
Захотелось с вами поделиться информацией о необычных неттопах, с которыми я лично хорошо знаком, так как их закупили в один из офисов, с которым я работал. До этого вообще не знал, что такие компы бывают и более нигде ничего подобного не видел.
Речь идёт о Мини ПК от Gigabite размером 100 мм x 105 мм со всторенным проектором и динамиками. Этот коробасик 10 на 10 см может работать без монитора. Ссылку привёл на конкретную модель, которую я наблюдал лично, вертел в руках, разбирал. Не знаю, есть ли сейчас что-то подобное в продаже. Просто делюсь информацией о необычной машинке.
Когда компы покупались, за проектор какой-то сильной доплаты не было, так что системники купили просто по совокупности технических характеристик. А проектор был в довесок, который специально никому нафиг не нужен был. Им и не пользовался никто. Удобство такого решения оценили только админы, так как эти системники можно было запустить и настроить вообще без монитора.
В общем и целом оказались очень удачные офисные компы. Внутри 16 Гб оперативной памяти, динамики, wifi, ssd диск. Все офисные задачи летают до сих пор, хотя компам лет по 5-6 уже, может даже больше. Шума от них почти нет, потребление энергии минимальное.
Если будете подбирать что-то компактное, обратите внимание на эту платформу. Хорошее решение.
#железо
Речь идёт о Мини ПК от Gigabite размером 100 мм x 105 мм со всторенным проектором и динамиками. Этот коробасик 10 на 10 см может работать без монитора. Ссылку привёл на конкретную модель, которую я наблюдал лично, вертел в руках, разбирал. Не знаю, есть ли сейчас что-то подобное в продаже. Просто делюсь информацией о необычной машинке.
Когда компы покупались, за проектор какой-то сильной доплаты не было, так что системники купили просто по совокупности технических характеристик. А проектор был в довесок, который специально никому нафиг не нужен был. Им и не пользовался никто. Удобство такого решения оценили только админы, так как эти системники можно было запустить и настроить вообще без монитора.
В общем и целом оказались очень удачные офисные компы. Внутри 16 Гб оперативной памяти, динамики, wifi, ssd диск. Все офисные задачи летают до сих пор, хотя компам лет по 5-6 уже, может даже больше. Шума от них почти нет, потребление энергии минимальное.
Если будете подбирать что-то компактное, обратите внимание на эту платформу. Хорошее решение.
#железо
{kind=link}
Иногда возникает задача быстро удалить все таблицы в базе данных mysql, не удаляя саму базу данных. Доступ к базе через консоль. В общем случае удалить конкретную таблицу в базе db можно следующей командой:
Если таблиц немного, то можно поступить и так. Но если их много, то нужен какой-то другой способ. Можно изобрести или поискать какой-то готовый велосипед на bash. Я предлагаю вам свой 😁
Берём mysqldump и делаем дамп только структуры, добавляя информацию об удалении таблиц перед их созданием:
Теперь получить консольные команды на удаление всех таблиц базы данных проще простого. Грепаем получившийся дамп:
То есть выводим все строки, которые начинаются с DROP. Это как раз то, что нам нужно.
Далее можно либо взять только нужные строки с определёнными таблицами для удаления, либо сразу весь вывод отправить в консоль mysql и удалить все таблицы, оставив саму базу данных:
Не забудьте добавить авторизацию, если у вас она не настроена каким-то другим способом:
Таким простым способом, без скриптов, можно прямо в консоли сервера удалить все таблицы из базы данных mysql, не удаляя саму базу.
❓Может возникнуть вопрос, а почему не удалить всё же базу и не создать заново. Причин может быть несколько:
1️⃣ У вас нет прав на создание и удаление баз данных (наиболее частый случай).
2️⃣ Не помните точно параметры базы данных, не хочется вспоминать, искать, как создать новую базу данных с теми же параметрами, что стоят у текущей (мой случай).
Если у вас есть какое-то свое простое решение по удалению таблиц из базы, делитесь в комментариях.
#terminal #mysql
> use db;> drop table00 table01, table02;Если таблиц немного, то можно поступить и так. Но если их много, то нужен какой-то другой способ. Можно изобрести или поискать какой-то готовый велосипед на bash. Я предлагаю вам свой 😁
Берём mysqldump и делаем дамп только структуры, добавляя информацию об удалении таблиц перед их созданием:
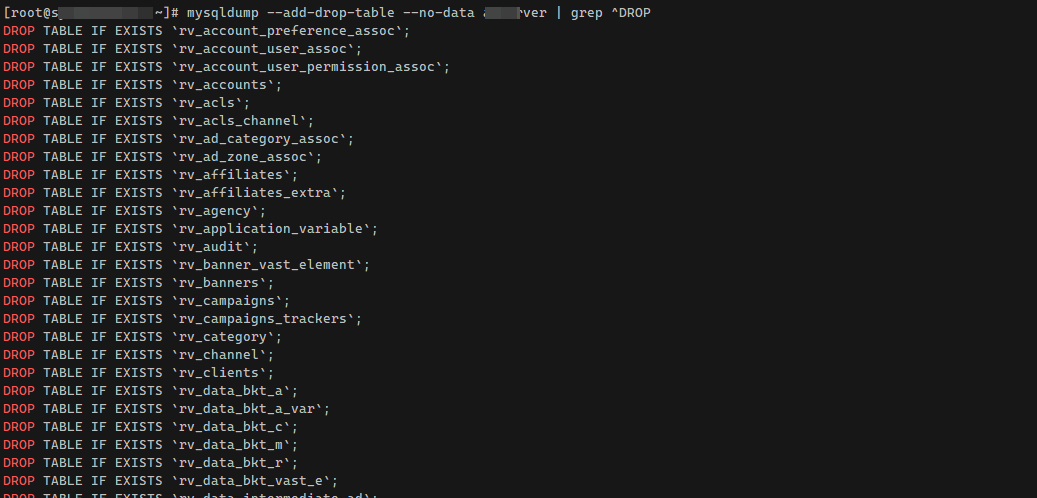
# mysqldump --add-drop-table --no-data dbТеперь получить консольные команды на удаление всех таблиц базы данных проще простого. Грепаем получившийся дамп:
# mysqldump --add-drop-table --no-data db | grep ^DROPТо есть выводим все строки, которые начинаются с DROP. Это как раз то, что нам нужно.
Далее можно либо взять только нужные строки с определёнными таблицами для удаления, либо сразу весь вывод отправить в консоль mysql и удалить все таблицы, оставив саму базу данных:
# mysqldump --add-drop-table --no-data db | grep ^DROP | mysql dbНе забудьте добавить авторизацию, если у вас она не настроена каким-то другим способом:
# mysqldump -uuser -ppassword --add-drop-table --no-data db \| grep ^DROP | mysql -uuser -ppassword dbТаким простым способом, без скриптов, можно прямо в консоли сервера удалить все таблицы из базы данных mysql, не удаляя саму базу.
❓Может возникнуть вопрос, а почему не удалить всё же базу и не создать заново. Причин может быть несколько:
1️⃣ У вас нет прав на создание и удаление баз данных (наиболее частый случай).
2️⃣ Не помните точно параметры базы данных, не хочется вспоминать, искать, как создать новую базу данных с теми же параметрами, что стоят у текущей (мой случай).
Если у вас есть какое-то свое простое решение по удалению таблиц из базы, делитесь в комментариях.
#terminal #mysql
{kind=link}
Думаю все, кто используют PVE (Proxmox Virtual Environment) знают про PBS (Proxmox Backup Server). А если кто не знает, то настоятельно рекомендую познакомиться. Это отличное средство для бесплатных инкрементных бэкапов виртуальных машин с дедупликацией.
Хочу одну идею подкинуть, которая не претендует ни на что, но лично мне сразу в голову не пришла. У Proxmox есть встроенная система бэкапа виртуалок, но она не такая удобная, как PBS. Но даже если у вас один гипервизор и нет локально железа под бэкап виртуалок, а хочется инкрементов и дедупликации, то это не проблема.
Поставьте PBS тут же в виртуальную машину и бэкапьте VM локально на него. Это не будет бэкапом в полной мере, потому что очевидно, при потере хоста, потеряете всё. Но лично я при возможности стараюсь держать бэкапы не только где-то на стороне, но и локально, чтобы в случае проблем быстро развернуть.
Это актуально, когда готовится какое-то важное обновление и нужен на всякий случай полный образ виртуальной машины. Или шифровальщик пришёл и грохнул вам данные внутри VM. С локальной копии восстановите их максимально быстро.
Для этой истории достаточно в сервер воткнуть лишний HDD и использовать его под PBS. Или заранее спланировать диски под это дело. Оптимально при аренде дедика взять SSD под рабочие виртулаки и HDD под локальные бэкапы. Для самой VM под PBS достаточно выделить 2-4 ядра CPU и 4 GB оперативной памяти.
При переносе виртуалок этот же PBS можно подключить на новом хосте и восстановить виртуальные машины из бэкапов. Я так делал, когда переехать нужно было. Быстрее и удобнее, чем ручной перенос дампов VM с хоста на хост.
#proxmox #backup
Хочу одну идею подкинуть, которая не претендует ни на что, но лично мне сразу в голову не пришла. У Proxmox есть встроенная система бэкапа виртуалок, но она не такая удобная, как PBS. Но даже если у вас один гипервизор и нет локально железа под бэкап виртуалок, а хочется инкрементов и дедупликации, то это не проблема.
Поставьте PBS тут же в виртуальную машину и бэкапьте VM локально на него. Это не будет бэкапом в полной мере, потому что очевидно, при потере хоста, потеряете всё. Но лично я при возможности стараюсь держать бэкапы не только где-то на стороне, но и локально, чтобы в случае проблем быстро развернуть.
Это актуально, когда готовится какое-то важное обновление и нужен на всякий случай полный образ виртуальной машины. Или шифровальщик пришёл и грохнул вам данные внутри VM. С локальной копии восстановите их максимально быстро.
Для этой истории достаточно в сервер воткнуть лишний HDD и использовать его под PBS. Или заранее спланировать диски под это дело. Оптимально при аренде дедика взять SSD под рабочие виртулаки и HDD под локальные бэкапы. Для самой VM под PBS достаточно выделить 2-4 ядра CPU и 4 GB оперативной памяти.
При переносе виртуалок этот же PBS можно подключить на новом хосте и восстановить виртуальные машины из бэкапов. Я так делал, когда переехать нужно было. Быстрее и удобнее, чем ручной перенос дампов VM с хоста на хост.
#proxmox #backup
{kind=link}
Каждый раз, когда речь заходит о брендовых системных блоках или серверах, возникает спор на тему того, зачем платить за брендовое железо x1.5-x2, если можно самому собрать из комплектующих и будет то же самое, только дешевле. Я всю свою профессиональную деятельность отстаиваю возможность купить брендовое железо. Доказываю и убеждаю. Оно в конечном счёте экономит деньги бизнеса, иначе бы просто не появилось.
Меня удивляет, когда сами технические специалисты не понимают такого простого вывода. Ладно бы обычные пользователи, им действительно может быть не очевидно, зачем покупать брендовый системник или сервер, если самосбор по характеристикам такой же, но в 2 раза дешевле. Но админы то как могут этого не понимать?
Гарантия и стандарты сборок мировых производителей компьютеров (таких как HP, Lenovo, Dell, Acer и т.д.) кратно выше любого сборщика компьютеров т.к. стоимость ошибки при больших объемах производства и поставках по всему миру очень высока, производится тщательное тестирование совместимости комплектующих (что отсутствует при штучной сборке) для сведения к минимуму отказов компьютеров и к осуществлению гарантии. Самостоятельная или локальная сборки не могут конкурировать по качеству и надежности собранного изделия.
Одной из полезных особенностей брендовых компов являются корпуса, которые часто собираются на основе принципа tool-less, то есть без инструмента. Чтобы разобрать корпус и выполнить модульную замену, не нужен вообще никакой инструмент. Все будет на защелках и задвижках. Это же очень удобно и практично в обслуживании.
С серверами разница по качеству ещё заметнее, чем с обычными компьютерами. Я вообще не могу припомнить ни одного случая, чтобы у меня полностью вышел из строя сервер HP или Dell, которые чаще всего покупаю. Может и было когда-то за 15 лет моей трудовой деятельности. Но даже не могу припомнить это событие. Материнку разок по гарантии менял, когда сервер периодически аварийно перезагружался, рейд-контроллер ломался. Пожалуй и всё.
❓А вы какое железо стараетесь брать, самосбор или известные бренды? Не касаемся пока текущей ситуации в РФ, так как я не знаю, что сейчас по наличию того или иного железа.
Когда то даже статью написал по мотивам одной из историй с сервером: Зачем нужен брендовый сервер?
#железо
Меня удивляет, когда сами технические специалисты не понимают такого простого вывода. Ладно бы обычные пользователи, им действительно может быть не очевидно, зачем покупать брендовый системник или сервер, если самосбор по характеристикам такой же, но в 2 раза дешевле. Но админы то как могут этого не понимать?
Гарантия и стандарты сборок мировых производителей компьютеров (таких как HP, Lenovo, Dell, Acer и т.д.) кратно выше любого сборщика компьютеров т.к. стоимость ошибки при больших объемах производства и поставках по всему миру очень высока, производится тщательное тестирование совместимости комплектующих (что отсутствует при штучной сборке) для сведения к минимуму отказов компьютеров и к осуществлению гарантии. Самостоятельная или локальная сборки не могут конкурировать по качеству и надежности собранного изделия.
Одной из полезных особенностей брендовых компов являются корпуса, которые часто собираются на основе принципа tool-less, то есть без инструмента. Чтобы разобрать корпус и выполнить модульную замену, не нужен вообще никакой инструмент. Все будет на защелках и задвижках. Это же очень удобно и практично в обслуживании.
С серверами разница по качеству ещё заметнее, чем с обычными компьютерами. Я вообще не могу припомнить ни одного случая, чтобы у меня полностью вышел из строя сервер HP или Dell, которые чаще всего покупаю. Может и было когда-то за 15 лет моей трудовой деятельности. Но даже не могу припомнить это событие. Материнку разок по гарантии менял, когда сервер периодически аварийно перезагружался, рейд-контроллер ломался. Пожалуй и всё.
❓А вы какое железо стараетесь брать, самосбор или известные бренды? Не касаемся пока текущей ситуации в РФ, так как я не знаю, что сейчас по наличию того или иного железа.
Когда то даже статью написал по мотивам одной из историй с сервером: Зачем нужен брендовый сервер?
#железо
Server Admin
Зачем нужен брендовый сервер? | serveradmin.ru
На днях произошла проблема с одним из серверов в ЦОД, которая разрешилась без потерь и последствий. По горячим следам решил поделиться опытом и немного порассуждать на актуальную для многих тему...
При настройке любой службы в Linux, которая пишет логи, надо обязательно следить за их ротацией. Типовая ситуация, когда логи забивают всё свободное место на диске, и сервак встаёт колом. Ротировать логи можно встроенной утилитой Linux - logrotate.
Для логов веб сайтов полезно включать ротацию не по заданному расписанию, а по размеру лог файла. Иногда случаются набеги ботов, которые могут раздуть логи до огромных размеров за несколько минут. Дождаться суточной ротации можно и не успеть. В этом случае полезно использовать следующий параметр logrotate:
Обычно люди ставят его и ожидают, что теперь логи будут автоматически ротироваться при достижении ими размера в 100 мегабайт. Ага, сейчас. Ничего подобного не произойдёт. По умолчанию logrotate запускается раз в сутки, поэтому он при всём желании не сможет следить за размером файла и ротировать его чаще, чем раз в сутки. Обычно за его запуск отвечает скрипт в директории /etc/cron.daily/logrotate.
Для того, чтобы logrotate мог проверять размер лог файла хотя бы раз в час, скрипт запуска надо перенести в директорию /etc/cron.hourly. А для более частой проверки, добавить его напрямую в cron с нужным интервалом запуска. Например, раз в 5 минут.
Допустим вы всё это сделали, но логи всё равно не будут ротироваться при достижении заданного размера. Понять, в чем же теперь проблема, не так просто. При запуске logrotate вы не увидите никаких ошибок. Он просто ничего не будет делать. Понять, в чём проблема, можно только при запуске в режиме отладки. Там вы увидите ошибку, если в этот день ротация уже была хотя бы раз.
Смысл тут в том, что logrotate сегодня уже произвел ротацию и создал архив лога с определенным именем и второй раз такой же файл он сделать не может. А маска имени файла при создании настроена в формате %Y%m%d. За эту маску отвечает параметр в /etc/logrotate.conf:
Самый простой вариант - это просто закомментировать этот параметр, тогда все архивы логов будут иметь следующую маску в файлах:
Если же вам хочется сохранить исходный формат лога для всех файлов, а для тех, что ротируются по размеру, настроить другую маску имени, используйте дополнительный параметр:
Формат имени архивного лога будет access.log.2022-04-26_15-1566819154.gz. Имена больше не будут дублироваться и logrotate сможет корректно запускать ротацию при достижении указанного размера файла.
Таким образом, чтобы настроить ротацию лог файла по достижении определенного размера, вам нужно:
1️⃣ Запускать через cron logrotate с достаточно высокой периодичностью, например раз в час или чаще.
2️⃣ Настроить маску файла для архива лога, чтобы она была уникальной в каждый момент запуска logrotate.
#logrotate #nginx #webserver
Для логов веб сайтов полезно включать ротацию не по заданному расписанию, а по размеру лог файла. Иногда случаются набеги ботов, которые могут раздуть логи до огромных размеров за несколько минут. Дождаться суточной ротации можно и не успеть. В этом случае полезно использовать следующий параметр logrotate:
size = 100MОбычно люди ставят его и ожидают, что теперь логи будут автоматически ротироваться при достижении ими размера в 100 мегабайт. Ага, сейчас. Ничего подобного не произойдёт. По умолчанию logrotate запускается раз в сутки, поэтому он при всём желании не сможет следить за размером файла и ротировать его чаще, чем раз в сутки. Обычно за его запуск отвечает скрипт в директории /etc/cron.daily/logrotate.
Для того, чтобы logrotate мог проверять размер лог файла хотя бы раз в час, скрипт запуска надо перенести в директорию /etc/cron.hourly. А для более частой проверки, добавить его напрямую в cron с нужным интервалом запуска. Например, раз в 5 минут.
Допустим вы всё это сделали, но логи всё равно не будут ротироваться при достижении заданного размера. Понять, в чем же теперь проблема, не так просто. При запуске logrotate вы не увидите никаких ошибок. Он просто ничего не будет делать. Понять, в чём проблема, можно только при запуске в режиме отладки. Там вы увидите ошибку, если в этот день ротация уже была хотя бы раз.
destination /var/log/nginx/access.log.20220426.gz already exists, skipping rotationСмысл тут в том, что logrotate сегодня уже произвел ротацию и создал архив лога с определенным именем и второй раз такой же файл он сделать не может. А маска имени файла при создании настроена в формате %Y%m%d. За эту маску отвечает параметр в /etc/logrotate.conf:
dateextСамый простой вариант - это просто закомментировать этот параметр, тогда все архивы логов будут иметь следующую маску в файлах:
access.log.1.gzaccess.log.2.gzaccess.log.3.gzЕсли же вам хочется сохранить исходный формат лога для всех файлов, а для тех, что ротируются по размеру, настроить другую маску имени, используйте дополнительный параметр:
dateformat -%Y-%m-%d_%H-%sФормат имени архивного лога будет access.log.2022-04-26_15-1566819154.gz. Имена больше не будут дублироваться и logrotate сможет корректно запускать ротацию при достижении указанного размера файла.
Таким образом, чтобы настроить ротацию лог файла по достижении определенного размера, вам нужно:
1️⃣ Запускать через cron logrotate с достаточно высокой периодичностью, например раз в час или чаще.
2️⃣ Настроить маску файла для архива лога, чтобы она была уникальной в каждый момент запуска logrotate.
#logrotate #nginx #webserver
В 6-й версии Zabbix появился совершенно новый функционал, который в русском переводе назван Услуги, а в английском - Service. Мне кажется, данный перевод выглядит не очень корректным, так как не совсем чётко отражает новый функционал. Пока я внимательно туда не заглянул, не понял, что это на практике значит. В информации о релизе эти нововведения упоминали, как мониторинг за бизнес процессами или метриками.
На деле это вот что значит. Вы можете создать Service, который по настроенным тэгам будет следить за состоянием хостов с этими тэгами. Состояние самого Service может быть гибко настроено в зависимости от состояния вложенных в него зависимых сервисов. То есть выстраивается иерархическая схема.
Статус родительского Service может меняться в зависимости от статуса дочерних услуг. Например, у вас есть какое-то приложение, работу которого обеспечивает некоторое количество хостов:
- Один балансер, принимающий входящие соединения.
- Кластер БД из мастер ноды и двух слейвов.
- 3 бэкенда для обработки запросов.
Если выйдет из строя слейв сервер с бд или один бэкенд, то это не приведёт к проблемам приложения. Оно будет обслуживать клиентов. Можно считать, что родительский Service в этом случае находится в статусе Warning. А вот если выйдет из строя мастер нода БД или входящий балансер, то клиенты не будут обслуживаться. Это повод перевести весь Service в статус Critical и отправить предупреждение кому-то из руководства. На каждый Service можно настраивать оповещения, отличные от оповещений триггеров. А заодно занести простой по этому Service в SLA.
Дочерним сервисам можно настраивать веса, которые будут так или иначе влиять на конечное состояние родительской службы. Можно настраивать влияние в SLA дочерних сервисов, указывать разные временные промежутки с разными весами и т.д. Это позволяет гибко управлять всей этой конструкцией. Как я уже сказал, сервисы выстраиваются в иерархическую структуру, где первым уровнем являются триггеры, потом хосты, а дальше службы, собранные из этих хостов.
Видео с примером настройки
Описание из Документации
#zabbix
На деле это вот что значит. Вы можете создать Service, который по настроенным тэгам будет следить за состоянием хостов с этими тэгами. Состояние самого Service может быть гибко настроено в зависимости от состояния вложенных в него зависимых сервисов. То есть выстраивается иерархическая схема.
Статус родительского Service может меняться в зависимости от статуса дочерних услуг. Например, у вас есть какое-то приложение, работу которого обеспечивает некоторое количество хостов:
- Один балансер, принимающий входящие соединения.
- Кластер БД из мастер ноды и двух слейвов.
- 3 бэкенда для обработки запросов.
Если выйдет из строя слейв сервер с бд или один бэкенд, то это не приведёт к проблемам приложения. Оно будет обслуживать клиентов. Можно считать, что родительский Service в этом случае находится в статусе Warning. А вот если выйдет из строя мастер нода БД или входящий балансер, то клиенты не будут обслуживаться. Это повод перевести весь Service в статус Critical и отправить предупреждение кому-то из руководства. На каждый Service можно настраивать оповещения, отличные от оповещений триггеров. А заодно занести простой по этому Service в SLA.
Дочерним сервисам можно настраивать веса, которые будут так или иначе влиять на конечное состояние родительской службы. Можно настраивать влияние в SLA дочерних сервисов, указывать разные временные промежутки с разными весами и т.д. Это позволяет гибко управлять всей этой конструкцией. Как я уже сказал, сервисы выстраиваются в иерархическую структуру, где первым уровнем являются триггеры, потом хосты, а дальше службы, собранные из этих хостов.
Видео с примером настройки
Описание из Документации
#zabbix
YouTube
Zabbix Handy Tips: Keeping track of your services with business service monitoring
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In this video, we will take a look at the redesigned Services section and configure monitoring for an online store business service.
Subscribe here: https://www.za…
Subscribe here: https://www.za…
SQLpedia - канал про SQL и базы данных, в котором вы найдете:
— Возможность предложить нам статью для перевода;
— Полезные видео;
— Интересные опросы;
— Профессиональный юмор;
Полезности с канала:
— Шпаргалка по SQL
— Выбор СУБД
— Обзор типов и подходов БД
Присоединяйтесь, давайте расти как профессионалы вместе 😉
Подписаться: @sql_wiki
#реклама
— Возможность предложить нам статью для перевода;
— Полезные видео;
— Интересные опросы;
— Профессиональный юмор;
Полезности с канала:
— Шпаргалка по SQL
— Выбор СУБД
— Обзор типов и подходов БД
Присоединяйтесь, давайте расти как профессионалы вместе 😉
Подписаться: @sql_wiki
#реклама
Нестареющая уже практически классика легкого айтишного юмора - Кремниевая Долина "Silicon Valley" - Удаление данных.
https://www.youtube.com/watch?v=SOuhTLeyVCE
Всмотрелся в некоторые скриншоты. Там, кстати, не привычный для фильмов бред, а вполне реальные данные. В консоли видно, как удаляются .mov файлы. Причём на одном из кадров хорошо видна консоль. Я очень внимательно посмотрел, но так и не узнал по тексту сообщений, откуда это. Путь для файлов указан как /mount/gluster/originals/... Походу сетевую файловую систему glusterfs используют 😁
Так и не посмотрел этот сериал, хотя очень хочется. Нет времени на просмотр киношек, а тем более сериалов.
#юмор
https://www.youtube.com/watch?v=SOuhTLeyVCE
Всмотрелся в некоторые скриншоты. Там, кстати, не привычный для фильмов бред, а вполне реальные данные. В консоли видно, как удаляются .mov файлы. Причём на одном из кадров хорошо видна консоль. Я очень внимательно посмотрел, но так и не узнал по тексту сообщений, откуда это. Путь для файлов указан как /mount/gluster/originals/... Походу сетевую файловую систему glusterfs используют 😁
Так и не посмотрел этот сериал, хотя очень хочется. Нет времени на просмотр киношек, а тем более сериалов.
#юмор
YouTube
Кремниевая Долина "Silicon Valley" - Удаление данных (Хакерская атака) . Кубик в кубе.
Кремниевая Долина (Silicon Valley). 2 сезон. 8 серия. Озвучка - Кубик в кубе.
Пока идут праздники, не хочется погружаться в рабочие темы и задачи, так что поговорим об играх. А точнее об автоматическом разворачивании игровых серверов с помощью Docker. Отсюда тэг devops 😉 Если у вас есть дети, то тема будет особенно актуальна. Как мне кажется, проще всего заводить детей в IT с помощью игр. Я как раз недавно изучал тему Minecraft и своих серверов для неё.
Есть бесплатная панель для управления игровыми серверами - Pterodactyl. Это бесплатная, Open Source разработка. Сама она ставится с помощью Docker. И с помощью него же разворачивает некоторый набор игровых серверов. Причём сама панель может стоять отдельно и объединять несколько хостов с играми.
Список наиболее известных игр, которые поддерживает панель (это не полный список, только популярные):
◽ Minecraft в различных редакциях
◽ Rust
◽ Terraria
◽ Team Fortress 2
◽ Counter Strike: Global Offensive
◽ Garry's Mod
◽ ARK: Survival Evolved
Сюда же к играм можно поставить Teamspeak и другие средства общения. Получается полный набор юного девопс-геймера. Помимо поддержки игр самой платформой, это может делать сообщество. На текущий момент с его помощью портированы следующие игры: Factorio, San Andreas: MP, Pocketmine MP и др.
У проекта неплохая документация. Ниже будет видео по полной установке и настройке. Так что особых проблем с запуском этого хозяйства быть не должно.
Сайт - https://pterodactyl.io
Исходники - https://github.com/pterodactyl/panel
Инструкция - https://www.youtube.com/watch?v=_ypAmCcIlBE
#игры #devops
Есть бесплатная панель для управления игровыми серверами - Pterodactyl. Это бесплатная, Open Source разработка. Сама она ставится с помощью Docker. И с помощью него же разворачивает некоторый набор игровых серверов. Причём сама панель может стоять отдельно и объединять несколько хостов с играми.
Список наиболее известных игр, которые поддерживает панель (это не полный список, только популярные):
◽ Minecraft в различных редакциях
◽ Rust
◽ Terraria
◽ Team Fortress 2
◽ Counter Strike: Global Offensive
◽ Garry's Mod
◽ ARK: Survival Evolved
Сюда же к играм можно поставить Teamspeak и другие средства общения. Получается полный набор юного девопс-геймера. Помимо поддержки игр самой платформой, это может делать сообщество. На текущий момент с его помощью портированы следующие игры: Factorio, San Andreas: MP, Pocketmine MP и др.
У проекта неплохая документация. Ниже будет видео по полной установке и настройке. Так что особых проблем с запуском этого хозяйства быть не должно.
Сайт - https://pterodactyl.io
Исходники - https://github.com/pterodactyl/panel
Инструкция - https://www.youtube.com/watch?v=_ypAmCcIlBE
#игры #devops
{kind=link}
Мониторинг и траблшутинг VOIP
Ниже мой краткий конспект интересного выступления с AsterConf 2021 на тему мониторинга и разбора проблем с VOIP. Я так или иначе стараюсь просматривать выступления со всех популярных конференций. Если что-то кажется интересным и полезным, то конспектирую для вас и себя в том числе.
📌 Мониторинг:
- Базовые метрики серверов (процессор, память, диск, сеть и т.д.). Мониторить просто, толку мало, особенно когда серверов, связанных со связью, несколько.
- Использовать сервисные метрики от SIP3, Homer, VoIPMonitor. Это специализированные open source системы для мониторинга SIP трафика. Минус этого решения - +еще одна система мониторинга.
- Что собираем: RFC-6076. Основное: ASR, SCR, SER, SEER, ISAs.
- Следим за временными метриками (пример из SIP3): sip_call_duration, sip_call_trying-delay, sip_call_setup-time, sip_call_establish-time, sip_call_cancel-time, sip_call_disconnect-time.
- Следим за RTP метриками: Rating Factor, Mean Opinion Score (latency, jitter, packet loss).
📌 Разбор проблем:
- Качественный разбор проблем возможен только если есть хороший мониторинг.
- Чем подробнее данные о трафике, который собирается, тем проще дебажить проблемы. В довесок к хранению должен быть хороший поиск по сохранённым данным. Соответственно, нужны системы для сбора, хранения и анализа трафика. Автор предлагает SIP3, но как я понял, это уже платный функционал.
Видео - https://www.youtube.com/watch?v=1I7Mxc_7rAw
Презентация - https://voxlink.ru/wp-content/uploads/2022/04/03_agafonov.pdf
#asterisk #мониторинг #voip
Ниже мой краткий конспект интересного выступления с AsterConf 2021 на тему мониторинга и разбора проблем с VOIP. Я так или иначе стараюсь просматривать выступления со всех популярных конференций. Если что-то кажется интересным и полезным, то конспектирую для вас и себя в том числе.
📌 Мониторинг:
- Базовые метрики серверов (процессор, память, диск, сеть и т.д.). Мониторить просто, толку мало, особенно когда серверов, связанных со связью, несколько.
- Использовать сервисные метрики от SIP3, Homer, VoIPMonitor. Это специализированные open source системы для мониторинга SIP трафика. Минус этого решения - +еще одна система мониторинга.
- Что собираем: RFC-6076. Основное: ASR, SCR, SER, SEER, ISAs.
- Следим за временными метриками (пример из SIP3): sip_call_duration, sip_call_trying-delay, sip_call_setup-time, sip_call_establish-time, sip_call_cancel-time, sip_call_disconnect-time.
- Следим за RTP метриками: Rating Factor, Mean Opinion Score (latency, jitter, packet loss).
📌 Разбор проблем:
- Качественный разбор проблем возможен только если есть хороший мониторинг.
- Чем подробнее данные о трафике, который собирается, тем проще дебажить проблемы. В довесок к хранению должен быть хороший поиск по сохранённым данным. Соответственно, нужны системы для сбора, хранения и анализа трафика. Автор предлагает SIP3, но как я понял, это уже платный функционал.
Видео - https://www.youtube.com/watch?v=1I7Mxc_7rAw
Презентация - https://voxlink.ru/wp-content/uploads/2022/04/03_agafonov.pdf
#asterisk #мониторинг #voip
{kind=link}
Продолжаю утреннюю тему диагностики VOIP серверов и анализа SIP трафика. В самом начале выступления, про которое я рассказал, автор упомянул, что весь дальнейший рассказ будет актуален для тех, кому возможностей SNGREP недостаточно. Я не стал поднимать эту тему в утренней заметке, потому что данная утилита заслуживает отдельного упоминания.
С помощью SNGREP можно анализировать SIP трафик, в том числе и в режиме реального времени. Причём это консольное приложение настолько удобно и наглядно сделано, что им можно пользоваться, даже если вы в SIP полный профан. Разобраться не составит труда.
Я впервые его поставил и запустил, когда мне достался в обслуживание небольшой call центр. На собеседовании я сказал, что знаю asterisk, хотя вообще не знал его (предполагал, что могу поставить). Это тот случай, когда можно приврать, если уверен в своих способностях. Linux админил давно, но с астером просто не сталкивался. За месяц освоил на очень хорошем уровне. Мог уже сам внедрять сервера и писать диалпланы. В итоге никто и не понял, что я не разбираюсь в астериске, а через 2 года, когда увольнялся, со мной очень не хотели расставаться.
Процесс установки и много примеров использования sngrep я привёл в своей статье Анализ SIP трафика в Asterisk с помощью sngrep. Она написана давно, но с тех пор ничего принципиально не изменилось. Скорее всего не изменилось вообще ничего.
Настоятельно рекомендую использовать sngrep, если у вас есть хотя бы один сервер Asterisk в управлении.
#asterisk #sip
С помощью SNGREP можно анализировать SIP трафик, в том числе и в режиме реального времени. Причём это консольное приложение настолько удобно и наглядно сделано, что им можно пользоваться, даже если вы в SIP полный профан. Разобраться не составит труда.
Я впервые его поставил и запустил, когда мне достался в обслуживание небольшой call центр. На собеседовании я сказал, что знаю asterisk, хотя вообще не знал его (предполагал, что могу поставить). Это тот случай, когда можно приврать, если уверен в своих способностях. Linux админил давно, но с астером просто не сталкивался. За месяц освоил на очень хорошем уровне. Мог уже сам внедрять сервера и писать диалпланы. В итоге никто и не понял, что я не разбираюсь в астериске, а через 2 года, когда увольнялся, со мной очень не хотели расставаться.
Процесс установки и много примеров использования sngrep я привёл в своей статье Анализ SIP трафика в Asterisk с помощью sngrep. Она написана давно, но с тех пор ничего принципиально не изменилось. Скорее всего не изменилось вообще ничего.
Настоятельно рекомендую использовать sngrep, если у вас есть хотя бы один сервер Asterisk в управлении.
#asterisk #sip
{kind=link}
Ранее я рассказывал про 3 программных продукта для организации тестовых полигонов на базе виртуальных машин. Рекомендую сохранить информацию о них:
▪ GNS3
▪ EVE-NG
▪ PNETLab
Сегодня речь пойдёт о похожей программе, только на базе контейнеров docker - Containerlab. Сами разработчики Containerlab называют её Framwork для построения сетевых лабораторий на основе контейнеров. Сразу становятся очевидны явные плюсы и минусы такого подхода. Плюсы - быстрый деплой систем, экономия ресурсов по сравнению с виртуальными машинами. Минусы - все ограничения контейнеров, и как итог - ограниченный набор готовых контейнеров операционной системой Linux.
Containerlab - бесплатное, open source решение. С его помощью можно разворачивать тестовые лаборатории в один клик с помощью преднастроенных заранее конфигураций. То есть реализуется современный подход Labs-as-a-code.
Посмотрите демонстрационное видео. Выглядит всё это действительно просто и удобно. Есть возможность запускать вместе с тестовыми виртуальными машинами на базе qemu. Они просто подключаются в сетевой бридж, который создаёт docker. Управляются нативно через общий конфигурационный файл вместе с контейнерами
Для Containerlab уже существуют готовые контейнеры с системами некоторых популярных вендоров (Nokia SR-Linux, Arista cEOS, Azure SONiC, Juniper cRPD, Cumulus VX). Если честно, я вообще впервые про них услышал 🧐 Когда не нашёл контейнера с RouterOS, продукт пал в моих глазах практически до самого пола. Но поднялся, после того, как я увидел, что поддержка RouterOS есть, но запускается она через qemu с нативной интеграцией в едином конфиге.
Стоит ещё добавить, что Containerlab поддерживает дистрибутив FRRouting, который является софтовой open source реализацией различных протоколов маршрутизации: BGP, OSPF, RIP, IS-IS, PIM, LDP, BFD, Babel, PBR, OpenFabric, VRRP и др. То есть отлично подходит для сетевых экспериментов.
Я вообще не нашёл никакой информации о Containerlab на русском языке. Насколько всё это удобно и юзабельно в реальности остаётся только догадываться. Сам я не тестировал. Но выглядит очень интересно. В первую очередь своим подходом Labs-as-a-code. Если кто-то пользовался, дайте обратную связь.
Сайт - https://containerlab.dev/
Исходники - https://github.com/srl-labs/containerlab
Видео с обзором - https://www.youtube.com/watch?v=xdi7rwdJgkg
#testlab
▪ GNS3
▪ EVE-NG
▪ PNETLab
Сегодня речь пойдёт о похожей программе, только на базе контейнеров docker - Containerlab. Сами разработчики Containerlab называют её Framwork для построения сетевых лабораторий на основе контейнеров. Сразу становятся очевидны явные плюсы и минусы такого подхода. Плюсы - быстрый деплой систем, экономия ресурсов по сравнению с виртуальными машинами. Минусы - все ограничения контейнеров, и как итог - ограниченный набор готовых контейнеров операционной системой Linux.
Containerlab - бесплатное, open source решение. С его помощью можно разворачивать тестовые лаборатории в один клик с помощью преднастроенных заранее конфигураций. То есть реализуется современный подход Labs-as-a-code.
Посмотрите демонстрационное видео. Выглядит всё это действительно просто и удобно. Есть возможность запускать вместе с тестовыми виртуальными машинами на базе qemu. Они просто подключаются в сетевой бридж, который создаёт docker. Управляются нативно через общий конфигурационный файл вместе с контейнерами
Для Containerlab уже существуют готовые контейнеры с системами некоторых популярных вендоров (Nokia SR-Linux, Arista cEOS, Azure SONiC, Juniper cRPD, Cumulus VX). Если честно, я вообще впервые про них услышал 🧐 Когда не нашёл контейнера с RouterOS, продукт пал в моих глазах практически до самого пола. Но поднялся, после того, как я увидел, что поддержка RouterOS есть, но запускается она через qemu с нативной интеграцией в едином конфиге.
Стоит ещё добавить, что Containerlab поддерживает дистрибутив FRRouting, который является софтовой open source реализацией различных протоколов маршрутизации: BGP, OSPF, RIP, IS-IS, PIM, LDP, BFD, Babel, PBR, OpenFabric, VRRP и др. То есть отлично подходит для сетевых экспериментов.
Я вообще не нашёл никакой информации о Containerlab на русском языке. Насколько всё это удобно и юзабельно в реальности остаётся только догадываться. Сам я не тестировал. Но выглядит очень интересно. В первую очередь своим подходом Labs-as-a-code. Если кто-то пользовался, дайте обратную связь.
Сайт - https://containerlab.dev/
Исходники - https://github.com/srl-labs/containerlab
Видео с обзором - https://www.youtube.com/watch?v=xdi7rwdJgkg
#testlab
{kind=link}
У меня давно написана статья на тему работы с дисками в Debian. С тех пор ничего не поменялось, так что она по прежнему актуальна. Думаю, будет полезна выжимка из этой статьи, чтобы сохранить полезные команды в закладки. Статья писалась на основе системы Debian, но практически всё без каких-то существенных изменений будет актуально в любом дистрибутиве Linux.
Информация о дисках (железо)
Hwinfo
На выходе максимально подробная информация о диске - вендор, модель, серийный номер, метки диска в системе и многое другое. Программа показывает принадлежность диска к рейд массиву (если он поддерживает, например adaptec), что бывает удобно.
Smartmontools
Показывает основную информацию о диске, в том числе SMART.
Информация о дисках (разделы)
Общая информация о разделах и их размерах.
Более подробная информация о структуре диска, в том числе используемых секторах каждого раздела.
Создать или удалить раздел.
Обновить информацию об изменённых разделах.
Просмотр меток разделов.
Cвободное место на диске
Общая информация о всех подмонтированных дисках.
10 самых больших папок в текущем каталоге:
Подключение сетевого диска
По smb.
- 0.1.4.4/backup - сетевая шара
- /mnt/backup - локальная директория, куда монтируем сетевой диск
- admin - пользователь с доступом к сетевому диску
- passadmin - пароль
По NFS.
Перед подключением диска можете проверить, а если вам вообще доступ к сетевому диску на сервере:
Создание файловой системы ext4, xfs
XFS
EXT4
Работа с LVM
Инициализация дисков для работы в LVM:
Создание группы томов:
Создание раздела, занимающего 100% размера группы томов:
Создание файловой системы:
Монтирование:
Удаление раздела:
Список физических томов:
Информация о Физическая томах:
Логическая информация о Физических томах:
Список логических разделов:
Показать информацию о логических разделах:
Протестировать скорость диска
Тест записи.
Тест чтения.
Проверить нагрузку на диск
или
Нагрузка процессов или конкретного процесса:
#bash #terminal
Информация о дисках (железо)
Hwinfo
# apt install hwinfo# hwinfo --diskНа выходе максимально подробная информация о диске - вендор, модель, серийный номер, метки диска в системе и многое другое. Программа показывает принадлежность диска к рейд массиву (если он поддерживает, например adaptec), что бывает удобно.
Smartmontools
# apt install smartmontools# smartctl -i /dev/sdaПоказывает основную информацию о диске, в том числе SMART.
Информация о дисках (разделы)
Общая информация о разделах и их размерах.
# lsblk -aБолее подробная информация о структуре диска, в том числе используемых секторах каждого раздела.
# fdisk -lСоздать или удалить раздел.
# cfdisk /dev/sdbОбновить информацию об изменённых разделах.
# partprobe -sПросмотр меток разделов.
# blkidCвободное место на диске
Общая информация о всех подмонтированных дисках.
# df -h10 самых больших папок в текущем каталоге:
# du . --max-depth=1 -ah | sort -rh | head -10Подключение сетевого диска
По smb.
# apt install cifs-utils# mount -t cifs //10.1.4.4/backup /mnt/backup \-o user=admin,password=passadmin- 0.1.4.4/backup - сетевая шара
- /mnt/backup - локальная директория, куда монтируем сетевой диск
- admin - пользователь с доступом к сетевому диску
- passadmin - пароль
По NFS.
# apt install nfs-common# mount -t nfs 10.1.4.4:/backup /mnt/backupПеред подключением диска можете проверить, а если вам вообще доступ к сетевому диску на сервере:
# showmount --exports 10.1.4.4Создание файловой системы ext4, xfs
XFS
# apt install xfsprogs# mkfs.xfs /dev/sdb1EXT4
# mkfs -t ext4 /dev/sdb1Работа с LVM
Инициализация дисков для работы в LVM:
# pvcreate /dev/sdb /dev/sdcСоздание группы томов:
# vgcreate vgbackup /dev/sdb /dev/sdcСоздание раздела, занимающего 100% размера группы томов:
# lvcreate -l100%FREE vgbackup -n lv_fullСоздание файловой системы:
# mkfs -t ext4 /dev/vgbackup/lv_fullМонтирование:
# mount /dev/vgbackup/lv_full /mnt/backupУдаление раздела:
# umount /mnt/backup# lvremove /dev/vgbackup/lv_fullСписок физических томов:
# vgscanИнформация о Физическая томах:
# pvscan# pvdisplayЛогическая информация о Физических томах:
# vgdisplayСписок логических разделов:
# lvscan# lvsПоказать информацию о логических разделах:
# lvdisplayПротестировать скорость диска
Тест записи.
# sync; dd if=/dev/zero of=tempfile bs=1M count=12000; syncТест чтения.
# apt install hdparm# hdparm -t /dev/vda1Проверить нагрузку на диск
# apt install sysstat# iostat -xk -t 2или
# apt install dstat# dstat --top-bio# dstat --top-io# dstat -tldnpms 10Нагрузка процессов или конкретного процесса:
# pidstat -d 1# pidstat -p `pgrep mysqld` -d 1#bash #terminal
{kind=link}
Давно не было заметок про инструменты для бэкапа. Вспомнил про один из них - Duplicati. С удивлением обнаружил, что ещё ни разу не упоминал эту программу на канале. Сейчас расскажу.
Duplicati - бесплатная open source программа для создания бэкапов на сетевых хранилищах. Отличает её от многих подобных программ готовая интеграция с различными облачными провайдерами и системами хранения данных. Например, Duplicati умеет складывать бэкапы в такие системы, как Amazon S3, Dropbox, OneDrive, OpenStack Storage (Swift), Google Cloud and Drive и многие другие, в том числе S3 совместимые хранилища (Yandex Object Storage, Selectel S3 и т.д.).
Помимо облачных провайдеров, поддерживаются и все основные протоколы передачи данных: SMB, NFS, FTP, SSH (SFTP), WebDAV. Полный список поддерживаемых хранилищ смотрите в документации.
Полезные возможности Duplicati:
◽ поддержка AES-256 шифрования;
◽ поддержка инкрементных бэкапов и дедупликации;
◽ возможность бэкапа разнородной информации по гибким правилам включения или исключения файлов;
◽ есть веб интерфейс и консольный режим работы, который позволяет использовать Duplicati в скриптах;
◽ умеет использовать Volume Snapshot Service (VSS) под Windows и Logical Volume Manager (LVM) под Linux для бэкапа залоченных (открытых) файлов;
◽ умеет хранить и ротировать данные по определённым правилам и расписаниям.
В целом, Duplicati создаёт приятное впечатление своим простым и понятным интерфейсом. Программа дружественна для новичков, бесплатна, кроссплатформенна. Можно посмотреть на неё, если подбираете решение для относительно простых бэкапов сырых данных не очень большой информационной системы.
❗️Важное замечание. Duplicati должна быть установлена на том сервере, который вы будете бэкапить. Она не умеет подключаться удалённо к хостам и забирать от них данные. Это важный нюанс, который ограничивает сферу применения программы. Нельзя установить Duplicati на сервер бэкапов и им обходить машины, собирая данные.
Существует проект duplicati-client, который может удалённо управлять несколькими Duplicati серверами, отправляя им команды через REST API, который использует веб клиент. Это позволяет управлять запуском бэкапов из единого центра.
Сайт - https://www.duplicati.com/
Исходники - https://github.com/duplicati/duplicati
#backup
Duplicati - бесплатная open source программа для создания бэкапов на сетевых хранилищах. Отличает её от многих подобных программ готовая интеграция с различными облачными провайдерами и системами хранения данных. Например, Duplicati умеет складывать бэкапы в такие системы, как Amazon S3, Dropbox, OneDrive, OpenStack Storage (Swift), Google Cloud and Drive и многие другие, в том числе S3 совместимые хранилища (Yandex Object Storage, Selectel S3 и т.д.).
Помимо облачных провайдеров, поддерживаются и все основные протоколы передачи данных: SMB, NFS, FTP, SSH (SFTP), WebDAV. Полный список поддерживаемых хранилищ смотрите в документации.
Полезные возможности Duplicati:
◽ поддержка AES-256 шифрования;
◽ поддержка инкрементных бэкапов и дедупликации;
◽ возможность бэкапа разнородной информации по гибким правилам включения или исключения файлов;
◽ есть веб интерфейс и консольный режим работы, который позволяет использовать Duplicati в скриптах;
◽ умеет использовать Volume Snapshot Service (VSS) под Windows и Logical Volume Manager (LVM) под Linux для бэкапа залоченных (открытых) файлов;
◽ умеет хранить и ротировать данные по определённым правилам и расписаниям.
В целом, Duplicati создаёт приятное впечатление своим простым и понятным интерфейсом. Программа дружественна для новичков, бесплатна, кроссплатформенна. Можно посмотреть на неё, если подбираете решение для относительно простых бэкапов сырых данных не очень большой информационной системы.
❗️Важное замечание. Duplicati должна быть установлена на том сервере, который вы будете бэкапить. Она не умеет подключаться удалённо к хостам и забирать от них данные. Это важный нюанс, который ограничивает сферу применения программы. Нельзя установить Duplicati на сервер бэкапов и им обходить машины, собирая данные.
Существует проект duplicati-client, который может удалённо управлять несколькими Duplicati серверами, отправляя им команды через REST API, который использует веб клиент. Это позволяет управлять запуском бэкапов из единого центра.
Сайт - https://www.duplicati.com/
Исходники - https://github.com/duplicati/duplicati
#backup
{kind=link}
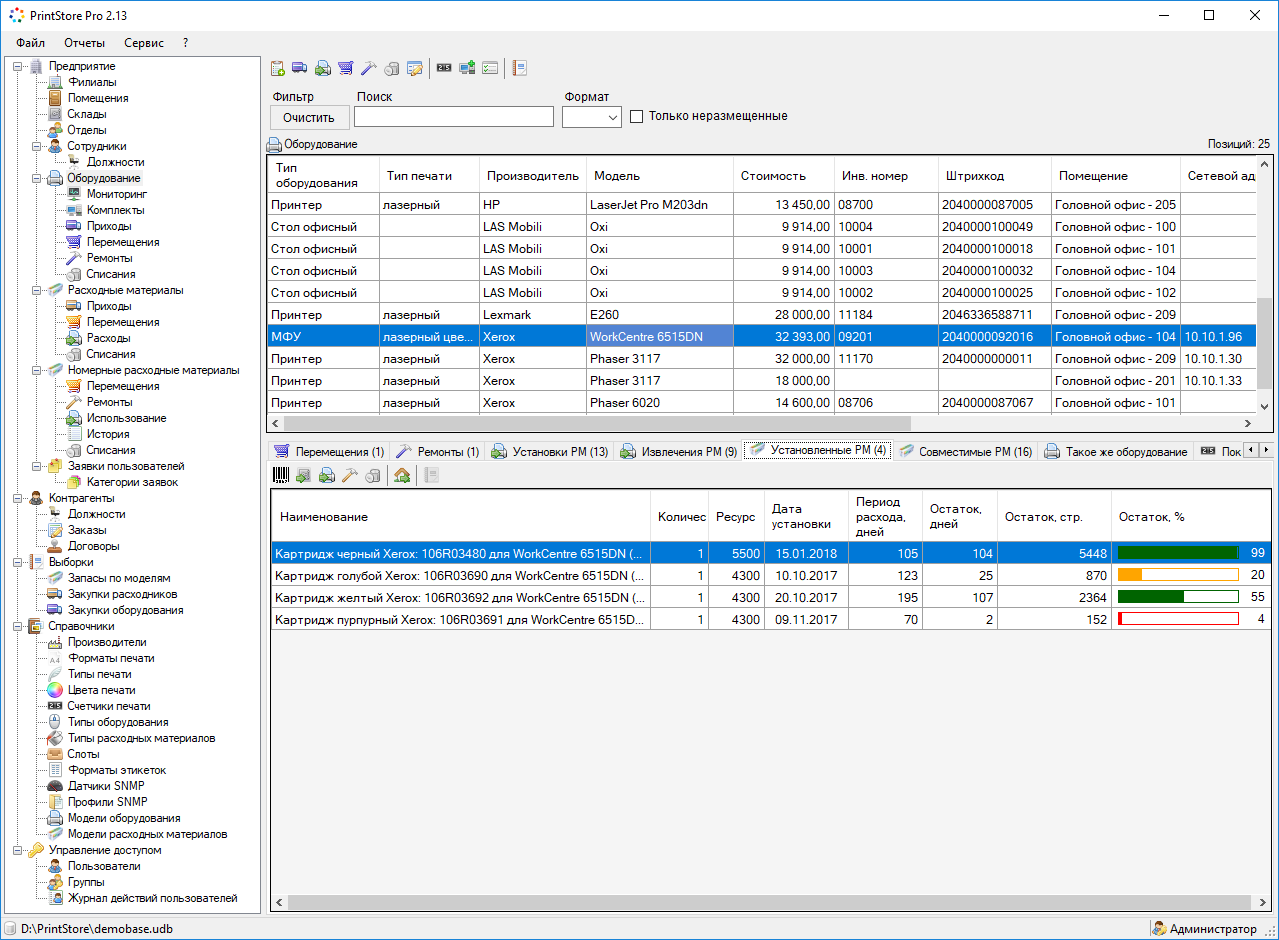
🖨️ PrintStore — учет и мониторинг техники и расходных материалов
Когда-то давно писал обзор на указанную программу. Она заточена на выполнение одной узкой задачи - учёт принтеров и расходников к ним. Я очень хорошо с ней познакомился, так как автор дал полную лицензию, и я её внедрил в одной организации.
Рассказываю об этой программе не потому, что меня просил автор. С ним я не знаком и больше не общался с момента публикации этой статьи. Просто программа нишевая, малоизвестная, но очень может кому-то помочь.
Полезна она будет средним и крупным компаниям, которые тратят значительные средства на печать документов. С учётом удорожания этой сферы, она стала ещё более актуальна, чем раньше. PrintStore позволит экономить средства.
Программа имеет огромную базу принтеров, так что мониторинг устройств ведёт практически автоматически. Вы заводите принтеры в систему, настраиваете доступ к ним, и программа по snmp пытается собирать данные о печати и расходниках. Она ведёт полный цикл жизни принтера и МФУ, начиная от покупки и заканчивая заменой запчастей и расходников, а затем и списанием.
Помимо этого вы упрощаете обслуживание техники и учёт расходных материалов. Программа напомнит об исчерпании ресурса принтера, о запасах картриджей для каждой модели, о количестве перезаправки б.у. картриджа и т.д.
С помощью PrintStore вы сможете понять, какие принтеры для вас наиболее экономичны, где меньше всего стоимость напечатанного листа. Думаю, что экономия может начаться, если у вас парк устройств от 10-15 штук с регулярной печатью на всех устройствах. Начиная с этого числа имеет смысл начать тратить время на учёт.
Программа написана русскоязычным автором, продаётся в РФ, есть в едином реестре российского ПО. Активно развивается уже много лет. Последняя версия от 27.04.2022.
Есть бесплатная версия со следующими ограничениями:
- максимальное количество устройств для учёта - 100 штук;
- автоматический мониторинг за расходниками устройств - 5 штук.
Как я уже сказал, программа нишевая, специфичная. Особой конкуренции и какого-то устоявшегося внешнего вида и функционала для данной сферы программ нет, так что придётся немного поразбираться во время внедрения и запуска. Но в целом каких-то особых сложностей нет. Я разобрался без проблем.
Сайт - https://perfectsoft.ru/
Реестр ПО - https://reestr.digital.gov.ru/reestr/309908/
#отечественное
Когда-то давно писал обзор на указанную программу. Она заточена на выполнение одной узкой задачи - учёт принтеров и расходников к ним. Я очень хорошо с ней познакомился, так как автор дал полную лицензию, и я её внедрил в одной организации.
Рассказываю об этой программе не потому, что меня просил автор. С ним я не знаком и больше не общался с момента публикации этой статьи. Просто программа нишевая, малоизвестная, но очень может кому-то помочь.
Полезна она будет средним и крупным компаниям, которые тратят значительные средства на печать документов. С учётом удорожания этой сферы, она стала ещё более актуальна, чем раньше. PrintStore позволит экономить средства.
Программа имеет огромную базу принтеров, так что мониторинг устройств ведёт практически автоматически. Вы заводите принтеры в систему, настраиваете доступ к ним, и программа по snmp пытается собирать данные о печати и расходниках. Она ведёт полный цикл жизни принтера и МФУ, начиная от покупки и заканчивая заменой запчастей и расходников, а затем и списанием.
Помимо этого вы упрощаете обслуживание техники и учёт расходных материалов. Программа напомнит об исчерпании ресурса принтера, о запасах картриджей для каждой модели, о количестве перезаправки б.у. картриджа и т.д.
С помощью PrintStore вы сможете понять, какие принтеры для вас наиболее экономичны, где меньше всего стоимость напечатанного листа. Думаю, что экономия может начаться, если у вас парк устройств от 10-15 штук с регулярной печатью на всех устройствах. Начиная с этого числа имеет смысл начать тратить время на учёт.
Программа написана русскоязычным автором, продаётся в РФ, есть в едином реестре российского ПО. Активно развивается уже много лет. Последняя версия от 27.04.2022.
Есть бесплатная версия со следующими ограничениями:
- максимальное количество устройств для учёта - 100 штук;
- автоматический мониторинг за расходниками устройств - 5 штук.
Как я уже сказал, программа нишевая, специфичная. Особой конкуренции и какого-то устоявшегося внешнего вида и функционала для данной сферы программ нет, так что придётся немного поразбираться во время внедрения и запуска. Но в целом каких-то особых сложностей нет. Я разобрался без проблем.
Сайт - https://perfectsoft.ru/
Реестр ПО - https://reestr.digital.gov.ru/reestr/309908/
#отечественное
{kind=link}
Раз уж я заговорил вчера о Duplicati, имеет смысл рассказать и о Duplicity. Из-за схожих названий я их иногда путаю, хотя они не сильно похожи друг на друга. Общее у них то, что обе программы поддерживают множество облачных провайдеров для хранения бэкапов. Duplicity из коробки умеет складывать данные в Amazon S3, DropBox, Microsoft Onedrive, SwiftStack и т.д. Ну и стандартные протоколы поддерживает - ssh (sftp), rsync, WebDAV, ftp и т.д.
Duplicity это тоже бесплатная open source программа, но только под Linux и только в консольном режиме. Даже статью в своё время написал про неё, так как использовал повсеместно. Пришёл в одну компанию, где её использовали. Мне понравилось, стал тоже пользоваться.
Для меня основное преимущество Duplicity в том, что она использует библиотеку librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
Duplicity обычно присутствует в стандартных репозиториях Linux систем, так что ставится через пакетный менеджер. Написана на Python, можно поставить через pip. Поддерживаются как полные, так и инкрементные бэкапы.
❗️Данные хранятся в формате tar архивов, по сути в исходном виде. Для распаковки не нужна сама Duplicity, но без неё распаковать цепочку архивов будет не очень просто.
❓Возникает резонный вопрос, а зачем нужна Duplicity, если можно использовать Rsync? Причин несколько:
- поддержка шифрования с помощью GnuPG;
- поддержка облачных сервисов (в том числе S3 совместимых) для хранения;
- возможность проверить бэкапы, посмотреть быстро список файлов в архиве;
- возможность авторотации и чистки архивов, то есть можно, к примеру, удалить одной командой все diff архивы или архивы старше какой-то даты;
- возможность быстро восстановить данные за какой-то конкретный день.
Эти возможности упрощают управления бэкапами. В случае с rsync всё это пришлось бы реализовывать в скриптах самостоятельно, так как никаких инкрементов и очистки rsync не умеет. По сути это просто прокачанный rsync со всеми его плюсами. Например, чтобы быстро найти какой-то файл в большом архиве, сделанном с помощью rsync, я в момент бэкапа создаю текстовый файл со списком всех файлов в архиве, чтобы по нему можно было быстро выполнить поиск. Duplicity делает то же самое, чтобы искать файлы, не залезая в сам архив.
Сайт - https://duplicity.gitlab.io
Исходники - https://gitlab.com/duplicity/duplicity
#backup
Duplicity это тоже бесплатная open source программа, но только под Linux и только в консольном режиме. Даже статью в своё время написал про неё, так как использовал повсеместно. Пришёл в одну компанию, где её использовали. Мне понравилось, стал тоже пользоваться.
Для меня основное преимущество Duplicity в том, что она использует библиотеку librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
Duplicity обычно присутствует в стандартных репозиториях Linux систем, так что ставится через пакетный менеджер. Написана на Python, можно поставить через pip. Поддерживаются как полные, так и инкрементные бэкапы.
❗️Данные хранятся в формате tar архивов, по сути в исходном виде. Для распаковки не нужна сама Duplicity, но без неё распаковать цепочку архивов будет не очень просто.
❓Возникает резонный вопрос, а зачем нужна Duplicity, если можно использовать Rsync? Причин несколько:
- поддержка шифрования с помощью GnuPG;
- поддержка облачных сервисов (в том числе S3 совместимых) для хранения;
- возможность проверить бэкапы, посмотреть быстро список файлов в архиве;
- возможность авторотации и чистки архивов, то есть можно, к примеру, удалить одной командой все diff архивы или архивы старше какой-то даты;
- возможность быстро восстановить данные за какой-то конкретный день.
Эти возможности упрощают управления бэкапами. В случае с rsync всё это пришлось бы реализовывать в скриптах самостоятельно, так как никаких инкрементов и очистки rsync не умеет. По сути это просто прокачанный rsync со всеми его плюсами. Например, чтобы быстро найти какой-то файл в большом архиве, сделанном с помощью rsync, я в момент бэкапа создаю текстовый файл со списком всех файлов в архиве, чтобы по нему можно было быстро выполнить поиск. Duplicity делает то же самое, чтобы искать файлы, не залезая в сам архив.
Сайт - https://duplicity.gitlab.io
Исходники - https://gitlab.com/duplicity/duplicity
#backup
{kind=link}
Делюсь с вами сокровенным. Сколько лет тружусь в IT, но так и не решил для себя один важный вопрос. Какой принтер или МФУ покупать? Всегда, когда начинает глючить какая-нибудь партия принтеров, начинаешь думать, на кого переходить. Я прошёл цикл по всем известным брендам и круг давно замкнулся.
Это как с сотовыми операторами в РФ. Когда людей в очередной раз разводят на подписки у какого-нибудь оператора, он в злобе уходит к другому, а там всё повторяется. И так по кругу, пока не попробуешь всех. Оказывается, они все мошенники. Вот и спринтерами так же, они год от года всё хуже и менее надёжные, ломучие и неремонтопригодные.
Я даже статью написал со своим опытом закупки принтеров различных брендов. В комментариях очень много дельных отзывов. В статье, кстати, не только про бренды но и в целом про выбор принтера в офис. Чем принципиально могут отличаться принтеры, на что обращать внимание при покупке и т.д. Так что советую почитать, если нет большого опыта в этом деле.
Ниже будет опрос: "Принтеры каких брендов вы предпочитаете закупать в офис для типовых задач документооборота". Интересно узнать, какой сейчас расклад по брендам среди нашей аудитории.
#разное
Это как с сотовыми операторами в РФ. Когда людей в очередной раз разводят на подписки у какого-нибудь оператора, он в злобе уходит к другому, а там всё повторяется. И так по кругу, пока не попробуешь всех. Оказывается, они все мошенники. Вот и спринтерами так же, они год от года всё хуже и менее надёжные, ломучие и неремонтопригодные.
Я даже статью написал со своим опытом закупки принтеров различных брендов. В комментариях очень много дельных отзывов. В статье, кстати, не только про бренды но и в целом про выбор принтера в офис. Чем принципиально могут отличаться принтеры, на что обращать внимание при покупке и т.д. Так что советую почитать, если нет большого опыта в этом деле.
Ниже будет опрос: "Принтеры каких брендов вы предпочитаете закупать в офис для типовых задач документооборота". Интересно узнать, какой сейчас расклад по брендам среди нашей аудитории.
#разное
{kind=link}
Принтеры каких брендов вы предпочитаете закупать в офис для типовых задач документооборота
Anonymous Poll
40%
HP
52%
Kyocera
19%
Canon
4%
Ricoh
11%
Brother
3%
Minolta
3%
Samsung
10%
Xerox
1%
Lexmark
2%
Катюша (katusha-it.ru)
⚡️ Вчера проскочила новость по пабликам, что TeamViewer перестал работать у пользователей России и Белоруссии. Я вчера вечером (5 мая 22:00) проверил у себя, реально не работает. Вот новость от самого TV.
При подключении просто получаю ошибку: "Невозможно подключиться к партнёру", без подробностей. Лично для меня некритично, так как уже несколько лет не пользуюсь TeamViewer. Думаю, что подобные истории будут продолжаться.
Очевидно, что противоречия с западом будут только нарастать. Отказываться нужно от всего, что имеет аналоги у нас уже сейчас. А если что-то аналогов не имеет, то думать, как выкручиваться. Выбора просто нет. Я совершенно не удивлюсь, если в какой-то момент будет заблокирован Youtube (вероятность оцениваю в 100%, аватарки каналов для теста уже заблочили) и прочие сервисы google. В частности, gmail. На ближайшее время (год-два) вероятность где-то в 30% оцениваю, но в долгосрочной перспективе ожидаю, что будет заблокирован gmail 100%. И не по инициативе извне.
Возвращаясь к TeamViewer. Есть огромное количество аналогов, как отечественных, так и Open Source. У меня на канале все более ли менее известные продукты можно посмотреть по тэгу #remote. Я их все тестировал. Или почитать статью с подборкой, но там не всё, что есть на канале. Надо обновлять:
✅ Топ 10 бесплатных программ для удалённого доступа
Из отечественных я бы обратил внимание на LiteManager и Ассистент. Из Open Source на Aspia и MeshCentral. Есть недорогой готовый сервис для управления через браузер - Getscreen_me (По промокоду SERVERADMIN получите не 2 бесплатных подключения, а 3. Это не реклама, мне не платили за промик, просто давно предложили для читателей такой бонус. Авторы судя по всему читают мой канал).
В настоящий момент я закончил писать платный обзор ещё одной отечественной программы для удалённого доступа. На днях будет анонс со ссылкой на статью, так что пока не буду называть. Я вообще не знал про неё, пока разработчики не написали.
Тут есть те, кто покупал лицензии TV? Работает у вас? В новости сказано, что все те, кто покупали, продолжат пользоваться, пока не истекла оплаченная лицензия, продление которой уже не состоится.
При подключении просто получаю ошибку: "Невозможно подключиться к партнёру", без подробностей. Лично для меня некритично, так как уже несколько лет не пользуюсь TeamViewer. Думаю, что подобные истории будут продолжаться.
Очевидно, что противоречия с западом будут только нарастать. Отказываться нужно от всего, что имеет аналоги у нас уже сейчас. А если что-то аналогов не имеет, то думать, как выкручиваться. Выбора просто нет. Я совершенно не удивлюсь, если в какой-то момент будет заблокирован Youtube (вероятность оцениваю в 100%, аватарки каналов для теста уже заблочили) и прочие сервисы google. В частности, gmail. На ближайшее время (год-два) вероятность где-то в 30% оцениваю, но в долгосрочной перспективе ожидаю, что будет заблокирован gmail 100%. И не по инициативе извне.
Возвращаясь к TeamViewer. Есть огромное количество аналогов, как отечественных, так и Open Source. У меня на канале все более ли менее известные продукты можно посмотреть по тэгу #remote. Я их все тестировал. Или почитать статью с подборкой, но там не всё, что есть на канале. Надо обновлять:
✅ Топ 10 бесплатных программ для удалённого доступа
Из отечественных я бы обратил внимание на LiteManager и Ассистент. Из Open Source на Aspia и MeshCentral. Есть недорогой готовый сервис для управления через браузер - Getscreen_me (По промокоду SERVERADMIN получите не 2 бесплатных подключения, а 3. Это не реклама, мне не платили за промик, просто давно предложили для читателей такой бонус. Авторы судя по всему читают мой канал).
В настоящий момент я закончил писать платный обзор ещё одной отечественной программы для удалённого доступа. На днях будет анонс со ссылкой на статью, так что пока не буду называть. Я вообще не знал про неё, пока разработчики не написали.
Тут есть те, кто покупал лицензии TV? Работает у вас? В новости сказано, что все те, кто покупали, продолжат пользоваться, пока не истекла оплаченная лицензия, продление которой уже не состоится.
{kind=link}
Media is too big
VIEW IN TELEGRAM
От утренней темы блокировок плавно переходим к тематическому пятничному юмору. В ожидании ссанкций от Microsoft что нужно делать? Правильно, ставить Linux.
Автор группы с отличной тематической музыкой на тему IT Научно-технический рэп нас в этом поддерживает.
Надо было ставить линукс.
https://www.youtube.com/watch?v=W87wOCSPA08
Мне нравятся песни этого исполнителя. Собрал их все в отдельной группе @srv_admin_humor. Я её не веду регулярно. Использую в основном сам для прослушивания музыки. Закидываю туда всё, что связано с айтишной тематикой. Собрал все песни НТР. Можете быстро и удобно скачать или перенести к себе. Если что-то забыл, дайте знать. Вроде бы всё есть.
#юмор
Автор группы с отличной тематической музыкой на тему IT Научно-технический рэп нас в этом поддерживает.
Надо было ставить линукс.
https://www.youtube.com/watch?v=W87wOCSPA08
Мне нравятся песни этого исполнителя. Собрал их все в отдельной группе @srv_admin_humor. Я её не веду регулярно. Использую в основном сам для прослушивания музыки. Закидываю туда всё, что связано с айтишной тематикой. Собрал все песни НТР. Можете быстро и удобно скачать или перенести к себе. Если что-то забыл, дайте знать. Вроде бы всё есть.
#юмор