
На прошлой неделе мне нужно было поднять новый сервер для сайта на движке Bitrix. Практически всё время до этого я и все известные мне разработчики разворачивали готовое окружение от авторов фреймворка - BitrixVM. Это готовый инструмент с TUI управлением. В целом, всё было удобно и функционально. Не без отдельных проблем, но это частности. Главное, что актуальность всего совместимого ПО поддерживали сами разработчики Битрикса. И оно было у всех идентичное, что упрощало разработку и перенос сайтов.
BitrixVM построено на базе Centos 7, которая через пару недель прекратит свою поддержку. В итоге встал вопрос, а какое окружение ставить? Я бегло поискал, но не нашёл никакой конкретики на этот счёт. К чему в итоге пришли разработчики и какое окружение они рекомендуют использовать? Я хз.
В итоге потратил кучу времени и поднял всё вручную на базе Debian 12. Установил и связал между собой все необходимые компоненты. Вместо Nginx взял сразу Angie, чтобы удобнее было мониторинг настроить. Да и в целом он мне больше Nginx нравится. Решил написать эту заметку, чтобы получить обратную связь. У кого-то есть конкретика по этой теме?
Судя по всему, все решают эту задачу кто во что горазд. Я нашёл несколько репозиториев с настройкой окружения для Bitrix. Вот они:
🔥https://gitlab.com/bitrix-docker/server
⇨ https://github.com/bitrixdock/bitrixdock
⇨ https://github.com/bestatter/bitrix-docker
⇨ https://github.com/paskal/bitrix.infra
Не захотелось во всём этом разбираться, поэтому настроил сам. Там ничего особенного, просто компонентов побольше, чем у обычного веб сервера на php. И конфиги немного понавороченней из-за особенностей Битрикса. Не хотелось бы всё это поддерживать теперь самостоятельно. И сейчас думаю, либо писать статью, подбивать все конфиги и как-то это упаковывать в ansible или docker. Либо всё-таки подождать какое-то решение от разработчиков.
В процессе настройки нашёл у Битрикса скрипт, который позволяет проверить соответствие хостинга требованиям движка. Раньше не видел его, да и необходимости не было. Забирайте, кто будет решать такую же задачу, пригодится:
⇨ Скрипт bitrix_server_test
Там заметка старая, но скрипт регулярно обновляется. Текущая версия от 29.02.2024.
#bitrix
BitrixVM построено на базе Centos 7, которая через пару недель прекратит свою поддержку. В итоге встал вопрос, а какое окружение ставить? Я бегло поискал, но не нашёл никакой конкретики на этот счёт. К чему в итоге пришли разработчики и какое окружение они рекомендуют использовать? Я хз.
В итоге потратил кучу времени и поднял всё вручную на базе Debian 12. Установил и связал между собой все необходимые компоненты. Вместо Nginx взял сразу Angie, чтобы удобнее было мониторинг настроить. Да и в целом он мне больше Nginx нравится. Решил написать эту заметку, чтобы получить обратную связь. У кого-то есть конкретика по этой теме?
Судя по всему, все решают эту задачу кто во что горазд. Я нашёл несколько репозиториев с настройкой окружения для Bitrix. Вот они:
🔥https://gitlab.com/bitrix-docker/server
⇨ https://github.com/bitrixdock/bitrixdock
⇨ https://github.com/bestatter/bitrix-docker
⇨ https://github.com/paskal/bitrix.infra
Не захотелось во всём этом разбираться, поэтому настроил сам. Там ничего особенного, просто компонентов побольше, чем у обычного веб сервера на php. И конфиги немного понавороченней из-за особенностей Битрикса. Не хотелось бы всё это поддерживать теперь самостоятельно. И сейчас думаю, либо писать статью, подбивать все конфиги и как-то это упаковывать в ansible или docker. Либо всё-таки подождать какое-то решение от разработчиков.
В процессе настройки нашёл у Битрикса скрипт, который позволяет проверить соответствие хостинга требованиям движка. Раньше не видел его, да и необходимости не было. Забирайте, кто будет решать такую же задачу, пригодится:
⇨ Скрипт bitrix_server_test
Там заметка старая, но скрипт регулярно обновляется. Текущая версия от 29.02.2024.
#bitrix
{kind=link}
Расскажу пару историй с ошибками бэкапов, с которыми столкнулся за последнее время. Я уже много раз рассказывал про свои подходы к созданию бэкапов. Вот примеры: 1, 2, 3, 4, 5, 6. Ничего нового не скажу, просто поделюсь своими историями.
Проблема номер 1. Есть сервер PBS для бэкапа виртуальных машин Proxmox. Бэкапы регулярно делаются, проходят проверку встроенными средствами, ошибок нет. Решаю проверить полное восстановление VM на новый сервер. Нашёл подходящий свободный сервер, подключил хранилище PBS, запустил восстановление виртуалки размером 450 Гб. А оно не проходит. Тупо ошибка:
в случайный момент времени. Ошибка неинформативная. Со стороны PBS просто:
Похоже на сетевую ошибку. Немного погуглил, увидел людей, которые сталкивались с похожими проблемами. Причины могут быть разными. У кого-то с драйвером сетевухи проблемы, какие-то настройки интерфейса меняют, у кого-то через VPN есть эта ошибка, без VPN нет. Я, кстати, по VPN каналу делал восстановление. Возможно, это мой случай.
Столкнуться с проблемами передачи такого большого файла через интернет вероятность очень большая. Никакой докачки нет. После ошибки, начинай всё заново. Поэтому я всегда делаю бэкап VM и в обязательном порядке сырых данных внутри этой виртуалки. Обычно с помощью rsync или чего-то подобного. Это позволит всегда иметь под рукой реальные данные без привязки к какой-то системе бэкапов, которая может тупо заглючить или умереть.
Хорошо, что это была просто проверка и у меня есть другие бэкапы данных. А если бы была авария и тут такой сюрприз в виде невозможности восстановиться. Кстати, бэкап на самом деле живой. Я вытащил из него данные через обзор файлов. Но целиком восстановить VM не получилось из-за каких-то сетевых проблем.
Проблема номер 2. События вообще в другом месте и никак не связаны. Разные компании. Появляется новый свободный сервер, который ещё не запустили в эксплуатацию. Решаю на него восстановить полную версию VM через Veeam Backup and Replication. Вим регулярное делает бэкапы, шлёт отчёты, бэкапы восстанавливаются через настроенную задачу репликации. То есть всё работает как надо.
Новый сервер в другой локации, с другой сетью, связь через VPN. Но тут сразу скажу, проблема не в этом. Запускаю восстановление, а оно раз за разом падает с ошибкой:
Налицо какая-то сетевая проблема, но не могу понять, в чём дело. SMB шара работает, доступна. Бэкапы туда складываются и разворачиваются планом репликации. На вид всё ОК.
Несколько дней я подходил к этой задаче и не мог понять, что не так. Решение пришло случайно. Я вспомнил, что NAS, с которого монтируется SMB шара, файрволом ограничен белым списком IP, которым разрешён доступ к данным. Я проверял с управляющей машины и реплицировал данные на сервера из этого списка, которые в одной локации. Проблем не было. А нового сервера в списках не было. Восстановление запускает агента на новом сервере и он напрямую от себя тянет данные с хранилища, а я думал, что через прокси на управляющей машине.
Хорошо, что всё это было выявлено во время проверки. А если бы всё грохнулось и я пытался бы восстановиться, то не факт, что вспомнил, в чём проблема, особенно в состоянии стресса. Столько бы кирпичей отложил, когда увидел, что бэкап не восстанавливается.
❗️В заключении скажу банальность - проверяйте бэкапы. Особенно большие VM и бэкапы баз данных.
#backup
Проблема номер 1. Есть сервер PBS для бэкапа виртуальных машин Proxmox. Бэкапы регулярно делаются, проходят проверку встроенными средствами, ошибок нет. Решаю проверить полное восстановление VM на новый сервер. Нашёл подходящий свободный сервер, подключил хранилище PBS, запустил восстановление виртуалки размером 450 Гб. А оно не проходит. Тупо ошибка:
restore failed: error:0A000119:SSL routines:ssl3_get_record:decryption failed or bad record mac:../ssl/record/ssl3_record.c:622в случайный момент времени. Ошибка неинформативная. Со стороны PBS просто:
TASK ERROR: connection error: connection resetПохоже на сетевую ошибку. Немного погуглил, увидел людей, которые сталкивались с похожими проблемами. Причины могут быть разными. У кого-то с драйвером сетевухи проблемы, какие-то настройки интерфейса меняют, у кого-то через VPN есть эта ошибка, без VPN нет. Я, кстати, по VPN каналу делал восстановление. Возможно, это мой случай.
Столкнуться с проблемами передачи такого большого файла через интернет вероятность очень большая. Никакой докачки нет. После ошибки, начинай всё заново. Поэтому я всегда делаю бэкап VM и в обязательном порядке сырых данных внутри этой виртуалки. Обычно с помощью rsync или чего-то подобного. Это позволит всегда иметь под рукой реальные данные без привязки к какой-то системе бэкапов, которая может тупо заглючить или умереть.
Хорошо, что это была просто проверка и у меня есть другие бэкапы данных. А если бы была авария и тут такой сюрприз в виде невозможности восстановиться. Кстати, бэкап на самом деле живой. Я вытащил из него данные через обзор файлов. Но целиком восстановить VM не получилось из-за каких-то сетевых проблем.
Проблема номер 2. События вообще в другом месте и никак не связаны. Разные компании. Появляется новый свободный сервер, который ещё не запустили в эксплуатацию. Решаю на него восстановить полную версию VM через Veeam Backup and Replication. Вим регулярное делает бэкапы, шлёт отчёты, бэкапы восстанавливаются через настроенную задачу репликации. То есть всё работает как надо.
Новый сервер в другой локации, с другой сетью, связь через VPN. Но тут сразу скажу, проблема не в этом. Запускаю восстановление, а оно раз за разом падает с ошибкой:
Restore job failed. Error: The network path was not found. Failed to open storage for read access. Storage: [\\10.30.5.21\veeam\Office\OfficeD2024-05-23T040102_8E4F.vib]. Failed to restore file from local backup. VFS link: [summary.xml]. Target file: [MemFs://frontend::CDataTransferCommandSet::RestoreText_{f81d9dbd-ee5b-4a4e-ae58-744bb6f46a6b}]. CHMOD mask: [226]. Agent failed to process method {DataTransfer.RestoreText}.Налицо какая-то сетевая проблема, но не могу понять, в чём дело. SMB шара работает, доступна. Бэкапы туда складываются и разворачиваются планом репликации. На вид всё ОК.
Несколько дней я подходил к этой задаче и не мог понять, что не так. Решение пришло случайно. Я вспомнил, что NAS, с которого монтируется SMB шара, файрволом ограничен белым списком IP, которым разрешён доступ к данным. Я проверял с управляющей машины и реплицировал данные на сервера из этого списка, которые в одной локации. Проблем не было. А нового сервера в списках не было. Восстановление запускает агента на новом сервере и он напрямую от себя тянет данные с хранилища, а я думал, что через прокси на управляющей машине.
Хорошо, что всё это было выявлено во время проверки. А если бы всё грохнулось и я пытался бы восстановиться, то не факт, что вспомнил, в чём проблема, особенно в состоянии стресса. Столько бы кирпичей отложил, когда увидел, что бэкап не восстанавливается.
❗️В заключении скажу банальность - проверяйте бэкапы. Особенно большие VM и бэкапы баз данных.
#backup
Прочитал интересную серию статей Building A 'Mini' 100TB NAS, где человек в трёх частях рассказывает, как он себе домой NAS собирал и обновлял. Железо там хорошее для дома. Было интересно почитать.
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
И после этого запускаете синхронизацию:
Данные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
/etc/snapraid.conf:parity /mnt/diskp/snapraid.paritycontent /var/snapraid/snapraid.contentcontent /mnt/disk1/snapraid.contentcontent /mnt/disk2/snapraid.contentdata d1 /mnt/disk1/data d2 /mnt/disk2/data d3 /mnt/disk3/И после этого запускаете синхронизацию:
# snapraid syncДанные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
{kind=link}
Напоминаю для тех, кто забыл, но всё ещё использует Centos 7. У неё заканчивается срок поддержи. Время окончания - ⏰ 30 июня 2024. Если у вас закрытый контур, то, думаю, нет смысла торопиться и что-то делать, роняя тапки. Ничего страшного не случится после этой даты. Открою страшную тайну. У меня есть в управлении пару серверов ещё на Centos 5 😱 Там настроено и работает ПО, которое настраивали очень давно. Просто взять и перенести его на современную систему не получится.
Все свои Centos 8 я в своё время конвертнул в Oracle Linux. А 8-я версия ещё долго поддерживаться будет. С седьмой ситуация похуже. Там я частично переехал на Debian, где это было критично, а где-то ещё оставил 7, пока она поддерживается. Конвертация системы с 7-й на 8-ю версию не всегда проходит гладко. Хотя в целом, это реально.
Вот инструкция для AlmaLinux по конвертации Centos 7 в AlmaLinux 9. Процесс проходит в 2 этапа: 7 ⇨ 8, 8 ⇨ 9. Работает на базе утилиты leapp.Я в своё время тестировал его. Обновление прошло успешно. Подобные инструкции есть у всех дистрибутивов, форков RHEL. Я честно говоря, даже затрудняюсь какой-то из них советовать. Откровенно не знаю, кто из них лучше, хуже и как будет развиваться дальше. В основном из-за этого я и переехал на Debian, чтобы потом не обломаться ещё раз с каким-нибудь загнувшимся форком RHEL. Как показывает реальность сегодняшнего дня, это было правильное решение.
Похоже, это уже финальный пост на тему Centos. Ставим жирную точку в этой истории. Я плотно работал с ней где-то с 2012 до 2021 года. До этого была в основном FreeBSD и немного Debian. Но на тот момент мне Centos нравилась больше, поэтому полностью переехал на неё. И вот снова Debian. Это практически единственный конкурент rpm дистрибутивам. Может ещё и на FreeBSD придётся возвращаться. Хрен знает, какая судьба ждёт Debian. Если бы не Ubuntu, которая на его основе, могли бы и поддушить коммерческие конкуренты.
#centos
Все свои Centos 8 я в своё время конвертнул в Oracle Linux. А 8-я версия ещё долго поддерживаться будет. С седьмой ситуация похуже. Там я частично переехал на Debian, где это было критично, а где-то ещё оставил 7, пока она поддерживается. Конвертация системы с 7-й на 8-ю версию не всегда проходит гладко. Хотя в целом, это реально.
Вот инструкция для AlmaLinux по конвертации Centos 7 в AlmaLinux 9. Процесс проходит в 2 этапа: 7 ⇨ 8, 8 ⇨ 9. Работает на базе утилиты leapp.Я в своё время тестировал его. Обновление прошло успешно. Подобные инструкции есть у всех дистрибутивов, форков RHEL. Я честно говоря, даже затрудняюсь какой-то из них советовать. Откровенно не знаю, кто из них лучше, хуже и как будет развиваться дальше. В основном из-за этого я и переехал на Debian, чтобы потом не обломаться ещё раз с каким-нибудь загнувшимся форком RHEL. Как показывает реальность сегодняшнего дня, это было правильное решение.
Похоже, это уже финальный пост на тему Centos. Ставим жирную точку в этой истории. Я плотно работал с ней где-то с 2012 до 2021 года. До этого была в основном FreeBSD и немного Debian. Но на тот момент мне Centos нравилась больше, поэтому полностью переехал на неё. И вот снова Debian. Это практически единственный конкурент rpm дистрибутивам. Может ещё и на FreeBSD придётся возвращаться. Хрен знает, какая судьба ждёт Debian. Если бы не Ubuntu, которая на его основе, могли бы и поддушить коммерческие конкуренты.
#centos
{kind=link}
Для бэкапа конфигураций Mikrotik есть простая и удобная программа от известного в узких кругах Васильева Кирилла. У него на сайте много интересных статей, рекомендую. Программа называется Pupirka.
Pupirka работает очень просто. Подключается по SSH, делает экспорт конфигурации и кладёт её рядом в папочку. Ничего особенного, но всё аккуратно организовано, с логированием, конфигами и т.д. То есть пользоваться удобно, не надо писать свои костыли на баше.
Достаточно скачать один исполняемый файл под свою систему. Поддерживаются все популярные. Пример для Linux:
Запускаем программу:
Она создаст структуру каталогов и базовый файл конфигурации:
▪️ backup - директория для бэкапов устройств
▪️ device - директория с конфигурациями устройств для подключения
▪️ keys - ssh ключи, если используются они вместо паролей
▪️ log - лог файлы для каждого устройства, которое бэкапится
▪️ pupirka.config.json - базовый файл конфигурации
Дефолтную конфигурацию можно не трогать, если будете подключаться на стандартный 22-й порт.
Вам достаточно в директорию device положить json файл с настройками подключения к устройству. Например, router.json:
Теперь можно запустить pupirka, она забэкапит это устройство:
В директории
Pupirka поддерживает хуки, так что после бэкапа конфиг можно запушить в git репозиторий. Для этого есть отдельные настройки в глобальном конфиге.
Описание программы можно посмотреть на сайте автора. В принципе, её можно использовать не только для бэкапов микротиков, но и каких-то других вещей. Команду, вывод которой она будет сохранять, можно указать в конфиге. То есть можно ходить и по серверам, собирать какую-то информацию.
Накидайте, кому не в лом, звёзд на гитхабе. Программа хоть и простая, но удобная.
#mikrotik
Pupirka работает очень просто. Подключается по SSH, делает экспорт конфигурации и кладёт её рядом в папочку. Ничего особенного, но всё аккуратно организовано, с логированием, конфигами и т.д. То есть пользоваться удобно, не надо писать свои костыли на баше.
Достаточно скачать один исполняемый файл под свою систему. Поддерживаются все популярные. Пример для Linux:
# wget https://github.com/vasilevkirill/pupirka/releases/download/v0.7/pupirka_linux_amd64# mv pupirka_linux_amd64 pupirka# chmod +x pupirkaЗапускаем программу:
# ./pupirkaОна создаст структуру каталогов и базовый файл конфигурации:
▪️ backup - директория для бэкапов устройств
▪️ device - директория с конфигурациями устройств для подключения
▪️ keys - ssh ключи, если используются они вместо паролей
▪️ log - лог файлы для каждого устройства, которое бэкапится
▪️ pupirka.config.json - базовый файл конфигурации
Дефолтную конфигурацию можно не трогать, если будете подключаться на стандартный 22-й порт.
Вам достаточно в директорию device положить json файл с настройками подключения к устройству. Например, router.json:
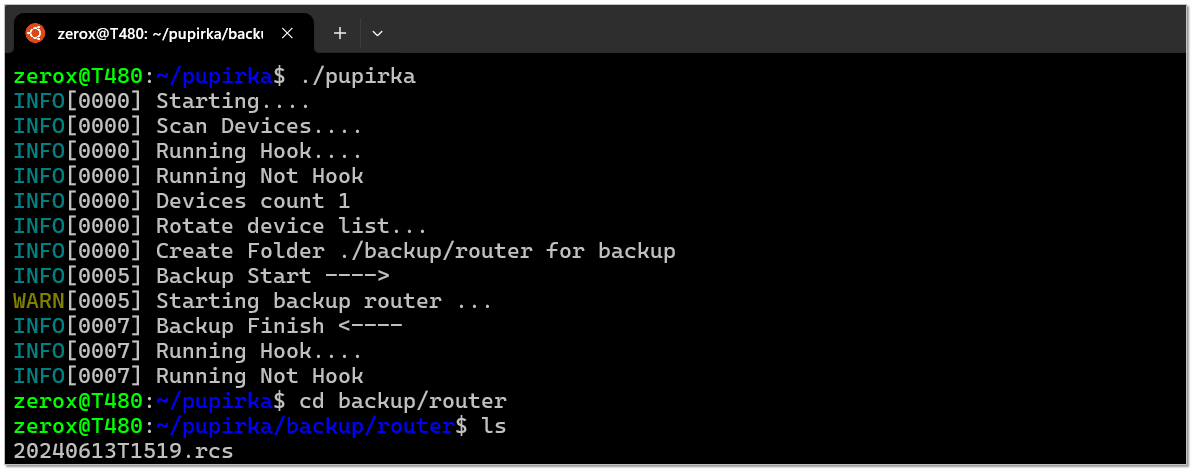
{ "address": "192.168.13.1", "username": "backuser", "password": "secpassw0rd"}Теперь можно запустить pupirka, она забэкапит это устройство:
zerox@T480:~/pipirka$ ./pupirkaINFO[0000] Starting....INFO[0000] Scan Devices....INFO[0000] Running Hook....INFO[0000] Running Not HookINFO[0000] Devices count 1INFO[0000] Rotate device list...INFO[0000] Create Folder ./backup/router for backupINFO[0005] Backup Start ---->WARN[0005] Starting backup router ...INFO[0008] Backup Finish <----INFO[0008] Running Hook....INFO[0008] Running Not HookВ директории
backup/router будет лежать экспорт конфигурации, а в log/router будет лог операции с ключевой фразой "Backup complete", по которой можно судить об успешности процедуры. Pupirka поддерживает хуки, так что после бэкапа конфиг можно запушить в git репозиторий. Для этого есть отдельные настройки в глобальном конфиге.
Описание программы можно посмотреть на сайте автора. В принципе, её можно использовать не только для бэкапов микротиков, но и каких-то других вещей. Команду, вывод которой она будет сохранять, можно указать в конфиге. То есть можно ходить и по серверам, собирать какую-то информацию.
Накидайте, кому не в лом, звёзд на гитхабе. Программа хоть и простая, но удобная.
#mikrotik
{kind=link}
У меня было очень много заметок про различные мониторинги. Кажется, что я уже про всё более-менее полезное что-то да писал. Оказалось, что нет. Расскажу про очередной небольшой и удобный мониторинг, который позволяет очень просто и быстро создать дашборд с зелёными и красными кнопками. Если зелёные, то всё ОК, если красные, то НЕ ОК.
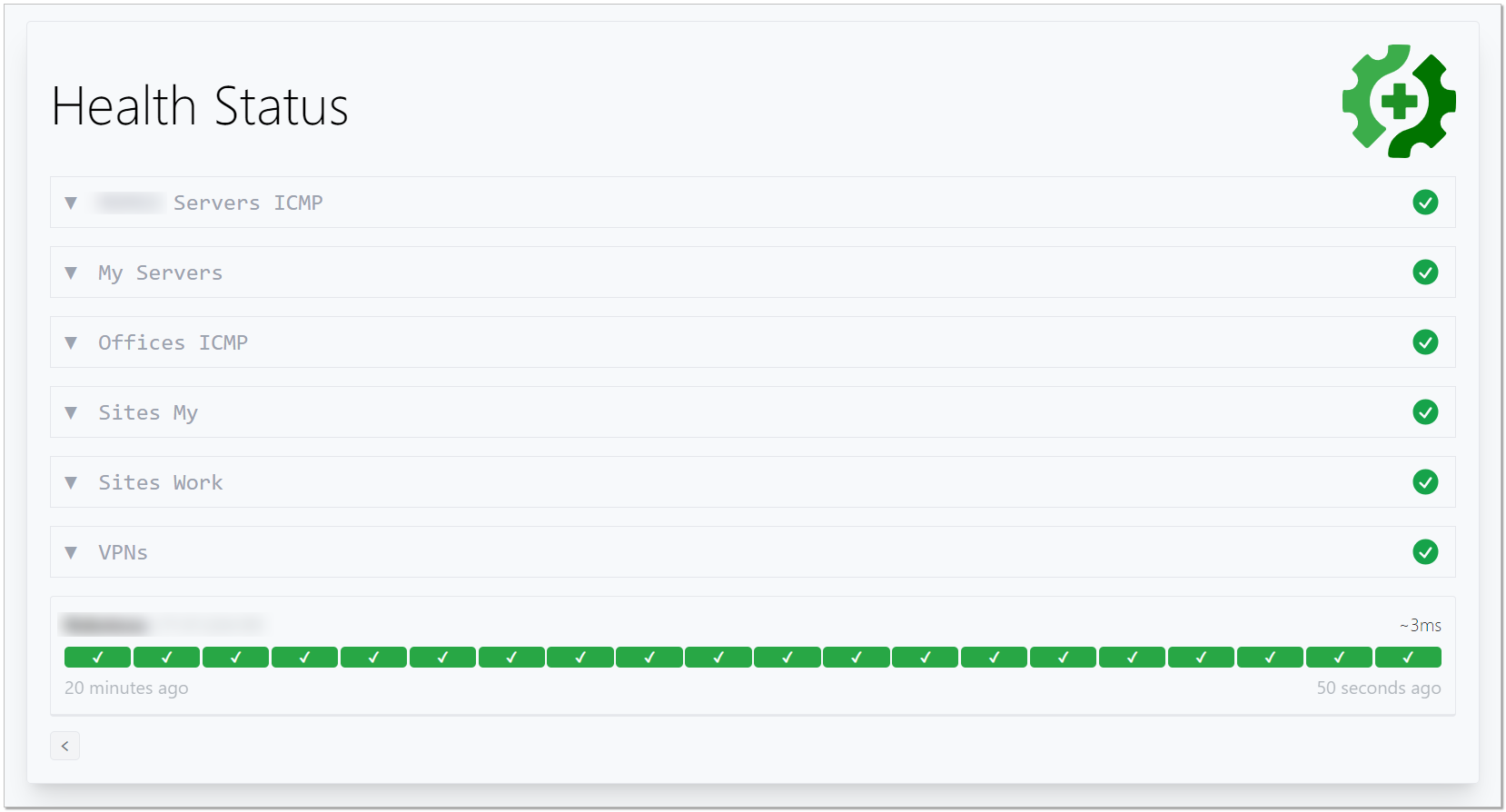
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
Запускаем Docker контейнер и цепляем к нему этот файл:
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
# mkdir gatus && cd gatus
# touch config.yaml
alerting:
telegram:
token: "1393668911:AAHtEAKqxUH7ZpyX28R-wxKfvH1WR6-vdNw"
id: "210806260"
endpoints:
- name: Zabbix Connection
url: "https://zabbix.com"
interval: 30s
conditions:
- "[CONNECTED] == true"
- "[IP] == 188.114.99.224"
- name: Github Title
url: "https://github.com"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY] == pat(*<title>GitHub: Let’s build from here · GitHub</title>*)"
- name: Yandex response
url: "https://ya.ru"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[RESPONSE_TIME] < 10"
alerts:
- type: telegram
send-on-resolved: true
- name: VK cert & domain
url: "https://vk.com"
interval: 5m
conditions:
- "[CERTIFICATE_EXPIRATION] > 48h"
- "[DOMAIN_EXPIRATION] > 720h"
Запускаем Docker контейнер и цепляем к нему этот файл:
# docker run -p 8080:8080 -d \
--mount type=bind,source="$(pwd)"/config.yaml,target=/config/config.yaml \
--name gatus twinproduction/gatus
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
▶️ Всем хороших тёплых летних купательных выходных. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными.
⇨ Zabbix Webinars: What's new in Zabbix 7.0
Я смотрел этот вебинар в режиме онлайн. Сразу могу сказать, что лично мне он не понравился, так как выступающий рассказывал по презентации. Я рассчитывал, что будут какие-то примеры на реальной системе, но их не было. Так что актуально только для тех, кто хочет посмотреть обзор нововведений. Лично я их и так знал.
⇨ Zabbix 7 - Synthetic Selenium Web Monitoring
Это более информативное видео, так как тут уже конкретные примеры, что и как настраивается. Кому актуальна тема - рекомендую.
⇨ Unleash Zabbix Power: Server and mass agent install!
Подробное практическое видео с установкой Zabbix сервера и агента в Docker за Reverse Proxy.
⇨ Synology SSO единый вход для всех служб и приложений на примере DSM и Proxmox
Пример настройки Synology SSO. Я и не знал, что у него такая служба есть. В видео рассказано в том числе как на это SSO завести аутентификацию в Proxmox.
⇨ Envoy Proxy — один за всех Load Balancer / Дмитрий Самохвалов (CROC Cloud Services)
Содержательный доклад про работу Envoy (аналог как балансировщиков Nginx и HAProxy) в крупной компании. На примерах показано, почему более современный Envoy оказался удобнее старых и проверенных инструментов.
⇨ Как я делал пылевую уборку домашнему серверу
Любопытное видео, где автор канала показывает свою инфру дома на фоне темы очистки её от пыли. Было интересно посмотреть, как у него всё устроено.
⇨ MOST POWERFUL WINDOWS SERVER 896 CPUs + 32TB RAM DDR5 running Notepad
Денис Астахов по приколу арендовал самый дорогой сервер в AWS с 896 CPUs + 32TB RAM, установил туда Windows Server и погонял на нём некоторый софт. На практике винда тормозит и виснет, софт падает и работает некорректно. Думаю, для таких конфигураций нужны специальные ОС и соответствующее ПО для них.
⇨ Why I’ve switched… // Obsidian vs Notion
Сравнение двух популярных систем для ведения заметок.
#видео
⇨ Zabbix Webinars: What's new in Zabbix 7.0
Я смотрел этот вебинар в режиме онлайн. Сразу могу сказать, что лично мне он не понравился, так как выступающий рассказывал по презентации. Я рассчитывал, что будут какие-то примеры на реальной системе, но их не было. Так что актуально только для тех, кто хочет посмотреть обзор нововведений. Лично я их и так знал.
⇨ Zabbix 7 - Synthetic Selenium Web Monitoring
Это более информативное видео, так как тут уже конкретные примеры, что и как настраивается. Кому актуальна тема - рекомендую.
⇨ Unleash Zabbix Power: Server and mass agent install!
Подробное практическое видео с установкой Zabbix сервера и агента в Docker за Reverse Proxy.
⇨ Synology SSO единый вход для всех служб и приложений на примере DSM и Proxmox
Пример настройки Synology SSO. Я и не знал, что у него такая служба есть. В видео рассказано в том числе как на это SSO завести аутентификацию в Proxmox.
⇨ Envoy Proxy — один за всех Load Balancer / Дмитрий Самохвалов (CROC Cloud Services)
Содержательный доклад про работу Envoy (аналог как балансировщиков Nginx и HAProxy) в крупной компании. На примерах показано, почему более современный Envoy оказался удобнее старых и проверенных инструментов.
⇨ Как я делал пылевую уборку домашнему серверу
Любопытное видео, где автор канала показывает свою инфру дома на фоне темы очистки её от пыли. Было интересно посмотреть, как у него всё устроено.
⇨ MOST POWERFUL WINDOWS SERVER 896 CPUs + 32TB RAM DDR5 running Notepad
Денис Астахов по приколу арендовал самый дорогой сервер в AWS с 896 CPUs + 32TB RAM, установил туда Windows Server и погонял на нём некоторый софт. На практике винда тормозит и виснет, софт падает и работает некорректно. Думаю, для таких конфигураций нужны специальные ОС и соответствующее ПО для них.
⇨ Why I’ve switched… // Obsidian vs Notion
Сравнение двух популярных систем для ведения заметок.
#видео
YouTube
Zabbix Webinars: What's new in Zabbix 7.0
Watch the webinar recording and learn more about the new features introduced in Zabbbix 7.0:
02:47 Synthetic end user web monitoring
07:25 Asynchronous data collection
11:57 Zabbix Proxy high availability and load balancing
17:05 Zabbix proxy memory buffer…
02:47 Synthetic end user web monitoring
07:25 Asynchronous data collection
11:57 Zabbix Proxy high availability and load balancing
17:05 Zabbix proxy memory buffer…
Я в пятницу рассказал про систему мониторинга Gatus. Система мне понравилась, так что решил её сразу внедрить у себя. Понравилась за 3 вещи:
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
◽
Когда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
.gitlab-ci.yml. Добавил туда всего 3 действия:deploy-prod: stage: deploy script: - cd /home/gitlab-runner/gatus - git pull - /usr/bin/docker restart gatus5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
config.yaml - конфигурация gatus◽
.gitlab-ci.yml - описание команд, которые будет выполнять gitlab-runnerКогда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
.gitlab-ci.yml и отдаёт команду gitlab-runner, установленному на VPS на выполнение заданных действий: обновление локального репозитория, чтобы поучить обновлённый конфиг и перезапуск контейнера, который необходим для применения изменений. На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
{kind=link}
Послушал недавно очень любопытное выступление про взлом Confluence у не самой маленькой компании. Иногда думаешь, что сам работаешь не идеально и где-то косячишь. Но когда смотришь такие выступления, понимаешь, что у тебя ещё всё нормально.
▶️ Как нам стерли всю базу в Confluence и как мы героически ее восстанавливали
Там классическая история произошла. У ребят была on-premise установка лицензионной Confluence. В какой-то момент обновить лицензию стало невозможно, но так как купленная была бессрочная, то решили дальше ей пользоваться, но без обновлений. А смотрела эта система веб интерфейсом в интернет на дедике в Hetzner. На Confluence и Jira была плотно завязана ежедневная деятельность компании.
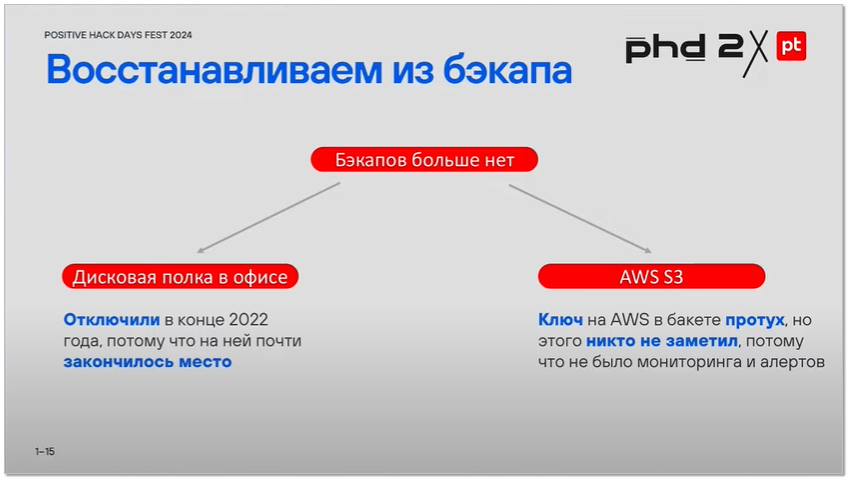
Ну и в какой-то момент появилась RCE (Remote Code Execution) уязвимость. Через неё им грохнули всю базу данных. А там было много всего. Стали искать бэкапы. Оказалось, что на своей СХД давно уже закончилось место и бэкапы не делались, а на AWS S3 архивы не копировались, потому что протух токен. И случились обе неприятности более года назад ❗️
В итоге случайно нашли дамп базы данных на самом сервере, от времени, когда делали миграцию 8 месяцев назад с одной СУБД на другую. Этот бэкап развернули, а более свежие данные восстанавливали из писем в ящиках пользователей. Привлекли для этого дела Java программиста из штата. Многие пользователи были подписаны на свои темы и получали уведомления на почту, когда на страницах происходили изменения. Из этого можно было вытянуть какой-то недостающий контент.
Восстановили, конечно не всё. Но каким-то образом всё же пережили инцидент и после этого настроили Prometheus для мониторинга с уведомлениями в Telegram. Главное, чтобы туда токен не протух, а то можно также год без мониторинга жить. Сказали, что планируют ещё и бэкапы проверять, а не только за местом следить. Также спрятали веб интерфейс Confluence за VPN.
По факту на практике до сих пор бывает так, что в немаленькой компании, где есть отдельно отдел разработки, может не быть мониторинга, контроля и проверки бэкапов. С самой Confluenсe работало в районе 80-ти человек. То есть масштаб компании не сказать, что маленький.
По факту их бы спас простейший мониторинг свободного места на СХД, но его не было. Эта мысль не озвучивалась в выступлении, но мне показалось, что эта компания из тех, кто считает, что сисадмины особо не нужны. Если был бы один хотя бы на полставки, то был бы и мониторинг, и VPN.
Выступление получилось живое и интересное. Выступающие молодцы, что не побоялись рассказать, про такой масштабный свой косяк.
#security
▶️ Как нам стерли всю базу в Confluence и как мы героически ее восстанавливали
Там классическая история произошла. У ребят была on-premise установка лицензионной Confluence. В какой-то момент обновить лицензию стало невозможно, но так как купленная была бессрочная, то решили дальше ей пользоваться, но без обновлений. А смотрела эта система веб интерфейсом в интернет на дедике в Hetzner. На Confluence и Jira была плотно завязана ежедневная деятельность компании.
Ну и в какой-то момент появилась RCE (Remote Code Execution) уязвимость. Через неё им грохнули всю базу данных. А там было много всего. Стали искать бэкапы. Оказалось, что на своей СХД давно уже закончилось место и бэкапы не делались, а на AWS S3 архивы не копировались, потому что протух токен. И случились обе неприятности более года назад ❗️
В итоге случайно нашли дамп базы данных на самом сервере, от времени, когда делали миграцию 8 месяцев назад с одной СУБД на другую. Этот бэкап развернули, а более свежие данные восстанавливали из писем в ящиках пользователей. Привлекли для этого дела Java программиста из штата. Многие пользователи были подписаны на свои темы и получали уведомления на почту, когда на страницах происходили изменения. Из этого можно было вытянуть какой-то недостающий контент.
Восстановили, конечно не всё. Но каким-то образом всё же пережили инцидент и после этого настроили Prometheus для мониторинга с уведомлениями в Telegram. Главное, чтобы туда токен не протух, а то можно также год без мониторинга жить. Сказали, что планируют ещё и бэкапы проверять, а не только за местом следить. Также спрятали веб интерфейс Confluence за VPN.
По факту на практике до сих пор бывает так, что в немаленькой компании, где есть отдельно отдел разработки, может не быть мониторинга, контроля и проверки бэкапов. С самой Confluenсe работало в районе 80-ти человек. То есть масштаб компании не сказать, что маленький.
По факту их бы спас простейший мониторинг свободного места на СХД, но его не было. Эта мысль не озвучивалась в выступлении, но мне показалось, что эта компания из тех, кто считает, что сисадмины особо не нужны. Если был бы один хотя бы на полставки, то был бы и мониторинг, и VPN.
Выступление получилось живое и интересное. Выступающие молодцы, что не побоялись рассказать, про такой масштабный свой косяк.
#security
{kind=link}
На днях случилась необычная ситуация, с которой раньше не сталкивался. На ноутбук прилетели обновления. Среди них было:
▪️ Intel Software Guard Extensions Device and Software
▪️ Intel Management Engine Firmware
▪️ BIOS Update
Всё это установил и перезагрузился. Никаких изменений не заметил, кроме одного - слетели все аутентификации в браузерах. Давно с таким не сталкивался. С учётом того, что много где настроено 2FA в том числе с подтверждением по смс, пришлось потратить время, чтобы везде обратно залогиниться. Причём сбросились аутентификации во всех браузерах. Я постоянно пользуюсь как минимум двумя, иногда третий запускаю.
Обновления, судя по всему, ставились в два этапа, так как после следующей перезагрузки всё опять слетело. Во всех браузерах логинился по-новой. Тут я немного приуныл и вспомнил неактуальную в наши дни поговорку:
"Не было печали, апдейтов накачали".
Думал, что словил какой-то баг и теперь это будет постоянно, пока не разберусь, в чём проблема. На деле всё было нормально. Аутентификации больше не слетали.
Попробовал немного поискать информации на эту тему, но ничего не нашёл по делу. Вся выдача поисковиков по теме сброса аутентификаций забита информацией о куках, их отключении, блокировке или очистке.
Кто-нибудь знает, что реально привело к сбросу всех аутентификаций? Это явно инициировал браузер. Вряд ли у всех сайтов есть доступ к информации о железе или установленному ПО. Яндекс браузер даже сохранённые пароли отказывался использовать, пока я вручную не зашёл в настройки и не тыкнул в какую-то кнопку, которая означала, что это реально я сбросил аутентификацию, а не само так вышло.
Любопытно, на что браузеры так отреагировали. На обновление биоса или каких-то интеловских примочек?
#разное
▪️ Intel Software Guard Extensions Device and Software
▪️ Intel Management Engine Firmware
▪️ BIOS Update
Всё это установил и перезагрузился. Никаких изменений не заметил, кроме одного - слетели все аутентификации в браузерах. Давно с таким не сталкивался. С учётом того, что много где настроено 2FA в том числе с подтверждением по смс, пришлось потратить время, чтобы везде обратно залогиниться. Причём сбросились аутентификации во всех браузерах. Я постоянно пользуюсь как минимум двумя, иногда третий запускаю.
Обновления, судя по всему, ставились в два этапа, так как после следующей перезагрузки всё опять слетело. Во всех браузерах логинился по-новой. Тут я немного приуныл и вспомнил неактуальную в наши дни поговорку:
"Не было печали, апдейтов накачали".
Думал, что словил какой-то баг и теперь это будет постоянно, пока не разберусь, в чём проблема. На деле всё было нормально. Аутентификации больше не слетали.
Попробовал немного поискать информации на эту тему, но ничего не нашёл по делу. Вся выдача поисковиков по теме сброса аутентификаций забита информацией о куках, их отключении, блокировке или очистке.
Кто-нибудь знает, что реально привело к сбросу всех аутентификаций? Это явно инициировал браузер. Вряд ли у всех сайтов есть доступ к информации о железе или установленному ПО. Яндекс браузер даже сохранённые пароли отказывался использовать, пока я вручную не зашёл в настройки и не тыкнул в какую-то кнопку, которая означала, что это реально я сбросил аутентификацию, а не само так вышло.
Любопытно, на что браузеры так отреагировали. На обновление биоса или каких-то интеловских примочек?
#разное
{kind=link}
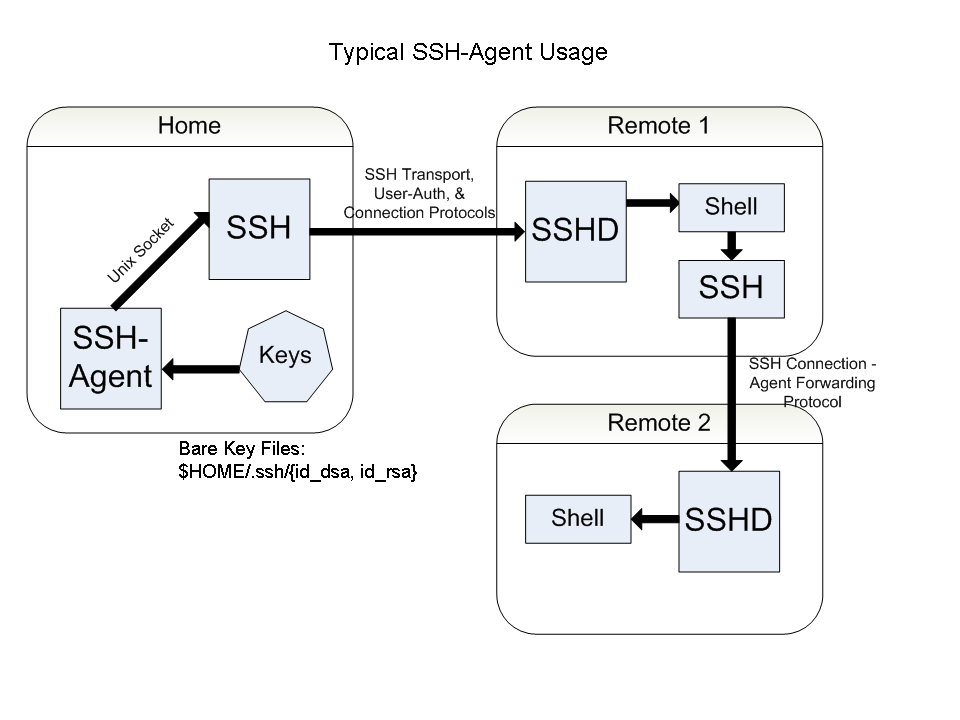
Иногда бывают ситуации, когда надо перекинуть файлы с одного сервера на другой, но при этом прямого доступа по ssh между этими серверами нет, не настроена аутентификация. Но вы при этом можете подключиться по ssh к каждому из этих серверов. Вариантов решения задачи как минимум два:
1️⃣ Скопировать файлы с одного сервера сначала к себе, а потом от себя на второй сервер. Я летом часто работаю по 4G, мне такой вариант не подходит. Как подвариант этого же варианта, копировать файлы на какой-то промежуточный сервер со скоростным интернетом.
2️⃣ Настроить аутентификацию между двумя серверами. Иногда это не хочется делать, а когда-то и невозможно. Для этого понадобится либо лишние сертификаты создавать, которые могут быть запаролены, либо включать аутентификацию по паролю. Я лично не против последнего, но часто её отключают.
Выйти из этой ситуации можно относительно просто без лишних телодвижений на серверах. На помощь придёт ssh-agent, который входит в состав ssh-client. Отдельно ставить не надо. Если его просто запустить, то он выведет свои переменные в терминал:
Нам нужно их загрузить в оболочку для последующего использования. Сделаем это так:
Проверяем переменные:
Теперь добавим свои ключи из ~/.ssh в ssh-agent:
Посмотреть все добавленные ключи можно командой:
Почти всё готово. Осталось разрешить проброс агента при ssh соединении. Для этого добавляем в конфигурационный файл
Всё, теперь можно подключаться:
Вы должны подключиться к серверу с пробросом агента. Проверьте это, зайдя в
Теперь если вы куда-то будете подключаться по ssh с этого сервера, будет использоваться проброшенный ключ с вашей машины. То есть вы можете выполнить что-то вроде этого:
Данные с сервера 1.2.3.4 будут скопированы на сервер 5.6.7.8 с использованием сертификата с вашей рабочей машины. Прямой аутентификации с 1.2.3.4 на 5.6.7.8 настроено не будет.
Простой трюк, который можно использовать не только для копирования файлов. Подобную цепочку можно делать бесконечно длинной, но нужно понимать, что если вы захотите с сервера 5.6.7.8 подключиться куда-то дальше с этим же сертификатом, вам нужно будет на 1.2.3.4 так же настраивать проброс агента.
Тут важно понимать один момент, связанный с безопасностью. Когда вы подключились к какому-то серверу с пробросом агента, root пользователь этого сервера тоже получает доступ к этому агенту и может его использовать по своему усмотрению. Так что аккуратнее с этим. На чужие сервера на всякий случай так не ходите. И не включайте проброс агента по умолчанию для всех серверов и соединений. Когда он не нужен, отключайте.
#ssh
1️⃣ Скопировать файлы с одного сервера сначала к себе, а потом от себя на второй сервер. Я летом часто работаю по 4G, мне такой вариант не подходит. Как подвариант этого же варианта, копировать файлы на какой-то промежуточный сервер со скоростным интернетом.
2️⃣ Настроить аутентификацию между двумя серверами. Иногда это не хочется делать, а когда-то и невозможно. Для этого понадобится либо лишние сертификаты создавать, которые могут быть запаролены, либо включать аутентификацию по паролю. Я лично не против последнего, но часто её отключают.
Выйти из этой ситуации можно относительно просто без лишних телодвижений на серверах. На помощь придёт ssh-agent, который входит в состав ssh-client. Отдельно ставить не надо. Если его просто запустить, то он выведет свои переменные в терминал:
# ssh-agentSSH_AUTH_SOCK=/tmp/ssh-XXXXXXm7P5A8/agent.259; export SSH_AUTH_SOCK;SSH_AGENT_PID=260; export SSH_AGENT_PID;echo Agent pid 260;Нам нужно их загрузить в оболочку для последующего использования. Сделаем это так:
# eval `ssh-agent`Agent pid 266Проверяем переменные:
# env | grep SSH_SSH_AUTH_SOCK=/tmp/ssh-XXXXXXrrbmpN/agent.265SSH_AGENT_PID=266Теперь добавим свои ключи из ~/.ssh в ssh-agent:
# ssh-addПосмотреть все добавленные ключи можно командой:
# ssh-add -lПочти всё готово. Осталось разрешить проброс агента при ssh соединении. Для этого добавляем в конфигурационный файл
~/.ssh/config параметр для каждого сервера, к которому будем подключаться. Сервер можно указать как по ip адресу, так и по имени, в зависимости от того, как вы будете подключаться:Host 1.2.3.4 ForwardAgent yesHost srv-01 ForwardAgent yesВсё, теперь можно подключаться:
# ssh root@1.2.3.4Вы должны подключиться к серверу с пробросом агента. Проверьте это, зайдя в
/tmp подключенного сервера. Там должен быть сокет агента:root@1.2.3.4# ls /tmp | grep ssh-ssh-vSnzLCX7LWТеперь если вы куда-то будете подключаться по ssh с этого сервера, будет использоваться проброшенный ключ с вашей машины. То есть вы можете выполнить что-то вроде этого:
root@1.2.3.4# rsync -av /var/www/ root@5.6.7.8:/var/www/Данные с сервера 1.2.3.4 будут скопированы на сервер 5.6.7.8 с использованием сертификата с вашей рабочей машины. Прямой аутентификации с 1.2.3.4 на 5.6.7.8 настроено не будет.
Простой трюк, который можно использовать не только для копирования файлов. Подобную цепочку можно делать бесконечно длинной, но нужно понимать, что если вы захотите с сервера 5.6.7.8 подключиться куда-то дальше с этим же сертификатом, вам нужно будет на 1.2.3.4 так же настраивать проброс агента.
Тут важно понимать один момент, связанный с безопасностью. Когда вы подключились к какому-то серверу с пробросом агента, root пользователь этого сервера тоже получает доступ к этому агенту и может его использовать по своему усмотрению. Так что аккуратнее с этим. На чужие сервера на всякий случай так не ходите. И не включайте проброс агента по умолчанию для всех серверов и соединений. Когда он не нужен, отключайте.
#ssh
{kind=link}
Возникла небольшая прикладная задача. Нужно было периодически с одного mysql сервера перекидывать дамп одной таблицы из базы на другой сервер в такую же базу. Решений этой задачи может быть много. Я взял и решил в лоб набором простых команд на bash. Делюсь с вами итоговым скриптом. Даже если он вам не нужен в рамках этой задачи, то можете взять какие-то моменты для использования в другой.
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
#!/bin/bash
# Дамп базы с заменой общего комплексного параметра --opt, где используется ключ --lock-tables на набор отдельных ключей, где вместо lock-tables используется --single-transaction
/usr/bin/mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases database01 -u'userdb' -p'password' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
# Из общего дампа вырезаю дамп только данных таблицы table01. Общий дамп тоже оставляю, потому что он нужен для других задач
/usr/bin/cat /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql | /usr/bin/awk '/LOCK TABLES `table01`/,/UNLOCK TABLES/' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Сжимаю оба дампа
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Копирую дамп таблицы на второй сервер, аутентификация по ключам
/usr/bin/scp /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql.gz sshuser@10.20.30.45:/tmp
# Выполняю на втором сервере ряд заданий в рамках ssh сессии: распаковываю дамп таблицы, очищаю таблицу на этом сервере, заливаю туда данные из дампа
/usr/bin/ssh sshuser@10.20.30.45 '/usr/bin/gunzip /tmp/"$(date +%Y-%m-%d)"-table01.sql.gz && /usr/bin/mysql -e "delete from database01.table01; use database01; source /tmp/"$(date +%Y-%m-%d)"-table01.sql;"'
# Удаляю дамп
/usr/bin/ssh sshuser@10.20.30.45 'rm /tmp/"$(date +%Y-%m-%d)"-table01.sql'
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
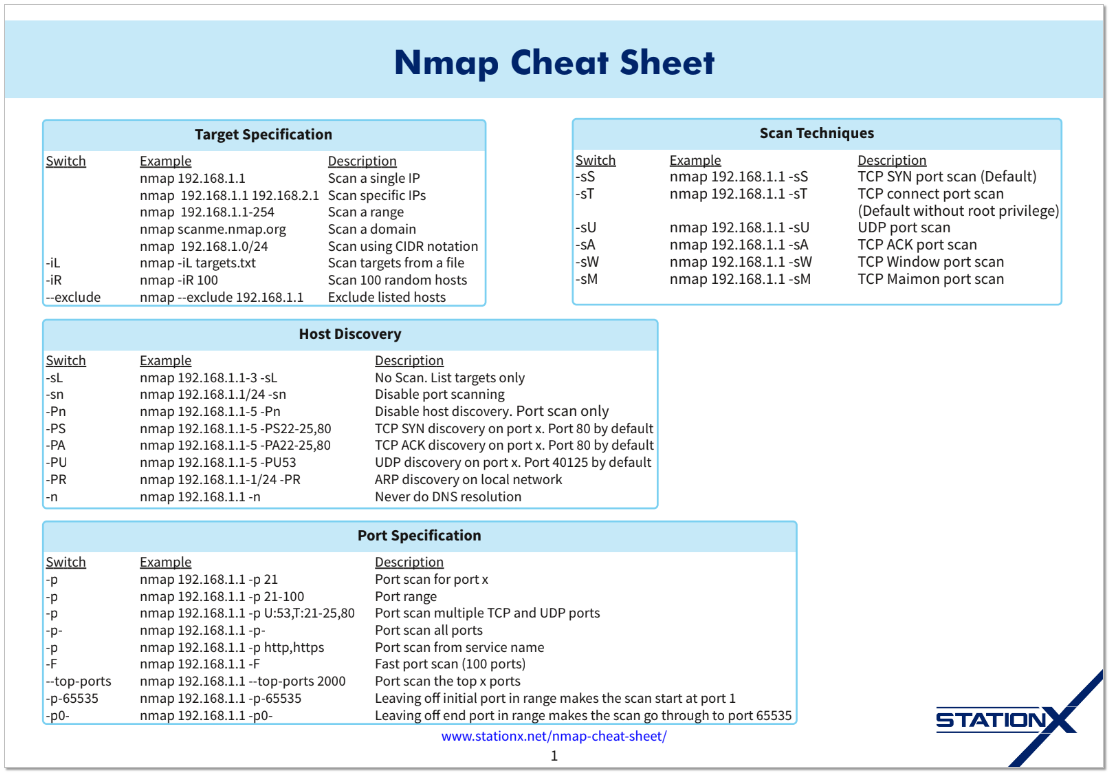
Несмотря на то, что существует много инструментов для сканирования узлов в сети, лично я всегда использую Nmap. И при этом никогда не помню точно, какие ключи применить для скана (как и в tcpdump). Использую либо свои заметки, либо Zenmap GUI, который установлен на винде.
Я когда-то давно уже показывал небольшую подборку как раз из своих заметок. Решил обновить и актуализировать. В интернете есть популярный материал по этой теме:
⇨ Nmap Cheat Sheet 2024: All the Commands & Flags
Он как раз недавно обновился. Там наглядно и аккуратно структурированы команды для Nmap. Он у меня давно в закладках, иногда пользуюсь. Для удобства, решил его в сокращённой форме подготовить здесь, плюс добавить свои примеры и комментарии.
✅ Простое и быстрое сканирование только открытых портов до 1024 без подробностей:
✅ Полное сканирование всех открытых портов:
Ключ
✅ Скан хоста, не отвечающего на пинг. Без этого ключа не отвечающий на пинг хост игнорируется в сканировании, как находящийся вне сети.
✅ Основные техники сканирования:
Обычно полное сканирование TCP и UDP портов запускают так (будет очень долго длиться):
✅ Обнаружение хостов в сети, без скана портов. Поиск с помощью пинга. Постоянно использую, когда надо получить список живых хостов в сети:
Если используете сложные списки хостов, или просто хотите быстро получить текстовый список какого-то набора IP адресов, то можно воспользоваться nmap:
Выведет список всех IP адресов в текстовом виде.
✅ Поиск хостов ARP запросами в локальной сети:
В локальной сети поиск хостов ARP запросами проходит в разы быстрее обычных. Подробно об этом и других техниках поиска хостов рассказано на сайте nmap. ❗️Данный метод используется принудительно в локальных сетях, даже если указать другой.
✅ Определение сервисов и их версий на открытых портах. Быстрая проверка с наглядным выводом всей информации, где 1 порт - одна строка. Удобно для визуального восприятия глазами:
Комбинированный ключ, который вызывает проверки ОС, версий сервисов, сканирование скриптами и использование traceroute. Более подробная и долгая проверка по сравнению с той, что выше. Вывод не очень нагляден для беглого просмотра:
Команда выше универсальная и подойдёт для комплексного анализа хоста по портам до 1024. Это позволяет ей отрабатывать относительно быстро. Если запускать её по всем портам, то будет долго выполняться. Но можно сделать небольшой трюк, который я применяю на практике. Сначала ищем открытые порты, а потом на них выполняем полную проверку с ключом
Использовать:
✅ Различные скорости и интенсивности проверок:
-T0 - paranoid (паранойдный)
-T1 - sneaky (хитрый)
-T2 - polite (вежливый)
-T3 - normal (обычный)
-T4 - aggressive (агрессивный)
-T5 - insane (безумный)
Описание этих шаблонов сканирования есть в документации. По умолчанию используется
По факту получилось, что из статьи ничего и не взял. Все примеры свои привёл, а подробности смотрел в man и на сайте nmap.
⇨ Полная шпаргалка по nmap в формате PDF.
#nmap
Я когда-то давно уже показывал небольшую подборку как раз из своих заметок. Решил обновить и актуализировать. В интернете есть популярный материал по этой теме:
⇨ Nmap Cheat Sheet 2024: All the Commands & Flags
Он как раз недавно обновился. Там наглядно и аккуратно структурированы команды для Nmap. Он у меня давно в закладках, иногда пользуюсь. Для удобства, решил его в сокращённой форме подготовить здесь, плюс добавить свои примеры и комментарии.
✅ Простое и быстрое сканирование только открытых портов до 1024 без подробностей:
nmap 192.168.1.1nmap 192.168.1.1 192.168.2.1nmap 192.168.1.1-254nmap 192.168.1.0/24✅ Полное сканирование всех открытых портов:
nmap 192.168.1.1 -p- Ключ
-p позволяет задавать диапазон портов в различных форматах. Например -p 21 или -p 21-100, -p http,https В примере выше сканируются абсолютно все порты. Проверка получается значительно дольше предыдущего примера без указания полного диапазона.✅ Скан хоста, не отвечающего на пинг. Без этого ключа не отвечающий на пинг хост игнорируется в сканировании, как находящийся вне сети.
nmap 192.168.1.1 -Pn✅ Основные техники сканирования:
nmap 192.168.1.1 -sS - TCP SYN, значение по умолчаниюnmap 192.168.1.1 -sT - TCP connectnmap 192.168.1.1 -sU - UDP сканированиеОбычно полное сканирование TCP и UDP портов запускают так (будет очень долго длиться):
nmap 192.168.1.1 -sS -sU -p- ✅ Обнаружение хостов в сети, без скана портов. Поиск с помощью пинга. Постоянно использую, когда надо получить список живых хостов в сети:
nmap 192.168.1.1/24 -snЕсли используете сложные списки хостов, или просто хотите быстро получить текстовый список какого-то набора IP адресов, то можно воспользоваться nmap:
nmap 192.168.1.1-15 -sLВыведет список всех IP адресов в текстовом виде.
✅ Поиск хостов ARP запросами в локальной сети:
nmap 192.168.1.1/24 -PRВ локальной сети поиск хостов ARP запросами проходит в разы быстрее обычных. Подробно об этом и других техниках поиска хостов рассказано на сайте nmap. ❗️Данный метод используется принудительно в локальных сетях, даже если указать другой.
✅ Определение сервисов и их версий на открытых портах. Быстрая проверка с наглядным выводом всей информации, где 1 порт - одна строка. Удобно для визуального восприятия глазами:
nmap 192.168.1.1 -sVКомбинированный ключ, который вызывает проверки ОС, версий сервисов, сканирование скриптами и использование traceroute. Более подробная и долгая проверка по сравнению с той, что выше. Вывод не очень нагляден для беглого просмотра:
nmap 192.168.13.1 -AКоманда выше универсальная и подойдёт для комплексного анализа хоста по портам до 1024. Это позволяет ей отрабатывать относительно быстро. Если запускать её по всем портам, то будет долго выполняться. Но можно сделать небольшой трюк, который я применяю на практике. Сначала ищем открытые порты, а потом на них выполняем полную проверку с ключом
-A. Это значительно быстрее полной проверки по всем портам.#!/bin/bashports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr '\n' ',' | sed s/,$//)nmap -p$ports -A $1Использовать:
./nmap.sh 192.168.1.1✅ Различные скорости и интенсивности проверок:
-T0 - paranoid (паранойдный)
-T1 - sneaky (хитрый)
-T2 - polite (вежливый)
-T3 - normal (обычный)
-T4 - aggressive (агрессивный)
-T5 - insane (безумный)
Описание этих шаблонов сканирования есть в документации. По умолчанию используется
-T3, в локалке иногда повышают до -T4. Чем ниже режим, тем меньше потоков, меньше пакетов, ниже скорость сканирования, но и заметность меньше. По факту получилось, что из статьи ничего и не взял. Все примеры свои привёл, а подробности смотрел в man и на сайте nmap.
⇨ Полная шпаргалка по nmap в формате PDF.
#nmap
{kind=link}
Словил вчера необычный глюк, когда подключал новый сервер в стойке. Купили бушный Dell PowerEdge R730. Я, кстати, люблю эти сервера. Если нужен обычный сервер общего назначения, то всегда сначала эти смотрю подходящих конфигураций. Туда и памяти, и дисков можно много поставить. И стоит всё это дёшево по сравнению с новым железом. А для каких-нибудь файловых серверов, бэкапов, почтовых, мониторингов и логов его за глаза хватает. Плюс, удалённое управление через iDRAC удобное. Есть хороший шаблон под Zabbix для мониторинга по SNMP. Настраивается за 5 минут.
Возвращаюсь к глюку. В стойке для серверов стоит старенький управляемый гигабитный свитч D-link DGS-1500-20. В этой компании вообще все свитчи этой фирмы. И на удивление, они нормально работают. На моей памяти ни один не сломался. Хотя я если подбираю свитчи, то стараюсь что-то подороже брать, например HPE. Не знаю, можно ли их сейчас купить. Давно не брал.
На сервере установлен Proxmox и подняты несколько виртуалок. Подключены через сетевой бридж, в который входит один из портов сетевой карты. Этот порт подключаю патч-кордом в свитч. И дальше начинаются какие-то странности. Вся сеть, подключенная в этот свитч, начинает глючить. Пропадает связь с другим свитчом, подключенным в этот. Частично пропадает связь между виртуальными машинами на серверах, подключенных в этот свитч.
Причём глюки очень необычные. Например, захожу на виртуалку другого сервера. Я с неё пингую виртуалку нового сервера, но при этом не пингую сам гипервизор. А где-то наоборот. Пингуется гипервизор, не пингуется виртуалка. Мониторинг накидал кучу оповещений о недоступности части хостов. Причём сам мониторинг что-то видит, а что-то нет. Так же и я сижу с ноутом в другой сети. К одной вируталке этого нового сервера могу подключиться, к другой уже нет.
Я даже как-то растерялся. Не смог в голове составить картинку, что вообще происходит. Решил даже схему нарисовать, кто кого видит, а кого нет. Никакой системы не смог распознать. Посмотрел в логи серверов, там ничего интересного нет. В веб интерфейсе свитча никаких ошибок на портах тоже не увидел. Запустил tcpdump, посмотрел трафик. Ничего необычного не заметил.
Особо не было времени разбираться, так как напрягает, что сеть так глючит. Если новый сервер отключить, то всё нормально. Думал попробовать где-то в другое место его временно поставить. Собственно, он в другом месте и стоял и там с ним проблем не было. Был ещё один порт свободен на этом свитче. Подключил сервер в него. И все глюки исчезли. Подождал некоторое время, всё проверил. Работает нормально, я уехал.
Что это было, даже не знаю. Идей нет. Только на глюки конкретного порта могу списать. Обычно если встречаешься с такими странностями, то либо в сети видишь спам пакетами от кого-нибудь, либо в статистике портов видно ошибки, либо тот же спам пакетами. Тут ничего подозрительного не увидел. У кого-то есть идеи, что это может быть?
#железо
Возвращаюсь к глюку. В стойке для серверов стоит старенький управляемый гигабитный свитч D-link DGS-1500-20. В этой компании вообще все свитчи этой фирмы. И на удивление, они нормально работают. На моей памяти ни один не сломался. Хотя я если подбираю свитчи, то стараюсь что-то подороже брать, например HPE. Не знаю, можно ли их сейчас купить. Давно не брал.
На сервере установлен Proxmox и подняты несколько виртуалок. Подключены через сетевой бридж, в который входит один из портов сетевой карты. Этот порт подключаю патч-кордом в свитч. И дальше начинаются какие-то странности. Вся сеть, подключенная в этот свитч, начинает глючить. Пропадает связь с другим свитчом, подключенным в этот. Частично пропадает связь между виртуальными машинами на серверах, подключенных в этот свитч.
Причём глюки очень необычные. Например, захожу на виртуалку другого сервера. Я с неё пингую виртуалку нового сервера, но при этом не пингую сам гипервизор. А где-то наоборот. Пингуется гипервизор, не пингуется виртуалка. Мониторинг накидал кучу оповещений о недоступности части хостов. Причём сам мониторинг что-то видит, а что-то нет. Так же и я сижу с ноутом в другой сети. К одной вируталке этого нового сервера могу подключиться, к другой уже нет.
Я даже как-то растерялся. Не смог в голове составить картинку, что вообще происходит. Решил даже схему нарисовать, кто кого видит, а кого нет. Никакой системы не смог распознать. Посмотрел в логи серверов, там ничего интересного нет. В веб интерфейсе свитча никаких ошибок на портах тоже не увидел. Запустил tcpdump, посмотрел трафик. Ничего необычного не заметил.
Особо не было времени разбираться, так как напрягает, что сеть так глючит. Если новый сервер отключить, то всё нормально. Думал попробовать где-то в другое место его временно поставить. Собственно, он в другом месте и стоял и там с ним проблем не было. Был ещё один порт свободен на этом свитче. Подключил сервер в него. И все глюки исчезли. Подождал некоторое время, всё проверил. Работает нормально, я уехал.
Что это было, даже не знаю. Идей нет. Только на глюки конкретного порта могу списать. Обычно если встречаешься с такими странностями, то либо в сети видишь спам пакетами от кого-нибудь, либо в статистике портов видно ошибки, либо тот же спам пакетами. Тут ничего подозрительного не увидел. У кого-то есть идеи, что это может быть?
#железо
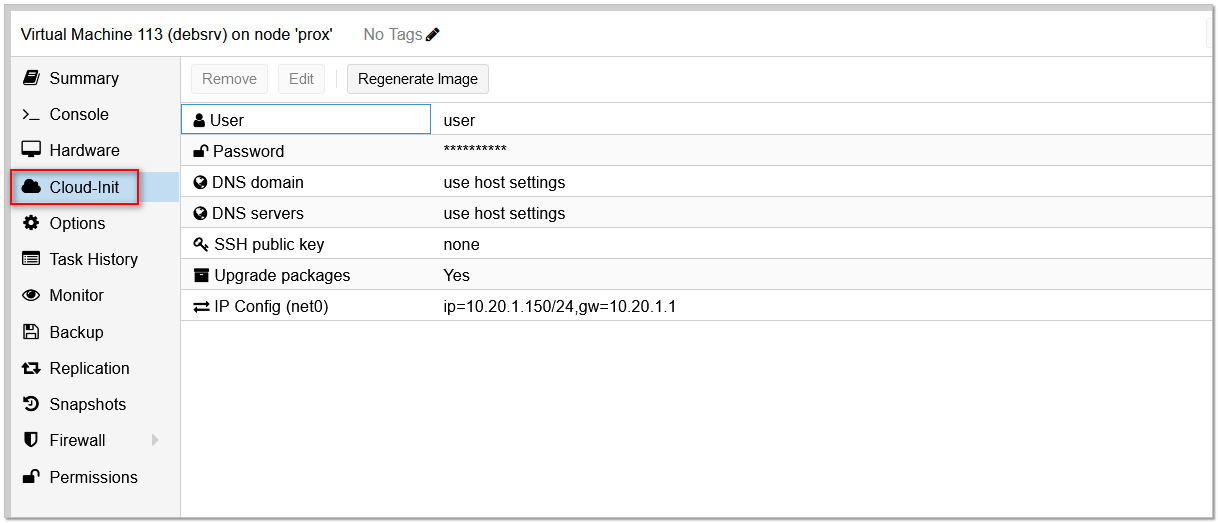
Если вам приходится регулярно вручную создавать новые виртуальные машины в Proxmox для различных целей, то могу посоветовать простой и быстрый способ это автоматизировать. Для этого понадобится технология Cloud-Init, которую Proxmox поддерживает по умолчанию.
С помощью Cloud-Init в Proxmox можно автоматически добавить в виртуальную машину:
- пользователей, пароли, ключи для SSH
- настройки DNS
- сетевые настройки
- выполнить принудительное обновление пакетов
Технически это выглядит следующим образом.
1️⃣ Вы настраиваете виртуальную машину так, как вам нужно. Ставите нужные пакеты, настраиваете ПО, если надо. Отдельно устанавливаете пакет с cloud-init:
Можно использовать готовые образы уже с cloud-init внутри:
https://cloud.debian.org/images/cloud/
https://cloud-images.ubuntu.com/
https://dl.astralinux.ru/ui/native/mg-generic/alse/cloud/
Proxmox поддерживает готовые образы, сформированные для OpenStack.
2️⃣ Из этой виртуальной машины делаете эталонный шаблон средствами Proxmox (пункт меню convert to template).
3️⃣ Создаёте из этого шаблона виртуальную машину. Добавляете к ней отдельное устройство Cloudinit Drive.
4️⃣ В настройках виртуальной машины есть отдельный раздел Cloud-init, где можно индивидуально для конкретной машины задать перечисленные выше настройки.
Без Cloud-Init пришлось бы руками лезть в новую виртуалку и менять эти параметры. А так они аккуратно задаются через интерфейс управления и потом применяются. Работает просто и удобно. Настраивается тоже без проблем.
Описанная выше инструкция с техническими подробностями есть в Wiki Proxmox. Там же FAQ по этой теме:
- Cloud-Init Support
- Cloud-Init FAQ
Каких-то подводных камней в этой настройке нет. Делается всё просто и почти сходу. Я специально проверил после написания заметки. Всё получилось сразу же, как я описал. Шаблон сделал свой, не брал готовый.
#proxmox
С помощью Cloud-Init в Proxmox можно автоматически добавить в виртуальную машину:
- пользователей, пароли, ключи для SSH
- настройки DNS
- сетевые настройки
- выполнить принудительное обновление пакетов
Технически это выглядит следующим образом.
1️⃣ Вы настраиваете виртуальную машину так, как вам нужно. Ставите нужные пакеты, настраиваете ПО, если надо. Отдельно устанавливаете пакет с cloud-init:
# apt install cloud-initМожно использовать готовые образы уже с cloud-init внутри:
https://cloud.debian.org/images/cloud/
https://cloud-images.ubuntu.com/
https://dl.astralinux.ru/ui/native/mg-generic/alse/cloud/
Proxmox поддерживает готовые образы, сформированные для OpenStack.
2️⃣ Из этой виртуальной машины делаете эталонный шаблон средствами Proxmox (пункт меню convert to template).
3️⃣ Создаёте из этого шаблона виртуальную машину. Добавляете к ней отдельное устройство Cloudinit Drive.
4️⃣ В настройках виртуальной машины есть отдельный раздел Cloud-init, где можно индивидуально для конкретной машины задать перечисленные выше настройки.
Без Cloud-Init пришлось бы руками лезть в новую виртуалку и менять эти параметры. А так они аккуратно задаются через интерфейс управления и потом применяются. Работает просто и удобно. Настраивается тоже без проблем.
Описанная выше инструкция с техническими подробностями есть в Wiki Proxmox. Там же FAQ по этой теме:
- Cloud-Init Support
- Cloud-Init FAQ
Каких-то подводных камней в этой настройке нет. Делается всё просто и почти сходу. Я специально проверил после написания заметки. Всё получилось сразу же, как я описал. Шаблон сделал свой, не брал готовый.
#proxmox
{kind=link}
Я давно знаю и работаю с программой для бэкапа виртуальных сред Veeam Backup & Replication. Как всем известно, этот бренд ушёл из России, заблокировал доступ к своим ресурсам, не осуществляет продажи и не оказывает тех. поддержку. Полноценных аналогов с такой же функциональностью не так много. Я даже затрудняюсь назвать их, хотя наверняка есть, но мне не знакомы. То есть не работал с ними. Отечественные решения, насколько я знаю, по возможностям пока не дотягивают до Veeam.
Есть китайский аналог Vinchin Backup & Recovery. Я года два назад про него узнал, когда начались всевозможные санкции. Были пару обзоров от наших интеграторов КРОК и ГК ЛАНИТ. Причём отзывы вполне нормальные. В то же время на меня выходили сами разработчики и хотели какой-то кооперации: статьи, заметок в telegram, анонсов вебинаров и т.д. Был необычный опыт, так как общаться приходилось явно с не русскоязычным человеком, но мы понимали друг друга. Но всё как-то не срасталось по срокам и форматам.
Чтобы как-то предметно общаться, я решил всё же своими глазами посмотреть и попробовать этот продукт. К тому же на сайте есть русскоязычная версия с описанием, а список возможностей выглядит очень привлекательно. Можно объединить в единой системе бэкап вообще всей информации. Плюс поддержка отечественных ОС и систем виртуализации.
Есть полностью бесплатная версия для бэкапа трёх виртуальных машин. Не густо, конечно, но хоть что-то.
📌 Vinchin Backup & Recovery умеет бэкапить:
◽Виртуальные машины на различных гипервизорах и системах виртуализации. Список там очень внушительный, перечислю наиболее популярные и актуальные: zVirt, ROSA Virtualization, RED Virtualization, Hyper-V, Proxmox, VMware, Citrix, XCP-ng, oVirt, OpenStack
◽Базы данных популярных СУБД: MS SQL, MySQL, Oracle, PostgreSQL, MariaDB
◽Файлы в операционных системах Windows и Linux с помощью установленных агентов. Есть поддержка Astra Linux и RED OS.
◽Целиком операционные системы Windows и Linux, либо отдельные диски в них.
◽Сетевые диски, подключаемые по протоколам CIFS и NFS.
◽Microsoft Exchange как локальной установки, так и облачной.
◽Виртуальные машины облачного провайдера AWS EC2
Получается, он покрывает все варианты информации. Тут и виртуальные машины, и сервера через агентов, и сетевые диски, и СУБД.
Я развернул у себя эту систему. Ставится автоматически из готового ISO образа. Всё управление через веб интерфейс. Попробовал забэкапить и восстановить виртуальные машины на Hyper-V и Proxmox, а также сетевой диск.
Всё получилось практически сходу. Система простая, функциональная и удобная. Мне прям она вообще понравилась. Оформил всё в простой обзор с картинками, чтобы наглядно показать, как всё это выглядит на практике:
⇨ Обзор Vinchin Backup & Recovery
Если выбираете себе подобный продукт, то посмотрите Vinchin. Честно говоря, я с некоторым скепсисом её разворачивал, ожидая увидеть какие-то нелогичности, мелкие баги как интерфейса, так и самой работы, возможно ещё какие-то проблемы. Но на удивление, всё прошло гладко и ровно. Никаких ошибок я не заметил.
За скобками остался вопрос стоимости. Так как на сайте в открытом доступе цен нет, сказать мне об этом нечего. Все цены только по запросу. В лучших традициях, так сказать. Ну и ещё раз напомню, что есть бесплатная версия для бэкапа трёх виртуальных машин.
#backup
Есть китайский аналог Vinchin Backup & Recovery. Я года два назад про него узнал, когда начались всевозможные санкции. Были пару обзоров от наших интеграторов КРОК и ГК ЛАНИТ. Причём отзывы вполне нормальные. В то же время на меня выходили сами разработчики и хотели какой-то кооперации: статьи, заметок в telegram, анонсов вебинаров и т.д. Был необычный опыт, так как общаться приходилось явно с не русскоязычным человеком, но мы понимали друг друга. Но всё как-то не срасталось по срокам и форматам.
Чтобы как-то предметно общаться, я решил всё же своими глазами посмотреть и попробовать этот продукт. К тому же на сайте есть русскоязычная версия с описанием, а список возможностей выглядит очень привлекательно. Можно объединить в единой системе бэкап вообще всей информации. Плюс поддержка отечественных ОС и систем виртуализации.
Есть полностью бесплатная версия для бэкапа трёх виртуальных машин. Не густо, конечно, но хоть что-то.
📌 Vinchin Backup & Recovery умеет бэкапить:
◽Виртуальные машины на различных гипервизорах и системах виртуализации. Список там очень внушительный, перечислю наиболее популярные и актуальные: zVirt, ROSA Virtualization, RED Virtualization, Hyper-V, Proxmox, VMware, Citrix, XCP-ng, oVirt, OpenStack
◽Базы данных популярных СУБД: MS SQL, MySQL, Oracle, PostgreSQL, MariaDB
◽Файлы в операционных системах Windows и Linux с помощью установленных агентов. Есть поддержка Astra Linux и RED OS.
◽Целиком операционные системы Windows и Linux, либо отдельные диски в них.
◽Сетевые диски, подключаемые по протоколам CIFS и NFS.
◽Microsoft Exchange как локальной установки, так и облачной.
◽Виртуальные машины облачного провайдера AWS EC2
Получается, он покрывает все варианты информации. Тут и виртуальные машины, и сервера через агентов, и сетевые диски, и СУБД.
Я развернул у себя эту систему. Ставится автоматически из готового ISO образа. Всё управление через веб интерфейс. Попробовал забэкапить и восстановить виртуальные машины на Hyper-V и Proxmox, а также сетевой диск.
Всё получилось практически сходу. Система простая, функциональная и удобная. Мне прям она вообще понравилась. Оформил всё в простой обзор с картинками, чтобы наглядно показать, как всё это выглядит на практике:
⇨ Обзор Vinchin Backup & Recovery
Если выбираете себе подобный продукт, то посмотрите Vinchin. Честно говоря, я с некоторым скепсисом её разворачивал, ожидая увидеть какие-то нелогичности, мелкие баги как интерфейса, так и самой работы, возможно ещё какие-то проблемы. Но на удивление, всё прошло гладко и ровно. Никаких ошибок я не заметил.
За скобками остался вопрос стоимости. Так как на сайте в открытом доступе цен нет, сказать мне об этом нечего. Все цены только по запросу. В лучших традициях, так сказать. Ну и ещё раз напомню, что есть бесплатная версия для бэкапа трёх виртуальных машин.
#backup
Server Admin
Обзор Vinchin Backup & Recovery – инструмента для бэкапа всей...
Обзор, знакомство и первый опыт использования системы бэкапов Vinchin Backup & Recovery для физических и виртуальных сред.
Видео про весёленький денёк у сисадмина - лучший юмористический ролик, что я знаю про сисадминские будни. Столько времени прошло, но ничего веселее и оригинальнее я не видел. Для тех, кто не знает (завидую таким), речь идёт вот об этом:
▶️ https://www.youtube.com/watch?v=uRGljemfwUE - оригинал
▶️ https://www.youtube.com/watch?v=W4uGoFBL-GM - субтитры на русском
Если знаете английский, смотрите оригинал, если нет - в русских субтитрах. Там забавные голоса.
А если хотите по-новому посмотреть этот шедевр, попробуйте включить онлайн озвучку в Яндекс.Браузере. Видео заиграет новыми красками 😁 Я искренне в очередной раз посмеялся при просмотре.
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они не такие забавные, как первый, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
▶️ https://www.youtube.com/watch?v=uRGljemfwUE - оригинал
▶️ https://www.youtube.com/watch?v=W4uGoFBL-GM - субтитры на русском
Если знаете английский, смотрите оригинал, если нет - в русских субтитрах. Там забавные голоса.
А если хотите по-новому посмотреть этот шедевр, попробуйте включить онлайн озвучку в Яндекс.Браузере. Видео заиграет новыми красками 😁 Я искренне в очередной раз посмеялся при просмотре.
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они не такие забавные, как первый, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
YouTube
The Website is Down #1: Sales Guy vs. Web Dude
The Website is Down: Sales Guy Vs. Web Dude High Quality
The original video in high resolution.
This video won a Webby award!
The original video in high resolution.
This video won a Webby award!
Давненько ничего не было на тему игр. Попалась одна, которая неплохо выглядит, и про которую я ещё не писал. Если что, полная подборка всех игр, про которые я писал на канале, есть в отдельной публикации.
Речь пойдёт про Cyber Attack. Это относительно свежая игра от 2020 года. Выглядит как стратегия, где вы играете за лидера хакерской группировки. Вам надо будет добывать различную информацию, взламывать сервера, вмешиваться в работу правительства, защищаться от внешних атак от других групп.
Игра, если что, есть на торрентах. Не знаю, можно ли сейчас в стиме что-то покупать. Стоит, как чашка кофе.
Видео с этой игрой записал популярный блоггер. Интересный небольшой ролик получился. Там хорошо видно геймплей. Взломы серверов выглядят в лучших традициях голливудских фильмов. Идёт процесс бар, что-то мелькает, прыгает и вуаля, сервер взломан:
▶️ ВОТ ТАК РАБОТАЮТ НАСТОЯЩИЕ ПРОФИ ( Cyber Attack )
У него ещё пара роликов с этой игрой есть. Игра, как я понял, чисто почилить пару часиков в бутафории. Покачать немного навыки в стиле игр на развитие 90-х, 2000-х годов, где вы копите деньги, качаете скилы, покупаете новое оборудование и т.д.
#игра
Речь пойдёт про Cyber Attack. Это относительно свежая игра от 2020 года. Выглядит как стратегия, где вы играете за лидера хакерской группировки. Вам надо будет добывать различную информацию, взламывать сервера, вмешиваться в работу правительства, защищаться от внешних атак от других групп.
Игра, если что, есть на торрентах. Не знаю, можно ли сейчас в стиме что-то покупать. Стоит, как чашка кофе.
Видео с этой игрой записал популярный блоггер. Интересный небольшой ролик получился. Там хорошо видно геймплей. Взломы серверов выглядят в лучших традициях голливудских фильмов. Идёт процесс бар, что-то мелькает, прыгает и вуаля, сервер взломан:
▶️ ВОТ ТАК РАБОТАЮТ НАСТОЯЩИЕ ПРОФИ ( Cyber Attack )
У него ещё пара роликов с этой игрой есть. Игра, как я понял, чисто почилить пару часиков в бутафории. Покачать немного навыки в стиле игр на развитие 90-х, 2000-х годов, где вы копите деньги, качаете скилы, покупаете новое оборудование и т.д.
#игра
{kind=link}
Я много раз упоминал в заметках, что надо стараться максимально скрывать сервисы от доступа из интернета. И проверять это, потому что часто они туда попадают случайно из-за того, что что-то забыли или неверно настроили. Решил через shodan глянуть открытые Node Exporter от Prometheus. Они часто болтаются в открытом виде, потому что по умолчанию никаких ограничений доступа в них нет. Заходи, кто хочешь, и смотри, что там есть.
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
Для тех, кто пользуется Proxmox Backup Server (PBS) важное предостережение. Я им пользуюсь практически с момента релиза, но только недавно столкнулся с проблемой. Не допускайте исчерпания свободного места на сервере с бэкапами.
Я краем уха слышал, что очистка от старых данных нетривиальная штука и нельзя просто взять, удалить ненужные бэкапы и освободить занятое место. Но сам с этим не сталкивался, так как обычно место планирую с запасом и настраиваю мониторинг. Так что своевременно предпринимаю какие-то действия.
А тут проспал. Точнее, неправильно отреагировал на сложившуюся ситуацию. Были видно, что место заканчивается. Я зашёл, удалил некоторые бэкапы в ожидании увеличения свободного объёма для хранения. Была сделана копия большой виртуалки, которая тоже поехала в архив. Рассчитывал, что благодаря дедупликации, реального места будет занято не так много. Но ошибся.
То ли место не успело освободиться, то ли дедупликация в реальности сработала не так, как я ожидал, но в итоге было занято 100% доступного объёма хранилища и все процессы в нём встали. Он даже сам себя очистить не мог. Процесс Garbage Collect не запускался из-за недостатка свободного места. Я решил вопрос просто - очистил логи systemd:
Они занимали несколько гигабайт, так что мне хватило для того, чтобы отработал процесс Garbage Collect. Но он не удаляет данные, а только помечает их к удалению. Реально данные будут удалены через 24 часа и 5 минут после того, как сборщик мусора пометит их на удаление. И никакого способа вручную запустить реальную очистку хранилища нет. По крайней мере я не нашёл.
Очень внимательно прочитал несколько тем на официальном форуме по этой проблеме и везде совет один - освобождайте место или расширяйте хранилище, если у вас zfs, запускайте сборщик мусора и ждите сутки. Других вариантов нет, кроме полного удаления Datastore со всеми бэкапами. Тогда место освободится сразу.
Это особенность реализации дедупликации в PBS. Помеченные на удаления chunks реально удаляются через 24 часа. Форсировать этот процесс не получится.
#proxmox #backup
Я краем уха слышал, что очистка от старых данных нетривиальная штука и нельзя просто взять, удалить ненужные бэкапы и освободить занятое место. Но сам с этим не сталкивался, так как обычно место планирую с запасом и настраиваю мониторинг. Так что своевременно предпринимаю какие-то действия.
А тут проспал. Точнее, неправильно отреагировал на сложившуюся ситуацию. Были видно, что место заканчивается. Я зашёл, удалил некоторые бэкапы в ожидании увеличения свободного объёма для хранения. Была сделана копия большой виртуалки, которая тоже поехала в архив. Рассчитывал, что благодаря дедупликации, реального места будет занято не так много. Но ошибся.
То ли место не успело освободиться, то ли дедупликация в реальности сработала не так, как я ожидал, но в итоге было занято 100% доступного объёма хранилища и все процессы в нём встали. Он даже сам себя очистить не мог. Процесс Garbage Collect не запускался из-за недостатка свободного места. Я решил вопрос просто - очистил логи systemd:
# journalctl --vacuum-size=256MОни занимали несколько гигабайт, так что мне хватило для того, чтобы отработал процесс Garbage Collect. Но он не удаляет данные, а только помечает их к удалению. Реально данные будут удалены через 24 часа и 5 минут после того, как сборщик мусора пометит их на удаление. И никакого способа вручную запустить реальную очистку хранилища нет. По крайней мере я не нашёл.
Очень внимательно прочитал несколько тем на официальном форуме по этой проблеме и везде совет один - освобождайте место или расширяйте хранилище, если у вас zfs, запускайте сборщик мусора и ждите сутки. Других вариантов нет, кроме полного удаления Datastore со всеми бэкапами. Тогда место освободится сразу.
Это особенность реализации дедупликации в PBS. Помеченные на удаления chunks реально удаляются через 24 часа. Форсировать этот процесс не получится.
#proxmox #backup
{kind=link}