
Максимально простой и быстрый способ перенести без остановки ОС Linux на другое железо или виртуальную машину. Не понадобится ничего, кроме встроенных средств. Проверял лично и не раз. Перед написанием этой заметки тоже проверил.
Допустим, у вас система виртуальной машины установлена на /dev/sda. Там, соответственно, будет три раздела: boot, корень и swap. Нам надо эту систему перенести куда-то в другое место. Желательно на однотипное железо, чтобы не возникло проблем. Если железо будет другое, то тоже реально, но нужно будет немного заморочиться и выполнить дополнительные действия. Заранее их все не опишешь, так как это сильно зависит от конкретной ситуации. Скорее всего придётся внутри системы что-то править (сеть, точки монтирования) и пересобрать initrd.
Создаём где-то новую виртуальную машину с таким же диском. Загружаемся с любого загрузочного диска. Например, с SystemRescue. Настраиваем в этой системе сеть, чтобы виртуальная машина, которую переносим, могла сюда подключиться. Запускаем сервер SSH. Не забываем открыть порты в файрволе. В SystemRescue он по умолчанию включен и всё закрыто на вход.
Идём на виртуалку, которую будем переносить. И делаем там простой трюк:
Мы с помощью dd читаем устройство
Процесс будет длительный, так как передача получается посекторная. Нужно понимать, что если машина большая и нагруженная, то в момент передачи целостность данных нарушается. Какую-нибудь СУБД так не перенести. Я лично не пробовал, но подозреваю, что с большой долей вероятности база будет битая. А вот обычный не сильно нагруженный сервер вполне.
После переноса он скорее всего ругнётся на ошибки файловой системы при загрузке, но сам себя починит с очень большой долей вероятности. Я как-то раз пытался так перенести виртуалку на несколько сотен гигабайт. Вот это не получилось. Содержимое судя по всему сильно билось по дороге, так как виртуалка не останавливалась. Не удалось её запустить. А что-то небольшое на 20-30 Гб вполне нормально переносится. Можно так виртуалку от какого-то хостера себе локально перенести. Главное сетевую связность между ними организовать.
Если по сети нет возможности передать образ, то можно сохранить его в файл, если есть доступный носитель:
Потом копируем образ и восстанавливаем из него систему:
Делаем всё это с какого-то загрузочного диска.
Напомню, что перенос системы можно выполнить и с помощью специально предназначенного для этого софта:
▪️ ReaR
▪️ Veeam Agent for Linux FREE
▪️ Clonezilla
#linux #backup
Допустим, у вас система виртуальной машины установлена на /dev/sda. Там, соответственно, будет три раздела: boot, корень и swap. Нам надо эту систему перенести куда-то в другое место. Желательно на однотипное железо, чтобы не возникло проблем. Если железо будет другое, то тоже реально, но нужно будет немного заморочиться и выполнить дополнительные действия. Заранее их все не опишешь, так как это сильно зависит от конкретной ситуации. Скорее всего придётся внутри системы что-то править (сеть, точки монтирования) и пересобрать initrd.
Создаём где-то новую виртуальную машину с таким же диском. Загружаемся с любого загрузочного диска. Например, с SystemRescue. Настраиваем в этой системе сеть, чтобы виртуальная машина, которую переносим, могла сюда подключиться. Запускаем сервер SSH. Не забываем открыть порты в файрволе. В SystemRescue он по умолчанию включен и всё закрыто на вход.
Идём на виртуалку, которую будем переносить. И делаем там простой трюк:
# dd if=/dev/sda | ssh root@10.20.1.28 "dd of=/dev/sda"Мы с помощью dd читаем устройство
/dev/sda и передаём его содержимое по ssh на другую машину такой же утилите dd, которая пишет информацию в устройство /dev/sda уже на другой машине. Удобство такого переноса в том, что не нужен промежуточный носитель для хранения образа. Всё передаётся налету. Процесс будет длительный, так как передача получается посекторная. Нужно понимать, что если машина большая и нагруженная, то в момент передачи целостность данных нарушается. Какую-нибудь СУБД так не перенести. Я лично не пробовал, но подозреваю, что с большой долей вероятности база будет битая. А вот обычный не сильно нагруженный сервер вполне.
После переноса он скорее всего ругнётся на ошибки файловой системы при загрузке, но сам себя починит с очень большой долей вероятности. Я как-то раз пытался так перенести виртуалку на несколько сотен гигабайт. Вот это не получилось. Содержимое судя по всему сильно билось по дороге, так как виртуалка не останавливалась. Не удалось её запустить. А что-то небольшое на 20-30 Гб вполне нормально переносится. Можно так виртуалку от какого-то хостера себе локально перенести. Главное сетевую связность между ними организовать.
Если по сети нет возможности передать образ, то можно сохранить его в файл, если есть доступный носитель:
# dd if=/dev/sda of=/mnt/backup/sda.imgПотом копируем образ и восстанавливаем из него систему:
# dd if=/mnt/backup/sda.img of=/dev/sdaДелаем всё это с какого-то загрузочного диска.
Напомню, что перенос системы можно выполнить и с помощью специально предназначенного для этого софта:
▪️ ReaR
▪️ Veeam Agent for Linux FREE
▪️ Clonezilla
#linux #backup
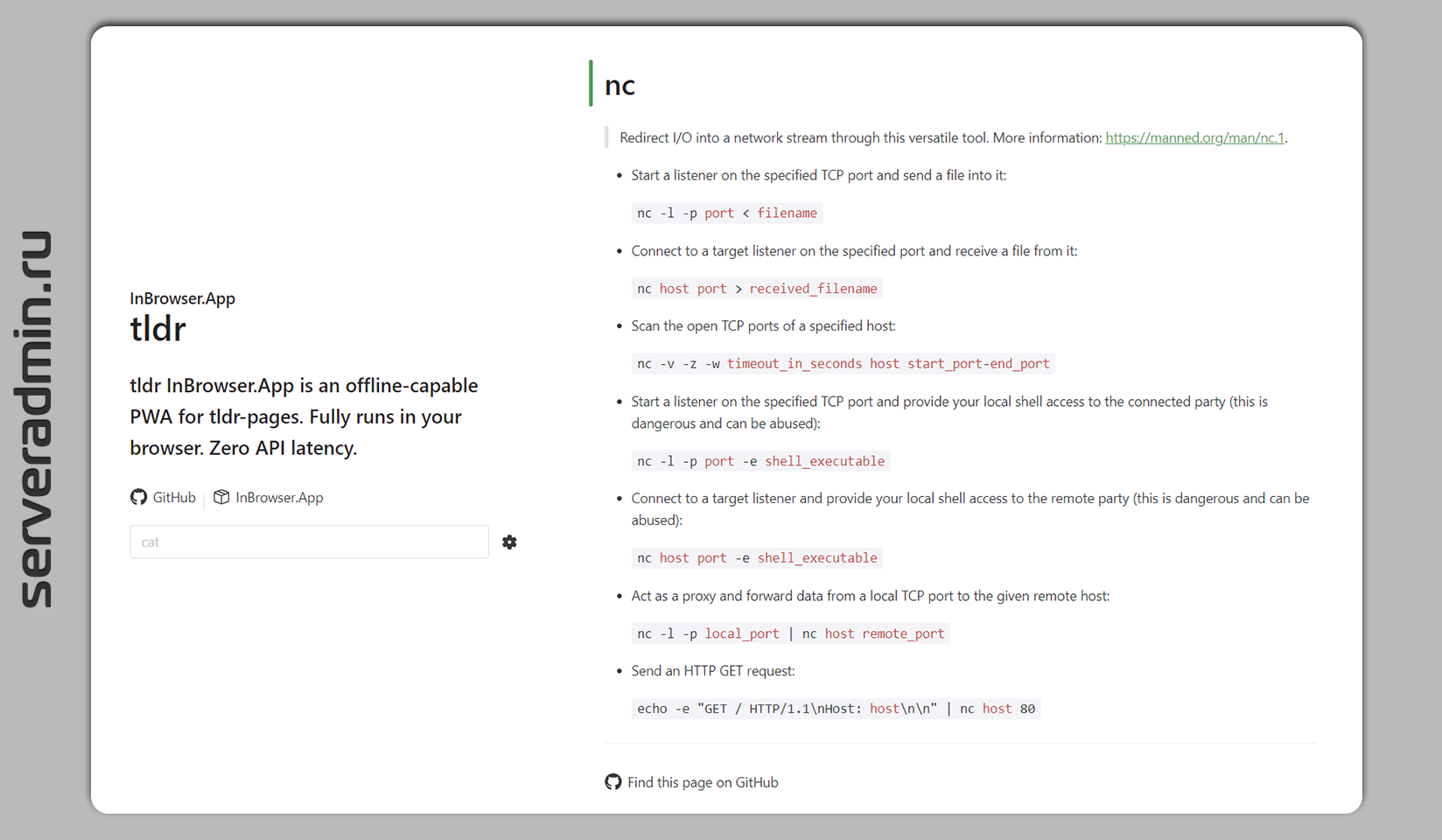
Для тех, кто не любит читать многостраничные man, существует его упрощённая версия, поддерживаемая сообществом — tldr. Аббревиатура как бы говорит сама за себя — Too long; didn't read. Это урезанный вариант man, где кратко представлены примеры использования консольных программ в Linux с минимальным описанием.
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
● Find the process that opened a local internet port:
● Only output the process ID (PID):
● List files opened by the given user:
● List files opened by the given command or process:
● List files opened by a specific process, given its PID:
● List open files in a directory:
● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
В принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
lsof path/to/file● Find the process that opened a local internet port:
lsof -i :port● Only output the process ID (PID):
lsof -t path/to/file● List files opened by the given user:
lsof -u username● List files opened by the given command or process:
lsof -c process_or_command_name● List files opened by a specific process, given its PID:
lsof -p PID● List open files in a directory:
lsof +D path/to/directory● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
lsof -i6TCP:port -sTCP:LISTEN -n -PВ принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
{kind=link}
После установки обновлений иногда необходимо выполнить перезагрузку системы. Точно надо это сделать, если обновилось ядро. Необходимо загрузиться с новым ядром. В коммерческих системах Linux от разных разработчиков есть механизмы обновления ядра без перезагрузки. В бесплатных системах такого не видел.
Для того, чтобы отслеживать этот момент, можно воспользоваться программой needrestart. Она есть в базовых репах:
В rpm дистрибутивах название будет needs-restarting. Если просто запустить программу, то она в интерактивном режиме покажет, какие службы необходимо перезапустить, чтобы подгрузить обновлённые библиотеки, либо скажет, что надо перезапустить систему, чтобы применить обновление ядра.
Для того, чтобы использовать её в автоматизации, есть ключ
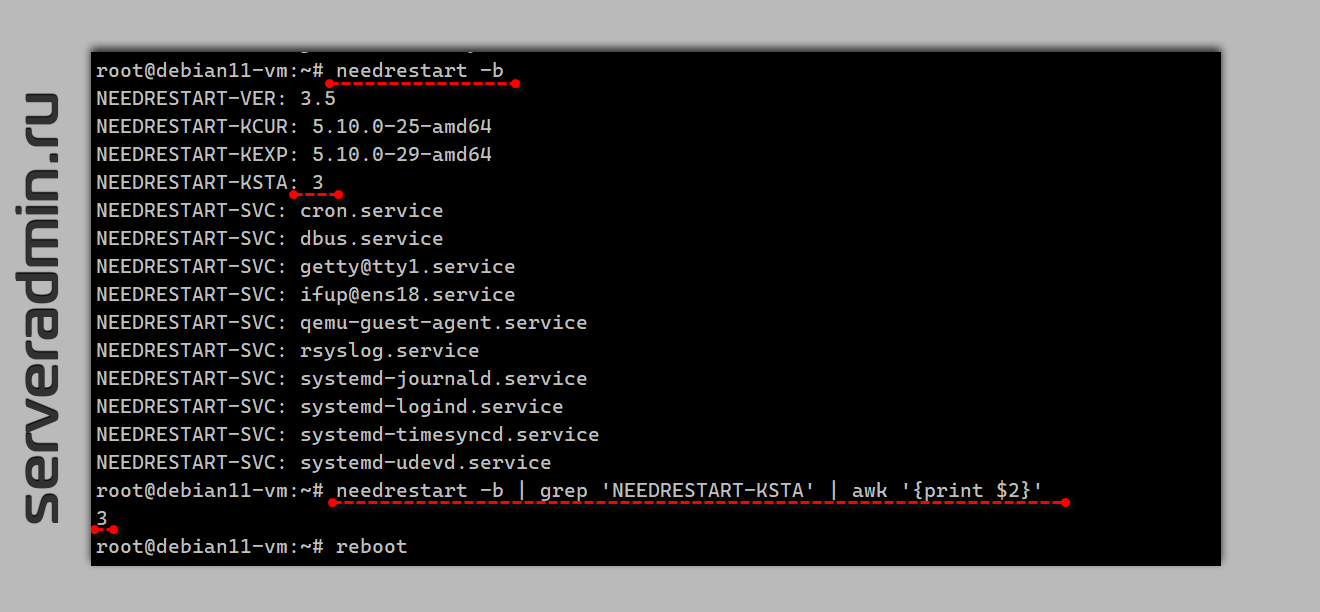
Здесь перечислены службы, которые нужно перезапустить после обновления системы. И показана информация об ядре. Значение NEEDRESTART-KSTA может принимать следующие состояния необходимости обновления ядра:
0: неизвестно, либо не удалось определить
1: нет необходимости в обновлении
2: ожидается какое-то ABI совместимое обновление (не понял, что это такое)
3: ожидается обновление версии
Если у вас значение 3, как у меня в примере, значит систему нужно перезагрузить, чтобы обновлённое ядро 5.10.0-29-amd64 заменило текущее загруженное 5.10.0-25-amd64.
Значение NEEDRESTART-KSTA можно передать в мониторинг и отслеживать необходимость перезагрузки. Например, В Zabbix можно передать вывод следующей команды:
Если на выходе будет 3, активируем триггер. Передать значение можно любым доступным способом, которому вы отдаёте предпочтение в своей инфраструктуре:
◽с помощью локального скрипта и параметра UserParameter в агенте
◽с помощью EnableRemoteCommands в агенте и ключа system.run на сервере
◽с помощью zabbix_sender
◽с помощью скрипта и передачи значения ключа напрямую в сервер через его API
Zabbix в этом плане очень гибкая система, предлагает разные способы решения одной и той же задачи.
После перезагрузки значение NEEDRESTART-KSTA станет равно единице:
В выводе не будет ни одной службы, которую следует перезапустить. Если нет системы мониторинга, но есть система сбора логов, то можно вывод отправить туда и там уже следить за службами и состоянием ядра.
Покажу, как строку сразу преобразовать в нормальный json, чтобы потом можно было легко анализировать:
Обработал в лоб. Взял утилиту jo, заменил
Придумал это без помощи ChatGPT. Даже не знаю уже, хорошо это или плохо. По привычке трачу время и пишу такие штуки сам.
#linux #мониторинг
Для того, чтобы отслеживать этот момент, можно воспользоваться программой needrestart. Она есть в базовых репах:
# apt install needrestartВ rpm дистрибутивах название будет needs-restarting. Если просто запустить программу, то она в интерактивном режиме покажет, какие службы необходимо перезапустить, чтобы подгрузить обновлённые библиотеки, либо скажет, что надо перезапустить систему, чтобы применить обновление ядра.
Для того, чтобы использовать её в автоматизации, есть ключ
-b, batch mode:# needrestart -bNEEDRESTART-VER: 3.5NEEDRESTART-KCUR: 5.10.0-25-amd64NEEDRESTART-KEXP: 5.10.0-29-amd64NEEDRESTART-KSTA: 3NEEDRESTART-SVC: cron.serviceNEEDRESTART-SVC: dbus.serviceNEEDRESTART-SVC: getty@tty1.serviceNEEDRESTART-SVC: ifup@ens18.serviceNEEDRESTART-SVC: qemu-guest-agent.serviceNEEDRESTART-SVC: rsyslog.serviceNEEDRESTART-SVC: systemd-journald.serviceNEEDRESTART-SVC: systemd-logind.serviceNEEDRESTART-SVC: systemd-timesyncd.serviceNEEDRESTART-SVC: systemd-udevd.serviceЗдесь перечислены службы, которые нужно перезапустить после обновления системы. И показана информация об ядре. Значение NEEDRESTART-KSTA может принимать следующие состояния необходимости обновления ядра:
0: неизвестно, либо не удалось определить
1: нет необходимости в обновлении
2: ожидается какое-то ABI совместимое обновление (не понял, что это такое)
3: ожидается обновление версии
Если у вас значение 3, как у меня в примере, значит систему нужно перезагрузить, чтобы обновлённое ядро 5.10.0-29-amd64 заменило текущее загруженное 5.10.0-25-amd64.
Значение NEEDRESTART-KSTA можно передать в мониторинг и отслеживать необходимость перезагрузки. Например, В Zabbix можно передать вывод следующей команды:
# needrestart -b | grep 'NEEDRESTART-KSTA' | awk '{print $2}'Если на выходе будет 3, активируем триггер. Передать значение можно любым доступным способом, которому вы отдаёте предпочтение в своей инфраструктуре:
◽с помощью локального скрипта и параметра UserParameter в агенте
◽с помощью EnableRemoteCommands в агенте и ключа system.run на сервере
◽с помощью zabbix_sender
◽с помощью скрипта и передачи значения ключа напрямую в сервер через его API
Zabbix в этом плане очень гибкая система, предлагает разные способы решения одной и той же задачи.
После перезагрузки значение NEEDRESTART-KSTA станет равно единице:
# needrestart -bNEEDRESTART-VER: 3.5NEEDRESTART-KCUR: 5.10.0-29-amd64NEEDRESTART-KEXP: 5.10.0-29-amd64NEEDRESTART-KSTA: 1В выводе не будет ни одной службы, которую следует перезапустить. Если нет системы мониторинга, но есть система сбора логов, то можно вывод отправить туда и там уже следить за службами и состоянием ядра.
Покажу, как строку сразу преобразовать в нормальный json, чтобы потом можно было легко анализировать:
# needrestart -b | tr ':' '=' | tr -d ' ' | jo -p{ "NEEDRESTART-VER": 3.5, "NEEDRESTART-KCUR": "5.10.0-29-amd64", "NEEDRESTART-KEXP": "5.10.0-29-amd64", "NEEDRESTART-KSTA": 1}Обработал в лоб. Взял утилиту jo, заменил
: на = c помощью tr, потому что jo понимает только =, потом убрал лишние пробелы опять же с помощью tr. Получили чистый json, из которого с помощью jsonpath можно забрать необходимое для анализа значение.# needrestart -b | tr ':' '=' | tr -d ' ' | jo -p | jq .'"NEEDRESTART-KSTA"'1Придумал это без помощи ChatGPT. Даже не знаю уже, хорошо это или плохо. По привычке трачу время и пишу такие штуки сам.
#linux #мониторинг
{kind=link}
Есть популярный вопрос для собеседования администраторов Linux:
❓Расскажите, как происходит загрузка операционной системы на базе Linux.
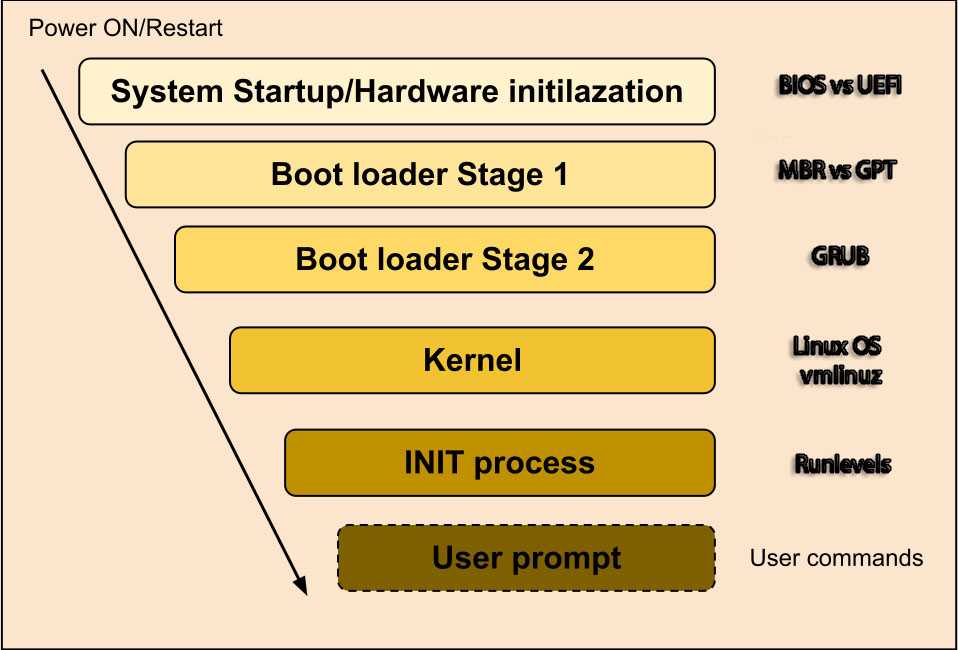
Тема, на самом деле полезная, в отличие от некоторых других, имеет прикладное значение, особенно если приходится переносить системы, либо сталкиваться с тем, что тот или иной сервер по какой-то причине не загружается. А причин может быть много. Не понимая процесс загрузки, решить их затруднительно. Расскажу эту тему своими словами с примерами из своей практики.
1️⃣ После запуска сервера или виртуалки, первым делом загружается bios или uefi. Bios ищет загрузчик на локальном или сетевом носителе и запускает его. Uefi может в себе содержать загрузчик. А может и нет. Если вы переносите виртуалку с одного гипервизора на другой, то обязательно учитывайте этот момент, используется bios или uefi. Если второе, то на другом гипервизоре нужно будет воспроизвести настройки uefi, чтобы виртуалка заработала. Если честно, я не совсем понимаю, зачем может быть нужен uefi для виртуальных машин, если не используется secure boot. Проще использовать обычный bios. Пример, как может на практике выглядеть перенос VM с uefi с HyperV на Proxmox.
2️⃣ Дальше загружается загрузчик с диска (не обязательно локального, может и сетевого). Для Linux обычно это GRUB. Я ничего другого не встречал, хотя есть и другие. У загрузчика есть небольшое меню и набор опций, которые иногда пригождаются. Например, если загрузчик по какой-то причине не смог загрузиться с диска или раздела, который у него указан загрузочным. Можно это сделать вручную через grub rescue. Пример, когда я так поступал, чтобы починить загрузку системы.
❗️Важно не забывать про загрузчик, когда вы используете в качестве загрузочного диска mdadm раздел софтового рейда. Загрузчик GRUB должен быть на всех дисках, входящих в рейд массив, чтобы в случае выхода из строя одного диска, вы могли загрузиться с любого другого. Он не реплицируется автоматически, так как mdadm работает на уровне разделов диска, а загрузчик располагается вне разделов.
3️⃣ В зависимости от настроек GRUB, загружается ядро Linux. Оно монтирует специально подготовленный образ файловой системы initramfs, загружаемый в оперативную память. Этот образ содержит все необходимые настройки и драйвера, чтобы загрузиться с нестандартный файловых систем, с LVM, с RAID, по сети и т.д. Там могут быть любые настройки. Можно выводить какую-то заставку, проверять диски и многое другое. Также с него запускается первый процесс init.
Процесс пересборки initramfs вы можете наблюдать при обновлениях ядра в системе. В конце обычно пакетный менеджер подвисает на несколько секунд как раз на пересборке initramfs. Если ему помешать в этот момент, то потом можете не загрузиться с новым ядром, для которого не собрался initramfs. Я с таким сталкивался. А вот пример, когда с этим же столкнулся человек на своём ноуте. Мой совет с пересборкой initramfs ему помог.
Иногда после переноса на другое железо, сервер или вируталка могут не запуститься, потому что в initramfs не будет поддержки необходимого железа. В
этом случае initramfs нужно будет пересобрать с поддержкой всего, что необходимо для успешной загрузки. Это можно сделать либо на старом месте, пока система ещё работает, либо загрузиться с какого-то livecd.
4️⃣ После запуска Init начинает загружаться система инициализации и управления службами. Сейчас это почти везде SystemD. Здесь я особо не знаю, что рассказать. С какими-то проблемами если и сталкивался, то это уже отдельные моменты в работающей системе, которые относительно легко исправить, так как чаще всего к системе уже есть удалённый доступ.
Написал всё так, как я это знаю и понимаю. Возможно в чём-то ошибаюсь, потому что в каждом из этих разделов есть много нюансов. Один только uefi чего стоит. Я как мог ужал материал, чтобы уместить в формат заметки и дать максимум информации, которая пригодится в реальной работе.
#linux #grub
❓Расскажите, как происходит загрузка операционной системы на базе Linux.
Тема, на самом деле полезная, в отличие от некоторых других, имеет прикладное значение, особенно если приходится переносить системы, либо сталкиваться с тем, что тот или иной сервер по какой-то причине не загружается. А причин может быть много. Не понимая процесс загрузки, решить их затруднительно. Расскажу эту тему своими словами с примерами из своей практики.
1️⃣ После запуска сервера или виртуалки, первым делом загружается bios или uefi. Bios ищет загрузчик на локальном или сетевом носителе и запускает его. Uefi может в себе содержать загрузчик. А может и нет. Если вы переносите виртуалку с одного гипервизора на другой, то обязательно учитывайте этот момент, используется bios или uefi. Если второе, то на другом гипервизоре нужно будет воспроизвести настройки uefi, чтобы виртуалка заработала. Если честно, я не совсем понимаю, зачем может быть нужен uefi для виртуальных машин, если не используется secure boot. Проще использовать обычный bios. Пример, как может на практике выглядеть перенос VM с uefi с HyperV на Proxmox.
2️⃣ Дальше загружается загрузчик с диска (не обязательно локального, может и сетевого). Для Linux обычно это GRUB. Я ничего другого не встречал, хотя есть и другие. У загрузчика есть небольшое меню и набор опций, которые иногда пригождаются. Например, если загрузчик по какой-то причине не смог загрузиться с диска или раздела, который у него указан загрузочным. Можно это сделать вручную через grub rescue. Пример, когда я так поступал, чтобы починить загрузку системы.
❗️Важно не забывать про загрузчик, когда вы используете в качестве загрузочного диска mdadm раздел софтового рейда. Загрузчик GRUB должен быть на всех дисках, входящих в рейд массив, чтобы в случае выхода из строя одного диска, вы могли загрузиться с любого другого. Он не реплицируется автоматически, так как mdadm работает на уровне разделов диска, а загрузчик располагается вне разделов.
3️⃣ В зависимости от настроек GRUB, загружается ядро Linux. Оно монтирует специально подготовленный образ файловой системы initramfs, загружаемый в оперативную память. Этот образ содержит все необходимые настройки и драйвера, чтобы загрузиться с нестандартный файловых систем, с LVM, с RAID, по сети и т.д. Там могут быть любые настройки. Можно выводить какую-то заставку, проверять диски и многое другое. Также с него запускается первый процесс init.
Процесс пересборки initramfs вы можете наблюдать при обновлениях ядра в системе. В конце обычно пакетный менеджер подвисает на несколько секунд как раз на пересборке initramfs. Если ему помешать в этот момент, то потом можете не загрузиться с новым ядром, для которого не собрался initramfs. Я с таким сталкивался. А вот пример, когда с этим же столкнулся человек на своём ноуте. Мой совет с пересборкой initramfs ему помог.
Иногда после переноса на другое железо, сервер или вируталка могут не запуститься, потому что в initramfs не будет поддержки необходимого железа. В
этом случае initramfs нужно будет пересобрать с поддержкой всего, что необходимо для успешной загрузки. Это можно сделать либо на старом месте, пока система ещё работает, либо загрузиться с какого-то livecd.
4️⃣ После запуска Init начинает загружаться система инициализации и управления службами. Сейчас это почти везде SystemD. Здесь я особо не знаю, что рассказать. С какими-то проблемами если и сталкивался, то это уже отдельные моменты в работающей системе, которые относительно легко исправить, так как чаще всего к системе уже есть удалённый доступ.
Написал всё так, как я это знаю и понимаю. Возможно в чём-то ошибаюсь, потому что в каждом из этих разделов есть много нюансов. Один только uefi чего стоит. Я как мог ужал материал, чтобы уместить в формат заметки и дать максимум информации, которая пригодится в реальной работе.
#linux #grub
{kind=link}
В ОС на базе Linux есть очень простой в настройке инструмент по ограничению сетевого доступа к сервисам. Он сейчас почти не применяется, так как не такой гибкий, как файрволы, но тем не менее работает до сих пор. Речь пойдёт про TCP Wrappers, которые используют библиотеку libwrap для ограничения доступа. По своей сути это файрвол уровня приложений, которые его поддерживают. Расскажу, как это работает.
В большинстве Linux дистрибутивов есть файлы
И одновременно в
Всё, теперь подключиться можно будет только из указанных сетей. При подключении из другого места в логе SSHD будут такие строки:
Не нужна ни перезагрузка, ни запуск каких-либо программ. Просто добавляете записи в указанные файлы и они сразу же применяются. Можно логировать заблокированные попытки:
В файле
Для того, чтобы эта функциональность работала, программа должна поддерживать указанную библиотеку. Проверить можно так:
В Debian 12 sshd поддерживает, но так не во всех дистрибутивах. Надо проверять. Из более-менее популярного софта libwrap поддерживается в vsftpd, nfs-server, apcupsd, syslog-ng, nut, dovecot, stunnel, nagios, Nutanix Controller VM.
Очевидно, что тот же iptables или nftables более функциональный инструмент и полагаться лучше на него. Но в каких-то простых случаях, особенно, если нужно ограничить только ssh, можно использовать и libwrap. Также можно продублировать в нём правила, чтобы в случае ошибки в файрволе, доступ к некоторым сервисам точно не был открыт. Ну и просто полезно знать, что есть такой инструмент. Мало ли, придётся столкнуться.
#linux #security
В большинстве Linux дистрибутивов есть файлы
/etc/hosts.allow и /etc/hosts.deny. Сразу покажу пример, как всем ограничить доступ к SSH и разрешить только с указанных локальных подсетей. Добавляем в /etc/hosts.allow:sshd : 10.20.1.0/24sshd : 192.168.13.0/24И одновременно в
/etc/hosts.deny:sshd : ALLВсё, теперь подключиться можно будет только из указанных сетей. При подключении из другого места в логе SSHD будут такие строки:
# journalctl -u ssh -n 10sshd[738]: refused connect from 10.8.2.2 (10.8.2.2)Не нужна ни перезагрузка, ни запуск каких-либо программ. Просто добавляете записи в указанные файлы и они сразу же применяются. Можно логировать заблокированные попытки:
sshd : ALL \ : spawn /usr/bin/echo "$(/bin/date +"%%d-%%m-%%y %%T") SSH access blocked from %h" >> /var/log/libwrapВ файле
/var/log/libwrap будет аккуратная запись:03-06-24 12:29:31 SSH access blocked from 10.8.2.2Для того, чтобы эта функциональность работала, программа должна поддерживать указанную библиотеку. Проверить можно так:
# ldd /usr/sbin/sshd | grep libwrap libwrap.so.0 => /lib/x86_64-linux-gnu/libwrap.so.0 (0x00007f55228a2000)В Debian 12 sshd поддерживает, но так не во всех дистрибутивах. Надо проверять. Из более-менее популярного софта libwrap поддерживается в vsftpd, nfs-server, apcupsd, syslog-ng, nut, dovecot, stunnel, nagios, Nutanix Controller VM.
Очевидно, что тот же iptables или nftables более функциональный инструмент и полагаться лучше на него. Но в каких-то простых случаях, особенно, если нужно ограничить только ssh, можно использовать и libwrap. Также можно продублировать в нём правила, чтобы в случае ошибки в файрволе, доступ к некоторым сервисам точно не был открыт. Ну и просто полезно знать, что есть такой инструмент. Мало ли, придётся столкнуться.
#linux #security
{kind=link}
Раньше были разные варианты перезагрузки системы Linux. Как минимум
То есть не важно, как вы перезагрузите сервер. Всё равно команда будет отправлена в systemd. В некоторых инструкциях и статьях вижу, что сервер перезагружают так:
Набирать systemctl не обязательно. Обычный reboot выполнит ту же самую команду.
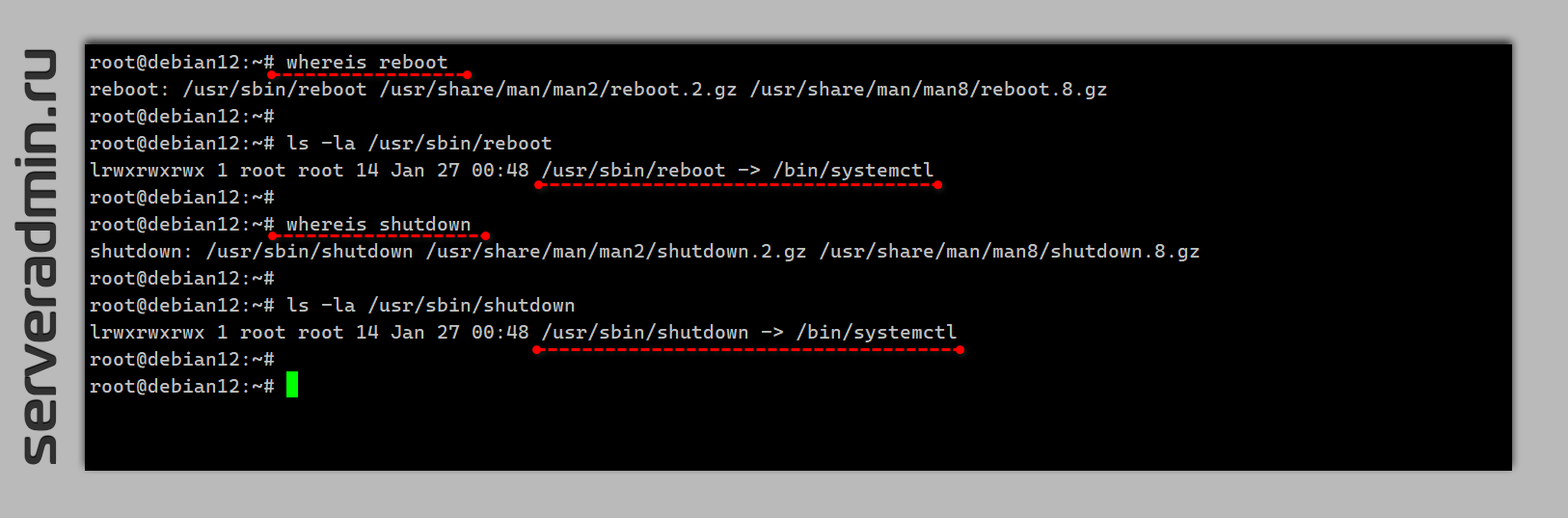
Возникает вопрос, а как systemctl понимает, какую команду надо выполнить? Символьные ссылки одинаковы в обоих случаях и ведут просто в
Эти команды делают то же самое, что и reboot. По крайней мере на первый взгляд. Остаётся только гадать, зачем там всё это. Ну либо где-то в манах или исходниках читать.
Дам ещё небольшую подсказку в рамках этой темы. И shutdown, и reboot, и systemctl в итоге обращаются к бинарнику на диске. Если у вас какие-то проблемы с диском и не удаётся прочитать этот бинарник, то перезагрузка не состоится. Всё будет продолжать висеть. Если запущена консоль, то можно через неё сразу передать команду на перезагрузку напрямую ядру
Сервер тут же перезагрузится, как будто у него физически нажали reset.
#linux
shutdown -r и reboot. Сейчас всё это не имеет значения, так как реально всем управляет systemd. А если посмотреть на shutdown и reboot, то окажется, что это символьные ссылки на systemctl. # whereis rebootreboot: /usr/sbin/reboot# ls -la /usr/sbin/reboot/usr/sbin/reboot -> /bin/systemctl# whereis shutdownshutdown: /usr/sbin/shutdown# ls -la /usr/sbin/shutdown/usr/sbin/shutdown -> /bin/systemctlТо есть не важно, как вы перезагрузите сервер. Всё равно команда будет отправлена в systemd. В некоторых инструкциях и статьях вижу, что сервер перезагружают так:
# systemctl rebootНабирать systemctl не обязательно. Обычный reboot выполнит ту же самую команду.
Возникает вопрос, а как systemctl понимает, какую команду надо выполнить? Символьные ссылки одинаковы в обоих случаях и ведут просто в
/bin/systemctl. С помощью механизма запуска программ execve можно узнать имя исполняемой команды. Примерно так:$ bash -c 'echo $0'bash$0 покажет имя запущенной команды. В systemctl стоит проверка вызванной команды, поэтому она определяет, что реально вы запустили - reboot или shutdown. Вообще, в systemctl столько всего наворочено. Перезагрузить компьютер так же можно следующими командами:# systemctl start reboot.target# systemctl start ctrl-alt-del.targetЭти команды делают то же самое, что и reboot. По крайней мере на первый взгляд. Остаётся только гадать, зачем там всё это. Ну либо где-то в манах или исходниках читать.
Дам ещё небольшую подсказку в рамках этой темы. И shutdown, и reboot, и systemctl в итоге обращаются к бинарнику на диске. Если у вас какие-то проблемы с диском и не удаётся прочитать этот бинарник, то перезагрузка не состоится. Всё будет продолжать висеть. Если запущена консоль, то можно через неё сразу передать команду на перезагрузку напрямую ядру
# echo b > /proc/sysrq-triggerСервер тут же перезагрузится, как будто у него физически нажали reset.
#linux
{kind=link}
Файловая система ext4 при создании резервирует 5% всего объёма создаваемого раздела. Иногда это очень сильно выручает, когда система встаёт колом и нет возможности освободить место. А без этого она не может нормально работать (привет zfs и lvm-thin). Тогда можно выполнить простую операцию:
или
Вместо 5% в резерв оставляем 3%, а высвободившееся место остаётся доступным для использования. На больших разделах 5% может быть существенным объёмом. Очень хочется этот резерв сразу поставить в 0 и использовать весь доступный объём. Сделать это можно так:
Сам так не делаю никогда и вам не рекомендую. Хотя бы 1% я всегда оставляю. Но чаще всего именно 3%, если уж совсем место поджимает. Меня не раз и не два выручал этот резерв.
Вторым приёмом для защиты от переполнения диска может быть использование файла подкачки в виде обычного файла в файловой системе, а не отдельного раздела. Я уже не раз упоминал, что сам всегда использую подкачку в виде обычного файла в корне, так как это позволяет гибко им управлять, как увеличивая в размере, так и ужимая, когда не хватает места.
Создаём swap размером в гигабайт и подключаем:
Если вдруг решите, что своп вам больше не нужен, отключить его так же просто, как и подключить:
Третьим вариантом страховки в случае отсутствия свободного места на разделе является заранее создание пустого файла большого объёма.
При его удалении, высвобождается место, которое позволит временно вернуть работоспособность системе и выполнить необходимые действия.
Может показаться, что это какие-то умозрительные примеры. Но на деле я много раз сталкивался с тем, что кончается место на сервере по той или иной причине, и службы на нём встают. А надо, чтобы работали. Пока разберёшься, что там случилось, уходит время. Я сначала добавляю свободное место из имеющихся возможностей (swap или резерв ext4), а потом начинаю разбираться. Это даёт возможность сразу вернуть работоспособность упавшим службам, а тебе несколько минут, чтобы разобраться, в чём тут проблема. Обычно это стремительно растущие логи каких-то служб.
#linux
# tune2fs -m 3 /dev/mapper/rootили
# tune2fs -m 3 /dev/sda3Вместо 5% в резерв оставляем 3%, а высвободившееся место остаётся доступным для использования. На больших разделах 5% может быть существенным объёмом. Очень хочется этот резерв сразу поставить в 0 и использовать весь доступный объём. Сделать это можно так:
# tune2fs -m 0 /dev/sda3Сам так не делаю никогда и вам не рекомендую. Хотя бы 1% я всегда оставляю. Но чаще всего именно 3%, если уж совсем место поджимает. Меня не раз и не два выручал этот резерв.
Вторым приёмом для защиты от переполнения диска может быть использование файла подкачки в виде обычного файла в файловой системе, а не отдельного раздела. Я уже не раз упоминал, что сам всегда использую подкачку в виде обычного файла в корне, так как это позволяет гибко им управлять, как увеличивая в размере, так и ужимая, когда не хватает места.
Создаём swap размером в гигабайт и подключаем:
# dd if=/dev/zero of=/swap bs=1024 count=1000000# mkswap /swap# chmod 0600 /swap# swapon /swapЕсли вдруг решите, что своп вам больше не нужен, отключить его так же просто, как и подключить:
# swapoff -a# rm /swapТретьим вариантом страховки в случае отсутствия свободного места на разделе является заранее создание пустого файла большого объёма.
# fallocate -l 10G /big_fileПри его удалении, высвобождается место, которое позволит временно вернуть работоспособность системе и выполнить необходимые действия.
Может показаться, что это какие-то умозрительные примеры. Но на деле я много раз сталкивался с тем, что кончается место на сервере по той или иной причине, и службы на нём встают. А надо, чтобы работали. Пока разберёшься, что там случилось, уходит время. Я сначала добавляю свободное место из имеющихся возможностей (swap или резерв ext4), а потом начинаю разбираться. Это даёт возможность сразу вернуть работоспособность упавшим службам, а тебе несколько минут, чтобы разобраться, в чём тут проблема. Обычно это стремительно растущие логи каких-то служб.
#linux
Медленно, но верно, я перестаю использовать
Самые популярные ключи к ss это tulnp:
Список открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
Вывести только сокеты можно и другой командой:
Но там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
И сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
То же самое, только выводим тех, у кого более 30 соединений с нами:
Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
Всё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
Больше лично я
#linux #terminal
netstat и привыкаю к ss. У неё хоть и не такой удобный для восприятия вывод, но цепляться за netstat уже не имеет смысла. Она давно устарела и не рекомендуется к использованию. Плюс, её нет в стандартных минимальных поставках дистрибутивов. Надо ставить отдельно. Это как с ifconfig. Поначалу упирался, но уже много лет использую только ip. Ifconfig вообще не запускаю. Даже ключи все забыл. Самые популярные ключи к ss это tulnp:
# ss -tulnpСписок открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
# ss -l | grep .sockВывести только сокеты можно и другой командой:
# ss -axНо там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
# ss -ntuИ сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'То же самое, только выводим тех, у кого более 30 соединений с нами:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//' | awk '{if ($1 > 30) print$2}'Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | wc -lВсё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
a:# ss -ntuaБольше лично я
ss ни для чего не использую. Если смотрите ещё что-то полезное с помощью этой утилиты, поделитесь в комментариях.#linux #terminal
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
Как уменьшить размер файловой системы с ext4?
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
Файловая система на разделе
Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
Добавляем ещё один исполняемый файл
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
# /sbin/resize2fs /dev/sda1 50GФайловая система на разделе
/dev/sda1 будет уменьшена до 50G, если там хватит свободного места для этого. То есть данных должно быть меньше. В общем случае перед выполнением операции и после рекомендуется проверить файловую систему на ошибки:# /sbin/e2fsck -yf /dev/sda1Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
# /sbin/resize2fs /dev/sda1 50Gresize2fs 1.47.0 (5-Feb-2023)Filesystem at /dev/sda1 is mounted on /; on-line resizing required/sbin/resize2fs: On-line shrinking not supported# /sbin/e2fsck -yf /dev/sda1e2fsck 1.47.0 (5-Feb-2023)/dev/sda1 is mounted.e2fsck: Cannot continue, aborting.Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
/etc/initramfs-tools/hooks/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case $1 in
prereqs)
prereqs
exit 0
;;
esac
. /usr/share/initramfs-tools/hook-functions
copy_exec /sbin/e2fsck
copy_exec /sbin/resize2fs
exit 0
Добавляем ещё один исполняемый файл
/etc/initramfs-tools/scripts/local-premount/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case "$1" in
prereqs)
prereqs
exit 0
;;
esac
# simple device example
/sbin/e2fsck -yf /dev/sda1
/sbin/resize2fs /dev/sda1 50G
/sbin/e2fsck -yf /dev/sda1
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
# ls /boot | grep configconfig-6.1.0-12-amd64config-6.1.0-13-amd64config-6.1.0-20-amd64config-6.1.0-22-amd64# update-initramfs -u -k 6.1.0-22-amd64update-initramfs: Generating /boot/initrd.img-6.1.0-22-amd64Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
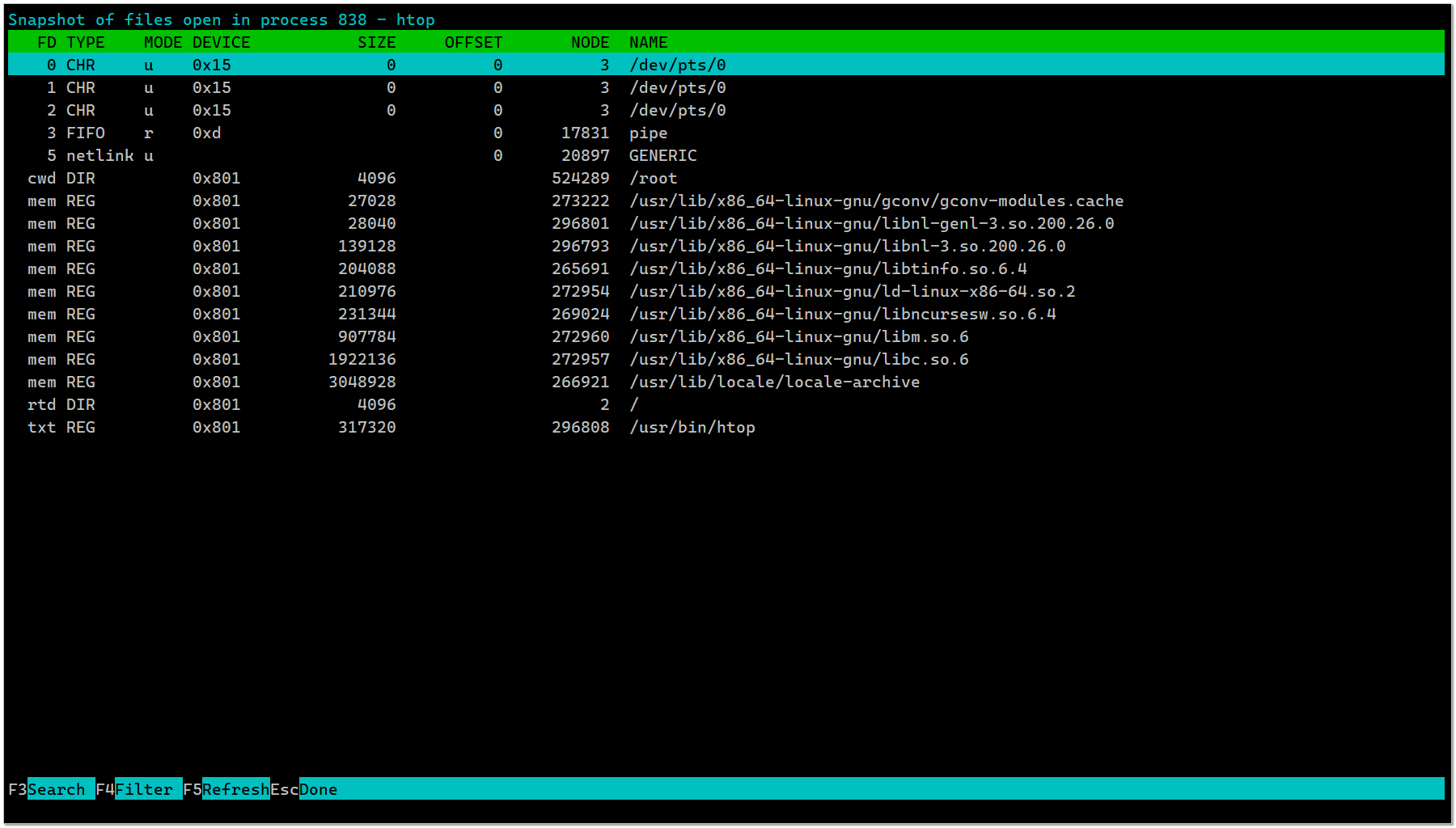
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}