
Подробно про Hazard Ratio
Путаница в интерпретации Hazard Ratio связано с путаницей в понятиях Hazard (опасность) и риск (вероятность, Probability). Часто то и другое называют "риском", но у них есть существенные различия. Во избежании путаницы риски в Hazard Ratio будем называть "опасностями".
Отношение опасностей (отношение "рисков" или угроз, Hazard Ratio) – отношение опасностей (Hazards) исхода в двух группах пациентов, например, на разной терапии. Hazard Ratio показывает пропорцию между опасностью исхода для пациента в одной группе с опасностью исхода для пациента в другой группе в один и тот же следующий момент времени на протяжении всего горизонта наблюдения при условии, что пациенты еще не достигли данного исхода!
Теперь подробнее:
Опасность (Hazard) - гипотетический риск или вероятность возникновения события, например, прогрессирования заболевания или смерти. Другими словами опасность – мгновенная возможность того, что событие произойдет в следующий новый момент времени. Например, это риск смерти (прогрессии) пациента завтра, если сегодня этот пациент в жив (в ремиссии). Значения опасности меняются со временем. Например, опасность смерти у больного возрастает со временем. Опасность рассчитывается по наклону кривой выживания в определенной точке.
Hazard Ratio (HR) сравнивает опасности (Hazard) двух пациентов методом пропорции, то есть во сколько раз значение одного риска (Hazard1) больше или меньше другого (Hazard2). Другими словами, HR - относительный риск исхода (например, смерти) одного пациента по отношению к другому, отличающемуся от первого, завтра, при условии, что сегодня они оба живы. Hazard Ratio НЕ меняется со временем (инвариантен времени), что называется пропорциональностью рисков. Это главное условие для применения регрессионного анализа Кокса. Если пропорциональность рисков не соблюдается (например, при пересечении кривых выживаемости вначале или тем более несколько раз), результаты регрессии Кокса нельзя интерпретировать! Допущение пропорциональности рисков проверяется специальными статистическими тестами.
Зная HR вы не можете высчитать Hazard1 и Hazard2. HR = 1 означает, что две группы имеют одинаковую опасность. Их гипотететические риски исхода (смерти/прогрессии) эквивалентны. HR = 0.5 означает, что одна группа имеет на 50% более низкую гипотетическую опасность по сравнению с контрольной группой. HR = 2 означает, что одна группа имеет в 2 раза более высокую гипотетическую опасность по сравнению с контрольной группой. Риск прогрессирования в 2 раза выше.
Вероятность (Probability) - абсолютная процентная вероятность наступления события (прогрессия/смерть). Абсолютная вероятность выживания для любой из групп пациентов оценивается по кривой выживания путем проведения перпендикуляра от оси Х (время) на кривую выживаемости и далее на ось У (вероятность). Разница абсолютного риска высчитывается путем нахождения разницы между вероятностями выживания в конкретной временной точке.
Опасность и вероятность связаны, но не тождественны. Вы не можете напрямую вычислить одно из другого, основываясь только на HR. Опасность (Hazard) описывает мгновенный риск события в определенный момент времени. Вероятность описывает общий шанс наступления события в течение определенного периода времени. HR - относительное сравнение опасностей между двумя группами или относительное влияние экспериментального лечения на прогрессирование/выживаемость по сравнению с контрольным лечением. Это некий усредненный показатель постоянного риска исхода на протяжении всего периода наблюдения.
Теперь на примере:
В исследовании при сравнении результатов новой и старой терапии HR выживания без прогрессирования = 0.73. Это означает, что новое лечение снизило опасность прогрессирования на 27% по сравнению с контрольным лечением. Снизило опасность, не вероятность! Хотя опасность прямо коррелирует с вероятностью события, непосредственные показатели рисков в том и другом случае могут и, как правило, существенно отличаются. Например, в данном же исследовании вероятность прогрессирования через 2 года была ниже только на 6%, а не на
Путаница в интерпретации Hazard Ratio связано с путаницей в понятиях Hazard (опасность) и риск (вероятность, Probability). Часто то и другое называют "риском", но у них есть существенные различия. Во избежании путаницы риски в Hazard Ratio будем называть "опасностями".
Отношение опасностей (отношение "рисков" или угроз, Hazard Ratio) – отношение опасностей (Hazards) исхода в двух группах пациентов, например, на разной терапии. Hazard Ratio показывает пропорцию между опасностью исхода для пациента в одной группе с опасностью исхода для пациента в другой группе в один и тот же следующий момент времени на протяжении всего горизонта наблюдения при условии, что пациенты еще не достигли данного исхода!
Теперь подробнее:
Опасность (Hazard) - гипотетический риск или вероятность возникновения события, например, прогрессирования заболевания или смерти. Другими словами опасность – мгновенная возможность того, что событие произойдет в следующий новый момент времени. Например, это риск смерти (прогрессии) пациента завтра, если сегодня этот пациент в жив (в ремиссии). Значения опасности меняются со временем. Например, опасность смерти у больного возрастает со временем. Опасность рассчитывается по наклону кривой выживания в определенной точке.
Hazard Ratio (HR) сравнивает опасности (Hazard) двух пациентов методом пропорции, то есть во сколько раз значение одного риска (Hazard1) больше или меньше другого (Hazard2). Другими словами, HR - относительный риск исхода (например, смерти) одного пациента по отношению к другому, отличающемуся от первого, завтра, при условии, что сегодня они оба живы. Hazard Ratio НЕ меняется со временем (инвариантен времени), что называется пропорциональностью рисков. Это главное условие для применения регрессионного анализа Кокса. Если пропорциональность рисков не соблюдается (например, при пересечении кривых выживаемости вначале или тем более несколько раз), результаты регрессии Кокса нельзя интерпретировать! Допущение пропорциональности рисков проверяется специальными статистическими тестами.
Зная HR вы не можете высчитать Hazard1 и Hazard2. HR = 1 означает, что две группы имеют одинаковую опасность. Их гипотететические риски исхода (смерти/прогрессии) эквивалентны. HR = 0.5 означает, что одна группа имеет на 50% более низкую гипотетическую опасность по сравнению с контрольной группой. HR = 2 означает, что одна группа имеет в 2 раза более высокую гипотетическую опасность по сравнению с контрольной группой. Риск прогрессирования в 2 раза выше.
Вероятность (Probability) - абсолютная процентная вероятность наступления события (прогрессия/смерть). Абсолютная вероятность выживания для любой из групп пациентов оценивается по кривой выживания путем проведения перпендикуляра от оси Х (время) на кривую выживаемости и далее на ось У (вероятность). Разница абсолютного риска высчитывается путем нахождения разницы между вероятностями выживания в конкретной временной точке.
Опасность и вероятность связаны, но не тождественны. Вы не можете напрямую вычислить одно из другого, основываясь только на HR. Опасность (Hazard) описывает мгновенный риск события в определенный момент времени. Вероятность описывает общий шанс наступления события в течение определенного периода времени. HR - относительное сравнение опасностей между двумя группами или относительное влияние экспериментального лечения на прогрессирование/выживаемость по сравнению с контрольным лечением. Это некий усредненный показатель постоянного риска исхода на протяжении всего периода наблюдения.
Теперь на примере:
В исследовании при сравнении результатов новой и старой терапии HR выживания без прогрессирования = 0.73. Это означает, что новое лечение снизило опасность прогрессирования на 27% по сравнению с контрольным лечением. Снизило опасность, не вероятность! Хотя опасность прямо коррелирует с вероятностью события, непосредственные показатели рисков в том и другом случае могут и, как правило, существенно отличаются. Например, в данном же исследовании вероятность прогрессирования через 2 года была ниже только на 6%, а не на
👍3🔥2
27%!
Итак, если описывать результаты клинического исследования через риски и опасности, следует понимать:
1. Когда мы интерпретируем HR, мы имеем в виду снижение и повышение гипотетического риска наступления события в одной группе больных по отношению к другой. Всегда присуствуют 2 группы! Риск - не абсолютный (истинный), а гипотетический и усредненный для всего периода наблюдения! Отношение опасностей (HR) одинаково на всем протяжении исследования и не может быть привязано к конкретной временной точке!
2. Абсолютный риск (вероятность исхода) определяется по графику выживаемости для каждой группы больных в отдельности! Риск всегда привязан к конкретной временной точке. Разница абсолютных рисков различается на всем протяжении исследования. Абсолютный риск отражает истинную, а не гипотетическую, вероятность исхода в прямом понимании слова "вероятность" и является более приближенной к реальности мерой оценки исходов, чем HR. Поэтому всегда смотрите на графики выживаемости.
Итак, если описывать результаты клинического исследования через риски и опасности, следует понимать:
1. Когда мы интерпретируем HR, мы имеем в виду снижение и повышение гипотетического риска наступления события в одной группе больных по отношению к другой. Всегда присуствуют 2 группы! Риск - не абсолютный (истинный), а гипотетический и усредненный для всего периода наблюдения! Отношение опасностей (HR) одинаково на всем протяжении исследования и не может быть привязано к конкретной временной точке!
2. Абсолютный риск (вероятность исхода) определяется по графику выживаемости для каждой группы больных в отдельности! Риск всегда привязан к конкретной временной точке. Разница абсолютных рисков различается на всем протяжении исследования. Абсолютный риск отражает истинную, а не гипотетическую, вероятность исхода в прямом понимании слова "вероятность" и является более приближенной к реальности мерой оценки исходов, чем HR. Поэтому всегда смотрите на графики выживаемости.
👍5
🤔 Немного терминологии в медицинском прогнозировании
✅ Прогностический фактор или предиктор - переменная, которая помогает прогнозировать (расчитывать вероятность) изучаемого исхода в конкретной прогностической модели.
✅ Фактор риска - переменная, определенное значение которой оказывает отрицательное (как правило) или положительное (защитный фактор) влияние на исход в популяции.
✅ Ковариата - любая переменная, которая используется для создания модели.
Пример: мы создали прогностическую модель инсульта, в котрую включили значение артериального давления (АД). Тогда АД будет являться ковариатой и предиктором. В тоже время не любое значение АД будет фактором риска инсульта, а например, только то, что выше 140/90. Курение в модели прогнозирования инсульта изначально являлось ковариатой, но не попав в итоговую модель, не стало предиктором. Тем не менее в целом в популяции курение может быть фактором риска инсульта.
✅ Прогностический фактор или предиктор - переменная, которая помогает прогнозировать (расчитывать вероятность) изучаемого исхода в конкретной прогностической модели.
✅ Фактор риска - переменная, определенное значение которой оказывает отрицательное (как правило) или положительное (защитный фактор) влияние на исход в популяции.
✅ Ковариата - любая переменная, которая используется для создания модели.
Пример: мы создали прогностическую модель инсульта, в котрую включили значение артериального давления (АД). Тогда АД будет являться ковариатой и предиктором. В тоже время не любое значение АД будет фактором риска инсульта, а например, только то, что выше 140/90. Курение в модели прогнозирования инсульта изначально являлось ковариатой, но не попав в итоговую модель, не стало предиктором. Тем не менее в целом в популяции курение может быть фактором риска инсульта.
👍2
О допущениях (assumptions) к линейной регресии
Линейная регрессия применяется для описания взаимосвязи между зависимой количественной и независимыми переменными, а также для создания прогностических моделей.
Обязательные допущения метода:
✅ Линейная зависимость между независимой переменной X и зависимой переменной Y
✅ Гомоскедастичность: остатки (ошибки регрессии) должны иметь постоянную дисперсию при любых значениях признаков
✅ Независимость: нет корреляции между последовательными остатками (автокорреляции), наблюдения должны быть независимыми друг от друга - случайная выборка, данные репрезентативны для генеральной совокупности (отсутствие систематической ошибки при отборе предикторов)
Опциональные допущения метода:
✅ Остатки модели должны быть нормально распределены
✅ Строгая экзогенность — независимые переменные не коррелируют с ошибками
✅ Достаточный размер выборки
Линейная регрессия применяется для описания взаимосвязи между зависимой количественной и независимыми переменными, а также для создания прогностических моделей.
Обязательные допущения метода:
✅ Линейная зависимость между независимой переменной X и зависимой переменной Y
✅ Гомоскедастичность: остатки (ошибки регрессии) должны иметь постоянную дисперсию при любых значениях признаков
✅ Независимость: нет корреляции между последовательными остатками (автокорреляции), наблюдения должны быть независимыми друг от друга - случайная выборка, данные репрезентативны для генеральной совокупности (отсутствие систематической ошибки при отборе предикторов)
Опциональные допущения метода:
✅ Остатки модели должны быть нормально распределены
✅ Строгая экзогенность — независимые переменные не коррелируют с ошибками
✅ Достаточный размер выборки
👍2🔥1
Как проверить линейную зависимость:
✅ постройте график зависимости Y от X и визуально проверьте на нелинейность
✅ постройте квадратичную или кубическую модель регрессии и сравните с линейной моделью в тесте ANOVA. Если модель более высокого порядка окажется лучше, это будет свидетельствовать о нелинейности
✅ постройте LOWESS (Locally Weighted Scatterplot Smoothing) диаграмму и визуально проверьте на нелинейность
✅ вычислите корреляцию X и Y после преобразования X (возведение в квадрат, квадратный корень). Более высокая корреляция для преобразованного X предполагает нелинейную зависимость
✅ используйте метод частичной корреляции
Что делать, если линейная зависимость отсутствует:
✅ можно попробовать преобразовать X, взяв log, квадратный корень, квадрат, куб и т.д. Иногда простое преобразование может привести к линейной зависимости
✅ добавьте полиномиальные члены - добавьте квадратичные (x^2) или кубические (x^3) члены к вашей модели: Y ~ x + x^2
✅ добавьте условия взаимодействия между X и другими переменными, чтобы проверить, существует ли условная линейная связь: Y ~ x + z + x:z
✅ используйте другую нелинейную модель
✅ используйте сплайны
✅ используйте LOESS регрессию
✅ уберите из модели переменную X, которая нелинейно связана с Y
✅ используйте методы машинного обучения
✅ постройте график зависимости Y от X и визуально проверьте на нелинейность
✅ постройте квадратичную или кубическую модель регрессии и сравните с линейной моделью в тесте ANOVA. Если модель более высокого порядка окажется лучше, это будет свидетельствовать о нелинейности
✅ постройте LOWESS (Locally Weighted Scatterplot Smoothing) диаграмму и визуально проверьте на нелинейность
✅ вычислите корреляцию X и Y после преобразования X (возведение в квадрат, квадратный корень). Более высокая корреляция для преобразованного X предполагает нелинейную зависимость
✅ используйте метод частичной корреляции
Что делать, если линейная зависимость отсутствует:
✅ можно попробовать преобразовать X, взяв log, квадратный корень, квадрат, куб и т.д. Иногда простое преобразование может привести к линейной зависимости
✅ добавьте полиномиальные члены - добавьте квадратичные (x^2) или кубические (x^3) члены к вашей модели: Y ~ x + x^2
✅ добавьте условия взаимодействия между X и другими переменными, чтобы проверить, существует ли условная линейная связь: Y ~ x + z + x:z
✅ используйте другую нелинейную модель
✅ используйте сплайны
✅ используйте LOESS регрессию
✅ уберите из модели переменную X, которая нелинейно связана с Y
✅ используйте методы машинного обучения
👍2❤1
Как оценить гомоскедастичность:
✅ Постройте график зависимости остатков и значений переменной отклика или Scale-Location график. Если остатки имеют постоянную дисперсию, они будут беспорядочно разбросаны вокруг 0. Если существует закономерность (например, расширяющаяся или сужающаяся форма воронки), это указывает на гетероскедастичность.
✅ Проведите формальный тест, например, тест Бреуша-Пагана, тест Гольдфельда-Квандта или тест Уайта. Если p-значение тестов меньше уровня значимости (α=0.05), то мы отвергаем нулевую гипотезу и делаем вывод о наличии гетероскедастичности в регрессионной модели.
✅ Изучите описательную статистику остатков. Посмотрите на среднее значение, дисперсию и стандартное отклонение остатков. Если они резко меняются при разных значениях предикторов, это говорит о гетероскедастичности.
✅ Преобразуйте переменные-предикторы и повторно запустите модель. Если преобразование предикторов (например, лог-преобразование) приводит к более случайному разбросу остатков, это указывает на то, что исходная модель страдала от гетероскедастичности.
Что делать, если есть гетероскедостичность:
✅ Преобразование переменных-предикторов. Применение логарифма, квадратного корня или другого преобразования предикторов иногда может стабилизировать дисперсию, что приводит к гомоскедастическим остаткам.
✅ Вместо или вместе с преобразованием предикторов, можно выполнить преобразование переменной отклика (например, логарифм или квадратный корень переменной Y), что иногда может стабилизировать дисперсию.
✅ Построить регрессионную модель методом взвешенных наименьших квадратов. Присвойте веса, обратно пропорциональные дисперсии в каждой точке данных. Это позволяет придать меньший вес точкам с высокой изменчивостью и больший - с низкой изменчивостью.
✅ Использовать робастную регрессию (Robust regression) в случае, если в даннымх есть выбросы или значения с высоким влиянием на прогнозируемый результат. Эта модель менее чувствительна к гетероскедастичности.
✅ Выполните очистку данных. Проверьте, нет ли выбросов, которые могут быть причиной гетероскедастичности. По возможности удалите (если позволяет размер выборки) или исправьте ошибки в данных, удалите выбросы с множественным вменением пустых значений.
✅ Используйте другую модель. Некоторые типы моделей по своей природе более устойчивы к гетероскедастичности, например, деревья решений, случайные леса и другие нелинейные модели машинного обучения.
✅ Постройте график зависимости остатков и значений переменной отклика или Scale-Location график. Если остатки имеют постоянную дисперсию, они будут беспорядочно разбросаны вокруг 0. Если существует закономерность (например, расширяющаяся или сужающаяся форма воронки), это указывает на гетероскедастичность.
✅ Проведите формальный тест, например, тест Бреуша-Пагана, тест Гольдфельда-Квандта или тест Уайта. Если p-значение тестов меньше уровня значимости (α=0.05), то мы отвергаем нулевую гипотезу и делаем вывод о наличии гетероскедастичности в регрессионной модели.
✅ Изучите описательную статистику остатков. Посмотрите на среднее значение, дисперсию и стандартное отклонение остатков. Если они резко меняются при разных значениях предикторов, это говорит о гетероскедастичности.
✅ Преобразуйте переменные-предикторы и повторно запустите модель. Если преобразование предикторов (например, лог-преобразование) приводит к более случайному разбросу остатков, это указывает на то, что исходная модель страдала от гетероскедастичности.
Что делать, если есть гетероскедостичность:
✅ Преобразование переменных-предикторов. Применение логарифма, квадратного корня или другого преобразования предикторов иногда может стабилизировать дисперсию, что приводит к гомоскедастическим остаткам.
✅ Вместо или вместе с преобразованием предикторов, можно выполнить преобразование переменной отклика (например, логарифм или квадратный корень переменной Y), что иногда может стабилизировать дисперсию.
✅ Построить регрессионную модель методом взвешенных наименьших квадратов. Присвойте веса, обратно пропорциональные дисперсии в каждой точке данных. Это позволяет придать меньший вес точкам с высокой изменчивостью и больший - с низкой изменчивостью.
✅ Использовать робастную регрессию (Robust regression) в случае, если в даннымх есть выбросы или значения с высоким влиянием на прогнозируемый результат. Эта модель менее чувствительна к гетероскедастичности.
✅ Выполните очистку данных. Проверьте, нет ли выбросов, которые могут быть причиной гетероскедастичности. По возможности удалите (если позволяет размер выборки) или исправьте ошибки в данных, удалите выбросы с множественным вменением пустых значений.
✅ Используйте другую модель. Некоторые типы моделей по своей природе более устойчивы к гетероскедастичности, например, деревья решений, случайные леса и другие нелинейные модели машинного обучения.
⁉ Как посчитать 95% доверительный интервал у коэффциента корреляции
Например, коэффциент корреляции Пирсона r = 0.7 при N=100
1. Считаем стандартную ошибку (se) r: SE(r) = √[(1-r^2)/(n-2)] = 0.07
2. Считаем нижний и верхний лимит 95%ДИ: r -/+ z*se, где z = 1.96, и получаем 0.56 - 0.84
3. Вывод: r = 0.7 (95%ДИ 0.56-0.84)
Например, коэффциент корреляции Пирсона r = 0.7 при N=100
1. Считаем стандартную ошибку (se) r: SE(r) = √[(1-r^2)/(n-2)] = 0.07
2. Считаем нижний и верхний лимит 95%ДИ: r -/+ z*se, где z = 1.96, и получаем 0.56 - 0.84
3. Вывод: r = 0.7 (95%ДИ 0.56-0.84)
Про минимальный размер выборки для регрессионного анализа
Минимальный размер выборки (minimum sample size) - минимальное количество наблюдений, необходимое, что начать эксперименты с применением регрессии. Это отправная точка, с которой можно начинать вычисления, однако, в ходе эскпериментов может оказаться (бывает очень часто), что размер выборки недостаточен и ее следует увеличить.
Недостаточный размер выборки - причина низкой мощности тестов (риск ошибок II рода), переобучения моделей (снижение оптимизма) и невыполнения допущений к регрессионным анализам, в результате анализ может дать неверные результаты или просто не получиться.
Несколько простых эмпирических правил определения самого минимального размера выборки:
✅ Линейная регрессия: N ≥ 10-30k, где k - число потенциальных предикторов (ковариат).
✅ Бинарная (биномиальная) логистическая регрессия и регрессионный анализ Кокса: 10-15 EPP (Events per predictor) - 10-15 наблюдений с изучаемым исходом на каждый предиктор (количественный или бинарный категориальный 1/0). Общий размер выборки будет складываться из наблюдений с исходом и без него, что можно выразить формулой N = 10 (15) * k/P, k - число потенциальных предикторов (количественных или бинарных категориальных 1/0), P - вероятность (частота) исхода. Например, у нас 3 предиктора, частота изучаемого исхода = 50%, тогда N = 10 (15) * 3/0.5 = 60-90.
✅ Мультиномиальная логистическая регрессия: N = 100k, k - число потенциальных предикторов (количественных или бинарных категориальных 1/0).
Более сложные, но более точные правила рассчета минимального размера выборки базируются на предположениях об ожидаемом уровне R2 модели Кокса-Снелла / С-статистики / средней абсолютной ошибки прогноза / предполагаемом значении Hazard Ratio (в анализе выживаемости) и на других вводных.
Что делать, если размер выборки меньше минимального:
✅ Дособрать данные
✅ Уменьшить число предикторов эмпирическим путем (исключить наименее важные, наименее логичные)
✅ Уменьшить размерность выборки путем применения специальных статистических тестов (например, метод главных компонент)
✅ Синтезировать искусственные данные с похожим распределением (dataclone.ru)
✅ Использовать бутстрэппинг при построении модели
Предварительная (перед построением модели) селекция предикторов через различного рода одно- и многофакторные анализы имеет ряд проблем и не рекомендуется, по крайней мере до того, как не испробованы другие методы.
Минимальный размер выборки (minimum sample size) - минимальное количество наблюдений, необходимое, что начать эксперименты с применением регрессии. Это отправная точка, с которой можно начинать вычисления, однако, в ходе эскпериментов может оказаться (бывает очень часто), что размер выборки недостаточен и ее следует увеличить.
Недостаточный размер выборки - причина низкой мощности тестов (риск ошибок II рода), переобучения моделей (снижение оптимизма) и невыполнения допущений к регрессионным анализам, в результате анализ может дать неверные результаты или просто не получиться.
Несколько простых эмпирических правил определения самого минимального размера выборки:
✅ Линейная регрессия: N ≥ 10-30k, где k - число потенциальных предикторов (ковариат).
✅ Бинарная (биномиальная) логистическая регрессия и регрессионный анализ Кокса: 10-15 EPP (Events per predictor) - 10-15 наблюдений с изучаемым исходом на каждый предиктор (количественный или бинарный категориальный 1/0). Общий размер выборки будет складываться из наблюдений с исходом и без него, что можно выразить формулой N = 10 (15) * k/P, k - число потенциальных предикторов (количественных или бинарных категориальных 1/0), P - вероятность (частота) исхода. Например, у нас 3 предиктора, частота изучаемого исхода = 50%, тогда N = 10 (15) * 3/0.5 = 60-90.
✅ Мультиномиальная логистическая регрессия: N = 100k, k - число потенциальных предикторов (количественных или бинарных категориальных 1/0).
Более сложные, но более точные правила рассчета минимального размера выборки базируются на предположениях об ожидаемом уровне R2 модели Кокса-Снелла / С-статистики / средней абсолютной ошибки прогноза / предполагаемом значении Hazard Ratio (в анализе выживаемости) и на других вводных.
Что делать, если размер выборки меньше минимального:
✅ Дособрать данные
✅ Уменьшить число предикторов эмпирическим путем (исключить наименее важные, наименее логичные)
✅ Уменьшить размерность выборки путем применения специальных статистических тестов (например, метод главных компонент)
✅ Синтезировать искусственные данные с похожим распределением (dataclone.ru)
✅ Использовать бутстрэппинг при построении модели
Предварительная (перед построением модели) селекция предикторов через различного рода одно- и многофакторные анализы имеет ряд проблем и не рекомендуется, по крайней мере до того, как не испробованы другие методы.
❤1🔥1
Про s-value
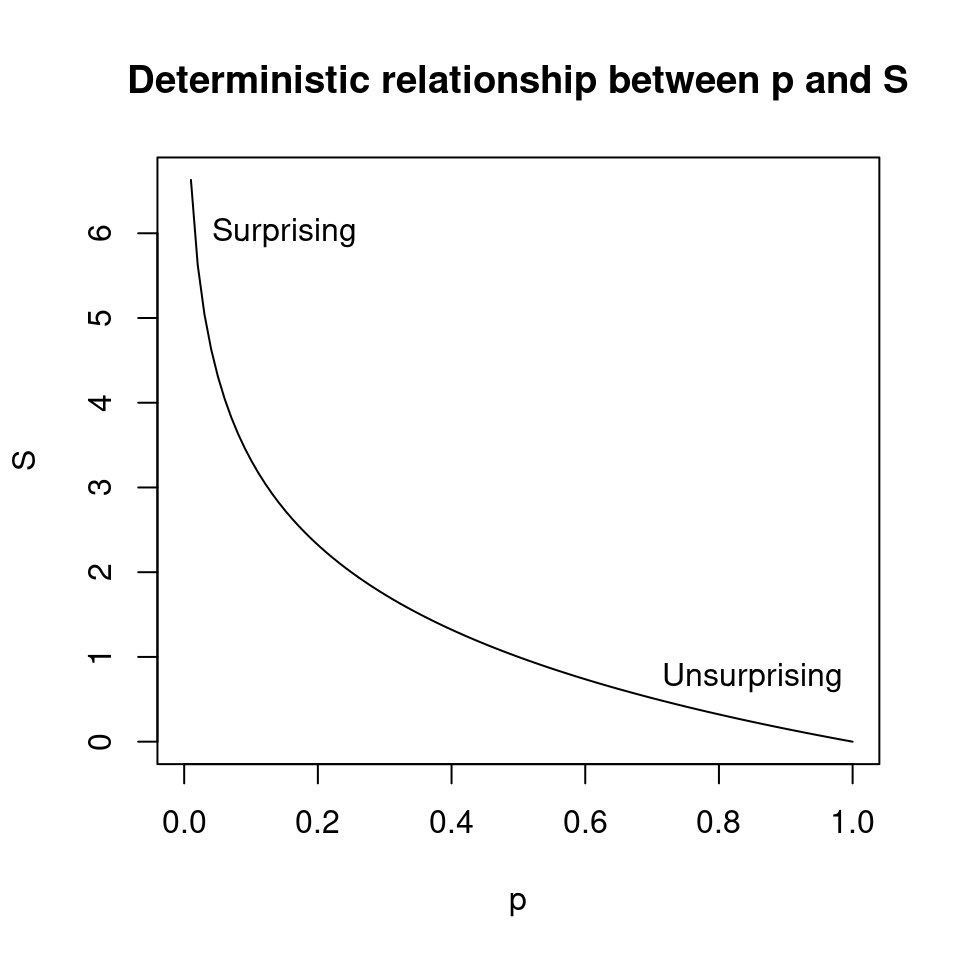
p-уровень статистической значимости (p-value) - интуитивно трудно понимаемый термин частотной статистики. Также у него есть ряд объективных проблем в практическом применении. Однако с p-уровнем можно сделать преобразование -log2(p), известное как информационный критерий Шеннона или "величиная сюрприза" (s-value). Например, для p=0.05, s-уровень будет равен ~4. Это соответствует ситуации, что при подбрасывании честной монетки 4 раза подряд выпадет "орел" или "решка". Другими словами полученный статистический результат не более удивителен, чем 4 раза выбросить монетку одной стороной. При p=0.005, "s-уровень значимости" будет равен ~8, а значит результаты не более удивительны, чем получение всех "орлов" при 8 честных подбрасываниях монеты. Вероятность такой ситуации равняется 0.5^8 = 0.39%. Сюрприз!
Зависимость p- и s-value представлена на картинке.
Калькулятор для конвертирования p-уровня в s-уровень: https://zadrafi.shinyapps.io/shinyapp/
p-уровень статистической значимости (p-value) - интуитивно трудно понимаемый термин частотной статистики. Также у него есть ряд объективных проблем в практическом применении. Однако с p-уровнем можно сделать преобразование -log2(p), известное как информационный критерий Шеннона или "величиная сюрприза" (s-value). Например, для p=0.05, s-уровень будет равен ~4. Это соответствует ситуации, что при подбрасывании честной монетки 4 раза подряд выпадет "орел" или "решка". Другими словами полученный статистический результат не более удивителен, чем 4 раза выбросить монетку одной стороной. При p=0.005, "s-уровень значимости" будет равен ~8, а значит результаты не более удивительны, чем получение всех "орлов" при 8 честных подбрасываниях монеты. Вероятность такой ситуации равняется 0.5^8 = 0.39%. Сюрприз!
Зависимость p- и s-value представлена на картинке.
Калькулятор для конвертирования p-уровня в s-уровень: https://zadrafi.shinyapps.io/shinyapp/
{kind=link}
👍2
This media is not supported in your browser
VIEW IN TELEGRAM
В линейной регрессии предполагается, что наблюдения (точки) являются результатом случайных отклонений от лежащей в ее основе зависимости, которую можно представить в виде прямой линии. На видео простая, но очень наглядная практическая реализация "линии наилучшего соответствия".
Про базовые понятия вероятности и статистики. Часть 1.
Случайности окружают нас повсюду. Теория вероятности - математическая основа (аппарат), которая позволяет нам анализировать случайные события логически обоснованным образом. Вероятность события - число, показывающее, насколько вероятно, что это событие произойдет. Это число всегда находится в диапазоне от 0 до 1, где 0 означает невозможность, а 1 - абсолютная уверенность.
Шансовые события
Классическим примером вероятностного эксперимента является подбрасывание монеты, в котором возможны два исхода: "орел" или "решка". В этом случае вероятность того, что выпадет орел или решка, равна 1/2 (шансы 1 к 1). В реальной серии подбрасываний честной монеты мы можем получить больше или меньше, чем ровно 50%. Но по мере увеличения числа подбрасываний частота выпадения орла или решка в долгосрочной перспективе будет все ближе и ближе к 50%.
Математическое ожидание
Математическое ожидание случайной величины - число, которое пытается определить срединный центр распределения этой случайной величины. Его можно интерпретировать как долгосрочное среднее значение многих независимых выборок из данного распределения. Более точно, оно определяется как взвешенная по вероятности сумма всех возможных значений в поддержке случайной величины. Рассмотрим вероятностный эксперимент по бросанию честного кубика с 6 гранями. Вероятность выпадания значения от 1 до 6 составляет 1/6 или 0.17. Среднее значение выборки при многократном подбрасывании такого кубика сходится к ожидаемому значению (1+2+3+4+5+6)/6 = 3.5.
Дисперсия
В то время как ожидание определяет меру центральности, дисперсия случайной переменной количественно определяет разброс распределения этой случайной переменной около средней. Дисперсия - среднее значение квадрата разности между случайной величиной и ее ожиданием: Σ(xi - x̅)2 / n. Например, если бросать честный кубик, то дисперсия его значений будет стремится к ((1-3.5)^2 + (2-3.5)^2 + (3-3.5)^2 + (4-3.5)^2 + (5-3.5)^2 + (6-3.5)^2) /6 = 2.9.
Случайности окружают нас повсюду. Теория вероятности - математическая основа (аппарат), которая позволяет нам анализировать случайные события логически обоснованным образом. Вероятность события - число, показывающее, насколько вероятно, что это событие произойдет. Это число всегда находится в диапазоне от 0 до 1, где 0 означает невозможность, а 1 - абсолютная уверенность.
Шансовые события
Классическим примером вероятностного эксперимента является подбрасывание монеты, в котором возможны два исхода: "орел" или "решка". В этом случае вероятность того, что выпадет орел или решка, равна 1/2 (шансы 1 к 1). В реальной серии подбрасываний честной монеты мы можем получить больше или меньше, чем ровно 50%. Но по мере увеличения числа подбрасываний частота выпадения орла или решка в долгосрочной перспективе будет все ближе и ближе к 50%.
Математическое ожидание
Математическое ожидание случайной величины - число, которое пытается определить срединный центр распределения этой случайной величины. Его можно интерпретировать как долгосрочное среднее значение многих независимых выборок из данного распределения. Более точно, оно определяется как взвешенная по вероятности сумма всех возможных значений в поддержке случайной величины. Рассмотрим вероятностный эксперимент по бросанию честного кубика с 6 гранями. Вероятность выпадания значения от 1 до 6 составляет 1/6 или 0.17. Среднее значение выборки при многократном подбрасывании такого кубика сходится к ожидаемому значению (1+2+3+4+5+6)/6 = 3.5.
Дисперсия
В то время как ожидание определяет меру центральности, дисперсия случайной переменной количественно определяет разброс распределения этой случайной переменной около средней. Дисперсия - среднее значение квадрата разности между случайной величиной и ее ожиданием: Σ(xi - x̅)2 / n. Например, если бросать честный кубик, то дисперсия его значений будет стремится к ((1-3.5)^2 + (2-3.5)^2 + (3-3.5)^2 + (4-3.5)^2 + (5-3.5)^2 + (6-3.5)^2) /6 = 2.9.
👍3
Про базовые понятия вероятности и статистики. Часть 2
Множество
Множество в теории множеств — совокупность объектов или единичных событий. В контексте теории вероятностей мы используем множества для описания составных событий. Другими словами это математический язык, на котором можно записать различные выражения и условия. Например, {1, 2, 3} - множество, содержащее числа 1, 2 и 3; 1 ∈ {1, 2, 3} - 1 является элементом множества {1, 2, 3}; b ∉ {1, 2, 3} - b не является элементом множества {1, 2, 3} и т.д. Более подробно о константах множества здесь
Множество всех возможных исходов эксперимента называется пространством выборки. Мы представляем пространство выборки как множество, содержащее все возможные исходы. Например, если подбросить честную монету дважды, то пространство выборки будет следующим: S = {орел-орел, орел-решка, решка-орел, решка-решка}.
Если мы возьмем пациента, который обратился к врачу с некими неспецифичными симптомами, то пространство выборки в виде возможных диагнозов может быть огромным.
Комбинаторика
Бывает трудно подсчитать количество последовательностей или множеств, удовлетворяющих определенным условиям. Например, рассмотрим мешок с шариками, в котором 4 шарика разного цвета. Если мы будем вынимать шарики последовательно по одному из мешка, сколько различных упорядоченных последовательностей (перестановок) и неупорядоченных наборов (комбинаций) из всех шариков возможно?
Количество всех последовательностей из 4 цветных шариков = n! = 4! = 24
🟡🟢🔵🟣, 🟢🟡🔵🟣, 🟡🟢🟣🔵, и т.д.
Количество комбинаций из 4 шариков (в любой последовательности) = n! / ((n-k)! * k!) = 4! / ((4-4)! * 4!) = 24 / (1*24) = 1
🟡🟢🔵🟣
Количество комбинаций из 3 шариков (в любой последовательности) = 4! / ((4-3)! * 3!) = 4
🟡🟢🔵, 🟡🔵🟣, 🟡🟢🟣, 🟢🔵🟣
Условная вероятность
Условные вероятности позволяют нам учитывать информацию, которую мы имеем об интересующей нас системе. Например, мы можем ожидать, что вероятность того, что у пациента (в общем случае) инфекция, будет меньше, чем вероятность того, что у пациента инфекция, учитывая, что у него повышена температура. Эта последняя вероятность является условной вероятностью, поскольку она учитывает соответствующую информацию, которой мы обладаем. С математической точки зрения, вычисление условной вероятности равносильно сокращению пространства выборки до конкретного события. В системе "пациент" - сокращение числа возможных диагнозов, при условии, что мы имеем информацию о результатах обследования.
Вот пример. Вероятность того, что у случайного человека есть заболевание, может быть низкой, скажем, 5% (соответствует распространенности заболевания в популяции). Но если мы знаем, что у этого человека положительный результат скринингового теста, вероятность того, что у него действительно есть болезнь, при положительном результате теста, может быть гораздо выше. Конечно, если тест обладает хорошими показателями чувствительности и специфичности. Это и есть условная вероятность P(болезнь | положительный результат теста).
Множество
Множество в теории множеств — совокупность объектов или единичных событий. В контексте теории вероятностей мы используем множества для описания составных событий. Другими словами это математический язык, на котором можно записать различные выражения и условия. Например, {1, 2, 3} - множество, содержащее числа 1, 2 и 3; 1 ∈ {1, 2, 3} - 1 является элементом множества {1, 2, 3}; b ∉ {1, 2, 3} - b не является элементом множества {1, 2, 3} и т.д. Более подробно о константах множества здесь
Множество всех возможных исходов эксперимента называется пространством выборки. Мы представляем пространство выборки как множество, содержащее все возможные исходы. Например, если подбросить честную монету дважды, то пространство выборки будет следующим: S = {орел-орел, орел-решка, решка-орел, решка-решка}.
Если мы возьмем пациента, который обратился к врачу с некими неспецифичными симптомами, то пространство выборки в виде возможных диагнозов может быть огромным.
Комбинаторика
Бывает трудно подсчитать количество последовательностей или множеств, удовлетворяющих определенным условиям. Например, рассмотрим мешок с шариками, в котором 4 шарика разного цвета. Если мы будем вынимать шарики последовательно по одному из мешка, сколько различных упорядоченных последовательностей (перестановок) и неупорядоченных наборов (комбинаций) из всех шариков возможно?
Количество всех последовательностей из 4 цветных шариков = n! = 4! = 24
🟡🟢🔵🟣, 🟢🟡🔵🟣, 🟡🟢🟣🔵, и т.д.
Количество комбинаций из 4 шариков (в любой последовательности) = n! / ((n-k)! * k!) = 4! / ((4-4)! * 4!) = 24 / (1*24) = 1
🟡🟢🔵🟣
Количество комбинаций из 3 шариков (в любой последовательности) = 4! / ((4-3)! * 3!) = 4
🟡🟢🔵, 🟡🔵🟣, 🟡🟢🟣, 🟢🔵🟣
Условная вероятность
Условные вероятности позволяют нам учитывать информацию, которую мы имеем об интересующей нас системе. Например, мы можем ожидать, что вероятность того, что у пациента (в общем случае) инфекция, будет меньше, чем вероятность того, что у пациента инфекция, учитывая, что у него повышена температура. Эта последняя вероятность является условной вероятностью, поскольку она учитывает соответствующую информацию, которой мы обладаем. С математической точки зрения, вычисление условной вероятности равносильно сокращению пространства выборки до конкретного события. В системе "пациент" - сокращение числа возможных диагнозов, при условии, что мы имеем информацию о результатах обследования.
Вот пример. Вероятность того, что у случайного человека есть заболевание, может быть низкой, скажем, 5% (соответствует распространенности заболевания в популяции). Но если мы знаем, что у этого человека положительный результат скринингового теста, вероятность того, что у него действительно есть болезнь, при положительном результате теста, может быть гораздо выше. Конечно, если тест обладает хорошими показателями чувствительности и специфичности. Это и есть условная вероятность P(болезнь | положительный результат теста).
Про базовые понятия вероятности и статистики. Часть 3
Распределение вероятностей - определение относительных вероятностей всех возможных исходов.
Случайная величина (переменная) - формально функция, которая присваивает действительное число каждому исходу в вероятностном пространстве. Например, выборка пациентов из популяции - набор случайных величин.
Существует два основных класса распределений вероятности: дискретные и непрерывные. Дискретная случайная величина имеет конечное число возможных значений, которые можно подсчитать. Непрерывная случайная величина принимает несчетно бесконечное число возможных значений (например, все действительные числа).
Распределение дискретных величин:
Случайная величина Бернулли принимает значение 1 с вероятностью p и 0 с вероятностью 1-p. Самый простой пример - представление бинарных экспериментов, таких как бросание монеты. В медицине бинарные эксперименты очень распространены, например, прогноз того умрет пациент или нет к определенному моменту времени.
Биномиальная случайная величина представляет собой сумму n независимых случайных величин Бернулли с параметром p. Она используется для моделирования числа успехов в определенном количестве одинаковых бинарных экспериментов, например, числа орлов в пяти подбрасываниях монеты или при расчете летальности в группе пациентов. Пример из медицины был ранее в статшоте №111: https://t.me/statshots/111
Геометрическая случайная величина подсчитывает количество испытаний, необходимых для наблюдения одного успеха, где каждое испытание является независимым и имеет вероятность успеха p. Например, это распределение можно использовать для вычисления количества бросков кубика для того, чтобы выпала шестерка.
Предположим, проводится испытание нового препарата для лечения высокого кровяного давления. Врач дает лекарство пациентам и проверяет, снижается ли у них давление до нормального уровня, что свидетельствует об успешном применении лекарства. Каждый пациент имеет независимую вероятность p того, что лекарство подействует с первой попытки, например, p=0.5. Количество пациентов, на которых врач должен испробовать лекарство, прежде чем увидит первый успех, соответствует геометрическому распределению = 1/p = 2 пациента. Однако геометрическое распределение дает только ожидаемое число испытаний. Фактическое количество необходимых пациентов может быть больше или меньше 2. Это может быть 1 пациент (если препарат сработает с первой попытки), или 3 пациента, 4 пациента и так далее. Геометрическое распределение просто говорит нам, что в среднем мы ожидаем, что препарат подействует после лечения 2 пациентов.
Массовая функция вероятности (probability mass function, PMF) дискретной случайной величины описывает вероятность того, что случайная величина примет определенное значение. Для геометрического распределения PMF дает вероятность того, что первый успех произойдет на n-ом испытании: P(X = n) = p(1-p)^(n-1), в примере выше p - вероятность того, что препарат окажется эффективным для каждого конкретного пациента, n - количество пациентов, необходимое для достижения первого успеха. При p=0.5 и n=2 значение PMF = 0.25. Вероятность того, что для того, чтобы препарат впервые подействовал, потребуется ровно 2 пациента, учитывая, что вероятность успеха для любого отдельного пациента равна 0.5, составляет 0.25 или 25%. Остальные возможности (1 пациент, 3 пациента, 4 пациента и так далее) составляют в сумме оставшиеся 75% вероятности.
Таким образом, в данном случае геометрическая случайная величина представляет собой количество пациентов, на которых врач должен опробовать новое лекарство от давления, прежде чем впервые убедиться в его эффективности. Среднее значение и массовая функция вероятности этого геометрического распределения будут зависеть от вероятности p того, что лекарство сработает для любого пациента.
Пуассоновская случайная величина подсчитывает количество событий, происходящих в фиксированном интервале времени или пространства, учитывая, что эти события происходят со средней скоростью. Пример из медцины был ранее: https://t.me/statshots/110
Распределение вероятностей - определение относительных вероятностей всех возможных исходов.
Случайная величина (переменная) - формально функция, которая присваивает действительное число каждому исходу в вероятностном пространстве. Например, выборка пациентов из популяции - набор случайных величин.
Существует два основных класса распределений вероятности: дискретные и непрерывные. Дискретная случайная величина имеет конечное число возможных значений, которые можно подсчитать. Непрерывная случайная величина принимает несчетно бесконечное число возможных значений (например, все действительные числа).
Распределение дискретных величин:
Случайная величина Бернулли принимает значение 1 с вероятностью p и 0 с вероятностью 1-p. Самый простой пример - представление бинарных экспериментов, таких как бросание монеты. В медицине бинарные эксперименты очень распространены, например, прогноз того умрет пациент или нет к определенному моменту времени.
Биномиальная случайная величина представляет собой сумму n независимых случайных величин Бернулли с параметром p. Она используется для моделирования числа успехов в определенном количестве одинаковых бинарных экспериментов, например, числа орлов в пяти подбрасываниях монеты или при расчете летальности в группе пациентов. Пример из медицины был ранее в статшоте №111: https://t.me/statshots/111
Геометрическая случайная величина подсчитывает количество испытаний, необходимых для наблюдения одного успеха, где каждое испытание является независимым и имеет вероятность успеха p. Например, это распределение можно использовать для вычисления количества бросков кубика для того, чтобы выпала шестерка.
Предположим, проводится испытание нового препарата для лечения высокого кровяного давления. Врач дает лекарство пациентам и проверяет, снижается ли у них давление до нормального уровня, что свидетельствует об успешном применении лекарства. Каждый пациент имеет независимую вероятность p того, что лекарство подействует с первой попытки, например, p=0.5. Количество пациентов, на которых врач должен испробовать лекарство, прежде чем увидит первый успех, соответствует геометрическому распределению = 1/p = 2 пациента. Однако геометрическое распределение дает только ожидаемое число испытаний. Фактическое количество необходимых пациентов может быть больше или меньше 2. Это может быть 1 пациент (если препарат сработает с первой попытки), или 3 пациента, 4 пациента и так далее. Геометрическое распределение просто говорит нам, что в среднем мы ожидаем, что препарат подействует после лечения 2 пациентов.
Массовая функция вероятности (probability mass function, PMF) дискретной случайной величины описывает вероятность того, что случайная величина примет определенное значение. Для геометрического распределения PMF дает вероятность того, что первый успех произойдет на n-ом испытании: P(X = n) = p(1-p)^(n-1), в примере выше p - вероятность того, что препарат окажется эффективным для каждого конкретного пациента, n - количество пациентов, необходимое для достижения первого успеха. При p=0.5 и n=2 значение PMF = 0.25. Вероятность того, что для того, чтобы препарат впервые подействовал, потребуется ровно 2 пациента, учитывая, что вероятность успеха для любого отдельного пациента равна 0.5, составляет 0.25 или 25%. Остальные возможности (1 пациент, 3 пациента, 4 пациента и так далее) составляют в сумме оставшиеся 75% вероятности.
Таким образом, в данном случае геометрическая случайная величина представляет собой количество пациентов, на которых врач должен опробовать новое лекарство от давления, прежде чем впервые убедиться в его эффективности. Среднее значение и массовая функция вероятности этого геометрического распределения будут зависеть от вероятности p того, что лекарство сработает для любого пациента.
Пуассоновская случайная величина подсчитывает количество событий, происходящих в фиксированном интервале времени или пространства, учитывая, что эти события происходят со средней скоростью. Пример из медцины был ранее: https://t.me/statshots/110
Отрицательная биномиальная случайная величина подсчитывает количество одних событий в последовательности независимых испытаний Бернулли с параметром p до того как произойдет нужное другое событие. Например, это распределение можно использовать для моделирования количества выпадения орлов, которые выпадут до появления трех решек в последовательности бросания монет. Предположим, врач пробует новый метод лечения определенного заболевания. Вероятность (p) ответа на лечение, например, p=0.5. Лечение считается успешным, если хотя бы 5 (r) пациентов на него ответили. Ожидаемое число пациентов, на которых врач должен опробовать лечение, пока не будет достигнуто 5 положительных результатов, соответствует отрицательному биномиальному распределению = r/p = 5/0.5 = 10 (количество "неудач" + "успехов"). Ожидаемое число неудач (не ответивших на лечение пациентов) = r*(1-p)/p = 5. Также в этом случаем можно рассчитать PMF, но уже по более сложной формуле: P(X = k) = (k-1)! / (r-1)!(k-r)! * p^r * (1-p)^(k-r), где k = необходимое количество "неудач" + "успехов".
Распределение непрерывных величин:
Равномерное распределение - непрерывное распределение, при котором все исходы имеют равную вероятность возникновения. Другими словами, все возможные значения в диапазоне имеют равные шансы быть выбранными. Пример равномерного распределения являются бросок несмещенного кубика - каждое число от 1 до 6 имеет вероятность 1/6 (формально это распределение дискретной случайной величины), измерение температуры / частоты сердечных сокращений / уровня гемоглобина и т.д. у пациента, находящегося в одинаковых условиях (с оговоркой, что показатели здоровья пациента не могут принимать какие угодно значения). То есть если мы будем измерять уровень гемоглобина у случайно взятых здоровых лиц, то мы получим разные его значения, но с одинаковой вероятностью в пределах референсного интервала.
Нормальное (или Гауссово) распределение имеет колоколообразную функцию плотности и используется в науке для представления реальных случайных величин, которые, как предполагается, аддитивно порождаются множеством малых воздействий (отдельные случайные события вносят фиксированный вклад в общий результат). Также см. https://t.me/statshots/73
t-распределение Стьюдента, или просто t-распределение, возникает при оценке среднего значения нормально распределенной совокупности в ситуациях, когда размер выборки мал (менее 30 наблюдений), а стандартное отклонение неизвестно. t-распределение учитывает эту большую неопределенность из-за малого размера выборки. Оно имеет более толстые "хвосты" по сравнению с нормальным распределением, поскольку более экстремальные отклонения от среднего значения более вероятны, когда среднее значение выборки оценивается с меньшей точностью. По мере увеличения объема выборки t-распределение начинает приближаться к нормальному распределению. Это происходит потому, что при увеличении выборки оценка среднего становится более точной и определенной. Практическое значение данного тезиса сводится к возможности применения теста Стьюдента на малых выборках вне нормального распределения, но при наличии некоторых других допущений (отсуствия экстремальных выбросов, равенстве дисперсий в группах).
Другие типы распределений: хи-квадрат, экспоненциальное, Фишера, гамма, бета.
Центральная предельная теорема (ЦПТ)
ЦПТ утверждает, что выборочное среднее достаточно большого числа случайных величин распределено приблизительно нормально. Чем больше выборка, тем лучше такая аппроксимация. Если мы последовательно будем формировать множество выборок пациентов из одной популяции, то распределение средних значений, например, возраста в данных выборках будет принимать приблизительно нормальное распределение.
Распределение непрерывных величин:
Равномерное распределение - непрерывное распределение, при котором все исходы имеют равную вероятность возникновения. Другими словами, все возможные значения в диапазоне имеют равные шансы быть выбранными. Пример равномерного распределения являются бросок несмещенного кубика - каждое число от 1 до 6 имеет вероятность 1/6 (формально это распределение дискретной случайной величины), измерение температуры / частоты сердечных сокращений / уровня гемоглобина и т.д. у пациента, находящегося в одинаковых условиях (с оговоркой, что показатели здоровья пациента не могут принимать какие угодно значения). То есть если мы будем измерять уровень гемоглобина у случайно взятых здоровых лиц, то мы получим разные его значения, но с одинаковой вероятностью в пределах референсного интервала.
Нормальное (или Гауссово) распределение имеет колоколообразную функцию плотности и используется в науке для представления реальных случайных величин, которые, как предполагается, аддитивно порождаются множеством малых воздействий (отдельные случайные события вносят фиксированный вклад в общий результат). Также см. https://t.me/statshots/73
t-распределение Стьюдента, или просто t-распределение, возникает при оценке среднего значения нормально распределенной совокупности в ситуациях, когда размер выборки мал (менее 30 наблюдений), а стандартное отклонение неизвестно. t-распределение учитывает эту большую неопределенность из-за малого размера выборки. Оно имеет более толстые "хвосты" по сравнению с нормальным распределением, поскольку более экстремальные отклонения от среднего значения более вероятны, когда среднее значение выборки оценивается с меньшей точностью. По мере увеличения объема выборки t-распределение начинает приближаться к нормальному распределению. Это происходит потому, что при увеличении выборки оценка среднего становится более точной и определенной. Практическое значение данного тезиса сводится к возможности применения теста Стьюдента на малых выборках вне нормального распределения, но при наличии некоторых других допущений (отсуствия экстремальных выбросов, равенстве дисперсий в группах).
Другие типы распределений: хи-квадрат, экспоненциальное, Фишера, гамма, бета.
Центральная предельная теорема (ЦПТ)
ЦПТ утверждает, что выборочное среднее достаточно большого числа случайных величин распределено приблизительно нормально. Чем больше выборка, тем лучше такая аппроксимация. Если мы последовательно будем формировать множество выборок пациентов из одной популяции, то распределение средних значений, например, возраста в данных выборках будет принимать приблизительно нормальное распределение.
Про базовые понятия вероятности и статистики. Часть 4
Частотный вывод (Frequentist Inference) - вид статистического вывода, процесс определения свойств базового распределения на основе наблюдения за данными.
Точечная оценка
Одна из основных целей статистики - оценка неизвестных параметров. Для аппроксимации этих параметров мы выбираем оценщик, который является просто любой функцией случайно отобранных наблюдений. Примеры простых оценщиков выборочных данных: средняя, медиана, пропорция и др.
Доверительный интервал (ДИ)
В отличие от точечных оценок, с помощью ДИ оценивают параметр, задавая диапазон возможных значений. Такой интервал связан с уровнем доверия, который представляет собой вероятность того, что при повторе эксперимента с теми же условиями мы получим результат, находящийся в пределах данного интервала. Другими словами, это уверенность (например, 95% или 99%), что истинный параметр популяции находится в пределах вычисленного интервала. Также можно сказать, что 95% ДИ означает, что если мы будем повторять экспермент (выборку и расчеты) много раз и каждый раз вычислять ДИ, то примерно 95% вычисленных интервалов будут содержать истинный, изучаемый нами, параметр популяции. Например, с помощью ДИ можно описать возрастное распределение пациентов.
Бутстрэп (Bootstrap)
Статистический метод, который обеспечивает удобный способ оценки свойств статистического вывода с помощью повторной выборки, что позволяет расчитать ДИ для изучаемого параметра.
Дополнительно здесь: https://t.me/statshots/138
Частотный вывод (Frequentist Inference) - вид статистического вывода, процесс определения свойств базового распределения на основе наблюдения за данными.
Точечная оценка
Одна из основных целей статистики - оценка неизвестных параметров. Для аппроксимации этих параметров мы выбираем оценщик, который является просто любой функцией случайно отобранных наблюдений. Примеры простых оценщиков выборочных данных: средняя, медиана, пропорция и др.
Доверительный интервал (ДИ)
В отличие от точечных оценок, с помощью ДИ оценивают параметр, задавая диапазон возможных значений. Такой интервал связан с уровнем доверия, который представляет собой вероятность того, что при повторе эксперимента с теми же условиями мы получим результат, находящийся в пределах данного интервала. Другими словами, это уверенность (например, 95% или 99%), что истинный параметр популяции находится в пределах вычисленного интервала. Также можно сказать, что 95% ДИ означает, что если мы будем повторять экспермент (выборку и расчеты) много раз и каждый раз вычислять ДИ, то примерно 95% вычисленных интервалов будут содержать истинный, изучаемый нами, параметр популяции. Например, с помощью ДИ можно описать возрастное распределение пациентов.
Бутстрэп (Bootstrap)
Статистический метод, который обеспечивает удобный способ оценки свойств статистического вывода с помощью повторной выборки, что позволяет расчитать ДИ для изучаемого параметра.
Дополнительно здесь: https://t.me/statshots/138
Про базовые понятия вероятности и статистики. Часть 5
Байесовский вывод - статистический подход, позволяющий получить вероятности изучаемых событий (явлений) по мере получения новых данных, учитывая предварительные знания и учась на новой информации. При байесовском выводе мы сначала задаем предварительное распределение вероятностей, которое отражает наши представления о параметрах до получения данных. Затем мы получаем новую информацию и, используя теорему Байеса, обновляем предварительное (априорное) распределение, чтобы получить апостериорное распределение вероятности.
Предположим, что во время последнего визита к врачу пациент решил пройти тест на некое заболевание. Если ему не повезло и результат оказался положительным, то логичным будет следующий вопрос: "Учитывая результат теста, какова вероятность того, что у пациента действительно есть это заболевание?" Медицинские тесты, в конце концов, не являются идеально точными. Ответ на вопрос следующий P(Disease|+) = P(+|Disease) x P(Disease) / P(+).
Как следует из уравнения, апостериорная вероятность наличия заболевания при положительном результате теста зависит от априорной вероятности заболевания P(Disease). Можно считать, что это частота встречаемости заболевания в общей популяции. Например, 0.1 (10%). Апостериорная вероятность также зависит от точности теста: как часто тест правильно сообщает об отрицательном результате для здорового пациента (специфичность) и как часто он сообщает о положительном результате для человека с заболеванием (чувствительность). Например, чувствительность = специфичность = 0.75. Наконец, нам необходимо знать общую вероятность положительного результата P(+) в популяции, например, 0.3.
Теперь у нас есть все необходимое для расчетов:
P(Disease|+) = 0.75 (чувствительность) x 0.1 / 0.3 = 0.25 (только 25%!)
P(Healthy|-) = 0.75 (специфичность) x (1-0.1) / (1-0.3) = 0.96
P(Disease|-) = 1-0.96 = 0.04
P(Healthy|+) = 1-0.25 = 0.75
Правдоподобие (Likelihood)
Понятие правдоподобия играет фундаментальную роль как в байесовской, так и в частотной статистике. В байесовском выводе под правдоподобием понимается вероятность получения данных с учетом гипотезы или модели. Правдоподобие представляет собой вероятность наблюдения тех значений данных, которые мы наблюдаем, в случае истинности определенной гипотезы или модели. Таким образом, правдоподобие по сути, является оценкой того, насколько хорошо конкретная модель соответствует наблюдаемым данным. Модель с более высоким значением правдоподобия означает, что данные с большей вероятностью соответствуют этой модели. Правдоподобие = вероятность той или иной гипотезы, которых может быть много. В примере выше правдоподобие, например, показывает, насколько вероятен результат теста (например, положительный результат), если у пациента действительно есть заболевание, что будет равно чувствительности 0.75 (вероятность гипотезы, что пациент болен при положительном результате теста).
Отношение правдоподобия (фактор Байеса, LR) – решение о том, какая из гипотез более правдоподобна в эксперименте. В примере выше чувствительность диагностического теста = 0.75 и специфичность = 0.75 (частота ложноположительных результатов = 1-0.75=0.25). Тогда, положительный тест будет верно прогнозировать заболевание у пациента, имеющего данное заболевание, в 0.75/0.25 = 3 раз чаще, чем отрицательный. Это и есть LR+ для положительного результата теста. Другими словами, если до применения теста вероятность заболевания у пациента расценивалась как 10% или шансы 1/9, то после получения результатов теста шансы увеличились до 1/9 x LR (3)=3/9=1/3 (~0.33), а вероятность заболевания составила 0.33/(1+0.33) = 25%. Другими словами вероятность, что пациент болен стала на 25-10=15% выше вероятности, что он болен исходя из априорной вероятности иметь болезнь в популяции, равной 10%.
Как видно из примеров выше, вероятность гипотезы (правдоподобие) не равно истинной вероятности события. Вероятность гипотезы, что пациент болен при положительном результате теста равняется 75%, а истинная вероятность, что пациент болен составила только 25%.
Байесовский вывод - статистический подход, позволяющий получить вероятности изучаемых событий (явлений) по мере получения новых данных, учитывая предварительные знания и учась на новой информации. При байесовском выводе мы сначала задаем предварительное распределение вероятностей, которое отражает наши представления о параметрах до получения данных. Затем мы получаем новую информацию и, используя теорему Байеса, обновляем предварительное (априорное) распределение, чтобы получить апостериорное распределение вероятности.
Предположим, что во время последнего визита к врачу пациент решил пройти тест на некое заболевание. Если ему не повезло и результат оказался положительным, то логичным будет следующий вопрос: "Учитывая результат теста, какова вероятность того, что у пациента действительно есть это заболевание?" Медицинские тесты, в конце концов, не являются идеально точными. Ответ на вопрос следующий P(Disease|+) = P(+|Disease) x P(Disease) / P(+).
Как следует из уравнения, апостериорная вероятность наличия заболевания при положительном результате теста зависит от априорной вероятности заболевания P(Disease). Можно считать, что это частота встречаемости заболевания в общей популяции. Например, 0.1 (10%). Апостериорная вероятность также зависит от точности теста: как часто тест правильно сообщает об отрицательном результате для здорового пациента (специфичность) и как часто он сообщает о положительном результате для человека с заболеванием (чувствительность). Например, чувствительность = специфичность = 0.75. Наконец, нам необходимо знать общую вероятность положительного результата P(+) в популяции, например, 0.3.
Теперь у нас есть все необходимое для расчетов:
P(Disease|+) = 0.75 (чувствительность) x 0.1 / 0.3 = 0.25 (только 25%!)
P(Healthy|-) = 0.75 (специфичность) x (1-0.1) / (1-0.3) = 0.96
P(Disease|-) = 1-0.96 = 0.04
P(Healthy|+) = 1-0.25 = 0.75
Правдоподобие (Likelihood)
Понятие правдоподобия играет фундаментальную роль как в байесовской, так и в частотной статистике. В байесовском выводе под правдоподобием понимается вероятность получения данных с учетом гипотезы или модели. Правдоподобие представляет собой вероятность наблюдения тех значений данных, которые мы наблюдаем, в случае истинности определенной гипотезы или модели. Таким образом, правдоподобие по сути, является оценкой того, насколько хорошо конкретная модель соответствует наблюдаемым данным. Модель с более высоким значением правдоподобия означает, что данные с большей вероятностью соответствуют этой модели. Правдоподобие = вероятность той или иной гипотезы, которых может быть много. В примере выше правдоподобие, например, показывает, насколько вероятен результат теста (например, положительный результат), если у пациента действительно есть заболевание, что будет равно чувствительности 0.75 (вероятность гипотезы, что пациент болен при положительном результате теста).
Отношение правдоподобия (фактор Байеса, LR) – решение о том, какая из гипотез более правдоподобна в эксперименте. В примере выше чувствительность диагностического теста = 0.75 и специфичность = 0.75 (частота ложноположительных результатов = 1-0.75=0.25). Тогда, положительный тест будет верно прогнозировать заболевание у пациента, имеющего данное заболевание, в 0.75/0.25 = 3 раз чаще, чем отрицательный. Это и есть LR+ для положительного результата теста. Другими словами, если до применения теста вероятность заболевания у пациента расценивалась как 10% или шансы 1/9, то после получения результатов теста шансы увеличились до 1/9 x LR (3)=3/9=1/3 (~0.33), а вероятность заболевания составила 0.33/(1+0.33) = 25%. Другими словами вероятность, что пациент болен стала на 25-10=15% выше вероятности, что он болен исходя из априорной вероятности иметь болезнь в популяции, равной 10%.
Как видно из примеров выше, вероятность гипотезы (правдоподобие) не равно истинной вероятности события. Вероятность гипотезы, что пациент болен при положительном результате теста равняется 75%, а истинная вероятность, что пациент болен составила только 25%.
Вычисление размера выборки для оценки арифметической средней. Предположим, что мы хотим оценить среднее систолическое артериальное давление в группе пациентов, чтобы 95% доверительный интервал (d) был шириной 10 мм рт.ст., т.е. 5 мм рт.ст. в обе стороны от среднего значения, не больше.
1. Посчитайте стандартное отклонение выборки, например, SD=11.
2. Воспользйтесь формулой: 1.96^2 x 4 x SD^2 / d^2 = 1.96^2 x 4 x 11^2 / 10^2 = 19 пациентов.
Если уменьшить ДИ до 5 мм рт.ст.: 1.96^2 x 4 x 11^2 / 5^2 = 74 пациента. Сокращение ДИ в 2 раза увеличивает размер выборки в 4.
Если ваша выборка меньше полученного значения, ее необходимо увеличить, чтобы соответствовать требуемым критериям.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4 x SD^2 / d^2
90% ДИ: N = 1.64^2 x 4 x SD^2 / d^2
99% ДИ: N = 2.58^2 x 4 x SD^2 / d^2
1. Посчитайте стандартное отклонение выборки, например, SD=11.
2. Воспользйтесь формулой: 1.96^2 x 4 x SD^2 / d^2 = 1.96^2 x 4 x 11^2 / 10^2 = 19 пациентов.
Если уменьшить ДИ до 5 мм рт.ст.: 1.96^2 x 4 x 11^2 / 5^2 = 74 пациента. Сокращение ДИ в 2 раза увеличивает размер выборки в 4.
Если ваша выборка меньше полученного значения, ее необходимо увеличить, чтобы соответствовать требуемым критериям.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4 x SD^2 / d^2
90% ДИ: N = 1.64^2 x 4 x SD^2 / d^2
99% ДИ: N = 2.58^2 x 4 x SD^2 / d^2
Вычисление размера выборки для оценки пропорции.
Предположим, что мы хотим оценить распространенность (частоту встречаемости) некоего заболевания среди взрослого населения чтобы 95% доверительный интервал (d) был шириной 0.1 (10%), т.е. 5% в обе стороны от доли заболевания в популяции.
1. Задайте ожидаемую долю заболевания в популяции (p), например, p=0.1 (10%). Ее можно предположить или взять из других исследований (литературы). Если никакие варианты не подходят, используйте p=0.5.
2. Воспользйтесь формулой: 1.96^2 x 4p x (1-p) / d^2 = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.1^2 = 138 пациентов.
Если мы удвоим точность измерения сузив ДИ до 0.05 (5%), то N = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.05^2 = 553 пациента.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4p x (1-p) / d^2
90% ДИ: N = 1.64^2 x 4p x (1-p) / d^2
99% ДИ: N = 2.58^2 x 4p x (1-p) / d^2
❗ Правда более классическая формула не включает в себя множитель "4", 95% ДИ: N = 1.96^2 x p x (1-p) / d^2. Калькулятор
Предположим, что мы хотим оценить распространенность (частоту встречаемости) некоего заболевания среди взрослого населения чтобы 95% доверительный интервал (d) был шириной 0.1 (10%), т.е. 5% в обе стороны от доли заболевания в популяции.
1. Задайте ожидаемую долю заболевания в популяции (p), например, p=0.1 (10%). Ее можно предположить или взять из других исследований (литературы). Если никакие варианты не подходят, используйте p=0.5.
2. Воспользйтесь формулой: 1.96^2 x 4p x (1-p) / d^2 = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.1^2 = 138 пациентов.
Если мы удвоим точность измерения сузив ДИ до 0.05 (5%), то N = 1.96^2 x 4 x 0.1 x (1-0.1) / 0.05^2 = 553 пациента.
Формулы для различных ДИ:
95% ДИ: N = 1.96^2 x 4p x (1-p) / d^2
90% ДИ: N = 1.64^2 x 4p x (1-p) / d^2
99% ДИ: N = 2.58^2 x 4p x (1-p) / d^2
❗ Правда более классическая формула не включает в себя множитель "4", 95% ДИ: N = 1.96^2 x p x (1-p) / d^2. Калькулятор
#глоссарий. Минимальная клинически значимая разница (minimum clinically important difference, MCID) - наименьший размер различия в данных, который исследователь считает настолько важным, что не хотел бы, чтобы его не заметили в ходе исследования. Другими словами, этот размер разницы между величинами считается клинически значимым. MCID необходима при расчете минимального размера выборки. Если выборка данных слишком мала для того, чтобы обнаружить эту величину различий, а она на самом деле существует, то сравнение не будет иметь клинической значимости, а исследование будет неубедительным и его нет смысла проводить. Выбор величины MCID не является статистическим правилом, а зависит от контекста исследования.