
Я смотрю почти все видео, что выпускает англоязычный IT блогер Christian Lempa. Его ролики регулярно попадают в мои обзоры. Недавно он рассказал в отдельном видео про свои репозитории, где он собирает кучу всевозможной информации по конфигам, шаблонам, настройкам различных популярных сервисов:
▶️ My Docker Compose *boilerplates* and update management
Тут он рассказывает только про один репозиторий - boilerplates, где собирает docker-compose популярных сервисов, шаблоны terraform, vagrant, packer для proxmox, роли ansible. Интересно и полезно посмотреть на работы другого человека.
Помимо этого у него есть и другие репозитории:
- Dotfiles - конфиги от его системы macOS
- Cheat-Sheets - подборка команд популярных консольных утилит
- Homelab - полное описание на уровне кода его домашней лаборатории
Последняя репа мне показалась наиболее интересной. Любопытно было глянуть, как у него там всё устроено. С учётом того, что за последний год-два я почти все его видео просмотрел.
Судя по коммитам, всё это регулярно обновляется и поддерживается.
#видео
▶️ My Docker Compose *boilerplates* and update management
Тут он рассказывает только про один репозиторий - boilerplates, где собирает docker-compose популярных сервисов, шаблоны terraform, vagrant, packer для proxmox, роли ansible. Интересно и полезно посмотреть на работы другого человека.
Помимо этого у него есть и другие репозитории:
- Dotfiles - конфиги от его системы macOS
- Cheat-Sheets - подборка команд популярных консольных утилит
- Homelab - полное описание на уровне кода его домашней лаборатории
Последняя репа мне показалась наиболее интересной. Любопытно было глянуть, как у него там всё устроено. С учётом того, что за последний год-два я почти все его видео просмотрел.
Судя по коммитам, всё это регулярно обновляется и поддерживается.
#видео
YouTube
BEST Docker Compose Templates + Update Process in Renovate
Get started with Mend Renovate: https://www.mend.io/mend-renovate/
In this video, I'll show you the latest updates on my famous boilerplates repository on GitHub. This project, which includes templates and config examples for technologies like Docker Compose…
In this video, I'll show you the latest updates on my famous boilerplates repository on GitHub. This project, which includes templates and config examples for technologies like Docker Compose…
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Сейчас очень большая конкуренция на рынке хостинг услуг, в частности в аренде VPS/VDS. Выбрать из множества предложений лучшее - трудная задача. Я вам не скажу, как её решить, потому что сам не знаю, но дам некоторые комментарии и рекомендации на основе своего опыта.
Первое, с чего хочу начать, так это разделить аренду виртуалок на 2 принципиально разные услуги: выделенные одиночные VPS и аренда VPS у облачных провайдеров, типа yandex cloud, vk cloud и других вендоров, где помимо VPS наберётся несколько десятков услуг, которые могут быть объединены в единой платформе. Цены у облаков будут на первый взгляд намного выше и вызывать недоумение. Но это только на первый взгляд.
Арендованные услуги могут очень сильно отличаться по производительности, подчас раз в 5-10, если брать скорость записи на диск. У меня много разных хостеров постоянно в работе. Зашёл в 5 разных VPS у разных хостеров и просто посмотрел на процессоры и скорость записи на диск.
Последний самый дорогой, но он и по производительности на голову выше. Ещё и передаёт в виртуалку модель процессора. Это Xeon Gold 6254 CPU 3.10GHz. Я тут упоминал этого хостера мельком и видел комментарии на тему того, что у него дорого, есть дешевле.
Да, дешевле всегда есть, но дёшево быстро точно не будет. Как и нет гарантии, что за дорого будет быстро. Но шанс есть. Дёшево быстро точно не будет. Я для тестов выше не назвал имена компаний, потому что по большому счёту это не имеет смысла. Там в списке есть виртуалка, которая покупалась дороже рынка по отдельному тарифу и поначалу работала быстро. Как обычно бывает, купишь, проверишь, и она работает годами. Вот я сейчас проверил, и процессор по частоте уже не тот, и скорость записи на диск одна из самых низких. То есть виртуалка судя по всему переехала со временем на более слабую ноду.
Как вы видите, разброс по производительности солидный. А люди зачастую выбирают тупо по ценам и рассказывают потом, что я тут такую же виртуалку купил в 2 раза дешевле. Такую, да не такую. Я так примерно для себя знаю, у каких хостеров будет дёшево и медленно, а у кого дорого и быстро. Это всё актуально в моменте, так как может измениться. Дорого и хорошо у Serverspace, RuVDS. Дёшево и медленно у VDSina, IHor, Simplecloud.
Публикация выходит за лимит символов, так что продолжение ниже
(комментарии пишите ко второй заметке)
👇👇👇👇👇
#хостинг
Первое, с чего хочу начать, так это разделить аренду виртуалок на 2 принципиально разные услуги: выделенные одиночные VPS и аренда VPS у облачных провайдеров, типа yandex cloud, vk cloud и других вендоров, где помимо VPS наберётся несколько десятков услуг, которые могут быть объединены в единой платформе. Цены у облаков будут на первый взгляд намного выше и вызывать недоумение. Но это только на первый взгляд.
Арендованные услуги могут очень сильно отличаться по производительности, подчас раз в 5-10, если брать скорость записи на диск. У меня много разных хостеров постоянно в работе. Зашёл в 5 разных VPS у разных хостеров и просто посмотрел на процессоры и скорость записи на диск.
# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2599.996# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB) copied, 57.8859 s, 74.2 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 3695.998# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 22.5497 s, 190 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2249.998# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 45.4332 s, 94.5 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2194.710# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 14.9843 s, 287 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 3100.000# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 7.25733 s, 592 MB/sПоследний самый дорогой, но он и по производительности на голову выше. Ещё и передаёт в виртуалку модель процессора. Это Xeon Gold 6254 CPU 3.10GHz. Я тут упоминал этого хостера мельком и видел комментарии на тему того, что у него дорого, есть дешевле.
Да, дешевле всегда есть, но дёшево быстро точно не будет. Как и нет гарантии, что за дорого будет быстро. Но шанс есть. Дёшево быстро точно не будет. Я для тестов выше не назвал имена компаний, потому что по большому счёту это не имеет смысла. Там в списке есть виртуалка, которая покупалась дороже рынка по отдельному тарифу и поначалу работала быстро. Как обычно бывает, купишь, проверишь, и она работает годами. Вот я сейчас проверил, и процессор по частоте уже не тот, и скорость записи на диск одна из самых низких. То есть виртуалка судя по всему переехала со временем на более слабую ноду.
Как вы видите, разброс по производительности солидный. А люди зачастую выбирают тупо по ценам и рассказывают потом, что я тут такую же виртуалку купил в 2 раза дешевле. Такую, да не такую. Я так примерно для себя знаю, у каких хостеров будет дёшево и медленно, а у кого дорого и быстро. Это всё актуально в моменте, так как может измениться. Дорого и хорошо у Serverspace, RuVDS. Дёшево и медленно у VDSina, IHor, Simplecloud.
Публикация выходит за лимит символов, так что продолжение ниже
(комментарии пишите ко второй заметке)
👇👇👇👇👇
#хостинг
Продолжение, начало выше 👆👆👆👆👆
Теперь ещё раз вернусь к облачным провайдерам. Почему у них дороже. Причин тут несколько. Их может не быть полным списком у кого-то одного, но так или иначе встречается у разных облаков.
1️⃣ Облака могут указывать конкретные модели процессоров, ядра которых вы арендуете. Чем современнее и быстрее, тем дороже. У обычных хостеров очень редко это указано. Только для каких-то отдельных тарифов на самых быстрых процессорах. Всё остальное будет безлико, берёте кота в мешке.
2️⃣ Облако может вам продать гарантированное ядро процессора, 20%, 50% от него. Градация может быть разной. Но смысл в том, что если вам оверселят процессор, то вы это знаете и это стоит дешевле. Хостеры обычных VPS все оверселят и вы никогда не узнаете до какой степени. Купить гарантированно одно ядро у них скорее всего не получится.
3️⃣ То же самое касается дисков. В облаке обычно на выбор даются разные вариантов дисков с разной гарантированной производительностью.
4️⃣ Облако предлагает набор дополнительных услуг, которые могут ничего не стоить. Например, программный маршрутизатор с файрволом, который умеет натить трафик в вашу локальную сеть из виртуалок. На нём могут висеть ваши внешние IP адреса, а виртуалки спокойно меняться, без потери IP адресов. Вы можете организовать локальную сеть из своих виртуальных машин, чего у обычных, особенно самых дешёвых хостеров, просто нет. Всё это ведёт к удорожанию услуги.
Если взять какое-то облако, купить там CPU с гарантированными 20% производительности самой низкой частоты, выбрать самый медленный диск, то окажется не сильно дороже какого-нибудь обычного хостера VPS. Будет скорее всего всё равно дороже, но уже не так сильно, как кажется на первый взгляд. Разница будет обусловлена дополнительными услугами облака.
Написал всё это к тому, чтобы вы не выбирали услуги тупо по стоимости. Любой хостинг имеет право на жизнь. И дорогой, и дешёвый. На каждую услугу найдётся запрос. Смотрите шире на эту тему, тестируйте то, что вы арендуете. Хотя, конечно, это не так просто сделать. Всё, что берётся на тест или покупается впервые, скорее всего получает какой-то приоритет по производительности, чтобы заманить клиента и оставить хорошее впечатление. И отзывы тут не помогут. Только свой опыт использования.
Для быстрого теста виртуалок удобно использовать какой-то софт. Например, утилиту stress. Я лично привык тупо проверять скорость записи на диск. Так как обычно это узкое место. Полной нагрузки по CPU или памяти у меня практически никогда не бывает.
#хостинг
Теперь ещё раз вернусь к облачным провайдерам. Почему у них дороже. Причин тут несколько. Их может не быть полным списком у кого-то одного, но так или иначе встречается у разных облаков.
1️⃣ Облака могут указывать конкретные модели процессоров, ядра которых вы арендуете. Чем современнее и быстрее, тем дороже. У обычных хостеров очень редко это указано. Только для каких-то отдельных тарифов на самых быстрых процессорах. Всё остальное будет безлико, берёте кота в мешке.
2️⃣ Облако может вам продать гарантированное ядро процессора, 20%, 50% от него. Градация может быть разной. Но смысл в том, что если вам оверселят процессор, то вы это знаете и это стоит дешевле. Хостеры обычных VPS все оверселят и вы никогда не узнаете до какой степени. Купить гарантированно одно ядро у них скорее всего не получится.
3️⃣ То же самое касается дисков. В облаке обычно на выбор даются разные вариантов дисков с разной гарантированной производительностью.
4️⃣ Облако предлагает набор дополнительных услуг, которые могут ничего не стоить. Например, программный маршрутизатор с файрволом, который умеет натить трафик в вашу локальную сеть из виртуалок. На нём могут висеть ваши внешние IP адреса, а виртуалки спокойно меняться, без потери IP адресов. Вы можете организовать локальную сеть из своих виртуальных машин, чего у обычных, особенно самых дешёвых хостеров, просто нет. Всё это ведёт к удорожанию услуги.
Если взять какое-то облако, купить там CPU с гарантированными 20% производительности самой низкой частоты, выбрать самый медленный диск, то окажется не сильно дороже какого-нибудь обычного хостера VPS. Будет скорее всего всё равно дороже, но уже не так сильно, как кажется на первый взгляд. Разница будет обусловлена дополнительными услугами облака.
Написал всё это к тому, чтобы вы не выбирали услуги тупо по стоимости. Любой хостинг имеет право на жизнь. И дорогой, и дешёвый. На каждую услугу найдётся запрос. Смотрите шире на эту тему, тестируйте то, что вы арендуете. Хотя, конечно, это не так просто сделать. Всё, что берётся на тест или покупается впервые, скорее всего получает какой-то приоритет по производительности, чтобы заманить клиента и оставить хорошее впечатление. И отзывы тут не помогут. Только свой опыт использования.
Для быстрого теста виртуалок удобно использовать какой-то софт. Например, утилиту stress. Я лично привык тупо проверять скорость записи на диск. Так как обычно это узкое место. Полной нагрузки по CPU или памяти у меня практически никогда не бывает.
#хостинг
В работе веб сервера иногда есть необходимость разработчикам получить доступ к исходникам сайта напрямую. Проще всего и безопаснее это сделать по протоколу sftp. Эта на первый взгляд простая задача на деле может оказаться не такой уж и простой с множеством нюансов. В зависимости от настроек веб сервера, может использоваться разный подход. Я сейчас рассмотрю один из них, а два других упомяну в самом конце. Подробно рассказывать обо всех методах очень длинно получится.
Для примера возьму классический стек на базе nginx (angie) + php-fpm. Допустим, у нас nginx и php-fpm работают от пользователя
Сразу предвижу комментарии на тему того, что так делать неправильно и в код лезть напрямую не надо. Я был бы только рад, если бы туда никто не лазил. Мне так проще управлять и настраивать. Но иногда надо и выбирать не приходится. Разработчиков выбираю не я, как и их методы работы.
Первым делом добавляю в систему нового пользователя, для которого не будет установлен shell. Подключаться он сможет только по sftp:
Теперь нам нужно настроить sshd таким образом, чтобы он разрешил только указанному пользователю подключаться по sftp, не пускал его дальше указанного каталога с сайтами, а так же сразу указывал необходимые нам права доступа через umask. Позже я поясню, зачем это надо.
Находим в файле
Вместо неё добавляем:
Перезапускаем sshd:
Если сейчас попробовать подключиться пользователем webdev, то ничего не получится. Особенность настройки ChrootDirectory в sshd в том, что у указанной директории владелец должен быть root, а у всех остальных не должно быть туда прав на запись. В данном случае нам это не помешает, но в некоторых ситуациях возникают неудобства. На остальных директориях внутри ChrootDirectory права доступа и владельцы могут быть любыми.
Теперь пользователь webdev может подключиться по sftp. Он сразу попадёт в директорию
Благодаря указанной umask 002 в настройках sshd все созданные пользователем webdev файлы будут иметь права 664 и каталоги 775. То есть будет полный доступ и у пользователя, и у группы. Так что веб сервер сможет нормально работать с этими файлами, и наоборот.
Способ немного корявый и в некоторых случаях может приводить к некоторым проблемам, но решаемым. Я придумал это сам по ходу дела, так как изначально к этим исходникам прямого доступа не должно было быть. Если кто-то знает, как сделать лучше, поделитесь.
Если же вы заранее планируете прямой доступ к исходникам сайта или сайтов разными людьми или сервисами, то сделать лучше по-другому. Сразу создавайте под каждый сайт отдельного системного пользователя. Запускайте под ним php-fpm пул. Для каждого сайта он будет свой. Владельцем исходников сайта делайте этого пользователя и его группу. А пользователя, под которым работает веб сервер, добавьте в группу этого пользователя. Это более удобный, практичный и безопасный способ. Я его описывал в своей статье.
Третий вариант - создавайте новых пользователей для доступа к исходникам с таким же uid, как и у веб сервера. Чрутьте их в свои домашние каталоги, а сайты им добавляйте туда же через mount bind. Я когда то давно этот способ тоже описывал в статье.
#webserver
Для примера возьму классический стек на базе nginx (angie) + php-fpm. Допустим, у нас nginx и php-fpm работают от пользователя
www-data, исходники сайта лежат в /var/www/html. Владельцем файлов и каталогов будет пользователь и группа www-data. Типичная ситуация. Нам надо дать доступ разработчику напрямую к исходникам, чтобы он мог вносить изменения в код сайта. Сразу предвижу комментарии на тему того, что так делать неправильно и в код лезть напрямую не надо. Я был бы только рад, если бы туда никто не лазил. Мне так проще управлять и настраивать. Но иногда надо и выбирать не приходится. Разработчиков выбираю не я, как и их методы работы.
Первым делом добавляю в систему нового пользователя, для которого не будет установлен shell. Подключаться он сможет только по sftp:
# useradd -s /sbin/nologin webdev# passwd webdevТеперь нам нужно настроить sshd таким образом, чтобы он разрешил только указанному пользователю подключаться по sftp, не пускал его дальше указанного каталога с сайтами, а так же сразу указывал необходимые нам права доступа через umask. Позже я поясню, зачем это надо.
Находим в файле
/etc/ssh/sshd_config строку и комментируем её:#Subsystem sftp /usr/lib/openssh/sftp-serverВместо неё добавляем:
Subsystem sftp internal-sftp -u 002Match User webdev ChrootDirectory /var/www ForceCommand internal-sftp -u 002Перезапускаем sshd:
# systemctl restart sshdЕсли сейчас попробовать подключиться пользователем webdev, то ничего не получится. Особенность настройки ChrootDirectory в sshd в том, что у указанной директории владелец должен быть root, а у всех остальных не должно быть туда прав на запись. В данном случае нам это не помешает, но в некоторых ситуациях возникают неудобства. На остальных директориях внутри ChrootDirectory права доступа и владельцы могут быть любыми.
# chown root:root /var/www# chmod 0755 /var/wwwТеперь пользователь webdev может подключиться по sftp. Он сразу попадёт в директорию
/var/www и не сможет из неё выйти дальше в систему. Осталось решить вопрос с правами. Я сделал так. Добавил пользователя webdev в группу www-data, а пользователя www-data в группу webdev:# usermod -aG www-data webdev# usermod -aG webdev www-dataБлагодаря указанной umask 002 в настройках sshd все созданные пользователем webdev файлы будут иметь права 664 и каталоги 775. То есть будет полный доступ и у пользователя, и у группы. Так что веб сервер сможет нормально работать с этими файлами, и наоборот.
Способ немного корявый и в некоторых случаях может приводить к некоторым проблемам, но решаемым. Я придумал это сам по ходу дела, так как изначально к этим исходникам прямого доступа не должно было быть. Если кто-то знает, как сделать лучше, поделитесь.
Если же вы заранее планируете прямой доступ к исходникам сайта или сайтов разными людьми или сервисами, то сделать лучше по-другому. Сразу создавайте под каждый сайт отдельного системного пользователя. Запускайте под ним php-fpm пул. Для каждого сайта он будет свой. Владельцем исходников сайта делайте этого пользователя и его группу. А пользователя, под которым работает веб сервер, добавьте в группу этого пользователя. Это более удобный, практичный и безопасный способ. Я его описывал в своей статье.
Третий вариант - создавайте новых пользователей для доступа к исходникам с таким же uid, как и у веб сервера. Чрутьте их в свои домашние каталоги, а сайты им добавляйте туда же через mount bind. Я когда то давно этот способ тоже описывал в статье.
#webserver
Юмор и не только на злобу дня. Думаю, все уже слышали сегодняшние новости про массовый BSOD на виндах. Пострадавшим, конечно, не до смеха. По факту получилось так, что ПО, которое должно защищать информационную систему, надёжно её положило получше всякого вируса.
Отец знакомого работает в Microsoft. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать всю технику, отключать автообновления и скачивать все драйвера на флешку. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется, началось.
Комментарий с англоязычного форума (но это не точно): Microsoft restricted updates for Russia, so they're fine. We are completely fucked.
Перевод: Microsoft заблокировал обновления в России, так что у них всё в порядке. У нас полная жопа.
Много интересных комментариев прочёл в ветке на реддите:
https://www.reddit.com/r/crowdstrike/comments/1e6vmkf/bsod_error_in_latest_crowdstrike_update/
Multibillion dollar NSW infrastructure project, most of the office is down.
Перевод: Многомиллиардный инфраструктурный проект в Новом Южном Уэльсе, большая часть офиса закрыта.
Workstations and servers here in Aus... fleet of 50k+ - someone is going to have fun.
Перевод: Рабочие станции и серверы здесь, в Австралии, насчитывают более 50 тысяч единиц - у кого-то будет весело.
Time to log in and check if it hit us…oh god I hope not…350k endpoints.
EDIT: 210K BSODS all at 10:57 PST....and it keeps going up...this is bad....
Перевод: Пора зайти и проверить, дошло ли это до нас…о боже, я надеюсь, что нет... 350 тысяч конечных точек.
Добавлено: 210 тысяч BSOD в 10: 57 по восточному времени .... и оно продолжает увеличиваться... это плохо....
Жуть берёт от таких сообщений. Их же автоматом теперь не реанимировать. Надо либо руками там что-то править, либо накатывать заново из бэкапов. У кого-то будут напряжённые выходные. Хорошо ещё, что сегодня пятница, а не понедельник.
А вообще, всё это выглядит как репетиция к инфоциду.
Гигакорпорация MAGMA, став глобальным цифровым монополистом после захвата китайской IT-индустрии по итогам Последней мировой войны, много лет целенаправленно добивалась сосредоточения всей цифровой информации в мире на своих серверах.
.......
Кроме того, перенос данных на магмовские облачные серверы рекламировался как "безопасный", потому что "уж Магма-то слишком велика, чтобы рухнуть, и уж эти-то данные точно не пострадают ни при каких обстоятельствах". В итоге к началу 2070-х гг. практически вся информация на планете хранилась и обрабатывалась на северах MAGMA, за исключением немногих "пиратских" (нелегальных или полулегальных) автономных устройств, а также военных и прочих правительственных систем США и их главных союзников - но и они работали на программном обеспечении от MAGMA.
.........
Непосредственно Второму инфоциду предшествовал глобальный финансовый крах, докатившийся ко второй декаде марта до США: банкротство крупнейших банков и компаний, в том числе самой MAGMA, государственный дефолт США и банкротство Федерального резерва. Неизвестно, кто и с какой целью отдал приказ на тотальное уничтожение информации. На этот счёт существует множество равно неподтверждённых версий и теорий заговора.
...........
С точки простого пользователя Второй инфоцид выглядел так, что вся связь пропала, все его электронные устройства превратились в кирпичи, деньги на банковских счетах и прочие цифровые активы перестали существовать (наличных денег давно нигде не было), машины-автопилоты встали (других тоже давно не было), а вся инфраструктура жизнеобеспечения "умных домов" и "умных городов" отключилась. Городская индустриальная цивилизация в той форме, к какой она пришла ко второй половине XXI века, прекратила существование.
#разное
Отец знакомого работает в Microsoft. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать всю технику, отключать автообновления и скачивать все драйвера на флешку. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется, началось.
Комментарий с англоязычного форума (но это не точно): Microsoft restricted updates for Russia, so they're fine. We are completely fucked.
Перевод: Microsoft заблокировал обновления в России, так что у них всё в порядке. У нас полная жопа.
Много интересных комментариев прочёл в ветке на реддите:
https://www.reddit.com/r/crowdstrike/comments/1e6vmkf/bsod_error_in_latest_crowdstrike_update/
Multibillion dollar NSW infrastructure project, most of the office is down.
Перевод: Многомиллиардный инфраструктурный проект в Новом Южном Уэльсе, большая часть офиса закрыта.
Workstations and servers here in Aus... fleet of 50k+ - someone is going to have fun.
Перевод: Рабочие станции и серверы здесь, в Австралии, насчитывают более 50 тысяч единиц - у кого-то будет весело.
Time to log in and check if it hit us…oh god I hope not…350k endpoints.
EDIT: 210K BSODS all at 10:57 PST....and it keeps going up...this is bad....
Перевод: Пора зайти и проверить, дошло ли это до нас…о боже, я надеюсь, что нет... 350 тысяч конечных точек.
Добавлено: 210 тысяч BSOD в 10: 57 по восточному времени .... и оно продолжает увеличиваться... это плохо....
Жуть берёт от таких сообщений. Их же автоматом теперь не реанимировать. Надо либо руками там что-то править, либо накатывать заново из бэкапов. У кого-то будут напряжённые выходные. Хорошо ещё, что сегодня пятница, а не понедельник.
А вообще, всё это выглядит как репетиция к инфоциду.
Гигакорпорация MAGMA, став глобальным цифровым монополистом после захвата китайской IT-индустрии по итогам Последней мировой войны, много лет целенаправленно добивалась сосредоточения всей цифровой информации в мире на своих серверах.
.......
Кроме того, перенос данных на магмовские облачные серверы рекламировался как "безопасный", потому что "уж Магма-то слишком велика, чтобы рухнуть, и уж эти-то данные точно не пострадают ни при каких обстоятельствах". В итоге к началу 2070-х гг. практически вся информация на планете хранилась и обрабатывалась на северах MAGMA, за исключением немногих "пиратских" (нелегальных или полулегальных) автономных устройств, а также военных и прочих правительственных систем США и их главных союзников - но и они работали на программном обеспечении от MAGMA.
.........
Непосредственно Второму инфоциду предшествовал глобальный финансовый крах, докатившийся ко второй декаде марта до США: банкротство крупнейших банков и компаний, в том числе самой MAGMA, государственный дефолт США и банкротство Федерального резерва. Неизвестно, кто и с какой целью отдал приказ на тотальное уничтожение информации. На этот счёт существует множество равно неподтверждённых версий и теорий заговора.
...........
С точки простого пользователя Второй инфоцид выглядел так, что вся связь пропала, все его электронные устройства превратились в кирпичи, деньги на банковских счетах и прочие цифровые активы перестали существовать (наличных денег давно нигде не было), машины-автопилоты встали (других тоже давно не было), а вся инфраструктура жизнеобеспечения "умных домов" и "умных городов" отключилась. Городская индустриальная цивилизация в той форме, к какой она пришла ко второй половине XXI века, прекратила существование.
#разное
{kind=link}
🎓 Сегодня будет очередная публикация с хорошими обучающими материалами по Linux, Asterisk, Zabbix. Публикация необычная, потому что я случайно посмотрел на автора материалов и понял, что я его знаю, причём не в качестве преподавателя и специалиста по Linux.
Итак, вот сайт:
⇨ https://wiki.koobik.net
Здесь 3 хороших структурированных курса в текстовом (❗️) виде с небольшой теорией и лабораторными работами. Я немного посмотрел их, формат понравился. Нигде не увидел дату курсов, но это не что-то сильно старое. Навскидку, где-то года 2-3 назад записаны, судя по скриншотам Zabbix и версиям Ubuntu.
Автор - преподаватель курсов в учебном центре Специалист. Я там когда-то давно учился. Это не тот формат, что сейчас представлен в большинстве онлайн курсов. Больше похоже на академическое обучение с посещением лекций, выполнением лабораторок и сдачей экзаменов. По крайней мере раньше было так. Как сейчас - не знаю. Я там сертификацию от Microsoft проходил. Получил MCP.
Я узнал этого человека в далёком 2011 году на общественных мероприятиях под названием Русские Пробежки. На первых порах он был одним из их организаторов. Я лично участвовал в этих пробежках практически с самого начала. Пропустил только самую первую и, возможно, вторую. Как увидел в соцсетях информацию об этом, сразу присоединился.
Сами пробежки представляли из себя собрания молодёжи, ведущей здоровый образ жизни, с целью пропагандирования этого здорового образа жизни и совместных тренировок на открытом воздухе. Движение очень быстро набрало популярность и разошлось по всем городам России. Я даже в своём районе устраивал эти пробежки. Мы бегали по парку, занимались на турниках, купались в проруби.
В то время власть зачем-то активно противодействовала всему этому. На пробежки вызывали ОМОН, перекрывали, проходы, задерживали и т.д. Мероприятия посещали люди в штатском, вели видеофиксацию лиц участников. Хотя движение не политизировалось и было полностью организовано снизу. Я просто сам всё это наблюдал. В обществе, особенно у молодёжи, был огромный запрос на трезвость, потому что постоянная реклама пива, прочего алкоголя, безнравственность, постоянное пьянство на улицах, в парках задолбало. Сейчас в этом плане всё значительно лучше.
В том числе такая массовая поддержка трезвости повлияла на то, что я в какой-то момент полностью отказался от алкоголя. Просто убрал его из своей жизни. Это случилось более 10-ти лет назад. Где-то как раз со времён этих пробежек. С тех пор алкоголь вообще не употребляю и не вижу в этом смысла.
Вообще, приятно было находиться в обществе трезвых, здоровых, молодых и физически развитых людей. Чувствовалось, что таким мужчина и должен быть: трезвым, здоровым, физически крепким и т.д. Потом появилось движение Русские спарринги. Я увлёкся единоборствами, занимался боксом, рукопашным и ножевым боем. Постоянно ходил на спарринги по выходным и там дрался с разными людьми. Было интересно и полезно. Считаю, что любой мужчина должен уметь драться. Это идёт ему на пользу, даже если драться ему нигде не придётся. Готовность ударить и идти до конца в отстаивании своих интересов зачастую решает многие вопросы и без драки. Когда мужчина боится из-за неуверенности, начинает мямлить и идти на попятную, выглядит это жалко. А в итоге он оказывается бит.
Так что будьте сильными и трезвыми. Особенно на пороге смутных времён, которые нам предстоит пройти и победить. На ум пришли строки из песни Цоя
«Ты должен быть сильным,
Ты должен уметь сказать:
Руки прочь, прочь от меня.
Ты должен быть сильным,
Иначе зачем тебе быть?
Что будут стоить тысячи слов,
Когда важна будет крепость руки?
И вот ты стоишь на берегу
И думаешь плыть или не плыть».
Нашёл видео из своего архива тех времён. Выглядит наивно, если смотреть с опыта прожитых лет. Но молодость есть молодость. Она всегда кажется наивной в зрелом возрсте:
▶️ https://disk.yandex.ru/i/kmteYLLxLk9sxA
#обучение
Итак, вот сайт:
⇨ https://wiki.koobik.net
Здесь 3 хороших структурированных курса в текстовом (❗️) виде с небольшой теорией и лабораторными работами. Я немного посмотрел их, формат понравился. Нигде не увидел дату курсов, но это не что-то сильно старое. Навскидку, где-то года 2-3 назад записаны, судя по скриншотам Zabbix и версиям Ubuntu.
Автор - преподаватель курсов в учебном центре Специалист. Я там когда-то давно учился. Это не тот формат, что сейчас представлен в большинстве онлайн курсов. Больше похоже на академическое обучение с посещением лекций, выполнением лабораторок и сдачей экзаменов. По крайней мере раньше было так. Как сейчас - не знаю. Я там сертификацию от Microsoft проходил. Получил MCP.
Я узнал этого человека в далёком 2011 году на общественных мероприятиях под названием Русские Пробежки. На первых порах он был одним из их организаторов. Я лично участвовал в этих пробежках практически с самого начала. Пропустил только самую первую и, возможно, вторую. Как увидел в соцсетях информацию об этом, сразу присоединился.
Сами пробежки представляли из себя собрания молодёжи, ведущей здоровый образ жизни, с целью пропагандирования этого здорового образа жизни и совместных тренировок на открытом воздухе. Движение очень быстро набрало популярность и разошлось по всем городам России. Я даже в своём районе устраивал эти пробежки. Мы бегали по парку, занимались на турниках, купались в проруби.
В то время власть зачем-то активно противодействовала всему этому. На пробежки вызывали ОМОН, перекрывали, проходы, задерживали и т.д. Мероприятия посещали люди в штатском, вели видеофиксацию лиц участников. Хотя движение не политизировалось и было полностью организовано снизу. Я просто сам всё это наблюдал. В обществе, особенно у молодёжи, был огромный запрос на трезвость, потому что постоянная реклама пива, прочего алкоголя, безнравственность, постоянное пьянство на улицах, в парках задолбало. Сейчас в этом плане всё значительно лучше.
В том числе такая массовая поддержка трезвости повлияла на то, что я в какой-то момент полностью отказался от алкоголя. Просто убрал его из своей жизни. Это случилось более 10-ти лет назад. Где-то как раз со времён этих пробежек. С тех пор алкоголь вообще не употребляю и не вижу в этом смысла.
Вообще, приятно было находиться в обществе трезвых, здоровых, молодых и физически развитых людей. Чувствовалось, что таким мужчина и должен быть: трезвым, здоровым, физически крепким и т.д. Потом появилось движение Русские спарринги. Я увлёкся единоборствами, занимался боксом, рукопашным и ножевым боем. Постоянно ходил на спарринги по выходным и там дрался с разными людьми. Было интересно и полезно. Считаю, что любой мужчина должен уметь драться. Это идёт ему на пользу, даже если драться ему нигде не придётся. Готовность ударить и идти до конца в отстаивании своих интересов зачастую решает многие вопросы и без драки. Когда мужчина боится из-за неуверенности, начинает мямлить и идти на попятную, выглядит это жалко. А в итоге он оказывается бит.
Так что будьте сильными и трезвыми. Особенно на пороге смутных времён, которые нам предстоит пройти и победить. На ум пришли строки из песни Цоя
«Ты должен быть сильным,
Ты должен уметь сказать:
Руки прочь, прочь от меня.
Ты должен быть сильным,
Иначе зачем тебе быть?
Что будут стоить тысячи слов,
Когда важна будет крепость руки?
И вот ты стоишь на берегу
И думаешь плыть или не плыть».
Нашёл видео из своего архива тех времён. Выглядит наивно, если смотреть с опыта прожитых лет. Но молодость есть молодость. Она всегда кажется наивной в зрелом возрсте:
▶️ https://disk.yandex.ru/i/kmteYLLxLk9sxA
#обучение
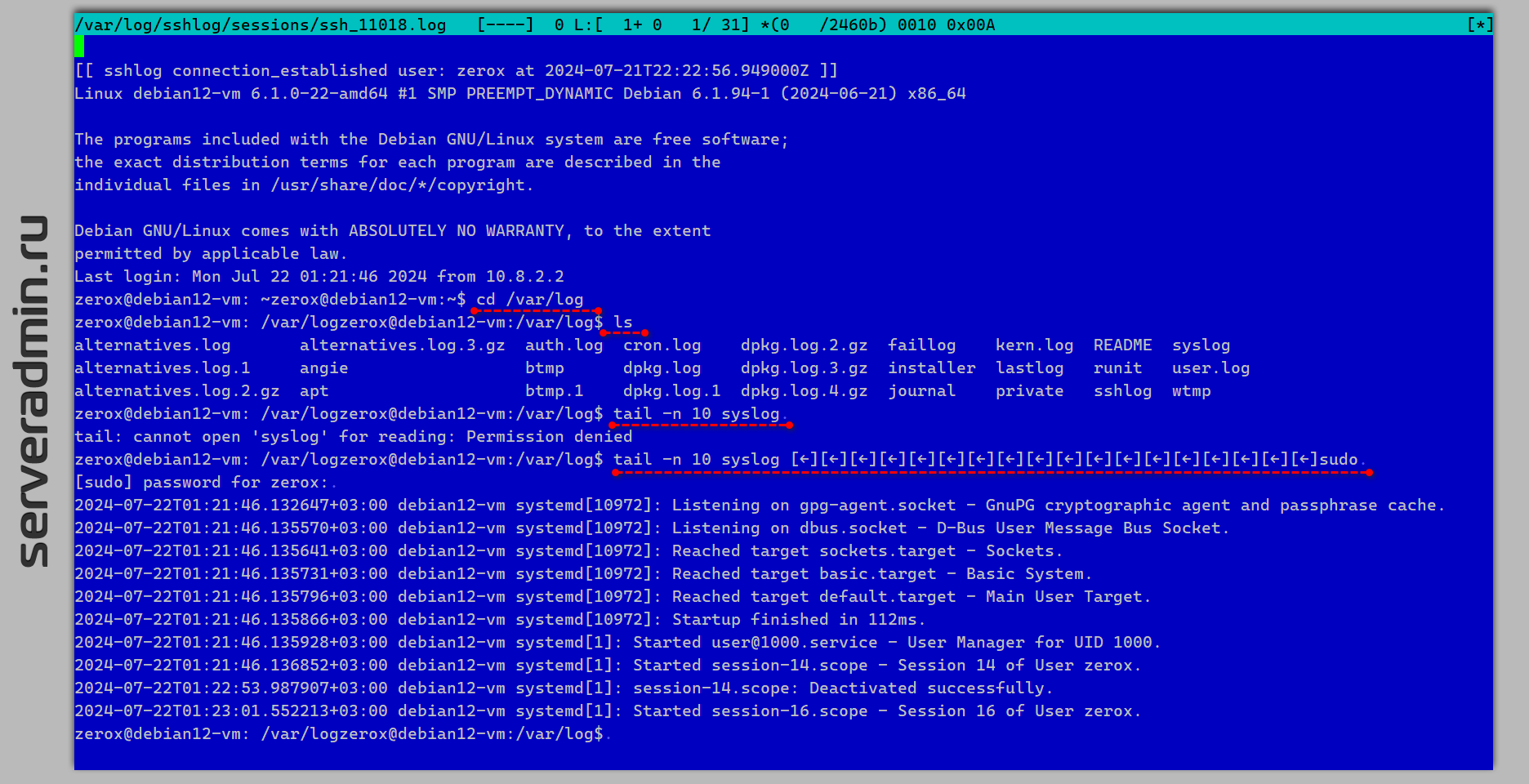
Нашёл очень функциональный инструмент для логирования действий пользователей в подключениях по SSH к серверам. Речь пойдёт про open sourse проект sshlog. Выглядит он так, как-будто хотели сделать на его основе коммерческий продукт, но в какой-то момент передумали и забросили. Сделан он добротно и целостно. Расскажу по порядку.
📌 С помощью sshlog можно:
▪️ Логировать все подключения и отключения по SSH.
▪️ Записывать всю активность пользователя в консоли, в том числе вывод.
▪️ Отправлять уведомления по различным каналам связи на события, связанные с SSH: подключение, отключение, запуск команды и т.д.
▪️ Отправлять все записанные события и сессии на Syslog сервер.
▪️ Собирать метрики по количествам подключений, отключений, выполненных команд и т.д.
▪️ Наблюдать за чьей-то сессией и подключаться к ней для просмотра или взаимодействия.
▪️ Расширять функциональность с помощью плагинов.
Сразу скажу важное замечание. Записывать события пользователя root нельзя. Только обычных пользователей, даже если они сделают
Установить sshlog можно из репозитория разработчиков:
Репозиторий для Ubuntu, но для Debian тоже подходит. После установки автоматически создаётся служба systemd. В директории
-
-
В директории
Функциональность sshlog расширяется плагинами. Они все находятся в отдельном разделе с описанием и принципом работы. Все оповещения реализованы в виде плагинов. Есть готовые для email, slack, syslog, webhook. Оповещения отправляются при срабатывании actions. Так же по этим событиям могут выполняться и другие действия, например, запуск какой-то команды.
В общем, продукт функциональный и целостный. Покрывает большой пласт задач по контролю за сессиями пользователей. Удобно всё это разом слать куда-то по syslog в централизованное хранилище. По простоте и удобству, если мне не изменяет память, это лучшее, что я видел. Есть, конечно, Tlog от RedHat, но он более просто выглядит по возможностям и сложнее в настройке по сравнению с sshlog.
В репозитории есть несколько обращений на тему большого потребления CPU при работе. Я лично не сталкивался с этим во время тестов, но имейте ввиду, что такое возможно. Судя по всему есть какой-то неисправленный баг.
⇨ Сайт / Исходники
#ssh #logs #security
📌 С помощью sshlog можно:
▪️ Логировать все подключения и отключения по SSH.
▪️ Записывать всю активность пользователя в консоли, в том числе вывод.
▪️ Отправлять уведомления по различным каналам связи на события, связанные с SSH: подключение, отключение, запуск команды и т.д.
▪️ Отправлять все записанные события и сессии на Syslog сервер.
▪️ Собирать метрики по количествам подключений, отключений, выполненных команд и т.д.
▪️ Наблюдать за чьей-то сессией и подключаться к ней для просмотра или взаимодействия.
▪️ Расширять функциональность с помощью плагинов.
Сразу скажу важное замечание. Записывать события пользователя root нельзя. Только обычных пользователей, даже если они сделают
sudo su. В описании нигде этого не сказано, но я сам на практике убедился. Плюс, увидел такие же комментарии в вопросах репозитория. Установить sshlog можно из репозитория разработчиков:
# curl https://repo.sshlog.com/sshlog-ubuntu/public.gpg | gpg --yes --dearmor -o /usr/share/keyrings/repo-sshlog-ubuntu.gpg# echo "deb [arch=any signed-by=/usr/share/keyrings/repo-sshlog-ubuntu.gpg] https://repo.sshlog.com/sshlog-ubuntu/ stable main" > /etc/apt/sources.list.d/repo-sshlog-ubuntu.list# apt update && apt install sshlogРепозиторий для Ubuntu, но для Debian тоже подходит. После установки автоматически создаётся служба systemd. В директории
/etc/sshlog/conf.d будут 2 файла конфигурации:-
log_all_sessions.yaml - запись ssh сессий в директорию /var/log/sshlog/sessions, каждая сессия в отдельном лог файле, сохраняется в том числе вывод в консоли, а не только введённые команды.-
log_events.yaml - запись событий: подключения, отключения, введённые команды, общий лог для всех.В директории
/etc/sshlog/samples будут примеры некоторых других настроек. Вся конфигурация в формате yaml, читается легко, интуитивно. Возможности программы большие. Можно логировать только какие-то конкретные события. Например, запуск sudo. Либо команды от отдельного пользователя. Это можно настроить либо в событиях, либо в исключениях. Подробно механизм описан отдельно: sshlog config.Функциональность sshlog расширяется плагинами. Они все находятся в отдельном разделе с описанием и принципом работы. Все оповещения реализованы в виде плагинов. Есть готовые для email, slack, syslog, webhook. Оповещения отправляются при срабатывании actions. Так же по этим событиям могут выполняться и другие действия, например, запуск какой-то команды.
В общем, продукт функциональный и целостный. Покрывает большой пласт задач по контролю за сессиями пользователей. Удобно всё это разом слать куда-то по syslog в централизованное хранилище. По простоте и удобству, если мне не изменяет память, это лучшее, что я видел. Есть, конечно, Tlog от RedHat, но он более просто выглядит по возможностям и сложнее в настройке по сравнению с sshlog.
В репозитории есть несколько обращений на тему большого потребления CPU при работе. Я лично не сталкивался с этим во время тестов, но имейте ввиду, что такое возможно. Судя по всему есть какой-то неисправленный баг.
⇨ Сайт / Исходники
#ssh #logs #security
{kind=link}
В операционных системах Windows традиционно есть некоторые сложности с использованием протокола NFS. Длительное время она его вообще штатно никак не поддерживала, приходилось использовать сторонний софт. Это объясняется в первую очередь тем, что для передачи файлов по сети у них есть свой протокол SMB. В какой-то момент, уже не помню, в какой точно версии, в Windows появился встроенный NFS клиент.
Установить его можно через Панель управления ⇨ Программы ⇨ Программы и компоненты ⇨ Включение и отключение компонентов Windows ⇨ Службы для NFS ⇨ Клиент для NFS.
Можно включить более простым и быстрым способом через Powershell:
Можно примонтировать диск с NFS сервера, к примеру, развёрнутого из этой заметки:
Диск N появится в качестве сетевого. С ним можно работать к с обычным сетевым диском. Условно, как с обычным, так как работа под Windows с NFS сервером на Linux будет сопряжена с множеством нюансов и неудобств, связанных с правами доступа, кодировкой, чувствительности к регистру в названиях файлов на Linux. В общем случае использовать такой сценарий работы не рекомендуется. Для постоянной работы с Windows проще поднять SMB сервер на Linux.
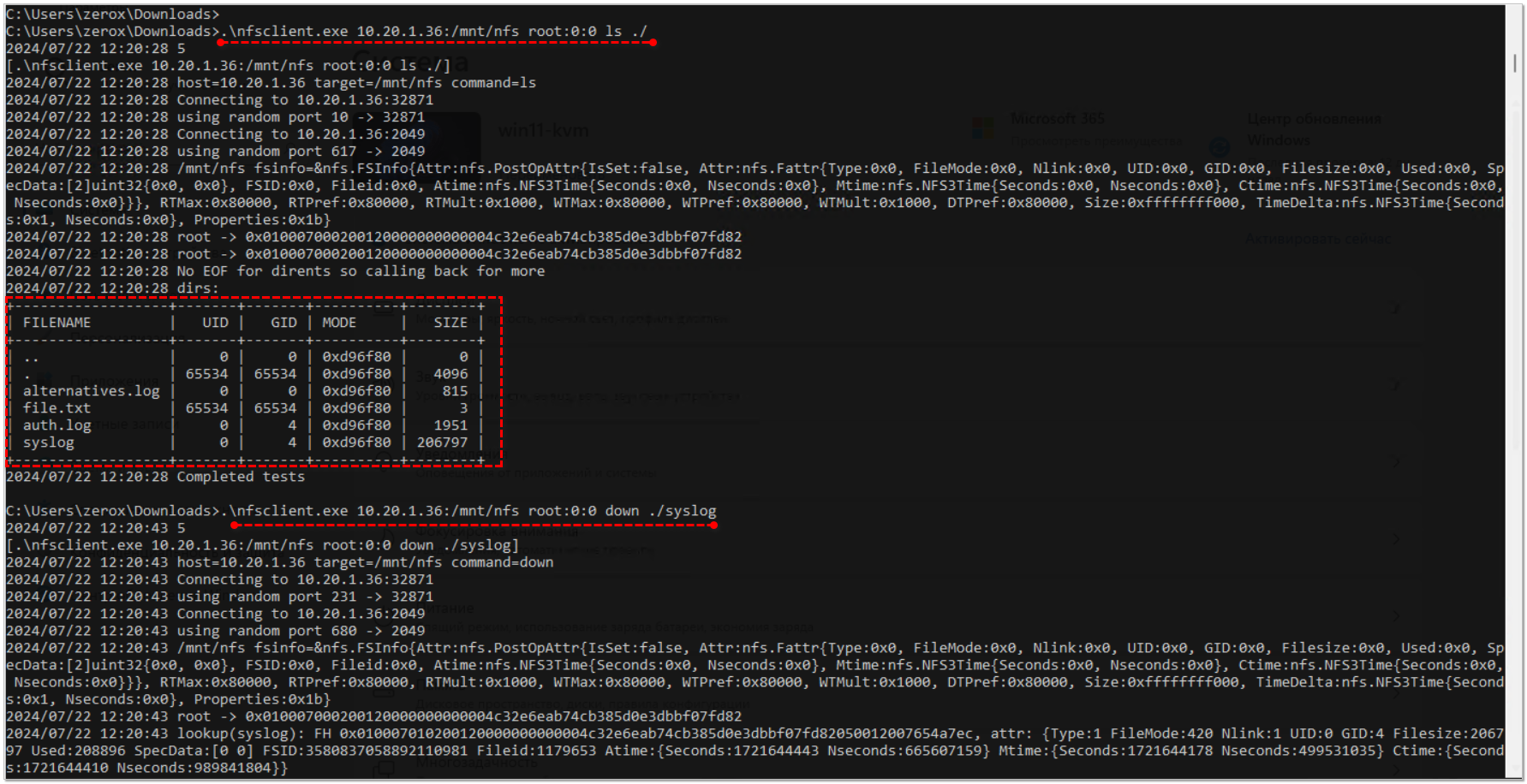
Для разовых задач или для использования в скриптах можно воспользоваться каким-то альтернативным консольным клиентом. Например, nfsclient. Это небольшая программа на Go уровня курсовой работы студента. Код самой программы простой, но используются готовые библиотеки для работы с NFS.
Программа кроссплатформенная и не требует установки. Это небольшой консольный клиент, который поддерживает простые операции:
◽просмотр содержимого ресурса
◽скачивание, загрузка, удаление файлов
◽создание и удаление каталогов
Работает примерно так. Монтировать диск не нужно. Смотрим список файлов на nfs диске:
Скачиваем файл syslog:
Загружаем в корень диска файл file.txt:
Синтаксис простой, потому что команд не так много: ls/up/down/rm/mkdir/rmdir.
#nfs #fileserver #windows
Установить его можно через Панель управления ⇨ Программы ⇨ Программы и компоненты ⇨ Включение и отключение компонентов Windows ⇨ Службы для NFS ⇨ Клиент для NFS.
Можно включить более простым и быстрым способом через Powershell:
> Enable-WindowsOptionalFeature -FeatureName ServicesForNFS-ClientOnly, ClientForNFS-Infrastructure -Online -NoRestartМожно примонтировать диск с NFS сервера, к примеру, развёрнутого из этой заметки:
> mount -o anon \\10.20.1.36\mnt\nfs N:N: успешно подключен к \\10.20.1.36\mnt\nfsКоманда успешно выполнена.> N:> dir..........Диск N появится в качестве сетевого. С ним можно работать к с обычным сетевым диском. Условно, как с обычным, так как работа под Windows с NFS сервером на Linux будет сопряжена с множеством нюансов и неудобств, связанных с правами доступа, кодировкой, чувствительности к регистру в названиях файлов на Linux. В общем случае использовать такой сценарий работы не рекомендуется. Для постоянной работы с Windows проще поднять SMB сервер на Linux.
Для разовых задач или для использования в скриптах можно воспользоваться каким-то альтернативным консольным клиентом. Например, nfsclient. Это небольшая программа на Go уровня курсовой работы студента. Код самой программы простой, но используются готовые библиотеки для работы с NFS.
Программа кроссплатформенная и не требует установки. Это небольшой консольный клиент, который поддерживает простые операции:
◽просмотр содержимого ресурса
◽скачивание, загрузка, удаление файлов
◽создание и удаление каталогов
Работает примерно так. Монтировать диск не нужно. Смотрим список файлов на nfs диске:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 ls ./Скачиваем файл syslog:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 down ./syslogЗагружаем в корень диска файл file.txt:
>.\nfsclient.exe 10.20.1.36:/mnt/nfs root:0:0 up .\file.txt ./file.txtСинтаксис простой, потому что команд не так много: ls/up/down/rm/mkdir/rmdir.
#nfs #fileserver #windows
{kind=link}
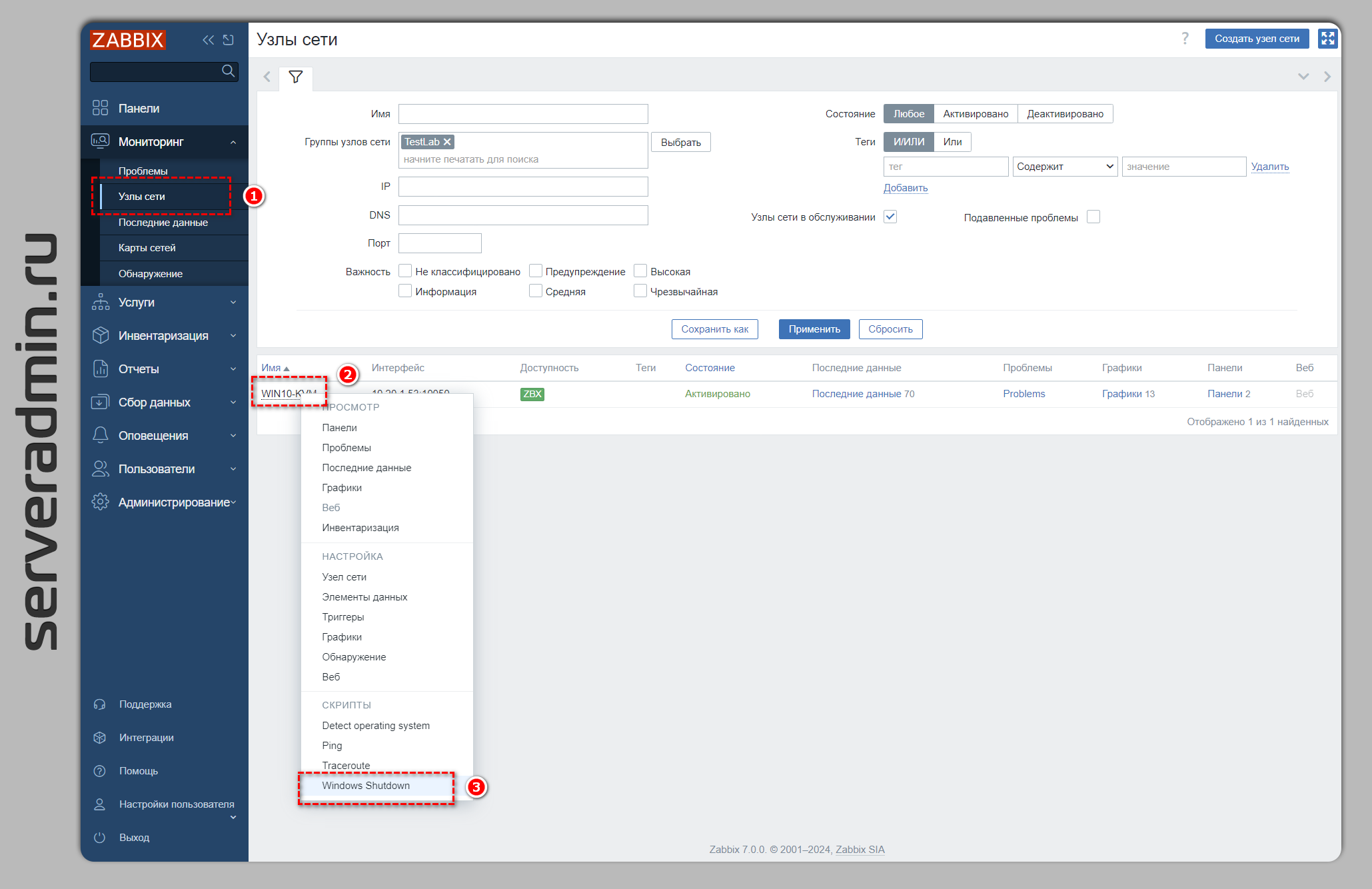
Расскажу про простую и удобную возможность мониторинга Zabbix, с помощью которой можно выполнять команды на наблюдаемых хостах. Покажу на конкретном примере, как это работает. Настрою отдельный пункт меню у хоста в веб интерфейсе, с помощью которого можно мышкой выключить систему. То есть выбираем Windows хост, жмём на него мышкой и выбираем в выпадающем списке пункт "Выключение системы" и компьютер выключается. Я так выключаю компы и прочее оборудование дома, а так же свои тестовые лабы. По аналогии можно будет настроить любые другие действия.
Настраиваем всё по шагам для Zabbix Server 7.0.
1️⃣ Идём в веб интерфейсе в раздел Оповещения ⇨ Скрипты и добавляем новый скрипт. Я его назвал Windows Shutdown. У него следующие параметры:
- Область: Действие вручную над узлом
- Тип: Скрипт
- Выполнение на: Zabbix Agent
- Команды:
- Описание: System shutdown
- Группы узлов сети: Выбранные, Windows (у меня все виндовые машины в отдельной группе)
- Текст подтверждения: Уверен, что хочешь потушить систему?
Сохраняем.
2️⃣ Идём на целевую систему, где установлен Zabbix agent 2. Для первой версии вроде бы настройки не поменяются, но я не проверял. Последнее время ставлю 2-й агент. Агент должен работать в пассивном режиме, то есть быть способен принимать команды от сервера.
Добавляем в конфиг агента два параметра:
Вторую команду не обязательно, но я предпочитаю логировать выполнение внешних команд. Перезапускаем агента.
Вот и вся настройка. Теперь открываем список хостов: Мониторинг ⇨ Узлы сети. Выбираем любой хост из группы Windows, для которой назначили добавленный скрипт, и выполняем на нём команду. Система завершит работу. Запись об этом ручном действии останется в разделе Отчёты ⇨ Журнал аудита. Нужно выбрать действие - Выполнить, ресурс - Скрипт.
Люди спорят, что лучше, Zabbix или Prometheus. Они разные. Как вы в Проме так же просто настроите подобную возможность? Причём её ещё можно и по пользователям разграничить, и по группам хостов, и аудит ко всему этому. И настраивается всё за 10 минут. Потом человек заходит в веб интерфейс и мышкой запускает готовый большой скрипт или выполняет одиночную команду. Туда ведь всё, что угодно можно засунуть: сброс кэшей, перезапуск сервиса, запуск какой-нибудь проверки. Не всё имеет смысл запускать автоматически, как реакцию на триггер. Какие-то вещи можно поставить на ручной контроль.
#zabbix
Настраиваем всё по шагам для Zabbix Server 7.0.
1️⃣ Идём в веб интерфейсе в раздел Оповещения ⇨ Скрипты и добавляем новый скрипт. Я его назвал Windows Shutdown. У него следующие параметры:
- Область: Действие вручную над узлом
- Тип: Скрипт
- Выполнение на: Zabbix Agent
- Команды:
shutdown /s- Описание: System shutdown
- Группы узлов сети: Выбранные, Windows (у меня все виндовые машины в отдельной группе)
- Текст подтверждения: Уверен, что хочешь потушить систему?
Сохраняем.
2️⃣ Идём на целевую систему, где установлен Zabbix agent 2. Для первой версии вроде бы настройки не поменяются, но я не проверял. Последнее время ставлю 2-й агент. Агент должен работать в пассивном режиме, то есть быть способен принимать команды от сервера.
Добавляем в конфиг агента два параметра:
AllowKey=system.run[shutdown /s]Plugins.SystemRun.LogRemoteCommands=1Вторую команду не обязательно, но я предпочитаю логировать выполнение внешних команд. Перезапускаем агента.
Вот и вся настройка. Теперь открываем список хостов: Мониторинг ⇨ Узлы сети. Выбираем любой хост из группы Windows, для которой назначили добавленный скрипт, и выполняем на нём команду. Система завершит работу. Запись об этом ручном действии останется в разделе Отчёты ⇨ Журнал аудита. Нужно выбрать действие - Выполнить, ресурс - Скрипт.
Люди спорят, что лучше, Zabbix или Prometheus. Они разные. Как вы в Проме так же просто настроите подобную возможность? Причём её ещё можно и по пользователям разграничить, и по группам хостов, и аудит ко всему этому. И настраивается всё за 10 минут. Потом человек заходит в веб интерфейс и мышкой запускает готовый большой скрипт или выполняет одиночную команду. Туда ведь всё, что угодно можно засунуть: сброс кэшей, перезапуск сервиса, запуск какой-нибудь проверки. Не всё имеет смысл запускать автоматически, как реакцию на триггер. Какие-то вещи можно поставить на ручной контроль.
#zabbix
{kind=link}
Я не так давно делал заметку про исчерпание свободного места на PBS (Proxmox Backup Server). Напомню, что если у вас закончилось свободное место, то нет штатной возможности освободить его здесь и сейчас, кроме как удалить весь Datastore полностью. Если вы просто удалите ненужные бэкапы, то придётся ждать сутки, когда они реально освободят занимаемое место.
В комментариях предложили способ, который обходит это ограничение. Я им уже активно пользуюсь, очень удобно. Комментарии читают не все, поэтому решил вынести в отдельную публикацию.
Итак, чтобы моментально освободить место, занимаемое ненужными бэкапами, сделайте следующее:
1️⃣ Удалите лишние бэкапы в разделе Datastore ⇨ Content
2️⃣ Перейдите в консоль PBS и выполните там команду:
3️⃣ Идём опять в веб интерфейс, выбираем наш Datastore и запускаем Garbage Collect.
Все удалённые бэкапы удалятся окончательно, освободив свободное место.
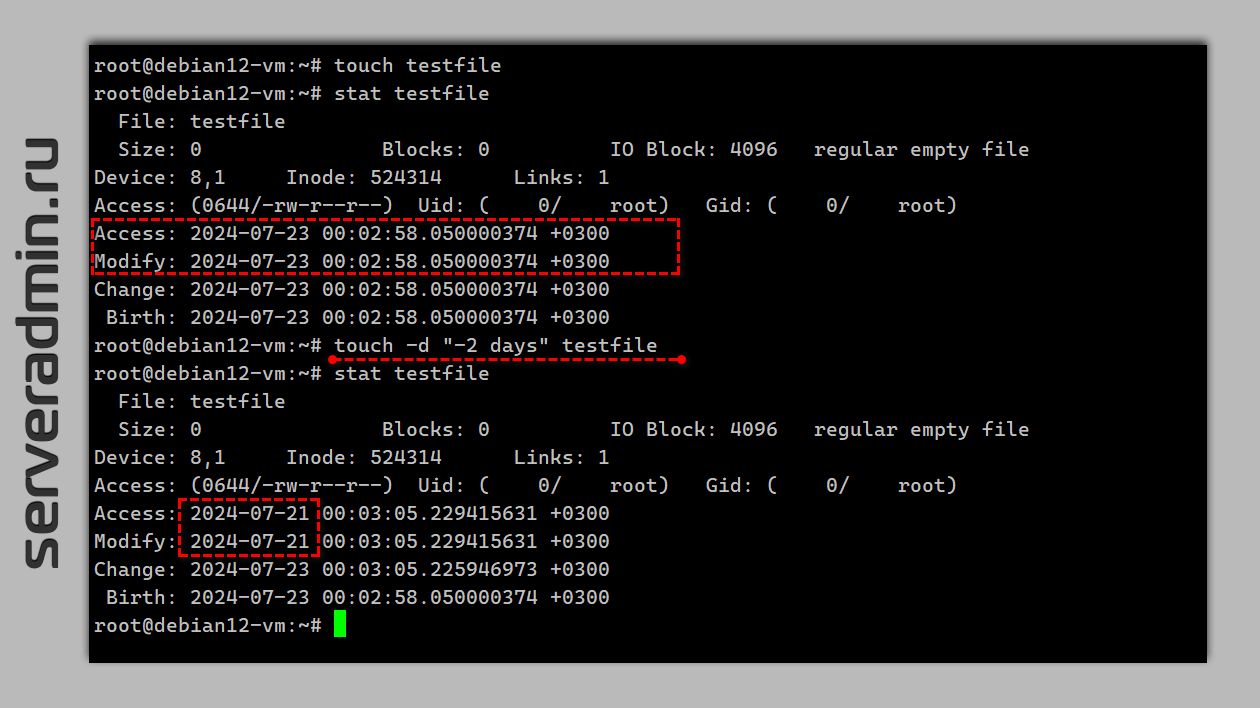
Поясню, что мы тут сделали. Я уже когда-то описывал возможности утилиты
После работы
Если я всё правильно понимаю, то штатный процесс Garbage Collect удаляет все помеченные на удаление блоки со временем последнего изменения больше суток назад. Соответственно, меняя дату блоков на 2 суток назад, мы гарантированно провоцируем их удаление. Не совсем понимаю, почему нельзя было сделать отдельным пунктом GC удаление помеченных на удаление блоков здесь и сейчас, но как есть, так есть.
❗️Используйте это на свой страх и риск, когда отступать уже некуда. Я не знаю точно, к каким последствиям это может привести, но у меня сработало несколько раз ожидаемо. Я специально проверял по результатам работы GC. Если удалить некоторые бэкапы и сдвинуть дату всех блоков на 2 дня назад, то очередная работа GC удаляет только помеченные на удаление бэкапы. Верификация оставшихся бэкапов проходит нормально.
#proxmox
В комментариях предложили способ, который обходит это ограничение. Я им уже активно пользуюсь, очень удобно. Комментарии читают не все, поэтому решил вынести в отдельную публикацию.
Итак, чтобы моментально освободить место, занимаемое ненужными бэкапами, сделайте следующее:
1️⃣ Удалите лишние бэкапы в разделе Datastore ⇨ Content
2️⃣ Перейдите в консоль PBS и выполните там команду:
find /path2pbs-datastore/.chunks -type f -print0 | xargs -0 touch -d "-2 days"3️⃣ Идём опять в веб интерфейс, выбираем наш Datastore и запускаем Garbage Collect.
Все удалённые бэкапы удалятся окончательно, освободив свободное место.
Поясню, что мы тут сделали. Я уже когда-то описывал возможности утилиты
touch. С её помощью можно изменять параметры файла, меняя временные метки. Об этом рассказано тут и тут. Покажу на примере. Создадим файл и изменим дату его изменения на 2 дня назад:# touch testfile# stat testfile# touch -d "-2 days" testfile# stat testfileПосле работы
touch с ключом -d метка Modify уехала на 2 дня назад.Если я всё правильно понимаю, то штатный процесс Garbage Collect удаляет все помеченные на удаление блоки со временем последнего изменения больше суток назад. Соответственно, меняя дату блоков на 2 суток назад, мы гарантированно провоцируем их удаление. Не совсем понимаю, почему нельзя было сделать отдельным пунктом GC удаление помеченных на удаление блоков здесь и сейчас, но как есть, так есть.
❗️Используйте это на свой страх и риск, когда отступать уже некуда. Я не знаю точно, к каким последствиям это может привести, но у меня сработало несколько раз ожидаемо. Я специально проверял по результатам работы GC. Если удалить некоторые бэкапы и сдвинуть дату всех блоков на 2 дня назад, то очередная работа GC удаляет только помеченные на удаление бэкапы. Верификация оставшихся бэкапов проходит нормально.
#proxmox
{kind=link}
Ещё один пример расскажу про неочевидное использование Zabbix. Люблю эту систему мониторинга больше всех остальных именно за то, что это с одной стороны целостная система, а с другой - конструктор, из которого можно слепить всё, что угодно. Безграничный простор для построения велосипедов и костылей.
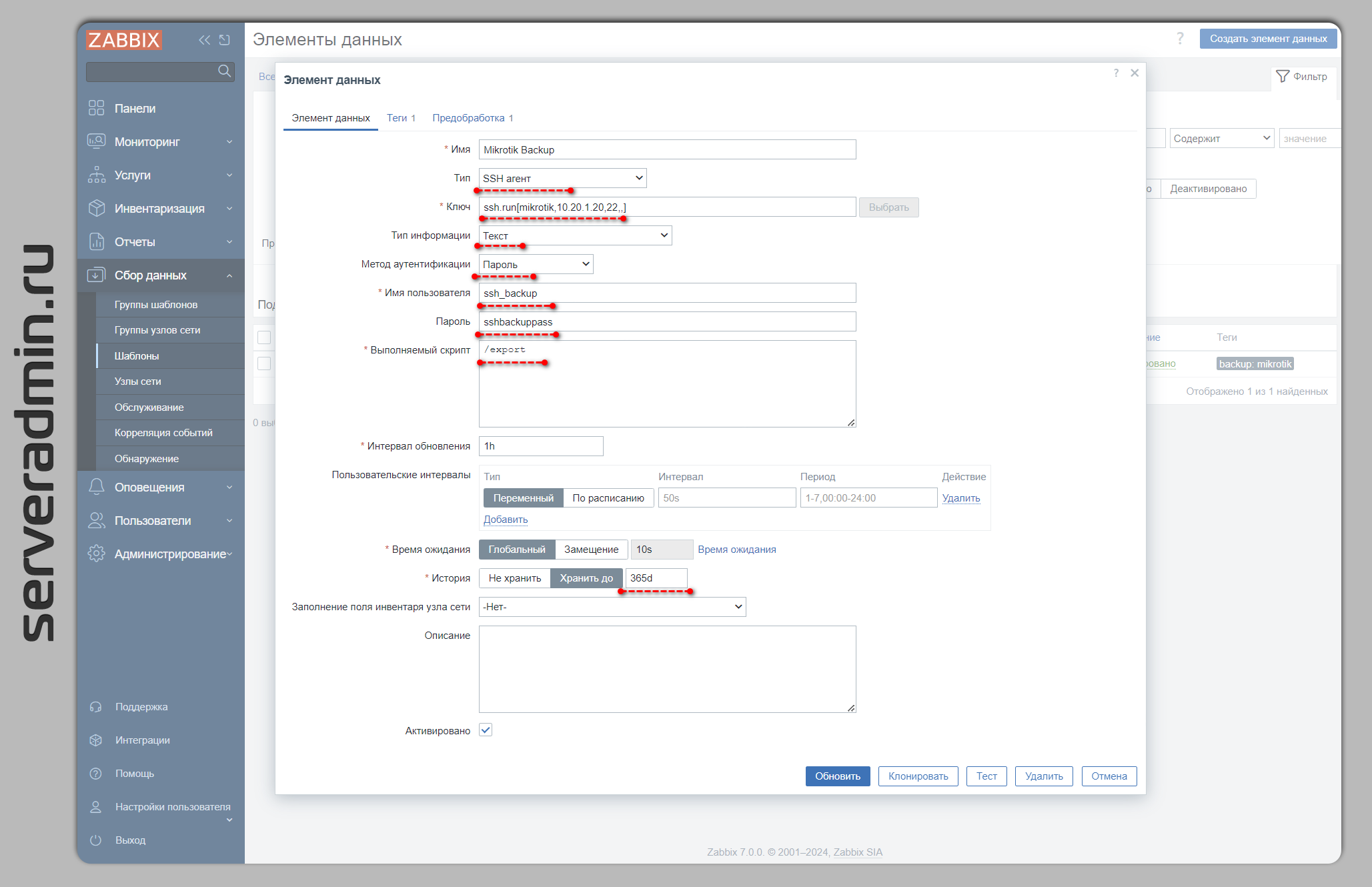
У Zabbix есть тип элемента данных - SSH Агент. Он может ходить по SSH на хосты с аутентификацией по паролю или ключу, выполнять какие-то действия и сохранять вывод. С помощью этого можно, к примеру, сохранять бэкапы Микротиков. Причём встроенные возможности Zabbix позволят без каких-то дополнительных телодвижений отбрасывать неизменившиеся настройки, чтобы не хранить одну и ту же информацию много раз. А также можно оповещать об изменениях в конфигурациях, если сохранённая ранее отличается от полученной в новой проверке.
Рассказываю, как это настроить. Создаём новый шаблон. Я всегда рекомендую использовать сразу шаблоны, не создавать айтемы и триггеры на хостах. Это неудобно и труднопереносимо. Лучше сразу делать в шаблоне. Добавляем новый айтем:
◽Тип: SSH агент
◽Ключ: ssh.run[mikrotik,10.20.1.20,22,,]
Формат этого ключа: ssh.run[description,<ip>,<port>,<encoding>,<ssh options>]
◽Тип информации: Текст
◽Метод аутентификации: Пароль (можете выбрать ключ)
◽Выполняемый скрипт:
Остальные параметры ставите по желанию. Логин и пароль лучше вынести в макросы шаблона и скрыть их, так будет удобнее и безопаснее. Я указал явно для наглядности. Переходим в этом же айтеме на вкладку Предобработка и добавляем один шаг:
◽Отбрасывать не изменившееся
Тэги добавьте по желанию. Сохраняем. Сразу добавим триггер, который сработает, если конфигурация изменилась. Параметры там выставляйте по желанию. Выражение можно сделать такое:
Сработает, если текст последней проверки будет отличаться от предыдущей.
Теперь можно прикрепить этот шаблон к хосту, который будет делать подключения и проверить. Я обычно на Zabbix Server подобную функциональность вешаю. Но это зависит от вашей конфигурации сети. Сервер должен мочь заходить по SSH на указанный в айтеме адрес.
В разделе Мониторинг -> Последние данные увидите выгрузку конфигурации своего Микротика. Единственный момент, который не понравился - добавляются лишние пустые строки. Не знаю, с чем это связано. Всё остальное проверил, конфиг нормальный. Символы не теряются. На вид рабочий.
Не знаю, насколько актуально делать бэкапы таким способом. В принципе, почему бы и нет. Тут сразу и бэкап, и мониторинг изменений в одном лице. Сам так не делал никогда. Написал эту заметку, чтобы просто продемонстрировать возможность. Вдохновился вот этой статьёй в блоге Zabbix, где они скрестили мониторинг с Oxidized:
⇨ https://blog.zabbix.com/monitoring-configuration-backups-with-zabbix-and-oxidized/28260/
Неплохой материал. Там берут json со статусами бэкапов из Oxidized и с помощью lld и jsonpath парсят его на статусы отдельных устройств.
Возвращаясь к бэкапу Микротиков. Если таки надумаете его делать, то в случае больших выгрузок увеличьте таймауты на сервере. И следите за размером бэкапов. У Zabbix вроде есть ограничение на размер текстовой записи айтема в 64KB. Если у вас конфиг будет больше, то он обрежется без каких-либо уведомлений. Ну а в общем случае всё заработает, и сбор, и триггер. Я лично проверил на своём стенде во время написания заметки.
А вообще интересна тема разных проверок с помощью Zabbix? Я могу много всяких примеров привести ещё. Что-то я уже писал раньше, что-то нет. С Zabbix постоянно работаю.
#zabbix #mikrotik
У Zabbix есть тип элемента данных - SSH Агент. Он может ходить по SSH на хосты с аутентификацией по паролю или ключу, выполнять какие-то действия и сохранять вывод. С помощью этого можно, к примеру, сохранять бэкапы Микротиков. Причём встроенные возможности Zabbix позволят без каких-то дополнительных телодвижений отбрасывать неизменившиеся настройки, чтобы не хранить одну и ту же информацию много раз. А также можно оповещать об изменениях в конфигурациях, если сохранённая ранее отличается от полученной в новой проверке.
Рассказываю, как это настроить. Создаём новый шаблон. Я всегда рекомендую использовать сразу шаблоны, не создавать айтемы и триггеры на хостах. Это неудобно и труднопереносимо. Лучше сразу делать в шаблоне. Добавляем новый айтем:
◽Тип: SSH агент
◽Ключ: ssh.run[mikrotik,10.20.1.20,22,,]
Формат этого ключа: ssh.run[description,<ip>,<port>,<encoding>,<ssh options>]
◽Тип информации: Текст
◽Метод аутентификации: Пароль (можете выбрать ключ)
◽Выполняемый скрипт:
/exportОстальные параметры ставите по желанию. Логин и пароль лучше вынести в макросы шаблона и скрыть их, так будет удобнее и безопаснее. Я указал явно для наглядности. Переходим в этом же айтеме на вкладку Предобработка и добавляем один шаг:
◽Отбрасывать не изменившееся
Тэги добавьте по желанию. Сохраняем. Сразу добавим триггер, который сработает, если конфигурация изменилась. Параметры там выставляйте по желанию. Выражение можно сделать такое:
last(/SSH Get/ssh.run[mikrotik,10.20.1.20,22,,],#1)<>last(/SSH Get/ssh.run[mikrotik,10.20.1.20,22,,],#2)Сработает, если текст последней проверки будет отличаться от предыдущей.
Теперь можно прикрепить этот шаблон к хосту, который будет делать подключения и проверить. Я обычно на Zabbix Server подобную функциональность вешаю. Но это зависит от вашей конфигурации сети. Сервер должен мочь заходить по SSH на указанный в айтеме адрес.
В разделе Мониторинг -> Последние данные увидите выгрузку конфигурации своего Микротика. Единственный момент, который не понравился - добавляются лишние пустые строки. Не знаю, с чем это связано. Всё остальное проверил, конфиг нормальный. Символы не теряются. На вид рабочий.
Не знаю, насколько актуально делать бэкапы таким способом. В принципе, почему бы и нет. Тут сразу и бэкап, и мониторинг изменений в одном лице. Сам так не делал никогда. Написал эту заметку, чтобы просто продемонстрировать возможность. Вдохновился вот этой статьёй в блоге Zabbix, где они скрестили мониторинг с Oxidized:
⇨ https://blog.zabbix.com/monitoring-configuration-backups-with-zabbix-and-oxidized/28260/
Неплохой материал. Там берут json со статусами бэкапов из Oxidized и с помощью lld и jsonpath парсят его на статусы отдельных устройств.
Возвращаясь к бэкапу Микротиков. Если таки надумаете его делать, то в случае больших выгрузок увеличьте таймауты на сервере. И следите за размером бэкапов. У Zabbix вроде есть ограничение на размер текстовой записи айтема в 64KB. Если у вас конфиг будет больше, то он обрежется без каких-либо уведомлений. Ну а в общем случае всё заработает, и сбор, и триггер. Я лично проверил на своём стенде во время написания заметки.
А вообще интересна тема разных проверок с помощью Zabbix? Я могу много всяких примеров привести ещё. Что-то я уже писал раньше, что-то нет. С Zabbix постоянно работаю.
#zabbix #mikrotik
{kind=link}
Открытый практикум Linux by Rebrain: Виртуальные интерфейсы и канальный уровень в Linux
Для знакомства с нами после регистрации мы отправим вам запись практикума «DevOps by Rebrain: Как жить, если у вас появился Nginx». Вы сможете найти её в ответном письме!
👉Регистрация
Время проведения:
31 июля (среда) в 19:00 по МСК
Программа практикума:
🔹Изучим протоколы туннелирования для сетевого и канального уровня: IPIP, GRE, L2TPv3, VXLAN
🔹Рассмотрим мосты и L2 stretching
🔹Познакомимся с другими виртуальными интерфейсами: dummy, macvlan, ifb
🔹Разберем зеркалирование и перенаправление трафика
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzquavtM9
Для знакомства с нами после регистрации мы отправим вам запись практикума «DevOps by Rebrain: Как жить, если у вас появился Nginx». Вы сможете найти её в ответном письме!
👉Регистрация
Время проведения:
31 июля (среда) в 19:00 по МСК
Программа практикума:
🔹Изучим протоколы туннелирования для сетевого и канального уровня: IPIP, GRE, L2TPv3, VXLAN
🔹Рассмотрим мосты и L2 stretching
🔹Познакомимся с другими виртуальными интерфейсами: dummy, macvlan, ifb
🔹Разберем зеркалирование и перенаправление трафика
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzquavtM9
Как можно закрыть веб интерфейс Proxmox от посторонних глаз? Если, к примеру, вы арендуете одиночный сервер и он смотрит напрямую в интернет. Как вы понимаете, способов тут может быть очень много. Расскажу про самые простые, быстрые в настройке и эффективные. Они все будут проще, чем настроить VPN и организовать доступ через него.
1️⃣ Самый простой способ - настроить ограничение по IP с помощью настроек pveproxy. Я об этом подробно рассказывал в отдельной заметке. Достаточно создать файл
И после этого перезапустить службу:
2️⃣ С помощью iptables. Если заранее не настроили iptables, то на работающем сервере лучше не пробовать настраивать, если у вас нет прямого доступа к консоли. Если файрвол вообще не настраивали, то в общем случае понадобятся два правила:
Первое разрешает подключения из подсети 192.168.13.0/24 и ip адреса 1.1.1.1. Второе правило запрещает все остальные подключения к веб интерфейсу. Правила эти можно сохранить в файл и подгружать во время загрузки сервера или явно прописать в
Если уже есть другие правила, то их надо увязывать вместе в зависимости от ситуации. Тут нет универсальной подсказки, как поступить. Если не разбираетесь в iptables, не трогайте его. Используйте другие методы.
Я сам всегда использую iptables. Настраиваю его по умолчанию на всех гипервизорах. Примерный набор правил показывал в заметке.
3️⃣ Вы можете установить Nginx прямо на хост с Proxmox, так как по своей сути это почти обычный Debian. У Nginx есть свои способы ограничения доступа по ip через allow/deny в конфигурации, либо по пользователю/паролю через basic auth. Бонусом сюда же идёт настройка TLS сертификатов от Let's Encrypt и доступ по 443 порту, а не стандартному 8006.
Ставим Nginx:
Настраиваем базовый конфиг /
Разрешили подключаться только с указанных адресов. Это пример с использованием стандартных сертификатов. Для Let's Encrypt нужна отдельная настройка, которая выходит за рамки этой заметки. Для того, чтобы закрыть доступ паролем, а не списком IP адресов, необходимо настроить auth_basic. Настройка легко гуглится по ключевым словам nginx auth_basic, не буду об этом рассказывать, так как не умещается в заметку. Там всё просто.
Этот же Nginx сервер можно использовать для проксирования запросов внутрь виртуалок. Удобный и универсальный способ, если вы не используете отдельную виртуалку для управления доступом к внутренним ресурсам.
После настройки Nginx, доступ к веб интерфейсу по порту 8006 можно закрыть либо через pveproxy, либо через iptables.
#proxmox
1️⃣ Самый простой способ - настроить ограничение по IP с помощью настроек pveproxy. Я об этом подробно рассказывал в отдельной заметке. Достаточно создать файл
/etc/default/pveproxy примерно такого содержимого:ALLOW_FROM="192.168.13.0/24,1.1.1.1"DENY_FROM="all"POLICY="allow"И после этого перезапустить службу:
# systemctl restart pveproxy.service2️⃣ С помощью iptables. Если заранее не настроили iptables, то на работающем сервере лучше не пробовать настраивать, если у вас нет прямого доступа к консоли. Если файрвол вообще не настраивали, то в общем случае понадобятся два правила:
/usr/sbin/iptables -A INPUT -i enp5s0 -s 192.168.13.0/24,1.1.1.1 -p tcp --dport 8006 -j ACCEPT/usr/sbin/iptables -A INPUT -i enp5s0 -p tcp --dport 8006 -j DROPПервое разрешает подключения из подсети 192.168.13.0/24 и ip адреса 1.1.1.1. Второе правило запрещает все остальные подключения к веб интерфейсу. Правила эти можно сохранить в файл и подгружать во время загрузки сервера или явно прописать в
/etc/network/interfaces примерно так:auto enp5s0iface enp5s0 inet static address 5.6.7.8/24 dns-nameservers 188.93.17.19 188.93.16.19 gateway 5.6.7.1 post-up /usr/sbin/iptables -A INPUT -i enp5s0 -s 192.168.13.0/24,1.1.1.1 -p tcp --dport 8006 -j ACCEPT post-up /usr/sbin/iptables -A INPUT -i enp5s0 -p tcp --dport 8006 -j DROPЕсли уже есть другие правила, то их надо увязывать вместе в зависимости от ситуации. Тут нет универсальной подсказки, как поступить. Если не разбираетесь в iptables, не трогайте его. Используйте другие методы.
Я сам всегда использую iptables. Настраиваю его по умолчанию на всех гипервизорах. Примерный набор правил показывал в заметке.
3️⃣ Вы можете установить Nginx прямо на хост с Proxmox, так как по своей сути это почти обычный Debian. У Nginx есть свои способы ограничения доступа по ip через allow/deny в конфигурации, либо по пользователю/паролю через basic auth. Бонусом сюда же идёт настройка TLS сертификатов от Let's Encrypt и доступ по 443 порту, а не стандартному 8006.
Ставим Nginx:
# apt install nginxНастраиваем базовый конфиг /
etc/nginx/sites-available/default:server { listen 80 default_server; server_name _; allow 192.168.13.0/24; allow 1.1.1.1/32; deny all; return 301 https://5.6.7.8;}server { listen 443 ssl; server_name _; ssl_certificate /etc/pve/local/pve-ssl.pem; ssl_certificate_key /etc/pve/local/pve-ssl.key; proxy_redirect off; allow 192.168.13.0/24; allow 1.1.1.1/32; deny all; location / { proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_pass https://localhost:8006; proxy_buffering off; client_max_body_size 0; }}Разрешили подключаться только с указанных адресов. Это пример с использованием стандартных сертификатов. Для Let's Encrypt нужна отдельная настройка, которая выходит за рамки этой заметки. Для того, чтобы закрыть доступ паролем, а не списком IP адресов, необходимо настроить auth_basic. Настройка легко гуглится по ключевым словам nginx auth_basic, не буду об этом рассказывать, так как не умещается в заметку. Там всё просто.
Этот же Nginx сервер можно использовать для проксирования запросов внутрь виртуалок. Удобный и универсальный способ, если вы не используете отдельную виртуалку для управления доступом к внутренним ресурсам.
После настройки Nginx, доступ к веб интерфейсу по порту 8006 можно закрыть либо через pveproxy, либо через iptables.
#proxmox
Я смотрю, заметки с Zabbix бодро заходят, а если ещё Mikrotik или Proxmox добавить, то вообще отлично. Сегодня опять Микротики будут. Типовая задача по настройке переключения канала с основного на резервный и обратно. Плюс, там ещё поднимается VPN канал. Хочется мониторить и переключение каналов, то есть получать уведомления, если канал переключился, и состояние VPN соединения, и состояние каналов, чтобы не получилось так, что резерв уже давно не работает, а мы не знаем об этом. Плюс, если точка висит на резервном канале, то это подсвечивается триггером в дашборде Zabbix.
Я делал это на базе скриптов Mikrotik. Как это может выглядеть, отражено в моей статье про переключение провайдеров. Это один из примеров. Я эти скрипты много раз менял, дорабатывал под конкретные условия. Там может быть много нюансов. Да, переключение провайдеров можно сделать проще через динамическую маршрутизацию, но это только часть задачи. Скрипт решает не только переключение, но и логирование, плюс выполнение некоторых других задач - сброс сетевых соединений, выключение и включение VPN соединения, чтобы оно сразу переподключилось через нового провайдера и т.д.
В итоге, я через скрипты настраивал переключение канала и проверку доступности каналов. Примерно так может выглядеть проверка работы канала:
Результат работы скриптов выводился в стандартный лог Микротика. Дальше этот лог может уезжать куда-то на хранение и анализ. Например, в ELK или Rsyslog. Если мы настраиваем мониторинг через Zabbix, то выбираем rsyslog.
Zabbix Server забирает к себе все логи через стандартный айтем с типом данных лог и анализирует. Потом создаётся триггер с примерно таким выражением, если брать приведённый выше скрипт Микротика:
и восстановление:
В таком подходе есть одно неудобство. Все триггеры будут привязаны к Zabbix Server, а имя устройства видно только в описании триггера. Если вам это не подходит, придётся использовать что-то другое.
Я придумывал другую схему, чтобы триггеры о состоянии каналов были привязаны к самим устройствам, чтобы на географической карте были видны хосты с проблемами. Уже точно не помню реализацию, но вроде порты куда-то внутрь пробрасывал через разные каналы. И делал стандартные TCP проверки этих портов через Zabbix сервер. Если какой-то порт не отвечает, то канал, через который он работает, считается неработающим.
И ещё один вариант мониторинга каналов. Через каждого провайдера поднимаем разное VPN соединение и мониторим его любым способом. Можно простыми пингами, если Zabbix сервер или его прокси заведён в эти VPN сети, можно по SNMP.
Мне лично больше всего нравятся варианты с логами. Я люблю всё собирать и хранить. Логи удобно анализировать, всегда на месте исторические данные по событиям. Другое дело, что Zabbix не любит большие логи и нагружать его ими не стоит. Он всё хранит в SQL базе, а она для логов плохо подходит. Какие-то простые вещи, типа вывод работы скриптов без проблем можно заводить, а вот полноценный сбор масштабных логов с их анализом устраивать не надо.
Через анализ логов удобно слать уведомления о каких-то событиях в системных логах. Например, информировать об аутентификации в системе через анализ лог файла
#mikrotik #zabbix
Я делал это на базе скриптов Mikrotik. Как это может выглядеть, отражено в моей статье про переключение провайдеров. Это один из примеров. Я эти скрипты много раз менял, дорабатывал под конкретные условия. Там может быть много нюансов. Да, переключение провайдеров можно сделать проще через динамическую маршрутизацию, но это только часть задачи. Скрипт решает не только переключение, но и логирование, плюс выполнение некоторых других задач - сброс сетевых соединений, выключение и включение VPN соединения, чтобы оно сразу переподключилось через нового провайдера и т.д.
В итоге, я через скрипты настраивал переключение канала и проверку доступности каналов. Примерно так может выглядеть проверка работы канала:
:local PingCount 3;:local CheckIp1 77.88.8.1;:local CheckIp8 77.88.8.8;:local isp1 [/ping $CheckIp1 count=$PingCount interface="ether1"];:local isp2 [/ping $CheckIp8 count=$PingCount interface="lte1"];:if ($isp1=0) do={:log warning "MAIN Internet NOT work";} else={:log warning "MAIN Internet WORK";}:if ($isp2=0) do={:log warning "RESERV Internet NOT work";} else={:log warning "RESERV Internet WORK";}Результат работы скриптов выводился в стандартный лог Микротика. Дальше этот лог может уезжать куда-то на хранение и анализ. Например, в ELK или Rsyslog. Если мы настраиваем мониторинг через Zabbix, то выбираем rsyslog.
Zabbix Server забирает к себе все логи через стандартный айтем с типом данных лог и анализирует. Потом создаётся триггер с примерно таким выражением, если брать приведённый выше скрипт Микротика:
find(/Mikrotik logs/log[/var/log/mikrotik/mikrotik.log],#1,"like","Router-01: MAIN Internet NOT work")=1'и восстановление:
find(/Mikrotik logs/log[/var/log/mikrotik/mikrotik.log],#1,"like","Router-01: MAIN Internet WORK")=1В таком подходе есть одно неудобство. Все триггеры будут привязаны к Zabbix Server, а имя устройства видно только в описании триггера. Если вам это не подходит, придётся использовать что-то другое.
Я придумывал другую схему, чтобы триггеры о состоянии каналов были привязаны к самим устройствам, чтобы на географической карте были видны хосты с проблемами. Уже точно не помню реализацию, но вроде порты куда-то внутрь пробрасывал через разные каналы. И делал стандартные TCP проверки этих портов через Zabbix сервер. Если какой-то порт не отвечает, то канал, через который он работает, считается неработающим.
И ещё один вариант мониторинга каналов. Через каждого провайдера поднимаем разное VPN соединение и мониторим его любым способом. Можно простыми пингами, если Zabbix сервер или его прокси заведён в эти VPN сети, можно по SNMP.
Мне лично больше всего нравятся варианты с логами. Я люблю всё собирать и хранить. Логи удобно анализировать, всегда на месте исторические данные по событиям. Другое дело, что Zabbix не любит большие логи и нагружать его ими не стоит. Он всё хранит в SQL базе, а она для логов плохо подходит. Какие-то простые вещи, типа вывод работы скриптов без проблем можно заводить, а вот полноценный сбор масштабных логов с их анализом устраивать не надо.
Через анализ логов удобно слать уведомления о каких-то событиях в системных логах. Например, информировать об аутентификации в системе через анализ лог файла
/var/log/auth.log. Можно о slow логах mysql или php-fpm сообщать. Это актуально, если у вас нет другой, полноценной системы для хранения и анализа логов. #mikrotik #zabbix
Если вам нужно ограничить процессу потребление памяти, то с systemd это сделать очень просто. Причём там есть гибкие варианты настройки. Вообще, все варианты ограничения ресурсов с помощью systemd описаны в документации. Там внушительный список. Покажу на примере памяти, какие настройки за что отвечают.
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
Потестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
Команда будет висеть без ошибок, по По
Теперь зажимаем её:
Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
Вообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
[Unit]Description=Python ScriptAfter=network.target[Service]WorkingDirectory=/opt/runExecStart=/opt/run/scrape.pyRestart=on-abnormalMemoryAccounting=1MemoryHigh=16GMemoryMax=20GMemorySwapMax=3GOOMPolicy=stop[Install]WantedBy=multi-user.targetПотестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
# python3 -c 'a="a"*1024**3; input()'Команда будет висеть без ошибок, по По
ps или free -m будет видно, что скушала 1G оперативы. Теперь зажимаем её:
# systemd-run --scope -p MemoryMax=256M -p MemoryHigh=200M python3 -c 'a="a"*1024**3; input()'Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
# ps ax | grep python 767 pts/0 S+ 0:00 /usr/bin/python3 -c a="a"*1024**3; input()# pmap 767 -x | grep totaltotal kB 1065048 173992 168284Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
# ps -e -o rss,args --sort -rssВообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
{kind=link}
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}
Media is too big
VIEW IN TELEGRAM
Один из самых прикольных моментов сериала Кремниевая Долина (Silicon Valley).
Вы создали форк бомбу и закрыли мне доступ в мою же систему.
Сервак не реагирует на клавиши. Не могу даже SIGKILL послать.
На экране в консоли видно, как удаляются .mov файлы из точки монтирования
#юмор
Вы создали форк бомбу и закрыли мне доступ в мою же систему.
Сервак не реагирует на клавиши. Не могу даже SIGKILL послать.
На экране в консоли видно, как удаляются .mov файлы из точки монтирования
/mount/gluster/originals/ от glusterfs. Редкое явление, когда в фильмах пытаются хоть что-то правдоподобное говорить и показывать по IT тематике. Обычно там какая-то бессмысленная бутафория. А тут постарались.#юмор
Всем привет и хороших выходных, точнее, выходного, если кто ещё или уже не в отпуске. У меня начинается отпуск, так что канал на 3 недели прекращает свою деятельность. Вернусь с новыми публикациями 19-го августа. Чат закрою от новых комментариев, чтобы за спамерами не следить.
Уйду на некоторое время в символический поход, но почти без связи и точно без электричества. Немного переживаю. Мысли проскакивают, нафиг я вообще в это ввязался. Не помню, когда последний раз оказывался в такой ситуации. Хоть и не припоминаю, чтобы хоть раз в отпуске приходилось прямо таки решать какие-то серьёзные проблемы, но на связи обычно всегда был и по мелочи мог что-то посмотреть, сказать, сделать.
У вас как проходят отпуска? На связи остаётесь? Приходится рабочими вопросами заниматься? Ритм современной жизни такой, что часто людям приходится это делать и не только в нашей профессии. Особенно если ты руководитель.
Сегодня вечером будет реклама мероприятия Яндекса. Они прям в последний момент успели, когда я уже подготовил последнюю публикацию и заявки не принимал. По самому мероприятию ничего не скажу, смотрите сами, кому это подходит, но рекомендую посмотреть видео, которое будет в этом сообщении. Мне оно понравилось, так что решил его опубликовать. Очень, такое, проникновенно-ностальгическое.
Уйду на некоторое время в символический поход, но почти без связи и точно без электричества. Немного переживаю. Мысли проскакивают, нафиг я вообще в это ввязался. Не помню, когда последний раз оказывался в такой ситуации. Хоть и не припоминаю, чтобы хоть раз в отпуске приходилось прямо таки решать какие-то серьёзные проблемы, но на связи обычно всегда был и по мелочи мог что-то посмотреть, сказать, сделать.
У вас как проходят отпуска? На связи остаётесь? Приходится рабочими вопросами заниматься? Ритм современной жизни такой, что часто людям приходится это делать и не только в нашей профессии. Особенно если ты руководитель.
Сегодня вечером будет реклама мероприятия Яндекса. Они прям в последний момент успели, когда я уже подготовил последнюю публикацию и заявки не принимал. По самому мероприятию ничего не скажу, смотрите сами, кому это подходит, но рекомендую посмотреть видео, которое будет в этом сообщении. Мне оно понравилось, так что решил его опубликовать. Очень, такое, проникновенно-ностальгическое.
Всем привет. Закончился продолжительный отпуск в 3 недели. Никогда такого не было. С самого начала моей трудовой деятельности везде отпуска были по 2 недели 2 раза в год. В этот раз получилось организовать 3 полных недели. Вообще выпал из рабочих будней. В походе замёрз ночью пипец (+8-9 несколько ночей было, спал в куртке, штанах, шапке). Убедился, что походы и жизнь в палатке это не моё. Больше не пойду. Сын тоже не проникся, хотя мы всего неделю в палатках прожили. Ещё неделю на даче родителей с семьёй прожил, и неделю у себя на даче поработал.
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
{kind=link}
🔝 Пока был в отпуске, закончился месяц. Но ТОП постов не хочу пропускать, поэтому подготовил его. Мне самому нравится такой формат. Иногда просматриваю, плюс, любопытно ещё раз посмотреть на самые удачные публикации.
Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год.
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.me/boost/srv_admin.
📌 Больше всего пересылок:
◽️Сборка Windows 11 Enterprise G (612)
◽️Настройка NFS сервера (482)
◽️RDP Defender для защиты RDP подключений (409)
◽️Утилита ss вместо netstat (387)
◽️Ограничение потребления памяти с помощью systemd (364)
📌 Больше всего комментариев:
◽️Массовый BSOD на Windows (362)
◽️Настройка NFS сервера (223)
◽️Гипервизор для одной виртуальной машины (207)
📌 Больше всего реакций:
◽️Гипервизор для одной виртуальной машины (233)
◽️Сборка Windows 11 Enterprise G (200)
◽️Утилита ss вместо netstat (181)
📌 Больше всего просмотров:
◽️Массовый BSOD на Windows (9855)
◽️Бесплатные курсы от Selectel (9854)
◽️Дистрибутивы Linux в браузере (9635)
#топ
Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год.
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.me/boost/srv_admin.
📌 Больше всего пересылок:
◽️Сборка Windows 11 Enterprise G (612)
◽️Настройка NFS сервера (482)
◽️RDP Defender для защиты RDP подключений (409)
◽️Утилита ss вместо netstat (387)
◽️Ограничение потребления памяти с помощью systemd (364)
📌 Больше всего комментариев:
◽️Массовый BSOD на Windows (362)
◽️Настройка NFS сервера (223)
◽️Гипервизор для одной виртуальной машины (207)
📌 Больше всего реакций:
◽️Гипервизор для одной виртуальной машины (233)
◽️Сборка Windows 11 Enterprise G (200)
◽️Утилита ss вместо netstat (181)
📌 Больше всего просмотров:
◽️Массовый BSOD на Windows (9855)
◽️Бесплатные курсы от Selectel (9854)
◽️Дистрибутивы Linux в браузере (9635)
#топ