
Один читатель рассказал про свой репозиторий на github:
⇨ https://github.com/Lifailon
Там очень много всего написано за много лет продуктивной деятельности. Автор захотел поделиться с аудиторией. Может кому-то будет полезно. Человек занимался в основном администрированием на Windows, поэтому большая часть работ на PowerShell, но не только.
Я посмотрел репу и сразу честно сказал, что это лютые костыли, которые решали конкретные задачи на конкретном рабочем месте, поэтому слабо применимы для широкой аудитории. Тем не менее, некоторые полезные вещи я увидел и для себя:
▪ Windows-User-Sessions - шаблон и скрипты к Zabbix для мониторинга за терминальными сессиями на сервере.
▪ ACL-Backup - небольшой скрипт с формой ввода, который позволяет сделать полный backup списка прав доступа (ACL) файловой системы NTFS в txt-файл с возможностью восстановления из этого списка. Я тоже писал и использовал скрипты для решения этой же задачи. Когда бэкаплю виндовые шары, записываю на них же списки прав доступа, чтобы можно было восстановить, если что-то пойдёт не так.
▪ PS-Commands - описание с примерами PowerShell cmdlets на русском языке.
▪ Remote Shadow Administrator - практически полноценная программа на PowerShell для управления терминальными серверами и подключения к текущим RDP-сессиям с помощью Shadow-подключения. Написана только с помощью PowerShell и Windows Forms. Если управляете терминальниками, то может быть очень полезным.
В репозитории ещё много всего необычного. Посмотрите, может найдёте что-то полезное для себя.
#windows
⇨ https://github.com/Lifailon
Там очень много всего написано за много лет продуктивной деятельности. Автор захотел поделиться с аудиторией. Может кому-то будет полезно. Человек занимался в основном администрированием на Windows, поэтому большая часть работ на PowerShell, но не только.
Я посмотрел репу и сразу честно сказал, что это лютые костыли, которые решали конкретные задачи на конкретном рабочем месте, поэтому слабо применимы для широкой аудитории. Тем не менее, некоторые полезные вещи я увидел и для себя:
▪ Windows-User-Sessions - шаблон и скрипты к Zabbix для мониторинга за терминальными сессиями на сервере.
▪ ACL-Backup - небольшой скрипт с формой ввода, который позволяет сделать полный backup списка прав доступа (ACL) файловой системы NTFS в txt-файл с возможностью восстановления из этого списка. Я тоже писал и использовал скрипты для решения этой же задачи. Когда бэкаплю виндовые шары, записываю на них же списки прав доступа, чтобы можно было восстановить, если что-то пойдёт не так.
▪ PS-Commands - описание с примерами PowerShell cmdlets на русском языке.
▪ Remote Shadow Administrator - практически полноценная программа на PowerShell для управления терминальными серверами и подключения к текущим RDP-сессиям с помощью Shadow-подключения. Написана только с помощью PowerShell и Windows Forms. Если управляете терминальниками, то может быть очень полезным.
В репозитории ещё много всего необычного. Посмотрите, может найдёте что-то полезное для себя.
#windows
GitHub
Lifailon - Overview
System Administrator and Automation Engineer. Lifailon has 79 repositories available. Follow their code on GitHub.
Много раз писал про различные возможности SSH на сервере, в том числе для использования в роли jumphost. Да и сам нередко использовал эту возможность. При этом либо в 2 этапа подключался к требуемому хосту, то есть вручную - сначала на jumphost, потом уже на целевой. Либо запускал команду на подключение к целевому хосту внутри команды на подключение к jumphost:
Особенность такого последовательного подключения в том, что к jumphost вы подключаетесь, используя свой сертификат на локальной машине, а с jumphost на server01 используя сертификат с сервера jumphost. Они могут быть как одинаковыми, так и разными. Происходит последовательное подключение сначала к первому хосту по ssh, потом с первого ко второму в рамках первой ssh сессии.
Мимо моего внимания прошла возможность ssh напрямую подключаться со своего хоста на server01 через jumphost. То есть это выглядит вот так:
Для этого даже отдельный ключ есть
Оба эти подхода имеют право на жизнь, в зависимости от ваших потребностей. Например, при первом подходе на jumphost можно более гибко раздать права, настроить логирование или запись сессий, уведомления о подключениях. В случае второго подхода всё это придётся делать на целевом сервере, но при этом будет более простое и стабильное соединение, так как ssh сессия будет одна, а не вложение одной в другую.
📌 Ссылки по теме:
▪ Логирование ssh активности с помощью: Tlog, snoopy, log-user-session, PROMPT_COMMAND
▪ Уведомления в Telegram о ssh сессиях
▪ Переадресация портов через ssh
▪ VPN туннели с помощью ssh
▪ Ограничение на выполнение команд по ssh
▪ Псевдографическое меню для jumphost
▪ Поддержание постоянного ssh соединения с помощью Autossh
#ssh
# ssh -t user@jumphost "ssh user@server01"Особенность такого последовательного подключения в том, что к jumphost вы подключаетесь, используя свой сертификат на локальной машине, а с jumphost на server01 используя сертификат с сервера jumphost. Они могут быть как одинаковыми, так и разными. Происходит последовательное подключение сначала к первому хосту по ssh, потом с первого ко второму в рамках первой ssh сессии.
Мимо моего внимания прошла возможность ssh напрямую подключаться со своего хоста на server01 через jumphost. То есть это выглядит вот так:
# ssh -J user@jumphost:22 user@server01Для этого даже отдельный ключ есть
-J. Это принципиально другой тип подключения, так как при этом пробрасывается TCP порт через jumphost. Подключение происходит напрямую с твоей машины. Ключ, соответственно, проверяется только у тебя.Оба эти подхода имеют право на жизнь, в зависимости от ваших потребностей. Например, при первом подходе на jumphost можно более гибко раздать права, настроить логирование или запись сессий, уведомления о подключениях. В случае второго подхода всё это придётся делать на целевом сервере, но при этом будет более простое и стабильное соединение, так как ssh сессия будет одна, а не вложение одной в другую.
📌 Ссылки по теме:
▪ Логирование ssh активности с помощью: Tlog, snoopy, log-user-session, PROMPT_COMMAND
▪ Уведомления в Telegram о ssh сессиях
▪ Переадресация портов через ssh
▪ VPN туннели с помощью ssh
▪ Ограничение на выполнение команд по ssh
▪ Псевдографическое меню для jumphost
▪ Поддержание постоянного ssh соединения с помощью Autossh
#ssh
Есть куча публичных сервисов по определению твоего внешнего ip адреса, в том числе через консоль. Например, ifconfig.co или ifconfig.me/ip.
Если вам постоянно нужна такая функциональность для каких-то своих проверок, то разумнее всего поднять свой сервис. Сделать это проще простого с помощью Nginx или Angie. Просто добавьте на любой виртуальный хост location:
И всё, больше ничего не надо. Можете хоть браузером, хоть консолью смотреть свой ip. Если запросы на ip адрес сервера не закрыты, то добавив location в стандартный виртуальный хост
Bash:
Powershell:
#сервис
Если вам постоянно нужна такая функциональность для каких-то своих проверок, то разумнее всего поднять свой сервис. Сделать это проще простого с помощью Nginx или Angie. Просто добавьте на любой виртуальный хост location:
location /ip { default_type text/plain; return 200 $remote_addr; }И всё, больше ничего не надо. Можете хоть браузером, хоть консолью смотреть свой ip. Если запросы на ip адрес сервера не закрыты, то добавив location в стандартный виртуальный хост
default.conf, смотреть свой ip можно так: Bash:
# curl http://1.2.3.4/ipPowershell:
> Invoke-RestMethod http://1.2.3.4/ip#сервис
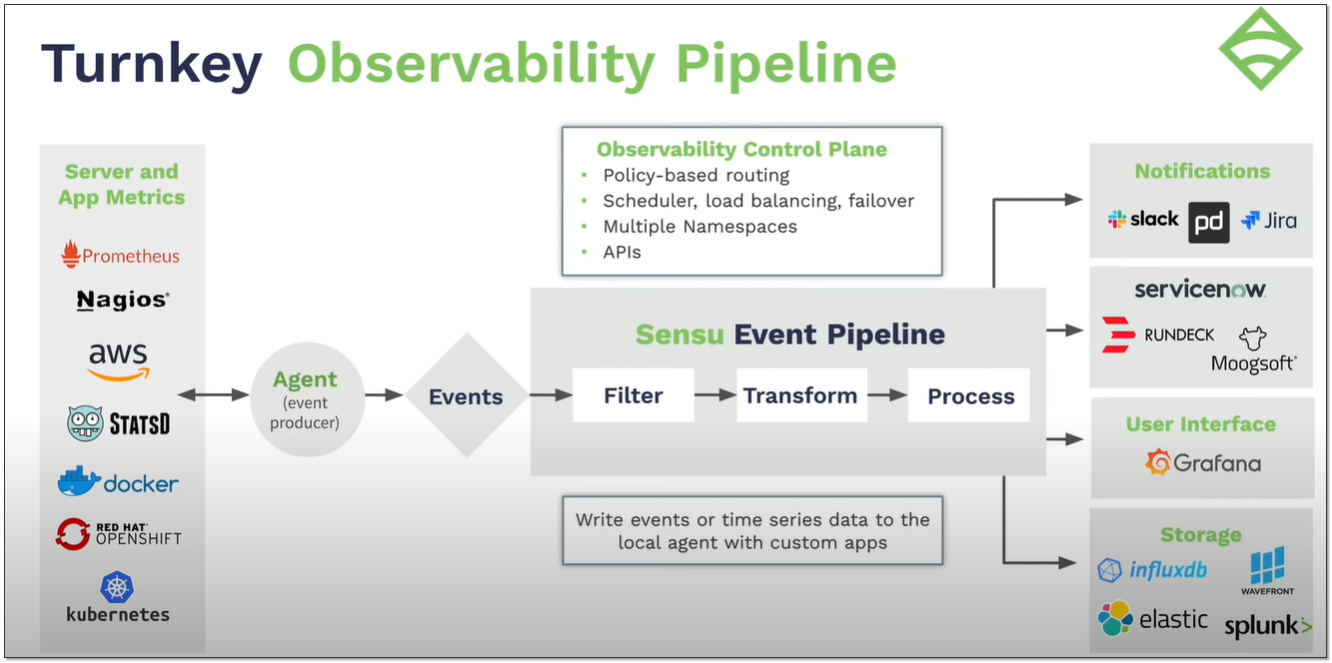
Существует довольно старая система мониторинга под названием Sensu. Ей лет 10 точно есть. Изначально она была написана на Ruby. На этом же языке писались и самостоятельные проверки, дополнения и т.д. Судя по всему в какой-то момент разработчики поняли, что это не самая удачная реализация и переписали всё на Go, а язык для проверок реализовали на JavaScript.
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
Создали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
# sensuctl create -f metric-storage/influxdb.yaml# sensuctl create -f alert/slack.yaml# sensuctl create -r -f system/linux/cpuСоздали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
{kind=link}
Пересчёт олдов. На днях искал в поиске что-то и на 3-м месте в выдаче выскочил сайт lissyara.su со статьей то ли 2007, то ли 2008 года. Я очень удивился, что такая старая информация всплывает в поиске. Ну а заодно и поностальгировал.
Этот сайт я очень активно изучал и использовал, когда начинал свой путь админом FreeBSD. Тогда ещё особо не была распространена должность Администратор Linux, потому что FreeBSD была распространена сильнее. Да и в целом не было явного разделения на администраторов различных систем.
Когда я принял решение, что помимо Windows надо изучать что-то ещё, узнал, что бОльшая часть серверов Яндекса на FreeBSD, поэтому решил, что стоит изучать эту систему. Ну и стал на работе и дома настраивать и разбираться. Сначала со шлюзом ковырялся, потом с веб сервером, потом с почтовым. В принципе, все азы современного Linux я получил тогда на FreeBSD. Настройка на самом деле не сильно отличается. Сейчас спокойно мог бы вернуться на FreeBSD без каких-то проблем.
Читая статьи на lissyara.su, я думал, какой нужен мозг, чтобы во всём этом разбираться и писать статьи. Причём авторы там так походя всё упоминали. Типа искал такой-то инструмент, нашёл его в портах (аналог базового репозитория linux), почитал описание, настроил, написал статью. А оказалось это дело техники. Поднабрался опыта и стал делать так же.
Интересно, много ли среди читателей людей, которые знают этот сайт, использовали его для настройки каких-то своих систем? Ещё очень интересно, что стало в итоге с автором, почему он забросил сайт, но при этом до сих пор поддерживает его в рабочем состоянии. Он так топил за фрюху и ругал линукс, но в итоге линукс победил.
Вообще, у меня небольшая мечта есть. Когда появится свободное время и не будет необходимости всё время бежать вперёд, настроить всю свою инфру на FreeBSD. Её наверное сейчас уже и не ломают, и уязвимости не ищут ввиду малой распространённости. В экзотику выродилась. Я уже лет 6-7 её в проде ни у кого не видел.
#freebsd
Этот сайт я очень активно изучал и использовал, когда начинал свой путь админом FreeBSD. Тогда ещё особо не была распространена должность Администратор Linux, потому что FreeBSD была распространена сильнее. Да и в целом не было явного разделения на администраторов различных систем.
Когда я принял решение, что помимо Windows надо изучать что-то ещё, узнал, что бОльшая часть серверов Яндекса на FreeBSD, поэтому решил, что стоит изучать эту систему. Ну и стал на работе и дома настраивать и разбираться. Сначала со шлюзом ковырялся, потом с веб сервером, потом с почтовым. В принципе, все азы современного Linux я получил тогда на FreeBSD. Настройка на самом деле не сильно отличается. Сейчас спокойно мог бы вернуться на FreeBSD без каких-то проблем.
Читая статьи на lissyara.su, я думал, какой нужен мозг, чтобы во всём этом разбираться и писать статьи. Причём авторы там так походя всё упоминали. Типа искал такой-то инструмент, нашёл его в портах (аналог базового репозитория linux), почитал описание, настроил, написал статью. А оказалось это дело техники. Поднабрался опыта и стал делать так же.
Интересно, много ли среди читателей людей, которые знают этот сайт, использовали его для настройки каких-то своих систем? Ещё очень интересно, что стало в итоге с автором, почему он забросил сайт, но при этом до сих пор поддерживает его в рабочем состоянии. Он так топил за фрюху и ругал линукс, но в итоге линукс победил.
Вообще, у меня небольшая мечта есть. Когда появится свободное время и не будет необходимости всё время бежать вперёд, настроить всю свою инфру на FreeBSD. Её наверное сейчас уже и не ломают, и уязвимости не ищут ввиду малой распространённости. В экзотику выродилась. Я уже лет 6-7 её в проде ни у кого не видел.
#freebsd
{kind=link}
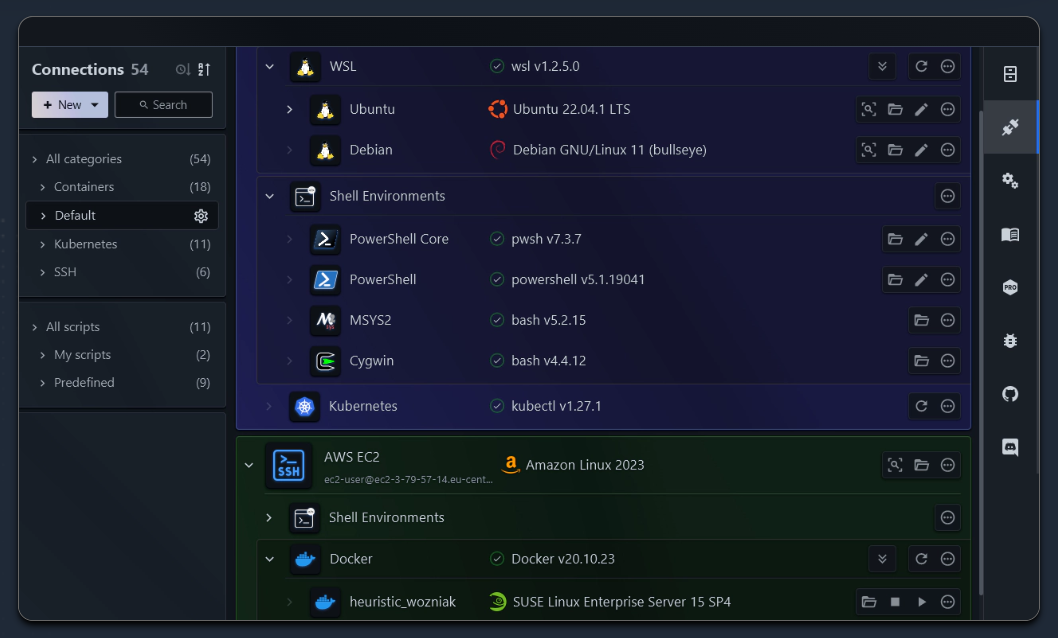
Нечасто бывает так, что пишешь о чём-то, что тебе реально понравилось. В этот раз будет именно такая заметка. Речь пойдёт о новом для меня менеджере SSH соединений - XPipe. Раньше о нём не слышал, что неудивительно, так как появился он в 2023 году. Не скажу, что это прям что-то такое, что вау, но лично мне нравится разбираться и изучать программы, с которыми взаимодействуешь каждый день. Иногда такое нововведение существенно изменяет качество ежедневной рутины в лучшую сторону.
Как я уже сказал, программа в целом мне понравилась, хотя иногда в ней что-то подглючивало и она подвисала. Провозился с ней пару часов. Изучал возможности, смотрел обзор, пробовал пользоваться. Настроил в ней соединения к своим серверам. Буду пользоваться и изучать. Программа кроссплатформенная, потому что на Java (слышу вздохи разочарования). Есть под Windows, Linux, MacOS.
Далее по порядку обо всём расскажу.
В целом, это плюс минус тот же самый менеджер соединений, как и все остальные. Настраиваешь соединения, раскидываешь их по разделам и подключаешься. Расскажу, что понравилось в XPipe.
🟢 Интеграция с Windows Shell. Все соединения открываются во вкладках стандартного виндового терминала. Мне нравится его внешний вид и поведение, так что для меня это плюс. Во многих других программах отталкивает именно терминал.
🟢 В отдельной вкладке программы можно открыть обзор файлов удалённого сервера, а сами файлы, соответственно, сразу открывать в VSCode. Не нужны никакие сторонние scp клиенты. На практике это удобно, особенно для контейнеров, которые XPipe автоматически находит на хосте и добавляет для каждого из них отдельное подключение.
🟢 Лично мне понравился простой и лаконичный внешний вид программы. По умолчанию она в светлой теме, но в тёмной показалась симпатичнее, хоть я и не любитель тёмных тем. Но VSCode тоже тёмная, как и терминал, так что всё вместе это нормально смотрится.
🟢 Можно напрямую подключаться к СУБД, к Docker контейнерам, к локальным экземплярам WSL.
🟢 Есть встроенная поддержка jumphost и SSH подключений через него. Настраиваете соединение к jumphost, а в остальных подключениях указываете его в качестве шлюза.
🟢 Есть возможность создавать свои скрипты и запускать их вручную или автоматически в настроенных соединениях. Лично я никогда не использовал такие возможности, поэтому упоминаю просто для галочки. Сам таким не пользуюсь. Не знаю, какие задачи с помощью этого решают.
🟢 Есть портабельные версии программы, что удобно для переносимости между рабочими машинами.
🟢 Есть мастер пароль для шифрования всей чувствительной информации о соединениях.
🟢 Умеет хранить и синхронизировать своё состояние через git репозиторий.
Базовая программа бесплатная без каких-либо ограничений. Более того, она open source. За деньги продаются отдельные плюшки в виде интеграции с коммерческими системами, такими как Google Kubernetes Engine, Red Hat OpenShift, Docker Enterprise и т.д. Полный список тут. В него же входят и коммерческие ОС Linux, с точки зрения разработчиков, а это Amazon Linux, RHEL, SUSE Enterprise Linux, Oracle Linux (!) и другие.
По тэгу в конце заметки можете посмотреть мои обзоры на другие программы подобного типа. Я сам по ним пробежался сейчас. Понял, что XPipe по совокупности возможностей понравилась больше, чем какая-либо другая из описанных ранее. Интересная была программа WindTerm, но меня оттолкнул её внешний вид. Визуально не понравилась, хотя набор возможностей хороший.
Если кто-то ещё не знает, чем пользуюсь я сам, хотя писал об этом много раз, то повторю. Для SSH соединений использую очень старую бесплатную версию xShell 5, а для RDP - mRemoteNG. Последняя тоже очень старая, так как в новых версиях ничего существенно по возможностям не добавили, но работает она медленнее.
⇨ Сайт / Исходники / Видеообзор
#менеджеры_подключений
Как я уже сказал, программа в целом мне понравилась, хотя иногда в ней что-то подглючивало и она подвисала. Провозился с ней пару часов. Изучал возможности, смотрел обзор, пробовал пользоваться. Настроил в ней соединения к своим серверам. Буду пользоваться и изучать. Программа кроссплатформенная, потому что на Java (слышу вздохи разочарования). Есть под Windows, Linux, MacOS.
Далее по порядку обо всём расскажу.
В целом, это плюс минус тот же самый менеджер соединений, как и все остальные. Настраиваешь соединения, раскидываешь их по разделам и подключаешься. Расскажу, что понравилось в XPipe.
🟢 Интеграция с Windows Shell. Все соединения открываются во вкладках стандартного виндового терминала. Мне нравится его внешний вид и поведение, так что для меня это плюс. Во многих других программах отталкивает именно терминал.
🟢 В отдельной вкладке программы можно открыть обзор файлов удалённого сервера, а сами файлы, соответственно, сразу открывать в VSCode. Не нужны никакие сторонние scp клиенты. На практике это удобно, особенно для контейнеров, которые XPipe автоматически находит на хосте и добавляет для каждого из них отдельное подключение.
🟢 Лично мне понравился простой и лаконичный внешний вид программы. По умолчанию она в светлой теме, но в тёмной показалась симпатичнее, хоть я и не любитель тёмных тем. Но VSCode тоже тёмная, как и терминал, так что всё вместе это нормально смотрится.
🟢 Можно напрямую подключаться к СУБД, к Docker контейнерам, к локальным экземплярам WSL.
🟢 Есть встроенная поддержка jumphost и SSH подключений через него. Настраиваете соединение к jumphost, а в остальных подключениях указываете его в качестве шлюза.
🟢 Есть возможность создавать свои скрипты и запускать их вручную или автоматически в настроенных соединениях. Лично я никогда не использовал такие возможности, поэтому упоминаю просто для галочки. Сам таким не пользуюсь. Не знаю, какие задачи с помощью этого решают.
🟢 Есть портабельные версии программы, что удобно для переносимости между рабочими машинами.
🟢 Есть мастер пароль для шифрования всей чувствительной информации о соединениях.
🟢 Умеет хранить и синхронизировать своё состояние через git репозиторий.
Базовая программа бесплатная без каких-либо ограничений. Более того, она open source. За деньги продаются отдельные плюшки в виде интеграции с коммерческими системами, такими как Google Kubernetes Engine, Red Hat OpenShift, Docker Enterprise и т.д. Полный список тут. В него же входят и коммерческие ОС Linux, с точки зрения разработчиков, а это Amazon Linux, RHEL, SUSE Enterprise Linux, Oracle Linux (!) и другие.
По тэгу в конце заметки можете посмотреть мои обзоры на другие программы подобного типа. Я сам по ним пробежался сейчас. Понял, что XPipe по совокупности возможностей понравилась больше, чем какая-либо другая из описанных ранее. Интересная была программа WindTerm, но меня оттолкнул её внешний вид. Визуально не понравилась, хотя набор возможностей хороший.
Если кто-то ещё не знает, чем пользуюсь я сам, хотя писал об этом много раз, то повторю. Для SSH соединений использую очень старую бесплатную версию xShell 5, а для RDP - mRemoteNG. Последняя тоже очень старая, так как в новых версиях ничего существенно по возможностям не добавили, но работает она медленнее.
⇨ Сайт / Исходники / Видеообзор
#менеджеры_подключений
{kind=link}
Часто слышал выражение, что трафик отправляют в blackhole. Обычно это делает провайдер, когда вас ддосят. Вас просто отключают, отбрасывая весь адресованный вам трафик. А что за сущность такая blackhole, я не знал. Решил узнать, заодно и вам рассказать.
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
Проверяем:
Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
# ip route add blackhole 1.2.3.4Проверяем:
# ip r | grep blackholeblackhole 1.2.3.4Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
{kind=link}
🔝 В этот раз ТОП постов за месяц выйдет немного пораньше, потому что завтра будет ещё топ за год.
Навскидку, в этом месяце был побит рекорд по пересылкам, а может и по реакциям и комментариям. Неожиданно много сохранений и пересылок получила заметка с подборкой бесплатных обучающих материалов. Практически каждый 8-й просмотревший сообщение сохранил его к себе. Не совсем понимаю, это всем так хочется учиться, или просто на всякий случай записали?
Несмотря на то, что многие написали, что раз канал про IT, то и заметки должны быть про IT, нетематические посты получили огромную реакцию. Для меня было полнейшей неожиданностью, что заметка про детей так затронет огромное количество людей. Судя по всему, задел за живое. Собрал в том числе кучу негатива, хотя всего лишь описал свой реальный жизненный опыт и взгляды, основанные на нём, а не какие-то абстрактные умозаключения. Если благодаря этой заметке родится хоть один незапланированный ранее ребёнок и осчастливит своих родителей, буду считать, что написал её не зря.
Отдельно отмечу цикл моих заметок про спину. Всё, что я там описал, реально работает. Своё состояние улучшил значительно. Можно сказать, что функционально вернулся в состояние среднестатистического здорового человека буквально за пару месяцев. Как минимум, ничего уже не болит. Разобрался в причинах проблем, в лечении, в профилактике. Кто не читал, но имеет проблемы с опорно-двигательным аппаратом, крайне рекомендую ознакомиться (хэштег #спина).
📌 Больше всего просмотров:
◽️Подборка бесплатных обучающих материалов (10373)
◽️Сервис по слежению за torrent раздачами (10195)
◽️Обучающие материалы по сетям (9497)
📌 Больше всего комментариев:
◽️Заметка про детей (305)
◽️Заметка про выбор пути, чтобы войти в IT (141)
◽️Домашняя серверная блоггера Techno Tim (132)
📌 Больше всего пересылок:
◽️Подборка обучающих материалов (1192)
◽️Обучающие материалы по сетям (512)
◽️Сервис по слежению за torrent раздачами (368)
◽️Программа LocalSend для передачи файлов (366)
📌 Больше всего реакций:
◽️Заметка про детей (518)
◽️Моя история про боли в спине (310)
◽️Отладка bash скриптов с помощью set -x (212)
#топ
Навскидку, в этом месяце был побит рекорд по пересылкам, а может и по реакциям и комментариям. Неожиданно много сохранений и пересылок получила заметка с подборкой бесплатных обучающих материалов. Практически каждый 8-й просмотревший сообщение сохранил его к себе. Не совсем понимаю, это всем так хочется учиться, или просто на всякий случай записали?
Несмотря на то, что многие написали, что раз канал про IT, то и заметки должны быть про IT, нетематические посты получили огромную реакцию. Для меня было полнейшей неожиданностью, что заметка про детей так затронет огромное количество людей. Судя по всему, задел за живое. Собрал в том числе кучу негатива, хотя всего лишь описал свой реальный жизненный опыт и взгляды, основанные на нём, а не какие-то абстрактные умозаключения. Если благодаря этой заметке родится хоть один незапланированный ранее ребёнок и осчастливит своих родителей, буду считать, что написал её не зря.
Отдельно отмечу цикл моих заметок про спину. Всё, что я там описал, реально работает. Своё состояние улучшил значительно. Можно сказать, что функционально вернулся в состояние среднестатистического здорового человека буквально за пару месяцев. Как минимум, ничего уже не болит. Разобрался в причинах проблем, в лечении, в профилактике. Кто не читал, но имеет проблемы с опорно-двигательным аппаратом, крайне рекомендую ознакомиться (хэштег #спина).
📌 Больше всего просмотров:
◽️Подборка бесплатных обучающих материалов (10373)
◽️Сервис по слежению за torrent раздачами (10195)
◽️Обучающие материалы по сетям (9497)
📌 Больше всего комментариев:
◽️Заметка про детей (305)
◽️Заметка про выбор пути, чтобы войти в IT (141)
◽️Домашняя серверная блоггера Techno Tim (132)
📌 Больше всего пересылок:
◽️Подборка обучающих материалов (1192)
◽️Обучающие материалы по сетям (512)
◽️Сервис по слежению за torrent раздачами (368)
◽️Программа LocalSend для передачи файлов (366)
📌 Больше всего реакций:
◽️Заметка про детей (518)
◽️Моя история про боли в спине (310)
◽️Отладка bash скриптов с помощью set -x (212)
#топ
▶️ Канал DevOps Channel перед праздниками опубликовал все выступления с прошедшей в марте 2023 года конференции DevOpsConf. Это чтобы нам не скучно было на выходных. Я аж устал список записей просматривать. Там очень много всего и на разные темы.
Я часто смотрю записи с подобных мероприятий и могу сразу сказать, что практической пользы для подавляющего числа слушателей там нет. Лично мне просто нравится это слушать как развлекательное видео. А если ещё и полезное что-то узнаю, то вдвойне хорошо. Как минимум, расширяется кругозор. Так что я включаю в фоне во время прогулок или когда на машине куда-то еду.
Добавил себе на просмотр следующие выступления:
🔹Топ некритичных ошибок в инфраструктуре, приводящих к критичным проблемам
▪ Как перестать быть YAML-разработчиком. Переходи на сторону CUE
🔹TechTalk "Выбор CI/CD-системы"
▪ Vault — интеграция куда угодно
🔹Гид автостопщика по HashiCorp Vault
▪ Как управлять базой знаний и не сойти с ума
🔹Мимо тёщиного дома я без метрик не хожу
▪ Ваши админы за 10 лет так и не смогли стать девопсами. Разработчики смогли
🔹Хочешь расти в DevOps, но не знаешь как? Приходи, расскажу!
▪ DevOps — путь на социальное дно, или Пробиваем дно DevOps-колодца
🔹Практика применения DevOps-аутсорса на разных этапах жизненного цикла продукта
#видео
Я часто смотрю записи с подобных мероприятий и могу сразу сказать, что практической пользы для подавляющего числа слушателей там нет. Лично мне просто нравится это слушать как развлекательное видео. А если ещё и полезное что-то узнаю, то вдвойне хорошо. Как минимум, расширяется кругозор. Так что я включаю в фоне во время прогулок или когда на машине куда-то еду.
Добавил себе на просмотр следующие выступления:
🔹Топ некритичных ошибок в инфраструктуре, приводящих к критичным проблемам
▪ Как перестать быть YAML-разработчиком. Переходи на сторону CUE
🔹TechTalk "Выбор CI/CD-системы"
▪ Vault — интеграция куда угодно
🔹Гид автостопщика по HashiCorp Vault
▪ Как управлять базой знаний и не сойти с ума
🔹Мимо тёщиного дома я без метрик не хожу
▪ Ваши админы за 10 лет так и не смогли стать девопсами. Разработчики смогли
🔹Хочешь расти в DevOps, но не знаешь как? Приходи, расскажу!
▪ DevOps — путь на социальное дно, или Пробиваем дно DevOps-колодца
🔹Практика применения DevOps-аутсорса на разных этапах жизненного цикла продукта
#видео
{kind=link}
Как это обычно бывает в обслуживании и поддержке, длинные выходные случаются не только лишь у всех. Я всегда стараюсь выстроить рабочий процесс так, чтобы в выходные всё же не работать. Но почти никогда это не получается. В этот раз поступила просьба, которой я не стал отказывать.
Сторонним разработчикам, нанятым незадолго до НГ, нужна была копия сайта для разработки. Пока с ними договаривались (не я), обсуждали детали, наметили план, наступило 28-е, четверг. В пятницу я уже не успел ничего сделать и благоразумно отложил решение всех вопросов на рабочие дни после праздников, так как не предполагал, что в праздники кто-то будет что-то делать. Но разработчики очень попросили всё сделать заранее, так как планировали начать работы уже 2-го января. Вот ещё категория трудоголиков, которая любит работать в праздники.
В итоге 1-го вечером я уже трудился за ноутом. В целом, задача не трудная, поэтому не стал динамить и всё сделал. В процессе возникло несколько затруднений, которые я решил. Об этом и хочу написать. Там ничего особенного, обычная рутина админа, но это может быть интересным и полезным.
Основная проблема в том, что сайт относительно большой, а свободных мощностей у компании мало. Все арендованные и дорогие. Нужно порядка 400 Гб места на дисках под сам сайт и база данных mysql примерно 10 гигов. Да ещё и сайт планировали с php 7.4 перенести на 8.0, так что нужна была отдельная виртуалка, где можно будет обновлять пакеты и будет полный доступ у разработчиков. Я перед началом работ прикинул и понял, что развернуть копию на длительное время тупо негде.
Что-то докупать или заказывать в праздники не получится, потому что нужно согласовывать расходы, оплачивать и заказывать. Начал искать варианты. У сайта есть директория с пользовательскими прикреплёнными файлами. Для разработки они не нужны, так что решил поднимать без них. Нашёл сервер, где было немного свободного места. Развернул там виртуалку, скопировал сайт без лишних файлов. Начал разворачивать базу, не хватает места. И сам дамп большой, и во время разворачивания надо много места.
Посмотрел, что в базе. Понял, что большая часть информации — это данные, которые регулярно обновляются и удаляются, и для разработки не нужны. Возникла задача из обычного текстового sql дампа вырезать содержимое некоторых таблиц. Так как файл текстовый, то придумал такое решение. Я уже когда-то делал похожую заметку, но раньше мне приходилось вытаскивать отдельную таблицу из дампа, а тут надо наоборот, удалить содержимое таблицы, но сохранить всю структуру базы.
Решил таким образом. Все данные таблицы в дампе располагаются между строк Dumping data for table нужной таблицы и Table structure, где начинается новая таблица. Вывел все такие строки в отдельный текстовый файл:
Нашёл там нужную таблицу и номера первой и второй указанных строк. И потом вырезал всё, что между ними с помощью sed. Первое число — номер строки Dumping data for table, которую нужно удалить и всё, что за ней. Второе — номер строки, предшествующей записи Table structure, так как эту строку нужно оставить. Она относится к структуре новой таблицы.
Таким образом можно очистить все ненужные таблицы, оставив только их структуру.
Места в итоге всё равно не хватило. Посмотрел, на каких виртуалках на этом сервере есть свободное место. Нашёл одну, где его было много. Поднял там nfs сервер, примонтировал каталог к новому серверу, разместил там сайт. Всё заработало. Далее настроил проксирование к этому сайту, пробросил со шлюза порты ssh для разработчиков и всё им отправил. Надеюсь, они успешно поработают, а мои праздничные костыли не окажутся напрасными.
❓Кто ещё работает в праздники? Чем занимаетесь? Я обычно что-то обновляю, переношу, пока никто не мешает. Но на этот НГ ничего не планировал. Столько лет всегда что-то делаю, что решил в этот раз отдохнуть.
#webserver
Сторонним разработчикам, нанятым незадолго до НГ, нужна была копия сайта для разработки. Пока с ними договаривались (не я), обсуждали детали, наметили план, наступило 28-е, четверг. В пятницу я уже не успел ничего сделать и благоразумно отложил решение всех вопросов на рабочие дни после праздников, так как не предполагал, что в праздники кто-то будет что-то делать. Но разработчики очень попросили всё сделать заранее, так как планировали начать работы уже 2-го января. Вот ещё категория трудоголиков, которая любит работать в праздники.
В итоге 1-го вечером я уже трудился за ноутом. В целом, задача не трудная, поэтому не стал динамить и всё сделал. В процессе возникло несколько затруднений, которые я решил. Об этом и хочу написать. Там ничего особенного, обычная рутина админа, но это может быть интересным и полезным.
Основная проблема в том, что сайт относительно большой, а свободных мощностей у компании мало. Все арендованные и дорогие. Нужно порядка 400 Гб места на дисках под сам сайт и база данных mysql примерно 10 гигов. Да ещё и сайт планировали с php 7.4 перенести на 8.0, так что нужна была отдельная виртуалка, где можно будет обновлять пакеты и будет полный доступ у разработчиков. Я перед началом работ прикинул и понял, что развернуть копию на длительное время тупо негде.
Что-то докупать или заказывать в праздники не получится, потому что нужно согласовывать расходы, оплачивать и заказывать. Начал искать варианты. У сайта есть директория с пользовательскими прикреплёнными файлами. Для разработки они не нужны, так что решил поднимать без них. Нашёл сервер, где было немного свободного места. Развернул там виртуалку, скопировал сайт без лишних файлов. Начал разворачивать базу, не хватает места. И сам дамп большой, и во время разворачивания надо много места.
Посмотрел, что в базе. Понял, что большая часть информации — это данные, которые регулярно обновляются и удаляются, и для разработки не нужны. Возникла задача из обычного текстового sql дампа вырезать содержимое некоторых таблиц. Так как файл текстовый, то придумал такое решение. Я уже когда-то делал похожую заметку, но раньше мне приходилось вытаскивать отдельную таблицу из дампа, а тут надо наоборот, удалить содержимое таблицы, но сохранить всю структуру базы.
Решил таким образом. Все данные таблицы в дампе располагаются между строк Dumping data for table нужной таблицы и Table structure, где начинается новая таблица. Вывел все такие строки в отдельный текстовый файл:
# grep -n 'Table structure\|Dumping data for table' dump.sql > tables.txtНашёл там нужную таблицу и номера первой и второй указанных строк. И потом вырезал всё, что между ними с помощью sed. Первое число — номер строки Dumping data for table, которую нужно удалить и всё, что за ней. Второе — номер строки, предшествующей записи Table structure, так как эту строку нужно оставить. Она относится к структуре новой таблицы.
# sed '22826,26719 d' dump.sql > cleanup.sqlТаким образом можно очистить все ненужные таблицы, оставив только их структуру.
Места в итоге всё равно не хватило. Посмотрел, на каких виртуалках на этом сервере есть свободное место. Нашёл одну, где его было много. Поднял там nfs сервер, примонтировал каталог к новому серверу, разместил там сайт. Всё заработало. Далее настроил проксирование к этому сайту, пробросил со шлюза порты ssh для разработчиков и всё им отправил. Надеюсь, они успешно поработают, а мои праздничные костыли не окажутся напрасными.
❓Кто ещё работает в праздники? Чем занимаетесь? Я обычно что-то обновляю, переношу, пока никто не мешает. Но на этот НГ ничего не планировал. Столько лет всегда что-то делаю, что решил в этот раз отдохнуть.
#webserver
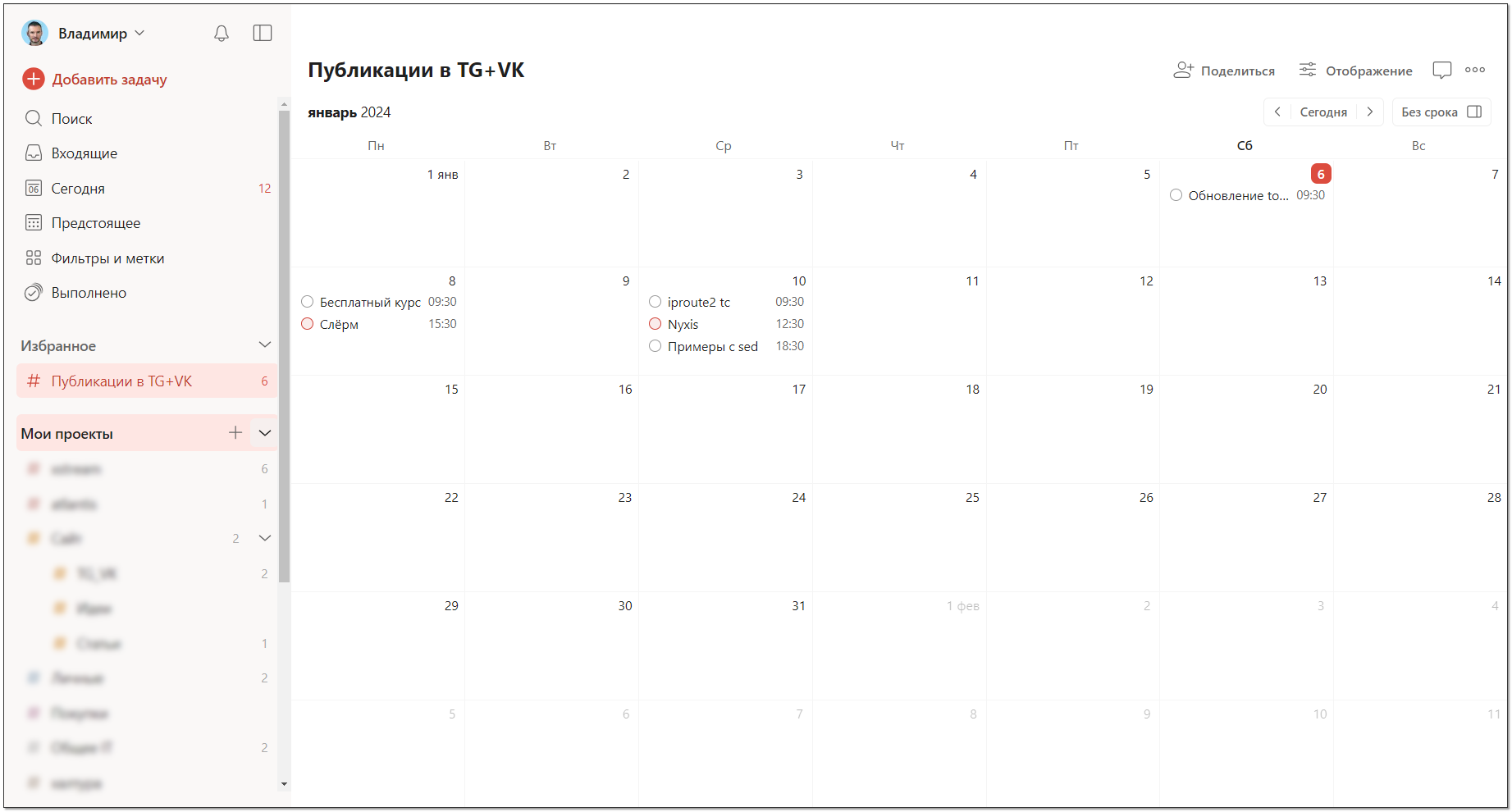
Уже много лет веду свои дела в сервисе todoist.com. Начал это делать ещё до того, как прочитал книгу Тайм-менеджмент для системных администраторов. При этом мне всегда было достаточно бесплатной версии. Правда есть один нюанс. Когда-то давно в сервисе не было ограничения на 5 проектов для бесплатного тарифа. У меня была создана куча проектов, которые до сих пор остались. Я не могу добавить новых, но все старые на месте и мне их хватает.
С нового года сервис выкатил очень крутое обновление. Появилось полноценное отображение проектов в виде календаря с нанесёнными на него задачами. Не понимаю, почему они так долго существовали без этого. Мне приходится использовать связку todoist.com + planyway.com. Первый для задач, второй для календаря и тех задач, что мне важно видеть на календаре. Это закрывает все мои потребности, но очевидно, что 2 сервиса это хуже, чем один, где всё это в единой базе.
И вот у Todoist появился очень похожий календарь. Такое ощущение, что они его с Planyway и скопировали, так как сильно похож и внешне и по возможностям. К сожалению, этот календарь доступен только в платных тарифах. Оплатить из РФ их сейчас невозможно. Прежде чем платить, хотелось лично попробовать, а триал у меня давно уже закончен. Нашёл в инете промокод 6K94QXHTQ6 на 2 месяца тарифа Pro (активировать тут), который на удивление сработал. У Todoist периодически появляются рекламные промокоды, но все, что я нашёл, уже не действовали, кроме этого. Так что если давно пользуетесь сервисом и хотите ещё на какое-то время получить платный тариф, можно воспользоваться. Даже если потом не надумаете покупать, можно себе проектов добавить, сколько нужно, чтобы они потом остались.
Календарь мне понравился. Реализация с привязкой календарей к проектам удобна. Возможностей тоже достаточно. Есть и метки, и продолжительность задач, и подзадачи. Когда все задачи добавлены, можно наглядно оценить план на ближайшие дни. Не понравилось только одно — решённые задачи исчезают из календаря полностью, а не остаются зачёркнутыми, как в Planyway. Для меня это критично, так как хочу видеть завершённые задачи на календаре, а не где-то потом в отдельном списке, как сейчас это реализовано в Todoist.
Я пробовал огромное количество сервисов и программ для ведения календаря. Ничего удобнее Planyway так и не нашёл. Продолжаю использовать его на бесплатном тарифе. Мне возможностей хватает. Если Todoist реализует возможность отображения завершённых задач, перейду на него, так как замкнуть всё на один сервис будет намного удобнее, чем вести два. Есть неплохие календари в yonote, но мне ещё один сервис заводить не хочется. Кто с нуля себе подбирает что-то для заметок, календаря, списка дел, то обратите внимание. Сервис неплохой.
#заметки
С нового года сервис выкатил очень крутое обновление. Появилось полноценное отображение проектов в виде календаря с нанесёнными на него задачами. Не понимаю, почему они так долго существовали без этого. Мне приходится использовать связку todoist.com + planyway.com. Первый для задач, второй для календаря и тех задач, что мне важно видеть на календаре. Это закрывает все мои потребности, но очевидно, что 2 сервиса это хуже, чем один, где всё это в единой базе.
И вот у Todoist появился очень похожий календарь. Такое ощущение, что они его с Planyway и скопировали, так как сильно похож и внешне и по возможностям. К сожалению, этот календарь доступен только в платных тарифах. Оплатить из РФ их сейчас невозможно. Прежде чем платить, хотелось лично попробовать, а триал у меня давно уже закончен. Нашёл в инете промокод 6K94QXHTQ6 на 2 месяца тарифа Pro (активировать тут), который на удивление сработал. У Todoist периодически появляются рекламные промокоды, но все, что я нашёл, уже не действовали, кроме этого. Так что если давно пользуетесь сервисом и хотите ещё на какое-то время получить платный тариф, можно воспользоваться. Даже если потом не надумаете покупать, можно себе проектов добавить, сколько нужно, чтобы они потом остались.
Календарь мне понравился. Реализация с привязкой календарей к проектам удобна. Возможностей тоже достаточно. Есть и метки, и продолжительность задач, и подзадачи. Когда все задачи добавлены, можно наглядно оценить план на ближайшие дни. Не понравилось только одно — решённые задачи исчезают из календаря полностью, а не остаются зачёркнутыми, как в Planyway. Для меня это критично, так как хочу видеть завершённые задачи на календаре, а не где-то потом в отдельном списке, как сейчас это реализовано в Todoist.
Я пробовал огромное количество сервисов и программ для ведения календаря. Ничего удобнее Planyway так и не нашёл. Продолжаю использовать его на бесплатном тарифе. Мне возможностей хватает. Если Todoist реализует возможность отображения завершённых задач, перейду на него, так как замкнуть всё на один сервис будет намного удобнее, чем вести два. Есть неплохие календари в yonote, но мне ещё один сервис заводить не хочется. Кто с нуля себе подбирает что-то для заметок, календаря, списка дел, то обратите внимание. Сервис неплохой.
#заметки
{kind=link}
Пока ещё не закончились праздники, а отдыхать уже надоело, есть возможность изучить что-то новое. Например, OpenStack 🤖 Для тех, кто не в курсе, поясню, что это модульная open source платформа, реализующая типовую функциональность современных облачных провайдеров. Установить её можно самостоятельно на своих мощностях. А для изучения есть упрощённые проекты для быстрого разворачивания.
Одним из таких проектов является snap пакет MicroStack от компании Canonical. С его помощью можно развернуть учебный OpenStack на одном хосте. Поставляется он в виде готового snap пакета под Ubuntu, так что ставится в пару действий. Внутри живёт Kubernetes, а MicroStack разворачивается поверх него. Установить можно даже в виртуальную машину на своём рабочем ноуте.
Cистемные требования MicroStack, заявленные на его сайте:
◽4 CPUs
◽16G Memory
◽50G Disk
Сама установка выполняется в пару команд:
Минут 10 будет длиться инициализация. Когда закончится, можно идти в веб интерфейс по ip адресу сервера. Логин - admin, а пароль смотрим так:
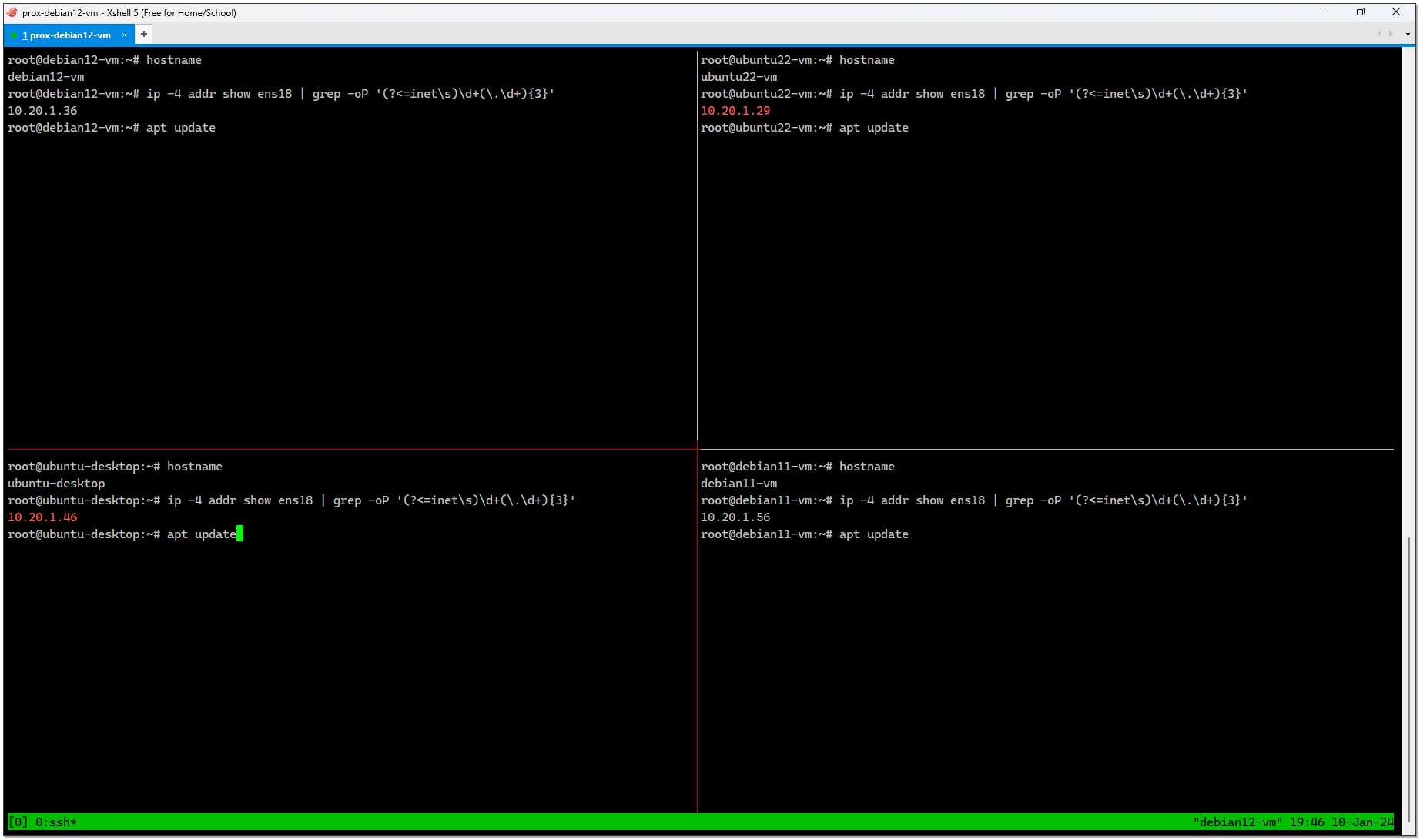
Если у вас в браузере указан русский язык, то вы получите 502 ошибку nginx после аутентификации. Так было у меня. Чтобы исправить, нужно залогиниться в систему, получить 502-ю ошибку, зайти по урлу https://10.20.1.29/identity/, он должен нормально открыться. В правом верхнем углу будут настройки пользователя. Нужно зайти туда и выбрать язык интерфейса English. После этого нормально заработает.
В консоли можно работать с кластером через клиента microstack.openstack. К примеру, смотрим список стандартных шаблонов:
Можно использовать стандартный openstackclient. Для этого там же в настройках пользователя в веб интерфейсе в выпадающем списке качаем OpenStack RC File. Ставим стандартный openstack client:
Читаем скачанный файл с переменными окружения:
Теперь можно использовать консольный клиент openstack, добавляя опцию
Если не хочется каждый раз вводить пароль администратора, можно добавить его явно в
На этом собирался закончить заметку, но всё же кратко покажу, как с этой штукой работать. Чтобы запустить виртуалку нам нужно:
1️⃣ Создать проект и добавить туда пользователя.
2️⃣ Создать сеть и подсеть в ней.
3️⃣ Создать роутер и связать его с бриджем во внешнюю сеть.
4️⃣ Создать виртуальную машину с бриджем в этой подсети.
5️⃣ Создать группу безопасности и правило в ней для разрешения подключений по ssh.
6️⃣ Связать эту группу безопасности и виртуалку.
Команды приведу кратко, без описаний, опустив в начале
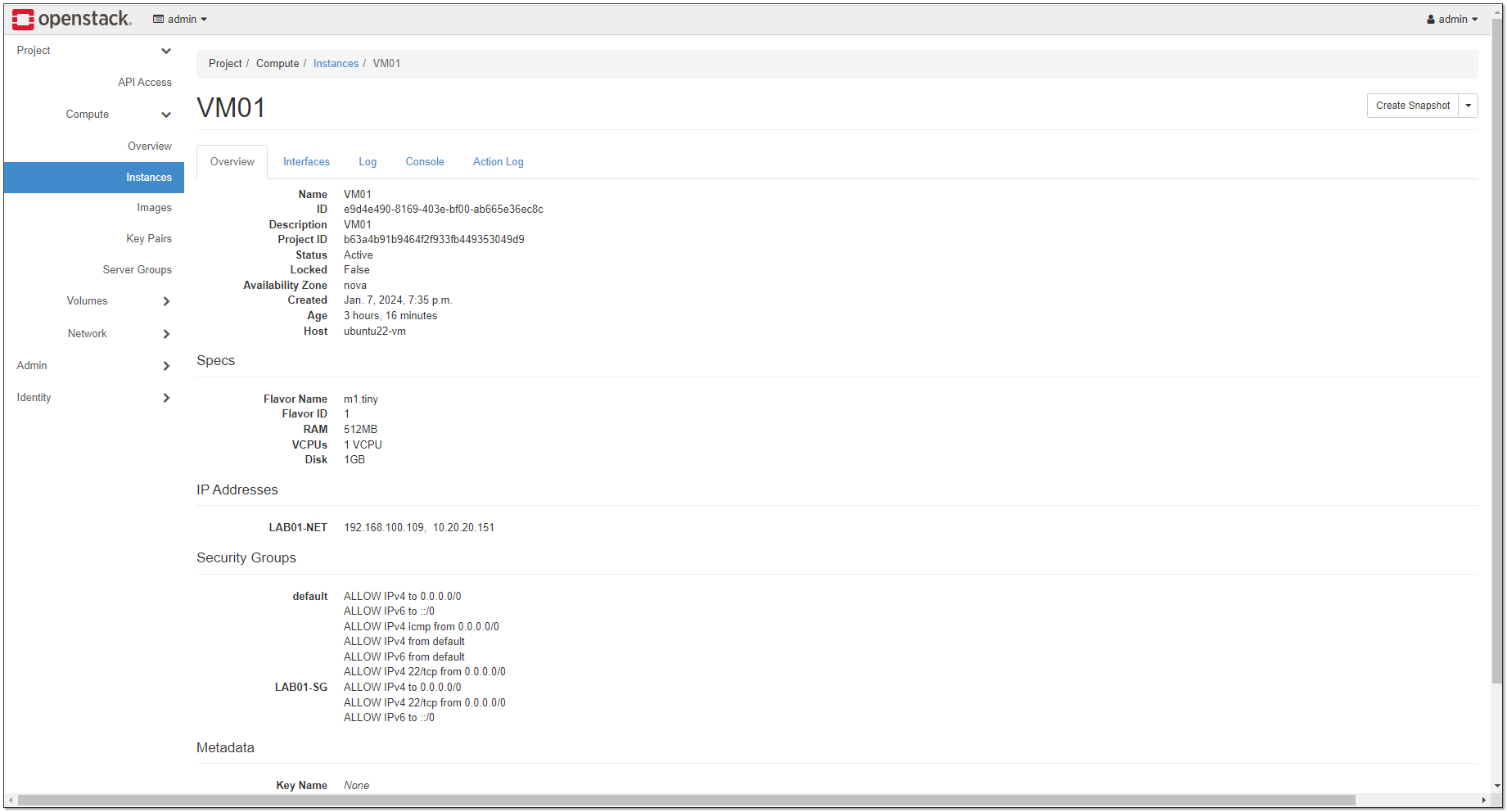
То же самое можно сделать руками через веб интерфейс. Можно подключиться к новой виртуалке через её floating ip из диапазона 10.20.20.0/24, который будет сопоставлен настроенному IP из 192.168.100.0/24. В веб интерфейсе все настройки будут отражены. Там же и консоль VM.
Поздравляю, теперь вы админ OpenStack. Можете развернуть для собственных нужд и тренироваться.
#виртуализация
Одним из таких проектов является snap пакет MicroStack от компании Canonical. С его помощью можно развернуть учебный OpenStack на одном хосте. Поставляется он в виде готового snap пакета под Ubuntu, так что ставится в пару действий. Внутри живёт Kubernetes, а MicroStack разворачивается поверх него. Установить можно даже в виртуальную машину на своём рабочем ноуте.
Cистемные требования MicroStack, заявленные на его сайте:
◽4 CPUs
◽16G Memory
◽50G Disk
Сама установка выполняется в пару команд:
# snap install microstack --beta# microstack init --auto --controlМинут 10 будет длиться инициализация. Когда закончится, можно идти в веб интерфейс по ip адресу сервера. Логин - admin, а пароль смотрим так:
# snap get microstack config.credentials.keystone-passwordЕсли у вас в браузере указан русский язык, то вы получите 502 ошибку nginx после аутентификации. Так было у меня. Чтобы исправить, нужно залогиниться в систему, получить 502-ю ошибку, зайти по урлу https://10.20.1.29/identity/, он должен нормально открыться. В правом верхнем углу будут настройки пользователя. Нужно зайти туда и выбрать язык интерфейса English. После этого нормально заработает.
В консоли можно работать с кластером через клиента microstack.openstack. К примеру, смотрим список стандартных шаблонов:
# microstack.openstack flavor listМожно использовать стандартный openstackclient. Для этого там же в настройках пользователя в веб интерфейсе в выпадающем списке качаем OpenStack RC File. Ставим стандартный openstack client:
# apt install python3-openstackclientЧитаем скачанный файл с переменными окружения:
# source ./admin-openrc.shТеперь можно использовать консольный клиент openstack, добавляя опцию
--insecure, так как сертификат самоподписанный:# openstack --insecure project listЕсли не хочется каждый раз вводить пароль администратора, можно добавить его явно в
admin-openrc.sh в переменную OS_PASSWORD. На этом собирался закончить заметку, но всё же кратко покажу, как с этой штукой работать. Чтобы запустить виртуалку нам нужно:
1️⃣ Создать проект и добавить туда пользователя.
2️⃣ Создать сеть и подсеть в ней.
3️⃣ Создать роутер и связать его с бриджем во внешнюю сеть.
4️⃣ Создать виртуальную машину с бриджем в этой подсети.
5️⃣ Создать группу безопасности и правило в ней для разрешения подключений по ssh.
6️⃣ Связать эту группу безопасности и виртуалку.
Команды приведу кратко, без описаний, опустив в начале
openstack --insecure, так как лимит на длину публикации:# project create LAB01# role add --user admin --project LAB01 admin# network create LAB01-NET# subnet create --network LAB01-NET --subnet-range 192.168.100.0/24 --allocation-pool start=192.168.100.10,end=192.168.100.200 --dns-nameserver 77.88.8.1 LAB01-SUBNET# router create LAB01-R# router set LAB01-R --external-gateway external# router add subnet LAB01-R LAB01-SUBNET# floating ip create external# server create --flavor m1.tiny --image cirros --network LAB01-NET --wait VM01# server add floating ip VM01 596909d8-5c8a-403f-a902-f31f5bd89eae# security group create LAB01-SG# security group rule create --remote-ip 0.0.0.0/0 --dst-port 22:22 --protocol tcp --ingress LAB01-SG# server add security group VM01 LAB01-SGТо же самое можно сделать руками через веб интерфейс. Можно подключиться к новой виртуалке через её floating ip из диапазона 10.20.20.0/24, который будет сопоставлен настроенному IP из 192.168.100.0/24. В веб интерфейсе все настройки будут отражены. Там же и консоль VM.
Поздравляю, теперь вы админ OpenStack. Можете развернуть для собственных нужд и тренироваться.
#виртуализация
{kind=link}
Продолжу тему OpenStack, так как вчера всё не уместилось в одну публикацию. Я немного поразбирался с ним, посмотрел, как работает. Стала понятна логика работы некоторых облачных провайдеров, так как в основе у них, судя по всему, OpenStack и есть. Все эти проекты, назначение прав, настройка портов на firewall для доступа, сопоставление внешнего IP внутренним и т.д.
🔹Для того, чтобы развернуть OpenStack, есть множество разных проектов помимо MicroStack. Для изучения и разработки наиболее известный - DevStac. Это набор скриптов для поднятия OpenStack как на одиночной машине, так и в составе кластера. Разрабатывается тем же сообществом, что и OpenStack.
🔹Для прода есть Ansible Playbooks - openstack-ansible. Вся функциональность там почему-то упакована в LXC контейнеры, что выглядит немного непривычно. Не знаю, почему выбрали именно их. Это тоже проект команды разработки OpenStack. Есть проект Kolla, который упаковывает стэк в Docker контейнеры. И от них же есть готовые плейбуки на основе docker - kolla-ansible.
🔹Для деплоя в Kubernetes есть helm-chart - OpenStack-Helm. Также развернуть OpenStack в кубере можно с помощью Sunbeam. В настоящий момент в официальном руководстве для MicroStack используется как раз он. Я, когда разбирался с ним, не сразу понял, почему в куче руководств в интернете используется один тип управления, а на самом сайте проекта уже используется Sunbeam. Судя по всему недавно на него перешли.
🔹На голое железо установить OpenStack можно с помощью kayobe. Для деплоя используются упомянутые ранее контейнеры Kolla и плейбуки с ними. Также для железа есть проект от OpenStack Foundation - Airship. Он разворачивает на железо кластер Kubernetes, а поверх уже можно накатить OpenStack.
Обратил внимание при изучении упомянутых выше проектов, что большая часть из них сделана на основе организации OpenInfra Foundation. Они все свои исходники размещают в репозитории opendev.org, который работает на базе gitea.
Кто-нибудь разворачивал кластер OpenStack хотя бы из трёх нод? Какой из описанных способов наиболее простой и дружелюбный для новичков? Когда изучал ceph и kuber, разворачивал из ansible playbooks с помощью kubespray и ceph-ansible соответственно. Не могу сказать, что это было просто.
#виртуализация
🔹Для того, чтобы развернуть OpenStack, есть множество разных проектов помимо MicroStack. Для изучения и разработки наиболее известный - DevStac. Это набор скриптов для поднятия OpenStack как на одиночной машине, так и в составе кластера. Разрабатывается тем же сообществом, что и OpenStack.
🔹Для прода есть Ansible Playbooks - openstack-ansible. Вся функциональность там почему-то упакована в LXC контейнеры, что выглядит немного непривычно. Не знаю, почему выбрали именно их. Это тоже проект команды разработки OpenStack. Есть проект Kolla, который упаковывает стэк в Docker контейнеры. И от них же есть готовые плейбуки на основе docker - kolla-ansible.
🔹Для деплоя в Kubernetes есть helm-chart - OpenStack-Helm. Также развернуть OpenStack в кубере можно с помощью Sunbeam. В настоящий момент в официальном руководстве для MicroStack используется как раз он. Я, когда разбирался с ним, не сразу понял, почему в куче руководств в интернете используется один тип управления, а на самом сайте проекта уже используется Sunbeam. Судя по всему недавно на него перешли.
🔹На голое железо установить OpenStack можно с помощью kayobe. Для деплоя используются упомянутые ранее контейнеры Kolla и плейбуки с ними. Также для железа есть проект от OpenStack Foundation - Airship. Он разворачивает на железо кластер Kubernetes, а поверх уже можно накатить OpenStack.
Обратил внимание при изучении упомянутых выше проектов, что большая часть из них сделана на основе организации OpenInfra Foundation. Они все свои исходники размещают в репозитории opendev.org, который работает на базе gitea.
Кто-нибудь разворачивал кластер OpenStack хотя бы из трёх нод? Какой из описанных способов наиболее простой и дружелюбный для новичков? Когда изучал ceph и kuber, разворачивал из ansible playbooks с помощью kubespray и ceph-ansible соответственно. Не могу сказать, что это было просто.
#виртуализация
{kind=link}
В Linux существует относительно простой способ шейпирования (ограничения) трафика с помощью утилиты tc (traffic control) из пакета iproute2. Простой в том плане, что какие-то базовые вещи делаются просто и быстро. Но в то же время это очень мощный инструмент с иерархической структурой, который позволяет очень гибко управлять трафиком.
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
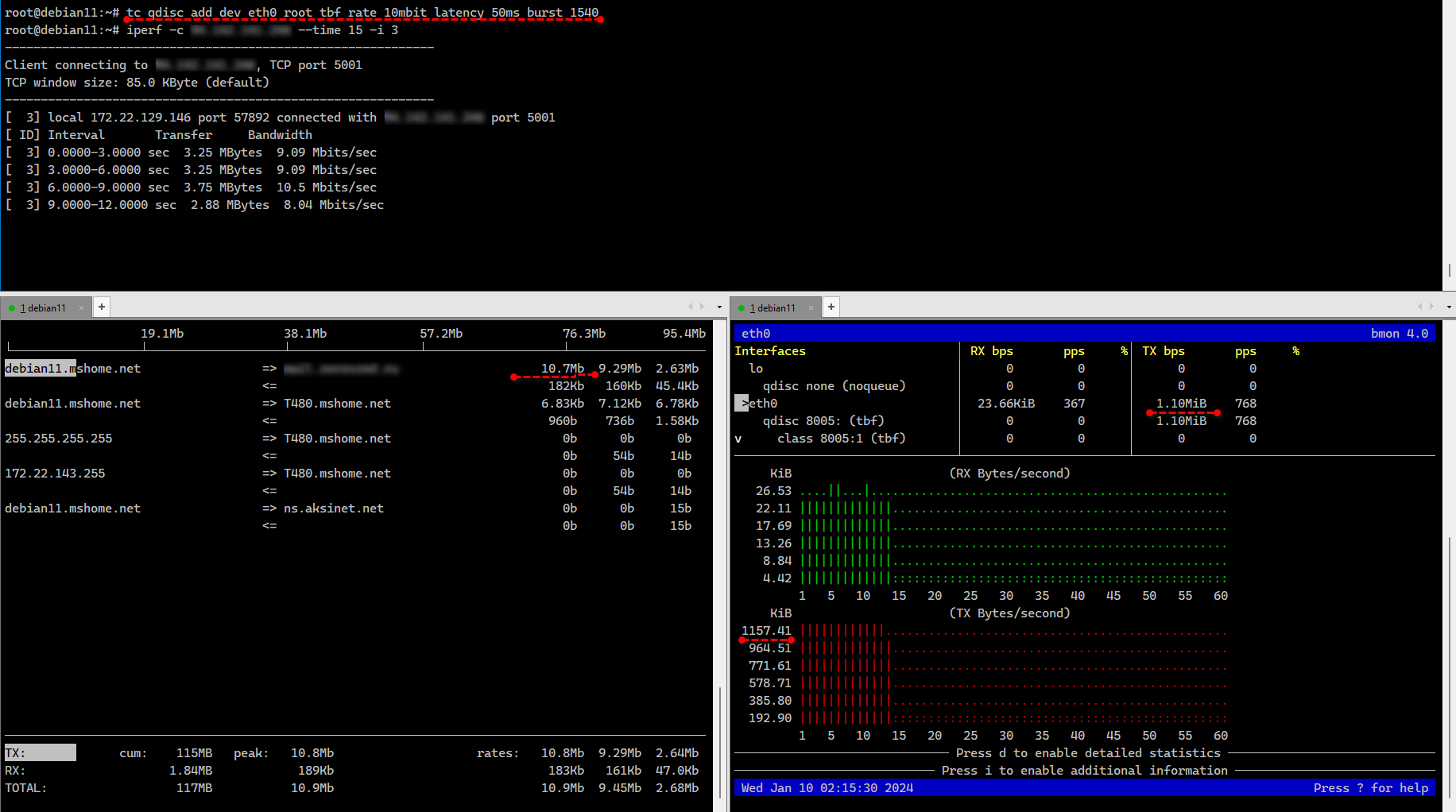
Ограничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
В примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
# tc qdisc add dev eth0 root tbf rate 10mbit latency 50ms burst 10kОграничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
# tc qdisc show dev eth0Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
# tc qdisc del dev eth0 root tbf rate 10mbit latency 50ms burst 10kВ примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
# tc qdisc add dev eth0 root handle 1: htb default 20# tc class add dev eth0 parent 1: classid 1:1 htb rate 10mbit ceil 10mbit# tc filter add dev eth0 protocol ip parent 1: prio 1 u32 match ip dport 5001 0xffff flowid 1:1Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
{kind=link}
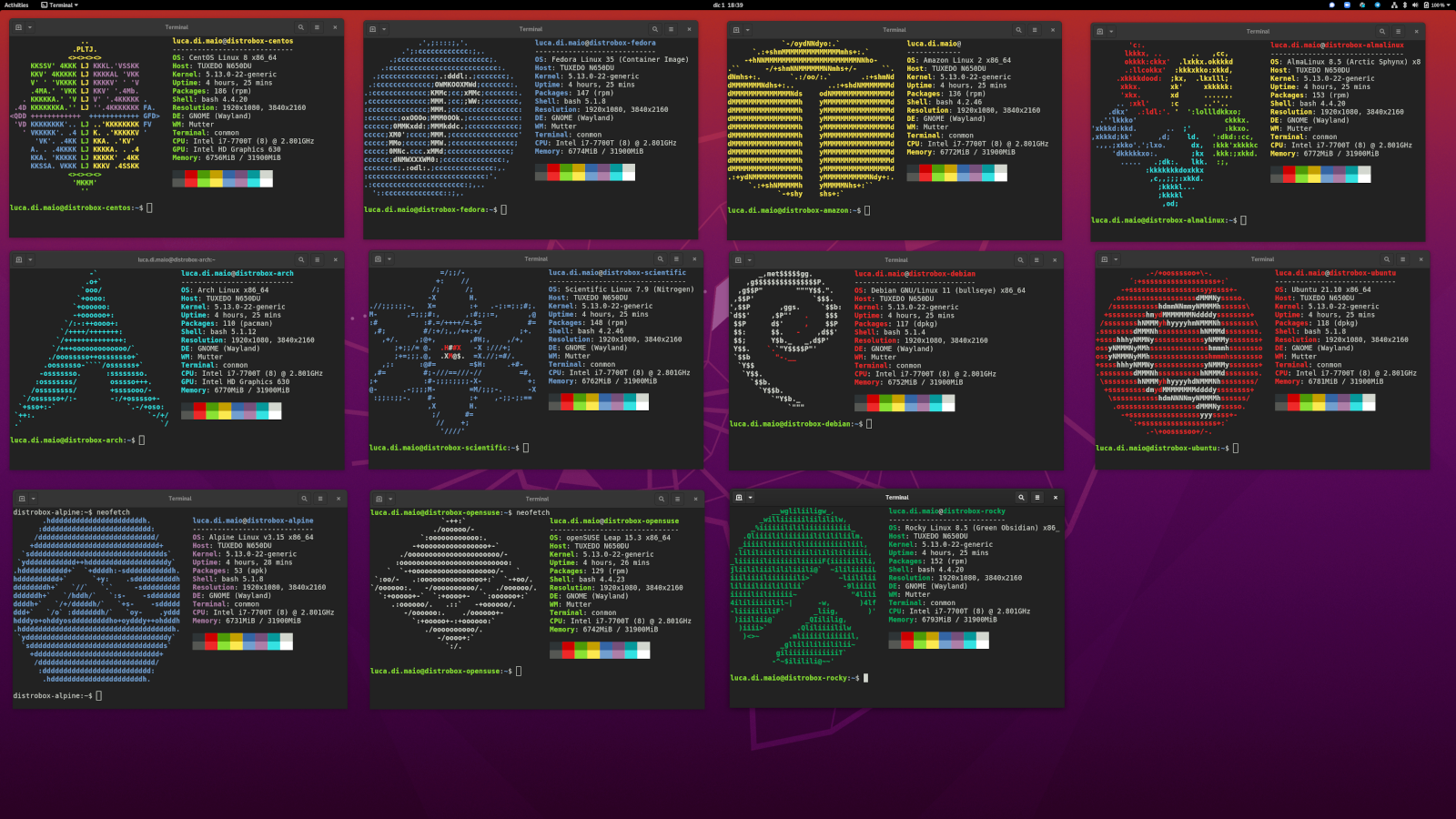
Расскажу про необычный инструмент, который в первую очередь будет полезен тем, у кого рабочая машина на Linux. Он для этого был создан. Возможно где-то и на сервере пригодится, но в основном для тестов. Речь пойдёт про Distrobox. Это надстройка над контейнерами, которая позволяет их прозрачно интегрировать в систему.
Допустим, вам надо запустить какой-то софт, возможно с графическим интерфейсом, но его нет под ваш дистрибутив. У вас вариант либо запустить его в виртуальной машине, либо как-то самому наколхозить нужный контейнер и примапить его к хосту. Distrobox решает эту задачу за вас. Вы просто выбираете нужную систему, запускаете её через Distrobox и работаете там с нужным вам приложением. Оно запускается и ведёт себя так, как будто установлено локально. Пробрасываются каталог пользователя, иксы или wayland, звук, d-bus и udev. Приложение ведёт себя как локальное.
Distrobox для популярных дистрибутивов есть в базовых репозиториях. В свежих Debian и Ubuntu присутствует, так что установка стандартна:
Например, запустим в Debian какую-нибудь программу, которая есть в Fedora. Для этого создаём контейнер с последней Федорой. Делать это нужно под обычным пользователем, не под root. Пользователь должен быть в группе docker. В самой свежей версии, установленной вручную, это уже поправлено и можно под root запускать.
Заходим в контейнер:
При первом входе будет выполнена преднастройка. После её окончания окажетесь в оболочке контейнера. Теперь можно установить какую-нибудь программу:
После установки выполняем экспорт этой программы из консоли контейнера:
Теперь с этой программой можно работать, как будто она установлена на хосте. По умолчанию distrobox захочет положить ярлык на рабочий стол. Если у вас машина без графического окружения, то получите ошибку. Вместо этого можно выгрузить через ключ
Бинарник (а точнее скрипт запуска) запуска программы из контейнера будет положен на хост в директорию
То есть всё это решение просто SHELL обёртка вокруг докера для удобного применения. Используются заранее подготовленные образы. В принципе, Distrobox удобен и для простого и быстрого запуска контейнеров с различными базовыми системами с примапленными ресурсами к хосту. Ими удобно управлять или работать. Смотрим список контейнеров:
Устанавливаем, удаляем:
Можно сделать себе тестовую виртуалку со всеми базовыми системами и заходить в нужную. Все ресурсы у всех систем примаплены к хосту.
⇨ Сайт / Исходники / Как это работает
#linux #docker
Допустим, вам надо запустить какой-то софт, возможно с графическим интерфейсом, но его нет под ваш дистрибутив. У вас вариант либо запустить его в виртуальной машине, либо как-то самому наколхозить нужный контейнер и примапить его к хосту. Distrobox решает эту задачу за вас. Вы просто выбираете нужную систему, запускаете её через Distrobox и работаете там с нужным вам приложением. Оно запускается и ведёт себя так, как будто установлено локально. Пробрасываются каталог пользователя, иксы или wayland, звук, d-bus и udev. Приложение ведёт себя как локальное.
Distrobox для популярных дистрибутивов есть в базовых репозиториях. В свежих Debian и Ubuntu присутствует, так что установка стандартна:
# apt install distroboxНапример, запустим в Debian какую-нибудь программу, которая есть в Fedora. Для этого создаём контейнер с последней Федорой. Делать это нужно под обычным пользователем, не под root. Пользователь должен быть в группе docker. В самой свежей версии, установленной вручную, это уже поправлено и можно под root запускать.
# distrobox-create --name fedora --image fedora:latestЗаходим в контейнер:
# distrobox-enter fedoraПри первом входе будет выполнена преднастройка. После её окончания окажетесь в оболочке контейнера. Теперь можно установить какую-нибудь программу:
# sudo dnf install appnameПосле установки выполняем экспорт этой программы из консоли контейнера:
# distrobox-export --app appnameТеперь с этой программой можно работать, как будто она установлена на хосте. По умолчанию distrobox захочет положить ярлык на рабочий стол. Если у вас машина без графического окружения, то получите ошибку. Вместо этого можно выгрузить через ключ
--bin, указав явно путь к бинарнику в контейнере:# distrobox-export --bin /usr/sbin/appnameБинарник (а точнее скрипт запуска) запуска программы из контейнера будет положен на хост в директорию
~/.local/bin. Она должна существовать. Там же можно посмотреть, как всё это работает:#!/bin/sh# distrobox_binary# name: fedoraif [ -z "${CONTAINER_ID}" ]; then exec "/usr/local/bin/distrobox-enter" -n fedora -- /bin/sh -l -c '/usr/sbin/appname$@' -- "$@"elif [ -n "${CONTAINER_ID}" ] && [ "${CONTAINER_ID}" != "fedora" ]; then exec distrobox-host-exec /home/zerox/.local/bin/appname"$@"else exec /usr/sbin/appname"$@"fiТо есть всё это решение просто SHELL обёртка вокруг докера для удобного применения. Используются заранее подготовленные образы. В принципе, Distrobox удобен и для простого и быстрого запуска контейнеров с различными базовыми системами с примапленными ресурсами к хосту. Ими удобно управлять или работать. Смотрим список контейнеров:
# distrobox listУстанавливаем, удаляем:
# distrobox stop fedora# istrobox rm fedoraМожно сделать себе тестовую виртуалку со всеми базовыми системами и заходить в нужную. Все ресурсы у всех систем примаплены к хосту.
⇨ Сайт / Исходники / Как это работает
#linux #docker
{kind=link}
Когда на тестовом стенде разворачиваешь что-то кластерное и надо на нескольких хостах выполнить одни и те же действия, внезапно может помочь tmux. У него есть режим синхронизации панелей. С его помощью можно делать одновременно одно и то же на разных хостах.
Работает это так. Ставим tmux:
Запускаем на одном из хостов и открываем несколько панелей. По одной панели на каждый хост. Делается это с помощью комбинации клавиш
После этого в каждой панели нужно подключиться по SSH к нужному хосту. У вас получится несколько панелей, в каждой отдельная консоль от удалённого хоста. Теперь включаем режим синхронизации панелей. Нажимаем опять префикс
Включён режим синхронизации панелей. Теперь всё, что вводится в активную панель, будет автоматически выполняться во всех остальных. Отключить этот режим можно точно так же, как и включали. Просто ещё раз вводим эту же команду.
Если постоянно используете один и тот же стенд, то можно автоматизировать запуск tmux и подключение по SSH, чтобы не делать это каждый раз вручную.
#linux #terminal
Работает это так. Ставим tmux:
# apt install tmuxЗапускаем на одном из хостов и открываем несколько панелей. По одной панели на каждый хост. Делается это с помощью комбинации клавиш
CTRL-B и дальше либо %, либо ". Первое - это вертикальное разделение, второе - горизонтальное. Переключаться между панелями с помощью CTRL-B и стрелочек. В общем, всё стандартно для тех, кто работает с tmux.После этого в каждой панели нужно подключиться по SSH к нужному хосту. У вас получится несколько панелей, в каждой отдельная консоль от удалённого хоста. Теперь включаем режим синхронизации панелей. Нажимаем опять префикс
CTRL-B и дальше пишем снизу в командной строке tmux::setw synchronize-panesВключён режим синхронизации панелей. Теперь всё, что вводится в активную панель, будет автоматически выполняться во всех остальных. Отключить этот режим можно точно так же, как и включали. Просто ещё раз вводим эту же команду.
Если постоянно используете один и тот же стенд, то можно автоматизировать запуск tmux и подключение по SSH, чтобы не делать это каждый раз вручную.
#linux #terminal
{kind=link}
Недавно, когда вырезал из дампа mysql содержимое одной таблицы с помощью sed, подумал, что неплохо было бы сделать подборочку с наиболее актуальными и прикладными примерами с sed.
Уже когда начал её составлять вдруг подумал, а нужно ли сейчас вообще всё это? Как считаете? Мы находимся на сломе эпох. Сейчас же ChatGPT сходу приводит все эти команды и практически не ошибается в типовых задачах. Я до сих пор так и не начал им пользоваться. Пробовал несколько раз, но постоянно не использую. По привычке ищу решение в своих записях, чаще всего тут на канале.
Брюзжать, как старый дед, на тему того, что надо своими мозгами думать, а то совсем захиреют, не буду. ИИ помощники это уже наше настоящее и 100% наше будущее, как сейчас калькуляторы. Надо начинать осваивать инструментарий и активно использовать. Ну а пока вернёмся к sed 😁
🟢 Вырезаем всё, что между указанными строками в файле:
🟢 Вырезать первую и последнюю строки. Часто нужно, когда отправляешь в мониторинг вывод каких-нибудь консольных команд. Там обычно в начале какие-то заголовки столбцов идут, а в конце тоже служебная информация:
🟢 Заменить в файле слово old_function на new_function:
🟢 Если нужен более гибкий вариант поиска нужного слова, то можно использовать регулярные выражения:
🟢 Удаляем комментарии и пустые строки:
🟢 Вывести записи в логе веб сервера в интервале 10.01.2024 15:20 - 16:20. Удобная штука, рекомендую сохранить.
🟢 Добавить после каждой строки ещё одну пустую. Иногда нужно, чтобы нагляднее текст оценить. Второй пример - добавление пустой строки после найденного слова в строке:
Про sed можно писать бесконечно, но лично я что-то более сложное редко использую, а вот эти простые конструкции постоянно. Чаще всего именно они используются в связке с другими консольными утилитами.
#bash #sed
Уже когда начал её составлять вдруг подумал, а нужно ли сейчас вообще всё это? Как считаете? Мы находимся на сломе эпох. Сейчас же ChatGPT сходу приводит все эти команды и практически не ошибается в типовых задачах. Я до сих пор так и не начал им пользоваться. Пробовал несколько раз, но постоянно не использую. По привычке ищу решение в своих записях, чаще всего тут на канале.
Брюзжать, как старый дед, на тему того, что надо своими мозгами думать, а то совсем захиреют, не буду. ИИ помощники это уже наше настоящее и 100% наше будущее, как сейчас калькуляторы. Надо начинать осваивать инструментарий и активно использовать. Ну а пока вернёмся к sed 😁
🟢 Вырезаем всё, что между указанными строками в файле:
# sed -i.back '22826,26719 d' dump.sql🟢 Вырезать первую и последнюю строки. Часто нужно, когда отправляешь в мониторинг вывод каких-нибудь консольных команд. Там обычно в начале какие-то заголовки столбцов идут, а в конце тоже служебная информация:
# sed -i.back '1d;$d' filename🟢 Заменить в файле слово old_function на new_function:
# sed -i.back 's/old_function/new_function/g' filename🟢 Если нужен более гибкий вариант поиска нужного слова, то можно использовать регулярные выражения:
# sed -i.back -r 's/old_function.*?/new_function/g' filename# sed -i.back -r 's/^post_max_size =.*/post_max_size = 32M/g' php.ini🟢 Удаляем комментарии и пустые строки:
# sed -i.back '/^;\|^$\|^#/d' php.ini🟢 Вывести записи в логе веб сервера в интервале 10.01.2024 15:20 - 16:20. Удобная штука, рекомендую сохранить.
# sed -n '/10\/Jan\/2024:15:20/,/10\/Jan\/2024:16:20/p' access.log🟢 Добавить после каждой строки ещё одну пустую. Иногда нужно, чтобы нагляднее текст оценить. Второй пример - добавление пустой строки после найденного слова в строке:
# sed -i.back G filename# sed -i.back '/pattern/G' filenameПро sed можно писать бесконечно, но лично я что-то более сложное редко использую, а вот эти простые конструкции постоянно. Чаще всего именно они используются в связке с другими консольными утилитами.
#bash #sed
{kind=link}
Для мониторинга загрузки сервера MySQL в режиме реального времени есть старый и известный инструмент - Mytop. Из названия понятно, что это топоподобная консольная программа. С её помощью можно смотреть какие пользователи и какие запросы отправляют к СУБД. Как минимум, это удобнее и нагляднее, чем смотреть
Когда попытался установить mytop на Debian 11, удивился, не обнаружив её в репозиториях. Обычно жила там. Немного погуглил и понял, что отдельный пакет mytop убрали, потому что теперь он входит в состав mariadb-client. Если вы используете mariadb, то mytop у вас скорее всего уже установлен. Если у вас другая система, то попробуйте установить mytop через пакетный менеджер. В rpm дистрибутивах она точно была раньше в репах. В Freebsd, кстати, тоже есть.
Для того, чтобы программа могла смотреть информацию обо всех базах и пользователях, у неё должны быть ко всему этому права. Если будете смотреть информацию по отдельной базе данных, то можно создать отдельного пользователя для этого с доступом только к этой базе.
Mytop можно запустить, передав все параметры через ключи, либо создать файл конфигурации
Обращаю внимание, что если укажите localhost вместо 127.0.0.1, то скорее всего не подключитесь. Вообще, это распространённая проблема, так что я стараюсь всегда и везде писать именно адрес, а не имя хоста. Локалхост часто отвечает по ipv6, и не весь софт корректно это отрабатывает. Лучше явно прописывать 127.0.0.1.
Теперь можно запускать
◽d - выбрать конкретную базу данных
◽p - остановить обновление информации на экране
◽i - отобразить соединения в статусе Sleep
◽V - посмотреть параметры СУБД
Хорошая программа в копилку тех, кто работает с MySQL, наряду с:
🔹 mysqltuner
🔹 MyDumper
Ещё полезные ссылки по теме:
▪ Оптимизация запросов в MySQL
▪ MySQL клиенты
▪ Скрипт для оптимизации потребления памяти
▪ Аудит запросов и прочих действия в СУБД
▪ Рекомендации CIS по настройке MySQL
▪ Список настроек, обязательных к проверке
▪ Сравнение mysql vs mariadb
▪ Индексы в Mysql
▪ Полный и инкрементный бэкап MySQL
▪ Мониторинг MySQL с помощью Zabbix
#mysql
show full processlist;. Я обычно туда первым делом заглядываю, если на сервере намечаются какие-то проблемы. Когда попытался установить mytop на Debian 11, удивился, не обнаружив её в репозиториях. Обычно жила там. Немного погуглил и понял, что отдельный пакет mytop убрали, потому что теперь он входит в состав mariadb-client. Если вы используете mariadb, то mytop у вас скорее всего уже установлен. Если у вас другая система, то попробуйте установить mytop через пакетный менеджер. В rpm дистрибутивах она точно была раньше в репах. В Freebsd, кстати, тоже есть.
Для того, чтобы программа могла смотреть информацию обо всех базах и пользователях, у неё должны быть ко всему этому права. Если будете смотреть информацию по отдельной базе данных, то можно создать отдельного пользователя для этого с доступом только к этой базе.
Mytop можно запустить, передав все параметры через ключи, либо создать файл конфигурации
~/.mytop (не забудьте ограничить к нему доступ):user=rootpass=passwordhost=127.0.0.1port=3306color=1delay=3idle=0Обращаю внимание, что если укажите localhost вместо 127.0.0.1, то скорее всего не подключитесь. Вообще, это распространённая проблема, так что я стараюсь всегда и везде писать именно адрес, а не имя хоста. Локалхост часто отвечает по ipv6, и не весь софт корректно это отрабатывает. Лучше явно прописывать 127.0.0.1.
Теперь можно запускать
mytop и смотреть информацию по всем базам. Если набрать ?, то откроется справка. Там можно увидеть все возможности программы. Наиболее актуальны: ◽d - выбрать конкретную базу данных
◽p - остановить обновление информации на экране
◽i - отобразить соединения в статусе Sleep
◽V - посмотреть параметры СУБД
Хорошая программа в копилку тех, кто работает с MySQL, наряду с:
🔹 mysqltuner
🔹 MyDumper
Ещё полезные ссылки по теме:
▪ Оптимизация запросов в MySQL
▪ MySQL клиенты
▪ Скрипт для оптимизации потребления памяти
▪ Аудит запросов и прочих действия в СУБД
▪ Рекомендации CIS по настройке MySQL
▪ Список настроек, обязательных к проверке
▪ Сравнение mysql vs mariadb
▪ Индексы в Mysql
▪ Полный и инкрементный бэкап MySQL
▪ Мониторинг MySQL с помощью Zabbix
#mysql
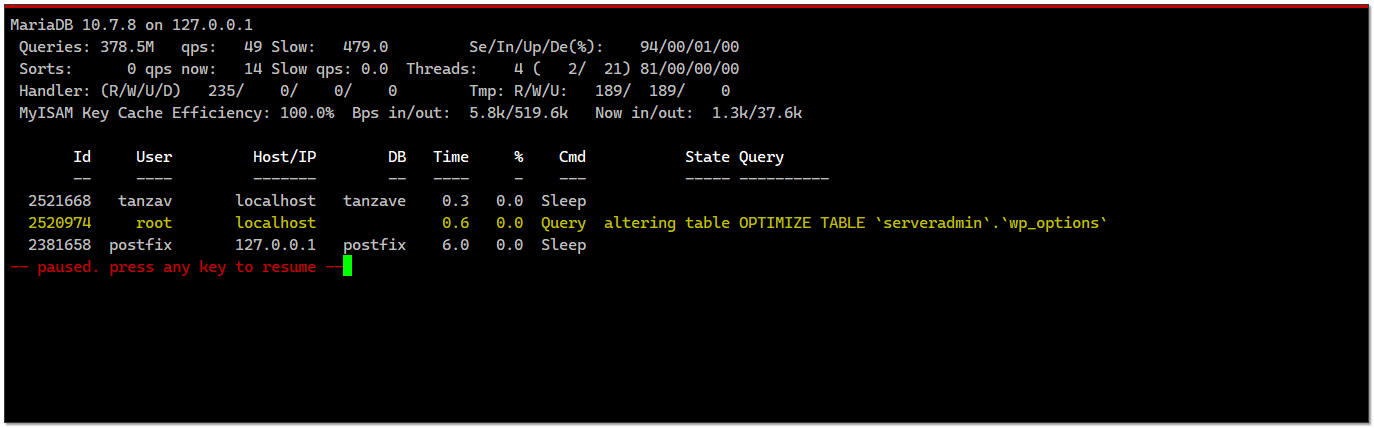{kind=link}
На прошлой неделе в паре каналов проскочил мем, который сразу привлёк моё внимание, потому что откликнулся внутри. Он актуален только для тех, кто ходил в интернет с помощью модема и обычной телефонной линии.
У меня был такой модем, были карточки в интернет и был бесплатный период ночью. Как сейчас всё это помню. Карточка стоила 300 р. на 10 часов интернета. У меня как раз была стипендия 300 рублей и я мог себе позволить купить на месяц 10 часов интернета. Провайдеры РОЛ и МТУ-ИНТЕЛ.
А в довесок к этой карточке давалась возможность подключаться к интернету без тарификации с 2 ночи до 7 утра. Я ставил будильник на 2 ночи, вставал и начинал пользоваться интернетом. Пару часов там лазил, что-то оставлял на загрузку до 7 утра и снова ложился спать. Иногда играл в Ultima Online. Но это было тяжело, потому что игра затягивала и сидел до самого утра. Утром ехал в универ учиться.
В таком режиме я довольно долго жил, пока не появился первый безлимитный ADSL от СТРИМ по тем же телефонным линиям. Скорость была 128 кбит/c. Началась другая эпоха безлимитного интернета и увлечения Lineage 2.
#мем
У меня был такой модем, были карточки в интернет и был бесплатный период ночью. Как сейчас всё это помню. Карточка стоила 300 р. на 10 часов интернета. У меня как раз была стипендия 300 рублей и я мог себе позволить купить на месяц 10 часов интернета. Провайдеры РОЛ и МТУ-ИНТЕЛ.
А в довесок к этой карточке давалась возможность подключаться к интернету без тарификации с 2 ночи до 7 утра. Я ставил будильник на 2 ночи, вставал и начинал пользоваться интернетом. Пару часов там лазил, что-то оставлял на загрузку до 7 утра и снова ложился спать. Иногда играл в Ultima Online. Но это было тяжело, потому что игра затягивала и сидел до самого утра. Утром ехал в универ учиться.
В таком режиме я довольно долго жил, пока не появился первый безлимитный ADSL от СТРИМ по тем же телефонным линиям. Скорость была 128 кбит/c. Началась другая эпоха безлимитного интернета и увлечения Lineage 2.
#мем
{kind=link}