
При создании прогностической модели существуют множество правил и последовательных действий. Одни из них связаны с разделением данных на тренировочный, валидационный и тестовый датасет. При малых размерах выборок это большая проблема, но сейчас не об этом.
❌ Вот как поступают многие при создании прогностической модели:
1. Преобразовывают свой набор данных (про преобразование данных)
2. Затем разбивают датасет (обучающий, валидационный и тестовый наборы)
3. Наконец, строят модель
Здесь кроется большая проблема. К сожалению, многие допускают эту ошибку. Например, выполнена min-max нормализация. Если не разделить набор данных сразу, то для вычисления минимального и максимального значений конкретного столбца будут использованы все данные. В том числе и информация из будущего тестового набора, о которой вы не должны знать! Это называется "утечкой данных". Вы используете информацию из тестовых данных, которая повлияет на ваш обучающий процесс.
✅ Вот правильный алгоритм:
1. Сначала нужно разделить данные и отложить тестовый набор в сторону!
2. Преобразовать обучающий набор данных и сделать модель
3. Преобразовать отложенные тестовые данные и проверить модель
После преобразования обучающего набора следует использовать тот же подход для трансформации тестовых данных. Вывод: никогда не преобразуйте данные перед их разбиением!
❌ Вот как поступают многие при создании прогностической модели:
1. Преобразовывают свой набор данных (про преобразование данных)
2. Затем разбивают датасет (обучающий, валидационный и тестовый наборы)
3. Наконец, строят модель
Здесь кроется большая проблема. К сожалению, многие допускают эту ошибку. Например, выполнена min-max нормализация. Если не разделить набор данных сразу, то для вычисления минимального и максимального значений конкретного столбца будут использованы все данные. В том числе и информация из будущего тестового набора, о которой вы не должны знать! Это называется "утечкой данных". Вы используете информацию из тестовых данных, которая повлияет на ваш обучающий процесс.
✅ Вот правильный алгоритм:
1. Сначала нужно разделить данные и отложить тестовый набор в сторону!
2. Преобразовать обучающий набор данных и сделать модель
3. Преобразовать отложенные тестовые данные и проверить модель
После преобразования обучающего набора следует использовать тот же подход для трансформации тестовых данных. Вывод: никогда не преобразуйте данные перед их разбиением!
В 1925 г. во время летнего послеобеденного чая одна дама, доктор Мюриэл Бристол, заявила, что она может определить, что налито в чашку первым - молоко или чай. Рональд А. Фишер, всегда готовый к статистическим вызовам, увидел возможность для эксперимента. Было приготовлено 8 чашек - 4 с вначале налитым молоком и 4 - с чаем. Дама правильно определила 3 из 4 чашек в каждой группе, что привело к вопросу: это случайность или ее настоящая способность? При проверке гипотез это означает выдвижение нулевой и альтернативной гипотез. Фишер сформулировал решение данного вопроса как комбинаторную задачу. Если бы это была простая удача, то вероятность того, что дама правильно ответит на все 8 вопросов, была бы невелика. Это заложило основу для концепции p-значимости. Р-значимость - вероятность наблюдения полученного или более экстремального результата при условии, что нулевая гипотеза верна. Доктор Мюриэл Бристол не смогла отгадать все чашки, но она справилась лучше, чем можно было бы предположить на основании простой вероятности. Это стало основной для дальнейших разработок Фишера в области экспериментального дизайна и проверки гипотез, а в итоге появился точный критерий Фишера.
"Дама, пробующая чай" - не просто причудливая история. Это рождение концепций, основополагающих для современной статистики. В следующий раз, когда вы будете пить чай, вспомните о богатом наследии, которое хранится в каждой чашке этого напитка.
"Дама, пробующая чай" - не просто причудливая история. Это рождение концепций, основополагающих для современной статистики. В следующий раз, когда вы будете пить чай, вспомните о богатом наследии, которое хранится в каждой чашке этого напитка.
{kind=link}
Про анализ выживаемости простым языком
✅ Анализ выживаемости - статистический метод изучения времени до наступления того или иного события, например, смерти пациента. В отличие от привычных средних значений, анализ выживаемости оценивает время - сколько времени требуется для того, чтобы произошло то или иное событие. Событием может быть что угодно: сколько времени пройдет до поломки машины? Сколько дней пройдет до выздоровления пациента? Как быстро погаснут свечи?
✅ Но не все свечи догорят за время нашего наблюдения, как и не все пациенты могут поправиться или умереть. Событие может еще не наступить, когда мы закончим исследование. Это называется "цензурированием". Анализ выживаемости обрабатывает эту неполную информацию.
✅ Функция выживания - кривая, которая показывает вероятность выживания (т.е. события, которое еще не произошло) с течением времени. Если вы изучаете выживаемость больных, то она будет показывать вероятность того, что проживет X (дней/месяцев/лет). Hazard Ratio (коэффициент опасности) - риск того, что событие произойдет в определенное время, учитывая, что до этого момента оно еще не произошло. Например, насколько вероятно, что свеча погаснет на 5-м часу, если через 4 часа она все еще горит?
✅ Почему бы просто не использовать средние значения? Допустим, у вас есть 2 батарейки. Одна сдохнет через 1 час, другая - через 9. Среднее значение = 5 часов. Но это не дает полной картины. Анализ выживаемости дает более подробную картину. С помощью кривых выживания мы можем понять такие нюансы, как процент батарей, проработавших определенное время, риск смерти в определенный период времени, а также сравнить различные группы между собой.
✅ Анализ выживаемости применяется повсеместно! Медицина - прогнозирование выживаемости пациентов, инженерия - прогнозирование срока службы машин, финансы - время до дефолта по кредиту и т.д. Анализ выживаемости - мощный инструмент, который выходит за рамки простых средних значений. Он позволяет детально рассмотреть, как время влияет на события.
Другие шоты по данной теме:
Кратко о тестах сравнения кривых Каплана-Мейера
Что нужно знать и понимать о кривой выживаемости
Про виды показателей выживаемости в медицине
Как оценить выживаемость пациентов при наличии конкурирующих событий
Подробно про Hazard Ratio
✅ Анализ выживаемости - статистический метод изучения времени до наступления того или иного события, например, смерти пациента. В отличие от привычных средних значений, анализ выживаемости оценивает время - сколько времени требуется для того, чтобы произошло то или иное событие. Событием может быть что угодно: сколько времени пройдет до поломки машины? Сколько дней пройдет до выздоровления пациента? Как быстро погаснут свечи?
✅ Но не все свечи догорят за время нашего наблюдения, как и не все пациенты могут поправиться или умереть. Событие может еще не наступить, когда мы закончим исследование. Это называется "цензурированием". Анализ выживаемости обрабатывает эту неполную информацию.
✅ Функция выживания - кривая, которая показывает вероятность выживания (т.е. события, которое еще не произошло) с течением времени. Если вы изучаете выживаемость больных, то она будет показывать вероятность того, что проживет X (дней/месяцев/лет). Hazard Ratio (коэффициент опасности) - риск того, что событие произойдет в определенное время, учитывая, что до этого момента оно еще не произошло. Например, насколько вероятно, что свеча погаснет на 5-м часу, если через 4 часа она все еще горит?
✅ Почему бы просто не использовать средние значения? Допустим, у вас есть 2 батарейки. Одна сдохнет через 1 час, другая - через 9. Среднее значение = 5 часов. Но это не дает полной картины. Анализ выживаемости дает более подробную картину. С помощью кривых выживания мы можем понять такие нюансы, как процент батарей, проработавших определенное время, риск смерти в определенный период времени, а также сравнить различные группы между собой.
✅ Анализ выживаемости применяется повсеместно! Медицина - прогнозирование выживаемости пациентов, инженерия - прогнозирование срока службы машин, финансы - время до дефолта по кредиту и т.д. Анализ выживаемости - мощный инструмент, который выходит за рамки простых средних значений. Он позволяет детально рассмотреть, как время влияет на события.
Другие шоты по данной теме:
Кратко о тестах сравнения кривых Каплана-Мейера
Что нужно знать и понимать о кривой выживаемости
Про виды показателей выживаемости в медицине
Как оценить выживаемость пациентов при наличии конкурирующих событий
Подробно про Hazard Ratio
{kind=link}
Про ансамбли в машинном обучении: Bagging, Boosting и Stacking
Для улучшения результатов прогнозирования существуют ансамблевые подходы в обучении и при применении прогностических моделей. Иногда их принципы уже заложены в тот или иной метод машинного обучения, в другом случае эти принципы можно использовать искусственно и комбинировать между собой.
1. Bagging. Представьте, что вы врач и пытаетесь поставить диагноз пациенту. Вместо того чтобы делать это самостоятельно, вы просите ваших коллег вам помочь и собираете консилиум. Каждый из врачей смотрит на пациента по-своему с позиции своих знаний, клинического мышления и высказывает свое мнение. Затем вы усредняете все их предположения. Это и есть Bagging! Говоря техническим языком, Bagging обучает несколько версий модели на разных подмножествах, чтобы уменьшить дисперсию (ошибки из-за шума). Самый популярный метод основанный на бэггинге - модель случайного леса (ансамбль из множества деревьев решений).
2. Boosting. Предположим, что первый врач поставил диагноз, но не очень точно и отправил пациента на дообследование. Теперь второй врач пытается исправить неточность первого с учетом новых данных, и так далее. Каждый врач учится на ошибках и результатах предыдущего. В машинном обучении бустинг позволяет построить серию моделей, каждая из которых исправляет ошибки предыдущей, уделяя больше внимания неверно классифицированным точкам данных. Популярные методы: градиентный бустинг, XGBoost, CatBoost, AdaBoost.
3. Stacking. Вы собрали междисциплинарный консилиум по пациенту из врачей разных специальностей. Один - клиницист, другой - генетик, третий - морфолог. Вместо того чтобы полагаться на мнение только одного врача, объедините сильные стороны всех участников консилиума! В методе Stacking мы объединяем (или "складываем") прогнозы нескольких моделей. Затем финальная модель (называемая мета-моделью) обучается на этих объединенных прогнозах, чтобы дать окончательный ответ. Это похоже на использование коллективной мудрости!
Перечисленные выше методы помогают:
✅ Улучшить точность прогноза
✅ Уменьшить систематическую ошибку и дисперсию
✅ Повысить надежность моделей
Одна голова - хорошо, а много - лучше!
Для улучшения результатов прогнозирования существуют ансамблевые подходы в обучении и при применении прогностических моделей. Иногда их принципы уже заложены в тот или иной метод машинного обучения, в другом случае эти принципы можно использовать искусственно и комбинировать между собой.
1. Bagging. Представьте, что вы врач и пытаетесь поставить диагноз пациенту. Вместо того чтобы делать это самостоятельно, вы просите ваших коллег вам помочь и собираете консилиум. Каждый из врачей смотрит на пациента по-своему с позиции своих знаний, клинического мышления и высказывает свое мнение. Затем вы усредняете все их предположения. Это и есть Bagging! Говоря техническим языком, Bagging обучает несколько версий модели на разных подмножествах, чтобы уменьшить дисперсию (ошибки из-за шума). Самый популярный метод основанный на бэггинге - модель случайного леса (ансамбль из множества деревьев решений).
2. Boosting. Предположим, что первый врач поставил диагноз, но не очень точно и отправил пациента на дообследование. Теперь второй врач пытается исправить неточность первого с учетом новых данных, и так далее. Каждый врач учится на ошибках и результатах предыдущего. В машинном обучении бустинг позволяет построить серию моделей, каждая из которых исправляет ошибки предыдущей, уделяя больше внимания неверно классифицированным точкам данных. Популярные методы: градиентный бустинг, XGBoost, CatBoost, AdaBoost.
3. Stacking. Вы собрали междисциплинарный консилиум по пациенту из врачей разных специальностей. Один - клиницист, другой - генетик, третий - морфолог. Вместо того чтобы полагаться на мнение только одного врача, объедините сильные стороны всех участников консилиума! В методе Stacking мы объединяем (или "складываем") прогнозы нескольких моделей. Затем финальная модель (называемая мета-моделью) обучается на этих объединенных прогнозах, чтобы дать окончательный ответ. Это похоже на использование коллективной мудрости!
Перечисленные выше методы помогают:
✅ Улучшить точность прогноза
✅ Уменьшить систематическую ошибку и дисперсию
✅ Повысить надежность моделей
Одна голова - хорошо, а много - лучше!
Про bias (предвзятость / смещенность)
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать по разным причинам и влиять как на процесс выборки, так и на анализ данных. Это может привести к результатам, которые неточно представляют истинную совокупность или изучаемое явление.
Вот некоторые распространенные виды предвзятости в статистике, которые часто могут дополнять друг друга:
⚠️ Предвзятость сбора данных. Возникает, когда выборка, используемая для анализа, не является репрезентативной для всей генеральной совокупности. Определенные группы или отдельные лица с большей вероятностью будут включены в выборку, что приведет к результатам, которые не будут хорошо обобщены на всю совокупность. Например, исследователь сознательно включит в выборку пациентов, у которых были хорошие результаты лечения, чтобы не дискредитировать лекарственный препарат или метод лечения. Другой пример, когда дизайн исследования подразумевает опрос респондентов, но не все возможные респонденты принимают в участие в исследовании, отвечают на вопросы или все ответы учитываются.
⚠️ Предвзятость измерения. Возникает при наличии неточностей или ошибок в способах сбора, регистрации или измерения данных. Это может быть следствием неисправности приборов, человеческого фактора или несоответствия методов измерения поставленным задачам. Можно считать это разновидностью предвзятости сбора данных.
⚠️ Предвзятость выборки. Метод отбора участников исследования не обеспечивает равных шансов для включения в него всех членов популяции, может возникнуть предвзятость выборки. Это приводит к получению нерепрезентативной выборки. Например, в отсуствии рандомизации.
⚠️ Предвзятость наблюдателя. Возникает, когда ожидания или убеждения исследователя влияют на интерпретацию результатов. Это может привести к непреднамеренным ошибкам при сборе или анализе данных. Например, стремление получить нужный результат приводит к искусственному искажению набора данных.
⚠️ Предвзятость при публикации. Возникает, когда принято публиковать исследования со статистически значимыми или положительными результатами, а исследования с незначимыми или отрицательными результатами публикуются реже и не публикуются совсем. Это может создать искаженное представление об общем объеме доказательств по теме.
⚠️ Сбивающие факторы. Ошибка происходит, когда третья переменная (конфаундер) влияет на независимые и зависимые переменные в исследовании, создавая ложную связь между ними. Контроль за сбивающими переменными важен для того, чтобы избежать необъективных результатов.
Необъективность статистических данных может существенно повлиять на достоверность и надежность результатов исследования. Для уменьшения bias исследователи должны тщательно планировать свои исследования, использовать методы случайной выборки (в т.ч. рандомизацию), применять стандартизированные методики измерений, прозрачно описывать свои данные, манипуляции с ними, методы анализа и возможные ограничения. Также очень важно критически оценивать исследования и их bias при интерпретации статистических результатов.
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать по разным причинам и влиять как на процесс выборки, так и на анализ данных. Это может привести к результатам, которые неточно представляют истинную совокупность или изучаемое явление.
Вот некоторые распространенные виды предвзятости в статистике, которые часто могут дополнять друг друга:
⚠️ Предвзятость сбора данных. Возникает, когда выборка, используемая для анализа, не является репрезентативной для всей генеральной совокупности. Определенные группы или отдельные лица с большей вероятностью будут включены в выборку, что приведет к результатам, которые не будут хорошо обобщены на всю совокупность. Например, исследователь сознательно включит в выборку пациентов, у которых были хорошие результаты лечения, чтобы не дискредитировать лекарственный препарат или метод лечения. Другой пример, когда дизайн исследования подразумевает опрос респондентов, но не все возможные респонденты принимают в участие в исследовании, отвечают на вопросы или все ответы учитываются.
⚠️ Предвзятость измерения. Возникает при наличии неточностей или ошибок в способах сбора, регистрации или измерения данных. Это может быть следствием неисправности приборов, человеческого фактора или несоответствия методов измерения поставленным задачам. Можно считать это разновидностью предвзятости сбора данных.
⚠️ Предвзятость выборки. Метод отбора участников исследования не обеспечивает равных шансов для включения в него всех членов популяции, может возникнуть предвзятость выборки. Это приводит к получению нерепрезентативной выборки. Например, в отсуствии рандомизации.
⚠️ Предвзятость наблюдателя. Возникает, когда ожидания или убеждения исследователя влияют на интерпретацию результатов. Это может привести к непреднамеренным ошибкам при сборе или анализе данных. Например, стремление получить нужный результат приводит к искусственному искажению набора данных.
⚠️ Предвзятость при публикации. Возникает, когда принято публиковать исследования со статистически значимыми или положительными результатами, а исследования с незначимыми или отрицательными результатами публикуются реже и не публикуются совсем. Это может создать искаженное представление об общем объеме доказательств по теме.
⚠️ Сбивающие факторы. Ошибка происходит, когда третья переменная (конфаундер) влияет на независимые и зависимые переменные в исследовании, создавая ложную связь между ними. Контроль за сбивающими переменными важен для того, чтобы избежать необъективных результатов.
Необъективность статистических данных может существенно повлиять на достоверность и надежность результатов исследования. Для уменьшения bias исследователи должны тщательно планировать свои исследования, использовать методы случайной выборки (в т.ч. рандомизацию), применять стандартизированные методики измерений, прозрачно описывать свои данные, манипуляции с ними, методы анализа и возможные ограничения. Также очень важно критически оценивать исследования и их bias при интерпретации статистических результатов.
👍1
🙈 Размер выборки не учитывается при разработке модели прогнозирования
Группа уважаемых статистиков выполнила систематический обзор 119 публикаций, в которых были описаны медицинские прогностические модели. Только 8% исследований указали и обосновали способ расчета размера выборки для своих моделей. При этом в 73% из них размер выборки не соответствовал минимально необходимому (по методу Riley et al.). Авторы призывают исследователей обосновывать, выполнять и сообщать о методах расчета размера выборки при создании прогностических моделей.
Источник: https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-023-02008-1
Группа уважаемых статистиков выполнила систематический обзор 119 публикаций, в которых были описаны медицинские прогностические модели. Только 8% исследований указали и обосновали способ расчета размера выборки для своих моделей. При этом в 73% из них размер выборки не соответствовал минимально необходимому (по методу Riley et al.). Авторы призывают исследователей обосновывать, выполнять и сообщать о методах расчета размера выборки при создании прогностических моделей.
Источник: https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-023-02008-1
SpringerLink
Sample size requirements are not being considered in studies developing prediction models for binary outcomes: a systematic review
BMC Medical Research Methodology - Having an appropriate sample size is important when developing a clinical prediction model. We aimed to review how sample size is considered in studies developing...
Про ассоциацию, корреляцию и причинно-следственную связь
"Корреляция не подразумевает причинно-следственной связи". Это краеугольный камень в анализе данных!
✅ Ассоциация. По своей сути ассоциация означает, что между двумя переменными существует некоторая связь. Это не говорит нам о силе или направлении связи, а только о том, что связь существует. Примеры ассоциации: продажа мороженого и посещение бассейна, размер обуви и способность к чтению у детей. В обоих случаях связь есть, но она не прямая. В первом случае она обусловлена жаркой погодой, во втором - возрастом ребенка.
✅ Корреляция. Корреляция, являющаяся более глубоким понятием, чем ассоциация, определяет силу и направление линейной связи между двумя переменными. Она измеряется коэффициентом корреляции (часто "r"), который варьируется от -1 до 1. Понимание корреляции: r = 1 - идеальная положительная корреляция, r = -1 - идеальная отрицательная корреляция, r = 0 - отсутствие линейной корреляции. Однако значение r, близкое к 0, не всегда означает отсутствие связи; связь может быть нелинейной.
✅ Причинно-следственная связь (Causation). Причинно-следственная связь означает, что изменение одной переменной вызывает изменение другой. Ее труднее всего доказать и для этого требуются контролируемые эксперименты, например, рандомизированное контролируемое клиническое исследование, исключение скрытых переменных. Многие факторы могут исказить взаимосвязь. Например, если вы обнаружили корреляцию между продажами мороженого и нападениями акул, это не означает, что одно является причиной другого. И то, и другое увеличивается летом в жаркую погоду - скрытая переменная! Корреляция (Correlation) ≠ Причинно-следственная связь (Causation).
Неправильное понимание этих концепций может привести к ошибочным выводам. При работе с данными и выводами тщательно анализируйте представленную взаимосвязь. Спрашивайте себя, не могут ли здесь играть роль другие факторы. Ищите экспериментальные доказательства, прежде чем соглашаться с утверждениями о причинно-следственной связи. Понимание нюансов между ассоциацией, корреляцией и причинно-следственной связью - не просто семантика. Оно является основополагающим для научной грамотности, принятия взвешенных решений и критического мышления.
"Корреляция не подразумевает причинно-следственной связи". Это краеугольный камень в анализе данных!
✅ Ассоциация. По своей сути ассоциация означает, что между двумя переменными существует некоторая связь. Это не говорит нам о силе или направлении связи, а только о том, что связь существует. Примеры ассоциации: продажа мороженого и посещение бассейна, размер обуви и способность к чтению у детей. В обоих случаях связь есть, но она не прямая. В первом случае она обусловлена жаркой погодой, во втором - возрастом ребенка.
✅ Корреляция. Корреляция, являющаяся более глубоким понятием, чем ассоциация, определяет силу и направление линейной связи между двумя переменными. Она измеряется коэффициентом корреляции (часто "r"), который варьируется от -1 до 1. Понимание корреляции: r = 1 - идеальная положительная корреляция, r = -1 - идеальная отрицательная корреляция, r = 0 - отсутствие линейной корреляции. Однако значение r, близкое к 0, не всегда означает отсутствие связи; связь может быть нелинейной.
✅ Причинно-следственная связь (Causation). Причинно-следственная связь означает, что изменение одной переменной вызывает изменение другой. Ее труднее всего доказать и для этого требуются контролируемые эксперименты, например, рандомизированное контролируемое клиническое исследование, исключение скрытых переменных. Многие факторы могут исказить взаимосвязь. Например, если вы обнаружили корреляцию между продажами мороженого и нападениями акул, это не означает, что одно является причиной другого. И то, и другое увеличивается летом в жаркую погоду - скрытая переменная! Корреляция (Correlation) ≠ Причинно-следственная связь (Causation).
Неправильное понимание этих концепций может привести к ошибочным выводам. При работе с данными и выводами тщательно анализируйте представленную взаимосвязь. Спрашивайте себя, не могут ли здесь играть роль другие факторы. Ищите экспериментальные доказательства, прежде чем соглашаться с утверждениями о причинно-следственной связи. Понимание нюансов между ассоциацией, корреляцией и причинно-следственной связью - не просто семантика. Оно является основополагающим для научной грамотности, принятия взвешенных решений и критического мышления.
{kind=link}
Про тесты Вальда, отношения правдоподобия, AIC и BIC при создании прогностических моделей
Тестирование параметров модели необходимо для подтверждения значимости переменных, входящих в ее состав, а также для сравнения моделей между собой. Когда мы говорим о "тестировании параметров модели", мы, по сути, спрашиваем "оказывает ли этот конкретный фактор (ковариата) существенное влияние на нашу модель или прогноз?".
✅ Тест Вальда. Использует отношение значения регрессионного коэффициента параметра к его стандартной ошибке. Это как бы измерение того, на сколько стандартных наша оценка отклоняется от нуля. Полученное соотношение сравнивается с критическим значением из соответствующего распределения, чтобы определить, является ли параметр статистически значимым. Если абсолютное значение рассчитанной статистики Вальда больше критического значения из эталонного распределения, то нулевая гипотеза отвергается и делается вывод о том, что параметр статистически значим. Критическое значение зависит от желаемого уровня значимости (например, 0.1). Тест прост в вычислениях и хорошо работает для больших выборок. Может давать сбои при малых выборках.
✅ Тест отношения правдоподобия. Сравнивает правдоподобие (пригодность) двух вложенных друг в друга моделей - модели с параметром и модели без параметра. Очень надежен и считается устойчивым, даже при малых выборках. Считается золотым стандартом для оценки вложенных (nested) моделей. Вложенная модель - регрессионная модель, которая содержит подмножество предикторных переменных другой регрессионной модели.
✅ AIC (информационный критерий Акаике) позволяет сравнивать несколько моделей, построенных на одних и тех же данных, поощряя хорошую подгонку модели к данным, но штрафуя за лишние параметры, что позволяет сбалансировать подгонку и простоту при выборе параметров. Более низкие значения AIC свидетельствуют о лучшем компромиссе между подгонкой и простотой. Основная идея AIC заключается в том, чтобы найти модель, которая хорошо соответствует данным, при этом накладывая штраф на количество параметров в модели. Это позволяет избежать чрезмерной подгонки, когда сложная модель отражает шум в данных, а не основные закономерности.
✅ BIC (Байесовский информационный критерий). Как и AIC, BIC направлен на достижение баланса между пригодностью модели и ее сложностью, однако для сложных моделей он вводит более сильный штраф.
Ключевое различие между AIC и BIC заключается в штрафной части формулы для рассчета. Более низкие значения BIC свидетельствуют о лучшем компромиссе между подгонкой и простотой.
Построение модели носит итеративный характер. Вы добавляете переменную, тестируете модель, а затем решаете, оставить переменную или отбросить. Тесты помогают принимать ключевые решения в данном контексте. В тоже время следует помнить, что статистическая значимость - это одно, а реальная значимость - совсем другое. Убедитесь, что значимый параметр также имеет практическое значение для вашей модели.
Тестирование параметров модели необходимо для подтверждения значимости переменных, входящих в ее состав, а также для сравнения моделей между собой. Когда мы говорим о "тестировании параметров модели", мы, по сути, спрашиваем "оказывает ли этот конкретный фактор (ковариата) существенное влияние на нашу модель или прогноз?".
✅ Тест Вальда. Использует отношение значения регрессионного коэффициента параметра к его стандартной ошибке. Это как бы измерение того, на сколько стандартных наша оценка отклоняется от нуля. Полученное соотношение сравнивается с критическим значением из соответствующего распределения, чтобы определить, является ли параметр статистически значимым. Если абсолютное значение рассчитанной статистики Вальда больше критического значения из эталонного распределения, то нулевая гипотеза отвергается и делается вывод о том, что параметр статистически значим. Критическое значение зависит от желаемого уровня значимости (например, 0.1). Тест прост в вычислениях и хорошо работает для больших выборок. Может давать сбои при малых выборках.
✅ Тест отношения правдоподобия. Сравнивает правдоподобие (пригодность) двух вложенных друг в друга моделей - модели с параметром и модели без параметра. Очень надежен и считается устойчивым, даже при малых выборках. Считается золотым стандартом для оценки вложенных (nested) моделей. Вложенная модель - регрессионная модель, которая содержит подмножество предикторных переменных другой регрессионной модели.
✅ AIC (информационный критерий Акаике) позволяет сравнивать несколько моделей, построенных на одних и тех же данных, поощряя хорошую подгонку модели к данным, но штрафуя за лишние параметры, что позволяет сбалансировать подгонку и простоту при выборе параметров. Более низкие значения AIC свидетельствуют о лучшем компромиссе между подгонкой и простотой. Основная идея AIC заключается в том, чтобы найти модель, которая хорошо соответствует данным, при этом накладывая штраф на количество параметров в модели. Это позволяет избежать чрезмерной подгонки, когда сложная модель отражает шум в данных, а не основные закономерности.
✅ BIC (Байесовский информационный критерий). Как и AIC, BIC направлен на достижение баланса между пригодностью модели и ее сложностью, однако для сложных моделей он вводит более сильный штраф.
Ключевое различие между AIC и BIC заключается в штрафной части формулы для рассчета. Более низкие значения BIC свидетельствуют о лучшем компромиссе между подгонкой и простотой.
Построение модели носит итеративный характер. Вы добавляете переменную, тестируете модель, а затем решаете, оставить переменную или отбросить. Тесты помогают принимать ключевые решения в данном контексте. В тоже время следует помнить, что статистическая значимость - это одно, а реальная значимость - совсем другое. Убедитесь, что значимый параметр также имеет практическое значение для вашей модели.
{kind=link}
👍2
Про типы наборов данных при создании прогностических моделей
При создании прогностической модели любым методом требуется предварительное разделение данных на несколько типов. Классическая картина - 3 различных набора данных: тренировочный (обучающий), валидационный и тестовый.
Тестовый набор. Первое, что следует сделать на этом этапе - "забыть" о существовании тестового набора (отложить его в сторону). Тестовые данные обычно составляют 10-20% от общего набора. Размер выборки для тестирования должен высчитываться с использованием методов определения минимального размера вборки для создания прогностических моделей.
Обучающий набор данных. Никаких других данных за пределами этого набора не существует. Эти данные используются для каждого нового эксперимента, преобразования и принятия решений.
Валидационный набор. Эти данные используются для расчета эффективности вашей модели и принятия решения о том, как ее улучшить (~10-20% от общего с обучающим набором объема данных). Валидационный датасет дает обратную связь. Вы можете использовать эту обратную связь для улучшения своей модели.
Если данных мало:
✅ Не создавать валидационный набор данных. Валидационные данные должны содержать не менее 100 событий (эмпирическое правило), чтобы быть значимыми. Вместо этого можно использовать k-кратную перекрестную валидацию или бутстрэппинг.
✅ Не создавать тестовый набор данных - использовать внешний датасет в рамках внешней валидации.
Вот итерационный процесс, которому нужно следовать:
1. Обучить модель на обучающем наборе
2. Оценить качество модели на валидационном наборе
3. Изменить параметрым модели для ее улучшения
4. Снова оценить ее на валидационном наборе, снова улучшить и т.д.
Через некоторое время модель неизбежно начнет подстраиваться под валидационный набор (переобучаться). В этом случае валидационный набор станет бесполезным.
Что делать:
✅ Через несколько итераций снова смешать валидационный и обучающий набор и повторно разделить его случайным образом
✅ Использовать k-кратную перекрестную валидацию или бутстрэппинг
Еще про тестовый набор:
✅ До самого конца вы никогда не смотрите на свои тестовые данные.
✅ Вы никогда не используете их для анализа или преобразований.
✅ Никогда не принимайте решений, влияющих на вашу модель, используя тестовые данные.
✅ Вы относитесь к тестовым данным так, как будто их не существует.
✅ Цель тестового набора - обеспечить окончательную, несмещенную оценку эффективности вашей модели.
✅ Хороший тестовый набор даст вам результаты, аналогичные тем, которые вы ожидаете получить при обработке реальных данных.
Многие запускают свою модель на тестовом наборе и обнаруживают, что модель не очень хороша. Они возвращаются назад и вносят изменения в модель до тех пор, пока производительность не улучшится. Ничего страшного, кроме того, что они снова используют тот же тестовый набор! Эффективность тестового набора уменьшается пропорционально количеству его использования. Вскоре тестовый набор перестанет быть точным показателем того, насколько хороша ваша модель. Используйте тестовые данные один раз!
При создании прогностической модели любым методом требуется предварительное разделение данных на несколько типов. Классическая картина - 3 различных набора данных: тренировочный (обучающий), валидационный и тестовый.
Тестовый набор. Первое, что следует сделать на этом этапе - "забыть" о существовании тестового набора (отложить его в сторону). Тестовые данные обычно составляют 10-20% от общего набора. Размер выборки для тестирования должен высчитываться с использованием методов определения минимального размера вборки для создания прогностических моделей.
Обучающий набор данных. Никаких других данных за пределами этого набора не существует. Эти данные используются для каждого нового эксперимента, преобразования и принятия решений.
Валидационный набор. Эти данные используются для расчета эффективности вашей модели и принятия решения о том, как ее улучшить (~10-20% от общего с обучающим набором объема данных). Валидационный датасет дает обратную связь. Вы можете использовать эту обратную связь для улучшения своей модели.
Если данных мало:
✅ Не создавать валидационный набор данных. Валидационные данные должны содержать не менее 100 событий (эмпирическое правило), чтобы быть значимыми. Вместо этого можно использовать k-кратную перекрестную валидацию или бутстрэппинг.
✅ Не создавать тестовый набор данных - использовать внешний датасет в рамках внешней валидации.
Вот итерационный процесс, которому нужно следовать:
1. Обучить модель на обучающем наборе
2. Оценить качество модели на валидационном наборе
3. Изменить параметрым модели для ее улучшения
4. Снова оценить ее на валидационном наборе, снова улучшить и т.д.
Через некоторое время модель неизбежно начнет подстраиваться под валидационный набор (переобучаться). В этом случае валидационный набор станет бесполезным.
Что делать:
✅ Через несколько итераций снова смешать валидационный и обучающий набор и повторно разделить его случайным образом
✅ Использовать k-кратную перекрестную валидацию или бутстрэппинг
Еще про тестовый набор:
✅ До самого конца вы никогда не смотрите на свои тестовые данные.
✅ Вы никогда не используете их для анализа или преобразований.
✅ Никогда не принимайте решений, влияющих на вашу модель, используя тестовые данные.
✅ Вы относитесь к тестовым данным так, как будто их не существует.
✅ Цель тестового набора - обеспечить окончательную, несмещенную оценку эффективности вашей модели.
✅ Хороший тестовый набор даст вам результаты, аналогичные тем, которые вы ожидаете получить при обработке реальных данных.
Многие запускают свою модель на тестовом наборе и обнаруживают, что модель не очень хороша. Они возвращаются назад и вносят изменения в модель до тех пор, пока производительность не улучшится. Ничего страшного, кроме того, что они снова используют тот же тестовый набор! Эффективность тестового набора уменьшается пропорционально количеству его использования. Вскоре тестовый набор перестанет быть точным показателем того, насколько хороша ваша модель. Используйте тестовые данные один раз!
{kind=link}
Про метод сопоставления оценок склонности (Propensity Score Matching, PSM)
Золотым стандартом сравнительных исследований являются рандомизированные. В таком идеальном сценарии пациенты случайным образом распределяются по группам исследования (например, лечение против контроля). Случайность распределения обеспечивает сопоставимость групп. Однако во многих реальных исследованиях мы не имеем такой возможности. Поэтому PSM - наш спаситель!
"Оценка склонности" - вероятность того, что пациент попадет в ту или иную группу сравнения, например, получит лечение, который высчитывается на основе его наблюдаемых характеристик. Чтобы рассчитать эту вероятность мы создаем прогностическую модель, например, логистической регрессии или другую и пропускаем через нее всю выборку. После того как каждый пациент получил свою оценку, мы объединяем пациентов с одинаковыми оценками, что обеспечивает более сбалансированное сравнение. После сопоставления, группы лечения и контроля становятся более похожими друг на друга по наблюдаемым характеристикам. Это уменьшает смещение, гарантируя, что эффект, который мы видим, скорее всего обусловлен лечением, а не какими-то скрытыми различиями. Магия PSM не безгранична. Она уравновешивает только то, что видит. Если существует ненаблюдаемый фактор, влияющий на выбор лечения, PSM не может его учесть.
PSM часто используется в обсервационных исследованиях, когда мы не можем применять рандомизацию. По сути, PSM - наш инструмент статистического подбора, помогающий исследователям сравнивать подобное с подобным, даже если природа или дизайн не позволяют сделать это легко. PSM помогает сделать наши результаты надежными, релевантными и готовыми к использованию в реальном мире!
Кратко этапы проведения PSM при сравнении терапии А (контроль) и В (новая терапия):
1. Выбрать факторы (ковариаты), которые наиболее хорошо характеризуют профиль пациента в группе А (исторический контроль). Возраст, стадия и т.д.
2. Сделать модель, например, логистической регрессии, где в качестве зависимой переменной будет факт назначения терапии А (1 - терапия назначалась, 0 - не назначалась).
3. Применить модель в группе В, тем самым выбрав только тех пациентов, которые подошли бы к назначению терапии А, но получили терапию В.
4. Сравнить группы А и выбранных пациентов из группы В между собой по результатам терапии.
Золотым стандартом сравнительных исследований являются рандомизированные. В таком идеальном сценарии пациенты случайным образом распределяются по группам исследования (например, лечение против контроля). Случайность распределения обеспечивает сопоставимость групп. Однако во многих реальных исследованиях мы не имеем такой возможности. Поэтому PSM - наш спаситель!
"Оценка склонности" - вероятность того, что пациент попадет в ту или иную группу сравнения, например, получит лечение, который высчитывается на основе его наблюдаемых характеристик. Чтобы рассчитать эту вероятность мы создаем прогностическую модель, например, логистической регрессии или другую и пропускаем через нее всю выборку. После того как каждый пациент получил свою оценку, мы объединяем пациентов с одинаковыми оценками, что обеспечивает более сбалансированное сравнение. После сопоставления, группы лечения и контроля становятся более похожими друг на друга по наблюдаемым характеристикам. Это уменьшает смещение, гарантируя, что эффект, который мы видим, скорее всего обусловлен лечением, а не какими-то скрытыми различиями. Магия PSM не безгранична. Она уравновешивает только то, что видит. Если существует ненаблюдаемый фактор, влияющий на выбор лечения, PSM не может его учесть.
PSM часто используется в обсервационных исследованиях, когда мы не можем применять рандомизацию. По сути, PSM - наш инструмент статистического подбора, помогающий исследователям сравнивать подобное с подобным, даже если природа или дизайн не позволяют сделать это легко. PSM помогает сделать наши результаты надежными, релевантными и готовыми к использованию в реальном мире!
Кратко этапы проведения PSM при сравнении терапии А (контроль) и В (новая терапия):
1. Выбрать факторы (ковариаты), которые наиболее хорошо характеризуют профиль пациента в группе А (исторический контроль). Возраст, стадия и т.д.
2. Сделать модель, например, логистической регрессии, где в качестве зависимой переменной будет факт назначения терапии А (1 - терапия назначалась, 0 - не назначалась).
3. Применить модель в группе В, тем самым выбрав только тех пациентов, которые подошли бы к назначению терапии А, но получили терапию В.
4. Сравнить группы А и выбранных пациентов из группы В между собой по результатам терапии.
{kind=link}
Введение про обобщенные линейные модели (Generalized Linear Models (GLM))
GLM связывает зависимую переменную с факторами (ковариатами) посредством задаваемой функции. Модель допускает наличие у зависимой переменной распределения, отличающегося от нормального. Представьте себе, что вы пытаетесь приложить прямую линейку к кривой дорожке. Жизнь не всегда прямая, и данные тоже. GLM позволяет нам справиться с этими кривыми, это большое семейство регрессионных моделей с разными переменными отклика, решаемыми задачами и типами взаимосвязей. GLM помогают понять, какие факторы являются значимыми, а также предсказать результат. После применения GLM вы получаете коэффициенты. В общем виде каждый коэффициент показывает, насколько сильно тот или иной фактор влияет на результат. Положительный - увеличивает шансы, отрицательный - уменьшает. Величина коэффициента показывает силу влияния переменной на исход.
GLM могут быть нескольких видов:
Логистическая регрессия: прогнозирование бинарных исходов, таких как "ответит на лечение" или "не ответит".
Регрессия Пуассона: например, прогноз числа новых случаев заболевания в месяц.
Линейная регрессия: старая добрая классика, для линейно зависимых неперерывных данных.
Гамма-регрессия: применяется только для положительных непрерывных значений. В медицине гамма-регрессия может быть применена для моделирования затрат на здравоохранение, которые часто имеют положительный перекос из-за наличия большого числа случаев с низкими затратами и небольшого числа случаев с высокими затратами.
У GLM методов есть общие допущения:
✅ Правильная функция взаимосвязи, которая выбирается, основываясь на распределении наших данных
✅ Отсутствие мультиколлинеарности. Переменные-предикторы не должны быть сильно коррелировать связаны друг с другом.
✅ Отсутствие чрезмерной дисперсии. Для счетных данных, если дисперсия превышает среднее, это признак того, что нам необходимо скорректировать модель (возможно, использовать отрицательную биномиальную регрессию).
✅ Все наблюдения должны быть независимыми друг от друга.
GLM связывает зависимую переменную с факторами (ковариатами) посредством задаваемой функции. Модель допускает наличие у зависимой переменной распределения, отличающегося от нормального. Представьте себе, что вы пытаетесь приложить прямую линейку к кривой дорожке. Жизнь не всегда прямая, и данные тоже. GLM позволяет нам справиться с этими кривыми, это большое семейство регрессионных моделей с разными переменными отклика, решаемыми задачами и типами взаимосвязей. GLM помогают понять, какие факторы являются значимыми, а также предсказать результат. После применения GLM вы получаете коэффициенты. В общем виде каждый коэффициент показывает, насколько сильно тот или иной фактор влияет на результат. Положительный - увеличивает шансы, отрицательный - уменьшает. Величина коэффициента показывает силу влияния переменной на исход.
GLM могут быть нескольких видов:
Логистическая регрессия: прогнозирование бинарных исходов, таких как "ответит на лечение" или "не ответит".
Регрессия Пуассона: например, прогноз числа новых случаев заболевания в месяц.
Линейная регрессия: старая добрая классика, для линейно зависимых неперерывных данных.
Гамма-регрессия: применяется только для положительных непрерывных значений. В медицине гамма-регрессия может быть применена для моделирования затрат на здравоохранение, которые часто имеют положительный перекос из-за наличия большого числа случаев с низкими затратами и небольшого числа случаев с высокими затратами.
У GLM методов есть общие допущения:
✅ Правильная функция взаимосвязи, которая выбирается, основываясь на распределении наших данных
✅ Отсутствие мультиколлинеарности. Переменные-предикторы не должны быть сильно коррелировать связаны друг с другом.
✅ Отсутствие чрезмерной дисперсии. Для счетных данных, если дисперсия превышает среднее, это признак того, что нам необходимо скорректировать модель (возможно, использовать отрицательную биномиальную регрессию).
✅ Все наблюдения должны быть независимыми друг от друга.
{kind=link}
Про анализ мощности
Анализ мощности позволяет определить размер выборки, необходимый для исследования, и гарантировать, что он сможет надежно обнаружить эффект, если он существует. По сути, речь идет о том, чтобы обеспечить достаточное количество данных для обоснованных выводов. Если не выполнить анализ мощности, то можно не собрать достаточно данных, что приведет к неубедительным результатам и к ошибочным выводам.
Компоненты анализа мощности:
✅ Размер эффекта - величина различия, которое мы пытаемся обнаружить. Например, разница средних, отношение шансов и т.д.
✅ Размер выборки - количество наблюдений в исследовании.
✅ Уровень статистической значимости (α) - порог, при котором результат считается статистически значимым (как правило, 0.05).
✅ Собственно мощность (1-β) - вероятность правильного обнаружения эффекта (β - ошибка 2 рода, как правило, не более 0.2).
Через размер эффекта и уровень значимости и используя специальные формулы можно рассчитать:
✅ Необходимый размер выборки для исследования при заданной мощности.
✅ Мощность статистического теста при заданном размере выборки.
Ошибки:
✅ Преувеличение размера эффекта - принятие нового метода лечения за очень эффективный, в то время как он оказывает лишь незначительное воздействие, может привести к проведению исследований с недостаточной мощностью. Например, задавая больше, чем есть отношение шансов, можно получить меньший, чем требуется на самом деле размер выборки для исследования.
✅ Игнорирование анализа мощности - неполучение значимых результатов, там где они есть (повышение риска ошибки 2 рода).
✅ Опора исключительно на p-уровень значимости - даже если результат статистически значим, это не всегда означает, что он практически значим.
Анализ мощности позволяет определить размер выборки, необходимый для исследования, и гарантировать, что он сможет надежно обнаружить эффект, если он существует. По сути, речь идет о том, чтобы обеспечить достаточное количество данных для обоснованных выводов. Если не выполнить анализ мощности, то можно не собрать достаточно данных, что приведет к неубедительным результатам и к ошибочным выводам.
Компоненты анализа мощности:
✅ Размер эффекта - величина различия, которое мы пытаемся обнаружить. Например, разница средних, отношение шансов и т.д.
✅ Размер выборки - количество наблюдений в исследовании.
✅ Уровень статистической значимости (α) - порог, при котором результат считается статистически значимым (как правило, 0.05).
✅ Собственно мощность (1-β) - вероятность правильного обнаружения эффекта (β - ошибка 2 рода, как правило, не более 0.2).
Через размер эффекта и уровень значимости и используя специальные формулы можно рассчитать:
✅ Необходимый размер выборки для исследования при заданной мощности.
✅ Мощность статистического теста при заданном размере выборки.
Ошибки:
✅ Преувеличение размера эффекта - принятие нового метода лечения за очень эффективный, в то время как он оказывает лишь незначительное воздействие, может привести к проведению исследований с недостаточной мощностью. Например, задавая больше, чем есть отношение шансов, можно получить меньший, чем требуется на самом деле размер выборки для исследования.
✅ Игнорирование анализа мощности - неполучение значимых результатов, там где они есть (повышение риска ошибки 2 рода).
✅ Опора исключительно на p-уровень значимости - даже если результат статистически значим, это не всегда означает, что он практически значим.
👍2
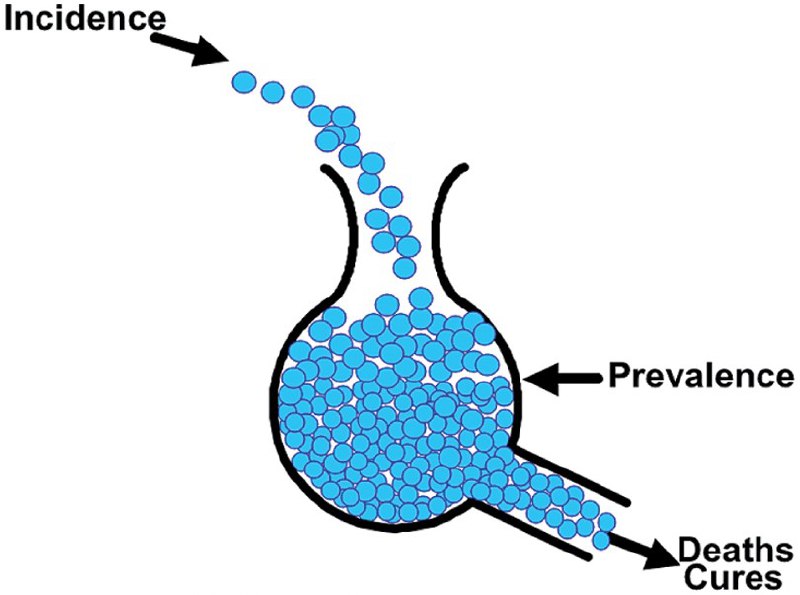
Про распространенность и заболеваемость
Распространенность и заболеваемость - два ключевых эпидемиологических показателя, используемых для изучения заболеваний.
📈 Распространенность - доля населения, у которого обнаружено состояние (например, заболевание) в определенный момент времени или за определенный период. Распространенность охватывает все случаи конкретного заболевания или состояния, имеющиеся в популяции в определенное время или за определенный период. Сюда входят как новые случаи (заболеваемость), так и уже существующие, которые еще не разрешились или привели к смерти. Например, общее число наблюдающихся больных на конец календарного года.
📉 Заболеваемость - число новых случаев заболевания в популяции в течение определенного периода времени. Она отражает скорость возникновения новых случаев заболевания. Заболеваемость учитывает только новые случаи, возникающие в популяции, подверженной риску, в течение определенного периода времени. Например, число новых случаев заболевания в течение года.
Факторы, влияющие на распространенность:
📌 Продолжительность заболевания: большая продолжительность заболевания увеличивает его распространенность.
📌 Заболеваемость: более высокий уровень заболеваемости увеличивает распространенность.
📌 Уровень излеченности: более высокая частота излечения снижает распространенность.
📌 Смертность: более высокая смертность снижает распространенность.
Факторы, влияющие на заболеваемость:
📌 Воздействие факторов риска: более высокий уровень риска увеличивает заболеваемость.
📌 Эффективность профилактических мер: более эффективная профилактика снижает заболеваемость.
📌 Динамика численности популяции: изменения в численности и структуре популяции влияют на заболеваемость, повышая или понижая ее.
Распространенность и заболеваемость - два ключевых эпидемиологических показателя, используемых для изучения заболеваний.
📈 Распространенность - доля населения, у которого обнаружено состояние (например, заболевание) в определенный момент времени или за определенный период. Распространенность охватывает все случаи конкретного заболевания или состояния, имеющиеся в популяции в определенное время или за определенный период. Сюда входят как новые случаи (заболеваемость), так и уже существующие, которые еще не разрешились или привели к смерти. Например, общее число наблюдающихся больных на конец календарного года.
📉 Заболеваемость - число новых случаев заболевания в популяции в течение определенного периода времени. Она отражает скорость возникновения новых случаев заболевания. Заболеваемость учитывает только новые случаи, возникающие в популяции, подверженной риску, в течение определенного периода времени. Например, число новых случаев заболевания в течение года.
Факторы, влияющие на распространенность:
📌 Продолжительность заболевания: большая продолжительность заболевания увеличивает его распространенность.
📌 Заболеваемость: более высокий уровень заболеваемости увеличивает распространенность.
📌 Уровень излеченности: более высокая частота излечения снижает распространенность.
📌 Смертность: более высокая смертность снижает распространенность.
Факторы, влияющие на заболеваемость:
📌 Воздействие факторов риска: более высокий уровень риска увеличивает заболеваемость.
📌 Эффективность профилактических мер: более эффективная профилактика снижает заболеваемость.
📌 Динамика численности популяции: изменения в численности и структуре популяции влияют на заболеваемость, повышая или понижая ее.
{kind=link}
👍1
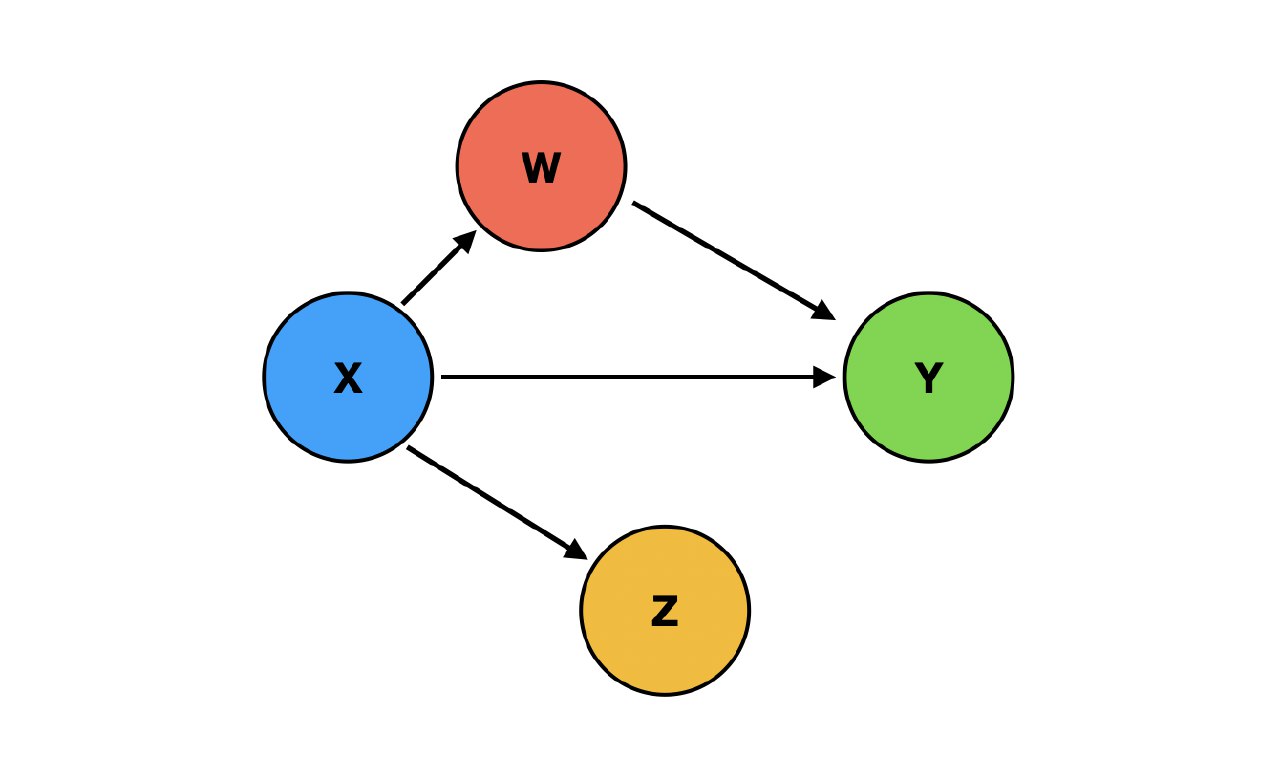
Про причинно-следственный вывод (causal inference)
Причинно-следственный вывод - основополагающий принцип, лежащий в основе всех логических и философских рассуждений. Именно на его основании строится принятие решений в жизни, в том числе и в медицине. Вся диагностика и лечение больных основывается на причинно-следственном выводе. Проблема заключается в том, что статистический вывод не равно причинно-следственный вывод. Ни один метод статистического анализа не говорит об абсолютности причинно-следственной связи между явлениями, а лишь позволяет найти некие математические закономерности и ассоциации. Окончательное решение принимает исследователь. Тем не менее, в статистике существуют ряд подходов, чтобы сделать вывод о причинно-следственной взаимосвязи между явлениями было проще.
Рандомизированное контролируемое исследование (РКИ). Считается золотым стандартом для вывода о причинно-следственных связях, когда люди случайным образом распределяются по различным группам и наблюдается эффект от лечения.
Инструментальные переменные. В этом методе используется экзогенная переменная, которая не зависит от предикторной переменной и влияет на переменную результата только через предикторную переменную. Инструментальная переменная - переменная, которая коррелирует с эндогенной независимой переменной, но не связана напрямую с зависимой переменной. Она выступает в качестве "моста" между эндогенной переменной и членом ошибки, помогая изолировать причинный эффект независимой переменной на зависимую переменную (решить проблему эндогенности). При ее введении статистическая связь между зависимой и независимой переменной исчезает или сильно обслабевает в случае отсуствия истинной причинно-следственной связи.
Метод сопоставления оценок склонности
Проведение естественных экспериментов - дизайн исследования, в которой используются естественно возникающие события или обстоятельства для приближения к условиям контролируемого эксперимента. В естественном эксперименте исследователи используют ситуации, когда определенные условия или события имитируют случайное распределение участников по различным группам, аналогичное тому, что происходит в контролируемом эксперименте. Это позволяет исследователям изучать влияние определенной переменной или метода лечения на результат в реальных условиях. Однако, здесь следует учитывать риск bias
Контрфактический анализ, также известный как контрфактическое рассуждение или контрфактическое мышление, является фундаментальной концепцией в области причинных умозаключений и рассуждений. Он предполагает рассмотрение того, что произошло бы, если бы определенное событие, действие или условие не произошло или если бы был сделан другой выбор. Другими словами, контрфактический анализ позволяет исследовать сценарии "что-если", в которых прошлое развивалось бы по-другому. Это способ сравнения фактических результатов с гипотетическими, которые могли бы произойти при других обстоятельствах. Это не статистический тест! По сути, контрфактический анализ помогает исследователям сформулировать гипотезы о причинно-следственных связях, а статистические методы - проверить и количественно оценить эти гипотезы на основе данных. Сочетание контрфактического анализа и статистических методов позволяет исследователям делать значимые выводы о причинно-следственных связях в сложных реальных ситуациях.
Структурные причинно-следственные модели, известные также как причинно-следственные графические модели (диаграммы) или моделирование структурными уравнениями, представляют собой формальные схемы, используемые для представления и анализа причинно-следственных связей между переменными. Эти модели помогают исследователям понять, как переменные взаимодействуют и влияют друг на друга в сложных системах. Это не статистический тест сам по себе. Они позволяют концептуально и наглядно представить, как переменные взаимодействуют и влияют друг на друга в системе.
Больше информации здесь
Причинно-следственный вывод - основополагающий принцип, лежащий в основе всех логических и философских рассуждений. Именно на его основании строится принятие решений в жизни, в том числе и в медицине. Вся диагностика и лечение больных основывается на причинно-следственном выводе. Проблема заключается в том, что статистический вывод не равно причинно-следственный вывод. Ни один метод статистического анализа не говорит об абсолютности причинно-следственной связи между явлениями, а лишь позволяет найти некие математические закономерности и ассоциации. Окончательное решение принимает исследователь. Тем не менее, в статистике существуют ряд подходов, чтобы сделать вывод о причинно-следственной взаимосвязи между явлениями было проще.
Рандомизированное контролируемое исследование (РКИ). Считается золотым стандартом для вывода о причинно-следственных связях, когда люди случайным образом распределяются по различным группам и наблюдается эффект от лечения.
Инструментальные переменные. В этом методе используется экзогенная переменная, которая не зависит от предикторной переменной и влияет на переменную результата только через предикторную переменную. Инструментальная переменная - переменная, которая коррелирует с эндогенной независимой переменной, но не связана напрямую с зависимой переменной. Она выступает в качестве "моста" между эндогенной переменной и членом ошибки, помогая изолировать причинный эффект независимой переменной на зависимую переменную (решить проблему эндогенности). При ее введении статистическая связь между зависимой и независимой переменной исчезает или сильно обслабевает в случае отсуствия истинной причинно-следственной связи.
Метод сопоставления оценок склонности
Проведение естественных экспериментов - дизайн исследования, в которой используются естественно возникающие события или обстоятельства для приближения к условиям контролируемого эксперимента. В естественном эксперименте исследователи используют ситуации, когда определенные условия или события имитируют случайное распределение участников по различным группам, аналогичное тому, что происходит в контролируемом эксперименте. Это позволяет исследователям изучать влияние определенной переменной или метода лечения на результат в реальных условиях. Однако, здесь следует учитывать риск bias
Контрфактический анализ, также известный как контрфактическое рассуждение или контрфактическое мышление, является фундаментальной концепцией в области причинных умозаключений и рассуждений. Он предполагает рассмотрение того, что произошло бы, если бы определенное событие, действие или условие не произошло или если бы был сделан другой выбор. Другими словами, контрфактический анализ позволяет исследовать сценарии "что-если", в которых прошлое развивалось бы по-другому. Это способ сравнения фактических результатов с гипотетическими, которые могли бы произойти при других обстоятельствах. Это не статистический тест! По сути, контрфактический анализ помогает исследователям сформулировать гипотезы о причинно-следственных связях, а статистические методы - проверить и количественно оценить эти гипотезы на основе данных. Сочетание контрфактического анализа и статистических методов позволяет исследователям делать значимые выводы о причинно-следственных связях в сложных реальных ситуациях.
Структурные причинно-следственные модели, известные также как причинно-следственные графические модели (диаграммы) или моделирование структурными уравнениями, представляют собой формальные схемы, используемые для представления и анализа причинно-следственных связей между переменными. Эти модели помогают исследователям понять, как переменные взаимодействуют и влияют друг на друга в сложных системах. Это не статистический тест сам по себе. Они позволяют концептуально и наглядно представить, как переменные взаимодействуют и влияют друг на друга в системе.
Больше информации здесь
{kind=link}
Про мета-анализ
Мета-анализ - метод, объединяющий результаты нескольких исследований по схожей теме для получения более надежного заключения. Это похоже на объединение знаний, полученных в разных местах, для получения более четкой картины.
Отдельные исследования часто имеют небольшой объем выборки и могут показывать разные результаты. Мета-анализ повышает мощность и точность оценки за счет объединения данных нескольких исследований. Первым шагом является постановка научной гипотезы. Необходимо четко сформулировать, что именно вы хотите узнать. Далее проводится поиск всех исследований, которые могут ответить на поставленный вопрос. Для этого необходимо просмотреть опубликованные статьи, доклады на конференциях и даже препринты. Теперь необходимо решить, какие исследования включить в мета-анализ. Нельзя включать все подряд! Исследования должны быть достаточно похожими и качественными. Чтобы быть уверенным в объективности, необходимо заранее установить критерии для этого. Получив результаты исследований, проводится извлечение из них необходимых данных. Это может быть размер эффекта, размер выборки и другая необходимая информация. Наконец, проводится статистический анализ. С помощью статистических методов результаты всех исследований объединяются в единую оценку эффекта.
Существуют различные модели объединения результатов. Модель с "фиксированным эффектом" предполагает, что существует один истинный размер эффекта, который одинаков во всех исследованиях. Модель "случайных эффектов" предполагает, что истинный эффект может варьироваться от исследования к исследованию.
Однако мета-анализ имеет свои недостатки. Например, он подвержен влиянию предвзятости (bias) публикации - тенденции к тому, что исследования с положительными результатами чаще публикуются. Это может привести к переоценке эффекта. Кроме того, качество мета-анализа зависит только от качества включенных в него исследований. Если исходные исследования имеют недостатки, то эти недостатки будут перенесены в мета-анализ и исказить обобщенный результат.
Мета-анализ - метод, объединяющий результаты нескольких исследований по схожей теме для получения более надежного заключения. Это похоже на объединение знаний, полученных в разных местах, для получения более четкой картины.
Отдельные исследования часто имеют небольшой объем выборки и могут показывать разные результаты. Мета-анализ повышает мощность и точность оценки за счет объединения данных нескольких исследований. Первым шагом является постановка научной гипотезы. Необходимо четко сформулировать, что именно вы хотите узнать. Далее проводится поиск всех исследований, которые могут ответить на поставленный вопрос. Для этого необходимо просмотреть опубликованные статьи, доклады на конференциях и даже препринты. Теперь необходимо решить, какие исследования включить в мета-анализ. Нельзя включать все подряд! Исследования должны быть достаточно похожими и качественными. Чтобы быть уверенным в объективности, необходимо заранее установить критерии для этого. Получив результаты исследований, проводится извлечение из них необходимых данных. Это может быть размер эффекта, размер выборки и другая необходимая информация. Наконец, проводится статистический анализ. С помощью статистических методов результаты всех исследований объединяются в единую оценку эффекта.
Существуют различные модели объединения результатов. Модель с "фиксированным эффектом" предполагает, что существует один истинный размер эффекта, который одинаков во всех исследованиях. Модель "случайных эффектов" предполагает, что истинный эффект может варьироваться от исследования к исследованию.
Однако мета-анализ имеет свои недостатки. Например, он подвержен влиянию предвзятости (bias) публикации - тенденции к тому, что исследования с положительными результатами чаще публикуются. Это может привести к переоценке эффекта. Кроме того, качество мета-анализа зависит только от качества включенных в него исследований. Если исходные исследования имеют недостатки, то эти недостатки будут перенесены в мета-анализ и исказить обобщенный результат.
👍1
Еще раз про ROC-анализ
ROC-анализ является фундаментальным инструментом для оценки эффективности моделей классификации. Он помогает нам понять, насколько хорошо наша модель может различать два класса, например, больной или здоровый пациент. ROC расшифровывается как Receiver Operating Characteristic. Это графическое представление, которое показывает диагностическую способность бинарного классификатора при изменении порога принятия решения. По сути, это помогает нам наглядно увидеть компромисс между чувствительностью и специфичностью.
На ROC-кривой по оси Y откладывается частота истинно положительных результатов (чувствительность), а по оси X - частота ложноположительных результатов (1-специфичность). Чувствительность - способность теста правильно идентифицировать людей с заболеванием (истинно положительный результат), а специфичность - способность теста правильно идентифицировать людей без заболевания (истинно отрицательный результат). ROC-кривая строится путем построения графика зависимости частоты истинно положительных результатов (TPR) от частоты ложноположительных результатов (FPR) путем перебора различных пороговых значений. Порог - значение, при превышении которого мы относим результат к положительному классу, а при понижении - к отрицательному.
Идеальный результат теста имеет точку в левом верхнем углу ROC-пространства (100% чувствительность, 100% специфичность), то есть он правильно определяет все положительные и отрицательные случаи. Бесполезная модель, не обладающая способностью к предсказанию класса, будет представлять собой 45-градусную диагональную линию от левого нижнего угла до правого верхнего. Площадь под ROC-кривой (AUC) - единое число, которое отражает общую эффективность диагностического теста (модели). AUC = 1.0 означает идеальный тест, а AUC = 0.5 - бесполезный тест. По сути, это количественная оценка общей способности модели различать положительные и отрицательные случаи. Важно отметить, что величина AUC не равна истинной точности модели, а является гипотетической точностью, по сути правдоподобием.
Выбор оптимальной точки отсечения с одной стороны важен, с другой несет в себе ряд проблем. Это точка, которая позволяет сбалансировать чувствительность и специфичность таким образом, чтобы это было целесообразно в конкретной клинической ситуации. Высокая точка отсечения может привести к меньшему количеству ложноположительных, но большему количеству ложноотрицательных результатов, и наоборот.
ROC-анализ является фундаментальным инструментом для оценки эффективности моделей классификации. Он помогает нам понять, насколько хорошо наша модель может различать два класса, например, больной или здоровый пациент. ROC расшифровывается как Receiver Operating Characteristic. Это графическое представление, которое показывает диагностическую способность бинарного классификатора при изменении порога принятия решения. По сути, это помогает нам наглядно увидеть компромисс между чувствительностью и специфичностью.
На ROC-кривой по оси Y откладывается частота истинно положительных результатов (чувствительность), а по оси X - частота ложноположительных результатов (1-специфичность). Чувствительность - способность теста правильно идентифицировать людей с заболеванием (истинно положительный результат), а специфичность - способность теста правильно идентифицировать людей без заболевания (истинно отрицательный результат). ROC-кривая строится путем построения графика зависимости частоты истинно положительных результатов (TPR) от частоты ложноположительных результатов (FPR) путем перебора различных пороговых значений. Порог - значение, при превышении которого мы относим результат к положительному классу, а при понижении - к отрицательному.
Идеальный результат теста имеет точку в левом верхнем углу ROC-пространства (100% чувствительность, 100% специфичность), то есть он правильно определяет все положительные и отрицательные случаи. Бесполезная модель, не обладающая способностью к предсказанию класса, будет представлять собой 45-градусную диагональную линию от левого нижнего угла до правого верхнего. Площадь под ROC-кривой (AUC) - единое число, которое отражает общую эффективность диагностического теста (модели). AUC = 1.0 означает идеальный тест, а AUC = 0.5 - бесполезный тест. По сути, это количественная оценка общей способности модели различать положительные и отрицательные случаи. Важно отметить, что величина AUC не равна истинной точности модели, а является гипотетической точностью, по сути правдоподобием.
Выбор оптимальной точки отсечения с одной стороны важен, с другой несет в себе ряд проблем. Это точка, которая позволяет сбалансировать чувствительность и специфичность таким образом, чтобы это было целесообразно в конкретной клинической ситуации. Высокая точка отсечения может привести к меньшему количеству ложноположительных, но большему количеству ложноотрицательных результатов, и наоборот.
{kind=link}
🔥1
Про доверительные интервалы
Представьте, что врач хочет определить среднее артериальное давление для всех взрослых. Измерить всех пациентов не представляется возможным, поэтому он берет выборку из 100 взрослых и рассчитывает, что среднее артериальное давление составляет 120 мм рт.ст. Врач знает, что это всего лишь оценка, и если он возьмет другую выборку, то может получить другое среднее значение. Чтобы количественно выразить данную неопределенность и существует доверительный интервал (ДИ). ДИ - диапазон значений, полученный на основе данных выборки, который, скорее всего, содержит истинное значение неизвестного параметра популяции. Например, врач может сказать, что он на 95% уверен в том, что среднее артериальное давление у всех взрослых находится в диапазоне от 118 до 122 мм рт.ст. Это и есть 95%-ный доверительный интервал.
Для расчета 95%-ного доверительного интервала используется среднее значение выборки (среднее) +|- 1.96 x (стандартное отклонение / √(размер выборки)). Величина 1.96 обусловлена тем, что 95% площади под кривой нормального распределения лежит в пределах 1.96 стандартных отклонений от среднего значения. Таким образом, если в выборке нашего врача стандартное отклонение составляет 10 мм рт.ст., то 95%-ный ДИ будет равен 120 +|- 1.96 x (10/√(100)) = от 118 до 122 мм рт.ст.
Интерпретация является ключевым моментом. Выражение "Я на 95% уверен, что среднее артериальное давление находится в диапазоне от 118 до 122 мм рт.ст." НЕ означает, что вероятность того, что истинное среднее значение находится в этом диапазоне, составляет 95%. Напротив, это означает, что если взять множество выборок и рассчитать 95% ДИ для каждой из них, то около 95% этих интервалов будут содержать истинное среднее артериальное давление в диапазоне от 118 до 122 мм рт.ст. А в 5% экспериментов среднее АД в популяции будет выходить за данные лимиты. Однако мы не знаем точного значения среднего АД, поскольку работаем с выборочными данными, а интервал дает нам возможность предположить, в каком диапазоне может находиться среднее АД. Также мы не знаем истинной вероятности того, что среднее АД будет находиться в данном интервале.
Обычно используется 95% ДИ, но в некоторых случаях может потребоваться более высокий или более низкий уровень. Например, если последствия ошибки очень серьезны, можно выбрать более высокий уровень доверия, например 99%.
✅ Расчет ДИ для оценки дает полезную информацию, даже если он не сообщает прямой информации о вероятности того, что истинное значение попадает в этот интервал. Это лучше, чем просто точечная оценка, поскольку дает диапазон значений, которые согласуются с данными.
✅ ДИ позволяет сравнивать различные оценки. Например, если ДИ эффективности двух методов лечения не пересекаются, это говорит о том, что один метод лечения может быть лучше другого.
✅ ДИ могут использоваться для проверки гипотез. Если 95%-ный ДИ для разницы между двумя группами не включает ноль, это говорит о наличии статистически значимой разницы при уровне 0.05.
✅ Практическая значимость. Малый ДИ предполагает наличие точной оценки, которая может быть очень ценной в процессе принятия решений.
✅ Зная максимальное и минимальное значения выборки, можно получить диапазон всех наблюдаемых данных, но этот диапазон может оказаться не очень хорошей оценкой истинного параметра популяции. Например, если вы измеряете артериальное давление у 100 взрослых, то наименьшее и наибольшее значения дадут вам диапазон артериального давления в вашей выборке, но это мало что скажет вам о среднем артериальном давлении в популяции в целом. ДИ, напротив, дают диапазон правдоподобных значений популяционного параметра, основанный на данных выборки. Это может быть гораздо более информативным для принятия решений или выводов о популяции.
Представьте, что врач хочет определить среднее артериальное давление для всех взрослых. Измерить всех пациентов не представляется возможным, поэтому он берет выборку из 100 взрослых и рассчитывает, что среднее артериальное давление составляет 120 мм рт.ст. Врач знает, что это всего лишь оценка, и если он возьмет другую выборку, то может получить другое среднее значение. Чтобы количественно выразить данную неопределенность и существует доверительный интервал (ДИ). ДИ - диапазон значений, полученный на основе данных выборки, который, скорее всего, содержит истинное значение неизвестного параметра популяции. Например, врач может сказать, что он на 95% уверен в том, что среднее артериальное давление у всех взрослых находится в диапазоне от 118 до 122 мм рт.ст. Это и есть 95%-ный доверительный интервал.
Для расчета 95%-ного доверительного интервала используется среднее значение выборки (среднее) +|- 1.96 x (стандартное отклонение / √(размер выборки)). Величина 1.96 обусловлена тем, что 95% площади под кривой нормального распределения лежит в пределах 1.96 стандартных отклонений от среднего значения. Таким образом, если в выборке нашего врача стандартное отклонение составляет 10 мм рт.ст., то 95%-ный ДИ будет равен 120 +|- 1.96 x (10/√(100)) = от 118 до 122 мм рт.ст.
Интерпретация является ключевым моментом. Выражение "Я на 95% уверен, что среднее артериальное давление находится в диапазоне от 118 до 122 мм рт.ст." НЕ означает, что вероятность того, что истинное среднее значение находится в этом диапазоне, составляет 95%. Напротив, это означает, что если взять множество выборок и рассчитать 95% ДИ для каждой из них, то около 95% этих интервалов будут содержать истинное среднее артериальное давление в диапазоне от 118 до 122 мм рт.ст. А в 5% экспериментов среднее АД в популяции будет выходить за данные лимиты. Однако мы не знаем точного значения среднего АД, поскольку работаем с выборочными данными, а интервал дает нам возможность предположить, в каком диапазоне может находиться среднее АД. Также мы не знаем истинной вероятности того, что среднее АД будет находиться в данном интервале.
Обычно используется 95% ДИ, но в некоторых случаях может потребоваться более высокий или более низкий уровень. Например, если последствия ошибки очень серьезны, можно выбрать более высокий уровень доверия, например 99%.
✅ Расчет ДИ для оценки дает полезную информацию, даже если он не сообщает прямой информации о вероятности того, что истинное значение попадает в этот интервал. Это лучше, чем просто точечная оценка, поскольку дает диапазон значений, которые согласуются с данными.
✅ ДИ позволяет сравнивать различные оценки. Например, если ДИ эффективности двух методов лечения не пересекаются, это говорит о том, что один метод лечения может быть лучше другого.
✅ ДИ могут использоваться для проверки гипотез. Если 95%-ный ДИ для разницы между двумя группами не включает ноль, это говорит о наличии статистически значимой разницы при уровне 0.05.
✅ Практическая значимость. Малый ДИ предполагает наличие точной оценки, которая может быть очень ценной в процессе принятия решений.
✅ Зная максимальное и минимальное значения выборки, можно получить диапазон всех наблюдаемых данных, но этот диапазон может оказаться не очень хорошей оценкой истинного параметра популяции. Например, если вы измеряете артериальное давление у 100 взрослых, то наименьшее и наибольшее значения дадут вам диапазон артериального давления в вашей выборке, но это мало что скажет вам о среднем артериальном давлении в популяции в целом. ДИ, напротив, дают диапазон правдоподобных значений популяционного параметра, основанный на данных выборки. Это может быть гораздо более информативным для принятия решений или выводов о популяции.
{kind=link}
❤1
Про многофакторный анализ
Большинство реальных проблем включает в себя несколько переменных, влияющих на результат. В однофакторном анализе рассматривается одна переменная, в многофакторном - две или более переменных одновременно. В реальной жизни переменные часто взаимодействуют друг с другом сложным образом. Многофакторный анализ помогает выявить эти взаимодействия и понять взаимосвязь между ними. Например, у любого пациента кроме изучаемого вами фактора как минимум есть еще пол и возраст, которые могут влиять на изучаемый исход.
Преимущества многофакторного анализа
✅ Многофакторный анализ позволяет контролировать сбивающие переменные, т.е. внешние переменные, которые могут влиять как на другие факторы, так и на зависимые переменные, что приводит к неверным выводам.
✅ Благодаря учету нескольких переменных многофакторный анализ часто приводит к созданию моделей с большей предсказательной силой и точностью по сравнению с однофакторными моделями.
✅ Выполнение нескольких однофакторных тестов повышает риск ошибки первого типа (ложноположительных результатов).
✅ Многофакторный анализ учитывает все переменные одновременно, что снижает этот риск.
✅ Многофакторный анализ позволяет получить более полное представление о взаимосвязях между переменными, что очень важно для принятия обоснованных решений и разработки эффективных стратегий.
Большинство реальных проблем включает в себя несколько переменных, влияющих на результат. В однофакторном анализе рассматривается одна переменная, в многофакторном - две или более переменных одновременно. В реальной жизни переменные часто взаимодействуют друг с другом сложным образом. Многофакторный анализ помогает выявить эти взаимодействия и понять взаимосвязь между ними. Например, у любого пациента кроме изучаемого вами фактора как минимум есть еще пол и возраст, которые могут влиять на изучаемый исход.
Преимущества многофакторного анализа
✅ Многофакторный анализ позволяет контролировать сбивающие переменные, т.е. внешние переменные, которые могут влиять как на другие факторы, так и на зависимые переменные, что приводит к неверным выводам.
✅ Благодаря учету нескольких переменных многофакторный анализ часто приводит к созданию моделей с большей предсказательной силой и точностью по сравнению с однофакторными моделями.
✅ Выполнение нескольких однофакторных тестов повышает риск ошибки первого типа (ложноположительных результатов).
✅ Многофакторный анализ учитывает все переменные одновременно, что снижает этот риск.
✅ Многофакторный анализ позволяет получить более полное представление о взаимосвязях между переменными, что очень важно для принятия обоснованных решений и разработки эффективных стратегий.
Telegram
статИИстик
Что такое конфаундеры (спутывающие/сбивающие факторы в исследованиях)
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать…
Про центральную предельную теорему
Центральная предельная теорема (ЦПТ) утверждает, что распределение среднего значения достаточно большой выборки, независимо от распределения самой генеральной совокупности, будет стремиться к нормальному распределению. В результате, даже если базовая совокупность не является нормально распределенной, распределение выборочных средних будет становиться приблизительно нормальным по мере увеличения объема выборки. Другими словами, если мы будем формировать случайные выборки из общей совокупности данных и находить в них средние значения, то по мере роста числа таких выборок их средние будут нормально распределяться. При этом распределение генеральной совокупности может быть любым.
ЦПТ позволяет делать выводы о параметрах популяции на основе выборочных данных. Поскольку многие статистические тесты предполагают нормальность, ЦПТ дает нам основу для применения этих тестов даже в тех случаях, когда базовая совокупность не является нормально распределенной. Например, это относится к t-тесту Стьюдента. t-тест можно использовать и без предположения об абсолютно нормальном распределении, особенно если объем выборки достаточно велик. Благодаря ЦПТ t-тест устойчив к отклонениям от нормальности, особенно при достаточно большом объеме выборки, обычно около 30 или более наблюдений в каждой группе. Однако это эмпирическое правило, а не абсолютная граница. В некоторых случаях даже меньший объем выборки может дать приемлемые результаты, в то время как в других случаях может потребоваться больший объем выборки.
Центральная предельная теорема (ЦПТ) утверждает, что распределение среднего значения достаточно большой выборки, независимо от распределения самой генеральной совокупности, будет стремиться к нормальному распределению. В результате, даже если базовая совокупность не является нормально распределенной, распределение выборочных средних будет становиться приблизительно нормальным по мере увеличения объема выборки. Другими словами, если мы будем формировать случайные выборки из общей совокупности данных и находить в них средние значения, то по мере роста числа таких выборок их средние будут нормально распределяться. При этом распределение генеральной совокупности может быть любым.
ЦПТ позволяет делать выводы о параметрах популяции на основе выборочных данных. Поскольку многие статистические тесты предполагают нормальность, ЦПТ дает нам основу для применения этих тестов даже в тех случаях, когда базовая совокупность не является нормально распределенной. Например, это относится к t-тесту Стьюдента. t-тест можно использовать и без предположения об абсолютно нормальном распределении, особенно если объем выборки достаточно велик. Благодаря ЦПТ t-тест устойчив к отклонениям от нормальности, особенно при достаточно большом объеме выборки, обычно около 30 или более наблюдений в каждой группе. Однако это эмпирическое правило, а не абсолютная граница. В некоторых случаях даже меньший объем выборки может дать приемлемые результаты, в то время как в других случаях может потребоваться больший объем выборки.
{kind=link}
Про выбор наилучшего подмножества (Best Subset Selection, BSS)
BSS - метод, целью которого является найти подмножество независимых переменных (X), которые лучше всего предсказывают результат (Y), и он делает это путем рассмотрения всех возможных комбинаций независимых переменных. Другими словами это перебор всех возможных комбинаций предикторов, для поиска наиболее оптимальной из них с целью получения наиболее эффективной прогностической модели.
Этапы BSS при k независимых переменных:
1. Анализ эффективности всех возможных моделей с 1 переменной, 2 переменными,..., k переменными.
2. Выбираем лучшую модель размера 1, лучшую модель размера 2, ..., лучшую модель размера k методом перекрестной проверки.
3. Наконец , из этих финалистов выбираем лучшую модель в целом.
📌 Выбор наилучшей модели осуществляется из 2 в степени k возможных моделей.
📌 Выбор лучшей модели осуществляется по известным метрикам, например, по AIC, BIC и скорректированному R2.
📌 Выбор лучшей модели по показателям RSS (сумма квадратов остатков) и нескорректированному R2 возможно только на шаге 1, так как модель с бОльшим числом переменных всегда будет иметь наименьший показатель RSS и самый высокий R2.
Преимущества метода:
📌 "Золотой стандарт" выбора предикторов в модель, который позволяет нам определить наилучшую возможную модель, поскольку мы рассматриваем все комбинации переменных-предикторов.
Недостатки метода:
📌 Вычислительное ограничение: количество возможных моделей, которые должен учитывать алгоритм подмножества, растет экспоненциально с количеством рассматриваемых предикторов. Для 20 предикторов 2^20 = 1 048 576 моделей!
📌 Выбор из тысяч, даже миллионов моделей можно рассматривать как р-хакинг, поскольку одна модель может случайно выглядеть лучше и в конечном итоге оказаться неэффективной, когда мы попытаемся проверить ее на новых данных.
BSS - метод, целью которого является найти подмножество независимых переменных (X), которые лучше всего предсказывают результат (Y), и он делает это путем рассмотрения всех возможных комбинаций независимых переменных. Другими словами это перебор всех возможных комбинаций предикторов, для поиска наиболее оптимальной из них с целью получения наиболее эффективной прогностической модели.
Этапы BSS при k независимых переменных:
1. Анализ эффективности всех возможных моделей с 1 переменной, 2 переменными,..., k переменными.
2. Выбираем лучшую модель размера 1, лучшую модель размера 2, ..., лучшую модель размера k методом перекрестной проверки.
3. Наконец , из этих финалистов выбираем лучшую модель в целом.
📌 Выбор наилучшей модели осуществляется из 2 в степени k возможных моделей.
📌 Выбор лучшей модели осуществляется по известным метрикам, например, по AIC, BIC и скорректированному R2.
📌 Выбор лучшей модели по показателям RSS (сумма квадратов остатков) и нескорректированному R2 возможно только на шаге 1, так как модель с бОльшим числом переменных всегда будет иметь наименьший показатель RSS и самый высокий R2.
Преимущества метода:
📌 "Золотой стандарт" выбора предикторов в модель, который позволяет нам определить наилучшую возможную модель, поскольку мы рассматриваем все комбинации переменных-предикторов.
Недостатки метода:
📌 Вычислительное ограничение: количество возможных моделей, которые должен учитывать алгоритм подмножества, растет экспоненциально с количеством рассматриваемых предикторов. Для 20 предикторов 2^20 = 1 048 576 моделей!
📌 Выбор из тысяч, даже миллионов моделей можно рассматривать как р-хакинг, поскольку одна модель может случайно выглядеть лучше и в конечном итоге оказаться неэффективной, когда мы попытаемся проверить ее на новых данных.
{kind=link}
Вредные советы в статистике. Выполните однофакторный анализ перед многофакторным, чтобы выбрать предикторы
Данный подход на сегодняшний день считается устаревшим и неэффективным потому что:
📌 Выбор предикторов осуществляется на основании множества однофакторных тестов с риском случайной ошибки при выполнении каждого из них, величина которой накапливается.
📌 Присутствует риск ошибки 1 рода.
📌 В однофакторном анализе не учитывается как прогностически значимое, так и спутывающее влияние одних переменных на другие, не учитываются нелинейные взаимосвязи между предикторами.
В итоге во многофакторный анализ не попадают нужные или попадают ненужные переменные, в том числе конфаундеры. Многофакторная модель необязательно должна
включать в себя только статистически значимые предикторы, поэтому стремление выбрать только их лишено смысла.
Как следует решать проблему большого числа предикторов при построении модели
✅ Проблема возникает в случае одновременно недостаточного количества данных и/или при желании сделать модель более простой. При достаточном количестве данных в изначальную модель следует включать все возможные предикторы, по которым собрана информация. Селекцию нужно начинать с ручного удаления тех из них, которые являются лишними с позиции логических рассуждений и знаний в данной предметной области. Машинные методы используются в том случае, когда эмпирического подхода становится недостаточно.
✅ Используйте метод выбора наилучшего подмножества (BSS)
✅ Используйте метод пошаговой регрессии (forward|backward)
✅ Используйте регрессии со штрафными коэффициентами (LASSO, Enet и др.)
✅ Используйте методы снижения размерности данных (например, метод главных компонент). В этом случае модель скорее всего станет "черным ящиком", но нам же главное результат ее эффективности.
Данный подход на сегодняшний день считается устаревшим и неэффективным потому что:
📌 Выбор предикторов осуществляется на основании множества однофакторных тестов с риском случайной ошибки при выполнении каждого из них, величина которой накапливается.
📌 Присутствует риск ошибки 1 рода.
📌 В однофакторном анализе не учитывается как прогностически значимое, так и спутывающее влияние одних переменных на другие, не учитываются нелинейные взаимосвязи между предикторами.
В итоге во многофакторный анализ не попадают нужные или попадают ненужные переменные, в том числе конфаундеры. Многофакторная модель необязательно должна
включать в себя только статистически значимые предикторы, поэтому стремление выбрать только их лишено смысла.
Как следует решать проблему большого числа предикторов при построении модели
✅ Проблема возникает в случае одновременно недостаточного количества данных и/или при желании сделать модель более простой. При достаточном количестве данных в изначальную модель следует включать все возможные предикторы, по которым собрана информация. Селекцию нужно начинать с ручного удаления тех из них, которые являются лишними с позиции логических рассуждений и знаний в данной предметной области. Машинные методы используются в том случае, когда эмпирического подхода становится недостаточно.
✅ Используйте метод выбора наилучшего подмножества (BSS)
✅ Используйте метод пошаговой регрессии (forward|backward)
✅ Используйте регрессии со штрафными коэффициентами (LASSO, Enet и др.)
✅ Используйте методы снижения размерности данных (например, метод главных компонент). В этом случае модель скорее всего станет "черным ящиком", но нам же главное результат ее эффективности.