
Вычисление размера выборки для оценки пропорции.
Предположим, что мы хотим оценить распространенность (частоту встречаемости) некоего заболевания среди взрослого населения чтобы 95% доверительный интервал (d) был шириной 0.1 (10%), т.е. 5% в обе стороны от доли заболевания в популяции.
1. Задайте ожидаемую долю заболевания в популяции (p), например, p=0.1 (10%). Ее можно предположить или взять из других исследований (литературы). Если никакие варианты не подходят, используйте p=0.5.
2. Воспользйтесь формулой: 1.96^2 x 4p x (1-p) / d^2 = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.1^2 = 138 пациентов.
Если мы удвоим точность измерения сузив ДИ до 0.05 (5%), то N = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.05^2 = 553 пациента.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4p x (1-p) / d^2
90% ДИ: N = 1.64^2 x 4p x (1-p) / d^2
99% ДИ: N = 2.58^2 x 4p x (1-p) / d^2
❗ Правда более классическая формула не включает в себя множитель "4", 95% ДИ: N = 1.96^2 x p x (1-p) / d^2. Калькулятор
Предположим, что мы хотим оценить распространенность (частоту встречаемости) некоего заболевания среди взрослого населения чтобы 95% доверительный интервал (d) был шириной 0.1 (10%), т.е. 5% в обе стороны от доли заболевания в популяции.
1. Задайте ожидаемую долю заболевания в популяции (p), например, p=0.1 (10%). Ее можно предположить или взять из других исследований (литературы). Если никакие варианты не подходят, используйте p=0.5.
2. Воспользйтесь формулой: 1.96^2 x 4p x (1-p) / d^2 = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.1^2 = 138 пациентов.
Если мы удвоим точность измерения сузив ДИ до 0.05 (5%), то N = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.05^2 = 553 пациента.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4p x (1-p) / d^2
90% ДИ: N = 1.64^2 x 4p x (1-p) / d^2
99% ДИ: N = 2.58^2 x 4p x (1-p) / d^2
❗ Правда более классическая формула не включает в себя множитель "4", 95% ДИ: N = 1.96^2 x p x (1-p) / d^2. Калькулятор
#глоссарий. Минимальная клинически значимая разница (minimum clinically important difference, MCID) - наименьший размер различия в данных, который исследователь считает настолько важным, что не хотел бы, чтобы его не заметили в ходе исследования. Другими словами, этот размер разницы между величинами считается клинически значимым. MCID необходима при расчете минимального размера выборки. Если выборка данных слишком мала для того, чтобы обнаружить эту величину различий, а она на самом деле существует, то сравнение не будет иметь клинической значимости, а исследование будет неубедительным и его нет смысла проводить. Выбор величины MCID не является статистическим правилом, а зависит от контекста исследования.
Расчет минимального размера выборки при сравнении средних при условии нормального распределения данных.
Для этого понадобятся следующие вводные:
- Стандартное отклонение (SD) выборки
- Минимальная разница (d), которая является клинически значимой (MCID)
- Уровень значимости (α - вероятность ошибки I рода, обычно 0.05)
- Мощность теста (1-β (вероятность ошибки II рода), обычно 0.8)
Формула: N = 2K x SD^2 / d^2
K - это множитель, который зависит от уровня значимости α и мощности 1-β, происходит из нормального распределения и определяется по специальным таблицам. Для α=0.05 и β=0.8, K = 7.8. Чем ниже α или выше β, тем выше K.
Например, мы захотели сравнить средние уровни гемоглобина в группах мужчин и женщин при заболевании X. SD всей выборки составила 20 г/л, d - 10 г/л (минимальная разница, которая будет по нашему мнению клинически значимой), K = 7.8.
Тогда N = 2 x 7.8 x 20^2 / 10^2 = 62 пациента в каждой группе!
Для этого понадобятся следующие вводные:
- Стандартное отклонение (SD) выборки
- Минимальная разница (d), которая является клинически значимой (MCID)
- Уровень значимости (α - вероятность ошибки I рода, обычно 0.05)
- Мощность теста (1-β (вероятность ошибки II рода), обычно 0.8)
Формула: N = 2K x SD^2 / d^2
K - это множитель, который зависит от уровня значимости α и мощности 1-β, происходит из нормального распределения и определяется по специальным таблицам. Для α=0.05 и β=0.8, K = 7.8. Чем ниже α или выше β, тем выше K.
Например, мы захотели сравнить средние уровни гемоглобина в группах мужчин и женщин при заболевании X. SD всей выборки составила 20 г/л, d - 10 г/л (минимальная разница, которая будет по нашему мнению клинически значимой), K = 7.8.
Тогда N = 2 x 7.8 x 20^2 / 10^2 = 62 пациента в каждой группе!
Одним из допущений логистической регрессии, которое не все считают обязательным проверять и выполнять, является предположение о линейности зависимости между непрерывными количественными предикторами и исходом. На самом деле отсутствие линейной взаимосвязи может негативно сказываться на интерпретации и качестве медицинской прогностической модели.
В недавней работе международная группа статистиков провела анализ, как данный фактор оценивается в ранее опубликованных прогностических моделях. В обзор было включено 118 исследований (в 18 исследованиях (15%) оценивалось предположение о линейности или использовались методы обработки нелинейности, а в 100 исследованиях (85%) - нет). Для обработки нелинейности часто использовались трансформация предикторов и сплайны, которые применялись в 7 (n=7/18, 39%) и 6 (n=6/18, 33%) исследованиях соответственно. Также для обработки непрерывных предикторов в большинстве исследований применялась категоризация (n=67/118, 56.8%) и дихотомия (n=40/67, 60%), что также является большой проблемой и ошибкой.
Дополнительные материалы по теме в группе:
Пример нелинейной взаимосвязи в медицине
Про допущения логистической регрессии
Как проверить линейную зависимость
Что может, а что не может категоризация
Цена дихотомии непрерывных (количественных) переменных
В недавней работе международная группа статистиков провела анализ, как данный фактор оценивается в ранее опубликованных прогностических моделях. В обзор было включено 118 исследований (в 18 исследованиях (15%) оценивалось предположение о линейности или использовались методы обработки нелинейности, а в 100 исследованиях (85%) - нет). Для обработки нелинейности часто использовались трансформация предикторов и сплайны, которые применялись в 7 (n=7/18, 39%) и 6 (n=6/18, 33%) исследованиях соответственно. Также для обработки непрерывных предикторов в большинстве исследований применялась категоризация (n=67/118, 56.8%) и дихотомия (n=40/67, 60%), что также является большой проблемой и ошибкой.
Дополнительные материалы по теме в группе:
Пример нелинейной взаимосвязи в медицине
Про допущения логистической регрессии
Как проверить линейную зависимость
Что может, а что не может категоризация
Цена дихотомии непрерывных (количественных) переменных
👍2
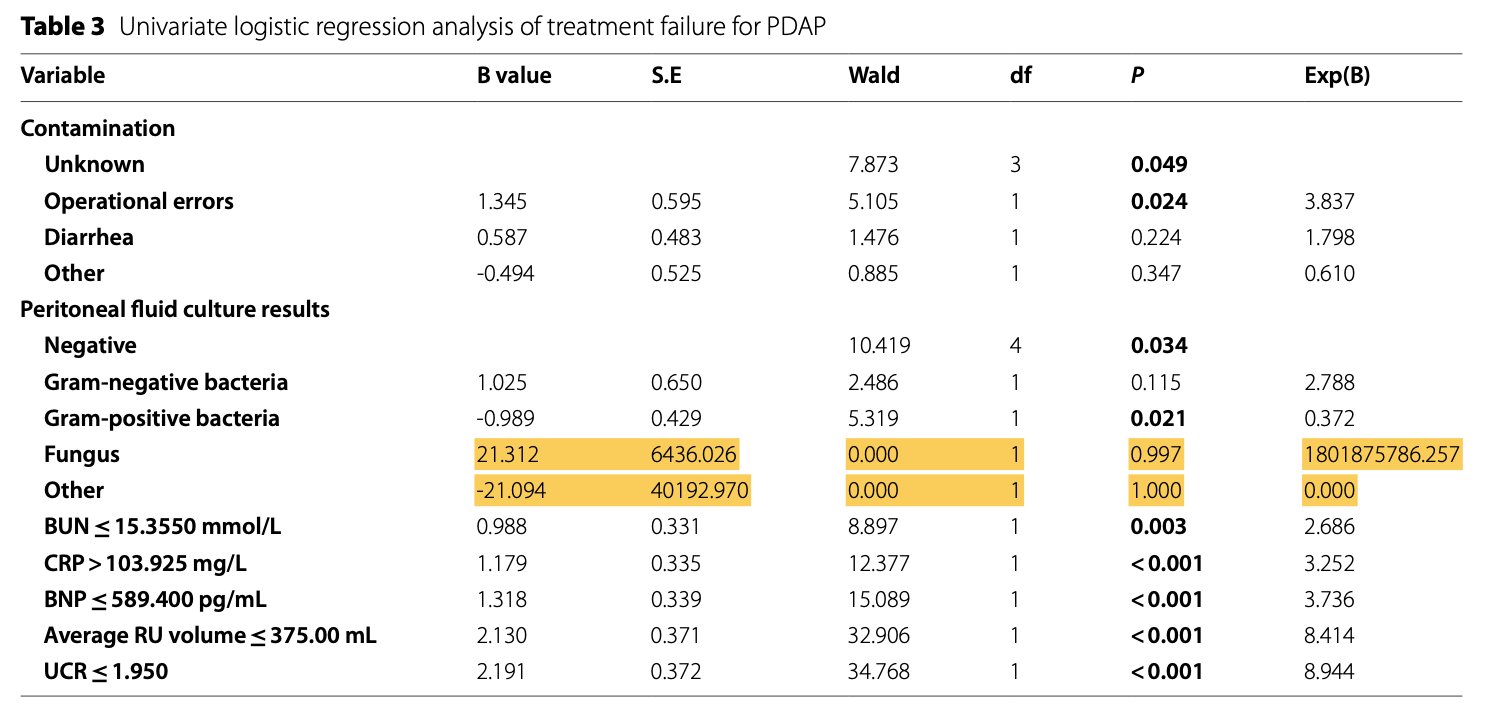
Внимательно смотрим на картинку и видим проблему в виде величин отношения шансов (Exp(b)) = 1.8 млрд. и 0 😳. Подобную картину можно иногда наблюдать для границ доверительных интервалов ОШ. Если вы столкнулись с такой ситуацией в научной публикации или сами получаете нечто похожее на своих данных, даже при намного меньших цифрах, то это связано с так называемой проблемой "разделения (сепарации)" в логистической регрессии, когда у вас есть бинарная (или категориальная ковариата) с почти или полным отсутствием событий в одной из катерогий. В итоге получаем "бесссмысленное отношение шансов". Ссылка на статью китайских исследователей будет в комментариях.
Проблема разделения (включая полное и квазиполное разделение) или монотонного правдоподобия наблюдается в процессе подгонки логистической модели. Разделение в основном происходит в небольших выборках с несколькими несбалансированными и высокопрогностичными факторами риска.
Что делать в случае проблемы:
✅ Проверить данные на ошибки
✅ Изменить размер выборки в сторону увеличения и/или устранить дисбаланс зависимой переменной
✅ Применить метод Firth's Bias-Reduced Logistic Regression
Показано, что регрессия Фирта, первоначально разработанная для уменьшения смещения оценок максимального правдоподобия, обеспечивает идеальное решение проблемы разделения. Она позволяет получить оценки конечных параметров с помощью пенализированной (оштрафованной) оценки максимального правдоподобия.
Проблема разделения (включая полное и квазиполное разделение) или монотонного правдоподобия наблюдается в процессе подгонки логистической модели. Разделение в основном происходит в небольших выборках с несколькими несбалансированными и высокопрогностичными факторами риска.
Что делать в случае проблемы:
✅ Проверить данные на ошибки
✅ Изменить размер выборки в сторону увеличения и/или устранить дисбаланс зависимой переменной
✅ Применить метод Firth's Bias-Reduced Logistic Regression
Показано, что регрессия Фирта, первоначально разработанная для уменьшения смещения оценок максимального правдоподобия, обеспечивает идеальное решение проблемы разделения. Она позволяет получить оценки конечных параметров с помощью пенализированной (оштрафованной) оценки максимального правдоподобия.
{kind=link}
Виды и отличия статистических анализов, связанных с обобщением агрегированных данных, в медицине
1. Pooled analysis (Объединенный анализ)
Объединение исходных данных нескольких отдельных исследований, как правило, схожего дизайна для создания более крупного набора данных для анализа. Простыми словами данные из разных исследований суммируются без взвешивания, так, как если бы они были получены из одной выборки. Это обеспечивает бОльшую статистическую мощность за счет бОльшего размера выборки. Также он полезен при субгрупповой оценке или для изучения взаимодействий (явлений), которые изначально не были запланированы как цели отдельных исследований.
2. Meta-analysis (Мета-анализ)
Предполагает анализ сводных статистических данных (средние значения, риски и др.), полученных в ходе нескольких независимых друг от друга исследованиях. Его цель - взвешенно обобщить результаты различных исследований для получения суммарной синтетической оценки эффекта лечения или связи между переменными. Мета-анализ используется в ситуациях, когда существует несколько исследований, посвященных одному и тому же вопросу, и их однотипные результаты необходимо объединить для получения более надежной и точной оценки основного эффекта.
3. Individual Participant Data (IPD) meta-analysis (Мета-нализ с индивидуальными данными участников)
Такой подход предполагает сбор и анализ исходных данных от каждого отдельного участника исследований (пациента). Это позволяет проводить более детальный и всесторонний анализ, а также лучше контролировать потенциальные конфаундеры (спутывающие переменные). Таким образом, IPD мета-нализ не опирается на сводную статистику или агрегированные результаты, но требует доступа к первичным сырым данным.
4. Network meta-analysis (Сетевой мета-анализ)
Также известен как анализ множественных методов лечения или косвенное сравнение методов лечения. Представляет собой статистический метод, используемый для анализа сравнительной эффективности нескольких видов терапии в отсутствии всех прямых "head-to-head" сравнений данных видов лечения между собой. Сетевой мета-анализ использует принципы традиционного мета-анализа в ситуации, когда существует сеть исследований, включающих различные методы лечения и их относительные эффекты (например, отношение шансов / рисков).
5. Component Network Meta-Analysis (CNMA)
CNMA представляет собой усовершенствованный вариант сетевого мета-анализа, предназначенный для анализа многокомпонентных схем лечения. В отличие от стандартного сетевого подхода, рассматривающего каждую комбинацию лечения как отдельную сущность, CNMA декомпозирует такие схемы на отдельные компоненты (например, лекарственные препараты) и оценивает вклад каждого в общий терапевтический эффект. Метод позволяет моделировать потенциальную эффективность новых комбинаций даже при отсутствии прямых клинических данных, а также уточнять роль каждого компонента в уже существующих схемах.
1. Pooled analysis (Объединенный анализ)
Объединение исходных данных нескольких отдельных исследований, как правило, схожего дизайна для создания более крупного набора данных для анализа. Простыми словами данные из разных исследований суммируются без взвешивания, так, как если бы они были получены из одной выборки. Это обеспечивает бОльшую статистическую мощность за счет бОльшего размера выборки. Также он полезен при субгрупповой оценке или для изучения взаимодействий (явлений), которые изначально не были запланированы как цели отдельных исследований.
2. Meta-analysis (Мета-анализ)
Предполагает анализ сводных статистических данных (средние значения, риски и др.), полученных в ходе нескольких независимых друг от друга исследованиях. Его цель - взвешенно обобщить результаты различных исследований для получения суммарной синтетической оценки эффекта лечения или связи между переменными. Мета-анализ используется в ситуациях, когда существует несколько исследований, посвященных одному и тому же вопросу, и их однотипные результаты необходимо объединить для получения более надежной и точной оценки основного эффекта.
3. Individual Participant Data (IPD) meta-analysis (Мета-нализ с индивидуальными данными участников)
Такой подход предполагает сбор и анализ исходных данных от каждого отдельного участника исследований (пациента). Это позволяет проводить более детальный и всесторонний анализ, а также лучше контролировать потенциальные конфаундеры (спутывающие переменные). Таким образом, IPD мета-нализ не опирается на сводную статистику или агрегированные результаты, но требует доступа к первичным сырым данным.
4. Network meta-analysis (Сетевой мета-анализ)
Также известен как анализ множественных методов лечения или косвенное сравнение методов лечения. Представляет собой статистический метод, используемый для анализа сравнительной эффективности нескольких видов терапии в отсутствии всех прямых "head-to-head" сравнений данных видов лечения между собой. Сетевой мета-анализ использует принципы традиционного мета-анализа в ситуации, когда существует сеть исследований, включающих различные методы лечения и их относительные эффекты (например, отношение шансов / рисков).
5. Component Network Meta-Analysis (CNMA)
CNMA представляет собой усовершенствованный вариант сетевого мета-анализа, предназначенный для анализа многокомпонентных схем лечения. В отличие от стандартного сетевого подхода, рассматривающего каждую комбинацию лечения как отдельную сущность, CNMA декомпозирует такие схемы на отдельные компоненты (например, лекарственные препараты) и оценивает вклад каждого в общий терапевтический эффект. Метод позволяет моделировать потенциальную эффективность новых комбинаций даже при отсутствии прямых клинических данных, а также уточнять роль каждого компонента в уже существующих схемах.
Telegram
Статистические шоты
Про мета-анализ
Мета-анализ - метод, объединяющий результаты нескольких исследований по схожей теме для получения более надежного заключения. Это похоже на объединение знаний, полученных в разных местах, для получения более четкой картины.
Отдельные исследования…
Мета-анализ - метод, объединяющий результаты нескольких исследований по схожей теме для получения более надежного заключения. Это похоже на объединение знаний, полученных в разных местах, для получения более четкой картины.
Отдельные исследования…
Что такое конфаундеры (спутывающие/сбивающие факторы в исследованиях)
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать ложное представление о связи между исследуемой переменной и результатом. Например, мы изучаем как употребление алкоголя влияет на риск заболеваний сердца, но не учитываем факт курения. При этом курение (конфаундер) будет самостоятельно влиять на исход.
Отсутствие учета конфаундеров может привести к:
1. Неверным выводам
2. Недостоверным результатам
3. Нерациональному использованию ресурсов
Перед началом работы необходимо определить потенциальные конфаундеры, через:
1. Обзор литературы
2. Мнения экспертов по теме исследования
3. Промежуточный анализ данных (корреляция, кросс-табуляция)
Особенности дизайна исследований с учетом конфаундеров:
1. Рандомизированные контролируемые исследования (РКИ)
В идеале в РКИ конфаундеры распределяются между группами поровну, но такие исследования далеко не всегда выполнимы по практическим причинам.
2. Сопоставление (Matching)
Подбор участников на основе конфаундеров. Например, если возраст является конфаундером, то в обеих группах должны быть участники одинакового возраста.
3. Стратификация
Сгруппировать участников по уровню сбивающих переменных. Проанализируйте каждую страту отдельно.
Post-Hoc методы
Проверьте, сохраняются ли какие-либо закономерности основных эффектов, если к ним добавить конфаундер. Например, если в уравнение регрессии добавить новую переменную, изменит ли это предыдущий результат. Если изучаемый нами предиктор сохраняет направление и статистическую значимость, то добавленная нами переменная не является конфаундером (помехой). Если же основной эффект меняет направленность или значимость, то добавленная ковариата - слабый или сильный конфаундер. Но надо помнить, что проблемы могут возникнуть и из-за нарушений к допущений к регрессионному анализу. Одним из признаков, что в данных есть конфаундер, является парадокс Симпсона.
Сбивающие факторы - переменные, которые могут влиять на интересующий нас исход, но при этом не являются промежуточными переменными в цепочке причинно-следственных связей. Они могут создать ложное представление о связи между исследуемой переменной и результатом. Например, мы изучаем как употребление алкоголя влияет на риск заболеваний сердца, но не учитываем факт курения. При этом курение (конфаундер) будет самостоятельно влиять на исход.
Отсутствие учета конфаундеров может привести к:
1. Неверным выводам
2. Недостоверным результатам
3. Нерациональному использованию ресурсов
Перед началом работы необходимо определить потенциальные конфаундеры, через:
1. Обзор литературы
2. Мнения экспертов по теме исследования
3. Промежуточный анализ данных (корреляция, кросс-табуляция)
Особенности дизайна исследований с учетом конфаундеров:
1. Рандомизированные контролируемые исследования (РКИ)
В идеале в РКИ конфаундеры распределяются между группами поровну, но такие исследования далеко не всегда выполнимы по практическим причинам.
2. Сопоставление (Matching)
Подбор участников на основе конфаундеров. Например, если возраст является конфаундером, то в обеих группах должны быть участники одинакового возраста.
3. Стратификация
Сгруппировать участников по уровню сбивающих переменных. Проанализируйте каждую страту отдельно.
Post-Hoc методы
Проверьте, сохраняются ли какие-либо закономерности основных эффектов, если к ним добавить конфаундер. Например, если в уравнение регрессии добавить новую переменную, изменит ли это предыдущий результат. Если изучаемый нами предиктор сохраняет направление и статистическую значимость, то добавленная нами переменная не является конфаундером (помехой). Если же основной эффект меняет направленность или значимость, то добавленная ковариата - слабый или сильный конфаундер. Но надо помнить, что проблемы могут возникнуть и из-за нарушений к допущений к регрессионному анализу. Одним из признаков, что в данных есть конфаундер, является парадокс Симпсона.
{kind=link}
👍1
Про оценку максимального правдоподобия (Maximum Likelihood Estimation или MLE)
MLE - одна из ключевых концепций в статистике, на базе которой построена работа регрессионного анализа и ряда методов машинного обучения. Разберем ее максимально простым языком без математического аппарата, хотя и здесь есть в чем запутаться.
Для начала нам нужны уже знакомые термины:
Вероятность (Probability, P) - вероятность того, что событие произойдет. Например, вероятность выпадения орла при подбрасывании правильной монеты равна 0.5.
Правдоподобие (Likelihood, L) - вероятность получить наблюдаемый результат с учетом известных входных параметров. Например, если мы 10 раз подрбросим монетку и N раз получим выпадение орла, а 1-N раз выпадение решки это будет нашим результатом. У этого результата (комбинации орлов и решек) будет своя вероятность, у другого результата - своя. Она называется правдоподобие.
Теперь, что такое MLE:
Через функцию MLE мы можем рассчитать какова максимальная вероятность того, что результаты получены при некоем условии, например, что у нас правильная монетка с P(орла) = 0.5 или любая другая монетка с любой P(орла/решки). Если вместо результатов с монеткой у нас какой-либо набор данных, от которого зависит вероятность исхода, то при оценке MLE мы можем определить при каких значениях этих данных вероятность исхода будет максимальной. Это используется в регрессионном анализе.
Итак, MLE — метод поиска значений параметров, которые делают ваши наблюдаемые данные наиболее вероятными, или, другими словами, максимизируют функцию правдоподобия. В примере с монетой MLE найдет значение P(орла/решки), которое делает наблюдаемое в эксперименте количество орлов и решек наиболее вероятным.Таким образом, оценка максимального правдоподобия — метод, который помогает вам найти наиболее подходящие значения параметров для вашей статистической модели, определяя значения, которые делают наблюдаемый исход (данные) наиболее вероятным.
Совсем простая аналогия — подбор ключа к замку. Представьте, что ключ это вероятность открыть замок, тогда MLE поможет вам найти наиболее подходящий для этого замка ключ, смотря на какие-то другие его характеристики. MLE не гарантирует, что вы найдете истинную вероятность, она лишь показывает, что из всех ключей (данных) что вы перебрали, именно этот наиболее вероятно окажется подходящим, чтобы достичь результата (открыть замок). MLE — это прекрасное сочетание логики, интуиции и математики, помогающее нам понять смысл окружающего мира.
Разновидностями классической MLE являются пенализированные (оштрафованные) функции MLE, используемые в соответствующих регрессиях, например, регрессия Фирта. Дело в том, что регрессионные модели очень чувствительны к размеру выборки. Оценки моделей могут оказаться не совсем корректными на малых выборках (например, при N менее 1000). В штрафных моделях максимизируется пенализированное (оштрафованное) правдоподобие L, а не обычное правдоподобие L. Дальше уже идет почти сплошная математика, поэтому следует остановиться и сделать выводы. Если вы делаете логистический регрессионный анализ, особенно при малых размерах выборок, да и при больших тоже, предпочтительнее использовать штрафные регрессии по умолчанию (регрессия Фирта (brglm2 package в R), LASSO, Ridge Regression, Elastic Net Regression). Какая практическая польза? Да просто ваши модели могут быть лучше и точнее!
MLE - одна из ключевых концепций в статистике, на базе которой построена работа регрессионного анализа и ряда методов машинного обучения. Разберем ее максимально простым языком без математического аппарата, хотя и здесь есть в чем запутаться.
Для начала нам нужны уже знакомые термины:
Вероятность (Probability, P) - вероятность того, что событие произойдет. Например, вероятность выпадения орла при подбрасывании правильной монеты равна 0.5.
Правдоподобие (Likelihood, L) - вероятность получить наблюдаемый результат с учетом известных входных параметров. Например, если мы 10 раз подрбросим монетку и N раз получим выпадение орла, а 1-N раз выпадение решки это будет нашим результатом. У этого результата (комбинации орлов и решек) будет своя вероятность, у другого результата - своя. Она называется правдоподобие.
Теперь, что такое MLE:
Через функцию MLE мы можем рассчитать какова максимальная вероятность того, что результаты получены при некоем условии, например, что у нас правильная монетка с P(орла) = 0.5 или любая другая монетка с любой P(орла/решки). Если вместо результатов с монеткой у нас какой-либо набор данных, от которого зависит вероятность исхода, то при оценке MLE мы можем определить при каких значениях этих данных вероятность исхода будет максимальной. Это используется в регрессионном анализе.
Итак, MLE — метод поиска значений параметров, которые делают ваши наблюдаемые данные наиболее вероятными, или, другими словами, максимизируют функцию правдоподобия. В примере с монетой MLE найдет значение P(орла/решки), которое делает наблюдаемое в эксперименте количество орлов и решек наиболее вероятным.Таким образом, оценка максимального правдоподобия — метод, который помогает вам найти наиболее подходящие значения параметров для вашей статистической модели, определяя значения, которые делают наблюдаемый исход (данные) наиболее вероятным.
Совсем простая аналогия — подбор ключа к замку. Представьте, что ключ это вероятность открыть замок, тогда MLE поможет вам найти наиболее подходящий для этого замка ключ, смотря на какие-то другие его характеристики. MLE не гарантирует, что вы найдете истинную вероятность, она лишь показывает, что из всех ключей (данных) что вы перебрали, именно этот наиболее вероятно окажется подходящим, чтобы достичь результата (открыть замок). MLE — это прекрасное сочетание логики, интуиции и математики, помогающее нам понять смысл окружающего мира.
Разновидностями классической MLE являются пенализированные (оштрафованные) функции MLE, используемые в соответствующих регрессиях, например, регрессия Фирта. Дело в том, что регрессионные модели очень чувствительны к размеру выборки. Оценки моделей могут оказаться не совсем корректными на малых выборках (например, при N менее 1000). В штрафных моделях максимизируется пенализированное (оштрафованное) правдоподобие L, а не обычное правдоподобие L. Дальше уже идет почти сплошная математика, поэтому следует остановиться и сделать выводы. Если вы делаете логистический регрессионный анализ, особенно при малых размерах выборок, да и при больших тоже, предпочтительнее использовать штрафные регрессии по умолчанию (регрессия Фирта (brglm2 package в R), LASSO, Ridge Regression, Elastic Net Regression). Какая практическая польза? Да просто ваши модели могут быть лучше и точнее!
{kind=link}
👍1
Про отношение шансов и относительный риск
Понимание различий и применения этих двух показателей важно для интерпретации результатов исследований и принятия обоснованных решений.
Отношение шансов (Odds Ratio, OR) - мера связи между воздействием и исходом. Оно представляет собой шансы наступления события в одной группе по сравнению с шансами наступления события в другой группе, которые отличаются между собой по каким-либо характеристикам. OR предпочтительнее использовать в исследованиях типа "случай-контроль".
Относительный риск (RR) - отношение вероятности события, произошедшего в группе, подвергшейся воздействию, к вероятности события, произошедшего в группе, не подвергшейся воздействию. RR часто используется в когортных исследованиях для оценки риска.
Шансы (Odds) - отношение числа наблюдений с возникшим исходом, по отношению к числу наблюдений без исхода в группе.
Риск (Risk) - отношение числа наблюдений с возникшим исходом, по отношению к общему числу наблюдений в группе.
OR и RR решают задачи поиска взаимосвязи между данными. Если вам нужно оценить распредление категориального признака между двумя группами, то это будет задачей сравнения распределения данных, которая решается непараметрическими методами (Хи2 / точный критерий Фишера).
Понимание различий и применения этих двух показателей важно для интерпретации результатов исследований и принятия обоснованных решений.
Отношение шансов (Odds Ratio, OR) - мера связи между воздействием и исходом. Оно представляет собой шансы наступления события в одной группе по сравнению с шансами наступления события в другой группе, которые отличаются между собой по каким-либо характеристикам. OR предпочтительнее использовать в исследованиях типа "случай-контроль".
Относительный риск (RR) - отношение вероятности события, произошедшего в группе, подвергшейся воздействию, к вероятности события, произошедшего в группе, не подвергшейся воздействию. RR часто используется в когортных исследованиях для оценки риска.
Шансы (Odds) - отношение числа наблюдений с возникшим исходом, по отношению к числу наблюдений без исхода в группе.
Риск (Risk) - отношение числа наблюдений с возникшим исходом, по отношению к общему числу наблюдений в группе.
OR и RR решают задачи поиска взаимосвязи между данными. Если вам нужно оценить распредление категориального признака между двумя группами, то это будет задачей сравнения распределения данных, которая решается непараметрическими методами (Хи2 / точный критерий Фишера).
{kind=link}
Размер выборки в регрессионом анализе имеет значение!
Результат в регрессионных моделях является асимптоматическим. В контексте регрессии «асимптотический результат» относится к изменению коэффициентов регрессии по мере того, как размер выборки (количество данных) приближается к бесконечности. Это связано с концепцией асимптотической теории в статистике, которая имеет дело с поведением статистических оценок и тестов, когда размер выборки становится очень большим. Хотя в жизни бесконечный объём выборки никогда не достигается, при заданном конечном объёме выборки можно рассматривать асимптотическое распределение как приближение (апроксимация) действительного распределения. Такое приближение улучшается с увеличением размера выборки.
Асимптотическая нормальность. Одним из ключевых асимптотических результатов регрессии является асимптотическая нормальность оценочных коэффициентов. По мере увеличения размера выборки распределение оцениваемых коэффициентов сходится к нормальному (гауссову) распределению. Это свойство позволяет строить доверительные интервалы и проверять гипотезы для коэффициентов.
Непротиворечивость. Еще одним важным свойством является согласованность оцениваемых коэффициентов. Это означает, что по мере увеличения размера выборки оценочные коэффициенты модели регрессии будут сходиться к истинным коэффициентам генеральной совокупности. Проще говоря, с большим количеством данных оценки становятся более точными.
Эффективность. Асимптотическая эффективность относится к тому свойству, что по мере увеличения размера выборки оценки коэффициентов регрессии становятся более эффективными, что означает, что они имеют меньшую дисперсию. Это означает, что чем больше размер выборки, тем точнее оценки.
Асимптотические результаты имеют решающее значение для статистических выводов с использованием регрессии. Проверки гипотез и доверительные интервалы для коэффициентов основаны на асимптотических свойствах оценок результатов регрессии. Это позволяет исследователям делать заявления о взаимосвязях между переменными с определенным уровнем достоверности и определенности. Экстраполируя результат оценки выборочной совокупности на генеральную совокупность мы принимаем его асимптоматичность, что возможно только при достаточном размере выборки.
Результат в регрессионных моделях является асимптоматическим. В контексте регрессии «асимптотический результат» относится к изменению коэффициентов регрессии по мере того, как размер выборки (количество данных) приближается к бесконечности. Это связано с концепцией асимптотической теории в статистике, которая имеет дело с поведением статистических оценок и тестов, когда размер выборки становится очень большим. Хотя в жизни бесконечный объём выборки никогда не достигается, при заданном конечном объёме выборки можно рассматривать асимптотическое распределение как приближение (апроксимация) действительного распределения. Такое приближение улучшается с увеличением размера выборки.
Асимптотическая нормальность. Одним из ключевых асимптотических результатов регрессии является асимптотическая нормальность оценочных коэффициентов. По мере увеличения размера выборки распределение оцениваемых коэффициентов сходится к нормальному (гауссову) распределению. Это свойство позволяет строить доверительные интервалы и проверять гипотезы для коэффициентов.
Непротиворечивость. Еще одним важным свойством является согласованность оцениваемых коэффициентов. Это означает, что по мере увеличения размера выборки оценочные коэффициенты модели регрессии будут сходиться к истинным коэффициентам генеральной совокупности. Проще говоря, с большим количеством данных оценки становятся более точными.
Эффективность. Асимптотическая эффективность относится к тому свойству, что по мере увеличения размера выборки оценки коэффициентов регрессии становятся более эффективными, что означает, что они имеют меньшую дисперсию. Это означает, что чем больше размер выборки, тем точнее оценки.
Асимптотические результаты имеют решающее значение для статистических выводов с использованием регрессии. Проверки гипотез и доверительные интервалы для коэффициентов основаны на асимптотических свойствах оценок результатов регрессии. Это позволяет исследователям делать заявления о взаимосвязях между переменными с определенным уровнем достоверности и определенности. Экстраполируя результат оценки выборочной совокупности на генеральную совокупность мы принимаем его асимптоматичность, что возможно только при достаточном размере выборки.
Про C-индекс и коэффициент корреляции Сомерса
Обе характеристики являются метриками дискриминативности прогностической модели, по которым определяется ее потенциальная прогностическая точность.
Коэффициент корреляции Сомерса Dxy – корреляция оценочных истинных и предсказанных вероятностей в регрессионных моделях. Чтобы вычислить Dxy Сомерса, необходимо сначала вычислить сумму предсказанных вероятностей Y для группы наблюдений с предсказанной вероятностью менее 0,5 (условная величина S1). Затем вычисляется сумма предсказанных вероятностей Y для группы наблюдений с предсказанной вероятностью, большей или равной 0,5 (условная величина S2). Dxy Сомерса = (S1 - S2) / (S1 + S2). Dxy Сомерса будет варьироваться от -1 до 1, при этом значение -1 указывает на полную отрицательную связь между двумя переменными (т.е., когда одна переменная равна 1, другая всегда равна 0), значение 0 указывает на отсутствие связи между переменными, и значение 1 указывает на совершенную положительную связь (т. е. когда одна переменная равна 1, другая всегда равна 1).
Индекс соответствия (C-индекс) – метрика для оценки точности прогнозов, сделанных моделью. Предложен Фрэнком Харреллом. C-индекс вычисляется по формуле 0.5 + Dxy/2. Значение C-индекса по своей сути соответствует AUC-ROC, а при бинарной модели C-индекс = AUC-ROC.
Обе характеристики являются метриками дискриминативности прогностической модели, по которым определяется ее потенциальная прогностическая точность.
Коэффициент корреляции Сомерса Dxy – корреляция оценочных истинных и предсказанных вероятностей в регрессионных моделях. Чтобы вычислить Dxy Сомерса, необходимо сначала вычислить сумму предсказанных вероятностей Y для группы наблюдений с предсказанной вероятностью менее 0,5 (условная величина S1). Затем вычисляется сумма предсказанных вероятностей Y для группы наблюдений с предсказанной вероятностью, большей или равной 0,5 (условная величина S2). Dxy Сомерса = (S1 - S2) / (S1 + S2). Dxy Сомерса будет варьироваться от -1 до 1, при этом значение -1 указывает на полную отрицательную связь между двумя переменными (т.е., когда одна переменная равна 1, другая всегда равна 0), значение 0 указывает на отсутствие связи между переменными, и значение 1 указывает на совершенную положительную связь (т. е. когда одна переменная равна 1, другая всегда равна 1).
Индекс соответствия (C-индекс) – метрика для оценки точности прогнозов, сделанных моделью. Предложен Фрэнком Харреллом. C-индекс вычисляется по формуле 0.5 + Dxy/2. Значение C-индекса по своей сути соответствует AUC-ROC, а при бинарной модели C-индекс = AUC-ROC.
Про трансформацию (преобразование) данных
Если количественные данные представлены в разных форматах и единицах измерения, а вам нужно провести регрессионный или корреляционный анализ, возможно, может потребоваться предварительная трансформация (преобразование) данных. Например, есть датасет, в котором присутствуют результат измерения АД в мм рт. ст, ЧСС в уд. в мин., уровень глюкозы в крови в ммоль/л, общий белок в крови в г/л и т.д. Значения данных сильно отличаются друг от друга как по величине, так и по распределению. Их преобразование может исправить ситуацию и улучшить результат статистических тестов или машинного обучения.
Есть разные варианты, которые можно комбинировать между собой:
1. Min-Max нормализация. Метод, который преобразует данные таким образом, что значения будут лежат в диапазоне от 0 до 1. Формула нормализации выглядит следующим образом: x' = (x - mean(x)) / (max(x) - min(x)), где x – исходное значение, x’ – нормализованное значение, mean(x) – среднее значение набора данных, min(x) и max(x) – минимальное и максимальное значения в наборе данных соответственно.
2. Z-преобразование. Метод, который нормализует данные на основе среднего значения (μ) и стандартного отклонения (σ) набора данных. Формула z-преобразования выглядит следующим образом: x' = (x - μ) / σ, где x – исходное значение, x’ – нормализованное значение, μ – среднее значение набора данных, σ – стандартное отклонение набора данных. Масштаб набора данных меняется так, чтобы среднее значение = 0, а стандартное отклонение = 1.
Обычно мы нормализуем данные при проведении анализа, в котором имеется несколько переменных, измеряемых по разным шкалам, и хотим, чтобы каждая из них имела одинаковый диапазон. Это позволяет избежать чрезмерного влияния одной переменной, особенно если она измеряется в разных единицах (например, если одна переменная измеряется в г/л, а другая - в ммоль/л).
3. Другое. Например, логарифмирование (логарифм с любым основанием), извлечение квадратного корня, извлечение кубического корня ... Такие преобразования могут убрать выбросы, уменьшить дисперсию, нормализовать распределение данных.
Нормализация данных (пункты 1-2) имеет ряд преимуществ:
✅ Упрощение сравнения данных: когда все данные представлены в едином масштабе, их легче сравнивать и анализировать.
✅ Ускорение обучения алгоритмов машинного обучения: многие алгоритмы обучаются быстрее, когда данные нормализованы.
✅ Повышение точности алгоритмов: нормализация данных может помочь алгоритмам сосредоточиться на важных аспектах данных, улучшая их точность и производительность.
Если количественные данные представлены в разных форматах и единицах измерения, а вам нужно провести регрессионный или корреляционный анализ, возможно, может потребоваться предварительная трансформация (преобразование) данных. Например, есть датасет, в котором присутствуют результат измерения АД в мм рт. ст, ЧСС в уд. в мин., уровень глюкозы в крови в ммоль/л, общий белок в крови в г/л и т.д. Значения данных сильно отличаются друг от друга как по величине, так и по распределению. Их преобразование может исправить ситуацию и улучшить результат статистических тестов или машинного обучения.
Есть разные варианты, которые можно комбинировать между собой:
1. Min-Max нормализация. Метод, который преобразует данные таким образом, что значения будут лежат в диапазоне от 0 до 1. Формула нормализации выглядит следующим образом: x' = (x - mean(x)) / (max(x) - min(x)), где x – исходное значение, x’ – нормализованное значение, mean(x) – среднее значение набора данных, min(x) и max(x) – минимальное и максимальное значения в наборе данных соответственно.
2. Z-преобразование. Метод, который нормализует данные на основе среднего значения (μ) и стандартного отклонения (σ) набора данных. Формула z-преобразования выглядит следующим образом: x' = (x - μ) / σ, где x – исходное значение, x’ – нормализованное значение, μ – среднее значение набора данных, σ – стандартное отклонение набора данных. Масштаб набора данных меняется так, чтобы среднее значение = 0, а стандартное отклонение = 1.
Обычно мы нормализуем данные при проведении анализа, в котором имеется несколько переменных, измеряемых по разным шкалам, и хотим, чтобы каждая из них имела одинаковый диапазон. Это позволяет избежать чрезмерного влияния одной переменной, особенно если она измеряется в разных единицах (например, если одна переменная измеряется в г/л, а другая - в ммоль/л).
3. Другое. Например, логарифмирование (логарифм с любым основанием), извлечение квадратного корня, извлечение кубического корня ... Такие преобразования могут убрать выбросы, уменьшить дисперсию, нормализовать распределение данных.
Нормализация данных (пункты 1-2) имеет ряд преимуществ:
✅ Упрощение сравнения данных: когда все данные представлены в едином масштабе, их легче сравнивать и анализировать.
✅ Ускорение обучения алгоритмов машинного обучения: многие алгоритмы обучаются быстрее, когда данные нормализованы.
✅ Повышение точности алгоритмов: нормализация данных может помочь алгоритмам сосредоточиться на важных аспектах данных, улучшая их точность и производительность.
{kind=link}
При создании прогностической модели существуют множество правил и последовательных действий. Одни из них связаны с разделением данных на тренировочный, валидационный и тестовый датасет. При малых размерах выборок это большая проблема, но сейчас не об этом.
❌ Вот как поступают многие при создании прогностической модели:
1. Преобразовывают свой набор данных (про преобразование данных)
2. Затем разбивают датасет (обучающий, валидационный и тестовый наборы)
3. Наконец, строят модель
Здесь кроется большая проблема. К сожалению, многие допускают эту ошибку. Например, выполнена min-max нормализация. Если не разделить набор данных сразу, то для вычисления минимального и максимального значений конкретного столбца будут использованы все данные. В том числе и информация из будущего тестового набора, о которой вы не должны знать! Это называется "утечкой данных". Вы используете информацию из тестовых данных, которая повлияет на ваш обучающий процесс.
✅ Вот правильный алгоритм:
1. Сначала нужно разделить данные и отложить тестовый набор в сторону!
2. Преобразовать обучающий набор данных и сделать модель
3. Преобразовать отложенные тестовые данные и проверить модель
После преобразования обучающего набора следует использовать тот же подход для трансформации тестовых данных. Вывод: никогда не преобразуйте данные перед их разбиением!
❌ Вот как поступают многие при создании прогностической модели:
1. Преобразовывают свой набор данных (про преобразование данных)
2. Затем разбивают датасет (обучающий, валидационный и тестовый наборы)
3. Наконец, строят модель
Здесь кроется большая проблема. К сожалению, многие допускают эту ошибку. Например, выполнена min-max нормализация. Если не разделить набор данных сразу, то для вычисления минимального и максимального значений конкретного столбца будут использованы все данные. В том числе и информация из будущего тестового набора, о которой вы не должны знать! Это называется "утечкой данных". Вы используете информацию из тестовых данных, которая повлияет на ваш обучающий процесс.
✅ Вот правильный алгоритм:
1. Сначала нужно разделить данные и отложить тестовый набор в сторону!
2. Преобразовать обучающий набор данных и сделать модель
3. Преобразовать отложенные тестовые данные и проверить модель
После преобразования обучающего набора следует использовать тот же подход для трансформации тестовых данных. Вывод: никогда не преобразуйте данные перед их разбиением!
В 1925 г. во время летнего послеобеденного чая одна дама, доктор Мюриэл Бристол, заявила, что она может определить, что налито в чашку первым - молоко или чай. Рональд А. Фишер, всегда готовый к статистическим вызовам, увидел возможность для эксперимента. Было приготовлено 8 чашек - 4 с вначале налитым молоком и 4 - с чаем. Дама правильно определила 3 из 4 чашек в каждой группе, что привело к вопросу: это случайность или ее настоящая способность? При проверке гипотез это означает выдвижение нулевой и альтернативной гипотез. Фишер сформулировал решение данного вопроса как комбинаторную задачу. Если бы это была простая удача, то вероятность того, что дама правильно ответит на все 8 вопросов, была бы невелика. Это заложило основу для концепции p-значимости. Р-значимость - вероятность наблюдения полученного или более экстремального результата при условии, что нулевая гипотеза верна. Доктор Мюриэл Бристол не смогла отгадать все чашки, но она справилась лучше, чем можно было бы предположить на основании простой вероятности. Это стало основной для дальнейших разработок Фишера в области экспериментального дизайна и проверки гипотез, а в итоге появился точный критерий Фишера.
"Дама, пробующая чай" - не просто причудливая история. Это рождение концепций, основополагающих для современной статистики. В следующий раз, когда вы будете пить чай, вспомните о богатом наследии, которое хранится в каждой чашке этого напитка.
"Дама, пробующая чай" - не просто причудливая история. Это рождение концепций, основополагающих для современной статистики. В следующий раз, когда вы будете пить чай, вспомните о богатом наследии, которое хранится в каждой чашке этого напитка.
{kind=link}
Про анализ выживаемости простым языком
✅ Анализ выживаемости - статистический метод изучения времени до наступления того или иного события, например, смерти пациента. В отличие от привычных средних значений, анализ выживаемости оценивает время - сколько времени требуется для того, чтобы произошло то или иное событие. Событием может быть что угодно: сколько времени пройдет до поломки машины? Сколько дней пройдет до выздоровления пациента? Как быстро погаснут свечи?
✅ Но не все свечи догорят за время нашего наблюдения, как и не все пациенты могут поправиться или умереть. Событие может еще не наступить, когда мы закончим исследование. Это называется "цензурированием". Анализ выживаемости обрабатывает эту неполную информацию.
✅ Функция выживания - кривая, которая показывает вероятность выживания (т.е. события, которое еще не произошло) с течением времени. Если вы изучаете выживаемость больных, то она будет показывать вероятность того, что проживет X (дней/месяцев/лет). Hazard Ratio (коэффициент опасности) - риск того, что событие произойдет в определенное время, учитывая, что до этого момента оно еще не произошло. Например, насколько вероятно, что свеча погаснет на 5-м часу, если через 4 часа она все еще горит?
✅ Почему бы просто не использовать средние значения? Допустим, у вас есть 2 батарейки. Одна сдохнет через 1 час, другая - через 9. Среднее значение = 5 часов. Но это не дает полной картины. Анализ выживаемости дает более подробную картину. С помощью кривых выживания мы можем понять такие нюансы, как процент батарей, проработавших определенное время, риск смерти в определенный период времени, а также сравнить различные группы между собой.
✅ Анализ выживаемости применяется повсеместно! Медицина - прогнозирование выживаемости пациентов, инженерия - прогнозирование срока службы машин, финансы - время до дефолта по кредиту и т.д. Анализ выживаемости - мощный инструмент, который выходит за рамки простых средних значений. Он позволяет детально рассмотреть, как время влияет на события.
Другие шоты по данной теме:
Кратко о тестах сравнения кривых Каплана-Мейера
Что нужно знать и понимать о кривой выживаемости
Про виды показателей выживаемости в медицине
Как оценить выживаемость пациентов при наличии конкурирующих событий
Подробно про Hazard Ratio
✅ Анализ выживаемости - статистический метод изучения времени до наступления того или иного события, например, смерти пациента. В отличие от привычных средних значений, анализ выживаемости оценивает время - сколько времени требуется для того, чтобы произошло то или иное событие. Событием может быть что угодно: сколько времени пройдет до поломки машины? Сколько дней пройдет до выздоровления пациента? Как быстро погаснут свечи?
✅ Но не все свечи догорят за время нашего наблюдения, как и не все пациенты могут поправиться или умереть. Событие может еще не наступить, когда мы закончим исследование. Это называется "цензурированием". Анализ выживаемости обрабатывает эту неполную информацию.
✅ Функция выживания - кривая, которая показывает вероятность выживания (т.е. события, которое еще не произошло) с течением времени. Если вы изучаете выживаемость больных, то она будет показывать вероятность того, что проживет X (дней/месяцев/лет). Hazard Ratio (коэффициент опасности) - риск того, что событие произойдет в определенное время, учитывая, что до этого момента оно еще не произошло. Например, насколько вероятно, что свеча погаснет на 5-м часу, если через 4 часа она все еще горит?
✅ Почему бы просто не использовать средние значения? Допустим, у вас есть 2 батарейки. Одна сдохнет через 1 час, другая - через 9. Среднее значение = 5 часов. Но это не дает полной картины. Анализ выживаемости дает более подробную картину. С помощью кривых выживания мы можем понять такие нюансы, как процент батарей, проработавших определенное время, риск смерти в определенный период времени, а также сравнить различные группы между собой.
✅ Анализ выживаемости применяется повсеместно! Медицина - прогнозирование выживаемости пациентов, инженерия - прогнозирование срока службы машин, финансы - время до дефолта по кредиту и т.д. Анализ выживаемости - мощный инструмент, который выходит за рамки простых средних значений. Он позволяет детально рассмотреть, как время влияет на события.
Другие шоты по данной теме:
Кратко о тестах сравнения кривых Каплана-Мейера
Что нужно знать и понимать о кривой выживаемости
Про виды показателей выживаемости в медицине
Как оценить выживаемость пациентов при наличии конкурирующих событий
Подробно про Hazard Ratio
{kind=link}
Про ансамбли в машинном обучении: Bagging, Boosting и Stacking
Для улучшения результатов прогнозирования существуют ансамблевые подходы в обучении и при применении прогностических моделей. Иногда их принципы уже заложены в тот или иной метод машинного обучения, в другом случае эти принципы можно использовать искусственно и комбинировать между собой.
1. Bagging. Представьте, что вы врач и пытаетесь поставить диагноз пациенту. Вместо того чтобы делать это самостоятельно, вы просите ваших коллег вам помочь и собираете консилиум. Каждый из врачей смотрит на пациента по-своему с позиции своих знаний, клинического мышления и высказывает свое мнение. Затем вы усредняете все их предположения. Это и есть Bagging! Говоря техническим языком, Bagging обучает несколько версий модели на разных подмножествах, чтобы уменьшить дисперсию (ошибки из-за шума). Самый популярный метод основанный на бэггинге - модель случайного леса (ансамбль из множества деревьев решений).
2. Boosting. Предположим, что первый врач поставил диагноз, но не очень точно и отправил пациента на дообследование. Теперь второй врач пытается исправить неточность первого с учетом новых данных, и так далее. Каждый врач учится на ошибках и результатах предыдущего. В машинном обучении бустинг позволяет построить серию моделей, каждая из которых исправляет ошибки предыдущей, уделяя больше внимания неверно классифицированным точкам данных. Популярные методы: градиентный бустинг, XGBoost, CatBoost, AdaBoost.
3. Stacking. Вы собрали междисциплинарный консилиум по пациенту из врачей разных специальностей. Один - клиницист, другой - генетик, третий - морфолог. Вместо того чтобы полагаться на мнение только одного врача, объедините сильные стороны всех участников консилиума! В методе Stacking мы объединяем (или "складываем") прогнозы нескольких моделей. Затем финальная модель (называемая мета-моделью) обучается на этих объединенных прогнозах, чтобы дать окончательный ответ. Это похоже на использование коллективной мудрости!
Перечисленные выше методы помогают:
✅ Улучшить точность прогноза
✅ Уменьшить систематическую ошибку и дисперсию
✅ Повысить надежность моделей
Одна голова - хорошо, а много - лучше!
Для улучшения результатов прогнозирования существуют ансамблевые подходы в обучении и при применении прогностических моделей. Иногда их принципы уже заложены в тот или иной метод машинного обучения, в другом случае эти принципы можно использовать искусственно и комбинировать между собой.
1. Bagging. Представьте, что вы врач и пытаетесь поставить диагноз пациенту. Вместо того чтобы делать это самостоятельно, вы просите ваших коллег вам помочь и собираете консилиум. Каждый из врачей смотрит на пациента по-своему с позиции своих знаний, клинического мышления и высказывает свое мнение. Затем вы усредняете все их предположения. Это и есть Bagging! Говоря техническим языком, Bagging обучает несколько версий модели на разных подмножествах, чтобы уменьшить дисперсию (ошибки из-за шума). Самый популярный метод основанный на бэггинге - модель случайного леса (ансамбль из множества деревьев решений).
2. Boosting. Предположим, что первый врач поставил диагноз, но не очень точно и отправил пациента на дообследование. Теперь второй врач пытается исправить неточность первого с учетом новых данных, и так далее. Каждый врач учится на ошибках и результатах предыдущего. В машинном обучении бустинг позволяет построить серию моделей, каждая из которых исправляет ошибки предыдущей, уделяя больше внимания неверно классифицированным точкам данных. Популярные методы: градиентный бустинг, XGBoost, CatBoost, AdaBoost.
3. Stacking. Вы собрали междисциплинарный консилиум по пациенту из врачей разных специальностей. Один - клиницист, другой - генетик, третий - морфолог. Вместо того чтобы полагаться на мнение только одного врача, объедините сильные стороны всех участников консилиума! В методе Stacking мы объединяем (или "складываем") прогнозы нескольких моделей. Затем финальная модель (называемая мета-моделью) обучается на этих объединенных прогнозах, чтобы дать окончательный ответ. Это похоже на использование коллективной мудрости!
Перечисленные выше методы помогают:
✅ Улучшить точность прогноза
✅ Уменьшить систематическую ошибку и дисперсию
✅ Повысить надежность моделей
Одна голова - хорошо, а много - лучше!
Про bias (предвзятость / смещенность)
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать по разным причинам и влиять как на процесс выборки, так и на анализ данных. Это может привести к результатам, которые неточно представляют истинную совокупность или изучаемое явление.
Вот некоторые распространенные виды предвзятости в статистике, которые часто могут дополнять друг друга:
⚠️ Предвзятость сбора данных. Возникает, когда выборка, используемая для анализа, не является репрезентативной для всей генеральной совокупности. Определенные группы или отдельные лица с большей вероятностью будут включены в выборку, что приведет к результатам, которые не будут хорошо обобщены на всю совокупность. Например, исследователь сознательно включит в выборку пациентов, у которых были хорошие результаты лечения, чтобы не дискредитировать лекарственный препарат или метод лечения. Другой пример, когда дизайн исследования подразумевает опрос респондентов, но не все возможные респонденты принимают в участие в исследовании, отвечают на вопросы или все ответы учитываются.
⚠️ Предвзятость измерения. Возникает при наличии неточностей или ошибок в способах сбора, регистрации или измерения данных. Это может быть следствием неисправности приборов, человеческого фактора или несоответствия методов измерения поставленным задачам. Можно считать это разновидностью предвзятости сбора данных.
⚠️ Предвзятость выборки. Метод отбора участников исследования не обеспечивает равных шансов для включения в него всех членов популяции, может возникнуть предвзятость выборки. Это приводит к получению нерепрезентативной выборки. Например, в отсуствии рандомизации.
⚠️ Предвзятость наблюдателя. Возникает, когда ожидания или убеждения исследователя влияют на интерпретацию результатов. Это может привести к непреднамеренным ошибкам при сборе или анализе данных. Например, стремление получить нужный результат приводит к искусственному искажению набора данных.
⚠️ Предвзятость при публикации. Возникает, когда принято публиковать исследования со статистически значимыми или положительными результатами, а исследования с незначимыми или отрицательными результатами публикуются реже и не публикуются совсем. Это может создать искаженное представление об общем объеме доказательств по теме.
⚠️ Сбивающие факторы. Ошибка происходит, когда третья переменная (конфаундер) влияет на независимые и зависимые переменные в исследовании, создавая ложную связь между ними. Контроль за сбивающими переменными важен для того, чтобы избежать необъективных результатов.
Необъективность статистических данных может существенно повлиять на достоверность и надежность результатов исследования. Для уменьшения bias исследователи должны тщательно планировать свои исследования, использовать методы случайной выборки (в т.ч. рандомизацию), применять стандартизированные методики измерений, прозрачно описывать свои данные, манипуляции с ними, методы анализа и возможные ограничения. Также очень важно критически оценивать исследования и их bias при интерпретации статистических результатов.
Под предвзятостью в статистике понимается систематическая ошибка или искажение в способе сбора, анализа или интерпретации данных, приводящие к неточным или вводящим в заблуждение результатам. Предвзятость может возникать по разным причинам и влиять как на процесс выборки, так и на анализ данных. Это может привести к результатам, которые неточно представляют истинную совокупность или изучаемое явление.
Вот некоторые распространенные виды предвзятости в статистике, которые часто могут дополнять друг друга:
⚠️ Предвзятость сбора данных. Возникает, когда выборка, используемая для анализа, не является репрезентативной для всей генеральной совокупности. Определенные группы или отдельные лица с большей вероятностью будут включены в выборку, что приведет к результатам, которые не будут хорошо обобщены на всю совокупность. Например, исследователь сознательно включит в выборку пациентов, у которых были хорошие результаты лечения, чтобы не дискредитировать лекарственный препарат или метод лечения. Другой пример, когда дизайн исследования подразумевает опрос респондентов, но не все возможные респонденты принимают в участие в исследовании, отвечают на вопросы или все ответы учитываются.
⚠️ Предвзятость измерения. Возникает при наличии неточностей или ошибок в способах сбора, регистрации или измерения данных. Это может быть следствием неисправности приборов, человеческого фактора или несоответствия методов измерения поставленным задачам. Можно считать это разновидностью предвзятости сбора данных.
⚠️ Предвзятость выборки. Метод отбора участников исследования не обеспечивает равных шансов для включения в него всех членов популяции, может возникнуть предвзятость выборки. Это приводит к получению нерепрезентативной выборки. Например, в отсуствии рандомизации.
⚠️ Предвзятость наблюдателя. Возникает, когда ожидания или убеждения исследователя влияют на интерпретацию результатов. Это может привести к непреднамеренным ошибкам при сборе или анализе данных. Например, стремление получить нужный результат приводит к искусственному искажению набора данных.
⚠️ Предвзятость при публикации. Возникает, когда принято публиковать исследования со статистически значимыми или положительными результатами, а исследования с незначимыми или отрицательными результатами публикуются реже и не публикуются совсем. Это может создать искаженное представление об общем объеме доказательств по теме.
⚠️ Сбивающие факторы. Ошибка происходит, когда третья переменная (конфаундер) влияет на независимые и зависимые переменные в исследовании, создавая ложную связь между ними. Контроль за сбивающими переменными важен для того, чтобы избежать необъективных результатов.
Необъективность статистических данных может существенно повлиять на достоверность и надежность результатов исследования. Для уменьшения bias исследователи должны тщательно планировать свои исследования, использовать методы случайной выборки (в т.ч. рандомизацию), применять стандартизированные методики измерений, прозрачно описывать свои данные, манипуляции с ними, методы анализа и возможные ограничения. Также очень важно критически оценивать исследования и их bias при интерпретации статистических результатов.
👍1
🙈 Размер выборки не учитывается при разработке модели прогнозирования
Группа уважаемых статистиков выполнила систематический обзор 119 публикаций, в которых были описаны медицинские прогностические модели. Только 8% исследований указали и обосновали способ расчета размера выборки для своих моделей. При этом в 73% из них размер выборки не соответствовал минимально необходимому (по методу Riley et al.). Авторы призывают исследователей обосновывать, выполнять и сообщать о методах расчета размера выборки при создании прогностических моделей.
Источник: https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-023-02008-1
Группа уважаемых статистиков выполнила систематический обзор 119 публикаций, в которых были описаны медицинские прогностические модели. Только 8% исследований указали и обосновали способ расчета размера выборки для своих моделей. При этом в 73% из них размер выборки не соответствовал минимально необходимому (по методу Riley et al.). Авторы призывают исследователей обосновывать, выполнять и сообщать о методах расчета размера выборки при создании прогностических моделей.
Источник: https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-023-02008-1
SpringerLink
Sample size requirements are not being considered in studies developing prediction models for binary outcomes: a systematic review
BMC Medical Research Methodology - Having an appropriate sample size is important when developing a clinical prediction model. We aimed to review how sample size is considered in studies developing...