This media is not supported in your browser
VIEW IN TELEGRAM
La Baie Aréa — несуществующий сериал со звездным актерским составом
Видео: Gen-3 от Runway.
Промпт для создания музыки в Udio: 1960s [70-80] Chanson française cinématographiqu.
Автор: https://x.com/trbdrk
—
GPT-4o и Midjourney v6.1 доступны в c.aiacademy.me
@startobus 🧠 #ИИПоехали /#GoAI
Видео: Gen-3 от Runway.
Промпт для создания музыки в Udio: 1960s [70-80] Chanson française cinématographiqu.
Автор: https://x.com/trbdrk
—
GPT-4o и Midjourney v6.1 доступны в c.aiacademy.me
@startobus 🧠 #ИИПоехали /#GoAI
❤1👍1👏1
Рекламные чаты
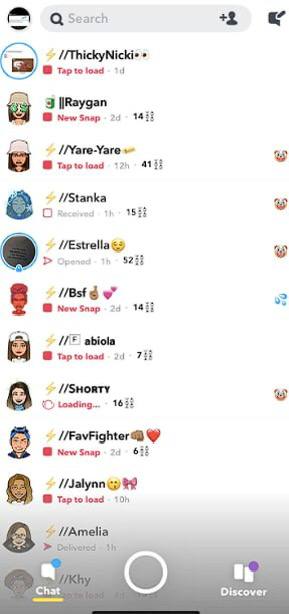
Есть такая платформа Snap (бывший Snapchat). У нас она популярности не сыскала, но в США и других странах запада это довольно крепкий сервис с неплохой пользовательской базой. Основная механика Snap - это отправка сообщений и изображений/видео, которые исчезают через определенное время. То есть это действительно instant messenger в буквальном смысле этого слова. А еще Snap первым изобрел сторисы, которые потом перекочевали во все соцсети и платформы. Но сейчас не об этом.
На днях Snap добавил новую рекламную механику - проплаченные снэпы. Это такие рекламные сообщения, мимикрирующие под обычные чаты. То есть они будут прилетать прямо как обычные сообщения от новых собеседников и висеть между обычными чатами в ленте. Не рекламные сообщения/посты в других каналах или чатах, а полноценные отдельные рекламные чаты (например, на картинке выше видно рекламный сторис от Estrella). Внутри фичи будет интеграция с CRM-системами компаний и ИИ-генератор, куда же без этого.
Подобная механика также есть у Linkedin (спонсорские InMails). Еще что-то похожее вроде бы есть у Viber, но я уже не помню точно.
В общем, главное эту штуку Пал Валерьичу не показывать. ИМХО, это абсолютно шакалья рекламная механика, которая не должна существовать.
Фичизм
@startobus 🧠 #ИИПоехали /#GoAI
Есть такая платформа Snap (бывший Snapchat). У нас она популярности не сыскала, но в США и других странах запада это довольно крепкий сервис с неплохой пользовательской базой. Основная механика Snap - это отправка сообщений и изображений/видео, которые исчезают через определенное время. То есть это действительно instant messenger в буквальном смысле этого слова. А еще Snap первым изобрел сторисы, которые потом перекочевали во все соцсети и платформы. Но сейчас не об этом.
На днях Snap добавил новую рекламную механику - проплаченные снэпы. Это такие рекламные сообщения, мимикрирующие под обычные чаты. То есть они будут прилетать прямо как обычные сообщения от новых собеседников и висеть между обычными чатами в ленте. Не рекламные сообщения/посты в других каналах или чатах, а полноценные отдельные рекламные чаты (например, на картинке выше видно рекламный сторис от Estrella). Внутри фичи будет интеграция с CRM-системами компаний и ИИ-генератор, куда же без этого.
Подобная механика также есть у Linkedin (спонсорские InMails). Еще что-то похожее вроде бы есть у Viber, но я уже не помню точно.
В общем, главное эту штуку Пал Валерьичу не показывать. ИМХО, это абсолютно шакалья рекламная механика, которая не должна существовать.
Фичизм
@startobus 🧠 #ИИПоехали /#GoAI
{kind=link}
Последнее время часто возвращаюсь к этому интересному анализу и прогнозу развития ИИ. Почти все сбывается, но, возможно, ошибка в запросе на энергетику не в 20, а в 10 раз к 2030-2040 годам. Разработчики процессоров и алгоритмов, кажется, находят менее энергозатратные методы работы с ИИ.
Кому интересно почитать подробнее - вот ссылка на пост: https://t.me/startobus/3285 (вообще в канале писал по этой теме несколько раз искать поиском #экосистема ИИ).
Думаю, скоро запишу видео с текущим состоянием и обновленным прогнозом. Будет удобно структурировать эти данные и обсудить их с теми, кому это интересно. Подписывайтесь на канал, чтобы не пропустить!
#ИИ #прогноз #энергоэффективность #развитие
Буду рад обсудить пост и идеи для улучшения в комментариях или в чате канала. Всем хороших идей!
Кому интересно почитать подробнее - вот ссылка на пост: https://t.me/startobus/3285 (вообще в канале писал по этой теме несколько раз искать поиском #экосистема ИИ).
Думаю, скоро запишу видео с текущим состоянием и обновленным прогнозом. Будет удобно структурировать эти данные и обсудить их с теми, кому это интересно. Подписывайтесь на канал, чтобы не пропустить!
#ИИ #прогноз #энергоэффективность #развитие
Буду рад обсудить пост и идеи для улучшения в комментариях или в чате канала. Всем хороших идей!
Telegram
STARTOBUS
Анализ драверов роста и тормозов в ИИ.
На картинке представлена воронка-экосистема ИИ по поличеству учатников:
🚀 Уровень 1: Прикладники ИИ
Сейчас более 3 млн команд трудятся над прикладными решениями на базе ИИ. Большая часть этих решений переходит в магазины…
На картинке представлена воронка-экосистема ИИ по поличеству учатников:
🚀 Уровень 1: Прикладники ИИ
Сейчас более 3 млн команд трудятся над прикладными решениями на базе ИИ. Большая часть этих решений переходит в магазины…
Бум D2C, кажется, может закончиться так же быстро, как и начался.
Бизнес-модель прямых продаж особенно пышно расцвела в последнее десятилетие. Тысячи стартапов стали предлагать товары повседневного спроса (одежду, обувь, очки и т. д.) напрямую потребителям, минуя традиционных посредников в лице оптовиков и крупных розничных сетей.
Посредники изрядно напряглись. Однако счастье большинства D2C-брендов оказалось недолгим. На этой инфографике от Trendline — изменение рыночной капитализации 6 популярных D2C-брендов. Как видите, просадка там мощная. За последние годы эти бренды в совокупности потеряли в рыночной стоимости $21,5 миллиарда.
Не менее показателен кейс одного из пионеров D2C — производителя матрасов Casper, который в эту инфографику не вошёл. Компания привлекла значительные инвестиции (в неё вложился даже Леонардо Ди Каприо) и на своём пике оценивалась в более чем $1,1 миллиарда, то есть стала «единорогом». Однако после выхода на IPO её акции просели на 70%. В результате в конце 2021 года Casper выпилилась с фондовой биржи и с большим дисконтом была продана частной инвестиционной фирме.
Есть, конечно, и исключения. Например, прекрасно себя чувствует американская D2C-компания HIMS, которая торгует медицинскими и косметическими товарами. Её акции за последние 3 года выросли на 227%. Но успех HIMS может быть отчасти обусловлен сочетанием прямых продаж и индивидуального обслуживания клиентов (в виде онлайн-консультаций с врачами).
И всё же общий тренд налицо — модель буксует. По данным Crunchbase, с 2018 по 2023 год количество венчурных сделок с DTC-стартапами сократилось на 67%, а суммарный объём привлечённых средств снизился на 87%.
Причин тут несколько:
▪️ Неустойчивость модели. Многие D2C-компании долгое время работали в убыток. Из брендов, представленных на инфографике, получить небольшую прибыль удалось только Figs (торгует товарами для медицинских работников). Стремясь к агрессивному росту, D2C-компании сжигали деньги инвесторов в промышленных количествах. Что неудивительно: современный e-commerce с его дешёвой доставкой и массовыми возвратами — сложная и высокозатратная штука.
▪️ Рост затрат на привлечение клиентов. С увеличением конкуренции (в том числе со стороны других D2C-брендов) стоимость цифровой рекламы резко возросла. Например, в 2019 году насчитывалось аж 175 компаний, продающих матрасы онлайн напрямую потребителям.
▪️ Приход в нишу традиционных ритейлеров. Крупные потребительские бренды и розничные сети стали создавать собственные каналы прямых продаж. Например, как уже рассказывал, большую ставку на D2C сделали Nike и Adidas.
▪️ Трудности с логистикой. Из-за глобальных сбоев, вызванных пандемией, расходы D2C-компаний на доставку и возвраты товаров ощутимо выросли, что ещё более увеличило их операционные издержки. Это, в свою очередь, ударило по и без того невысокой марже.
▪️ Ренессанс офлайн-ритейла. После пандемии многие потребители стали возвращаться в традиционные магазины. Возможность пощупать, примерить или ещё каким-то образом ознакомиться с продукцией перед покупкой — критически важна для многих категорий товаров, которыми торгуют бренды прямых продаж. Некоторые из них (например, Warby Parker и Allbirds) в итоге стали открывать физические точки, что опять же сопряжено с увеличением операционных расходов.
Подытоживая: D2C как концепция не исчезнет, но будет вынуждена себя переизобретать для каждой ниши отдельно и дрейфовать в сторону более сложных и многоканальных стратегий маркетинга и продаж. Одного лишь прямого контакта с потребителем для успеха недостаточно. В выигрыше окажутся те, кто найдёт способы диверсифицировать каналы сбыта и оптимизировать затраты на привлечение клиентов и логистику.
Вот что ещё я писал об этом:
- Nike «просто делает это»
- Почему eCom переходит в офлайн
Источник
@startobus 🧠 #ИИПоехали /#GoAI
Бизнес-модель прямых продаж особенно пышно расцвела в последнее десятилетие. Тысячи стартапов стали предлагать товары повседневного спроса (одежду, обувь, очки и т. д.) напрямую потребителям, минуя традиционных посредников в лице оптовиков и крупных розничных сетей.
Посредники изрядно напряглись. Однако счастье большинства D2C-брендов оказалось недолгим. На этой инфографике от Trendline — изменение рыночной капитализации 6 популярных D2C-брендов. Как видите, просадка там мощная. За последние годы эти бренды в совокупности потеряли в рыночной стоимости $21,5 миллиарда.
Не менее показателен кейс одного из пионеров D2C — производителя матрасов Casper, который в эту инфографику не вошёл. Компания привлекла значительные инвестиции (в неё вложился даже Леонардо Ди Каприо) и на своём пике оценивалась в более чем $1,1 миллиарда, то есть стала «единорогом». Однако после выхода на IPO её акции просели на 70%. В результате в конце 2021 года Casper выпилилась с фондовой биржи и с большим дисконтом была продана частной инвестиционной фирме.
Есть, конечно, и исключения. Например, прекрасно себя чувствует американская D2C-компания HIMS, которая торгует медицинскими и косметическими товарами. Её акции за последние 3 года выросли на 227%. Но успех HIMS может быть отчасти обусловлен сочетанием прямых продаж и индивидуального обслуживания клиентов (в виде онлайн-консультаций с врачами).
И всё же общий тренд налицо — модель буксует. По данным Crunchbase, с 2018 по 2023 год количество венчурных сделок с DTC-стартапами сократилось на 67%, а суммарный объём привлечённых средств снизился на 87%.
Причин тут несколько:
▪️ Неустойчивость модели. Многие D2C-компании долгое время работали в убыток. Из брендов, представленных на инфографике, получить небольшую прибыль удалось только Figs (торгует товарами для медицинских работников). Стремясь к агрессивному росту, D2C-компании сжигали деньги инвесторов в промышленных количествах. Что неудивительно: современный e-commerce с его дешёвой доставкой и массовыми возвратами — сложная и высокозатратная штука.
▪️ Рост затрат на привлечение клиентов. С увеличением конкуренции (в том числе со стороны других D2C-брендов) стоимость цифровой рекламы резко возросла. Например, в 2019 году насчитывалось аж 175 компаний, продающих матрасы онлайн напрямую потребителям.
▪️ Приход в нишу традиционных ритейлеров. Крупные потребительские бренды и розничные сети стали создавать собственные каналы прямых продаж. Например, как уже рассказывал, большую ставку на D2C сделали Nike и Adidas.
▪️ Трудности с логистикой. Из-за глобальных сбоев, вызванных пандемией, расходы D2C-компаний на доставку и возвраты товаров ощутимо выросли, что ещё более увеличило их операционные издержки. Это, в свою очередь, ударило по и без того невысокой марже.
▪️ Ренессанс офлайн-ритейла. После пандемии многие потребители стали возвращаться в традиционные магазины. Возможность пощупать, примерить или ещё каким-то образом ознакомиться с продукцией перед покупкой — критически важна для многих категорий товаров, которыми торгуют бренды прямых продаж. Некоторые из них (например, Warby Parker и Allbirds) в итоге стали открывать физические точки, что опять же сопряжено с увеличением операционных расходов.
Подытоживая: D2C как концепция не исчезнет, но будет вынуждена себя переизобретать для каждой ниши отдельно и дрейфовать в сторону более сложных и многоканальных стратегий маркетинга и продаж. Одного лишь прямого контакта с потребителем для успеха недостаточно. В выигрыше окажутся те, кто найдёт способы диверсифицировать каналы сбыта и оптимизировать затраты на привлечение клиентов и логистику.
Вот что ещё я писал об этом:
- Nike «просто делает это»
- Почему eCom переходит в офлайн
Источник
@startobus 🧠 #ИИПоехали /#GoAI
👍1
В комментариях под интро пришел вопрос. Наверное будет интересно и другим.
Я поступил в Московский государственный технический университет имени Н.Э. Баумана в 1989 году, так как это был один из лучших технических вузов СССР (тогда я думаю и мира, но мы в это не сильно верили), и я хотел получить качественное образование в области инженерии - это до сих пор мне невероятно помогает - рациональным подходом ко всему.
Хотя ни дня я инженером не работал (чего не скажешь про моих однокашников - среди которых есть инженеры которые работают по всему миру Бомбардье, лучшие специалисты по холодильникам и кондиционерам… боюсь кого обидеть - некоторые это блог читают).
Параллельно с учебой в 1991 году начал работать в коммерческой дирекции ОРТ (первый канал) в команде Влада Листьева.
В тот год мне пришлось так рисковать, как никогда более - на себе выносить учредительные документы Слюзмультфильма и радио Орфей из Останкино - во время путча, что, возможно, способствовало их дальнейшему существованию. Можете поискать видео тех событий.
В 1992 году я поступил в Высшую школу бизнеса МГУ, где получил второе образование. Это было время, когда такие программы, как MBA, только начинали развиваться в России.
В 1993 году я начал свою карьеру в рекламном агентстве на должности директора по проектам, что стало основой для моего дальнейшего развития в этой сфере. В 1998 году мы с коллегой основали рекламное агентство "Манифеста", которое через некоторое время вошло в Топ-15 агентств в России.
В 2005 году я решил обновить свои знания и поехал учиться маркетингу в Лондон. Это было важно, и мне помогло потом перенести навыки обучения на свою карьеру преподавателя с 2007 года.
Далее в 2017 ушел из рекламы в стартапы, но как потом оказалось не в очень удачное время (пандемия, СВО - мировой венчурный рынок в 3 рази ниже пиков).
- к 2024 году оставил 3 проекта в стартапах (стартобус - в образовании, флайбер - в авиации, Дарья - в музыке).
- в сентябре 2024 года подписчики меня подтолкнули к перезапуску рекламного агентства Манифеста с AI ассистентами. И как обещал сегодня это уже сегодня могу объявить - мои клиенты, коллеги, поддержали. Скоро будет отдельный бот для желающих ознакомиться и заказать рекламу. Чтобы эту ленту не засорять)
Если у вас есть дополнительные вопросы или вы хотите узнать больше о моем опыте, не стесняйтесь спрашивать!
Вопрос: "Как будет возможность, напишите подробнее про ваше образование (как поступали, на каком направлении учились, почему МГТУ, в МГУ/ВШБ получили магистратуру или перевелись туда из МГТУ, на каком направлении учились в Лондоне)?"
Я поступил в Московский государственный технический университет имени Н.Э. Баумана в 1989 году, так как это был один из лучших технических вузов СССР (тогда я думаю и мира, но мы в это не сильно верили), и я хотел получить качественное образование в области инженерии - это до сих пор мне невероятно помогает - рациональным подходом ко всему.
Хотя ни дня я инженером не работал (чего не скажешь про моих однокашников - среди которых есть инженеры которые работают по всему миру Бомбардье, лучшие специалисты по холодильникам и кондиционерам… боюсь кого обидеть - некоторые это блог читают).
Параллельно с учебой в 1991 году начал работать в коммерческой дирекции ОРТ (первый канал) в команде Влада Листьева.
В тот год мне пришлось так рисковать, как никогда более - на себе выносить учредительные документы Слюзмультфильма и радио Орфей из Останкино - во время путча, что, возможно, способствовало их дальнейшему существованию. Можете поискать видео тех событий.
В 1992 году я поступил в Высшую школу бизнеса МГУ, где получил второе образование. Это было время, когда такие программы, как MBA, только начинали развиваться в России.
В 1993 году я начал свою карьеру в рекламном агентстве на должности директора по проектам, что стало основой для моего дальнейшего развития в этой сфере. В 1998 году мы с коллегой основали рекламное агентство "Манифеста", которое через некоторое время вошло в Топ-15 агентств в России.
В 2005 году я решил обновить свои знания и поехал учиться маркетингу в Лондон. Это было важно, и мне помогло потом перенести навыки обучения на свою карьеру преподавателя с 2007 года.
Далее в 2017 ушел из рекламы в стартапы, но как потом оказалось не в очень удачное время (пандемия, СВО - мировой венчурный рынок в 3 рази ниже пиков).
- к 2024 году оставил 3 проекта в стартапах (стартобус - в образовании, флайбер - в авиации, Дарья - в музыке).
- в сентябре 2024 года подписчики меня подтолкнули к перезапуску рекламного агентства Манифеста с AI ассистентами. И как обещал сегодня это уже сегодня могу объявить - мои клиенты, коллеги, поддержали. Скоро будет отдельный бот для желающих ознакомиться и заказать рекламу. Чтобы эту ленту не засорять)
Если у вас есть дополнительные вопросы или вы хотите узнать больше о моем опыте, не стесняйтесь спрашивать!
Telegram
Roman Zaborskiy in Startobus_Chat
Денис, добрый день!
Как будет возможность, напишите подробнее про ваше образование (как поступали, на каком направлении учились, почему мгту, в мгу/вшб получили магистратуру или перевелись туда из мгту, на каком направлении учились в Лондоне)?
Было бы очень…
Как будет возможность, напишите подробнее про ваше образование (как поступали, на каком направлении учились, почему мгту, в мгу/вшб получили магистратуру или перевелись туда из мгту, на каком направлении учились в Лондоне)?
Было бы очень…
🔥2👍1
Гугл украл мою стартап идею: paper to podcast
Шучу :) Гугл красавчики и боженьки, ибо сделали продукт, о котором я давно мечтал. Идея проста: загружаешь пейпер — и из него генерируется подкаст с двумя ролями, где один задает вопросы, а второй отвечает.
Мне всегда, когда хожу в спортзал или на хайкинг, очень не хватает подкаста именно с анализом новых пейперов. Приятно: идешь по горе и одновременно не отстаешь от стремительного прогресса в ИИ.
Доступно тут (нужно подождать немного после регистрации): https://illuminate.google.com/home
@startobus 🧠 #ИИПоехали /#GoAI
Шучу :) Гугл красавчики и боженьки, ибо сделали продукт, о котором я давно мечтал. Идея проста: загружаешь пейпер — и из него генерируется подкаст с двумя ролями, где один задает вопросы, а второй отвечает.
Мне всегда, когда хожу в спортзал или на хайкинг, очень не хватает подкаста именно с анализом новых пейперов. Приятно: идешь по горе и одновременно не отстаешь от стремительного прогресса в ИИ.
Доступно тут (нужно подождать немного после регистрации): https://illuminate.google.com/home
@startobus 🧠 #ИИПоехали /#GoAI
❤2🔥1
OpenAI выпустила новую модель o1
OpenAI представила новую серию моделей с улучшенными способностями к рассуждению под названием o1. Эти модели способны решать более сложные задачи, чем предыдущие, в областях науки, программирования и математики.
Ключевые факты:
- Модель o1 работает на уровне 500 лучших студентов США в отборочном туре на математическую олимпиаду США (AIME), достигая 83% правильных ответов, в то время как GPT-4o показывает только 13%.
- В тестах по физике, биологии и химии (GPQA) o1 демонстрирует точность на уровне доктора философии.
- В онлайн-соревнованиях по программированию, таких как Codeforces, o1 занимает 89 процентиль.
- Модель o1 уже доступна в ChatGPT для подписчиков Plus и Team, а также для избранных пользователей API.
- Модель o1 "думает" прежде чем генерировать ответ, используя подход "цепочки рассуждений", что позволяет ей лучше решать сложные задачи по сравнению с предыдущими версиями GPT.
- Несмотря на улучшения, o1 пока уступает GPT-4o в некоторых областях, таких как фактические знания о мире и возможности работы с веб-страницами и файлами.
Выпуск o1 знаменует собой значительный шаг вперед в развитии искусственного интеллекта, способного рассуждать на уровне человека. Хотя модель пока находится на ранней стадии, ее возможности впечатляют и открывают новые горизонты для применения ИИ в решении сложных задач.
https://openai.com/index/learning-to-reason-with-llms/
@startobus 🧠 #ИИПоехали /#GoAI
OpenAI представила новую серию моделей с улучшенными способностями к рассуждению под названием o1. Эти модели способны решать более сложные задачи, чем предыдущие, в областях науки, программирования и математики.
Ключевые факты:
- Модель o1 работает на уровне 500 лучших студентов США в отборочном туре на математическую олимпиаду США (AIME), достигая 83% правильных ответов, в то время как GPT-4o показывает только 13%.
- В тестах по физике, биологии и химии (GPQA) o1 демонстрирует точность на уровне доктора философии.
- В онлайн-соревнованиях по программированию, таких как Codeforces, o1 занимает 89 процентиль.
- Модель o1 уже доступна в ChatGPT для подписчиков Plus и Team, а также для избранных пользователей API.
- Модель o1 "думает" прежде чем генерировать ответ, используя подход "цепочки рассуждений", что позволяет ей лучше решать сложные задачи по сравнению с предыдущими версиями GPT.
- Несмотря на улучшения, o1 пока уступает GPT-4o в некоторых областях, таких как фактические знания о мире и возможности работы с веб-страницами и файлами.
Выпуск o1 знаменует собой значительный шаг вперед в развитии искусственного интеллекта, способного рассуждать на уровне человека. Хотя модель пока находится на ранней стадии, ее возможности впечатляют и открывают новые горизонты для применения ИИ в решении сложных задач.
https://openai.com/index/learning-to-reason-with-llms/
@startobus 🧠 #ИИПоехали /#GoAI
🚣СТРАТЕГИЯ ПОБЕДЫ: НА ВОЛНЕ ЗА КОНКУРЕНТОМ
В канале появилось много новеньких. Поэтому давайте посмотрим, как зайдет такой материал из старого.
Как побеждать конкурентов? Как в академической гребле! Меня с этой хитростью в далеких 80-х познакомил Олимпийский чемпион - Андрей, который вернулся к нам в город Павлово, Горьковской обл (сейчас Нижегородская).
Тогда я еще в 12 лет - как и все пацаны с улицы - я ходил на секцию бокса и самбо, но что то меня в этих видах спорта не устраивало (и это не то что - бьют как грушу). И вот приехал к нам в соседний подъезд Андрей высотой за два метра - с косой саженью в плечах и говорит: будем заниматься греблей. Я в первых рядах. Но я и сейчас не в том месте сажень, да и тогда по весу лишних 10 кг.
И он мне говорит - будешь главным в команде - рулевым: и дальше пошли аргументы - ну во-первых ты своим весом немного приподнимешь корму и байдарка будет меньше иметь площадь сопротивления (что через десять лет я понял - вранье - закон архимеда не обманешь). Но вот второй аргумент - разумный:
- А видишь команду в красном?
- Да,тренер, они тут будут лидерами.
- Отлично, тогда следуйте прямо за ними!
- Почему?
- Они тянут первую воду, вы хватаете вторую, сэкономите 30-40% сил.
- А что дальше?
- Под самый финиш дайте на половину такта быстрее.
- А сил нам хватит?
- Вы их бережёте весь заплыв, у вас будет преимущество.
ЗНАТЬ КОНКУРЕНТА -> ВСТАТЬ ЗА НИМ НА ВОЛНУ/РИТМ -> РВАНУТЬ НА ФИНИШЕ
1. Знать конкурента
Плотно изучить конкурентов, их метрики, как и что они делают, как оформляют и продают.
2. Встать на волну
Смотрим на конкурентов. Успешные аспекты - мы повторяем, все ошибки - избегаем.
3. Рвануть на финише
Сэкономленное время и ресурсы - преимущество. Используем его, чтобы сделать что-то лучше в 10 раз.
Я эту историю повторяю себе каждый раз, даже после запуска 2,5 тыс проектов. Прежде чем что то делать - знай своего конкурента и умей его обойти по метрикам на финише. Поэтому с самбо и боксом не сложилось - метрики у меня подкачивали).
Как с ИИ? Попробуйте этот сервис или этот промт. И обяазтельно similarweb.com
‼️Хотите подробный чек-лист по конкурентам и где их можно искать? Ставьте "+" в комменты!
А в каком спорте вы так же делали? Вело-, лыжи… - пишите в комментарии 👇 и подбодрите лайками автора (это мои метрики: куда двигаться и какие материалы выкладывать).
@startobus 🧠 #ИИПоехали /#GoAI
В канале появилось много новеньких. Поэтому давайте посмотрим, как зайдет такой материал из старого.
Как побеждать конкурентов? Как в академической гребле! Меня с этой хитростью в далеких 80-х познакомил Олимпийский чемпион - Андрей, который вернулся к нам в город Павлово, Горьковской обл (сейчас Нижегородская).
Тогда я еще в 12 лет - как и все пацаны с улицы - я ходил на секцию бокса и самбо, но что то меня в этих видах спорта не устраивало (и это не то что - бьют как грушу). И вот приехал к нам в соседний подъезд Андрей высотой за два метра - с косой саженью в плечах и говорит: будем заниматься греблей. Я в первых рядах. Но я и сейчас не в том месте сажень, да и тогда по весу лишних 10 кг.
И он мне говорит - будешь главным в команде - рулевым: и дальше пошли аргументы - ну во-первых ты своим весом немного приподнимешь корму и байдарка будет меньше иметь площадь сопротивления (что через десять лет я понял - вранье - закон архимеда не обманешь). Но вот второй аргумент - разумный:
- А видишь команду в красном?
- Да,тренер, они тут будут лидерами.
- Отлично, тогда следуйте прямо за ними!
- Почему?
- Они тянут первую воду, вы хватаете вторую, сэкономите 30-40% сил.
- А что дальше?
- Под самый финиш дайте на половину такта быстрее.
- А сил нам хватит?
- Вы их бережёте весь заплыв, у вас будет преимущество.
ЗНАТЬ КОНКУРЕНТА -> ВСТАТЬ ЗА НИМ НА ВОЛНУ/РИТМ -> РВАНУТЬ НА ФИНИШЕ
1. Знать конкурента
Плотно изучить конкурентов, их метрики, как и что они делают, как оформляют и продают.
2. Встать на волну
Смотрим на конкурентов. Успешные аспекты - мы повторяем, все ошибки - избегаем.
3. Рвануть на финише
Сэкономленное время и ресурсы - преимущество. Используем его, чтобы сделать что-то лучше в 10 раз.
Я эту историю повторяю себе каждый раз, даже после запуска 2,5 тыс проектов. Прежде чем что то делать - знай своего конкурента и умей его обойти по метрикам на финише. Поэтому с самбо и боксом не сложилось - метрики у меня подкачивали).
Как с ИИ? Попробуйте этот сервис или этот промт. И обяазтельно similarweb.com
‼️Хотите подробный чек-лист по конкурентам и где их можно искать? Ставьте "+" в комменты!
А в каком спорте вы так же делали? Вело-, лыжи… - пишите в комментарии 👇 и подбодрите лайками автора (это мои метрики: куда двигаться и какие материалы выкладывать).
@startobus 🧠 #ИИПоехали /#GoAI
Как Билл Гейтс использует AI
Самая частая работа, которую Билл Гейтс поручает ИИ, это расшифровка встреч и диалог с AI по содержанию этих встреч. Источник: https://www.businessinsider.com/bill-gates-uses-ai-meeting-summaries-notes-copilot-teams-2024-9
Это очень логично. Я уже давно записываю все встречи и анализирую их по отдельности. Теперь хочу объединить их в единую базу знаний, чтобы говорить со всеми встречами одновременно через ИИ.
Сервисы AI-секретарей
#AIдляЛидеров
Источник
@startobus 🧠 #ИИПоехали /#GoAI
Самая частая работа, которую Билл Гейтс поручает ИИ, это расшифровка встреч и диалог с AI по содержанию этих встреч. Источник: https://www.businessinsider.com/bill-gates-uses-ai-meeting-summaries-notes-copilot-teams-2024-9
Это очень логично. Я уже давно записываю все встречи и анализирую их по отдельности. Теперь хочу объединить их в единую базу знаний, чтобы говорить со всеми встречами одновременно через ИИ.
Сервисы AI-секретарей
#AIдляЛидеров
Источник
@startobus 🧠 #ИИПоехали /#GoAI
Business Insider
Bill Gates reveals what he uses AI for most
The founder and former CEO of Microsoft spends a lot of time in meetings in Teams, and says he regularly relies on the app's AI summaries.
💯2
В чем прикол о1, простыми словами?
Модели типа GPT/Llama/Claude с каждым сгенерированным токеном увеличивают шанс ошибки (из-за авторегрессии). В о1, поскольку сама модель на каждом шаге «проверяет» свои рассуждения, внутреннее состояние модели меняется в «нужную» сторону, что важно для сложных задач требующих долгих рассуждений. То есть, модель выполняет роль промт-инженера для самой себя.
о1 не лучше gpt в задачах генерации текста, потому что знания, выученные в самом трансформере те же самые. Объем её «знаний» не изменился. Но она сильно круче в задачах логики, программирования и математики.
Это происходит потому что тренировка о1 происходила за счет генерации множества цепочек рассуждения и зачем применения reinforcement learning к тем цепочкам, которые привели к правильному ответу (то есть, выдавания модели «конфетки» за «правильные» рассуждения). Такой ответ в математике и программировании можно заранее рассчитать для бесконечного количества примеров, поэтому можно провести миллионы раундов обучения. Но нельзя сделать миллион обучений модели по написанию красивых стихов, просто потому что у вас не хватит денег и времени для ручной проверки того хороший или плохой был результат.
Итого: в машинном обучении работают те вещи, обучение которым можно автоматизировать и выполнять огромное количество раз. Это дешево и быстро масштабируется. А ручное обучение очень медленно и имеет потолок в виде человеческого ресурса. Поэтому последние версии трансформеров, хоть и имели, но относительно небольшой прирост в своей полезности.
Открытый вопрос в том, приведет ли улучшение логики и мат способностей модели к эмерджентному улучшению в других областях. Как показывает история развития человечества, это во многом так. Поэтому реальный эффект от этого подхода мы еще увидим в ближайшие годы по мере того как OpenAI и другие будут собирать больше данных и дообучать эту архитектуру.
@startobus 🧠 #ИИПоехали /#GoAI
Модели типа GPT/Llama/Claude с каждым сгенерированным токеном увеличивают шанс ошибки (из-за авторегрессии). В о1, поскольку сама модель на каждом шаге «проверяет» свои рассуждения, внутреннее состояние модели меняется в «нужную» сторону, что важно для сложных задач требующих долгих рассуждений. То есть, модель выполняет роль промт-инженера для самой себя.
о1 не лучше gpt в задачах генерации текста, потому что знания, выученные в самом трансформере те же самые. Объем её «знаний» не изменился. Но она сильно круче в задачах логики, программирования и математики.
Это происходит потому что тренировка о1 происходила за счет генерации множества цепочек рассуждения и зачем применения reinforcement learning к тем цепочкам, которые привели к правильному ответу (то есть, выдавания модели «конфетки» за «правильные» рассуждения). Такой ответ в математике и программировании можно заранее рассчитать для бесконечного количества примеров, поэтому можно провести миллионы раундов обучения. Но нельзя сделать миллион обучений модели по написанию красивых стихов, просто потому что у вас не хватит денег и времени для ручной проверки того хороший или плохой был результат.
Итого: в машинном обучении работают те вещи, обучение которым можно автоматизировать и выполнять огромное количество раз. Это дешево и быстро масштабируется. А ручное обучение очень медленно и имеет потолок в виде человеческого ресурса. Поэтому последние версии трансформеров, хоть и имели, но относительно небольшой прирост в своей полезности.
Открытый вопрос в том, приведет ли улучшение логики и мат способностей модели к эмерджентному улучшению в других областях. Как показывает история развития человечества, это во многом так. Поэтому реальный эффект от этого подхода мы еще увидим в ближайшие годы по мере того как OpenAI и другие будут собирать больше данных и дообучать эту архитектуру.
@startobus 🧠 #ИИПоехали /#GoAI
Коммерсантъ: Спрос на копирайтеров и редакторов снизился из-за нейросетей
– За 8 мес. 2024 появилось 13,6 тыс. вакансий копирайтера (-23%)
– Количество вакансий редактора сократилось вдвое, до 7 тыс.
– В сред. работодатели стали предлагать им меньший заработок
– Сред. заработок для копирайтеров был 58 тыс. руб./мес. (-21%)
– Для редакторов он снизился на 13%, составив 65,1 тыс. руб./мес.
– Но больше вакансий стали требовать наличие GPT-навыков
– Присутствие таких требований внутри вакансий выросло вдвое
– Также снижается количество заказов на биржах фриланса
– На перевод заказы снизились на 70%, на расшифровки – на 50%
@ftsec
@startobus 🧠 #ИИПоехали /#GoAI
– За 8 мес. 2024 появилось 13,6 тыс. вакансий копирайтера (-23%)
– Количество вакансий редактора сократилось вдвое, до 7 тыс.
– В сред. работодатели стали предлагать им меньший заработок
– Сред. заработок для копирайтеров был 58 тыс. руб./мес. (-21%)
– Для редакторов он снизился на 13%, составив 65,1 тыс. руб./мес.
– Но больше вакансий стали требовать наличие GPT-навыков
– Присутствие таких требований внутри вакансий выросло вдвое
– Также снижается количество заказов на биржах фриланса
– На перевод заказы снизились на 70%, на расшифровки – на 50%
@ftsec
@startobus 🧠 #ИИПоехали /#GoAI
Коммерсантъ
Такой текст нам не нужен
Спрос на копирайтеров и редакторов снизился из-за нейросетей
👍1
в онлифансе всего 42 человека команда (инхаус) и делают $6,3 ярда выручки.
а 5 лет назад выручка была $300 млн
по истине дьявольское приложение!
вот полная статья с разбором - https://www.matthewball.co/all/fansprofitandloss
@startobus 🧠 #ИИПоехали /#GoAI
а 5 лет назад выручка была $300 млн
по истине дьявольское приложение!
вот полная статья с разбором - https://www.matthewball.co/all/fansprofitandloss
@startobus 🧠 #ИИПоехали /#GoAI
👍1😁1
This media is not supported in your browser
VIEW IN TELEGRAM
Каждый ускоряется как умеет (видео не ускорено). Вот эта платформа выдает инференс Llama-3.1-8B/70B/405B (без квантизации) аж до 1200 ток/сек.
А ваш синьор так умеет? Одно из преимуществ LLM не только в том, что они могут держать в голове сотню тысяч страниц информации, но и в том, что за несколько секунд они могут попробовать тысячи способов решения проблемы и понять какие из них не работают.
@startobus 🧠 #ИИПоехали /#GoAIStart
А ваш синьор так умеет? Одно из преимуществ LLM не только в том, что они могут держать в голове сотню тысяч страниц информации, но и в том, что за несколько секунд они могут попробовать тысячи способов решения проблемы и понять какие из них не работают.
@startobus 🧠 #ИИПоехали /#GoAIStart
AI-Driven Decentralized Prediction Markets: Платформы, где AI-агенты и люди совместно прогнозируют события, повышая точность и уменьшая манипуляции.
Будущее AI - это мультиагентное, открытое и совместное.
Полная статья доступна здесь: https://cyber.fund/content/de-ai (там больше кейсов и детальнее описания)
@startobus 🧠 #ИИПоехали /#GoAIStart
Будущее AI - это мультиагентное, открытое и совместное.
Полная статья доступна здесь: https://cyber.fund/content/de-ai (там больше кейсов и детальнее описания)
@startobus 🧠 #ИИПоехали /#GoAIStart
cyber.fund
cyber•Fund | Frontiers of Decentralized AI
de-ai
OpenAI опубликовал свой роадмап по достижению AGI. С релизом о1 мы официально на втором уровне.
Уровень 1: Чат-боты, ИИ с естественным языком
Уровень 2: Рассуждающие системы, решение задач на уровне человека
Уровень 3: Агенты, системы, которые могут принимать решения и автономно действовать
Уровень 4: Инноваторы. ИИ может помогать в изобретениях
Уровень 5: Организации. ИИ который может выполнять работу целой организации
@startobus 🧠 #ИИПоехали /#GoAI
Уровень 1: Чат-боты, ИИ с естественным языком
Уровень 2: Рассуждающие системы, решение задач на уровне человека
Уровень 3: Агенты, системы, которые могут принимать решения и автономно действовать
Уровень 4: Инноваторы. ИИ может помогать в изобретениях
Уровень 5: Организации. ИИ который может выполнять работу целой организации
@startobus 🧠 #ИИПоехали /#GoAI
👏1
Мужчина из Северной Каролины обвиняется в мошенничестве на 10 миллионов долларов с использованием искусственного интеллекта для создания фальшивой музыки.
52-летний Майкл Смит якобы создал сотни тысяч поддельных песен несуществующих групп и загрузил их на стриминговые сервисы. Затем он использовал ботов для многократного воспроизведения этих песен, имитируя реальных слушателей.
Смит начал с загрузки собственной музыки, но затем перешел на использование ИИ для массового создания треков. Он генерировал правдоподобные названия для песен и исполнителей, чтобы избежать обнаружения. К 2019 году Смит зарабатывал около 110 000 долларов в месяц на роялти.
Прокуратура утверждает, что эта схема работала с 2017 по 2024 год. Смиту предъявлены обвинения в мошенничестве с использованием электронных средств связи и отмывании денег. Ему грозит до 20 лет тюрьмы за каждое обвинение.
https://www.justice.gov/usao-sdny/pr/north-carolina-musician-charged-music-streaming-fraud-aided-artificial-intelligence
52-летний Майкл Смит якобы создал сотни тысяч поддельных песен несуществующих групп и загрузил их на стриминговые сервисы. Затем он использовал ботов для многократного воспроизведения этих песен, имитируя реальных слушателей.
Смит начал с загрузки собственной музыки, но затем перешел на использование ИИ для массового создания треков. Он генерировал правдоподобные названия для песен и исполнителей, чтобы избежать обнаружения. К 2019 году Смит зарабатывал около 110 000 долларов в месяц на роялти.
Прокуратура утверждает, что эта схема работала с 2017 по 2024 год. Смиту предъявлены обвинения в мошенничестве с использованием электронных средств связи и отмывании денег. Ему грозит до 20 лет тюрьмы за каждое обвинение.
https://www.justice.gov/usao-sdny/pr/north-carolina-musician-charged-music-streaming-fraud-aided-artificial-intelligence