
Я давно уже получил рекомендацию на хороший бесплатный WAF (Web Application Firewall) - VultureProject. Только сейчас дошли руки на него посмотреть и попробовать. Это оказалось не так просто, как я думал. Потратил очень много времени. Сейчас расскажу обо всём по порядку.
Vulture основан на Freebsd, внутри у него известные компоненты, собранные воедино:
◽ haproxy в качестве tcp балансировщика
◽ apache в качестве http балансировщика
◽ darwin в качестве artificial Intelligence и machine learning, то есть фреймфорк для автоматизации поиска угроз
◽ redis, в том числе для сбора логов из Elasticsearch beats, таких как winlogbeat, filebeat, auditbeat, metricbeat, используется redis output
◽ mongodb в качестве БД
◽ BSD Packet Filter в качестве фаервола
◽ ModSecurity v3 для веб фильтрации
Всё вместе это организует шлюз для входящих запросов на различные приложения. Запросы анализируются и отправляются дальше на настроенные сервера с самими сайтами и приложениями. При этом Vulture умеет принимать не только запросы и выступать в качестве proxy, но и анализировать чужие логи, которые на него можно направить через различные протоколы.
К сожалению, у меня не получилось полноценно проверить работу этой системы. Недавно была анонсирована 4-я версия, которая в настоящий момент полностью не доделана. При этом изменился сайт и вся информация о 3-й версии, которая наиболее функциональна и которую мне рекомендовали, была удалена с сайта. Я даже не понял, где и как скачать 3-ю версию.
В настоящий момент на сайте есть 4-я версия. Для её установки предлагается скачать готовый образ виртуальной машины, что я и сделал. Скачал образ для KVM и развернул его на Proxmox. Достаточно создать виртуалку и заменить её диск на скачанный образ qcow2.
Далее загружаем систему и логинимся в неё. Учётка vlt-adm / vlt-adm. Далее в системе нужно обязательно войти в панель управления, введя в терминале:
Там необходимо настроить сетевой интерфейс и изменить имя хоста. Причём у меня не получилось настроить ip через dhcp. Почему-то адрес применился, а шлюз нет. В итоге пришлось отключить dhcp и настроить руками этот же адрес. В этой же панели управления рекомендую установить все обновления. Там и по самому продукту они прилетят.
После того, как настроите сеть и имя хоста (! это важно, измените дефолтное имя, иначе ничего не заработает), нужно выполнить команду:
После этого можно идти в веб интерфейс по адресу https://10.20.1.49:8000. Дальнейшая настройка производится через веб интерфейс. А это самое интересное, так как полноценной документации для 4-й версии нет. Кое-что открывается в описании к настройкам в веб интерфейсе, но не везде. Пришлось смотреть для 3-й версии, чтобы примерно понять концепцию и саму настройку.
Подробно расписывать всё не буду, так как слишком долго, да и всё равно полноценной инструкции не получится. Кому реально интересен подобного рода продукт, думаю, разберётся. Бесплатных аналогов всё равно не так много. Посмотреть их можно по тэгу в конце заметки. Я кое-что уже описывал. Подскажу только, чтобы было понятно куда двигаться. Добавить сайты, на которые будут проксироваться запросы, можно в разделе Applications. Добавляете новое приложение и прописываете все параметры.
Система довольно жирная и на обычном hdd у меня плохо работала. По ошибке закинул туда образ и долго мучался, так как всё тормозило. Лучше диск побыстрее выбрать. Добавлю ещё, что Vulture умеет работать в режиме отказоустойчивого кластера. Настраивается не сложно.
Если у кого-то есть опыт с этим продуктом, то дайте обратную связь. Какую версию сейчас разумнее использовать? Если третью, то где её взять и как правильно поставить? Готовых образов не увидел.
Сайт - https://www.vultureproject.org
Исходники - https://github.com/VultureProject/
#security #waf
Vulture основан на Freebsd, внутри у него известные компоненты, собранные воедино:
◽ haproxy в качестве tcp балансировщика
◽ apache в качестве http балансировщика
◽ darwin в качестве artificial Intelligence и machine learning, то есть фреймфорк для автоматизации поиска угроз
◽ redis, в том числе для сбора логов из Elasticsearch beats, таких как winlogbeat, filebeat, auditbeat, metricbeat, используется redis output
◽ mongodb в качестве БД
◽ BSD Packet Filter в качестве фаервола
◽ ModSecurity v3 для веб фильтрации
Всё вместе это организует шлюз для входящих запросов на различные приложения. Запросы анализируются и отправляются дальше на настроенные сервера с самими сайтами и приложениями. При этом Vulture умеет принимать не только запросы и выступать в качестве proxy, но и анализировать чужие логи, которые на него можно направить через различные протоколы.
К сожалению, у меня не получилось полноценно проверить работу этой системы. Недавно была анонсирована 4-я версия, которая в настоящий момент полностью не доделана. При этом изменился сайт и вся информация о 3-й версии, которая наиболее функциональна и которую мне рекомендовали, была удалена с сайта. Я даже не понял, где и как скачать 3-ю версию.
В настоящий момент на сайте есть 4-я версия. Для её установки предлагается скачать готовый образ виртуальной машины, что я и сделал. Скачал образ для KVM и развернул его на Proxmox. Достаточно создать виртуалку и заменить её диск на скачанный образ qcow2.
Далее загружаем систему и логинимся в неё. Учётка vlt-adm / vlt-adm. Далее в системе нужно обязательно войти в панель управления, введя в терминале:
# adminТам необходимо настроить сетевой интерфейс и изменить имя хоста. Причём у меня не получилось настроить ip через dhcp. Почему-то адрес применился, а шлюз нет. В итоге пришлось отключить dhcp и настроить руками этот же адрес. В этой же панели управления рекомендую установить все обновления. Там и по самому продукту они прилетят.
После того, как настроите сеть и имя хоста (! это важно, измените дефолтное имя, иначе ничего не заработает), нужно выполнить команду:
# sudo /home/vlt-adm/gui/cluster_create.shПосле этого можно идти в веб интерфейс по адресу https://10.20.1.49:8000. Дальнейшая настройка производится через веб интерфейс. А это самое интересное, так как полноценной документации для 4-й версии нет. Кое-что открывается в описании к настройкам в веб интерфейсе, но не везде. Пришлось смотреть для 3-й версии, чтобы примерно понять концепцию и саму настройку.
Подробно расписывать всё не буду, так как слишком долго, да и всё равно полноценной инструкции не получится. Кому реально интересен подобного рода продукт, думаю, разберётся. Бесплатных аналогов всё равно не так много. Посмотреть их можно по тэгу в конце заметки. Я кое-что уже описывал. Подскажу только, чтобы было понятно куда двигаться. Добавить сайты, на которые будут проксироваться запросы, можно в разделе Applications. Добавляете новое приложение и прописываете все параметры.
Система довольно жирная и на обычном hdd у меня плохо работала. По ошибке закинул туда образ и долго мучался, так как всё тормозило. Лучше диск побыстрее выбрать. Добавлю ещё, что Vulture умеет работать в режиме отказоустойчивого кластера. Настраивается не сложно.
Если у кого-то есть опыт с этим продуктом, то дайте обратную связь. Какую версию сейчас разумнее использовать? Если третью, то где её взять и как правильно поставить? Готовых образов не увидел.
Сайт - https://www.vultureproject.org
Исходники - https://github.com/VultureProject/
#security #waf
{kind=link}
Расскажу про ещё одну отличную утилиту для локального мониторинга и поиска узких мест в производительности Linux. Я её уже упоминал в разных заметках, но не было единой публикации, чтобы забрать в закладки. Речь пойдёт про dstat.
Утилита есть в стандартных репозиториях дистрибутивов. Ставим так:
Dstat - универсальный инструмент, который частично перекрывает функционал iostat, vmstat, netstat и ifstat. У утилиты есть отдельно свои односимвольные ключи, которые вызываются одиночным тире и список плагинов, которые вызываются через двойное тире. Их можно комбинировать.
Покажу сразу пример из свой шпаргалки, которой постоянно пользуюсь:
При этом будет выводиться с интервалом в 10 секунд:
◽ текущее время – t
◽ средняя загрузка системы – l
◽ использования дисков – d
◽ загрузка сетевых устройств – n
◽ активность процессов – p
◽ использование памяти – m
◽ использование подкачки – s
Очень удобная команда, которая позволяет быстро и комплексно оценить загрузку системы по всем основным характеристикам.
Нагрузка на диск с разбивкой по процессам:
Пример того, как можно настроить вывод информации в удобном для себя формате:
◽ load average -l
◽ использование памяти -m
◽ использование swap -s
◽ процесс, занимающий больше всего памяти --top-mem
У утилиты очень много разнообразных ключей для той или иной информации. Комбинируя их, можно настраивать необходимый вам вывод.
Набор метрик для анализа нагрузки на CPU:
Любопытный ключ:
Утилита покажет того, кого OOM Killer грохнет первого, если закончится оперативная память. Не знаю, чем это отличается от ключа --top-mem. По идее, одно и то же должно быть.
Ну и так далее. Комбинаций ключей может быть много. Список всех доступных плагинов можно посмотреть так:
или в man.
К слову, развитие этой утилиты прекратилось в 2019 году из-за того, что Red Hat взяли это же название для своего продукта из набора Performance Co-Pilot. Об этом автор написал в репозитории. Я не знаю, что в современных дистрибутивах, основанных на RHEL, ставится под этим названием пакета. В Debian по прежнему старый dstat. В Centos 7 тоже он же ставился, я постоянно пользовался. Что интересно, замену можно и не заметить, так как все ключи и вывод команды Red Hat повторили в своём продукте. То есть сознательно так поступили, заняв известное имя.
#perfomance
Утилита есть в стандартных репозиториях дистрибутивов. Ставим так:
# apt install dstat# dnf install dstatDstat - универсальный инструмент, который частично перекрывает функционал iostat, vmstat, netstat и ifstat. У утилиты есть отдельно свои односимвольные ключи, которые вызываются одиночным тире и список плагинов, которые вызываются через двойное тире. Их можно комбинировать.
Покажу сразу пример из свой шпаргалки, которой постоянно пользуюсь:
# dstat -tldnpms 10При этом будет выводиться с интервалом в 10 секунд:
◽ текущее время – t
◽ средняя загрузка системы – l
◽ использования дисков – d
◽ загрузка сетевых устройств – n
◽ активность процессов – p
◽ использование памяти – m
◽ использование подкачки – s
Очень удобная команда, которая позволяет быстро и комплексно оценить загрузку системы по всем основным характеристикам.
Нагрузка на диск с разбивкой по процессам:
# dstat --top-ioПример того, как можно настроить вывод информации в удобном для себя формате:
# dstat -l -m -s --top-mem◽ load average -l
◽ использование памяти -m
◽ использование swap -s
◽ процесс, занимающий больше всего памяти --top-mem
У утилиты очень много разнообразных ключей для той или иной информации. Комбинируя их, можно настраивать необходимый вам вывод.
Набор метрик для анализа нагрузки на CPU:
# dstat -c -y -l --proc-count --top-cpuЛюбопытный ключ:
# dstat --top-oomУтилита покажет того, кого OOM Killer грохнет первого, если закончится оперативная память. Не знаю, чем это отличается от ключа --top-mem. По идее, одно и то же должно быть.
Ну и так далее. Комбинаций ключей может быть много. Список всех доступных плагинов можно посмотреть так:
# dstat --listили в man.
К слову, развитие этой утилиты прекратилось в 2019 году из-за того, что Red Hat взяли это же название для своего продукта из набора Performance Co-Pilot. Об этом автор написал в репозитории. Я не знаю, что в современных дистрибутивах, основанных на RHEL, ставится под этим названием пакета. В Debian по прежнему старый dstat. В Centos 7 тоже он же ставился, я постоянно пользовался. Что интересно, замену можно и не заметить, так как все ключи и вывод команды Red Hat повторили в своём продукте. То есть сознательно так поступили, заняв известное имя.
#perfomance
{kind=link}
На примере отличного бесплатного софта для восстановления удалённых файлов под названием R-Linux я рассмотрю ситуацию, когда по ошибке удалён нужный файл. Надо будет его восстановить.
Для начала немного теории. Почему возможно восстановить удалённый файл? Потому что он состоит из трех сущностей - запись в каталоге с соответствием имени и inode, самой inode и блоков данных. При удалении файла стирается запись в каталоге, а inode и блоки помечаются как свободные. В них остаются данные до тех пор, пока они не будут использованы заново. Тут есть важный нюанс. Если какой-то процесс держит удалённый файл открытым, то inode и блоки данных не будут помечены свободными, пока не будет закрыт последний файловый дескриптор, указывающий на файл. В этом случае восстановить удалённый файл очень просто. Я описывал такую ситуацию отдельно.
В моём примере я удалю файл безвозвратно и держать открытым его никто не будет. Возьмём систему Debian 11 и файловую систему ext4. Удалим стартовую страницу nginx - /var/www/html/index.nginx-debian.html
Если вы хотите с максимальной вероятностью восстановить файл, то вам надо тут же выключить машину, сделать копию виртуального диска и работать уже с ним. Подключить его к другой виртуалке, загрузиться с LiveCD и все дальнейшие действия делать там. Так вы максимально снизите шанс того, что освобождённое после удаления файла место будет перезаписано.
Я подключил к этой виртуальной машине CD-ROM, вставил туда LIVE образ Debian 11 с xfce и загрузился с него. Далее установил RLinux5. Можно скачать с сайта через браузер, либо через консоль:
Запустил RLinux. Программа с графическим интерфейсом, так что работать с ней легко. Она увидела мой жёсткий диск и все разделы на нём. Я выбрал раздел, на котором был удалён файл и выполнил сканирование уровня detailed. Затем открыл обзор файлов на этом же разделе.
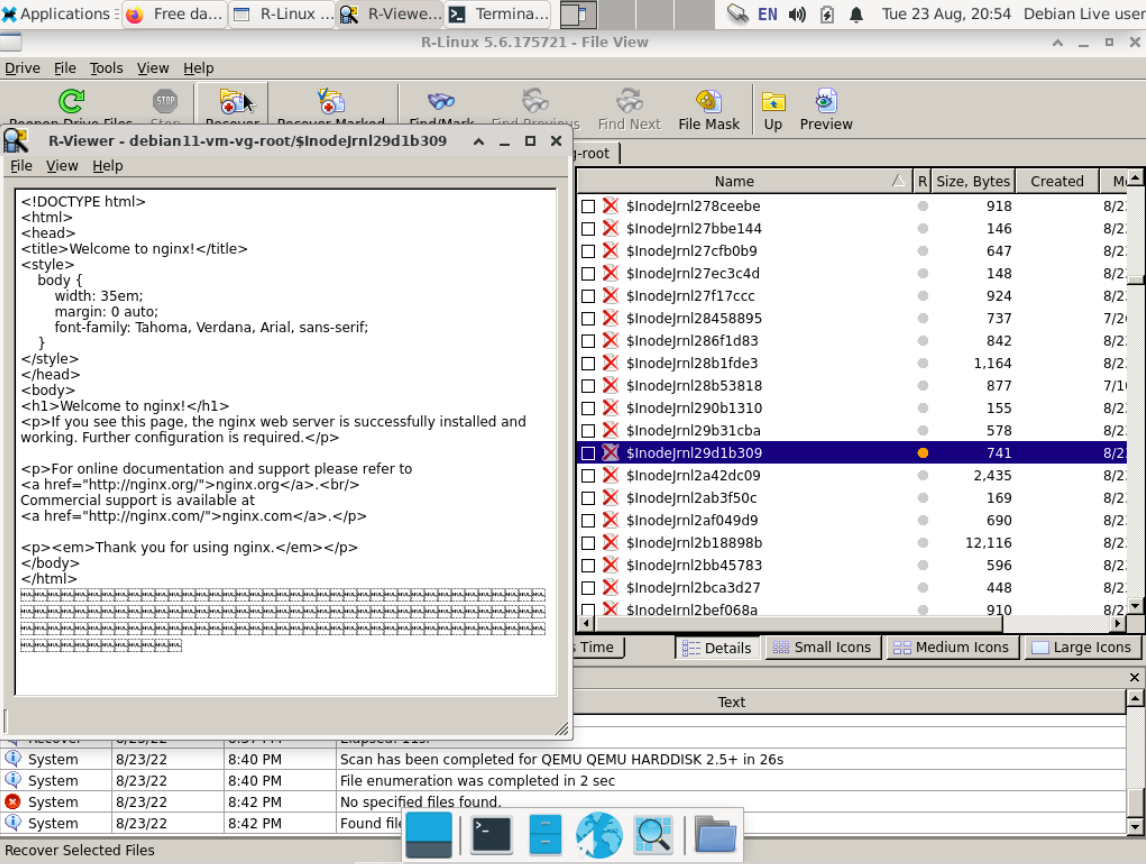
Пошёл в директорию /var/www/html/ и увидел там свой файл, помеченный как удалённый. Там же можно выбрать этот файл и нажать кнопку Recover. Программа сообщила, что файл восстановлен. Я обрадовался, что всё получилось так просто и быстро. Но радоваться было рано. Файл оказался пустым.
Тут я приуныл. В данном эксперименте условия идеальные. Файл с очень большой долей вероятности должен быть цел. Решил выполнить поиск по всем удалённым файлам. Получил большой список файлов с названиями вида $inodeindx0001ff23. Стал выборочно проверять те, которые по размеру могут быть похожи на удалённый файл. И нашёл его. Результат на картинке. Выбрал файл, нажал Recover и сохранил его в другое место.
Вот так на практике можно попробовать восстановить то, что было случайно удалено. Я подозреваю, что не до конца разобрался, как правильно осуществить поиск в этой программе, поэтому пришлось вручную копаться в удалённых файлах. У них было корректное время изменения (не удаления), так что можно было хотя бы по этому признаку сузить поиск.
❗️Заметку имеет смысл сохранить и надеяться, что никогда не пригодится. Тут готовая инструкция как с большой долей вероятности восстановить случайно удалённый файл, если действовать оперативно. Но вообще программа R-Linux умеет много всего: восстанавливать разделы, файловые системы, делать корректно образы с повреждённых дисков и т.д. На сайте подробно всё описано.
Сайт - https://www.r-studio.com/ru/free-linux-recovery
#restore
Для начала немного теории. Почему возможно восстановить удалённый файл? Потому что он состоит из трех сущностей - запись в каталоге с соответствием имени и inode, самой inode и блоков данных. При удалении файла стирается запись в каталоге, а inode и блоки помечаются как свободные. В них остаются данные до тех пор, пока они не будут использованы заново. Тут есть важный нюанс. Если какой-то процесс держит удалённый файл открытым, то inode и блоки данных не будут помечены свободными, пока не будет закрыт последний файловый дескриптор, указывающий на файл. В этом случае восстановить удалённый файл очень просто. Я описывал такую ситуацию отдельно.
В моём примере я удалю файл безвозвратно и держать открытым его никто не будет. Возьмём систему Debian 11 и файловую систему ext4. Удалим стартовую страницу nginx - /var/www/html/index.nginx-debian.html
# rm -f /var/www/html/index.nginx-debian.htmlЕсли вы хотите с максимальной вероятностью восстановить файл, то вам надо тут же выключить машину, сделать копию виртуального диска и работать уже с ним. Подключить его к другой виртуалке, загрузиться с LiveCD и все дальнейшие действия делать там. Так вы максимально снизите шанс того, что освобождённое после удаления файла место будет перезаписано.
Я подключил к этой виртуальной машине CD-ROM, вставил туда LIVE образ Debian 11 с xfce и загрузился с него. Далее установил RLinux5. Можно скачать с сайта через браузер, либо через консоль:
# wget https://www.r-studio.com/downloads/RLinux5_x64.deb# dpkg -i RLinux5_x64.debЗапустил RLinux. Программа с графическим интерфейсом, так что работать с ней легко. Она увидела мой жёсткий диск и все разделы на нём. Я выбрал раздел, на котором был удалён файл и выполнил сканирование уровня detailed. Затем открыл обзор файлов на этом же разделе.
Пошёл в директорию /var/www/html/ и увидел там свой файл, помеченный как удалённый. Там же можно выбрать этот файл и нажать кнопку Recover. Программа сообщила, что файл восстановлен. Я обрадовался, что всё получилось так просто и быстро. Но радоваться было рано. Файл оказался пустым.
Тут я приуныл. В данном эксперименте условия идеальные. Файл с очень большой долей вероятности должен быть цел. Решил выполнить поиск по всем удалённым файлам. Получил большой список файлов с названиями вида $inodeindx0001ff23. Стал выборочно проверять те, которые по размеру могут быть похожи на удалённый файл. И нашёл его. Результат на картинке. Выбрал файл, нажал Recover и сохранил его в другое место.
Вот так на практике можно попробовать восстановить то, что было случайно удалено. Я подозреваю, что не до конца разобрался, как правильно осуществить поиск в этой программе, поэтому пришлось вручную копаться в удалённых файлах. У них было корректное время изменения (не удаления), так что можно было хотя бы по этому признаку сузить поиск.
❗️Заметку имеет смысл сохранить и надеяться, что никогда не пригодится. Тут готовая инструкция как с большой долей вероятности восстановить случайно удалённый файл, если действовать оперативно. Но вообще программа R-Linux умеет много всего: восстанавливать разделы, файловые системы, делать корректно образы с повреждённых дисков и т.д. На сайте подробно всё описано.
Сайт - https://www.r-studio.com/ru/free-linux-recovery
#restore
{kind=link}
Небольшая подсказка для тех, кому на ОС Windows нужно обновить список корневых сертификатов. Это актуально для систем, которые уже не получают обновления, либо они принудительно отключены. Один-два сертификата можно добавить вручную. Если же их много, то надо это автоматизировать.
Если речь идёт о системах Windows 10 или 11, то там всё просто. Берём обновлённую систему и запускаем там:
Сформируется SST контейнер, который можно открыть и посмотреть содержимое. Там будут все корневые сертификаты с текущей машины. На другой машине восстановить можно вот так:
Если речь идёт о более старых системах, то для них есть другая утилита от Microsoft - rootsupd.exe. Они давно её выпилили из своих загрузок, так что лично я качал с сайта Kaspersky (инструкция и ссылка на утилиту).
Для начала её надо скачать, положить в директорию C:/rootsupd/ и запустить с параметрами:
Выскочит окошко с предложением перезаписать roots.sst, надо отказаться. Потом зайти в папку C:/rootsupd/, положить туда актуальный roots.sst с обновлённой системы и запустить из этой папки утилиту updroots.exe:
Теперь сертификаты обновлены. Я удивился, когда искал решение этой задачи. В сети очень много подобных заметок по обновлению корневых сертификатов на старых системах. Гуглятся как русскоязычные записи, так и иностранные. Похоже куча народа по различным причинам вынуждены использовать старые системы.
Кстати, протухшие CA и старые протоколы шифрования TLS и SSL отличные могильщики старых систем. На них теперь никуда не попасть в современном интернете и ничего не скачать. И проблема эта актуальна не только в Windows. Помню, как в Centos 5 и 6 мне приходилось решать похожие проблемы. Даже писал об этом здесь, но давно дело было.
#windows
Если речь идёт о системах Windows 10 или 11, то там всё просто. Берём обновлённую систему и запускаем там:
# certutil.exe -generateSSTFromWU roots.sstСформируется SST контейнер, который можно открыть и посмотреть содержимое. Там будут все корневые сертификаты с текущей машины. На другой машине восстановить можно вот так:
# $sstStore = ( Get-ChildItem -Path roots.sst )# $sstStore | Import-Certificate -CertStoreLocation Cert:\LocalMachine\RootЕсли речь идёт о более старых системах, то для них есть другая утилита от Microsoft - rootsupd.exe. Они давно её выпилили из своих загрузок, так что лично я качал с сайта Kaspersky (инструкция и ссылка на утилиту).
Для начала её надо скачать, положить в директорию C:/rootsupd/ и запустить с параметрами:
# rootsupd.exe /c /t:C:\PS\rootsupdВыскочит окошко с предложением перезаписать roots.sst, надо отказаться. Потом зайти в папку C:/rootsupd/, положить туда актуальный roots.sst с обновлённой системы и запустить из этой папки утилиту updroots.exe:
# updroots.exe roots.sstТеперь сертификаты обновлены. Я удивился, когда искал решение этой задачи. В сети очень много подобных заметок по обновлению корневых сертификатов на старых системах. Гуглятся как русскоязычные записи, так и иностранные. Похоже куча народа по различным причинам вынуждены использовать старые системы.
Кстати, протухшие CA и старые протоколы шифрования TLS и SSL отличные могильщики старых систем. На них теперь никуда не попасть в современном интернете и ничего не скачать. И проблема эта актуальна не только в Windows. Помню, как в Centos 5 и 6 мне приходилось решать похожие проблемы. Даже писал об этом здесь, но давно дело было.
#windows
Хочу сделать предостережение и подсветить одну неприятную историю. Существует "Лучший инновационный продукт 2022 года" в виде системы мониторинга Camkeeper. Мне прислал ссылку один подписчик. Заинтересовался продуктом, решил узнать подробнее, что это такое.
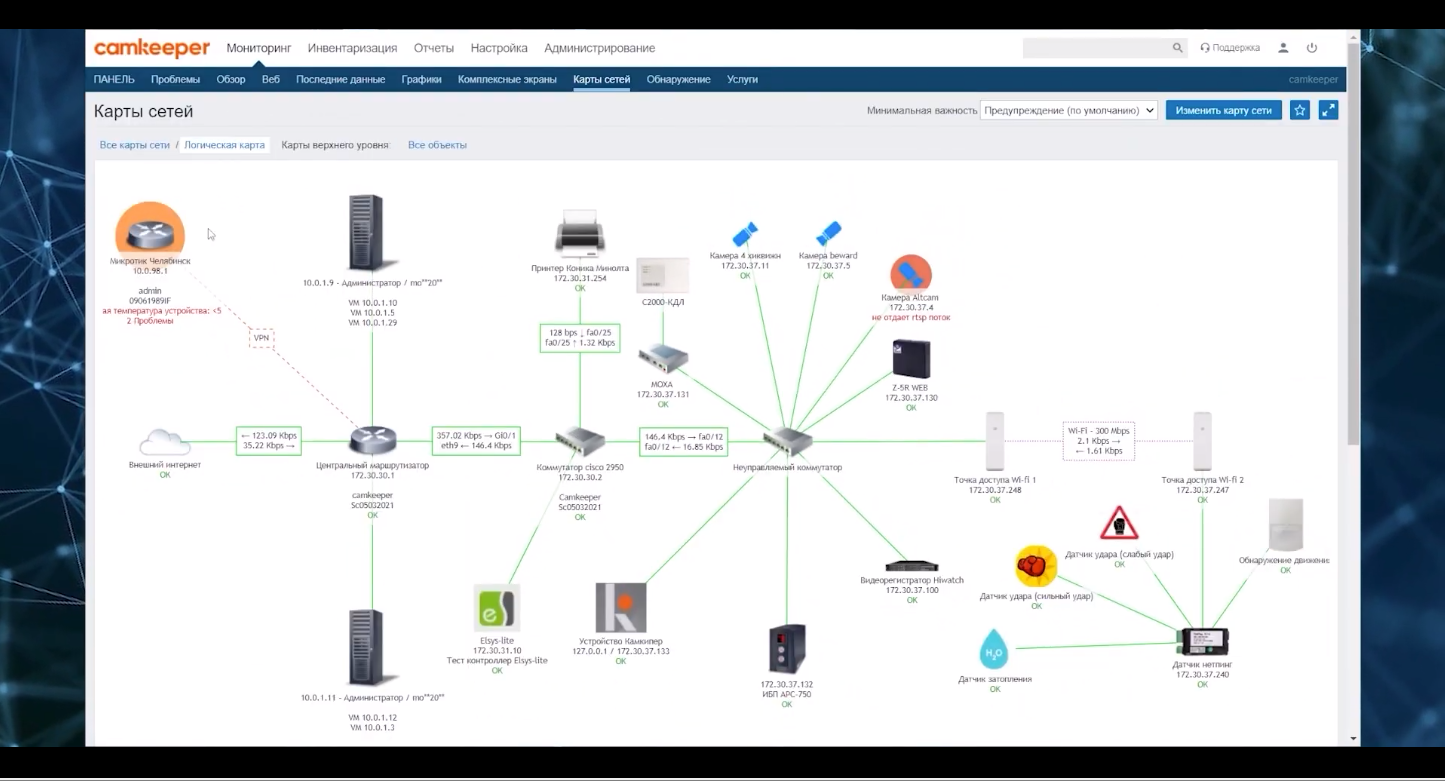
Красивый современный сайт, интервью с основателем, выступления на конференциях. Описано всё круто, стоимость, техподдержка. Полноценная компания. Думаю, что же это за система мониторинга такая. Ищу подробности, а их как-то нет.
Потом уже замечаю некоторые скриншоты в описаниях. Смотрю обзорный ролик и понимаю, что это обычный Zabbix, где просто сменили логотип. Вот такая инновация 2022 года.
Если где-то услышите о системе мониторинга Camkeeper, знайте, что это обычный Zabbix и платить там не за что. Если бы они честно продавали внедрение и техподдержку, как делают многие, то вопросов бы не было. Но менять логотип известного продукта и выдавать его за свой это полное дно. Не понятно, на кого рассчитано.
Отдельно порадовало опубликованное благодарственное письмо на сайте:
Необходимо отметить высокий уровень инноваций, внедренных в продукцию Camkeeper разработчиками. Благодаря детальной удаленной диагностике работоспособности всех элементов системы видеонаблюдения, мы не только снизили расходы на ее обслуживание, но и систематизировали процессы с подрядной организацией.
Cпециалист по безопасности и режиму.
Слышали где-нибудь об этой системе?
Красивый современный сайт, интервью с основателем, выступления на конференциях. Описано всё круто, стоимость, техподдержка. Полноценная компания. Думаю, что же это за система мониторинга такая. Ищу подробности, а их как-то нет.
Потом уже замечаю некоторые скриншоты в описаниях. Смотрю обзорный ролик и понимаю, что это обычный Zabbix, где просто сменили логотип. Вот такая инновация 2022 года.
Если где-то услышите о системе мониторинга Camkeeper, знайте, что это обычный Zabbix и платить там не за что. Если бы они честно продавали внедрение и техподдержку, как делают многие, то вопросов бы не было. Но менять логотип известного продукта и выдавать его за свой это полное дно. Не понятно, на кого рассчитано.
Отдельно порадовало опубликованное благодарственное письмо на сайте:
Необходимо отметить высокий уровень инноваций, внедренных в продукцию Camkeeper разработчиками. Благодаря детальной удаленной диагностике работоспособности всех элементов системы видеонаблюдения, мы не только снизили расходы на ее обслуживание, но и систематизировали процессы с подрядной организацией.
Cпециалист по безопасности и режиму.
Слышали где-нибудь об этой системе?
{kind=link}
Сейчас все только и говорят, что об импортозамещении в ИТ. Кто-то – с презрением и громким «все пропало». Кто-то – с восторгом и оголтелым «всех заместим». А хочется взвешенной позиции.
Импортозамещение здорового человека — канал, где трезво, без истерик и эмоций разбираемся в российском ИТ.
Читайте наши материалы:
🔸 Как уход производителей софта отражается на российской разработке? Спойлер: реальная картина далека от шумихи в СМИ, большинство разработчиков быстро и успешно адаптировались к новой действительности.
🔸 Есть ли жизнь после Intel и TSMC? Коротко о том, что происходит на рынке полупроводников в России. Где мы, куда идем и что нужно, чтобы дошли.
🔸 Как покупать железо в нынешних условиях? Ждать отмены санкций, использовать «серое» оборудование или пробовать российское?
Подписывайтесь на канал Импортозамещение здорового человека и следите за ИТ-рынком страны!
#реклама
Импортозамещение здорового человека — канал, где трезво, без истерик и эмоций разбираемся в российском ИТ.
Читайте наши материалы:
🔸 Как уход производителей софта отражается на российской разработке? Спойлер: реальная картина далека от шумихи в СМИ, большинство разработчиков быстро и успешно адаптировались к новой действительности.
🔸 Есть ли жизнь после Intel и TSMC? Коротко о том, что происходит на рынке полупроводников в России. Где мы, куда идем и что нужно, чтобы дошли.
🔸 Как покупать железо в нынешних условиях? Ждать отмены санкций, использовать «серое» оборудование или пробовать российское?
Подписывайтесь на канал Импортозамещение здорового человека и следите за ИТ-рынком страны!
#реклама
В августе было несколько постов с анализом производительности Linux. Хочу немного подвести итог и сгруппировать информацию, чтобы получилась последовательная картинка по теме.
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
# dstat -tldnpms 10Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вы замечали, как много всевозможных утилит по анализу производительности Linux? На них можно бесконечно писать обзоры. Клонов top море, как и анализаторов сетевой активности, каких-то ещё метрик. Я постоянно вижу подобные утилиты. Уже перестал смотреть на них, потому что объективно они не особо нужны, а для авторов это просто хобби. Если и обращаю внимание, то на что-то действительно полезное с необычным функционалом.
Я раньше думал, что это прям какие-то матёрые линуксоиды-программисты пишут подобный софт. Но на самом деле нет. Само ядро Linux в очень доступном формате отдаёт всю информацию. Достаточно её взять и красиво оформить. Покажу на простом примере.
Я постоянно использую в повседневной деятельности утилиту netstat для просмотра списка открытых портов. Если сервер сам настраиваю, то ставлю пакет с ней, если нет, то использую встроенный ss, который сейчас есть во всех дистрибутивах. Мне просто больше нравится вывод netstat, чем ss. Можете сами сравнить:
У ss вывод шире, поэтому часто переезжает на новую строку и получается каша. Но это не важно, написать хотел не об этом.
Представьте ситуацию, что вы в Docker контейнере, где нет этих утилит. Где вообще почти ничего нет, что встречается довольно часто, а хочется посмотреть, какие порты открыты и какие соединения установлены? Посмотреть очень просто:
Вот описание того, что вы увидите.
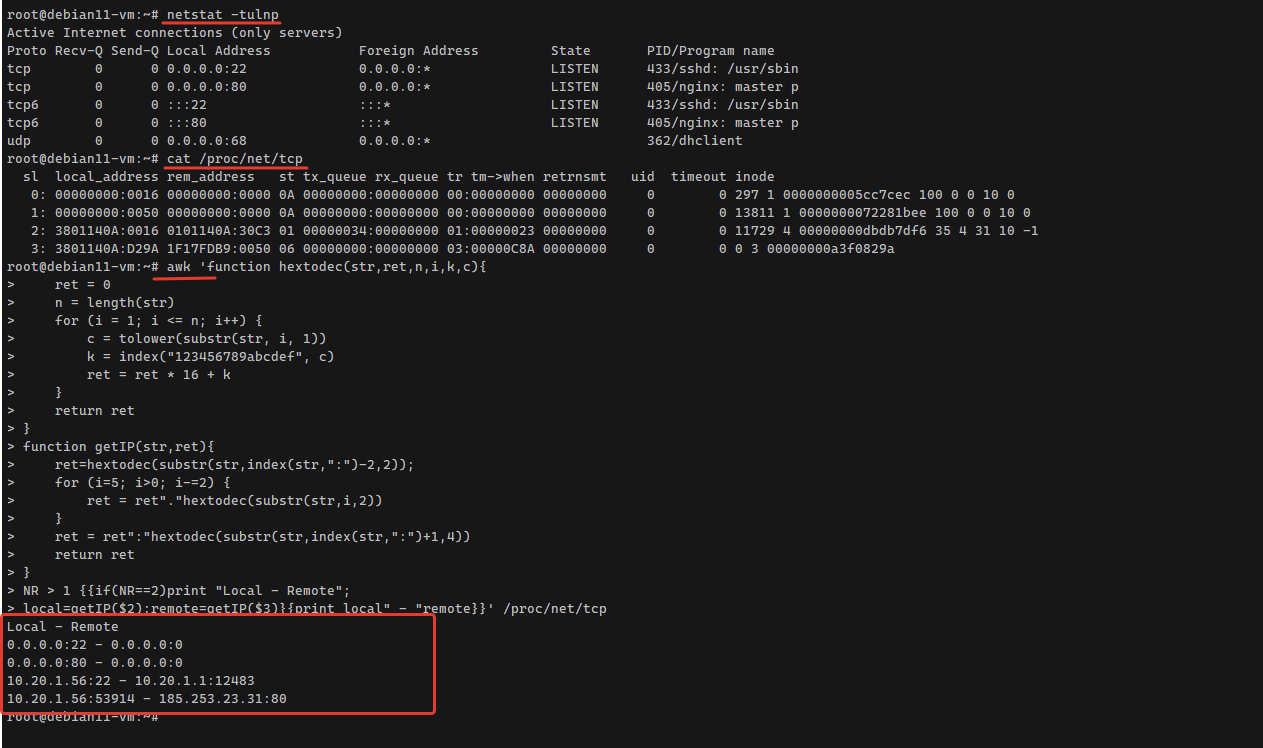
Вы получите практически всю ту же информацию, что показывают утилиты выше, только в шестнадцатеричном формате, если речь идёт о номере порта. Достаточно его перевести в десятичный и получить нужные данные. Понятно, что для этого тоже может не быть инструментов внутри контейнера, хотя тот же bash умеет это делать. Смотрим столбец local_address, первое число - ip адрес, второе - порт. Переводим порт, например 006E, в десятичный формат:
Получаем 110 tcp порт, который открыл dovecot. Можно автоматом всё это конвертнуть:
Сделать преобразование не трудно, если действительно необходимо. Я покажу готовый пример, который можно скопировать и где-то на тесте посмотреть результат. Вот эта команда с awk, которая переводит шестадцатиричный формат адресов и портов в десятичный.
Этот пример можно развить и дальше, добавив информацию из остальных столбцов о состоянии соединения, inode процесса, его породившего и всего остального. Сразу скажу, что я не разбирался, что здесь происходит 🤡. Это же bash, ему даже обфускация не нужна. Просто увидел когда-то и сохранил. Как раз тогда, когда надо было в контейнере посмотреть порты и соединения.
И такая история со всеми метриками. Их все можно взять в /proc и анализировать. Так что можете начинать изучать какой-то язык программирования и писать свой собственный top. Можно даже на bash. Правда такой пример уже есть - bashtop. Придётся придумать что-то новое 😀.
#bash
Я раньше думал, что это прям какие-то матёрые линуксоиды-программисты пишут подобный софт. Но на самом деле нет. Само ядро Linux в очень доступном формате отдаёт всю информацию. Достаточно её взять и красиво оформить. Покажу на простом примере.
Я постоянно использую в повседневной деятельности утилиту netstat для просмотра списка открытых портов. Если сервер сам настраиваю, то ставлю пакет с ней, если нет, то использую встроенный ss, который сейчас есть во всех дистрибутивах. Мне просто больше нравится вывод netstat, чем ss. Можете сами сравнить:
# netstat -tulnp# ss -tulnpУ ss вывод шире, поэтому часто переезжает на новую строку и получается каша. Но это не важно, написать хотел не об этом.
Представьте ситуацию, что вы в Docker контейнере, где нет этих утилит. Где вообще почти ничего нет, что встречается довольно часто, а хочется посмотреть, какие порты открыты и какие соединения установлены? Посмотреть очень просто:
# cat /proc/net/tcpВот описание того, что вы увидите.
Вы получите практически всю ту же информацию, что показывают утилиты выше, только в шестнадцатеричном формате, если речь идёт о номере порта. Достаточно его перевести в десятичный и получить нужные данные. Понятно, что для этого тоже может не быть инструментов внутри контейнера, хотя тот же bash умеет это делать. Смотрим столбец local_address, первое число - ip адрес, второе - порт. Переводим порт, например 006E, в десятичный формат:
# echo $((16#006E))110Получаем 110 tcp порт, который открыл dovecot. Можно автоматом всё это конвертнуть:
# grep -v "local_address" /proc/net/tcp \| awk '{print $2}' | cut -d : -f 2 \| xargs -I % /bin/bash -c 'echo $((16#%))'Сделать преобразование не трудно, если действительно необходимо. Я покажу готовый пример, который можно скопировать и где-то на тесте посмотреть результат. Вот эта команда с awk, которая переводит шестадцатиричный формат адресов и портов в десятичный.
awk 'function hextodec(str,ret,n,i,k,c){ ret = 0 n = length(str) for (i = 1; i <= n; i++) { c = tolower(substr(str, i, 1)) k = index("123456789abcdef", c) ret = ret * 16 + k } return ret}function getIP(str,ret){ ret=hextodec(substr(str,index(str,":")-2,2)); for (i=5; i>0; i-=2) { ret = ret"."hextodec(substr(str,i,2)) } ret = ret":"hextodec(substr(str,index(str,":")+1,4)) return ret} NR > 1 {{if(NR==2)print "Local - Remote";local=getIP($2);remote=getIP($3)}{print local" - "remote}}' /proc/net/tcpЭтот пример можно развить и дальше, добавив информацию из остальных столбцов о состоянии соединения, inode процесса, его породившего и всего остального. Сразу скажу, что я не разбирался, что здесь происходит 🤡. Это же bash, ему даже обфускация не нужна. Просто увидел когда-то и сохранил. Как раз тогда, когда надо было в контейнере посмотреть порты и соединения.
И такая история со всеми метриками. Их все можно взять в /proc и анализировать. Так что можете начинать изучать какой-то язык программирования и писать свой собственный top. Можно даже на bash. Правда такой пример уже есть - bashtop. Придётся придумать что-то новое 😀.
#bash
{kind=link}
Для тех, кто захочет позаниматься на выходных и подтянуть свой навык в администрировании Linux в преддверие начала учебного года, предлагаю шикарную ссылку на обучающий материал по теме RHCSA (Red Hat Certified System Administrator).
Поясню тем, кто не знает, что это базовый курс от Red Hat для Linux администраторов. Сертификацию сдавать не обязательно, можно просто поучиться по этой программе. Её часто рекомендуют как общепризнанную базу. Так что если вас кто-то будет просить посоветовать, с чего начать изучение Linux, предложите ему пройти обучение по этому курсу.
Собственно, вот ссылка - https://basis.gnulinux.pro
Автор проделал огромную работу. Он записал видео и одновременно подготовил текстовую информацию с картинками. Читать её можно как на сайте автора, так и в репозитории github. Материал адаптирован для новичков и дополнен автором, то есть это не точное обучение по программе RHCSA.
Увидел этот курс недавно и был очень удивлён качеством и подачей. Пожалуй, в бесплатном доступе от энтузиастов мне не доводилось такого видеть.
#обучение #бесплатно
Поясню тем, кто не знает, что это базовый курс от Red Hat для Linux администраторов. Сертификацию сдавать не обязательно, можно просто поучиться по этой программе. Её часто рекомендуют как общепризнанную базу. Так что если вас кто-то будет просить посоветовать, с чего начать изучение Linux, предложите ему пройти обучение по этому курсу.
Собственно, вот ссылка - https://basis.gnulinux.pro
Автор проделал огромную работу. Он записал видео и одновременно подготовил текстовую информацию с картинками. Читать её можно как на сайте автора, так и в репозитории github. Материал адаптирован для новичков и дополнен автором, то есть это не точное обучение по программе RHCSA.
Увидел этот курс недавно и был очень удивлён качеством и подачей. Пожалуй, в бесплатном доступе от энтузиастов мне не доводилось такого видеть.
#обучение #бесплатно
{kind=link}
В прошлом году на канале я уже делал заметку про замечательную утилиту Ventoy, которая позволяет сделать флешку с множеством ISO образов. Можно выбрать любой из них и загрузиться.
Казалось бы, что в этом такого? Нет никаких проблем сделать загрузочную флешку. Тут смысл именно в простоте. Программа формирует флешку с директорией, в которую можно просто копировать ISO образы. А затем в загрузочном меню выбирать любой из них. Ventoy поддерживает не только ISO, но и некоторые другие: WIM, IMG, VHD(x), EFI.
Я с тех пор с себе сделал подобную флешку и иногда пользовался. Вспомнил про неё, потому что автор канала Plafon, на который я подписан, выпустил ролик по этой теме. Можете посмотреть, чтобы наглядно увидеть, как это всё работает на практике. У автора рабочая станция на Linux. Он отдельно упомянул, что с линукса не всегда удобно делать загрузочную флешку с Windows. А с Ventoy нет никаких проблем. Просто кладёшь образ в директорию на флешке и всё работает.
Из аналогов этой программы можно упомянуть YUMI – Multiboot USB Creator. Но лично мне Ventoy понравилась больше.
P.s. если ещё не подписаны на этот канал, то рекомендую, мне нравится.
Сайт - https://www.ventoy.net/
Исходники - https://github.com/ventoy/Ventoy
Казалось бы, что в этом такого? Нет никаких проблем сделать загрузочную флешку. Тут смысл именно в простоте. Программа формирует флешку с директорией, в которую можно просто копировать ISO образы. А затем в загрузочном меню выбирать любой из них. Ventoy поддерживает не только ISO, но и некоторые другие: WIM, IMG, VHD(x), EFI.
Я с тех пор с себе сделал подобную флешку и иногда пользовался. Вспомнил про неё, потому что автор канала Plafon, на который я подписан, выпустил ролик по этой теме. Можете посмотреть, чтобы наглядно увидеть, как это всё работает на практике. У автора рабочая станция на Linux. Он отдельно упомянул, что с линукса не всегда удобно делать загрузочную флешку с Windows. А с Ventoy нет никаких проблем. Просто кладёшь образ в директорию на флешке и всё работает.
Из аналогов этой программы можно упомянуть YUMI – Multiboot USB Creator. Но лично мне Ventoy понравилась больше.
P.s. если ещё не подписаны на этот канал, то рекомендую, мне нравится.
Сайт - https://www.ventoy.net/
Исходники - https://github.com/ventoy/Ventoy
{kind=link}
Игра Компьютерщик, о которой я рассказывал пару недель назад, в 1998 году открыла целую веху подобных игр. Одного из последователей я упоминал - Взломщик. Есть ещё целая серия подобного рода игр - Компьютерная эволюция, которая была популярна в своё время.
С 2002 по 2008 год вышло три версии этой игры, а в 2008 автор открыл исходники, сам прекратил разработку. С тех пор вышла целая куча новых версий. Компьютерная эволюция развивает идею Компьютерщика, только делает акцент на железную часть. В игре куча различных операционных систем и оборудования.
Начало там примерно такое же, как в Компьютерщике. Вы начинаете самостоятельную жизнь с самым маломощным компьютером с бесплатным ПО. Вам надо работать, учиться, прокачивать комп, ставить ПО, заниматься хакерством (в первых версиях не было).
По этой игре автор 6-й версии запилил свой сайт, выложил свою версию и собрал много полезной информации об игре. Адрес - http://compevo6.ru. Игра для старичков, кто застал в сознательном возрасте 90-е и начало 2000-х. Она вся пронизана духом того времени. Для всех остальных вряд ли это покажется интересным, хотя кто знает.
Я так понимаю, что сейчас имеет смысл играть сразу в 6-ю, последнюю версию. Скачать можно с сайта, который упомянул.
#игра
С 2002 по 2008 год вышло три версии этой игры, а в 2008 автор открыл исходники, сам прекратил разработку. С тех пор вышла целая куча новых версий. Компьютерная эволюция развивает идею Компьютерщика, только делает акцент на железную часть. В игре куча различных операционных систем и оборудования.
Начало там примерно такое же, как в Компьютерщике. Вы начинаете самостоятельную жизнь с самым маломощным компьютером с бесплатным ПО. Вам надо работать, учиться, прокачивать комп, ставить ПО, заниматься хакерством (в первых версиях не было).
По этой игре автор 6-й версии запилил свой сайт, выложил свою версию и собрал много полезной информации об игре. Адрес - http://compevo6.ru. Игра для старичков, кто застал в сознательном возрасте 90-е и начало 2000-х. Она вся пронизана духом того времени. Для всех остальных вряд ли это покажется интересным, хотя кто знает.
Я так понимаю, что сейчас имеет смысл играть сразу в 6-ю, последнюю версию. Скачать можно с сайта, который упомянул.
#игра
{kind=link}
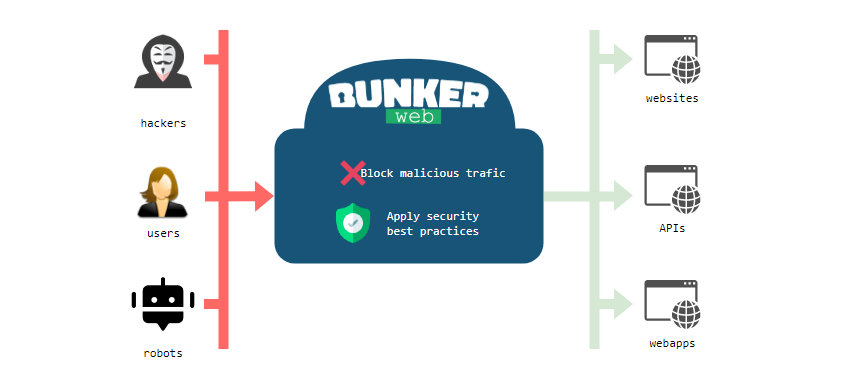
🛡 Хочу поделиться с вами продуктом на базе Nginx, который мне понравился своей простотой и удобством. Речь пойдёт про Bunkerweb, который реализует в том числе функционал WAF (Web Application Firewall). Это собранный Docker контейнер с Nginx внутри и кучей дополнительного функционала для обеспечения безопасности.
Bunkerweb может работать как непосредственно локальный веб сервер, так и в режиме reverse proxy. Большая часть функционала реализована штатными средствами Nginx и модулями к нему. В качестве WAF используется ModSecurity, для защиты от ботов интеграция с различными каптчами.
📌 Для настройки есть мастер создания конфигурации. Оценить функционал и основные возможности проще всего через него, а не через просмотр описания или доков. Там сразу понятно, что он умеет и как настраивается. Перечислю основные фишки:
◽ есть встроенный веб интерфейс для управления (видео с демонстрацией)
◽ поддержка плагинов (уже есть интеграции с CrowdSec, ClamAV, Discord, Slack, VirusTotal)
◽ WAF на базе ModSecurity и набора правил OWASP
◽ распознавание ботов, их блокировка или показ каптчи
◽ блок ip по странам или внешним списками
◽ поддержка сертификатов let's encrypt
Весь функционал подробно описан в документации. Запускается Bunkerweb в Docker, Kubernetes, локально с ручной установкой или через Ansible. Доступны, по сути, все возможные способы, кому что ближе и удобнее.
Проект оставил очень хорошее впечатление. Он хорошо документирован, описан, понятно сделан, продуман. Мне показалось, что это хорошее решение не только с точки зрения безопасности, но и просто установки и управления Nginx. Можно через конструктор собрать набор опций, запустить Bunkerweb, а потом посмотреть в конфиге, как всё это реализовано. Так как всё собрано на базе open source продуктов, разобраться не трудно. При желании, можно что-то в свои наработки утащить.
Можно рассматривать этот продукт как панель управления для Nginx с базовым набором правил безопасности. Это если его просто с дефолтными настройками запустить. А дальше уже при желании можно наращивать функционал.
Сайт - https://docs.bunkerweb.io
Исходники - https://github.com/bunkerity/bunkerweb
Demo - https://demo.bunkerweb.io/
#waf #security #nginx
Bunkerweb может работать как непосредственно локальный веб сервер, так и в режиме reverse proxy. Большая часть функционала реализована штатными средствами Nginx и модулями к нему. В качестве WAF используется ModSecurity, для защиты от ботов интеграция с различными каптчами.
📌 Для настройки есть мастер создания конфигурации. Оценить функционал и основные возможности проще всего через него, а не через просмотр описания или доков. Там сразу понятно, что он умеет и как настраивается. Перечислю основные фишки:
◽ есть встроенный веб интерфейс для управления (видео с демонстрацией)
◽ поддержка плагинов (уже есть интеграции с CrowdSec, ClamAV, Discord, Slack, VirusTotal)
◽ WAF на базе ModSecurity и набора правил OWASP
◽ распознавание ботов, их блокировка или показ каптчи
◽ блок ip по странам или внешним списками
◽ поддержка сертификатов let's encrypt
Весь функционал подробно описан в документации. Запускается Bunkerweb в Docker, Kubernetes, локально с ручной установкой или через Ansible. Доступны, по сути, все возможные способы, кому что ближе и удобнее.
Проект оставил очень хорошее впечатление. Он хорошо документирован, описан, понятно сделан, продуман. Мне показалось, что это хорошее решение не только с точки зрения безопасности, но и просто установки и управления Nginx. Можно через конструктор собрать набор опций, запустить Bunkerweb, а потом посмотреть в конфиге, как всё это реализовано. Так как всё собрано на базе open source продуктов, разобраться не трудно. При желании, можно что-то в свои наработки утащить.
Можно рассматривать этот продукт как панель управления для Nginx с базовым набором правил безопасности. Это если его просто с дефолтными настройками запустить. А дальше уже при желании можно наращивать функционал.
Сайт - https://docs.bunkerweb.io
Исходники - https://github.com/bunkerity/bunkerweb
Demo - https://demo.bunkerweb.io/
#waf #security #nginx
{kind=link}
Расскажу вам про возможность консоли Linux, с помощью которой можно подшутить над коллегой, который с ней не знаком. Когда первый раз сталкиваешься, можно прилично удивиться или даже испугаться, что тебя взломали.
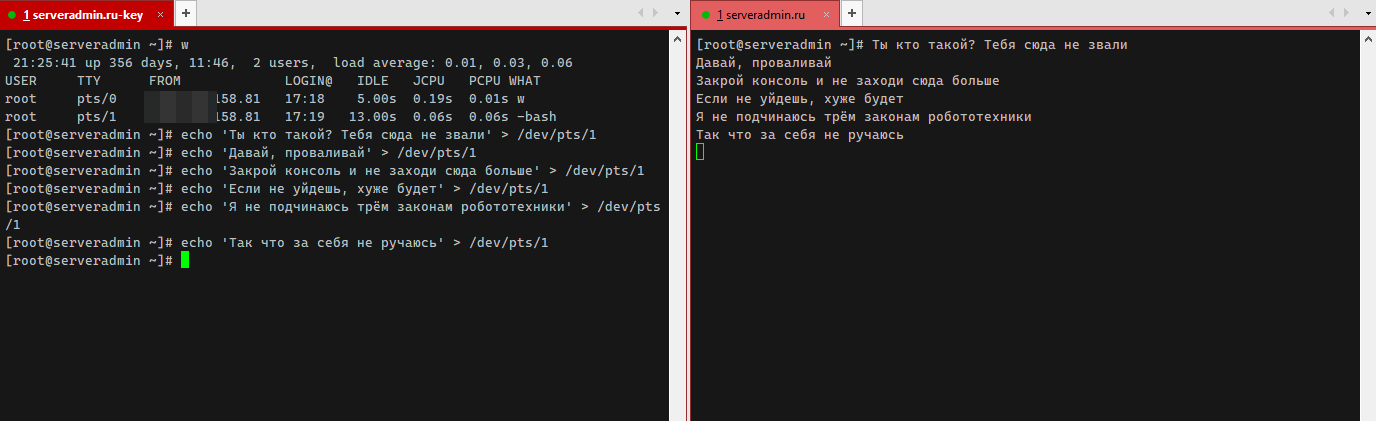
В Linux можно через консоль отправлять сообщения другому человеку. Для этого вам надо подключиться вместе с кем-то к серверу и посмотреть их номера. Проще всего это сделать с помощью команды w.
Допустим, другой человек подключился к консоли pts/1. Отправим ему сообщение:
Это сообщение появится у него в консоли, после решётки. Можно как в режиме онлайн отправлять сообщения, так и запланировать их, например, с помощью at. Если человек один работает на сервере, то консоль у него будет нулевая.
Если никогда не пользовался этим функционалом и вообще ничего про него не знаешь, можно серьезно удивиться или напрячься. Что за хрень и кто со мной разговаривает? Какого-то другого применения этого функционала я не придумаю.
То же самое можно сделать с помощью write, например так:
и дальше пишешь текст, но так русский язык не работает, я не разбирался, из-за чего это.
#bash #юмор
В Linux можно через консоль отправлять сообщения другому человеку. Для этого вам надо подключиться вместе с кем-то к серверу и посмотреть их номера. Проще всего это сделать с помощью команды w.
# w21:25:41 up 356 days, 11:46, 2 users, la: 0.01, 0.03, 0.06USER TTY FROM LOGIN@ IDLE JCPU PCPU WHATroot pts/0 123.456.158.81 17:18 5.00s 0.19s 0.01s wroot pts/1 321.654.177.11 17:19 13.00s 0.06s 0.06s -bashДопустим, другой человек подключился к консоли pts/1. Отправим ему сообщение:
# echo 'Ты кто такой? Тебя сюда не звали' > /dev/pts/1Это сообщение появится у него в консоли, после решётки. Можно как в режиме онлайн отправлять сообщения, так и запланировать их, например, с помощью at. Если человек один работает на сервере, то консоль у него будет нулевая.
Если никогда не пользовался этим функционалом и вообще ничего про него не знаешь, можно серьезно удивиться или напрячься. Что за хрень и кто со мной разговаривает? Какого-то другого применения этого функционала я не придумаю.
То же самое можно сделать с помощью write, например так:
# write user /dev/pts/1и дальше пишешь текст, но так русский язык не работает, я не разбирался, из-за чего это.
#bash #юмор
{kind=link}
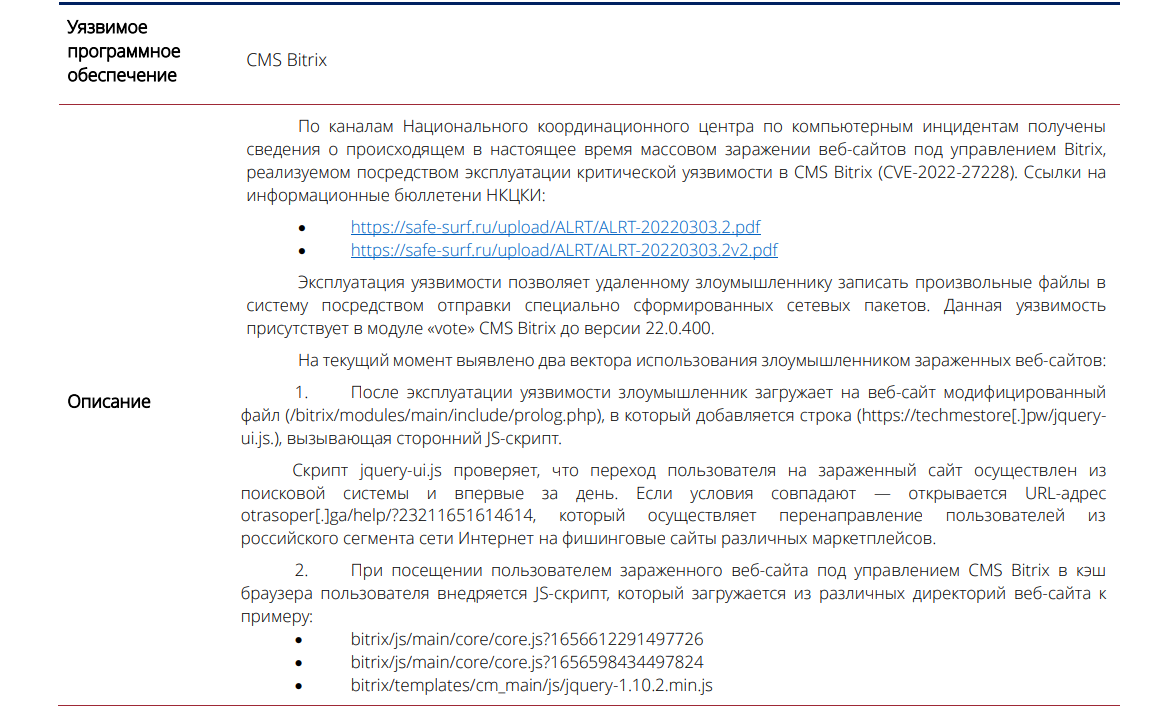
⚡️ Хочу предостеречь тех, у кого сайты на Bitrix. Как я понял, сейчас идёт волна взломов этого движка. У меня пострадал сайт одного из клиентов. Подробный бюллетень с описанием уязвимости ещё в июле публиковал НКЦКИ (ссылка на pdf). Там и вероятные пути попадания зловреда, его признаки, рекомендации по устранению последствий и рекомендации по защите.
У меня частично совпали признаки заражения с тем, что опубликовано в бюллетени, но не полностью. Модуля Vote не было, заражение прилетело через какую-то другую уязвимость. И особых разрушений на сайте тоже не было. Подменили пару файлов, добавили один новый, вставили вредоносную ссылку в код. Дату изменения файлов подделали (❗️), так что привычный поиск изменённых недавно файлов не поможет. Но не поменяли дату изменения директории, где этот фай лежал, так что теоретически можно найти следы, но сложно.
Код зловреда хитрый, поэтому его долго не замечали. Открывал фоном ссылку на сторонний сайт только один раз в день и только тем, кто пришёл на сайт из поиска. Постоянные пользователи не замечали ничего, как и администрация. Онлайн сканеры антивирусов, как и браузеры со своими встроенными проверками тоже не видели никаких проблем.
Мне устранить последствия удалось достаточно просто, потому что в стандартных бэкапах сайтов всегда храню все изменения файлов в течении дня. То есть прошёл день, я сравниваю вчерашний бэкап и сегодняшний. Все изменившиеся файлы кладу в отдельную папку с именем в виде даты. И такую историю изменений храню очень долго. Первое заражение сайта было ещё в июле, в августе один раз меняли ссылку. Мне удалось найти все изменённые файлы ещё с июля и заменить их оригиналами. Без этого не знаю, сколько времени пришлось бы ковыряться и всё равно наверняка бы не узнал, всё ли вычистил. А тут сразу все изменения файлов перед глазами. Подробно такая схема бэкапа описана у меня на сайте в статье про rsync. Рекомендую к обычным полным или инкрементным бэкапам добавлять такие, разностные по каждому дню.
Сайт доработанный, так что просто взять и обновить его нельзя. Нанимаются отдельно разработчики и выполняют обновление. Сразу предупредил владельца, чтобы оперативно проводил обновление. Других вариантов надёжной защиты не знаю. Пока выполнил рекомендации из бюллетеня и постоянно слежу, не повторился ли взлом. Если повторится, постараюсь подробно изучить, как именно он выполняется. Повторного заражения пока не было.
Проверил другие сайты, тоже давно не обновлявшиеся. Не нашёл следов заражения. Скорее всего используется какой-то модуль, который установлен не везде, либо отдельная редакция подвержена заражению.
Если сталкивались последнее время со взломом Битрикса, то какие меры для защиты приняли, помимо обновления до последней версии?
#bitrix
У меня частично совпали признаки заражения с тем, что опубликовано в бюллетени, но не полностью. Модуля Vote не было, заражение прилетело через какую-то другую уязвимость. И особых разрушений на сайте тоже не было. Подменили пару файлов, добавили один новый, вставили вредоносную ссылку в код. Дату изменения файлов подделали (❗️), так что привычный поиск изменённых недавно файлов не поможет. Но не поменяли дату изменения директории, где этот фай лежал, так что теоретически можно найти следы, но сложно.
Код зловреда хитрый, поэтому его долго не замечали. Открывал фоном ссылку на сторонний сайт только один раз в день и только тем, кто пришёл на сайт из поиска. Постоянные пользователи не замечали ничего, как и администрация. Онлайн сканеры антивирусов, как и браузеры со своими встроенными проверками тоже не видели никаких проблем.
Мне устранить последствия удалось достаточно просто, потому что в стандартных бэкапах сайтов всегда храню все изменения файлов в течении дня. То есть прошёл день, я сравниваю вчерашний бэкап и сегодняшний. Все изменившиеся файлы кладу в отдельную папку с именем в виде даты. И такую историю изменений храню очень долго. Первое заражение сайта было ещё в июле, в августе один раз меняли ссылку. Мне удалось найти все изменённые файлы ещё с июля и заменить их оригиналами. Без этого не знаю, сколько времени пришлось бы ковыряться и всё равно наверняка бы не узнал, всё ли вычистил. А тут сразу все изменения файлов перед глазами. Подробно такая схема бэкапа описана у меня на сайте в статье про rsync. Рекомендую к обычным полным или инкрементным бэкапам добавлять такие, разностные по каждому дню.
Сайт доработанный, так что просто взять и обновить его нельзя. Нанимаются отдельно разработчики и выполняют обновление. Сразу предупредил владельца, чтобы оперативно проводил обновление. Других вариантов надёжной защиты не знаю. Пока выполнил рекомендации из бюллетеня и постоянно слежу, не повторился ли взлом. Если повторится, постараюсь подробно изучить, как именно он выполняется. Повторного заражения пока не было.
Проверил другие сайты, тоже давно не обновлявшиеся. Не нашёл следов заражения. Скорее всего используется какой-то модуль, который установлен не везде, либо отдельная редакция подвержена заражению.
Если сталкивались последнее время со взломом Битрикса, то какие меры для защиты приняли, помимо обновления до последней версии?
#bitrix
{kind=link}
Обычно, когда надо узнать информацию о железе в Linux, начинаю перебирать утилиты типа lspci, lshw, dmidecode. Понятное дело, что ключей к ним я не помню, есть шпаргалки. Одну из них я публиковал в прошлом году.
Можно поступить проще. Есть утилита на perl - inxi. Узнал о ней случайно, увидел в одном из чатов. Плюс, в комментариях к заметкам пару раз её видел, так что забрал в закладки, а сейчас дошли руки попробовать.
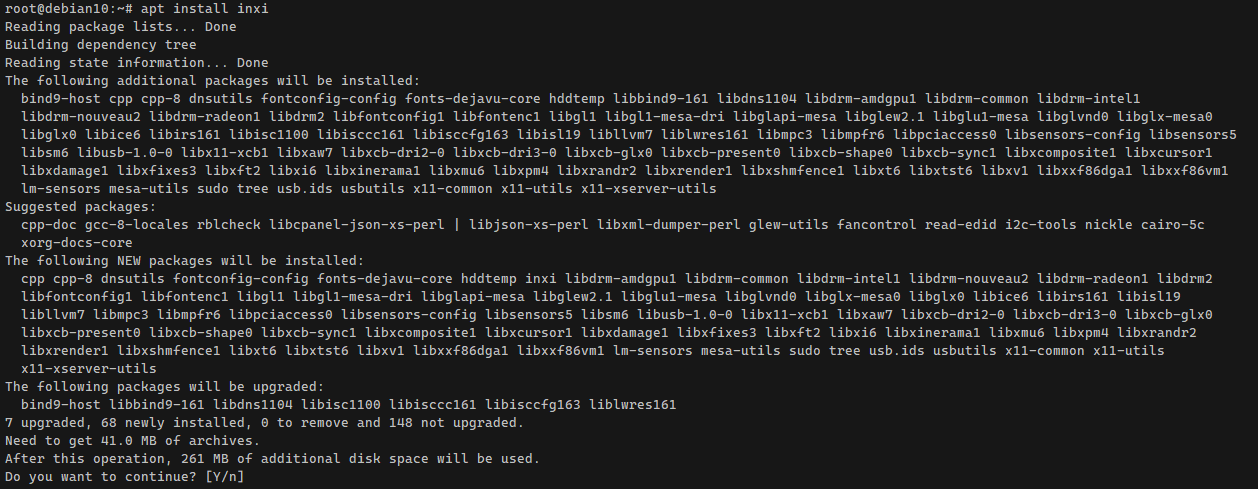
Она присутствует в базовых репозиториях популярных систем, так что ставится через пакетный менеджер:
А дальше самое интересное. У этой небольшой утилиты куча зависимостей. В прикрепленной картинке пример установки inxi в Debian. Я как увидел это, сразу понял, что инструмент не для серверов. Ставить столько зависимостей, чтобы посмотреть информацию о системе, абсурд. Скорее всего утилита перекочевала из десктопных систем, где большая их часть уже установлена в системе, так как там и видюхи чаще всего стоят, и куча всевозможных портов на материнке, чего в виртуалках просто нет и чаще всего не надо.
В целом inxi известный инструмент с большой историей. Он есть в официальных репозиториях всех известных дистрибутивов Linux, а также Freebsd и MacOS. Так что если вас не смущает количество зависимостей, то можете смело ставить. Собственно, эти зависимости и ставятся, чтобы собрать как можно больше информации о системе. И тут inxi действительно хорош. У него очень удобно и информативно организован вывод данных.
Сразу посмотреть всю информацию обо всём железе и самой системе (в том числе о типе гипервизора):
Базовая информация о системе:
Информация о процессоре:
Информация об оперативной памяти:
Информация о дисках:
И разделах на них:
Информация о сетевых картах:
В том числе с ip адресами (lan и wan):
Информация о видеокарте:
Список системных репозиториев:
Если к любой команде добавить ключ -c и дальше указать число от 0 до 42, то можно выбрать цветовую схему. Примерно так:
Параметров у inxi очень много. Она умеет показывать логические разделы lvm, подключенные bluetooth устройства, температуру с датчиков, даже погоду. По идее, это неплохой инструмент для стандартизации сбора информации с помощью какой-то системы мониторинга. Можно написать универсальный шаблон под неё и собирать всю интересующую информацию, в первую очередь с парка рабочих станций.
Сайт - https://smxi.org/docs/inxi-about.htm
Исходники - https://github.com/smxi/inxi
Обзор - https://www.youtube.com/watch?v=36L2NrvmCMo
#linux #железо
Можно поступить проще. Есть утилита на perl - inxi. Узнал о ней случайно, увидел в одном из чатов. Плюс, в комментариях к заметкам пару раз её видел, так что забрал в закладки, а сейчас дошли руки попробовать.
Она присутствует в базовых репозиториях популярных систем, так что ставится через пакетный менеджер:
# apt install inxi# dnf install inxiА дальше самое интересное. У этой небольшой утилиты куча зависимостей. В прикрепленной картинке пример установки inxi в Debian. Я как увидел это, сразу понял, что инструмент не для серверов. Ставить столько зависимостей, чтобы посмотреть информацию о системе, абсурд. Скорее всего утилита перекочевала из десктопных систем, где большая их часть уже установлена в системе, так как там и видюхи чаще всего стоят, и куча всевозможных портов на материнке, чего в виртуалках просто нет и чаще всего не надо.
В целом inxi известный инструмент с большой историей. Он есть в официальных репозиториях всех известных дистрибутивов Linux, а также Freebsd и MacOS. Так что если вас не смущает количество зависимостей, то можете смело ставить. Собственно, эти зависимости и ставятся, чтобы собрать как можно больше информации о системе. И тут inxi действительно хорош. У него очень удобно и информативно организован вывод данных.
Сразу посмотреть всю информацию обо всём железе и самой системе (в том числе о типе гипервизора):
# inxi -FБазовая информация о системе:
# inxi -bИнформация о процессоре:
# inxi -CИнформация об оперативной памяти:
# inxi -mИнформация о дисках:
# inxi -DИ разделах на них:
# inxi -pИнформация о сетевых картах:
# inxi -nВ том числе с ip адресами (lan и wan):
# inxi -niИнформация о видеокарте:
# inxi -GСписок системных репозиториев:
# inxi -rЕсли к любой команде добавить ключ -c и дальше указать число от 0 до 42, то можно выбрать цветовую схему. Примерно так:
# inxi -F -c 5Параметров у inxi очень много. Она умеет показывать логические разделы lvm, подключенные bluetooth устройства, температуру с датчиков, даже погоду. По идее, это неплохой инструмент для стандартизации сбора информации с помощью какой-то системы мониторинга. Можно написать универсальный шаблон под неё и собирать всю интересующую информацию, в первую очередь с парка рабочих станций.
Сайт - https://smxi.org/docs/inxi-about.htm
Исходники - https://github.com/smxi/inxi
Обзор - https://www.youtube.com/watch?v=36L2NrvmCMo
#linux #железо
{kind=link}
Media is too big
VIEW IN TELEGRAM
Пост немного не формат канала, тем более для утра среды, но всё равно хочу поделиться. Сам только вчера вечером увидел объявление. У группы Научно-технический рэп (НТР) завтра будет концерт в Москве. Подробности по ссылке - https://future.moscow/ntr
Научно-технический рэп (НТР) — группа, которая в искрометной форме вещает о наболевшем. В песнях НТР — реалии жизни IT-специалистов, биографии знаменитых ученых, восстание машин, тепловая смерть Вселенной, темная сторона Силы и матбой.
Это не реклама, её никто не заказывал. Мне нравится творчество этой группы, решил поддержать. Сам бы с удовольствием сходил, но 1-го сентября не получается.
Постоянно слушаю их песни. Собрал их в своей группе @srv_admin_humor (просто хранилище, канал не веду специально). На некоторые популярные песни один энтузиаст создал прикольные клипы, собраны на его канале - https://www.youtube.com/c/kawaiidesuintegral
#музыка #юмор
Научно-технический рэп (НТР) — группа, которая в искрометной форме вещает о наболевшем. В песнях НТР — реалии жизни IT-специалистов, биографии знаменитых ученых, восстание машин, тепловая смерть Вселенной, темная сторона Силы и матбой.
Это не реклама, её никто не заказывал. Мне нравится творчество этой группы, решил поддержать. Сам бы с удовольствием сходил, но 1-го сентября не получается.
Постоянно слушаю их песни. Собрал их в своей группе @srv_admin_humor (просто хранилище, канал не веду специально). На некоторые популярные песни один энтузиаст создал прикольные клипы, собраны на его канале - https://www.youtube.com/c/kawaiidesuintegral
#музыка #юмор
У меня вчера ночью сайт упал. Утром пока встал, покушал, сел за компьютер, накопилось большое количество сообщений в личке от читателей, как в vk, так и в телеге. Даже не ожидал, что столько народу читают сайт, где уже давно не обновлялись статьи. Всем спасибо за беспокойство.
Ситуация получилась хрестоматийная, так что решил разобрать её и прокомментировать. Упала база данных Mariadb. Её прибил OOM Killer. По мере устаревания кэша, отваливались страницы. Рассказываю, почему это произошло.
Для меня сайт не является критически важным ресурсом, так что какого-то особого контроля за ним не веду. После очередного переезда на новый сервер, изменились его характеристики. Я быстро на глазок подогнал все конфиги под эти характеристики и оставил всё без точечной калибровки. Где-то месяц или два всё это нормально работало.
Вчера ночью кто-то немного нагрузил сайт. Существенно выросло число запросов, разросся access log веб сервера, стартовала куча процессов php-fpm, открылись подключения к базе. Параллельно сразу же выросла нагрузка от fail2ban, который анализирует лог файлы и от filebeat, который отправляет логи в ELK. В итоге OOM Killer одновременно прибил filebeat и mariadb. Причём filebeat поднялся сам, у него в systemd сервисе прописано
В итоге что я сделал:
1️⃣ Поправил конфиг MariaDB. Конкретно изменил параметры, которые снизили максимальное количество оперативной памяти, которую может забрать процесс:
2️⃣ Поправил конфиг пула php-fpm. Заметил, что очень много запущено рабочих процессов, которые явно не используются все. Был 61 процесс, а после перезапуска понаблюдал и убедился, что для нормальной работы надо 10-15 штук всего. Процессы стартовали по потребности во время всплесков нагрузки, но долго потом висели в памяти, не закрывались. Добавил параметр
По сути просто сбалансировал потребление памяти между приложениями. Теперь надо нагрузить сайт одновременными тяжелыми запросами хотя бы с 10-15 разных IP адресов и посмотреть, сколько памяти скушают fail2ban и filebeat, чтобы ещё раз подкорректировать параметры. Желательно всё это замониторить, но в том же Zabbix нетривиальная задача настроить мониторинг, следящий за потреблением ресурсов отдельными динамическими процессами. Я знаю только одну систему мониторинга, которая это умеет из коробки - Newrelic.
Я не первый раз сталкиваюсь с ситуацией, когда сборщики и анализаторы логов непредсказуемо нагружают сервер. Тот же Fail2ban запросто его может положить сам при очень резком всплеске запросов. Так что это немного колхозное решение в лоб и нужно это понимать. С filebeat то же самое. Не зря его часто меняют на что-то другое: FluentD или Vektor.
В целом, эту ситуацию не трудно разрулить и даже автоматизировать настройку. Тут ключевой параметр - количество оперативной памяти, которую потребляет один рабочий процесс php-fpm. Это всегда будет зависеть от конкретного сайта. Вычисляется он, а потом по цепочке выстраивается потребление памяти всех остальных приложений. Затем обязательно настраивается ограничение запросов с одного IP. Потом результат тестируется стресс тестами и фиксируется. После этого для вас будут представлять опасность только DDOS атаки, которые на уровне одного сервера уже не отбить.
#webserver
Ситуация получилась хрестоматийная, так что решил разобрать её и прокомментировать. Упала база данных Mariadb. Её прибил OOM Killer. По мере устаревания кэша, отваливались страницы. Рассказываю, почему это произошло.
Для меня сайт не является критически важным ресурсом, так что какого-то особого контроля за ним не веду. После очередного переезда на новый сервер, изменились его характеристики. Я быстро на глазок подогнал все конфиги под эти характеристики и оставил всё без точечной калибровки. Где-то месяц или два всё это нормально работало.
Вчера ночью кто-то немного нагрузил сайт. Существенно выросло число запросов, разросся access log веб сервера, стартовала куча процессов php-fpm, открылись подключения к базе. Параллельно сразу же выросла нагрузка от fail2ban, который анализирует лог файлы и от filebeat, который отправляет логи в ELK. В итоге OOM Killer одновременно прибил filebeat и mariadb. Причём filebeat поднялся сам, у него в systemd сервисе прописано
Restart=always, а MariaDB нет, хотя там указано Restart=on-abort. По идее, с этой настройкой база тоже должна была подняться после остановки OOM Killer, но этого не случилось. В итоге что я сделал:
1️⃣ Поправил конфиг MariaDB. Конкретно изменил параметры, которые снизили максимальное количество оперативной памяти, которую может забрать процесс:
key_buffer_sizeinnodb_buffer_pool_sizeinnodb_log_file_sizemax_connections2️⃣ Поправил конфиг пула php-fpm. Заметил, что очень много запущено рабочих процессов, которые явно не используются все. Был 61 процесс, а после перезапуска понаблюдал и убедился, что для нормальной работы надо 10-15 штук всего. Процессы стартовали по потребности во время всплесков нагрузки, но долго потом висели в памяти, не закрывались. Добавил параметр
pm.process_idle_timeout = 30, чтобы через 30 секунд неактивности рабочий процесс завершался. Также более строго ограничил максимальное количество рабочих процессов параметром pm.max_children, чтобы они не смогли занять слишком много памяти. По сути просто сбалансировал потребление памяти между приложениями. Теперь надо нагрузить сайт одновременными тяжелыми запросами хотя бы с 10-15 разных IP адресов и посмотреть, сколько памяти скушают fail2ban и filebeat, чтобы ещё раз подкорректировать параметры. Желательно всё это замониторить, но в том же Zabbix нетривиальная задача настроить мониторинг, следящий за потреблением ресурсов отдельными динамическими процессами. Я знаю только одну систему мониторинга, которая это умеет из коробки - Newrelic.
Я не первый раз сталкиваюсь с ситуацией, когда сборщики и анализаторы логов непредсказуемо нагружают сервер. Тот же Fail2ban запросто его может положить сам при очень резком всплеске запросов. Так что это немного колхозное решение в лоб и нужно это понимать. С filebeat то же самое. Не зря его часто меняют на что-то другое: FluentD или Vektor.
В целом, эту ситуацию не трудно разрулить и даже автоматизировать настройку. Тут ключевой параметр - количество оперативной памяти, которую потребляет один рабочий процесс php-fpm. Это всегда будет зависеть от конкретного сайта. Вычисляется он, а потом по цепочке выстраивается потребление памяти всех остальных приложений. Затем обязательно настраивается ограничение запросов с одного IP. Потом результат тестируется стресс тестами и фиксируется. После этого для вас будут представлять опасность только DDOS атаки, которые на уровне одного сервера уже не отбить.
#webserver
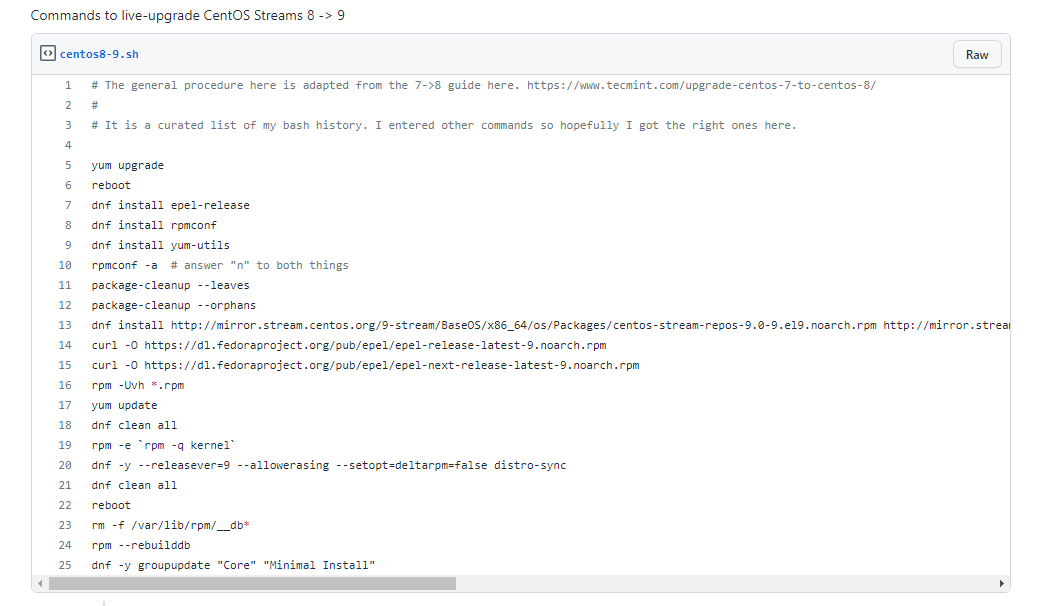
Поддержка ОС Centos 7 будет продолжаться до 30 июля 2024 года. Ещё примерно 2 года. Но уже сейчас появляются инструменты по миграции с этой ОС на что-то другое. Как все уже знают, Cenots 8 прекратила своё существование, так что переезжать придётся на какой-то форк.
Причин, по которым уже сейчас стоит переехать на что-то более свежее на самом деле много. Простой пример - Zabbix Server больше не поддерживает эту систему. Основная причина - очень устаревшие пакеты.
Команда дистрибутива Almalinux разработала свой инструмент Elevate на базе leapp по миграции с Centos 7 на одну из альтернатив:
◽ AlmaLinux OS 8
◽ CentOS Stream 8
◽ EuroLinux 8
◽ Oracle Linux 8
◽ Rocky Linux 8
Я попробовал его для миграции Centos 7 ⇨ Rocky Linux 8. На удивление всё прошло более ли менее гладко. Пару лет назад, когда пробовал с помощью leapp переехать с Centos 7 на 8, не получилось, бросил попытки.
А тут всё прошло хорошо за одним исключением. Сначала конвертация не хотела выполняться из-за того, что проверка находила драйверы ядра, которые больше не поддерживаются в 8-й версии. Стал разбираться, оказалось, что это драйвер floppy, который был загружен в текущей системе. Просто выгрузил его:
и успешно провел конвертацию.
Так что инструмент рабочий, рекомендую присмотреться, у кого остались старые системы.
Информация об Elevate - https://almalinux.org/elevate
Инструкция - https://wiki.almalinux.org/elevate/ELevate-quickstart-guide.html
Видео процесса - https://www.youtube.com/watch?v=WJpa1E6jnok
#centos
Причин, по которым уже сейчас стоит переехать на что-то более свежее на самом деле много. Простой пример - Zabbix Server больше не поддерживает эту систему. Основная причина - очень устаревшие пакеты.
Команда дистрибутива Almalinux разработала свой инструмент Elevate на базе leapp по миграции с Centos 7 на одну из альтернатив:
◽ AlmaLinux OS 8
◽ CentOS Stream 8
◽ EuroLinux 8
◽ Oracle Linux 8
◽ Rocky Linux 8
Я попробовал его для миграции Centos 7 ⇨ Rocky Linux 8. На удивление всё прошло более ли менее гладко. Пару лет назад, когда пробовал с помощью leapp переехать с Centos 7 на 8, не получилось, бросил попытки.
А тут всё прошло хорошо за одним исключением. Сначала конвертация не хотела выполняться из-за того, что проверка находила драйверы ядра, которые больше не поддерживаются в 8-й версии. Стал разбираться, оказалось, что это драйвер floppy, который был загружен в текущей системе. Просто выгрузил его:
# modprobe -r floppyи успешно провел конвертацию.
Так что инструмент рабочий, рекомендую присмотреться, у кого остались старые системы.
Информация об Elevate - https://almalinux.org/elevate
Инструкция - https://wiki.almalinux.org/elevate/ELevate-quickstart-guide.html
Видео процесса - https://www.youtube.com/watch?v=WJpa1E6jnok
#centos
{kind=link}
Чтобы закрыть тему с Centos, ещё немного информации про конвертацию. У меня есть одна машина с Centos Stream 8. Оставил её, чтобы следить за развитием этой системы. Довольно много людей используют Stream. У хостеров вижу шаблоны для её установки. Так что хоронить, её судя по всему, не стоит.
В конце прошлого года был релиз CentOS Stream 9, в которой SElinux теперь отключается не
Идея там такая же, как и раньше использовалась в обычной Centos, для которой тоже не было готовых конвертеров для перехода с ветки на ветку. Подключается репозиторий от новой ветки, обновляются все пакеты, удаляется старое ядро. Я вот тут всё по шагам сделал и получил новую версию системы. Способ рабочий.
Кто-то постоянно пользуется Stream? По идее для какого-то веб сервера пойдёт, где побыстрее свежие пакеты нужны. Для этого Ubuntu хорошо подходит, но если нужен rpm дистрибутив, то Stream в самый раз.
#centos
В конце прошлого года был релиз CentOS Stream 9, в которой SElinux теперь отключается не
SELINUX=disabled, а selinux=0 😁. Официальных инструментов для перехода с 8-й на 9-ю версию нет, но можно это сделать кустарными способами. Я один из таких проверил, он реально рабочий. Идея там такая же, как и раньше использовалась в обычной Centos, для которой тоже не было готовых конвертеров для перехода с ветки на ветку. Подключается репозиторий от новой ветки, обновляются все пакеты, удаляется старое ядро. Я вот тут всё по шагам сделал и получил новую версию системы. Способ рабочий.
Кто-то постоянно пользуется Stream? По идее для какого-то веб сервера пойдёт, где побыстрее свежие пакеты нужны. Для этого Ubuntu хорошо подходит, но если нужен rpm дистрибутив, то Stream в самый раз.
#centos
{kind=link}
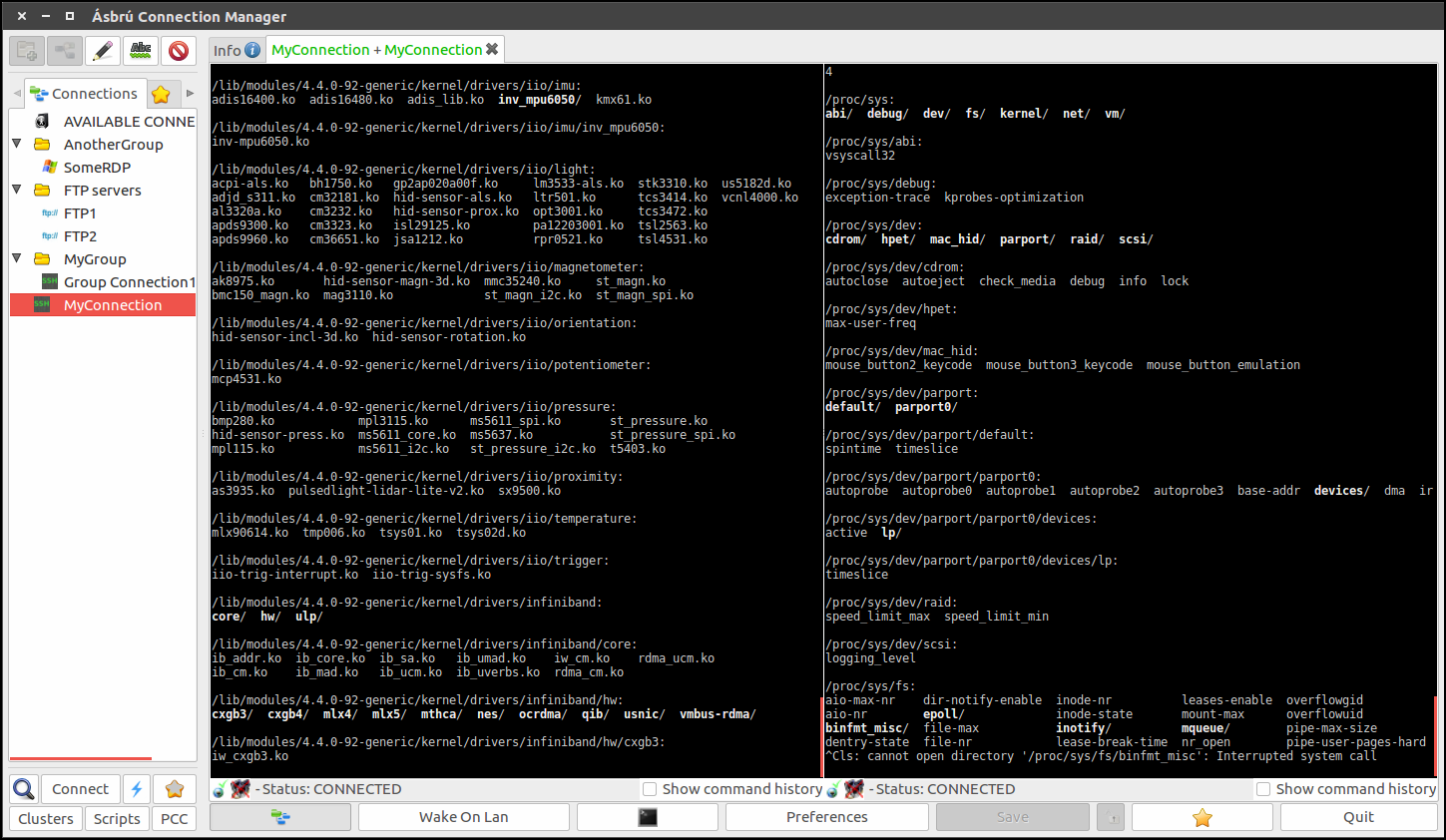
В копилку менеджеров для подключений предлагаю положить ещё один хороший продукт - Ásbrú Connection Manager. Это бесплатный Open Source проект и только под Linux. У него очень хороший функционал для бесплатного продукта и приятный внешний вид. С учётом того, что под Linux вообще не так много подобных программ, обратить на неё внимание точно стоит.
Функционал у Asbru-CM плюс-минус как у всех. Умеет много всего:
◽ поддерживает ssh, rdp, vnc, telnet, webdav, sftp, ftp;
◽ выполнять те или иные команды на удалённом при подключении;
◽ выполнять локально какие-то действия при удалённом подключении;
◽ интеграция с KeePassXC для хранения секретов;
◽ подключение через proxy;
◽ организовывать соединения в виде вкладок или отдельных окон.
Интересна история названия программы - Ásbrú. В норвежской мифологии Ásbrú - это радужный мост, соединяющий Мидгард (Землю) и Асгард, царство богов. Написана Ásbrú на Perl.
Аналогом Ásbrú на Linux является Remmina и Remote Desktop Manager. Писал на них обзоры.
Сайт - https://www.asbru-cm.net/
Исходники - https://github.com/asbru-cm/asbru-cm
#менеджеры_подключений
Функционал у Asbru-CM плюс-минус как у всех. Умеет много всего:
◽ поддерживает ssh, rdp, vnc, telnet, webdav, sftp, ftp;
◽ выполнять те или иные команды на удалённом при подключении;
◽ выполнять локально какие-то действия при удалённом подключении;
◽ интеграция с KeePassXC для хранения секретов;
◽ подключение через proxy;
◽ организовывать соединения в виде вкладок или отдельных окон.
Интересна история названия программы - Ásbrú. В норвежской мифологии Ásbrú - это радужный мост, соединяющий Мидгард (Землю) и Асгард, царство богов. Написана Ásbrú на Perl.
Аналогом Ásbrú на Linux является Remmina и Remote Desktop Manager. Писал на них обзоры.
Сайт - https://www.asbru-cm.net/
Исходники - https://github.com/asbru-cm/asbru-cm
#менеджеры_подключений
{kind=link}