клинического значения, что приводит к чрезмерному акцентированию внимания на тривиальных результатах. С другой стороны, игнорирование статистической значимости также может быть проблематичным. Без нее мы не можем быть уверены, являются ли наблюдаемые различия истинными или просто результатом случайных колебаний данных.
Таким образом, при принятии обоснованных медицинских решений необходимо учитывать оба типа значимости. Это все равно, что при вождении автомобиля использовать и GPS, и собственные суждения. Полагаясь только на одно, можно сбиться с пути.Читая результаты медицинских исследований, задавайте себе вопрос является ли этот результат статистически значимым? Если да, то достаточно ли велика величина этого эффекта, чтобы иметь значение в реальных сценариях? Это обеспечит наилучшие результаты для пациентов.
{kind=link}
👍1🔥1
Про систематические и случайные ошибки в научных исследованиях
В любом процессе измерения существует вероятность возникновения ошибок. Случайные и систематические ошибки - два типа ошибок, которые могут возникать в ходе научных экспериментов, измерений и процессов сбора данных. Понимание различий между этими двумя типами ошибок имеет решающее значение для обеспечения точности и надежности научных результатов.
Систематические ошибки, или смещения (bias) - устойчивые и повторяющиеся неточности в измерениях. Эти погрешности не являются случайными, а вызваны определенными факторами или условиями, которые постоянно влияют на измерения одним и тем же образом. Сюда относятся неисправность измерительного прибора, ошибки в анализе данных, предвзятость исследователя. Систематические погрешности бывает сложно обнаружить, поскольку они не приводят к случайным колебаниям, а скорее вносят постоянное смещение от истинного значения. Для выявления систематических ошибок сравните результаты измерений с известными значениями или выполните повторные измерения. Если ошибка постоянно возникает в одном и том же направлении (месте), то это, скорее всего, систематическая ошибка. Для исправления систематических ошибок необходимо определить источник ошибки и предпринять соответствующие действия, например, откалибровать оборудование, использовать другую методику измерения или обемпечить более качественный сбор данных. Поэтому в медицине нужны повторные исследования, например, чтобы подтвердить эффективность нового метода лечения, если изначально дизайн выполненного исследования содержал в себе риск систематической ошибки.
Случайные ошибки - непредсказуемые флуктуации, возникающие в разных направлениях и варьирующиеся от измерения (анализа) к измерению. Они могут быть вызваны разичными непредсказуемыми факторами, такими как неточность измерения из-за погрешности прибора, влияние неучтенных внешних факторов или человеческий фактор. Случайные ошибки можно выявить, проанализировав разброс или дисперсию данных. Если данные разбросаны и нет последовательной закономерности или направления, то ошибки, скорее всего, являются случайными. К случайным ошибкам могут быть отнесеные некоторые типы выбросов. Чтобы минимизировать случайные ошибки, увеличьте объем выборки или проведите несколько измерений и усредните результаты. Это поможет нивелировать случайные колебания и повысить точность данных.
Систематические ошибки можно свести к минимуму путем выявления и устранения их источников, а случайные ошибки - путем увеличения объема выборки или усреднения результатов нескольких измерений.
В любом процессе измерения существует вероятность возникновения ошибок. Случайные и систематические ошибки - два типа ошибок, которые могут возникать в ходе научных экспериментов, измерений и процессов сбора данных. Понимание различий между этими двумя типами ошибок имеет решающее значение для обеспечения точности и надежности научных результатов.
Систематические ошибки, или смещения (bias) - устойчивые и повторяющиеся неточности в измерениях. Эти погрешности не являются случайными, а вызваны определенными факторами или условиями, которые постоянно влияют на измерения одним и тем же образом. Сюда относятся неисправность измерительного прибора, ошибки в анализе данных, предвзятость исследователя. Систематические погрешности бывает сложно обнаружить, поскольку они не приводят к случайным колебаниям, а скорее вносят постоянное смещение от истинного значения. Для выявления систематических ошибок сравните результаты измерений с известными значениями или выполните повторные измерения. Если ошибка постоянно возникает в одном и том же направлении (месте), то это, скорее всего, систематическая ошибка. Для исправления систематических ошибок необходимо определить источник ошибки и предпринять соответствующие действия, например, откалибровать оборудование, использовать другую методику измерения или обемпечить более качественный сбор данных. Поэтому в медицине нужны повторные исследования, например, чтобы подтвердить эффективность нового метода лечения, если изначально дизайн выполненного исследования содержал в себе риск систематической ошибки.
Случайные ошибки - непредсказуемые флуктуации, возникающие в разных направлениях и варьирующиеся от измерения (анализа) к измерению. Они могут быть вызваны разичными непредсказуемыми факторами, такими как неточность измерения из-за погрешности прибора, влияние неучтенных внешних факторов или человеческий фактор. Случайные ошибки можно выявить, проанализировав разброс или дисперсию данных. Если данные разбросаны и нет последовательной закономерности или направления, то ошибки, скорее всего, являются случайными. К случайным ошибкам могут быть отнесеные некоторые типы выбросов. Чтобы минимизировать случайные ошибки, увеличьте объем выборки или проведите несколько измерений и усредните результаты. Это поможет нивелировать случайные колебания и повысить точность данных.
Систематические ошибки можно свести к минимуму путем выявления и устранения их источников, а случайные ошибки - путем увеличения объема выборки или усреднения результатов нескольких измерений.
{kind=link}
👍1
Про бутстрэппинг в статистике
Метод бутстрэппинга заключается в том, что из исходных данных берется множество "повторных выборок" с повтором выбранных ранее значений и пересчитывается необходимая статистика (например, среднее значение или медиана). Проделав это тысячи раз, вы получите распределение этой статистики, что позволит вам принимать более обоснованные решения и делать выводы. Реальные наборы данных могут быть сложными для анализа. Например, они могут быть небольшими, содержать выбросы, или вы просто не уверены в том, что можете делать сильные предположения об их распределении. Бутстрэппинг - инструмент, который может помочь, поскольку он не опирается на предположения о форме или типе распределения данных.
Бутстрэппинг – генерация N случайных выборок одинакового размера (псевдовыборок) из исходного набора данных методом ресэмплинга (одно и тоже значение может быть выбрано сколько угодно раз). Размер бутстрэп выборки равен размеру исходной.
По своей сути бутстрэппинг использует возможности повторной выборки для получения более четкого представления о свойствах данных. Это все равно что получить несколько точек зрения на предмет, просто изменив свой взгляд!
Шаги бутстрэппирования:
1. Сделайте случайную выборку из ваших данных с заменой
2. Вычислите интересующую статистику
3. Повторить шаги 1 и 2 много раз (например, 10 000!)
4. Изучите распределение статистики по всем бутстреп-выборкам.
Одно из наиболее популярных применений бутстрэппинга - создание доверительных интервалов. Рассматривая распределение статистики, можно определить интервалы, в которых, например, медианное значение данных, скорее всего, будет попадать в 95% случайных выборок.
Несмотря на свою эффективность, бутстрэппинг не всегда является правильным решением. Если исходная выборка не является репрезентативной для всей совокупности, бутстрэппинг не исправит ситуацию. Кроме того, он может потребовать больших вычислительных затрат и не всегда хорошо работает с очень сложными статистическими данными. Тем не менее, мощности современных компьютеров сделали бутстрэппинг более доступным, чем когда-либо. Такие программы, как R и Python, позволяют легко проводить бутстрэппинг, что дает возможность выполнять более надежные и интересные статистические анализы.
Метод бутстрэппинга заключается в том, что из исходных данных берется множество "повторных выборок" с повтором выбранных ранее значений и пересчитывается необходимая статистика (например, среднее значение или медиана). Проделав это тысячи раз, вы получите распределение этой статистики, что позволит вам принимать более обоснованные решения и делать выводы. Реальные наборы данных могут быть сложными для анализа. Например, они могут быть небольшими, содержать выбросы, или вы просто не уверены в том, что можете делать сильные предположения об их распределении. Бутстрэппинг - инструмент, который может помочь, поскольку он не опирается на предположения о форме или типе распределения данных.
Бутстрэппинг – генерация N случайных выборок одинакового размера (псевдовыборок) из исходного набора данных методом ресэмплинга (одно и тоже значение может быть выбрано сколько угодно раз). Размер бутстрэп выборки равен размеру исходной.
По своей сути бутстрэппинг использует возможности повторной выборки для получения более четкого представления о свойствах данных. Это все равно что получить несколько точек зрения на предмет, просто изменив свой взгляд!
Шаги бутстрэппирования:
1. Сделайте случайную выборку из ваших данных с заменой
2. Вычислите интересующую статистику
3. Повторить шаги 1 и 2 много раз (например, 10 000!)
4. Изучите распределение статистики по всем бутстреп-выборкам.
Одно из наиболее популярных применений бутстрэппинга - создание доверительных интервалов. Рассматривая распределение статистики, можно определить интервалы, в которых, например, медианное значение данных, скорее всего, будет попадать в 95% случайных выборок.
Несмотря на свою эффективность, бутстрэппинг не всегда является правильным решением. Если исходная выборка не является репрезентативной для всей совокупности, бутстрэппинг не исправит ситуацию. Кроме того, он может потребовать больших вычислительных затрат и не всегда хорошо работает с очень сложными статистическими данными. Тем не менее, мощности современных компьютеров сделали бутстрэппинг более доступным, чем когда-либо. Такие программы, как R и Python, позволяют легко проводить бутстрэппинг, что дает возможность выполнять более надежные и интересные статистические анализы.
{kind=link}
Робастное масштабирование (Robust Scaling) - способ борьбы с выбросами в данных.
В этом методе для масштабирования используются медиана и интерквартильный размах. Используйте этот метод, когда данные содержат много выбросов и необходимо обеспечить устойчивость к ним. Из значений вариационного ряда проводится вычитание медианы этого ряда и выполняется деление на межквартильных размах (IQR).
В этом методе для масштабирования используются медиана и интерквартильный размах. Используйте этот метод, когда данные содержат много выбросов и необходимо обеспечить устойчивость к ним. Из значений вариационного ряда проводится вычитание медианы этого ряда и выполняется деление на межквартильных размах (IQR).
{kind=link}
👍1
Про информационные критерии AIC и BIC
Когда строится прогностическая модель возникает вопрос, делает ли добавление дополнительных переменных ее действительно лучше? Или просто более сложной? AIC и BIC - инструменты, помогающие найти баланс между хорошей подгонкой и простотой! Выбор "лучшей" модели заключается не только в том, что она наиболее точно соответствует данным, но и в том, что она использует наименьшее количество ненужных переменных. Это компромисс между соответствием и простотой.
AIC (информационный критерий Акаике) был предложенн Хиротугу Акаике в 1970-х годах. AIC оценивает соответствие модели данным, а затем добавляет штраф за каждый используемый параметр (или переменную). Идея в том, чтобы предотвратить излишнее усложнение модели.
BIC (Байесовский информационный критерий) введен Гидеоном Шварцем в 1970-х годах. BIC также балансирует между пригодностью и простотой. Но он более строгий! Его штраф растет более существенно с добавлением параметров, особенно при увеличении размера выборки.
Оба показателя штрафуют за сложность, но если AIC более нацелен на качество прогнозирования, то BIC - на выявление более простой модели среди множества кандидатов. На больших выборках BIC, как правило, предпочитает более простые модели, чем AIC. Ни один критерий не является идеальным! AIC и BIC иногда могут выбирать слишком сложные или слишком упрощенные модели. Это все лишь рекомендательные критерии. Всегда используйте их в сочетании со знанием предметной области и другими диагностическими методами. При сравнении нескольких моделей лучшей считается модель с наименьшим AIC или BIC. Однако следует помнить, что небольшие различия между моделями (особенно по AIC) не всегда могут быть значимыми. Помимо AIC и BIC существует много других критериев: скорректированный AIC, DIC и др. Каждый из них обладает своими уникальными преимуществами и возможностями.
Когда строится прогностическая модель возникает вопрос, делает ли добавление дополнительных переменных ее действительно лучше? Или просто более сложной? AIC и BIC - инструменты, помогающие найти баланс между хорошей подгонкой и простотой! Выбор "лучшей" модели заключается не только в том, что она наиболее точно соответствует данным, но и в том, что она использует наименьшее количество ненужных переменных. Это компромисс между соответствием и простотой.
AIC (информационный критерий Акаике) был предложенн Хиротугу Акаике в 1970-х годах. AIC оценивает соответствие модели данным, а затем добавляет штраф за каждый используемый параметр (или переменную). Идея в том, чтобы предотвратить излишнее усложнение модели.
BIC (Байесовский информационный критерий) введен Гидеоном Шварцем в 1970-х годах. BIC также балансирует между пригодностью и простотой. Но он более строгий! Его штраф растет более существенно с добавлением параметров, особенно при увеличении размера выборки.
Оба показателя штрафуют за сложность, но если AIC более нацелен на качество прогнозирования, то BIC - на выявление более простой модели среди множества кандидатов. На больших выборках BIC, как правило, предпочитает более простые модели, чем AIC. Ни один критерий не является идеальным! AIC и BIC иногда могут выбирать слишком сложные или слишком упрощенные модели. Это все лишь рекомендательные критерии. Всегда используйте их в сочетании со знанием предметной области и другими диагностическими методами. При сравнении нескольких моделей лучшей считается модель с наименьшим AIC или BIC. Однако следует помнить, что небольшие различия между моделями (особенно по AIC) не всегда могут быть значимыми. Помимо AIC и BIC существует много других критериев: скорректированный AIC, DIC и др. Каждый из них обладает своими уникальными преимуществами и возможностями.
{kind=link}
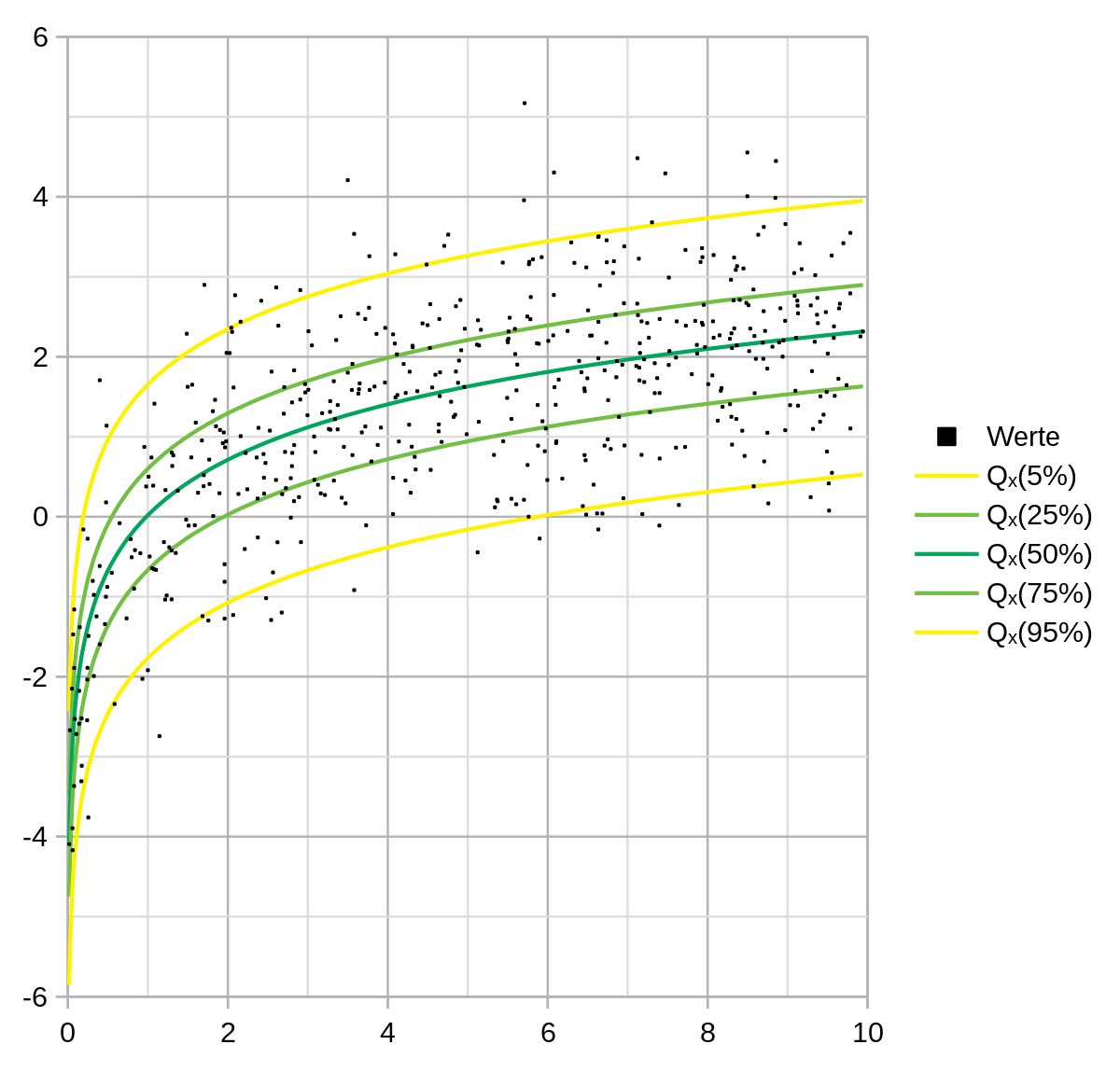
Про квантильную регрессию
Средние значения далеко не всегда хорошо отражают данные. Традиционная линейная регрессия предсказывает среднее значение зависимой переменной. Но что, если нас интересует, скажем, медиана? Или 90-й процентиль? Квантильная регрессия (КР) - рассматривает различные квантили (процентили) в качестве переменной ответа (отклика) и позволяет моделировать эти специфические квантили, давая более полное представление о распределении данных. КР минимизирует сумму взвешенных абсолютных остатков, в отличие от регрессии по методу наименьших квадратов, которая минимизирует квадратичные остатки. Изменяя весовые коэффициенты, мы ориентируемся на различные квантили. КР является универсальным инструментом для понимания взаимосвязей в данных, выходящих за рамки среднего значения. Она освещает все распределение, позволяя получить более глубокие выводы, однако интерпретация может быть менее интуитивной, чем при использовании методов, ориентированных на средние значения.
Преимущества КР:
✅ Дает понимание взаимосвязи между независимыми переменным с зависимой в различных ее точках (квантилях)
✅ Высокая устойчивость к выбросам
✅ Полезна, когда остатки линейной модели не являются гомоскедастичными (т.е. имеют непостоянную дисперсию).
✅ Совместное визуальное построение нескольких квантильных регрессий может дать более целостное представление о взаимосвязи данных. Например, можно увидеть, как меняется влияние лечения на уровень сахара в крови в зависимости от распределения пациентов с изначально разным уровнем сахара.
Показания к использованию КР:
✅ При подозрении на гетероскедастичность
✅ При интересе к высоким или низким экстремумам (например, какие факторы влияют на 10% пациентов с самым высоким уровнем сахара в крови).
Средние значения далеко не всегда хорошо отражают данные. Традиционная линейная регрессия предсказывает среднее значение зависимой переменной. Но что, если нас интересует, скажем, медиана? Или 90-й процентиль? Квантильная регрессия (КР) - рассматривает различные квантили (процентили) в качестве переменной ответа (отклика) и позволяет моделировать эти специфические квантили, давая более полное представление о распределении данных. КР минимизирует сумму взвешенных абсолютных остатков, в отличие от регрессии по методу наименьших квадратов, которая минимизирует квадратичные остатки. Изменяя весовые коэффициенты, мы ориентируемся на различные квантили. КР является универсальным инструментом для понимания взаимосвязей в данных, выходящих за рамки среднего значения. Она освещает все распределение, позволяя получить более глубокие выводы, однако интерпретация может быть менее интуитивной, чем при использовании методов, ориентированных на средние значения.
Преимущества КР:
✅ Дает понимание взаимосвязи между независимыми переменным с зависимой в различных ее точках (квантилях)
✅ Высокая устойчивость к выбросам
✅ Полезна, когда остатки линейной модели не являются гомоскедастичными (т.е. имеют непостоянную дисперсию).
✅ Совместное визуальное построение нескольких квантильных регрессий может дать более целостное представление о взаимосвязи данных. Например, можно увидеть, как меняется влияние лечения на уровень сахара в крови в зависимости от распределения пациентов с изначально разным уровнем сахара.
Показания к использованию КР:
✅ При подозрении на гетероскедастичность
✅ При интересе к высоким или низким экстремумам (например, какие факторы влияют на 10% пациентов с самым высоким уровнем сахара в крови).
{kind=link}
👍1
Три мифа о пороговых значениях риска для медицинских прогностических моделей
Миф 1: группы риска более полезны, чем прогнозы риска в виде непрерывного расчета вероятности прогнозируемого события - нет, конкретное значение вероятности события позволяет принимать более точные решения на индивидуальном уровне. Например, гораздо полезнее знать, что риск рака составляет 83%, чем то, что он просто выше 50%.
Миф 2: оптимальный порог высчитывается статистическими методами непосредственно по данным - нет, хороший порог тот, который отражает клинический контекст.
Например, порог высчитанный при помощий ROC-кривой не имеет никакой пользы, по сравнению с пороговым значением той же вероятности, когда врач в данной конкретной клинической ситуации считает необходимым предпринять какие-то действия из-за высокого риска прогнозируемого моделью события.
Миф 3: порог является частью прогностической модели - нет, это лишь частный случай модели, точность которой может быть проверена для разных порогов риска. Например, показатели чувствительности, специфичности и точности модели, полученные при использовании порога, не отражают истинные метрики модели, а лишь характеризуют частный случай ее применения.
Медицинские прогностические модели полезны для принятия решений в клинической практике. Для этой цели ключевое значение имеют надежные непрерывные оценки риска. Если для выявления пациентов с высоким риском необходимы пороговые значения, оптимальные пороговые значения не могут быть рассчитаны только на основании каких-либо статистических методов. Вместо этого выбор порога должен отражать вред от ложноположительных результатов и пользу от истинно положительных, что зависит от клинического контекста. Следует сосредоточиться на методах, которые оценивают прогностическую эффективность модели независимо от порога (например, AUC и калибровочные графики) или включают диапазон порогов риска (например, анализ кривой принятия решений).
Миф 1: группы риска более полезны, чем прогнозы риска в виде непрерывного расчета вероятности прогнозируемого события - нет, конкретное значение вероятности события позволяет принимать более точные решения на индивидуальном уровне. Например, гораздо полезнее знать, что риск рака составляет 83%, чем то, что он просто выше 50%.
Миф 2: оптимальный порог высчитывается статистическими методами непосредственно по данным - нет, хороший порог тот, который отражает клинический контекст.
Например, порог высчитанный при помощий ROC-кривой не имеет никакой пользы, по сравнению с пороговым значением той же вероятности, когда врач в данной конкретной клинической ситуации считает необходимым предпринять какие-то действия из-за высокого риска прогнозируемого моделью события.
Миф 3: порог является частью прогностической модели - нет, это лишь частный случай модели, точность которой может быть проверена для разных порогов риска. Например, показатели чувствительности, специфичности и точности модели, полученные при использовании порога, не отражают истинные метрики модели, а лишь характеризуют частный случай ее применения.
Медицинские прогностические модели полезны для принятия решений в клинической практике. Для этой цели ключевое значение имеют надежные непрерывные оценки риска. Если для выявления пациентов с высоким риском необходимы пороговые значения, оптимальные пороговые значения не могут быть рассчитаны только на основании каких-либо статистических методов. Вместо этого выбор порога должен отражать вред от ложноположительных результатов и пользу от истинно положительных, что зависит от клинического контекста. Следует сосредоточиться на методах, которые оценивают прогностическую эффективность модели независимо от порога (например, AUC и калибровочные графики) или включают диапазон порогов риска (например, анализ кривой принятия решений).
👍3
Использование бутстрэппинга для внутренней валидации прогностической модели
Одним из этапов создания медицинских прогностических моделей является внутренняя валидация. Чтобы не терять данные, которых как правило никогда не хватает, не стоит делить датасет на тренировочную и валидационную (тестовую) выборки. Делайте модель на всем наборе данных, а для внутренней валидации используйте бутстрэпп.
Чтобы рассчитать оптимизм модели, скорректированный с помощью бутстрэппинга, необходимо выполнить следующие шаги:
1. Сделайте модель прогнозирования, используя все исходные данные, и рассчитайте ее эффективность (например, по значению С-индекса или AUC-ROC)
2. Создайте бутстрэпп-выборку (того же размера, что и исходные данные), выбрав наблюдения с заменой из исходных данных. Подробнее здесь
3. Создайте бутстрэпп-модель на основе бутстрэпп-выборки (применяя все те же методы моделирования и выбора предикторов, что и на шаге 1):
3.1 Определите эффективность (например, по значению С-индекса или AUC-ROC) этой бутстрэпп-модели.
3.2. Определите эффективность бутстрэпп-модели на исходных данных.
4. Рассчитайте оптимизм как разницу между эффективностью модели, протестированной на бутстрэпп-выборке и на исходных данных.
5. Повторите шаги 2-4 много раз (не менее 500 раз).
6. Усредните оценки оптимизма на шаге 5.
7. Вычтите среднее значение оптимизма (на шаге 6) из кажущейся эффективности первоначальной модели, полученной на шаге 1, чтобы получить оценку производительности с поправкой на оптимизм.
Поздравляю! Вы провели внутреннюю валидацию своей модели и скорректировали метрики ее эффективности.
Одним из этапов создания медицинских прогностических моделей является внутренняя валидация. Чтобы не терять данные, которых как правило никогда не хватает, не стоит делить датасет на тренировочную и валидационную (тестовую) выборки. Делайте модель на всем наборе данных, а для внутренней валидации используйте бутстрэпп.
Чтобы рассчитать оптимизм модели, скорректированный с помощью бутстрэппинга, необходимо выполнить следующие шаги:
1. Сделайте модель прогнозирования, используя все исходные данные, и рассчитайте ее эффективность (например, по значению С-индекса или AUC-ROC)
2. Создайте бутстрэпп-выборку (того же размера, что и исходные данные), выбрав наблюдения с заменой из исходных данных. Подробнее здесь
3. Создайте бутстрэпп-модель на основе бутстрэпп-выборки (применяя все те же методы моделирования и выбора предикторов, что и на шаге 1):
3.1 Определите эффективность (например, по значению С-индекса или AUC-ROC) этой бутстрэпп-модели.
3.2. Определите эффективность бутстрэпп-модели на исходных данных.
4. Рассчитайте оптимизм как разницу между эффективностью модели, протестированной на бутстрэпп-выборке и на исходных данных.
5. Повторите шаги 2-4 много раз (не менее 500 раз).
6. Усредните оценки оптимизма на шаге 5.
7. Вычтите среднее значение оптимизма (на шаге 6) из кажущейся эффективности первоначальной модели, полученной на шаге 1, чтобы получить оценку производительности с поправкой на оптимизм.
Поздравляю! Вы провели внутреннюю валидацию своей модели и скорректировали метрики ее эффективности.
👍4
статИИстик
🤔 Немного терминологии в медицинском прогнозировании ✅ Прогностический фактор или предиктор - переменная, которая помогает прогнозировать (расчитывать вероятность) изучаемого исхода в конкретной прогностической модели. ✅ Фактор риска - переменная, определенное…
🤨 На дворе 2024 год, а в медицинской литературе до сих пор принято подставлять кучу ковариат в регрессионную модель для какого-нибудь плохого исхода и объявлять значимые ассоциации "факторами риска", о которых следует беспокоиться. Псевдонаука!
👍2🤔1
Матрица ошибок (Confusion matrix) – таблица, помогающая проанализировать эффективность модели классификации на наборе данных, для которых известны истинные значения классов. Матрица позволяет вычислить частоты истинно положительных (TP), истинно отрицательных (TN), ложно положительных (FP, ошибка 1 рода) и ложно отрицательных (FN, ошибка 2 рода) результатов. Размерность таблицы соответствует числу прогнозируемых классов. Матрица ошибок – простой способ визуализировать ошибки, которые допускает модель по каждому из классов.
❤1
По матрице ошибок можно высчитать другие метрики модели классификации:
🟢 Точность (Accuracy) – показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен (нет классового дисбаланса). Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Точность = (TP+TN)/(TP+TN+FP+FN).
🟢 Положительная прогностическая ценность (PPV, Precision) – частота правильно предсказанных TP результатов из общего числа истинно и ложно предсказанных положительных результатов.
PPV = TP/(TP+FP).
🟢 Отрицательная прогностическая ценность (NPV) – частота правильно предсказанных TN результатов из общего числа истинно и ложно предсказанных отрицательных результатов.
NPV = TN/(FN+TN).
🟢 Чувствительность (Recall) – частота правильно предсказанных TP результатов из их общего числа.
Чувствительность = TP/(TP+FN).
🟢 Специфичность – частота правильно предсказанных TN результатов из их общего числа.
Специфичность = TN/(TN+FP)
🟢 F-мера (F-score, F1) – показатель, который помогает комплексно оценивать Recall и Precision, используя среднее гармоническое вместо среднего арифметического.
F1 = (2*Recall*Precision)/(Recall+Precision).
🟢 Точность (Accuracy) – показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен (нет классового дисбаланса). Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Точность = (TP+TN)/(TP+TN+FP+FN).
🟢 Положительная прогностическая ценность (PPV, Precision) – частота правильно предсказанных TP результатов из общего числа истинно и ложно предсказанных положительных результатов.
PPV = TP/(TP+FP).
🟢 Отрицательная прогностическая ценность (NPV) – частота правильно предсказанных TN результатов из общего числа истинно и ложно предсказанных отрицательных результатов.
NPV = TN/(FN+TN).
🟢 Чувствительность (Recall) – частота правильно предсказанных TP результатов из их общего числа.
Чувствительность = TP/(TP+FN).
🟢 Специфичность – частота правильно предсказанных TN результатов из их общего числа.
Специфичность = TN/(TN+FP)
🟢 F-мера (F-score, F1) – показатель, который помогает комплексно оценивать Recall и Precision, используя среднее гармоническое вместо среднего арифметического.
F1 = (2*Recall*Precision)/(Recall+Precision).
❤1
Классовый дисбаланс - одна из тех проблем, которые обычно оказываются не проблемами, но превращаются в настоящие проблемы только тогда, когда вы начинаете их "исправлять".
Пояснение: дисбаланс классов при маленькой выборке может проблемой при создании моделей прогнозирования, подробнее здесь. Но методы исправления дисбаланаса могут привести еще к большим проблемам, в частности к увеличению ошибки калибровки модели и риску предвзятости полученных результатов. Что делать? Варианты: ничего и строить модель как есть, увеличить выборку (собрать больше данных), использовать методы устранения дисбаланса, но очень осторожно.
Пояснение: дисбаланс классов при маленькой выборке может проблемой при создании моделей прогнозирования, подробнее здесь. Но методы исправления дисбаланаса могут привести еще к большим проблемам, в частности к увеличению ошибки калибровки модели и риску предвзятости полученных результатов. Что делать? Варианты: ничего и строить модель как есть, увеличить выборку (собрать больше данных), использовать методы устранения дисбаланса, но очень осторожно.
PubMed Central (PMC)
The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression
Methods to correct class imbalance (imbalance between the frequency of outcome events and nonevents) are receiving increasing interest for developing prediction models. We examined the effect of imbalance correction on the performance of logistic regression…
🔥1