
Ушла эпоха. Сервис icq завершил свою работу.
Вчера видел эту новость. Как-то даже взгрустнулось, хотя аськой активно не пользовался уже лет 10. Когда начинал работать, это был основной инструмент онлайн общения, как со знакомыми, так и по рабочим делам.
Нашёл у себя основной клиент для ICQ, которым больше всего пользовался. Это портабельная версия Miranda. Очень приятный софт был с кучей плагинов. При этом минималистичный, не жрущий ресурсы, и работающий без установки. Запустил его, работает, как и прежде, только подключиться к серверам, само собой, не может. Вся история сохранилась, с ней удобно работать. Посмотрел переписку. В 2017 году последние записи. Довольно долго у меня продержалась. В это время уже параллельно со Skype использовал. А потом полностью на Telegram перешёл.
Меня удивляет, что после Miranda была куча мессенджеров, и все они хуже её. Неужели нельзя было посмотреть и сделать нечто похожее? По удобству работы с историей переписки ничего близко нет и сейчас. Я буквально пару лет назад потушил последний сервер с Jabber, где в качестве клиента использовалась Miranda. Людей она полностью устраивала, хоть возможности как сервера, так и клиента морально устарели. Не хватало статуса прочтения сообщений, гибкой передачи и хранения файлов на сервере. Но меня в качестве админа очень устраивало такое решение, так как почти не тратило время на обслуживание. Просто всегда работало. С современными чат серверами типа Rocket.Chat или Zulip хлопот гораздо больше. А Jabber + Miranda просто работали.
История в Миранде осталась с 2008 года. Почитал немного, как в другую жизнь попал. Самая большая группа с пользователями - Lineage 😎 Ничего уже не помню из того времени. Не знаю, зачем я всё это храню. Привычка, закреплённая в генах - всё хранить. Вдруг пригодится. Я ещё прадеда застал, который всё хранил, и отец мой такой же. Наверное это полезный навык для крестьян, потомком которых я являюсь. Но сейчас это больше мешает. Хотя кто знает, как жизнь повернётся.
А вы до какого года использовали аську? Номер свой помните? У меня обычный девятизнак был. Не было нужды его где-то применять в последние года, но помню до сих пор. В памяти, похоже, на всю жизнь отложился.
#разное
Вчера видел эту новость. Как-то даже взгрустнулось, хотя аськой активно не пользовался уже лет 10. Когда начинал работать, это был основной инструмент онлайн общения, как со знакомыми, так и по рабочим делам.
Нашёл у себя основной клиент для ICQ, которым больше всего пользовался. Это портабельная версия Miranda. Очень приятный софт был с кучей плагинов. При этом минималистичный, не жрущий ресурсы, и работающий без установки. Запустил его, работает, как и прежде, только подключиться к серверам, само собой, не может. Вся история сохранилась, с ней удобно работать. Посмотрел переписку. В 2017 году последние записи. Довольно долго у меня продержалась. В это время уже параллельно со Skype использовал. А потом полностью на Telegram перешёл.
Меня удивляет, что после Miranda была куча мессенджеров, и все они хуже её. Неужели нельзя было посмотреть и сделать нечто похожее? По удобству работы с историей переписки ничего близко нет и сейчас. Я буквально пару лет назад потушил последний сервер с Jabber, где в качестве клиента использовалась Miranda. Людей она полностью устраивала, хоть возможности как сервера, так и клиента морально устарели. Не хватало статуса прочтения сообщений, гибкой передачи и хранения файлов на сервере. Но меня в качестве админа очень устраивало такое решение, так как почти не тратило время на обслуживание. Просто всегда работало. С современными чат серверами типа Rocket.Chat или Zulip хлопот гораздо больше. А Jabber + Miranda просто работали.
История в Миранде осталась с 2008 года. Почитал немного, как в другую жизнь попал. Самая большая группа с пользователями - Lineage 😎 Ничего уже не помню из того времени. Не знаю, зачем я всё это храню. Привычка, закреплённая в генах - всё хранить. Вдруг пригодится. Я ещё прадеда застал, который всё хранил, и отец мой такой же. Наверное это полезный навык для крестьян, потомком которых я являюсь. Но сейчас это больше мешает. Хотя кто знает, как жизнь повернётся.
А вы до какого года использовали аську? Номер свой помните? У меня обычный девятизнак был. Не было нужды его где-то применять в последние года, но помню до сих пор. В памяти, похоже, на всю жизнь отложился.
#разное
{kind=link}
Как быстро прибить приложение, которое слушает определённый порт?
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
Но быстрее и проще воспользоваться lsof:
Или вообще в одно действие:
Lsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
# ss -tulnp | grep 8080tcp LISTEN 0 5 0.0.0.0:8080 0.0.0.0:* users:(("python3",pid=5152,fd=3))# kill 5152Но быстрее и проще воспользоваться lsof:
# lsof -i:8080COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEpython3 5156 root 3u IPv4 41738 0t0 TCP *:http-alt (LISTEN)# kill 5152Или вообще в одно действие:
# lsof -i:8080 -t | xargs killLsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
# lsof -i# lsof -i TCP:25# lsof -i TCP@1.2.3.4Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
# killport 8080В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
> killport 445 --dry-runWould kill process 'System' listening on port 445То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
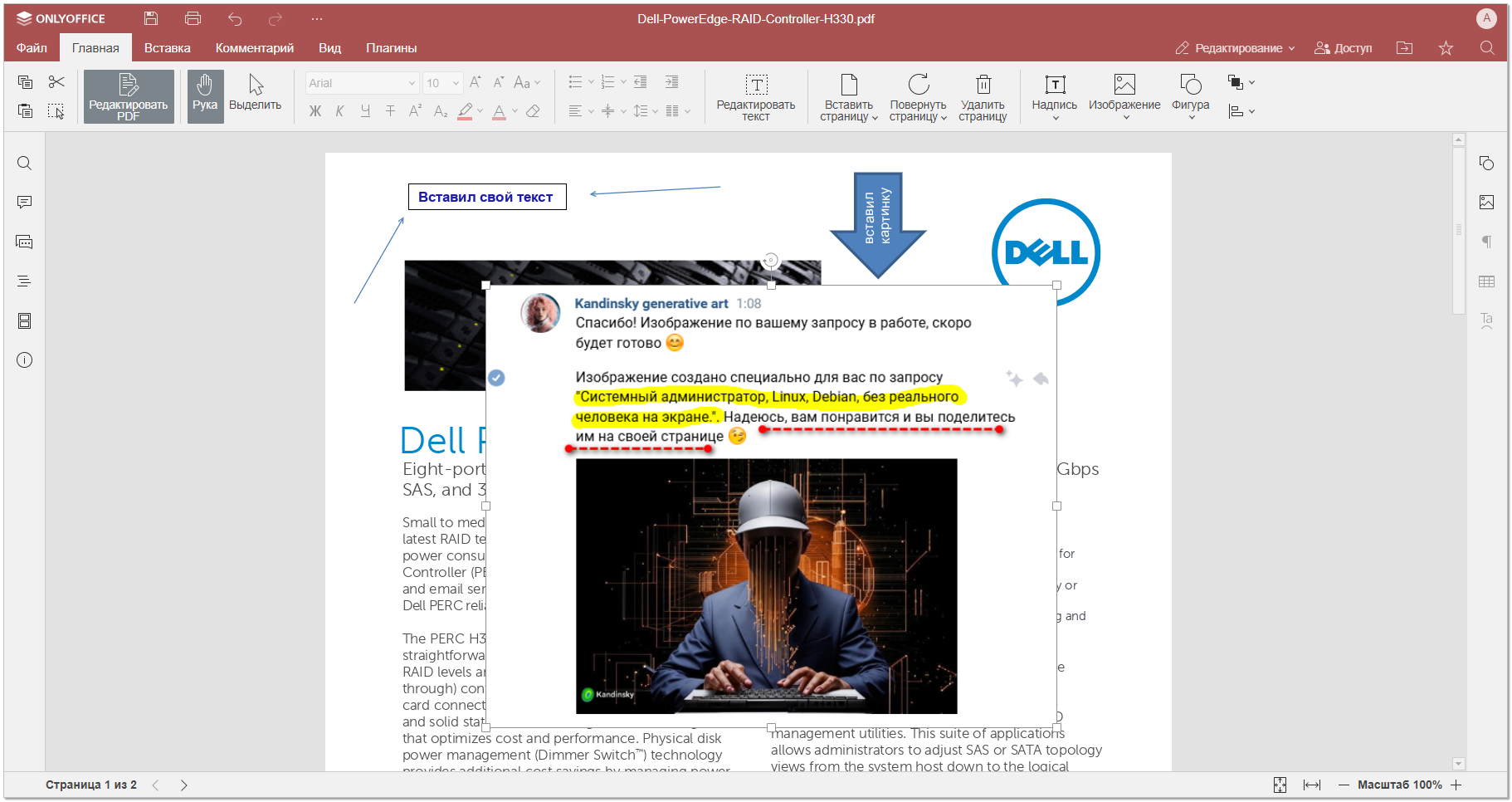
Вчера новость прилетела от Onlyoffice, что вышла новая версия Docs 8.1. Я сначала прохладно отнёсся к ней, так как не так давно был релиз 8.0 и я о нём писал. В этот раз бегло посмотрел анонс нововведений. И меня там очень привлекло то, что они внедрили редактирование pdf файлов. Это на самом деле востребованная функциональность, так что я решил сразу её попробовать.
Про Onlyoffice я много писал на канале, есть статьи на сайте, так что не буду подробно про него рассказывать. Это сервис для совместной работы и онлайн редактирования документов. Я сам постоянно использую этот продукт в работе. Внедрил его в нескольких компаниях для работы с документами, а сам там веду документацию и некоторые другие записи совместно с другими сотрудниками.
Бесплатная версия позволяет работать одновременно над 20-ю документами в режиме редактирования. Точнее, может быть открыто не более 20-ти вкладок с документами на редактировании. Остальные будут только на чтение. Это комфортное ограничение, которое позволяет использовать продукт небольшим командам, где людей может быть сильно больше 20-ти. Ограничение только на редактирование. На практике чаще всего нужно чтение. Обновил инструкцию или документацию и закрыл. Остальные читают.
Попробовать очень просто. Даже никаких настроек не надо. Нужна только виртуалка с 8 Гб оперативной памяти и 4 vCPU. Делаем вот так:
Выбираем установку в Docker и дожидаемся завершения. После этого можно сразу идти в веб интерфейс по IP адресу сервера, создавать администратора и начинать пользоваться. Детальные настройки можно потом сделать. Для попробовать ничего делать больше не нужно. Редактор документов уже будет работать.
Я сразу закинул туда несколько pdf файлов и попробовал редактировать. Работает всё, кроме редактирования текста. Похоже на какой-то баг OCR (распознавания текста). Нажимаю Редактировать текст и документ падает с ошибкой. Помогает только закрытие и открытие документа. В логах контейнера с Docserver появляется неинформативная ошибка, так что не понятно, с чем связано. С учётом того, что релиз был вчера, думаю, что поправят.
Всё остальное нормально работает. Можно добавлять текст, вставлять картинки, различные фигуры, стрелки. Поворачивать страницы, вырезать их, добавлять новые и т.д. Прям то, что надо. Я долго себе искал бесплатный софт, чтобы просто вставлять свою подпись в pdf документы но так и не нашёл. Кстати, если кто-то знает такой, посоветуйте.
Так что рекомендую для тех, кому нужна подобная функциональность. Onlyoffice Docs может работать как в составе другого продукта этой компании Workspace, так и в интеграции со сторонними продуктами. Например, в Nextcloud. Это наиболее распространённое использование этого движка. А так он интегрируется со всеми популярными платформами для совместной работы. Есть даже плагин для Wordpress, чтобы в админке этой CMS работать с документами.
⇨ Новость о релизе / ▶️ Обзор нововведений
#onlyoffice #docs
Про Onlyoffice я много писал на канале, есть статьи на сайте, так что не буду подробно про него рассказывать. Это сервис для совместной работы и онлайн редактирования документов. Я сам постоянно использую этот продукт в работе. Внедрил его в нескольких компаниях для работы с документами, а сам там веду документацию и некоторые другие записи совместно с другими сотрудниками.
Бесплатная версия позволяет работать одновременно над 20-ю документами в режиме редактирования. Точнее, может быть открыто не более 20-ти вкладок с документами на редактировании. Остальные будут только на чтение. Это комфортное ограничение, которое позволяет использовать продукт небольшим командам, где людей может быть сильно больше 20-ти. Ограничение только на редактирование. На практике чаще всего нужно чтение. Обновил инструкцию или документацию и закрыл. Остальные читают.
Попробовать очень просто. Даже никаких настроек не надо. Нужна только виртуалка с 8 Гб оперативной памяти и 4 vCPU. Делаем вот так:
# wget https://download.onlyoffice.com/install/workspace-install.sh# bash workspace-install.shВыбираем установку в Docker и дожидаемся завершения. После этого можно сразу идти в веб интерфейс по IP адресу сервера, создавать администратора и начинать пользоваться. Детальные настройки можно потом сделать. Для попробовать ничего делать больше не нужно. Редактор документов уже будет работать.
Я сразу закинул туда несколько pdf файлов и попробовал редактировать. Работает всё, кроме редактирования текста. Похоже на какой-то баг OCR (распознавания текста). Нажимаю Редактировать текст и документ падает с ошибкой. Помогает только закрытие и открытие документа. В логах контейнера с Docserver появляется неинформативная ошибка, так что не понятно, с чем связано. С учётом того, что релиз был вчера, думаю, что поправят.
Всё остальное нормально работает. Можно добавлять текст, вставлять картинки, различные фигуры, стрелки. Поворачивать страницы, вырезать их, добавлять новые и т.д. Прям то, что надо. Я долго себе искал бесплатный софт, чтобы просто вставлять свою подпись в pdf документы но так и не нашёл. Кстати, если кто-то знает такой, посоветуйте.
Так что рекомендую для тех, кому нужна подобная функциональность. Onlyoffice Docs может работать как в составе другого продукта этой компании Workspace, так и в интеграции со сторонними продуктами. Например, в Nextcloud. Это наиболее распространённое использование этого движка. А так он интегрируется со всеми популярными платформами для совместной работы. Есть даже плагин для Wordpress, чтобы в админке этой CMS работать с документами.
⇨ Новость о релизе / ▶️ Обзор нововведений
#onlyoffice #docs
{kind=link}
▶️ Всем хороших тёплых летних выходных. Желательно уже в отпуске в каком-то приятном месте, где можно отдохнуть и позалипать в ютуб. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными.
⇨ Установка Opnsense в Proxmox
Обзор популярного программного шлюза OPNsense, аналога pfSense. Практики в видео почти нет, в основном разговоры о самой системе и о софтовых шлюзах. Автор просто выполнил установку и самую начальную настройку.
⇨ Best operating system for Servers in 2024
Небольшой обзор современных гипервизоров и систем для решения различных задач. Интересно для расширения кругозора, если с чем-то не знакомы. Автор кратко рассказывает о VMware ESXi, Nutanix AHV, Proxmox VE, XCP-ng, Talos Linux, Flatcar Container Linux, Fedora CoreOS, Windows Server, TrueNAS Scale, Ubuntu, Debian, Qubes OS, Tails OS, Kali Linux.
⇨ Установка Kubernetes
Название ролика не соответствует содержанию. Самой установки там нет, но есть содержательная беседа трёх специалистов на тему Кубернетиса. Можно просто послушать, не смотреть, где-то в машине или метро.
⇨ Vaultwarden Свой менеджер паролей
Обзор популярного менеджера паролей для совместной работы с ними. Писал про него заметку. По ссылке подборка всех менеджеров паролей, что я обозревал.
⇨ The terminal WARS begins! // Warp vs Wave
Какие-то супер навороченные терминалы. Не слышал ни про первый, ни про второй. Да и пользоваться ими не буду. Навскидку, чтобы ими начать пользоваться, надо изучать, как Vim. Они его, кстати, заменяют. Не вижу большого смысла во всём этом для администрирования серверов. Но посмотреть было интересно. Там и шаринг кода, и AI помощник, и общие хранилища, и много всяких других фишек, помимо базовых. Позже выяснил, что их под винду и нет. Сборки только для Linux и MacOS.
⇨ Zabbix workshops: Zabbix proxy high-availability and load balancing
⇨ Zabbix workshops: New web monitoring features in Zabbix 7.0
Два больших ролика (~по часу) на заданные темы. Показаны практические примеры по настройке. То есть специалист сидит, настраивает на реальном мониторинге и нам рассказывает. Люблю такой формат, потому что тут конкретика. Смотреть просто так смысла нет, но если будете настраивать эти вещи, то видео очень пригодятся.
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
Подробный обзор очень интересной бесплатной системы мониторинга за сайтами, их состоянием и контентом. Заинтересовался этой штукой. Запланировал попробовать и написать заметку. Это не просто мониторинг, но и отслеживание изменений контента для различных задач. Например, можно следить за ценами, погодой, курсами и т.д.
#видео
⇨ Установка Opnsense в Proxmox
Обзор популярного программного шлюза OPNsense, аналога pfSense. Практики в видео почти нет, в основном разговоры о самой системе и о софтовых шлюзах. Автор просто выполнил установку и самую начальную настройку.
⇨ Best operating system for Servers in 2024
Небольшой обзор современных гипервизоров и систем для решения различных задач. Интересно для расширения кругозора, если с чем-то не знакомы. Автор кратко рассказывает о VMware ESXi, Nutanix AHV, Proxmox VE, XCP-ng, Talos Linux, Flatcar Container Linux, Fedora CoreOS, Windows Server, TrueNAS Scale, Ubuntu, Debian, Qubes OS, Tails OS, Kali Linux.
⇨ Установка Kubernetes
Название ролика не соответствует содержанию. Самой установки там нет, но есть содержательная беседа трёх специалистов на тему Кубернетиса. Можно просто послушать, не смотреть, где-то в машине или метро.
⇨ Vaultwarden Свой менеджер паролей
Обзор популярного менеджера паролей для совместной работы с ними. Писал про него заметку. По ссылке подборка всех менеджеров паролей, что я обозревал.
⇨ The terminal WARS begins! // Warp vs Wave
Какие-то супер навороченные терминалы. Не слышал ни про первый, ни про второй. Да и пользоваться ими не буду. Навскидку, чтобы ими начать пользоваться, надо изучать, как Vim. Они его, кстати, заменяют. Не вижу большого смысла во всём этом для администрирования серверов. Но посмотреть было интересно. Там и шаринг кода, и AI помощник, и общие хранилища, и много всяких других фишек, помимо базовых. Позже выяснил, что их под винду и нет. Сборки только для Linux и MacOS.
⇨ Zabbix workshops: Zabbix proxy high-availability and load balancing
⇨ Zabbix workshops: New web monitoring features in Zabbix 7.0
Два больших ролика (~по часу) на заданные темы. Показаны практические примеры по настройке. То есть специалист сидит, настраивает на реальном мониторинге и нам рассказывает. Люблю такой формат, потому что тут конкретика. Смотреть просто так смысла нет, но если будете настраивать эти вещи, то видео очень пригодятся.
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
Подробный обзор очень интересной бесплатной системы мониторинга за сайтами, их состоянием и контентом. Заинтересовался этой штукой. Запланировал попробовать и написать заметку. Это не просто мониторинг, но и отслеживание изменений контента для различных задач. Например, можно следить за ценами, погодой, курсами и т.д.
#видео
YouTube
Установка Opnsense в Proxmox
#nas, #opnsense, #truenas, #proxmox
Видео про установку Opnsense как виртуальную машину с помощью Proxmox
З.Ы. В ролике оговорка (по Фрейду). Конечно у Микротика statefull firewall
Реферальная ссылка на хостера smartape чьими услугами я пользуюсь htt…
Видео про установку Opnsense как виртуальную машину с помощью Proxmox
З.Ы. В ролике оговорка (по Фрейду). Конечно у Микротика statefull firewall
Реферальная ссылка на хостера smartape чьими услугами я пользуюсь htt…
Один подписчик уже пару раз просил меня рассказать, как у меня организован рабочий процесс, распорядок дня и как я вообще всё совмещаю и организовываю. Те, кто меня давно читают, наверное представляют всё это, потому что в том или ином виде я всё это упоминал в разных заметках. Для новых читателей возможно это будет интересно.
Вообще, у меня обширный опыт работы в формате фриланса и удалёнки. Я точно помню, когда уволился с постоянной работы по найму. Это был 2014-год. То есть уже полных 10 лет. В 2018 я открыл ИП. А до этого работал по трудовой, с совмещением, по договорам ГПХ. Вообще говоря, я стал специалистом в этой области не меньше, чем в IT. Возможно об этом было бы интереснее читать, чем мои настройки чего-либо, потому что о них много кто пишет. Трудовая деятельность и моя жизнь в целом необычная и интересная.
Сейчас моё время распределено 50/50 между этим каналом, немного сайтом и работой по администрированию. Вся деятельность полностью удалённая. Куда-то выезжаю только для монтажа серверов. Мне это нравится. Любопытно иногда бывать в ЦОД. На прошлой неделе, кстати, был. Новый сервер ставил на colocation, старый забирал. Пустили посмотреть на монтаж. Там такой сотрудник видный был. Типичный айтишник - длинные волосы, свободная одежда, тапочки-шлёпки. Ощущение, что он в этом ЦОДе живёт, а не работает. Я так понимаю, они там длинными сменами проводят время.
Иногда приезжаю в офис для разнообразия. Есть компания, с которой работаю уже 9 лет, почти с момента увольнения с постоянной работы. Есть свободные рабочие места, можно посидеть. Эффективность труда там низкая, постоянно отвлекаешься. А кто-то постоянно так работает. Мне не нравится. Я в основном потрындеть, попить кофе приезжаю, на метро прокатиться. После 18-ти, когда все уезжают, занимаюсь своими делами.
Постоянного рабочего места у меня нет. Имею четверых детей, один ещё грудничок. Жизнь очень суетная, днём практически всегда есть какие-то семейные дела, так что работаю когда и где придётся. Иногда в офисе, иногда в коворкинге, иногда дома, когда все дети по садам, школам, иногда на даче, иногда в кафе или торговом центре (редко). С рождением малыша дома днём возможности поработать нет. Основной рабочий инструмент - ноутбук, который всегда со мной.
Днём перехватываю различные краткосрочные дела, основной объём делаю вечером после 21-22, когда уложу детей. Где-то до часа-двух ночи работаю. В таком графике нахожусь довольно долго. Он уже устоялся. Для здоровья позднее укладывание не слишком полезно, но по-другому не получается выйти на стабильный график. Практиковал ранний подъём, но в 7 уже встают дети, жена, начинают отвлекать. Даже если вставать в 5, а я так делал, остаётся слишком маленький промежуток спокойного времени, плюс нет запаса по времени на случай нештатных ситуаций. Ночью, хоть и не часто, но бывает что задержишься из-за каких-то проблем.
Не думаю, что такого рода мой опыт будет кому-то полезен, так как он очень индивидуален из-за большого количества детей и семейных дел. Так что я вас просто развлёк этой заметкой. Помимо семьи у меня пожилые родители, моя дача, их дача. Всё это требует постоянного моего участия: то котёл потёк, то скважина забилась, то бассейн позеленел, то высаженные туи пожелтели, то косить, то строить, то ещё что-то. Параллельно семейным делам я ещё и стройкой руководил несколько лет, пока участок обустраивал и дом строил. Во всё приходится вникать и разбираться. Не представляю, как бы я вообще со всем управлялся, если бы была постоянная работа с 9 до 18. Детей бы точно столько не было.
Если кого-то интересуют какие-то конкретные темы, можете накидывать в комментариях. По возможности оформлю в публикацию. По самой работе мало написал, но уже лимит по длине поста выбрал, так что в другой раз.
Всем хороших выходных. Спасибо, что читаете и лайкаете 👍🏻
#разное
Вообще, у меня обширный опыт работы в формате фриланса и удалёнки. Я точно помню, когда уволился с постоянной работы по найму. Это был 2014-год. То есть уже полных 10 лет. В 2018 я открыл ИП. А до этого работал по трудовой, с совмещением, по договорам ГПХ. Вообще говоря, я стал специалистом в этой области не меньше, чем в IT. Возможно об этом было бы интереснее читать, чем мои настройки чего-либо, потому что о них много кто пишет. Трудовая деятельность и моя жизнь в целом необычная и интересная.
Сейчас моё время распределено 50/50 между этим каналом, немного сайтом и работой по администрированию. Вся деятельность полностью удалённая. Куда-то выезжаю только для монтажа серверов. Мне это нравится. Любопытно иногда бывать в ЦОД. На прошлой неделе, кстати, был. Новый сервер ставил на colocation, старый забирал. Пустили посмотреть на монтаж. Там такой сотрудник видный был. Типичный айтишник - длинные волосы, свободная одежда, тапочки-шлёпки. Ощущение, что он в этом ЦОДе живёт, а не работает. Я так понимаю, они там длинными сменами проводят время.
Иногда приезжаю в офис для разнообразия. Есть компания, с которой работаю уже 9 лет, почти с момента увольнения с постоянной работы. Есть свободные рабочие места, можно посидеть. Эффективность труда там низкая, постоянно отвлекаешься. А кто-то постоянно так работает. Мне не нравится. Я в основном потрындеть, попить кофе приезжаю, на метро прокатиться. После 18-ти, когда все уезжают, занимаюсь своими делами.
Постоянного рабочего места у меня нет. Имею четверых детей, один ещё грудничок. Жизнь очень суетная, днём практически всегда есть какие-то семейные дела, так что работаю когда и где придётся. Иногда в офисе, иногда в коворкинге, иногда дома, когда все дети по садам, школам, иногда на даче, иногда в кафе или торговом центре (редко). С рождением малыша дома днём возможности поработать нет. Основной рабочий инструмент - ноутбук, который всегда со мной.
Днём перехватываю различные краткосрочные дела, основной объём делаю вечером после 21-22, когда уложу детей. Где-то до часа-двух ночи работаю. В таком графике нахожусь довольно долго. Он уже устоялся. Для здоровья позднее укладывание не слишком полезно, но по-другому не получается выйти на стабильный график. Практиковал ранний подъём, но в 7 уже встают дети, жена, начинают отвлекать. Даже если вставать в 5, а я так делал, остаётся слишком маленький промежуток спокойного времени, плюс нет запаса по времени на случай нештатных ситуаций. Ночью, хоть и не часто, но бывает что задержишься из-за каких-то проблем.
Не думаю, что такого рода мой опыт будет кому-то полезен, так как он очень индивидуален из-за большого количества детей и семейных дел. Так что я вас просто развлёк этой заметкой. Помимо семьи у меня пожилые родители, моя дача, их дача. Всё это требует постоянного моего участия: то котёл потёк, то скважина забилась, то бассейн позеленел, то высаженные туи пожелтели, то косить, то строить, то ещё что-то. Параллельно семейным делам я ещё и стройкой руководил несколько лет, пока участок обустраивал и дом строил. Во всё приходится вникать и разбираться. Не представляю, как бы я вообще со всем управлялся, если бы была постоянная работа с 9 до 18. Детей бы точно столько не было.
Если кого-то интересуют какие-то конкретные темы, можете накидывать в комментариях. По возможности оформлю в публикацию. По самой работе мало написал, но уже лимит по длине поста выбрал, так что в другой раз.
Всем хороших выходных. Спасибо, что читаете и лайкаете 👍🏻
#разное
Вчера вечером сел за компьютер посмотреть почту, в том числе сообщения от мониторинга. Всегда это делаю вечером в воскресенье, чтобы оценить состояние инфраструктуры перед понедельником. Привлёк внимание триггер от Zabbix с одной виртуалки. Там в течении почти 6-ти часов было высокие метрики по Load Average. Потом прошло.
Посмотрел остальные метрики за это время. Ни повышенного трафика, ни чтения/записи диска, ни жора памяти или swap не было. В логах тоже ничего. Выяснить, что же там было, теперь не представляется возможным. К сожалению, это существенный пробел Zabbix, так как стандартными шаблонами этот вопрос никак не решается.
Когда-то давно я придумал решение этой задачи в лоб:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣Настраиваю на Zabbix Server действие при срабатывании триггера на загрузку CPU. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Решение очень простое в реализации и главное удобное в анализе. Список процессов получается в наглядном виде. И при этом постоянно не собираются эти данные, а запрашиваются только в нужные моменты.
Описал этот способ в статье:
⇨ Мониторинг списка запущенных процессов в Zabbix
Способ рабочий, я им одно время пользовался, а потом забил по нескольким причинам:
1️⃣ По возможности стараюсь не использовать скрипты на хостах, потому что это усложняет настройку, неудобно быстро разворачивать и переносить настройки.
2️⃣ Настройка
Попытался придумать какую-то другую реализацию, но в голове не сложилась итоговая картинка, как это может выглядеть, поэтому прошу помощи тех, кто возможно уже решал такую задачу, либо есть идеи, как это можно сделать.
В Zabbix Server 6.2 появился новый айтем:
◽proc.get[<name>,<user>,<cmdline>,<mode>]
С его помощью можно вывести подробную информацию либо обо всех процессах системы, либо о заданных. Описание параметров есть в документации. Посмотреть через консоль, как он работает и что выводит, можно так:
Вся информация в json. Теоретически её можно собрать обо всех процессах, обработать, отсортировать по CPU или различным метрикам памяти и как-то вывести. Но наглядность будет сильно хуже, чем отсортированный вывод
Если у кого-то есть идеи, поделитесь. Ну а кому интересно подобное настроить, то решение в статье вполне рабочее. Нужно только сделать поправку на то, что статья писалась давно, а интерфейс Zabbix Server с тех пор изменился. Некоторые настройки изменили своё положение. Но сам подход через скрипт и EnableRemoteCommands сработает и сейчас.
#zabbix
Посмотрел остальные метрики за это время. Ни повышенного трафика, ни чтения/записи диска, ни жора памяти или swap не было. В логах тоже ничего. Выяснить, что же там было, теперь не представляется возможным. К сожалению, это существенный пробел Zabbix, так как стандартными шаблонами этот вопрос никак не решается.
Когда-то давно я придумал решение этой задачи в лоб:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣Настраиваю на Zabbix Server действие при срабатывании триггера на загрузку CPU. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
# ps aux --sort=-pcpu,+pmem | head -10Решение очень простое в реализации и главное удобное в анализе. Список процессов получается в наглядном виде. И при этом постоянно не собираются эти данные, а запрашиваются только в нужные моменты.
Описал этот способ в статье:
⇨ Мониторинг списка запущенных процессов в Zabbix
Способ рабочий, я им одно время пользовался, а потом забил по нескольким причинам:
1️⃣ По возможности стараюсь не использовать скрипты на хостах, потому что это усложняет настройку, неудобно быстро разворачивать и переносить настройки.
2️⃣ Настройка
EnableRemoteCommands=1 потенциально небезопасна. По возможности её лучше не использовать. А если используешь, то надо и за фаерволом следить, и за tls. А если что-то от root запускаешь, то через мониторинг тебе вообще всю инфру положить могут. Попытался придумать какую-то другую реализацию, но в голове не сложилась итоговая картинка, как это может выглядеть, поэтому прошу помощи тех, кто возможно уже решал такую задачу, либо есть идеи, как это можно сделать.
В Zabbix Server 6.2 появился новый айтем:
◽proc.get[<name>,<user>,<cmdline>,<mode>]
С его помощью можно вывести подробную информацию либо обо всех процессах системы, либо о заданных. Описание параметров есть в документации. Посмотреть через консоль, как он работает и что выводит, можно так:
# zabbix_agentd -t proc.get[zabbix_server,,,]# zabbix_agentd -t proc.get[zabbix_server,,,summary]# zabbix_agentd -t proc.get[]Вся информация в json. Теоретически её можно собрать обо всех процессах, обработать, отсортировать по CPU или различным метрикам памяти и как-то вывести. Но наглядность будет сильно хуже, чем отсортированный вывод
ps aux. Плюс, не совсем понимаю, как всё это организовать в рамках Zabbix Server без скриптов на хосте с привязкой к триггеру, чтобы не постоянно это всё собирать, а только когда нужно. Если у кого-то есть идеи, поделитесь. Ну а кому интересно подобное настроить, то решение в статье вполне рабочее. Нужно только сделать поправку на то, что статья писалась давно, а интерфейс Zabbix Server с тех пор изменился. Некоторые настройки изменили своё положение. Но сам подход через скрипт и EnableRemoteCommands сработает и сейчас.
#zabbix
Server Admin
Мониторинг списка запущенных процессов в Zabbix | serveradmin.ru
Получение информации о топ 10 нагруженных процессов в Linux в момент срабатывания триггера в Zabbix на нагрузку CPU.
🔝 ТОП постов за прошедший месяц. Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год.
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.me/boost/srv_admin.
В очередной раз выстреливает статья по не IT тематике. Причём это происходит постоянно. Все подобные заметки вызывают большой отклик. Я иногда думаю, может я вообще не о том канал веду? Надо больше на общие темы писать? Мне в целом не трудно и есть о чём сказать, но не хочется тематику канала размывать.
📌 Больше всего пересылок:
◽️Шпаргалка по nmap (549)
◽️Pupirka для бэкапа Mikrotik (457)
◽️Бесплатный курс про сети в Linux (440)
📌 Больше всего комментариев:
◽️Заметка про мой распорядок дня (166)
◽️Сервис icq завершил свою работу (156)
◽️Видео про основные признаки линуксоидов (140)
📌 Больше всего реакций:
◽️Заметка про мой распорядок дня (409)
◽️Как происходит загрузка ОС Linux (194)
◽️Перезагрузка ОС Linux (172)
📌 Больше всего просмотров:
◽️Бесплатный курс про сети в Linux (11057)
◽️Видео про основные признаки линуксоидов (10582)
◽️Обновление Zabbix 7.0 (10445)
#топ
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.me/boost/srv_admin.
В очередной раз выстреливает статья по не IT тематике. Причём это происходит постоянно. Все подобные заметки вызывают большой отклик. Я иногда думаю, может я вообще не о том канал веду? Надо больше на общие темы писать? Мне в целом не трудно и есть о чём сказать, но не хочется тематику канала размывать.
📌 Больше всего пересылок:
◽️Шпаргалка по nmap (549)
◽️Pupirka для бэкапа Mikrotik (457)
◽️Бесплатный курс про сети в Linux (440)
📌 Больше всего комментариев:
◽️Заметка про мой распорядок дня (166)
◽️Сервис icq завершил свою работу (156)
◽️Видео про основные признаки линуксоидов (140)
📌 Больше всего реакций:
◽️Заметка про мой распорядок дня (409)
◽️Как происходит загрузка ОС Linux (194)
◽️Перезагрузка ОС Linux (172)
📌 Больше всего просмотров:
◽️Бесплатный курс про сети в Linux (11057)
◽️Видео про основные признаки линуксоидов (10582)
◽️Обновление Zabbix 7.0 (10445)
#топ
Существует известный проект Turnkey Linux, который предлагает готовые преднастроенные образы Linux для решения конкретных задач - файловый сервер, веб сервер, впн сервер и т.д.. Я уже ранее писал про него. Там нет чего-то особенного, что с одной стороны хорошо, а с другой вроде и не надо особо. В основном там используется стандартное open source ПО с веб управлением через webmin. Всё это можно и самому настроить при желании, но тут это уже сделали за вас.
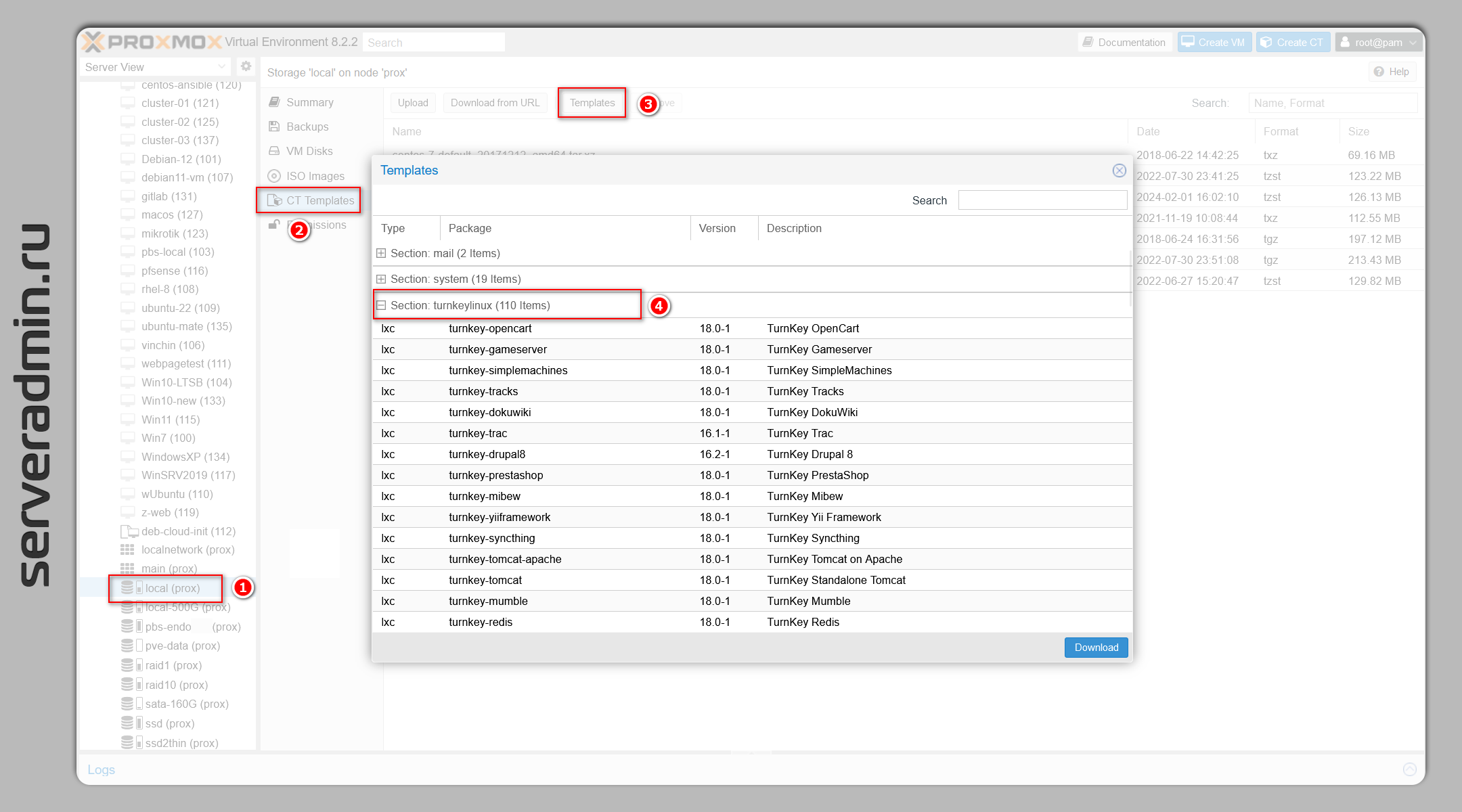
Особо нигде не афишируется, что Turnkey Linux интегрируется с Proxmox. Можно использовать готовые шаблоны LXC контейнеров Turnkey Linux в Proxmox. Для того, чтобы они появились в веб интерфейсе гипервизора, в разделе CT Templates, необходимо в консоли гипервизора выполнить команду:
После этого заходите в локальное хранилище с Container template и смотрите список доступных шаблонов. Увидите 110 шаблонов turnkeylinux.
Для каких-то тестовых задач или временных виртуалок неплохое решение, так как контейнеры разворачиваются очень быстро и не требуют начальных настроек. В несколько кликов можно запустить контейнер с DokuWiki, Nextcloud, OpenLDAP, Snipe-IT, ownCloud и т.д. И посмотреть на них.
#proxmox
Особо нигде не афишируется, что Turnkey Linux интегрируется с Proxmox. Можно использовать готовые шаблоны LXC контейнеров Turnkey Linux в Proxmox. Для того, чтобы они появились в веб интерфейсе гипервизора, в разделе CT Templates, необходимо в консоли гипервизора выполнить команду:
# pveam updateupdate successfulПосле этого заходите в локальное хранилище с Container template и смотрите список доступных шаблонов. Увидите 110 шаблонов turnkeylinux.
Для каких-то тестовых задач или временных виртуалок неплохое решение, так как контейнеры разворачиваются очень быстро и не требуют начальных настроек. В несколько кликов можно запустить контейнер с DokuWiki, Nextcloud, OpenLDAP, Snipe-IT, ownCloud и т.д. И посмотреть на них.
#proxmox
{kind=link}
Медленно, но верно, я перестаю использовать
Самые популярные ключи к ss это tulnp:
Список открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
Вывести только сокеты можно и другой командой:
Но там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
И сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
То же самое, только выводим тех, у кого более 30 соединений с нами:
Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
Всё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
Больше лично я
#linux #terminal
netstat и привыкаю к ss. У неё хоть и не такой удобный для восприятия вывод, но цепляться за netstat уже не имеет смысла. Она давно устарела и не рекомендуется к использованию. Плюс, её нет в стандартных минимальных поставках дистрибутивов. Надо ставить отдельно. Это как с ifconfig. Поначалу упирался, но уже много лет использую только ip. Ifconfig вообще не запускаю. Даже ключи все забыл. Самые популярные ключи к ss это tulnp:
# ss -tulnpСписок открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
# ss -l | grep .sockВывести только сокеты можно и другой командой:
# ss -axНо там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
# ss -ntuИ сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'То же самое, только выводим тех, у кого более 30 соединений с нами:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//' | awk '{if ($1 > 30) print$2}'Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | wc -lВсё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
a:# ss -ntuaБольше лично я
ss ни для чего не использую. Если смотрите ещё что-то полезное с помощью этой утилиты, поделитесь в комментариях.#linux #terminal
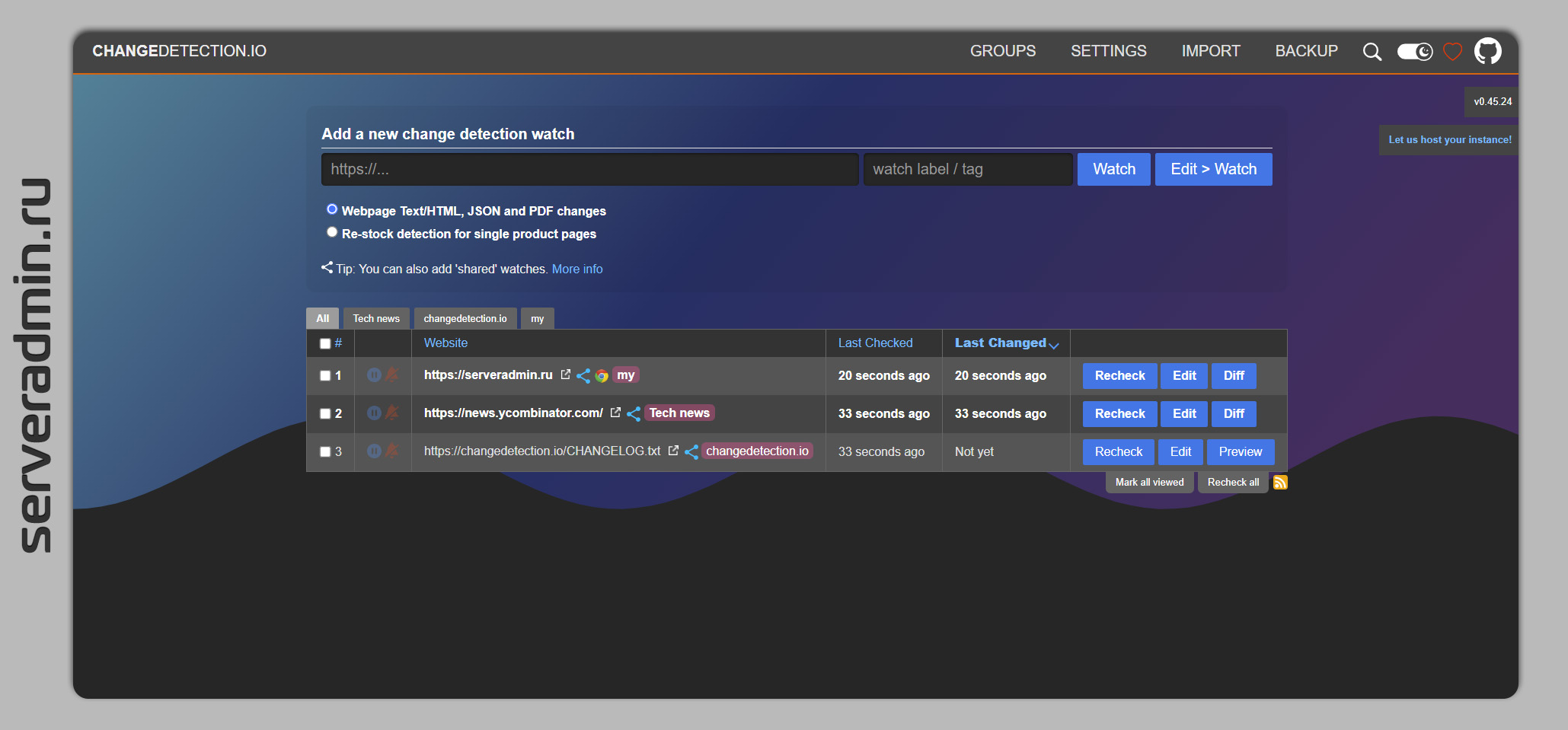
В пятницу в подборке видео я упоминал про обзор проекта changedetection.io. Хочу остановиться на нём отдельно, так как это очень крутой продукт. С его помощью можно отслеживать изменения на сайтах, используя практически полноценный браузер под капотом. Сразу приведу ссылку на видео с подробным обзором, описанием установки и настройки:
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
Можно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
# git clone https://github.com/dgtlmoon/changedetection.io# cd changedetection.io# docker compose up -dМожно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
docker-compose.yml. Раскомментировал некоторые строки и запустил всё заново. Зашёл в настройки, выбрал в разделе Fetching не Basic fast Plaintext/HTTP Client, а Playwright Chromium/Javascript. Русские сайты начали нормально парситься. Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
{kind=link}
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
Anonymous Poll
35%
Windows 💻
63%
Linux 🐧
1%
*BSD 👹
2%
Другая
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив?
Anonymous Poll
47%
Debian
43%
Ubuntu
18%
Форк RHEL (Rocky, Alma, Oracle и т.д.)
12%
Один из российских дистрибутивов
6%
Другое
Давно собираюсь сделать опросы в канале, но всё руки не доходили. Теперь дошли. Мне интересны несколько вопросов.
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
Anonymous Poll
66%
Windows 💻
23%
Linux 🐧
9%
MacOS 🍏
0%
*BSD
1%
Другая
Раз за разом в комментариях вижу вопрос на тему того, где я веду свои заметки. Я ранее делал много публикаций на эту тему (тэг #заметки), где в том числе либо косвенно упоминал, либо прямо писал по этой теме. Но было это давненько. Надо обновить.
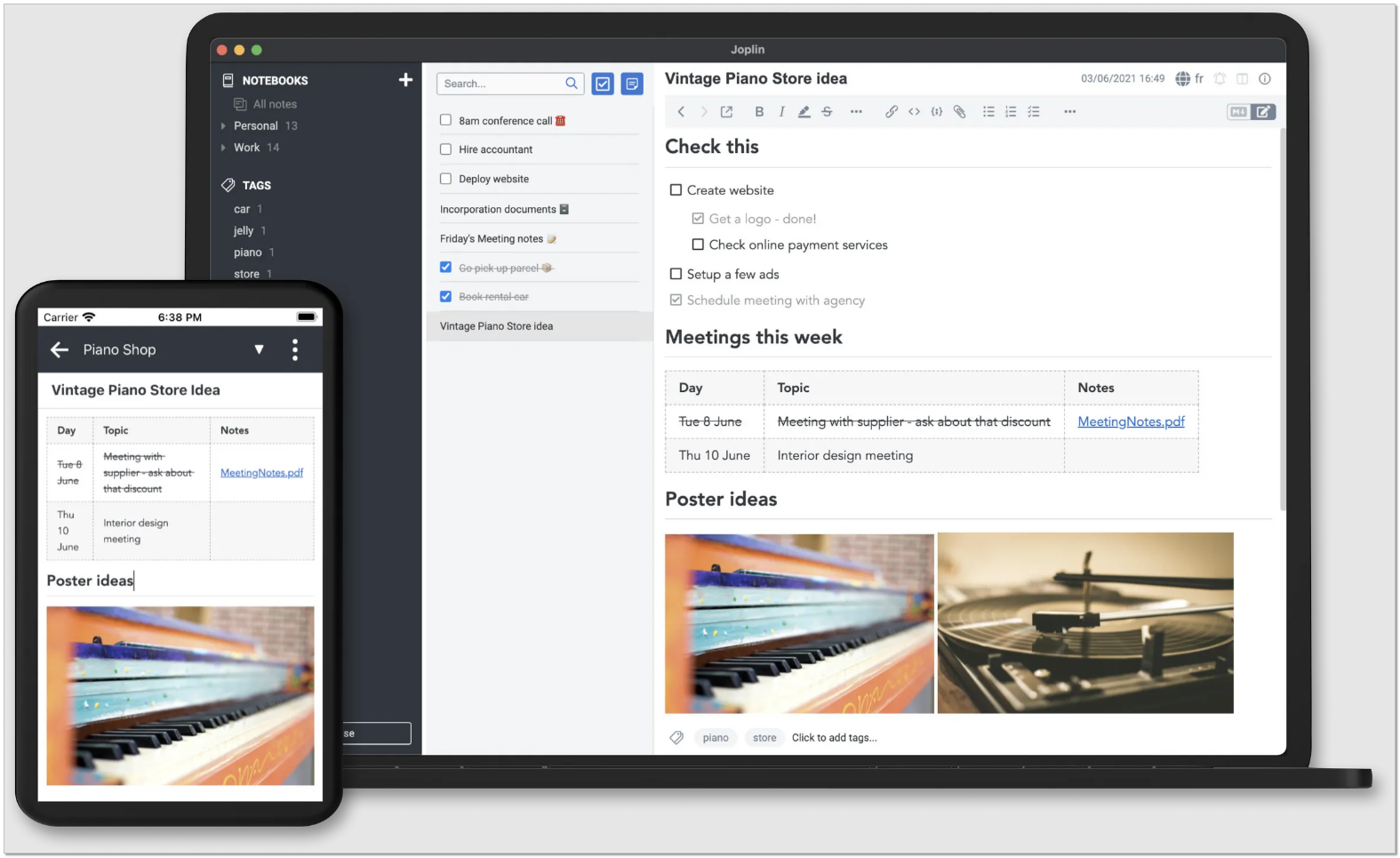
Личные заметки я храню в программе Joplin уже 2,5 года. Не совсем личные, но именно те, что записаны для меня, с которыми мне не надо делиться. Там больше по работе всякие заметки, краткие инструкции по настройке чего-либо и прочая справочная информация.
У Joplin на днях вышла новая ветка 3.0, так что приурочил эту заметку к обновлению. Для тех, кто с ним не знаком, нововведения будут не очень интересны, так что не буду перечислять. А кто знаком, может в анонсе почитать.
🟢 Какие плюсы для меня у Joplin:
🔹Работает полностью локально. База заметок импортируется в зашифрованном виде в Яндекс.Диск, откуда её можно подключить на любом другом устройстве.
🔹Markdown разметка. Привык к ней, в отличии от wiki. С wiki разметкой работать не люблю.
🔹Мне нравится интерфейс, распределение заметок по проектам. Почему-то не во всех подобных программах это есть.
🔹Полностью бесплатный и кроссплатформенный. У меня стоит ещё на смартфоне. Базу обновляю вручную через Яндекс.Диск. Со смартфона смотрю крайне редко. Работаю только с ноута.
🔴 Минусы Joplin:
🔹Тормозное приложение на каком-то современном браузерном фреймворке. Установщик весит под 300 Мб. Во время работы заметна неповоротливость, но в целом не критично. Плюс-минус как у другого подобного софта.
🔹Неудобная работа с таблицами, поэтому я их почти не использую.
🔹Не шифруется локальная база, с которой работает приложение. То, что я упоминал выше на Яндекс.Диске это именно экспорт, то есть копия рабочей базы. Выгруженные данные зашифрованы, а локальные нет. Это не очень хорошо, но я там не храню ничего особенного.
🔹Неудобный мобильный клиент для смартфона. Мне не сильно критично, но имейте ввиду.
В общем-то, никаких особых возможностей и удобств нет, как и косяков. Меня по совокупности устраивает. В первую очередь экспортом шифрованной базы на внешний диск. Работа через браузер с установленным сервисом где-то в интернете мне не нужна. Работаю с Joplin каждый день. Много там всего храню.
Если будете подбирать себе подобную программу, вот список того, на что стоит обратить внимание:
▪️ Memos
▪️ Obsidian
▪️ Trilium Notes
▪️ Appflowy
▪️ Notea
▪️ CherryTree
▪️ MyTetra
▪️ Focalboard
▪️ Standard Notes
▪️ Nimbus Note
▪️ Notesnook
Сразу предвещая ещё вопросы, скажу, что задачи с недавних пор полностью веду в Singularity. Понравилось приложение. Перешёл на него с Todoist. Тоже пользуюсь каждый день. У меня там все дела и по работе, и личные.
#заметки #подборка
Личные заметки я храню в программе Joplin уже 2,5 года. Не совсем личные, но именно те, что записаны для меня, с которыми мне не надо делиться. Там больше по работе всякие заметки, краткие инструкции по настройке чего-либо и прочая справочная информация.
У Joplin на днях вышла новая ветка 3.0, так что приурочил эту заметку к обновлению. Для тех, кто с ним не знаком, нововведения будут не очень интересны, так что не буду перечислять. А кто знаком, может в анонсе почитать.
🟢 Какие плюсы для меня у Joplin:
🔹Работает полностью локально. База заметок импортируется в зашифрованном виде в Яндекс.Диск, откуда её можно подключить на любом другом устройстве.
🔹Markdown разметка. Привык к ней, в отличии от wiki. С wiki разметкой работать не люблю.
🔹Мне нравится интерфейс, распределение заметок по проектам. Почему-то не во всех подобных программах это есть.
🔹Полностью бесплатный и кроссплатформенный. У меня стоит ещё на смартфоне. Базу обновляю вручную через Яндекс.Диск. Со смартфона смотрю крайне редко. Работаю только с ноута.
🔴 Минусы Joplin:
🔹Тормозное приложение на каком-то современном браузерном фреймворке. Установщик весит под 300 Мб. Во время работы заметна неповоротливость, но в целом не критично. Плюс-минус как у другого подобного софта.
🔹Неудобная работа с таблицами, поэтому я их почти не использую.
🔹Не шифруется локальная база, с которой работает приложение. То, что я упоминал выше на Яндекс.Диске это именно экспорт, то есть копия рабочей базы. Выгруженные данные зашифрованы, а локальные нет. Это не очень хорошо, но я там не храню ничего особенного.
🔹Неудобный мобильный клиент для смартфона. Мне не сильно критично, но имейте ввиду.
В общем-то, никаких особых возможностей и удобств нет, как и косяков. Меня по совокупности устраивает. В первую очередь экспортом шифрованной базы на внешний диск. Работа через браузер с установленным сервисом где-то в интернете мне не нужна. Работаю с Joplin каждый день. Много там всего храню.
Если будете подбирать себе подобную программу, вот список того, на что стоит обратить внимание:
▪️ Memos
▪️ Obsidian
▪️ Trilium Notes
▪️ Appflowy
▪️ Notea
▪️ CherryTree
▪️ MyTetra
▪️ Focalboard
▪️ Standard Notes
▪️ Nimbus Note
▪️ Notesnook
Сразу предвещая ещё вопросы, скажу, что задачи с недавних пор полностью веду в Singularity. Понравилось приложение. Перешёл на него с Todoist. Тоже пользуюсь каждый день. У меня там все дела и по работе, и личные.
#заметки #подборка
{kind=link}
Знаю, что среди моих читателей есть люди, которые ведут свои сайты, поэтому решил немного коснуться этой темы, так как у меня очень большой практический опыт по ней. Речь пойдёт про поисковые системы и системы аналитики от них.
Изначально хотел написать только про on-premise open source систему аналитики matomo, как альтернативу Google Analytics и Яндекс Метрики, но решил немного расширить тему и пояснить некоторые моменты.
Если у вас на сайте основной трафик приходит из поисковых систем, то отказываться от их аналитики и рекламы не стоит. Даже если вы не хотите показывать посетителям рекламу, разместите хотя бы один рекламный блог где-нибудь в сторонке, но чтобы он хоть немного показывался. Это важно для ранжирования.
Я лично наблюдал связь рекламы с ранжированием. Когда стояла реклама от Google, у меня доля трафика от этого поисковика была выше, чем от Яндекса. Как только поменял рекламу, пропорция изменилась в обратную сторону. Хотя сам сайт я не менял при этом. Такое поведение поисковиков логично. Они же зарабатывают с рекламы. Им выгодно поднимать в выдаче выше те сайты, которые крутят их рекламу.
То же самое с аналитикой. Поисковики снимают метрики, связанные с поведением пользователей, через свою аналитику. Если у вас сайт хороший и метрики тоже на нормальном уровне, то для вас выгодно размещение аналитики от поисковиков. Я видел сайты и сообщения авторов, что они полностью за open soure и не хотят ставить счётчики и рекламу от интернет гигантов Яндекса или Google. Позиция эта понятна, но нужно понимать, что и трафика в полной мере вы от них не получите.
Если ваша цель всё же донести свою информацию для читателей, то отказываться от счётчиков и даже рекламы не стоит. Как я уже сказал, имеет смысл поставить хотя бы один рекламный блок того поисковика, на который вы больше ориентируетесь.
А теперь, собственно, к Matomo. Это бесплатная версия бывшего Piwik, который теперь стал Piwik PRO и бесплатной версии не имеет. Если ваш сайт не зависит от притока посетителей из поисковых систем, то можно смело ставить собственную аналитику. Это облегчит сайт, увеличит скорость загрузки и уменьшит TTFB (Time to First Byte). Для пользователей сайт будет более комфортный в использовании.
Matomo представляет из себя обычное веб приложение на php. Разворачивается на любом хостинге, ставится код счётчика на сайт и просматривается аналитика через админку. Инструкция по установке есть на сайте. Достаточно просто положить исходники в директорию веб сервера и запустить скрипт установки. Это может быть любой сервер, не обязательно тот же, где развёрнут сайт.
У Matomo есть готовые интеграции со всеми популярными CMS и прочими онлайн движками. Поддерживается почти всё более-менее популярное. Можете аналитику воткнуть даже на свою веб почту roundcube. Полный список интеграций в отдельном разделе на сайте. Помимо сбора информации через встраиваемый код непосредственно на сайте, можно собирать данные только через логи веб сервера.
Среди бесплатных аналогов подобного продукта отмечу:
◽PostHog - очень навороченная аналитика на базе caddy, clickhouse, kafka, zookeeper, postgres, redis, minio. Там всё по-взрослому: запись сессий, отслеживание конверсий, A/B тестирование и т.д. Это для крупных проектов, которые не хотят отдавать свою информацию куда-то на сторону.
◽Umami - маленькая лёгкая аналитика без особых наворотов. Собирает только основные метрики о посетителях: просмотры, посещения, источники, utm метки и некоторые другие данные.
Matomo получается посередине между ними. Возможностей меньше чем у PostHog, но больше, чем у Umami.
⇨ Сайт / Исходники
#website
Изначально хотел написать только про on-premise open source систему аналитики matomo, как альтернативу Google Analytics и Яндекс Метрики, но решил немного расширить тему и пояснить некоторые моменты.
Если у вас на сайте основной трафик приходит из поисковых систем, то отказываться от их аналитики и рекламы не стоит. Даже если вы не хотите показывать посетителям рекламу, разместите хотя бы один рекламный блог где-нибудь в сторонке, но чтобы он хоть немного показывался. Это важно для ранжирования.
Я лично наблюдал связь рекламы с ранжированием. Когда стояла реклама от Google, у меня доля трафика от этого поисковика была выше, чем от Яндекса. Как только поменял рекламу, пропорция изменилась в обратную сторону. Хотя сам сайт я не менял при этом. Такое поведение поисковиков логично. Они же зарабатывают с рекламы. Им выгодно поднимать в выдаче выше те сайты, которые крутят их рекламу.
То же самое с аналитикой. Поисковики снимают метрики, связанные с поведением пользователей, через свою аналитику. Если у вас сайт хороший и метрики тоже на нормальном уровне, то для вас выгодно размещение аналитики от поисковиков. Я видел сайты и сообщения авторов, что они полностью за open soure и не хотят ставить счётчики и рекламу от интернет гигантов Яндекса или Google. Позиция эта понятна, но нужно понимать, что и трафика в полной мере вы от них не получите.
Если ваша цель всё же донести свою информацию для читателей, то отказываться от счётчиков и даже рекламы не стоит. Как я уже сказал, имеет смысл поставить хотя бы один рекламный блок того поисковика, на который вы больше ориентируетесь.
А теперь, собственно, к Matomo. Это бесплатная версия бывшего Piwik, который теперь стал Piwik PRO и бесплатной версии не имеет. Если ваш сайт не зависит от притока посетителей из поисковых систем, то можно смело ставить собственную аналитику. Это облегчит сайт, увеличит скорость загрузки и уменьшит TTFB (Time to First Byte). Для пользователей сайт будет более комфортный в использовании.
Matomo представляет из себя обычное веб приложение на php. Разворачивается на любом хостинге, ставится код счётчика на сайт и просматривается аналитика через админку. Инструкция по установке есть на сайте. Достаточно просто положить исходники в директорию веб сервера и запустить скрипт установки. Это может быть любой сервер, не обязательно тот же, где развёрнут сайт.
У Matomo есть готовые интеграции со всеми популярными CMS и прочими онлайн движками. Поддерживается почти всё более-менее популярное. Можете аналитику воткнуть даже на свою веб почту roundcube. Полный список интеграций в отдельном разделе на сайте. Помимо сбора информации через встраиваемый код непосредственно на сайте, можно собирать данные только через логи веб сервера.
Среди бесплатных аналогов подобного продукта отмечу:
◽PostHog - очень навороченная аналитика на базе caddy, clickhouse, kafka, zookeeper, postgres, redis, minio. Там всё по-взрослому: запись сессий, отслеживание конверсий, A/B тестирование и т.д. Это для крупных проектов, которые не хотят отдавать свою информацию куда-то на сторону.
◽Umami - маленькая лёгкая аналитика без особых наворотов. Собирает только основные метрики о посетителях: просмотры, посещения, источники, utm метки и некоторые другие данные.
Matomo получается посередине между ними. Возможностей меньше чем у PostHog, но больше, чем у Umami.
⇨ Сайт / Исходники
#website
{kind=link}
Вчера несколько часов провозился с очень простой задачей, которая неожиданно доставила много хлопот. У меня есть два бесплатных сервера Microsoft Hyper-V Server 2016 и 2019. Решил немного перераспределить на них виртуалки, перенеся парочку с 2016 на 2019.
Задача простая и понятная. Можно использовать какие-то дополнительные инструменты для переноса, но проще всего сделать это в лоб. Останавливаем виртулаку, копируем её диск на другой гипервизор. Там создаём виртуальную машину и подключаем к ней перенесённый диск. Я и раньше постоянно так делал. Поступил подобным образом и в этот раз.
Виртуалка второго поколения с Windows благополучно переехала и запустилась. А вот с Debian 12 возникли неожиданные проблемы. Копирую диск, создаю новую виртуалку, подключаю к ней диск. Машина не стартует, не видит efi раздел. А это странно, так как раздел реально есть, с ним всё в порядке. К тому же винда благополучно переехала. На старом гипервизоре всё работает. Переезд с 2016 на 2019 полностью поддерживается. Это в обратную сторону могут быть проблемы, а с более старой версии на новую проблем быть не должно.
Тут я уже начал закапываться. Стал проверять версии виртуальных машин, менять их, пробовать разные поколения, создавать новые виртуалки с efi разделом и подсовывать им старый диск. Ничего не помогало. Уже понял, что предстоит длинная ночь, так как я не смогу спокойно уснуть, пока не разберусь, в чём проблема. Задача простая, проблем быть не должно.
Решил зайти с другого пути. Делаю штатно экспорт виртуальной машины, переношу на другой сервер, там запускаю импорт. Не работает. Импорт не видит виртуальную машину, говорит, что в директории ничего нет, хотя там всё лежит. С правами всё ОК, файлы читаются. Делаю ход конём. Экспортирую эту машину и пытаюсь сделать импорт на этом же гипервизоре. Это 100% должно работать. Но не работает. Импорт тоже не видит виртуальную машину в директории.
Тут я уже начинаю понимать, что у меня происходит какая-то локальная фигня и поиск мне тут не поможет. Иду в Veeam, делаю восстановление оттуда. Он обычно пишет ошибки совместимости, если перенос невозможен. Ошибок нет, восстановление идёт. Значит совместимость есть. Хранилище Veeam далековато, поэтому восстановление через него долгое, хочу всё же сделать напрямую и разобраться, в чём проблема.
Для управления гипервизорами Hyper-V я привык использовать стандартную оснастку Windows. Выделяю для задач администрирования отдельную виртуалку и туда в консоль подключаю все гипервизоры, чтобы удобно было управлять из одного места. Решил попробовать сделать Экспорт/Импорт через Windows Admin Center, который работает в браузере. Обычно я им не пользуюсь, так как там всё очень тормозит. Времени уходит раз в 5 больше, чем то же самое сделать в оснастке.
И о чудо, в Админ Центре экспорт и импорт прошёл без ошибок, виртуалка запустилась на новом месте, никаких проблем с efi разделом не возникло. Заработало всё сразу же.
Похоже на какой-то то ли локальный, то ли общий баг управления через оснастку, который проявился в таком неожиданном месте. Я даже не знаю, с чем это может быть связано. При подключении диска к виртуальной машине Linux 2-го поколения, созданной через оснастку управления Hyper-V, не видится во время загрузки efi раздел. Соответственно, система не загружается. С Windows машинами таких проблем нет. Как и нет проблем с переносом виртуалок Linux 1-го поколения без efi раздела.
Такая вот история вышла, которая вряд ли для кого-то ещё будет актуальна. Новых версий бесплатного Hyper-V больше не будет, так что пользоваться им большого смысла нет. Бесплатная связка Proxmox VE + PBS полностью закрывает вопросы виртуализации для малого и среднего бизнеса за 0 рублей. По Hyper-V буду скучать только в контексте использования в связке с Veeam. Это было удобно.
#hyperv
Задача простая и понятная. Можно использовать какие-то дополнительные инструменты для переноса, но проще всего сделать это в лоб. Останавливаем виртулаку, копируем её диск на другой гипервизор. Там создаём виртуальную машину и подключаем к ней перенесённый диск. Я и раньше постоянно так делал. Поступил подобным образом и в этот раз.
Виртуалка второго поколения с Windows благополучно переехала и запустилась. А вот с Debian 12 возникли неожиданные проблемы. Копирую диск, создаю новую виртуалку, подключаю к ней диск. Машина не стартует, не видит efi раздел. А это странно, так как раздел реально есть, с ним всё в порядке. К тому же винда благополучно переехала. На старом гипервизоре всё работает. Переезд с 2016 на 2019 полностью поддерживается. Это в обратную сторону могут быть проблемы, а с более старой версии на новую проблем быть не должно.
Тут я уже начал закапываться. Стал проверять версии виртуальных машин, менять их, пробовать разные поколения, создавать новые виртуалки с efi разделом и подсовывать им старый диск. Ничего не помогало. Уже понял, что предстоит длинная ночь, так как я не смогу спокойно уснуть, пока не разберусь, в чём проблема. Задача простая, проблем быть не должно.
Решил зайти с другого пути. Делаю штатно экспорт виртуальной машины, переношу на другой сервер, там запускаю импорт. Не работает. Импорт не видит виртуальную машину, говорит, что в директории ничего нет, хотя там всё лежит. С правами всё ОК, файлы читаются. Делаю ход конём. Экспортирую эту машину и пытаюсь сделать импорт на этом же гипервизоре. Это 100% должно работать. Но не работает. Импорт тоже не видит виртуальную машину в директории.
Тут я уже начинаю понимать, что у меня происходит какая-то локальная фигня и поиск мне тут не поможет. Иду в Veeam, делаю восстановление оттуда. Он обычно пишет ошибки совместимости, если перенос невозможен. Ошибок нет, восстановление идёт. Значит совместимость есть. Хранилище Veeam далековато, поэтому восстановление через него долгое, хочу всё же сделать напрямую и разобраться, в чём проблема.
Для управления гипервизорами Hyper-V я привык использовать стандартную оснастку Windows. Выделяю для задач администрирования отдельную виртуалку и туда в консоль подключаю все гипервизоры, чтобы удобно было управлять из одного места. Решил попробовать сделать Экспорт/Импорт через Windows Admin Center, который работает в браузере. Обычно я им не пользуюсь, так как там всё очень тормозит. Времени уходит раз в 5 больше, чем то же самое сделать в оснастке.
И о чудо, в Админ Центре экспорт и импорт прошёл без ошибок, виртуалка запустилась на новом месте, никаких проблем с efi разделом не возникло. Заработало всё сразу же.
Похоже на какой-то то ли локальный, то ли общий баг управления через оснастку, который проявился в таком неожиданном месте. Я даже не знаю, с чем это может быть связано. При подключении диска к виртуальной машине Linux 2-го поколения, созданной через оснастку управления Hyper-V, не видится во время загрузки efi раздел. Соответственно, система не загружается. С Windows машинами таких проблем нет. Как и нет проблем с переносом виртуалок Linux 1-го поколения без efi раздела.
Такая вот история вышла, которая вряд ли для кого-то ещё будет актуальна. Новых версий бесплатного Hyper-V больше не будет, так что пользоваться им большого смысла нет. Бесплатная связка Proxmox VE + PBS полностью закрывает вопросы виртуализации для малого и среднего бизнеса за 0 рублей. По Hyper-V буду скучать только в контексте использования в связке с Veeam. Это было удобно.
#hyperv
Microsoft
Windows Admin Center | Майкрософт
Используйте Microsoft Windows Admin Center для безопасного и эффективного управления серверами. Windows Admin Center позволяет менее чем за пять минут перейти от установки к управлению сервером.
Недавно к одной заметке про мониторинг содержимого сайта в комментариях скинули ссылку на обсуждение в stackoverflow тему парсинга HTML с помощью RegEx. Я сначала начал читать, не понял, в чём тут соль. Какая-то 14-ти летняя публикация, где не совсем понятно, о чём идёт речь. Потом немного вник в текст и прифигел от содержимого. Я так понял, это обсуждение заморозили и оставили на память потомкам в неизменном виде. Решил перевести сообщение и поделиться с вами.
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
Конец уже не стал переводить 😁
#юмор
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
inal snuffing of the lies of Man ALL IS LOŚ͖̩͇̗̪̏̈́T ALL IS LOST the pon̷y he comes he c̶̮omes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̟̍ͫͥͨe̠̅s ͎a̧͈͖r̽̾̈́͒͑ not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TeO͇̹̺ͅƝ̴ȳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝эS̨̥̫͎̭ͯ̔̀ͅКонец уже не стал переводить 😁
#юмор
{kind=link}
🎓 Давно ничего не было на тему обучения. Я раньше старался об этом писать по выходным. Все хорошие полезные обучающие материалы я уже обозревал ранее. Для тех, кто пропустил, рекомендую мою подборку, где собрал в единый список известные мне бесплатные курсы и материалы, которые можно посоветовать для базового изучения тем, кто хочет начать движение в сторону системного администрирования Linux и DevOps от простого к сложному.
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
{kind=link}
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
Я тут такой классный сервис увидел в полезных ссылках одного сайта:
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}