
У меня есть личная подборка скринов после некоторых аварий крупных хостеров. Парочку из них я застал лично. Это Ihor и Masterhost. Оба лежали несколько дней из-за войн собственников, которые сопровождались обесточиванием дата центров.
В этой же подборке ещё пару аварий уже не помню кого. Я читал форумы и немного поскринил то, что показалось интересным. К публикации только 10 картинок можно приложить, так что тут не все. Может потом ещё сделаю.
А у вас умирали хостеры? Кто-нибудь погорел в OVH в 2021? По-моему это самое эпичное было. Помню как там сгорела (из известных мне) инфраструктура Okmeter.
#мем
В этой же подборке ещё пару аварий уже не помню кого. Я читал форумы и немного поскринил то, что показалось интересным. К публикации только 10 картинок можно приложить, так что тут не все. Может потом ещё сделаю.
А у вас умирали хостеры? Кто-нибудь погорел в OVH в 2021? По-моему это самое эпичное было. Помню как там сгорела (из известных мне) инфраструктура Okmeter.
#мем
▶️ Мне один читатель предложил переименовать канал в "Мир Забикса". Много выходит материалов по нему, что логично. Это мой авторский канал, а пишу я в том числе о том, чем сам занимаюсь. С Zabbix я работаю регулярно, практически каждый день, поэтому и заметок много.
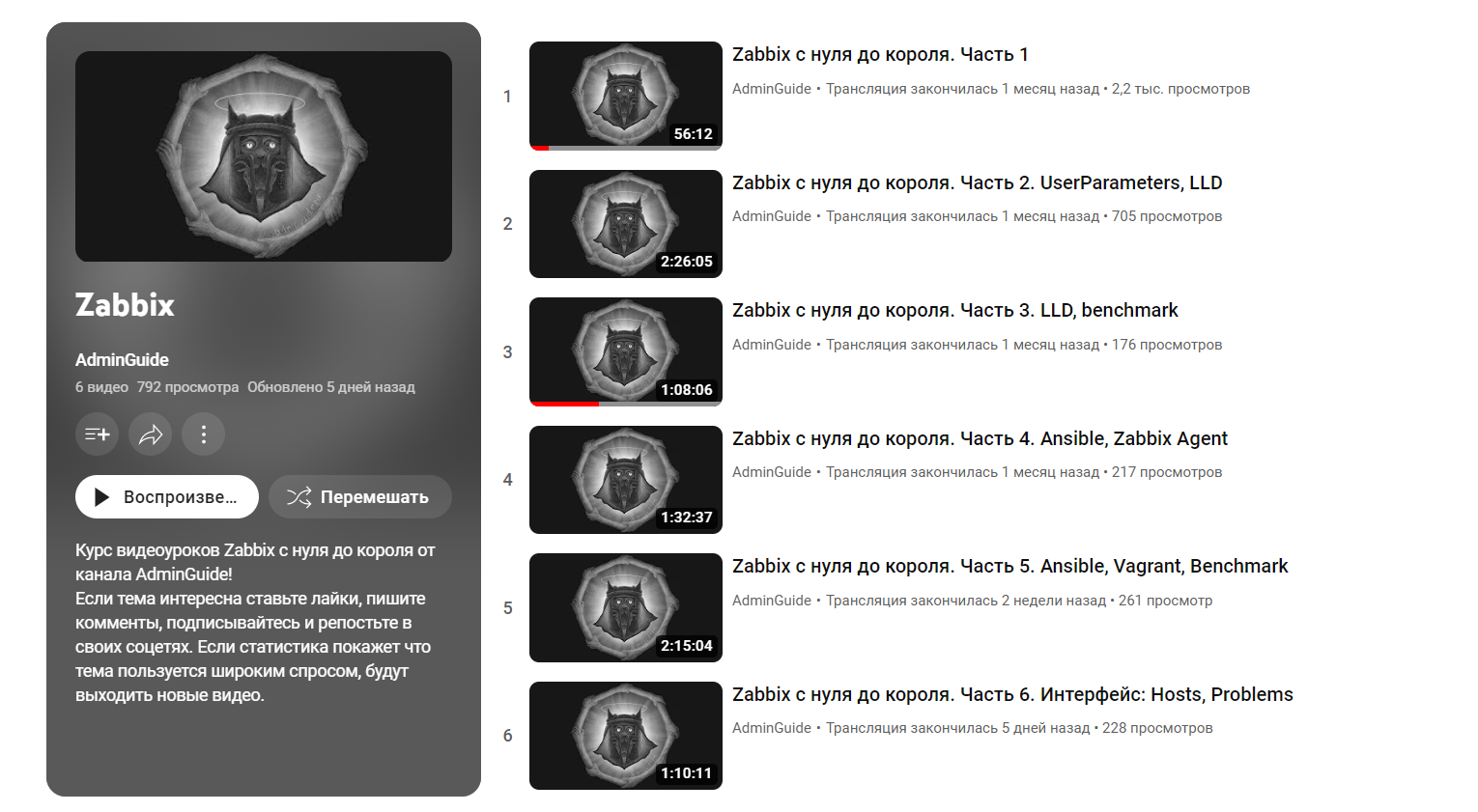
Со мной поделились ссылкой на серию вебинаров с броским названием Zabbix с нуля до короля. Смотреть там много: 6 уроков по 1-2 часа. Материал свежайший, первая часть вышла месяц назад. Автор с нуля, с самых азов в виде установки, показывает настройку системы мониторинга. Если хотите освоить эту систему, то рекомендую. Материала достаточно, чтобы повторить и настроить свою систему.
Автор в режиме онлайн трансляции всё настраивает, поэтому видео затянуты, материал не сжат, но зато вы видите от и до как специалист всё делает: разворачивает окружение, ставит пакеты, правит конфиги и т.д. Профи в таком виде материал смотреть не интересно, потому что много времени уходит на очевидные для него вещи. А вот для новичков такой формат идеален. Можно подсмотреть программы, методы работы, рассуждения специалиста и побыстрее научиться самому.
🎓 Первая часть: https://www.youtube.com/watch?v=_NQTDra4Fds
Остальные части в разделе Трансляции этого канала. В списке видео их нет. Но там в самом начале есть другие любопытные видео. Например, серия Контроллер домена Ubuntu 20 04. AD DC из трёх частей.
#zabbix #видео #обучение
Со мной поделились ссылкой на серию вебинаров с броским названием Zabbix с нуля до короля. Смотреть там много: 6 уроков по 1-2 часа. Материал свежайший, первая часть вышла месяц назад. Автор с нуля, с самых азов в виде установки, показывает настройку системы мониторинга. Если хотите освоить эту систему, то рекомендую. Материала достаточно, чтобы повторить и настроить свою систему.
Автор в режиме онлайн трансляции всё настраивает, поэтому видео затянуты, материал не сжат, но зато вы видите от и до как специалист всё делает: разворачивает окружение, ставит пакеты, правит конфиги и т.д. Профи в таком виде материал смотреть не интересно, потому что много времени уходит на очевидные для него вещи. А вот для новичков такой формат идеален. Можно подсмотреть программы, методы работы, рассуждения специалиста и побыстрее научиться самому.
🎓 Первая часть: https://www.youtube.com/watch?v=_NQTDra4Fds
Остальные части в разделе Трансляции этого канала. В списке видео их нет. Но там в самом начале есть другие любопытные видео. Например, серия Контроллер домена Ubuntu 20 04. AD DC из трёх частей.
#zabbix #видео #обучение
{kind=link}
На днях вышел из строя диск на одном из дедиков в Selectel. Это бюджетный сервак под бэкапы на 4-х HDD дисках по 3ТБ каждый. К сожалению, там больше нет таких конфигураций, а жаль. Очень удобный формат. Специально спрашивал у поддержки, сказали, что больше этой платформы не будет. Такие сервера стоили изначально года 4 назад 5000 р. в месяц, сейчас плачу 8000 р. Хотелось бы где-то ещё такие сервера арендовать, но я не видел подобных предложений за эти деньги в РФ. Если кто-то знает такие, поделитесь информацией.
Там собран raid10 на mdadm. У меня есть заметка по замене диска на одном из подобных серверов. Действовал по ней, всё прошло штатно. Единственное, я там забыл упомянуть, что после замены диска, на новом надо установить grub на всякий случай.
На этом сервере установлен Proxmox, на нём две виртуалки. Одна обычный Debian под бэкап на уровне файлов. На второй стоит PBS (Proxmox Backup Server) для бэкапа виртуалок. Удобно на одном железе получить оба формата бэкапов. Если есть возможность, стараюсь под бэкапы брать либо сервер, либо на худой конец VPS с большим диском. Это намного удобнее и универсальнее, чем готовое хранилище. Хотя, понятное дело, стоить это будет гораздо дороже, чем условное хранилище в S3 или по nfs/smb/ftp/scp. На полноценные сервера можно пробовать и виртуалки разворачивать, и основной или резервный мониторинг там поднимать. Можно найти применение помимо хранения бэкапов.
Напомню, что недавно была заметка про мониторинг mdadm. Обязательно его настраиваю. Последовательность действий у меня получилась следующая. Пришло оповещение о degraded массиве. Захожу на сервер, система уже не видит диска. Он полностью исчез. Перезагружаю сервер, диска так и нет. Лезу в мониторинг и смотрю, какой серийный номер был у диска. ❗️Это важно. После аренды сервера сразу записывайте серийники всех дисков или настраивайте мониторинг. Они нужны для заявки в ТП на замену диска.
Пишу в тех. поддержку, что диск вышел из строя. Называю серийный номер диска, который надо заменить. Мне подтверждают, что готовы это сделать. Выключаю сервер, прошу сделать замену. Отдельно прошу внимательно проверить диски, чтобы не заменить не тот диск, как разок у меня случилось. В течении 10 минут заменили диск, включили сервер. Я зашёл на него и запустил пересборку массива. Вся проблема решена в течении часа.
Многие пишут, что арендовать сервера дорого, дешевле всё хранить у себя. Это смотря как считать. Если полностью весь жизненный цикл сервера проследить с резервированием питания, интернета, кондиционирования, замены сломавшихся комплектующих или всего сервера, то математика получится не такая очевидная, особенно если твой сервер в какой-то момент сломается. Специализация появилась во всех сферах деятельности человека и аренда серверов тут не исключение. Многие компании (если не большинство) арендуют сервера, потому что это выгодно.
#backup
Там собран raid10 на mdadm. У меня есть заметка по замене диска на одном из подобных серверов. Действовал по ней, всё прошло штатно. Единственное, я там забыл упомянуть, что после замены диска, на новом надо установить grub на всякий случай.
# dpkg-reconfigure grub-pcНа этом сервере установлен Proxmox, на нём две виртуалки. Одна обычный Debian под бэкап на уровне файлов. На второй стоит PBS (Proxmox Backup Server) для бэкапа виртуалок. Удобно на одном железе получить оба формата бэкапов. Если есть возможность, стараюсь под бэкапы брать либо сервер, либо на худой конец VPS с большим диском. Это намного удобнее и универсальнее, чем готовое хранилище. Хотя, понятное дело, стоить это будет гораздо дороже, чем условное хранилище в S3 или по nfs/smb/ftp/scp. На полноценные сервера можно пробовать и виртуалки разворачивать, и основной или резервный мониторинг там поднимать. Можно найти применение помимо хранения бэкапов.
Напомню, что недавно была заметка про мониторинг mdadm. Обязательно его настраиваю. Последовательность действий у меня получилась следующая. Пришло оповещение о degraded массиве. Захожу на сервер, система уже не видит диска. Он полностью исчез. Перезагружаю сервер, диска так и нет. Лезу в мониторинг и смотрю, какой серийный номер был у диска. ❗️Это важно. После аренды сервера сразу записывайте серийники всех дисков или настраивайте мониторинг. Они нужны для заявки в ТП на замену диска.
Пишу в тех. поддержку, что диск вышел из строя. Называю серийный номер диска, который надо заменить. Мне подтверждают, что готовы это сделать. Выключаю сервер, прошу сделать замену. Отдельно прошу внимательно проверить диски, чтобы не заменить не тот диск, как разок у меня случилось. В течении 10 минут заменили диск, включили сервер. Я зашёл на него и запустил пересборку массива. Вся проблема решена в течении часа.
Многие пишут, что арендовать сервера дорого, дешевле всё хранить у себя. Это смотря как считать. Если полностью весь жизненный цикл сервера проследить с резервированием питания, интернета, кондиционирования, замены сломавшихся комплектующих или всего сервера, то математика получится не такая очевидная, особенно если твой сервер в какой-то момент сломается. Специализация появилась во всех сферах деятельности человека и аренда серверов тут не исключение. Многие компании (если не большинство) арендуют сервера, потому что это выгодно.
#backup
Простой и эффективный способ запретить скан портов на своём сервере с помощью iptables. Просто баним всех, кто стучится не на открытый целевой порт. Допустим, у вас запущен OpenVPN на TCP и UDP портах 34881. Забаним на 10 минут всех, кто обращается не к ним.
Я использую multiport с заделом на список из нескольких портов, которые в случае необходимости можно перечислить через запятую. Посмотреть список забаненых:
Удалить оттуда:
Очистить список:
Такой вот простой способ скрыть от посторонних глаз сервис, который не получается ограничить какими-то списками. Понятное дело, это не 100% защита, так как найти открытый порт всё равно возможно, но для этого нужно приложить довольно много усилий. Если бан сделать вечным, то нужно очень много IP адресов, чтобы найти открытый порт.
Подобным способом можно скрыть проброс RDP или какого-то ещё порта от посторонних глаз. Когда будете настраивать, не забудьте разместить эти правила в общем списке правил фаервола так, чтобы они реально работали, и пакеты не попадали раньше в какие-то разрешающие правила.
#iptables #security
# Блокируем тех, кто обращается на неоткрытые порты tcpiptables -A INPUT -m recent --rcheck --seconds 600 --name BANPORT -j DROPiptables -A INPUT -p tcp -m multiport ! --dports 34881 -m recent --set --name BANPORT -j DROPiptables -A INPUT -p tcp --syn -m multiport --dports 34881 -j ACCEPT# Блокируем тех, кто обращается на неоткрытые порты udpiptables -A INPUT -m recent --rcheck --seconds 600 --name BANPORT -j DROPiptables -A INPUT -p udp -m multiport ! --dports 34881 -m recent --set --name BANPORT -j DROPiptables -A INPUT -p udp -m multiport --dports 34881 -j ACCEPTЯ использую multiport с заделом на список из нескольких портов, которые в случае необходимости можно перечислить через запятую. Посмотреть список забаненых:
# cat /proc/net/xt_recent/BANPORTУдалить оттуда:
# echo -1.1.1.1 > /proc/net/xt_recent/BANPORTОчистить список:
# echo / > /proc/net/xt_recent/BANPORTТакой вот простой способ скрыть от посторонних глаз сервис, который не получается ограничить какими-то списками. Понятное дело, это не 100% защита, так как найти открытый порт всё равно возможно, но для этого нужно приложить довольно много усилий. Если бан сделать вечным, то нужно очень много IP адресов, чтобы найти открытый порт.
Подобным способом можно скрыть проброс RDP или какого-то ещё порта от посторонних глаз. Когда будете настраивать, не забудьте разместить эти правила в общем списке правил фаервола так, чтобы они реально работали, и пакеты не попадали раньше в какие-то разрешающие правила.
#iptables #security
Проработал ещё один документ по безопасной настройки от CIS. На этот раз на тему Apache 2.4. Изучил 217 😱 страниц документа и постарался сделать универсальную краткую выжимку для постоянного использования. Те параметры, что есть в рекомендациях, но по умолчанию уже настроены, я не упоминаю.
📌 Как обычно, первая рекомендация по настройке — проверить список модулей и отключить ненужные. В зависимости от дистрибутива, команда на запуск бинарника может быть разная. В Debian и Ubuntu — apache2ctl, в Centos и клонах — httpd или apachectl.
Описание модулей можно посмотреть в документации. Для отключения комментируем строку с
◽модуль логирования log_config_module загружен;
◽модули, связанные с webdav (имеют dav в названии), отключены, если не нужны.
◽модуль статистики status_module отключен, если не используется, либо настроен, чтобы исключить доступ к статистике посторонним.
◽модуль autoindex_module отключен, он позволяет выполнять листинг директорий с файлами, если не задана индексная страница (index.html и т.д.)
◽отключены модули проксирования (proxy в названии), если не используются;
◽отключён модуль mod_info, который выводит информацию о сервере;
📌 Не используйте модуль mod_auth_basic, если доступ к сайту по http. В этом случае учётные данные передаются по сети в открытом виде и могут быть перехвачены кем угодно по пути следования пакетов.
📌 Обратите внимание на параметры для директорий
📌 Для корневой системной директории отключите все
📌 Традиционная рекомендация по настройке любого веб сервера — удалите весь контент, что идёт по умолчанию с установочным пакетом. Это относится к стартовой странице, страницам с кодами ошибок и т.д. Всё это помогает определить версию системы и веб сервера. Для apache это обычно директории
📌 Отключите всё, что касается cgi скриптов, если вы их не используете. Выполнение этих скриптов — наследие прошлого и сейчас чаще всего не используется, но может быть включено по умолчанию. Отключите модуль mod_cgi и настройки с упоминанием алиаса /cgi-bin/ или опции ExecCGI.
📌 Веб клиенты не должны иметь доступ к файлам .htaccess, .htpasswd и .htgroup. Обязательно настройте для них запрет.
📌 Запретите доступ к веб серверу по IP адресу или по несуществующему домену (rewrite_module должен быть включён). Для этого создайте виртуальный хост, который будет первым в списке. И добавьте в него редирект всех, кто обращается не на ваш домен:
Если доменов много, можно сделать редирект тех, кто обращается по IP на любой другой домен:
📌 Проверьте, что настроено логирование. Как минимум, должен быть включён error лог.
Если настроены access логи, не забудьте настроить их ротацию.
📌 По возможности, установите и настройте модуль mod_security. Это популярный web application firewall (WAF).
📌 Не используйте устаревшие версии TLS и Ciphers:
📌 Отключите вывод информации о версии сервера:
📌 Уменьшите дефолтный таймаут запросов:
#cis #apache #security
📌 Как обычно, первая рекомендация по настройке — проверить список модулей и отключить ненужные. В зависимости от дистрибутива, команда на запуск бинарника может быть разная. В Debian и Ubuntu — apache2ctl, в Centos и клонах — httpd или apachectl.
# apache2ctl -MОписание модулей можно посмотреть в документации. Для отключения комментируем строку с
LoadModule и именем модуля в конфигурационном файле. Здесь же стоит убедиться, что:◽модуль логирования log_config_module загружен;
◽модули, связанные с webdav (имеют dav в названии), отключены, если не нужны.
◽модуль статистики status_module отключен, если не используется, либо настроен, чтобы исключить доступ к статистике посторонним.
◽модуль autoindex_module отключен, он позволяет выполнять листинг директорий с файлами, если не задана индексная страница (index.html и т.д.)
◽отключены модули проксирования (proxy в названии), если не используются;
◽отключён модуль mod_info, который выводит информацию о сервере;
📌 Не используйте модуль mod_auth_basic, если доступ к сайту по http. В этом случае учётные данные передаются по сети в открытом виде и могут быть перехвачены кем угодно по пути следования пакетов.
📌 Обратите внимание на параметры для директорий
AllowOverride и AllowOverrideList. Они разрешают или запрещают использование различных настроек для файлов конфигураций .htaccess, которые могут переопределять многие настройки сервера. По умолчанию подобные разрешения имеет смысл отключить и включать только точечно.<Directory /> . . . AllowOverride None . . .</Directory>📌 Для корневой системной директории отключите все
Options. По умолчанию включена опция FollowSymLinks. <Directory /> . . . Options None . . .</Directory>📌 Традиционная рекомендация по настройке любого веб сервера — удалите весь контент, что идёт по умолчанию с установочным пакетом. Это относится к стартовой странице, страницам с кодами ошибок и т.д. Всё это помогает определить версию системы и веб сервера. Для apache это обычно директории
/var/www/html и /usr/share/apache2/error/.📌 Отключите всё, что касается cgi скриптов, если вы их не используете. Выполнение этих скриптов — наследие прошлого и сейчас чаще всего не используется, но может быть включено по умолчанию. Отключите модуль mod_cgi и настройки с упоминанием алиаса /cgi-bin/ или опции ExecCGI.
📌 Веб клиенты не должны иметь доступ к файлам .htaccess, .htpasswd и .htgroup. Обязательно настройте для них запрет.
<FilesMatch "^\.ht"> Require all denied</FilesMatch>📌 Запретите доступ к веб серверу по IP адресу или по несуществующему домену (rewrite_module должен быть включён). Для этого создайте виртуальный хост, который будет первым в списке. И добавьте в него редирект всех, кто обращается не на ваш домен:
RewriteEngine OnRewriteCond %{HTTP_HOST} !^example\.com [NC]RewriteRule ^.(.*) - [L,F]Если доменов много, можно сделать редирект тех, кто обращается по IP на любой другой домен:
RewriteEngine OnRewriteBase /RewriteCond %{HTTP_HOST} ^192\.168\.0\.1$RewriteRule ^(.*)$ https://example.com/$1 [L,R=301]📌 Проверьте, что настроено логирование. Как минимум, должен быть включён error лог.
LogLevel notice core:infoErrorLog "logs/error_log"Если настроены access логи, не забудьте настроить их ротацию.
📌 По возможности, установите и настройте модуль mod_security. Это популярный web application firewall (WAF).
📌 Не используйте устаревшие версии TLS и Ciphers:
SSLProtocol TLSv1.2 TLSv1.3SSLHonorCipherOrder OnSSLCipherSuite ALL:!EXP:!NULL:!LOW:!SSLv2:!RC4:!aNULL📌 Отключите вывод информации о версии сервера:
ServerTokens ProdServerSignature Off📌 Уменьшите дефолтный таймаут запросов:
Timeout 10#cis #apache #security
{kind=link}
В разных заметках я вскользь касался утилиты командной строки Linux — netcat или сокращённо nc. Эта старя и полезная unix утилита, которая заслуживает отдельной публикации, чтобы сохранить её в закладки. С помощью nc удобно устанавливать TCP соединения и принимать и отправлять UDP пакеты во время отладки и настройки сети и фаерволов.
✅ Самый простой случай. Проверим, отвечает ли TCP порт:
Ключ
✅ Можно быстро просканировать диапазон портов, не прибегая к посторонним инструментам. Это удобнее и быстрее, чем ставить и вспомнить ключи nmap.
Я тут сразу обработал вывод, показав только открытые порты. Без фильтрации nc вывалит информацию по всем портам сразу в консоль, что неудобно для больших диапазонов.
✅ Отправляем UDP пакет:
Просто добавляем ключ
Netcat удобно использовать, когда отлаживаешь firewall. С его помощью можно поднять сервис на нужном порту и постучаться в него. Я чаще всего использую его для проверки правил, когда делаю заметки на тему фаерволов.
✅ Поднимаем службу на 11222 порту:
С другого сервера подключаемся:
Теперь в терминал клиента можно что-то написать, а на сервере в терминале он отобразится. Если всё нормально, в настройках firewall всё в порядке. Можно для верности соответствующие правила посмотреть и счётчики пакетов на них.
✅ Таким образом даже файлы можно передавать, или целые директории. Для этого надо открыть сервер и направить его вывод в файл.
А на клиенте подключиться и передать файл:
Передавать таким образом можно любой файл, а не только текстовый. Также вывод можно направить сразу в shell. Этим пользуются злоумышленники, если имеют возможность запустить nc на сервере.
Из этой же серии возможность передать образ диска по сети с помощью dd и nc. Выглядит примерно так. Сервер:
Клиент:
Но конкретно эту задачу удобнее решить с помощью ssh:
✅ Netcat может выступать в качестве веб сервера, если ему передать html страницу на вход.
По ip адресу сервера откроется дефолтная апачевская страничка.
У netcat насыщенный функционал. Можно почитать в man. Он хорошо оформлен с реальными примерами и описанием функционала. Netcat умеет менять адрес и порт клиента, использовать прокси с аутентификацией, подключаться к unix сокету и т.д.
#terminal #linux
✅ Самый простой случай. Проверим, отвечает ли TCP порт:
# nc -vz 192.168.13.113 139Connection to 192.168.13.113 139 port [tcp/*] succeeded!Ключ
-v выводит отладочную информацию, которая как раз включает информацию о статусе подключения, -z — режим сканирования.✅ Можно быстро просканировать диапазон портов, не прибегая к посторонним инструментам. Это удобнее и быстрее, чем ставить и вспомнить ключи nmap.
# nc -vz 192.168.13.113 1-1023 2>&1 | grep succeededConnection to 192.168.13.113 135 port [tcp/*] succeeded!Connection to 192.168.13.113 139 port [tcp/*] succeeded!Connection to 192.168.13.113 445 port [tcp/*] succeeded!Я тут сразу обработал вывод, показав только открытые порты. Без фильтрации nc вывалит информацию по всем портам сразу в консоль, что неудобно для больших диапазонов.
✅ Отправляем UDP пакет:
# nc -zvu 212.193.62.10 53Connection to 212.193.62.10 53 port [udp/domain] succeeded!Просто добавляем ключ
-u к командам выше. Статус порта тут не всегда показывает правду, так что ориентироваться на него не стоит. Это инструмент именно для отправки пакета. Для сканирования udp портов лучше взять nmap, zmap или masscan.Netcat удобно использовать, когда отлаживаешь firewall. С его помощью можно поднять сервис на нужном порту и постучаться в него. Я чаще всего использую его для проверки правил, когда делаю заметки на тему фаерволов.
✅ Поднимаем службу на 11222 порту:
# nc -lvp 11222Ncat: Listening on 0.0.0.0:11222С другого сервера подключаемся:
# nc -v 192.168.13.113 11222Connection to 192.168.13.113 11222 port [tcp/*] succeeded!Теперь в терминал клиента можно что-то написать, а на сервере в терминале он отобразится. Если всё нормально, в настройках firewall всё в порядке. Можно для верности соответствующие правила посмотреть и счётчики пакетов на них.
✅ Таким образом даже файлы можно передавать, или целые директории. Для этого надо открыть сервер и направить его вывод в файл.
# nc -lvp 11222 > recive.txtА на клиенте подключиться и передать файл:
# nc -v 192.168.13.113 11222 < info.txtПередавать таким образом можно любой файл, а не только текстовый. Также вывод можно направить сразу в shell. Этим пользуются злоумышленники, если имеют возможность запустить nc на сервере.
Из этой же серии возможность передать образ диска по сети с помощью dd и nc. Выглядит примерно так. Сервер:
# nc -lvp 11222 > dd of=/backup/sda.img.gzКлиент:
# dd if=/dev/sda | gzip -c | nc 192.168.13.113 11222Но конкретно эту задачу удобнее решить с помощью ssh:
# dd if=/dev/sda | ssh root@192.168.13.113 "dd of=/dev/sda"✅ Netcat может выступать в качестве веб сервера, если ему передать html страницу на вход.
# while true; do nc -lp 80 < /var/www/html/index.html; doneПо ip адресу сервера откроется дефолтная апачевская страничка.
У netcat насыщенный функционал. Можно почитать в man. Он хорошо оформлен с реальными примерами и описанием функционала. Netcat умеет менять адрес и порт клиента, использовать прокси с аутентификацией, подключаться к unix сокету и т.д.
#terminal #linux
{kind=link}
Думаю, многие знают про программный шлюза на базе Freebsd — pfSense. Он, мне кажется, безусловный лидер в этой нише с очень большой историей. У него есть клон, который отпочковался в 2015 году и получил название OPNsense. У этих продуктов первое время была какая-то война с дискредитацией друг друга, но в итоге закончилась.
У OPNSense более современный и функциональный веб интерфейс. Он и выглядит приятнее, и по факту более удобен в том числе компоновкой разделов. Особенно что касается обновления пакетов. Там всё очень подробно расписано по новым пакетам. Также удобен функционал поиска, который помогает быстрее найти нужные настройки. Да и банально, первый раз зайдя в интерфейс pfSense, вы вряд ли быстро найдёте раздел меню, перезагружающий или выключающий сервер. Он почему-то находится в Diagnostics.
Оба продукта на базе ОС Freebsd. Базовый функционал у них примерно одинаковый:
◽DNS Server;
◽DHCP Server, Relay;
◽NAT;
◽Zone based Firewall;
◽WAN Failover и load balancing, VLAN, WLAN;
◽VPN (OpenVPN, Ipsec и другие);
◽Web Proxy (squid), Netflow Exporter;
◽QoS;
◽HA кластер;
◽Логирование всех изменений и настроек. Возможность откатить их обратно.
OPNSense в целом более активно внедряет что-то новое, какие-то изменения. У него нет большого шлейфа поддержки старых версий и пакетов. PfSense в этом плане более консервативен, но и как следствие, более стабилен. В PfSense меньше плагинов, но в целом их качество выше, по сравнению с OPNSense, где их больше, но многие из них могут глючить или работать не так, как ожидается. Но каких-то критических проблем, которые бы вынуждали отказаться от OPNSense нет.
В мониторинге Zabbix есть шаблон для сбора метрик с обоих систем по SNMP.
Если присматриваете себе программный шлюз, то посмотрите обоих. Базовый функционал у них примерно одинаков, а различия не критичные, хоть и в некоторых случаях существенные. Например, OPNSense умеет автоматически складывать свои шифрованные бэкапы в Nextcloud. Поддержка этого реализована в веб интерфейсе и настраивается просто и быстро. Мелочь, но весьма приятная. В pfSense этого просто нет. Можно только вручную сохранить xml файл с настройками. Ну а про веб интерфейс я в начале уже сказал. У OPNsense он приятнее, логичнее и современнее.
⇨ Сайт / Исходники
#gateway
У OPNSense более современный и функциональный веб интерфейс. Он и выглядит приятнее, и по факту более удобен в том числе компоновкой разделов. Особенно что касается обновления пакетов. Там всё очень подробно расписано по новым пакетам. Также удобен функционал поиска, который помогает быстрее найти нужные настройки. Да и банально, первый раз зайдя в интерфейс pfSense, вы вряд ли быстро найдёте раздел меню, перезагружающий или выключающий сервер. Он почему-то находится в Diagnostics.
Оба продукта на базе ОС Freebsd. Базовый функционал у них примерно одинаковый:
◽DNS Server;
◽DHCP Server, Relay;
◽NAT;
◽Zone based Firewall;
◽WAN Failover и load balancing, VLAN, WLAN;
◽VPN (OpenVPN, Ipsec и другие);
◽Web Proxy (squid), Netflow Exporter;
◽QoS;
◽HA кластер;
◽Логирование всех изменений и настроек. Возможность откатить их обратно.
OPNSense в целом более активно внедряет что-то новое, какие-то изменения. У него нет большого шлейфа поддержки старых версий и пакетов. PfSense в этом плане более консервативен, но и как следствие, более стабилен. В PfSense меньше плагинов, но в целом их качество выше, по сравнению с OPNSense, где их больше, но многие из них могут глючить или работать не так, как ожидается. Но каких-то критических проблем, которые бы вынуждали отказаться от OPNSense нет.
В мониторинге Zabbix есть шаблон для сбора метрик с обоих систем по SNMP.
Если присматриваете себе программный шлюз, то посмотрите обоих. Базовый функционал у них примерно одинаков, а различия не критичные, хоть и в некоторых случаях существенные. Например, OPNSense умеет автоматически складывать свои шифрованные бэкапы в Nextcloud. Поддержка этого реализована в веб интерфейсе и настраивается просто и быстро. Мелочь, но весьма приятная. В pfSense этого просто нет. Можно только вручную сохранить xml файл с настройками. Ну а про веб интерфейс я в начале уже сказал. У OPNsense он приятнее, логичнее и современнее.
⇨ Сайт / Исходники
#gateway
{kind=link}
Самый популярный движок для сайтов во всём мире — Wordpress. Именно на нём создано больше всего сайтов. Сам я все сайты делал исключительно на нём, хотя администрировать приходилось разные движки. Если меня спросит кто-нибудь посоветовать движок для информационного сайта или сайта-визитки, то совет будет однозначный. Я не вижу смысла использовать что-то другое.
Wordpress обычно предъявляют пару основных претензий: он небезопасный и он тормозной. Небезопасные чаще всего плагины, а не сам движок, в котором даже если и находят уязвимости, то исправления выходят в тот же день. А вот насчёт скорости дам один практический совет, как решить эту проблему для информационного сайта, который можно закэшировать.
Ставим плагин WP Super Cache. Включаем кэширование, указываем директорию для кэша, настраиваем предварительную загрузку кэша (отдельный раздел настроек). С такими настройками плагин будет автоматически создавать и периодически обновлять статические страницы, размещая их в определённой директории.
Теперь идём в настройки Nginx и настраиваем отдачу этих статических страниц напрямую через веб сервер, в обход php движка. Для этого настраиваем корневой location примерно так:
Убедитесь, что маска пути, указанная в настройках, совпадает с реальным расположением файлов кэша. С данными настройками первым делом страница будет проверяться в директории с кэшом, где она уже сформирована в статическом виде. Отдача такой страницы будет максимально быстрой.
С этими настройками вы закрываете вопрос тормознутости сайта на Wordpress процентов на 90. Остальное останется под другие оптимизации, которые можно уже не делать. Сайт и так будет грузиться очень быстро. Он фактически стал статическим.
В WP Super Cache есть возможность указать настройки обновления или сброса кэша, например, при появлении нового комментария или новой статьи. Также можно выбрать пользователей или группы, для которых кэширование работать не будет. Кэшированием можно гибко управлять, в отличие от такого же кэша, только средствами Nginx. Он по быстродействию будет такой же, только без настроек, что неудобно.
Более подробно этот метод описан в документации самого плагина:
https://wordpress.org/documentation/article/nginx/#wp-super-cache-rules
Там имеет смысл добавить ещё немного настроек для исключения кэширования некоторых запросов. Примерно так. Эти настройки должны быть выше в конфигу виртуального хоста, чем предыдущий корневой location.
Далее можно заняться оптимизацией картинок и включением сжатия brotli. Но это если хотите сделать всё максимально возможное. В общем случае и так нормально будет.
Тема ускорения Wordpress плотно оккупирована в поисковой выдаче сеошниками. А они про настройки Nginx ничего не знают и не умеют, поэтому найти подобное решение с плагином где-то через поиск вряд ли получится. А если искать по-серьёзному материалы админов, то найдёте скорее всего кэширование напрямую через сам Nginx или какой-нибудь Varnish. Но это будет не так гибко и удобно.
#webserver #wordpress
Wordpress обычно предъявляют пару основных претензий: он небезопасный и он тормозной. Небезопасные чаще всего плагины, а не сам движок, в котором даже если и находят уязвимости, то исправления выходят в тот же день. А вот насчёт скорости дам один практический совет, как решить эту проблему для информационного сайта, который можно закэшировать.
Ставим плагин WP Super Cache. Включаем кэширование, указываем директорию для кэша, настраиваем предварительную загрузку кэша (отдельный раздел настроек). С такими настройками плагин будет автоматически создавать и периодически обновлять статические страницы, размещая их в определённой директории.
Теперь идём в настройки Nginx и настраиваем отдачу этих статических страниц напрямую через веб сервер, в обход php движка. Для этого настраиваем корневой location примерно так:
location / { try_files /wp-content/cache/supercache/$http_host/$cache_uri/index-https.html $uri $uri/ /index.php?$args;}Убедитесь, что маска пути, указанная в настройках, совпадает с реальным расположением файлов кэша. С данными настройками первым делом страница будет проверяться в директории с кэшом, где она уже сформирована в статическом виде. Отдача такой страницы будет максимально быстрой.
С этими настройками вы закрываете вопрос тормознутости сайта на Wordpress процентов на 90. Остальное останется под другие оптимизации, которые можно уже не делать. Сайт и так будет грузиться очень быстро. Он фактически стал статическим.
В WP Super Cache есть возможность указать настройки обновления или сброса кэша, например, при появлении нового комментария или новой статьи. Также можно выбрать пользователей или группы, для которых кэширование работать не будет. Кэшированием можно гибко управлять, в отличие от такого же кэша, только средствами Nginx. Он по быстродействию будет такой же, только без настроек, что неудобно.
Более подробно этот метод описан в документации самого плагина:
https://wordpress.org/documentation/article/nginx/#wp-super-cache-rules
Там имеет смысл добавить ещё немного настроек для исключения кэширования некоторых запросов. Примерно так. Эти настройки должны быть выше в конфигу виртуального хоста, чем предыдущий корневой location.
set $cache_uri $request_uri;if ($request_method = POST) { set $cache_uri 'null cache'; }if ($query_string != "") { set $cache_uri 'null cache'; }if ($request_uri ~* "(/wp-admin/|/forum/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php|wp-.*.php|/feed/|index.php|wp-comments-popup.php|wp-links-opml.php|wp-locations.php|sitemap(_index)?.xml|[a-z0-9_-]+-sitemap([0-9]+)?.xml)") { set $cache_uri 'null cache'; }if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass|wordpress_logged_in") { set $cache_uri 'null cache'; }Далее можно заняться оптимизацией картинок и включением сжатия brotli. Но это если хотите сделать всё максимально возможное. В общем случае и так нормально будет.
Тема ускорения Wordpress плотно оккупирована в поисковой выдаче сеошниками. А они про настройки Nginx ничего не знают и не умеют, поэтому найти подобное решение с плагином где-то через поиск вряд ли получится. А если искать по-серьёзному материалы админов, то найдёте скорее всего кэширование напрямую через сам Nginx или какой-нибудь Varnish. Но это будет не так гибко и удобно.
#webserver #wordpress
{kind=link}
Вчерашняя заметка про OPNsense вызвала повышенную активность в комментариях. Решил немного подбить информацию по этой теме, чтобы было всё в одном месте.
Существует несколько условных категорий программных шлюзов, которые можно установить на своё железо.
🟢 Начнём со шлюзов на базе FreeBSD с веб интерфейсом.
◽PfSense — безусловный лидер всей этой отрасли шлюзов с веб интерфейсом. Несмотря на то, что ОС FreeBSD переживает не лучшие времена в плане развития и популярности, никаких проблем в самой pfSense с этим нет, если вы не используете какое-то специфическое железо. В виртуальных машинах популярных гипервизоров всё заводится без проблем.
◽OPNsense — форк pfSense с более интенсивным развитием и современным веб интерфейсом. У него есть некоторые замечания к работе, но в целом некритичные. Можно смело использовать, если понравится. Функционал примерно как у pfSense.
◽ИКС — отечественная разработка на базе FreeBSD. Это платный продукт. Включил его в эту подборку, потому что есть бесплатная версия для 9-ти устройств в сети. Мне нравится этот программный шлюз. Неплохо его знаю. Одно время использовал дома, но не захотелось держать железку постоянно включённой для него, удалил.
🟢 Шлюзы на базе Linux с веб интерфейсом. Основной их плюс в том, что там внутри более популярный и понятный линуксоидам (но не всем остальным людям) iptables.
◽IPFire — мне кажется, он наиболее известный и функциональный из линуксовых шлюзов. Я сам им немного пользовался. В настройке он проще, в функционале беднее, чем тот же pfSense. Но для простых случаев это может оказаться плюсом. В основе не популярный, как это обычно бывает в таких случаях, дистрибутив, а собственная сборка на базе ядра Linux.
◽ClearOS — ещё одна коммерческая система, но есть Community версия с ограниченным базовым функционалом, которого во многих случаях хватает за глаза. Эту систему я одно время активно использовал, потому что она была на базе CentOS. Когда у меня везде стояли CentOS, мне это было удобно. В своё время написал статью про неё, которая была популярной.
◽Endian — ещё один шлюз на базе CentOS с большой историей. Первый релиз был в 2009 году. Мне трудно про него сказать что-то конкретное, потому что сам его не разворачивал и никогда не видел. В РФ он как-то не снискал популярности и малоизвестен. По описанию с сайта плюс-минус всё то же самое, что у остальных. Есть как коммерческая, так и Community версия.
◽Zentyal — это не совсем шлюз, скорее сборка всё в одном для малого бизнеса. Позиционируют себя как замена AD и Exchange для небольших компаний. Базовый функционал шлюза тоже представлен (dns, dhcp, nat, firewall, vpn и т.д.). Есть платная и Community версия. Построен на базе Ubuntu.
Шлюзы без веб интерфейса, только CLI.
◽VyOS — безусловный лидер и вообще единственный известный мне шлюз с настройкой через CLI. Построен на базе Debian, синтаксис максимально приближён к JunOS. VyOS заточен исключительно под сетевые функции, которых у него максимальное количество из всех программных шлюзов. Это не только уровень шлюза для офиса или виртуальной инфраструктуры. Он подойдёт и для провайдеров. VyOS больше инструмент сетевых инженеров.
❗️Все шлюзы, которыми я управлял лично, настраивал сам на базе стандартных дистрибутивов. Благодаря этому очень быстро прокачал свои навыки в этой сфере и без проблем могу заходить в консоль всех описанных шлюзов, разбираться с проблемами, что-то править. Я понимаю как работу фаерволов, в том числе в FreeBSD, так и отдельных пакетов. Рекомендую начинать с этого. А потом уже выбирать какие-то готовые сборки для упрощения и экономии времени. Мои статьи по шлюзам на freebsd, centos, debian.
#подборка #gateway
Существует несколько условных категорий программных шлюзов, которые можно установить на своё железо.
🟢 Начнём со шлюзов на базе FreeBSD с веб интерфейсом.
◽PfSense — безусловный лидер всей этой отрасли шлюзов с веб интерфейсом. Несмотря на то, что ОС FreeBSD переживает не лучшие времена в плане развития и популярности, никаких проблем в самой pfSense с этим нет, если вы не используете какое-то специфическое железо. В виртуальных машинах популярных гипервизоров всё заводится без проблем.
◽OPNsense — форк pfSense с более интенсивным развитием и современным веб интерфейсом. У него есть некоторые замечания к работе, но в целом некритичные. Можно смело использовать, если понравится. Функционал примерно как у pfSense.
◽ИКС — отечественная разработка на базе FreeBSD. Это платный продукт. Включил его в эту подборку, потому что есть бесплатная версия для 9-ти устройств в сети. Мне нравится этот программный шлюз. Неплохо его знаю. Одно время использовал дома, но не захотелось держать железку постоянно включённой для него, удалил.
🟢 Шлюзы на базе Linux с веб интерфейсом. Основной их плюс в том, что там внутри более популярный и понятный линуксоидам (но не всем остальным людям) iptables.
◽IPFire — мне кажется, он наиболее известный и функциональный из линуксовых шлюзов. Я сам им немного пользовался. В настройке он проще, в функционале беднее, чем тот же pfSense. Но для простых случаев это может оказаться плюсом. В основе не популярный, как это обычно бывает в таких случаях, дистрибутив, а собственная сборка на базе ядра Linux.
◽ClearOS — ещё одна коммерческая система, но есть Community версия с ограниченным базовым функционалом, которого во многих случаях хватает за глаза. Эту систему я одно время активно использовал, потому что она была на базе CentOS. Когда у меня везде стояли CentOS, мне это было удобно. В своё время написал статью про неё, которая была популярной.
◽Endian — ещё один шлюз на базе CentOS с большой историей. Первый релиз был в 2009 году. Мне трудно про него сказать что-то конкретное, потому что сам его не разворачивал и никогда не видел. В РФ он как-то не снискал популярности и малоизвестен. По описанию с сайта плюс-минус всё то же самое, что у остальных. Есть как коммерческая, так и Community версия.
◽Zentyal — это не совсем шлюз, скорее сборка всё в одном для малого бизнеса. Позиционируют себя как замена AD и Exchange для небольших компаний. Базовый функционал шлюза тоже представлен (dns, dhcp, nat, firewall, vpn и т.д.). Есть платная и Community версия. Построен на базе Ubuntu.
Шлюзы без веб интерфейса, только CLI.
◽VyOS — безусловный лидер и вообще единственный известный мне шлюз с настройкой через CLI. Построен на базе Debian, синтаксис максимально приближён к JunOS. VyOS заточен исключительно под сетевые функции, которых у него максимальное количество из всех программных шлюзов. Это не только уровень шлюза для офиса или виртуальной инфраструктуры. Он подойдёт и для провайдеров. VyOS больше инструмент сетевых инженеров.
❗️Все шлюзы, которыми я управлял лично, настраивал сам на базе стандартных дистрибутивов. Благодаря этому очень быстро прокачал свои навыки в этой сфере и без проблем могу заходить в консоль всех описанных шлюзов, разбираться с проблемами, что-то править. Я понимаю как работу фаерволов, в том числе в FreeBSD, так и отдельных пакетов. Рекомендую начинать с этого. А потом уже выбирать какие-то готовые сборки для упрощения и экономии времени. Мои статьи по шлюзам на freebsd, centos, debian.
#подборка #gateway
👨💻 Тайм-менеджмент для системных администраторов
Я давно написал на сайте обзор книги тайм менеджмент для системного администратора. Думаю, многие подписчики ее не читали, так как упоминание о ней на канале было несколько лет назад, а сама статья написана ещё раньше. Решил напомнить про статью и порекомендовать прочитать, так как актуальность она не потеряла вообще нисколько. Эта тема вечная, пока роботы не заменили людей в решение насущных дел.
От традиционных подходов в области организации рабочих процессов системных администраторов отличает то, что они постоянно отвлекаются на текущие задачи и это мешает им работать над долгосрочными проектами. Автор книги прорабатывает этот момент.
Со времени написания статьи у меня мало что поменялось в организации рабочего процесса. Я по прежнему придерживаюсь озвученных принципов и в целом доволен, как удается решать задачи. Советую очень внимательно и вдумчиво прочитать мою статью. Я потратил на нее много времени, постарался хорошо проработать и дать самую суть. Применение на практике советов из статьи и книги вам помогут улучшить свою производительность.
Вообще, самодисциплина и умение организовать себя на продуктивную деятельность — основа успеха любой деятельности. Какой бы ты умный специалист ни был, но если регулярно что-то забываешь или затягиваешь решение задач, ничего путного не получится.
Мне кажется, что за последние несколько лет я подрастерял свою собранность и целеустремлённость. Не знаю, с чем связано. Может подустал от своей работы, может возраст сказывается. А может фокус внимания сместился в другую сферу. Как-то надоело постоянно пытаться быть более результативным в повседневных делах. Разве человек для этого пришёл в этот мир? Для чего он здесь? Вопрос всех вопросов.
Но это я уже в другую область полез. Хотел у вас спросить, как упорядочиваете свои дела? Какие программы или подходы используете? Может ещё какие-то книги посоветуете на эту тему?
#разное
Я давно написал на сайте обзор книги тайм менеджмент для системного администратора. Думаю, многие подписчики ее не читали, так как упоминание о ней на канале было несколько лет назад, а сама статья написана ещё раньше. Решил напомнить про статью и порекомендовать прочитать, так как актуальность она не потеряла вообще нисколько. Эта тема вечная, пока роботы не заменили людей в решение насущных дел.
От традиционных подходов в области организации рабочих процессов системных администраторов отличает то, что они постоянно отвлекаются на текущие задачи и это мешает им работать над долгосрочными проектами. Автор книги прорабатывает этот момент.
Со времени написания статьи у меня мало что поменялось в организации рабочего процесса. Я по прежнему придерживаюсь озвученных принципов и в целом доволен, как удается решать задачи. Советую очень внимательно и вдумчиво прочитать мою статью. Я потратил на нее много времени, постарался хорошо проработать и дать самую суть. Применение на практике советов из статьи и книги вам помогут улучшить свою производительность.
Вообще, самодисциплина и умение организовать себя на продуктивную деятельность — основа успеха любой деятельности. Какой бы ты умный специалист ни был, но если регулярно что-то забываешь или затягиваешь решение задач, ничего путного не получится.
Мне кажется, что за последние несколько лет я подрастерял свою собранность и целеустремлённость. Не знаю, с чем связано. Может подустал от своей работы, может возраст сказывается. А может фокус внимания сместился в другую сферу. Как-то надоело постоянно пытаться быть более результативным в повседневных делах. Разве человек для этого пришёл в этот мир? Для чего он здесь? Вопрос всех вопросов.
Но это я уже в другую область полез. Хотел у вас спросить, как упорядочиваете свои дела? Какие программы или подходы используете? Может ещё какие-то книги посоветуете на эту тему?
#разное
Server Admin
Книга Тайм-менеджмент для системных администраторов
Некоторое время назад я писал заметку о книге Тайм-менеджмент для системных администраторов, когда она только попала мне в руки. На текущий момент я давно ее прочел, но только сейчас нашел время...
С выходом версии Zabbix Server 6.4 была анонсирована новая схема интеграции с LDAP. В блоге Zabbix вышла статья, которая подробно раскрывает эту тему — Just-in-Time user provisioning explained. Передам кратко её суть.
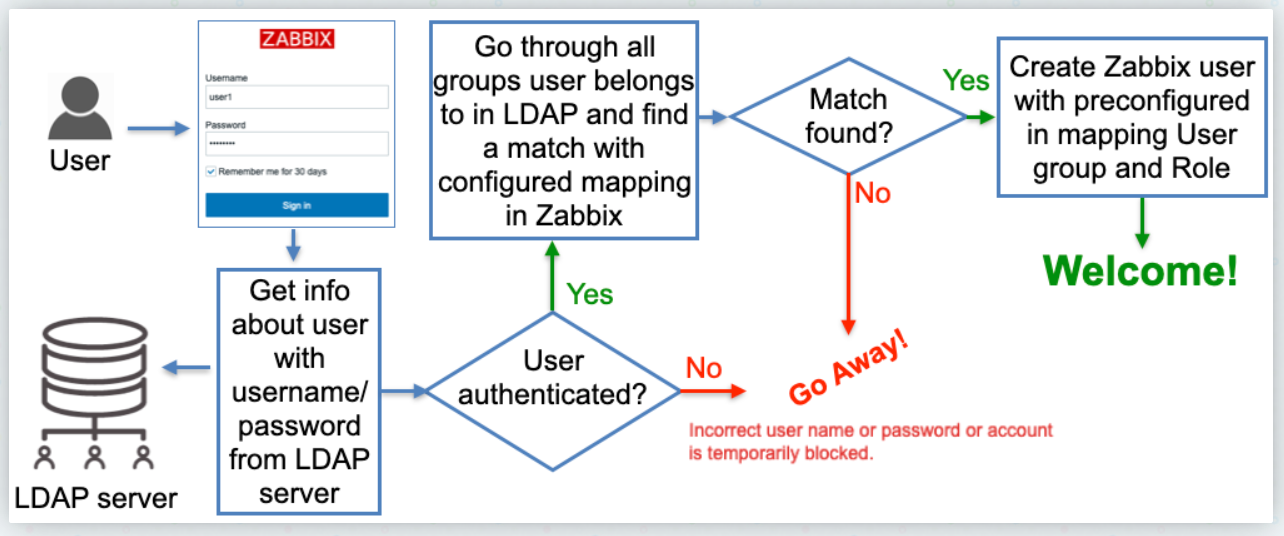
Раньше, чтобы пользователь мог аутентифицироваться через LDAP, его обязательно надо было создать в локальной базе данных пользователей. Во время аутентификации шла проверка в LDAP на предмет соответствия введённых имени пользователя и пароля. Заданный локальный пароль игнорировался. Очевидно, что такая схема работы неудобна, так как подразумевает двойную работу по заведению пользователя.
В версии 6.4 заводить вручную локального пользователя не надо. После ввода логина и пароля в форму веб интерфейса, Zabbix сам идёт на LDAP сервер и проверяет введённые данные, а также группы и email пользователя, если он там найден. Если всё в порядке, то Zabbix сам создаёт пользователя с соответствующими настройками групп доступа и email.
В статье поэтапно показана процедура настройки LDAP аутентификации. В том числе показан пример запуска LDAP сервера с phpldapadmin в составе для веб интерфейса управления. Этот LDAP каталог подключается к Zabbix Server. Далее очень подробно описан механизм взаимодействия и создания зависимостей между Zabbix и LDAP.
Статья написана подробно и информативно. Если вам интересна данная тема, то рекомендую. Хорошо всё раскрыто. Функционал ожидаемый и очень востребованный.
#zabbix
Раньше, чтобы пользователь мог аутентифицироваться через LDAP, его обязательно надо было создать в локальной базе данных пользователей. Во время аутентификации шла проверка в LDAP на предмет соответствия введённых имени пользователя и пароля. Заданный локальный пароль игнорировался. Очевидно, что такая схема работы неудобна, так как подразумевает двойную работу по заведению пользователя.
В версии 6.4 заводить вручную локального пользователя не надо. После ввода логина и пароля в форму веб интерфейса, Zabbix сам идёт на LDAP сервер и проверяет введённые данные, а также группы и email пользователя, если он там найден. Если всё в порядке, то Zabbix сам создаёт пользователя с соответствующими настройками групп доступа и email.
В статье поэтапно показана процедура настройки LDAP аутентификации. В том числе показан пример запуска LDAP сервера с phpldapadmin в составе для веб интерфейса управления. Этот LDAP каталог подключается к Zabbix Server. Далее очень подробно описан механизм взаимодействия и создания зависимостей между Zabbix и LDAP.
Статья написана подробно и информативно. Если вам интересна данная тема, то рекомендую. Хорошо всё раскрыто. Функционал ожидаемый и очень востребованный.
#zabbix
{kind=link}
Держите готовый набор объяснений и оправданий по поводу падения прода. Для вашего удобства, перевожу в копируемый вид.
🔥Падает тот, кто бежит. Кто ползёт, не падает.
◽️Не упав, не узнаешь, кто тебя поддержит.
◽️Опуститься легко — подняться трудно.
◽️Если придётся упасть — упади красиво.
◽️Падение — не провал. Провал — остаться жить там, где упал.
◽️Почему сервера падают? Для того, чтобы научиться подниматься.
🔥 Не тот велик, кто никогда не падал, а тот — кто падал и вставал.
◽️Победитель тот, кто встанет на один раз больше, чем упал.
Надеюсь ваши сервера поднимаются чаще, чем падают. У меня вот позавчера ночью сервера в Selectel упали на 2 часа. Пишу через час заявку в ТП, а мне в ответ предупреждение, которое было неделю назад. Там говорили о том, что будут какие-то работы по электроснабжению. Понятное дело, что я прочитал и сразу же забыл. Не думал, что это к двухчасовым простоям приведёт.
Сижу, думаю, интересно, как они сервера погасили. Их же обесточили. Дождался, когда загрузится, посмотрел логи. Выключился сервер штатно. Либо у них централизованно это управляется, либо специально обученный человек ходит и жмёт на кнопки.
#мем
🔥Падает тот, кто бежит. Кто ползёт, не падает.
◽️Не упав, не узнаешь, кто тебя поддержит.
◽️Опуститься легко — подняться трудно.
◽️Если придётся упасть — упади красиво.
◽️Падение — не провал. Провал — остаться жить там, где упал.
◽️Почему сервера падают? Для того, чтобы научиться подниматься.
🔥 Не тот велик, кто никогда не падал, а тот — кто падал и вставал.
◽️Победитель тот, кто встанет на один раз больше, чем упал.
Надеюсь ваши сервера поднимаются чаще, чем падают. У меня вот позавчера ночью сервера в Selectel упали на 2 часа. Пишу через час заявку в ТП, а мне в ответ предупреждение, которое было неделю назад. Там говорили о том, что будут какие-то работы по электроснабжению. Понятное дело, что я прочитал и сразу же забыл. Не думал, что это к двухчасовым простоям приведёт.
Сижу, думаю, интересно, как они сервера погасили. Их же обесточили. Дождался, когда загрузится, посмотрел логи. Выключился сервер штатно. Либо у них централизованно это управляется, либо специально обученный человек ходит и жмёт на кнопки.
#мем