
Вы знаете, как узнать, кто и насколько активно использует swap в Linux? Можно использовать для этого top, там можно вывести отдельную колонку со swap. Для этого запустите top, нажмите f и выберите колонку со swap, которой по умолчанию нет в отображении. Насколько я слышал, это не совсем корректный способ, поэтому, к примеру, в htop эту колонку вообще убрали, чтобы не вводить людей в заблуждение.
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
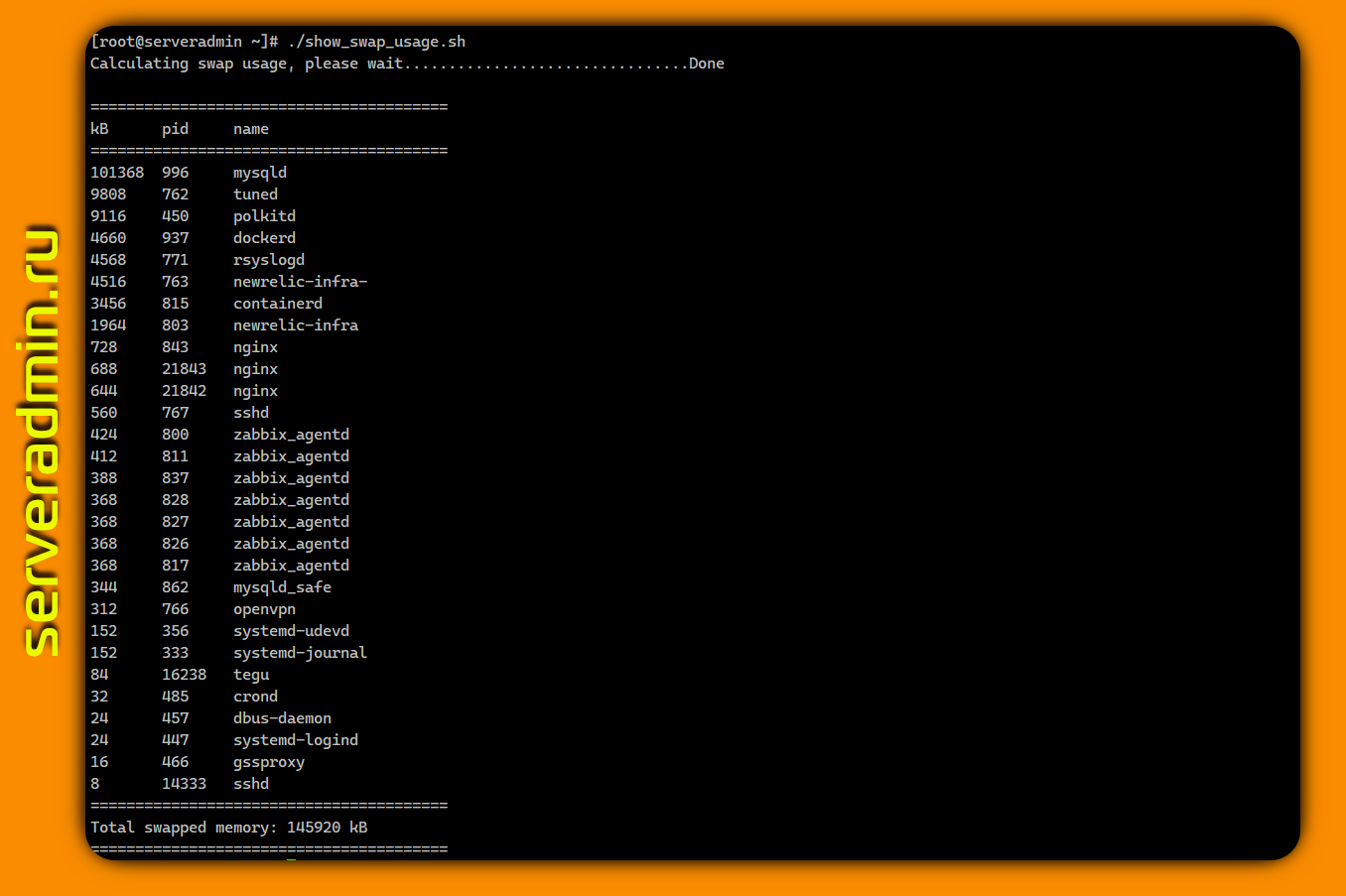
В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
#linux #script #perfomance
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
/proc/$PID/smaps или /proc/$PID/status. Первая метрика будет самая точная, но там нужно будет вручную вычислить суммарный объём по отдельным кусочкам используемой памяти. Вторая метрика сразу идёт суммой. В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
#!/bin/bash SUM=0OVERALL=0for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0doneecho "Overall swap used: $OVERALL KB"Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
# for file in /proc/*/status ; \do awk '/VmSwap|Name/{printf $2 " " $3} END { print ""}' \$file; done | sort -k 2 -n -r | less#linux #script #perfomance
{kind=link}
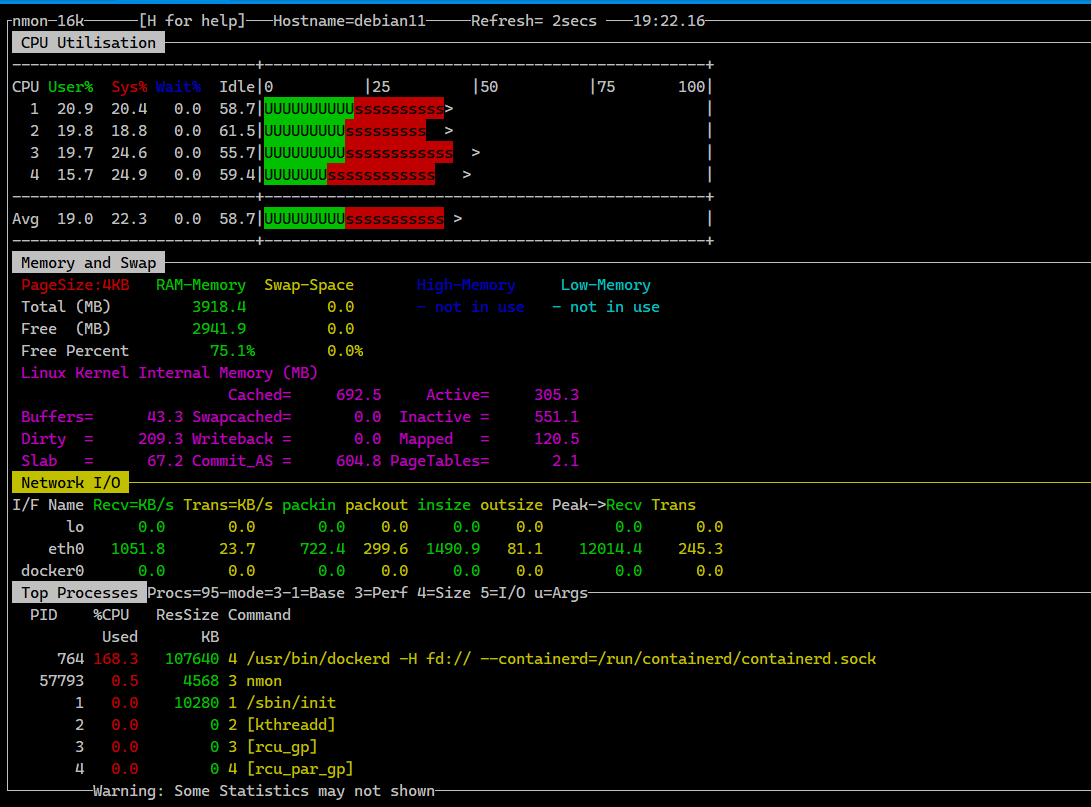
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера слушал вебинар Rebrain на тему диагностики производительности в Linux. Его вёл Лавлинский Николай. Выступление получилось интересное, хотя чего-то принципиально нового я не услышал. Все эти темы так или иначе разбирал в своих заметках в разное время, но всё это сейчас разрознено. Постараюсь оформить на днях в какую-то удобную единую заметку со ссылками. Заодно дополню той информацией, что узнал из вебинара.
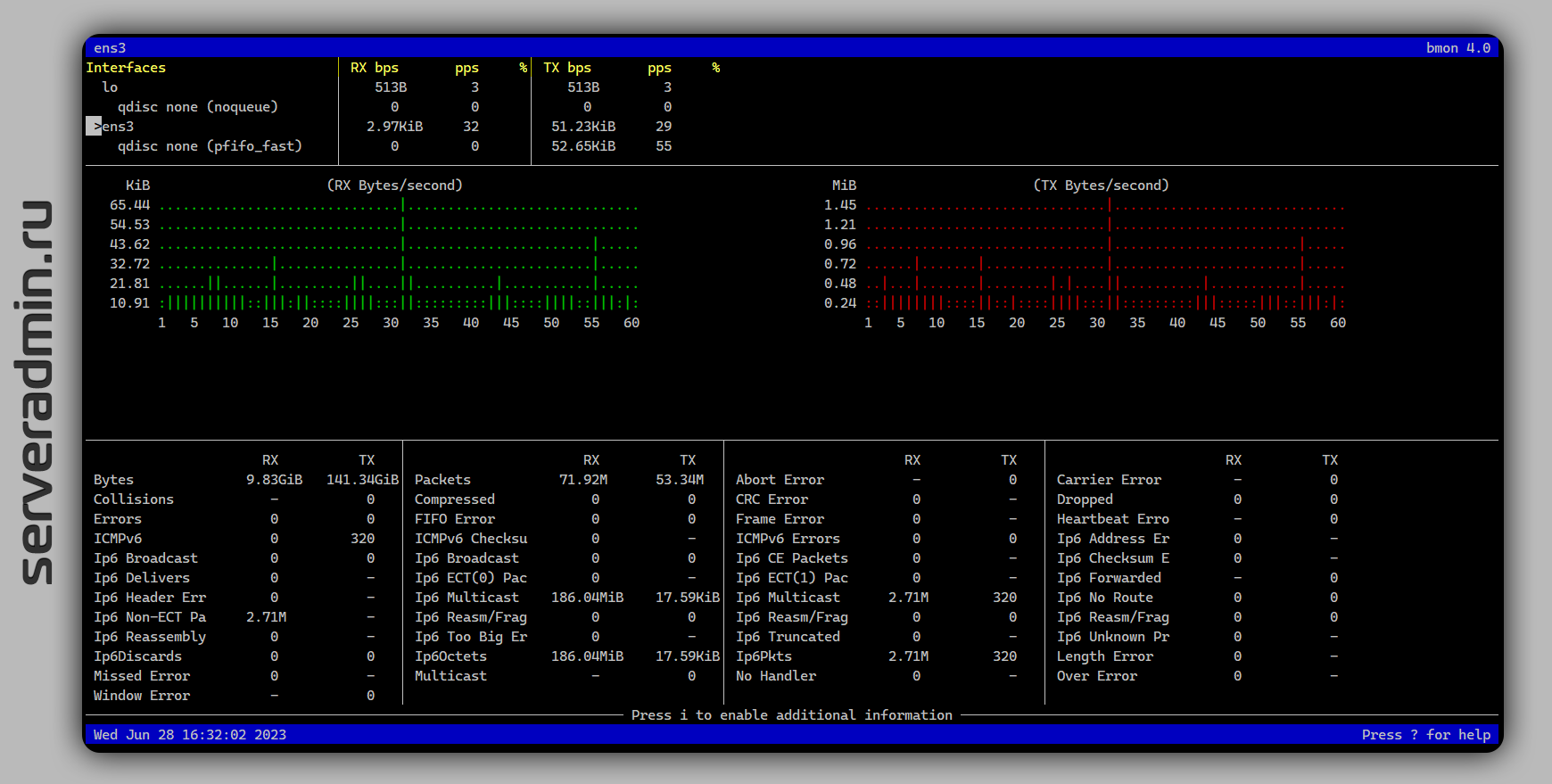
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
Рекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
# apt install bmonРекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
{kind=link}
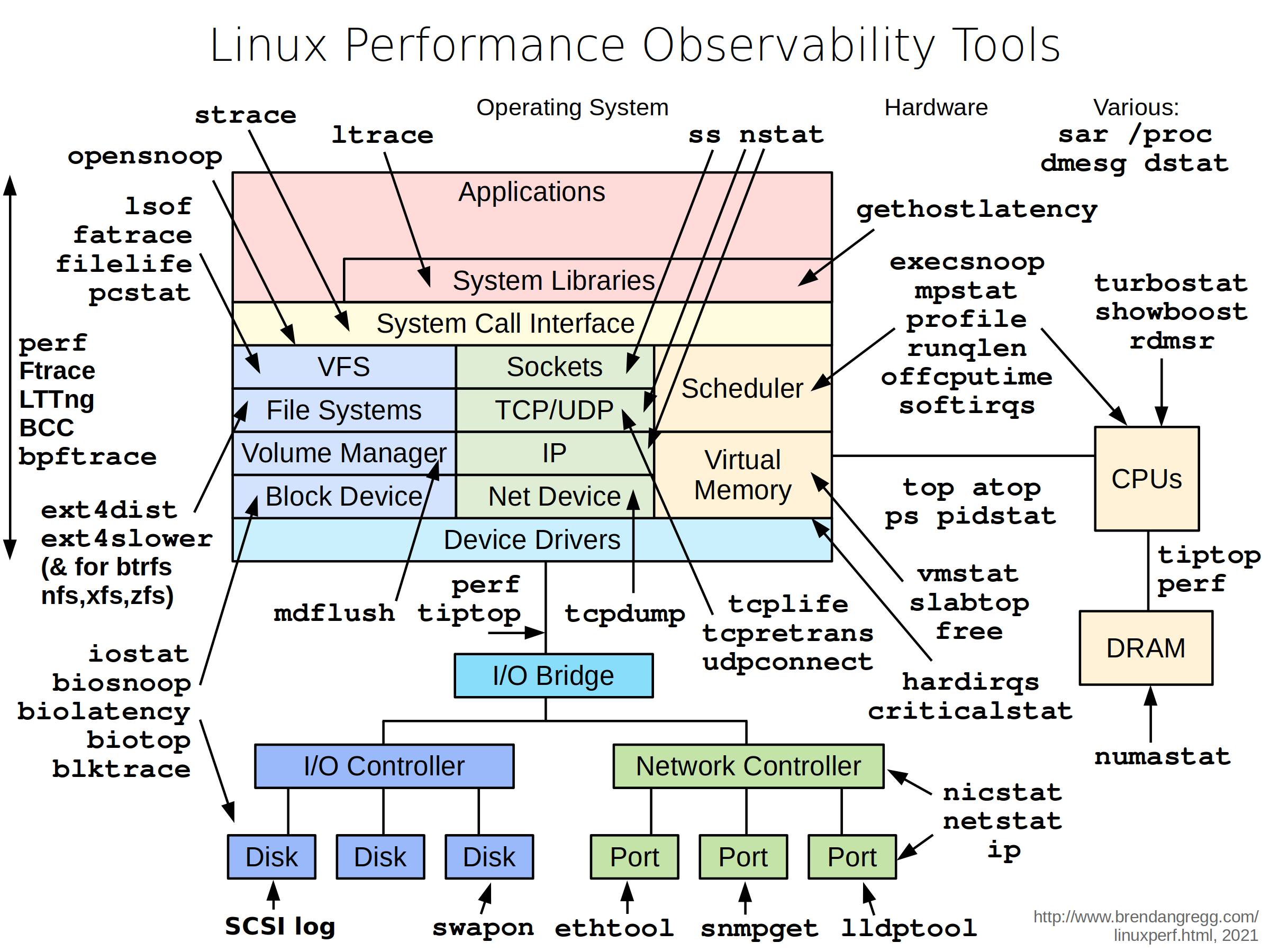
Как и обещал, подготовил заметку по профилированию нагрузки в Linux. Первое, что нужно понимать — для диагностики нужна методика. Хаотичное использование различных инструментов только в самом простом случае даст положительный результат.
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
top ,atop или любом другом менеджере процессов. Это универсальная метрика, с которой обязательно надо разобраться и понять, что конкретно она показывает. У меня есть заметка по ней. ✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
free -m. С памятью в Linux тоже не всё так просто. Недавно делал заметку на эту тему в рамках рассказа о pmon. Там же подробности того, как оценивать используемую и доступную память. Наряду с памятью стоит заглянуть в swap и посмотреть, кто и как его использует.✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
{kind=link}