
Медленно, но верно, я перестаю использовать
Самые популярные ключи к ss это tulnp:
Список открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
Вывести только сокеты можно и другой командой:
Но там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
И сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
То же самое, только выводим тех, у кого более 30 соединений с нами:
Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
Всё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
Больше лично я
#linux #terminal
netstat и привыкаю к ss. У неё хоть и не такой удобный для восприятия вывод, но цепляться за netstat уже не имеет смысла. Она давно устарела и не рекомендуется к использованию. Плюс, её нет в стандартных минимальных поставках дистрибутивов. Надо ставить отдельно. Это как с ifconfig. Поначалу упирался, но уже много лет использую только ip. Ifconfig вообще не запускаю. Даже ключи все забыл. Самые популярные ключи к ss это tulnp:
# ss -tulnpСписок открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
# ss -l | grep .sockВывести только сокеты можно и другой командой:
# ss -axНо там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
# ss -ntuИ сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'То же самое, только выводим тех, у кого более 30 соединений с нами:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//' | awk '{if ($1 > 30) print$2}'Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | wc -lВсё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
a:# ss -ntuaБольше лично я
ss ни для чего не использую. Если смотрите ещё что-то полезное с помощью этой утилиты, поделитесь в комментариях.#linux #terminal
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
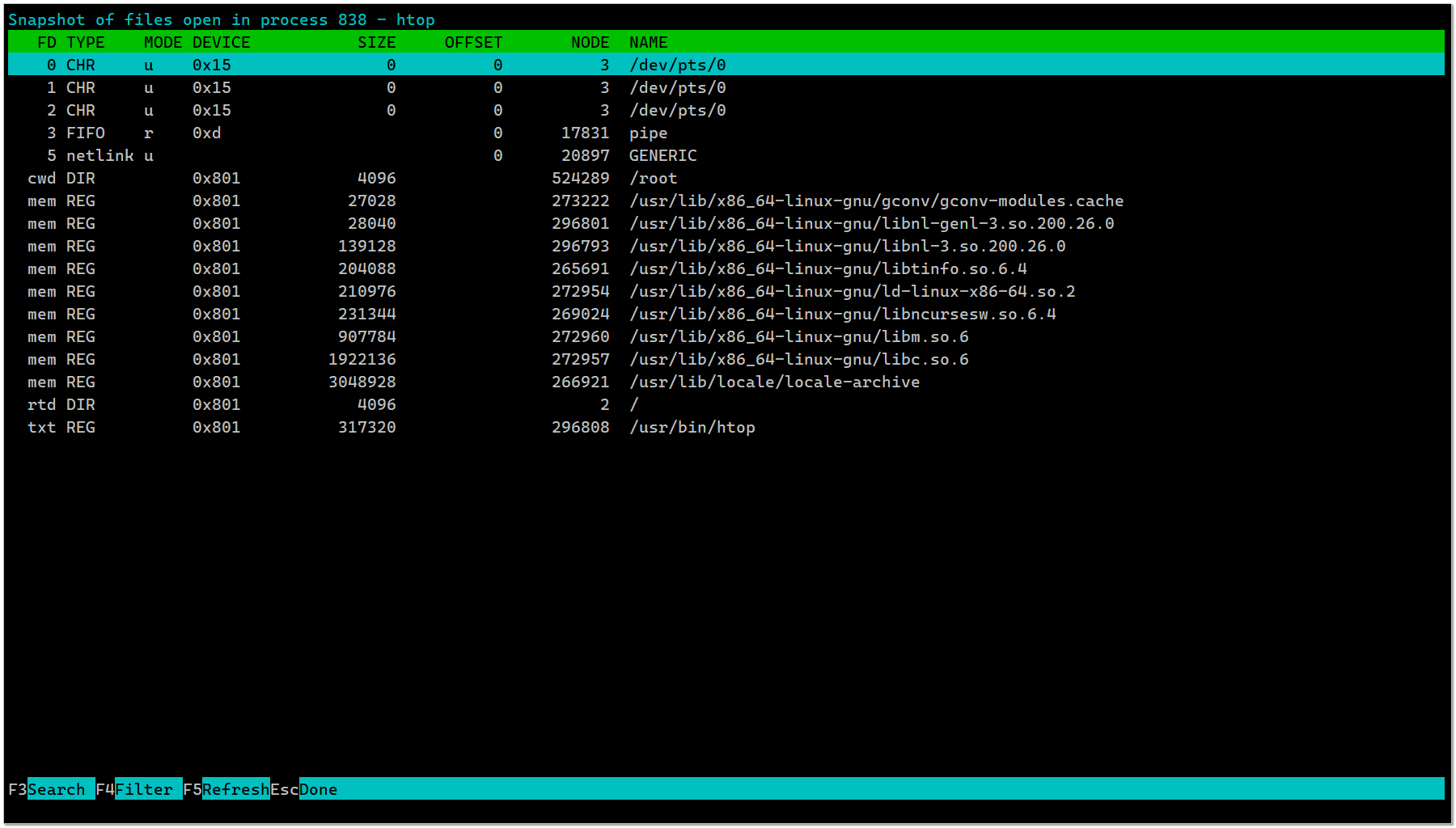
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}
Полезной возможностью Tmux является расширение функциональности за счёт плагинов. Для тех, кто не знает, поясню, что с помощью Tmux можно не переживать за разрыв SSH сессии. Исполнение всех команд продолжится даже после вашего отключения. Потом можно подключиться заново и попасть в свою сессию. Я в обязательном порядке все более-менее долгосрочные операции делаю в подобных программах. Раньше использовал Screen для этого, но последнее время перехожу на Tmux, так как он удобнее и функциональнее.
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
Добавляем в ~/.tmux.conf в самое начало:
Заходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
# git clone https://github.com/tmux-plugins/tmux-resurrectДобавляем в ~/.tmux.conf в самое начало:
run-shell ~/tmux-resurrect/resurrect.tmuxЗаходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
{kind=link}
В репозиториях популярных дистрибутивов есть маленькая, но в некоторых случаях полезная программа progress. Из названия примерно понятно, что она делает - показывает шкалу в % выполнения различных дисковых операций. Она поддерживает так называемые coreutils - cp, mv, dd, tar, gzip/gunzip, cat и т.д.
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
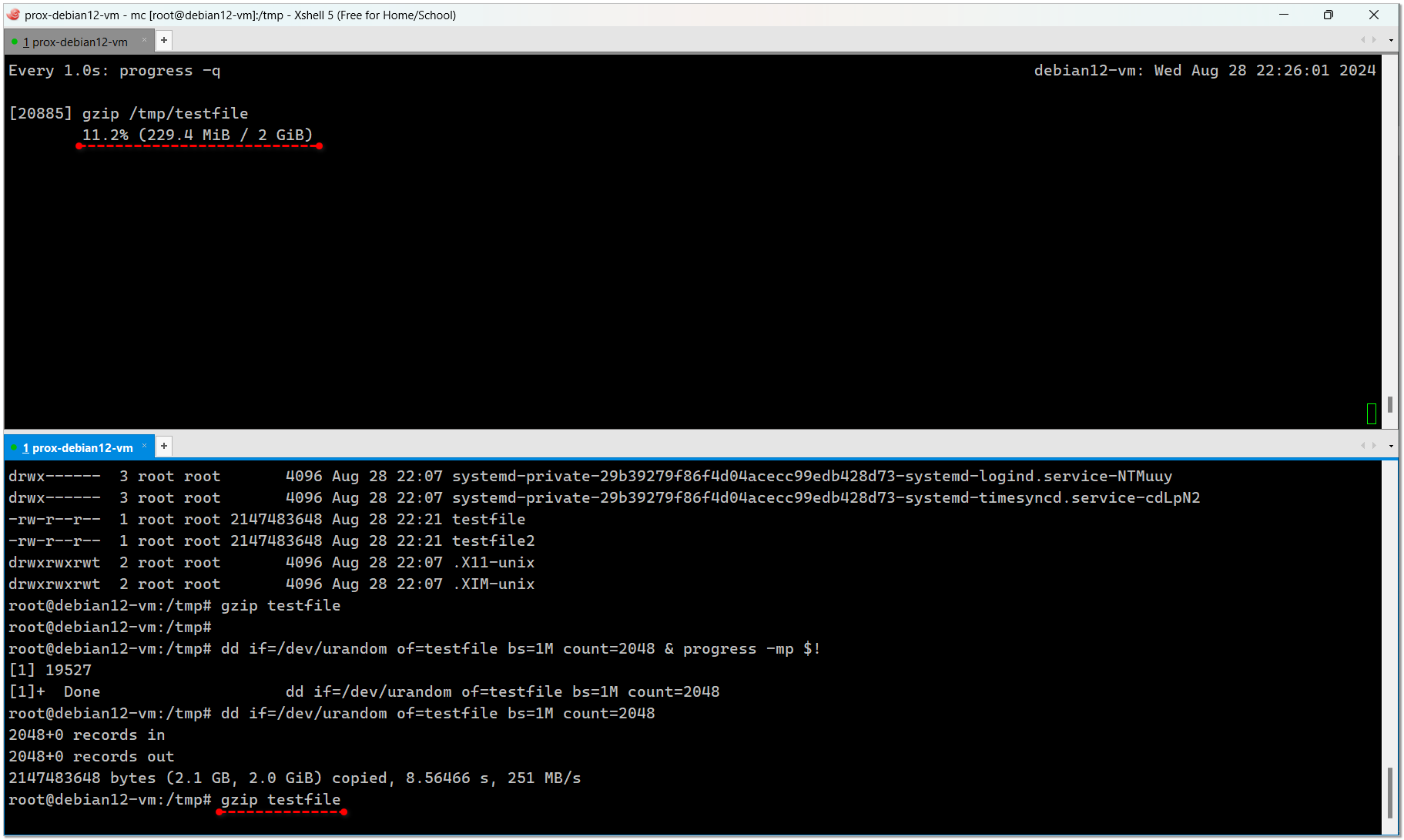
Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
Покажу сразу на примере. Создадим файл:
За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
Открываем вторую консоль и там смотрим за процессом:
Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
В соседней консоли смотрим:
Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
⇨ Исходники
#terminal #linux
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
/proc, находит там поддерживаемые утилиты, далее идёт в fd и fdinfo, находит там открытые файлы и следит за их изменениями.Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
Покажу сразу на примере. Создадим файл:
# dd if=/dev/urandom of=testfile bs=1M count=2048За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
# gzip testfileОткрываем вторую консоль и там смотрим за процессом:
# watch -n 1 progress -q[34209] gzip /tmp/testfile 6.5% (132.2 MiB / 2 GiB)Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
# gunzip testfile.gzВ соседней консоли смотрим:
# watch -n 1 progress -q[35685] gzip /tmp/testfile.gz 76.1% (1.5 GiB / 2.0 GiB)Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
# apt install progress# dnf install progress ⇨ Исходники
#terminal #linux
{kind=link}
Я уже как-то упоминал, что последнее время в репозитории популярных дистрибутивов попадают современные утилиты, аналоги более старых с расширенной функциональностью. Я писал о некоторых из них:
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
Это небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
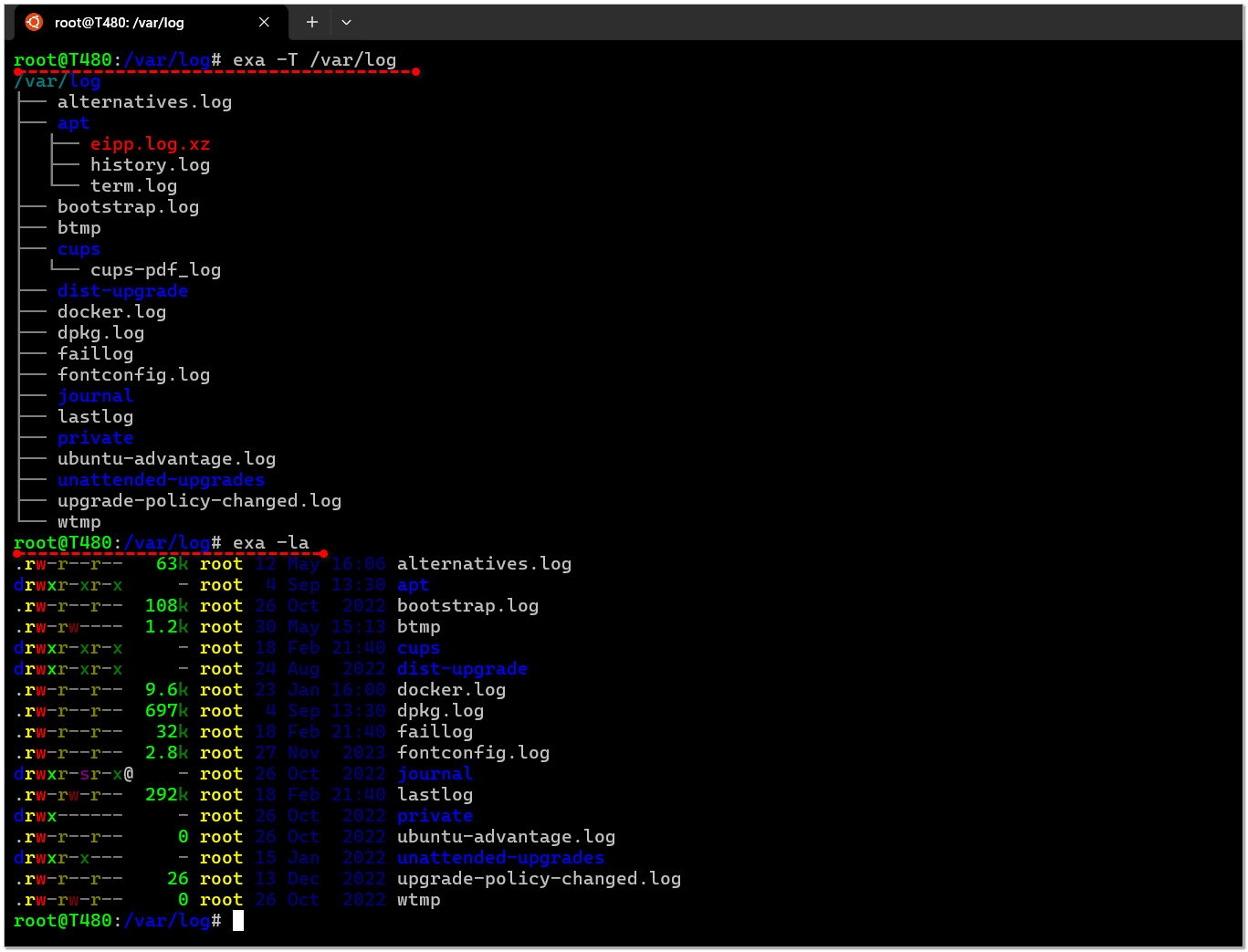
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
Можно ограничить максимальный уровень вложенности:
Привычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
# apt install exaЭто небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
# exa -T /var/log├── alternatives.log├── alternatives.log.1├── alternatives.log.2.gz├── alternatives.log.3.gz├── alternatives.log.4.gz├── apt│ ├── eipp.log.xz│ ├── history.log│ ├── history.log.1.gz│ ├── history.log.2.gz......................................Можно ограничить максимальный уровень вложенности:
# exa -T -L 2 /var/logПривычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
# echo 'alias ls=exa' >> ~/.bashrc# source ~/.bashrc# ls -la❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
{kind=link}
Небольшая заметка про одну команду, которая у меня уже вошла в привычку и используется почти каждый день. Возможно и вам она будет полезна. Я недавно делал заметку про netstat и ss. Рассказал, что постепенно почти перешёл на
В комментариях один человек посоветовал использовать утилиту column. Что самое интересное, я про неё знаю, писал заметку. Тоже посоветовали в комментариях. Но с
А самое главное, что я cразу эту конструкцию запомнил и теперь постоянно пользуюсь, так как и
Теперь вот и с
Netstat вообще не выводит пользователей, только название процесса. В
Но тут вывод о процессе ненагляден, так как выводится имя юнита systemd, а не непосредственно рабочего процесса.
#linux #terminal
ss, но не нравится широкий вывод команды. На узком терминале разъезжается одна строка на две и вывод выглядит ненаглядно.В комментариях один человек посоветовал использовать утилиту column. Что самое интересное, я про неё знаю, писал заметку. Тоже посоветовали в комментариях. Но с
ss не догадался её попробовать. А это удобно. Вывод получается более компактный и наглядный:# ss -tulnp | column -t# ss -nte | column -tА самое главное, что я cразу эту конструкцию запомнил и теперь постоянно пользуюсь, так как и
ss, и column есть во всех дистрах из коробки. Рекомендую попробовать. Я column привык с mount использовать для удобного вывода:# mount | column -tТеперь вот и с
ss. Про netstat стал забывать. Не использую почти, перешёл на ss. Один неприятный нюанс всё равно остался. Даже с column в ss бывают длинные строки, если поле с users очень длинное, типа такого:users:(("smtpd",pid=1680589,fd=6),("smtpd",pid=1680587,fd=6),("smtpd",pid=1680585,fd=6),("smtpd",pid=1678705,fd=6),("smtpd",pid=1678348,fd=6),("smtpd",pid=1675803,fd=6),("master",pid=1837,fd=13))Netstat вообще не выводит пользователей, только название процесса. В
ss тоже можно убрать, например вот так (заменили p на e):# ss -tulneНо тут вывод о процессе ненагляден, так как выводится имя юнита systemd, а не непосредственно рабочего процесса.
#linux #terminal
Пройдусь немного по важной теории по поводу работы в консоли bash. Я в разное время всё это затрагивал в заметках, но информация размазана через большие промежутки в публикациях. Имеет смысл повторить базу.
Покажу сразу очень наглядный пример:
В первом случае ключ не сработал, а во втором сработал, хотя запускал вроде бы одно и то же. А на самом деле нет. В первом примере я запустил echo из состава оболочки bash, а во втором случае - это бинарник в файловой системе. Это по факту разные программы. У них даже ключи разные.
Узнать, что конкретно мы запускаем, проще всего через type:
В первом случае прямо указано, что echo - встроена в оболочку.
И ещё один очень характерный пример:
Очень часто ls это не утилита ls, а алиас с дополнительными параметрами.
Когда вы вводите команду в терминал, происходит следующее:
1️⃣ Проверяются алиасы. Если команда будет там найдена, то поиск остановится и она исполнится.
2️⃣ Далее команда проверяется, встроена в ли она в оболочку, или нет. Если встроена, то выполнится именно она.
3️⃣ Только теперь идёт поиск бинарника в директориях, определённых в
У последнего варианта тоже есть свои нюансы. У вас может быть несколько исполняемых файлов в разных директориях с одинаковым именем. Ситуация нередкая. Можно столкнуться при наличии разных версий python или php в системе. Поиск бинарника ведётся по порядку следования этих директорий в переменной слева направо.
Что раньше будет найдено в директориях, определённых в этой строке, то и будет исполнено.
И ещё важный нюанс по этой теме. Есть привычные команды из оболочки, которых нет в бинарниках. Например, cd.
В выводе последней команды пусто, то есть бинарника
А вот если вы cd используете в юните systemd, то ничего не заработает:
Вот так работать не будет. Systemd не будет запускать автоматом оболочку. Надо это явно указать:
То есть либо явно указывайте bash, либо запускайте скрипт, где bash будет прописан в шебанге.
❗️В связи с этим могу дать совет, который вам сэкономит кучу времени на отладке. Всегда и везде в скриптах, в кронах, в юнитах systemd и т.д. пишите полные пути до бинарников. Команда, в зависимости от пользователя, прав доступа и многих других условий, может быть запущена в разных оболочках и окружениях. Чтобы не было неожиданностей, пишите явно, что вы хотите запустить.
#bash #terminal
Покажу сразу очень наглядный пример:
# echo --version--version# /usr/bin/echo --versionecho (GNU coreutils) 9.1В первом случае ключ не сработал, а во втором сработал, хотя запускал вроде бы одно и то же. А на самом деле нет. В первом примере я запустил echo из состава оболочки bash, а во втором случае - это бинарник в файловой системе. Это по факту разные программы. У них даже ключи разные.
Узнать, что конкретно мы запускаем, проще всего через type:
# type echoecho is a shell builtin# type /usr/bin/echo/usr/bin/echo is /usr/bin/echoВ первом случае прямо указано, что echo - встроена в оболочку.
И ещё один очень характерный пример:
# type lsls is aliased to `ls --color=auto'Очень часто ls это не утилита ls, а алиас с дополнительными параметрами.
Когда вы вводите команду в терминал, происходит следующее:
1️⃣ Проверяются алиасы. Если команда будет там найдена, то поиск остановится и она исполнится.
2️⃣ Далее команда проверяется, встроена в ли она в оболочку, или нет. Если встроена, то выполнится именно она.
3️⃣ Только теперь идёт поиск бинарника в директориях, определённых в
$PATH.У последнего варианта тоже есть свои нюансы. У вас может быть несколько исполняемых файлов в разных директориях с одинаковым именем. Ситуация нередкая. Можно столкнуться при наличии разных версий python или php в системе. Поиск бинарника ведётся по порядку следования этих директорий в переменной слева направо.
# echo $PATH/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binЧто раньше будет найдено в директориях, определённых в этой строке, то и будет исполнено.
И ещё важный нюанс по этой теме. Есть привычные команды из оболочки, которых нет в бинарниках. Например, cd.
# type cdcd is a shell builtin# which cdВ выводе последней команды пусто, то есть бинарника
cd нет. Если вы будете использовать cd в скриптах, то проблем у вас не будет, так как там обычно в шебанге указан интерпретатор. Обычно это bash или sh, и там cd присутствует.А вот если вы cd используете в юните systemd, то ничего не заработает:
ExecStart=cd /var/www/ ....... && .........Вот так работать не будет. Systemd не будет запускать автоматом оболочку. Надо это явно указать:
ExecStart=/usr/bin/bash -с "cd /var/www/ ......."То есть либо явно указывайте bash, либо запускайте скрипт, где bash будет прописан в шебанге.
❗️В связи с этим могу дать совет, который вам сэкономит кучу времени на отладке. Всегда и везде в скриптах, в кронах, в юнитах systemd и т.д. пишите полные пути до бинарников. Команда, в зависимости от пользователя, прав доступа и многих других условий, может быть запущена в разных оболочках и окружениях. Чтобы не было неожиданностей, пишите явно, что вы хотите запустить.
#bash #terminal
И вновь возвращаемся к рубрике с современными утилитами, которые можно использовать в качестве альтернативы более старым, потому что они уже поселились в официальных репозиториях. Речь пойдёт об уже упоминаемой мной несколько лет назад программе fd, которую можно использовать вместо find. Она приехала в стабильные репы:
Короткое название fd использовать не получится, потому что оно уже занято. Придётся использовать
В чём особенность fd? Авторы называют её более быстрой и дружелюбной к пользователю программой, по сравнению с find. В принципе, с этим не поспоришь. Ключи и синтаксис find нельзя назвать дружелюбным. Я по памяти могу только какие-то самые простые вещи делать. Всё остальное ищу в своих шпаргалках. Не понимаю, как подобные конструкции можно запоминать, если каждый день с ними не работаешь.
Ищем файл syslog в текущей директории:
Ищем файл в конкретной директории:
Ищем файл по всему серверу:
Вот то же самое, только с find:
По умолчанию find найдёт только полное совпадение по имени. Файл должен будет точно называться syslog, чтобы попасть в результаты поиска. Fd в примере отобразит все файлы, где встречается слово syslog. Это и интуитивнее, и проще для запоминания. Хотя этот момент субъективен. С find такой же поиск будет выглядеть вот так:
Отличия от find, которые отмечают авторы:
◽️Более скоростной поиск за счёт параллельных запросов. Приводят свои измерения, где это подтверждается.
◽️Подсветка результатов поиска.
◽️По умолчанию поиск ведётся без учёта регистра.
◽️Итоговые команды в среднем на 50% короче, чем то же самое получается с find.
⚠️ Отдельный ключ
Несколько простых примеров для наглядности. Поиск файлов с определённым расширением:
Найти все архивы и распаковать их:
Найти файлы с расширением gz и удалить одной командой rm:
Вызванный без аргументов в директории, fd рекурсивно выведет все файлы в ней:
Это примерно то же самое, что с find:
Только у fd вывод нагляднее, так как уже отсортирован по именам. А find всё вперемешку выводит. Ему надо sort добавлять, чтобы то же самое получилось:
Fd умеет результаты выводить не по одному значению на каждую строку, а непрерывной строкой с разделением с помощью так называемого NULL character. Все символы воспринимаются буквально, не являются специальными, их не надо экранировать. Актуально, когда результаты поиска имеют пробелы, кавычки, косые черты и т.д. Например, xargs умеет принимать на вход значения, разделённые NULL character. У него для этого отдельный ключ
Покажу на примере, как это работает:
Xargs не смог обработать файл с пробелом. А вот так смог:
И ничего экранировать не пришлось. Полезная возможность, стоит запомнить. Find то же самое делает через ключ
В заключении резюмирую, что fd не заменяет find, не претендует на это и не обеспечивает такую же функциональность, как у последнего. Он предоставляет обоснованные настройки по умолчанию для наиболее массовых применений поиска пользователями.
#terminal #linux #find
# apt install fd-findКороткое название fd использовать не получится, потому что оно уже занято. Придётся использовать
fdfind. Под Windows она, кстати, тоже есть:> winget install sharkdp.fdВ чём особенность fd? Авторы называют её более быстрой и дружелюбной к пользователю программой, по сравнению с find. В принципе, с этим не поспоришь. Ключи и синтаксис find нельзя назвать дружелюбным. Я по памяти могу только какие-то самые простые вещи делать. Всё остальное ищу в своих шпаргалках. Не понимаю, как подобные конструкции можно запоминать, если каждый день с ними не работаешь.
Ищем файл syslog в текущей директории:
# fdfind syslogИщем файл в конкретной директории:
# fdfind syslog /var/logИщем файл по всему серверу:
# fdfind syslog /Вот то же самое, только с find:
# find . -name syslog# find /var/log -name syslog# find / -name syslogПо умолчанию find найдёт только полное совпадение по имени. Файл должен будет точно называться syslog, чтобы попасть в результаты поиска. Fd в примере отобразит все файлы, где встречается слово syslog. Это и интуитивнее, и проще для запоминания. Хотя этот момент субъективен. С find такой же поиск будет выглядеть вот так:
# find / -name '*syslog*'Отличия от find, которые отмечают авторы:
◽️Более скоростной поиск за счёт параллельных запросов. Приводят свои измерения, где это подтверждается.
◽️Подсветка результатов поиска.
◽️По умолчанию поиск ведётся без учёта регистра.
◽️Итоговые команды в среднем на 50% короче, чем то же самое получается с find.
⚠️ Отдельный ключ
--exec-batch или -X в дополнение к традиционному --exec. Разница в том, что --exec выполняется параллельно для каждого результата поиска, а с помощью --exec-batch можно во внешнюю команду передать весь результат поиска. Это важный момент, который где-то может сильно выручить и упростить задачу. Даже если вам сейчас это не надо, запомните, что с fd так можно. Где-то в скриптах это может пригодиться.Несколько простых примеров для наглядности. Поиск файлов с определённым расширением:
# fdfind -e php -p /var/wwwНайти все архивы и распаковать их:
# fdfind -e zip -p /home/user -x unzipНайти файлы с расширением gz и удалить одной командой rm:
# fdfind -e gz -p /var/log -X rmВызванный без аргументов в директории, fd рекурсивно выведет все файлы в ней:
# cd /var/log# fdfindЭто примерно то же самое, что с find:
# find -name '*'Только у fd вывод нагляднее, так как уже отсортирован по именам. А find всё вперемешку выводит. Ему надо sort добавлять, чтобы то же самое получилось:
# find -name '*' | sortFd умеет результаты выводить не по одному значению на каждую строку, а непрерывной строкой с разделением с помощью так называемого NULL character. Все символы воспринимаются буквально, не являются специальными, их не надо экранировать. Актуально, когда результаты поиска имеют пробелы, кавычки, косые черты и т.д. Например, xargs умеет принимать на вход значения, разделённые NULL character. У него для этого отдельный ключ
-0, --null. Покажу на примере, как это работает:
# touch 'test test.log'# fdfind -e log...test test.log# fdfind -e log | xargs wc -l...wc: test: No such file or directorywc: test.log: No such file or directoryXargs не смог обработать файл с пробелом. А вот так смог:
# fdfind -0 -e log | xargs -0 wc -l...0 ./test test.logИ ничего экранировать не пришлось. Полезная возможность, стоит запомнить. Find то же самое делает через ключ
-print0:# find . -name '*.log' -print0 | xargs -0 wc -lВ заключении резюмирую, что fd не заменяет find, не претендует на это и не обеспечивает такую же функциональность, как у последнего. Он предоставляет обоснованные настройки по умолчанию для наиболее массовых применений поиска пользователями.
#terminal #linux #find
На всех серверах на базе Linux, а раньше и не только Linux, которые настраиваю и обслуживаю сам, изменяю параметры хранения истории команд, то есть history. Настройки обычно добавляю в файл
✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
Для применения настроек можно выполнить:
Посмотреть свои применённые параметры для истории можно вот так:
Если вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
🦖 Selectel — дешёвые и не очень дедики с аукционом!
~/.bashrc. Постоянно обращаюсь к истории команд, поэтому стараюсь, чтобы они туда попадали и сохранялись. Покажу свои привычные настройки:✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
history -a сохраняет историю команд этого сеанса в файл с историей.PROMPT_COMMAND='history -a'✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
export HISTTIMEFORMAT='%F %T '✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
export HISTSIZE=10000✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
export HISTIGNORE="ls:history:w:htop:pwd:top:iftop"✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
export HISTCONTROL=ignorespace Для применения настроек можно выполнить:
# source ~/.bashrcПосмотреть свои применённые параметры для истории можно вот так:
# export | grep -i histЕсли вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
history.sh и положите его в директорию /etc/profile.d. Скрипты из этой директории выполняются при запуске шелла пользователя. ❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
# history | grep 'apt install'Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
Please open Telegram to view this post
VIEW IN TELEGRAM
На днях на одном из серверов VPN с IP 175.115.158.81 заметил странные строки в логе:
Внимание привлекло то, что 95.145.141.246 это мой IP адрес ещё одного VPN сервера. Я не припомнил, чтобы настраивал на нем клиента для подключения к серверу 175.115.158.81. На всякий случай сходил туда и убедился в этом:
Никакого openvpn клиента тут не было запущено. Да и настроек для него тоже нет. У меня настроена разветвлённая система VPN туннелей с маршрутизацией, так что иногда начинаю в ней путаться. Надо схему рисовать.
Я немного напрягся и стал разбираться, в чём тут дело. Решил посмотреть на сервере с IP 95.145.141.246 исходящие сетевые соединения:
Соединения разные были, но к указанному VPN серверу ничего не было. Стало ещё интереснее. Расчехлил tcpdump и стал смотреть им:
Подождал, когда в логе на VPN сервере 175.115.158.81 опять появится запись о неудачном соединении. Вернулся в консоль сервера 95.145.141.246 и увидел запись:
1778 - порт VPN сервера. Смотрю на адрес 172.17.0.4 и тут до меня доходит, что это Docker контейнер. Проверяю IP адреса контейнеров:
А там мониторинг Gatus. И тут я вспоминаю, что настроил мониторинг VPN канала через проверку доступности порта, на котором он принимает подключения. Всё встало на свои места. Не думал, что проверка порта будет такими записями в логе отмечаться. Хотя на самом деле с таким встречаюсь иногда, когда через Zabbix порты проверяю через simple check.
Получилась мини-инструкция по диагностике исходящих соединений. В принципе, можно было сразу запустить tcpdump, но я по памяти не помню ключи и синтаксис выборки для него. Приходится куда-то лезть за подсказками. Мне казалось, что я делал по tcpdump заметку с популярными командами, но нет, не нашёл. Надо будет при случае исправить это.
#linux #terminal
ovpn-server[3742533]: TCP connection established with [AF_INET] 95.145.141.246:58560ovpn-server[3742533]: 95.145.141.246:58560 Connection reset, restarting [0]ovpn-server[3742533]: 95.145.141.246:58560 SIGUSR1[soft,connection-reset] received, client-instance restartingВнимание привлекло то, что 95.145.141.246 это мой IP адрес ещё одного VPN сервера. Я не припомнил, чтобы настраивал на нем клиента для подключения к серверу 175.115.158.81. На всякий случай сходил туда и убедился в этом:
# ps axf Никакого openvpn клиента тут не было запущено. Да и настроек для него тоже нет. У меня настроена разветвлённая система VPN туннелей с маршрутизацией, так что иногда начинаю в ней путаться. Надо схему рисовать.
Я немного напрягся и стал разбираться, в чём тут дело. Решил посмотреть на сервере с IP 95.145.141.246 исходящие сетевые соединения:
# ss -ntuСоединения разные были, но к указанному VPN серверу ничего не было. Стало ещё интереснее. Расчехлил tcpdump и стал смотреть им:
# tcpdump -nn 'dst host 175.115.158.81'Подождал, когда в логе на VPN сервере 175.115.158.81 опять появится запись о неудачном соединении. Вернулся в консоль сервера 95.145.141.246 и увидел запись:
14:29:38.706375 IP 172.17.0.4.58700 > 175.115.158.81.17781778 - порт VPN сервера. Смотрю на адрес 172.17.0.4 и тут до меня доходит, что это Docker контейнер. Проверяю IP адреса контейнеров:
# docker ps -q | xargs -n 1 docker inspect --format '{{ .NetworkSettings.IPAddress }} {{ .Name }}' | sed 's/ \// /'...........172.17.0.4 gatus...........А там мониторинг Gatus. И тут я вспоминаю, что настроил мониторинг VPN канала через проверку доступности порта, на котором он принимает подключения. Всё встало на свои места. Не думал, что проверка порта будет такими записями в логе отмечаться. Хотя на самом деле с таким встречаюсь иногда, когда через Zabbix порты проверяю через simple check.
Получилась мини-инструкция по диагностике исходящих соединений. В принципе, можно было сразу запустить tcpdump, но я по памяти не помню ключи и синтаксис выборки для него. Приходится куда-то лезть за подсказками. Мне казалось, что я делал по tcpdump заметку с популярными командами, но нет, не нашёл. Надо будет при случае исправить это.
#linux #terminal