
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
Как уменьшить размер файловой системы с ext4?
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
Файловая система на разделе
Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
Добавляем ещё один исполняемый файл
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
# /sbin/resize2fs /dev/sda1 50GФайловая система на разделе
/dev/sda1 будет уменьшена до 50G, если там хватит свободного места для этого. То есть данных должно быть меньше. В общем случае перед выполнением операции и после рекомендуется проверить файловую систему на ошибки:# /sbin/e2fsck -yf /dev/sda1Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
# /sbin/resize2fs /dev/sda1 50Gresize2fs 1.47.0 (5-Feb-2023)Filesystem at /dev/sda1 is mounted on /; on-line resizing required/sbin/resize2fs: On-line shrinking not supported# /sbin/e2fsck -yf /dev/sda1e2fsck 1.47.0 (5-Feb-2023)/dev/sda1 is mounted.e2fsck: Cannot continue, aborting.Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
/etc/initramfs-tools/hooks/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case $1 in
prereqs)
prereqs
exit 0
;;
esac
. /usr/share/initramfs-tools/hook-functions
copy_exec /sbin/e2fsck
copy_exec /sbin/resize2fs
exit 0
Добавляем ещё один исполняемый файл
/etc/initramfs-tools/scripts/local-premount/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case "$1" in
prereqs)
prereqs
exit 0
;;
esac
# simple device example
/sbin/e2fsck -yf /dev/sda1
/sbin/resize2fs /dev/sda1 50G
/sbin/e2fsck -yf /dev/sda1
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
# ls /boot | grep configconfig-6.1.0-12-amd64config-6.1.0-13-amd64config-6.1.0-20-amd64config-6.1.0-22-amd64# update-initramfs -u -k 6.1.0-22-amd64update-initramfs: Generating /boot/initrd.img-6.1.0-22-amd64Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
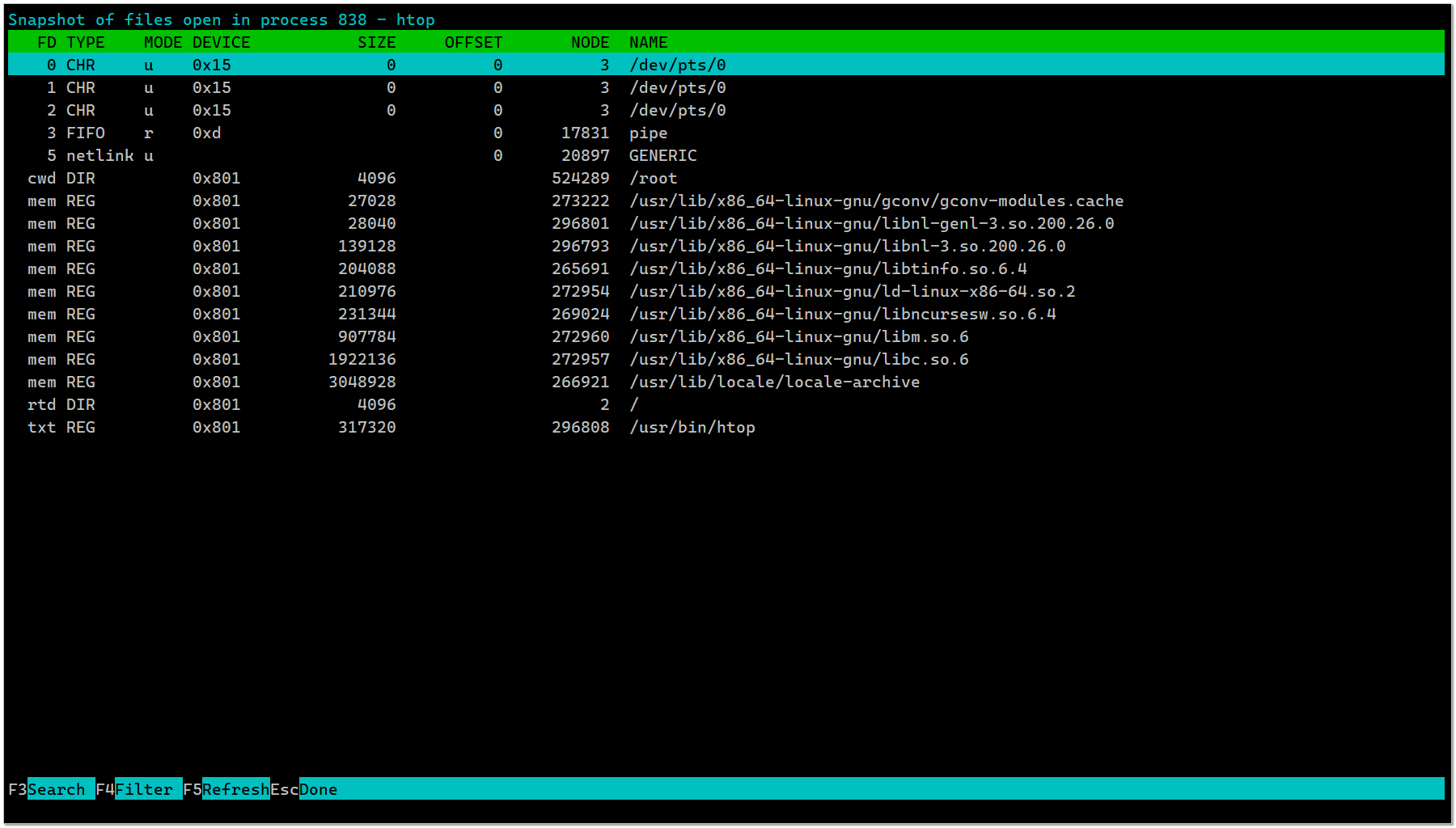
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}