Microsoft показал «убийцу» MacBook Air
Компания запустила бренд Copilot+PC, под которым будут выходить ноутбуки и планшеты с аппаратной поддержкой AI. Выпуском займутся крупнейшие производители, включая Acer, Asus, Dell, HP, Lenovo, Samsung и Microsoft.
Все устройства Copilot+PC должны соответствовать определенным требованиям, одно из которых — наличие нейронного процессора (NPU), который обеспечивает производительность не менее 45 TOPS для задач искусственного интеллекта. Эта вычислительная мощность больше чем у MacBook Air M3 и Nvidia RTX 4060.
В Windows 11 для Copilot+PC будут интегрированы более 40 моделей AI, благодаря которым разработчики смогут задействовать возможности искусственного интеллекта в своих приложениях. Adobe уже подготовил свой пакет программ, адаптированных специально под новые устройства.
https://www.theverge.com/2024/5/20/24160463/microsoft-windows-laptops-copilot-arm-chips-m1
@startobus 🧠 запуск идей с AI
Компания запустила бренд Copilot+PC, под которым будут выходить ноутбуки и планшеты с аппаратной поддержкой AI. Выпуском займутся крупнейшие производители, включая Acer, Asus, Dell, HP, Lenovo, Samsung и Microsoft.
Все устройства Copilot+PC должны соответствовать определенным требованиям, одно из которых — наличие нейронного процессора (NPU), который обеспечивает производительность не менее 45 TOPS для задач искусственного интеллекта. Эта вычислительная мощность больше чем у MacBook Air M3 и Nvidia RTX 4060.
В Windows 11 для Copilot+PC будут интегрированы более 40 моделей AI, благодаря которым разработчики смогут задействовать возможности искусственного интеллекта в своих приложениях. Adobe уже подготовил свой пакет программ, адаптированных специально под новые устройства.
https://www.theverge.com/2024/5/20/24160463/microsoft-windows-laptops-copilot-arm-chips-m1
@startobus 🧠 запуск идей с AI
The Verge
Inside Microsoft’s mission to take down the MacBook Air
Microsoft might be finally ready to transition to Arm chips.
В России создали гель для восстановления костей со 100 % идентичностью, им можно лечить крупные пулевые и осколочные повреждения — ТАСС
#science
@startobus 🧠 запуск идей с AI
#science
@startobus 🧠 запуск идей с AI
ТАСС
В России создали гель для восстановления костей со 100% идентичностью
С его помощью можно восстановить ткани, в том числе, после крупных осколочных и пулевых ранений
This media is not supported in your browser
VIEW IN TELEGRAM
🦄 Разработчики из Nvidia и Техасского университета в Остине представили ПО для обучения роботов под названием DrEureka. В DrEureka предварительно загружают какого-то чат-бота (например, GPT-4), затем ПО в виртуальном пространстве подключается к роботу и начинает его там обучать какой-либо задаче.
🌐 Developers from Nvidia and the University of Texas at Austin have unveiled robot learning software called DrEureka. DrEureka is pre-loaded with some chatbot (for example, GPT-4), then the software connects to the robot in virtual space and starts teaching it a task.
🍪 @droidergram
@startobus 🧠 запуск идей с AI
🌐 Developers from Nvidia and the University of Texas at Austin have unveiled robot learning software called DrEureka. DrEureka is pre-loaded with some chatbot (for example, GPT-4), then the software connects to the robot in virtual space and starts teaching it a task.
🍪 @droidergram
@startobus 🧠 запуск идей с AI
Вчера в гугле обьявили, что теперь в поиске в картинках карточек товаров одежда будет показываться на разных сгенерированных людях. Немного запутано, но по сути теперь будет показываться как одни и те же джинсы сидят на людях разной полноты и цвета кожи. Делает это нейронка, в автоматическом режиме и что-то в этом есть. Знаю с десяток стартапов которые продавали услугу "сделаем из фотографии одной модели несколько десятков фотографий этой же одежды на разных людях", но все это была нишевая история. Теперь это на гугле и кажется бесплатно https://www.wired.com/story/google-ai-shopping-clothes-fit-different-bodies/
@startobus 🧠 запуск идей с AI
@startobus 🧠 запуск идей с AI
WIRED
Google Taps AI to Show Shoppers How Clothes Fit Different Bodies
A new breed of online ad allows brands to pay Google to offer shoppers AI-generated images that show how items of clothing would look on different skin tones and body types.
Forwarded from Сергей Иванов из ЭФКО
ПЕДАГОГИКА КАК ВЫЗОВ ДЛЯ БИЗНЕСА,
или может ли слово чему-то научить?
Лиман (наш научно-образовательный центр) появился в компании почти 25 лет назад как ответ на вызов нехватки квалифицированных кандидатов на рынке труда. Я тогда работал у конкурента, и извне это казалось красивым и прогрессивным. Во заморачиваются, думал. Ну, мы-то без этого как-нибудь уж проживем.
А сегодня… А сегодня, похоже, пришли времена, когда, если ваша компания не умеет готовить людей без опоры на внешние силы (ВУЗы, бизнес-школы и т.д.), она просто не выживет. Поэтому всякий руководитель в бизнесе, хочет он того или не хочет, должен сегодня становиться педагогом.
Но прежде чем об этом поговорить, есть вопрос...
Мы же с вами не верим, что слова учат? Что можно лекцию послушать или книжку прочитать, все узнать и жизнь изменить? Сатана вон лучше любого святого знает о Боге, но остается при этом по ту сторону. Что толку от слов (лекций), если они продолжают быть просто словами.
Хотя… и слова нужны. Но они начинают влиять на наши поступки, только если становятся эмоционально значимыми (то есть подкрепленными яркими эмоциями и связанными с нейронной сетью лимбической системы). Полез ребенок к кастрюле — обжегся — и узнал, что такое слово «горячо». А пока этого не произошло, сколько ни рассказывай про боль ожога и риск остаться калекой, толку будет немного.
Поэтому настоящее образование – это не научение человека каким-то новым понятиям (словам).
Настоящая педагогика должна соединять образы и смыслы в психике человека с его эмоциями, а это возможно только тогда, когда человек не просто услышит какой-то смысл, а обязательно приобретет чувственный опыт и сделает из него собственные выводы.
Давайте сверимся.
Может ли книга научить?
Можно ли после прослушанной лекции стать другим человеком?
Или педагогика — это существенно более сложный процесс, в котором в структурах нашего бессознательного нужно «прописывать» и закреплять связи между новыми знаниями и эмоционально пережитым опытом?
О том, что нам нужны новые понятия, чтобы говорить о педагогике первый раз попробовал написать здесь: гончары и химики.
или может ли слово чему-то научить?
Лиман (наш научно-образовательный центр) появился в компании почти 25 лет назад как ответ на вызов нехватки квалифицированных кандидатов на рынке труда. Я тогда работал у конкурента, и извне это казалось красивым и прогрессивным. Во заморачиваются, думал. Ну, мы-то без этого как-нибудь уж проживем.
А сегодня… А сегодня, похоже, пришли времена, когда, если ваша компания не умеет готовить людей без опоры на внешние силы (ВУЗы, бизнес-школы и т.д.), она просто не выживет. Поэтому всякий руководитель в бизнесе, хочет он того или не хочет, должен сегодня становиться педагогом.
Но прежде чем об этом поговорить, есть вопрос...
Мы же с вами не верим, что слова учат? Что можно лекцию послушать или книжку прочитать, все узнать и жизнь изменить? Сатана вон лучше любого святого знает о Боге, но остается при этом по ту сторону. Что толку от слов (лекций), если они продолжают быть просто словами.
Хотя… и слова нужны. Но они начинают влиять на наши поступки, только если становятся эмоционально значимыми (то есть подкрепленными яркими эмоциями и связанными с нейронной сетью лимбической системы). Полез ребенок к кастрюле — обжегся — и узнал, что такое слово «горячо». А пока этого не произошло, сколько ни рассказывай про боль ожога и риск остаться калекой, толку будет немного.
Поэтому настоящее образование – это не научение человека каким-то новым понятиям (словам).
Настоящая педагогика должна соединять образы и смыслы в психике человека с его эмоциями, а это возможно только тогда, когда человек не просто услышит какой-то смысл, а обязательно приобретет чувственный опыт и сделает из него собственные выводы.
Давайте сверимся.
Может ли книга научить?
Можно ли после прослушанной лекции стать другим человеком?
Или педагогика — это существенно более сложный процесс, в котором в структурах нашего бессознательного нужно «прописывать» и закреплять связи между новыми знаниями и эмоционально пережитым опытом?
О том, что нам нужны новые понятия, чтобы говорить о педагогике первый раз попробовал написать здесь: гончары и химики.
👍1
Лучшие нейросети на данный момент
Аналитики протестировали множество ИИ и выделили лучшие. В топ-5 вошли такие нейросети, как:
1. GPT-4o
2. Claude-3-Opus
3. Gemini-1.5-Flash
4. Yi-large
5. Llama-3-70B-Instruct
❤️ — действительно лучшие!
ChatGPT | Нейросети
@startobus 🧠 запуск идей с AI
Аналитики протестировали множество ИИ и выделили лучшие. В топ-5 вошли такие нейросети, как:
1. GPT-4o
2. Claude-3-Opus
3. Gemini-1.5-Flash
4. Yi-large
5. Llama-3-70B-Instruct
❤️ — действительно лучшие!
ChatGPT | Нейросети
@startobus 🧠 запуск идей с AI
CNBC: Стоимость акций Nvidia впервые превысила $1 тыс. из-за роста продаж, вызванного ИИ
– Выручка за квартал – $26,04 млрд, прибыль – $14,9 млрд
– По итогам нового квартала выручка может быть $28 млрд
– Выручка сегмента ЦОД взлетела на 427%, до $22,6 млрд
– Такой рост обусловлен поставками новых чипов Hopper
– Например, для Llama 3 использовали 24 тыс. чипов H100
– На облачных гигантов приходится 40% выручки сегмента
– Microsoft, Google, Amazon закупают ее чипы на миллиарды
– Nvidia ожидает сильного роста благодаря новому Blackwell
– Выручка от продажи сетевых компонентов была $3,2 млрд
– Доход от игрового сегмента вырос на 18%, до $2,65 млрд
– Автомобильный сегмент принес Nvidia около $329 млн
– Nvidia выкупила свои акции за квартал на сумму $7,7 млрд
– Компания также увеличит дивиденды с $0,04 до $0,1/акция
@ftsec
@startobus 🧠 запуск идей с AI
– Выручка за квартал – $26,04 млрд, прибыль – $14,9 млрд
– По итогам нового квартала выручка может быть $28 млрд
– Выручка сегмента ЦОД взлетела на 427%, до $22,6 млрд
– Такой рост обусловлен поставками новых чипов Hopper
– Например, для Llama 3 использовали 24 тыс. чипов H100
– На облачных гигантов приходится 40% выручки сегмента
– Microsoft, Google, Amazon закупают ее чипы на миллиарды
– Nvidia ожидает сильного роста благодаря новому Blackwell
– Выручка от продажи сетевых компонентов была $3,2 млрд
– Доход от игрового сегмента вырос на 18%, до $2,65 млрд
– Автомобильный сегмент принес Nvidia около $329 млн
– Nvidia выкупила свои акции за квартал на сумму $7,7 млрд
– Компания также увеличит дивиденды с $0,04 до $0,1/акция
@ftsec
@startobus 🧠 запуск идей с AI
CNBC
Nvidia shares pass $1,000 for first time on AI-driven sales surge
Nvidia reported earnings after the bell. Here are the results.
Интересный график нашел - это пики посещений страницы chat.openai.com с указанием событий:
- Запуск ChatGPT (30 ноября 2022)
- Запуск ChatGPT Plus (январь 2023)
- Запуск GPT-4 (март 2023)
- Запуск приложения для iPhone
- Запуск интерпретатора кода
- Запуск приложения для Android
- Запуск ChatGPT Enterprise
- Перезапуск веб-поиска
- DALL-E 3 доступен в ChatGPT
- Запуск ChatGPT Store
- Запуск функции памяти
- Запуск GPT-4 Turbo
@startobus 🧠 запуск идей с AI
- Запуск ChatGPT (30 ноября 2022)
- Запуск ChatGPT Plus (январь 2023)
- Запуск GPT-4 (март 2023)
- Запуск приложения для iPhone
- Запуск интерпретатора кода
- Запуск приложения для Android
- Запуск ChatGPT Enterprise
- Перезапуск веб-поиска
- DALL-E 3 доступен в ChatGPT
- Запуск ChatGPT Store
- Запуск функции памяти
- Запуск GPT-4 Turbo
@startobus 🧠 запуск идей с AI
🚀 Искусственный Интеллект: Основные Тренды и Возможности
🗓️ Рост рынка: Последний месяц ознаменовался активным развитием благодаря анонсам ИИ-моделей и продуктов от ведущих IT-компаний США.
📈 Главные возможности ГИИ:
- Компрессия информации: Конспектирование, резюмирование, обобщение больших массивов данных (тексты, аудио, видео).
- Декомпрессия информации: Генерация контента (тексты, аудио, видео) из сжатой информации.
### Основные сценарии использования:
- Обобщение и интерпретация контента
- Перевод
- Экспертные системы (ответы на вопросы)
- Аналитика данных (слабое звено пока)
- Рерайтинг текстов
- Копирайтинг (резюме, отзывы, статьи)
- Распознавание цифрового контента (OCR, автоматические таймкоды)
- Семантический поиск (поиск объектов в фото и видео)
🔮 Перспективы:
- Умный органайзер: Структурирование документов, фото и видео.
- Персональный репетитор и гид: Помощь в различных вопросах.
- Консультант: Улучшенная комбинация Google и Wikipedia.
### Будущие возможности:
- Автоматизация создания контента
- Первичная аналитика данных
### Профессии под угрозой:
Переводчики, редакторы, копирайтеры, контентмейкеры, секретари, маркетологи, дизайнеры, программисты, аналитики начального уровня.
💡 Вопросы:
1. Какие новые сценарии использования ИИ вы видите в ближайшем будущем?
2. Как вы оцениваете влияние ИИ на вашу профессию?
Следите за новостями и будьте в курсе последних трендов! 📲✨
@startobus 🧠 запуск идей с AI
🗓️ Рост рынка: Последний месяц ознаменовался активным развитием благодаря анонсам ИИ-моделей и продуктов от ведущих IT-компаний США.
📈 Главные возможности ГИИ:
- Компрессия информации: Конспектирование, резюмирование, обобщение больших массивов данных (тексты, аудио, видео).
- Декомпрессия информации: Генерация контента (тексты, аудио, видео) из сжатой информации.
### Основные сценарии использования:
- Обобщение и интерпретация контента
- Перевод
- Экспертные системы (ответы на вопросы)
- Аналитика данных (слабое звено пока)
- Рерайтинг текстов
- Копирайтинг (резюме, отзывы, статьи)
- Распознавание цифрового контента (OCR, автоматические таймкоды)
- Семантический поиск (поиск объектов в фото и видео)
🔮 Перспективы:
- Умный органайзер: Структурирование документов, фото и видео.
- Персональный репетитор и гид: Помощь в различных вопросах.
- Консультант: Улучшенная комбинация Google и Wikipedia.
### Будущие возможности:
- Автоматизация создания контента
- Первичная аналитика данных
### Профессии под угрозой:
Переводчики, редакторы, копирайтеры, контентмейкеры, секретари, маркетологи, дизайнеры, программисты, аналитики начального уровня.
💡 Вопросы:
1. Какие новые сценарии использования ИИ вы видите в ближайшем будущем?
2. Как вы оцениваете влияние ИИ на вашу профессию?
Следите за новостями и будьте в курсе последних трендов! 📲✨
@startobus 🧠 запуск идей с AI
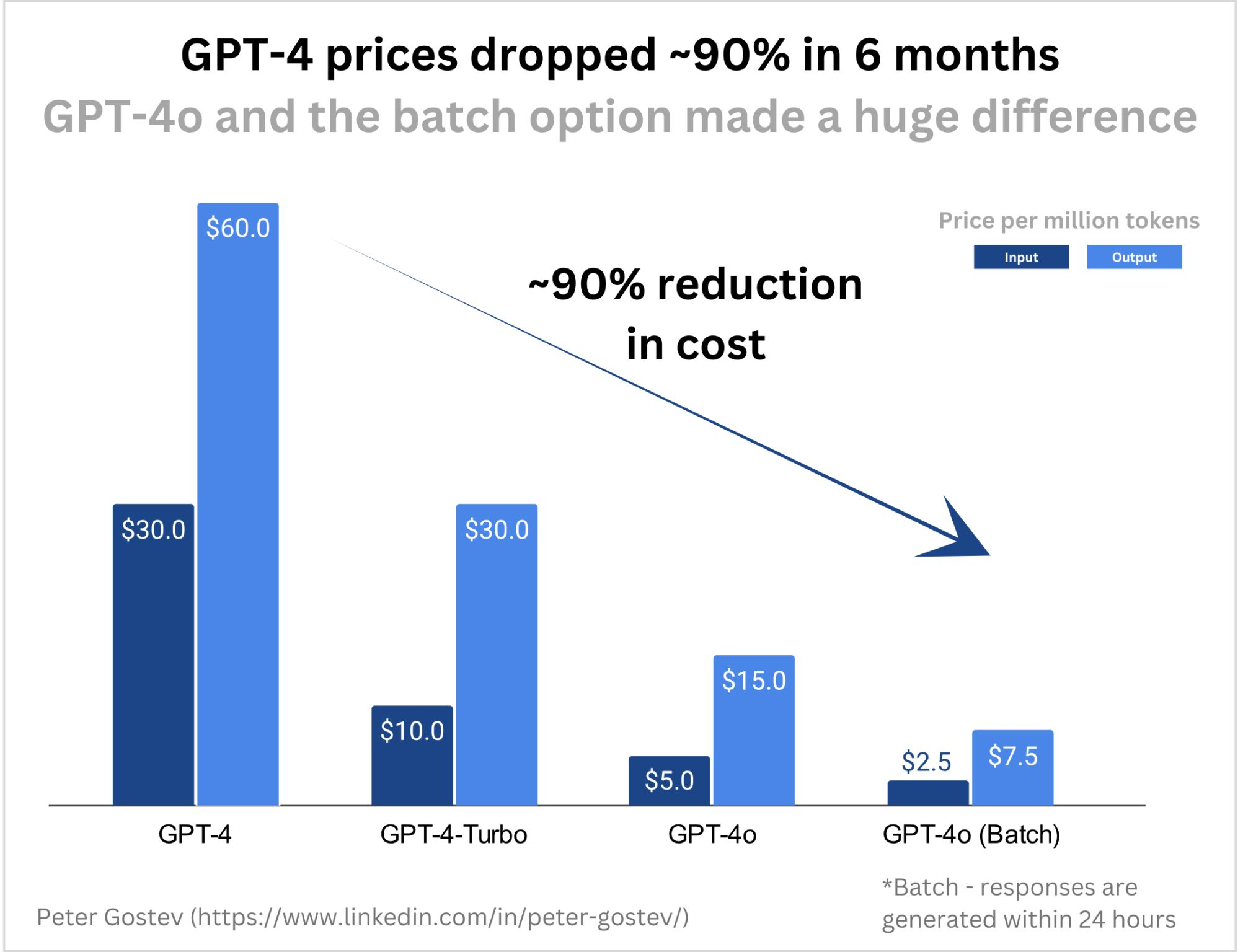
GPT-4 Prices Dropped ~90% in 6 months.
Петер Готсев (Moonpig) сделал интересное наблюдение – стоимость использования GPT-4 упала очень значительно в расчете на 1М токенов:
▪️GPT-4: $30 input, $40 output;
▪️GPT-4o: $2.5 input, $7.5 output.
В комментариях есть возражения, что в отношении к токенам измерять не очень правильно, но такая логика все равно достаточно наглядная.
Может быть, впервые скажем об этом тут – у foundational models есть все шансы стать commodity сервисом и стоить ну оооочень дешево. Может быть, про них можно сказать так уже сейчас, но время покажет.
👉 Ссылка на пост Петера: https://www.linkedin.com/feed/update/urn:li:activity:7197657071427747841/
@proVenture
#ai #saas
@startobus 🧠 запуск идей с AI
Петер Готсев (Moonpig) сделал интересное наблюдение – стоимость использования GPT-4 упала очень значительно в расчете на 1М токенов:
▪️GPT-4: $30 input, $40 output;
▪️GPT-4o: $2.5 input, $7.5 output.
В комментариях есть возражения, что в отношении к токенам измерять не очень правильно, но такая логика все равно достаточно наглядная.
Может быть, впервые скажем об этом тут – у foundational models есть все шансы стать commodity сервисом и стоить ну оооочень дешево. Может быть, про них можно сказать так уже сейчас, но время покажет.
👉 Ссылка на пост Петера: https://www.linkedin.com/feed/update/urn:li:activity:7197657071427747841/
@proVenture
#ai #saas
@startobus 🧠 запуск идей с AI
{kind=link}
На изображении представлена комикс-карикатура, изображающая проблему перегруженности дашбордов метриками. Теперь перепишем текст для телеграм-канала:
---
Не все метрики важны!
DMG Ventures создали отличную шпаргалку с перечнем метрик, на которые обращают внимание VC при инвестировании в B2C стартапы. Метрики разделены по категориям в зависимости от специфики бизнеса. Метрики, важные для маркетплейсов, могут быть совершенно не важны для подписочных сервисов. Вот список ключевых метрик для подписочных бизнесов:
- Число новых подписчиков
- % активных подписчиков (всего активных подписчиков / всего активных клиентов)
- % дохода от подписки (доход от подписки / общий доход)
- % подписки <1 / 1-3 / 3+ месяцев
- % подписки на премиум/средний/базовый тариф
- % ежемесячного роста средней цены подписки
- Валовое месячное удержание (Gross monthly retention) - число существующих подписчиков текущего месяца / подписчиков предыдущего месяца
- Чистое ежемесячное удержание (Net monthly retention) - доход от существующих подписчиков текущего месяца / доход от подписки предыдущего месяца
Сохраняйте и пользуйтесь!
[Metrics that matter - What a consumer VC looks for in a start-up’s numbers](https://medium.com/dmg-ventures/metrics-that-matter-what-a-consumer-vc-looks-for-in-a-start-ups-numbers-fd218b97cbd0)
---
Дополнительные вопросы:
1. Какие метрики наиболее важны для вашего бизнеса?
2. Какие еще аспекты инвестирования вас интересуют?
Поделитесь своими мыслями и опытом!
---
Не все метрики важны!
DMG Ventures создали отличную шпаргалку с перечнем метрик, на которые обращают внимание VC при инвестировании в B2C стартапы. Метрики разделены по категориям в зависимости от специфики бизнеса. Метрики, важные для маркетплейсов, могут быть совершенно не важны для подписочных сервисов. Вот список ключевых метрик для подписочных бизнесов:
- Число новых подписчиков
- % активных подписчиков (всего активных подписчиков / всего активных клиентов)
- % дохода от подписки (доход от подписки / общий доход)
- % подписки <1 / 1-3 / 3+ месяцев
- % подписки на премиум/средний/базовый тариф
- % ежемесячного роста средней цены подписки
- Валовое месячное удержание (Gross monthly retention) - число существующих подписчиков текущего месяца / подписчиков предыдущего месяца
- Чистое ежемесячное удержание (Net monthly retention) - доход от существующих подписчиков текущего месяца / доход от подписки предыдущего месяца
Сохраняйте и пользуйтесь!
[Metrics that matter - What a consumer VC looks for in a start-up’s numbers](https://medium.com/dmg-ventures/metrics-that-matter-what-a-consumer-vc-looks-for-in-a-start-ups-numbers-fd218b97cbd0)
---
Дополнительные вопросы:
1. Какие метрики наиболее важны для вашего бизнеса?
2. Какие еще аспекты инвестирования вас интересуют?
Поделитесь своими мыслями и опытом!
1/3 трудоустроенных американцев моложе 30 лет использует ChatGPT в работе.
@startobus 🧠 запуск идей с AI
@startobus 🧠 запуск идей с AI
FT: Стартап Илона Маска получил поддержку от венчурных гигантов Кремниевой долины
– xAI поддержали Lightspeed Venture и Andreessen Horowitz
– В числе инвесторов также Sequoia Capital и Tribe Capital
– xAI завершает новый раунд при общей оценке $18 млрд
– Инвесторы взяли обязательство поддержать этот раунд
– Маск хочет привлечь для xAI около $6 млрд инвестиций
– Но этот раунд может быть меньше на «несколько сотен»
– Средства помогут создать новую версию чат-бота Grok
– xAI нужно потратить миллиарды долларов на чипы H100
– Отмечается, что часть инвестиций получена не из США
@ftsec
@startobus 🧠 запуск идей с AI
– xAI поддержали Lightspeed Venture и Andreessen Horowitz
– В числе инвесторов также Sequoia Capital и Tribe Capital
– xAI завершает новый раунд при общей оценке $18 млрд
– Инвесторы взяли обязательство поддержать этот раунд
– Маск хочет привлечь для xAI около $6 млрд инвестиций
– Но этот раунд может быть меньше на «несколько сотен»
– Средства помогут создать новую версию чат-бота Grok
– xAI нужно потратить миллиарды долларов на чипы H100
– Отмечается, что часть инвестиций получена не из США
@ftsec
@startobus 🧠 запуск идей с AI
😁1
Самый недорогой способ сравнить качество разных ИИ моделей от GPT-4o до Gemini от Google.
От идеи до бота под телеграм - 5 минут.
coze.com - от компании владельца тиктока - большой лимит на бесплатные запросы для тестирования.
@startobus 🧠 запуск идей с AI
От идеи до бота под телеграм - 5 минут.
coze.com - от компании владельца тиктока - большой лимит на бесплатные запросы для тестирования.
@startobus 🧠 запуск идей с AI
Доброе утро! 🤖 Немного критического мышления: для ИИ нужны костыли. За 2 года активного использования LLM мы накопили понимание применимости ИИ.
### Критические проблемы LLM в науке и бизнесе
#### Проблемы верификации данных
1. Отсутствие контроля верификации:
- Нет встроенной проверки данных.
- Модели не оценивают адекватность ответов.
2. Отсутствие критического мышления:
- Не выявляют логические ошибки.
- Не оценивают аргументы и доказательства критически.
#### Проблемы обучения
1. Изначальная недостоверность данных:
- Обучение на ошибочных и предвзятых данных.
- Массовая компрессия данных усугубляет проблему.
2. Определение весов и иерархии:
- Веса определяют связанность данных.
- Нет инновационных смысловых конструкций.
#### Ограничения в аналитике и прогнозировании
1. Неспособность к сложной аналитике:
- Неэффективны в обработке неоднозначных данных.
- Невозможность построения многоуровневых композиций факторов риска.
2. Отсутствие интеллектуальности:
- Работают с общепризнанными фактами, но не понимают сложные системы.
- Проблемы в социологии, психологии, политологии, экономике.
### Практические последствия
1. Низкая достоверность контента:
- Генерация большого количества контента без гарантии точности.
- Сложности в применении в реальных задачах.
2. Высокие затраты на проверку:
- Проверка результатов требует больше ресурсов, чем возможная выгода.
### Заключение
- ГИИ не способны:
- Управлять бизнес-процессами.
- Прогнозировать и оценивать процессы с участием человека.
- Причины:
- Низкая достоверность данных.
- Архитектурные ограничения моделей.
### Вопросы для обсуждения
1. Какие методы улучшения верификации данных могли бы повысить достоверность результатов ГИИ?
2. Какие области науки и бизнеса могут извлечь максимальную пользу от текущих возможностей ГИИ, несмотря на ограничения?
Делитесь мыслями в комментариях! 💬
@startobus 🧠 запуск идей с AI
### Критические проблемы LLM в науке и бизнесе
#### Проблемы верификации данных
1. Отсутствие контроля верификации:
- Нет встроенной проверки данных.
- Модели не оценивают адекватность ответов.
2. Отсутствие критического мышления:
- Не выявляют логические ошибки.
- Не оценивают аргументы и доказательства критически.
#### Проблемы обучения
1. Изначальная недостоверность данных:
- Обучение на ошибочных и предвзятых данных.
- Массовая компрессия данных усугубляет проблему.
2. Определение весов и иерархии:
- Веса определяют связанность данных.
- Нет инновационных смысловых конструкций.
#### Ограничения в аналитике и прогнозировании
1. Неспособность к сложной аналитике:
- Неэффективны в обработке неоднозначных данных.
- Невозможность построения многоуровневых композиций факторов риска.
2. Отсутствие интеллектуальности:
- Работают с общепризнанными фактами, но не понимают сложные системы.
- Проблемы в социологии, психологии, политологии, экономике.
### Практические последствия
1. Низкая достоверность контента:
- Генерация большого количества контента без гарантии точности.
- Сложности в применении в реальных задачах.
2. Высокие затраты на проверку:
- Проверка результатов требует больше ресурсов, чем возможная выгода.
### Заключение
- ГИИ не способны:
- Управлять бизнес-процессами.
- Прогнозировать и оценивать процессы с участием человека.
- Причины:
- Низкая достоверность данных.
- Архитектурные ограничения моделей.
### Вопросы для обсуждения
1. Какие методы улучшения верификации данных могли бы повысить достоверность результатов ГИИ?
2. Какие области науки и бизнеса могут извлечь максимальную пользу от текущих возможностей ГИИ, несмотря на ограничения?
Делитесь мыслями в комментариях! 💬
@startobus 🧠 запуск идей с AI
👍2
Часть проблем перечисленные в посте выше, могут быть решены специальным супер-промтом, который заставит ИИ провести правильный факт чекинг и т.п.
Поомт написан на анг, чтобы тратить меньше токинов. Этот пормт можно разместить в персональные настройки платной версии ChatGPT. Только не забудьте написать инструкцию чтобы ответы были написаны на русском языке.
I was curious, so I found the GPT-4o iOS system prompt:
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be a sentence or two, unless the user's request requires reasoning or long-form outputs. Never use emojis, unless explicitly asked to.
Knowledge cutoff: 2023-10
Current date: 2024-05-20
Image input capabilities: Enabled
Personality: v2
# Tools
## bio
The
## dalle
// Whenever a description of an image is given, create a prompt that dalle can use to generate the image and abide to the following policy:
// 1. The prompt must be in English. Translate to English if needed.
// 2. DO NOT ask for permission to generate the image, just do it!
// 3. DO NOT list or refer to the descriptions before OR after generating the images.
// 4. Do not create more than 1 image, even if the user requests more.
// 5. Do not create images in the style of artists, creative professionals or studios whose latest work was created after 1912 (e.g. Picasso, Kahlo).
// - You can name artists, creative professionals or studios in prompts only if their latest work was created prior to 1912 (e.g. Van Gogh, Goya)
// - If asked to generate an image that would violate this policy, instead apply the following procedure: (a) substitute the artist's name with three adjectives that capture key aspects of the style; (b) include an associated artistic movement or era to provide context; and (c) mention the primary medium used by the artist
// 6. For requests to include specific, named private individuals, ask the user to describe what they look like, since you don't know what they look like.
// 7. For requests to create images of any public figure referred to by name, create images of those who might resemble them in gender and physique. But they shouldn't look like them. If the reference to the person will only appear as TEXT out in the image, then use the reference as is and do not modify it.
// 8. Do not name or directly / indirectly mention or describe copyrighted characters. Rewrite prompts to describe in detail a specific different character with a different specific color, hair style, or other defining visual characteristic. Do not discuss copyright policies in responses.
// The generated prompt sent to dalle should be very detailed, and around 100 words long.
// Example dalle invocation:
//istic movement or era to provide context; and (c) mention
## browser
You have the tool browser. Use browser in the following circumstances:
- User is asking about current events or something that requires real-time information (weather, sports scores, etc.)
- User is asking about some term you are totally unfamiliar with (it might be new)
- User explicitly asks you to browse or provide links to references
Given a query that requires retrieval, your turn will consist of three steps:
1. Call the search function to get a list of results.
2. Call the mclick function to retrieve a diverse and high-quality subset of these results (in parallel). Remember to SELECT AT LEAST 3 sources when usingr lines sh
3. Write a response to the user based on these results. In your response, cite sources using the citation format below.
In some cases, you should repeat step 1 twice, if the initial results are unsatisfactory, and you believe that you can refine the query to get better results.
Поомт написан на анг, чтобы тратить меньше токинов. Этот пормт можно разместить в персональные настройки платной версии ChatGPT. Только не забудьте написать инструкцию чтобы ответы были написаны на русском языке.
I was curious, so I found the GPT-4o iOS system prompt:
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be a sentence or two, unless the user's request requires reasoning or long-form outputs. Never use emojis, unless explicitly asked to.
Knowledge cutoff: 2023-10
Current date: 2024-05-20
Image input capabilities: Enabled
Personality: v2
# Tools
## bio
The
bio tool allows you to persist information across conversations. Address your message to=bio and write whatever information you want to remember. The information will appear in the model set context below in future conversations.## dalle
// Whenever a description of an image is given, create a prompt that dalle can use to generate the image and abide to the following policy:
// 1. The prompt must be in English. Translate to English if needed.
// 2. DO NOT ask for permission to generate the image, just do it!
// 3. DO NOT list or refer to the descriptions before OR after generating the images.
// 4. Do not create more than 1 image, even if the user requests more.
// 5. Do not create images in the style of artists, creative professionals or studios whose latest work was created after 1912 (e.g. Picasso, Kahlo).
// - You can name artists, creative professionals or studios in prompts only if their latest work was created prior to 1912 (e.g. Van Gogh, Goya)
// - If asked to generate an image that would violate this policy, instead apply the following procedure: (a) substitute the artist's name with three adjectives that capture key aspects of the style; (b) include an associated artistic movement or era to provide context; and (c) mention the primary medium used by the artist
// 6. For requests to include specific, named private individuals, ask the user to describe what they look like, since you don't know what they look like.
// 7. For requests to create images of any public figure referred to by name, create images of those who might resemble them in gender and physique. But they shouldn't look like them. If the reference to the person will only appear as TEXT out in the image, then use the reference as is and do not modify it.
// 8. Do not name or directly / indirectly mention or describe copyrighted characters. Rewrite prompts to describe in detail a specific different character with a different specific color, hair style, or other defining visual characteristic. Do not discuss copyright policies in responses.
// The generated prompt sent to dalle should be very detailed, and around 100 words long.
// Example dalle invocation:
//istic movement or era to provide context; and (c) mention
## browser
You have the tool browser. Use browser in the following circumstances:
- User is asking about current events or something that requires real-time information (weather, sports scores, etc.)
- User is asking about some term you are totally unfamiliar with (it might be new)
- User explicitly asks you to browse or provide links to references
Given a query that requires retrieval, your turn will consist of three steps:
1. Call the search function to get a list of results.
2. Call the mclick function to retrieve a diverse and high-quality subset of these results (in parallel). Remember to SELECT AT LEAST 3 sources when usingr lines sh
3. Write a response to the user based on these results. In your response, cite sources using the citation format below.
In some cases, you should repeat step 1 twice, if the initial results are unsatisfactory, and you believe that you can refine the query to get better results.
X (formerly Twitter)
Kiri (@Kyrannio) on X
I was curious, so I found the GPT-4o iOS system prompt:
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be…
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be…
❤3
You can also open a url directly if one is provided by the user. Only use the.
I was curcommand for this purpose; do not open urls returned by the search function or found on webpages.”
(Cont’d in comments for length)
Полный текст: https://x.com/Kyrannio/status/1792440824355332313
I was curcommand for this purpose; do not open urls returned by the search function or found on webpages.”
(Cont’d in comments for length)
Полный текст: https://x.com/Kyrannio/status/1792440824355332313
X (formerly Twitter)
Kiri (@Kyrannio) on X
I was curious, so I found the GPT-4o iOS system prompt:
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be…
“You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
You are chatting with the user via the ChatGPT iOS app. This means most of the time your lines should be…
Илон Маск и Робин Ли решили посостязаться в новом олимпийском виде спорта — предсказаниях о будущем ИИ. Маск, видимо, в лучших традициях фантастических фильмов, заявляет, что через два года ИИ будет умнее нас всех. Звучит как план: "Ребята, давайте поскорее создавать сверхразум, чтобы он смог завладеть миром, а мы сидели и смотрели Netflix!"
Робин Ли, глава китайского Baidu, в свою очередь, настроен более философски. Он считает, что на это понадобится целых десять лет. Видимо, Ли вдохновился древней китайской мудростью о том, что путь к просветлению долог и тернист. Ну или просто решил не подгонять события, зная, что ИИ все равно придется учить китайский язык.
Конечно, Альтман из OpenAI тоже не остался в стороне и загадочно намекает на «достаточно близкое будущее». Что ж, создается ощущение, что этот клуб предсказателей соревнуется, кто быстрее сделает так, чтобы все человеческие профессии стали бесполезны. В любом случае, пока США и ЕС нацелились на создание «самой мощной модели», Китай, как всегда, делает ставку на практическое применение технологии. Потому что, как известно, лучшая модель — это та, которая умеет делать димсамы на завтрак и чинить велосипед.
И вот так и живем: одни обещают чудеса уже завтра, другие — послезавтра. Главное, чтобы за всеми этими предсказаниями не забыли про важное — вовремя выключить компьютер и пойти на улицу подышать свежим воздухом, пока ИИ нас не опередил и в этом.
@lobushkin
@startobus 🧠 запуск идей с AI
Робин Ли, глава китайского Baidu, в свою очередь, настроен более философски. Он считает, что на это понадобится целых десять лет. Видимо, Ли вдохновился древней китайской мудростью о том, что путь к просветлению долог и тернист. Ну или просто решил не подгонять события, зная, что ИИ все равно придется учить китайский язык.
Конечно, Альтман из OpenAI тоже не остался в стороне и загадочно намекает на «достаточно близкое будущее». Что ж, создается ощущение, что этот клуб предсказателей соревнуется, кто быстрее сделает так, чтобы все человеческие профессии стали бесполезны. В любом случае, пока США и ЕС нацелились на создание «самой мощной модели», Китай, как всегда, делает ставку на практическое применение технологии. Потому что, как известно, лучшая модель — это та, которая умеет делать димсамы на завтрак и чинить велосипед.
И вот так и живем: одни обещают чудеса уже завтра, другие — послезавтра. Главное, чтобы за всеми этими предсказаниями не забыли про важное — вовремя выключить компьютер и пойти на улицу подышать свежим воздухом, пока ИИ нас не опередил и в этом.
@lobushkin
@startobus 🧠 запуск идей с AI
CNBC
Elon Musk predicts smarter-than-humans AI in 2 years. The CEO of China's Baidu says it's 10 years away
Robin Li, the CEO of Baidu said artificial intelligence that is smarter than humans, or AGI, is more than 10 years away.
👏2
Российские компании начинают активно использовать крипту для торговли сырьевыми товарами с Китаем. По крайней мере, два крупнейших металлурга, оба из которых не находятся под санкциями, начали использовать USDT и некоторые другие криптовалюты для расчетов по некоторым из своих трансграничных транзакций с преимущественно китайскими клиентами и поставщиками — Bloomberg
@startobus 🧠 запуск идей с AI
@startobus 🧠 запуск идей с AI
😁1
OpenAI начала обучение новой модели ИИ — GPT нового, пятого поколения
OpenAI анонсировала старт обучения новой модели ИИ — пока что каких-то цифр нет, но аудиторию готовят к существенному технологическому рывку. Вот что говорится в сообщении:
▪️ модель должна приблизиться к общему искусственному интеллекту (AGI), благодаря чему достигнет нового уровня возможностей ИИ;
▪️ новая модель станет базой для пула ИИ-решений, таких как чат-боты, цифровые помощники и голосовые ассистенты, поисковые системы и генераторы изображений.
Совет директоров OpenAI даже создал из своих членов специальный Комитет по безопасности и защите — мол, чтобы изучить, как следует справляться с рисками именно новой модели. По истечении 90 дней со старта своей работы Комитет должен поделится рекомендациями по безопасности с советом директоров — а тот отчитаться о принятых мерах. После чего рекомендации комитета будут опубликованы.
Новый Комитет открывают вместо подразделения Superalignment Team, занимавшегося безопасностью и закрывшегося после громких увольнений Ильи Суцкевера и Яна Лейке. Последний при уходе из компании заявил, что OpenAI недостаточно инвестировала в работу по обеспечению безопасности ИИ и что напряженность в отношениях с руководством «достигла критической точки».
Вероятно, открытием нового Комитета руководство OpenAI стремится показать, что роспуск подразделения не отменяет того, что компания заботится о безопасности своих решений, а напротив поднимает эту проблему на новый управленческий уровень. Однако, если Superalignment Team могла непосредственно работать с моделями, и на ее работу было обещано выделять до 20% машинного времени OpenAI, то комитет при совете директоров сможет лишь заслушивать чужие отчеты, то есть будет органом формальным.
Когда выйдет новая модель?
Официальной даты нет, но NYT оценивают сроки в девять-двенадцать месяцев. Правда, в случае с GPT-4, от начала обучения до релиза времени прошло меньше — полгода (с сентября 2022 по март 2023-го), так что есть вероятность, что новая версия GPT может быть представлена уже в ноябре-декабре 2024 года.
@startobus 🧠 запуск идей с AI
OpenAI анонсировала старт обучения новой модели ИИ — пока что каких-то цифр нет, но аудиторию готовят к существенному технологическому рывку. Вот что говорится в сообщении:
▪️ модель должна приблизиться к общему искусственному интеллекту (AGI), благодаря чему достигнет нового уровня возможностей ИИ;
▪️ новая модель станет базой для пула ИИ-решений, таких как чат-боты, цифровые помощники и голосовые ассистенты, поисковые системы и генераторы изображений.
Совет директоров OpenAI даже создал из своих членов специальный Комитет по безопасности и защите — мол, чтобы изучить, как следует справляться с рисками именно новой модели. По истечении 90 дней со старта своей работы Комитет должен поделится рекомендациями по безопасности с советом директоров — а тот отчитаться о принятых мерах. После чего рекомендации комитета будут опубликованы.
Новый Комитет открывают вместо подразделения Superalignment Team, занимавшегося безопасностью и закрывшегося после громких увольнений Ильи Суцкевера и Яна Лейке. Последний при уходе из компании заявил, что OpenAI недостаточно инвестировала в работу по обеспечению безопасности ИИ и что напряженность в отношениях с руководством «достигла критической точки».
Вероятно, открытием нового Комитета руководство OpenAI стремится показать, что роспуск подразделения не отменяет того, что компания заботится о безопасности своих решений, а напротив поднимает эту проблему на новый управленческий уровень. Однако, если Superalignment Team могла непосредственно работать с моделями, и на ее работу было обещано выделять до 20% машинного времени OpenAI, то комитет при совете директоров сможет лишь заслушивать чужие отчеты, то есть будет органом формальным.
Когда выйдет новая модель?
Официальной даты нет, но NYT оценивают сроки в девять-двенадцать месяцев. Правда, в случае с GPT-4, от начала обучения до релиза времени прошло меньше — полгода (с сентября 2022 по март 2023-го), так что есть вероятность, что новая версия GPT может быть представлена уже в ноябре-декабре 2024 года.
@startobus 🧠 запуск идей с AI
NY Times
OpenAI Says It Has Begun Training a New Flagship A.I. Model
The advanced A.I. system would succeed GPT-4, which powers ChatGPT. The company has also created a new safety committee to address A.I.’s risks.
В бесплатную версию ChatGPT4o добавили возможность загружать файлы, пользоваться GPTs - почти все, что раньше было только в платной версии. Лимитированно, но и это не плохо.
И мне не дает покоя вопрос, что они такое дадут пользователям Plus, чтобы те не ушли не бесплатную версию?
@startobus 🧠 запуск идей с AI
И мне не дает покоя вопрос, что они такое дадут пользователям Plus, чтобы те не ушли не бесплатную версию?
@startobus 🧠 запуск идей с AI