
Веб сервер Nginx уже давно умеет писать логи в json формате. В настройке по умолчанию используются текстовые логи. Да и почти везде, где мне приходится видеть логи веб сервера, они в текстовом формате. Если ещё не используете json формат для логов, то предлагаю вам пересмотреть свои привычки и использовать. Это удобно и для ручного просмотра логов, и для парсинга в тех или иных системах.
Настроить json логи очень просто. Вот пример для привычного формата combined, только в json. Добавляем в основной конфиг в раздел http { }.
И дальше либо в общую настройку, либо в настройку логов виртуального хоста добавляем:
Теперь, если отправить логи в ELK или Zabbix, их обработка будет упрощена, так как для json формата там есть готовые обработчики. А в консоли логи удобно смотреть с помощью jq. Смотрим весь лог:
Смотрим только список урлов, к которым были обращения:
Выводим полные записи логов, где только 404 коды ответов:
Теперь то же самое, только выводим не полные строки, а урл, где код ответа был 404:
Добавим сюда же информацию о времени запроса:
Думаю, идею вы поняли. Json смотреть проще, быстрее и гибче, нежели грепать или обрабатывать утилитами типа sed, awk и т.д. Надо только немного изучить синтаксис jq. Если хотите получить значения без кавычек " ", то добавьте к jq ключ -r:
Все переменные, которые вы можете использовать в логе, перечислены в документации к модулю ngx_http_core_module. Я обычно добавляю некоторые переменные к стандартным, а именно:
◽$request_length, $upstream_addr,
◽$upstream_status,
◽$upstream_response_time,
◽$upstream_connect_time,
◽$upstream_header_time,
◽$server_name,
◽$ssl_protocol,
◽$ssl_cipher.
#nginx #jq
Настроить json логи очень просто. Вот пример для привычного формата combined, только в json. Добавляем в основной конфиг в раздел http { }.
log_format json_combined escape=json '{' '"time_local":"$time_local",' '"remote_addr":"$remote_addr",' '"remote_user":"$remote_user",' '"request":"$request",' '"status": "$status",' '"body_bytes_sent":"$body_bytes_sent",' '"request_time":"$request_time",' '"http_referrer":"$http_referer",' '"http_user_agent":"$http_user_agent"' '}';И дальше либо в общую настройку, либо в настройку логов виртуального хоста добавляем:
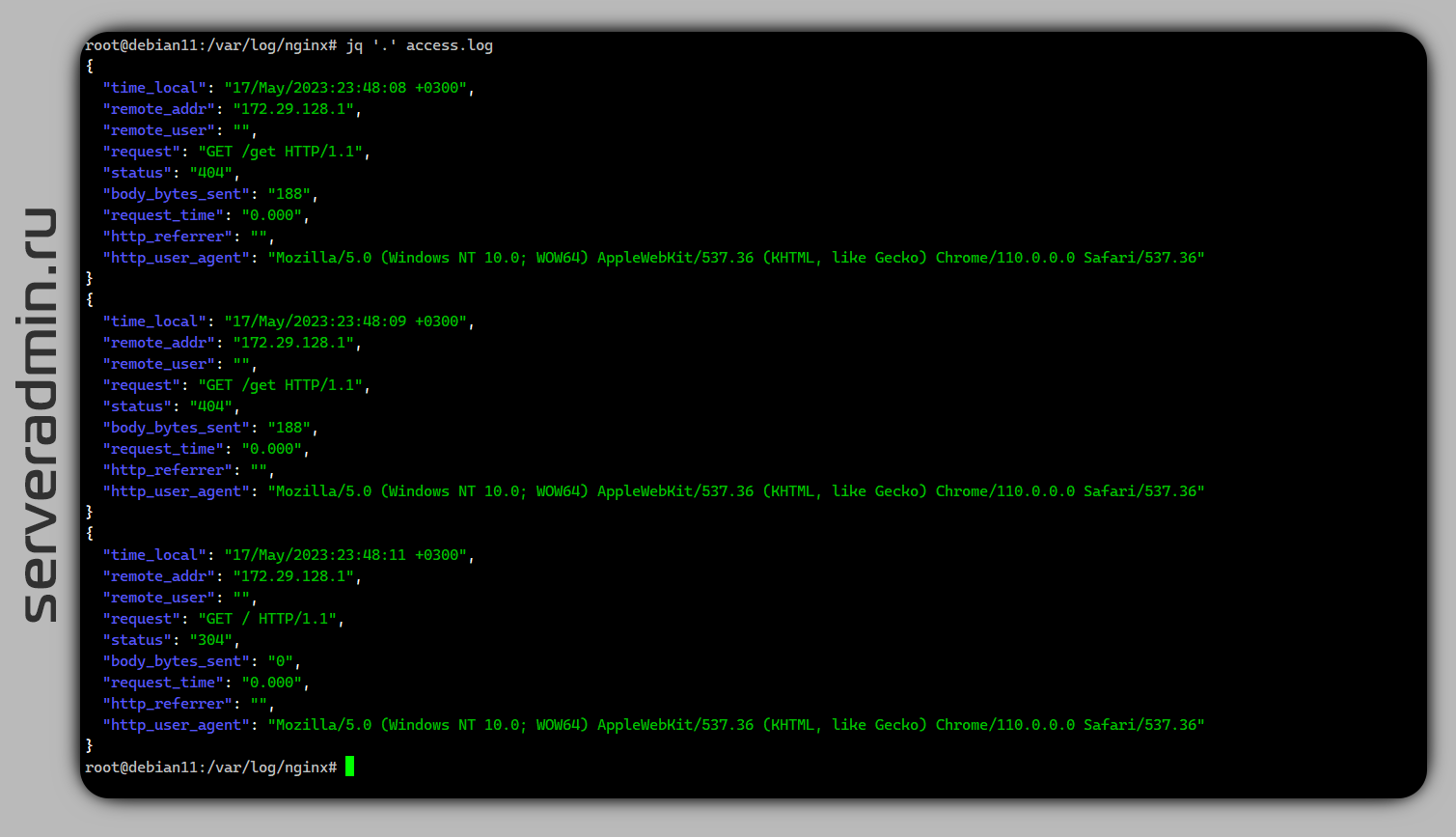
access_log /var/log/nginx/access.log json_combined;Теперь, если отправить логи в ELK или Zabbix, их обработка будет упрощена, так как для json формата там есть готовые обработчики. А в консоли логи удобно смотреть с помощью jq. Смотрим весь лог:
# jq '.' access.logСмотрим только список урлов, к которым были обращения:
# jq '.request' access.logВыводим полные записи логов, где только 404 коды ответов:
# jq '. | select(.status=="404")' access.logТеперь то же самое, только выводим не полные строки, а урл, где код ответа был 404:
# jq '. | select(.status=="404") | .request' access.logДобавим сюда же информацию о времени запроса:
# jq '. | select(.status=="404") | .time_local,.request' access.logДумаю, идею вы поняли. Json смотреть проще, быстрее и гибче, нежели грепать или обрабатывать утилитами типа sed, awk и т.д. Надо только немного изучить синтаксис jq. Если хотите получить значения без кавычек " ", то добавьте к jq ключ -r:
# jq -r '.request' access.logВсе переменные, которые вы можете использовать в логе, перечислены в документации к модулю ngx_http_core_module. Я обычно добавляю некоторые переменные к стандартным, а именно:
◽$request_length, $upstream_addr,
◽$upstream_status,
◽$upstream_response_time,
◽$upstream_connect_time,
◽$upstream_header_time,
◽$server_name,
◽$ssl_protocol,
◽$ssl_cipher.
#nginx #jq
{kind=link}
Ранее я пробовал и рассказывал, как настроить VDI (Virtual Desktop Infrastructure) на базе Proxmox. Для этого нужно немного поднастроить гипервизор и использовать PVE-VDIClient для подключения к рабочим местам. Читайте, кому интересно, отдельную заметку по этому поводу.
С тех времён у меня в закладках осталась система Ravada VDI, которую я хотел попробовать, но так руки и не дошли. Нужен железный сервер, но он так и не подвернулся под руку. Поэтому рассказываю как есть по информации с их сайта.
Ravada — open source проект для организации VDI на базе гипервизора KVM. Разворачивается на типовых дистрибутивах: Debian, Ubuntu или Fedora. Для установки есть собранные deb и rpm пакеты, так что установка очень простая — скачиваем и устанавливаем пакет. Пример установки на Debian. Для хранения информации необходим MariaDB сервер. В комплекте с Ravada идёт веб сервер. Всё управление системой выполняется через браузер.
Судя по документации, настройка простая и быстрая. С помощью Ravada можно организовать рабочие места как на Linux, так и Windows. Для подключения к виртуальным машинам можно использовать virt-viewer. Подключение работает по протоколу SPICE. Есть интеграция с LDAP сервером. Пользователей можно брать оттуда.
Проект мне показался интересным и полезным. Бесплатных продуктов по данной тематике почти нет. Это удел крупных корпоративных систем за много денег. А для какого-нибудь учебного класса система, подобная Ravada, будет в самый раз. К тому же она активно развивается. Регулярно выходят новые релизы.
⇨ Сайт / Исходники
С тех времён у меня в закладках осталась система Ravada VDI, которую я хотел попробовать, но так руки и не дошли. Нужен железный сервер, но он так и не подвернулся под руку. Поэтому рассказываю как есть по информации с их сайта.
Ravada — open source проект для организации VDI на базе гипервизора KVM. Разворачивается на типовых дистрибутивах: Debian, Ubuntu или Fedora. Для установки есть собранные deb и rpm пакеты, так что установка очень простая — скачиваем и устанавливаем пакет. Пример установки на Debian. Для хранения информации необходим MariaDB сервер. В комплекте с Ravada идёт веб сервер. Всё управление системой выполняется через браузер.
Судя по документации, настройка простая и быстрая. С помощью Ravada можно организовать рабочие места как на Linux, так и Windows. Для подключения к виртуальным машинам можно использовать virt-viewer. Подключение работает по протоколу SPICE. Есть интеграция с LDAP сервером. Пользователей можно брать оттуда.
Проект мне показался интересным и полезным. Бесплатных продуктов по данной тематике почти нет. Это удел крупных корпоративных систем за много денег. А для какого-нибудь учебного класса система, подобная Ravada, будет в самый раз. К тому же она активно развивается. Регулярно выходят новые релизы.
⇨ Сайт / Исходники
{kind=link}
Тема тюнинга сетевого стека очень узкая и сложная. В сети в основном все перепечатывают статьи друг у друга. Когда изучал тему, сразу это бросилось в глаза. За основу имеет смысл взять вот эти материалы, которые мне понравились больше всего:
⇨ Описание некоторых sysctl переменных ядра Linux
⇨ Настройка ядра Linux для тяжелых проектов и защиты от DDOS
⇨ Настройка Linux для HL и защиты от DDoS
⇨ Когда TCP-сокеты отказываются умирать
Многое устарело, либо не соответствует текущим настройкам по умолчанию. Какие-то механизмы и так в современных ядрах включены. Ниже моя компиляция того, что показалось актуальным на текущий момент. В основном это то, что касается таймаутов и потребления памяти. Её сейчас много и она дешёвая.
📌 Увеличиваем значение tcp_max_orphans, которое отвечает за максимальное число осиротевших (не связанных ни с одним процессом) сокетов TCP. Каждый такой сокет съедает примерно 64 Кб памяти. Так что параметр нужно сопоставлять с доступной памятью на сервере.
📌 Уменьшаем tcp_fin_timeout (по умолчанию 60). Параметр отвечает за максимальное время пребывания сокета в состоянии FIN-WAIT-2. Это состояние используется в тех случаях, когда другая сторона не закрыла соединение. Каждый сокет занимает порядка 1.5 Кб памяти, что может подъедать её, когда их очень много.
📌 Параметры, отвечающие за проверку TCP соединений в статусе SO_KEEPALIVE: keepalive_time определяет время, через которое начнутся проверки после последней активности соединения, keepalive_intvl определяет интервал проверки, а keepalive_probes количество этих проверок.
📌 Стоит обратить внимание на параметры
📌 Отключаем (по умолчанию включено) передачу syncookies вызывающему хосту в случае переполнения очереди SYN-пакетов для заданного сокета.
📌 Отдельное внимание алгоритму, который используется для контроля перегрузки в TCP сетях. Их много (cubic, htcp, bic, westwood и т.д.) и однозначно сказать, что лучше использовать, трудно. В разных схемах нагрузки алгоритмы показывают разные результаты. Управляет этим параметр ядра tcp_congestion_control:
📌 При большом количестве исходящих соединений сервера может не хватать локальных портов для них. По умолчанию используется диапазон 32768 - 60999. Его можно расширить:
📌 Включаем защиту от TIME_WAIT атак. По умолчанию она отключена.
📌 Максимальное число открытых сокетов, ждущих соединения, по умолчанию имеет довольно низкое значение. В ядрах до 5.3 это 128, в 5.4 увеличили до 4096. На нагруженных и мощных серверах имеет смысл увеличить:
📌 На мощных и нагруженных серверах можно увеличить стандартные значения размера буфера приёма и передачи для всех соединений. Параметр измеряется в байтах. По умолчанию это 212992 или 208 КБ.
📌 Отключаем локальные перенаправления ICMP пакетов. Делать это стоит только в том случае, если ваш сервер не выполняет роль маршрутизатора, то есть у вас обычный веб сервер.
Дополнительно можно вообще отключить ответ на ICMP запросы на уровне ядра. Я сам так не делаю обычно, но видел компанию, где вообще все сервера не отвечали на пинги.
#linux #sysctl #network
⇨ Описание некоторых sysctl переменных ядра Linux
⇨ Настройка ядра Linux для тяжелых проектов и защиты от DDOS
⇨ Настройка Linux для HL и защиты от DDoS
⇨ Когда TCP-сокеты отказываются умирать
Многое устарело, либо не соответствует текущим настройкам по умолчанию. Какие-то механизмы и так в современных ядрах включены. Ниже моя компиляция того, что показалось актуальным на текущий момент. В основном это то, что касается таймаутов и потребления памяти. Её сейчас много и она дешёвая.
📌 Увеличиваем значение tcp_max_orphans, которое отвечает за максимальное число осиротевших (не связанных ни с одним процессом) сокетов TCP. Каждый такой сокет съедает примерно 64 Кб памяти. Так что параметр нужно сопоставлять с доступной памятью на сервере.
net.ipv4.tcp_max_orphans = 65536📌 Уменьшаем tcp_fin_timeout (по умолчанию 60). Параметр отвечает за максимальное время пребывания сокета в состоянии FIN-WAIT-2. Это состояние используется в тех случаях, когда другая сторона не закрыла соединение. Каждый сокет занимает порядка 1.5 Кб памяти, что может подъедать её, когда их очень много.
net.ipv4.tcp_fin_timeout = 10📌 Параметры, отвечающие за проверку TCP соединений в статусе SO_KEEPALIVE: keepalive_time определяет время, через которое начнутся проверки после последней активности соединения, keepalive_intvl определяет интервал проверки, а keepalive_probes количество этих проверок.
net.ipv4.tcp_keepalive_time = 1800net.ipv4.tcp_keepalive_intvl = 15net.ipv4.tcp_keepalive_probes = 5📌 Стоит обратить внимание на параметры
net.ipv4.tcp_mem, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem. Они очень сильно зависят от памяти на сервере и в момент загрузки системы вычисляются автоматически. В общем случае их трогать не обязательно, но иногда можно и вручную подредактировать в сторону увеличения значений. 📌 Отключаем (по умолчанию включено) передачу syncookies вызывающему хосту в случае переполнения очереди SYN-пакетов для заданного сокета.
net.ipv4.tcp_syncookies = 0📌 Отдельное внимание алгоритму, который используется для контроля перегрузки в TCP сетях. Их много (cubic, htcp, bic, westwood и т.д.) и однозначно сказать, что лучше использовать, трудно. В разных схемах нагрузки алгоритмы показывают разные результаты. Управляет этим параметр ядра tcp_congestion_control:
net.ipv4.tcp_congestion_control = cubic📌 При большом количестве исходящих соединений сервера может не хватать локальных портов для них. По умолчанию используется диапазон 32768 - 60999. Его можно расширить:
net.ipv4.ip_local_port_range = 10240 65535📌 Включаем защиту от TIME_WAIT атак. По умолчанию она отключена.
net.ipv4.tcp_rfc1337 = 1📌 Максимальное число открытых сокетов, ждущих соединения, по умолчанию имеет довольно низкое значение. В ядрах до 5.3 это 128, в 5.4 увеличили до 4096. На нагруженных и мощных серверах имеет смысл увеличить:
net.core.somaxconn = 16384📌 На мощных и нагруженных серверах можно увеличить стандартные значения размера буфера приёма и передачи для всех соединений. Параметр измеряется в байтах. По умолчанию это 212992 или 208 КБ.
net.core.rmem_default = 851968net.core.wmem_default = 851968net.core.rmem_max = 12582912net.core.wmem_max = 12582912📌 Отключаем локальные перенаправления ICMP пакетов. Делать это стоит только в том случае, если ваш сервер не выполняет роль маршрутизатора, то есть у вас обычный веб сервер.
net.ipv4.conf.all.accept_redirects = 0net.ipv4.conf.all.secure_redirects = 0net.ipv4.conf.all.send_redirects = 0Дополнительно можно вообще отключить ответ на ICMP запросы на уровне ядра. Я сам так не делаю обычно, но видел компанию, где вообще все сервера не отвечали на пинги.
net.ipv4.icmp_echo_ignore_all = 1#linux #sysctl #network
▶️ Если кто-то ещё не видел, предлагаю насладиться просмотром великолепного саркастического ролика на тему работы технической поддержки по телефону: The Expert: IT Support.
▪ Оригинал:
⇨ https://www.youtube.com/watch?v=ZOzzRlc_qho
▪ Дубляж:
⇨ https://www.youtube.com/watch?v=F0T0Y91npYg
Мне лично оригинал намного больше понравился.
У меня была очень похожая по своему абсурду и безвыходности история. И тоже с тех. поддержкой по телефону. Зимой ездил проверять загородный дом, где у меня постоянно включен электрический котёл для отопления, который управляется через GSM модуль.
Особенность этого котла и модуля такова, что когда настроено управление по GSM, вручную ничего изменить нельзя. Надо отключать модуль и менять настройки. Днём я экспериментировал с режимами, а вечером собрался уезжать в квартиру. Это была пятница. И как назло, связь с котлом пропала, и я не могу поменять режим на тот, что мне нужен. А уехать, не поменяв режим, тоже не могу, потому что там выставлена комфортная температура для всего дома, а уезжая, я оставляю 12 градусов. Топить дом на полную мощность, когда там никого нет, не хотелось.
В котле стоит симка от известного оператора связи, но продавалась она вместе с GSM модулем. Управляется симка только через личный кабинет вендора модуля. Она по сути мне не принадлежит, так как является корпоративной для их юр. лица.
Я уже стою готовый выехать и понимаю, что не знаю, что делать. Подождал минут 10, связи нет. Облазил весь сайт продавца GSM модуля, телефона поддержки нигде нет. Его походу просто не существует. Пишу через тикет систему в тех. поддержку. Думаю, ну раз номера нет, значит тех. поддержка отвечает оперативно и решает проблему. Прождал час, никто не ответил на почту.
Звоню в тех. поддержку мобильного оператора. Там огроменное голосовое меню и я не понимаю, куда мне нужно обратиться по своему вопросу. Несколько раз прослушал голосового помощника и не понял, во-первых, как решить вопрос через голосовое меню, во-вторых, как попасть на живого оператора. Тут уже конкретно раздражённый был. Начал искать в интернете информацию, как попасть к живому оператору. В итоге нашёл номер, позвонил туда и попал к человеку. Слава богу, пока это ещё возможно!
Назвал оператору номер телефона. Она всё проверила, сказала, что тариф корпоративный, и он в минусе, поэтому не работает. У меня все платежи были в срок и баланс с запасом, так что не понял, как так вышло. Это уже проблемы продавца GSM модулей, с их биллингом что-то не так. Объяснил ситуацию оператору и попросил придумать хоть что-нибудь, чтобы номер заработал. Какой-нибудь обещанный платёж или что-то ещё, лишь бы вернулась связь. Она сказала, что сделать ничего нельзя.
В общем, я смирился и уезжать не стал. Остался ночевать. Побоялся уехать, а то потом придётся возвращаться, чтобы перезагружать GSM модуль. Не было уверенности, что потом всё заработает само. В итоге ночью связь появилась, управление заработало. Утром я всё настроил и уехал домой.
И только в понедельник днём мне тех. поддержка написала, что были проблемы с биллингом у сотового оператора, поэтому временно связь не работала, а теперь всё ок.
Такие вот современные технологии. Я лично себе не стал никаких умных домов делать. Всё провёл проводами и для электрики, и для слаботочки. Хотя мне предлагал электрик сделать выключатели на радиоуправлении, и провода не пришлось бы тащить к каждому. В бревенчатом доме это довольно хлопотно. Отказался. Как представлю, аккумуляторы там менять, или какие-нибудь помехи начнутся. Все камеры, все рабочие места, везде кабели протянул. Ну его нафиг.
Я не сторонник автоматизации в доме. Хотя казалось бы, со всем этим работаю и разбираюсь. Купить приборы, сервачок поставить, WiFi и т.д. Вот из-за того, что разбираюсь, и не хочу связываться. Пусть хоть дома всё будет чётко и по старинке — пришёл, шлёпнул по выключателю и всё работает. Система реального времени. Котёл тоже переделаю, когда перееду постоянно жить, а не наездами.
#юмор
▪ Оригинал:
⇨ https://www.youtube.com/watch?v=ZOzzRlc_qho
▪ Дубляж:
⇨ https://www.youtube.com/watch?v=F0T0Y91npYg
Мне лично оригинал намного больше понравился.
У меня была очень похожая по своему абсурду и безвыходности история. И тоже с тех. поддержкой по телефону. Зимой ездил проверять загородный дом, где у меня постоянно включен электрический котёл для отопления, который управляется через GSM модуль.
Особенность этого котла и модуля такова, что когда настроено управление по GSM, вручную ничего изменить нельзя. Надо отключать модуль и менять настройки. Днём я экспериментировал с режимами, а вечером собрался уезжать в квартиру. Это была пятница. И как назло, связь с котлом пропала, и я не могу поменять режим на тот, что мне нужен. А уехать, не поменяв режим, тоже не могу, потому что там выставлена комфортная температура для всего дома, а уезжая, я оставляю 12 градусов. Топить дом на полную мощность, когда там никого нет, не хотелось.
В котле стоит симка от известного оператора связи, но продавалась она вместе с GSM модулем. Управляется симка только через личный кабинет вендора модуля. Она по сути мне не принадлежит, так как является корпоративной для их юр. лица.
Я уже стою готовый выехать и понимаю, что не знаю, что делать. Подождал минут 10, связи нет. Облазил весь сайт продавца GSM модуля, телефона поддержки нигде нет. Его походу просто не существует. Пишу через тикет систему в тех. поддержку. Думаю, ну раз номера нет, значит тех. поддержка отвечает оперативно и решает проблему. Прождал час, никто не ответил на почту.
Звоню в тех. поддержку мобильного оператора. Там огроменное голосовое меню и я не понимаю, куда мне нужно обратиться по своему вопросу. Несколько раз прослушал голосового помощника и не понял, во-первых, как решить вопрос через голосовое меню, во-вторых, как попасть на живого оператора. Тут уже конкретно раздражённый был. Начал искать в интернете информацию, как попасть к живому оператору. В итоге нашёл номер, позвонил туда и попал к человеку. Слава богу, пока это ещё возможно!
Назвал оператору номер телефона. Она всё проверила, сказала, что тариф корпоративный, и он в минусе, поэтому не работает. У меня все платежи были в срок и баланс с запасом, так что не понял, как так вышло. Это уже проблемы продавца GSM модулей, с их биллингом что-то не так. Объяснил ситуацию оператору и попросил придумать хоть что-нибудь, чтобы номер заработал. Какой-нибудь обещанный платёж или что-то ещё, лишь бы вернулась связь. Она сказала, что сделать ничего нельзя.
В общем, я смирился и уезжать не стал. Остался ночевать. Побоялся уехать, а то потом придётся возвращаться, чтобы перезагружать GSM модуль. Не было уверенности, что потом всё заработает само. В итоге ночью связь появилась, управление заработало. Утром я всё настроил и уехал домой.
И только в понедельник днём мне тех. поддержка написала, что были проблемы с биллингом у сотового оператора, поэтому временно связь не работала, а теперь всё ок.
Такие вот современные технологии. Я лично себе не стал никаких умных домов делать. Всё провёл проводами и для электрики, и для слаботочки. Хотя мне предлагал электрик сделать выключатели на радиоуправлении, и провода не пришлось бы тащить к каждому. В бревенчатом доме это довольно хлопотно. Отказался. Как представлю, аккумуляторы там менять, или какие-нибудь помехи начнутся. Все камеры, все рабочие места, везде кабели протянул. Ну его нафиг.
Я не сторонник автоматизации в доме. Хотя казалось бы, со всем этим работаю и разбираюсь. Купить приборы, сервачок поставить, WiFi и т.д. Вот из-за того, что разбираюсь, и не хочу связываться. Пусть хоть дома всё будет чётко и по старинке — пришёл, шлёпнул по выключателю и всё работает. Система реального времени. Котёл тоже переделаю, когда перееду постоянно жить, а не наездами.
#юмор
YouTube
The Expert: IT Support (Short Comedy Sketch)
Subscribe for more short comedy sketches & films: http://bit.ly/laurisb Buy Expert shirts & hoodies at https://laurisb.myshopify.com/ Square Project Ep2. A funny video about a phone call to IT Support. Another day in the life of Anderson, an engineer trying…
▶️ Rebrain наконец-то стали выкладывать некоторые свои вебинары в публичный доступ. Теперь можно их пропускать и откладывать на потом 😁 И зашли сразу с козыря. Выложили вебинар:
Networks by Rebrain: Траблшутинг сетевых сервисов. Инструменты и утилиты для диагностики
⇨ https://www.youtube.com/watch?v=5Ppg5PHQFH4
Я смотрел два вебинара с этим ведущим. Очень понравилось. Ольга чётко всё рассказывает, в теме разбирается отлично. Видно, что к вебинарам готовится: план мероприятия, теория, подготовленная лаба, практика. На одном из вебинаров, Сегментация сети без разделения на подсети (интересная и новая для меня тема), не удержался и выразил своё восхищение 👍
В общем, рекомендую. Ольга Яновская, Василий Озеров, Андрей Буранов. Их стараюсь не пропускать, так как всегда гарантированно интересно и полезно.
#видео #обучение #network
Networks by Rebrain: Траблшутинг сетевых сервисов. Инструменты и утилиты для диагностики
⇨ https://www.youtube.com/watch?v=5Ppg5PHQFH4
Я смотрел два вебинара с этим ведущим. Очень понравилось. Ольга чётко всё рассказывает, в теме разбирается отлично. Видно, что к вебинарам готовится: план мероприятия, теория, подготовленная лаба, практика. На одном из вебинаров, Сегментация сети без разделения на подсети (интересная и новая для меня тема), не удержался и выразил своё восхищение 👍
В общем, рекомендую. Ольга Яновская, Василий Озеров, Андрей Буранов. Их стараюсь не пропускать, так как всегда гарантированно интересно и полезно.
#видео #обучение #network
YouTube
Networks by Rebrain: Траблшутинг сетевых сервисов.Инструменты и утилиты для диагностики
Анонсы живых открытых практикумов https://t.me/rebrain_devops
Запись открытого практикума Networks by Rebrain: Траблшутинг сетевых сервисов. Инструменты и утилиты для диагностики
Проводим открытые уроки по DevOps, Linux, Golang, Networks каждую неделю…
Запись открытого практикума Networks by Rebrain: Траблшутинг сетевых сервисов. Инструменты и утилиты для диагностики
Проводим открытые уроки по DevOps, Linux, Golang, Networks каждую неделю…
На днях поставил себе на ноут программу по управлению оборотами вентилятора TPFanControl (https://thinkwiki.de/TPFanControl). Она вроде бы специально для серии Thinkpad написана, но может и с другими работает. Но это не суть. Таких программ много.
Я раньше пользовался подобной программой, потом как-то подзабыл и при переезде на другой ноут не поставил. Сейчас вспомнил и исправил. Программа нужна вот для чего. Я настроил включение вентилятора только если температура процессора становится выше 70-ти градусов. Это случается не так часто. В итоге почти всё время ноут полностью бесшумен. Очень удобно.
Стандартные алгоритмы управления вентилятором другие. Обычно хоть немного, но он шевелится и прибавляет обороты значительно раньше. Хотя температуры до 70-80 градусов вполне безопасны для процессора. Перегреться всё равно не успеет, он тротлить начинает сразу при перегреве.
У TPFanControl немного замороченный текстовый конфиг. Все настройки только в нём. После установки не понятно, с чего начать настройку. Если кому-то нужен, напишите в комментах, я свой выложу.
Обзор и настройка программы:
⇨ https://www.youtube.com/watch?v=5IPn0Jt7oA8
#железо
Я раньше пользовался подобной программой, потом как-то подзабыл и при переезде на другой ноут не поставил. Сейчас вспомнил и исправил. Программа нужна вот для чего. Я настроил включение вентилятора только если температура процессора становится выше 70-ти градусов. Это случается не так часто. В итоге почти всё время ноут полностью бесшумен. Очень удобно.
Стандартные алгоритмы управления вентилятором другие. Обычно хоть немного, но он шевелится и прибавляет обороты значительно раньше. Хотя температуры до 70-80 градусов вполне безопасны для процессора. Перегреться всё равно не успеет, он тротлить начинает сразу при перегреве.
У TPFanControl немного замороченный текстовый конфиг. Все настройки только в нём. После установки не понятно, с чего начать настройку. Если кому-то нужен, напишите в комментах, я свой выложу.
Обзор и настройка программы:
⇨ https://www.youtube.com/watch?v=5IPn0Jt7oA8
#железо
YouTube
Make Your Thinkpad Laptop Quiet TPFanControl : Software Sunday EP 17
I am a big fan of Lenovo / IBM Thinkpads, however they tend to be a bit on the loud side when it comes to fan noise. With TPFanControl you can create what is essentially a custom fan curve for your Thinkpad. With the right configuration, you can make your…
🎓 Недавно вспомнил про образовательную платформу stepik.org, где я когда-то давно проходил несколько курсов. Зашёл посмотреть, что там есть интересного и полезного. С удивлением заметил довольно много бесплатных и на вид неплохих курсов с тысячами отзывов и оценок.
Ещё обратил внимание, что некоторые курсы после прохождения предлагают получить именной сертификат. Мне кажется, может быть полезным получить 1-2 таких сертификата и добавить их к своему резюме. При условии, что у вас там будет 2-3 сертификата с полноценного платного обучения с сертификацией в конце. Разбавить их тематическими бесплатными для увеличения значимости в глазах рекрутёра не думаю, что будет лишним. Разумеется всё это актуально для тех, у кого небольшой опыт.
📌 Несколько бесплатных курсов по Linux:
▪ Введение в Linux — самый большой и масштабный бесплатный курс по Linux. В целом, отзывы положительные, но в последних видны упоминания, что курс уже устарел. На курсе даётся база, которая в Linux меняется очень слабо, так что скорее всего устаревание некритичное. К курсу полагается сертификат.
▪ Основы Linux — более свежий и короткий курс по сравнению с предыдущим. Но объём всё равно внушительный. Не на один день.
▪ Linux CLI — наиболее свежий курс с основами командной строки. Объём небольшой, на один вечер.
▪ Архитектура параллельных вычислительных систем — название неговорящие, хотя сам курс про Linux. В нём учат настраивать линуксовую базу: apache, nginx, iptables, bind9 (dns), nfs, samba, docker.
#обучение
Ещё обратил внимание, что некоторые курсы после прохождения предлагают получить именной сертификат. Мне кажется, может быть полезным получить 1-2 таких сертификата и добавить их к своему резюме. При условии, что у вас там будет 2-3 сертификата с полноценного платного обучения с сертификацией в конце. Разбавить их тематическими бесплатными для увеличения значимости в глазах рекрутёра не думаю, что будет лишним. Разумеется всё это актуально для тех, у кого небольшой опыт.
📌 Несколько бесплатных курсов по Linux:
▪ Введение в Linux — самый большой и масштабный бесплатный курс по Linux. В целом, отзывы положительные, но в последних видны упоминания, что курс уже устарел. На курсе даётся база, которая в Linux меняется очень слабо, так что скорее всего устаревание некритичное. К курсу полагается сертификат.
▪ Основы Linux — более свежий и короткий курс по сравнению с предыдущим. Но объём всё равно внушительный. Не на один день.
▪ Linux CLI — наиболее свежий курс с основами командной строки. Объём небольшой, на один вечер.
▪ Архитектура параллельных вычислительных систем — название неговорящие, хотя сам курс про Linux. В нём учат настраивать линуксовую базу: apache, nginx, iptables, bind9 (dns), nfs, samba, docker.
#обучение
Stepik: online education
Введение в Linux
Курс знакомит слушателей с операционной системой Linux и основами её использования. В рамках курса мы покажем как установить Linux на ваш компьютер, расскажем о программах в нем, поработаем в терминале, зайдем на удаленный сервер и рассмотрим еще несколько…
Бессмысленная воскресная тема. Дело было вечером, делать было нечего. Увидел в одной из подборок софта с github информацию о консольном видео проигрывателе Terminal Media Player. Причём там было указано, что может проигрывать видео из youtube.
Мне стало очень любопытно, неужели действительно в терминале можно посмотреть ютубовское видео. Взял чистую виртулаку с Debian 11, без иксов, без видеокарты, без звуковой карты. Типичная VPS. Решил проверить, смогу ли я запустить ролик из ютуба на ней. Сразу скажу, что у меня получилось, но пришлось повозиться.
Все ошибки, исправления, поиски решений я опущу. Покажу сразу рабочий вариант, к которому я в итоге пришёл через несколько итераций с версиями софта и решением проблем.
Подключаем contrib non-free репозитории:
Ставим зависимости:
Ставим yt-dlp, который будет качать ролики с ютуба:
Устанавливаем свежую версию Rust и Cargo:
Собираем tplay:
Пробуем проиграть видео:
Если у вас нет звуковой карты, то скорее всего увидите ошибку, типа такой:
Оказывается, в ядре линукс с некоторого времени появилась звуковая карта пустышка, как раз для таких случаев. Загружаем модуль ядра:
И снова пробуем запустить ролик:
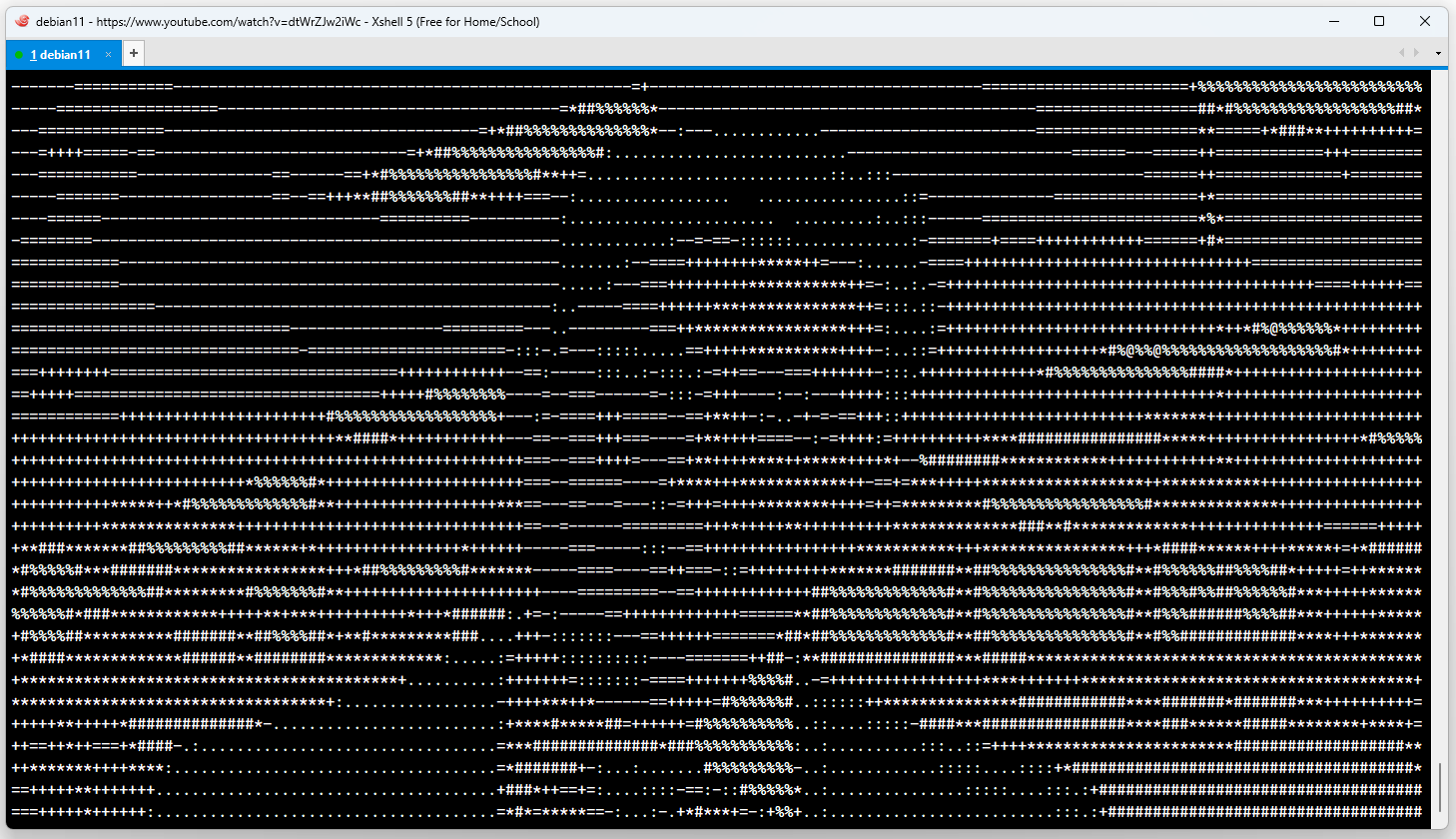
Теперь должны увидеть изображение. С настройками по умолчанию у меня картинка была слишком непонятной. Сделал таблицу символов чёрно-белой, стало получше:
А когда заменил на другую, стало ещё лучше:
Разные настройки цвета и набора символов можно менять в процессе воспроизведения видео, нажимая на цифры 0-9 и клавиши g.
Такая вот бесполезная фигня получилась, которая реально работает. Можно в терминале по ssh смотреть видео на VPS в режиме ASCII. Единственное, где это может пригодиться — быстро получить картинку в ASCII из какого-то кадра в видео. Если делать всё это на ноуте или компе, то можно картинку с веб камеры вывести в терминал.
#разное #linux
Мне стало очень любопытно, неужели действительно в терминале можно посмотреть ютубовское видео. Взял чистую виртулаку с Debian 11, без иксов, без видеокарты, без звуковой карты. Типичная VPS. Решил проверить, смогу ли я запустить ролик из ютуба на ней. Сразу скажу, что у меня получилось, но пришлось повозиться.
Все ошибки, исправления, поиски решений я опущу. Покажу сразу рабочий вариант, к которому я в итоге пришёл через несколько итераций с версиями софта и решением проблем.
Подключаем contrib non-free репозитории:
deb http://deb.debian.org/debian/ bullseye main contrib non-freeСтавим зависимости:
# apt install libopencv-dev clang libclang-dev ffmpeg libavfilter-dev \libavdevice-dev libasound2-devСтавим yt-dlp, который будет качать ролики с ютуба:
# curl -L https://github.com/yt-dlp/yt-dlp/releases/latest/download/yt-dlp \-o /usr/local/bin/yt-dlp# chmod a+rx /usr/local/bin/yt-dlpУстанавливаем свежую версию Rust и Cargo:
# curl https://sh.rustup.rs -sSf | shСобираем tplay:
# cargo install tplayПробуем проиграть видео:
# tplay https://www.youtube.com/watch?v=dtWrZJw2iWcЕсли у вас нет звуковой карты, то скорее всего увидите ошибку, типа такой:
ALSA lib confmisc.c:767:(parse_card) cannot find card '0'Оказывается, в ядре линукс с некоторого времени появилась звуковая карта пустышка, как раз для таких случаев. Загружаем модуль ядра:
# modprobe snd-dummyИ снова пробуем запустить ролик:
# tplay https://www.youtube.com/watch?v=dtWrZJw2iWcТеперь должны увидеть изображение. С настройками по умолчанию у меня картинка была слишком непонятной. Сделал таблицу символов чёрно-белой, стало получше:
# tplay https://www.youtube.com/watch?v=dtWrZJw2iWc -g А когда заменил на другую, стало ещё лучше:
# tplay https://www.youtube.com/watch?v=dtWrZJw2iWc -g --char-map ".:-=+*"Разные настройки цвета и набора символов можно менять в процессе воспроизведения видео, нажимая на цифры 0-9 и клавиши g.
Такая вот бесполезная фигня получилась, которая реально работает. Можно в терминале по ssh смотреть видео на VPS в режиме ASCII. Единственное, где это может пригодиться — быстро получить картинку в ASCII из какого-то кадра в видео. Если делать всё это на ноуте или компе, то можно картинку с веб камеры вывести в терминал.
#разное #linux
{kind=link}
На днях в рассылке увидел любопытный инструмент, на который сразу обратил внимание. Название простое и неприметное — Task. Это утилита, написанная на Gо, которая умеет запускать задачи на основе конфигурации в формате yaml. Сейчас сразу на примерах покажу, как это работает, чтобы было понятно, для чего может быть нужно.
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
Сохраняем и запускаем. Для начала посмотрим список задач:
Запустим первую задачу:
Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
Скопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
version: "3"tasks: default: desc: Run all tasks cmds: - task: task01 - task: task02 task01: desc: Task 01 cmds: - echo "Task 01" task02: desc: Task 02 cmds: - echo "Task 02"Сохраняем и запускаем. Для начала посмотрим список задач:
# task --listtask: Available tasks for this project:* default: Run all tasks* task01: Task 01* task02: Task 02Запустим первую задачу:
# task task01task: [task01] echo "Task 01"Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
# tasktask: [task01] echo "Task 01"Task 01task: [task02] echo "Task 02"Task 02Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
COPY --from=bins /usr/bin/task /usr/local/bin/taskCOPY tasks/Taskfile.yaml ./Taskfile.yamlRUN taskСкопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
{kind=link}
Я одно время перебирал программы для личных заметок, аналоги Evernote. В какой-то момент мне надоело. Понял, что это пустая трата времени. Остался в итоге на Joplin, которым пользуюсь уже пару лет. В нём не всё устраивает, но в целом — сойдёт.
У меня накопился большой список подобных программ. Часть из них я пробовал и писал заметки, часть так и не смотрел. Скорее всего уже не буду, поэтому составляю этот список как есть. Может кому-нибудь пригодится.
◽Joplin. Писал о нём много, как в отдельных заметках (1, 2), так и косвенно упоминал в других. Не нравится тормознутость, отсутствие нормальных таблиц, отсутствие локального шифрования базы.
◽Obsidian. По отзывам одно из самых популярных решений. Я бы советовал начинать именно с него, если ищите что-то подобное. В нём хорошо реализованы связи между документами. Это прям его фишка. В плюсы можно отнести большое количество плагинов для расширения функциональности.
◽Trilium Notes. Тоже популярное приложение, как и предыдущее. Часто давали рекомендации на него. Есть возможность установить на свой сервер и все устройства синхронизировать с него.
◽Appflowy. Авторы позиционируют его как аналог Notion. Из явных плюсов — приложение шустрое, так как написано на Rust и Flutter. С Notion оно никак не конкурирует, потому что функционал заметно ниже. Это просто заметки.
◽Notea. Ещё одна попытка сделать копию Notion. Можно запустить в Docker, базу хранить в S3. Выглядит приятно и современно. Похож на Appflowy. Даже не знаю, как их сравнить. На вид почти одно и то же.
◽CherryTree. Необычная программа для заметок в старом стиле. Написана на C++, поэтому работает очень быстро. Минус один и самый существенный — это локальная программа, мобильной версии нет вообще.
◽MyTetra. Ещё одно олдскульное приложение на C++. Я его начал использовать. Сначала показалось удобным, потому что быстрое с хорошей навигацией. Но когда немного попользовался, заметил много минусов и в итоге забросил. Там был какой-то один жирнющий минус в редакторе, из-за которого я прекратил использование. К сожалению, уже забыл, что не понравилось.
◽️Wreeto. Веб сервис с адаптированным под мобильники интерфейсом. Так что можно через браузер ходить со смартфона. Умеет хранить заметки в формате Markdown и Wiki. Можно настроить Google oAuth. Написано на Ruby, что неплохо, так как аналоги чаще всего на Javascript. Хотя у меня тут нет уверенности, что руби явно быстрее яваскрипта.
◽️PMS - персональная система менеджмента. Тут есть всё — от календаря с ToDo, адресной книги до ведения целей личностного развития. Даже личная хранилка для паролей есть. Система интересная. Думаю, сделаю про неё отдельную заметку.
◽️Focalboard. Ещё одна заявленная альтернатива Trello, Notion, и Asana от авторов бесплатного чат-сервера Mattermost. Выглядит круто, особенно в связке с Mattermost. Но это больше про командную работу, а не персональные заметки. Хотя сейчас заметил в репозитории информацию, что проект для персонального использования останется как есть, а все командные фишки и развитие этого направления переедут в Mattermost как единую платформу.
◽️Standard Notes. Похожий на все остальные подобные приложения, аналоги Notion и Trello. В этом разработчики делают упор на безопасность и приватность. Обещают шифрованное хранение и передачу информации при синхронизации. Внешне особых отличий от остальных не увидел.
◽️Nimbus Note. Видел несколько положительных отзывов на него. Приложение коммерческое с бесплатным тарифным планом. Это не Open Source. Для одиночного использования бесплатного тарифного плана за глаза, как раньше было у Evernote. Выглядит приятнее open source аналогов, что логично для коммерческого продукта.
◽️Notesnook. Авторы позиционируют приложение как замену Evernote. Сделан упор на шифровании хранения и передачи информации. В мобильном приложении есть отдельный пароль на запуск. Можно шарить отдельные заметки и шифровать их паролем. Написан на JavaScript, внешне похож на аналоги.
#заметки
У меня накопился большой список подобных программ. Часть из них я пробовал и писал заметки, часть так и не смотрел. Скорее всего уже не буду, поэтому составляю этот список как есть. Может кому-нибудь пригодится.
◽Joplin. Писал о нём много, как в отдельных заметках (1, 2), так и косвенно упоминал в других. Не нравится тормознутость, отсутствие нормальных таблиц, отсутствие локального шифрования базы.
◽Obsidian. По отзывам одно из самых популярных решений. Я бы советовал начинать именно с него, если ищите что-то подобное. В нём хорошо реализованы связи между документами. Это прям его фишка. В плюсы можно отнести большое количество плагинов для расширения функциональности.
◽Trilium Notes. Тоже популярное приложение, как и предыдущее. Часто давали рекомендации на него. Есть возможность установить на свой сервер и все устройства синхронизировать с него.
◽Appflowy. Авторы позиционируют его как аналог Notion. Из явных плюсов — приложение шустрое, так как написано на Rust и Flutter. С Notion оно никак не конкурирует, потому что функционал заметно ниже. Это просто заметки.
◽Notea. Ещё одна попытка сделать копию Notion. Можно запустить в Docker, базу хранить в S3. Выглядит приятно и современно. Похож на Appflowy. Даже не знаю, как их сравнить. На вид почти одно и то же.
◽CherryTree. Необычная программа для заметок в старом стиле. Написана на C++, поэтому работает очень быстро. Минус один и самый существенный — это локальная программа, мобильной версии нет вообще.
◽MyTetra. Ещё одно олдскульное приложение на C++. Я его начал использовать. Сначала показалось удобным, потому что быстрое с хорошей навигацией. Но когда немного попользовался, заметил много минусов и в итоге забросил. Там был какой-то один жирнющий минус в редакторе, из-за которого я прекратил использование. К сожалению, уже забыл, что не понравилось.
◽️Wreeto. Веб сервис с адаптированным под мобильники интерфейсом. Так что можно через браузер ходить со смартфона. Умеет хранить заметки в формате Markdown и Wiki. Можно настроить Google oAuth. Написано на Ruby, что неплохо, так как аналоги чаще всего на Javascript. Хотя у меня тут нет уверенности, что руби явно быстрее яваскрипта.
◽️PMS - персональная система менеджмента. Тут есть всё — от календаря с ToDo, адресной книги до ведения целей личностного развития. Даже личная хранилка для паролей есть. Система интересная. Думаю, сделаю про неё отдельную заметку.
◽️Focalboard. Ещё одна заявленная альтернатива Trello, Notion, и Asana от авторов бесплатного чат-сервера Mattermost. Выглядит круто, особенно в связке с Mattermost. Но это больше про командную работу, а не персональные заметки. Хотя сейчас заметил в репозитории информацию, что проект для персонального использования останется как есть, а все командные фишки и развитие этого направления переедут в Mattermost как единую платформу.
◽️Standard Notes. Похожий на все остальные подобные приложения, аналоги Notion и Trello. В этом разработчики делают упор на безопасность и приватность. Обещают шифрованное хранение и передачу информации при синхронизации. Внешне особых отличий от остальных не увидел.
◽️Nimbus Note. Видел несколько положительных отзывов на него. Приложение коммерческое с бесплатным тарифным планом. Это не Open Source. Для одиночного использования бесплатного тарифного плана за глаза, как раньше было у Evernote. Выглядит приятнее open source аналогов, что логично для коммерческого продукта.
◽️Notesnook. Авторы позиционируют приложение как замену Evernote. Сделан упор на шифровании хранения и передачи информации. В мобильном приложении есть отдельный пароль на запуск. Можно шарить отдельные заметки и шифровать их паролем. Написан на JavaScript, внешне похож на аналоги.
#заметки
{kind=link}
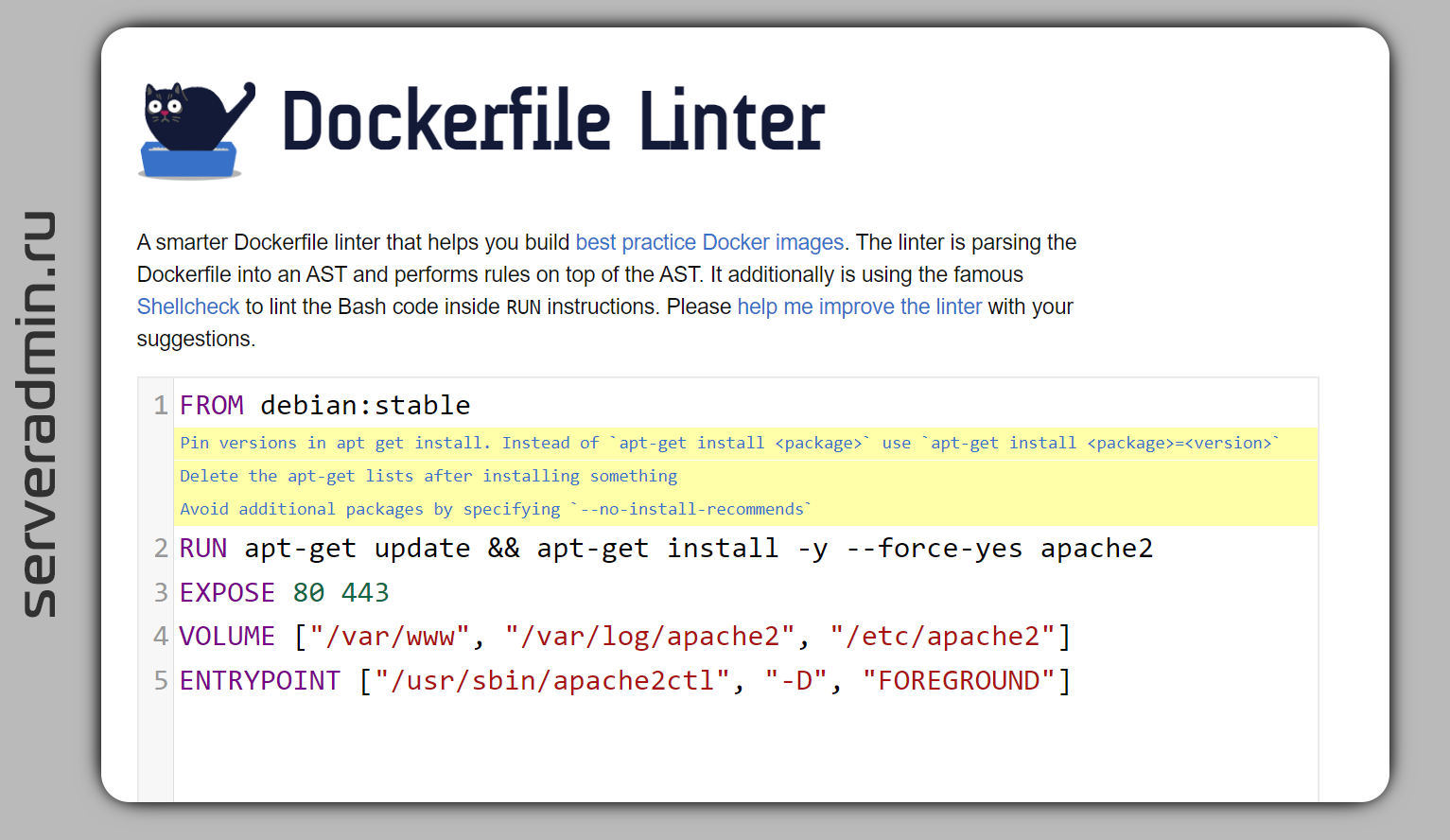
Если вам приходится самому писать Dockerfiles для сборки образов, то рекомендую удобный и функциональный линтер для проверки синтаксиса и общих рекомендаций по оптимизации — Hadolint (Haskell Dockerfile Linter). Он проверяет Dockerfile на предмет использования общепринятых best practice, а shell код в
Hadolint можно использовать как локально, так и с помощью веб сервиса. Работает он чётко, все рекомендации по делу. Покажу несколько примеров. Простенький Dockerfile:
Казалось бы, что тут может быть не так. Проверяем рекомендации hadolint:
-:6 DL3007 warning: Using latest is prone to errors if the image will ever update. Pin the version explicitly to a release tag
-:7 DL3018 warning: Pin versions in apk add. Instead of `apk add <package>` use `apk add <package>=<version>`
Вполне резонные замечания. Он не рекомендует использовать тэг latest и советует явно указывать версию софта в пакетном менеджере. В данном случае это скорее всего не критично. Но в общем случае за этим стоит следить, особенно за latest. Это разом может всё сломать в самый неподходящий момент.
Ещё небольшой пример:
Проверяем:
-:2 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
-:2 DL3009 info: Delete the apt-get lists after installing something
-:2 DL3015 info: Avoid additional packages by specifying `--no-install-recommends`
Здесь та же рекомендация — указывать конкретную версию в установке пакетов. Дальше рекомендация подчистить за работой apt-get. Речь тут скорее всего про что-то типа в самом конце:
Ну и последняя рекомендация добавить ключ
То есть hadolint рекомендует привести
Как видите, все рекомендации адекватные, хотя каких-то явных ошибок тут нет.
#devops #docker
RUN с помощью рекомендаций ShellCheck.Hadolint можно использовать как локально, так и с помощью веб сервиса. Работает он чётко, все рекомендации по делу. Покажу несколько примеров. Простенький Dockerfile:
FROM golang:1.7.3 AS buildWORKDIR /go/src/github.com/alexellis/href-counter/RUN go get -d -v golang.org/x/net/html COPY app.go .RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .FROM alpine:latestRUN apk --no-cache add ca-certificatesWORKDIR /root/COPY --from=build /go/src/github.com/alexellis/href-counter/app .CMD ["./app"]Казалось бы, что тут может быть не так. Проверяем рекомендации hadolint:
# docker run --rm -i hadolint/hadolint < Dockerfile-:6 DL3007 warning: Using latest is prone to errors if the image will ever update. Pin the version explicitly to a release tag
-:7 DL3018 warning: Pin versions in apk add. Instead of `apk add <package>` use `apk add <package>=<version>`
Вполне резонные замечания. Он не рекомендует использовать тэг latest и советует явно указывать версию софта в пакетном менеджере. В данном случае это скорее всего не критично. Но в общем случае за этим стоит следить, особенно за latest. Это разом может всё сломать в самый неподходящий момент.
Ещё небольшой пример:
FROM debian:stableRUN apt-get update && apt-get install -y --force-yes apache2EXPOSE 80 443VOLUME ["/var/www", "/var/log/apache2", "/etc/apache2"]ENTRYPOINT ["/usr/sbin/apache2ctl", "-D", "FOREGROUND"]Проверяем:
# docker run --rm -i hadolint/hadolint < Dockerfile-:2 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
-:2 DL3009 info: Delete the apt-get lists after installing something
-:2 DL3015 info: Avoid additional packages by specifying `--no-install-recommends`
Здесь та же рекомендация — указывать конкретную версию в установке пакетов. Дальше рекомендация подчистить за работой apt-get. Речь тут скорее всего про что-то типа в самом конце:
&& apt-get clean \&& rm -rf /var/lib/apt/lists/*Ну и последняя рекомендация добавить ключ
--no-install-recommends в apt-get, что тоже не лишено смысла. То есть hadolint рекомендует привести
RUN к следующему виду:RUN apt-get update && \apt-get install -y --force-yes --no-install-recommends apache2=2.4 \&& apt-get clean && rm -rf /var/lib/apt/lists/*Как видите, все рекомендации адекватные, хотя каких-то явных ошибок тут нет.
#devops #docker
{kind=link}
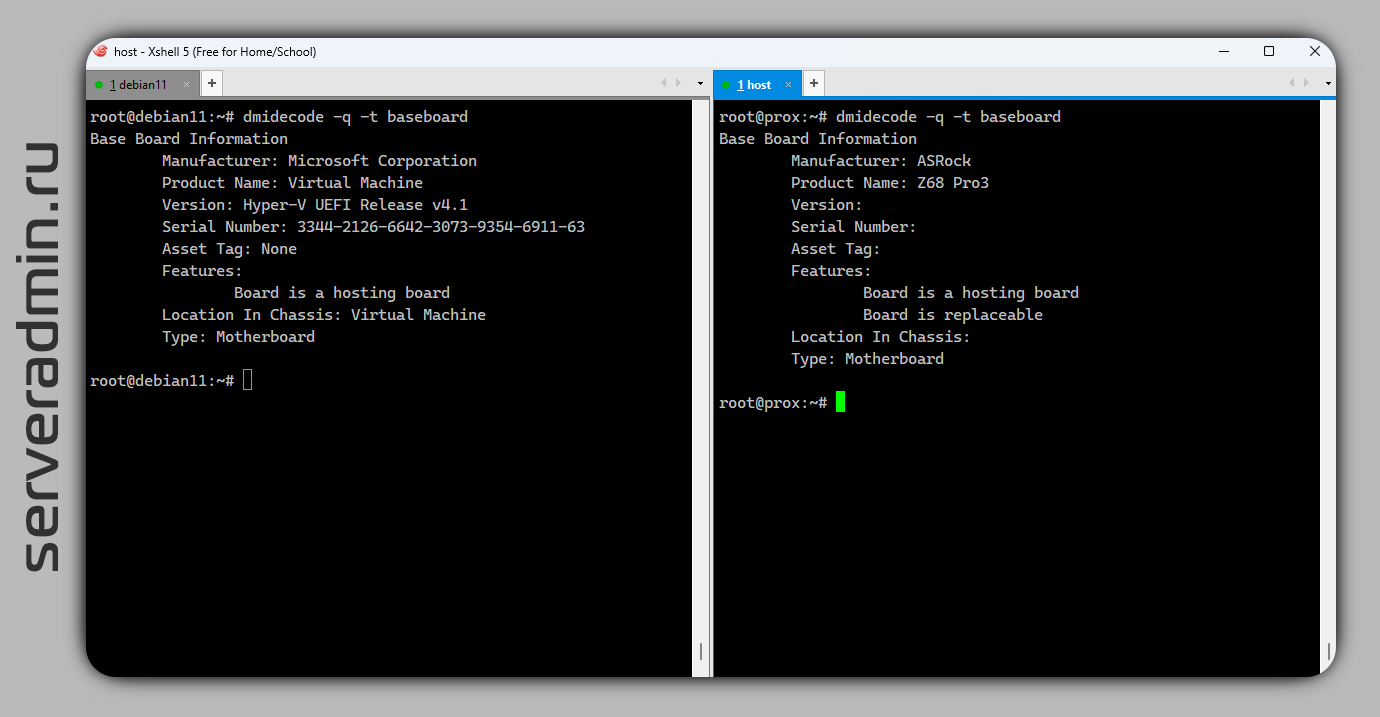
Среди большинства программ в Linux для сбора информации об оборудовании и системе, в стороне стоит dmidecode. Она, в отличие, к примеру, от lshw, hwinfo, inxi, не опрашивает оборудование, а берёт информацию из таблицы DMI (Desktop Management Interface) или SMBIOS. Поэтому все запросы выполняются практически мгновенно. Плюс к её использованию — она практически всегда есть в базовых дистрибутивах. Не припоминаю, чтобы хоть раз приходилось её ставить отдельно.
Demidecode легко использовать, так как у неё немного параметров. В основном это тип аппаратного устройства, о котором мы хотим получить информацию. Вот полный список :
Наиболее популярные идентификаторы объединены кодовыми словами:
То есть информацию о процессоре смотрим:
или
С помощью dmidecode удобно централизованно собирать информацию о каких-то характеристиках. Например, смотрим информацию о процессоре:
Ничего лишнего, только запрошенная информация. Полный список ключевых слов для запроса можно увидеть в выводе команды:
Вывод dmidecode имеет смысл упрощать ключом
❗️Dmidecode нормально показывает информацию, когда запущен на реальном железе. Если его запускать в виртуальных машинах, то часто информацию о тех или иных компонентах в DMI не будет. Например, о процессоре или материнской плате. Наличие информации будет зависеть от гипервизора и его настроек.
#linux #железо
Demidecode легко использовать, так как у неё немного параметров. В основном это тип аппаратного устройства, о котором мы хотим получить информацию. Вот полный список :
0 BIOS1 Система2 Материнская плата3 Корпус4 Процессор5 Контроллер памяти6 Модуль памяти7 Кэш8 Коннекторы портов9 Системные слоты10 Интегрированные устройства11 Строки OEM12 Параметры системной конфигурации13 Язык BIOS14 Ассоциации групп15 Журнал системных событий16 Массив физической памяти17 Устройство памяти18 32-битные ошибки доступа к памяти19 Отображенный адрес массива памяти20 Отображенный адрес устройства памяти21 Встроенное указывающее устройство22 Батарея мобильного устройства23 Устройство сброса состояния системы24 Устройства безопасности25 Управление питанием системы26 Датчик напряжения27 Устройство охлаждения28 Датчик температуры29 Датчик тока30 Механизм удаленного доступа31 Сервисы проверки целостности данных загрузки32 Загрузочные устройства33 64-битные ошибки доступа к памяти34 Устройство управления35 Компонент устройства управления36 Граничные данные устройства управления37 Канал памяти38 Устройство IPMI39 Блок питания40 Дополнительная информация41 Дополнительная информация об интегрированных устройствах42 Хост-интерфейс контроллера управления126 Деактивированная строка127 Маркер конца таблицыНаиболее популярные идентификаторы объединены кодовыми словами:
bios 1, 13system 1, 12, 15, 23, 32baseboard 2, 10, 41chassis 3processor 4memory 5, 6, 16, 17cache 7connector 8slot 9То есть информацию о процессоре смотрим:
# dmidecode -t 4или
# dmidecode -t processorС помощью dmidecode удобно централизованно собирать информацию о каких-то характеристиках. Например, смотрим информацию о процессоре:
# dmidecode -s processor-versionIntel(R) Core(TM) i5-2500K CPU @ 3.30GHz# dmidecode -s processor-frequency4200 MHzНичего лишнего, только запрошенная информация. Полный список ключевых слов для запроса можно увидеть в выводе команды:
# dmidecode -sВывод dmidecode имеет смысл упрощать ключом
-q, который убирает некоторую техническую информацию, которая чаще всего не нужна. Например, убирает информацию о handle (уникальный идентификатор железа) и мета данных.❗️Dmidecode нормально показывает информацию, когда запущен на реальном железе. Если его запускать в виртуальных машинах, то часто информацию о тех или иных компонентах в DMI не будет. Например, о процессоре или материнской плате. Наличие информации будет зависеть от гипервизора и его настроек.
#linux #железо
{kind=link}
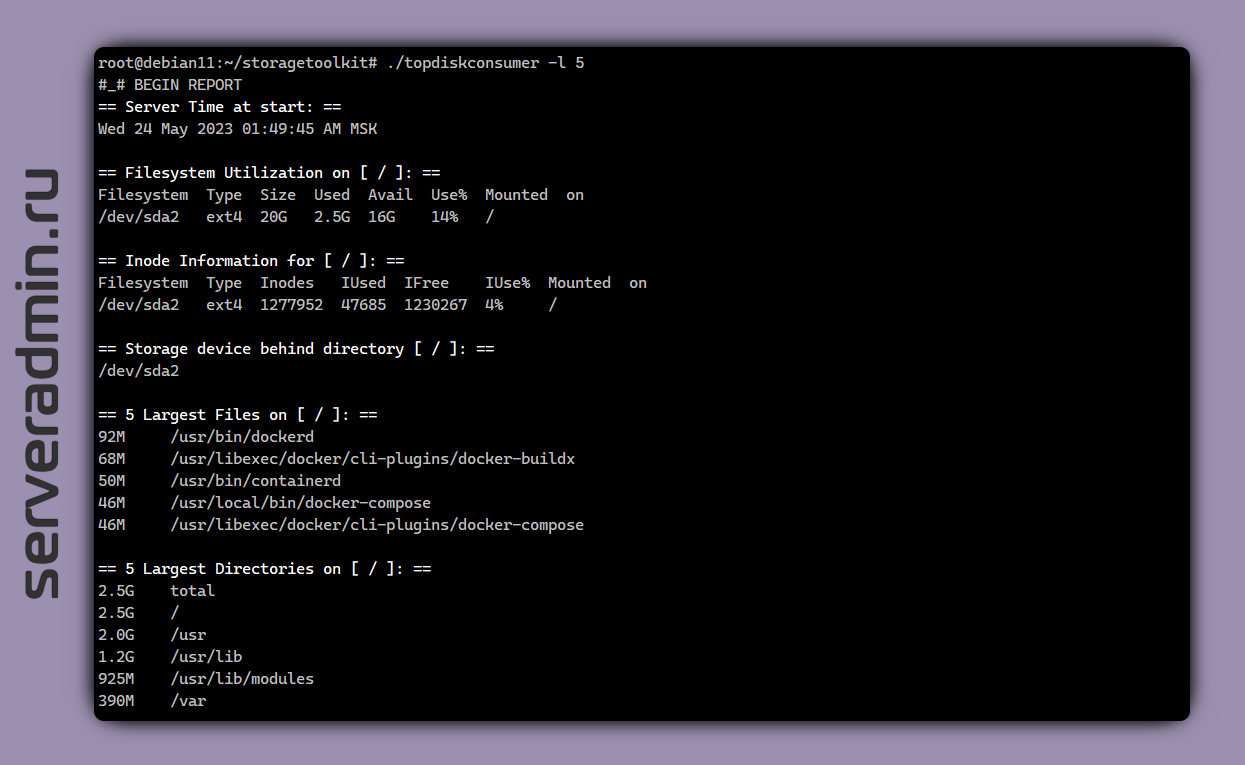
Предлагаю вам сохранить в закладки простой и удобный скрипт для Linux, который поможет быстро разобраться на сервере, кто и чем занял свободное место — topdiskconsumer. Единственный файл в репозитории, кроме README и есть этот скрипт.
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
Топ 20 файлов:
Топ 20 старых файлов:
Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
Там много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
# du -hcx --max-depth=6 / 2>/dev/null | sort -rh | head -n 20Топ 20 файлов:
# find / -mount -ignore_readdir_race -type f -exec du -h "{}" + 2>&1 \| sort -rh | head -n 20Топ 20 старых файлов:
# find / -mount -ignore_readdir_race -type f -mtime +30 -exec du -h "{}" + 2>&1 \| sort -rh | head -20Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
-l. Описание всех возможностей можно посмотреть вот так:# ./topdiskconsumer --helpТам много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
{kind=link}
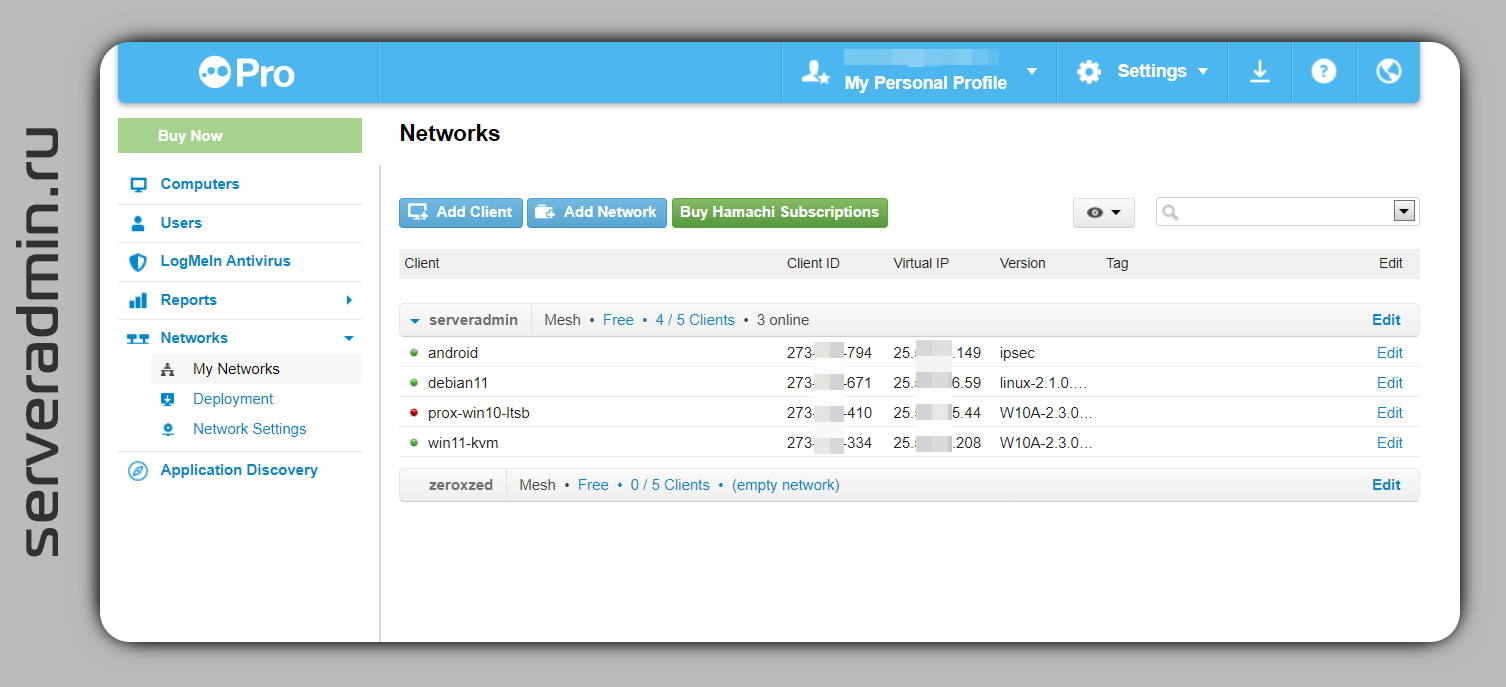
Думаю, многие из вас слышали или пользовались такими сервисами как Hamachi и Logmein. Если я не ошибаюсь, то раньше это были разные продукты. Hamachi использовался для быстрой настройки локальной сети через интернет. Я её использовал в 2000-е для сетевой игры по интернету. Например, в те же Герои 3. А Logmein — это сервис, похожий на Teamviewer, но появился раньше. Там тоже можно было подключаться к компьютеру, передавать файлы и т.д. И всё это управлялось через личный кабинет в браузере. Было удобно.
Одно время эти сервисы были с бесплатными тарифными планами. Я пользовался ими. Потом бесплатные тарифные планы убрали, пользоваться перестал. На днях решил посмотреть, как они поживают. Старая учётка сохранилась. Как оказалось, для Hamachi вернули бесплатный тарифный план на 5 устройств для каждой отдельной сети. Ограничений по количеству самих сетей не увидел.
Решил посмотреть, как это всё работает сейчас. Сервис довольно удобный. Всё управление возможно через личный кабинет. В единую сеть можно объединить Windows, Linux, MacOS машины и смартфоны на Android и iOS. Я проверил и добавил 2 виндовые машины, одну линуксовую без иксов, только с консолью (ставится консольный клиент из deb или rpm пакета), и свой смартфон на Android. Всё настроил довольно быстро. Немного повозился только со смартфоном. Там настраивается штатное VPN соединение с сервером Hamachi. Для этого надо закинуть личный сертификат на устройство и использовать его в настройки подключения через IPSEC Xauth RSA. Но можно было и попроще сделать через PPTP.
В итоге все 4 устройства оказались в общей локальной сети. Можно обмениваться файлами или какие-то сервисы запускать, типа Syncthing. На выходе удобный функционал в бесплатном тарифном плане. Для личного использования вполне достаточный.
Личный кабинет регистрировать на https://www.logmein.com, описание функционала Hamachi на отдельном сайте https://www.vpn.net. После регистрации в личном кабинете, вы можете добавить компьютеры в раздел Computers, это для функционала удалённого управления. Там бесплатного тарифа нет, только триал на 30 дней. А в разделе Networks можно создать свою сеть и добавить туда до 5-ти устройств бесплатно. Сетей может быть много.
Похожая функциональность есть у сервиса Tailscale, про который я несколько заметок делал. Там в бесплатном тарифном плане было 20 устройств и не было поддержки мобильных клиентов. Сейчас зашёл проверить, уже после написания этой заметки, а в бесплатном тарифном плане 100 устройств и поддержка смартфонов. Получается по всем параметрам лучше Hamachi, кроме некоторых нюансов. В Hamachi вы очень просто и быстро создаёте локальную сеть и закидываете туда клиентов. Сетей может быть несколько, клиенты будут изолированы друг от друга и видеть только участников своей сети. В Tailscale не помню, каким образом реализован этот же функционал. В таком простом и явном виде я его не помню.
#vpn #бесплатно
Одно время эти сервисы были с бесплатными тарифными планами. Я пользовался ими. Потом бесплатные тарифные планы убрали, пользоваться перестал. На днях решил посмотреть, как они поживают. Старая учётка сохранилась. Как оказалось, для Hamachi вернули бесплатный тарифный план на 5 устройств для каждой отдельной сети. Ограничений по количеству самих сетей не увидел.
Решил посмотреть, как это всё работает сейчас. Сервис довольно удобный. Всё управление возможно через личный кабинет. В единую сеть можно объединить Windows, Linux, MacOS машины и смартфоны на Android и iOS. Я проверил и добавил 2 виндовые машины, одну линуксовую без иксов, только с консолью (ставится консольный клиент из deb или rpm пакета), и свой смартфон на Android. Всё настроил довольно быстро. Немного повозился только со смартфоном. Там настраивается штатное VPN соединение с сервером Hamachi. Для этого надо закинуть личный сертификат на устройство и использовать его в настройки подключения через IPSEC Xauth RSA. Но можно было и попроще сделать через PPTP.
В итоге все 4 устройства оказались в общей локальной сети. Можно обмениваться файлами или какие-то сервисы запускать, типа Syncthing. На выходе удобный функционал в бесплатном тарифном плане. Для личного использования вполне достаточный.
Личный кабинет регистрировать на https://www.logmein.com, описание функционала Hamachi на отдельном сайте https://www.vpn.net. После регистрации в личном кабинете, вы можете добавить компьютеры в раздел Computers, это для функционала удалённого управления. Там бесплатного тарифа нет, только триал на 30 дней. А в разделе Networks можно создать свою сеть и добавить туда до 5-ти устройств бесплатно. Сетей может быть много.
Похожая функциональность есть у сервиса Tailscale, про который я несколько заметок делал. Там в бесплатном тарифном плане было 20 устройств и не было поддержки мобильных клиентов. Сейчас зашёл проверить, уже после написания этой заметки, а в бесплатном тарифном плане 100 устройств и поддержка смартфонов. Получается по всем параметрам лучше Hamachi, кроме некоторых нюансов. В Hamachi вы очень просто и быстро создаёте локальную сеть и закидываете туда клиентов. Сетей может быть несколько, клиенты будут изолированы друг от друга и видеть только участников своей сети. В Tailscale не помню, каким образом реализован этот же функционал. В таком простом и явном виде я его не помню.
#vpn #бесплатно
{kind=link}
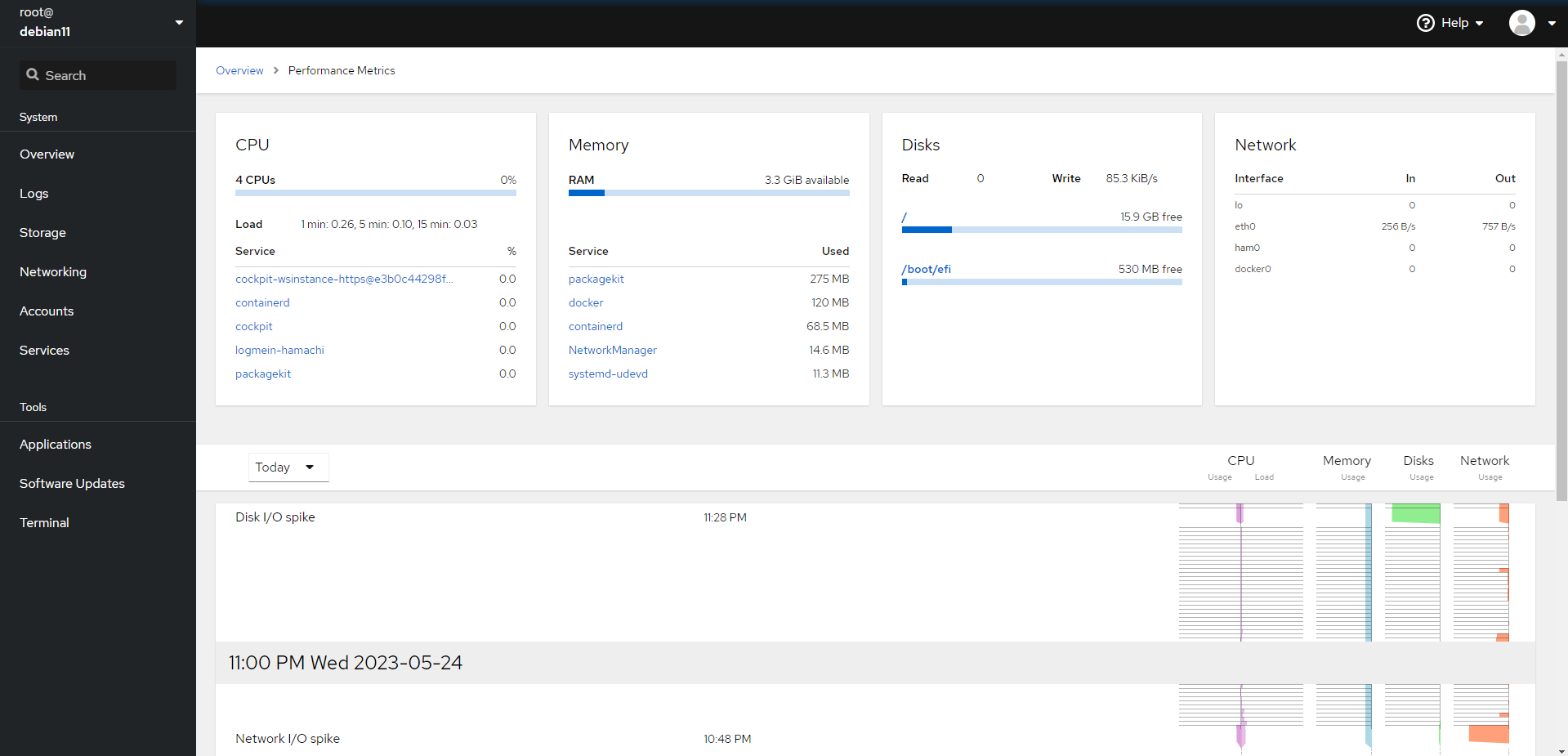
На днях читал новости от Red Hat. Там был анонс новой версии web console с кучей интересных обновлений. Я ещё такой думаю, что за веб консоль, у них вроде cockpit всегда была. Оказалось это она и есть. Немного взгрустнул о Centos. Всё же хорошая система была с кучей дополнительных продуктов от Red Hat.
Думаю, дай-ка проверю, а не работает ли, случайно, cockpit на Debian. Не стал ничего искать, просто зашёл на виртуалку и проверил:
Оказалось, что эта веб панель не только под Debian работает, но и живёт в стандартных репозиториях. Я сам лично никогда ей не пользовался в проде, как и webmin, но отдаю должное обоим. Это неплохие панели, которые решают многие поставленные задачи. Webmin монструозен и немного неповоротлив с кучей модулей,
Cockpit проста, быстра и лаконична. Red Hat её развивает и всячески продвигает. Там есть в том числе удобный интерфейс для управления виртуальными машинами KVM. Для базовой функциональности достаточно, не обязательно ставить Proxmox.
В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
Функциональность cockpit расширяется с помощью модулей, которые устанавливаются как отдельные пакеты. Для управления виртуальными машинами есть модуль cockpit-machines, который тоже присутствует в репозиториях Debian:
В один веб интерфейс cockpit можно собрать множество серверов, настроив к ним подключение по SSH. Если вам нужна веб панель управления сервером Linux, то рекомендую cockpit. Я ничего удобнее не видел.
⇨ Документация
#linux
Думаю, дай-ка проверю, а не работает ли, случайно, cockpit на Debian. Не стал ничего искать, просто зашёл на виртуалку и проверил:
# apt install cockpitОказалось, что эта веб панель не только под Debian работает, но и живёт в стандартных репозиториях. Я сам лично никогда ей не пользовался в проде, как и webmin, но отдаю должное обоим. Это неплохие панели, которые решают многие поставленные задачи. Webmin монструозен и немного неповоротлив с кучей модулей,
Cockpit проста, быстра и лаконична. Red Hat её развивает и всячески продвигает. Там есть в том числе удобный интерфейс для управления виртуальными машинами KVM. Для базовой функциональности достаточно, не обязательно ставить Proxmox.
В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
Функциональность cockpit расширяется с помощью модулей, которые устанавливаются как отдельные пакеты. Для управления виртуальными машинами есть модуль cockpit-machines, который тоже присутствует в репозиториях Debian:
# apt install cockpit-machinesВ один веб интерфейс cockpit можно собрать множество серверов, настроив к ним подключение по SSH. Если вам нужна веб панель управления сервером Linux, то рекомендую cockpit. Я ничего удобнее не видел.
⇨ Документация
#linux
{kind=link}
С вами бывало такое, что вы вместо ls в терминале Linux набирали sl? Оказывается, это популярная ошибка, тему которой развили и написали приложение sl, которое можно поставить через стандартный менеджер пакетов. Оно есть в deb, и в rpm дистрибутивах:
SL — Steam Locomotive. Теперь при ошибке в терминале, к вам приедет ASCII локомотив. С ключом
В Debian приложение будет установлено в
Не знал об этом.
#игра #terminal #linux
# dnf install sl# apt install slSL — Steam Locomotive. Теперь при ошибке в терминале, к вам приедет ASCII локомотив. С ключом
-l он будет маленьким, с -F он будет летать, а с -e его можно будет остановить по Ctrl+C. В Debian приложение будет установлено в
/usr/games/sl. Этот путь не включен в $PATH для root, так что паровоз не поедет. А вот у обычных пользователей по дефолту он добавлен. $ echo $PATH/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/gamesНе знал об этом.
#игра #terminal #linux
{kind=link}
На днях реализовал мониторинг безопасности Linux сервера с помощью Lynis и Zabbix. Я давно планировал реализовать что-то подобное, но всё руки не доходили. Lynis делает неплохие проверки, которые легко читаются и понимаются. В нём есть хорошая база, на которую удобно ориентироваться.
Изначально планировал написать полноценную статью, но, как обычно, не нашёл для этого времени. Целый день потратил на реализацию, так что когда напишу статью — неизвестно. Пусть хоть заметка будет. Может кому-то пригодиться.
Основная идея мониторинга — получать оповещения от Zabbix на тему безопасности. В первую очередь интересуют пакеты с уязвимостями, во вторую — права доступа на системные бинари и директории. Ну и всё остальное тоже не будет лишним. Lynis в этом плане хорош, так как закрывает базу. Про его возможности читайте отдельно, не буду сейчас останавливаться.
Основная проблема данной задачи — длительность проверки Lynis. Она может длиться минуту-две. Из-за этого неудобно запускать проверку через Zabbix, ждать вывода и потом его парсить. Нужны очень большие таймауты. К тому же вывод у Lynis очень длинный. Пришлось идти другим путём, менее удобным и гибким — писать bash скрипт, запускать его по таймеру и анализировать вывод.
Со скриптом тоже есть варианты. Можно результат работы скрипта обработать и сразу отправить через zabbix_sender. Отмёл этот подход, потому что проверки выполнять часто не имеет смысла, они слишком ресурсозатратные и долгие. А если по какой-то причине из-за потери пакетов sender не отправит результат, то до следующей проверки он не появится в мониторинге, а проверки редкие.
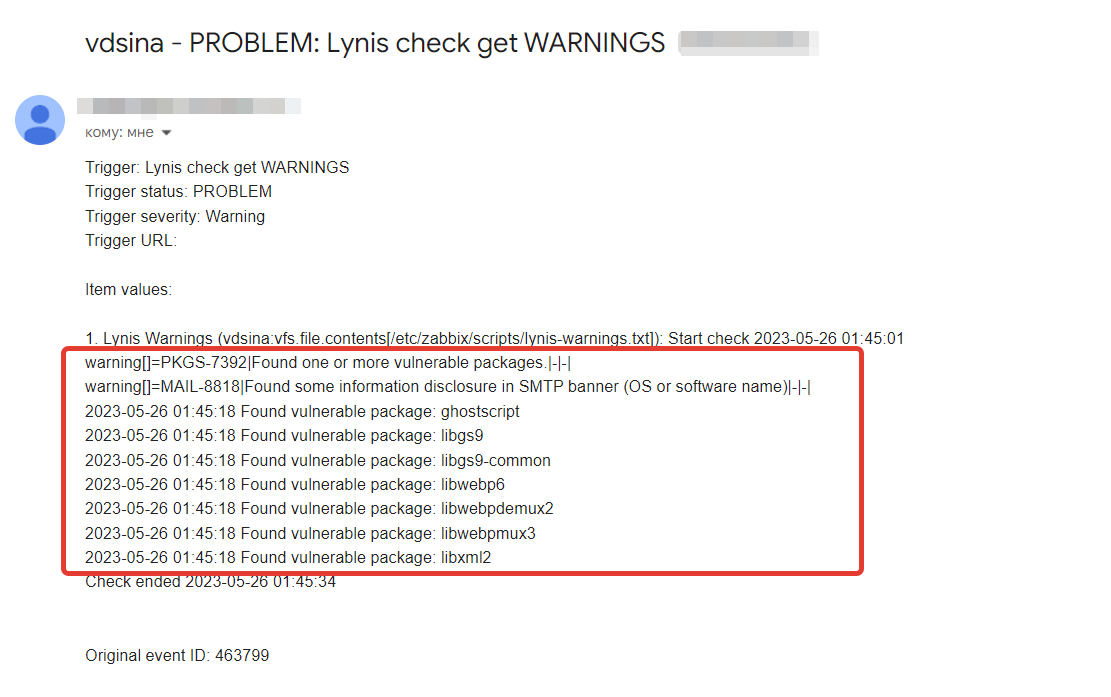
В итоге написал скрипт, результат его работы вывел в 2 текстовых файла:
◽
◽
Сам скрипт выложил на pastebin. Я положил его в
Далее сделал простой шаблон под Zabbix 6.0 с двумя айтемами типа лог, которые забирают значения из
Для того, чтобы отключить ту или иную проверку на хосте, надо в файл конфигурации Lynis, который живёт по адресу
Отладка работы примерно так и выглядит. Запускаете скрипт, смотрите результат. Будут какие-то замечания. Сделайте для них исключение и снова запустите скрипт. Так и проверяйте всю последовательность действий вплоть до оповещений. Потом, соответственно, так же на хосте настраиваются исключения, если какие-то проверки для него неактуальны. Например, тест tls сертификатов. Он по какой-то причине очень долго идёт. Я его отключил.
Заметка получилась немного сумбурная. Тема не для новичков, а для тех, кто умеет работать с Zabbix и bash. В коротком очерке её не раскрыть. Надеюсь, получится написать статью. Там уже подробно всё распишу.
Мне понравился результат. Удобно сразу получить информацию о проблеме на почту. Подробную информацию по коду ошибки можно получить либо в полном логе Lynis на самом сервере в файлах /var/log/lynis.log и /var/log/lynis-report.dat или на сайте https://cisofy.com/lynis/controls/ в разделе с описанием проверок.
#zabbix
Изначально планировал написать полноценную статью, но, как обычно, не нашёл для этого времени. Целый день потратил на реализацию, так что когда напишу статью — неизвестно. Пусть хоть заметка будет. Может кому-то пригодиться.
Основная идея мониторинга — получать оповещения от Zabbix на тему безопасности. В первую очередь интересуют пакеты с уязвимостями, во вторую — права доступа на системные бинари и директории. Ну и всё остальное тоже не будет лишним. Lynis в этом плане хорош, так как закрывает базу. Про его возможности читайте отдельно, не буду сейчас останавливаться.
Основная проблема данной задачи — длительность проверки Lynis. Она может длиться минуту-две. Из-за этого неудобно запускать проверку через Zabbix, ждать вывода и потом его парсить. Нужны очень большие таймауты. К тому же вывод у Lynis очень длинный. Пришлось идти другим путём, менее удобным и гибким — писать bash скрипт, запускать его по таймеру и анализировать вывод.
Со скриптом тоже есть варианты. Можно результат работы скрипта обработать и сразу отправить через zabbix_sender. Отмёл этот подход, потому что проверки выполнять часто не имеет смысла, они слишком ресурсозатратные и долгие. А если по какой-то причине из-за потери пакетов sender не отправит результат, то до следующей проверки он не появится в мониторинге, а проверки редкие.
В итоге написал скрипт, результат его работы вывел в 2 текстовых файла:
◽
lynis-exitcode.txt — в Lynis есть отличный параметр error-on-warnings=yes. Если его активировать, то статус выхода lynis после проверки будет ненулевым, если есть какие-то замечания по безопасности. Скрипт выводит exit code команды в этот файл. ◽
lynis-warnings.txt — в этот файл через парсинг лога Lynis я вывожу все его замечания и список пакетов с уязвимостями. Сам скрипт выложил на pastebin. Я положил его в
/etc/zabbix/scripts, туда же кладу логи. Настройте выполнение скрипта через systemd.timers. Мне кажется, достаточно раз в час выполнять или даже реже, пару раз в день. Далее сделал простой шаблон под Zabbix 6.0 с двумя айтемами типа лог, которые забирают значения из
lynis-exitcode.txt и lynis-warnings.txt. И там же один триггер, который срабатывает, если в файле lynis-warnings.txt нет строки All is OK, которую туда пишет скрипт, если exit code после работы Lynis равен 0 (т.е. всё в порядке). Когда срабатывает триггер, на почту прилетает оповещение, в тексте которого есть информация из lynis-warnings.txt, куда записаны предупреждения и список проблемных пакетов.Для того, чтобы отключить ту или иную проверку на хосте, надо в файл конфигурации Lynis, который живёт по адресу
/etc/lynis/default.prf добавить исключения по одному в каждой строке:skip-test=CRYP-7902skip-test=PKGS-7392skip-test=MAIL-8818Отладка работы примерно так и выглядит. Запускаете скрипт, смотрите результат. Будут какие-то замечания. Сделайте для них исключение и снова запустите скрипт. Так и проверяйте всю последовательность действий вплоть до оповещений. Потом, соответственно, так же на хосте настраиваются исключения, если какие-то проверки для него неактуальны. Например, тест tls сертификатов. Он по какой-то причине очень долго идёт. Я его отключил.
Заметка получилась немного сумбурная. Тема не для новичков, а для тех, кто умеет работать с Zabbix и bash. В коротком очерке её не раскрыть. Надеюсь, получится написать статью. Там уже подробно всё распишу.
Мне понравился результат. Удобно сразу получить информацию о проблеме на почту. Подробную информацию по коду ошибки можно получить либо в полном логе Lynis на самом сервере в файлах /var/log/lynis.log и /var/log/lynis-report.dat или на сайте https://cisofy.com/lynis/controls/ в разделе с описанием проверок.
#zabbix
{kind=link}
Ребят, чтобы вы чувствовали себя увереннее на собеседованиях, перевёл вам забавный диалог из Silicon Valley, где на работу принимают сетевого администратора.
Silicon Valley - Network Administrator
⇨ https://www.youtube.com/watch?v=Abwd3VQTQrk
Он нормально пояснил, кем себя видит в этой компании. И почему на работу должны взять именно его. Перевод мой, так что не судите строго. Возможно, где-то и ошибся. Меня его речь очень впечатлила, захотелось перевести. Сам фильм не смотрел, кроме отдельных фрагментов, типа этого.
- Можете рассказать, кем вы видите себя в нашей компании? Чем будете заниматься?
- Чем буду заниматься? Я буду создавать архитектуру небезопасных сетей (system architecture networking insecurity). И никто в этом офисе не сможет упрекнуть меня в чём-то по этой теме.
- Окей, интересно было узнать.
- Но можете ли вы это оценить? Пока вы были заняты гендерными исследованиями и пели акапеллу Сары Лоуренс, я получал root доступ к серверам NSA (АНБ, агентство гос. безопасности). Я был в одном клике от начала второй иранской революции.
- Вообще-то, я ходил в Вассар (колледж какой-то).
- Я предотвращаю межсайтовый скриптинг. Я мониторю DDoS-атаки, откатываю базы данных и ищу ошибки в обработке транзакций. Интернет передает полпетабайта данных каждую минуту. Ты хоть представляешь, как это происходит? Как твои порнографические нолики и единички каждый день попадают тебе в смартфон? Каждый чувак исходит на говно, если его dubstep Skrillex remix качается дольше 12-ти секунд. И это не магия. Это навыки и тяжёлый труд. И такие как я следят, чтобы пакеты не бились по пути. Так чем я занимаюсь? Я слежу за тем, чтобы один кривой конфиг в одном конкретном месте не разорил к ебеням вашу контору. Вот, млять, чем я занимаюсь.
#юмор
Silicon Valley - Network Administrator
⇨ https://www.youtube.com/watch?v=Abwd3VQTQrk
Он нормально пояснил, кем себя видит в этой компании. И почему на работу должны взять именно его. Перевод мой, так что не судите строго. Возможно, где-то и ошибся. Меня его речь очень впечатлила, захотелось перевести. Сам фильм не смотрел, кроме отдельных фрагментов, типа этого.
- Можете рассказать, кем вы видите себя в нашей компании? Чем будете заниматься?
- Чем буду заниматься? Я буду создавать архитектуру небезопасных сетей (system architecture networking insecurity). И никто в этом офисе не сможет упрекнуть меня в чём-то по этой теме.
- Окей, интересно было узнать.
- Но можете ли вы это оценить? Пока вы были заняты гендерными исследованиями и пели акапеллу Сары Лоуренс, я получал root доступ к серверам NSA (АНБ, агентство гос. безопасности). Я был в одном клике от начала второй иранской революции.
- Вообще-то, я ходил в Вассар (колледж какой-то).
- Я предотвращаю межсайтовый скриптинг. Я мониторю DDoS-атаки, откатываю базы данных и ищу ошибки в обработке транзакций. Интернет передает полпетабайта данных каждую минуту. Ты хоть представляешь, как это происходит? Как твои порнографические нолики и единички каждый день попадают тебе в смартфон? Каждый чувак исходит на говно, если его dubstep Skrillex remix качается дольше 12-ти секунд. И это не магия. Это навыки и тяжёлый труд. И такие как я следят, чтобы пакеты не бились по пути. Так чем я занимаюсь? Я слежу за тем, чтобы один кривой конфиг в одном конкретном месте не разорил к ебеням вашу контору. Вот, млять, чем я занимаюсь.
#юмор
YouTube
Silicon Valley - Network Administrator
Hilarious take on being a Network Administrator on HBO's show Silicon Valley.
Ещё немного полезных для сисадминов и девопсов бесплатных курсов со stepik. Я и не думал, что столько народу их знает и проходит. Эта площадка как-то не на слуху. Мало от кого слышал про неё.
Сегодня предлагаю изучать Python. Я когда-то проходил небольшой курс по нему, кое-что программировал. Сделал бота для TG, разобрался, как там всё работает. Но в итоге забросил. В работе особо не нужно. Привык всё на bash писать. Для моих задач хватает. Но если надо какой-то python код посмотреть, разобраться, что там происходит и внести небольшие правки, то могу это сделать. В принципе, это как раз тот уровень, что нужен мне.
◽"Поколение Python": курс для начинающих. Курс разработан для школьников, для тех, кто изучает программирование с нуля. В нём даётся база: ввод-вывод, условия, типы данных, циклы, списки, функции. Ровно то, что нужно и нам в своей работе. Курс свежий, писался в 2020 году, обновляется, нет плохих отзывов. Победитель конкурса Stepik Awards 2020 в номинации "Лучший бесплатный онлайн-курс размещенный на платформе Stepik". За прохождение дают именной сертификат.
◽Программирование на Python. Курс от Института биоинформатики, созданного на базе Санкт-Петербургского академического университета РАН и с поддержкой JetBrains. У них в Питере офисы по соседству. Я его сам где-то на треть прошёл и забросил. Как и первый курс, этот адаптирован для новичков непрограммистов, поэтому даётся база. Он значительно короче первого курса, так что если нужны какие-то обзорные знания, то можно пройти его. А потом закрепить первым.
◽Телеграм-боты на Python и AIOgram. Более прикладной курс для тех, кто уже освоил базу. Здесь учат настраивать окружение, использовать IDE (VS Code), использоваться GIT, работать с API, деплоить код и т.д. Как раз тот уровень, который будет достаточен для инфраструктурщиков.
#обучение #бесплатно #python
Сегодня предлагаю изучать Python. Я когда-то проходил небольшой курс по нему, кое-что программировал. Сделал бота для TG, разобрался, как там всё работает. Но в итоге забросил. В работе особо не нужно. Привык всё на bash писать. Для моих задач хватает. Но если надо какой-то python код посмотреть, разобраться, что там происходит и внести небольшие правки, то могу это сделать. В принципе, это как раз тот уровень, что нужен мне.
◽"Поколение Python": курс для начинающих. Курс разработан для школьников, для тех, кто изучает программирование с нуля. В нём даётся база: ввод-вывод, условия, типы данных, циклы, списки, функции. Ровно то, что нужно и нам в своей работе. Курс свежий, писался в 2020 году, обновляется, нет плохих отзывов. Победитель конкурса Stepik Awards 2020 в номинации "Лучший бесплатный онлайн-курс размещенный на платформе Stepik". За прохождение дают именной сертификат.
◽Программирование на Python. Курс от Института биоинформатики, созданного на базе Санкт-Петербургского академического университета РАН и с поддержкой JetBrains. У них в Питере офисы по соседству. Я его сам где-то на треть прошёл и забросил. Как и первый курс, этот адаптирован для новичков непрограммистов, поэтому даётся база. Он значительно короче первого курса, так что если нужны какие-то обзорные знания, то можно пройти его. А потом закрепить первым.
◽Телеграм-боты на Python и AIOgram. Более прикладной курс для тех, кто уже освоил базу. Здесь учат настраивать окружение, использовать IDE (VS Code), использоваться GIT, работать с API, деплоить код и т.д. Как раз тот уровень, который будет достаточен для инфраструктурщиков.
#обучение #бесплатно #python
Stepik: online education
"Поколение Python": курс для начинающих
Курс с кучей тренировочных задач, удобный как для самостоятельного изучения, так и для работы в группе в рамках внеурочной деятельности.
Не написал ни одной заметки про очень популярный инструмент тестирования пропускной способности сети — iperf. Сам я им пользуюсь регулярно, а начал ещё со времен работы в тех. поддержке Windows.
Iperf мультиплатформенная программа, работающая в режиме клиент-сервер. Вы можете запустить сервер на Linux, а тестировать скорость, подключаясь к нему с Windows или Android. И наоборот. Достаточно при запуске выбрать режим, в котором он будет работать: сервер или клиент.
Ставим iperf на сервер:
Запускаем в режиме сервера:
По умолчанию он слушает TCP порт 5201. Не забудьте открыть его на firewall.
Ставим на Windows систему:
Открываем приложение iPerf Network Speed Test Benchmark и, указав ip адрес сервера, запускаем тест. Это GUI приложение на базе iperf от стороннего разработчика. За оригинальной версией надо отправиться на официальный сайт и скачать консольную версию.
Распаковываем архив. Там будет приложение. Запускаем cmd, переходим в эту директорию и запускаем тестирование:
Всю информацию о процессе и результатах увидите тут же в консоли. Причём всё это в очень наглядном виде.
Результат работы Iperf очень удобно использовать для мониторинга. Она умеет выводить результат работы в файл, в том числе в json формате.
Дальше результат можно распарсить любой системой мониторинга.
Но не увлекайтесь мониторингом пропускной способности. Во-первых, это не очень достоверные данные, так как результат зависит от множества параметров. Во-вторых, во время теста вы будете занимать весь канал, что может навредить работе остальных сервисов. Надо настраивать приоритизацию трафика. Но если её настроить и отдать iperf наименьший приоритет, то и достоверность тестов будет сомнительной. В общем, это нетривиальная задача. Я много раз к ней подходил и пришёл к мнению, что лучше не заниматься этим в автоматическом режиме. Потом не понятно, как оценить достоверность результатов и что в связи с этим делать. Речь идёт про тестирование канала в интернет. В локальной сети с этим проще.
Ещё немного полезных параметров iperf. По умолчанию, тестирование длится 10 секунд. Можно увеличить этот интервал, указав его в секундах:
Можно вместо времени указать число байт, которое будет передано. Пример для 100 мегабайт:
Можно запустить проверку в несколько потоков для лучшей утилизации канала:
Ключи можно комбинировать. Они одни и те же для всех платформ. Точно так же можно поднять сервер на Windows и подключаться к нему линуксом.
А вы чем обычно тестируете скорость между хостами? Я кроме iperf ничего и не знаю, не использую.
⇨ Сайт / Исходники
#network
Iperf мультиплатформенная программа, работающая в режиме клиент-сервер. Вы можете запустить сервер на Linux, а тестировать скорость, подключаясь к нему с Windows или Android. И наоборот. Достаточно при запуске выбрать режим, в котором он будет работать: сервер или клиент.
Ставим iperf на сервер:
# apt install iperf3Запускаем в режиме сервера:
# iperf3 -sПо умолчанию он слушает TCP порт 5201. Не забудьте открыть его на firewall.
Ставим на Windows систему:
> winget install iperf3Открываем приложение iPerf Network Speed Test Benchmark и, указав ip адрес сервера, запускаем тест. Это GUI приложение на базе iperf от стороннего разработчика. За оригинальной версией надо отправиться на официальный сайт и скачать консольную версию.
Распаковываем архив. Там будет приложение. Запускаем cmd, переходим в эту директорию и запускаем тестирование:
> iperf3 -c 1.1.1.1Всю информацию о процессе и результатах увидите тут же в консоли. Причём всё это в очень наглядном виде.
Результат работы Iperf очень удобно использовать для мониторинга. Она умеет выводить результат работы в файл, в том числе в json формате.
> iperf3 -c 94.142.141.246 --logfile log.txt -JДальше результат можно распарсить любой системой мониторинга.
Но не увлекайтесь мониторингом пропускной способности. Во-первых, это не очень достоверные данные, так как результат зависит от множества параметров. Во-вторых, во время теста вы будете занимать весь канал, что может навредить работе остальных сервисов. Надо настраивать приоритизацию трафика. Но если её настроить и отдать iperf наименьший приоритет, то и достоверность тестов будет сомнительной. В общем, это нетривиальная задача. Я много раз к ней подходил и пришёл к мнению, что лучше не заниматься этим в автоматическом режиме. Потом не понятно, как оценить достоверность результатов и что в связи с этим делать. Речь идёт про тестирование канала в интернет. В локальной сети с этим проще.
Ещё немного полезных параметров iperf. По умолчанию, тестирование длится 10 секунд. Можно увеличить этот интервал, указав его в секундах:
> iperf3 -c 94.142.141.246 -t 60Можно вместо времени указать число байт, которое будет передано. Пример для 100 мегабайт:
> iperf3 -c 94.142.141.246 -n 100MМожно запустить проверку в несколько потоков для лучшей утилизации канала:
> iperf3 -c 94.142.141.246 -P 4Ключи можно комбинировать. Они одни и те же для всех платформ. Точно так же можно поднять сервер на Windows и подключаться к нему линуксом.
А вы чем обычно тестируете скорость между хостами? Я кроме iperf ничего и не знаю, не использую.
⇨ Сайт / Исходники
#network
{kind=link}