
Хочу дать вам очень простой, но может быть для кого-то крайне полезный совет. Сам я его получил где-то год-два назад и очень рад, что со мной поделились полезной информацией.
В нашей профессии постоянно приходится взаимодействовать с англоязычными источниками. Я вполне могу осмысленно прочитать английский текст и перевести его практически полностью. Но если хочется быстро понять о чём написано, пробежав по началам абзацев, то я его прогоняю через переводчик.
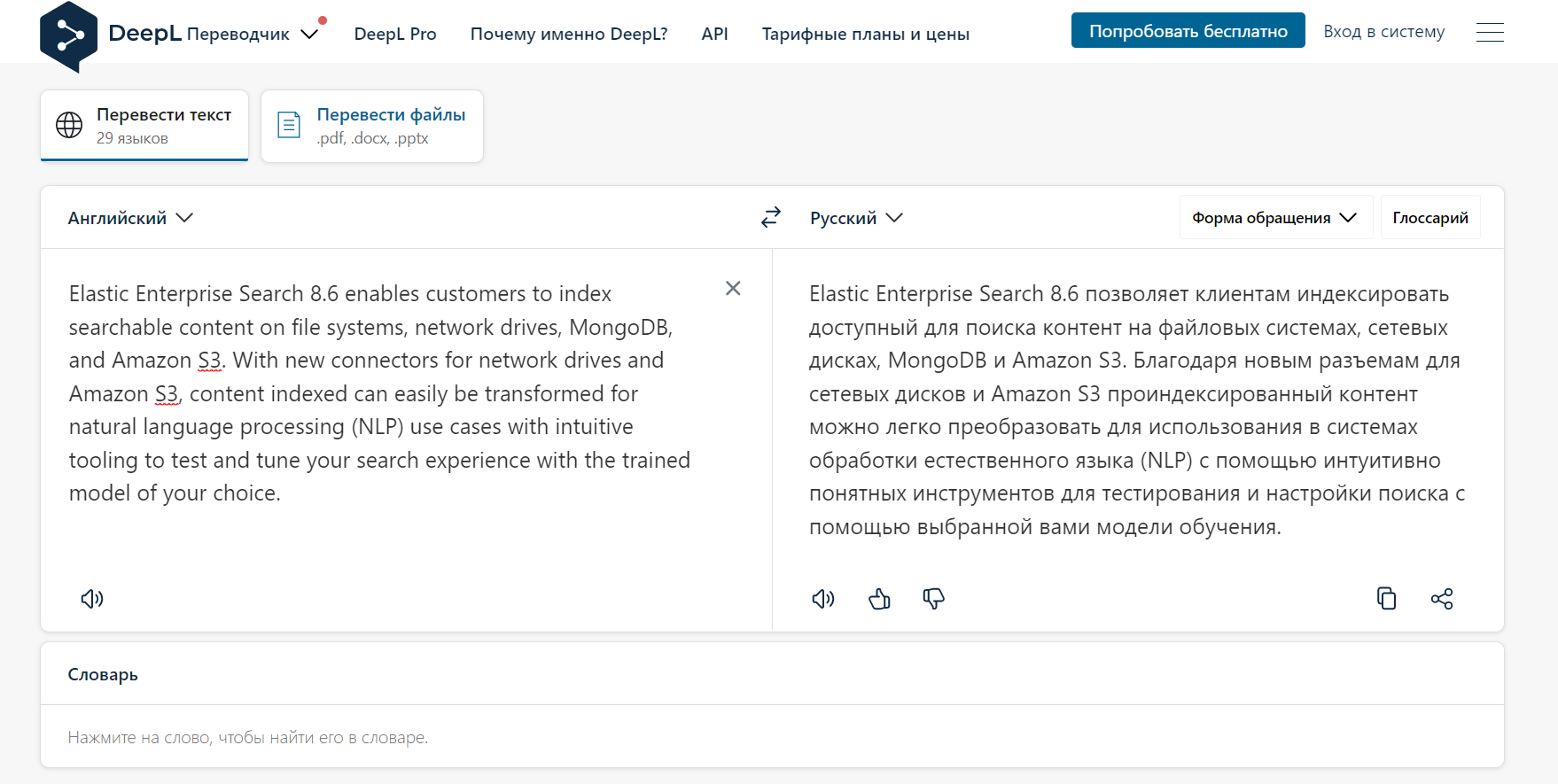
По привычке много лет пользовался бесплатным переводчиком от Google. Мне казалось, что он самый лучший, так как у гугла огромные ресурсы для его развития. Но оказывается, есть более качественный автоматический переводчик — deepl.com. С тех пор как попробовал его, пользуюсь только им.
Попробуйте, может вы тоже до сих пор пользуетесь translate.google.ru, который переводит не так хорошо. С deepl я понял, что совсем скоро изучать иностранные языки для тех, кто не собирается общаться на них, потеряет смысл. Просто перевести текст или видео можно будет совсем без знания языка. Уже сейчас видео в режиме реального времени неплохо переводит Яндекс.Браузер, а deepl текст и вовсе хорошо, даже технической направленности.
💡 И ещё дам один совет по поводу автоматических переводов. Когда ищите какую-то информацию в Википедии, особенно про исторические события или персоналии, посмотрите текст на разных языках. Там иногда представлена либо дополненная информация, либо вообще другая по смыслу. Это позволяет лучше разобраться в событии или понять, что за человек описан. Причём перевод имеет смысл смотреть не только с английского, а чаще даже именно с других языков. Там может оказаться много всего нового и полезного.
#разное
В нашей профессии постоянно приходится взаимодействовать с англоязычными источниками. Я вполне могу осмысленно прочитать английский текст и перевести его практически полностью. Но если хочется быстро понять о чём написано, пробежав по началам абзацев, то я его прогоняю через переводчик.
По привычке много лет пользовался бесплатным переводчиком от Google. Мне казалось, что он самый лучший, так как у гугла огромные ресурсы для его развития. Но оказывается, есть более качественный автоматический переводчик — deepl.com. С тех пор как попробовал его, пользуюсь только им.
Попробуйте, может вы тоже до сих пор пользуетесь translate.google.ru, который переводит не так хорошо. С deepl я понял, что совсем скоро изучать иностранные языки для тех, кто не собирается общаться на них, потеряет смысл. Просто перевести текст или видео можно будет совсем без знания языка. Уже сейчас видео в режиме реального времени неплохо переводит Яндекс.Браузер, а deepl текст и вовсе хорошо, даже технической направленности.
💡 И ещё дам один совет по поводу автоматических переводов. Когда ищите какую-то информацию в Википедии, особенно про исторические события или персоналии, посмотрите текст на разных языках. Там иногда представлена либо дополненная информация, либо вообще другая по смыслу. Это позволяет лучше разобраться в событии или понять, что за человек описан. Причём перевод имеет смысл смотреть не только с английского, а чаще даже именно с других языков. Там может оказаться много всего нового и полезного.
#разное
{kind=link}
Для профессиональной работы с документацией есть open source продукт Antora. С её помощью можно автоматически генерировать статический сайт с документацией в формате AsciiDoc. При этом вся информация для сайта хранится в git репозиториях.
Как я уже сказал, Antora стоит рассматривать, если вам нужна документация профессионального уровня с различными продуктами, ветками, версиями. Это инструмент для технических писателей. Хотя ничего особо сложного там нет, просто нужно будет погрузиться в продукт и немного его изучить, прежде чем начать пользоваться. Это посложнее, чем та же wiki разметка.
У Antora свой язык разметки и взаимосвязей, с которым нужно будет ознакомиться, чтобы создавать и поддерживать более ли менее сложную документацию. Всё это описано в документации Анторы. Там же приведён Demo репозиторий, на основе которого можно собрать документацию и посмотреть, как работает генерация, и как потом выглядит сам сайт.
Я установил себе на Debian всё необходимо и сгенерировал сайт с документацией на основе Demo репозитория. На Debian 11 это выглядит следующим образом.
Ставим nodejs и npm:
В Debian в репах слишком старая версия nodejs, поэтому поставим nvm и с её помощью более свежую версию nodejs. Возможно предыдущий шаг не нужен, но я на всякий случай всё равно установил сначала старую версию, чтобы минимизировать возможные проблемы с какими-то зависимостями.
Смотрим версию:
Всё ОК.
Устанавливаем Antora.
Проверяем установленную версию:
Установка завершена. Теперь можно сгенерировать сайт на основе существующих репозиториев. Формат конфигурации antora - yaml. Вот примерный конфиг:
Взяли два разных источника в git, разные версии и ветки. Анторе достаточно доступа для чтения. Запускаем генерацию сайта:
В директории build/site находятся статические файлы сайта. Можете скопировать директорию к себе и запустить локально, либо установить nginx и скопировать содержимое этой директории в дефолтную директорию /var/www/html и посмотреть содержимое.
В принципе, большого смысла устанавливать Andora у себя нет, так как её достаточно один раз запустить и сгенерировать сайт. Можно воспользоваться готовым Docker контейнером.
Структура и формат такой документации прост, удобен и функционален. Документация самой Antora сделана с её же помощью, так что можно оценить функционал.
Напомню, что ранее я уже делал обзоры на популярные системы для ведения документации:
▪️ Mermaid — известный и популярный инструмент для создания визуализаций и диаграмм на основе написанного кода.
▪️ MkDocs — инструмент для генерации документации в виде статического сайта на базе текстовых файлов в формате markdown.
▪️ BookStack — open source платформа для создания документации и вики-контента.
▪️ Wiki.js — готовая wiki платформа с поддержкой редакторов wiki, markdown, wysiwyg.
⇨ Сайт / Исходники
#docs
Как я уже сказал, Antora стоит рассматривать, если вам нужна документация профессионального уровня с различными продуктами, ветками, версиями. Это инструмент для технических писателей. Хотя ничего особо сложного там нет, просто нужно будет погрузиться в продукт и немного его изучить, прежде чем начать пользоваться. Это посложнее, чем та же wiki разметка.
У Antora свой язык разметки и взаимосвязей, с которым нужно будет ознакомиться, чтобы создавать и поддерживать более ли менее сложную документацию. Всё это описано в документации Анторы. Там же приведён Demo репозиторий, на основе которого можно собрать документацию и посмотреть, как работает генерация, и как потом выглядит сам сайт.
Я установил себе на Debian всё необходимо и сгенерировал сайт с документацией на основе Demo репозитория. На Debian 11 это выглядит следующим образом.
Ставим nodejs и npm:
# apt install nodejs npmВ Debian в репах слишком старая версия nodejs, поэтому поставим nvm и с её помощью более свежую версию nodejs. Возможно предыдущий шаг не нужен, но я на всякий случай всё равно установил сначала старую версию, чтобы минимизировать возможные проблемы с какими-то зависимостями.
# curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh \| bash# source .bashrc# nvm install --ltsСмотрим версию:
# node --versionv18.13.0Всё ОК.
Устанавливаем Antora.
# mkdir docs-site && cd docs-site# node -e "fs.writeFileSync('package.json', '{}')"# npm i -D -E @antora/cli@3.1 @antora/site-generator@3.1# npm i -g @antora/cli@3.1 @antora/site-generator@3.1Проверяем установленную версию:
# antora -v@antora/cli: 3.1.2@antora/site-generator: 3.1.2Установка завершена. Теперь можно сгенерировать сайт на основе существующих репозиториев. Формат конфигурации antora - yaml. Вот примерный конфиг:
site: title: Antora Docs start_page: component-b::index.adoc content: sources: - url: https://gitlab.com/antora/demo/demo-component-a.git branches: HEAD - url: https://gitlab.com/antora/demo/demo-component-b.git branches: [v2.0, v1.0] start_path: docsui: bundle: url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/HEAD/raw/build/ui-bundle.zip?job=bundle-stable snapshot: trueВзяли два разных источника в git, разные версии и ветки. Анторе достаточно доступа для чтения. Запускаем генерацию сайта:
# antora --fetch antora-playbook.ymlВ директории build/site находятся статические файлы сайта. Можете скопировать директорию к себе и запустить локально, либо установить nginx и скопировать содержимое этой директории в дефолтную директорию /var/www/html и посмотреть содержимое.
В принципе, большого смысла устанавливать Andora у себя нет, так как её достаточно один раз запустить и сгенерировать сайт. Можно воспользоваться готовым Docker контейнером.
Структура и формат такой документации прост, удобен и функционален. Документация самой Antora сделана с её же помощью, так что можно оценить функционал.
Напомню, что ранее я уже делал обзоры на популярные системы для ведения документации:
▪️ Mermaid — известный и популярный инструмент для создания визуализаций и диаграмм на основе написанного кода.
▪️ MkDocs — инструмент для генерации документации в виде статического сайта на базе текстовых файлов в формате markdown.
▪️ BookStack — open source платформа для создания документации и вики-контента.
▪️ Wiki.js — готовая wiki платформа с поддержкой редакторов wiki, markdown, wysiwyg.
⇨ Сайт / Исходники
#docs
{kind=link}
Недавно делал обзор простых систем мониторинга для одиночного сервера Linux. Меня один человек спросил, а есть ли что-то похожее для Windows. Я призадумался и понял, что ничего подобного не знаю. Под Windows судя по всему не принято писать подобные программы. Возможно это связано с тем, что там есть встроенный Системный монитор (perfmon), в котором можно собрать всевозможные счётчики и метрики.
Заменой простого мониторинга в Windows часто выступают виджеты рабочего стола, которые то появляются в какой-то редакции, то исчезают в следующей. Не знаю, зачем это делают. Я помню, что когда-то давно активно использовал виджеты, выводя на рабочий стол основные системные метрики. Сейчас, к примеру, есть довольно популярный open source продукт на эту тему — rainmeter.
Также для Windows существует много программ с отображением системных метрик и датчиков в режиме реального времени. Например, Open Hardware Monitor и другие подобные программы. Её консольную версию, кстати, удобно использовать для своего мониторинга, забирая нужные метрики.
Всё это, конечно, не тянет на полноценный мониторинг, потому что не хватает хранения исторических данных и оповещений. Я потратил немного времени и поискал что-то на подобии Munin, только для Windows. И не нашёл. Хотя по идее, потребность в этом должна быть. Я и видел, и настраивал много одиночных Windows серверов под тот же терминал, 1С или файловый сервер, где не было централизованной системы мониторинга. Было бы неплохо поставить что-то локально и хотя бы собирать исторические данные, чтобы посмотреть среднюю нагрузку на систему, к примеру, на прошлой недели. Как это быстро реализовать для одиночного сервера?
#windows
Заменой простого мониторинга в Windows часто выступают виджеты рабочего стола, которые то появляются в какой-то редакции, то исчезают в следующей. Не знаю, зачем это делают. Я помню, что когда-то давно активно использовал виджеты, выводя на рабочий стол основные системные метрики. Сейчас, к примеру, есть довольно популярный open source продукт на эту тему — rainmeter.
Также для Windows существует много программ с отображением системных метрик и датчиков в режиме реального времени. Например, Open Hardware Monitor и другие подобные программы. Её консольную версию, кстати, удобно использовать для своего мониторинга, забирая нужные метрики.
Всё это, конечно, не тянет на полноценный мониторинг, потому что не хватает хранения исторических данных и оповещений. Я потратил немного времени и поискал что-то на подобии Munin, только для Windows. И не нашёл. Хотя по идее, потребность в этом должна быть. Я и видел, и настраивал много одиночных Windows серверов под тот же терминал, 1С или файловый сервер, где не было централизованной системы мониторинга. Было бы неплохо поставить что-то локально и хотя бы собирать исторические данные, чтобы посмотреть среднюю нагрузку на систему, к примеру, на прошлой недели. Как это быстро реализовать для одиночного сервера?
#windows
{kind=link}
Обновил и полностью актуализировал популярную статью на своём сайте на тему отправки уведомлений из Zabbix в Telegram. Обновил некоторые картинки, проверил все описанные способы. Всё актуально и в рабочем состоянии. Если аккуратно повторить по статье, то всё получится.
Отправка уведомлений и графиков из zabbix в telegram
⇨ https://serveradmin.ru/nastroyka-opoveshheniy-zabbix-v-telegram
🟢 В статье описаны три способа отправки оповещений:
1️⃣ Стандартный шаблон, отправляющий сообщения через webhook. Максимально простая и быстрая настройка. Шаблон идёт стандартный вместе с сервером. Если обновлялись со старых релизов и шаблона у вас нет, то взять его можно в репозитории Zabbix. Функционал очень простой — отправлять можно только текст, без какого-либо форматирования или графиков.
2️⃣ Использование скрипта от известного автора ableev (Ilia Ableev). Это внешний скрипт на Python, который нужно отдельно настроить, а потом интегрировать в Zabbix. Тут всё придётся настроить самостоятельно, начиная от настройки самого скрипта, до создания способа оповещения с его помощью. Скрипт умеет отправлять графики в отдельном от текста сообщении.
3️⃣ Третий способ через ещё один внешний скрипт от xxsokolov (Dmitry Sokolov). Там немного сложнее настройка, но функционал скрипта чуть побольше. Основное преимущество над предыдущим скриптом — умеет отправлять графики вместе с текстом в одном сообщении. Так удобнее воспринимать информацию. Плюс настроек по оформлению побольше.
Я в разное время использовал все три способа. Сейчас ещё раз их проверил — работают нормально. Если лень заморачиваться, то использую первый способ. Если для себя делаю, то настраиваю второй или третий.
Статья довольно популярная. И в комментариях море вопросов и ошибок. И все они от невнимательности. Если аккуратно и вдумчиво повторять, то всё получится.
Помимо непосредственно отправки оповещений, в статье показываю, как реализуются различные схемы уведомлений на разные события разным пользователям и группам. Одни получают оповещения по почте, вторые только конкретные сообщения в личку телеграм, третьи оповещения летят в общую группу.
#zabbix
Отправка уведомлений и графиков из zabbix в telegram
⇨ https://serveradmin.ru/nastroyka-opoveshheniy-zabbix-v-telegram
🟢 В статье описаны три способа отправки оповещений:
1️⃣ Стандартный шаблон, отправляющий сообщения через webhook. Максимально простая и быстрая настройка. Шаблон идёт стандартный вместе с сервером. Если обновлялись со старых релизов и шаблона у вас нет, то взять его можно в репозитории Zabbix. Функционал очень простой — отправлять можно только текст, без какого-либо форматирования или графиков.
2️⃣ Использование скрипта от известного автора ableev (Ilia Ableev). Это внешний скрипт на Python, который нужно отдельно настроить, а потом интегрировать в Zabbix. Тут всё придётся настроить самостоятельно, начиная от настройки самого скрипта, до создания способа оповещения с его помощью. Скрипт умеет отправлять графики в отдельном от текста сообщении.
3️⃣ Третий способ через ещё один внешний скрипт от xxsokolov (Dmitry Sokolov). Там немного сложнее настройка, но функционал скрипта чуть побольше. Основное преимущество над предыдущим скриптом — умеет отправлять графики вместе с текстом в одном сообщении. Так удобнее воспринимать информацию. Плюс настроек по оформлению побольше.
Я в разное время использовал все три способа. Сейчас ещё раз их проверил — работают нормально. Если лень заморачиваться, то использую первый способ. Если для себя делаю, то настраиваю второй или третий.
Статья довольно популярная. И в комментариях море вопросов и ошибок. И все они от невнимательности. Если аккуратно и вдумчиво повторять, то всё получится.
Помимо непосредственно отправки оповещений, в статье показываю, как реализуются различные схемы уведомлений на разные события разным пользователям и группам. Одни получают оповещения по почте, вторые только конкретные сообщения в личку телеграм, третьи оповещения летят в общую группу.
#zabbix
Server Admin
Настройка оповещений zabbix в telegram
Несколько способов отправки оповещений из zabbix в telegram. В том числе пример с отправкой графиков вместе с событиями.
У меня основная рабочая система Windows 11, поэтому периодически пишу заметки по её настройке. Кстати, 11-ю версию не советую ставить. В ней есть неприятные баги. Например, аутентификация по RDP не работает, если использовать в качестве имени пользователя Администратор по-русски. Проблема исключительно с этим именем. Английский Administrator нормально проходит аутентификацию. У меня есть сервера с русским администратором и меня напрягает решать каждый раз эту задачу. Если кто-то сталкивался и решил проблему, дайте знать. Я не смог найти решение. Перепробовал всё, что только нашёл по ней.
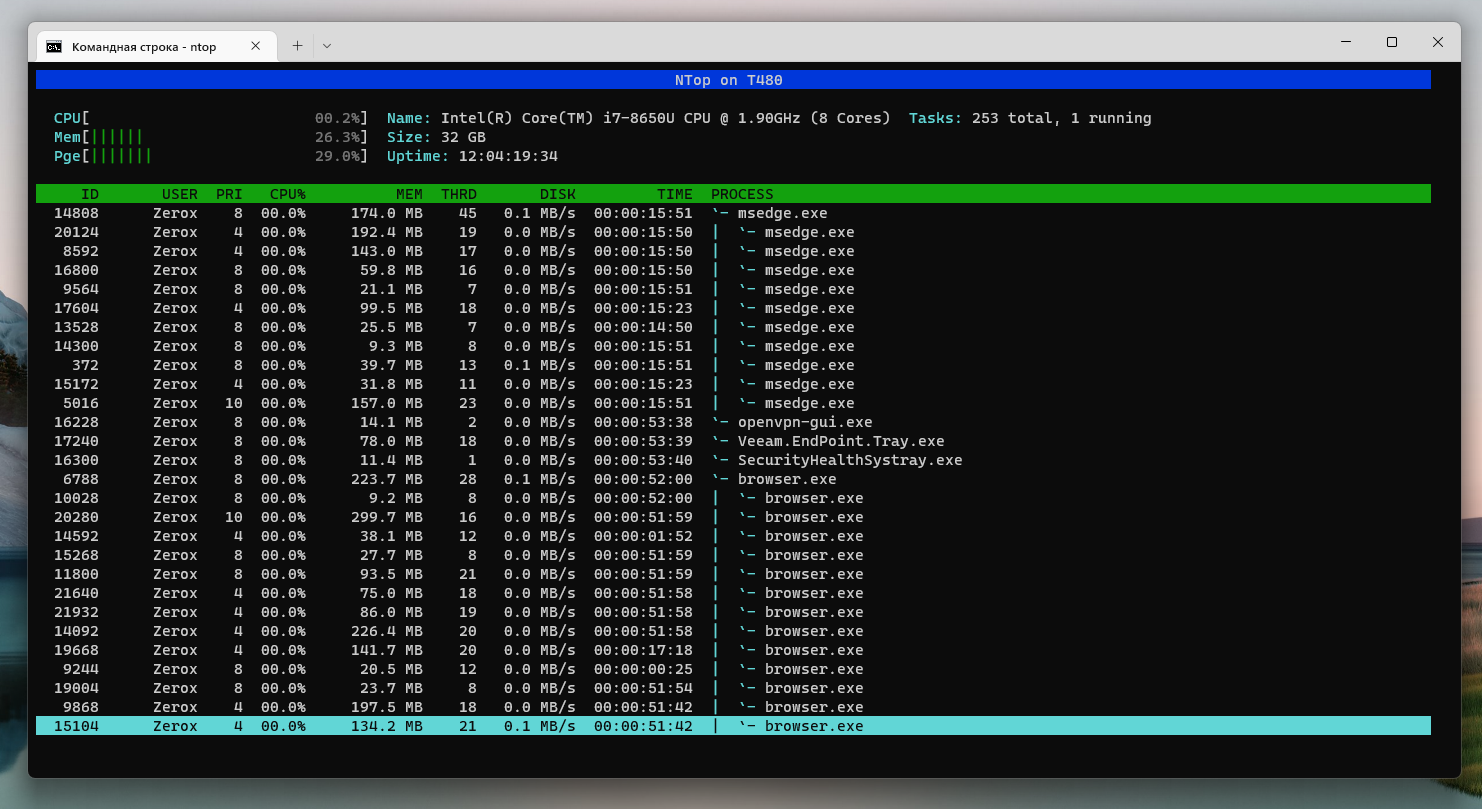
Рассказать я хотел не об этом. Когда искал что-то на github для Windows, попался в поиске репозиторий с NTop. Заинтересовало название, поэтому решил посмотреть, что это такое. Оказалось, что это попытка сделать клон линуксового диспетчера задач htop, который лично я ставлю на все сервера под своим управлением. Мне нравится эта программа.
NTop есть в виндовом магазине приложений. Так что поставить его просто:
Консоль должна быть запущена с правами администратора.
После этого можно запускать аналог htop в консоли Windows. Она у меня почти всегда запущена, так что довольно удобно получается. Этот диспетчер более легкий и информативный для беглого просмотра списка процессов. Так что я себе установил и буду пользоваться.
Функционал у NTop беднее, чем у htop. Практически ничего не реализовано, кроме базового просмотра процессов, их завершение и различная сортировка на основе потребления памяти или cpu. Также поддерживается древовидное отображение процессов, что удобно и более информативно по сравнению с встроенным диспетчером задач.
Попробуйте, может вам тоже понравится.
⇨ Исходники
#windows
Рассказать я хотел не об этом. Когда искал что-то на github для Windows, попался в поиске репозиторий с NTop. Заинтересовало название, поэтому решил посмотреть, что это такое. Оказалось, что это попытка сделать клон линуксового диспетчера задач htop, который лично я ставлю на все сервера под своим управлением. Мне нравится эта программа.
NTop есть в виндовом магазине приложений. Так что поставить его просто:
> winget install ntopКонсоль должна быть запущена с правами администратора.
После этого можно запускать аналог htop в консоли Windows. Она у меня почти всегда запущена, так что довольно удобно получается. Этот диспетчер более легкий и информативный для беглого просмотра списка процессов. Так что я себе установил и буду пользоваться.
Функционал у NTop беднее, чем у htop. Практически ничего не реализовано, кроме базового просмотра процессов, их завершение и различная сортировка на основе потребления памяти или cpu. Также поддерживается древовидное отображение процессов, что удобно и более информативно по сравнению с встроенным диспетчером задач.
Попробуйте, может вам тоже понравится.
⇨ Исходники
#windows
{kind=link}
На днях по новостным лентам пролетела новость на тему рекомендаций по безопасной настройки Linux от ФСТЭК. Думаю, многие из вас её видели. Меня заинтересовал документ, и я его внимательно прочитал и постарался осмыслить.
⇨ Сразу приведу ссылку на оригинал
В целом, документ показался полезным, так как на русском языке таких материалов довольно мало. Где-то половину рекомендаций я не понял, особенно связанных с настройками ядер и загрузчика. Нужно погружаться в тему. А то, что касается пользователей, прав доступа к бинарникам и задачам из cron всё по делу. Также понятны рекомендации отключить некоторый функционал ядра, если он не используется (user_namespaces, vsyscall и т.д.).
Я бы обратил ваше внимание и взял на вооружение, как лист проверки при настройке системы первые несколько разделов:
▪ Настройка авторизации в операционных системах Linux
▪ Ограничение механизмов получения привилегий
▪ Настройка прав доступа к объектам файловой системы
По ним также полезно пройтись после взлома вашей системы, если нет возможности её переустановить, а стоит задача вернуть работоспособность.
В документе очень не хватает подробностей про вектора атаки. Некоторые рекомендации по ядру не понятны даже с учётом того, что ты понимаешь смысл настроек.
Также я совершенно не понял, почему не уделили внимание настройке firewall. Какая может быть безопасность сервера, если к его сервисам не ограничили доступ на уровне брендмауэера. Для безопасности как минимум нужно упомянуть о том, что по умолчанию должен быть включен режим работы нормально закрытый. При этом виде настройки firewall всё запрещено, что не разрешено явно.
Практика подобных рекомендаций от гос. структур распространена в мире. Можете для общего развития или из любопытства посмотреть похожие рекомендации от гос. органов USA и UK:
⇨ https://ncp.nist.gov/checklist/909
⇨ https://security-guidance.service.justice.gov.uk/system-lockdown-and-hardening-standard/
У американцев сразу представлены готовые плейбуки ansible для применения на системах RHEL. А у англичан текстом перечислены прямо на странице. Интересно было ознакомиться. Про сеть там, кстати, не забыли:
◽ An application firewall shall be installed. The firewall shall be configured to ‘allow only essential services’, log firewall activity, and operate in ‘stealth mode’ (undiscoverable).
◽ ICMP redirects shall be disabled.
◽ Idle connections shall be disconnected after a default period; normally less than 30 minutes.
⚡️И ещё вам в копилочку очень подробный англоязычный материал на тему повышения безопасности в ОС на базе ядра Linux - Linux Hardening Guide. У неё любопытное начало: Linux is not a secure operating system. И дальше представлены шаги, следуя которым это можно исправить.
Если кто-то ознакомился и увидел явно вредные советы или скрытые неочевидные проблемы от настроек в документе ФСТЭК, поделитесь информацией. У меня появилось желание оформить это как-то более подробно в отдельную статью. Думаю, это было бы полезно.
#security
⇨ Сразу приведу ссылку на оригинал
В целом, документ показался полезным, так как на русском языке таких материалов довольно мало. Где-то половину рекомендаций я не понял, особенно связанных с настройками ядер и загрузчика. Нужно погружаться в тему. А то, что касается пользователей, прав доступа к бинарникам и задачам из cron всё по делу. Также понятны рекомендации отключить некоторый функционал ядра, если он не используется (user_namespaces, vsyscall и т.д.).
Я бы обратил ваше внимание и взял на вооружение, как лист проверки при настройке системы первые несколько разделов:
▪ Настройка авторизации в операционных системах Linux
▪ Ограничение механизмов получения привилегий
▪ Настройка прав доступа к объектам файловой системы
По ним также полезно пройтись после взлома вашей системы, если нет возможности её переустановить, а стоит задача вернуть работоспособность.
В документе очень не хватает подробностей про вектора атаки. Некоторые рекомендации по ядру не понятны даже с учётом того, что ты понимаешь смысл настроек.
Также я совершенно не понял, почему не уделили внимание настройке firewall. Какая может быть безопасность сервера, если к его сервисам не ограничили доступ на уровне брендмауэера. Для безопасности как минимум нужно упомянуть о том, что по умолчанию должен быть включен режим работы нормально закрытый. При этом виде настройки firewall всё запрещено, что не разрешено явно.
Практика подобных рекомендаций от гос. структур распространена в мире. Можете для общего развития или из любопытства посмотреть похожие рекомендации от гос. органов USA и UK:
⇨ https://ncp.nist.gov/checklist/909
⇨ https://security-guidance.service.justice.gov.uk/system-lockdown-and-hardening-standard/
У американцев сразу представлены готовые плейбуки ansible для применения на системах RHEL. А у англичан текстом перечислены прямо на странице. Интересно было ознакомиться. Про сеть там, кстати, не забыли:
◽ An application firewall shall be installed. The firewall shall be configured to ‘allow only essential services’, log firewall activity, and operate in ‘stealth mode’ (undiscoverable).
◽ ICMP redirects shall be disabled.
◽ Idle connections shall be disconnected after a default period; normally less than 30 minutes.
⚡️И ещё вам в копилочку очень подробный англоязычный материал на тему повышения безопасности в ОС на базе ядра Linux - Linux Hardening Guide. У неё любопытное начало: Linux is not a secure operating system. И дальше представлены шаги, следуя которым это можно исправить.
Если кто-то ознакомился и увидел явно вредные советы или скрытые неочевидные проблемы от настроек в документе ФСТЭК, поделитесь информацией. У меня появилось желание оформить это как-то более подробно в отдельную статью. Думаю, это было бы полезно.
#security
{kind=link}
В дистрибутивах на базе Linux по умолчанию нет никакой корзины, куда бы попадали файлы после обычного удаления, как это происходит в Windows. Мне кажется, что механизм корзины очень удобен. Можно было бы по умолчанию в каком-то виде его реализовать. В некоторых десктопных системах это решается тем или иными способом. Я вам хочу предложить самый простой и очевидный подход, который я придумал просто в лоб.
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
Создайте директорию для корзины:
Добавьте в .bashrc новый алиас:
Перечитайте .bashrc:
Теперь при удалении файла:
он будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
#!/bin/shTRASH_DIR="/tmp/trash"TIMESTAMP=`date +'%d-%b-%Y-%H:%M:%S'`for i in $*; do FILE=`basename $i` mv $i ${TRASH_DIR}/${FILE}.${TIMESTAMP}doneСоздайте директорию для корзины:
# mkdir /tmp/trashДобавьте в .bashrc новый алиас:
alias rm='sh ~/trash.sh'Перечитайте .bashrc:
# source ~/.bashrcТеперь при удалении файла:
# rm filename.txtон будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
filename.txt.26-Jan-2023-17:38:01Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
{kind=link}
Когда только начинал писать скрипты на Linux, в начале скрипта на автомате всегда ставил строку
SH, BASH и DASH — это всё программные оболочки, которые принимают команды, интерпретируют их и передают операционной системе для обработки. Условно их можно назвать интерфейсом между пользователем и операционной системой. В современных дистрибутивах Unix, а также на базе ядра Linux, почти всегда присутствует оболочка SH, чаще всего есть и BASH, а на Debian или Ubuntu есть ещё и DASH.
◽ SH — Bourne Shell, поддерживает стандарт POSIX
◽ BASH — Bourne Again Shell, по умолчанию не совместим с POSIX
◽ DASH — Debian Almquist Shell, поддерживает стандарт POSIX
Скажу кратко, чем они различаются. SH имеет минимальный набор возможностей. BASH включает в себя всё, что умеет SH и добавляет сверху дополнительный функционал. После появления BASH, эта оболочка стала фактически стандартом для большинства операционных систем. Даже если в системе присутствует SH, скорее всего это будет символьная ссылка на BASH. Поэтому в большинстве случаев не имеет значения, какую оболочку вы укажите в скрипте, исполнена она будет в BASH.
Отдельно стоит оболочка DASH, которую можно встретить в дистрибутивах на базе Debian. В них символьная ссылка SH ведёт на DASH.
DASH это тоже Bourne Shell совместимая оболочка, только более легковесная по сравнению с BASH. Соответственно и функционала у неё меньше. На обычных скриптах разницу между BASH и DASH вы вряд ли заметите. А вот если у вас циклы на тысячи или десятки тысяч операций, разница будет существенна. DASH может отработать быстрее в несколько раз.
❗️Поддержка стандарта POSIX означает, что скрипт в любой оболочке, поддерживающей этот стандарт, будет выполнен корректно и одинаково. Что, как вы понимаете, для BASH будет не так. Хотя у него есть отдельный ключ, включающий исполнение кода в соответствии с POSIX.
Я для себя сделал вывод, что проще всего везде явно указывать BASH, потому что во всех системах, с которыми я работаю, есть эта оболочка. Если вы точно знаете, что функционала SH будет достаточно, а скрипт будет выполняться часто, например, как в скрипте с реализацией корзины, то можно явно указать SH или DASH. Отклик на команду будет чуть меньше, чем в BASH, что в некоторых случаях может быть заметно. Также, если вам нужен код, который будет одинаково работать на максимально возможном количестве систем, имеет смысл писать его сразу в SH.
#terminal #linux #bash
#!/bin/sh без особого понимания, для чего это. Потом заметил в других скриптах, что у кого-то там стоит #!/bin/bash. Пришлось разобраться с этой темой. Недавно случайно заметил, когда перешёл на Debian, что там используется dash. Раньше вообще не припоминаю, чтобы сталкивался с таким названием оболочки. Постараюсь своими словами рассказать вам, что всё это значит. SH, BASH и DASH — это всё программные оболочки, которые принимают команды, интерпретируют их и передают операционной системе для обработки. Условно их можно назвать интерфейсом между пользователем и операционной системой. В современных дистрибутивах Unix, а также на базе ядра Linux, почти всегда присутствует оболочка SH, чаще всего есть и BASH, а на Debian или Ubuntu есть ещё и DASH.
◽ SH — Bourne Shell, поддерживает стандарт POSIX
◽ BASH — Bourne Again Shell, по умолчанию не совместим с POSIX
◽ DASH — Debian Almquist Shell, поддерживает стандарт POSIX
Скажу кратко, чем они различаются. SH имеет минимальный набор возможностей. BASH включает в себя всё, что умеет SH и добавляет сверху дополнительный функционал. После появления BASH, эта оболочка стала фактически стандартом для большинства операционных систем. Даже если в системе присутствует SH, скорее всего это будет символьная ссылка на BASH. Поэтому в большинстве случаев не имеет значения, какую оболочку вы укажите в скрипте, исполнена она будет в BASH.
Отдельно стоит оболочка DASH, которую можно встретить в дистрибутивах на базе Debian. В них символьная ссылка SH ведёт на DASH.
# ls -l /bin/shlrwxrwxrwx 1 root root 4 Dec 6 21:51 /bin/sh -> dashDASH это тоже Bourne Shell совместимая оболочка, только более легковесная по сравнению с BASH. Соответственно и функционала у неё меньше. На обычных скриптах разницу между BASH и DASH вы вряд ли заметите. А вот если у вас циклы на тысячи или десятки тысяч операций, разница будет существенна. DASH может отработать быстрее в несколько раз.
❗️Поддержка стандарта POSIX означает, что скрипт в любой оболочке, поддерживающей этот стандарт, будет выполнен корректно и одинаково. Что, как вы понимаете, для BASH будет не так. Хотя у него есть отдельный ключ, включающий исполнение кода в соответствии с POSIX.
Я для себя сделал вывод, что проще всего везде явно указывать BASH, потому что во всех системах, с которыми я работаю, есть эта оболочка. Если вы точно знаете, что функционала SH будет достаточно, а скрипт будет выполняться часто, например, как в скрипте с реализацией корзины, то можно явно указать SH или DASH. Отклик на команду будет чуть меньше, чем в BASH, что в некоторых случаях может быть заметно. Также, если вам нужен код, который будет одинаково работать на максимально возможном количестве систем, имеет смысл писать его сразу в SH.
#terminal #linux #bash
{kind=link}
Решил начать новую рубрику на канале с мемасиками. Я сам не особо люблю, когда постоянно публикуются картинки в каналах. Тем не менее, я их иногда смотрю, и что-то нравится, вызывает улыбку. Так что, думаю, одной картинки в неделю по пятницам будет достаточно. Публиковать буду то, что сам видел в течении недели и то, что показалось наиболее интересным.
Если у вас есть желание поделиться чем-то прикольным, то можно это делать в комментариях. К подобным постам это будет уместно. Мультик из мема недавно просматривал с детьми. Очень клёвый, рекомендую.
#мем
Если у вас есть желание поделиться чем-то прикольным, то можно это делать в комментариях. К подобным постам это будет уместно. Мультик из мема недавно просматривал с детьми. Очень клёвый, рекомендую.
#мем
▶️ Недавно школа Слёрм проводила бесплатную трехдневную онлайн конференцию на тему мониторинга. Если она вам близка, то обратите внимание. У меня, конечно, не было времени всё это смотреть, но краем уха в фоне кое-что слушал.
Все выступления аккуратно обрезаны по темам и залиты на youtube канал. Можете быстро оценить по названиям, что вам интересно, и посмотреть. Выступления комфортной длины в 20-30 минут. Если же хотите увидеть полные записи всех трёх дней, то они выложены в отдельном play листе.
Конференция была сделана не для галочки. Выступали хорошие специалисты, некоторые известные люди в своих кругах. Темы рассматривали злободневные и актуальные.
Описание всех докладов есть на отдельной странице мероприятия. Там же и ссылки на выступления в более удобном виде. Мне понравились следующие темы:
◽Начинаем внедрять мониторинг, без боли, регистрации и смс
◽Горшочек, не вари! Сколько алертов вам нужно?
◽Удобная работа с алертами, организация дежурных ротаций с помощью GrafanaOncall
◽Grafana Loki как инструмент для сбора логов с вашей инфраструктуры
◽Кастомизация шаблонов для Zabbix
◽Мониторинг маркетинговых показателей
#видео #мониторинг
Все выступления аккуратно обрезаны по темам и залиты на youtube канал. Можете быстро оценить по названиям, что вам интересно, и посмотреть. Выступления комфортной длины в 20-30 минут. Если же хотите увидеть полные записи всех трёх дней, то они выложены в отдельном play листе.
Конференция была сделана не для галочки. Выступали хорошие специалисты, некоторые известные люди в своих кругах. Темы рассматривали злободневные и актуальные.
Описание всех докладов есть на отдельной странице мероприятия. Там же и ссылки на выступления в более удобном виде. Мне понравились следующие темы:
◽Начинаем внедрять мониторинг, без боли, регистрации и смс
◽Горшочек, не вари! Сколько алертов вам нужно?
◽Удобная работа с алертами, организация дежурных ротаций с помощью GrafanaOncall
◽Grafana Loki как инструмент для сбора логов с вашей инфраструктуры
◽Кастомизация шаблонов для Zabbix
◽Мониторинг маркетинговых показателей
#видео #мониторинг
{kind=link}
Мне на днях в комментариях подсказали полезный сайт на тему безопасности. Раньше про него не слышал. Я обычно все рекомендации в общую очередь постов ставлю, где они чаще всего несколько месяцев проводят и при моём повторном внимании с подтверждением полезности оформляются в отдельную публикацию. А тут решил сразу изучить и написать, потому что сайт очень понравился.
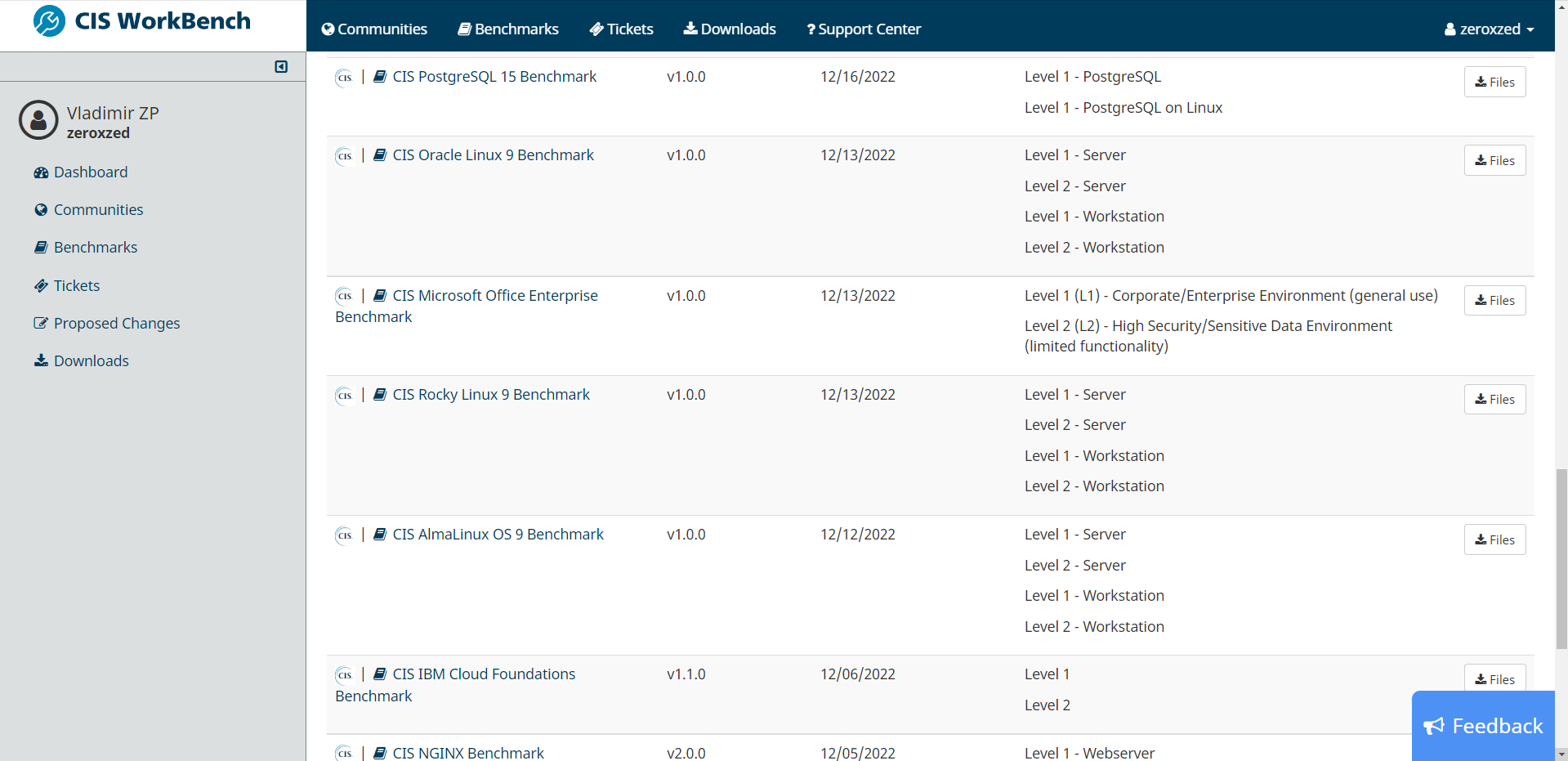
Речь пойдёт про workbench.cisecurity.org (CIS — Center for Internet Security). Это некоммерческая организация, которая разрабатывает собственные рекомендации по обеспечению безопасности различных систем. Там представлены как настройки различных операционных систем (win, lin, macos и т.д.) и готовых продуктов на их основе (sophos, pfsense и т.д.), так и одиночных программ (nginx, apache, mysql, elasticsearch, mongodb и т.д.)
При этом рекомендации максимально подробные с описанием конкретных действий, которые надо сделать, вектором атак и общей теории по проблеме. Например, есть какая-то ОС Linux. Есть рекомендация отключить поддержку всех неиспользуемых файловых систем. И сразу представлены команды, как посмотреть, какие фс поддерживаются и как выгрузить модули ядра, которые осуществляют поддержку. Всё очень понятно и подробно.
Я посмотрел некоторые документы по системам и программам, которые сам использую. Очень понравилась подача. Увидел некоторые вещи, про которые даже не слышал раньше. Появилось большое желание что-то нужное мне перевести, сократить и оформить в короткие рекомендации. Но не знаю, как получится. На это надо много времени. Документы на сайте CIS очень объёмные. С одной стороны это хорошо, если хочешь подробно изучить тему, а с другой плохо, потому что если тебе нужно только выполнить основные рекомендации, без детального погружения, ничего не выйдет. А не всем и не всегда нужно изучать материал на уровне специалиста по безопасности.
Для примера скачал и выложил 3 документа оттуда по настройке Debian 11, Nginx, PostgreSQL 15.
⇨ https://disk.yandex.ru/d/P1Ph7IvUKHmnKQ
#security #cis
Речь пойдёт про workbench.cisecurity.org (CIS — Center for Internet Security). Это некоммерческая организация, которая разрабатывает собственные рекомендации по обеспечению безопасности различных систем. Там представлены как настройки различных операционных систем (win, lin, macos и т.д.) и готовых продуктов на их основе (sophos, pfsense и т.д.), так и одиночных программ (nginx, apache, mysql, elasticsearch, mongodb и т.д.)
При этом рекомендации максимально подробные с описанием конкретных действий, которые надо сделать, вектором атак и общей теории по проблеме. Например, есть какая-то ОС Linux. Есть рекомендация отключить поддержку всех неиспользуемых файловых систем. И сразу представлены команды, как посмотреть, какие фс поддерживаются и как выгрузить модули ядра, которые осуществляют поддержку. Всё очень понятно и подробно.
Я посмотрел некоторые документы по системам и программам, которые сам использую. Очень понравилась подача. Увидел некоторые вещи, про которые даже не слышал раньше. Появилось большое желание что-то нужное мне перевести, сократить и оформить в короткие рекомендации. Но не знаю, как получится. На это надо много времени. Документы на сайте CIS очень объёмные. С одной стороны это хорошо, если хочешь подробно изучить тему, а с другой плохо, потому что если тебе нужно только выполнить основные рекомендации, без детального погружения, ничего не выйдет. А не всем и не всегда нужно изучать материал на уровне специалиста по безопасности.
Для примера скачал и выложил 3 документа оттуда по настройке Debian 11, Nginx, PostgreSQL 15.
⇨ https://disk.yandex.ru/d/P1Ph7IvUKHmnKQ
#security #cis
{kind=link}
Максимально простое, автоматизированное и современное решение для управления удаленным доступом сотрудников.
Alphabyte ZTNA позволит вам легко управлять доступом к корпоративным ресурсам, а вашим сотрудникам — быстро подключаться к любой корпоративной сети и безопасно работать из любой точки мира. Устанавливайте свои правила доступа к тем или иным корпоративным ресурсам: по ролям, типу трафика, дню недели, протоколу и порту.
Демоверсия с полным доступом к сервису — 90 дней до конца января. Попробуйте сами: https://clck.ru/33JARa
#реклама
Alphabyte ZTNA позволит вам легко управлять доступом к корпоративным ресурсам, а вашим сотрудникам — быстро подключаться к любой корпоративной сети и безопасно работать из любой точки мира. Устанавливайте свои правила доступа к тем или иным корпоративным ресурсам: по ролям, типу трафика, дню недели, протоколу и порту.
Демоверсия с полным доступом к сервису — 90 дней до конца января. Попробуйте сами: https://clck.ru/33JARa
#реклама
Хочу познакомить вас с простой и крайне полезной консольной утилитой в Linux — basename. Я её регулярно использую при написании bash скриптов для различных задач. В примерах, которыми я с вами делился здесь, она тоже встречалась.
С помощью basename удобно извлечь имя файла из полного пути.
Вместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
Вот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
Очевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
Или ещё раз то же самое, только с помощью find, sed, xargs:
Скрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
С помощью basename удобно извлечь имя файла из полного пути.
# basename /var/log/auth.logauth.logВместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
# basename /var/log/auth.log .logauthВот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
# rsync -av --files-from=<(ssh root@10.20.1.50 '/usr/bin/find /var/lib/pgpro/backup -type f -mtime -1 -exec basename {} \; | egrep -v timestamp') root@10.20.1.5:/var/lib/pgpro/backup/ /data/backup/Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
--files-from. Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
# for file in *.txt; do mv -- "$file" "$(basename $file .txt).log"; doneОчевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
# rename 's/.txt/.log/g' *.txtИли ещё раз то же самое, только с помощью find, sed, xargs:
# find . -type f | sed 'p;s:.txt:.log:g' | xargs -n2 mvСкрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
{kind=link}
Ранее я уже затрагивал тему работы с регулярными выражениями, рассказав про сервис regex101.com. Хочу её немного развить и дополнить ещё несколькими полезными ссылками, которые имеет смысл собрать в одном месте, чтобы воспользоваться, когда нужно будет написать очередную регулярку.
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
Копирую полученную строку в grex, получаю регулярку:
Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
#!/bin/bashcount=1while [ $count -le 256 ]doecho 192.168.0.$countcount=$(( $count + 1 ))doneКопирую полученную строку в grex, получаю регулярку:
^192\.168\.0\.(?:2(?:5[0-6]|[6-9])|(?:1[0-9]|2[0-4]|[3-9])[0-9]?|25?|1)$Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
{kind=link}
Летом была новость, что у платной программы HDDSuperClone были открыты исходники. Она стала полностью бесплатной, в том числе Pro версия. Я сейчас кратко поясню в чём её особенность и предложу вам связку из двух программ, сохранить себе на чёрный день, если вдруг понадобится восстановить данные с обычных дисков. Их хоть активно и заменяют SSD, но тем не мнее, HDD ещё используются. У меня как-то в NAS накрылся обычный диск, пришлось восстанавливать данные. Писал статью об этом.
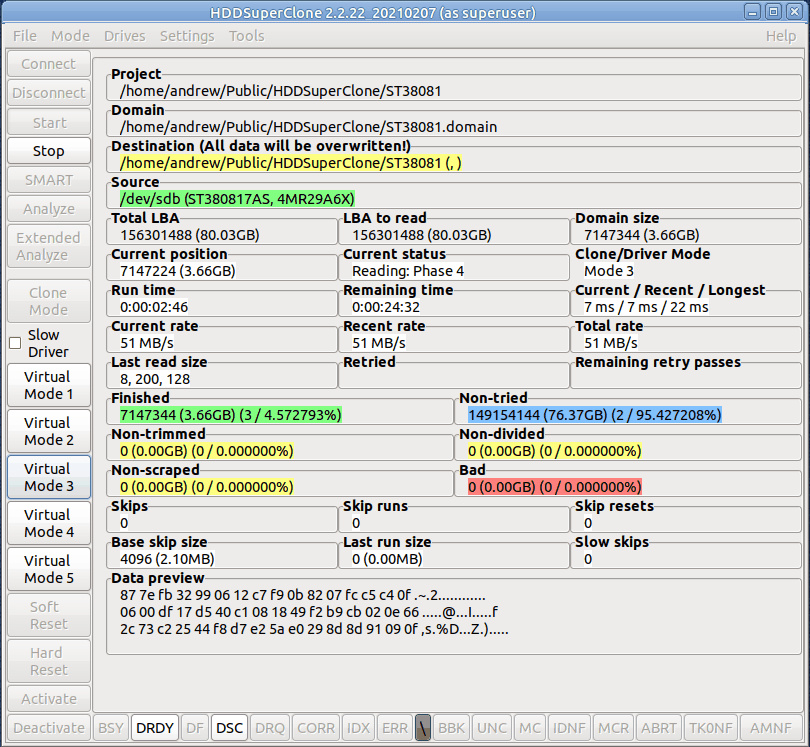
Как ясно из названия, HDDSuperClone предназначена для клонирования неисправных жёстких дисков. Подобного рода программ много, но у этой есть некоторые особенности. Она умеет напрямую обращаться к жёстким дискам и, к примеру, перезапускать их по питанию в случае зависания. Также у неё есть собственный драйвер для работы с дисками.
Принцип работы драйвера следующий. Во время чтения с диска различными программами по восстановлению данных, всё, что удалось прочитать, драйвер пишет на виртуальный диск. А те данные, что нестабильны или их не удаётся сразу прочитать, считываются с диска. Таким образом, увеличивается шанс восстановления данных с минимальным беспокойством сбойного диска. Всё, что удалось с него прочитать и сохранить, считывается с копии, а всё остальное пробуют прочитать с него. Это функционал в прошлом платной версии. Сейчас она бесплатна.
На сайте популярной бесплатной программы для восстановления данных R-Linux есть подробная статья с описанием восстановления данных с умирающего жёсткого диска с помощью связки R-Studio и HDDSuperClone. Сохраните себе эту информацию, чтобы потом не пришлось искать и подбирать программы для этих целей.
⇨ Сайт / Исходники / R-Studio и HDDSuperClone / Видеоинструкции
#restore
Как ясно из названия, HDDSuperClone предназначена для клонирования неисправных жёстких дисков. Подобного рода программ много, но у этой есть некоторые особенности. Она умеет напрямую обращаться к жёстким дискам и, к примеру, перезапускать их по питанию в случае зависания. Также у неё есть собственный драйвер для работы с дисками.
Принцип работы драйвера следующий. Во время чтения с диска различными программами по восстановлению данных, всё, что удалось прочитать, драйвер пишет на виртуальный диск. А те данные, что нестабильны или их не удаётся сразу прочитать, считываются с диска. Таким образом, увеличивается шанс восстановления данных с минимальным беспокойством сбойного диска. Всё, что удалось с него прочитать и сохранить, считывается с копии, а всё остальное пробуют прочитать с него. Это функционал в прошлом платной версии. Сейчас она бесплатна.
На сайте популярной бесплатной программы для восстановления данных R-Linux есть подробная статья с описанием восстановления данных с умирающего жёсткого диска с помощью связки R-Studio и HDDSuperClone. Сохраните себе эту информацию, чтобы потом не пришлось искать и подбирать программы для этих целей.
⇨ Сайт / Исходники / R-Studio и HDDSuperClone / Видеоинструкции
#restore
{kind=link}
На днях писал про CIS. Решил не откладывать задачу и проработать документ с рекомендациями по Nginx. Делюсь с вами краткой выжимкой. Я буду брать более ли менее актуальные рекомендации для среднетиповых веб серверов. Например, отключать все лишние модули и делать свою сборку в обход готовых пакетов я не вижу для себя смыла.
📌Проверяем наличие настройки autoindex. В большинстве случаев она не нужна. С её помощью работает автоматический обзор содержимого директорий, если в них напрямую зайти, минуя конкретный или индексный файл.
Не должно быть настройки
📌Обращения на несуществующие домены или по ip адресу лучше сразу отклонять. По умолчанию отдаётся приветственная страница. Проверить можно так:
Если в ответ показывает приветственную страницу или что-то отличное от 404, то надо добавить в самую первую секцию server следующие настройки:
Можно просто удалить конфиг с дефолтным хостом, а приведённый код добавить в основной nginx.conf. Тогда это точно будет первая секция server. В остальных секциях server везде должны быть явно указаны
📌Параметр keep-alive timeout имеет смысл сделать 10 секунд или меньше. По умолчанию он не указан и им управляет подключающийся.
То же самое имеет смысл сделать для send_timeout.
Скрываем версию сервера параметром server_tokens. Проверяем так:
Отключаем:
📌Дефолтные страницы index.html и error page лучше отредактировать, удалив всё лишнее. Обычно они хранятся в директориях /usr/share/nginx/html или /var/www/html.
📌Запрещаем доступ к скрытым файлам и директориям, начинающимся с точки. Для этого в добавляем в самое начало виртуального хоста location:
Если нужно исключение, например для директории .well-known, которую использует let's encrypt для выпуска сертификатов, то добавьте его выше предыдущего правила.
📌Скрываем proxy headers. Добавляем в location:
📌Не забываем про настройку логирования. Логи нужны, но настройка сильно индивидуальна. Если логи хранятся локально, то обязательно настроить ротацию не только с привязкой ко времени, но и к занимаемому объёму. В идеале, логи должны храниться где-то удалённо без доступа к ним с веб сервера.
📌Настраиваем передачу реального IP адреса клиента в режиме работы Nginx в качестве прокси.
📌Ограничиваем версию TLS только актуальными 1.2 и 1.3. Если используется режим проксирования, то надо убедиться, что эти версии совпадают на прокси и на сервере. Если не уверены, что все ваши клиенты используют современные версии TLS, то оставьте поддержку более старых, но это не рекомендуется. Настройка для секции http в nginx.conf
📌Настраиваем ssl_ciphers. Список нужно уточнять, вот пример из документа CIS:
Дальше идут более узкие рекомендации типа ограничения доступа по IP, отдельных методов, настройка лимитов, более тонкие настройки таймаутов и т.д. В общем случае это не всегда требует настройки.
Ничего особо нового в документе не увидел. Большую часть представленных настроек я и раньше всегда делал. В дополнение к этому материалу будет актуальна ссылка на предыдущую заметку по настройке Nginx. Надо будет всё свести в общий типовой конфиг для Nginx и опубликовать.
#cis #nginx #security
📌Проверяем наличие настройки autoindex. В большинстве случаев она не нужна. С её помощью работает автоматический обзор содержимого директорий, если в них напрямую зайти, минуя конкретный или индексный файл.
# egrep -i '^\s*autoindex\s+' /etc/nginx/nginx.conf # egrep -i '^\s*autoindex\s+' /etc/nginx/conf.d/*# egrep -i '^\s*autoindex\s+' /etc/nginx/sites-available/*Не должно быть настройки
autoindex on. Если увидите, отключите. 📌Обращения на несуществующие домены или по ip адресу лучше сразу отклонять. По умолчанию отдаётся приветственная страница. Проверить можно так:
# curl -k -v https://127.0.0.1 -H 'Host: invalid.host.com'Если в ответ показывает приветственную страницу или что-то отличное от 404, то надо добавить в самую первую секцию server следующие настройки:
server { return 404;}Можно просто удалить конфиг с дефолтным хостом, а приведённый код добавить в основной nginx.conf. Тогда это точно будет первая секция server. В остальных секциях server везде должны быть явно указаны
server_name. 📌Параметр keep-alive timeout имеет смысл сделать 10 секунд или меньше. По умолчанию он не указан и им управляет подключающийся.
keepalive_timeout 10;То же самое имеет смысл сделать для send_timeout.
send_timeout 10;Скрываем версию сервера параметром server_tokens. Проверяем так:
# curl -I 127.0.0.1 | grep -i serverОтключаем:
server { ... server_tokens off; ... }📌Дефолтные страницы index.html и error page лучше отредактировать, удалив всё лишнее. Обычно они хранятся в директориях /usr/share/nginx/html или /var/www/html.
📌Запрещаем доступ к скрытым файлам и директориям, начинающимся с точки. Для этого в добавляем в самое начало виртуального хоста location:
location ~ /\. { deny all; return 404; }Если нужно исключение, например для директории .well-known, которую использует let's encrypt для выпуска сертификатов, то добавьте его выше предыдущего правила.
location ~ /\.well-known\/acme-challenge { allow all; }📌Скрываем proxy headers. Добавляем в location:
location /docs { .... proxy_hide_header X-Powered-By; proxy_hide_header Server; .... }📌Не забываем про настройку логирования. Логи нужны, но настройка сильно индивидуальна. Если логи хранятся локально, то обязательно настроить ротацию не только с привязкой ко времени, но и к занимаемому объёму. В идеале, логи должны храниться где-то удалённо без доступа к ним с веб сервера.
📌Настраиваем передачу реального IP адреса клиента в режиме работы Nginx в качестве прокси.
server { ... location / { proxy_pass 127.0.0.1:8080); proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; }}📌Ограничиваем версию TLS только актуальными 1.2 и 1.3. Если используется режим проксирования, то надо убедиться, что эти версии совпадают на прокси и на сервере. Если не уверены, что все ваши клиенты используют современные версии TLS, то оставьте поддержку более старых, но это не рекомендуется. Настройка для секции http в nginx.conf
ssl_protocols TLSv1.2 TLSv1.3;📌Настраиваем ssl_ciphers. Список нужно уточнять, вот пример из документа CIS:
ssl_ciphers ALL:!EXP:!NULL:!ADH:!LOW:!SSLv2:!SSLv3:!MD5:!RC4;Дальше идут более узкие рекомендации типа ограничения доступа по IP, отдельных методов, настройка лимитов, более тонкие настройки таймаутов и т.д. В общем случае это не всегда требует настройки.
Ничего особо нового в документе не увидел. Большую часть представленных настроек я и раньше всегда делал. В дополнение к этому материалу будет актуальна ссылка на предыдущую заметку по настройке Nginx. Надо будет всё свести в общий типовой конфиг для Nginx и опубликовать.
#cis #nginx #security
{kind=link}
Давно не писал ничего на тему программ для бэкапа, потому что все наиболее популярные и удобные программы я уже описывал. Рекомендую посмотреть мои прошлые заметки по тэгу #backup, вот эту заметку с подборкой или статью на сайте. Там всё в одном месте собрано. Только не хватает программы restic, писал про неё позже.
Я узнал и попробовал программу bup, про которую раньше не слышал. Она мне понравилась и показалась очень полезной, поэтому решил написать и поделиться с вами. Bup использует тот же алгоритм, что и rsync для деления файлов на фрагменты и проверки контрольных сумм, так что производительность у него на хорошем уровне.
Особенность bup в том, что она использует гитовский формат хранения данных в репозиториях. При этом не возникает проблем с огромным числом файлов и большим объёмом. Плюс такого хранения в том, что легко создаются инкрементные копии, причём данные могут быть совсем разные с разных хостов. Но если они одинаковые, то станут частью инкрементной копии. Это хорошо экономит дисковое пространство.
Bup умеет делать как локальные бэкапы, так и ходить за ними на удалённые серверы по SSH. Есть простенький встроенный веб интерфейс. Всё управление через консоль. Это в первую очередь консольный инструмент для самостоятельного велосипедостроения. Показываю, как его установить на Debian.
Теперь надо выполнить инициализацию репозитория. По умолчанию, он будет в ~/.bup. Задать его можно через переменную окружения BUP_DIR. Добавим её сразу в .bashrc и применим изменения:
Инициализируем репозиторий:
Создаём индекс бэкапа. Для примера возьму директорию /etc на сервере:
Делаем бэкап, назвав его etc с помощью параметра -n:
Посмотреть список репозиториев, файлов или бэкапов можно вот так:
Бэкап удалённой машины делается примерно так:
Доступ к серверу надо настроить по ключам.
Восстановление данных:
Восстановили директорию /etc с ветки latest бэкапа local-etc в директорию /.dest. Соответственно, выбирая разные ветки, вы восстанавливаете данные с того или иного инкрементного бэкапа.
Очень необычная для бэкапов, но при этом весьма удобная схема хранения и работы с данными, точно так же, как с обычными git репозиториями.
У bup есть простенький веб интерфейс, через который можно посмотреть и скачать файлы. По умолчанию он запускается на localhost, поэтому явно указываю интерфейс и порт:
Если кто-то пользуется bup, поделитесь впечатлением. Программа старая и известная, но я про неё ранее не слышал и не пользовался.
⇨ Сайт / Исходники
#backup
Я узнал и попробовал программу bup, про которую раньше не слышал. Она мне понравилась и показалась очень полезной, поэтому решил написать и поделиться с вами. Bup использует тот же алгоритм, что и rsync для деления файлов на фрагменты и проверки контрольных сумм, так что производительность у него на хорошем уровне.
Особенность bup в том, что она использует гитовский формат хранения данных в репозиториях. При этом не возникает проблем с огромным числом файлов и большим объёмом. Плюс такого хранения в том, что легко создаются инкрементные копии, причём данные могут быть совсем разные с разных хостов. Но если они одинаковые, то станут частью инкрементной копии. Это хорошо экономит дисковое пространство.
Bup умеет делать как локальные бэкапы, так и ходить за ними на удалённые серверы по SSH. Есть простенький встроенный веб интерфейс. Всё управление через консоль. Это в первую очередь консольный инструмент для самостоятельного велосипедостроения. Показываю, как его установить на Debian.
# git clone https://github.com/bup/bup# cd bup# git checkout 0.33# apt-get build-dep bup# apt install python3-pip# pip install tornado# make# make installТеперь надо выполнить инициализацию репозитория. По умолчанию, он будет в ~/.bup. Задать его можно через переменную окружения BUP_DIR. Добавим её сразу в .bashrc и применим изменения:
export BUP_DIR=/mnt/backup# source ~./bashrcИнициализируем репозиторий:
# bup initСоздаём индекс бэкапа. Для примера возьму директорию /etc на сервере:
# bup index /etcДелаем бэкап, назвав его etc с помощью параметра -n:
# bup save -n local-etc /etcПосмотреть список репозиториев, файлов или бэкапов можно вот так:
# bup ls# bup ls local-etc# bup ls local-etc/2023-01-31-190941Бэкап удалённой машины делается примерно так:
# bup index /etc# bup save -r SERVER -n backupname /etcДоступ к серверу надо настроить по ключам.
Восстановление данных:
# bup restore -C ./dest local-etc/latest/etcВосстановили директорию /etc с ветки latest бэкапа local-etc в директорию /.dest. Соответственно, выбирая разные ветки, вы восстанавливаете данные с того или иного инкрементного бэкапа.
Очень необычная для бэкапов, но при этом весьма удобная схема хранения и работы с данными, точно так же, как с обычными git репозиториями.
У bup есть простенький веб интерфейс, через который можно посмотреть и скачать файлы. По умолчанию он запускается на localhost, поэтому явно указываю интерфейс и порт:
# bup web 172.25.84.75:8080Если кто-то пользуется bup, поделитесь впечатлением. Программа старая и известная, но я про неё ранее не слышал и не пользовался.
⇨ Сайт / Исходники
#backup
{kind=link}
Когда искал в сети материалы по Loki, наткнулся на интересную статью, где автор хранит в Loki все введённые команды в bash. Понравился подход, поэтому решил его приспособить под свои нужды. Я большого смысла для себя не вижу собирать эти логи где-то во вне, поэтому проработал момент только с сохранением их локально в лог с помощью syslog.
Подход тут простой. Используется переменная bash PROMPT_COMMAND. Её содержимое выполняется после каждой введённой интерактивной команды. Так что достаточно указать выполнение нужного кода в этой переменной, чтобы собирать логи. Я предлагаю такой вариант:
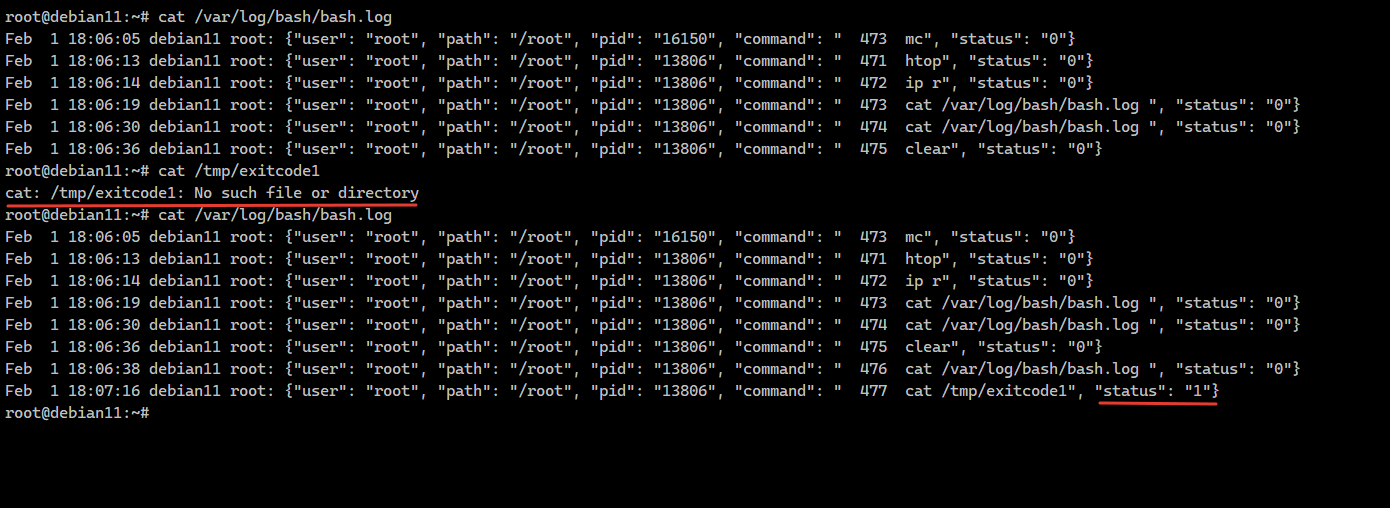
Эту переменную нужно добавить в файл ~/.bashrc и применить изменения, либо просто перезайти пользователем. Данная команда сохраняет имя пользователя, путь, откуда выполнялась команда, pid процесса (в данном случае это всегда будет pid баша, не уверен, что эта информация где-то нужна), сама команда, которая берётся из history, и статус её выполнения. Всё это отправляется в syslog в local6.debug.
Теперь нам надо перехватить этот local6.debug. Добавляем в конфиг /etc/rsyslog.conf одну строку:
создаём директорию и перезапускаем его:
Вот, в принципе, и всё. Теперь после выполнения команды в консоли, она будет сразу улетать в лог. Формат лога - json. Можете его подредактировать для своего удобства.
В статье автор также рассказывает, как можно сохранять вывод команды, но у меня не получилось настроить по его инструкции. Не смог разобраться, как это делать. Да и у него на всех скринах эта функция тоже не работает. А было бы неплохо это реализовать. Если кто-то знает или видел, как это делают, подскажите.
И ещё есть один момент. Если вы работаете в MC, то в историю команд будет прилетать много мусора. Это типичная проблема MC и сохранения истории. Она постоянно возникает, когда пользуешься этим файловым менеджером. Ещё со времён Freebsd с этим сталкивался, так как у MC есть своя отдельная баш консоль, куда залетают команды во время перемещения по директориям.
Напомню ещё способы логирования консольных команд:
◽snoopy
◽log-user-session
Решение с PROMPT_COMMAND наиболее простое и универсальное, так как не требует стороннего софта. Logger и syslog обычно присутствуют во всех популярных дистрибутивах.
#bash #terminal #linux #security
Подход тут простой. Используется переменная bash PROMPT_COMMAND. Её содержимое выполняется после каждой введённой интерактивной команды. Так что достаточно указать выполнение нужного кода в этой переменной, чтобы собирать логи. Я предлагаю такой вариант:
export PROMPT_COMMAND='RETRN_VAL=$?; logger -S 10000 -p local6.debug "{\"user\": \"$(whoami)\", \"path\": \"$(pwd)\", \"pid\": \"$$\", \"command\": \"$(history 1)\", \"status\": \"$RETRN_VAL\"}";'Эту переменную нужно добавить в файл ~/.bashrc и применить изменения, либо просто перезайти пользователем. Данная команда сохраняет имя пользователя, путь, откуда выполнялась команда, pid процесса (в данном случае это всегда будет pid баша, не уверен, что эта информация где-то нужна), сама команда, которая берётся из history, и статус её выполнения. Всё это отправляется в syslog в local6.debug.
Теперь нам надо перехватить этот local6.debug. Добавляем в конфиг /etc/rsyslog.conf одну строку:
local6.* /var/log/bash/bash.logсоздаём директорию и перезапускаем его:
# mkdir -p /var/log/bash# systemctl restart rsyslogВот, в принципе, и всё. Теперь после выполнения команды в консоли, она будет сразу улетать в лог. Формат лога - json. Можете его подредактировать для своего удобства.
В статье автор также рассказывает, как можно сохранять вывод команды, но у меня не получилось настроить по его инструкции. Не смог разобраться, как это делать. Да и у него на всех скринах эта функция тоже не работает. А было бы неплохо это реализовать. Если кто-то знает или видел, как это делают, подскажите.
И ещё есть один момент. Если вы работаете в MC, то в историю команд будет прилетать много мусора. Это типичная проблема MC и сохранения истории. Она постоянно возникает, когда пользуешься этим файловым менеджером. Ещё со времён Freebsd с этим сталкивался, так как у MC есть своя отдельная баш консоль, куда залетают команды во время перемещения по директориям.
Напомню ещё способы логирования консольных команд:
◽snoopy
◽log-user-session
Решение с PROMPT_COMMAND наиболее простое и универсальное, так как не требует стороннего софта. Logger и syslog обычно присутствуют во всех популярных дистрибутивах.
#bash #terminal #linux #security
{kind=link}
Серверы для бизнеса и частных проектов 📱
EKACOD. Data Center предлагает выделенные серверы в аренду от 4990 руб./мес.
Собственная инфраструктура в Екатеринбурге 🇷🇺, уровень Tier III, SLA от 99,98%, опыт работы с 2013 года.
✅ 70+ готовых к работе конфигураций или любая сборка из 1000+ комплектующих;
✅ Полный доступ к управлению сервером: личный кабинет, KVM-консоль, установка ОС, статистика по трафику;
✅ Техническая поддержка 24/7, помощь в настройке и переносе проектов;
✅ Бесплатная замена любых вышедших из строя комплектующих;
✅ Решения для бизнес задач: серверы с GPU, для 1С-Битрикс и 1С:Бухгалтерии;
✅ Сопутствующие услуги ЦОД: каналы связи, диск для бэкапов, защита от DDOS-атак.
Работаем с юридическими и физическими лицами, поддерживаем ЭДО Диадок.
Оформите заказ в несколько кликов на 👉 https://ekacod.ru/
Или напишите нам, мы подберем нужный сервер для ваших задач по выгодной цене.
#реклама
EKACOD. Data Center предлагает выделенные серверы в аренду от 4990 руб./мес.
Собственная инфраструктура в Екатеринбурге 🇷🇺, уровень Tier III, SLA от 99,98%, опыт работы с 2013 года.
✅ 70+ готовых к работе конфигураций или любая сборка из 1000+ комплектующих;
✅ Полный доступ к управлению сервером: личный кабинет, KVM-консоль, установка ОС, статистика по трафику;
✅ Техническая поддержка 24/7, помощь в настройке и переносе проектов;
✅ Бесплатная замена любых вышедших из строя комплектующих;
✅ Решения для бизнес задач: серверы с GPU, для 1С-Битрикс и 1С:Бухгалтерии;
✅ Сопутствующие услуги ЦОД: каналы связи, диск для бэкапов, защита от DDOS-атак.
Работаем с юридическими и физическими лицами, поддерживаем ЭДО Диадок.
Оформите заказ в несколько кликов на 👉 https://ekacod.ru/
Или напишите нам, мы подберем нужный сервер для ваших задач по выгодной цене.
#реклама
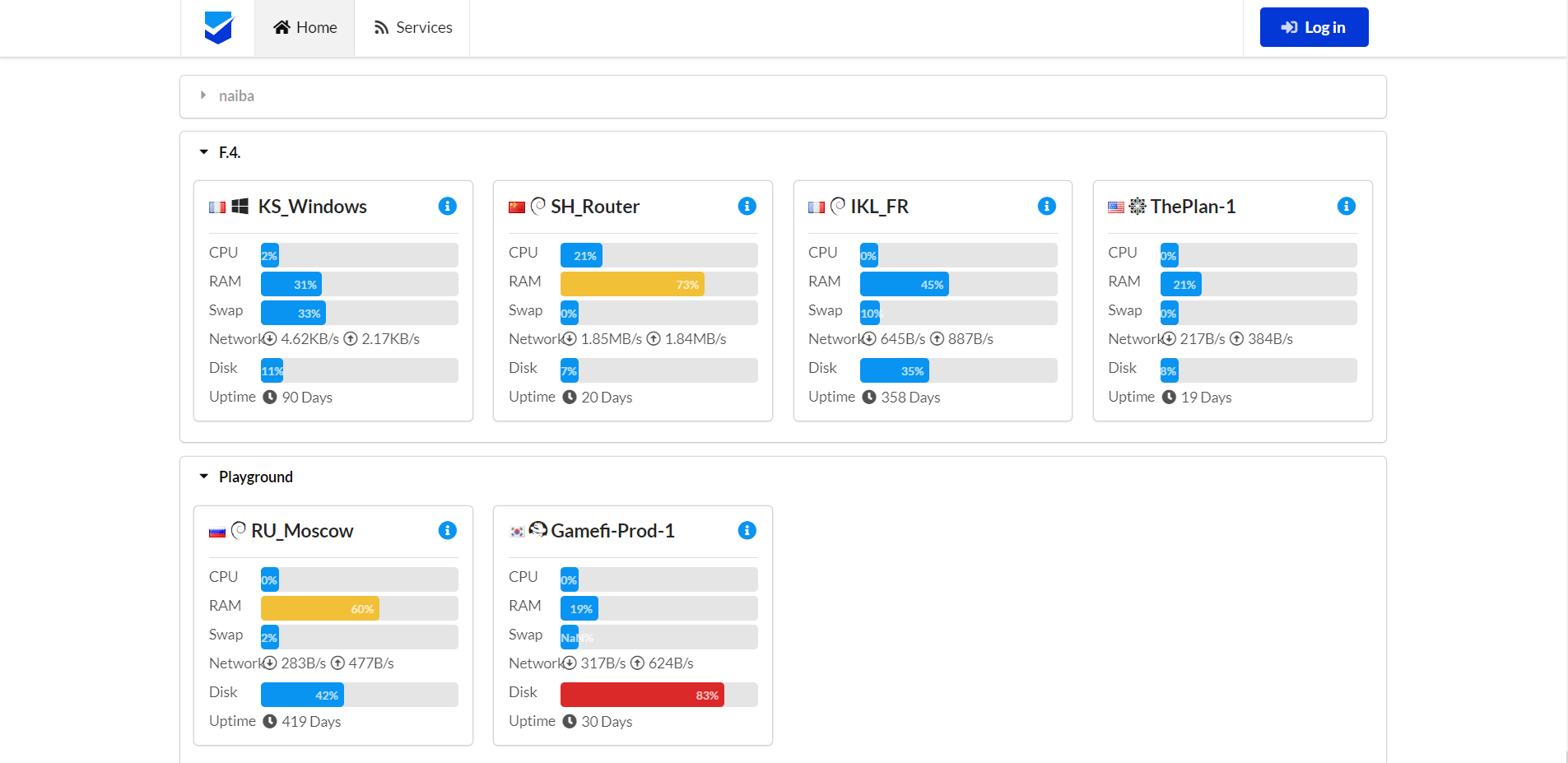
Предлагаю вашему вниманию необычный мониторинг от китайских программистов. Сразу уточню, что поддержка английского языка там есть, так что китайские корни не являются проблемой. А сам мониторинг необычен своей визуализацией. Выглядит непривычно, но интересно и функционально.
Речь идёт про open source проект nezha. Можете сразу оценить функционал в публичном demo - https://ops.naibahq.com. Данный мониторинг поддерживает следующие метрики:
▪ базовые системные метрики (cpu, mem, disik, network)
▪ HTTP, в том числе TLS сертификаты
▪ TCP порты и ICMP проверки
То есть это простой, легковесный мониторинг на GO, который можно развернуть у себя. Проект живой, регулярно обновляется. Попробовать можно в докере, есть готовый образ - ghcr.io/naiba/nezha-dashboard, либо воспользоваться установщиком в виде bash скрипта.
Все инструкции живут в на отдельном сайте - https://nezha.wiki/en_US/index.html. Единственное, что я не понял — аутентификацию в панели зачем-то привязали к Github. Не знаю, в чём тут фишка. Может кто-то считает это удобным, но точно не я. Скрипт установки попросит Client ID и Secret, которые можно получить в github developers, создав новый OAuth app. В принципе, ничего сложного нет и делается за 3 минуты, но я как-то не оценил. Зато после этого доступ можно выдавать на основе учёток Github.
Метрики с серверов собираются с помощью агентов (поддерживаются Windows, Linux, macOS, Synology, OpenWRT). Установить его очень просто. Достаточно добавить новый сервер в панель, и для него появится ссылка для скачивания агента. После установки агента данные автоматически появятся в панели управления. То есть сами агенты настраивать не надо. На серверы с агентами можно зайти по SSH через веб интерфейс панели управления.
Мониторинг максимально простой и удобный, кроме привязки к Github. Если бы не она, можно было смело рекомендовать как вариант простого легко настраиваемого мониторинга. А так решать вам, подходит такой вариант или нет.
#мониторинг
Речь идёт про open source проект nezha. Можете сразу оценить функционал в публичном demo - https://ops.naibahq.com. Данный мониторинг поддерживает следующие метрики:
▪ базовые системные метрики (cpu, mem, disik, network)
▪ HTTP, в том числе TLS сертификаты
▪ TCP порты и ICMP проверки
То есть это простой, легковесный мониторинг на GO, который можно развернуть у себя. Проект живой, регулярно обновляется. Попробовать можно в докере, есть готовый образ - ghcr.io/naiba/nezha-dashboard, либо воспользоваться установщиком в виде bash скрипта.
# bash curl -L \ https://raw.githubusercontent.com/naiba/nezha/master/script/install_en.sh \-o nezha.sh && chmod +x nezha.sh && ./nezha.shВсе инструкции живут в на отдельном сайте - https://nezha.wiki/en_US/index.html. Единственное, что я не понял — аутентификацию в панели зачем-то привязали к Github. Не знаю, в чём тут фишка. Может кто-то считает это удобным, но точно не я. Скрипт установки попросит Client ID и Secret, которые можно получить в github developers, создав новый OAuth app. В принципе, ничего сложного нет и делается за 3 минуты, но я как-то не оценил. Зато после этого доступ можно выдавать на основе учёток Github.
Метрики с серверов собираются с помощью агентов (поддерживаются Windows, Linux, macOS, Synology, OpenWRT). Установить его очень просто. Достаточно добавить новый сервер в панель, и для него появится ссылка для скачивания агента. После установки агента данные автоматически появятся в панели управления. То есть сами агенты настраивать не надо. На серверы с агентами можно зайти по SSH через веб интерфейс панели управления.
Мониторинг максимально простой и удобный, кроме привязки к Github. Если бы не она, можно было смело рекомендовать как вариант простого легко настраиваемого мониторинга. А так решать вам, подходит такой вариант или нет.
#мониторинг
{kind=link}