
У меня было очень много заметок про различные мониторинги. Кажется, что я уже про всё более-менее полезное что-то да писал. Оказалось, что нет. Расскажу про очередной небольшой и удобный мониторинг, который позволяет очень просто и быстро создать дашборд с зелёными и красными кнопками. Если зелёные, то всё ОК, если красные, то НЕ ОК.
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
Запускаем Docker контейнер и цепляем к нему этот файл:
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
# mkdir gatus && cd gatus
# touch config.yaml
alerting:
telegram:
token: "1393668911:AAHtEAKqxUH7ZpyX28R-wxKfvH1WR6-vdNw"
id: "210806260"
endpoints:
- name: Zabbix Connection
url: "https://zabbix.com"
interval: 30s
conditions:
- "[CONNECTED] == true"
- "[IP] == 188.114.99.224"
- name: Github Title
url: "https://github.com"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY] == pat(*<title>GitHub: Let’s build from here · GitHub</title>*)"
- name: Yandex response
url: "https://ya.ru"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[RESPONSE_TIME] < 10"
alerts:
- type: telegram
send-on-resolved: true
- name: VK cert & domain
url: "https://vk.com"
interval: 5m
conditions:
- "[CERTIFICATE_EXPIRATION] > 48h"
- "[DOMAIN_EXPIRATION] > 720h"
Запускаем Docker контейнер и цепляем к нему этот файл:
# docker run -p 8080:8080 -d \
--mount type=bind,source="$(pwd)"/config.yaml,target=/config/config.yaml \
--name gatus twinproduction/gatus
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
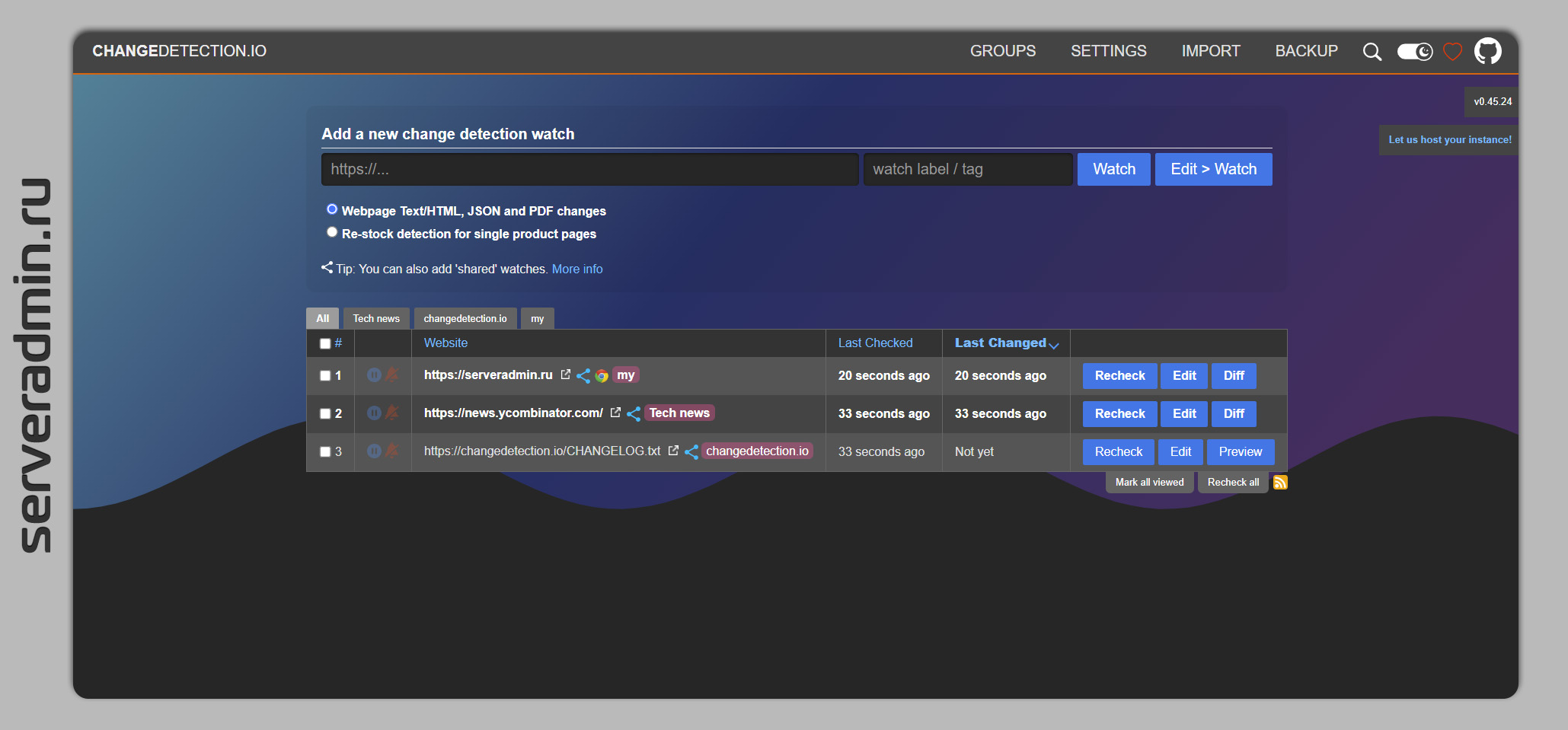
В пятницу в подборке видео я упоминал про обзор проекта changedetection.io. Хочу остановиться на нём отдельно, так как это очень крутой продукт. С его помощью можно отслеживать изменения на сайтах, используя практически полноценный браузер под капотом. Сразу приведу ссылку на видео с подробным обзором, описанием установки и настройки:
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
Можно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
# git clone https://github.com/dgtlmoon/changedetection.io# cd changedetection.io# docker compose up -dМожно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
docker-compose.yml. Раскомментировал некоторые строки и запустил всё заново. Зашёл в настройки, выбрал в разделе Fetching не Basic fast Plaintext/HTTP Client, а Playwright Chromium/Javascript. Русские сайты начали нормально парситься. Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
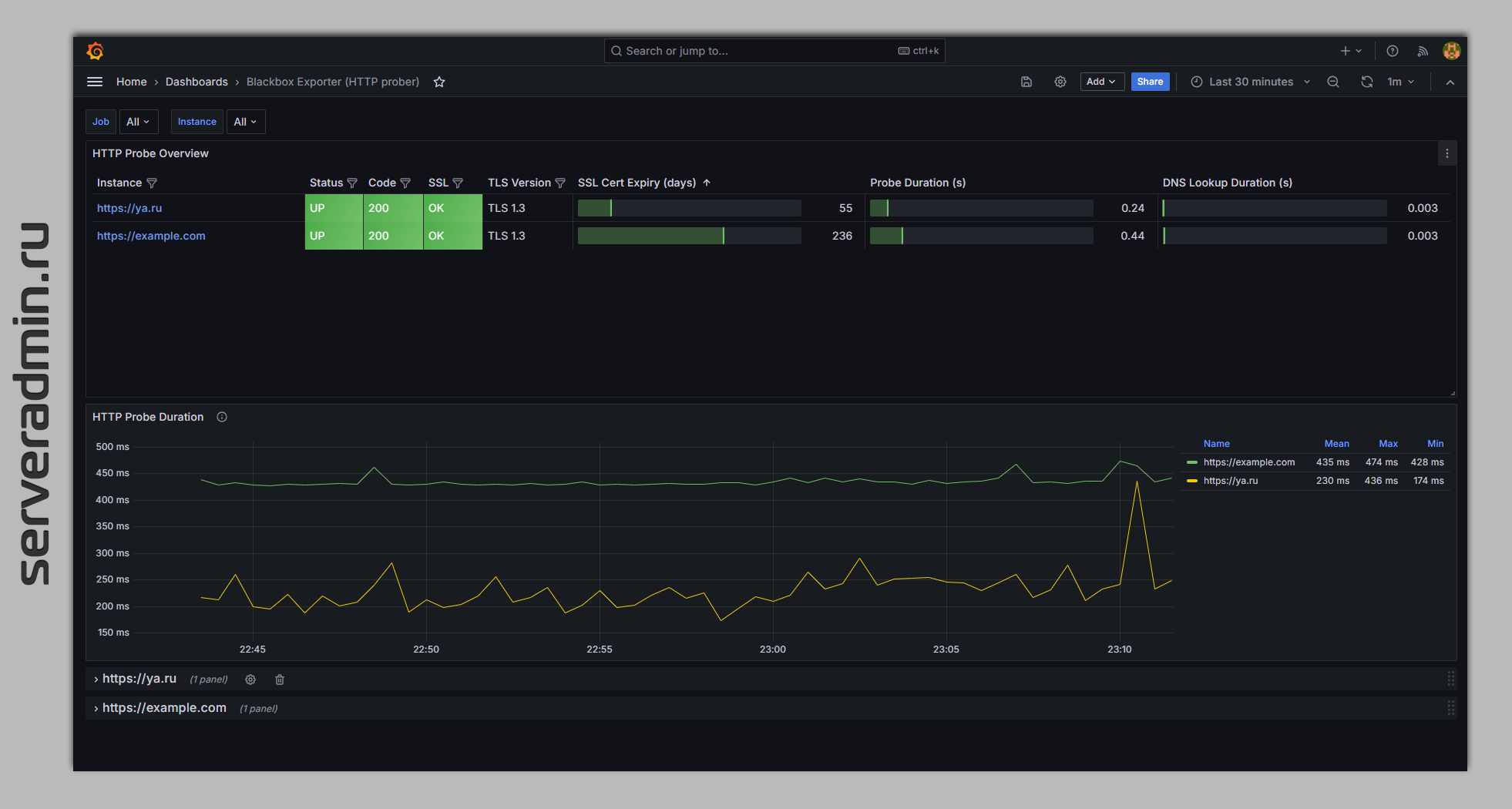
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}
Недавно рассказывал про бесплатную версию Veeam Backup & Replication Community Edition. В дополнение к нему есть другой бесплатный продукт - Veeam ONE Community Edition. С главной страницы сайта я не смог его найти. Помог поиск в гугле по соответствующему запросу, чтобы попасть на страницу продукта. Это бесплатная версия мониторинга для сервера Veeam Backup & Replication и хостов виртуализации.
Мне стало интересно, во-первых, посмотреть на этот продукт, так как ранее вообще не был с ним знаком и никогда не видел. А во-вторых посмотреть, поддерживает ли он мониторинг недавно добавленного в Backup & Replication Proxmox. На второй вопрос отвечу сразу. Veeam ONE поддерживает в качестве серверов виртуализации только VMware и Hyper-V. Больше ничего.
Я установил Veeam ONE Community Edition (прямая ссылка ~2.5 ГБ) и подключил к нему бесплатный Veeam Backup & Replication и один из хостов Hyper-V. Продукт удобный, ничего не скажешь. Просто добавляешь сервер и получаешь готовый мониторинг и управление. Ограничение бесплатной версии - 10 объектов мониторинга. Из описания не очень понятно, одна виртуалка гипервизора - это один объект мониторинга, или подсчёт идёт по добавленным сущностям в мониторинг в виде отдельных серверов. Виртуалки он потом сам определяет на гипервизоре, в том числе неактивные.
Monitoring for up to 10 workloads with ANY combination of Veeam Backup & Replication, Veeam Agent for Microsoft Windows or for Linux workloads, including vSphere and Hyper-V infrastructures with no license required!
На удалённые машины можно установить Veeam ONE Client, чтобы подключаться к серверу. То есть не обязательно запускать его локально. Так же есть веб версия для подключения через браузер. Если вам хватает ограничений бесплатного Backup & Replication, то не вижу причин не использовать ещё и Veeam ONE. Хорошее дополнение к первому продукту.
В Veeam ONE в единой консоли управления вы получаете доступ к основным метрикам и событиям Veeam B&R: загрузки хранилищ и полосы пропускания, статусы задач архивации, метрики производительности, журнал задач и т.д. Можно настроить оповещения на какие-то события. Для виртуальной инфраструктуры доступны стандартные метрики производительности как хостов, так и виртуальных машин, подключенных хранилищ, обзор занятых и свободных ресурсов и т.д. Оповещения и основные триггеры преднастроены, так что система сразу после установки готова к работе. Дальнейшее допиливание можно делать по желанию. Настраивается всё довольно просто и интуитивно мышкой в панели управления.
#мониторинг
🦖 Selectel — дешёвые и не очень дедики с аукционом!
Мне стало интересно, во-первых, посмотреть на этот продукт, так как ранее вообще не был с ним знаком и никогда не видел. А во-вторых посмотреть, поддерживает ли он мониторинг недавно добавленного в Backup & Replication Proxmox. На второй вопрос отвечу сразу. Veeam ONE поддерживает в качестве серверов виртуализации только VMware и Hyper-V. Больше ничего.
Я установил Veeam ONE Community Edition (прямая ссылка ~2.5 ГБ) и подключил к нему бесплатный Veeam Backup & Replication и один из хостов Hyper-V. Продукт удобный, ничего не скажешь. Просто добавляешь сервер и получаешь готовый мониторинг и управление. Ограничение бесплатной версии - 10 объектов мониторинга. Из описания не очень понятно, одна виртуалка гипервизора - это один объект мониторинга, или подсчёт идёт по добавленным сущностям в мониторинг в виде отдельных серверов. Виртуалки он потом сам определяет на гипервизоре, в том числе неактивные.
Monitoring for up to 10 workloads with ANY combination of Veeam Backup & Replication, Veeam Agent for Microsoft Windows or for Linux workloads, including vSphere and Hyper-V infrastructures with no license required!
На удалённые машины можно установить Veeam ONE Client, чтобы подключаться к серверу. То есть не обязательно запускать его локально. Так же есть веб версия для подключения через браузер. Если вам хватает ограничений бесплатного Backup & Replication, то не вижу причин не использовать ещё и Veeam ONE. Хорошее дополнение к первому продукту.
В Veeam ONE в единой консоли управления вы получаете доступ к основным метрикам и событиям Veeam B&R: загрузки хранилищ и полосы пропускания, статусы задач архивации, метрики производительности, журнал задач и т.д. Можно настроить оповещения на какие-то события. Для виртуальной инфраструктуры доступны стандартные метрики производительности как хостов, так и виртуальных машин, подключенных хранилищ, обзор занятых и свободных ресурсов и т.д. Оповещения и основные триггеры преднастроены, так что система сразу после установки готова к работе. Дальнейшее допиливание можно делать по желанию. Настраивается всё довольно просто и интуитивно мышкой в панели управления.
#мониторинг
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Не Заббиксом единым живёт мониторинг традиционной инфраструктуры на базе хостов и сервисов на них. Расскажу вам про не очень известную в русскоязычном сегменте систему мониторинга Checkmk. Я уже писал про неё несколько лет назад. Она мне тогда понравилась, так что решил посмотреть на неё спустя несколько лет. В этот раз немного подробнее, погрузившись в детали настройки.
Checkmk сделана на базе Nagios. Но насколько я понял, она уже очень далеко от неё ушла. Сразу отвечу на главный вопрос. Зачем изучать и использовать какой-то другой мониторинг, отличный от наиболее популярных Zabbix и Prometheus (и совместимых систем на его базе)? В целом, незачем, если у вас задача расти и развиваться в системном администрировании и devops. Использовать такие системы, типа Checkmk имеет смысл для решения конкретных задач, которые она решает удобнее и проще других, ну и плюс, если вы уже постигли дзен и вам просто нравится изучать что-то новое.
Мониторинг на базе Checkmk внедрить проще, чем тот же Zabbix или Prometheus. Работает он по модели pull, то есть ставите агент, он слушает определённый порт, а сервер шлёт на него команды по сбору метрик.
Развернуть Checkmk можно в докере буквально в одну команду:
Далее ждём пару минут и смотрим лог контейнера. Там будет учётка администратора:
Можно идти в веб интерфейс на порт 8080 и настраивать систему. Агенты можно скачивать прямо с сервера в разделе Setup ⇨ Agents ⇨ Linux или Windows.
Потом идём на сервер в раздел Setup ⇨ Hosts ⇨ Add host и добавляем машину по IP. После выполнения настроек, необходимо их принять. До этого их можно откатить. То есть сразу изменения не принимаются.
Далее нужно зайти в настройки хоста, в раздел Save & run service discovery, выполнить поиск служб, которые преднастроены для хостов с определённой системой. Там будут в основном базовые метрики: сеть, диск, процессор, память и т.д. Выбрать то, что вам нужно, либо сразу всё и сохранить.
Возможности Checkmk расширяются плагинами. Расскажу про один из таких плагинов, который показался мне полезным. Я настроил его и проверил работу. Плагин называется filestats. С его помощью можно следить за файлами. Конкретно мне это интересно в контексте мониторинга бэкапов.
С помощью этого плагина можно настроить следующие условия:
◽️минимальный возраст самого старого файла
◽️минимальный возраст самого нового файла
◽️минимальный или максимальный размер файла
◽️минимальное число файлов
Допустим, у вас есть директория с бэкапами, которая регулярно очищается. Вы хотите быть уверенным, что директория реально очищается, в неё складываются свежие бэкапы, самый свежий не старее суток, всего в директории не менее 10-ти файлов, а самый старый не старше 11-ти дней.
Этот плагин Checkmk без проблем решает задачу. Чтобы сделать то же самое на Zabbix, мне приходилось писать велосипеды на баше, а тут это уже реализовано. Только галочки ставь на условия, которые тебя интересуют. Пример, как это настраивается, можно посмотреть в документации. Не скажу, что я быстро разобрался, но с учётом того, что я вижу фактически впервые эту систему, пришлось для начала разобраться с самой концепцией плагинов и их настройки. За пару-тройку часов разобрался.
Подобных плагинов в Checkmk не меньше сотни. Скорее больше. Полный список есть тут. Чего там только нет. Если вам нужен базовый мониторинг и не хочется разбираться с более сложными и масштабными системами, попробуйте Checkmk. Некоторые вещи с его помощью решаются значительно проще, чем в других системах.
#мониторинг
🦖 Selectel — дешёвые и не очень дедики с аукционом!
Checkmk сделана на базе Nagios. Но насколько я понял, она уже очень далеко от неё ушла. Сразу отвечу на главный вопрос. Зачем изучать и использовать какой-то другой мониторинг, отличный от наиболее популярных Zabbix и Prometheus (и совместимых систем на его базе)? В целом, незачем, если у вас задача расти и развиваться в системном администрировании и devops. Использовать такие системы, типа Checkmk имеет смысл для решения конкретных задач, которые она решает удобнее и проще других, ну и плюс, если вы уже постигли дзен и вам просто нравится изучать что-то новое.
Мониторинг на базе Checkmk внедрить проще, чем тот же Zabbix или Prometheus. Работает он по модели pull, то есть ставите агент, он слушает определённый порт, а сервер шлёт на него команды по сбору метрик.
Развернуть Checkmk можно в докере буквально в одну команду:
# docker run -dit -p 8080:5000 -p 8000:8000 --tmpfs /opt/omd/sites/cmk/tmp:uid=1000,gid=1000 -v monitoring:/omd/sites --name monitoring -v /etc/localtime:/etc/localtime:ro --restart always checkmk/check-mk-raw:2.3.0-latestДалее ждём пару минут и смотрим лог контейнера. Там будет учётка администратора:
# docker logs monitoring...The admin user for the web applications is cmkadmin with password: RliEfjVR9H3J...Можно идти в веб интерфейс на порт 8080 и настраивать систему. Агенты можно скачивать прямо с сервера в разделе Setup ⇨ Agents ⇨ Linux или Windows.
# wget http://10.20.1.36:8080/cmk/check_mk/agents/check-mk-agent_2.3.0p17-1_all.deb# dpkg -i check-mk-agent_2.3.0p17-1_all.debПотом идём на сервер в раздел Setup ⇨ Hosts ⇨ Add host и добавляем машину по IP. После выполнения настроек, необходимо их принять. До этого их можно откатить. То есть сразу изменения не принимаются.
Далее нужно зайти в настройки хоста, в раздел Save & run service discovery, выполнить поиск служб, которые преднастроены для хостов с определённой системой. Там будут в основном базовые метрики: сеть, диск, процессор, память и т.д. Выбрать то, что вам нужно, либо сразу всё и сохранить.
Возможности Checkmk расширяются плагинами. Расскажу про один из таких плагинов, который показался мне полезным. Я настроил его и проверил работу. Плагин называется filestats. С его помощью можно следить за файлами. Конкретно мне это интересно в контексте мониторинга бэкапов.
С помощью этого плагина можно настроить следующие условия:
◽️минимальный возраст самого старого файла
◽️минимальный возраст самого нового файла
◽️минимальный или максимальный размер файла
◽️минимальное число файлов
Допустим, у вас есть директория с бэкапами, которая регулярно очищается. Вы хотите быть уверенным, что директория реально очищается, в неё складываются свежие бэкапы, самый свежий не старее суток, всего в директории не менее 10-ти файлов, а самый старый не старше 11-ти дней.
Этот плагин Checkmk без проблем решает задачу. Чтобы сделать то же самое на Zabbix, мне приходилось писать велосипеды на баше, а тут это уже реализовано. Только галочки ставь на условия, которые тебя интересуют. Пример, как это настраивается, можно посмотреть в документации. Не скажу, что я быстро разобрался, но с учётом того, что я вижу фактически впервые эту систему, пришлось для начала разобраться с самой концепцией плагинов и их настройки. За пару-тройку часов разобрался.
Подобных плагинов в Checkmk не меньше сотни. Скорее больше. Полный список есть тут. Чего там только нет. Если вам нужен базовый мониторинг и не хочется разбираться с более сложными и масштабными системами, попробуйте Checkmk. Некоторые вещи с его помощью решаются значительно проще, чем в других системах.
#мониторинг
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
На днях новость проскочила про новый мониторинг - Astra Monitoring. Продукты Астры сейчас популярны, поэтому решил посмотреть, что это вообще такое. Честно говоря, первое, о чём подумал, что взяли исходники Zabbix и сделали что-то поверх. Я ошибся в частностях, но не в самой сути.
На сайте есть вся информация о новом мониторинге, в том числе состав продуктов, из которых он состоит. Это сборка на базе:
▪️Prometheus
▪️Grafana
▪️VictoriaMetrics
▪️Postgresql
▪️Keycloak
▪️Vector
▪️Clickhouse
Там же есть и инструкция по установке. Решил установить и посмотреть своими глазами. Не получилось. Сборка на базе контейнеров доступна публично. Устанавливать от обычного пользователя, который должен быть в группе Docker:
Тут можно посмотреть весь состав продукта со всеми конфигами и итоговый docker-compose.yml. В инструкции сказано, что можно сразу запускать:
У меня не заработало. Постоянно падал контейнер gatekeeper с веб интерфейсом. По какой-то причине он не мог получить информацию от keycloak, хотя контейнер с ним запускался и урлы, на которые ругался gatekeeper, были доступны. Keycloak отклонял соединения со стороны gatekeeper.
Я некоторое время поковырялся в проекте, но починить не смог. Помогал в отладке, кстати, вот этот подход. Позволил из контейнеров попинговать и проверить урлы, доступность адресов. В архиве нашёлся скрипт
Подход Астры в этом продукте такой же как и в RuPost и многих других, когда берутся open source компоненты и объединяются в единое управление. С точки зрения администрирования это неплохо, так как те, кто будут с этим работать, будут взаимодействовать с лучшими общемировыми продуктами, что только в плюс к компетенциям и опыту.
С другой стороны хотелось и что-то собственной разработки увидеть, помимо веб интерфейса. С чего-то надо начинать. Мне кажется, у Астры хватает ресурсов, чтобы вести более глубокую разработку. Но это так, взгляд сильно со стороны. По идее, чтобы что-то разрабатывать своё, надо увидеть, какой вопрос закрывается недостаточно хорошо уже существующими решениями и придумать улучшенное своё. Глядя на используемый стек, я не знаю, что тут можно улучшать. Веб интерфейс, если только. Разобраться с нуля в Grafana с каждым релизом всё сложнее и сложнее. Обычно берёшь готовые дашборды, чтобы самому не разбираться и не составлять. Сложновато и трудозатратно.
#мониторинг
На сайте есть вся информация о новом мониторинге, в том числе состав продуктов, из которых он состоит. Это сборка на базе:
▪️Prometheus
▪️Grafana
▪️VictoriaMetrics
▪️Postgresql
▪️Keycloak
▪️Vector
▪️Clickhouse
Там же есть и инструкция по установке. Решил установить и посмотреть своими глазами. Не получилось. Сборка на базе контейнеров доступна публично. Устанавливать от обычного пользователя, который должен быть в группе Docker:
# curl -sLo astra-monitoring.tgz https://dl.astralinux.ru/am/generic/compose/astra-monitoring-latest.tgz# tar zxvf astra-monitoring.tgz# cd astra-monitoring/Тут можно посмотреть весь состав продукта со всеми конфигами и итоговый docker-compose.yml. В инструкции сказано, что можно сразу запускать:
# docker compose upУ меня не заработало. Постоянно падал контейнер gatekeeper с веб интерфейсом. По какой-то причине он не мог получить информацию от keycloak, хотя контейнер с ним запускался и урлы, на которые ругался gatekeeper, были доступны. Keycloak отклонял соединения со стороны gatekeeper.
Я некоторое время поковырялся в проекте, но починить не смог. Помогал в отладке, кстати, вот этот подход. Позволил из контейнеров попинговать и проверить урлы, доступность адресов. В архиве нашёлся скрипт
start.sh и файл .env. Попробовал через скрипт запускать, заполнять инвентарь. Результат тот же - падает gatekeeper. Так и не смог попасть в веб интерфейс. Если кто-то уже устанавливал и запускал этот мониторинг, подскажите, что надо поправить. В инструкции, к сожалению, никаких подробностей.Подход Астры в этом продукте такой же как и в RuPost и многих других, когда берутся open source компоненты и объединяются в единое управление. С точки зрения администрирования это неплохо, так как те, кто будут с этим работать, будут взаимодействовать с лучшими общемировыми продуктами, что только в плюс к компетенциям и опыту.
С другой стороны хотелось и что-то собственной разработки увидеть, помимо веб интерфейса. С чего-то надо начинать. Мне кажется, у Астры хватает ресурсов, чтобы вести более глубокую разработку. Но это так, взгляд сильно со стороны. По идее, чтобы что-то разрабатывать своё, надо увидеть, какой вопрос закрывается недостаточно хорошо уже существующими решениями и придумать улучшенное своё. Глядя на используемый стек, я не знаю, что тут можно улучшать. Веб интерфейс, если только. Разобраться с нуля в Grafana с каждым релизом всё сложнее и сложнее. Обычно берёшь готовые дашборды, чтобы самому не разбираться и не составлять. Сложновато и трудозатратно.
#мониторинг
Я постоянно использую Grafana как в связке с Zabbix Server, так и с Prometheus. У неё довольно часто выходят новые версии, но я обычно не спешу с обновлением, так как нет большой нужды. Смотрю через неё простые дашборды, так что обновления обычно не приносят конкретно мне каких-то необходимых нововведений.
Очень долго использовал 7-ю версию, не обновлялся. Потом собрался с силами и обновился до 10-й. Пришлось повозиться и сделать сначала экспорт всего через API, а потом импортировать уже в новую 10-ю версию. Из-за большой разницы в версиях просто обновиться поверх старой не получилось.
Не так давно вышла очередная версия уже 11-й ветки. Там много изменений. Конкретно меня привлеки улучшения в плане оповещений (alerts), экспорт в pdf, некие действия (actions) в визуализациях. Полный список обновлений 11-й версии и недавней 11.3 смотрите по ссылкам:
⇨ What’s new in Grafana v11.0
⇨ Grafana 11.3 release
Обновление с 10-й версии прошло вообще без проблем. Конкретно у меня это выглядело так:
То есть просто удалил контейнер, обновил образ и запустил контейнер с теми же параметрами, что и предыдущий. Всё обновилось автоматически. По логам видно, что были выполнены все миграции со старой версии. Предварительно сделал снэпшот виртуалки перед обновлением.
Изменений реально много. Тут и алерты, и разные методы аутентификации, и управление пользователями, и ещё что-то. Сразу и не вспомню. Вижу, что меню слева сильно поменялось, но уже не помню, что там раньше было. Не так часто по настройкам лазил.
Если кому интересно, то я использую следующие дашборды в Grafana:
◽️Сводный дашборд активных триггеров со всех серверов Zabbix. Удобно все их открыть на одной странице. Разработчики Zabbix обещают реализовать это в рамках своего сервера, но пока такого нет. Объединить несколько серверов в дашборде Zabbix пока невозможно. Как это выглядит, можно посмотреть в моей статье на сайте. Внешний вид дашборда с триггерами с тех пор вообще не изменился.
◽️Дашборд Node Exporter Full от Prometheus для некоторых серверов
◽️Родной дашборд Angie от разработчиков.
◽️Дашборд от моего шаблона Zabbix для Linux Server.
◽️Мой сводный дашборд с личными метриками - сайты, каналы, статус компов в доме, на даче, электрокотёл, камеры и т.д.
Grafana - удобный универсальный инструмент, который позволил объединить две разнородные системы мониторинга в едином веб интерфейсе. Не приходится идти на компромиссы в выборе системы мониторинга. Какая лучше подходит, ту и используешь. А потом всё это объединяешь.
Изначально заметку планировал по нововведениям Grafana сделать, но там не так просто всё это попробовать. Сходу не нашёл, всё, что хотел. Соответственно и не потестировал ещё. Надо больше времени на это. Если наберётся материала на заметку, сделаю её отдельно. Отмечу только одно важное для меня изменение, которое сразу заметил. Если вкладку с Grafana открыть в фоне, то эта падлюка не подгружает метрики, пока не сделаешь её активной. А некоторые метрики долго подгружаются. Хочется её открыть в фоне, а потом к ней вернуться, когда она уже точно метрики подгрузит. Но не тут то было. Теперь она в таких вкладках из фона быстрее показывает метрики. Видно, что она всё равно что-то подгружает, но делает это быстрее, чем раньше.
#grafana #мониторинг
Очень долго использовал 7-ю версию, не обновлялся. Потом собрался с силами и обновился до 10-й. Пришлось повозиться и сделать сначала экспорт всего через API, а потом импортировать уже в новую 10-ю версию. Из-за большой разницы в версиях просто обновиться поверх старой не получилось.
Не так давно вышла очередная версия уже 11-й ветки. Там много изменений. Конкретно меня привлеки улучшения в плане оповещений (alerts), экспорт в pdf, некие действия (actions) в визуализациях. Полный список обновлений 11-й версии и недавней 11.3 смотрите по ссылкам:
⇨ What’s new in Grafana v11.0
⇨ Grafana 11.3 release
Обновление с 10-й версии прошло вообще без проблем. Конкретно у меня это выглядело так:
# docker stop grafana# docker rm grafana# docker pull grafana/grafana:latest# docker run -d -p 3000:3000 --name=grafana \ -v grafana_data:/var/lib/grafana \ -e "GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource,alexanderzobnin-zabbix-app" \ grafana/grafana:latestТо есть просто удалил контейнер, обновил образ и запустил контейнер с теми же параметрами, что и предыдущий. Всё обновилось автоматически. По логам видно, что были выполнены все миграции со старой версии. Предварительно сделал снэпшот виртуалки перед обновлением.
Изменений реально много. Тут и алерты, и разные методы аутентификации, и управление пользователями, и ещё что-то. Сразу и не вспомню. Вижу, что меню слева сильно поменялось, но уже не помню, что там раньше было. Не так часто по настройкам лазил.
Если кому интересно, то я использую следующие дашборды в Grafana:
◽️Сводный дашборд активных триггеров со всех серверов Zabbix. Удобно все их открыть на одной странице. Разработчики Zabbix обещают реализовать это в рамках своего сервера, но пока такого нет. Объединить несколько серверов в дашборде Zabbix пока невозможно. Как это выглядит, можно посмотреть в моей статье на сайте. Внешний вид дашборда с триггерами с тех пор вообще не изменился.
◽️Дашборд Node Exporter Full от Prometheus для некоторых серверов
◽️Родной дашборд Angie от разработчиков.
◽️Дашборд от моего шаблона Zabbix для Linux Server.
◽️Мой сводный дашборд с личными метриками - сайты, каналы, статус компов в доме, на даче, электрокотёл, камеры и т.д.
Grafana - удобный универсальный инструмент, который позволил объединить две разнородные системы мониторинга в едином веб интерфейсе. Не приходится идти на компромиссы в выборе системы мониторинга. Какая лучше подходит, ту и используешь. А потом всё это объединяешь.
Изначально заметку планировал по нововведениям Grafana сделать, но там не так просто всё это попробовать. Сходу не нашёл, всё, что хотел. Соответственно и не потестировал ещё. Надо больше времени на это. Если наберётся материала на заметку, сделаю её отдельно. Отмечу только одно важное для меня изменение, которое сразу заметил. Если вкладку с Grafana открыть в фоне, то эта падлюка не подгружает метрики, пока не сделаешь её активной. А некоторые метрики долго подгружаются. Хочется её открыть в фоне, а потом к ней вернуться, когда она уже точно метрики подгрузит. Но не тут то было. Теперь она в таких вкладках из фона быстрее показывает метрики. Видно, что она всё равно что-то подгружает, но делает это быстрее, чем раньше.
#grafana #мониторинг