
Я много раз упоминал в заметках, что надо стараться максимально скрывать сервисы от доступа из интернета. И проверять это, потому что часто они туда попадают случайно из-за того, что что-то забыли или неверно настроили. Решил через shodan глянуть открытые Node Exporter от Prometheus. Они часто болтаются в открытом виде, потому что по умолчанию никаких ограничений доступа в них нет. Заходи, кто хочешь, и смотри, что там есть.
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
Часто доступ к веб ресурсам осуществляется не напрямую, а через обратные прокси. Причём чаще доступ именно такой, а не прямой. При возможности, я всегда ставлю обратные прокси перед сайтами даже в небольших проектах. Это и удобнее, и безопаснее, но немного более хлопотно в управлении.
Для проксирования запросов в Docker контейнеры очень удобно использовать Traefik. Удобство это в первую очередь проявляется в тестовых задачах, где часто меняется конфигурация контейнеров с приложениями, их домены, а также возникают задачи по запуску нескольких копий типовых проектов. Для прода это не так актуально, потому что он обычно более статичен в этом плане.
Сразу покажу на практике, в чём заключается удобство Traefik и в каких случаях имеет смысл им воспользоваться. Для примера запущу через Traefik 2 проекта test1 и test2, состоящих из nginx и apache и тестовой страницы, где будет указано имя проекта. В этом примере будет наглядно виден принцип работы Traefik.
Запускаем Traefik через
Можно сходить в веб интерфейс по ip адресу сервера на порт 8080. Пока там пусто, так как нет проектов. Создаём первый тестовый проект. Готовим для него файлы:
Запускаем этот проект:
В веб интерфейсе Traefik, в разделе HTTP появится запись:
Теперь можно скопировать проект test1, изменить в нём имя домена и имя внутренней сети на test2 и запустить. Traefik автоматом подцепит этот проект и будет проксировать запросы к test2.server.local в nginx-test2. Работу этой схемы легко проверить, зайдя откуда-то извне браузером на test1.server.local и test2.server.local. Вы получите соответствующую страницу index.html от запрошенного проекта.
К Traefik легко добавить автоматическое получение TLS сертификатов от Let's Encrypt. Примеров в сети и документации много, настроить не составляет проблемы. Не стал показывать этот пример, так как не уместил бы его в формат заметки. Мне важно было показать суть - запустив один раз Traefik, можно его больше не трогать. По меткам в контейнерах он будет автоматом настраивать проксирование. В некоторых ситуациях это очень удобно.
#webserver #traefik #devops
Для проксирования запросов в Docker контейнеры очень удобно использовать Traefik. Удобство это в первую очередь проявляется в тестовых задачах, где часто меняется конфигурация контейнеров с приложениями, их домены, а также возникают задачи по запуску нескольких копий типовых проектов. Для прода это не так актуально, потому что он обычно более статичен в этом плане.
Сразу покажу на практике, в чём заключается удобство Traefik и в каких случаях имеет смысл им воспользоваться. Для примера запущу через Traefik 2 проекта test1 и test2, состоящих из nginx и apache и тестовой страницы, где будет указано имя проекта. В этом примере будет наглядно виден принцип работы Traefik.
Запускаем Traefik через
docker-compose.yaml:# mkdir traefik && cd traefik
# mcedit docker-compose.yaml
services:
reverse-proxy:
image: traefik:v3.0
command: --api.insecure=true --providers.docker
ports:
- "80:80"
- "8080:8080"
networks:
- traefik_default
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
traefik_default:
external: true
# docker compose up
Можно сходить в веб интерфейс по ip адресу сервера на порт 8080. Пока там пусто, так как нет проектов. Создаём первый тестовый проект. Готовим для него файлы:
# mkdir test1 && cd test1
# mcedit docker-compose.yaml
services:
nginx:
image: nginx:latest
volumes:
- ./app/index.html:/app/index.html
- ./default.conf:/etc/nginx/conf.d/default.conf
labels:
- "traefik.enable=true"
- "traefik.http.routers.nginx-test1.rule=Host(`test1.server.local`)"
- "traefik.http.services.nginx-test1.loadbalancer.server.port=8080"
- "traefik.docker.network=traefik_default"
networks:
- traefik_default
- test1
httpd:
image: httpd:latest
volumes:
- ./app/index.html:/usr/local/apache2/htdocs/index.html
networks:
- test1
networks:
traefik_default:
external: true
test1:
internal: true
# mcedit default.conf
server {
listen 8080;
server_name _;
root /app;
index index.php index.html;
location / {
proxy_pass http://httpd:80;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}# mcedit app/index.html
It's Container for project test1
Запускаем этот проект:
# docker compose up
В веб интерфейсе Traefik, в разделе HTTP появится запись:
Host(`test1.server.local`) http nginx-test1@docker nginx-test1Он по меткам в docker-compose проекта test1 автоматом подхватил настройки и включил проксирование всех запросов к домену test1.server.local в контейнер nginx-test1. При этом сам проект test1 внутри себя взаимодействует по своей внутренней сети test1, а с Traefik по сети traefik_default, которая является внешней для приёма запросов извне.
Теперь можно скопировать проект test1, изменить в нём имя домена и имя внутренней сети на test2 и запустить. Traefik автоматом подцепит этот проект и будет проксировать запросы к test2.server.local в nginx-test2. Работу этой схемы легко проверить, зайдя откуда-то извне браузером на test1.server.local и test2.server.local. Вы получите соответствующую страницу index.html от запрошенного проекта.
К Traefik легко добавить автоматическое получение TLS сертификатов от Let's Encrypt. Примеров в сети и документации много, настроить не составляет проблемы. Не стал показывать этот пример, так как не уместил бы его в формат заметки. Мне важно было показать суть - запустив один раз Traefik, можно его больше не трогать. По меткам в контейнерах он будет автоматом настраивать проксирование. В некоторых ситуациях это очень удобно.
#webserver #traefik #devops
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
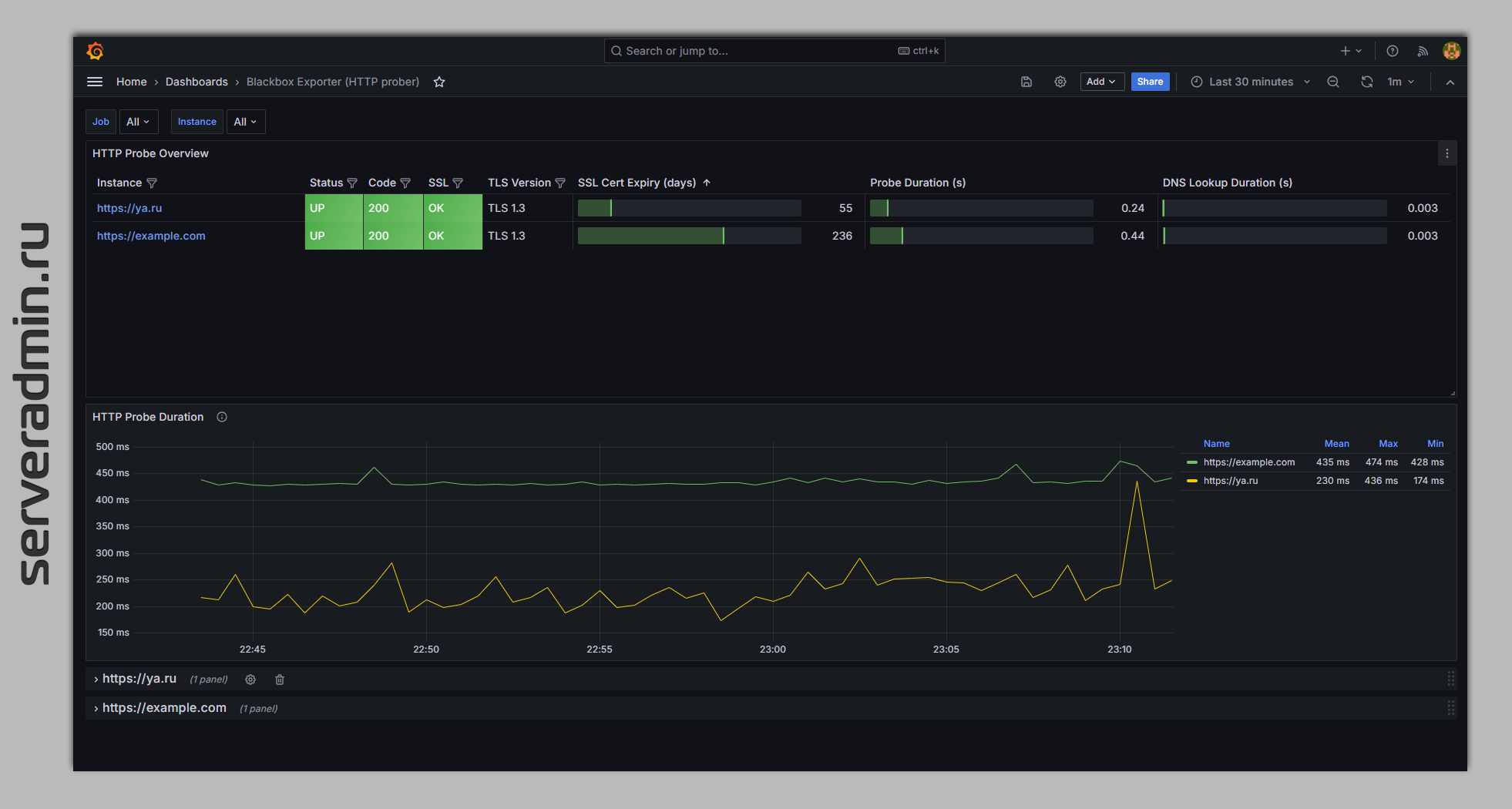
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}