
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
Как уменьшить размер файловой системы с ext4?
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
Файловая система на разделе
Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
Добавляем ещё один исполняемый файл
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
# /sbin/resize2fs /dev/sda1 50GФайловая система на разделе
/dev/sda1 будет уменьшена до 50G, если там хватит свободного места для этого. То есть данных должно быть меньше. В общем случае перед выполнением операции и после рекомендуется проверить файловую систему на ошибки:# /sbin/e2fsck -yf /dev/sda1Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
# /sbin/resize2fs /dev/sda1 50Gresize2fs 1.47.0 (5-Feb-2023)Filesystem at /dev/sda1 is mounted on /; on-line resizing required/sbin/resize2fs: On-line shrinking not supported# /sbin/e2fsck -yf /dev/sda1e2fsck 1.47.0 (5-Feb-2023)/dev/sda1 is mounted.e2fsck: Cannot continue, aborting.Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
/etc/initramfs-tools/hooks/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case $1 in
prereqs)
prereqs
exit 0
;;
esac
. /usr/share/initramfs-tools/hook-functions
copy_exec /sbin/e2fsck
copy_exec /sbin/resize2fs
exit 0
Добавляем ещё один исполняемый файл
/etc/initramfs-tools/scripts/local-premount/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case "$1" in
prereqs)
prereqs
exit 0
;;
esac
# simple device example
/sbin/e2fsck -yf /dev/sda1
/sbin/resize2fs /dev/sda1 50G
/sbin/e2fsck -yf /dev/sda1
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
# ls /boot | grep configconfig-6.1.0-12-amd64config-6.1.0-13-amd64config-6.1.0-20-amd64config-6.1.0-22-amd64# update-initramfs -u -k 6.1.0-22-amd64update-initramfs: Generating /boot/initrd.img-6.1.0-22-amd64Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
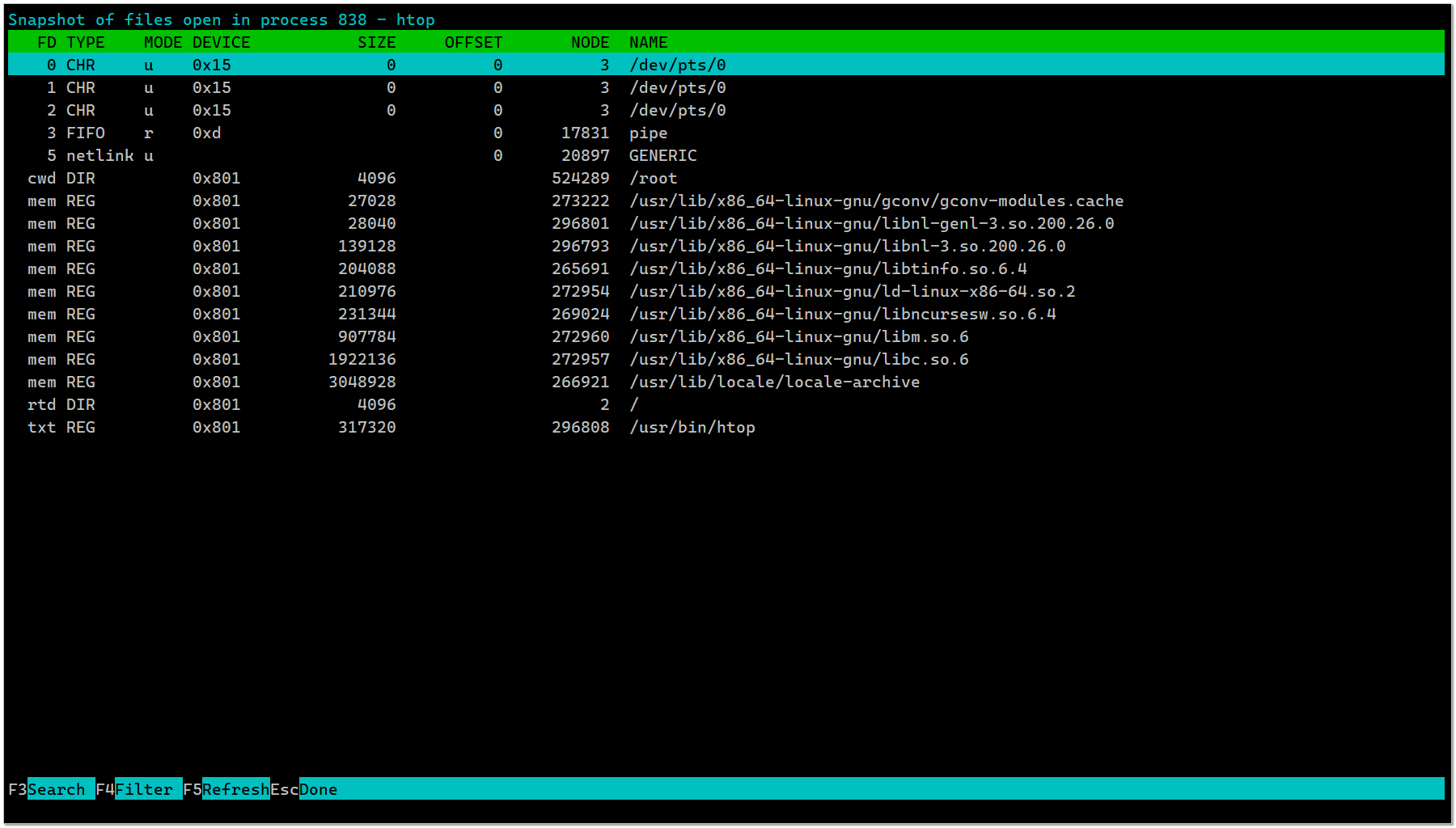
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}
Настраивал скрипт бэкапа с автоматическим удалением старых копий. Во время отладки и бэкапы, и сам скрипт лежали в одной директории. Напутал с условием удаления и случайно был удалён сам скрипт после выполнения. Так как ещё не успел его никуда сохранить, это была единственная копия.
Не сказать, что там была какая-то особенная информация, но откровенно не хотелось всё переписывать с нуля. Не знаю, как вы, а меня полностью деморализует ситуация, когда надо повторить ту же задачу, которую ты только что решал. Так что решил попытаться восстановить то, что только что удалил. На практике это сделать не так трудно, а шанс восстановление небольшого файла велик, если сделать это сразу же.
Сразу вспомнил про программу scalpel, о которой уже когда-то давно писал. Но там был пример синтетический, хотя он и сработал. А тут будет самый что ни на есть реальный. Ставим программу:
Далее нам нужно указать сигнатуры восстанавливаемых файлов. Часть сигнатур есть в самом файле конфигураций -
В данном случае
zabbix-vg-root - корневой и единственный lvm раздел этого сервера. Если у вас не используется lvm, то это будет что-то вроде /dev/sda2 и т.д.
Программа минуты за 3-4 просканировала раздел на 50G и вывела результаты в указанную директорию. Там было около сотни различных текстовых скриптов, а нужный мне был где-то в самом начале списка, так что мне даже по содержимому искать не пришлось. Сразу нашёл при беглом осмотре. Всё содержимое файла сохранилось.
Так что сохраняйте заметку и берите на вооружение. Кто знает, когда пригодится. Мне спустя более двух лет в итоге понадобилась информация, о которой писал ранее.
#restore #linux
Не сказать, что там была какая-то особенная информация, но откровенно не хотелось всё переписывать с нуля. Не знаю, как вы, а меня полностью деморализует ситуация, когда надо повторить ту же задачу, которую ты только что решал. Так что решил попытаться восстановить то, что только что удалил. На практике это сделать не так трудно, а шанс восстановление небольшого файла велик, если сделать это сразу же.
Сразу вспомнил про программу scalpel, о которой уже когда-то давно писал. Но там был пример синтетический, хотя он и сработал. А тут будет самый что ни на есть реальный. Ставим программу:
# apt install scalpelДалее нам нужно указать сигнатуры восстанавливаемых файлов. Часть сигнатур есть в самом файле конфигураций -
/etc/scalpel/scalpel.conf. Ещё более подробный список можно посмотреть тут в репозитории. Я не совсем понял, какие заголовки должный быть у обычного текстового файла, коим являлся мой скрипт. По идее там особых заголовков и нет, а искать можно по содержимому. Так что я добавил в scalpel.conf следующее: NONE y 1000 #!/bin/bashВ данном случае
#!/bin/bash это начало моего скрипта. Я их все так начинаю. Запускаем сканирование с выводом результатов в /tmp/restored:# mkdir /tmp/restored# scalpel /dev/mapper/zabbix-vg-root -o /tmp/restoredzabbix-vg-root - корневой и единственный lvm раздел этого сервера. Если у вас не используется lvm, то это будет что-то вроде /dev/sda2 и т.д.
Программа минуты за 3-4 просканировала раздел на 50G и вывела результаты в указанную директорию. Там было около сотни различных текстовых скриптов, а нужный мне был где-то в самом начале списка, так что мне даже по содержимому искать не пришлось. Сразу нашёл при беглом осмотре. Всё содержимое файла сохранилось.
Так что сохраняйте заметку и берите на вооружение. Кто знает, когда пригодится. Мне спустя более двух лет в итоге понадобилась информация, о которой писал ранее.
#restore #linux
{kind=link}
Полезной возможностью Tmux является расширение функциональности за счёт плагинов. Для тех, кто не знает, поясню, что с помощью Tmux можно не переживать за разрыв SSH сессии. Исполнение всех команд продолжится даже после вашего отключения. Потом можно подключиться заново и попасть в свою сессию. Я в обязательном порядке все более-менее долгосрочные операции делаю в подобных программах. Раньше использовал Screen для этого, но последнее время перехожу на Tmux, так как он удобнее и функциональнее.
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
Добавляем в ~/.tmux.conf в самое начало:
Заходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
# git clone https://github.com/tmux-plugins/tmux-resurrectДобавляем в ~/.tmux.conf в самое начало:
run-shell ~/tmux-resurrect/resurrect.tmuxЗаходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
{kind=link}
Вчера очень внимательно читал статью на хабре про расследование паразитного чтения диска, когда не было понятно, кто и почему его постоянно читает и таким образом нагружает:
⇨ Расследуем фантомные чтения с диска в Linux
Я люблю такие материалы, так как обычно конспектирую, если нахожу что-то новое. Записываю себе в свою базу знаний. Частично из неё потом получаются заметки здесь.
Там расследовали чтение с помощью blktrace. Я знаю этот инструмент, но он довольно сложный с большим количеством подробностей, которые не нужны, если ты не разбираешься в нюансах работы ядра. Я воспроизвёл описанную историю. Покажу по шагам:
1️⃣ Через
2️⃣ Запускаем
Вывод примерно такой:
В данном случае
3️⃣ Смотрим, что это за блок:
То есть этот блок имеет номер айноды
4️⃣ Смотрим, что это за файл:
Нашли файл, который активно читает процесс questdb-ilpwrit.
Я всё это воспроизвёл у себя на тесте, записал последовательность. Вариант рабочий, но утомительный, если всё делать вручную. Может быть много временных файлов, которых уже не будет существовать, когда ты будешь искать номер айноды соответствующего блока.
Был уверен, что это можно сделать проще, так как я уже занимался подобными вопросами. Вспомнил про утилиту fatrace. Она заменяет более сложные strace или blktrace в простых случаях.
Просто запускаем её и наблюдаем
В соседней консоли откроем лог:
Смотрим в консоль fatrace:
Результат тот же самый, что и выше с blktrace, только намного проще. В fatrace можно сразу отфильтровать вывод по типам операций. Например, только чтение или запись:
Собираем все события в течении 30 секунд с записью в текстовый лог:
Не хватает только наблюдения за конкретным процессом. Почему-то ключ
Можно исключить, к примеру bash или sshd. Они обычно не нужны для расследований.
Рекомендую заметку сохранить, особенно про fatrace. Я себе отдельно записал ещё вот это:
#linux #perfomance
⇨ Расследуем фантомные чтения с диска в Linux
Я люблю такие материалы, так как обычно конспектирую, если нахожу что-то новое. Записываю себе в свою базу знаний. Частично из неё потом получаются заметки здесь.
Там расследовали чтение с помощью blktrace. Я знаю этот инструмент, но он довольно сложный с большим количеством подробностей, которые не нужны, если ты не разбираешься в нюансах работы ядра. Я воспроизвёл описанную историю. Покажу по шагам:
1️⃣ Через
iostat смотрим нагрузку на диск и убеждаемся, что кто-то его активно читает. Сейчас уже не обязательно iostat ставить, так как htop может показать то же самое. 2️⃣ Запускаем
blktrace в режиме наблюдения за операциями чтения с выводом результата в консоль:# blktrace -d /dev/sda1 -a read -o - | blkparse -i -Вывод примерно такой:
259,0 7 4618 5.943408644 425548 Q RA 536514808 + 8 [questdb-ilpwrit]В данном случае
RA 536514808 это событие чтения с диска начиная с блока 536514808.3️⃣ Смотрим, что это за блок:
# debugfs -R 'icheck 536514808 ' /dev/sda1debugfs 1.46.5 (30-Dec-2021)Block Inode number536514808 8270377То есть этот блок имеет номер айноды
8270377. 4️⃣ Смотрим, что это за файл:
debugfs -R 'ncheck 8270377' /dev/sda1Inode Pathname8270377 /home/ubuntu/.questdb/db/table_name/2022-10-04/symbol_col9.d.1092Нашли файл, который активно читает процесс questdb-ilpwrit.
Я всё это воспроизвёл у себя на тесте, записал последовательность. Вариант рабочий, но утомительный, если всё делать вручную. Может быть много временных файлов, которых уже не будет существовать, когда ты будешь искать номер айноды соответствующего блока.
Был уверен, что это можно сделать проще, так как я уже занимался подобными вопросами. Вспомнил про утилиту fatrace. Она заменяет более сложные strace или blktrace в простых случаях.
# apt install fatraceПросто запускаем её и наблюдаем
# fatraceВ соседней консоли откроем лог:
# tail -n 10 /var/log/syslogСмотрим в консоль fatrace:
bash(2143): RO /usr/bin/tailtail(2143): RO /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2tail(2143): O /etc/ld.so.cachetail(2143): RO /usr/lib/x86_64-linux-gnu/libc.so.6tail(2143): C /etc/ld.so.cachetail(2143): O /usr/lib/locale/locale-archivetail(2143): RCO /etc/locale.aliastail(2143): O /var/log/syslogtail(2143): R /var/log/syslogРезультат тот же самый, что и выше с blktrace, только намного проще. В fatrace можно сразу отфильтровать вывод по типам операций. Например, только чтение или запись:
# fatrace -f R# fatrace -f WСобираем все события в течении 30 секунд с записью в текстовый лог:
# fatrace -s -t 30 -o /tmp/fatrace.logНе хватает только наблюдения за конкретным процессом. Почему-то ключ
-p позволяет не задать конкретный пид процесса для наблюдения, а исключить из результатов операции процесса с этим pid:# fatrace -p 697Можно исключить, к примеру bash или sshd. Они обычно не нужны для расследований.
Рекомендую заметку сохранить, особенно про fatrace. Я себе отдельно записал ещё вот это:
# debugfs -R 'icheck 536514808 ' /dev/sda1# debugfs -R 'ncheck 8270377' /dev/sda1#linux #perfomance
{kind=link}
В репозиториях популярных дистрибутивов есть маленькая, но в некоторых случаях полезная программа progress. Из названия примерно понятно, что она делает - показывает шкалу в % выполнения различных дисковых операций. Она поддерживает так называемые coreutils - cp, mv, dd, tar, gzip/gunzip, cat и т.д.
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
Покажу сразу на примере. Создадим файл:
За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
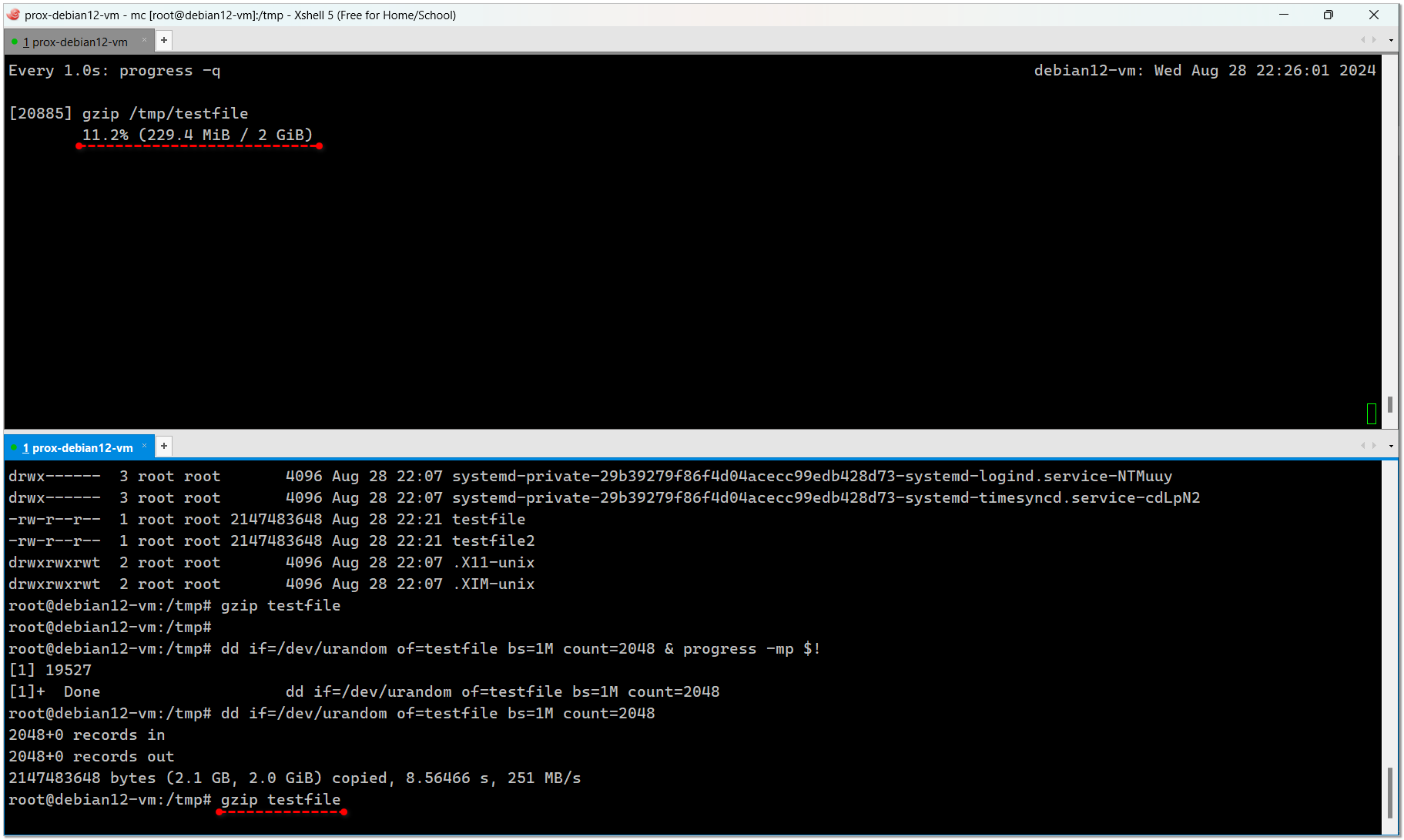
Открываем вторую консоль и там смотрим за процессом:
Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
В соседней консоли смотрим:
Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
⇨ Исходники
#terminal #linux
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
/proc, находит там поддерживаемые утилиты, далее идёт в fd и fdinfo, находит там открытые файлы и следит за их изменениями.Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
Покажу сразу на примере. Создадим файл:
# dd if=/dev/urandom of=testfile bs=1M count=2048За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
# gzip testfileОткрываем вторую консоль и там смотрим за процессом:
# watch -n 1 progress -q[34209] gzip /tmp/testfile 6.5% (132.2 MiB / 2 GiB)Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
# gunzip testfile.gzВ соседней консоли смотрим:
# watch -n 1 progress -q[35685] gzip /tmp/testfile.gz 76.1% (1.5 GiB / 2.0 GiB)Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
# apt install progress# dnf install progress ⇨ Исходники
#terminal #linux
{kind=link}
Собрал в одну заметку замечания по настройке службы SSHD, которая обеспечивает подключение к серверам по SSH. Эта служба присутствует практически во всех серверах. Сказал бы даже, что во всех. Я не припоминаю ни одной виртуалки или железного сервера, куда бы не было доступа по SSH. По возможности, доступ к этой службе лучше закрывать от публичного доступа, но иногда это либо затруднительно, либо вообще невозможно.
Настройки этой службы обычно живут в конфигурационном файле
1️⃣ Аутентификация по паролю. Включать или отключать, каждый решает сам для себя. Я лично всегда аутентификацию по паролю оставляю. Просто на всякий случай. Если пароль несловарный, то подобрать его всё равно практически нереально. Проблем с безопасностью это не вызывает.
Если аутентификацию по паролю отключить, то сразу отваливаются все боты, что непрерывно долбятся в службу. Лог будет менее замусорен.
2️⃣ Аутентификация с использованием публичных ключей. По умолчанию она включена и какой-то отдельной настройки не требует. Решил добавить этот пункт, чтобы лишний раз напомнить про ed25519 ключи. Они более надёжны и, что полезно на практике, более короткие. С ними удобнее работать. У меня была отдельная заметка про их использование.
3️⃣ Разрешение на аутентификацию пользователю root. Тут тоже не буду ничего рекомендовать. Каждый сам решает, разрешает он руту аутентификацию или нет. Если я работаю на сервере один, то обычно аутентификацию разрешаю и работаю всегда под root. Я туда только для этого и захожу, мне не нужны другие пользователи с ограниченными правами. Если же вы работаете не один, то разумнее разделять пользователей, работать через sudo и логировать действия всех пользователей. Так что универсального совета быть не может.
Если вы сами ещё не определились, как вам лучше, то отключите эту возможность. Когда разберётесь, сделаете, как вам надо.
4️⃣ Ограничение на подключение на уровне группы или пользователей. Только пользователи определённой группы или явно указанные смогут подключаться по SSH. Я на практике именно для SSH не пользуюсь этой возможностью, а вот пользователей, которые подключаются по SFTP, обычно завожу в отдельную группу и разрешаю по SFTP подключаться только им. Но это другая настройка. Будет ниже.
5️⃣ Порт, на котором работает служба. Стандартный - 22. Большого смысла менять его нет. Как только первые боты разузнают, что у вас на каком-то порту работает служба, начнут туда долбиться, так же, как и на 22-й. Да и в shodan скорее всего информация об этом появится. Я по привычке порт меняю, если он доступен публично. Хуже от этого не будет, особенно если вы от сканирования портов тоже закрылись. Если служба закрыта от публичного доступа, то оставляю, как есть.
6️⃣ Количество попыток входа в систему за один сеанс. При достижении максимально разрешенного числа попыток, сеанс обрывается.
Пользователь подключился, 3 раза неправильно ввёл пароль, его отключает. После этого нужно устанавливать новое соединение.
7️⃣ Ограничение сессий внутри одного SSH-подключения. Не путать с ограничением на количество параллельных сессий с одного хоста. Этот параметр отвечает не за это. Если вы просто подключаетесь к серверу и его администрируете, то вам хватит и одной сессии.
8️⃣ Принудительный запуск какой-то конкретной команды после регистрации пользователя в системе. Например, запускаем не стандартную оболочку, а прокладку, которая будет логировать все действия пользователей. Вот пример с log-user-session. А вот с принудительным запуском подсистемы sftp. Показываю сразу рабочий пример с подключением по sftp заданной группы пользователей, с chroot в конкретную директорию и с umask 002 для новых файлов.
#linux #security
Настройки этой службы обычно живут в конфигурационном файле
/etc/ssh/sshd_config.1️⃣ Аутентификация по паролю. Включать или отключать, каждый решает сам для себя. Я лично всегда аутентификацию по паролю оставляю. Просто на всякий случай. Если пароль несловарный, то подобрать его всё равно практически нереально. Проблем с безопасностью это не вызывает.
PasswordAuthentication yesЕсли аутентификацию по паролю отключить, то сразу отваливаются все боты, что непрерывно долбятся в службу. Лог будет менее замусорен.
2️⃣ Аутентификация с использованием публичных ключей. По умолчанию она включена и какой-то отдельной настройки не требует. Решил добавить этот пункт, чтобы лишний раз напомнить про ed25519 ключи. Они более надёжны и, что полезно на практике, более короткие. С ними удобнее работать. У меня была отдельная заметка про их использование.
PubkeyAuthentication yes3️⃣ Разрешение на аутентификацию пользователю root. Тут тоже не буду ничего рекомендовать. Каждый сам решает, разрешает он руту аутентификацию или нет. Если я работаю на сервере один, то обычно аутентификацию разрешаю и работаю всегда под root. Я туда только для этого и захожу, мне не нужны другие пользователи с ограниченными правами. Если же вы работаете не один, то разумнее разделять пользователей, работать через sudo и логировать действия всех пользователей. Так что универсального совета быть не может.
Если вы сами ещё не определились, как вам лучше, то отключите эту возможность. Когда разберётесь, сделаете, как вам надо.
PermitRootLogin no4️⃣ Ограничение на подключение на уровне группы или пользователей. Только пользователи определённой группы или явно указанные смогут подключаться по SSH. Я на практике именно для SSH не пользуюсь этой возможностью, а вот пользователей, которые подключаются по SFTP, обычно завожу в отдельную группу и разрешаю по SFTP подключаться только им. Но это другая настройка. Будет ниже.
AllowGroups sshgroupAllowUsers user01 user025️⃣ Порт, на котором работает служба. Стандартный - 22. Большого смысла менять его нет. Как только первые боты разузнают, что у вас на каком-то порту работает служба, начнут туда долбиться, так же, как и на 22-й. Да и в shodan скорее всего информация об этом появится. Я по привычке порт меняю, если он доступен публично. Хуже от этого не будет, особенно если вы от сканирования портов тоже закрылись. Если служба закрыта от публичного доступа, то оставляю, как есть.
Port 226️⃣ Количество попыток входа в систему за один сеанс. При достижении максимально разрешенного числа попыток, сеанс обрывается.
MaxAuthTries 3Пользователь подключился, 3 раза неправильно ввёл пароль, его отключает. После этого нужно устанавливать новое соединение.
7️⃣ Ограничение сессий внутри одного SSH-подключения. Не путать с ограничением на количество параллельных сессий с одного хоста. Этот параметр отвечает не за это. Если вы просто подключаетесь к серверу и его администрируете, то вам хватит и одной сессии.
MaxSessions 18️⃣ Принудительный запуск какой-то конкретной команды после регистрации пользователя в системе. Например, запускаем не стандартную оболочку, а прокладку, которая будет логировать все действия пользователей. Вот пример с log-user-session. А вот с принудительным запуском подсистемы sftp. Показываю сразу рабочий пример с подключением по sftp заданной группы пользователей, с chroot в конкретную директорию и с umask 002 для новых файлов.
Subsystem sftp internal-sftp -u 002Match User sftpusers ChrootDirectory /var/www ForceCommand internal-sftp -u 002#linux #security
Я уже как-то упоминал, что последнее время в репозитории популярных дистрибутивов попадают современные утилиты, аналоги более старых с расширенной функциональностью. Я писал о некоторых из них:
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
Это небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
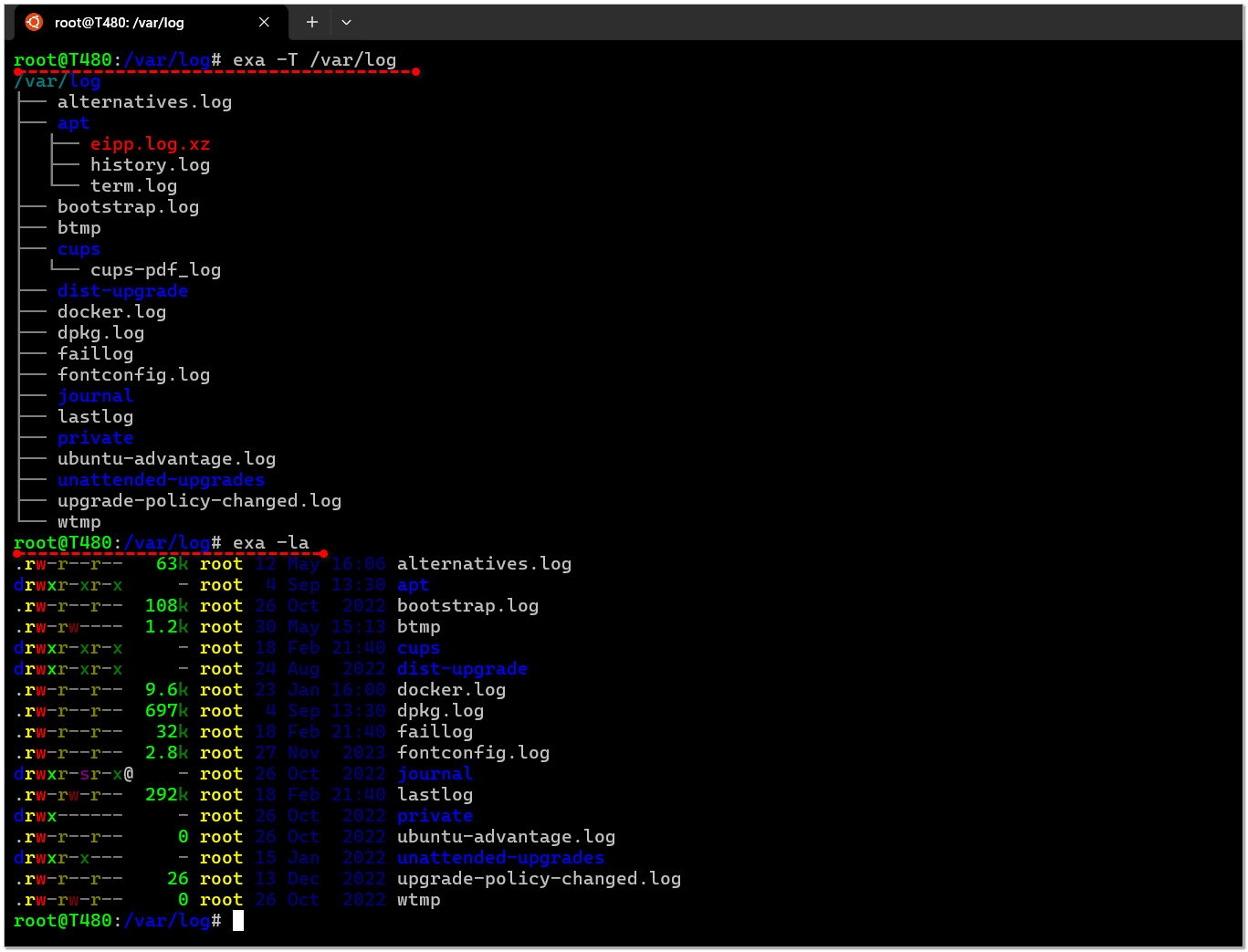
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
Можно ограничить максимальный уровень вложенности:
Привычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
# apt install exaЭто небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
# exa -T /var/log├── alternatives.log├── alternatives.log.1├── alternatives.log.2.gz├── alternatives.log.3.gz├── alternatives.log.4.gz├── apt│ ├── eipp.log.xz│ ├── history.log│ ├── history.log.1.gz│ ├── history.log.2.gz......................................Можно ограничить максимальный уровень вложенности:
# exa -T -L 2 /var/logПривычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
# echo 'alias ls=exa' >> ~/.bashrc# source ~/.bashrc# ls -la❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
{kind=link}
▶️ Очередная подборка авторских IT роликов, которые я лично посмотрел и посчитал интересными/полезными. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными и полезными.
⇨ FreeBSD in 100 Seconds
Очень короткий ролик про FreeBSD. Там нет ничего особенного. Интересен будет только тем, кто не знает, что это за система, но хочет иметь о ней представление. В конце ролика реклама, ради которой он и записывался, можно не досматривать. На этом канале много видео в таком же стиле, где за 100 секунд кратко рассказывают о каком-то продукте. Можно смело смотреть с синхронным переводом от Яндекса. Всё понятно.
⇨ Secure your HomeLab for FREE // Wazuh
Информативное и подробное видео про настройку open source SIEM-системы Wazuh. Автор выполнил single-node установку через docker на домашнем сервере, настроил доступ к веб интерфейсу через traefik. Потом установил агентов на Windows и Linux сервер. Далее показал, как выглядит анализ конфигурации систем на соответствие рекомендациям CIS. В конце рассказал про обнаружение вирусов и вторжений.
⇨ Настройка Suricata в OPNsense
Недавно делал заметку по мотивам ролика от этого автора на тему настройки Zenarmor в OPNsense. Теперь то же самое, только про бесплатную Сурикату.
⇨ Запуск Llama 405b на своем сервере. vLLM, docker.
Подробное описание того, как запустить самую мощную открытую нейросеть Llama 405b на своем сервере. Там и про объём данных, системные требования, где можно взять в аренду сервер (стоимость аховая 🙈) и т.д. В общем, всё. Хорошая инструкция. Было интересно посмотреть для общего развития. Подписался на канал.
⇨ Установка Docmost на Synology в контейнер Docker
Видео про установку и настройку бесплатной open source замены Notion, заблокировавшей всех пользователей из РФ. Автор ставит на Synology, но так как продукт запускается с помощью docker-compose, не принципиально, где это будет запущено. Если хочется просто посмотреть, как выглядит Docmost, мотайте сразу на 8-ю минуту.
⇨ My NEW HomeLab storage server!
Бодрое видео от весёлого блогера, который собрал себе новый сервер хранения, установил туда unraid и рассказал об этом. Будет интересно тем, кто любит такой формат. Пользы там нет, чисто развлечение. Я люблю смотреть такие видео. Может у самого когда-то появится время собирать себе домой какие-то сервера. Сейчас не до этого.
⇨ Zabbix Meetup online, August 2024: Synthetic browser monitoring in Zabbix 7.0
Рассказ с недавнего митапа Zabbix о том, как работает новый мониторинг веб сайтов в Zabbix 7.0. Наглядной практики в записи нет, в основном теория и описание возможных настроек.
⇨ Сети для несетевиков // OSI/ISO, IP и MAC, NAT, TCP и UDP, DNS
Хорошее обзорное видео по основам сетевых технологий. Даётся база для тех, кто почти нулевой в этой теме: модель OSI, MAC адреса, IP адреса, порты, NAT и т.д. У автора явно есть потенциал, желание и знания для создания хороших роликов, но он почему-то пошёл по самым азам, по которым уже есть много материала в интернете и в ютубе в частности. Было бы интереснее, если бы он в какую-то практическую область сместился. Надеюсь, до него как-то дойдёт этот посыл.
⇨ Какой роутер взять для NAS и дома (подкаст)
Личное мнение автора по выбору роутера для дома. Интересно послушать рассуждения, а не какие-то пересказы. Он делает акцент на Wifi и считает, что отталкиваться надо от этих возможностей железа. Всё остальное вторично. Я с этим не согласен, так как везде стараюсь тянуть провод, а по WiFi работают в основном смартфоны, которым некритична скорость подключения.
#видео
⇨ FreeBSD in 100 Seconds
Очень короткий ролик про FreeBSD. Там нет ничего особенного. Интересен будет только тем, кто не знает, что это за система, но хочет иметь о ней представление. В конце ролика реклама, ради которой он и записывался, можно не досматривать. На этом канале много видео в таком же стиле, где за 100 секунд кратко рассказывают о каком-то продукте. Можно смело смотреть с синхронным переводом от Яндекса. Всё понятно.
⇨ Secure your HomeLab for FREE // Wazuh
Информативное и подробное видео про настройку open source SIEM-системы Wazuh. Автор выполнил single-node установку через docker на домашнем сервере, настроил доступ к веб интерфейсу через traefik. Потом установил агентов на Windows и Linux сервер. Далее показал, как выглядит анализ конфигурации систем на соответствие рекомендациям CIS. В конце рассказал про обнаружение вирусов и вторжений.
⇨ Настройка Suricata в OPNsense
Недавно делал заметку по мотивам ролика от этого автора на тему настройки Zenarmor в OPNsense. Теперь то же самое, только про бесплатную Сурикату.
⇨ Запуск Llama 405b на своем сервере. vLLM, docker.
Подробное описание того, как запустить самую мощную открытую нейросеть Llama 405b на своем сервере. Там и про объём данных, системные требования, где можно взять в аренду сервер (стоимость аховая 🙈) и т.д. В общем, всё. Хорошая инструкция. Было интересно посмотреть для общего развития. Подписался на канал.
⇨ Установка Docmost на Synology в контейнер Docker
Видео про установку и настройку бесплатной open source замены Notion, заблокировавшей всех пользователей из РФ. Автор ставит на Synology, но так как продукт запускается с помощью docker-compose, не принципиально, где это будет запущено. Если хочется просто посмотреть, как выглядит Docmost, мотайте сразу на 8-ю минуту.
⇨ My NEW HomeLab storage server!
Бодрое видео от весёлого блогера, который собрал себе новый сервер хранения, установил туда unraid и рассказал об этом. Будет интересно тем, кто любит такой формат. Пользы там нет, чисто развлечение. Я люблю смотреть такие видео. Может у самого когда-то появится время собирать себе домой какие-то сервера. Сейчас не до этого.
⇨ Zabbix Meetup online, August 2024: Synthetic browser monitoring in Zabbix 7.0
Рассказ с недавнего митапа Zabbix о том, как работает новый мониторинг веб сайтов в Zabbix 7.0. Наглядной практики в записи нет, в основном теория и описание возможных настроек.
⇨ Сети для несетевиков // OSI/ISO, IP и MAC, NAT, TCP и UDP, DNS
Хорошее обзорное видео по основам сетевых технологий. Даётся база для тех, кто почти нулевой в этой теме: модель OSI, MAC адреса, IP адреса, порты, NAT и т.д. У автора явно есть потенциал, желание и знания для создания хороших роликов, но он почему-то пошёл по самым азам, по которым уже есть много материала в интернете и в ютубе в частности. Было бы интереснее, если бы он в какую-то практическую область сместился. Надеюсь, до него как-то дойдёт этот посыл.
⇨ Какой роутер взять для NAS и дома (подкаст)
Личное мнение автора по выбору роутера для дома. Интересно послушать рассуждения, а не какие-то пересказы. Он делает акцент на Wifi и считает, что отталкиваться надо от этих возможностей железа. Всё остальное вторично. Я с этим не согласен, так как везде стараюсь тянуть провод, а по WiFi работают в основном смартфоны, которым некритична скорость подключения.
#видео
YouTube
FreeBSD in 100 Seconds
Try Brilliant free for 30 days https://brilliant.org/fireship You’ll also get 20% off an annual premium subscription.
Learn the basics of FreeBSD - a UNIX-like operating system that shares code with projects like iOS, MacOS, Nintendo, PlayStation, and many…
Learn the basics of FreeBSD - a UNIX-like operating system that shares code with projects like iOS, MacOS, Nintendo, PlayStation, and many…
Небольшая заметка про одну команду, которая у меня уже вошла в привычку и используется почти каждый день. Возможно и вам она будет полезна. Я недавно делал заметку про netstat и ss. Рассказал, что постепенно почти перешёл на
В комментариях один человек посоветовал использовать утилиту column. Что самое интересное, я про неё знаю, писал заметку. Тоже посоветовали в комментариях. Но с
А самое главное, что я cразу эту конструкцию запомнил и теперь постоянно пользуюсь, так как и
Теперь вот и с
Netstat вообще не выводит пользователей, только название процесса. В
Но тут вывод о процессе ненагляден, так как выводится имя юнита systemd, а не непосредственно рабочего процесса.
#linux #terminal
ss, но не нравится широкий вывод команды. На узком терминале разъезжается одна строка на две и вывод выглядит ненаглядно.В комментариях один человек посоветовал использовать утилиту column. Что самое интересное, я про неё знаю, писал заметку. Тоже посоветовали в комментариях. Но с
ss не догадался её попробовать. А это удобно. Вывод получается более компактный и наглядный:# ss -tulnp | column -t# ss -nte | column -tА самое главное, что я cразу эту конструкцию запомнил и теперь постоянно пользуюсь, так как и
ss, и column есть во всех дистрах из коробки. Рекомендую попробовать. Я column привык с mount использовать для удобного вывода:# mount | column -tТеперь вот и с
ss. Про netstat стал забывать. Не использую почти, перешёл на ss. Один неприятный нюанс всё равно остался. Даже с column в ss бывают длинные строки, если поле с users очень длинное, типа такого:users:(("smtpd",pid=1680589,fd=6),("smtpd",pid=1680587,fd=6),("smtpd",pid=1680585,fd=6),("smtpd",pid=1678705,fd=6),("smtpd",pid=1678348,fd=6),("smtpd",pid=1675803,fd=6),("master",pid=1837,fd=13))Netstat вообще не выводит пользователей, только название процесса. В
ss тоже можно убрать, например вот так (заменили p на e):# ss -tulneНо тут вывод о процессе ненагляден, так как выводится имя юнита systemd, а не непосредственно рабочего процесса.
#linux #terminal
Вчера случайно заметил очень любопытную вещь в Debian, которая касается различий между apt и apt-get. Я всегда был уверен, что различия там в основном организационные в плане названия команд. Apt объединил в себе возможности apt-get и apt-cache, добавился прогресс бар, и что важно
Я обычно использую apt, потому что короче набирать и в целом удобнее. Оказалось, что команды
А заметил я разницу, когда установил на Debian 12 версию php 8.2 и захотел обновить её до 8.3, подключив сторонний репозиторий. Покажу наглядно по шагам, что сделал.
Сначала полностью обновил систему и установил туда php 8.2 из стандартного репозитория:
Далее подключил репозиторий sury, а точнее его зеркало в домене на su, так как автор ограничил к нему доступ из РФ:
В репозитории есть версия php 8.3. Пробую обновиться через apt:
Предлагает установить php 8.3 и удалить 8.2:
Делаю full-upgrade:
Вывод один в один как для upgrade. Предлагает удалить 8.2 и поставить 8.3. Я выполнил обе эти команды и убедился, что результат идентичный. Они отработали обе как full-upgrade. Я получил в системе php 8.3.
Делаю то же самое, только с apt-get:
Предлагает только обновить 8.2, что от него и ожидаешь. Выполняю full-upgrade:
Вывод такой же, как у apt full-upgrade. То есть в apt-get upgrade и full-upgrade работают ожидаемо, как и описано в документации. А вот с apt мне непонятна ситуация. Не так часто приходится в рамках одной системы переходить на другую ветку ПО, поэтому раньше не обращал на это внимание. А теперь буду.
Вот отличия apt upgrade от apt full-upgrade согласно man:
▪️ upgrade - upgrade is used to install available upgrades of all packages currently installed on the system from the sources configured via sources.list(5). New packages will be installed if required to satisfy dependencies, but existing packages will never be removed.
▪️ full-upgrade - full-upgrade performs the function of upgrade but will remove currently installed packages if this is needed to upgrade the system as a whole.
Apt-get ведёт себя согласно описанию, а вот apt - нет. Не знаю, баг это или особенность конкретно веток php и подключенного репозитория. Если бы оба apt-get и apt вели себя одинаково, я бы не обратил на это внимания. Но тут разница в поведении налицо. Их поведение не идентично не только в плане синтаксиса и некоторых ключей, но и функциональности.
#linux
apt list --upgradable. Я обычно использую apt, потому что короче набирать и в целом удобнее. Оказалось, что команды
apt upgrade и apt-get upgrade тоже отличаются. Фактически разницы между apt upgrade и apt full-upgrade нет, а она должна быть. Напомню, что команда upgrade обновляет только текущую версию пакета, ничего не удаляя. В то же время full-upgrade может удалить текущую версию пакета и установить новую. Поэтому эта команда используется при обновлении с релиза на релиз. Там без удаления не обойтись. А заметил я разницу, когда установил на Debian 12 версию php 8.2 и захотел обновить её до 8.3, подключив сторонний репозиторий. Покажу наглядно по шагам, что сделал.
Сначала полностью обновил систему и установил туда php 8.2 из стандартного репозитория:
# apt update && apt upgrade# apt install phpДалее подключил репозиторий sury, а точнее его зеркало в домене на su, так как автор ограничил к нему доступ из РФ:
# wget -O /etc/apt/trusted.gpg.d/php.gpg https://packages.sury.su/php/apt.gpg # sh -c 'echo "deb https://packages.sury.su/php/ $(lsb_release -sc) main" > /etc/apt/sources.list.d/php.list'В репозитории есть версия php 8.3. Пробую обновиться через apt:
# apt update && apt upgradeПредлагает установить php 8.3 и удалить 8.2:
The following packages were automatically installed and are no longer required: libapache2-mod-php8.2 php8.2 php8.2-cli php8.2-common php8.2-opcache php8.2-readlineUse 'apt autoremove' to remove them.The following NEW packages will be installed: debsuryorg-archive-keyring libapache2-mod-php8.3 php8.3 php8.3-cli php8.3-common php8.3-opcache php8.3-readlineДелаю full-upgrade:
# apt full-upgradeВывод один в один как для upgrade. Предлагает удалить 8.2 и поставить 8.3. Я выполнил обе эти команды и убедился, что результат идентичный. Они отработали обе как full-upgrade. Я получил в системе php 8.3.
Делаю то же самое, только с apt-get:
# apt-get upgradeThe following packages will be upgraded: libapache2-mod-php8.2 php8.2 php8.2-cli php8.2-common php8.2-opcache php8.2-readlineПредлагает только обновить 8.2, что от него и ожидаешь. Выполняю full-upgrade:
# apt-get full-upgradeThe following packages were automatically installed and are no longer required: libapache2-mod-php8.2 php8.2 php8.2-cli php8.2-common php8.2-opcache php8.2-readlineUse 'apt autoremove' to remove them.The following NEW packages will be installed: debsuryorg-archive-keyring libapache2-mod-php8.3 php8.3 php8.3-cli php8.3-common php8.3-opcache php8.3-readlineВывод такой же, как у apt full-upgrade. То есть в apt-get upgrade и full-upgrade работают ожидаемо, как и описано в документации. А вот с apt мне непонятна ситуация. Не так часто приходится в рамках одной системы переходить на другую ветку ПО, поэтому раньше не обращал на это внимание. А теперь буду.
Вот отличия apt upgrade от apt full-upgrade согласно man:
▪️ upgrade - upgrade is used to install available upgrades of all packages currently installed on the system from the sources configured via sources.list(5). New packages will be installed if required to satisfy dependencies, but existing packages will never be removed.
▪️ full-upgrade - full-upgrade performs the function of upgrade but will remove currently installed packages if this is needed to upgrade the system as a whole.
Apt-get ведёт себя согласно описанию, а вот apt - нет. Не знаю, баг это или особенность конкретно веток php и подключенного репозитория. Если бы оба apt-get и apt вели себя одинаково, я бы не обратил на это внимания. Но тут разница в поведении налицо. Их поведение не идентично не только в плане синтаксиса и некоторых ключей, но и функциональности.
#linux
И вновь возвращаемся к рубрике с современными утилитами, которые можно использовать в качестве альтернативы более старым, потому что они уже поселились в официальных репозиториях. Речь пойдёт об уже упоминаемой мной несколько лет назад программе fd, которую можно использовать вместо find. Она приехала в стабильные репы:
Короткое название fd использовать не получится, потому что оно уже занято. Придётся использовать
В чём особенность fd? Авторы называют её более быстрой и дружелюбной к пользователю программой, по сравнению с find. В принципе, с этим не поспоришь. Ключи и синтаксис find нельзя назвать дружелюбным. Я по памяти могу только какие-то самые простые вещи делать. Всё остальное ищу в своих шпаргалках. Не понимаю, как подобные конструкции можно запоминать, если каждый день с ними не работаешь.
Ищем файл syslog в текущей директории:
Ищем файл в конкретной директории:
Ищем файл по всему серверу:
Вот то же самое, только с find:
По умолчанию find найдёт только полное совпадение по имени. Файл должен будет точно называться syslog, чтобы попасть в результаты поиска. Fd в примере отобразит все файлы, где встречается слово syslog. Это и интуитивнее, и проще для запоминания. Хотя этот момент субъективен. С find такой же поиск будет выглядеть вот так:
Отличия от find, которые отмечают авторы:
◽️Более скоростной поиск за счёт параллельных запросов. Приводят свои измерения, где это подтверждается.
◽️Подсветка результатов поиска.
◽️По умолчанию поиск ведётся без учёта регистра.
◽️Итоговые команды в среднем на 50% короче, чем то же самое получается с find.
⚠️ Отдельный ключ
Несколько простых примеров для наглядности. Поиск файлов с определённым расширением:
Найти все архивы и распаковать их:
Найти файлы с расширением gz и удалить одной командой rm:
Вызванный без аргументов в директории, fd рекурсивно выведет все файлы в ней:
Это примерно то же самое, что с find:
Только у fd вывод нагляднее, так как уже отсортирован по именам. А find всё вперемешку выводит. Ему надо sort добавлять, чтобы то же самое получилось:
Fd умеет результаты выводить не по одному значению на каждую строку, а непрерывной строкой с разделением с помощью так называемого NULL character. Все символы воспринимаются буквально, не являются специальными, их не надо экранировать. Актуально, когда результаты поиска имеют пробелы, кавычки, косые черты и т.д. Например, xargs умеет принимать на вход значения, разделённые NULL character. У него для этого отдельный ключ
Покажу на примере, как это работает:
Xargs не смог обработать файл с пробелом. А вот так смог:
И ничего экранировать не пришлось. Полезная возможность, стоит запомнить. Find то же самое делает через ключ
В заключении резюмирую, что fd не заменяет find, не претендует на это и не обеспечивает такую же функциональность, как у последнего. Он предоставляет обоснованные настройки по умолчанию для наиболее массовых применений поиска пользователями.
#terminal #linux #find
# apt install fd-findКороткое название fd использовать не получится, потому что оно уже занято. Придётся использовать
fdfind. Под Windows она, кстати, тоже есть:> winget install sharkdp.fdВ чём особенность fd? Авторы называют её более быстрой и дружелюбной к пользователю программой, по сравнению с find. В принципе, с этим не поспоришь. Ключи и синтаксис find нельзя назвать дружелюбным. Я по памяти могу только какие-то самые простые вещи делать. Всё остальное ищу в своих шпаргалках. Не понимаю, как подобные конструкции можно запоминать, если каждый день с ними не работаешь.
Ищем файл syslog в текущей директории:
# fdfind syslogИщем файл в конкретной директории:
# fdfind syslog /var/logИщем файл по всему серверу:
# fdfind syslog /Вот то же самое, только с find:
# find . -name syslog# find /var/log -name syslog# find / -name syslogПо умолчанию find найдёт только полное совпадение по имени. Файл должен будет точно называться syslog, чтобы попасть в результаты поиска. Fd в примере отобразит все файлы, где встречается слово syslog. Это и интуитивнее, и проще для запоминания. Хотя этот момент субъективен. С find такой же поиск будет выглядеть вот так:
# find / -name '*syslog*'Отличия от find, которые отмечают авторы:
◽️Более скоростной поиск за счёт параллельных запросов. Приводят свои измерения, где это подтверждается.
◽️Подсветка результатов поиска.
◽️По умолчанию поиск ведётся без учёта регистра.
◽️Итоговые команды в среднем на 50% короче, чем то же самое получается с find.
⚠️ Отдельный ключ
--exec-batch или -X в дополнение к традиционному --exec. Разница в том, что --exec выполняется параллельно для каждого результата поиска, а с помощью --exec-batch можно во внешнюю команду передать весь результат поиска. Это важный момент, который где-то может сильно выручить и упростить задачу. Даже если вам сейчас это не надо, запомните, что с fd так можно. Где-то в скриптах это может пригодиться.Несколько простых примеров для наглядности. Поиск файлов с определённым расширением:
# fdfind -e php -p /var/wwwНайти все архивы и распаковать их:
# fdfind -e zip -p /home/user -x unzipНайти файлы с расширением gz и удалить одной командой rm:
# fdfind -e gz -p /var/log -X rmВызванный без аргументов в директории, fd рекурсивно выведет все файлы в ней:
# cd /var/log# fdfindЭто примерно то же самое, что с find:
# find -name '*'Только у fd вывод нагляднее, так как уже отсортирован по именам. А find всё вперемешку выводит. Ему надо sort добавлять, чтобы то же самое получилось:
# find -name '*' | sortFd умеет результаты выводить не по одному значению на каждую строку, а непрерывной строкой с разделением с помощью так называемого NULL character. Все символы воспринимаются буквально, не являются специальными, их не надо экранировать. Актуально, когда результаты поиска имеют пробелы, кавычки, косые черты и т.д. Например, xargs умеет принимать на вход значения, разделённые NULL character. У него для этого отдельный ключ
-0, --null. Покажу на примере, как это работает:
# touch 'test test.log'# fdfind -e log...test test.log# fdfind -e log | xargs wc -l...wc: test: No such file or directorywc: test.log: No such file or directoryXargs не смог обработать файл с пробелом. А вот так смог:
# fdfind -0 -e log | xargs -0 wc -l...0 ./test test.logИ ничего экранировать не пришлось. Полезная возможность, стоит запомнить. Find то же самое делает через ключ
-print0:# find . -name '*.log' -print0 | xargs -0 wc -lВ заключении резюмирую, что fd не заменяет find, не претендует на это и не обеспечивает такую же функциональность, как у последнего. Он предоставляет обоснованные настройки по умолчанию для наиболее массовых применений поиска пользователями.
#terminal #linux #find
На всех серверах на базе Linux, а раньше и не только Linux, которые настраиваю и обслуживаю сам, изменяю параметры хранения истории команд, то есть history. Настройки обычно добавляю в файл
✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
Для применения настроек можно выполнить:
Посмотреть свои применённые параметры для истории можно вот так:
Если вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
🦖 Selectel — дешёвые и не очень дедики с аукционом!
~/.bashrc. Постоянно обращаюсь к истории команд, поэтому стараюсь, чтобы они туда попадали и сохранялись. Покажу свои привычные настройки:✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
history -a сохраняет историю команд этого сеанса в файл с историей.PROMPT_COMMAND='history -a'✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
export HISTTIMEFORMAT='%F %T '✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
export HISTSIZE=10000✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
export HISTIGNORE="ls:history:w:htop:pwd:top:iftop"✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
export HISTCONTROL=ignorespace Для применения настроек можно выполнить:
# source ~/.bashrcПосмотреть свои применённые параметры для истории можно вот так:
# export | grep -i histЕсли вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
history.sh и положите его в директорию /etc/profile.d. Скрипты из этой директории выполняются при запуске шелла пользователя. ❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
# history | grep 'apt install'Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
Please open Telegram to view this post
VIEW IN TELEGRAM
Одной из обязательных настроек, которую делаю на новом сервере, касается ротации текстовых логов. Несмотря на то, что их активно заменяют бинарные логи systemd, я предпочитаю возвращать текстовые логи syslog. Для этого на чистый сервер устанавливаю rsyslog:
Далее выполняю некоторые настройки, которые относятся к ротации логов с помощью logrotate. В первую очередь в фале
Он нужен, чтобы в имени файла была указана дата, когда лог-файл был ротирован. С этой настройкой связан один очень важный момент, если вы хотите ротировать логи чаще, чем раз в сутки. По умолчанию logrotate во время ротации лога с этой настройкой переименовывает текущий лог файл, назначая ему имя вида access.log.20241001.gz. То есть в имени файла будет указан текущий день. Второй раз в этот день ротация закончится ошибкой, так как logrotate скажет, что не могу переименовать лог, так как файл с таким именем уже существует. Для тех логов, что точно будут ротироваться чаще, чем раз в сутки, нужно обязательно добавить параметр:
В таком случае каждое имя файла будет уникальным и проблем не возникнет.
Далее в обязательном порядке нужно настроить запуск logrotate чаще, чем раз в сутки. По умолчанию в Debian запуск logrotate настроен в
Эти настройки особенно актуальны для веб серверов, где очень быстро могут разрастись лог файлы.
Все возможные настройки файлов logrotate можно почитать в man. Там довольно подробно всё описано. Если не хочется читать man, можно воспользоваться простым конфигуратором:
🌐 https://scoin.github.io/logrotate-tool
Там наглядно перечислены настройки с описанием. Можно мышкой потыкать и посмотреть, как меняется конфигурационный файл. Вот пример моего файла ротации логов веб сервера:
Маска
◽️/web/sites/site01.ru/logs/
◽️/web/sites/site02.ru/logs/
и т.д.
Когда будете настраивать ротацию логов, проверяйте, чтобы у службы, для которой управляем логами, в итоге оказался доступ к этим логам. Я иногда ошибаюсь и потом приходится разбираться, почему после ротации логи нулевого размера. Это актуально, когда логи куда-то выносятся из /var/log и отдельно настраиваются права, например, для того, чтобы какие-то пользователи имели к ним доступ, к примеру, только на чтение.
#linux #logs #logrotate #webserver
# apt install rsyslogДалее выполняю некоторые настройки, которые относятся к ротации логов с помощью logrotate. В первую очередь в фале
/etc/logrotate.conf включаю параметр:dateextОн нужен, чтобы в имени файла была указана дата, когда лог-файл был ротирован. С этой настройкой связан один очень важный момент, если вы хотите ротировать логи чаще, чем раз в сутки. По умолчанию logrotate во время ротации лога с этой настройкой переименовывает текущий лог файл, назначая ему имя вида access.log.20241001.gz. То есть в имени файла будет указан текущий день. Второй раз в этот день ротация закончится ошибкой, так как logrotate скажет, что не могу переименовать лог, так как файл с таким именем уже существует. Для тех логов, что точно будут ротироваться чаще, чем раз в сутки, нужно обязательно добавить параметр:
dateformat -%Y-%m-%d_%H-%sВ таком случае каждое имя файла будет уникальным и проблем не возникнет.
Далее в обязательном порядке нужно настроить запуск logrotate чаще, чем раз в сутки. По умолчанию в Debian запуск logrotate настроен в
/etc/cron.daily и запускается не чаще раза в сутки. Я обычно просто добавляю запуск в /etc/crontab каждые 5 минут:*/5 * * * * root logrotate /etc/logrotate.confЭти настройки особенно актуальны для веб серверов, где очень быстро могут разрастись лог файлы.
Все возможные настройки файлов logrotate можно почитать в man. Там довольно подробно всё описано. Если не хочется читать man, можно воспользоваться простым конфигуратором:
Там наглядно перечислены настройки с описанием. Можно мышкой потыкать и посмотреть, как меняется конфигурационный файл. Вот пример моего файла ротации логов веб сервера:
/web/sites/*/logs/*.log { create 644 angie webuser size=50M dateext dateformat -%Y-%m-%d_%H-%s missingok rotate 30 compress notifempty sharedscripts postrotate if [ -f /run/angie.pid ]; then kill -USR1 $(cat /run/angie.pid) fi endscript}Маска
/web/sites/*/logs/*.log захватывает все виртуальные хосты веб сервера, где логи располагаются в директориях:◽️/web/sites/site01.ru/logs/
◽️/web/sites/site02.ru/logs/
и т.д.
Когда будете настраивать ротацию логов, проверяйте, чтобы у службы, для которой управляем логами, в итоге оказался доступ к этим логам. Я иногда ошибаюсь и потом приходится разбираться, почему после ротации логи нулевого размера. Это актуально, когда логи куда-то выносятся из /var/log и отдельно настраиваются права, например, для того, чтобы какие-то пользователи имели к ним доступ, к примеру, только на чтение.
#linux #logs #logrotate #webserver
Please open Telegram to view this post
VIEW IN TELEGRAM
На днях на одном из серверов VPN с IP 175.115.158.81 заметил странные строки в логе:
Внимание привлекло то, что 95.145.141.246 это мой IP адрес ещё одного VPN сервера. Я не припомнил, чтобы настраивал на нем клиента для подключения к серверу 175.115.158.81. На всякий случай сходил туда и убедился в этом:
Никакого openvpn клиента тут не было запущено. Да и настроек для него тоже нет. У меня настроена разветвлённая система VPN туннелей с маршрутизацией, так что иногда начинаю в ней путаться. Надо схему рисовать.
Я немного напрягся и стал разбираться, в чём тут дело. Решил посмотреть на сервере с IP 95.145.141.246 исходящие сетевые соединения:
Соединения разные были, но к указанному VPN серверу ничего не было. Стало ещё интереснее. Расчехлил tcpdump и стал смотреть им:
Подождал, когда в логе на VPN сервере 175.115.158.81 опять появится запись о неудачном соединении. Вернулся в консоль сервера 95.145.141.246 и увидел запись:
1778 - порт VPN сервера. Смотрю на адрес 172.17.0.4 и тут до меня доходит, что это Docker контейнер. Проверяю IP адреса контейнеров:
А там мониторинг Gatus. И тут я вспоминаю, что настроил мониторинг VPN канала через проверку доступности порта, на котором он принимает подключения. Всё встало на свои места. Не думал, что проверка порта будет такими записями в логе отмечаться. Хотя на самом деле с таким встречаюсь иногда, когда через Zabbix порты проверяю через simple check.
Получилась мини-инструкция по диагностике исходящих соединений. В принципе, можно было сразу запустить tcpdump, но я по памяти не помню ключи и синтаксис выборки для него. Приходится куда-то лезть за подсказками. Мне казалось, что я делал по tcpdump заметку с популярными командами, но нет, не нашёл. Надо будет при случае исправить это.
#linux #terminal
ovpn-server[3742533]: TCP connection established with [AF_INET] 95.145.141.246:58560ovpn-server[3742533]: 95.145.141.246:58560 Connection reset, restarting [0]ovpn-server[3742533]: 95.145.141.246:58560 SIGUSR1[soft,connection-reset] received, client-instance restartingВнимание привлекло то, что 95.145.141.246 это мой IP адрес ещё одного VPN сервера. Я не припомнил, чтобы настраивал на нем клиента для подключения к серверу 175.115.158.81. На всякий случай сходил туда и убедился в этом:
# ps axf Никакого openvpn клиента тут не было запущено. Да и настроек для него тоже нет. У меня настроена разветвлённая система VPN туннелей с маршрутизацией, так что иногда начинаю в ней путаться. Надо схему рисовать.
Я немного напрягся и стал разбираться, в чём тут дело. Решил посмотреть на сервере с IP 95.145.141.246 исходящие сетевые соединения:
# ss -ntuСоединения разные были, но к указанному VPN серверу ничего не было. Стало ещё интереснее. Расчехлил tcpdump и стал смотреть им:
# tcpdump -nn 'dst host 175.115.158.81'Подождал, когда в логе на VPN сервере 175.115.158.81 опять появится запись о неудачном соединении. Вернулся в консоль сервера 95.145.141.246 и увидел запись:
14:29:38.706375 IP 172.17.0.4.58700 > 175.115.158.81.17781778 - порт VPN сервера. Смотрю на адрес 172.17.0.4 и тут до меня доходит, что это Docker контейнер. Проверяю IP адреса контейнеров:
# docker ps -q | xargs -n 1 docker inspect --format '{{ .NetworkSettings.IPAddress }} {{ .Name }}' | sed 's/ \// /'...........172.17.0.4 gatus...........А там мониторинг Gatus. И тут я вспоминаю, что настроил мониторинг VPN канала через проверку доступности порта, на котором он принимает подключения. Всё встало на свои места. Не думал, что проверка порта будет такими записями в логе отмечаться. Хотя на самом деле с таким встречаюсь иногда, когда через Zabbix порты проверяю через simple check.
Получилась мини-инструкция по диагностике исходящих соединений. В принципе, можно было сразу запустить tcpdump, но я по памяти не помню ключи и синтаксис выборки для него. Приходится куда-то лезть за подсказками. Мне казалось, что я делал по tcpdump заметку с популярными командами, но нет, не нашёл. Надо будет при случае исправить это.
#linux #terminal
Очень простой и быстрый способ измерить ширину канала с помощью Linux без установки дополнительных пакетов. Понадобится только netcat, который чаще всего есть в составе базовых утилит. По крайней мере в Debian это так.
Берём условный сервер 10.20.1.50 и запускаем там netcat на порту 5201:
Идём на другую машину и запускаем netcat в режиме клиента, передавая туда 10 блоков размером 10 мегабайт:
Когда измерял так скорость, немного усомнился в достоверности результатов. Решил провести одинаковые тесты с помощью netcat и iperf3. На скоростях до 1 Gbits/sec замеры показывают одинаковые числа, плюс-минус в районе погрешности измерений. Можно смело использовать netcat. Это реально работает для быстрой проверки канала до какой-то VPS.
А вот в сетях в рамках гипервизора, где скорости значительно больше, идут большие расхождения. Iperf3 показывает раза в 4 больше скорость (~15.0 Gbits/sec), чем netcat (~4.0 Gbits/sec). Гипервизор объявляет скорость своего бриджа в 10 Gbits/sec. И тут уже трудно судить, кто ближе к истине. Корректно выполнить замеры на реальных данных затруднительно, так как много факторов, которые влияют на итоговый результат.
Напомню, что у меня есть хорошая заметка про netcat с различными практическими примерами применения этой утилиты.
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #network
Берём условный сервер 10.20.1.50 и запускаем там netcat на порту 5201:
# nc -lvp 5201 > /dev/nullИдём на другую машину и запускаем netcat в режиме клиента, передавая туда 10 блоков размером 10 мегабайт:
# dd if=/dev/zero bs=10M count=10 | nc 10.20.1.50 5201Когда измерял так скорость, немного усомнился в достоверности результатов. Решил провести одинаковые тесты с помощью netcat и iperf3. На скоростях до 1 Gbits/sec замеры показывают одинаковые числа, плюс-минус в районе погрешности измерений. Можно смело использовать netcat. Это реально работает для быстрой проверки канала до какой-то VPS.
А вот в сетях в рамках гипервизора, где скорости значительно больше, идут большие расхождения. Iperf3 показывает раза в 4 больше скорость (~15.0 Gbits/sec), чем netcat (~4.0 Gbits/sec). Гипервизор объявляет скорость своего бриджа в 10 Gbits/sec. И тут уже трудно судить, кто ближе к истине. Корректно выполнить замеры на реальных данных затруднительно, так как много факторов, которые влияют на итоговый результат.
Напомню, что у меня есть хорошая заметка про netcat с различными практическими примерами применения этой утилиты.
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #network
Существует популярная панель для управления сервером с прицелом на персональное использование в качестве некоего домашнего сервера. Речь пойдёт про CasaOS - популярный open source проект. Ставится поверх обычного дистрибутива Linux. Я установил на Debian и попробовал его для решения некоторых задач. В частности своего личного WireGuard сервера в связке с AdGuard Home для блокировки рекламы на компьютерах или смартфонах.
Не знаю, за что CasaOS снискала свою популярность. Скорее всего за лёгкий и красивый веб интерфейс. Похожие проекты существую давно. Например, Runtipi, про который я ранее уже писал. Там, кстати, в комментариях как раз CasaOS упоминали. По своей сути это просто веб интерфейс поверх работающих Docker контейнеров, которые устанавливаются из встроенного магазина преднастроенных приложений.
Можно было бы предположить, что это продукт для тех, кто не умеет и не хочет уметь работать с консолью Linux, ничего не знает, а хочет просто мышкой потыкать и получить настроенный сервер. Но на самом деле с CasaOS это так не работает. Без знаний особенностей работы Docker контейнеров настроить нормальную работу всех сервисов скорее всего не получится. В консоль ходить не обязательно, но некоторые настройки контейнеров после установки нужно будет делать.
Сразу приведу список приложений, которые можно установить в CasaOS. Вообще, их огромное количество. Есть всё, что только можно. Сообщество насоздавало своих магазинов, которые регулярно поддерживаются и обновляются. Вот самые популярные:
◽️big-bear-casaos
◽️CasaOS-LinuxServer-AppStore
◽️CasaOS-Coolstore
◽️CasaOS-HomeAutomation-AppStore
Получается внушительный набор. Для личного сервера есть всё необходимое: FileBrowser, Nginx Proxy Manager, WireGuard, AdGuard Home, Syncthing, Transmission, Nextcloud и многое другое.
Установить CasaOS очень просто. Берём чистый сервер и ставим:
На выходе получаем работающий веб интерфейс по IP адресу сервера. При первом входе нужно будет создать учётку. Дальше я настроил и потестировал прикладную связку из WireGuard + AdGuard. Сначала установил AdGuard Home. Первый вход из админки запускает стандартный установщик AdGuard, который в том числе настраивает доступ к веб интерфейсу. По умолчанию это будет 80-й порт, но он уже занят интерфейсом самого CasaOS. Поэтому после установки контейнера, надо зайти в настройки AdGuard Home и добавить проброс ещё одного порта к уже существующим: 8080 ⇨ 80. Теперь по IP адресу сервера и порту 8080 можно попасть в веб интерфейс AdGuard.
Потом установил WireGuard Easy. После установки зашёл в настройки приложения и отредактировал некоторые параметры. В переменной PASSWORD установил свой пароль. В переменной WG_HOST указал IP адрес сервера, в WG_DEFAULT_DNS указал IP адрес контейнера с AdGuard Home. Так как он устанавливался первым, IP адрес у него 172.17.0.2.
Ну и всё. Дальше зашёл в веб интерфейс WG-Easy, создал пользователя. Импортировал конфиг в смартфон и подключился. Смартфон автоматом весь трафик завернул в туннель, а в качестве DNS сервера стал использовать контейнер AdGuard Home. А в нём можно настроить различные блокировки как по спискам рекламы, так и целые сервисы. Например, можно заблокировать полностью Youtube или VK. Таким же образом WG можно подключить на компьютере (проверил, работает) или на роутере. Причём на роутере не обязательно весь трафик заворачивать в туннель. Можно использовать только DNS сервер от AdGuard Home для блокировки рекламы.
Эту связку можно использовать для различных задач. Не буду подробно на этом останавливаться, так как за это уже начали наказывать. Пока в виде предупреждений. Авторы сайтов и ютуб каналов уже получают уведомления от Роскомнадзора. Так что если вы автор контента, имейте ввиду.
В целом, панель приятная. Если понимаешь особенности работы контейнеров, проблем не будет. Можно быстро всё настроить и связать друг с другом.
⇨ Сайт / Исходники / Demo (casaos / casaos)
#linux
Не знаю, за что CasaOS снискала свою популярность. Скорее всего за лёгкий и красивый веб интерфейс. Похожие проекты существую давно. Например, Runtipi, про который я ранее уже писал. Там, кстати, в комментариях как раз CasaOS упоминали. По своей сути это просто веб интерфейс поверх работающих Docker контейнеров, которые устанавливаются из встроенного магазина преднастроенных приложений.
Можно было бы предположить, что это продукт для тех, кто не умеет и не хочет уметь работать с консолью Linux, ничего не знает, а хочет просто мышкой потыкать и получить настроенный сервер. Но на самом деле с CasaOS это так не работает. Без знаний особенностей работы Docker контейнеров настроить нормальную работу всех сервисов скорее всего не получится. В консоль ходить не обязательно, но некоторые настройки контейнеров после установки нужно будет делать.
Сразу приведу список приложений, которые можно установить в CasaOS. Вообще, их огромное количество. Есть всё, что только можно. Сообщество насоздавало своих магазинов, которые регулярно поддерживаются и обновляются. Вот самые популярные:
◽️big-bear-casaos
◽️CasaOS-LinuxServer-AppStore
◽️CasaOS-Coolstore
◽️CasaOS-HomeAutomation-AppStore
Получается внушительный набор. Для личного сервера есть всё необходимое: FileBrowser, Nginx Proxy Manager, WireGuard, AdGuard Home, Syncthing, Transmission, Nextcloud и многое другое.
Установить CasaOS очень просто. Берём чистый сервер и ставим:
# curl -fsSL https://get.casaos.io | sudo bashНа выходе получаем работающий веб интерфейс по IP адресу сервера. При первом входе нужно будет создать учётку. Дальше я настроил и потестировал прикладную связку из WireGuard + AdGuard. Сначала установил AdGuard Home. Первый вход из админки запускает стандартный установщик AdGuard, который в том числе настраивает доступ к веб интерфейсу. По умолчанию это будет 80-й порт, но он уже занят интерфейсом самого CasaOS. Поэтому после установки контейнера, надо зайти в настройки AdGuard Home и добавить проброс ещё одного порта к уже существующим: 8080 ⇨ 80. Теперь по IP адресу сервера и порту 8080 можно попасть в веб интерфейс AdGuard.
Потом установил WireGuard Easy. После установки зашёл в настройки приложения и отредактировал некоторые параметры. В переменной PASSWORD установил свой пароль. В переменной WG_HOST указал IP адрес сервера, в WG_DEFAULT_DNS указал IP адрес контейнера с AdGuard Home. Так как он устанавливался первым, IP адрес у него 172.17.0.2.
Ну и всё. Дальше зашёл в веб интерфейс WG-Easy, создал пользователя. Импортировал конфиг в смартфон и подключился. Смартфон автоматом весь трафик завернул в туннель, а в качестве DNS сервера стал использовать контейнер AdGuard Home. А в нём можно настроить различные блокировки как по спискам рекламы, так и целые сервисы. Например, можно заблокировать полностью Youtube или VK. Таким же образом WG можно подключить на компьютере (проверил, работает) или на роутере. Причём на роутере не обязательно весь трафик заворачивать в туннель. Можно использовать только DNS сервер от AdGuard Home для блокировки рекламы.
Эту связку можно использовать для различных задач. Не буду подробно на этом останавливаться, так как за это уже начали наказывать. Пока в виде предупреждений. Авторы сайтов и ютуб каналов уже получают уведомления от Роскомнадзора. Так что если вы автор контента, имейте ввиду.
В целом, панель приятная. Если понимаешь особенности работы контейнеров, проблем не будет. Можно быстро всё настроить и связать друг с другом.
⇨ Сайт / Исходники / Demo (casaos / casaos)
#linux
Предлагаю вашему вниманию ping нетрадиционной графической ориентации - gping. Ну а если серьёзно, то эта заметка будет про две пинговалки, дополняющие стандартный ping.
1️⃣ Про gping я уже писал несколько лет назад. Она умеет строить график времени отклика пингуемого хоста или группы (❗️) хостов. В целом, ничего особенного в этом нет, но тот, кто формирует списки пакетов к дистрибутивам решил, что утилита достойна внимания и включил её в стандартные репозитории Debian и Ubuntu. В Убутне она уже есть, начиная с 23-й версии. В Debian появится в 13-й. Она уже там.
Ставим так:
Пингуем несколько хостов и смотрим отклик:
1.1.1.1 отвечает заметно быстрее. Есть версия и под Windows. Скачать можно в репозитории. Gping скорее нужен для побаловаться в личном терминале. Я себе в WSL поставил. А вот следующий пример будет более востребован на серверах и прикладных задачах.
2️⃣ Fping позволяет быстро пинговать списки узлов. Это старя программа, которая давно живёт в стандартных репозиториях. Мониторинг Zabbix с самых первых версий именно её использует для своих icmp проверок (icmpping, icmppingloss, icmppingsec).
Ставим так:
Fping удобен для массовых проверок. Например, быстро находим активные узлы в локальной сети:
Очень удобный вывод - 1 строка, 1 адрес. Не нужна дополнительная обработка, если используется в скриптах. Диапазон можно явно указать:
Если пингануть одиночный хост без дополнительных параметров, то будет простой ответ:
Можно скрыть вывод, а результат отследить кодом выхода:
Успех, то есть хост ответил.
Хост не ответил, код выхода 1. Удобно, что нет лишнего вывода. Ничего обрезать и скрывать не надо.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #terminal
1️⃣ Про gping я уже писал несколько лет назад. Она умеет строить график времени отклика пингуемого хоста или группы (❗️) хостов. В целом, ничего особенного в этом нет, но тот, кто формирует списки пакетов к дистрибутивам решил, что утилита достойна внимания и включил её в стандартные репозитории Debian и Ubuntu. В Убутне она уже есть, начиная с 23-й версии. В Debian появится в 13-й. Она уже там.
Ставим так:
# apt install gpingПингуем несколько хостов и смотрим отклик:
# gping 1.1.1.1 8.8.8.8 8.8.4.41.1.1.1 отвечает заметно быстрее. Есть версия и под Windows. Скачать можно в репозитории. Gping скорее нужен для побаловаться в личном терминале. Я себе в WSL поставил. А вот следующий пример будет более востребован на серверах и прикладных задачах.
2️⃣ Fping позволяет быстро пинговать списки узлов. Это старя программа, которая давно живёт в стандартных репозиториях. Мониторинг Zabbix с самых первых версий именно её использует для своих icmp проверок (icmpping, icmppingloss, icmppingsec).
Ставим так:
# apt install fpingFping удобен для массовых проверок. Например, быстро находим активные узлы в локальной сети:
# fping -g 192.168.13.0/24 -qa192.168.13.1192.168.13.2192.168.13.17192.168.13.50192.168.13.186Очень удобный вывод - 1 строка, 1 адрес. Не нужна дополнительная обработка, если используется в скриптах. Диапазон можно явно указать:
# fping -s -g 192.168.13.1 192.168.13.50 -qaЕсли пингануть одиночный хост без дополнительных параметров, то будет простой ответ:
# fping 10.20.1.210.20.1.2 is aliveМожно скрыть вывод, а результат отследить кодом выхода:
# fping 10.20.1.2 -q# echo $?0Успех, то есть хост ответил.
# fping 10.20.1.3 -q# echo $?1Хост не ответил, код выхода 1. Удобно, что нет лишнего вывода. Ничего обрезать и скрывать не надо.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #terminal