
Audio
Понравилась частушка одна, закинул ее в текстовом виде в мой канал с подборкой юмора на it тематику @srv_admin_humor.
Сквозь пайплайн проплыл коммит,
"Simlpe fix" (c) Kukueva.
Весь продакшн уложила,
Одна строчка x*ева.
Один подписчик прислал озвучку этого текста. По-моему, получилось прикольно.
#юмор
Сквозь пайплайн проплыл коммит,
"Simlpe fix" (c) Kukueva.
Весь продакшн уложила,
Одна строчка x*ева.
Один подписчик прислал озвучку этого текста. По-моему, получилось прикольно.
#юмор
Решил понемногу переезжать на Debian там, где относительно безопасно можно обновлять версию релизов. Например, в файловых серверах. Создал виртуальную машину с диском на 4Tb и поставил туда Debian.
Сделал дефолтную установку с автоматической разбивкой диска, когда только один корневой раздел. Перезагружаюсь и попадаю в grub rescue. Удивился. Подумал, что наверное установщик не добавил раздел bios_boot. Выполнил еще раз установку и убедился, что раздел на месте, а grub установлен на диск. Но после установки система все равно не грузится с диска, хотя на вид все было сделано правильно. Начал разбираться.
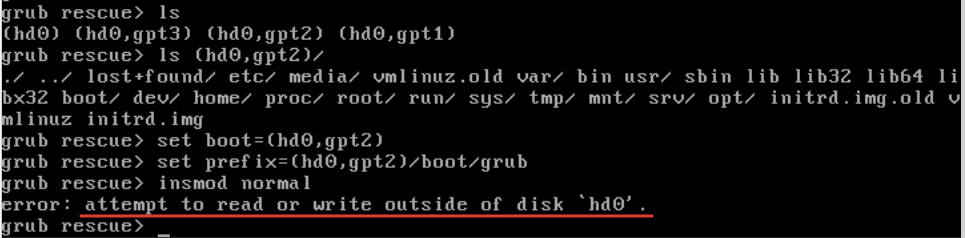
В целом, я понимаю, что надо делать в grub rescue, так как много раз сталкивался и успешно решал проблемы загрузки системы. Есть статья на эту тему. Проверяем список разделов вручную и пытаемся загрузиться с раздела, где живет grub. Выполняю в консоли:
Вижу, что это системный раздел, где живет в том числе и /boot. Указываю его загрузочным и пытаюсь с него загрузиться.
Получаю ошибку:
error: attempt to read or write outside of disk hd0
Гугл быстро выдал решение. Нужно /boot раздел сделать отдельно самым первым. Из-за того, что системный диск большой, а boot на нем, возникает эта ошибка. Смысл понятен, не понятно только, что за глюк. Почему эта ошибка в принципе существует, а установщик не может ее автоматически пофиксить.
Запустил еще раз установку, сам разбил диск, отдав под /boot первый гигабайт диска, остальное в единый раздел 4Tb под корень / . Система успешно установилась и загрузилась после установки.
Сейчас не буду придумывать, что в Centos такой проблемы нет с автоматической разбивкой, не проверял. Я не помню, делал ли там большие диски одним разделом. Такие виртуалки не так часто нужны. А еще я частенько делаю системный раздел небольшого размера, а уже потом отдельно монтирую большой диск под данные. Но то, что Debian автоматически не разруливает эту ситуацию, для меня странно. Фикс этой ошибки не такой уж и очевидный и требует уверенных знаний Linux для быстрого решения.
#grub #ошибка
Сделал дефолтную установку с автоматической разбивкой диска, когда только один корневой раздел. Перезагружаюсь и попадаю в grub rescue. Удивился. Подумал, что наверное установщик не добавил раздел bios_boot. Выполнил еще раз установку и убедился, что раздел на месте, а grub установлен на диск. Но после установки система все равно не грузится с диска, хотя на вид все было сделано правильно. Начал разбираться.
В целом, я понимаю, что надо делать в grub rescue, так как много раз сталкивался и успешно решал проблемы загрузки системы. Есть статья на эту тему. Проверяем список разделов вручную и пытаемся загрузиться с раздела, где живет grub. Выполняю в консоли:
> ls> ls (hd0,gpt2)/Вижу, что это системный раздел, где живет в том числе и /boot. Указываю его загрузочным и пытаюсь с него загрузиться.
> set boot=(hd0,gpt2)> set prefix=(hd0,gpt2)/boot/grub> insmod normalПолучаю ошибку:
error: attempt to read or write outside of disk hd0
Гугл быстро выдал решение. Нужно /boot раздел сделать отдельно самым первым. Из-за того, что системный диск большой, а boot на нем, возникает эта ошибка. Смысл понятен, не понятно только, что за глюк. Почему эта ошибка в принципе существует, а установщик не может ее автоматически пофиксить.
Запустил еще раз установку, сам разбил диск, отдав под /boot первый гигабайт диска, остальное в единый раздел 4Tb под корень / . Система успешно установилась и загрузилась после установки.
Сейчас не буду придумывать, что в Centos такой проблемы нет с автоматической разбивкой, не проверял. Я не помню, делал ли там большие диски одним разделом. Такие виртуалки не так часто нужны. А еще я частенько делаю системный раздел небольшого размера, а уже потом отдельно монтирую большой диск под данные. Но то, что Debian автоматически не разруливает эту ситуацию, для меня странно. Фикс этой ошибки не такой уж и очевидный и требует уверенных знаний Linux для быстрого решения.
#grub #ошибка
{kind=link}
Небольшой мотивирующий пост в начале трудовой недели. Пишу в воскресенье вечером, но вы прочитаете в понедельник утром 😊.
Так получилось, что на прошлой неделе было много задач по настройке чего-либо. Была авария и переезд сервера, были другие технические задачи и проблемы. Появился новый коллектив разработчиков, с которыми надо выстраивать рабочий процесс. И несмотря на то, что задач было много, пару раз сидел допоздна за ноутом и что-то донастраивал, я прям кайфанул.
Я делал ровно то, что я люблю. При этом организовал свой рабочий процесс именно так, как мне нравится. Всё планирую и принимаю решения самостоятельно. Максимум мне надо кого-то уведомить, а чаще всего и это не требуется. Я просто беру и делаю так, как считаю нужным. Мне так нравится, поэтому подобрал именно такой рабочий процесс. С людьми, которые хотели во всё вникать и говорить мне, как делать, я прощался.
И дело не в том, что я не люблю советов, критики и т.д. Если мне нужно советоваться и обсуждать что-то с технически грамотными и компетентными людьми, то такие разговоры мне нравятся. Я люблю учиться и перенимать чужой опыт. В том числе поэтому веду канал и сайт. Но иногда получается так, что приходится что-то обсуждать и договариваться с теми, кто не очень-то разбирается в теме. А это пустая трата времени и сил. Особенно если руководство не разбирается в теме и его надо долго уговаривать и убеждать. С такими вообще не сотрудничаю.
Я к чему всё это написал. Ищите всегда то, что вам нравится и приносит удовольствие. Если чувствуете, что вам неуютно на своем месте, решите для себя, что конкретно вам не нравится и убирайте это. Кому то нравится видеть перспективы роста и развития в крупной корпорации, а он сидит в конторе на 50 человек. Кто-то любит сидеть один и молча делать свое дело на протяжении многих лет. Кому-то, как мне, нравится все делать самостоятельно, принимать решения и нести ответственность в одно лицо. Кто-то любит собирать команды и мутить какие-то проекты. Постоянно про таких на vc.ru читаю :) Люблю предпринимателей читать.
В общем, не сидите на месте, а стремитесь к улучшению своей жизни. Не терпите руководство, которое вас раздражает и не делайте работу, от которой тошнит. Её невозможно делать хорошо, так как раздражение закрывает творческий подход. А без творчества уныние и скука. Сейчас уникальное время, когда все дороги и границы открыты (пока немного призакрылись). Реализуйте эти возможности.
#мысли
Так получилось, что на прошлой неделе было много задач по настройке чего-либо. Была авария и переезд сервера, были другие технические задачи и проблемы. Появился новый коллектив разработчиков, с которыми надо выстраивать рабочий процесс. И несмотря на то, что задач было много, пару раз сидел допоздна за ноутом и что-то донастраивал, я прям кайфанул.
Я делал ровно то, что я люблю. При этом организовал свой рабочий процесс именно так, как мне нравится. Всё планирую и принимаю решения самостоятельно. Максимум мне надо кого-то уведомить, а чаще всего и это не требуется. Я просто беру и делаю так, как считаю нужным. Мне так нравится, поэтому подобрал именно такой рабочий процесс. С людьми, которые хотели во всё вникать и говорить мне, как делать, я прощался.
И дело не в том, что я не люблю советов, критики и т.д. Если мне нужно советоваться и обсуждать что-то с технически грамотными и компетентными людьми, то такие разговоры мне нравятся. Я люблю учиться и перенимать чужой опыт. В том числе поэтому веду канал и сайт. Но иногда получается так, что приходится что-то обсуждать и договариваться с теми, кто не очень-то разбирается в теме. А это пустая трата времени и сил. Особенно если руководство не разбирается в теме и его надо долго уговаривать и убеждать. С такими вообще не сотрудничаю.
Я к чему всё это написал. Ищите всегда то, что вам нравится и приносит удовольствие. Если чувствуете, что вам неуютно на своем месте, решите для себя, что конкретно вам не нравится и убирайте это. Кому то нравится видеть перспективы роста и развития в крупной корпорации, а он сидит в конторе на 50 человек. Кто-то любит сидеть один и молча делать свое дело на протяжении многих лет. Кому-то, как мне, нравится все делать самостоятельно, принимать решения и нести ответственность в одно лицо. Кто-то любит собирать команды и мутить какие-то проекты. Постоянно про таких на vc.ru читаю :) Люблю предпринимателей читать.
В общем, не сидите на месте, а стремитесь к улучшению своей жизни. Не терпите руководство, которое вас раздражает и не делайте работу, от которой тошнит. Её невозможно делать хорошо, так как раздражение закрывает творческий подход. А без творчества уныние и скука. Сейчас уникальное время, когда все дороги и границы открыты (пока немного призакрылись). Реализуйте эти возможности.
#мысли
{kind=link}
Ранее я делал заметку про текстовый редактор Atom, который иногда использую для редактирования скриптов и конфигов. В комментариях было очень много отзывов о том, что Visual Studio Code (VSCode) удобнее и лучше. Мне знаком этот продукт, потому что он у всех на слуху, но сам я им не пользовался, потому что нет нужды. Решил все же посмотреть на него.
VSCode достаточно большой и универсальный редактор (тормозной, написан на Electron 😩). Он подходит как для написания скриптов и кода под Linux, так и под виндовый PowerShell (расширение ms-vscode.PowerShell). При первом запуске в Windows предложил настроить интеграцию с WSL, чтобы запускать код сразу в Linux окружении.
Я попробовал на примере python скрипта. Просто и удобно. Понравилось больше, чем бесплатный PyCharm. Он интерпретатор в винду ставил и настраивал интеграцию. Но вариант с WSL мне понравился больше. Настроил и разобрался сразу же, никаких проблем.
В VSCode удобная интеграция с git (странно, что мастер ветка все еще называется master, а не main 🤦🏾♂️), которая позволяет работать с репозиторием даже если вы не особо хорошо разбираетесь в этой системе контроля версий. Для bash есть подсветка синтаксиса и автодополнение кода.
Существует огромное количество расширений, которые устанавливаются из самого редактора через отдельный раздел. Например, можно поставить расширение для интеграции с docker, который будет поставлен в тот же WSL. Можно будет докер файлы править и проверять прямо в винде. Удобно, если винда ваша рабочая система.
В общем, там много всего интересного и полезного. Если бы не его тормознутость (хотя все относительно, тот же PyCharm тормозит еще сильнее), я бы точно стал им пользоваться. А так вроде и любопытно, но особо не надо. Те же докерфайлы я привык сразу в линуксе писать и запускать.
#программа #редактор
VSCode достаточно большой и универсальный редактор (тормозной, написан на Electron 😩). Он подходит как для написания скриптов и кода под Linux, так и под виндовый PowerShell (расширение ms-vscode.PowerShell). При первом запуске в Windows предложил настроить интеграцию с WSL, чтобы запускать код сразу в Linux окружении.
Я попробовал на примере python скрипта. Просто и удобно. Понравилось больше, чем бесплатный PyCharm. Он интерпретатор в винду ставил и настраивал интеграцию. Но вариант с WSL мне понравился больше. Настроил и разобрался сразу же, никаких проблем.
В VSCode удобная интеграция с git (странно, что мастер ветка все еще называется master, а не main 🤦🏾♂️), которая позволяет работать с репозиторием даже если вы не особо хорошо разбираетесь в этой системе контроля версий. Для bash есть подсветка синтаксиса и автодополнение кода.
Существует огромное количество расширений, которые устанавливаются из самого редактора через отдельный раздел. Например, можно поставить расширение для интеграции с docker, который будет поставлен в тот же WSL. Можно будет докер файлы править и проверять прямо в винде. Удобно, если винда ваша рабочая система.
В общем, там много всего интересного и полезного. Если бы не его тормознутость (хотя все относительно, тот же PyCharm тормозит еще сильнее), я бы точно стал им пользоваться. А так вроде и любопытно, но особо не надо. Те же докерфайлы я привык сразу в линуксе писать и запускать.
#программа #редактор
{kind=link}
Вчера внимательно изучал утилиту для бэкапов Borgbackup или просто Borg.
https://github.com/borgbackup/borg
https://www.borgbackup.org/
Я не просто так уделяю внимание именно бэкапам и постоянно тестирую новые для себя инструменты. Для меня это очень актуальная тема, как и мониторинг, потому что бэкапам уделяю очень много внимания и постоянно с ними работаю.
Чем привлек конкретно Borg и почему обратил на него внимание:
◽ Простая установка и настройка. По сути это просто один бинарник. Ничего дополнительно, типа базы данных, ставить не надо. Работает на всех системах Linux, MacOS. Поддержки винды нет.
◽ Эффективная и честная дедупликация, ну и сжатие до кучи разными алгоритмами.
◽ Работает по ssh. Соответственно, не надо ничего настраивать на хостах, ставить агент и т.д. Ssh чаще всего есть везде.
◽ Гибкий в плане автоматизации с помощью скриптов. Отлично подходит для любителей костылей и велосипедов, как я.
Сам я по-прежнему бэкаплю все с помощью rsync и самописной обвязки в виде bash. Реализовано, все, что мне обычно требуется - полные, инкрементные бэкапы, мониторинг.
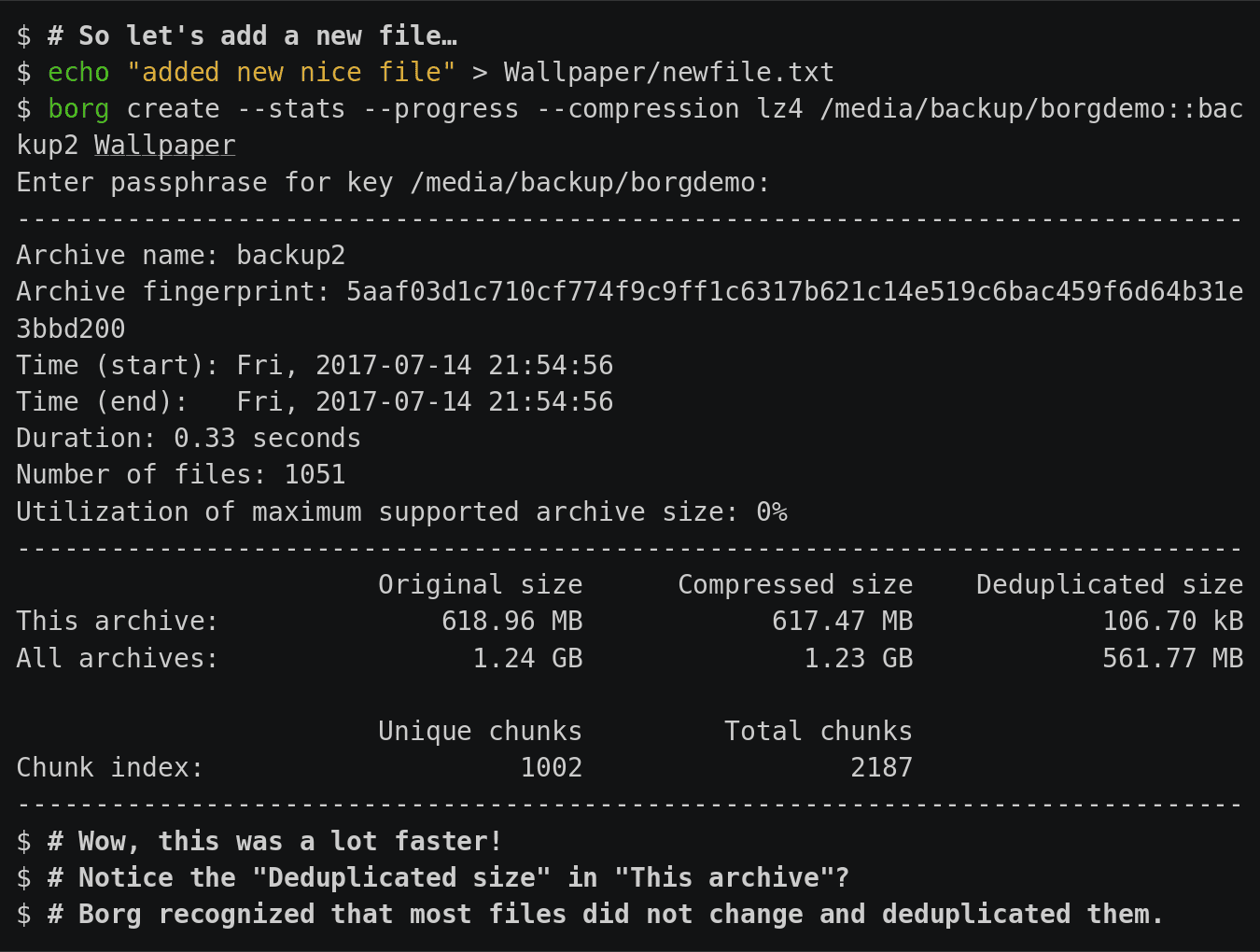
Хочется избавиться от своих велосипедов, но найти что-то, что на 100% меня устроило, не получается. Я внимательно посмотрел на Borg, попробовал. В целом, все круто и удобно. Дедупликация отлично работает, diff бэкапы делаются очень быстро.
Но всплывает одна особенность всех бинарных бэкапов с дедупликацией, типа borg. Допустим, у вас есть большой архив данных, ну скажем на 1-2 Тб с 500 000 файлов. Чтобы просто сделать листинг файлов в таком бэкапе уйдет очень много времени. Если же у меня обычный бэкап данных через rsync, я делаю это практически мгновенно.
И еще один минус конкретно Borg. Он сохраняет права файлов, когда вы делаете полный бэкап. Но потом, если вы восстановите отдельный файл, его права не будут восстановлены, так как они хранятся условно в полном бэкапе. Чтобы восстановить и права файлов, надо сделать полное восстановление. Где-то не не принципиально, а где-то создаст много неудобств.
Моё резюме такое. Borg отличный консольный инструмент для бэкапов с честной дедупликацией и сжатием. Очень хорошо экономит место на дисках. Но имеет описанные выше минусы. Если вам они не критичны, можно пользоваться. Я для себя в итоге решил не использовать его. Пока останусь с rsync.
Если вас реально заинтересовал Borg, то посмотреть, как он работает, можно тут - https://www.borgbackup.org/demo.html Сразу получите практически полное представление о его работе. Я начал с того, что посмотрел все 4 demo ролика.
Если кто-то использует в проде эту утилиту, дайте, пожалуйста, обратную связь. В чем увидели преимущество, с какими недостатками столкнулись.
#backup
https://github.com/borgbackup/borg
https://www.borgbackup.org/
Я не просто так уделяю внимание именно бэкапам и постоянно тестирую новые для себя инструменты. Для меня это очень актуальная тема, как и мониторинг, потому что бэкапам уделяю очень много внимания и постоянно с ними работаю.
Чем привлек конкретно Borg и почему обратил на него внимание:
◽ Простая установка и настройка. По сути это просто один бинарник. Ничего дополнительно, типа базы данных, ставить не надо. Работает на всех системах Linux, MacOS. Поддержки винды нет.
◽ Эффективная и честная дедупликация, ну и сжатие до кучи разными алгоритмами.
◽ Работает по ssh. Соответственно, не надо ничего настраивать на хостах, ставить агент и т.д. Ssh чаще всего есть везде.
◽ Гибкий в плане автоматизации с помощью скриптов. Отлично подходит для любителей костылей и велосипедов, как я.
Сам я по-прежнему бэкаплю все с помощью rsync и самописной обвязки в виде bash. Реализовано, все, что мне обычно требуется - полные, инкрементные бэкапы, мониторинг.
Хочется избавиться от своих велосипедов, но найти что-то, что на 100% меня устроило, не получается. Я внимательно посмотрел на Borg, попробовал. В целом, все круто и удобно. Дедупликация отлично работает, diff бэкапы делаются очень быстро.
Но всплывает одна особенность всех бинарных бэкапов с дедупликацией, типа borg. Допустим, у вас есть большой архив данных, ну скажем на 1-2 Тб с 500 000 файлов. Чтобы просто сделать листинг файлов в таком бэкапе уйдет очень много времени. Если же у меня обычный бэкап данных через rsync, я делаю это практически мгновенно.
И еще один минус конкретно Borg. Он сохраняет права файлов, когда вы делаете полный бэкап. Но потом, если вы восстановите отдельный файл, его права не будут восстановлены, так как они хранятся условно в полном бэкапе. Чтобы восстановить и права файлов, надо сделать полное восстановление. Где-то не не принципиально, а где-то создаст много неудобств.
Моё резюме такое. Borg отличный консольный инструмент для бэкапов с честной дедупликацией и сжатием. Очень хорошо экономит место на дисках. Но имеет описанные выше минусы. Если вам они не критичны, можно пользоваться. Я для себя в итоге решил не использовать его. Пока останусь с rsync.
Если вас реально заинтересовал Borg, то посмотреть, как он работает, можно тут - https://www.borgbackup.org/demo.html Сразу получите практически полное представление о его работе. Я начал с того, что посмотрел все 4 demo ролика.
Если кто-то использует в проде эту утилиту, дайте, пожалуйста, обратную связь. В чем увидели преимущество, с какими недостатками столкнулись.
#backup
{kind=link}
Хочу немного порассуждать о Docker. Сейчас появились тенденции отказа от него в пользу других решений. В первую очередь это:
▪ podman от Red Hat
▪ containerd, отпочковавшийся в независимый проект от Docker
Слышал мнение, что Docker типа всё, от него отказываются и заменяют. "Даже Kubernetes объявил Docker deprecated". Дальше расскажу свое мнение, как всё это понимаю я сам. Не обязательно, что прав. Для того, чтобы собрать более широкую картинку по теме, пишу эту заметку. Рассчитываю на ваши содержательные комментарии.
Никуда Docker как инструмент для разработки не уйдет в ближайшее время. Сейчас только наметилась его замена непосредственно в эксплуатации на продуктовых серверах. Докер в первую очередь удобен разработчикам для быстрого разворачивания готового окружения под свое ПО.
При этом в эксплуатации он не так удобен из-за некоторых архитектурных особенностей (мое предположение). Вопросы как минимум возникают с безопасностью, с хранением данных, с работой с сетью. В целом, это и не удивительно. Трудно получить простой универсальный инструмент, который будет удобен везде и всем - в разработке, и в эксплуатации. Традиционно, для этого используются разные инструменты и подходы. А тут взяли и засунули докер везде. Получили много проблем.
У Докера хорошая обвязка, которая позволяет очень просто с ним работать разработчикам. Херак, херак и у тебя на машине для разработки все нужные контейнеры подняты. Никакие веб сервера, базы данных, сети настраивать не надо, связывать все это как-то, с dns разбираться. Контейнеры всё делают сами. Скачал готовый докер файл, что-то поправил и запустил. Много видел такого подхода у молодых разработчиков. Они буквально все запускают в докере, потому что ничего не умеют сами настраивать. В таком качестве докер и продолжит свое существование.
А уже в эксплуатации будут думать, чем и как удобнее запустить те же самые приложения в контейнерах. Возможно, появятся некоторые несущественные различия между средой разработки и эксплуатации, но с ними будут мириться.
Так что если вы по какой-то причине до сих пор не знакомы 😱 с докером и не используете его, познакомьтесь. Он может в первую очередь упростить вам жизнь даже в каких-то повседневных мелочах - попробовать какой-то продукт, что-то запустить у себя для теста и т.д. Он есть даже в винде.
#docker
▪ podman от Red Hat
▪ containerd, отпочковавшийся в независимый проект от Docker
Слышал мнение, что Docker типа всё, от него отказываются и заменяют. "Даже Kubernetes объявил Docker deprecated". Дальше расскажу свое мнение, как всё это понимаю я сам. Не обязательно, что прав. Для того, чтобы собрать более широкую картинку по теме, пишу эту заметку. Рассчитываю на ваши содержательные комментарии.
Никуда Docker как инструмент для разработки не уйдет в ближайшее время. Сейчас только наметилась его замена непосредственно в эксплуатации на продуктовых серверах. Докер в первую очередь удобен разработчикам для быстрого разворачивания готового окружения под свое ПО.
При этом в эксплуатации он не так удобен из-за некоторых архитектурных особенностей (мое предположение). Вопросы как минимум возникают с безопасностью, с хранением данных, с работой с сетью. В целом, это и не удивительно. Трудно получить простой универсальный инструмент, который будет удобен везде и всем - в разработке, и в эксплуатации. Традиционно, для этого используются разные инструменты и подходы. А тут взяли и засунули докер везде. Получили много проблем.
У Докера хорошая обвязка, которая позволяет очень просто с ним работать разработчикам. Херак, херак и у тебя на машине для разработки все нужные контейнеры подняты. Никакие веб сервера, базы данных, сети настраивать не надо, связывать все это как-то, с dns разбираться. Контейнеры всё делают сами. Скачал готовый докер файл, что-то поправил и запустил. Много видел такого подхода у молодых разработчиков. Они буквально все запускают в докере, потому что ничего не умеют сами настраивать. В таком качестве докер и продолжит свое существование.
А уже в эксплуатации будут думать, чем и как удобнее запустить те же самые приложения в контейнерах. Возможно, появятся некоторые несущественные различия между средой разработки и эксплуатации, но с ними будут мириться.
Так что если вы по какой-то причине до сих пор не знакомы 😱 с докером и не используете его, познакомьтесь. Он может в первую очередь упростить вам жизнь даже в каких-то повседневных мелочах - попробовать какой-то продукт, что-то запустить у себя для теста и т.д. Он есть даже в винде.
#docker
{kind=link}
Небольшая подборка моих команд в bash, которыми регулярно пользуюсь. Не претендую на уникальность и идеальный код. Просто беру примеры из своих шпаргалок. Специально ничего не оптимизировал. Если кто знает более удачные реализации того же функционала, делитесь в комментариях.
Удаляем дубли строк (для анализа логов помогает):
Вывести строки, начиная с третьей (в костылях с мониторингом помогает):
Вырезаем первую и последнюю строки (тоже самое, для мониторинга обычно надо):
Выполняем команду cat file.txt 5 раз (в консоли пригождается):
Удаление последнего или двух последних символов в строках (какой-то мусор в строках удобно убирать):
Удаление первого или двух первых символов в строках (то же самое):
Находим все строки с hello=какое-то значение и меняем на hello=1000:
Находим все строки с admin: и удаляем их (часто пригождалось, когда менял права доступа на линуксовых шарах, предварительн выгрузив их):
Заменяем все вхождения строки search на replace:
Удаляем все пробелы и символы табуляции в начале каждой строки файла (помогает чистить конфиги):
Удаляем строки, где знак комментария ; стоит в начале строки (то же самое, помогает чистить конфиги, особенно астериска):
Удаляем пустые строки:
Заменить рукурсивно текст во всех файлах:
Считаем количество процессов nodejs:
Считаем количество процессов в системе и выводим 5, которые запустили больше всего экземпляров:
Когда уже стал составлять пост понял, что получилась какая-то каша. Надо было на категории разбить, но мне стало лень это делать. Просто прошелся про всем записям и выбрал то, что показалось наиболее универсальным и актуальным для самых популярных задач.
Рекомендую забрать в закладки. Никогда заранее не знаешь, где и что пригодится. Я все записываю. Bash по-моему невозможно выучить, постоянно все по своим записям собираю. Понятно, что с опытом это становится проще. Кто-то может и пишет по памяти, но точно не я. Списываю обычно.
Написал и сам себе в закладки добавил, чтобы проше найти было 😎
#bash
Удаляем дубли строк (для анализа логов помогает):
awk '!seen[$0]++' file.txt > file_new.txtВывести строки, начиная с третьей (в костылях с мониторингом помогает):
awk 'NR > 3' file.txtВырезаем первую и последнюю строки (тоже самое, для мониторинга обычно надо):
cat file.txt | awk 'NR > 1' | head -n-1Выполняем команду cat file.txt 5 раз (в консоли пригождается):
for n in {1..5}; do cat file.txt; doneУдаление последнего или двух последних символов в строках (какой-то мусор в строках удобно убирать):
sed 's/.$//' file.txtsed 's/..$//' file.txtУдаление первого или двух первых символов в строках (то же самое):
sed 's/^.//' file.txtsed 's/^..//' file.txtНаходим все строки с hello=какое-то значение и меняем на hello=1000:
cat file.txt | sed 's/^hello=.*/hello=1000/g' > file_new.txtНаходим все строки с admin: и удаляем их (часто пригождалось, когда менял права доступа на линуксовых шарах, предварительн выгрузив их):
sed '/admin:/d' file.acl > file_new.aclЗаменяем все вхождения строки search на replace:
sed 's/search/replace/g' file.txt > file_new.txtУдаляем все пробелы и символы табуляции в начале каждой строки файла (помогает чистить конфиги):
sed 's/^[ \t]*//' extensions.conf > extensions.conf.newУдаляем строки, где знак комментария ; стоит в начале строки (то же самое, помогает чистить конфиги, особенно астериска):
sed '/^;/d' sip.confgrep -E -v ';|^$' php.iniУдаляем пустые строки:
sed '/^$/d' file.txtЗаменить рукурсивно текст во всех файлах:
grep 'надо поменять' -P -R -I -l * | xargs sed -i 's/надо_поменять/меняем_на_это/g'Считаем количество процессов nodejs:
ps ax | grep "nodejs" | wc -lСчитаем количество процессов в системе и выводим 5, которые запустили больше всего экземпляров:
ps -ef | awk '{ print $8 }' | sort -n | uniq -c | sort -n | tail -5Когда уже стал составлять пост понял, что получилась какая-то каша. Надо было на категории разбить, но мне стало лень это делать. Просто прошелся про всем записям и выбрал то, что показалось наиболее универсальным и актуальным для самых популярных задач.
Рекомендую забрать в закладки. Никогда заранее не знаешь, где и что пригодится. Я все записываю. Bash по-моему невозможно выучить, постоянно все по своим записям собираю. Понятно, что с опытом это становится проще. Кто-то может и пишет по памяти, но точно не я. Списываю обычно.
Написал и сам себе в закладки добавил, чтобы проше найти было 😎
#bash
{kind=link}
Небольшая заметка-напоминание на основе своего опыта. Сам регулярно забываю то, о чем ниже напишу. Иногда настраиваешь какой-то сервис. Вроде все сделал правильно, firewall настроил, убедился, что на сервере порт открыт и слушает соединения, а извне нет коннектов.
Плёвое дело для опытного сисадмина. Начинаешь разбираться. Проверяешь еще раз все правила фаервола, убеждаешься, что они применились. Смотришь на счетчики, а пакеты по ним не бегают. Извне коннекты не идут. Разбираешься и начинаешь раздражаться, так как не понимаешь, в чем проблема. Отключаешь полностью firewall, а коннектов все равно нет.
Еще раз проверяешь запущенный сервис и убеждаешься, что порт все же открыт. У тебя дедик, внешнего фаервола нет и проверять нечего. Но коннектов нет. Думаешь, думаешь и тут вспоминаешь, что этот порт может быть заблочен хостером из-за того, что через него могут эксплуатировать какие-то уязвимости. Пишешь запрос хостеру и убеждаешься в этом.
По моему опыту, чаще всего для подключения извне закрывают следующие порты:
25 - smtp протокол для работы почты
123 - для подключений по протоколу ntp
445 - smb подключения виндовой службы шаринга директорий
137, 139 - виндовый NetBIOS протокол
Собственно, я последний раз и наткнулся на блок 445 порта, когда хотел через инет с виндовой шары данные забирать. Разумеется, настроил ограничение по белым спискам ip. Но не тут то было. Хостер не дает подключаться по этим портам извне. Не стал разбираться и писать к нему запросы. Забрал файлы другим способом.
25-й вообще много где закрыт. Например, в DO или Linode. Там даже через запрос в тех. поддержку порт не открывают. Просят кучу дополнительных действий сделать. Зарегистрировать домен, настроить dns, привязать их к серверу и т.д. Я даже разбираться не стал, слишком муторно. Приходится сторонние сервисы отправки использовать.
❓Сталкивались еще с какими-то неявными блоками портов у хостеров?
Плёвое дело для опытного сисадмина. Начинаешь разбираться. Проверяешь еще раз все правила фаервола, убеждаешься, что они применились. Смотришь на счетчики, а пакеты по ним не бегают. Извне коннекты не идут. Разбираешься и начинаешь раздражаться, так как не понимаешь, в чем проблема. Отключаешь полностью firewall, а коннектов все равно нет.
Еще раз проверяешь запущенный сервис и убеждаешься, что порт все же открыт. У тебя дедик, внешнего фаервола нет и проверять нечего. Но коннектов нет. Думаешь, думаешь и тут вспоминаешь, что этот порт может быть заблочен хостером из-за того, что через него могут эксплуатировать какие-то уязвимости. Пишешь запрос хостеру и убеждаешься в этом.
По моему опыту, чаще всего для подключения извне закрывают следующие порты:
25 - smtp протокол для работы почты
123 - для подключений по протоколу ntp
445 - smb подключения виндовой службы шаринга директорий
137, 139 - виндовый NetBIOS протокол
Собственно, я последний раз и наткнулся на блок 445 порта, когда хотел через инет с виндовой шары данные забирать. Разумеется, настроил ограничение по белым спискам ip. Но не тут то было. Хостер не дает подключаться по этим портам извне. Не стал разбираться и писать к нему запросы. Забрал файлы другим способом.
25-й вообще много где закрыт. Например, в DO или Linode. Там даже через запрос в тех. поддержку порт не открывают. Просят кучу дополнительных действий сделать. Зарегистрировать домен, настроить dns, привязать их к серверу и т.д. Я даже разбираться не стал, слишком муторно. Приходится сторонние сервисы отправки использовать.
❓Сталкивались еще с какими-то неявными блоками портов у хостеров?
{kind=link}
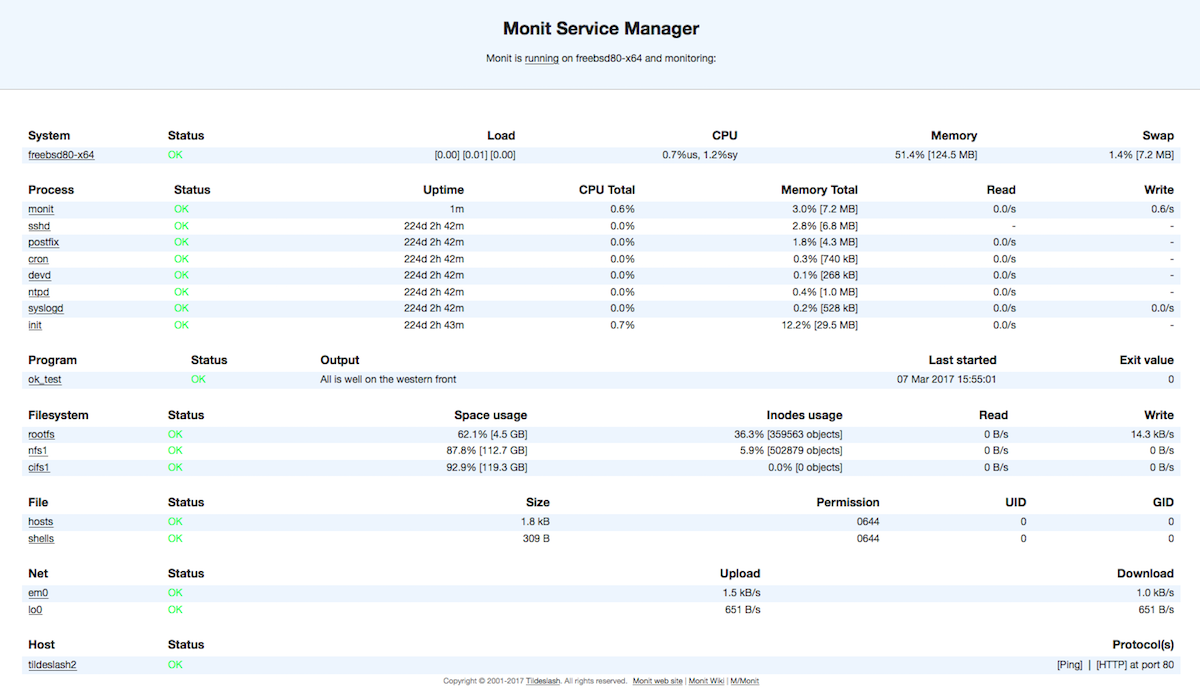
Существует простой и легкий мониторинг Monit. Проекту очень много лет. Я знал его, когда только начинал администрировать. Тем не менее, он развивается и живет своей жизнью. Есть в системных репах популярных дистрибутивов.
https://mmonit.com/monit/
https://bitbucket.org/tildeslash/monit/
Основная его фишка - легковесность и простота настройки. Ставится как правило локально. Есть преднастроенные конфиги для популярных сервисов. Причем Monit из коробки умеет не только мониторить, слать алерты, но и перезапускать сервисы.
Например, есть готовый конфиг, который проверяет, работает ли postfix. Если видит, что не работает, выполняет команды на перезапуск сервиса. При этом конфиги удобочитаемые. Настраивать можно сразу же, без изучения документации. Вот пример с тем же postfix.
Управляется Monit через веб интерфейс и конфиги. Для работы нужна база данных. В простом варианте это может быть SQLite. Для одиночного хоста хватает за глаза. Например, для веб сервера, чтобы автоматом поднимать упавший apache или php-fpm.
Мониторинг для тех, кто устал (это про меня) от всяких модных штук, yaml конфигов, докеров, jsonoв и вот этого всего хипстерского. Кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать понятные конфиги без учёта отступов, пробелов, скобок.
Есть еще те, кто использует Monit?
#мониторинг
https://mmonit.com/monit/
https://bitbucket.org/tildeslash/monit/
Основная его фишка - легковесность и простота настройки. Ставится как правило локально. Есть преднастроенные конфиги для популярных сервисов. Причем Monit из коробки умеет не только мониторить, слать алерты, но и перезапускать сервисы.
Например, есть готовый конфиг, который проверяет, работает ли postfix. Если видит, что не работает, выполняет команды на перезапуск сервиса. При этом конфиги удобочитаемые. Настраивать можно сразу же, без изучения документации. Вот пример с тем же postfix.
check process postfix with pidfile /var/spool/postfix/pid/master.pid start program = "systemctl start postfix" stop program = "systemctl stop postfix" if cpu > 60% for 2 cycles then alert if cpu > 80% for 5 cycles then restart if totalmem > 200.0 MB for 5 cycles then restart if children > 250 then restart if loadavg(5min) greater than 10 for 8 cycles then stop if failed host INSERT_THE_RELAY_HOST port 25 type tcp protocol smtp with timeout 15 seconds then alert if 3 restarts within 5 cycles then timeoutУправляется Monit через веб интерфейс и конфиги. Для работы нужна база данных. В простом варианте это может быть SQLite. Для одиночного хоста хватает за глаза. Например, для веб сервера, чтобы автоматом поднимать упавший apache или php-fpm.
Мониторинг для тех, кто устал (это про меня) от всяких модных штук, yaml конфигов, докеров, jsonoв и вот этого всего хипстерского. Кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать понятные конфиги без учёта отступов, пробелов, скобок.
Есть еще те, кто использует Monit?
#мониторинг
{kind=link}
У меня есть такая привычка, что-то вроде бзика, всегда выделять виртуальным машинам память кратно 1024. То есть не 2000 Мб, а 2048, не 4000 Мб, 4096 и т.д. Принципиальной разницы нет, сколько памяти будет выделено, но я абсолютно всегда придерживаюсь этой схемы. Подключаю калькулятор, если в голове не могу правильно сосчитать. Даже была идея распечатать лист бумаги и наклеить на стену, чтобы не тратить время на вычисления.
С процессорами другой бзик. Я их всегда выделяю четное число, либо 1. Никаких 3, 5, 7 процессоров для виртуальной машины. Только 1, 2, 4, 6, 8 и т.д. Логического объяснения этого у меня в голове нет. Просто делаю так и всё.
Диски подключаю как попало.
Мне интересно, много таких же людей? Делаю опрос только по памяти. Выделяете память для виртуалок как попало или тоже кратно 512, 1024 и т.д.?
С процессорами другой бзик. Я их всегда выделяю четное число, либо 1. Никаких 3, 5, 7 процессоров для виртуальной машины. Только 1, 2, 4, 6, 8 и т.д. Логического объяснения этого у меня в голове нет. Просто делаю так и всё.
Диски подключаю как попало.
Мне интересно, много таких же людей? Делаю опрос только по памяти. Выделяете память для виртуалок как попало или тоже кратно 512, 1024 и т.д.?
На днях прочитал англоязычную новость, которая мне показалась важной. В переводе не видел нигде, хотя не факт, что нету. Тезисно решил перевести.
https://blog.devgenius.io/lets-encrypt-change-affects-openssl-1-0-x-and-centos-7-49bd66016af3
История затрагивает тех, кто использует бесплатные сертификаты Let's Encrypt и Centos 7. Я уже не раз говорил, что в современных реалиях использовать Centos 7 становится проблематичным из-за устаревших пакетов, которые уже не собираются обновлять. И вот еще одно тому подтверждение.
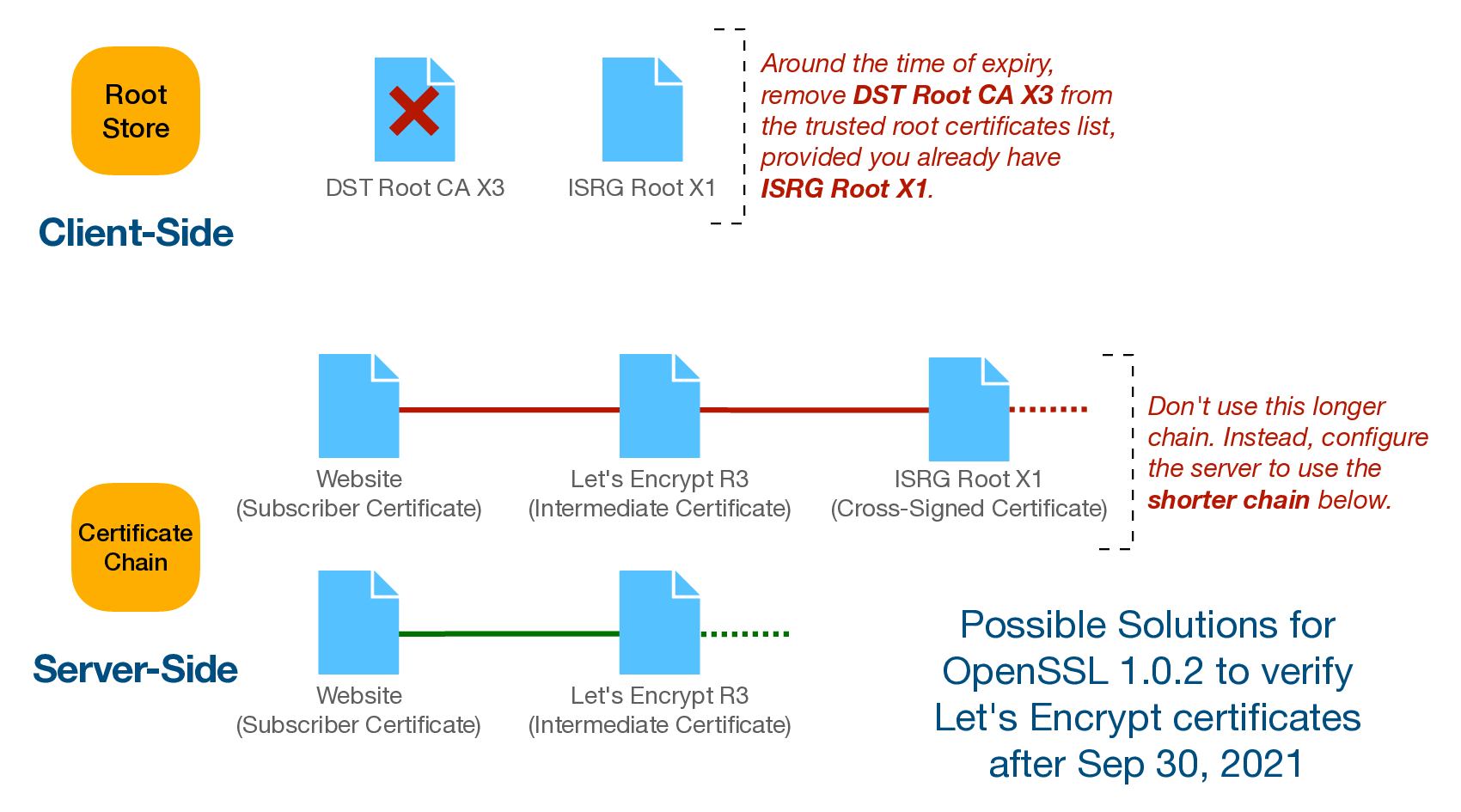
Let's Encrypt использует цепочку корневых сертификатов, в которой парочка скоро протухнет. Конкретно Cross-Signed Let’s Encrypt R3 29 сентября 2021 года и DST Root CA X3 30 сентября 2021 года.
Проект стартовал в 2015 году и чтобы ему сразу начали доверять уже существующие устройства и системы, где зашиты корневые CA, ему пришлось сделать cross-sign (не знаю как правильно перевести термин) с одним из таких сертификатов. Сделали они это с помощью промежуточного сертификата сроком на 5 лет, который протух в прошлом году.
Это не стало большой проблемой, так как к тому времени родной CA от Let's Encrypt ISRG Root X1 разошелся по системам и стал доверенным. Но тем не менее, для поддержки старых Android систем LE еще раз сделали cross-sign с хитрой замутой, которая сработает даже при условии протухания DST Root CA X3. Не буду вдаваться в технические подробности, чтобы не раздувать заметку.
Проблема возникла следующая. Все эти cross-sign манипуляции поддерживают не все версии OpenSSL. В Centos 7 используется версия OpenSSL 1.0.2 и она не может корректно распознать получившуюся цепочку сертификатов, чтобы проверить серт от Let's Enrypt и организовать безопасное TLS соединение. Обновление на более свежие версии openssl может сломать совместимость со многими приложениями.
Есть различные способы решения этой проблемы. Не буду их сейчас приводить, так как по мере приближения к часу икс, возможно появится что-то еще. В любом случае, просто будьте в курсе, что могут случиться проблемы и в начале сентября подумайте, что будете предпринимать на своих Centos 7. Я тоже буду думать, у меня много таких систем.
В статье больше подробностей и примеров, так что если тема заинтересовала, можете там все посмотреть со ссылками, картинками и т.д.
https://blog.devgenius.io/lets-encrypt-change-affects-openssl-1-0-x-and-centos-7-49bd66016af3
История затрагивает тех, кто использует бесплатные сертификаты Let's Encrypt и Centos 7. Я уже не раз говорил, что в современных реалиях использовать Centos 7 становится проблематичным из-за устаревших пакетов, которые уже не собираются обновлять. И вот еще одно тому подтверждение.
Let's Encrypt использует цепочку корневых сертификатов, в которой парочка скоро протухнет. Конкретно Cross-Signed Let’s Encrypt R3 29 сентября 2021 года и DST Root CA X3 30 сентября 2021 года.
Проект стартовал в 2015 году и чтобы ему сразу начали доверять уже существующие устройства и системы, где зашиты корневые CA, ему пришлось сделать cross-sign (не знаю как правильно перевести термин) с одним из таких сертификатов. Сделали они это с помощью промежуточного сертификата сроком на 5 лет, который протух в прошлом году.
Это не стало большой проблемой, так как к тому времени родной CA от Let's Encrypt ISRG Root X1 разошелся по системам и стал доверенным. Но тем не менее, для поддержки старых Android систем LE еще раз сделали cross-sign с хитрой замутой, которая сработает даже при условии протухания DST Root CA X3. Не буду вдаваться в технические подробности, чтобы не раздувать заметку.
Проблема возникла следующая. Все эти cross-sign манипуляции поддерживают не все версии OpenSSL. В Centos 7 используется версия OpenSSL 1.0.2 и она не может корректно распознать получившуюся цепочку сертификатов, чтобы проверить серт от Let's Enrypt и организовать безопасное TLS соединение. Обновление на более свежие версии openssl может сломать совместимость со многими приложениями.
Есть различные способы решения этой проблемы. Не буду их сейчас приводить, так как по мере приближения к часу икс, возможно появится что-то еще. В любом случае, просто будьте в курсе, что могут случиться проблемы и в начале сентября подумайте, что будете предпринимать на своих Centos 7. Я тоже буду думать, у меня много таких систем.
В статье больше подробностей и примеров, так что если тема заинтересовала, можете там все посмотреть со ссылками, картинками и т.д.
{kind=link}
Очень жизненный юмор 😁 Прям улыбнулся, когда прочитал. Я часто смотрю history, когда подключаюсь к чужим серверам. Зачастую это может помочь решить проблему. Всякое там вижу. Иногда смешное, иногда грустное.
Сам всегда слежу за тем, что пишу в терминале если знаю, что history может посмотреть кто-то другой. Но я знаю одну очень простую фишку, как вводить команды, чтобы они не попадали в историю. При этом команды вводятся один в один, как и должны вводиться. Ни в начало, ни в конец ничего добавлять не надо. Работаешь как обычно, следить ни за чем не надо. Но хистори после тебя не остается. Очищать тоже не надо.
Предлагаю попробовать угадать, что это за способ.
#юмор
Сам всегда слежу за тем, что пишу в терминале если знаю, что history может посмотреть кто-то другой. Но я знаю одну очень простую фишку, как вводить команды, чтобы они не попадали в историю. При этом команды вводятся один в один, как и должны вводиться. Ни в начало, ни в конец ничего добавлять не надо. Работаешь как обычно, следить ни за чем не надо. Но хистори после тебя не остается. Очищать тоже не надо.
Предлагаю попробовать угадать, что это за способ.
#юмор
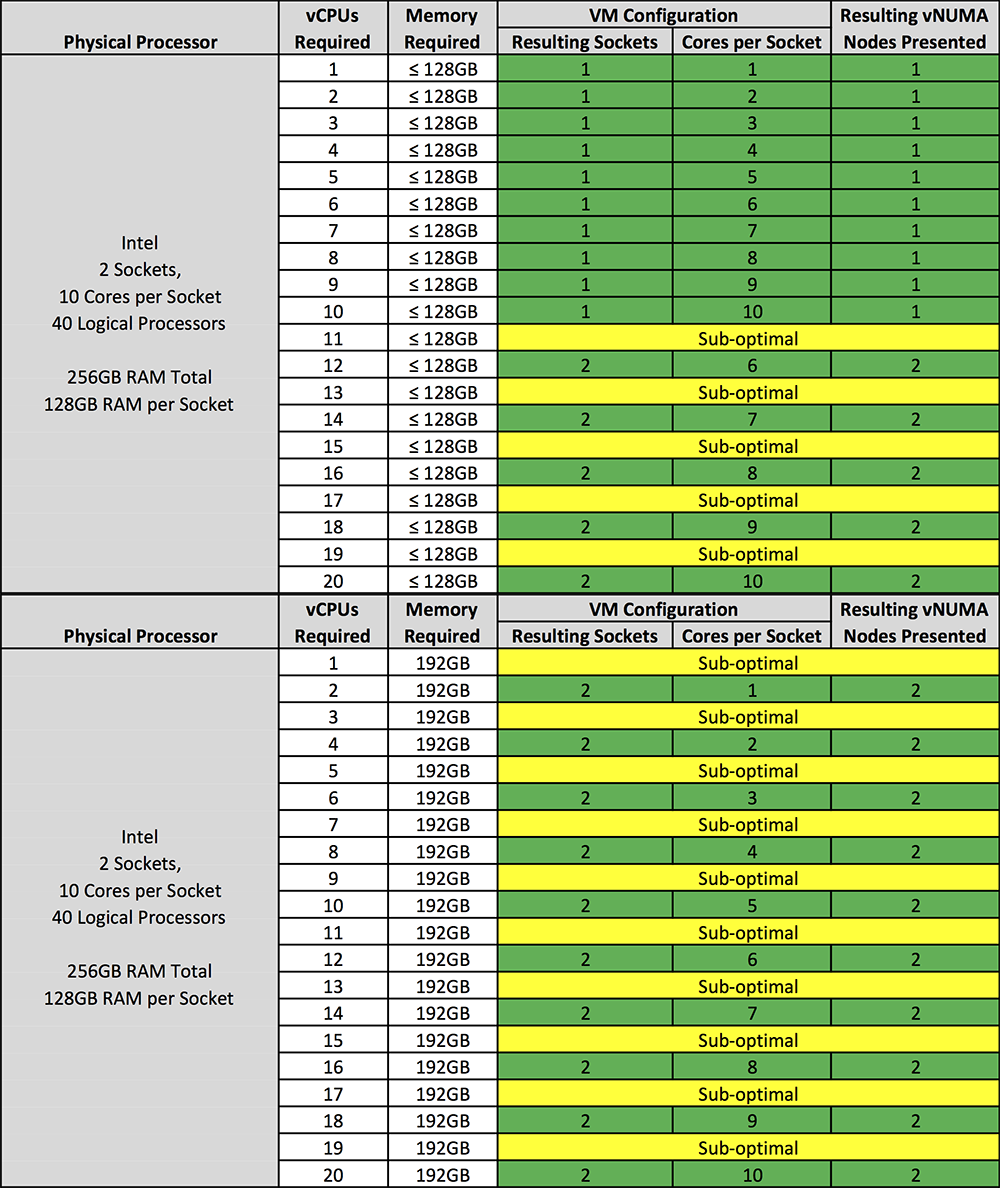
Недавно сделал заметку про выделение памяти для VM, кратной 512Мб, а так же чётное количество процессоров. Оказывается этому есть вполне осмысленное обоснование и отражено оно в блоге vmware - https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html
Материал большой и насыщенный. Приведу только конечные выводы по оптимальному распределению RAM и CPU между виртуалками. Там есть нюансы, о которых лично я не знал. Рассматривается в том числе вопрос с сокетами. Части вижу вопросы на тему того, как распределить процессоры и сокеты в VM.
На основе статьи рекомендации будут следующие. Для примера взят хост:
▪ 2 сокета
▪ 10 ядер на сокет
▪ 40 логических процессоров
▪ 256 GB памяти, по 128 GB на сокет
Разбираем сначала виртуалки с количеством памяти меньше 128 GB. В
этом случае мы добавляем 1 сокет и максимум 10 vCPU. Как только процессоров нужно больше, чем есть на одном сокете, дальше мы добавляем только по чётным числам и делим на 2 сокета поровну. То есть должно быть 2 сокета, 6 vCPU на сокет, в сумме 12. Это будет оптимальная конфигурация для 12 vCPU. И так дальше до 20 ядер добавляем, деля их поровну между сокетами. Напоминаю, что это для виртуалок с памятью меньше чем 128 GB.
Если в виртуальную машину надо выделить более 128 GB памяти, арифметика будет другая. Нечётное количество ядер не используем вообще. Сокетов всегда добавляем два. То есть надо виртуалке 2 vCPU и 192 GB памяти. Делаем два сокета, в каждом по ядру и сколько надо памяти, кратно числу ядер.
Я не знаю, актуально ли это для всех систем виртуализации или только для vmware. Специально не узнавал, но подозреваю, что актуально везде, так как исходит из архитектуры самой платформы хоста.
Краткий вывод такой. Если на одну виртуальную машину условно приходится ресурсов не более, чем в рамках одного сокета (vNUMA, cpu + ram), то процессоров ставим любое число, сокет всегда один. Если на vm уходит больше ресурсов одного сокета, то надо делить процессоры равномерно по сокетам. Причем даже если процессоров всего 2, а памяти больше, чем достанется сокету, все равно vCPU разделяем на сокеты.
Такая вот арифметика. Спасибо читателю за ссылку. Сам я не знал таких подробностей и неизвестно когда узнал бы. А тут реклама заказывается, деньги платятся, посты пишутся. Никуда не деться 😁 Приходится учиться.
Заметку имеет смысл сохранить, чтобы потом не вспоминать, как оптимально выделять ресурсы большой vm.
#виртуализация
Материал большой и насыщенный. Приведу только конечные выводы по оптимальному распределению RAM и CPU между виртуалками. Там есть нюансы, о которых лично я не знал. Рассматривается в том числе вопрос с сокетами. Части вижу вопросы на тему того, как распределить процессоры и сокеты в VM.
На основе статьи рекомендации будут следующие. Для примера взят хост:
▪ 2 сокета
▪ 10 ядер на сокет
▪ 40 логических процессоров
▪ 256 GB памяти, по 128 GB на сокет
Разбираем сначала виртуалки с количеством памяти меньше 128 GB. В
этом случае мы добавляем 1 сокет и максимум 10 vCPU. Как только процессоров нужно больше, чем есть на одном сокете, дальше мы добавляем только по чётным числам и делим на 2 сокета поровну. То есть должно быть 2 сокета, 6 vCPU на сокет, в сумме 12. Это будет оптимальная конфигурация для 12 vCPU. И так дальше до 20 ядер добавляем, деля их поровну между сокетами. Напоминаю, что это для виртуалок с памятью меньше чем 128 GB.
Если в виртуальную машину надо выделить более 128 GB памяти, арифметика будет другая. Нечётное количество ядер не используем вообще. Сокетов всегда добавляем два. То есть надо виртуалке 2 vCPU и 192 GB памяти. Делаем два сокета, в каждом по ядру и сколько надо памяти, кратно числу ядер.
Я не знаю, актуально ли это для всех систем виртуализации или только для vmware. Специально не узнавал, но подозреваю, что актуально везде, так как исходит из архитектуры самой платформы хоста.
Краткий вывод такой. Если на одну виртуальную машину условно приходится ресурсов не более, чем в рамках одного сокета (vNUMA, cpu + ram), то процессоров ставим любое число, сокет всегда один. Если на vm уходит больше ресурсов одного сокета, то надо делить процессоры равномерно по сокетам. Причем даже если процессоров всего 2, а памяти больше, чем достанется сокету, все равно vCPU разделяем на сокеты.
Такая вот арифметика. Спасибо читателю за ссылку. Сам я не знал таких подробностей и неизвестно когда узнал бы. А тут реклама заказывается, деньги платятся, посты пишутся. Никуда не деться 😁 Приходится учиться.
Заметку имеет смысл сохранить, чтобы потом не вспоминать, как оптимально выделять ресурсы большой vm.
#виртуализация
{kind=link}
Заметка про блокировку хостерами некоторых tcp/udp портов вызвала некоторую дискуссию. На мое удивление, что в TG, что в VK нашлись люди, которые одобряют такой подход. В частности, блок на отправку почты по 25 порту. Переведу его на более простой язык.
Вы регистрируетесь и сразу же считаетесь спамером. Вам тут же блокируют отправку сообщений, хотя потребность в этом есть достаточно большая. Например, я иногда настраиваю отправку почты прямо с сервера на свои ящики, не используя внешние smtp сервера. Не вижу в этом ничего криминального. Никакие ptr и dns записи мне не нужны. Это моя личная почта, адресованная тоже мне. Это может быть локальное дублирование каких-то критичных событий мониторинга. Не суть важно, зачем мне может быть нужно. Отправка почты актуальный в наше время функционал.
Так вот, нормальная блокировка должна выглядеть следующим образом. Вы начали рассылать спам и это заметили по активности вашего публичного трафика на выходе из инфраструктуры провайдера. Например, количество smtp пакетов, потоков превышено. Если вы выходите за рамки каких-то разумных лимитов, вам блокируют 25-й порт и просят пояснить, что вы там рассылаете.
Это клиентоориентированный подход, который экономит время и силы клиента, но тратит больше ресурсов провайдера. Поэтому некоторые провайдеры в целях экономии, просто блокируют 25-й порт всем, а открывают только тем, кто потратит свое время и докажет, что он не спамер, различными способами. Это выгодно провайдеру. Он за ваш счет решает свои проблемы.
Налицо явная презумпция виновности. Показываю пример этой логики, доведенной до абсурда. Всех мужчин можно сразу сажать в тюрьму и выпускать только тогда, когда они докажут, что не насильники. Ведь они с рождения обладают инструментом насилия. Думаю, мало кому понравится такой подход. Так вот, здесь то же самое. Я лично не одобряю это и не вижу оправданий, а вижу попытку сэкономить.
❓А вам какой подход больше нравится? Наказание сразу всем, а потом доказательство невиновности, или наказание только тех, кто реально виновен?
Вы регистрируетесь и сразу же считаетесь спамером. Вам тут же блокируют отправку сообщений, хотя потребность в этом есть достаточно большая. Например, я иногда настраиваю отправку почты прямо с сервера на свои ящики, не используя внешние smtp сервера. Не вижу в этом ничего криминального. Никакие ptr и dns записи мне не нужны. Это моя личная почта, адресованная тоже мне. Это может быть локальное дублирование каких-то критичных событий мониторинга. Не суть важно, зачем мне может быть нужно. Отправка почты актуальный в наше время функционал.
Так вот, нормальная блокировка должна выглядеть следующим образом. Вы начали рассылать спам и это заметили по активности вашего публичного трафика на выходе из инфраструктуры провайдера. Например, количество smtp пакетов, потоков превышено. Если вы выходите за рамки каких-то разумных лимитов, вам блокируют 25-й порт и просят пояснить, что вы там рассылаете.
Это клиентоориентированный подход, который экономит время и силы клиента, но тратит больше ресурсов провайдера. Поэтому некоторые провайдеры в целях экономии, просто блокируют 25-й порт всем, а открывают только тем, кто потратит свое время и докажет, что он не спамер, различными способами. Это выгодно провайдеру. Он за ваш счет решает свои проблемы.
Налицо явная презумпция виновности. Показываю пример этой логики, доведенной до абсурда. Всех мужчин можно сразу сажать в тюрьму и выпускать только тогда, когда они докажут, что не насильники. Ведь они с рождения обладают инструментом насилия. Думаю, мало кому понравится такой подход. Так вот, здесь то же самое. Я лично не одобряю это и не вижу оправданий, а вижу попытку сэкономить.
❓А вам какой подход больше нравится? Наказание сразу всем, а потом доказательство невиновности, или наказание только тех, кто реально виновен?
В пятницу был юмор на тему bash_history. А вот уже не такая смешная история, как бывает на практике. Я не знал пароль root от mysql, но очень быстро его выяснил.
Так что следите за своей history в терминале. Не надо там светить пароли. По аналогии иногда можно пароль root посмотреть в логе авторизаций ssh. Если открыт доступ по паролю, то не редко бывает так, что вместо имени пользователя туда копируют пароль и он оседает в логе.
#безопасность
Так что следите за своей history в терминале. Не надо там светить пароли. По аналогии иногда можно пароль root посмотреть в логе авторизаций ssh. Если открыт доступ по паролю, то не редко бывает так, что вместо имени пользователя туда копируют пароль и он оседает в логе.
#безопасность
У меня было несколько заметок на канале про различные mysql клиенты. Я не знаю, с чем это связано, но их очень активно обсуждали, сохраняли в закладки, vk активно показывал эти посты, так что они набирали до 10к. просмотров. Походу все любят юзать mysql клиенты 😃
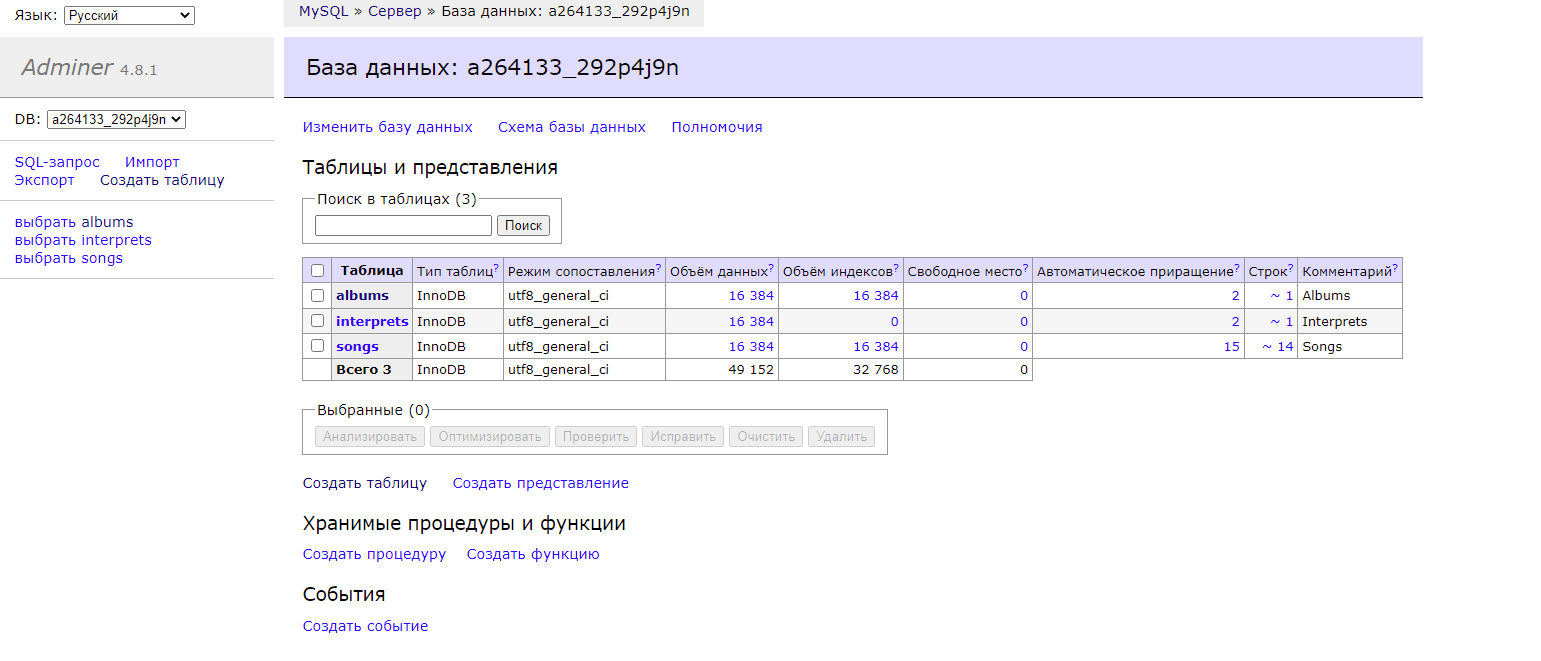
Держите еще один, которым я сам иногда пользовался. Речь пойдет про Adminer - https://www.adminer.org Это небольшой php файл (~500к, где треть объема переводы), который можно положить на любой php хостинг, чтобы использовать его как панель управления mysql сервером. Очень удобно для различных php хостингов, где по какой-то причине нет хостеровской панели управления базами, либо она неудобная.
Рассказывать про эту утилитку особо нечего. Она просто работает. Можете демку глянуть - https://demo.adminer.org/adminer.php. Пользователя и пароль указывать не обязательно. Для типовых операций у неё примерно тот же функционал, что и у phpmyadmin, но последний просто монстр, а тут только один файл.
#mysql
Держите еще один, которым я сам иногда пользовался. Речь пойдет про Adminer - https://www.adminer.org Это небольшой php файл (~500к, где треть объема переводы), который можно положить на любой php хостинг, чтобы использовать его как панель управления mysql сервером. Очень удобно для различных php хостингов, где по какой-то причине нет хостеровской панели управления базами, либо она неудобная.
Рассказывать про эту утилитку особо нечего. Она просто работает. Можете демку глянуть - https://demo.adminer.org/adminer.php. Пользователя и пароль указывать не обязательно. Для типовых операций у неё примерно тот же функционал, что и у phpmyadmin, но последний просто монстр, а тут только один файл.
#mysql
{kind=link}
Информационный пост на тему ssh и его возможностей по туннелированию трафика. С помощью ssh подключения можно совершать очень много простых, полезных и неочевидных вещей. Иногда это очень удобно. Я рассмотрю два примера, которые сам регулярно использую. Для их реализации вам необходим обычный ssh доступ к какому-то серверу в интернете.
SOCKS-прокси через ssh. Вы можете без проблем поднять у себя на компьютере локальный socks прокси с использованием удаленного сервера. Для этого локально подключитесь к серверу по ssh примерно таким образом:
Дальше идёте в любой браузер в настройки прокси и указываете там в параметрах для socks 5 свой локальный socks сервер: localhost, порт 3128. Дальше можете сразу же проверить, какой внешний ip адрес будет показывать ваш браузер. В общем случае это должен быть ip адрес сервера, к которому вы подключились по ssh.
Для подобного подключения подойдет современный windows terminal, который уже имеет встроенный ssh клиент. То есть подключиться проще простого и ничего особо настраивать не надо. На самом сервере, к примеру, можно быстро поднять adguard и использовать его как собственный блокировщик рекламы. При этом не придется замусоривать локальную машину для установки блокировщиков, которые точно не известно, что делают на вашем компе.
Можно завести отдельный браузер и использовать его только с прокси для фильтра рекламы или обхода блокировок. Тогда не придется постоянно менять настройки на основном. Применения для подобного прокси может быть много.
Переадресация портов через ssh. Это тоже очень простая и полезная история. С помощью ssh можно удаленный порт переадресовать себе локально.
В данном случай я удаленный порт 8080, который слушает только localhost (127.0.0.1) переадресовал себе локально на порт 8181. Тут важно не перепутать удаленную и локальную машины. 127.0.0.1:8080 - это удалённый сервер, к которому мы подключились по ssh, а 8181 локальный порт на машине, с которой происходит подключение к серверу.
С помощью этой переадресации можно локально получить доступ к порту, который закрыт для удаленных подключений. Обычно локальные mysql клиенты используют такие подключения. Но не обязательно. Можно банально какой-то веб сервер запустить на сервере, закрыв к нему доступ из интернета, а подключаться к нему со своего компа через ssh. Так можно закрывать какие-то панели управления от посторонних глаз.
#ssh #полезности
SOCKS-прокси через ssh. Вы можете без проблем поднять у себя на компьютере локальный socks прокси с использованием удаленного сервера. Для этого локально подключитесь к серверу по ssh примерно таким образом:
ssh -D 3128 root@95.145.142.226Дальше идёте в любой браузер в настройки прокси и указываете там в параметрах для socks 5 свой локальный socks сервер: localhost, порт 3128. Дальше можете сразу же проверить, какой внешний ip адрес будет показывать ваш браузер. В общем случае это должен быть ip адрес сервера, к которому вы подключились по ssh.
Для подобного подключения подойдет современный windows terminal, который уже имеет встроенный ssh клиент. То есть подключиться проще простого и ничего особо настраивать не надо. На самом сервере, к примеру, можно быстро поднять adguard и использовать его как собственный блокировщик рекламы. При этом не придется замусоривать локальную машину для установки блокировщиков, которые точно не известно, что делают на вашем компе.
Можно завести отдельный браузер и использовать его только с прокси для фильтра рекламы или обхода блокировок. Тогда не придется постоянно менять настройки на основном. Применения для подобного прокси может быть много.
Переадресация портов через ssh. Это тоже очень простая и полезная история. С помощью ssh можно удаленный порт переадресовать себе локально.
ssh -L 8181:127.0.0.1:8080 root@95.145.142.226В данном случай я удаленный порт 8080, который слушает только localhost (127.0.0.1) переадресовал себе локально на порт 8181. Тут важно не перепутать удаленную и локальную машины. 127.0.0.1:8080 - это удалённый сервер, к которому мы подключились по ssh, а 8181 локальный порт на машине, с которой происходит подключение к серверу.
С помощью этой переадресации можно локально получить доступ к порту, который закрыт для удаленных подключений. Обычно локальные mysql клиенты используют такие подключения. Но не обязательно. Можно банально какой-то веб сервер запустить на сервере, закрыв к нему доступ из интернета, а подключаться к нему со своего компа через ssh. Так можно закрывать какие-то панели управления от посторонних глаз.
#ssh #полезности
{kind=link}
Прошлая заметка с командами bash собрала большое количество пересылок, так что я сделал вывод, что материал был интересен и полезен. Имеет смысл развить тему.
В прошлой подборке был акцент на работу со строками и текстом, а сейчас сделаю его на анализ сети сервера.
Подсчет подключений с каждого IP. Если сервер публичный и вы видите, что он тормозит, первое, что стоит проверить, это количество подключений к нему.
netstat -ntu | awk '{print $5}' | grep -vE "(Address|servers|127.0.0.1)" | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'
Чаще всего имеет смысл сразу же исключить из списка адреса с малым количеством подключений. Например, можно вывести только те ip, с которых более 10-ти подключений. Для этого к предыдущей команде надо добавить небольшое дополнение
| awk '{if ($1 > 10 ) print$2}';
Подсчет запросов к веб серверу с разных IP. Если вас какой-то бот спамит запросами к веб серверу, то похожим образом можно быстро вычислить его по записям в логе.
tail -1000 /var/log/nginx/access.log | awk '{print $1}' | sort -n | uniq -c | sort -n | tail -n100 | awk '{if ($1 > 10 ) print $2}'
Рекомендую обрабатывать только часть лога, так как если он очень большой, можете подвешивать сервер своими запросами. Здесь взяты последние 1000 строк. Если надо весь файл проанализировать, используйте вместо tail команду cat.
cat /var/log/nginx/access.log | awk '{print $1}' | sort -n | uniq -c | sort -n | tail -n100 | awk '{if ($1 > 10 ) print $2}'
Список установленных соединений с сервером. Бывает нужно, когда есть подозрения на взлом и какую-то паразитную активность. В этом примере не вычисляется количество соединений, а просто приводится список уникальных ip адресов, с которыми установлено соединение.
netstat -lantp | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort -u
При необходимости можно сделать подсчет соединений из примеров прошлых команд.
Список tcp соединений. Это то же самое, что было в прошлой команде, но мне вывод больше нравится. Более наглядный, если смотреть его весь.
lsof -ni
Список всех активных входящих сокетов unix. Этой командой я не видел, чтобы особо пользовались, но по факту бывает быстрее через нее посмотреть открытый сокет, нежели каким-то другим способом. Например, сразу смотрим, запустился ли нужный нам сокет php-fpm.
netstat -lx | grep php-fpm
Кстати, то же самое можно смотреть и через ss, но лично мне вывод netstat просто больше нравится, особенно если смотришь его полностью глазами. Можете сами сравнить. Те же сокеты с помощью ss:
ss -xa
Информации выводится больше, но чаще всего лично мне эта дополнительная информация не нужна.
Напоминаю про то, что заметку имеет смысл сохранить. В следующей подборке будет набор консольных команд для анализа нагрузки на сервер.
#bash
В прошлой подборке был акцент на работу со строками и текстом, а сейчас сделаю его на анализ сети сервера.
Подсчет подключений с каждого IP. Если сервер публичный и вы видите, что он тормозит, первое, что стоит проверить, это количество подключений к нему.
netstat -ntu | awk '{print $5}' | grep -vE "(Address|servers|127.0.0.1)" | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'
Чаще всего имеет смысл сразу же исключить из списка адреса с малым количеством подключений. Например, можно вывести только те ip, с которых более 10-ти подключений. Для этого к предыдущей команде надо добавить небольшое дополнение
| awk '{if ($1 > 10 ) print$2}';
Подсчет запросов к веб серверу с разных IP. Если вас какой-то бот спамит запросами к веб серверу, то похожим образом можно быстро вычислить его по записям в логе.
tail -1000 /var/log/nginx/access.log | awk '{print $1}' | sort -n | uniq -c | sort -n | tail -n100 | awk '{if ($1 > 10 ) print $2}'
Рекомендую обрабатывать только часть лога, так как если он очень большой, можете подвешивать сервер своими запросами. Здесь взяты последние 1000 строк. Если надо весь файл проанализировать, используйте вместо tail команду cat.
cat /var/log/nginx/access.log | awk '{print $1}' | sort -n | uniq -c | sort -n | tail -n100 | awk '{if ($1 > 10 ) print $2}'
Список установленных соединений с сервером. Бывает нужно, когда есть подозрения на взлом и какую-то паразитную активность. В этом примере не вычисляется количество соединений, а просто приводится список уникальных ip адресов, с которыми установлено соединение.
netstat -lantp | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort -u
При необходимости можно сделать подсчет соединений из примеров прошлых команд.
Список tcp соединений. Это то же самое, что было в прошлой команде, но мне вывод больше нравится. Более наглядный, если смотреть его весь.
lsof -ni
Список всех активных входящих сокетов unix. Этой командой я не видел, чтобы особо пользовались, но по факту бывает быстрее через нее посмотреть открытый сокет, нежели каким-то другим способом. Например, сразу смотрим, запустился ли нужный нам сокет php-fpm.
netstat -lx | grep php-fpm
Кстати, то же самое можно смотреть и через ss, но лично мне вывод netstat просто больше нравится, особенно если смотришь его полностью глазами. Можете сами сравнить. Те же сокеты с помощью ss:
ss -xa
Информации выводится больше, но чаще всего лично мне эта дополнительная информация не нужна.
Напоминаю про то, что заметку имеет смысл сохранить. В следующей подборке будет набор консольных команд для анализа нагрузки на сервер.
#bash
{kind=link}
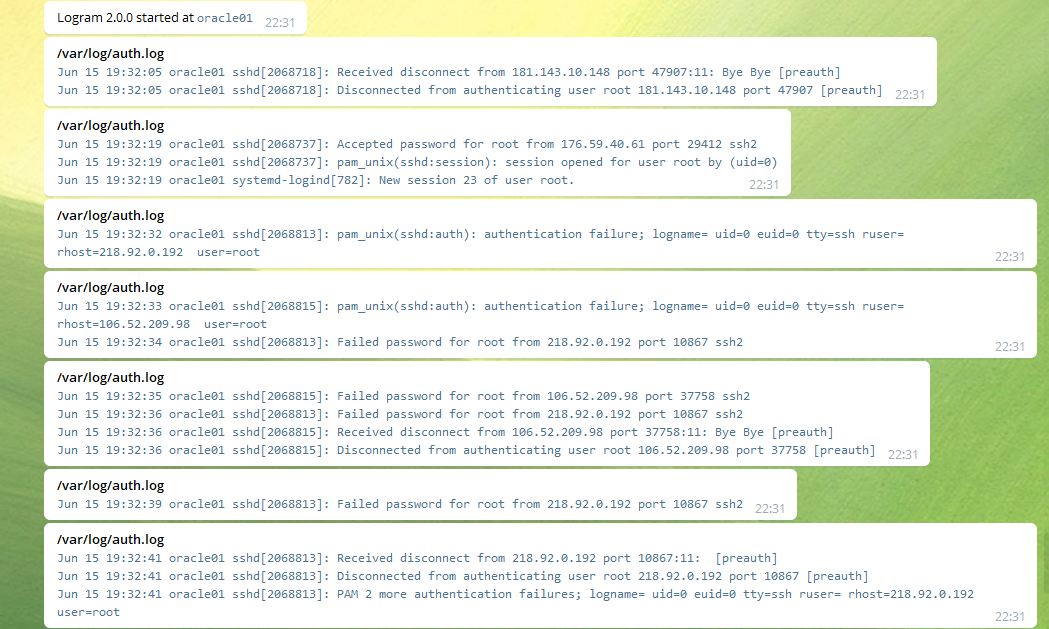
Вчера потестировал любопытную утилиту, которая умеет отправлять логи напрямую в Telegram. Называется Logram - https://github.com/mxseev/logram
Ставится и настраивается очень просто. Качаем deb или rpm пакет из репозитория и ставим на машину:
wget https://github.com/mxseev/logram/releases/download/v2.0.0/logram-2.0.0.amd64.deb
dpkg -i logram-2.0.0.amd64.deb
Далее редактируем конфиг /etc/logram.yaml. Я поменял только следующие строки:
telegram:
token: <bot_token>
chat_id: <id чата>
filesystem:
enabled: true
entries:
- /var/log/auth.log
С такой настройкой бот будет отправлять вам в чат все новые строки лога /var/log/auth.log
Остается только запустить его:
systemctl start logram
Быстро узнать id чата можно с помощью бота и logram. Добавьте вашего бота в чат и запустите в консоли:
logram echo_id -t <bot_token>
The chat ID of group "srvadmin_zabbix_group": -1001998787756
На Centos 7 у меня эта штука не завелась, ругнулась на неподходящую версию glibc:
/usr/bin/logram: /lib64/libc.so.6: version `GLIBC_2.32' not found (required by /usr/bin/logram)
А вот на ubuntu 20 сразу заработала.
#утилита
Ставится и настраивается очень просто. Качаем deb или rpm пакет из репозитория и ставим на машину:
wget https://github.com/mxseev/logram/releases/download/v2.0.0/logram-2.0.0.amd64.deb
dpkg -i logram-2.0.0.amd64.deb
Далее редактируем конфиг /etc/logram.yaml. Я поменял только следующие строки:
telegram:
token: <bot_token>
chat_id: <id чата>
filesystem:
enabled: true
entries:
- /var/log/auth.log
С такой настройкой бот будет отправлять вам в чат все новые строки лога /var/log/auth.log
Остается только запустить его:
systemctl start logram
Быстро узнать id чата можно с помощью бота и logram. Добавьте вашего бота в чат и запустите в консоли:
logram echo_id -t <bot_token>
The chat ID of group "srvadmin_zabbix_group": -1001998787756
На Centos 7 у меня эта штука не завелась, ругнулась на неподходящую версию glibc:
/usr/bin/logram: /lib64/libc.so.6: version `GLIBC_2.32' not found (required by /usr/bin/logram)
А вот на ubuntu 20 сразу заработала.
#утилита
{kind=link}
Бесплатный курс по основам git от Слёрм - https://slurm.io/git
Это не заказная реклама данной площадки, а просто моя рекомендация. Ранее у меня уже были заметки по этому учебному центру, так как я там проходил несколько платных курсов. Лично мне нравится качество курсов и то, как там организован учебный процесс.
Спикеры обычно известные специалисты с бэкаграундом публичных выступлений. Так что можно даже чисто по ведущим сделать некоторый анализ материала. Ну и плюс есть несколько бесплатных курсов, по которым можно получить представление о том, как там все организовано.
Когда зарегистрируетесь, в списке всех курсов будет несколько бесплатных, так что можете их к себе добавить и начать проходить.
#обучение
Это не заказная реклама данной площадки, а просто моя рекомендация. Ранее у меня уже были заметки по этому учебному центру, так как я там проходил несколько платных курсов. Лично мне нравится качество курсов и то, как там организован учебный процесс.
Спикеры обычно известные специалисты с бэкаграундом публичных выступлений. Так что можно даже чисто по ведущим сделать некоторый анализ материала. Ну и плюс есть несколько бесплатных курсов, по которым можно получить представление о том, как там все организовано.
Когда зарегистрируетесь, в списке всех курсов будет несколько бесплатных, так что можете их к себе добавить и начать проходить.
#обучение
{kind=link}
💡Делюсь небольшим советом, основанным на своем опыте работы в профессии. Старайтесь всегда и везде по максимуму вести свои дела в каком-то менеджере задач (таск трекере). Да, это лениво делать, так как не всегда очевиден смысл, плюс занимает время. А некоторые задачи дольше описывать, чем делать.
Смысл тут вот в чём. Первое и самое очевидное - он может вам помогать вести дела и что-то запоминать. Но это не обязательно. Зависит от конкретного человека. Кто-то и без трекеров нормально всё успевает. Хотя лично мне они помогают, когда идёт интенсивный поток задач. Последнее время сам не веду таких трекеров и дальше поясню почему.
Список своих задач супер актуален, когда вам нужно предметно побеседовать с руководством. Без него для руководителя, не сильно вникающего в IT, будет не понятно, чем конкретно ты занимаешься. Что значит, ты в прошлом месяце настраивал бэкапы, неделю назад и вчера снова ими занимался. Он не понимает, что бэкапы, или, к примеру, мониторинг, это непрерывные процессы. В задачах можно отразить эти нюансы, чуть конкретизировав каждую задачу.
Подробный список задач поможет убедить нанять помощника, если у вас действительно не хватает времени на все свои задачи. Так же на основе своих задач вы сможете объяснить, почему новая задача откладывается на какой-то срок, так как сейчас вы занимаетесь другой. Со списком задач вы можете более предметно обсуждать повышение зарплаты.
❗️Таким образом, записанный реальный список задач это ваш надежный помощник, а не просто какая-то формальность, которая отнимает время.
От списка задач сплошные плюсы. Когда я начинал работать как самозанятый, со всеми заказчиками в обязательном порядке вел список дел, даже если меня об этом не просили. Я все записывал и периодически отправлял отчеты вместе с паролями, схемами, документацией и т.д.
Сейчас я этим не занимаюсь, потому что со всеми сотрудничаю по многу лет и есть взаимопонимание без лишних подтверждений. Все свои подтверждения я уже сделал делами и отчетами на начальном этапе знакомства.
Рекомендую подумать над этим и взять на вооружение.
#совет
Смысл тут вот в чём. Первое и самое очевидное - он может вам помогать вести дела и что-то запоминать. Но это не обязательно. Зависит от конкретного человека. Кто-то и без трекеров нормально всё успевает. Хотя лично мне они помогают, когда идёт интенсивный поток задач. Последнее время сам не веду таких трекеров и дальше поясню почему.
Список своих задач супер актуален, когда вам нужно предметно побеседовать с руководством. Без него для руководителя, не сильно вникающего в IT, будет не понятно, чем конкретно ты занимаешься. Что значит, ты в прошлом месяце настраивал бэкапы, неделю назад и вчера снова ими занимался. Он не понимает, что бэкапы, или, к примеру, мониторинг, это непрерывные процессы. В задачах можно отразить эти нюансы, чуть конкретизировав каждую задачу.
Подробный список задач поможет убедить нанять помощника, если у вас действительно не хватает времени на все свои задачи. Так же на основе своих задач вы сможете объяснить, почему новая задача откладывается на какой-то срок, так как сейчас вы занимаетесь другой. Со списком задач вы можете более предметно обсуждать повышение зарплаты.
❗️Таким образом, записанный реальный список задач это ваш надежный помощник, а не просто какая-то формальность, которая отнимает время.
От списка задач сплошные плюсы. Когда я начинал работать как самозанятый, со всеми заказчиками в обязательном порядке вел список дел, даже если меня об этом не просили. Я все записывал и периодически отправлял отчеты вместе с паролями, схемами, документацией и т.д.
Сейчас я этим не занимаюсь, потому что со всеми сотрудничаю по многу лет и есть взаимопонимание без лишних подтверждений. Все свои подтверждения я уже сделал делами и отчетами на начальном этапе знакомства.
Рекомендую подумать над этим и взять на вооружение.
#совет