
В комментариях к заметкам про синхронизацию файлов не раз упоминались отказоустойчивые сетевые файловые системы. Прямым представителем такой файловой системы является GlusterFS. Это условный аналог Ceph, которая по своей сути не файловая система, а отказоустойчивая сеть хранения данных. Но в целом обе эти системы используются для решения одних и тех же задач. Про Ceph я писал (#ceph) уже не раз, а вот про GlusterFS не было ни одного упоминания.
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
На все 3 сервера устанавливаем glusterfs-server:
Запускаем также на всех серверах:
На server1 добавляем в пул два других сервера:
На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
На каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
Создаём на этой точке монтирования том glusterfs:
Если получите ошибку:
то проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
Если всё пошло без ошибок, то можно запускать том:
Смотрим о нём информацию:
Теперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
Можете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
/etc/hosts на каждый сервер примерно такие записи:server1 10.20.1.1server2 10.20.1.2server3 10.20.1.3На все 3 сервера устанавливаем glusterfs-server:
# apt install glusterfs-serverЗапускаем также на всех серверах:
# service glusterd startНа server1 добавляем в пул два других сервера:
# gluster peer probe server2# gluster peer probe server3На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
# gluster peer statusНа каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
/mnt/gv0.# mkfs.ext4 /dev/sdb1# mkdir /mnt/gv0# mount /dev/sdb1 /mnt/gv0Создаём на этой точке монтирования том glusterfs:
# gluster volume create gv0 replica 3 server1:/mnt/gv0 server2:/mnt/gv0 server3:/mnt/gv0Если получите ошибку:
volume create: gv0: failed: Host server1 is not in 'Peer in Cluster' stateто проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
/var/lib/glusterd.Если всё пошло без ошибок, то можно запускать том:
# gluster volume start gv0Смотрим о нём информацию:
# gluster volume infoТеперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
# mkdir /mnt/gluster-test# mount -t glusterfs server1:/gv0 /mnt/gluster-testМожете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
/mnt/gv0. По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
{kind=link}
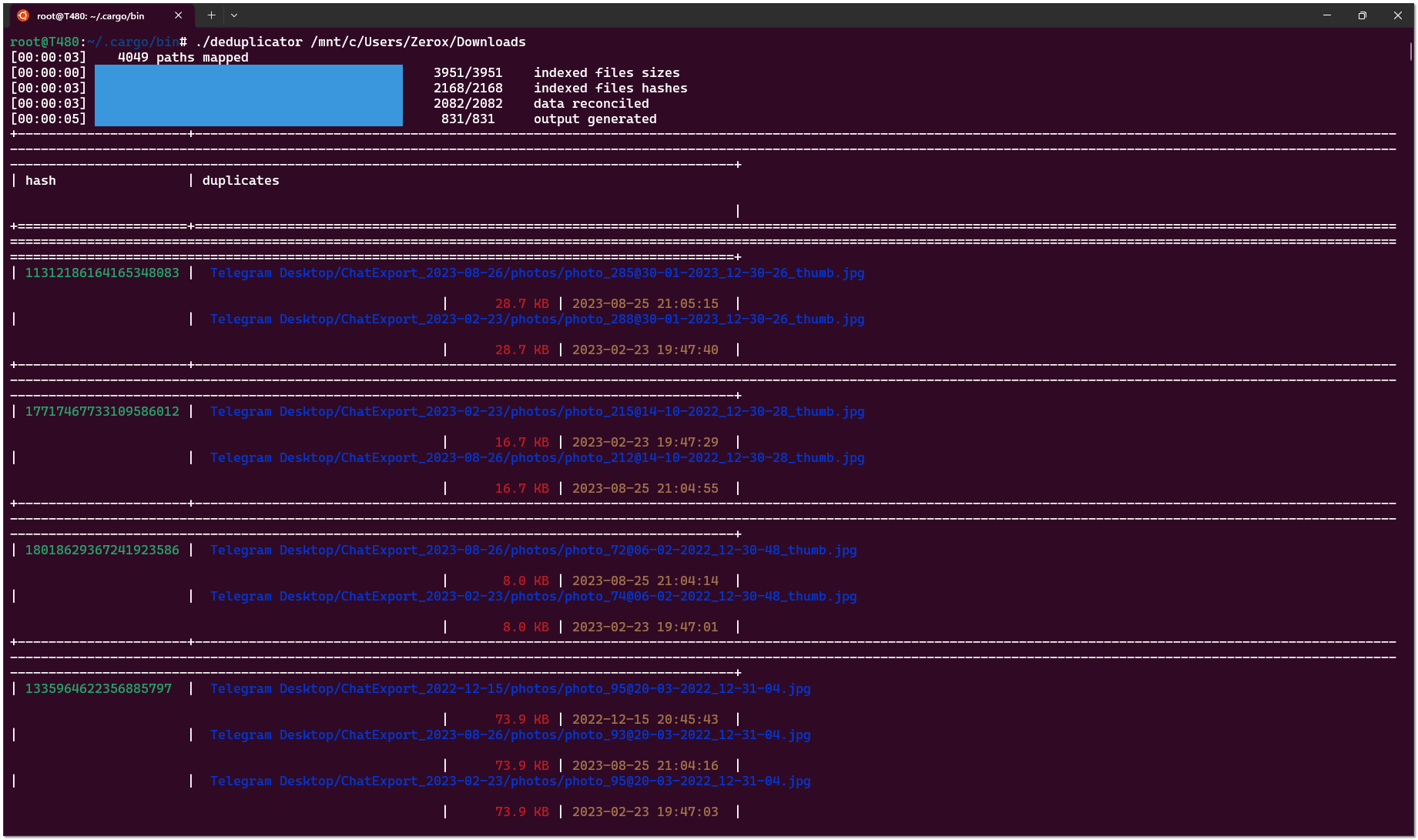
Мне неизвестны какие-то простые и эффективные способы поиска дубликатов файлов в Linux с использованием стандартного набора системных программ и утилит. Если встаёт такая задача, то приходится искать какие-то сторонние средства. Я предлагаю один из них - Deduplicator.
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
На выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
Он будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
# apt install cargo# cargo install deduplicatorНа выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
# ./deduplicator /mnt/backup/design > deduplicator.txtОн будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
--json с помощью соответствующего ключа.Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
{kind=link}
У меня дома есть NAS и на всех компах и ноутах подключены сетевые папки. Домашние слабо представляют, как всё это работает. На смартфоне использую TotalCommander с плагином для доступа к тем же сетевым папкам. Жена наверное через TG или VK перекидывает файлы. По-другому вряд ли умеет. Детям это пока не надо.
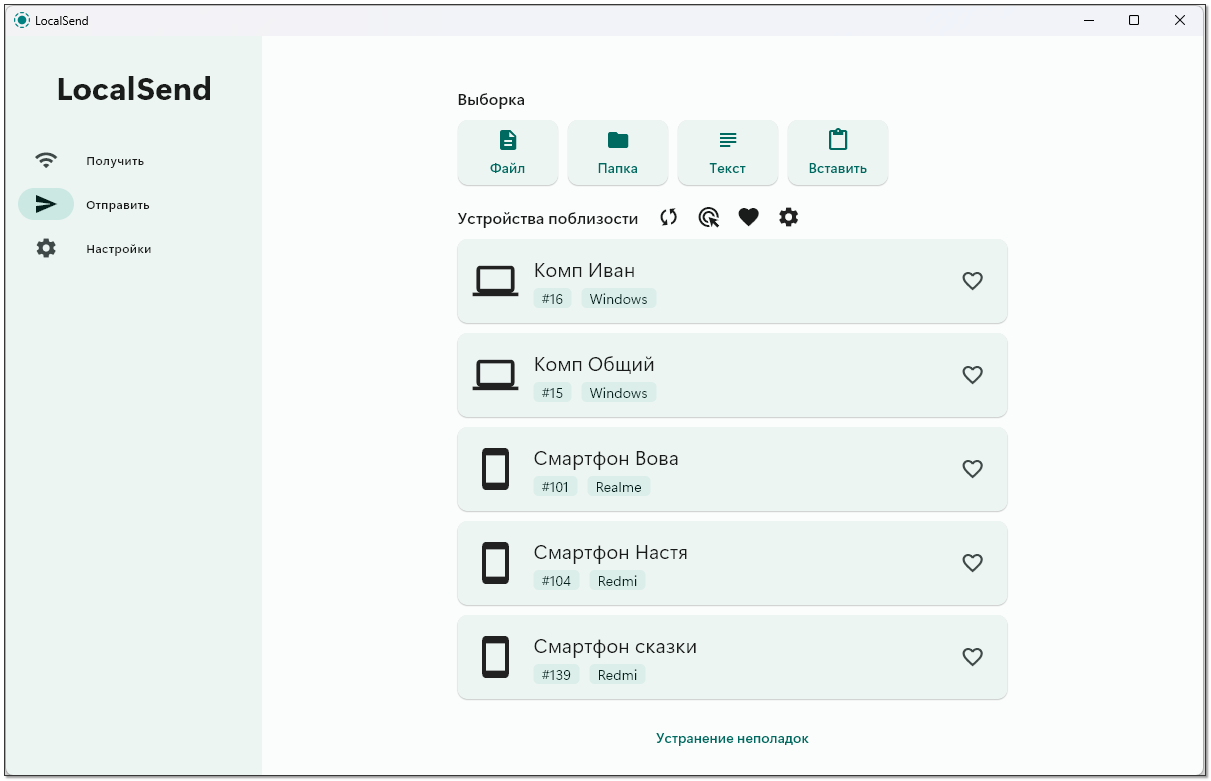
Есть простое и удобное open source решение для этого вопроса - LocalSend. Поддерживает все операционные системы, в том числе на смартфонах. Это небольшое приложение, которое запускается на определённом порту (53317), принимает входящие соединения и с помощью нескольких методов (описание протокола, в основе поиска Multicast UDP, если не помогает, то POST запрос на все адреса локальной сети) осуществляет поиск таких же серверов в локальной сети. Передача данных осуществляется по протоколу HTTP.
На практике всё это работает автоматически. Приложение под Windows можно поставить, к примеру, через wingwet или скачать portable версию. На смартфоне ставим через Google Play, F-Droid или просто качаем apk. Работает всё в локальной сети, без необходимости каких-то внешних сервисов в интернете. Запускаем на обоих устройствах приложение, они сразу же находят друг друга. Можно передавать файлы. При этом можно на том же компе настроить такой режим, чтобы он автоматом принимал файлы со смартфона и складывал в определённую директорию.
Каждое устройство в приложении можно обозвать своим именем и передавать файлы между ними. Не знаю, где это в работе может пригодиться, но для дома очень удобно. В первую очередь простотой и поддержкой всех платформ. В программе хороший русский язык, пользоваться просто и понятно.
Мне иногда надо сыну передать со своего смартфона из родительского чата информацию от учителя с пояснениями по домашке. Я для этого делал скриншот чата, клал его на NAS, на компе с NAS копировал сыну. Через приложение передать в разы удобнее. Запустил прогу и перекинул на комп с именем СЫН. Всё. Мессенджеров и соц. сетей у него пока нет.
Это приложение, которое я попробовал и сразу развернул на всех устройствах. Жене очень понравилось.
Отдельно отмечу, что приложение написано на языке программирования Dart. Впервые о нём услышал. Сначала показалось, что это типичное приложение на JavaScript под NodeJS. Но смутил небольшой размер. После этого и пошёл смотреть, на чём написано. Оказалось, что этот язык программирования разрабатывает Google как раз для замены JavaScript, взяв от него всё лучшее, но исправив недостатки. В целом, выглядит всё это неплохо.
⇨ Сайт / Исходники
#fileserver
Есть простое и удобное open source решение для этого вопроса - LocalSend. Поддерживает все операционные системы, в том числе на смартфонах. Это небольшое приложение, которое запускается на определённом порту (53317), принимает входящие соединения и с помощью нескольких методов (описание протокола, в основе поиска Multicast UDP, если не помогает, то POST запрос на все адреса локальной сети) осуществляет поиск таких же серверов в локальной сети. Передача данных осуществляется по протоколу HTTP.
На практике всё это работает автоматически. Приложение под Windows можно поставить, к примеру, через wingwet или скачать portable версию. На смартфоне ставим через Google Play, F-Droid или просто качаем apk. Работает всё в локальной сети, без необходимости каких-то внешних сервисов в интернете. Запускаем на обоих устройствах приложение, они сразу же находят друг друга. Можно передавать файлы. При этом можно на том же компе настроить такой режим, чтобы он автоматом принимал файлы со смартфона и складывал в определённую директорию.
Каждое устройство в приложении можно обозвать своим именем и передавать файлы между ними. Не знаю, где это в работе может пригодиться, но для дома очень удобно. В первую очередь простотой и поддержкой всех платформ. В программе хороший русский язык, пользоваться просто и понятно.
Мне иногда надо сыну передать со своего смартфона из родительского чата информацию от учителя с пояснениями по домашке. Я для этого делал скриншот чата, клал его на NAS, на компе с NAS копировал сыну. Через приложение передать в разы удобнее. Запустил прогу и перекинул на комп с именем СЫН. Всё. Мессенджеров и соц. сетей у него пока нет.
Это приложение, которое я попробовал и сразу развернул на всех устройствах. Жене очень понравилось.
Отдельно отмечу, что приложение написано на языке программирования Dart. Впервые о нём услышал. Сначала показалось, что это типичное приложение на JavaScript под NodeJS. Но смутил небольшой размер. После этого и пошёл смотреть, на чём написано. Оказалось, что этот язык программирования разрабатывает Google как раз для замены JavaScript, взяв от него всё лучшее, но исправив недостатки. В целом, выглядит всё это неплохо.
⇨ Сайт / Исходники
#fileserver
{kind=link}
Когда мне нужно было быстро поднять smb сервер, чтобы разово перекинуть какие-то файлы, раньше я устанавливал samba и делал для неё простейший конфиг.
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
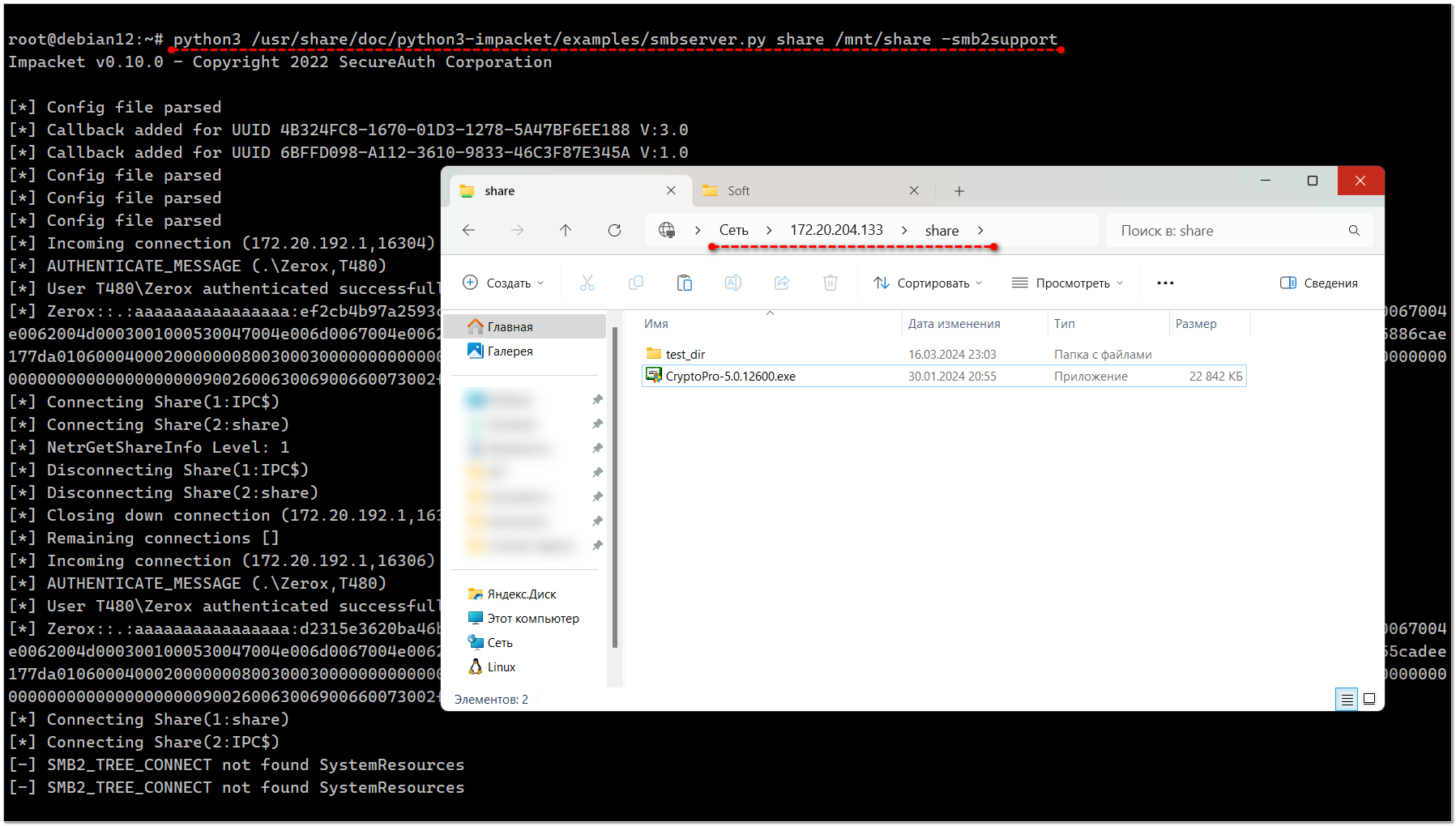
Это довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
Подключаемся к настроенной шаре:
Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
# apt install python3-impacketЭто довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
# cd /usr/share/doc/python3-impacket/examples/# python3 smbserver.py share /mnt/share -smb2support◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
# python3 smbserver.py share /mnt/share -smb2support -username user -password 123Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
# smbclient -L 172.20.204.133 --user user --password=123Подключаемся к настроенной шаре:
# smbclient //172.20.204.133/share --user user --password=123Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
{kind=link}
Прочитал интересную серию статей Building A 'Mini' 100TB NAS, где человек в трёх частях рассказывает, как он себе домой NAS собирал и обновлял. Железо там хорошее для дома. Было интересно почитать.
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
И после этого запускаете синхронизацию:
Данные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
/etc/snapraid.conf:parity /mnt/diskp/snapraid.paritycontent /var/snapraid/snapraid.contentcontent /mnt/disk1/snapraid.contentcontent /mnt/disk2/snapraid.contentdata d1 /mnt/disk1/data d2 /mnt/disk2/data d3 /mnt/disk3/И после этого запускаете синхронизацию:
# snapraid syncДанные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
{kind=link}
Регулярно приходится настраивать NFS сервер для различных прикладных задач. Причём в основном не на постоянное использование, а временное. На практике именно по nfs достигается максимальная скорость копирования, быстрее чем по scp, ssh, smb или http.
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
Устанавливаем пакет для nfs-server:
Добавляем в файл
Для всей подсети просто добавляем маску:
Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
Перезапускаем сервер
Проверяем работу:
Для работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
Проверяем, видит ли клиент что-то на сервере:
Всё в порядке, видим ресурс для нас. Монтируем его к себе:
Проверяем:
Смотрим версию протокола. Желательно, чтобы работало по v4:
Создаём файл:
При желании можно в fstab добавить на постоянку:
Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
/mnt:# mkdir /mnt/nfs# chown nobody:nogroup /mnt/nfsУстанавливаем пакет для nfs-server:
# apt install nfs-kernel-serverДобавляем в файл
/etc/exports описание экспортируемой файловой системы только для ip адреса 10.20.1.56:/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)Для всей подсети просто добавляем маску:
/mnt/nfs 10.20.1.56/24(rw,all_squash,no_subtree_check,crossmnt)Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)/mnt/nfs 10.20.1.52(rw,all_squash,no_subtree_check,crossmnt)Перезапускаем сервер
# systemctl restart nfs-serverПроверяем работу:
# systemctl status nfs-serverДля работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
# apt install nfs-commonПроверяем, видит ли клиент что-то на сервере:
# showmount -e 10.20.1.36Export list for 10.20.1.36:/mnt/nfs 10.20.1.56Всё в порядке, видим ресурс для нас. Монтируем его к себе:
# mkdir /mnt/nfs# mount 10.20.1.36:/mnt/nfs /mnt/nfsПроверяем:
# df -h | grep nfs10.20.1.36:/mnt/nfs 48G 3.2G 43G 7% /mnt/nfsСмотрим версию протокола. Желательно, чтобы работало по v4:
# mount -t nfs410.20.1.36:/ on /mnt/nfs type nfs4 (rw,relatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.20.1.56,local_lock=none,addr=10.20.1.36)Создаём файл:
# echo "test" > /mnt/nfs/testfileПри желании можно в fstab добавить на постоянку:
10.20.1.36:/mnt/nfs /mnt/nfs nfs4 defaults 0 0Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
В операционных системах Windows традиционно есть некоторые сложности с использованием протокола NFS. Длительное время она его вообще штатно никак не поддерживала, приходилось использовать сторонний софт. Это объясняется в первую очередь тем, что для передачи файлов по сети у них есть свой протокол SMB. В какой-то момент, уже не помню, в какой точно версии, в Windows появился встроенный NFS клиент.
Установить его можно через Панель управления ⇨ Программы ⇨ Программы и компоненты ⇨ Включение и отключение компонентов Windows ⇨ Службы для NFS ⇨ Клиент для NFS.
Можно включить более простым и быстрым способом через Powershell:
Можно примонтировать диск с NFS сервера, к примеру, развёрнутого из этой заметки:
Диск N появится в качестве сетевого. С ним можно работать к с обычным сетевым диском. Условно, как с обычным, так как работа под Windows с NFS сервером на Linux будет сопряжена с множеством нюансов и неудобств, связанных с правами доступа, кодировкой, чувствительности к регистру в названиях файлов на Linux. В общем случае использовать такой сценарий работы не рекомендуется. Для постоянной работы с Windows проще поднять SMB сервер на Linux.
Для разовых задач или для использования в скриптах можно воспользоваться каким-то альтернативным консольным клиентом. Например, nfsclient. Это небольшая программа на Go уровня курсовой работы студента. Код самой программы простой, но используются готовые библиотеки для работы с NFS.
Программа кроссплатформенная и не требует установки. Это небольшой консольный клиент, который поддерживает простые операции:
◽просмотр содержимого ресурса
◽скачивание, загрузка, удаление файлов
◽создание и удаление каталогов
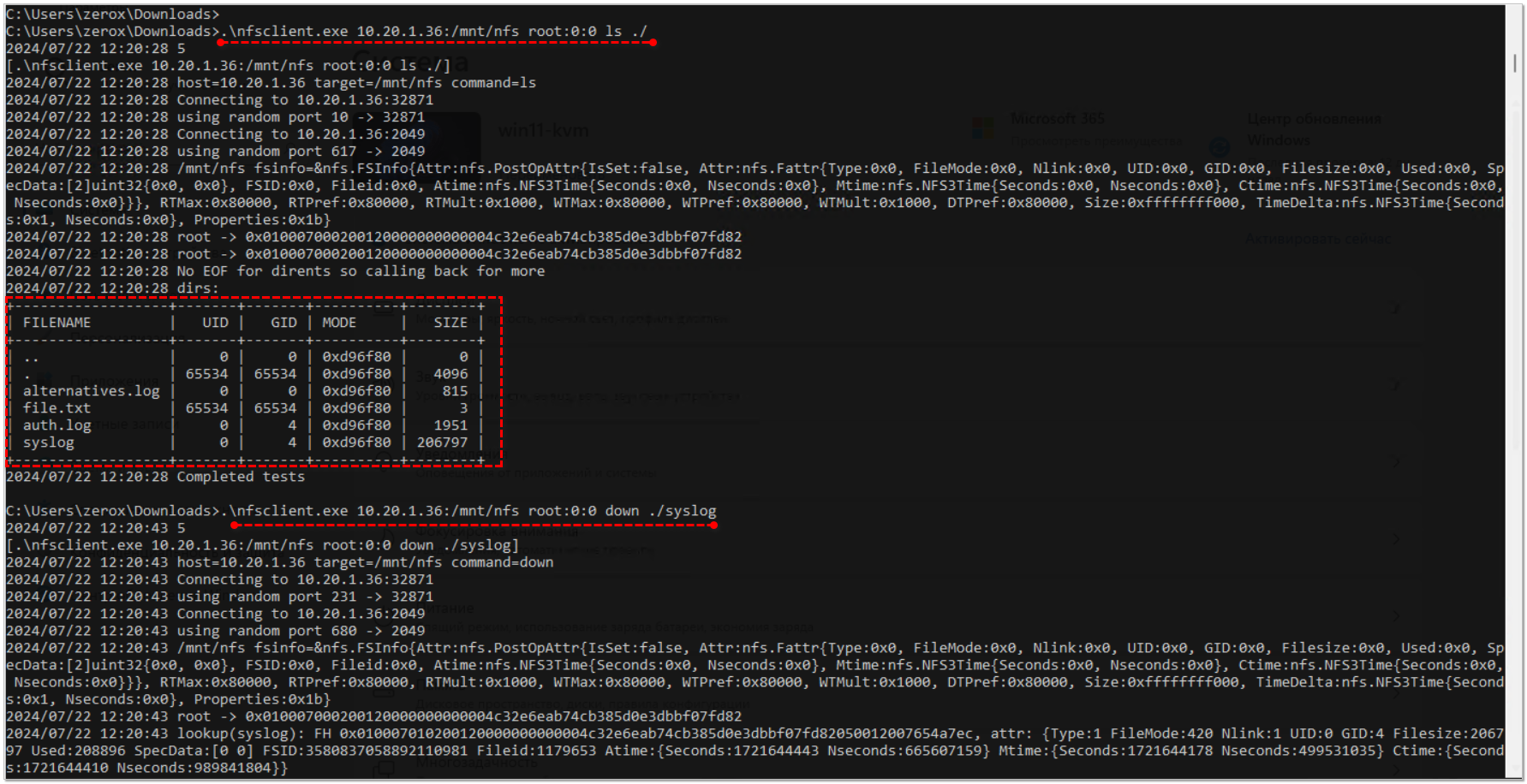
Работает примерно так. Монтировать диск не нужно. Смотрим список файлов на nfs диске:
Скачиваем файл syslog:
Загружаем в корень диска файл file.txt:
Синтаксис простой, потому что команд не так много: ls/up/down/rm/mkdir/rmdir.
#nfs #fileserver #windows
Установить его можно через Панель управления ⇨ Программы ⇨ Программы и компоненты ⇨ Включение и отключение компонентов Windows ⇨ Службы для NFS ⇨ Клиент для NFS.
Можно включить более простым и быстрым способом через Powershell:
> Enable-WindowsOptionalFeature -FeatureName ServicesForNFS-ClientOnly, ClientForNFS-Infrastructure -Online -NoRestartМожно примонтировать диск с NFS сервера, к примеру, развёрнутого из этой заметки:
> mount -o anon \\10.20.1.36\mnt\nfs N:N: успешно подключен к \\10.20.1.36\mnt\nfsКоманда успешно выполнена.> N:> dir..........Диск N появится в качестве сетевого. С ним можно работать к с обычным сетевым диском. Условно, как с обычным, так как работа под Windows с NFS сервером на Linux будет сопряжена с множеством нюансов и неудобств, связанных с правами доступа, кодировкой, чувствительности к регистру в названиях файлов на Linux. В общем случае использовать такой сценарий работы не рекомендуется. Для постоянной работы с Windows проще поднять SMB сервер на Linux.
Для разовых задач или для использования в скриптах можно воспользоваться каким-то альтернативным консольным клиентом. Например, nfsclient. Это небольшая программа на Go уровня курсовой работы студента. Код самой программы простой, но используются готовые библиотеки для работы с NFS.
Программа кроссплатформенная и не требует установки. Это небольшой консольный клиент, который поддерживает простые операции:
◽просмотр содержимого ресурса
◽скачивание, загрузка, удаление файлов
◽создание и удаление каталогов
Работает примерно так. Монтировать диск не нужно. Смотрим список файлов на nfs диске:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 ls ./Скачиваем файл syslog:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 down ./syslogЗагружаем в корень диска файл file.txt:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 up .\file.txt ./file.txtСинтаксис простой, потому что команд не так много: ls/up/down/rm/mkdir/rmdir.
#nfs #fileserver #windows
{kind=link}
Для редактирования и совместной работы с документами через браузер есть два наиболее популярных движка с открытым исходным кодом:
▪️ OnlyOffice
▪️ Collabora Online
Про #OnlyOffice я регулярно пишу, можно посмотреть материалы под соответствующим тэгом. Там же есть инструкции по быстрому запуску продукта. Решил то же самое подготовить по Collabora Online, чтобы можно было быстро их сравнить и выбрать то, что больше понравится.
Движок для редактирования документов работает в связке с каким-то другим продуктом по управлению файлами. Проще всего потестировать его в связке с ownCloud. Запускаем его:
Идём по IP адресу сервера http://10.20.1.36, создаём учётку админа и логинимся. В левом верхнем углу нажимаем на 3 полоски, раскрывая меню и переходим в раздел Market. Ставим приложение Collabora Online.
Переходим опять в консоль сервера и запускаем сервер collabora:
Возвращаемся в веб интерфейс owncloud, переходим в Настройки ⇨ Администрирование ⇨ Дополнительно. В качестве адреса сервера Collabora Online указываем http://10.20.1.36:9980. На этом всё. Можно загружать документы и открывать их с помощью Collabora Online. У меня без каких-либо проблем сразу всё заработало по этой инструкции. Работает, кстати, эта связка довольно шустро. Мне понравилось. Погонял там с десяток своих документов и таблиц.
Редактор Collabora Online сильно отличается от Onlyoffice как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняется на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice. Но при таком подходе надёжнее работает совместное редактирование, так как реально оно происходит на сервере, а клиентам передаётся только картинка.
Интерфейс Onlyoffice больше похож на Excel, интуитивно с ним проще работать. Основные форматы - .docx, .xlsx, .pptx. Соответственно и совместимость с ними лучше. Collabora построена на базе LibreOffice, а он заметно отличается от Excel, так что переход будет более болезненный. Основные форматы - .odt, .ods, .odp. Майкрософтовские документы открывает хуже.
Какой из этих продуктов лучше и предпочтительнее в использовании, сказать трудно. Надо тестировать самому на своём наборе документов. В целом, оба продукта уже давно на рынке, каких-то критических проблем с ними нет, люди работают. Но, разумеется, есть свои нюансы, проблемы и особенности.
#docs #fileserver
▪️ OnlyOffice
▪️ Collabora Online
Про #OnlyOffice я регулярно пишу, можно посмотреть материалы под соответствующим тэгом. Там же есть инструкции по быстрому запуску продукта. Решил то же самое подготовить по Collabora Online, чтобы можно было быстро их сравнить и выбрать то, что больше понравится.
Движок для редактирования документов работает в связке с каким-то другим продуктом по управлению файлами. Проще всего потестировать его в связке с ownCloud. Запускаем его:
# docker run -d -p 80:80 owncloudИдём по IP адресу сервера http://10.20.1.36, создаём учётку админа и логинимся. В левом верхнем углу нажимаем на 3 полоски, раскрывая меню и переходим в раздел Market. Ставим приложение Collabora Online.
Переходим опять в консоль сервера и запускаем сервер collabora:
# docker run -t -d -p 9980:9980 -e "extra_params=--o:ssl.enable=false" collabora/codeВозвращаемся в веб интерфейс owncloud, переходим в Настройки ⇨ Администрирование ⇨ Дополнительно. В качестве адреса сервера Collabora Online указываем http://10.20.1.36:9980. На этом всё. Можно загружать документы и открывать их с помощью Collabora Online. У меня без каких-либо проблем сразу всё заработало по этой инструкции. Работает, кстати, эта связка довольно шустро. Мне понравилось. Погонял там с десяток своих документов и таблиц.
Редактор Collabora Online сильно отличается от Onlyoffice как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняется на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice. Но при таком подходе надёжнее работает совместное редактирование, так как реально оно происходит на сервере, а клиентам передаётся только картинка.
Интерфейс Onlyoffice больше похож на Excel, интуитивно с ним проще работать. Основные форматы - .docx, .xlsx, .pptx. Соответственно и совместимость с ними лучше. Collabora построена на базе LibreOffice, а он заметно отличается от Excel, так что переход будет более болезненный. Основные форматы - .odt, .ods, .odp. Майкрософтовские документы открывает хуже.
Какой из этих продуктов лучше и предпочтительнее в использовании, сказать трудно. Надо тестировать самому на своём наборе документов. В целом, оба продукта уже давно на рынке, каких-то критических проблем с ними нет, люди работают. Но, разумеется, есть свои нюансы, проблемы и особенности.
#docs #fileserver
{kind=link}