
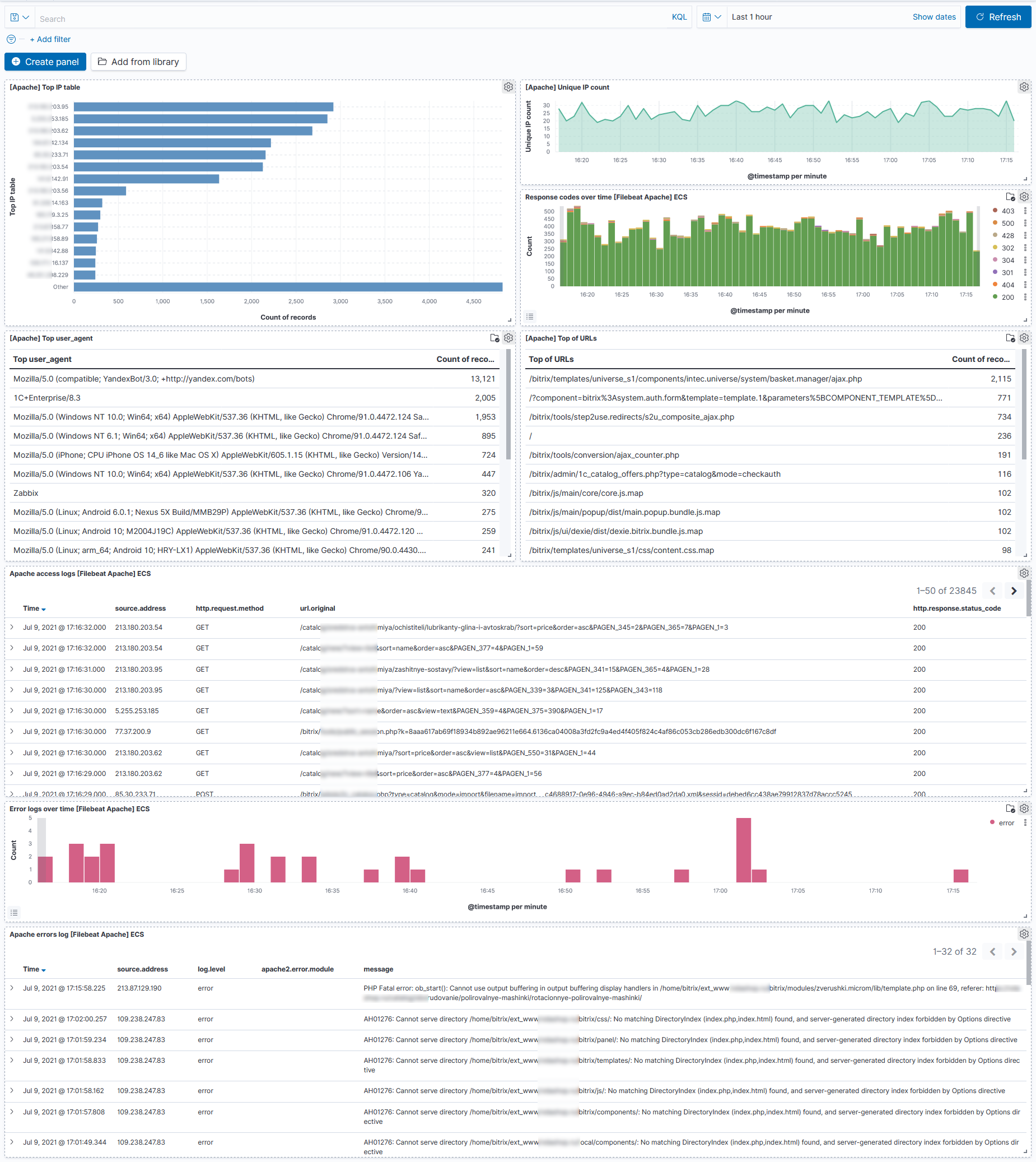
В пятницу пол дня настраивал сбор и анализ логов одного магазина на битриксе. Производительность потихоньку начала в потолок сервера упираться. Надо было внимательно посмотреть, что там происходит. Одного мониторинга уже не хватало.
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
{kind=link}
Я неоднократно уже упоминал на канале про ELK Stack. Это достаточно громоздкая, тяжелая в плане ресурсов и не очень простая в плане настройки система хранения и анализа логов. Но она очень функциональная и полезная. Эту услугу можно купить как сервис, а не разворачивать и настраивать на своих мощностях.
Для теста можно взять 14-ти дневный триал и посмотреть, как там всё работает. Если понравится, можно перейти на платный тариф. Самый простой стоит 16$ в месяц. Для начала хватит. Это дешевле стоимости виртуальных машин, которые вам понадобятся, если будете арендовать VPS под них. Для небольшого проекта это однозначно выгоднее, чем устанавливать и поддерживать свой сервер.
У меня есть статья с пошаговым руководством, как всё запустить и потестировать работу с использованием триала. Для примера я собираю логи веб сервера от сайта на bitrix и отправляю в elastic cloud.
https://serveradmin.ru/bystraya-nastrojka-elastic-stack-v-elastic-cloud-dlya-sbora-logov/
#elk #devops
Для теста можно взять 14-ти дневный триал и посмотреть, как там всё работает. Если понравится, можно перейти на платный тариф. Самый простой стоит 16$ в месяц. Для начала хватит. Это дешевле стоимости виртуальных машин, которые вам понадобятся, если будете арендовать VPS под них. Для небольшого проекта это однозначно выгоднее, чем устанавливать и поддерживать свой сервер.
У меня есть статья с пошаговым руководством, как всё запустить и потестировать работу с использованием триала. Для примера я собираю логи веб сервера от сайта на bitrix и отправляю в elastic cloud.
https://serveradmin.ru/bystraya-nastrojka-elastic-stack-v-elastic-cloud-dlya-sbora-logov/
#elk #devops
Server Admin
Сбор логов в Elastic Stack Cloud | serveradmin.ru
Подробное описание регистрации и начала работы с Elastic Cloud для сбора логов с помощью filebeat на примере логов apache.
Узнал вчера про существование проекта для предобработки текста Tremor. Продукт нишевый и нужен только в определенных ситуациях. Это аналог Logstash, который входит в состав ELK. Я Logstash достаточно часто использую. В целом, привык к нему и к его языку парсинга в виде grok фильтров. Значительный минус Logstash - он очень требователен к ресурсам. Такое тяжелое Java приложение. Первого запуска достаточно, чтобы понять, какой он тормозной. Запускается секунд 5-7 даже без нагрузки.
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
{kind=link}
Написал статью по настройке Elastic Enterprise Search. Это отдельная служба, которая работает на базе ELK Stack и может быть установлена и интегрирована в указанную инфраструктуру. Но при этом остается независимым, отдельным компонентом.
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Server Admin
Установка Elastic Enterprise Search | serveradmin.ru
xpack.security.enabled: true После этого перезапустите службу elasticsearch: # systemctl restart elasticsearch Теперь сгенерируем пароли к встроенным учётным записям (built-in users) elastic. Для...
Многие наверно слышали про разногласия между Elastic и Amazon, в результате чего последний сделал форк ELK Stack на момент действия старой лицензии и начал развивать свой продукт на его основе - OpenSearch. Причём это не то же самое, что они уже ранее анонсировали и поддерживают - Open Distro. Поясню своими словами, так как сам до конца не понимал, что там к чему.
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
{kind=link}
Проверил и актуализировал свою статью про настройку ELK Stack. Добавил информацию про автоматическую очистку индексов встроенными средствами стэка. А также про авторизацию с помощью паролей средствами X-Pack Security.
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Server Admin
Установка и настройка Elasticsearch, Logstash, Kibana (ELK Stack)
Подробное описание установки ELK Stack - Elasticsearch, Logstash, Kibana для централизованного сбора логов.
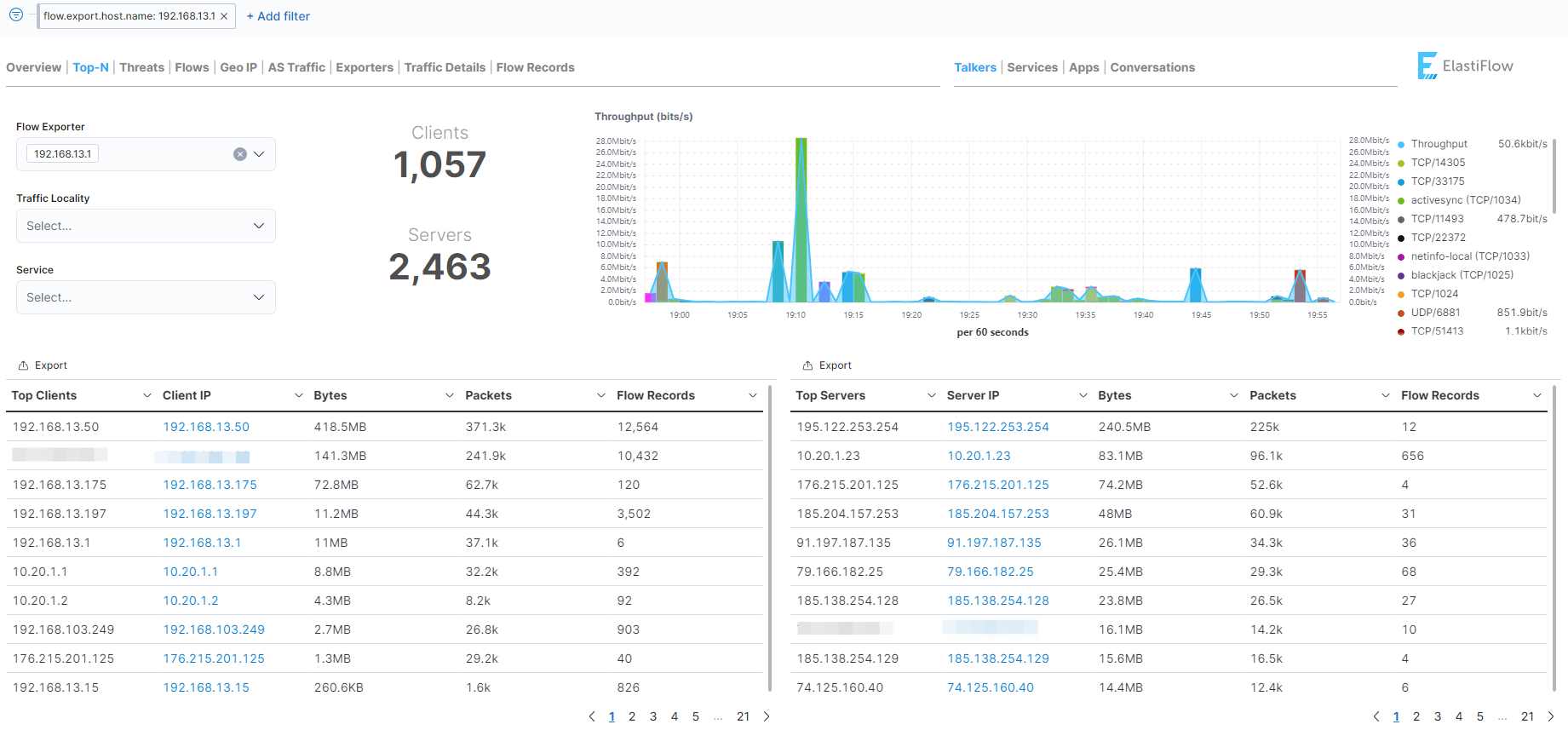
Пока у меня остался свежий стенд с ELK Stack, решил попробовать софт для разбора NetFlow потоков в Elasticsearch - Elastiflow. Идея там такая. Ставите куда угодно коллектор, который собирает NetFlow и принимаете трафик. А этот коллектор передаёт всю информацию в Elasticsearch. В комплекте с Elastiflow идёт все необходимое для визуализации данных - шаблоны, дашборды для Kibana.
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
{kind=link}