
Попробовал вчера интересную систему мониторинга checkmk. Думал очередная система, по которой быстро напишу заметку и забуду, как это обычно бывает. Но на деле получилось немного не так.
Система мне очень понравилась. Я установил ее, посмотрел. Добавил пару агентов, изучил функционал. Как я понял, checkmk построена на базе nagios, но сильно доработана. Расскажу по порядку, на что конкретно обратил внимание.
Для теста систему можно запустить в докер. Всё упаковано в один контейнер.
# docker container run -dit -p 8080:5000 --tmpfs /opt/omd/sites/cmk/tmp:uid=1000,gid=1000 -v/omd/sites --name monitoring -v/etc/localtime:/etc/localtime:ro --restart always checkmk/check-mk-raw:2.0.0-latest
После запуска надо посмотреть пароль для доступа в web интерфейс. Он отобразится в логах запуска контейнера:
# docker logs monitoring
Переходим в веб интерфейс http://192.168.13.171:8080, логин cmkadmin, пароль из лога. Интерфейс лично мне понравился. Особенно его идея, когда ты сначала вносишь изменения, а потом подтверждаешь их. Пока не подтвердишь, изменения не применяются, как в некоторых сетевых устройствах.
На самом сервере хранятся пакеты для агентов. Для того, чтобы добавить новый хост, достаточно просто установить пакет, примерно так:
# rpm -ivh http://192.168.13.171:8080/cmk/check_mk/agents/check-mk-agent-2.0.0p12-1.noarch.rpm
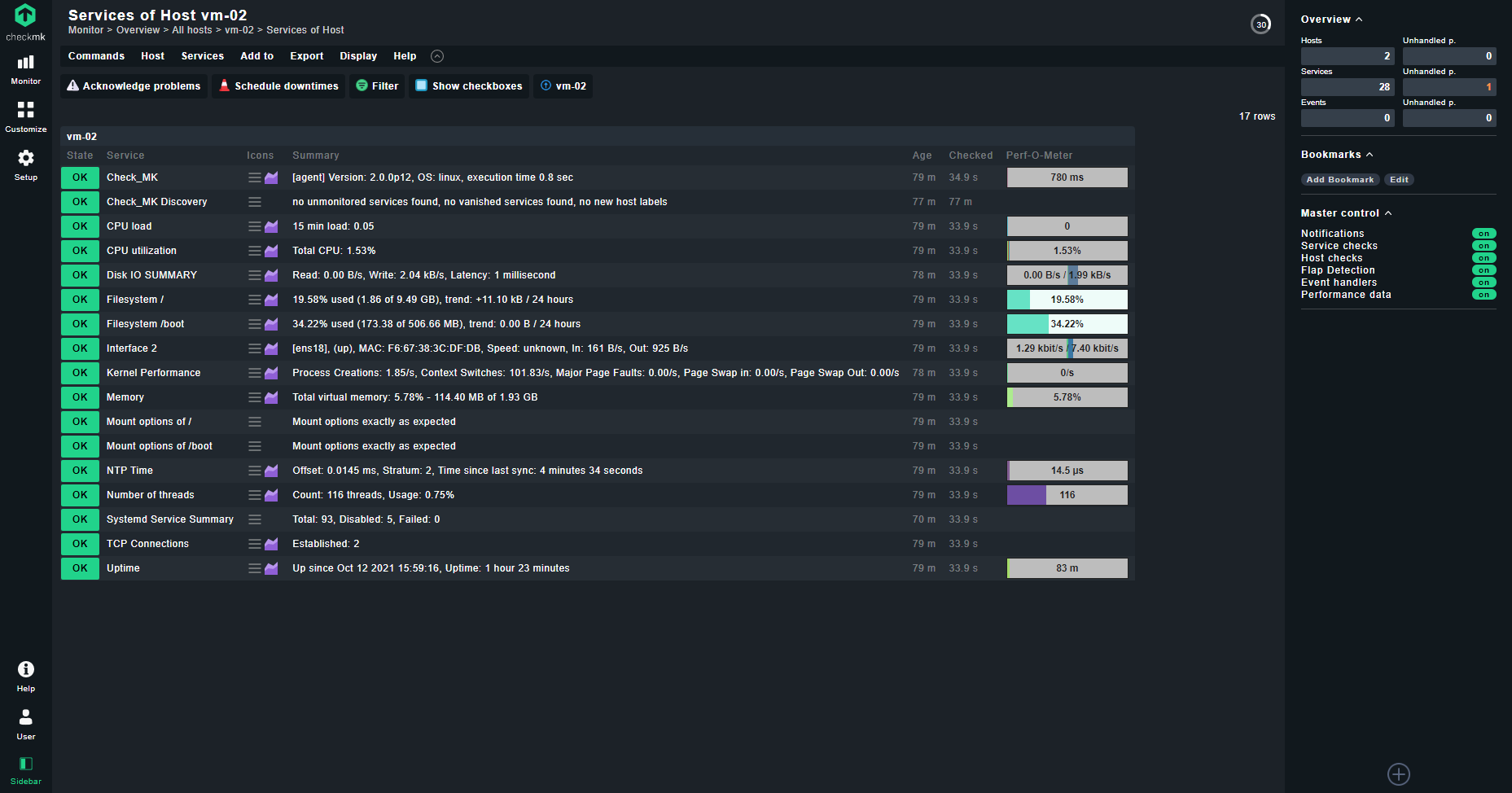
На самом хосте больше делать ничего не надо. Идём на сервер и добавляем новый хост по ip. Checkmk автоматом к нему подключается, делает базовые проверки, выставляет метки. Например, контейнер lxc он распознал и повесил две метки - Container, Linux. Так же он сам находит службы на хосте по своим встроенным правилам Discovery. Вы тут же смотрите список служб и выбираете, какие хотите поставить на мониторинг.
Мой итог такой. Система простая, удобная и функциональная. Я в течении часа ее развернул, добавил хосты, поизучал, посмотрел на графики, дашборды и т.д. То есть порог входа очень низкий. Разобраться сможет почти любой. Это одна из немногих систем, которые я рассматривал и которая мне реально понравилась. Из форков nagios показалась самой интересной.
Сайт - https://checkmk.com/
Gihub - https://github.com/tribe29/checkmk/
Dockerhub - https://hub.docker.com/r/checkmk/check-mk-raw/
#мониторинг
Система мне очень понравилась. Я установил ее, посмотрел. Добавил пару агентов, изучил функционал. Как я понял, checkmk построена на базе nagios, но сильно доработана. Расскажу по порядку, на что конкретно обратил внимание.
Для теста систему можно запустить в докер. Всё упаковано в один контейнер.
# docker container run -dit -p 8080:5000 --tmpfs /opt/omd/sites/cmk/tmp:uid=1000,gid=1000 -v/omd/sites --name monitoring -v/etc/localtime:/etc/localtime:ro --restart always checkmk/check-mk-raw:2.0.0-latest
После запуска надо посмотреть пароль для доступа в web интерфейс. Он отобразится в логах запуска контейнера:
# docker logs monitoring
Переходим в веб интерфейс http://192.168.13.171:8080, логин cmkadmin, пароль из лога. Интерфейс лично мне понравился. Особенно его идея, когда ты сначала вносишь изменения, а потом подтверждаешь их. Пока не подтвердишь, изменения не применяются, как в некоторых сетевых устройствах.
На самом сервере хранятся пакеты для агентов. Для того, чтобы добавить новый хост, достаточно просто установить пакет, примерно так:
# rpm -ivh http://192.168.13.171:8080/cmk/check_mk/agents/check-mk-agent-2.0.0p12-1.noarch.rpm
На самом хосте больше делать ничего не надо. Идём на сервер и добавляем новый хост по ip. Checkmk автоматом к нему подключается, делает базовые проверки, выставляет метки. Например, контейнер lxc он распознал и повесил две метки - Container, Linux. Так же он сам находит службы на хосте по своим встроенным правилам Discovery. Вы тут же смотрите список служб и выбираете, какие хотите поставить на мониторинг.
Мой итог такой. Система простая, удобная и функциональная. Я в течении часа ее развернул, добавил хосты, поизучал, посмотрел на графики, дашборды и т.д. То есть порог входа очень низкий. Разобраться сможет почти любой. Это одна из немногих систем, которые я рассматривал и которая мне реально понравилась. Из форков nagios показалась самой интересной.
Сайт - https://checkmk.com/
Gihub - https://github.com/tribe29/checkmk/
Dockerhub - https://hub.docker.com/r/checkmk/check-mk-raw/
#мониторинг
{kind=link}
Предлагаю к просмотру обзор программы для анализа и мониторинга сетевого трафика - Noction Flow Analyzer. Она принимает, обрабатывает данные NetFlow, sFlow, IPFIX, NetStream и BGP и визуализирует их.
Я настроил анализ трафика в своей тестовой лаборатории и разобрал основной функционал программы. Знаю, что мониторинг того, что происходит в сети - востребованный функционал. Периодически вижу вопросы на тему того, как лучше и удобнее решать эту задачу. NFA как раз делает это быстро и просто.
Для тех, кто не понимает полностью, о чем идёт речь, поясню. С помощью указанной программы можно с точностью до пакета узнать, кто, куда и что именно отправлял по сети. То есть берём какой-то конкретный ip адрес и смотрим куда и что он отправлял, какую пропускную полосу занимал. Всё это можно агрегировать по разным признакам, визуализировать, настраивать предупреждения о превышении каких-то заданных сетевых метрик.
Noction Flow Analyzer устанавливается локально с помощью deb или rpm пакетов из репозитория разработчиков. Никакой хипстоты, контейнеров, кубернетисов, облаков и saas. Программа платная с ежемесячной подпиской. Есть триал на 30 дней. Под капотом - Yandex ClickHouse.
https://serveradmin.ru/analiz-setevogo-trafika-v-noction-flow-analyzer/
#gateway #статья #netflow
Я настроил анализ трафика в своей тестовой лаборатории и разобрал основной функционал программы. Знаю, что мониторинг того, что происходит в сети - востребованный функционал. Периодически вижу вопросы на тему того, как лучше и удобнее решать эту задачу. NFA как раз делает это быстро и просто.
Для тех, кто не понимает полностью, о чем идёт речь, поясню. С помощью указанной программы можно с точностью до пакета узнать, кто, куда и что именно отправлял по сети. То есть берём какой-то конкретный ip адрес и смотрим куда и что он отправлял, какую пропускную полосу занимал. Всё это можно агрегировать по разным признакам, визуализировать, настраивать предупреждения о превышении каких-то заданных сетевых метрик.
Noction Flow Analyzer устанавливается локально с помощью deb или rpm пакетов из репозитория разработчиков. Никакой хипстоты, контейнеров, кубернетисов, облаков и saas. Программа платная с ежемесячной подпиской. Есть триал на 30 дней. Под капотом - Yandex ClickHouse.
https://serveradmin.ru/analiz-setevogo-trafika-v-noction-flow-analyzer/
#gateway #статья #netflow
Server Admin
Анализ сетевого трафика в Noction Flow Analyzer | serveradmin.ru
Подробная статья с установкой и настройкой программы для мониторинга и анализа сетевого трафика Noction Flow Analyzer.
Продолжаю тему хранения паролей для командной работы. На этот раз речь пойдет про известный сервис passbolt. У него современный веб интерфейс и стандартный набор возможностей для подобных программ:
◽ Возможность установки на своем сервере
◽ Доступ к сервису на основе пользователей и групп
◽ Импорт, экспорт в csv, xls, kdbx (формат keepass)
◽ Расширение для браузера, встроенный CLI
◽ Работа с сервисом через Open API
Passbolt есть в бесплатной редакции и платной с дополнительным набором возможностей, таких как интеграция с ldap, тэгирование записей, лог событий, поддержка и некоторые другие возможности.
Установка. Клонируем репозиторий с docker-compose:
# git clone https://github.com/passbolt/passbolt_docker
# cd passbolt_docker
Открываем файл env/passbolt.env и обязательно указываем ваш url. Без этого ничего не заработает. Я указал просто ip адрес тестовой машины:
APP_FULL_BASE_URL=https://192.168.13.171
После этого запускаем контейнеры:
# docker-compose -d docker-compose.yml up
Дожидаемся запуска и создаем администратора, не выходя из директории репозитория, откуда запущен docker-compose.
# docker-compose exec passbolt su -m -c "/usr/share/php/passbolt/bin/cake \
passbolt register_user \
-u <your@email.com> \
-f <yourname> \
-l <surname> \
-r admin" -s /bin/sh www-data
Не забудьте указать свои данные. В консоль вам будет выдана некоторая информация, в том числе ссылка, вида:
https://192.168.13.171/setup/install/27942498-8aa3-4587-b105-1092d4c0c864/e3f1dc15-1b4e-4264-84c4-e480b96bf4c1
По ней нужно пройти и активировать учётную запись. Для этого нужно будет установить официальное расширение для браузера. После этого окажитесь в системе и можете начинать ей пользоваться.
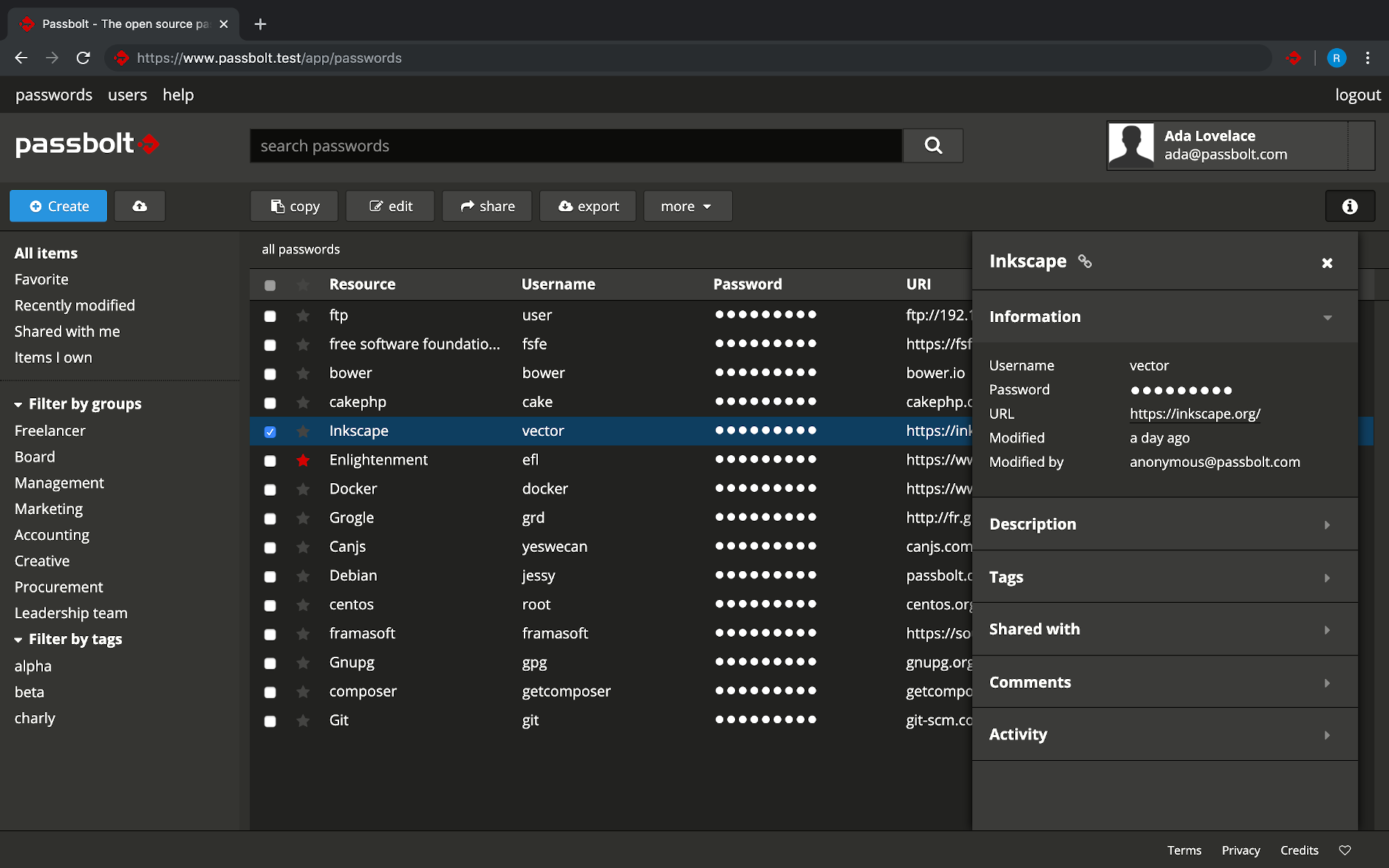
Из всех систем, что я тестировал ранее, passbolt понравился больше всего. Тут и интерфейс современный, удобный. Живой проект с большим сообществом, хорошей документацией. Есть платная версия, которая теоретически должна обеспечивать поддержку и развитие проекта.
Сайт - https://www.passbolt.com/
Github - https://github.com/passbolt/passbolt_api
Demo - https://www.passbolt.com/cloud/signup
Документация - https://help.passbolt.com/
#password
◽ Возможность установки на своем сервере
◽ Доступ к сервису на основе пользователей и групп
◽ Импорт, экспорт в csv, xls, kdbx (формат keepass)
◽ Расширение для браузера, встроенный CLI
◽ Работа с сервисом через Open API
Passbolt есть в бесплатной редакции и платной с дополнительным набором возможностей, таких как интеграция с ldap, тэгирование записей, лог событий, поддержка и некоторые другие возможности.
Установка. Клонируем репозиторий с docker-compose:
# git clone https://github.com/passbolt/passbolt_docker
# cd passbolt_docker
Открываем файл env/passbolt.env и обязательно указываем ваш url. Без этого ничего не заработает. Я указал просто ip адрес тестовой машины:
APP_FULL_BASE_URL=https://192.168.13.171
После этого запускаем контейнеры:
# docker-compose -d docker-compose.yml up
Дожидаемся запуска и создаем администратора, не выходя из директории репозитория, откуда запущен docker-compose.
# docker-compose exec passbolt su -m -c "/usr/share/php/passbolt/bin/cake \
passbolt register_user \
-u <your@email.com> \
-f <yourname> \
-l <surname> \
-r admin" -s /bin/sh www-data
Не забудьте указать свои данные. В консоль вам будет выдана некоторая информация, в том числе ссылка, вида:
https://192.168.13.171/setup/install/27942498-8aa3-4587-b105-1092d4c0c864/e3f1dc15-1b4e-4264-84c4-e480b96bf4c1
По ней нужно пройти и активировать учётную запись. Для этого нужно будет установить официальное расширение для браузера. После этого окажитесь в системе и можете начинать ей пользоваться.
Из всех систем, что я тестировал ранее, passbolt понравился больше всего. Тут и интерфейс современный, удобный. Живой проект с большим сообществом, хорошей документацией. Есть платная версия, которая теоретически должна обеспечивать поддержку и развитие проекта.
Сайт - https://www.passbolt.com/
Github - https://github.com/passbolt/passbolt_api
Demo - https://www.passbolt.com/cloud/signup
Документация - https://help.passbolt.com/
#password
{kind=link}
Я практически всегда, когда настраиваю Linux сервер, одним из первых действий меняю параметры history. Это такая штука, которая обычно не нужна, но иногда может сильно выручить. Также я всегда смотрю history, когда подключаюсь к незнакомому серверу. Так можно быстро оценить, что здесь раньше делали, особенно если за кем-то что-то переделать надо.
Изменяю следующие параметры:
◽ количество строк, которые будут храниться в истории, в файле .bash_history
◽ сохранение даты выполнения команды
◽ записывать команду в историю сразу же после её выполнения
◽ настраиваю исключения, которые не будут сохраняться в истории, чтобы не забивать список неинформативными командами
Для этого в ~/.bashrc добавляю следующие настройки:
Первый параметр увеличивает размер файла до 10000 строк. Можно сделать и больше, хотя обычно хватает такого размера. Второй параметр указывает, что необходимо сохранять дату и время выполнения команды. Третья строка вынуждает сразу же после выполнения команды сохранять ее в историю. В последней строке мы создаем список исключений для тех команд, запись которых в историю не требуется. Я привел пример самого простого списка. Можете дополнить его на свое усмотрение.
Консольная команда history запускает встроенную в оболочку утилиту. Если запустить её без параметров, то она выведет в терминал всё содержимое истории. Ограничить список можно указав число строк:
Удалить строку с указанным номером. Обычно нужно, если пароль в истории засветил.
Очистить историю команд для текущего сеанса:
В этом случае сам файл с историей не очищается и при повторном подключении вы снова увидите всю историю. Для того, чтобы окончательно очистить файл с историей, надо после очистки через ключ -с, запустить еще и запись пустого списка:
Но тут опять есть нюанс. В истории останется последняя команда с очисткой. Чтобы гарантированно удалить всю историю и не оставить следов, можно сделать так:
При этом стоит помнить, что запуск команд в командной строке MC не попадает в общую историю, а записывается в историю самого MC. Она живет в /root/.local/share/mc/history. Если будете чистить историю, не забудьте и туда заглянуть.
А для того, чтобы команда не попала в history, можно перед ней поставить пробел. Она исполнится как обычно, но в историю не попадёт.
#bash #terminal
Изменяю следующие параметры:
◽ количество строк, которые будут храниться в истории, в файле .bash_history
◽ сохранение даты выполнения команды
◽ записывать команду в историю сразу же после её выполнения
◽ настраиваю исключения, которые не будут сохраняться в истории, чтобы не забивать список неинформативными командами
Для этого в ~/.bashrc добавляю следующие настройки:
export HISTSIZE=10000export HISTTIMEFORMAT="%h %d %H:%M:%S "PROMPT_COMMAND='history -a'export HISTIGNORE="ls:ll:history:w:htop:pwd"Первый параметр увеличивает размер файла до 10000 строк. Можно сделать и больше, хотя обычно хватает такого размера. Второй параметр указывает, что необходимо сохранять дату и время выполнения команды. Третья строка вынуждает сразу же после выполнения команды сохранять ее в историю. В последней строке мы создаем список исключений для тех команд, запись которых в историю не требуется. Я привел пример самого простого списка. Можете дополнить его на свое усмотрение.
Консольная команда history запускает встроенную в оболочку утилиту. Если запустить её без параметров, то она выведет в терминал всё содержимое истории. Ограничить список можно указав число строк:
# history 10Удалить строку с указанным номером. Обычно нужно, если пароль в истории засветил.
# history -d 5Очистить историю команд для текущего сеанса:
# history -сВ этом случае сам файл с историей не очищается и при повторном подключении вы снова увидите всю историю. Для того, чтобы окончательно очистить файл с историей, надо после очистки через ключ -с, запустить еще и запись пустого списка:
# history -wНо тут опять есть нюанс. В истории останется последняя команда с очисткой. Чтобы гарантированно удалить всю историю и не оставить следов, можно сделать так:
# cat /dev/null > ~/.bash_history && history -c && exitПри этом стоит помнить, что запуск команд в командной строке MC не попадает в общую историю, а записывается в историю самого MC. Она живет в /root/.local/share/mc/history. Если будете чистить историю, не забудьте и туда заглянуть.
А для того, чтобы команда не попала в history, можно перед ней поставить пробел. Она исполнится как обычно, но в историю не попадёт.
#bash #terminal
{kind=link}
Media is too big
VIEW IN TELEGRAM
Вторая часть приключений сисадмина Васи и Гипермена. В новой серии герои сталкиваются с миром виртуализации. Узнайте, что было дальше в видео.
👉 https://clck.ru/Y8ZoY
#реклама #гипермен
👉 https://clck.ru/Y8ZoY
#реклама #гипермен
Друзья, несмотря на то, что сегодня пятничный вечер, видео будет грустное 😂 Автор затронул очень болезненную тему - Почему НЕ СТОИТ работать СИСАДМИНОМ!. С его слов он проработал сисадмином 5 лет и вот к чему пришёл. Предлагаю обсудить озвученное.
Видео хоть и не смешное, но я смеялся во время просмотра. Как вам такая озвученная аллегория отношений сисадмина и юзеров:
"Представь, что ты живешь в хрущёвке, а твои соседи вокруг сплошные алкаши. По моральному воздействию это примерно одно и то же."
Автор назвал 5 минусов профессии сисадмина и пообещал за 2 минуты убедить слушателя, почему ему не стоит связываться с этой работой. И вы знаете, он меня убедил. Не хочу больше работать офисным сисадмином.
https://www.youtube.com/watch?v=4iXXEgFo1og
#юмор #грусть #тоска #печаль
Видео хоть и не смешное, но я смеялся во время просмотра. Как вам такая озвученная аллегория отношений сисадмина и юзеров:
"Представь, что ты живешь в хрущёвке, а твои соседи вокруг сплошные алкаши. По моральному воздействию это примерно одно и то же."
Автор назвал 5 минусов профессии сисадмина и пообещал за 2 минуты убедить слушателя, почему ему не стоит связываться с этой работой. И вы знаете, он меня убедил. Не хочу больше работать офисным сисадмином.
https://www.youtube.com/watch?v=4iXXEgFo1og
#юмор #грусть #тоска #печаль
YouTube
Почему НЕ СТОИТ работать СИСАДМИНОМ!
про работу сисадмином полная правда жизни
Существует любопытная консольная утилита для пинга хостов - gping. Казалось бы, что тут можно придумать. Утилита ping есть почти во всех системах и работает примерно одинаково. Что еще можно ожидать от обычного пинга?
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
{kind=link}
Многие наверно слышали про разногласия между Elastic и Amazon, в результате чего последний сделал форк ELK Stack на момент действия старой лицензии и начал развивать свой продукт на его основе - OpenSearch. Причём это не то же самое, что они уже ранее анонсировали и поддерживают - Open Distro. Поясню своими словами, так как сам до конца не понимал, что там к чему.
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
{kind=link}
На неделе прослушал интересный доклад с HighLoad ++ 2021 - MySQL orchestrator, ProxySQL от Ситимобил. Тема актуальна только для очень нагруженных сервисов, где много MySQL серверов в кластере, но тем не менее мне понравилось, хоть и вряд ли когда-то пригодится. Качественный рассказ и построение повествования.
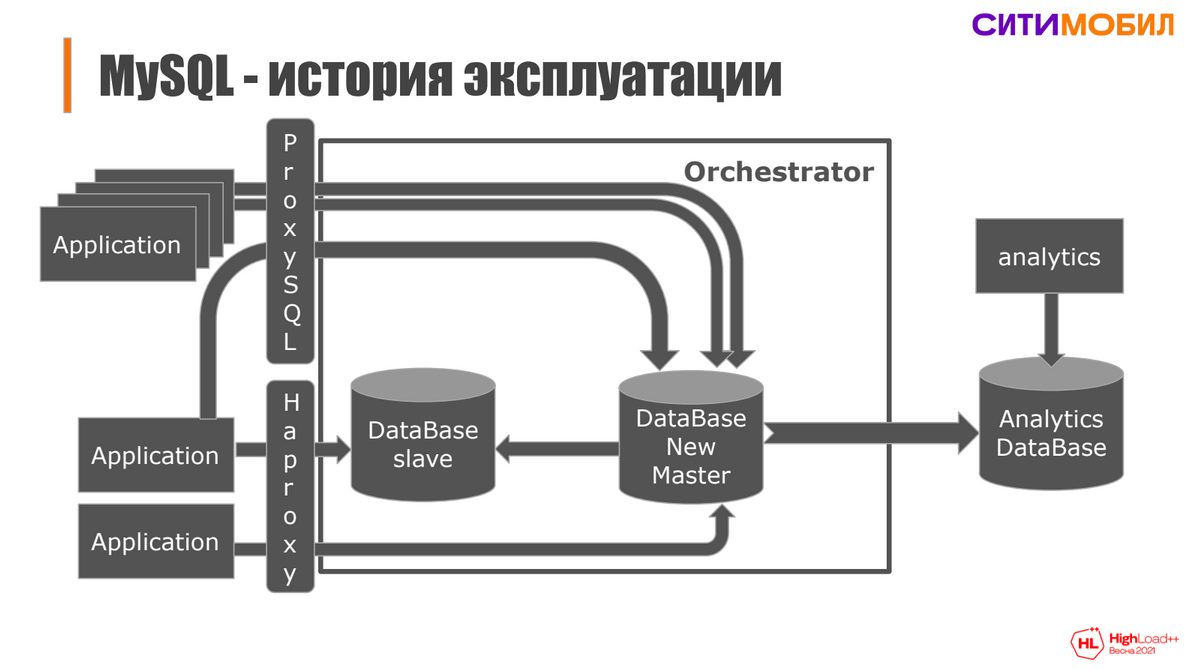
Авторы рассказали всю историю поддержки MySQL сервера с одиночного инстанса на старте проекта до довольно сложной структуры. Особенность их схемы в том, что они очень хотели оставить только один Master сервер, не выстраивая Master-Master репликацию. В итоге у них всё получилось. Есть один Master сервер, очень много Slave серверов. А у различных веб приложений свои персональные ProxySQL, которые сглаживают пики запросов, кэшируют и всячески оберегают Master от большой нагрузки.
Видео рекомендую для общего развития. Прошу заметить, что никакого Кубера, хотя им в конце прямо задали вопрос, как вы запускаете свои ProxySQL инстансы, в отдельных подах? Но нет, у них они на железе работают.
Видео - https://www.youtube.com/watch?v=YvbELUvqLm8
Презентация - https://drive.google.com/file/d/1zyC9JLiiRGHuKHmMzPAQu52B0XwIw4o7/view
#видео #mysql
Авторы рассказали всю историю поддержки MySQL сервера с одиночного инстанса на старте проекта до довольно сложной структуры. Особенность их схемы в том, что они очень хотели оставить только один Master сервер, не выстраивая Master-Master репликацию. В итоге у них всё получилось. Есть один Master сервер, очень много Slave серверов. А у различных веб приложений свои персональные ProxySQL, которые сглаживают пики запросов, кэшируют и всячески оберегают Master от большой нагрузки.
Видео рекомендую для общего развития. Прошу заметить, что никакого Кубера, хотя им в конце прямо задали вопрос, как вы запускаете свои ProxySQL инстансы, в отдельных подах? Но нет, у них они на железе работают.
Видео - https://www.youtube.com/watch?v=YvbELUvqLm8
Презентация - https://drive.google.com/file/d/1zyC9JLiiRGHuKHmMzPAQu52B0XwIw4o7/view
#видео #mysql
{kind=link}
Год назад я написал подробную статью на тему Построения ИТ инфраструктуры небольшого офиса. С тех пор аудитория канала выросла почти в полтора раза, так что многие ее не видели. Плюс, накопилось достаточно много подробных и содержательных комментариев, которые тоже могут быть полезны. Постарался на все вопросы дать подробные ответы.
В статье я рассматриваю выбор следующих продуктов:
◽ Шлюз: стандартная ОС Linux, сборка на базе какой-то ОС, железное решение.
◽ Железо для сервера: бренд, самосбор.
◽ Гипервизор: VMWare, Hyper-V, KVM, XenServer.
◽ Почтовый сервер: свой сервер, готовая сборка, публичный сервис.
◽ Сервер телефонии: Asterisk, Freepbx, готовое софтовое решение, аппаратное решение, публичный сервис.
◽ Self-hosted чат: Zulip, Mattermost, Matrix Synapse, MyChat.
◽ Cистема мониторинга.
◽ Сбор и хранение логов.
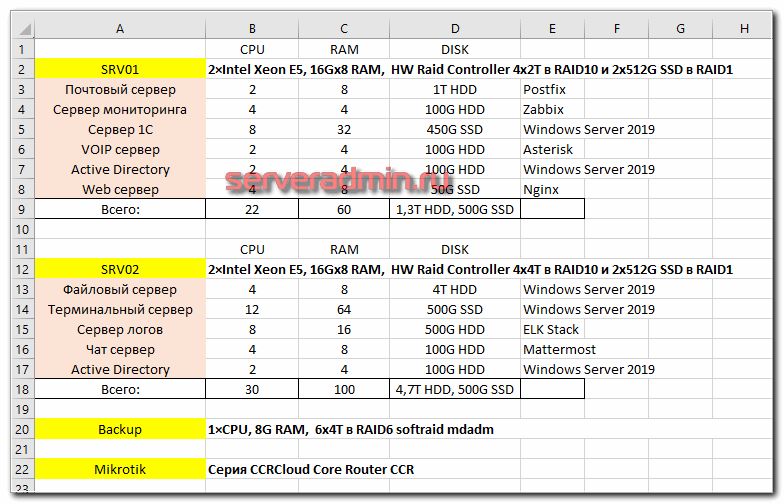
В завершении привожу пример подбора железа с конкретными техническими характеристиками и разбивку его на виртуальные машины для настройки типового функционала.
https://serveradmin.ru/postroenie-it-infrastruktury-nebolshogo-ofisa/
В статье я рассматриваю выбор следующих продуктов:
◽ Шлюз: стандартная ОС Linux, сборка на базе какой-то ОС, железное решение.
◽ Железо для сервера: бренд, самосбор.
◽ Гипервизор: VMWare, Hyper-V, KVM, XenServer.
◽ Почтовый сервер: свой сервер, готовая сборка, публичный сервис.
◽ Сервер телефонии: Asterisk, Freepbx, готовое софтовое решение, аппаратное решение, публичный сервис.
◽ Self-hosted чат: Zulip, Mattermost, Matrix Synapse, MyChat.
◽ Cистема мониторинга.
◽ Сбор и хранение логов.
В завершении привожу пример подбора железа с конкретными техническими характеристиками и разбивку его на виртуальные машины для настройки типового функционала.
https://serveradmin.ru/postroenie-it-infrastruktury-nebolshogo-ofisa/
{kind=link}
▶️ Делюсь с вами наглядным видео по настройке общего хранилища iso образов для кластера proxmox. Технически ничего сложного в этом нет и в видео это хорошо видно. Мне понравилось другое. Автор последовательно, на практике, показал и объяснил, зачем нужно общее хранилище не только для образов, но и для виртуальных машин. Как работает репликация и как локальные хранилища не дают ей состояться. Плюс, все это делается на работающих хостах. То есть идёт не просто рассказ, а наглядная демонстрация с рабочей машины автора и на его серверах.
https://www.youtube.com/watch?v=f1g_Vll8GAk
#proxmox #видео
https://www.youtube.com/watch?v=f1g_Vll8GAk
#proxmox #видео
YouTube
Proxmox + NFS сервер - внешнее хранилище для iso и дисков
Поднимем внешнее хранилище для iso, контейнеров и дисков для ВМ. решим проблему привязки к конкретной ноде, дублирование iso-образов.
Курс посвящен: "Proxmox: храним и бекапим"
Полностью курс доступен в нашей онлайн-школе
https://realmanual.ru/proxmox2
…
Курс посвящен: "Proxmox: храним и бекапим"
Полностью курс доступен в нашей онлайн-школе
https://realmanual.ru/proxmox2
…
Проверил и актуализировал свою статью про настройку ELK Stack. Добавил информацию про автоматическую очистку индексов встроенными средствами стэка. А также про авторизацию с помощью паролей средствами X-Pack Security.
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Server Admin
Установка и настройка Elasticsearch, Logstash, Kibana (ELK Stack)
Подробное описание установки ELK Stack - Elasticsearch, Logstash, Kibana для централизованного сбора логов.
Корпоративные телеграм-каналы - это не всегда унылая новостная лента. Пример тому - канал из мира IT «Салатовая телега». Ведёт его российский облачный провайдер DataLine.
Авторы на своем опыте рассказывают о работе с инфраструктурой VMware, миграции ИТ-систем и даже о том, как самим собрать и запустить радио.
А еще постят вакансии, проводят бесплатные вебинары (следующий по DBaaS) и квизы с призами - можно отхватить себе классный салатовый мерч.
Присоединяйтесь и будьте в курсе всего самого актуального из мира облаков и дата-центров!
👉🏼 https://t.me/unidataline
#реклама
Авторы на своем опыте рассказывают о работе с инфраструктурой VMware, миграции ИТ-систем и даже о том, как самим собрать и запустить радио.
А еще постят вакансии, проводят бесплатные вебинары (следующий по DBaaS) и квизы с призами - можно отхватить себе классный салатовый мерч.
Присоединяйтесь и будьте в курсе всего самого актуального из мира облаков и дата-центров!
👉🏼 https://t.me/unidataline
#реклама
{kind=link}
Простая и современная утилита для шифрования данных - age. Написана в духе Unix-style. Никаких конфигов. Всё управление ключами. Для шифрования используется связка приватного и публичного ключа.
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
{kind=link}
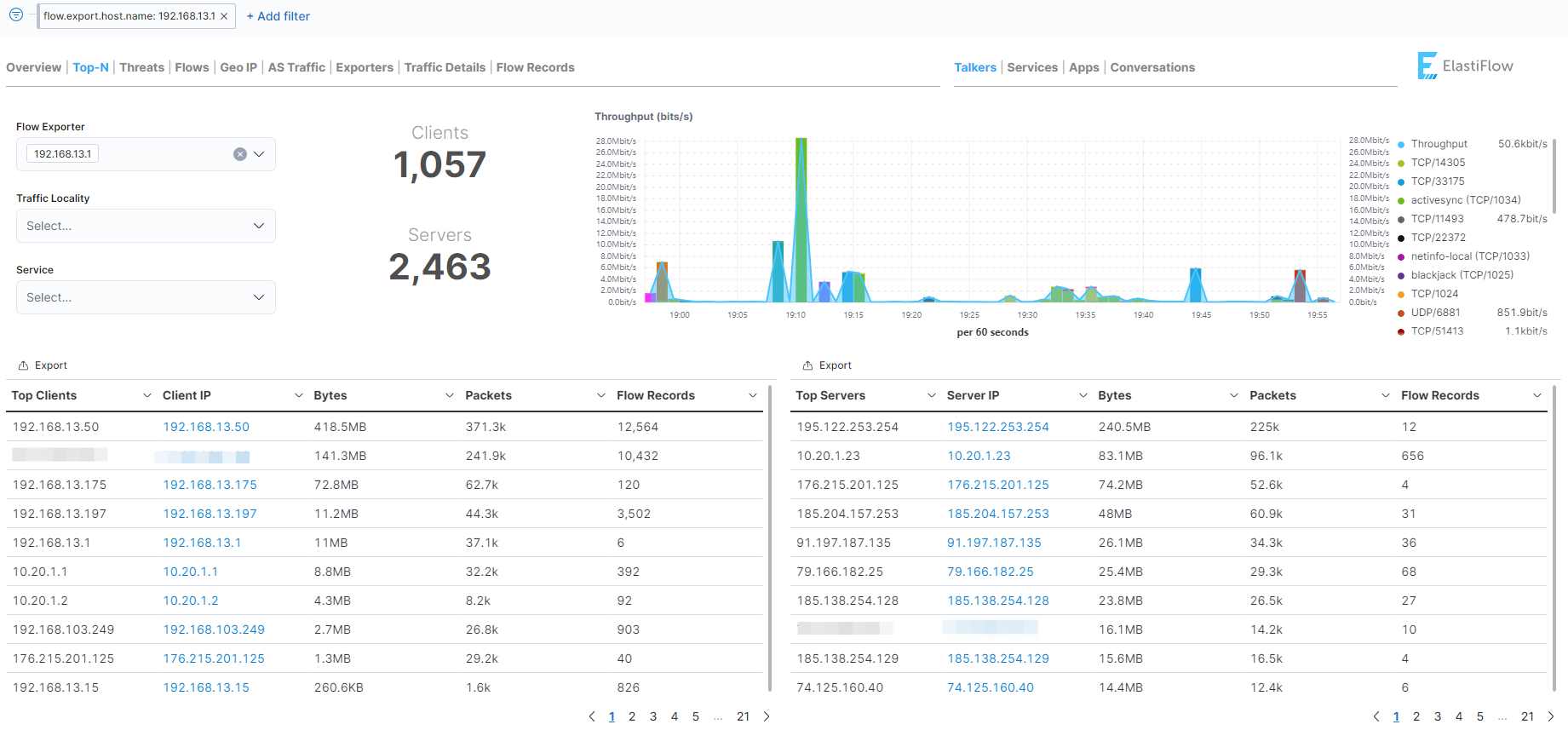
Пока у меня остался свежий стенд с ELK Stack, решил попробовать софт для разбора NetFlow потоков в Elasticsearch - Elastiflow. Идея там такая. Ставите куда угодно коллектор, который собирает NetFlow и принимаете трафик. А этот коллектор передаёт всю информацию в Elasticsearch. В комплекте с Elastiflow идёт все необходимое для визуализации данных - шаблоны, дашборды для Kibana.
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
{kind=link}
Я уже неоднократно писал, что в качестве сервера для совместного редактирования документов обычно использую Onlyoffice, если получается вписаться в его бесплатные лимиты. Написал несколько статей по этой теме.
Вчера была рассылка, в которой упоминалось про обновление Android приложения для работы с документами. Я решил попробовать. Раньше даже не пытался это сделать. Установил приложение, подключился к своему порталу. Работает все очень неплохо. Понятно, что со смартфона редактировать документы и тем более таблицы не очень удобно просто в силу маленького размера экрана. Но если надо что-то поправить и посмотреть, то никаких проблем.
Так что имейте ввиду, если кому-то нужен подобный функционал. Onlyoffice хороший self-hosted продукт для использования приватного сервера документов. Не без проблем и глюков, но лучше все равно ничего нет.
#onlyoffice
Вчера была рассылка, в которой упоминалось про обновление Android приложения для работы с документами. Я решил попробовать. Раньше даже не пытался это сделать. Установил приложение, подключился к своему порталу. Работает все очень неплохо. Понятно, что со смартфона редактировать документы и тем более таблицы не очень удобно просто в силу маленького размера экрана. Но если надо что-то поправить и посмотреть, то никаких проблем.
Так что имейте ввиду, если кому-то нужен подобный функционал. Onlyoffice хороший self-hosted продукт для использования приватного сервера документов. Не без проблем и глюков, но лучше все равно ничего нет.
#onlyoffice
{kind=link}
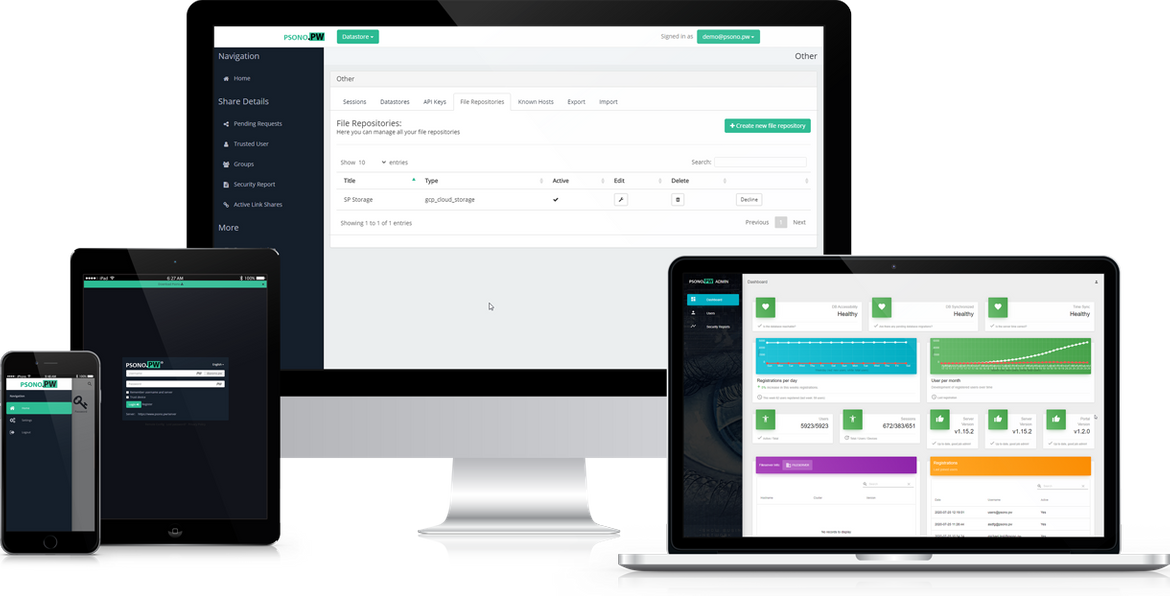
Продолжаю обзор бесплатных self-hosted решений для командной работы с паролями. Сегодня речь пойдёт о psono. Я много раз слышал его упоминание в комментариях к предыдущим статьям этой серии, так что решил посмотреть на него.
Это полностью open source проект. Доступны исходники мобильных и обычных клиентов, а также сервера. Есть 2 редакции: Community Edition (CE) и Enterprise Edition (EE). Первая без ограничений, но функционал беден. Нет ни интеграции ldap, ни логов аудита. Редакция EE все это имеет, но бесплатна только для 10-ти пользователей. Дальше уже нужно лицензии на каждого пользователя приобретать.
Из особенностей psono я заметил возможность встроенной интеграции с файловым хранилищем на базе различных технологий (s3, ftp, sftp и т.д.) для хранения зашифрованных файлов. Причём можно не только подключать что-то стороннее, но и поднимать свой psonofileserver с функционалом HA и Failover. Было удивительно всё это видеть в данном продукте. Если кто-то все это настраивал и использовал, то скажите, что это за решение. В чём его смысл и стоит ли пользоваться. Я не стал тратить время на его настройку и проверку.
Второй полезной особенностью является встроенная интеграция с сервисом haveibeenpwned.com, который позволяет автоматически проверять ваши пароли на нахождение в публичных базах.
Сам psono достаточно просто поднимается в Docker. Но перед этим ему нужна будет база данных Postgres. Я сначала начал всё это настраивать у себя, но когда поднял сервер, понял, что он выполняет роль только бэкенда. Далее нужно ставить отдельно клиент для администрирования (веб панель) и для пользователей (веб панель или приложение). Понял, что муторно всё это делать, и пошел регистрироваться в Demo. Там и посмотрел, как всё выглядит на практике.
Сначала прохладно отнёсся к psono, но потом, когда вник в его структуру и особенности, он мне показался весьма интересным. Распределённая структура приложения будет скорее плюсом, чем минусом, особенно для больших распределённых команд. Удобнее настроить и ограничить доступ. Да и в целом разделение бэкенда и фронта для подобного продукта выглядит разумным подходом.
Сайт - https://psono.com/
Документация - https://doc.psono.com/
DockerHub - https://hub.docker.com/r/psono/psono-server/
Исходники - https://gitlab.com/psono
Demo - https://www.psono.pw/
#password #selfhosted
Это полностью open source проект. Доступны исходники мобильных и обычных клиентов, а также сервера. Есть 2 редакции: Community Edition (CE) и Enterprise Edition (EE). Первая без ограничений, но функционал беден. Нет ни интеграции ldap, ни логов аудита. Редакция EE все это имеет, но бесплатна только для 10-ти пользователей. Дальше уже нужно лицензии на каждого пользователя приобретать.
Из особенностей psono я заметил возможность встроенной интеграции с файловым хранилищем на базе различных технологий (s3, ftp, sftp и т.д.) для хранения зашифрованных файлов. Причём можно не только подключать что-то стороннее, но и поднимать свой psonofileserver с функционалом HA и Failover. Было удивительно всё это видеть в данном продукте. Если кто-то все это настраивал и использовал, то скажите, что это за решение. В чём его смысл и стоит ли пользоваться. Я не стал тратить время на его настройку и проверку.
Второй полезной особенностью является встроенная интеграция с сервисом haveibeenpwned.com, который позволяет автоматически проверять ваши пароли на нахождение в публичных базах.
Сам psono достаточно просто поднимается в Docker. Но перед этим ему нужна будет база данных Postgres. Я сначала начал всё это настраивать у себя, но когда поднял сервер, понял, что он выполняет роль только бэкенда. Далее нужно ставить отдельно клиент для администрирования (веб панель) и для пользователей (веб панель или приложение). Понял, что муторно всё это делать, и пошел регистрироваться в Demo. Там и посмотрел, как всё выглядит на практике.
Сначала прохладно отнёсся к psono, но потом, когда вник в его структуру и особенности, он мне показался весьма интересным. Распределённая структура приложения будет скорее плюсом, чем минусом, особенно для больших распределённых команд. Удобнее настроить и ограничить доступ. Да и в целом разделение бэкенда и фронта для подобного продукта выглядит разумным подходом.
Сайт - https://psono.com/
Документация - https://doc.psono.com/
DockerHub - https://hub.docker.com/r/psono/psono-server/
Исходники - https://gitlab.com/psono
Demo - https://www.psono.pw/
#password #selfhosted
{kind=link}
В мире Unix и Linux существует полезная утилита at, о которой многие даже не слышали. Я редко где-то вижу, чтобы её использовали. Сам я с ней знаком еще со времён Freebsd. Это планировщик наподобие cron, используется только для разовых задач.
Например, с помощью at можно запланировать откат правил фаервола через 5 минут, если что-то пошло не так. Именно для этой задачи я с at и познакомился, пока не узнал, что в Freebsd есть встроенный скрипт change_rules.sh для безопасной настройки правил ipfw.
Для того, чтобы планировщик at работал, должен быть запущен демон atd. Проверить можно через systemd:
Создание задания на выполнение в 20:07:
Дальше откроется простая оболочка, где можно ввести текст. Напишите команду, которую хотите выполнить:
Затем нажмите ctrl+shift+d для сохранения задания. Получите об этом информацию:
Можно автоматом создать эту же задачу одной командой через pipe:
Посмотреть очередь задач можно так:
Подробности задачи:
Удалить задачу:
Когда будете писать команды, используйте полные пути к бинарникам, чтобы не было проблем с несуществующим path. Лог выполненных команд можно посмотреть там же, куда стекаются логи cron. По крайней мере в Centos.
Утилиту at любят использовать всякие зловреды, чтобы маскировать свою деятельность. Про cron все знают и помнят, поэтому сразу туда идут проверять подозрительную активность. А вместо этого вирус может насоздавать кучу задач at, которые не сразу догадаются посмотреть.
Я, когда подключаюсь к незнакомым серверам, чаще всего сразу проверяю очередь заданий atq. Мало ли, какие там сюрпризы могут быть.
С помощью файлов /etc/at.allow и /etc/at.deny можно ограничивать список пользователей, которым разрешено использовать at.
#terminal
Например, с помощью at можно запланировать откат правил фаервола через 5 минут, если что-то пошло не так. Именно для этой задачи я с at и познакомился, пока не узнал, что в Freebsd есть встроенный скрипт change_rules.sh для безопасной настройки правил ipfw.
Для того, чтобы планировщик at работал, должен быть запущен демон atd. Проверить можно через systemd:
# systemctl status atdСоздание задания на выполнение в 20:07:
# at 20:07Дальше откроется простая оболочка, где можно ввести текст. Напишите команду, которую хотите выполнить:
at> /usr/bin/echo "Hello" > /tmp/hello.txtЗатем нажмите ctrl+shift+d для сохранения задания. Получите об этом информацию:
at> <EOT>job 6 at Wed Oct 20 20:07:00 2021Можно автоматом создать эту же задачу одной командой через pipe:
echo '/usr/bin/echo "Hello" > /tmp/hello.txt' | at 20:55Посмотреть очередь задач можно так:
# atqПодробности задачи:
# at -c 7Удалить задачу:
# atrm 7Когда будете писать команды, используйте полные пути к бинарникам, чтобы не было проблем с несуществующим path. Лог выполненных команд можно посмотреть там же, куда стекаются логи cron. По крайней мере в Centos.
Утилиту at любят использовать всякие зловреды, чтобы маскировать свою деятельность. Про cron все знают и помнят, поэтому сразу туда идут проверять подозрительную активность. А вместо этого вирус может насоздавать кучу задач at, которые не сразу догадаются посмотреть.
Я, когда подключаюсь к незнакомым серверам, чаще всего сразу проверяю очередь заданий atq. Мало ли, какие там сюрпризы могут быть.
С помощью файлов /etc/at.allow и /etc/at.deny можно ограничивать список пользователей, которым разрешено использовать at.
#terminal
{kind=link}
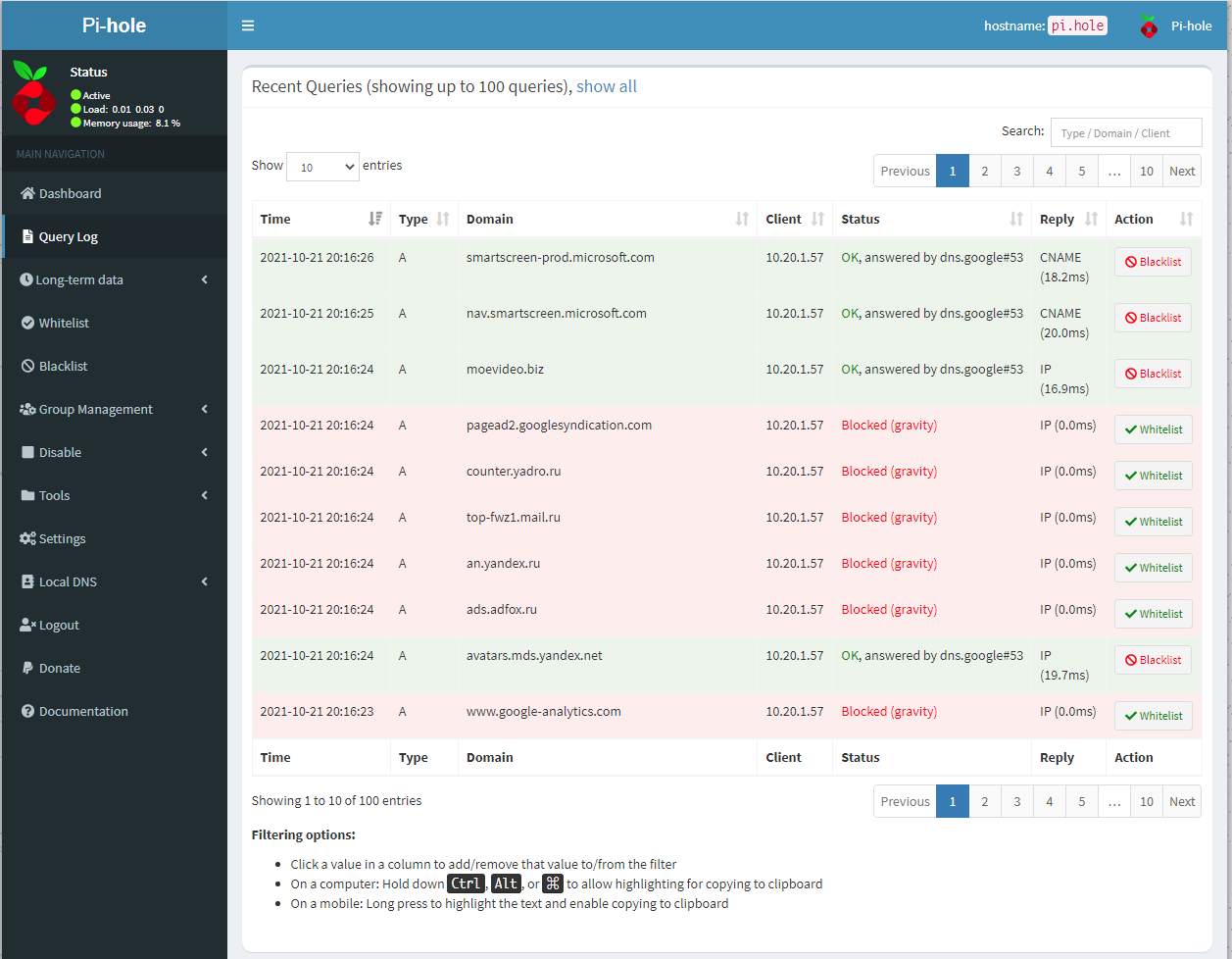
Есть простой и эффективный фильтрующий DNS сервер Pi-hole. Построен на базе известного dnsmasq. Pi-hole вполне можно использовать для реализации функций dns и dhcp сервера с удобным веб интерфейсом.
Основная задумка Pi-hole - фильтрация dns запросов для блокировки рекламы. Я прохладно отношусь к подобным решениям на базе DNS. Если что-то будет глючить на сайте из-за блокировки, нельзя быстро настроить исключение. Надо либо dns сервер менять, либо идти в настройки сервера и разбираться, что именно приводит к проблемам.
Pi-hole имеет очень удобный веб интерфейс. Его даже без блокировки рекламы имеет смысл использовать, если нужен функционал dns сервера с удобным управлением. Запускать проще всего в Docker. Буквально за одну команду всё стартует и начинает работать. Есть готовый скрипт для этого.
Подобные решения удобно использовать, чтобы быстро понять, куда в сеть обращается программа или устройство. Запускаете контейнер с Pi-hole, назначаете его в качестве dns на целевой машине. Потом в веб интерфейсе проверяете все dns запросы.
Такой же функционал есть у adguard. Тестировал его. Запускается тоже очень быстро и просто в контейнере. Лично мне веб интерфейс Pi-hole понравился больше.
Сайт - https://pi-hole.net/
Исходники - https://github.com/pi-hole/pi-hole
Основная задумка Pi-hole - фильтрация dns запросов для блокировки рекламы. Я прохладно отношусь к подобным решениям на базе DNS. Если что-то будет глючить на сайте из-за блокировки, нельзя быстро настроить исключение. Надо либо dns сервер менять, либо идти в настройки сервера и разбираться, что именно приводит к проблемам.
Pi-hole имеет очень удобный веб интерфейс. Его даже без блокировки рекламы имеет смысл использовать, если нужен функционал dns сервера с удобным управлением. Запускать проще всего в Docker. Буквально за одну команду всё стартует и начинает работать. Есть готовый скрипт для этого.
Подобные решения удобно использовать, чтобы быстро понять, куда в сеть обращается программа или устройство. Запускаете контейнер с Pi-hole, назначаете его в качестве dns на целевой машине. Потом в веб интерфейсе проверяете все dns запросы.
Такой же функционал есть у adguard. Тестировал его. Запускается тоже очень быстро и просто в контейнере. Лично мне веб интерфейс Pi-hole понравился больше.
Сайт - https://pi-hole.net/
Исходники - https://github.com/pi-hole/pi-hole
{kind=link}
Как на самом деле пишется и проверяется код в больших технологичных компаниях? Ответ в видео.
https://www.youtube.com/watch?v=rR4n-0KYeKQ
Для тех, кто не понял, поясню. Чувак (junior) что-то накодил, но его код не проходил один тест. Он просто удалил этот тест, а тот, кто должен был проверять его работу (senior), не обратил внимание, что тестов стало на один меньше.
Нет теста, нет ошибки, нет проблемы.
LGTM = Looks good to me.
#юмор
https://www.youtube.com/watch?v=rR4n-0KYeKQ
Для тех, кто не понял, поясню. Чувак (junior) что-то накодил, но его код не проходил один тест. Он просто удалил этот тест, а тот, кто должен был проверять его работу (senior), не обратил внимание, что тестов стало на один меньше.
Нет теста, нет ошибки, нет проблемы.
LGTM = Looks good to me.
#юмор
YouTube
how we write/review code in big tech companies
📱 SOCIAL MEDIA
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
https://www.instagram.com/jomakaze/
https://twitter.com/jomakaze
https://www.facebook.com/jomakaze
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
https://www.instagram.com/jomakaze/
https://twitter.com/jomakaze
https://www.facebook.com/jomakaze