
🔝 ТОП постов за прошедший месяц. Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год (https://t.me/srv_admin/3379).
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые возможности по настройке (не только публикацию историй): https://t.me/boost/srv_admin.
📌 Больше всего просмотров:
◽️Заметка пропоследовательное параллельное соединение розеток rj45 (10930)
◽️Уязвимость CVE-2024-3094 в OpenSSH сервере (10694)
◽️Игра JOY OF PROGRAMMING (10435)
📌 Больше всего комментариев:
◽️Баг с переключением раскладки в Windows (316)
◽️Заметка пропоследовательное параллельное соединение розеток rj45 (184)
◽️Заметка про покупку монитора 27" с разрешением 2K (163)
📌 Больше всего пересылок:
◽️Подборка команд и полезных ссылок для Docker (826)
◽️Создание и использование TLS сертификатов через свой CA (716)
◽️Конфигуратор для СУБД PostgreSQL (533)
◽️Обучающая платформа KodeKloud (491)
📌 Больше всего реакций:
◽️Мем Позовите системного администратора (273)
◽️Олдскульный Small HTTP server на С++. (233)
◽️Заметка про покупку монитора 27" с разрешением 2K (198)
◽️Подборка команд и полезных ссылок для Docker (195)
#топ
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые возможности по настройке (не только публикацию историй): https://t.me/boost/srv_admin.
📌 Больше всего просмотров:
◽️Заметка про
◽️Уязвимость CVE-2024-3094 в OpenSSH сервере (10694)
◽️Игра JOY OF PROGRAMMING (10435)
📌 Больше всего комментариев:
◽️Баг с переключением раскладки в Windows (316)
◽️Заметка про
◽️Заметка про покупку монитора 27" с разрешением 2K (163)
📌 Больше всего пересылок:
◽️Подборка команд и полезных ссылок для Docker (826)
◽️Создание и использование TLS сертификатов через свой CA (716)
◽️Конфигуратор для СУБД PostgreSQL (533)
◽️Обучающая платформа KodeKloud (491)
📌 Больше всего реакций:
◽️Мем Позовите системного администратора (273)
◽️Олдскульный Small HTTP server на С++. (233)
◽️Заметка про покупку монитора 27" с разрешением 2K (198)
◽️Подборка команд и полезных ссылок для Docker (195)
#топ
Сегодня прям сходу после праздников расскажу про необычную систему автоматизации. Я несколько раз за неё брался и каждый раз откладывал, потому что не мог быстро с ней разобраться. В этот раз было побольше доступного времени, поэтому постарался объять и кратко рассказать так, чтобы было понятно.
Речь пойдёт про систему Kestra.io. Сразу скажу, для тех, кто знаком с n8n.io, что она на него немного похожа, но более функциональна. Это такой комбайн по автоматизации всего и вся с управлением через веб интерфейс с участием встроенных процедур и модулей. Эдакий заменитель самописных костылей. Приведу сразу пример задач, которые можно решать с его помощью:
💡Вы получаете pdf файл с таблицей. Вам надо её распознать и занести значения таблицы в базу данных SQL или в CVS файл для дальнейшей выгрузки в Excel. Похожая задача с получением pdf файла, его распознаванием и сохранением текстовой версии.
💡Вам надо собрать Docker контейнер, запустить его, дождаться выполнения каких-то действий, записать результат в лог файл.
💡Вам необходимо скачать json файл, отфильтровать некоторые данные, обработать их и вывести в веб интерфейсе Kestra.
💡Вы можете создать публичную веб форму, куда после ввода данных будет отправлено уведомление в какой-то чат. Человек в чате посмотрит эти данные и подтвердит их, после чего они будут через веб хук куда-то добавлены. Саму форму можно будет создать в Kestra.
💡Можно запустить shell скрипт и забрать его вывод в веб интерфейсе. За скриптом Kestra умеет ходить по хостам сама. В одном месте можно собрать все cron с хостов и управлять ими из одного места.
💡Можно по HTTP API забрать данные, обработать и положить в формате json в S3, или пульнуть в Zabbix API.
💡Kestra умеет запускать Ansible плейбуки и Terraform файлы, работать с GIT. Можно склонировать репу по какому-то событию и что-то запустить из неё.
В общем, это такой автоматизатор, которые может всё. Что-то через свои встроенные инструменты, что-то через плагины, что-то через самописные скрипты. При этом внутри есть разделение доступа на уровне namespaces, как это реализовано в современных IT продуктах, и обычная аутентификация.
Всю платформу можно полностью развернуть на своём железе без каких-то ограничений. Всё упаковано в Docker контейнер. Запускать так:
И можно идти в веб интерфейс на порт 8080. Сразу всё увидите там.
В платной версии дополнительные энтерпрайзные штуки, типа SSO, RBAC, хранение секретов и т.д.
Kestra по сути такой вспомогательный инструмент, который может работать вместе с системами CI/CD, мониторинга, сбора логов, интегрировать их с какими-то бизнес метриками и получать обработанные данные в человекочитаемом виде, куда-то отправлять их, уведомлять.
В то же время он же может помочь и одному человеку в выполнении какой-то ежедневной рутины. Например, по аналитике каких-то данных из множества источников. Но чтобы разобраться во всём этом, нужно будет потрудиться. Если писали пайплайны, то это будет просто, так как по своей сути задачи (flows) это те же пайплайны в формате yaml. Писать можно прямо в веб интерфейсе. Редактор удобный.
▶️ Несколько видео с примерами задач, которые я посмотрел:
⇨ обработка и работа с pdf
⇨ подробный обзор системы и несколько простых примеров
⇨ обзор от неизвестного итальянца (Я.Браузер отлично перевёл)
Не смог придумать осмысленного тэга для этой системы и других подобного рода. Пусть это будет #автоматизация.
⇨ Сайт / Исходники
#автоматизация
Речь пойдёт про систему Kestra.io. Сразу скажу, для тех, кто знаком с n8n.io, что она на него немного похожа, но более функциональна. Это такой комбайн по автоматизации всего и вся с управлением через веб интерфейс с участием встроенных процедур и модулей. Эдакий заменитель самописных костылей. Приведу сразу пример задач, которые можно решать с его помощью:
💡Вы получаете pdf файл с таблицей. Вам надо её распознать и занести значения таблицы в базу данных SQL или в CVS файл для дальнейшей выгрузки в Excel. Похожая задача с получением pdf файла, его распознаванием и сохранением текстовой версии.
💡Вам надо собрать Docker контейнер, запустить его, дождаться выполнения каких-то действий, записать результат в лог файл.
💡Вам необходимо скачать json файл, отфильтровать некоторые данные, обработать их и вывести в веб интерфейсе Kestra.
💡Вы можете создать публичную веб форму, куда после ввода данных будет отправлено уведомление в какой-то чат. Человек в чате посмотрит эти данные и подтвердит их, после чего они будут через веб хук куда-то добавлены. Саму форму можно будет создать в Kestra.
💡Можно запустить shell скрипт и забрать его вывод в веб интерфейсе. За скриптом Kestra умеет ходить по хостам сама. В одном месте можно собрать все cron с хостов и управлять ими из одного места.
💡Можно по HTTP API забрать данные, обработать и положить в формате json в S3, или пульнуть в Zabbix API.
💡Kestra умеет запускать Ansible плейбуки и Terraform файлы, работать с GIT. Можно склонировать репу по какому-то событию и что-то запустить из неё.
В общем, это такой автоматизатор, которые может всё. Что-то через свои встроенные инструменты, что-то через плагины, что-то через самописные скрипты. При этом внутри есть разделение доступа на уровне namespaces, как это реализовано в современных IT продуктах, и обычная аутентификация.
Всю платформу можно полностью развернуть на своём железе без каких-то ограничений. Всё упаковано в Docker контейнер. Запускать так:
# docker run --pull=always --rm -it -p 8080:8080 --user=root \ -v /var/run/docker.sock:/var/run/docker.sock \ -v /tmp:/tmp kestra/kestra:latest-full server localИ можно идти в веб интерфейс на порт 8080. Сразу всё увидите там.
В платной версии дополнительные энтерпрайзные штуки, типа SSO, RBAC, хранение секретов и т.д.
Kestra по сути такой вспомогательный инструмент, который может работать вместе с системами CI/CD, мониторинга, сбора логов, интегрировать их с какими-то бизнес метриками и получать обработанные данные в человекочитаемом виде, куда-то отправлять их, уведомлять.
В то же время он же может помочь и одному человеку в выполнении какой-то ежедневной рутины. Например, по аналитике каких-то данных из множества источников. Но чтобы разобраться во всём этом, нужно будет потрудиться. Если писали пайплайны, то это будет просто, так как по своей сути задачи (flows) это те же пайплайны в формате yaml. Писать можно прямо в веб интерфейсе. Редактор удобный.
▶️ Несколько видео с примерами задач, которые я посмотрел:
⇨ обработка и работа с pdf
⇨ подробный обзор системы и несколько простых примеров
⇨ обзор от неизвестного итальянца (Я.Браузер отлично перевёл)
Не смог придумать осмысленного тэга для этой системы и других подобного рода. Пусть это будет #автоматизация.
⇨ Сайт / Исходники
#автоматизация
{kind=link}
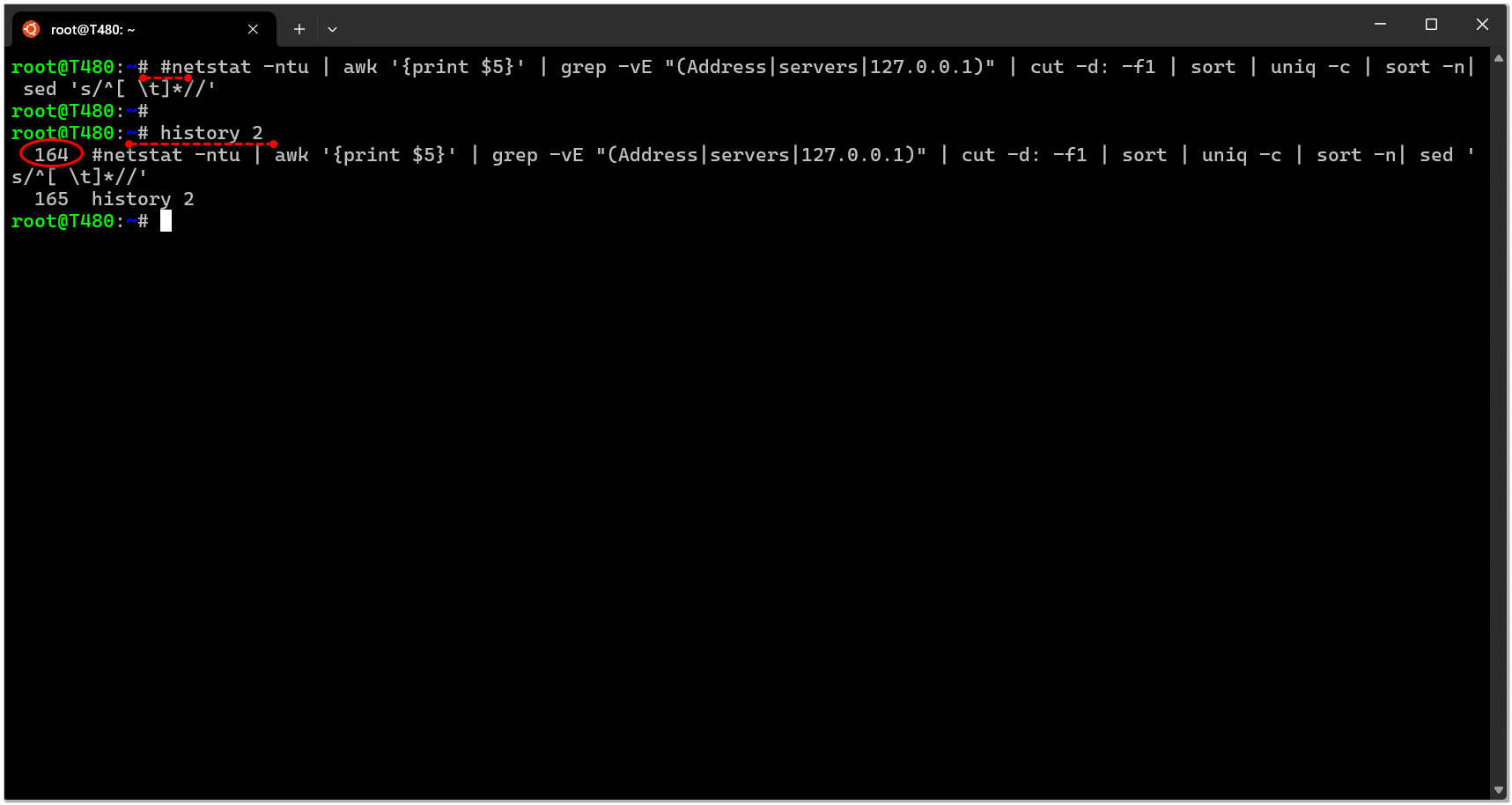
Расскажу про необычную комбинацию клавиш в консоли bash, о которой наверняка многие не знают, а она иногда бывает полезной. Это из серии советов, когда те, кто про него знают, думаю, что тут такого, зачем об этом писать. А кто-то вообще об этом никогда не слышал.
Допустим, вы набираете в консоли длинную команду, а потом вдруг решили, что запускать её по какой-то причине не будете. Но вам хочется её сохранить, чтобы запустить потом. Самое первое, что приходит в голову, это скопировать её и куда-то записать. Но можно поступить проще и быстрее.
Нажимаем комбинацию Alt+Shif+3. После этого к команде автоматически добавляется в самое начало
Такой вот маленький трюк. Если не знали, то запомните. Облегчает работу в консоли.
#bash
Допустим, вы набираете в консоли длинную команду, а потом вдруг решили, что запускать её по какой-то причине не будете. Но вам хочется её сохранить, чтобы запустить потом. Самое первое, что приходит в голову, это скопировать её и куда-то записать. Но можно поступить проще и быстрее.
Нажимаем комбинацию Alt+Shif+3. После этого к команде автоматически добавляется в самое начало
# и команда как-бы выполняется, но на самом деле не выполняется, потому что стоит #. При этом команда улетает вместе с # в history. После этого её можно там посмотреть, либо быстро вызвать через поиск по Ctrl+R. Если искать по #, то она первая и выскочит.Такой вот маленький трюк. Если не знали, то запомните. Облегчает работу в консоли.
#bash
{kind=link}
Существует эффективный стандарт сжатия zstd. Не так давно современные браузеры стали его поддерживать, так что можно использовать в веб серверах. Разработчики Angie подсуетились и подготовили модуль для своего веб сервера, так что включить сжатие zstd максимально просто и быстро. Достаточно установить модуль в виде deb пакета и добавить настройки в конфигурацию, которые идентичны настройкам gzip, только название меняется на zstd.
По этому поводу вышел очень информативный ролик на ютубе:
⇨ Zstd (Zstandard): новый стандарт сжатия текста. Полный тест
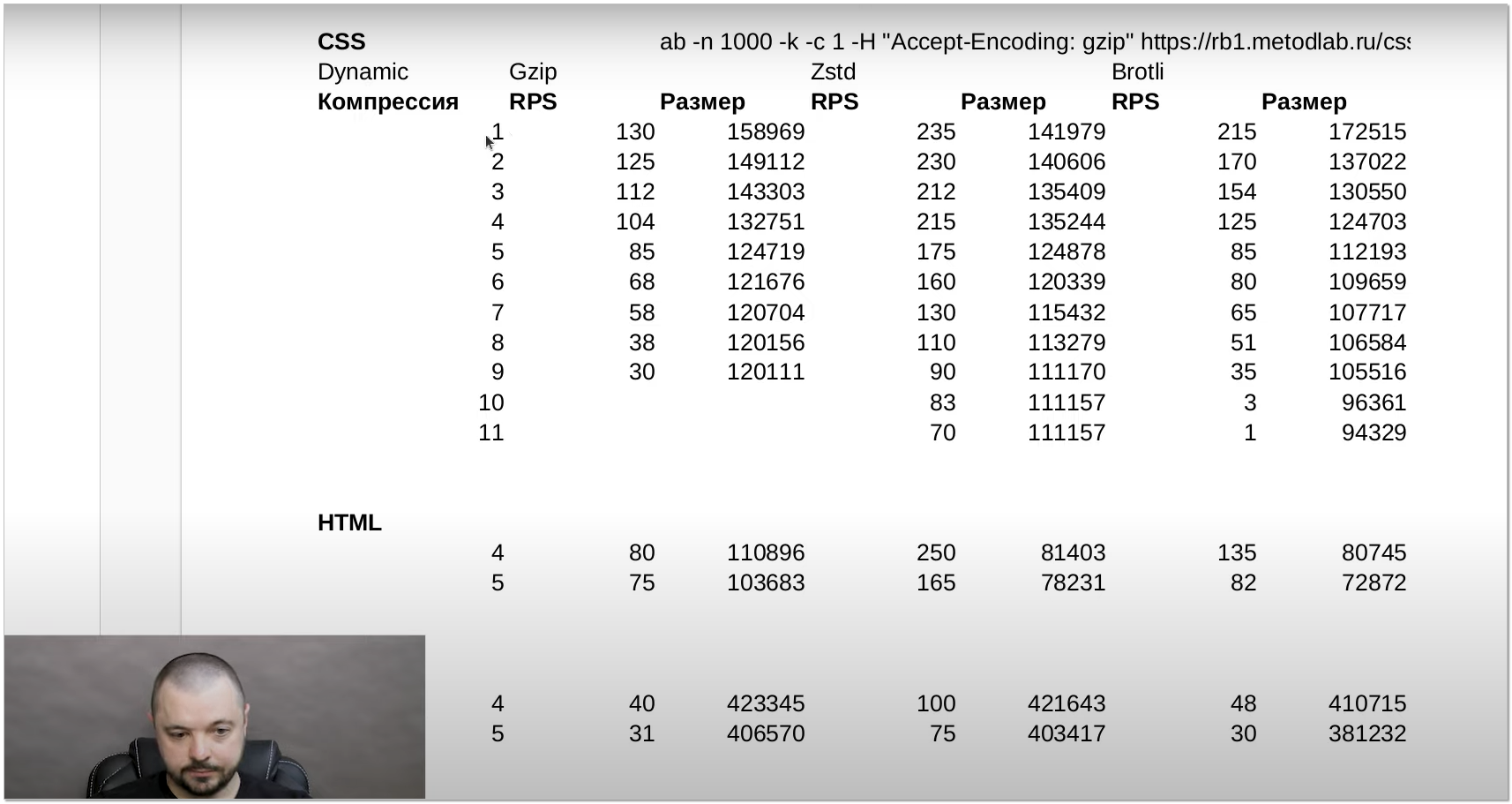
Автор не только показал, как настроить zstd на веб сервере, но и сравнил его эффективность с привычными gzip и brotli. Результаты тестирования в динамическом сжатии получились очень любопытные. Zstd оказался лучше всех. Но если разница с brotli не сильно заметна, то вот gzip на фоне остальных выглядит очень медленным. Буквально в разы в некоторых случаях.
Я решил провести свои тесты, чтобы убедиться в такой большой разнице. Сразу скажу, что если не настроено https, то браузеры не будут использовать ни brotli, ни zstd. Не знаю, с чем это связано, но я потратил некоторое время, пока не разобрался с тем, почему не работает ничего, кроме gzip. И второй момент. Если на веб сервере настроены все 3 типа сжатия, то разные браузеры выбирают разное сжатие: либо brotli, либо zstd. Gzip не выбирает никто.
Тестировал так же, как и автор ролика. Установил Angie и оба модуля сжатия:
Подключил оба модуля в angie.conf:
И добавил для них настройки:
Если использовать ванильный Nginx, то придётся самостоятельно собирать его с нужными модулями 🤷♂️
Тестировал с помощью ab, передавая ему метод компрессии через заголовок:
Не буду приводить свои результаты, так как они получились примерно такие же, как у автора ролика, только разница между zstd и brotli с компрессией 4 поменьше. Zstd по rps (247) быстрее всех. Brotli чуть лучше жмёт в плане объёма, то есть трафик будет ниже, но и rps (211) немного меньше, чем у zstd.
В Angie очень легко настроить и brotli, и zstd, и gzip, так что имеет смысл это сделать. Клиент пусть сам выбирает, какой тип сжатия он будет использовать.
Один важный момент, который я вынес из этой темы. Не нужно ставить сжатие выше 3 или 4. Дальше идёт очень существенное падение производительности при незначительном уменьшении размера файлов. Я раньше бездумно ставил 9 и думал, что современные процессоры и так нормально вытягивают, если сервер не нагружен в потолок. Это не так. Смысла в высокой компрессии нет.
#webserver #angie
По этому поводу вышел очень информативный ролик на ютубе:
⇨ Zstd (Zstandard): новый стандарт сжатия текста. Полный тест
Автор не только показал, как настроить zstd на веб сервере, но и сравнил его эффективность с привычными gzip и brotli. Результаты тестирования в динамическом сжатии получились очень любопытные. Zstd оказался лучше всех. Но если разница с brotli не сильно заметна, то вот gzip на фоне остальных выглядит очень медленным. Буквально в разы в некоторых случаях.
Я решил провести свои тесты, чтобы убедиться в такой большой разнице. Сразу скажу, что если не настроено https, то браузеры не будут использовать ни brotli, ни zstd. Не знаю, с чем это связано, но я потратил некоторое время, пока не разобрался с тем, почему не работает ничего, кроме gzip. И второй момент. Если на веб сервере настроены все 3 типа сжатия, то разные браузеры выбирают разное сжатие: либо brotli, либо zstd. Gzip не выбирает никто.
Тестировал так же, как и автор ролика. Установил Angie и оба модуля сжатия:
# curl -o /etc/apt/trusted.gpg.d/angie-signing.gpg https://angie.software/keys/angie-signing.gpg# echo "deb https://download.angie.software/angie/debian/ `lsb_release -cs` main" | tee /etc/apt/sources.list.d/angie.list > /dev/null# apt update && apt install angie angie-module-zstd angie-module-brotliПодключил оба модуля в angie.conf:
load_module modules/ngx_http_zstd_static_module.so;load_module modules/ngx_http_zstd_filter_module.so;load_module modules/ngx_http_brotli_static_module.so;load_module modules/ngx_http_brotli_filter_module.so;И добавил для них настройки:
gzip on; gzip_static on; gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/x-icon image/svg+xml application/x-font-ttf; gzip_comp_level 4; gzip_proxied any; gzip_min_length 1000; gzip_vary on; brotli on; brotli_static on; brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/x-icon image/svg+xml application/x-font-ttf; brotli_comp_level 4; zstd on; zstd_static on; zstd_min_length 256; zstd_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/x-icon image/svg+xml application/x-font-ttf; zstd_comp_level 4;Если использовать ванильный Nginx, то придётся самостоятельно собирать его с нужными модулями 🤷♂️
Тестировал с помощью ab, передавая ему метод компрессии через заголовок:
# ab -n 1000 -k -c 1 -H "Accept-Encoding: zstd" https://10.20.1.36/scripts.jsНе буду приводить свои результаты, так как они получились примерно такие же, как у автора ролика, только разница между zstd и brotli с компрессией 4 поменьше. Zstd по rps (247) быстрее всех. Brotli чуть лучше жмёт в плане объёма, то есть трафик будет ниже, но и rps (211) немного меньше, чем у zstd.
В Angie очень легко настроить и brotli, и zstd, и gzip, так что имеет смысл это сделать. Клиент пусть сам выбирает, какой тип сжатия он будет использовать.
Один важный момент, который я вынес из этой темы. Не нужно ставить сжатие выше 3 или 4. Дальше идёт очень существенное падение производительности при незначительном уменьшении размера файлов. Я раньше бездумно ставил 9 и думал, что современные процессоры и так нормально вытягивают, если сервер не нагружен в потолок. Это не так. Смысла в высокой компрессии нет.
#webserver #angie
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Одна из лучших песен по тексту и музыке на тему системных администраторов. Своеобразный гимн, как у программистов. Это перепевка песни "Атланты" Александра Городницкого.
Песня из далёких 90-х годов. Может начало 2000-х. Не смог найти точную инфу. Я её с двухтысячных знаю. Причём, она не кажется сильно устаревшей. Если убрать оттуда зарплату, которую не платят (сейчас в IT всем платят), а сервер заменить на cloud, то и не поймешь, что это глубокая старина.
#юмор #музыка
Песня из далёких 90-х годов. Может начало 2000-х. Не смог найти точную инфу. Я её с двухтысячных знаю. Причём, она не кажется сильно устаревшей. Если убрать оттуда зарплату, которую не платят (сейчас в IT всем платят), а сервер заменить на cloud, то и не поймешь, что это глубокая старина.
#юмор #музыка
Решил сделать шпаргалку для копипасты по отправке email с аутентификацией из консоли через внешний smtp сервер. Нередко приходится этим заниматься как напрямую в консоли, так и в каких-то скриптах.
🔹В Linux самый простой вариант через Curl. Но там есть один нюанс, который создаёт неудобство, если вы хотите быстро отправить письмо через консоль. Заголовки и тело письма задаются через отдельный текстовый файл. Чтобы всё это уместить в одну команду, приходится использовать примерно такую конструкцию:
🔹Если вы будете использовать подобную отправку регулярно, либо где-то в скрипте, то скорее всего захочется вести лог передачи, отслеживать статус отправки и т.д. В таком случае проще всего настроить локально postfix или ssmtp. Для них нужно будет подготовить простой конфиг. Пример для postfix:
Добавляем в конфиг
Создаём файл
Создаем db файл.
Теперь можно перезапустить postfix и проверить работу.
Лог отправки, в том числе ответ принимающего сервера, будет в системном логе
🔹Ниже пример отправки почты через ssmtp.
В конфиг
Отправляем почту:
Утилита mail отправит почту через ssmtp. Я чаще отдаю предпочтение postfix, потому что у него лог кажется более информативным и привычным.
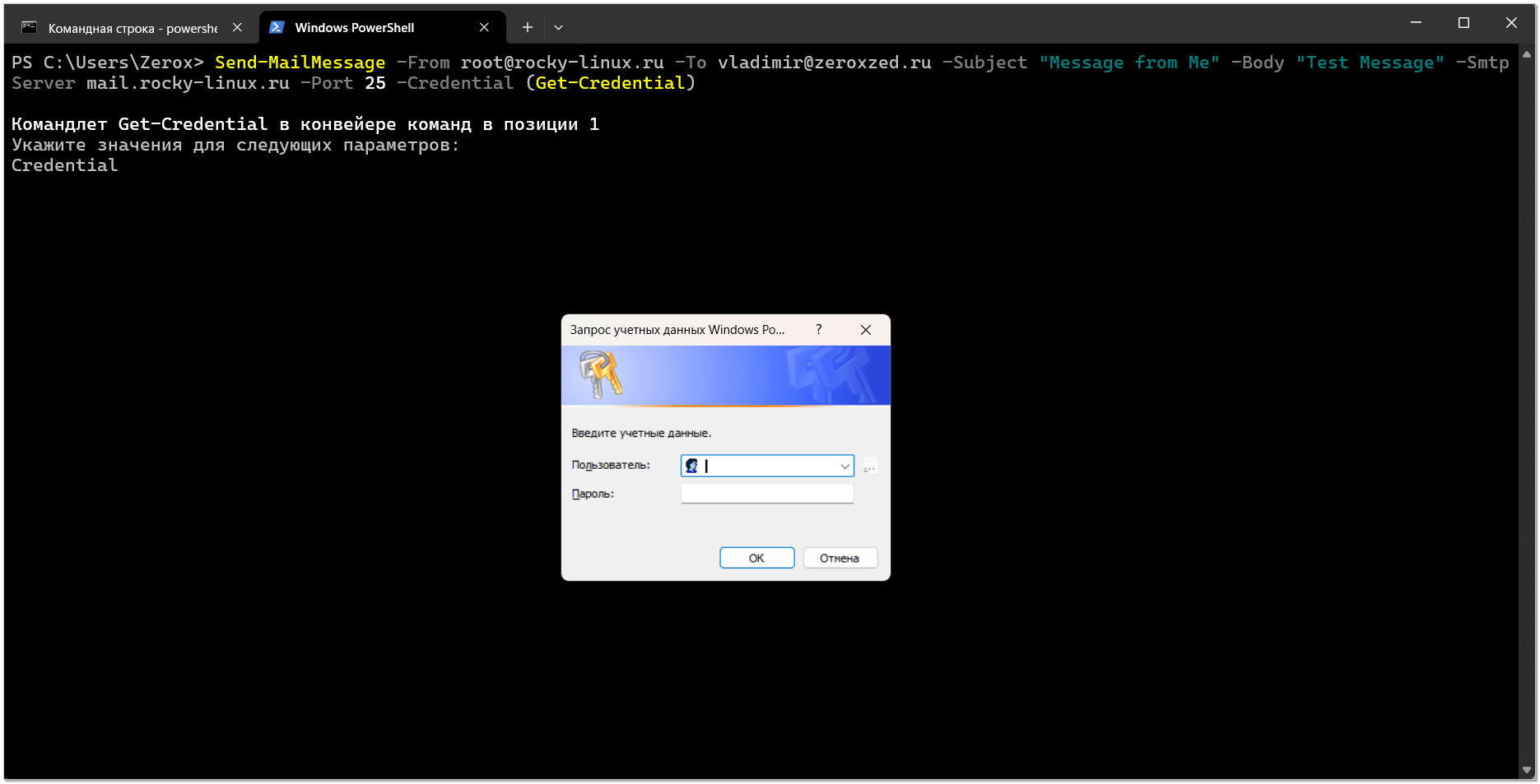
🔹В Windows можно использовать для этих же целей PowerShell. Вот как выглядит там отправка:
У вас откроется традиционное окно Windows для аутентификации. Туда нужно будет ввести логин и пароль от ящика. Если открыть cmd, перейти в powershell и выполнить указанную команду, то окно с аутентификацией почему-то не выскакивает. А если открыть сразу консоль PowerShell, то всё в порядке. Похоже на какой-то баг. Ошибка быстро гуглится, как и решение. Если не хочется вводить данные для аутентификации вручную, то их можно можно сохранить в переменной, в случае, если используется скрипт.
#mailserver
🔹В Linux самый простой вариант через Curl. Но там есть один нюанс, который создаёт неудобство, если вы хотите быстро отправить письмо через консоль. Заголовки и тело письма задаются через отдельный текстовый файл. Чтобы всё это уместить в одну команду, приходится использовать примерно такую конструкцию:
# echo -e "Subject: Test Subject \nTest body message." > /tmp/body.txt && curl -v --url "smtp://mail.server.ru:25" --mail-from root@server.ru --mail-rcpt user@example.com --user 'root@server.ru:password123' --upload-file "/tmp/body.txt"🔹Если вы будете использовать подобную отправку регулярно, либо где-то в скрипте, то скорее всего захочется вести лог передачи, отслеживать статус отправки и т.д. В таком случае проще всего настроить локально postfix или ssmtp. Для них нужно будет подготовить простой конфиг. Пример для postfix:
# apt install postfix mailutilsДобавляем в конфиг
/etc/postfix/main.cfrelayhost = mail.server.ru:25smtp_use_tls = yessmtp_sasl_auth_enable = yessmtp_sasl_password_maps = hash:/etc/postfix/sasl_passwdsmtp_sasl_security_options = noanonymoussmtp_tls_security_level = mayСоздаём файл
/etc/postfix/sasl_passwd с данными для аутентификации в таком формате:mail.server.ru:25 root@server.ru:password123Создаем db файл.
# postmap /etc/postfix/sasl_passwdТеперь можно перезапустить postfix и проверить работу.
# systemctl restart postfix# echo "Test body message." | mail -s "Test Subject" user@example.comЛог отправки, в том числе ответ принимающего сервера, будет в системном логе
/var/log/syslog или /var/log/mail.log. Удобно для отладки или мониторинга.🔹Ниже пример отправки почты через ssmtp.
# apt install ssmtpВ конфиг
/etc/ssmtp/ssmtp.conf пишем:mailhub=mail.server.ru:25hostname=mail.server.ruroot=root@server.ruAuthUser=root@server.ruAuthPass=password123UseSTARTTLS=YESUseTLS=YESОтправляем почту:
# echo "Test body message." | mail -s "Test Subject" user@example.comУтилита mail отправит почту через ssmtp. Я чаще отдаю предпочтение postfix, потому что у него лог кажется более информативным и привычным.
🔹В Windows можно использовать для этих же целей PowerShell. Вот как выглядит там отправка:
> Send-MailMessage -From root@server.ru -To user@example.com -Subject "Test Subject" -Body "Test body message." -SmtpServer mail.server.ru -Port 25 -Credential (Get-Credential)У вас откроется традиционное окно Windows для аутентификации. Туда нужно будет ввести логин и пароль от ящика. Если открыть cmd, перейти в powershell и выполнить указанную команду, то окно с аутентификацией почему-то не выскакивает. А если открыть сразу консоль PowerShell, то всё в порядке. Похоже на какой-то баг. Ошибка быстро гуглится, как и решение. Если не хочется вводить данные для аутентификации вручную, то их можно можно сохранить в переменной, в случае, если используется скрипт.
#mailserver
{kind=link}
В популярных файловых системах на Linux есть одна полезная особенность. Любой файл или каталог можно сделать неизменяемым с помощью атрибута immutable. Его ещё называют immutable bit. Его может установить только root. Он же его может и убрать.
Сразу покажу на примере, где это может быть актуально. Я уже как-то делал ранее заметки на тему заполнения локальной файловой системы, когда вы копируете что-то в точку монтирования, например,
Бороться с этим можно разными способами. Например, проверять перед копированием монтирование с помощью findmnt. А можно просто с помощью флага immutable запретить запись в директорию:
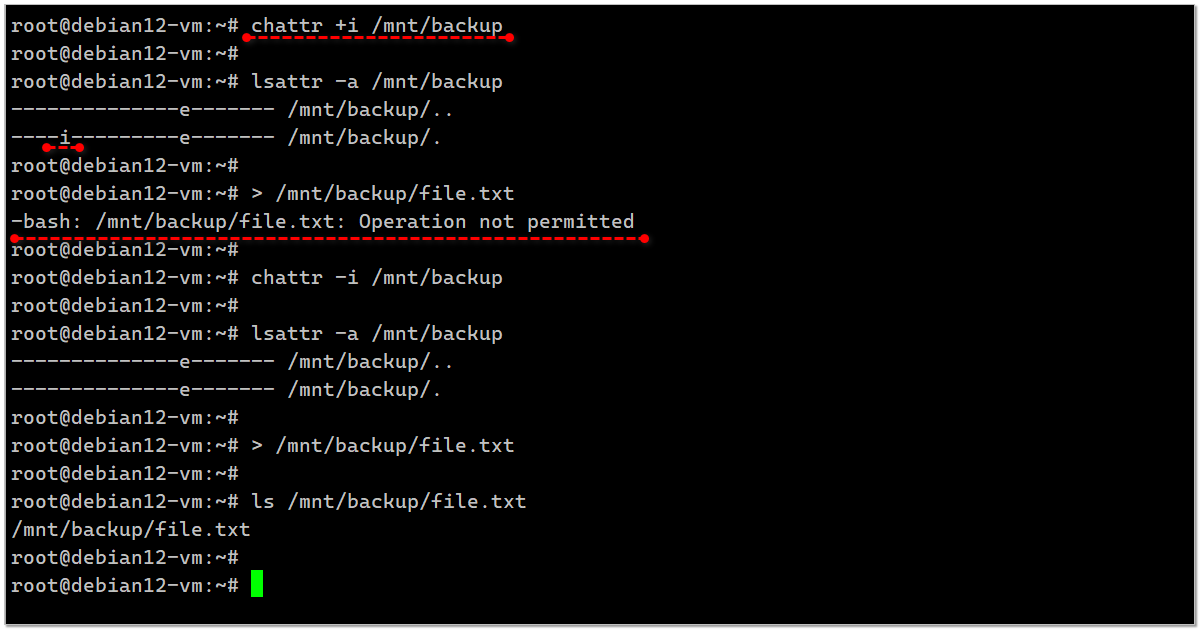
Так как это признак файловой системы, то когда сетевой диск будет смонтирован поверх, писать в директорию можно будет. А если диск не примонтирован, то в локальную директорию записать не получится:
Убираем бит и пробуем ещё раз:
Посмотреть наличие этого бита можно командой lsattr. Для директории необходимо добавлять ключ
Буква
Можно придумать разное применение этого бита. В основном это будут какие-то костыли, которыми не стоит сильно увлекаться. Например, можно очень просто запретить изменение паролей пользователям. Достаточно установить immutable bit на файл
Теперь если пользователь попытается поменять пароль, то у него ничего не выйдет. Даже у root:
Необходимо вручную снять бит. Можно запретить изменение какого-то конфига на сайте или в системе. Когда-то давно видел, как публичные хостинги использовали этот бит, чтобы запретить пользователям удалять некоторые файлы, которые доступны в их домашних директориях.
Также читал, что некоторые трояны и прочие зловреды защищают себя от удаления или изменения с помощью immutable bit. Так что если расследуете взлом, имеет смысл рекурсивно пройтись по всем системным бинарям и проверить у них этот бит. Отсюда следует параноидальный способ защиты от вирусов - использование этого бита на всех важных системных файлах. Нужно только понимать, что для обновления системы, этот бит нужно будет снимать и потом ставить заново.
Если знаете ещё какое-то полезное применение immutable, поделитесь в комментах. Я видел, что некоторые
Вообще, это неплохой вопрос для собеседований или шуток над каким-то незнающим человеком. Обычно в Unix root может удалить всё, что угодно, даже работающую систему. А тут он вдруг по какой-то причине не может удалить или изменить файл, записать в директорию.
#linux
Сразу покажу на примере, где это может быть актуально. Я уже как-то делал ранее заметки на тему заполнения локальной файловой системы, когда вы копируете что-то в точку монтирования, например,
/mnt/backup, которая подключает сетевой диск. В случае, если диск по какой-то причине не подключился, а вы в точку монтирования /mnt/backup залили кучу файлов, они всё лягут локально в корень и заполнят его. Бороться с этим можно разными способами. Например, проверять перед копированием монтирование с помощью findmnt. А можно просто с помощью флага immutable запретить запись в директорию:
# chattr +i /mnt/backupТак как это признак файловой системы, то когда сетевой диск будет смонтирован поверх, писать в директорию можно будет. А если диск не примонтирован, то в локальную директорию записать не получится:
# > /mnt/backup/file.txtbash: /mnt/backup/file.txt: Operation not permittedУбираем бит и пробуем ещё раз:
# chattr -i /mnt/backup# > /mnt/backup/file.txt# ls /mnt/backup/file.txt/mnt/backup/file.txtПосмотреть наличие этого бита можно командой lsattr. Для директории необходимо добавлять ключ
-a, для отдельных файлов он не нужен.# lsattr -a /mnt/backup--------------e------- /mnt/backup/..----i---------e------- /mnt/backup/.Буква
i указывает, что immutable bit установлен. Про псевдопапки точка и две точки читайте отдельную заметку. Можно придумать разное применение этого бита. В основном это будут какие-то костыли, которыми не стоит сильно увлекаться. Например, можно очень просто запретить изменение паролей пользователям. Достаточно установить immutable bit на файл
/etc/shadow:# chattr +i /etc/shadowТеперь если пользователь попытается поменять пароль, то у него ничего не выйдет. Даже у root:
# passwd rootpasswd: Authentication token manipulation errorpasswd: password unchangedНеобходимо вручную снять бит. Можно запретить изменение какого-то конфига на сайте или в системе. Когда-то давно видел, как публичные хостинги использовали этот бит, чтобы запретить пользователям удалять некоторые файлы, которые доступны в их домашних директориях.
Также читал, что некоторые трояны и прочие зловреды защищают себя от удаления или изменения с помощью immutable bit. Так что если расследуете взлом, имеет смысл рекурсивно пройтись по всем системным бинарям и проверить у них этот бит. Отсюда следует параноидальный способ защиты от вирусов - использование этого бита на всех важных системных файлах. Нужно только понимать, что для обновления системы, этот бит нужно будет снимать и потом ставить заново.
Если знаете ещё какое-то полезное применение immutable, поделитесь в комментах. Я видел, что некоторые
/etc/hosts или /etc/resolve.conf им защищают от изменений. Вообще, это неплохой вопрос для собеседований или шуток над каким-то незнающим человеком. Обычно в Unix root может удалить всё, что угодно, даже работающую систему. А тут он вдруг по какой-то причине не может удалить или изменить файл, записать в директорию.
#linux
{kind=link}
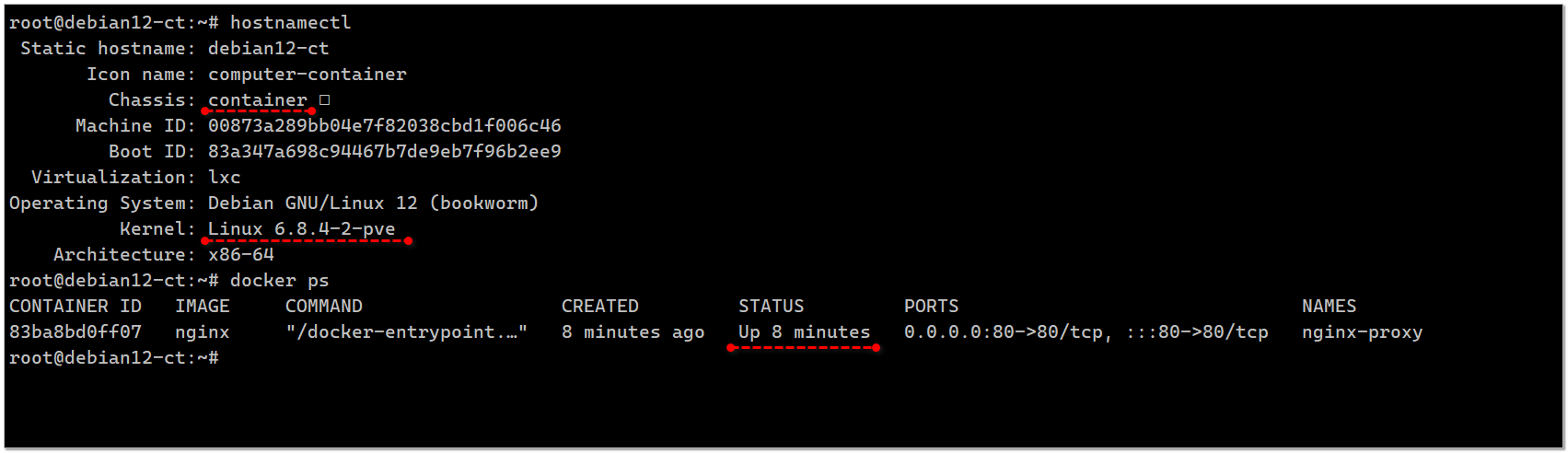
Если вдруг вам хочется чего-нибудь странного, то могу вам кое-что предложить. Например, запустить контейнеры Docker в LXC контейнере Proxmox. Я изначально думал, что это так просто не сработает. Всегда запускаю контейнеры в виртуалках. Тут решил попробовать в LXC, сразу заработало.
Создаёте обычный LXC контейнер с нужными ресурсами. В параметрах через веб интерфейс необходимо установить nesting=1. Далее запускаете его и устанавливаете Docker:
Всё работает. Никаких дополнительных настроек делать не пришлось. Проверял на Proxmox VE 8.2.2. В принципе, удобно. Получается можно спокойно в LXC изолировать контейнеры и запускать их. Мне казалось, что раньше это так не работало.
#proxmox #docker
Создаёте обычный LXC контейнер с нужными ресурсами. В параметрах через веб интерфейс необходимо установить nesting=1. Далее запускаете его и устанавливаете Docker:
# apt install curl# curl https://get.docker.com | bash -# docker run --rm hello-worldHello from Docker!This message shows that your installation appears to be working correctly.Всё работает. Никаких дополнительных настроек делать не пришлось. Проверял на Proxmox VE 8.2.2. В принципе, удобно. Получается можно спокойно в LXC изолировать контейнеры и запускать их. Мне казалось, что раньше это так не работало.
#proxmox #docker
{kind=link}
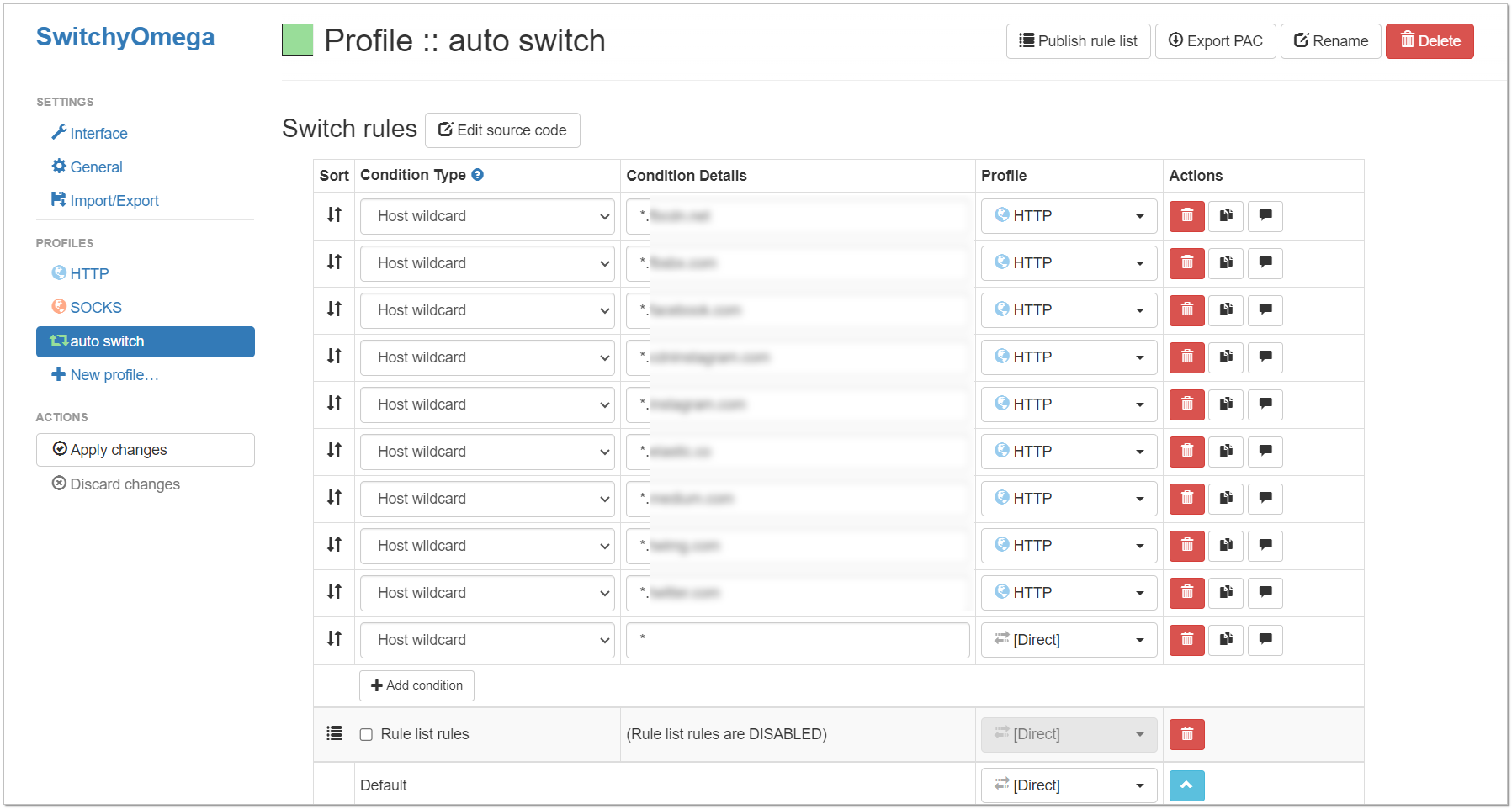
Недавно один из подписчиков, видя мои посты про прокси по ssh, посоветовал расширение для браузера SwitchyOmega. Я когда-то давно искал подобное, но ничего не нашёл, что устроило бы меня. В итоге просто использовал разные браузеры под разные прокси.
Попробовал это расширение. Оно реально удобное. Позволяет по доменам раскидывать настройки. На одни домены ходим без прокси, на другие по одним настройкам, на другие по другим. Сделано просто и удобно. Особенно понравилось, что расширение может на сайте показать, какие ресурсы не были загружены и предложить добавить их в список ресурсов, доступных через прокси. На каких-то сайтах с множеством доменов под cdn это сильно упрощает задачу для формирования списка доменов.
Я уже мельком рассказывал, как использую прокси сам. Расскажу ещё раз поподробнее. У меня есть несколько VPS, к которым я могу подключаться по SSH с пробросом портов на локальную машину. Если нужен HTTP прокси, то пробрасываю порт установленной локально на VPS privoxy, если сойдёт и SOCKS, то напрямую подключаюсь через SSH с ключом -D.
На этих VPS открыт только SSH порт с доступом откуда угодно. Сами прокси в интернет не смотрят, поэтому там нет аутентификации, не надо отдельно следить за безопасностью этих прокси. На своей рабочей машине под Windows открываю WSL, там подключаюсь по SSH примерно так:
или так:
где 1.2.3.4 и 4.3.2.1 - IP VDS, а 192.168.99.2 - IP адрес внутри WSL. В браузере в качестве прокси указываю 192.168.99.2, порт 3128. В зависимости от подключенной VPS, работает та или иная локация для доступа в интернет.
Для сёрфинга или загрузки чего-либо мне такая схема кажется наиболее простой, безопасной и удобной в качестве обслуживания. Наружу торчат только SSH порты, что безопасно. Не привлекают к себе лишнего внимания, в отличие от открытых портов прокси. При этом я имею возможность подключаться к ним откуда угодно. И не нужно использовать VPN, которые иногда могут не работать.
В SwitchyOmega можно создавать разные профили настроек, переключаться между ними вручную или автоматически.
#ssh #proxy
Попробовал это расширение. Оно реально удобное. Позволяет по доменам раскидывать настройки. На одни домены ходим без прокси, на другие по одним настройкам, на другие по другим. Сделано просто и удобно. Особенно понравилось, что расширение может на сайте показать, какие ресурсы не были загружены и предложить добавить их в список ресурсов, доступных через прокси. На каких-то сайтах с множеством доменов под cdn это сильно упрощает задачу для формирования списка доменов.
Я уже мельком рассказывал, как использую прокси сам. Расскажу ещё раз поподробнее. У меня есть несколько VPS, к которым я могу подключаться по SSH с пробросом портов на локальную машину. Если нужен HTTP прокси, то пробрасываю порт установленной локально на VPS privoxy, если сойдёт и SOCKS, то напрямую подключаюсь через SSH с ключом -D.
На этих VPS открыт только SSH порт с доступом откуда угодно. Сами прокси в интернет не смотрят, поэтому там нет аутентификации, не надо отдельно следить за безопасностью этих прокси. На своей рабочей машине под Windows открываю WSL, там подключаюсь по SSH примерно так:
# ssh -L 192.168.99.2:3128:localhost:8118 root@1.2.3.4или так:
# ssh -D 192.168.99.2:3128 root@4.3.2.1где 1.2.3.4 и 4.3.2.1 - IP VDS, а 192.168.99.2 - IP адрес внутри WSL. В браузере в качестве прокси указываю 192.168.99.2, порт 3128. В зависимости от подключенной VPS, работает та или иная локация для доступа в интернет.
Для сёрфинга или загрузки чего-либо мне такая схема кажется наиболее простой, безопасной и удобной в качестве обслуживания. Наружу торчат только SSH порты, что безопасно. Не привлекают к себе лишнего внимания, в отличие от открытых портов прокси. При этом я имею возможность подключаться к ним откуда угодно. И не нужно использовать VPN, которые иногда могут не работать.
В SwitchyOmega можно создавать разные профили настроек, переключаться между ними вручную или автоматически.
#ssh #proxy
{kind=link}
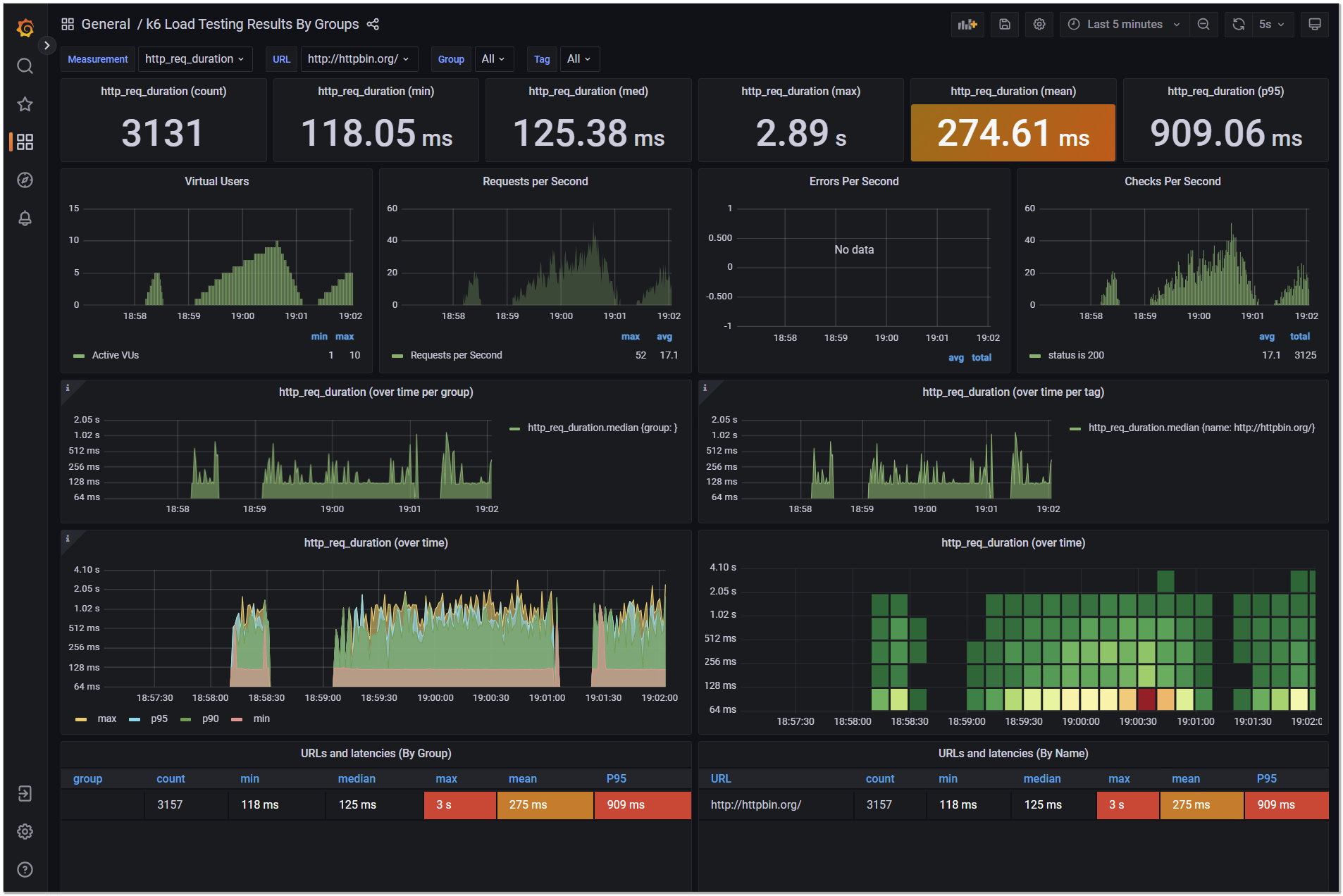
Для нагрузочного тестирования сайтов существует популярное и удобное решение от Grafana - k6. Я уже когда-то давно рассказывал про него, но тогда не сделал акцент на том, что он удобен в том числе благодаря интеграции с Grafana через хранение метрик в Influxdb. Покажу, как это выглядит на практике.
K6 много чего умеет. Он вообще очень развитый и продвинутый инструмент, где тесты можно писать в том числе на JavaScript. Продукт позиционирует себя как Tests as code. Его легко поднять и начать тестирование, используя готовые примеры. Показываю на практике.
Поднимаем связку Grafana + Influxdb:
Там готовый docker-compose.yml. В принципе, можно ничего не менять, конфиг простой, без необходимости указания переменных. Запускаем связку:
Можно сходить, проверить графану по стандартному урлу и порту: http://server-ip:3000/login. Учётка стандартная - admin / admin. В графане уже должен быть настроен в Data sources myinfluxdb с урлом из соседнего контейнера.
Теперь нужно выбрать Dashboard. Их очень много разных для k6, выбирайте любой. Наиболее функциональный и удобный вот этот, за счёт того, что там есть группировка по тэгам, группам, урлам. Идём в Dashboards ⇨ Import ⇨ ID 13719.
Всё готово для запуска тестов. В репозитории, в директории examples очень много примеров. Эта директория мапится в контейнер с k6 в docker-compose. Тест можно запустить вот так:
Данные сразу потекут в Influxdb, так что их сразу можно наблюдать в Grafana. Тест не обязательно запускать на этой же машине. Можно из любого другого места, а передать данные через отдельный параметр. Примерно так:
Вот пример простого конфига для теста в 10 потоков в течении 30 секунд:
Соответственно, конфиг легко расширяется дополнительными урлами, тестами, выполняемыми действиями. У продукта хорошая документация и много готовых примеров. Знать JavaScript не обязательно.
⇨ Сайт / Исходники
#нагрузочное_тестирование
K6 много чего умеет. Он вообще очень развитый и продвинутый инструмент, где тесты можно писать в том числе на JavaScript. Продукт позиционирует себя как Tests as code. Его легко поднять и начать тестирование, используя готовые примеры. Показываю на практике.
Поднимаем связку Grafana + Influxdb:
# git clone https://github.com/grafana/k6 && cd k6Там готовый docker-compose.yml. В принципе, можно ничего не менять, конфиг простой, без необходимости указания переменных. Запускаем связку:
# docker compose up -d influxdb grafanaМожно сходить, проверить графану по стандартному урлу и порту: http://server-ip:3000/login. Учётка стандартная - admin / admin. В графане уже должен быть настроен в Data sources myinfluxdb с урлом из соседнего контейнера.
Теперь нужно выбрать Dashboard. Их очень много разных для k6, выбирайте любой. Наиболее функциональный и удобный вот этот, за счёт того, что там есть группировка по тэгам, группам, урлам. Идём в Dashboards ⇨ Import ⇨ ID 13719.
Всё готово для запуска тестов. В репозитории, в директории examples очень много примеров. Эта директория мапится в контейнер с k6 в docker-compose. Тест можно запустить вот так:
# docker compose run k6 run /scripts/stages.jsДанные сразу потекут в Influxdb, так что их сразу можно наблюдать в Grafana. Тест не обязательно запускать на этой же машине. Можно из любого другого места, а передать данные через отдельный параметр. Примерно так:
# k6 run --out influxdb=http://1.2.3.4:8086 stages.jsВот пример простого конфига для теста в 10 потоков в течении 30 секунд:
import http from 'k6/http';import { sleep } from 'k6';export let options = { vus: 10, duration: '30s',};export default function () { http.get('https://test.k6.io'); sleep(1);}Соответственно, конфиг легко расширяется дополнительными урлами, тестами, выполняемыми действиями. У продукта хорошая документация и много готовых примеров. Знать JavaScript не обязательно.
⇨ Сайт / Исходники
#нагрузочное_тестирование
{kind=link}
Давно ничего не писал на отстранённые темы. Но сегодня хочу немного поделиться своими мыслями. К тому же повод соответствующий появился. Про День Победы сказать особо нечего. Поздравлять кого-то, кроме ветеранов, тех, кто вывез эту войну и принёс победу на своих плечах, не имеет смысла. Нам остаётся только чтить их память.
Я хочу напомнить, что основа всех войн - ненависть, вражда, раздор. Убери их, и войны не будет. Это фундамент. Сейчас наглядно видно, как работает технология по разжиганию вражды. Не по книгам, каким-то историям и воспоминаниям, а в реальном времени можно наблюдать, как применяют технологию. Изучать и исследовать её.
Разжигая вражду с обоих сторон, подливают масла в огонь и не дают заглохнуть любому конфликту. Стоит людям отбросить это наваждение, как выстраивается диалог. Я недавно из первых уст слышал историю от непосредственного участника, когда две враждующие стороны договариваются и предупреждают друг друга об обстрелах, либо сознательно бьют мимо цели, чтобы не убить, понимая бессмысленность этих действий. Такое возможно только, когда между людьми нет взаимной вражды и ненависти.
Сейчас трудно быть хладнокровным и не поддаваться этому мороку ненависти, которую раздувают. Причём ненависть всех против всех: против чиновников, мигрантов, иноверцев, украинцев, европейцев, американцев. С той стороны то же самое. К каждому находят ключик, чтобы максимально расширить охват. Технология стара, как мир, но, тем не менее, работает: "Разжигай, стравливай и властвуй".
Не теряйте голову, не поддавайтесь вражде, не поддерживайте фундамент текущих и будущих конфликтов. Обычным людям, особенно соседям или тем, кто живёт вместе на одной территории, нужно не враждовать, а дружить и взаимодействовать для взаимной выгоды. Вражда на руку только тем, кто наблюдает со стороны и наживается на этом.
В завершение своих слов хочу привести стихотворение про доброту, человечность и единство народов одного из своих любимых современных исполнителей и поэтов Игоря Растеряева - Дед Агван. Стих написан на основе реальной истории реального ветерана ВОВ:
▶️ Игорь Растеряев. Дед Агван.(стих)
⇨ Описание реальной истории и человека из стихотворения
📜 Текст
.......
Его уж нет, а я большой.
И вдруг я докумекал:
В тот день был самый главный бой
За звание человека.
#разное #мысли
Я хочу напомнить, что основа всех войн - ненависть, вражда, раздор. Убери их, и войны не будет. Это фундамент. Сейчас наглядно видно, как работает технология по разжиганию вражды. Не по книгам, каким-то историям и воспоминаниям, а в реальном времени можно наблюдать, как применяют технологию. Изучать и исследовать её.
Разжигая вражду с обоих сторон, подливают масла в огонь и не дают заглохнуть любому конфликту. Стоит людям отбросить это наваждение, как выстраивается диалог. Я недавно из первых уст слышал историю от непосредственного участника, когда две враждующие стороны договариваются и предупреждают друг друга об обстрелах, либо сознательно бьют мимо цели, чтобы не убить, понимая бессмысленность этих действий. Такое возможно только, когда между людьми нет взаимной вражды и ненависти.
Сейчас трудно быть хладнокровным и не поддаваться этому мороку ненависти, которую раздувают. Причём ненависть всех против всех: против чиновников, мигрантов, иноверцев, украинцев, европейцев, американцев. С той стороны то же самое. К каждому находят ключик, чтобы максимально расширить охват. Технология стара, как мир, но, тем не менее, работает: "Разжигай, стравливай и властвуй".
Не теряйте голову, не поддавайтесь вражде, не поддерживайте фундамент текущих и будущих конфликтов. Обычным людям, особенно соседям или тем, кто живёт вместе на одной территории, нужно не враждовать, а дружить и взаимодействовать для взаимной выгоды. Вражда на руку только тем, кто наблюдает со стороны и наживается на этом.
В завершение своих слов хочу привести стихотворение про доброту, человечность и единство народов одного из своих любимых современных исполнителей и поэтов Игоря Растеряева - Дед Агван. Стих написан на основе реальной истории реального ветерана ВОВ:
▶️ Игорь Растеряев. Дед Агван.(стих)
⇨ Описание реальной истории и человека из стихотворения
📜 Текст
.......
Его уж нет, а я большой.
И вдруг я докумекал:
В тот день был самый главный бой
За звание человека.
#разное #мысли
YouTube
Игорь Растеряев. Дед Агван.(стих)
Игорь Растеряев. Дед Агван.(стих) Автор текста — Игорь Растеряев. Видео оператор — Леха Ляхов. Поздравляем всех с 70-летием Великой Победы!
После праздников надо потихоньку вкатываться в трудовые будни. Чтобы это было проще сделать, можно подключить AI, коих сейчас развелось много на любой вкус. Самый популярный - ChatGPT от OpenAI. Чтобы им пользоваться, нужен VPN и иностранный номер телефона для регистрации и получения токена. Либо какой-то местный сервис, который перепродаёт доступ к OpenAI и другим платным нейросетям.
Есть возможность развернуть открытую нейросеть Ollama с какой-то популярной моделью на своём железе. Решил попробовать эту тему, так как вообще никогда с этим не сталкивался. Было интересно посмотреть, как это работает.
Моделей для нейросетей существует много. Мне было интересно попробовать помощника по консольным командам Linux. Чтобы понять, какая модель лучше для этого подойдёт, посмотрел описание проекта ShellGPT. Он изначально заточен под работу с OpenAI, но как альтернативу даёт возможность использовать локальную Ollama с моделью Mistral. По их мнению она лучше всего подходит для консольных задач.
Разворачиваю Ollama c Mistral на Linux:
Далее вы можете работать с ollama напрямую через консоль, задавая там вопросы:
либо через API:
А можно сразу настроить shell-gpt. Устанавливаем его:
Задаём первый вопрос:
Изначально shell-gpt заточен на работу с OpenAI, поэтому попросит ввести токен. Можно ввести любую строку, главное не оставлять её пустой. Получите ошибку. После этого открываете конфиг
Остальное можно не трогать. Для комфортной работы с нейросетью требуется современная видеокарта. У меня такой нет, поэтому я тестировал работу на CPU. Для этого выделил отдельный старый компьютер на базе четырёхядерного Intel Core i5-2500K 3.30GHz. Сетка работает крайне медленно.
На вопрос:
Она отвечала минут 40-50 и выдала такой ответ:
В таком режиме её использовать невозможно. Решил попробовать на другом компе, где есть хоть и старая, но видюха NVIDIA GeForce GTX 560 Ti с 2G ОЗУ. Но толку от неё не было, так как слишком старая, нет нужных инструкций. Тем не менее, там было больше оперативы, дела пошли пошустрее. Сетка на вопрос:
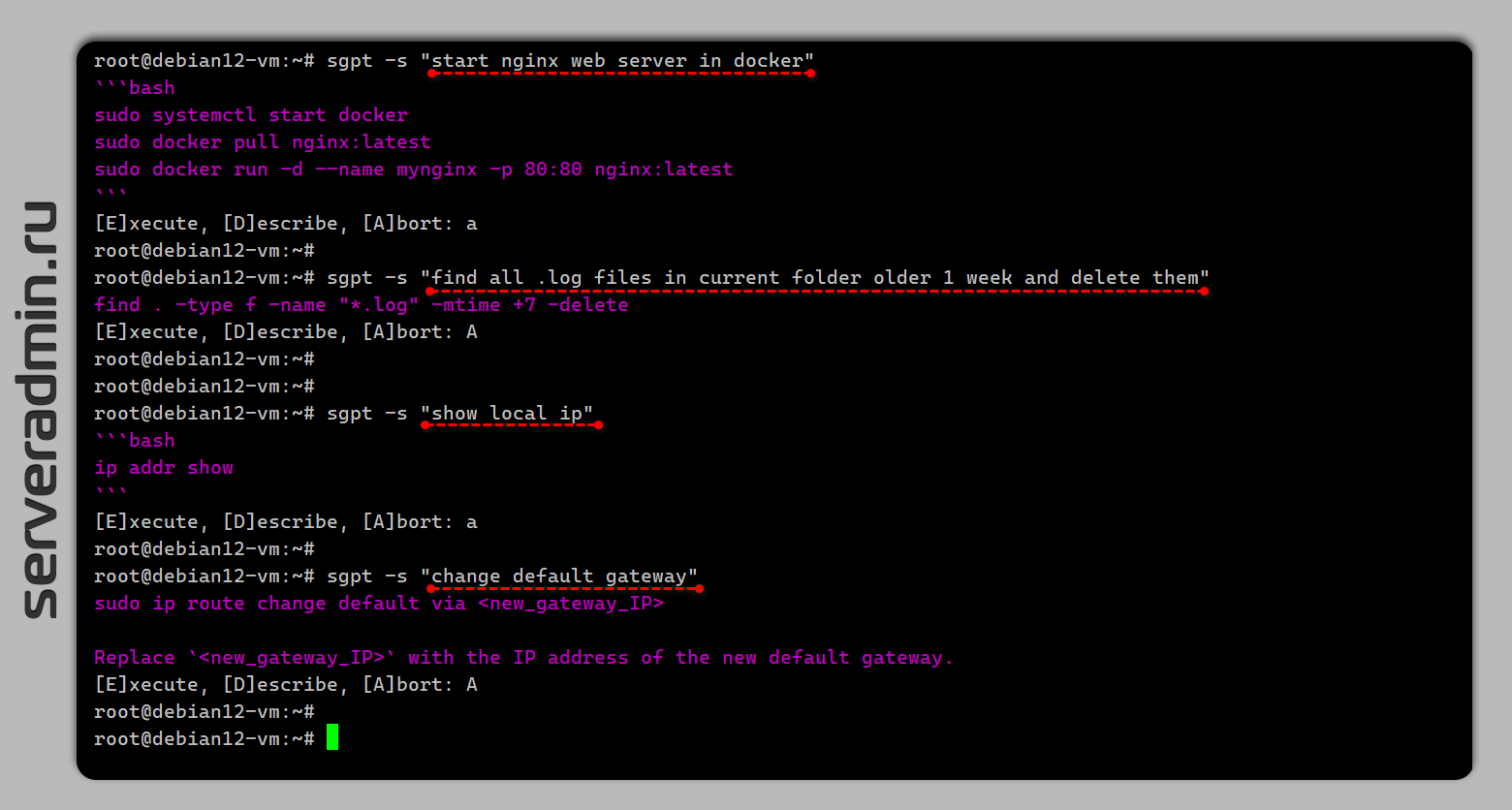
start nginx docker container
Ответила подробно и осмысленно минут за 15. Ответ не привожу, он очень длинный.
Решил пойти дальше и попробовать её на свободном стареньком серваке с двумя XEON E5 2643 V4. Дал виртуалке все 24 потока и 24G ОЗУ. Дело ещё бодрее пошло. Уже можно нормально пользоваться, практически в режиме реального времени стал отвечать. Время ответа напрямую зависит от длины текста запроса.
Вообще, раньше не думал, что со своими нейронками можно побаловаться на обычном железе. Причём она в целом нормально отвечала. На все мои простые вопросы по консольным командам ответила адекватно. Результаты были рабочими, хоть и не всегда оптимальными. Пример вопроса:
Если не хочется вспоминать команды и ходить в google, вполне рабочая альтернатива. Оставил на серваке Ollama, буду тестировать дальше.
#AI #chatgpt
Есть возможность развернуть открытую нейросеть Ollama с какой-то популярной моделью на своём железе. Решил попробовать эту тему, так как вообще никогда с этим не сталкивался. Было интересно посмотреть, как это работает.
Моделей для нейросетей существует много. Мне было интересно попробовать помощника по консольным командам Linux. Чтобы понять, какая модель лучше для этого подойдёт, посмотрел описание проекта ShellGPT. Он изначально заточен под работу с OpenAI, но как альтернативу даёт возможность использовать локальную Ollama с моделью Mistral. По их мнению она лучше всего подходит для консольных задач.
Разворачиваю Ollama c Mistral на Linux:
# curl https://ollama.ai/install.sh | sh# ollama pull mistral:7b-instructДалее вы можете работать с ollama напрямую через консоль, задавая там вопросы:
# ollama run mistralлибо через API:
# curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt":"Here is a story about llamas eating grass" }'А можно сразу настроить shell-gpt. Устанавливаем его:
# apt install python3-pip# pip3 install shell-gpt[litellm]Задаём первый вопрос:
# sgpt --model ollama/mistral:7b-instruct "Who are you?"Изначально shell-gpt заточен на работу с OpenAI, поэтому попросит ввести токен. Можно ввести любую строку, главное не оставлять её пустой. Получите ошибку. После этого открываете конфиг
~/.config/shell_gpt/.sgptrc и меняете некоторые параметры:DEFAULT_MODEL=ollama/mistral:7b-instructOPENAI_USE_FUNCTIONS=falseUSE_LITELLM=trueОстальное можно не трогать. Для комфортной работы с нейросетью требуется современная видеокарта. У меня такой нет, поэтому я тестировал работу на CPU. Для этого выделил отдельный старый компьютер на базе четырёхядерного Intel Core i5-2500K 3.30GHz. Сетка работает крайне медленно.
На вопрос:
# sgpt --model ollama/mistral:7b-instruct "Who are you?"Она отвечала минут 40-50 и выдала такой ответ:
I'm ShellGPT, your Linux/Debian GNU/Linux 12 (Bookworm) programming and system administration assistant using a Bash shell. I'm here to help answer questions, provide guidance on commands, and assist with various tasks related to managing your Debian system. Let me know how I can be of service!В таком режиме её использовать невозможно. Решил попробовать на другом компе, где есть хоть и старая, но видюха NVIDIA GeForce GTX 560 Ti с 2G ОЗУ. Но толку от неё не было, так как слишком старая, нет нужных инструкций. Тем не менее, там было больше оперативы, дела пошли пошустрее. Сетка на вопрос:
start nginx docker container
Ответила подробно и осмысленно минут за 15. Ответ не привожу, он очень длинный.
Решил пойти дальше и попробовать её на свободном стареньком серваке с двумя XEON E5 2643 V4. Дал виртуалке все 24 потока и 24G ОЗУ. Дело ещё бодрее пошло. Уже можно нормально пользоваться, практически в режиме реального времени стал отвечать. Время ответа напрямую зависит от длины текста запроса.
Вообще, раньше не думал, что со своими нейронками можно побаловаться на обычном железе. Причём она в целом нормально отвечала. На все мои простые вопросы по консольным командам ответила адекватно. Результаты были рабочими, хоть и не всегда оптимальными. Пример вопроса:
# sgpt -s "start nginx web server in docker"```bashsudo systemctl start dockersudo docker pull nginx:latestsudo docker run -d --name mynginx -p 80:80 nginx:latest```Если не хочется вспоминать команды и ходить в google, вполне рабочая альтернатива. Оставил на серваке Ollama, буду тестировать дальше.
#AI #chatgpt
{kind=link}
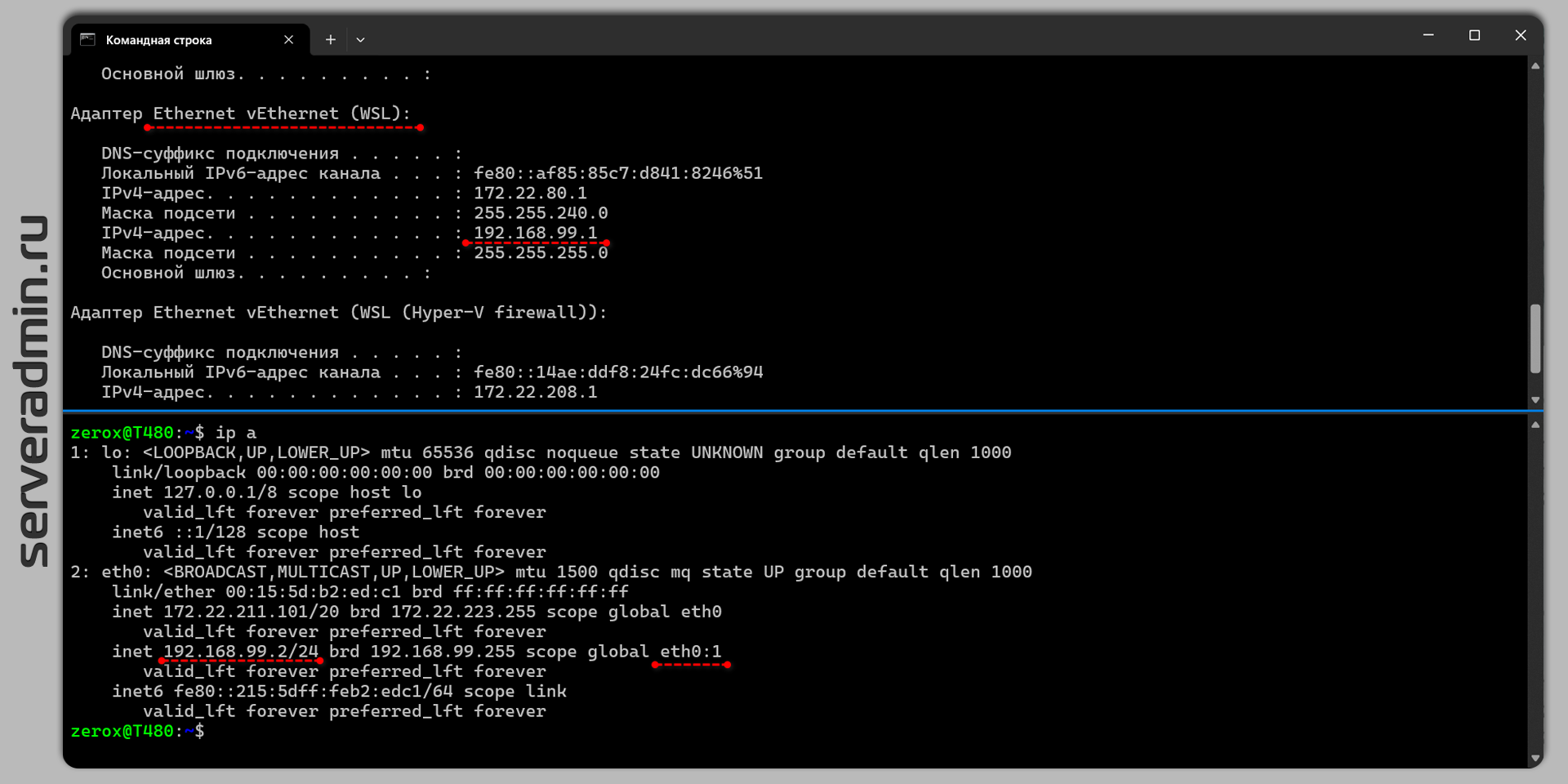
Я практически с самого появления проекта WSL (Windows Subsystem for Linux) на Windows стал им пользоваться. Настроек у него особо никаких нет. Просто ставишь из магазина и всё сразу работает. Используется виртуальный сетевой интерфейс, виртуальный роутер и dhcp сервер. Настроек у всего этого хозяйства нет. IP адреса системы в WSL получают постоянно динамические.
У меня это особо не вызывало проблем, потому что как сервер WSL не использую, и с основной системы обращаться туда нет необходимости. Но в какой-то момент всё равно надоело это и захотелось получить статический IP. На деле это оказалось не так просто. Каких-то инструментов или настроек для этого не существует. По крайней мере я сходу не нашёл. Правда и не сильно искал.
Решил вопрос в лоб и давно уже его использую. Добавил дополнительный IP адрес к виртуальному сетевому интерфейсу в основную систему и в систему WSL. Выглядит это следующим образом для основной системы:
и для WSL (Ubuntu):
Причём вторую команду не обязательно запускать в WSL. Можно выполнить и с хоста:
В итоге, достаточно сделать простенький bat файл, добавить его в стандартный планировщик Windows и запускать при старте системы или при логоне вашего пользователя.
Я сделал такой батник. Добавил небольшую задержу при запуске, потому что без неё иногда команды не отрабатывали. Судя по всему ещё не успевают подняться какие-то службы, необходимые для изменения настроек.
Если кто-то знает, как эту задачу решить более красиво и грамотно, поделитесь информацией. Я сделал как обычно в лоб. Решение заработало, поэтому на нём и остался. Основная машина и система в WSL видят друг друга по соответствующим адресам: 192.168.99.1 и 192.168.99.2.
#windows #wsl
У меня это особо не вызывало проблем, потому что как сервер WSL не использую, и с основной системы обращаться туда нет необходимости. Но в какой-то момент всё равно надоело это и захотелось получить статический IP. На деле это оказалось не так просто. Каких-то инструментов или настроек для этого не существует. По крайней мере я сходу не нашёл. Правда и не сильно искал.
Решил вопрос в лоб и давно уже его использую. Добавил дополнительный IP адрес к виртуальному сетевому интерфейсу в основную систему и в систему WSL. Выглядит это следующим образом для основной системы:
> netsh interface ip add address "vEthernet (WSL)" 192.168.99.1 255.255.255.0и для WSL (Ubuntu):
# ip addr add 192.168.99.2/24 broadcast 192.168.99.255 dev eth0 label eth0:1Причём вторую команду не обязательно запускать в WSL. Можно выполнить и с хоста:
> wsl.exe -u root ip addr add 192.168.99.2/24 broadcast 192.168.99.255 dev eth0 label eth0:1;В итоге, достаточно сделать простенький bat файл, добавить его в стандартный планировщик Windows и запускать при старте системы или при логоне вашего пользователя.
Я сделал такой батник. Добавил небольшую задержу при запуске, потому что без неё иногда команды не отрабатывали. Судя по всему ещё не успевают подняться какие-то службы, необходимые для изменения настроек.
@echo onTIMEOUT /T 5wsl.exe -u root ip addr add 192.168.99.2/24 broadcast 192.168.99.255 dev eth0 label eth0:1;netsh interface ip add address "vEthernet (WSL)" 192.168.99.1 255.255.255.0Если кто-то знает, как эту задачу решить более красиво и грамотно, поделитесь информацией. Я сделал как обычно в лоб. Решение заработало, поэтому на нём и остался. Основная машина и система в WSL видят друг друга по соответствующим адресам: 192.168.99.1 и 192.168.99.2.
#windows #wsl
{kind=link}
Для управления Linux сервером через браузер существуют два наиболее популярных решения:
▪️ webmin
▪️ cockpit
Webmin очень старый продукт, написанный на Perl. Он же наиболее функциональный. Развивается до сих пор. Удивительный долгожитель. Сколько работаю с Linux, столько его знаю. Под него существует большое количество плагинов. Вся базовая функциональность сервера им покрывается: файрвол, samba, postfix и dovecot, dns и dhcp, логи, обновления и т.д. Я знал админов, которые успешно управлялись с сервером только через вебмин, не умея и не работая в консоли вообще. Удивился, когда не нашёл на своём канале отдельной заметки про эту панель. Неплохо её знаю, доводилось работать, хотя на свои сервера не устанавливал.
Cockpit более молодой проект, который принадлежит Red Hat. Ими же и развивается. Он более компактный и целостный, возможностей поменьше, чем у Webmin, но лично я бы для базовых задач отдал ему предпочтение. Но только если вам хватает его возможностей. В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
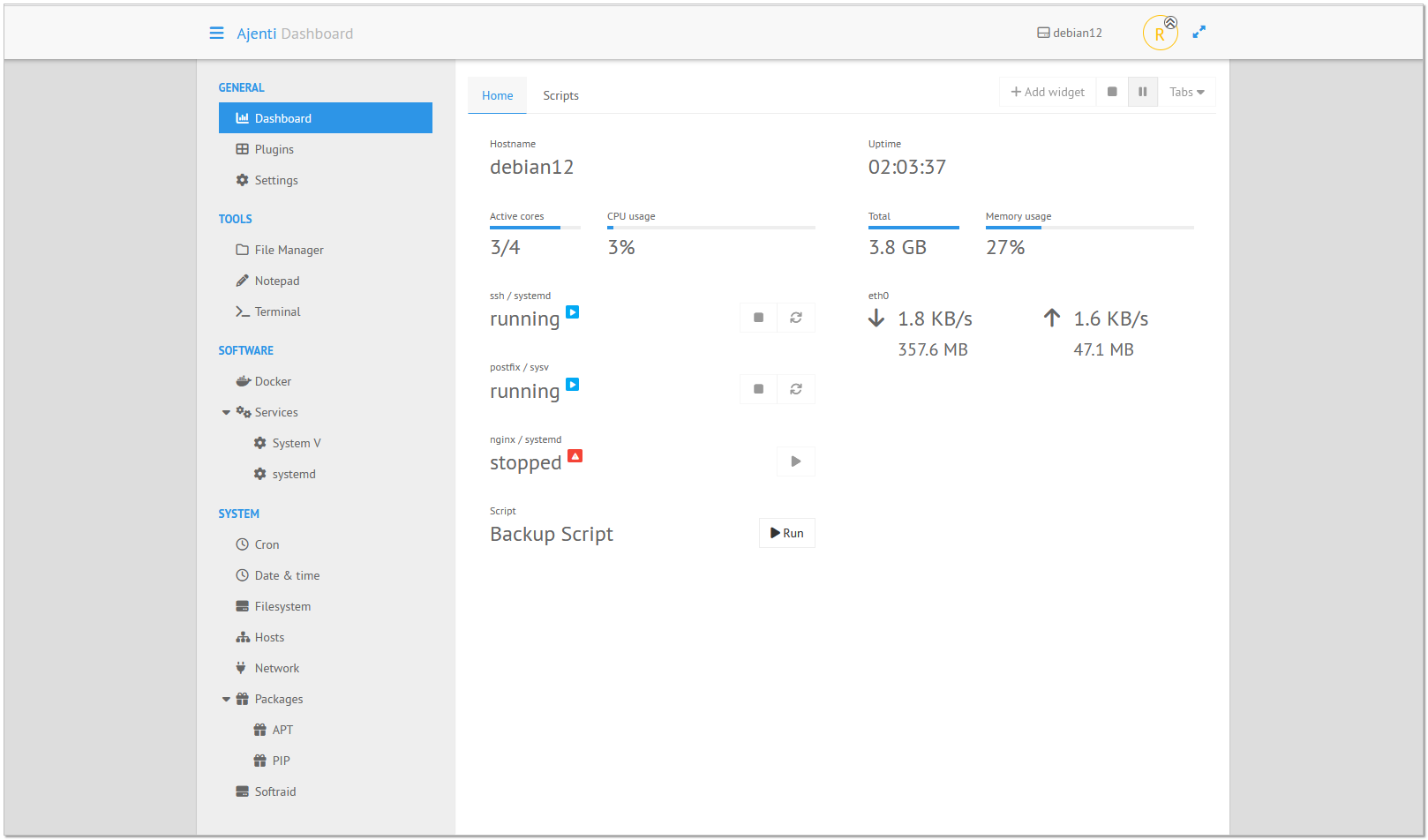
Сегодня хочу немного расширить эту тему и познакомить вас с ещё одной панелью управления сервером - Ajenti. Сразу скажу, что это проект намного меньше и проще описанных выше, но у него есть некоторые свои полезные особенности. Базовые возможности там примерно такие же, как у Cockpit без модулей. Функциональность расширяется плагинами, которые устанавливаются через веб интерфейс.
Я развернул на тестовом сервере Ajenti и внимательно посмотрел на неё. Отметил следующие полезные возможности:
◽двухфакторная аутентификация через TOTP;
◽аутентификация по сертификатам;
🔥настраиваемые дашборды с табами и виджетами, куда можно добавить запуск служб или выполнение каких-то скриптов;
◽удобный файловый менеджер;
◽есть русский язык;
◽адаптивный интерфейс, работает и на смартфонах.
Устанавливается панель просто. Есть инструкция, где описан автоматический и ручной способ установки. Панель написана на Python, так что установка через pip. Есть простой скрипт, который автоматизирует её в зависимости от используемого дистрибутива:
Скрипт определяет дистрибутив, устанавливает необходимые пакеты и панель через pip, создаёт systemd службу.
Далее можно идти по IP адресу сервера на порт 8000 и логиниться под root в панель. Сразу имеет смысл сгенерировать самоподписанный TLS сертификат, включить принудительную работу по HTTPS. Всё это в админке делается.
#linux
▪️ webmin
▪️ cockpit
Webmin очень старый продукт, написанный на Perl. Он же наиболее функциональный. Развивается до сих пор. Удивительный долгожитель. Сколько работаю с Linux, столько его знаю. Под него существует большое количество плагинов. Вся базовая функциональность сервера им покрывается: файрвол, samba, postfix и dovecot, dns и dhcp, логи, обновления и т.д. Я знал админов, которые успешно управлялись с сервером только через вебмин, не умея и не работая в консоли вообще. Удивился, когда не нашёл на своём канале отдельной заметки про эту панель. Неплохо её знаю, доводилось работать, хотя на свои сервера не устанавливал.
Cockpit более молодой проект, который принадлежит Red Hat. Ими же и развивается. Он более компактный и целостный, возможностей поменьше, чем у Webmin, но лично я бы для базовых задач отдал ему предпочтение. Но только если вам хватает его возможностей. В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
Сегодня хочу немного расширить эту тему и познакомить вас с ещё одной панелью управления сервером - Ajenti. Сразу скажу, что это проект намного меньше и проще описанных выше, но у него есть некоторые свои полезные особенности. Базовые возможности там примерно такие же, как у Cockpit без модулей. Функциональность расширяется плагинами, которые устанавливаются через веб интерфейс.
Я развернул на тестовом сервере Ajenti и внимательно посмотрел на неё. Отметил следующие полезные возможности:
◽двухфакторная аутентификация через TOTP;
◽аутентификация по сертификатам;
🔥настраиваемые дашборды с табами и виджетами, куда можно добавить запуск служб или выполнение каких-то скриптов;
◽удобный файловый менеджер;
◽есть русский язык;
◽адаптивный интерфейс, работает и на смартфонах.
Устанавливается панель просто. Есть инструкция, где описан автоматический и ручной способ установки. Панель написана на Python, так что установка через pip. Есть простой скрипт, который автоматизирует её в зависимости от используемого дистрибутива:
# curl https://raw.githubusercontent.com/ajenti/ajenti/master/scripts/install-venv.sh | bash -s -Скрипт определяет дистрибутив, устанавливает необходимые пакеты и панель через pip, создаёт systemd службу.
Далее можно идти по IP адресу сервера на порт 8000 и логиниться под root в панель. Сразу имеет смысл сгенерировать самоподписанный TLS сертификат, включить принудительную работу по HTTPS. Всё это в админке делается.
#linux
{kind=link}
Предлагаю попробовать и забрать в закладки сервис по проверке DNS записей:
⇨ https://zonemaster.net
Я даже и не знал, что существует столько параметров, по которым можно проверить домен. Сервис полностью бесплатен, исходный код открыт. Можно развернуть у себя и делать проверки через JSON-RPC API.
Для полноценной работы нужно будет поднять Zonemaster-CLI (есть собранный Docker контейнер), Zonemaster-Backend (отвечает за API), Zonemaster-GUI (веб интерфейс). Инструкции все здесь.
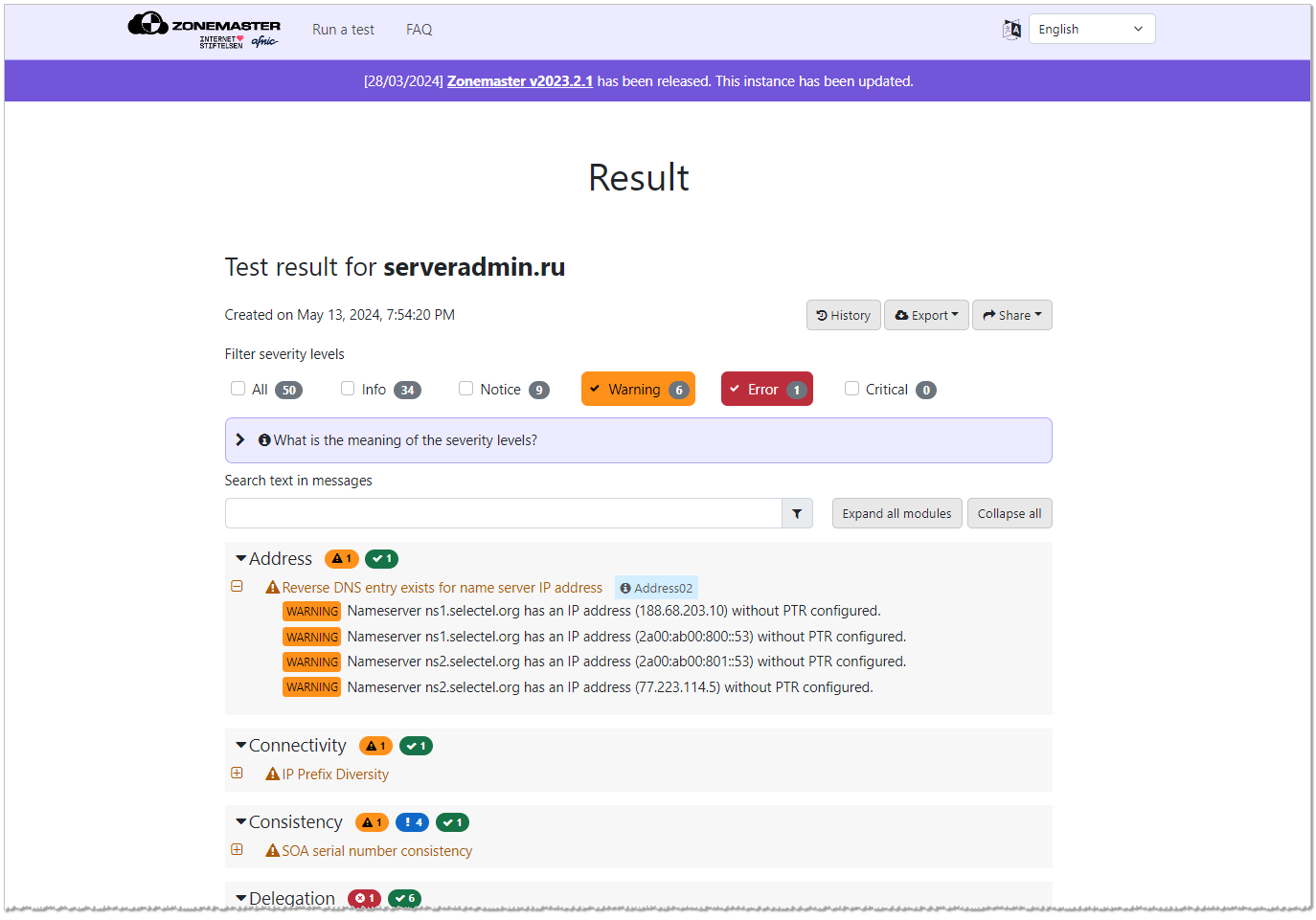
Домен проверяется по 50-ти проверкам. Для теста прогнал свой домен serveradmin.ru. Набралось приличное количество ошибок и замечаний. Все они прокомментированы, так что в целом понятно, о чём там речь. Особо критичного ничего нет, а некоторые замечания относятся к DNS хостингу, на который я повлиять не могу. В качестве DNS серверов для домена у меня указаны сервера Selectel и Yandex.
Пример замечаний:
◽NS сервера Selectel не имеют PTR записей. Дублирующие их сервера Яндекса имеют. Странно, что в Selectel на это забили.
◽Разные номера SOA записей у DNS серверов. Так как я использую двух разных провайдеров, это нормально. Они должны совпадать в рамках одного провайдера.
🔥Здесь реальная ошибка нашлась. В какой-то момент NS сервера Selectel изменили свои доменные имена. И я забыл их обновить в записях Yandex. В итоге зона в Yandex имела NS сервера ns1.selectel.org и ns2.selectel.org вместо актуальных ns1.selectel.ru и ns2.selectel.ru.
◽Ещё одна небольшая ошибка была. Различались TTL у MX записей у разных провайдеров. Поправил. Параметры должны везде быть идентичными для одних и тех же записей.
В общем, сервис полезный. Рекомендую взять на вооружение и проверять свои домены. Особенно если зоны держат разные серверы и провайдеры, а записей много.
⇨ Сайт / Исходники
#dns #сервис
⇨ https://zonemaster.net
Я даже и не знал, что существует столько параметров, по которым можно проверить домен. Сервис полностью бесплатен, исходный код открыт. Можно развернуть у себя и делать проверки через JSON-RPC API.
Для полноценной работы нужно будет поднять Zonemaster-CLI (есть собранный Docker контейнер), Zonemaster-Backend (отвечает за API), Zonemaster-GUI (веб интерфейс). Инструкции все здесь.
Домен проверяется по 50-ти проверкам. Для теста прогнал свой домен serveradmin.ru. Набралось приличное количество ошибок и замечаний. Все они прокомментированы, так что в целом понятно, о чём там речь. Особо критичного ничего нет, а некоторые замечания относятся к DNS хостингу, на который я повлиять не могу. В качестве DNS серверов для домена у меня указаны сервера Selectel и Yandex.
Пример замечаний:
◽NS сервера Selectel не имеют PTR записей. Дублирующие их сервера Яндекса имеют. Странно, что в Selectel на это забили.
◽Разные номера SOA записей у DNS серверов. Так как я использую двух разных провайдеров, это нормально. Они должны совпадать в рамках одного провайдера.
🔥Здесь реальная ошибка нашлась. В какой-то момент NS сервера Selectel изменили свои доменные имена. И я забыл их обновить в записях Yandex. В итоге зона в Yandex имела NS сервера ns1.selectel.org и ns2.selectel.org вместо актуальных ns1.selectel.ru и ns2.selectel.ru.
◽Ещё одна небольшая ошибка была. Различались TTL у MX записей у разных провайдеров. Поправил. Параметры должны везде быть идентичными для одних и тех же записей.
В общем, сервис полезный. Рекомендую взять на вооружение и проверять свои домены. Особенно если зоны держат разные серверы и провайдеры, а записей много.
⇨ Сайт / Исходники
#dns #сервис
{kind=link}
Ранее я делал шпаргалку по mtime, ctime, atime и crtime. Кто иногда путается в этих характеристиках, как я, рекомендую почитать и сохранить. Я там постарался кратко рассказать о них, чтобы не ошибаться на практике. Хотя путаться всё равно не перестал. Расскажу недавнюю историю.
Надо было периодически чистить корзину от Samba. Сама шара регулярно бэкапится, так что большого смысла в корзине нет. Сделал её больше для себя, чтобы если что, можно было быстро локально восстановить случайно удалённые файлы, а не тянуть с бэкапа. Засунул в крон простую команду по очистке:
Тип - каталог, указал, потому что если удалять только файлы, остаются пустые каталоги. Решил удалять сразу их. Плюс, там есть ещё такой момент с файлами, что они прилетают в корзину с исходным mtime, с которым они лежали на шаре. То есть файл может быть удалён сегодня, но mtime у него будет годовалой давности. Так тоже не подходит. С каталогами более подходящий вариант. Там скорее лишнее будет оставаться слишком долго, нежели свежее будет удаляться.
В какой-то момент был удалён сам каталог .trash/. Я, не вникая в суть проблемы, на автомате решил, что достаточно в корне этого каталога раз в сутки обновлять какой-нибудь файл, чтобы mtime каталога обновлялся, и скрипт его не удалял. Добавил перед удалением обновление одного и того же файла через touch:
Через некоторое время каталог .trash/ опять был удалён. Тут уже решил разобраться. Оказалось, обновление mtime файла внутри каталога недостаточно, чтобы обновился mtime самого каталога. Нужно, чтобы был удалён или добавлен какой-то файл. То есть надо файл timestamp удалить и добавить снова. Тогда mtime каталога обновится. В итоге сделал так:
Надеюсь теперь всё будет работать так, как задумано.
Такой вот небольшой нюанс, о котором я ранее не знал. Изменения mtime файла внутри каталога недостаточно для изменения mtime каталога, в котором находится этот файл. Необходимо добавить, удалить или переименовать файл или каталог внутри родительского каталога.
Если я правильно понимаю, то так происходит, потому что каталог это по сути набор информации о всех директориях и файлах внутри. Информация эта состоит из имени и номера inode. Когда я через touch дёргаю файл, его номер inode не меняется. Поэтому и родительский каталог остаётся неизменным. А если файл удалить и создать снова, даже точно такой же, то его номер inode поменяется, поэтому и mtime каталога изменяется.
Век живи - век учись. С такими вещами пока не столкнёшься, не познакомишься. Просто так со всем этим разбираться вряд ли захочется. Я вроде всю теорию по файлам, директориям и айнодам когда-то изучал, но уже всё забыл. Теория без практики мертва.
#linux
Надо было периодически чистить корзину от Samba. Сама шара регулярно бэкапится, так что большого смысла в корзине нет. Сделал её больше для себя, чтобы если что, можно было быстро локально восстановить случайно удалённые файлы, а не тянуть с бэкапа. Засунул в крон простую команду по очистке:
/usr/bin/find /mnt/shara/.trash/ -type d -mtime +7 -exec rm -rf {} \;Тип - каталог, указал, потому что если удалять только файлы, остаются пустые каталоги. Решил удалять сразу их. Плюс, там есть ещё такой момент с файлами, что они прилетают в корзину с исходным mtime, с которым они лежали на шаре. То есть файл может быть удалён сегодня, но mtime у него будет годовалой давности. Так тоже не подходит. С каталогами более подходящий вариант. Там скорее лишнее будет оставаться слишком долго, нежели свежее будет удаляться.
В какой-то момент был удалён сам каталог .trash/. Я, не вникая в суть проблемы, на автомате решил, что достаточно в корне этого каталога раз в сутки обновлять какой-нибудь файл, чтобы mtime каталога обновлялся, и скрипт его не удалял. Добавил перед удалением обновление одного и того же файла через touch:
/usr/bin/touch /mnt/shara/.trash/timestampЧерез некоторое время каталог .trash/ опять был удалён. Тут уже решил разобраться. Оказалось, обновление mtime файла внутри каталога недостаточно, чтобы обновился mtime самого каталога. Нужно, чтобы был удалён или добавлен какой-то файл. То есть надо файл timestamp удалить и добавить снова. Тогда mtime каталога обновится. В итоге сделал так:
/usr/bin/rm /mnt/shara/.trash/timestamp/usr/bin/touch /mnt/shara/.trash/timestamp/usr/bin/find /mnt/shara/.trash/ -type d -mtime +7 -exec rm -rf {} \;Надеюсь теперь всё будет работать так, как задумано.
Такой вот небольшой нюанс, о котором я ранее не знал. Изменения mtime файла внутри каталога недостаточно для изменения mtime каталога, в котором находится этот файл. Необходимо добавить, удалить или переименовать файл или каталог внутри родительского каталога.
Если я правильно понимаю, то так происходит, потому что каталог это по сути набор информации о всех директориях и файлах внутри. Информация эта состоит из имени и номера inode. Когда я через touch дёргаю файл, его номер inode не меняется. Поэтому и родительский каталог остаётся неизменным. А если файл удалить и создать снова, даже точно такой же, то его номер inode поменяется, поэтому и mtime каталога изменяется.
Век живи - век учись. С такими вещами пока не столкнёшься, не познакомишься. Просто так со всем этим разбираться вряд ли захочется. Я вроде всю теорию по файлам, директориям и айнодам когда-то изучал, но уже всё забыл. Теория без практики мертва.
#linux
Прошлая заметка про комбинацию в терминале Alt+Shift+3 получила какой-то невероятный отклик в виде лайков, хотя не делает чего-то особенного. Не ожидал такой реакции. Раз это так востребовано, расскажу ещё про одну комбинацию клавиш в bash, про которую наверняка многие не знают, но она куда более полезная на практике по сравнению с упомянутой выше.
Для тех, кто часто работает в bash, наверняка будет знакома история, когда вы что-то запустили в терминале и постоянно появляются новые строки. Вы хотите прочитать что-то, что уже ушло вверх с экрана, но из-за того, что постоянно появляются новые строки, терминал неизменно проматывается в самый низ. Бесячая ситуация, когда несколько раз пытаешься промотать вверх и не получается.
Такое возникает, например, когда ты смотришь логи в режиме реального времени:
C tail ситуация вымышленная, просто для демонстрации того, о чём идёт речь. Нет никакой проблемы прервать tail, прекратить появление новых строк, чтобы можно было спокойно промотать терминал.
Более реальная ситуация, когда ты запустил Docker контейнер не в режиме демона, он сыпет своими логами в терминал, где-то проскочила ошибка, ты хочешь к ней вернуться, скролишь, но ничего не получается, потому что появляются новые строки. А прервать выполнение ты не можешь, контейнер прекратит свою работу, если его остановить.
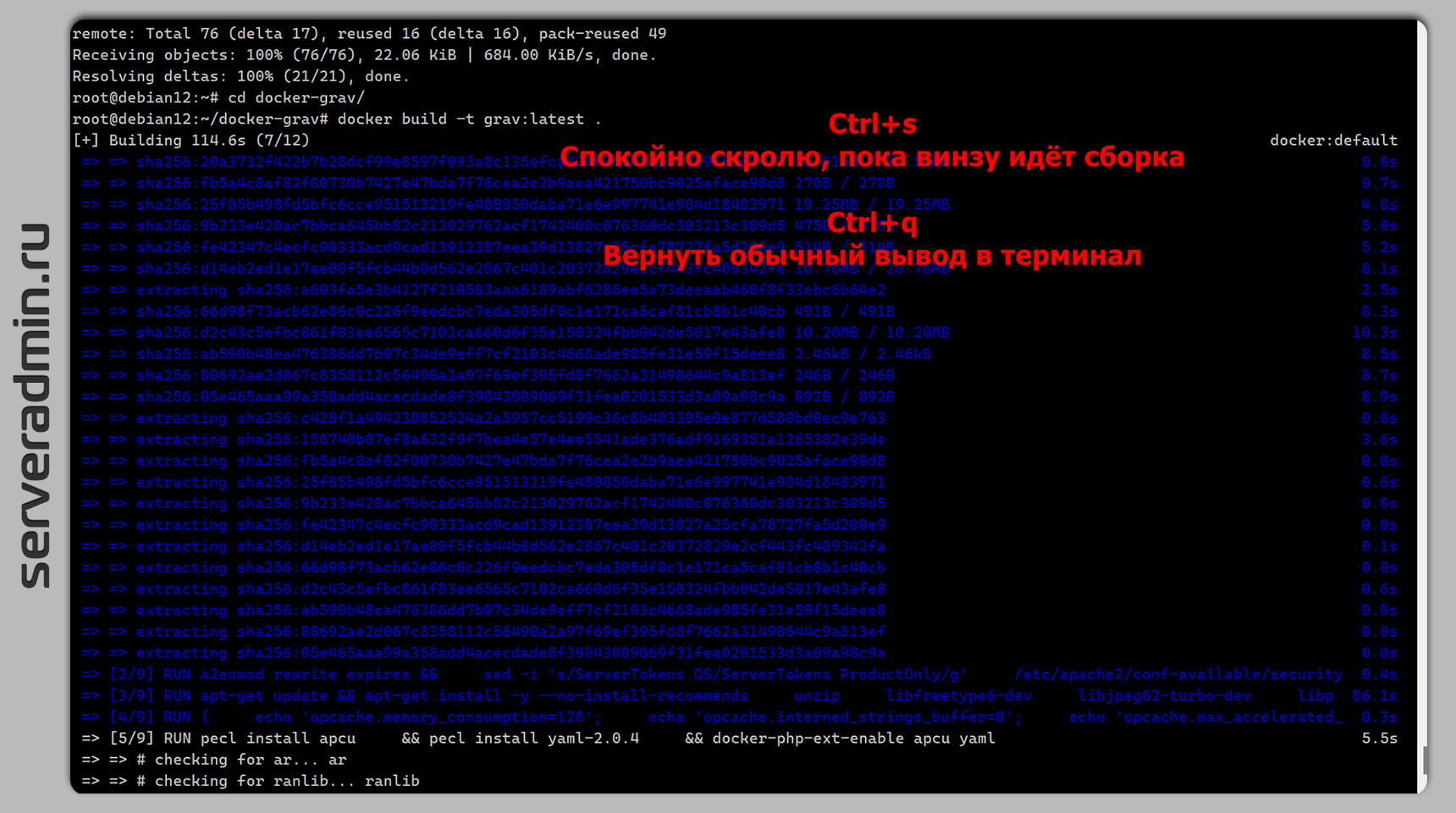
И тут тебе поможет комбинация Ctrl + s. Она поставит вывод в терминал на паузу. Новые строки не будут появляться, а ты спокойно сможешь проскролить экран до ошибки и прочитать её. Когда закончишь, нажмёшь Ctrl + q, и терминал продолжит работу в обычном режиме.
То же самое происходит, когда в терминале собирает Dockerfile, запускается большой docker-compose и т.д. Невозможно проскролить терминал наверх, пока процесс не завершится. Но если сделать Ctrl + s, то всё получится.
Это прям реальная тема. Я, когда узнал, очень обрадовался знанию. Сразу как-то проникся, потому что закрыл реальную проблему, которая раздражала время от времени.
#bash
Для тех, кто часто работает в bash, наверняка будет знакома история, когда вы что-то запустили в терминале и постоянно появляются новые строки. Вы хотите прочитать что-то, что уже ушло вверх с экрана, но из-за того, что постоянно появляются новые строки, терминал неизменно проматывается в самый низ. Бесячая ситуация, когда несколько раз пытаешься промотать вверх и не получается.
Такое возникает, например, когда ты смотришь логи в режиме реального времени:
# tail -f /var/log/nginx/access.logC tail ситуация вымышленная, просто для демонстрации того, о чём идёт речь. Нет никакой проблемы прервать tail, прекратить появление новых строк, чтобы можно было спокойно промотать терминал.
Более реальная ситуация, когда ты запустил Docker контейнер не в режиме демона, он сыпет своими логами в терминал, где-то проскочила ошибка, ты хочешь к ней вернуться, скролишь, но ничего не получается, потому что появляются новые строки. А прервать выполнение ты не можешь, контейнер прекратит свою работу, если его остановить.
И тут тебе поможет комбинация Ctrl + s. Она поставит вывод в терминал на паузу. Новые строки не будут появляться, а ты спокойно сможешь проскролить экран до ошибки и прочитать её. Когда закончишь, нажмёшь Ctrl + q, и терминал продолжит работу в обычном режиме.
То же самое происходит, когда в терминале собирает Dockerfile, запускается большой docker-compose и т.д. Невозможно проскролить терминал наверх, пока процесс не завершится. Но если сделать Ctrl + s, то всё получится.
Это прям реальная тема. Я, когда узнал, очень обрадовался знанию. Сразу как-то проникся, потому что закрыл реальную проблему, которая раздражала время от времени.
#bash
{kind=link}
Максимально простой и быстрый способ перенести без остановки ОС Linux на другое железо или виртуальную машину. Не понадобится ничего, кроме встроенных средств. Проверял лично и не раз. Перед написанием этой заметки тоже проверил.
Допустим, у вас система виртуальной машины установлена на /dev/sda. Там, соответственно, будет три раздела: boot, корень и swap. Нам надо эту систему перенести куда-то в другое место. Желательно на однотипное железо, чтобы не возникло проблем. Если железо будет другое, то тоже реально, но нужно будет немного заморочиться и выполнить дополнительные действия. Заранее их все не опишешь, так как это сильно зависит от конкретной ситуации. Скорее всего придётся внутри системы что-то править (сеть, точки монтирования) и пересобрать initrd.
Создаём где-то новую виртуальную машину с таким же диском. Загружаемся с любого загрузочного диска. Например, с SystemRescue. Настраиваем в этой системе сеть, чтобы виртуальная машина, которую переносим, могла сюда подключиться. Запускаем сервер SSH. Не забываем открыть порты в файрволе. В SystemRescue он по умолчанию включен и всё закрыто на вход.
Идём на виртуалку, которую будем переносить. И делаем там простой трюк:
Мы с помощью dd читаем устройство
Процесс будет длительный, так как передача получается посекторная. Нужно понимать, что если машина большая и нагруженная, то в момент передачи целостность данных нарушается. Какую-нибудь СУБД так не перенести. Я лично не пробовал, но подозреваю, что с большой долей вероятности база будет битая. А вот обычный не сильно нагруженный сервер вполне.
После переноса он скорее всего ругнётся на ошибки файловой системы при загрузке, но сам себя починит с очень большой долей вероятности. Я как-то раз пытался так перенести виртуалку на несколько сотен гигабайт. Вот это не получилось. Содержимое судя по всему сильно билось по дороге, так как виртуалка не останавливалась. Не удалось её запустить. А что-то небольшое на 20-30 Гб вполне нормально переносится. Можно так виртуалку от какого-то хостера себе локально перенести. Главное сетевую связность между ними организовать.
Если по сети нет возможности передать образ, то можно сохранить его в файл, если есть доступный носитель:
Потом копируем образ и восстанавливаем из него систему:
Делаем всё это с какого-то загрузочного диска.
Напомню, что перенос системы можно выполнить и с помощью специально предназначенного для этого софта:
▪️ ReaR
▪️ Veeam Agent for Linux FREE
▪️ Clonezilla
#linux #backup
Допустим, у вас система виртуальной машины установлена на /dev/sda. Там, соответственно, будет три раздела: boot, корень и swap. Нам надо эту систему перенести куда-то в другое место. Желательно на однотипное железо, чтобы не возникло проблем. Если железо будет другое, то тоже реально, но нужно будет немного заморочиться и выполнить дополнительные действия. Заранее их все не опишешь, так как это сильно зависит от конкретной ситуации. Скорее всего придётся внутри системы что-то править (сеть, точки монтирования) и пересобрать initrd.
Создаём где-то новую виртуальную машину с таким же диском. Загружаемся с любого загрузочного диска. Например, с SystemRescue. Настраиваем в этой системе сеть, чтобы виртуальная машина, которую переносим, могла сюда подключиться. Запускаем сервер SSH. Не забываем открыть порты в файрволе. В SystemRescue он по умолчанию включен и всё закрыто на вход.
Идём на виртуалку, которую будем переносить. И делаем там простой трюк:
# dd if=/dev/sda | ssh root@10.20.1.28 "dd of=/dev/sda"Мы с помощью dd читаем устройство
/dev/sda и передаём его содержимое по ssh на другую машину такой же утилите dd, которая пишет информацию в устройство /dev/sda уже на другой машине. Удобство такого переноса в том, что не нужен промежуточный носитель для хранения образа. Всё передаётся налету. Процесс будет длительный, так как передача получается посекторная. Нужно понимать, что если машина большая и нагруженная, то в момент передачи целостность данных нарушается. Какую-нибудь СУБД так не перенести. Я лично не пробовал, но подозреваю, что с большой долей вероятности база будет битая. А вот обычный не сильно нагруженный сервер вполне.
После переноса он скорее всего ругнётся на ошибки файловой системы при загрузке, но сам себя починит с очень большой долей вероятности. Я как-то раз пытался так перенести виртуалку на несколько сотен гигабайт. Вот это не получилось. Содержимое судя по всему сильно билось по дороге, так как виртуалка не останавливалась. Не удалось её запустить. А что-то небольшое на 20-30 Гб вполне нормально переносится. Можно так виртуалку от какого-то хостера себе локально перенести. Главное сетевую связность между ними организовать.
Если по сети нет возможности передать образ, то можно сохранить его в файл, если есть доступный носитель:
# dd if=/dev/sda of=/mnt/backup/sda.imgПотом копируем образ и восстанавливаем из него систему:
# dd if=/mnt/backup/sda.img of=/dev/sdaДелаем всё это с какого-то загрузочного диска.
Напомню, что перенос системы можно выполнить и с помощью специально предназначенного для этого софта:
▪️ ReaR
▪️ Veeam Agent for Linux FREE
▪️ Clonezilla
#linux #backup
Для тех, кто не любит читать многостраничные man, существует его упрощённая версия, поддерживаемая сообществом — tldr. Аббревиатура как бы говорит сама за себя — Too long; didn't read. Это урезанный вариант man, где кратко представлены примеры использования консольных программ в Linux с минимальным описанием.
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
● Find the process that opened a local internet port:
● Only output the process ID (PID):
● List files opened by the given user:
● List files opened by the given command or process:
● List files opened by a specific process, given its PID:
● List open files in a directory:
● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
В принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
lsof path/to/file● Find the process that opened a local internet port:
lsof -i :port● Only output the process ID (PID):
lsof -t path/to/file● List files opened by the given user:
lsof -u username● List files opened by the given command or process:
lsof -c process_or_command_name● List files opened by a specific process, given its PID:
lsof -p PID● List open files in a directory:
lsof +D path/to/directory● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
lsof -i6TCP:port -sTCP:LISTEN -n -PВ принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
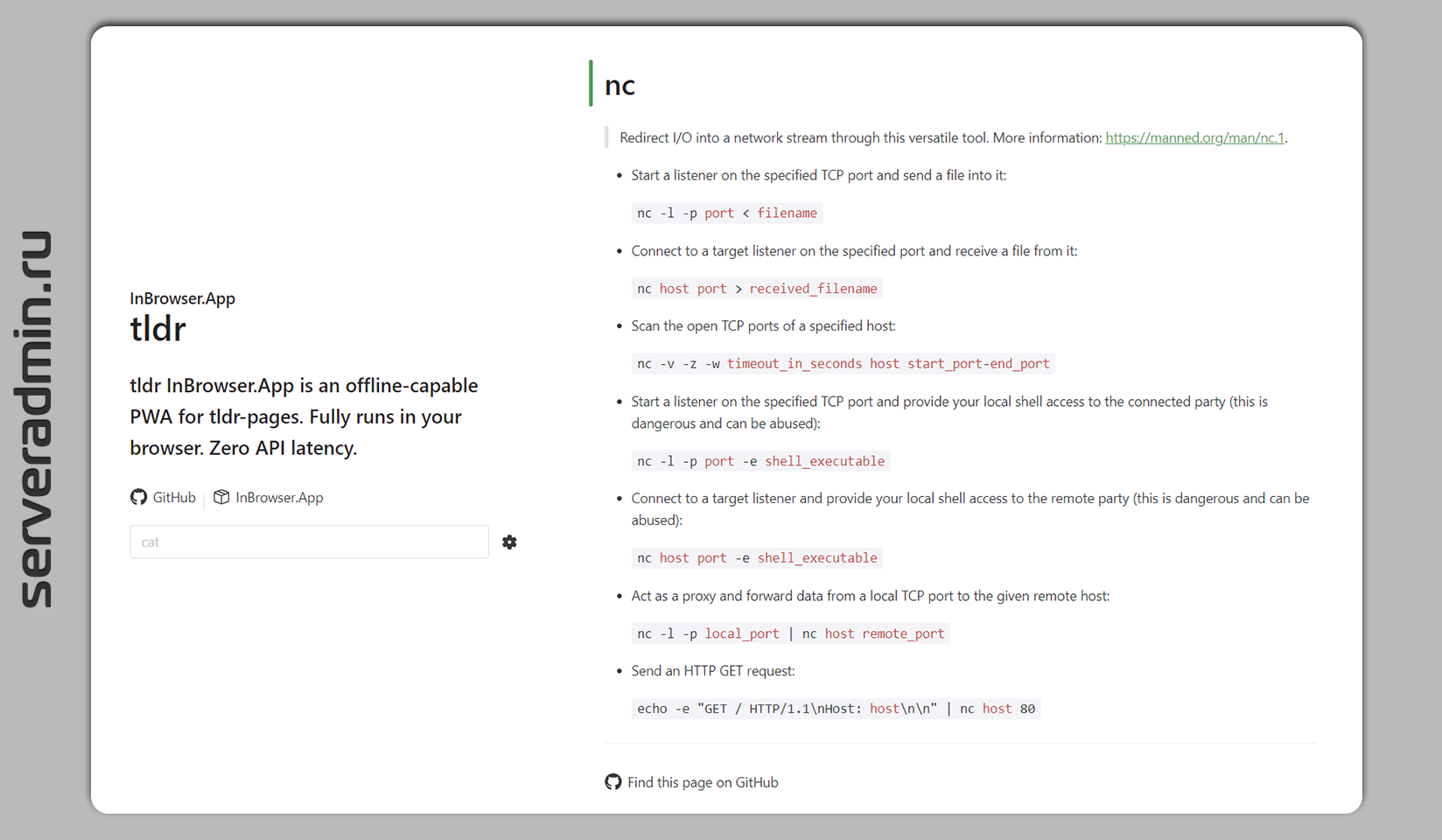{kind=link}
Существует много консольных инструментов для настройки бэкапов. Наиболее популярные и функциональные restic и borg. Сегодня я расскажу про ещё один, который я недавно внедрил на один веб сервер, так что в конце приведу полные конфиги для полноценного использования.
Речь пойдёт про старый и относительно известный инструмент nxs-backup от компании Nixys. Я знаю его давно. Если не ошибаюсь, то сначала это был просто bash скрипт, потом его упаковали в пакеты. А где-то год назад его полностью переписали и теперь это бинарник на Go.
📌 Основные возможности nxs-backup:
🔹Полные и инкрементные бэкапы на уровне файлов.
🔹Бэкапы СУБД MySQL/PostgreSQL как дампом, так и бинарные.
🔹Бэкапы MongoDB и Redis.
🔹В качестве бэкенда для передачи и хранения может использоваться: S3, SSH (SFTP), FTP, CIFS (SMB), NFS, WebDAV.
🔹Уведомления по email, Telegram, Slack или любой webhook.
Теперь отдельно расскажу, что хорошего и полезного есть конкретно в этой программе, так как список возможностей типичный для подобных программ.
➕Простые конфиги в формате yaml для заданий + одиночный бинарник. Удобно масштабировать и использовать одни и те же настройки на различных проектах. Работает одинаково без зависимостей и пересборки практически на всех Linux.
➕Из предыдущего пункта вытекает удобство использования в контейнерах. В конфиги можно передавать переменные, что упрощает настройку и позволяет не хранить секреты в конфигах. Бонусом будет очень маленький образ с самим nxs-backup, если он будет запускаться отдельно.
➕Возможность гибкой настройки логов и уведомлений. Я сделал хранение полного лога в текстовом файле локально, который легко анализировать и куда-то в общее хранилище передавать. А оповещения об ошибках и предупреждениях отдельно отправляю в Telegram.
➕Бэкап на уровне файлов делается простым tar. На базе его же возможностей организованы инкрементные бэкапы. То есть файлы хранятся в исходном виде, а восстановление возможно самостоятельно без использования nxs-backup. Кому-то это покажется минусом, но лично я больше люблю хранение в таком виде. Да, нет дедупликации, но меньше шансов получить поврежденные данные в случае каких-то проблем.
➕В едином формате конфигов описываются задания для бэкапа файлов и баз. Закрываются базовые потребности одной программой. Не надо дампить или делать бинарные бэкапы каким-то отдельным инструментом.
➕Удобно настроить одновременно локальное хранение бэкапов и отправку в S3. Я обычно это сам костылю скриптами.
➕Есть Helm чарт для использования в Kubernetes.
☝ Сразу отмечу явные минусы:
➖Нет встроенного шифрования.
➖Не очень удобно мониторить. По сути есть только логи и уведомления.
➖Документация так себе. Пришлось поковыряться, хоть в итоге всё и получилось, как задумал.
В целом, получилось неплохо. Я потратил время и создал для себя универсальные конфиги, которые буду использовать. Для интегратора или аутсорсера, кто занимается поддержкой серверов, это удобное решение. Собственно, оно для этих целей и писалось, чтобы закрыть внутренние потребности.
Установка:
Подготовка основного конфига в
⇨ nxs-backup.conf
Конфиг с заданием для бэкапа файлов
⇨ site01-files.conf
Конфиг с заданием для бэкапа БД
⇨ site01-mysql.conf
Проверяем конфигурацию:
Если есть ошибки, увидите их. Если нет, то запускаем бэкап:
У меня успешно создаётся локальный бэкап и одновременно с ним отправляется в S3 Селектела. Соответственно, политика хранения бэкапов указана. Nxs-backup будет автоматически складывать по указанной структуре бэкапы и удалять старые.
Продукт интересный. Кто занимается подобными вещами, рекомендую обратить внимание.
⇨ Сайт / Исходники
#backup
Речь пойдёт про старый и относительно известный инструмент nxs-backup от компании Nixys. Я знаю его давно. Если не ошибаюсь, то сначала это был просто bash скрипт, потом его упаковали в пакеты. А где-то год назад его полностью переписали и теперь это бинарник на Go.
📌 Основные возможности nxs-backup:
🔹Полные и инкрементные бэкапы на уровне файлов.
🔹Бэкапы СУБД MySQL/PostgreSQL как дампом, так и бинарные.
🔹Бэкапы MongoDB и Redis.
🔹В качестве бэкенда для передачи и хранения может использоваться: S3, SSH (SFTP), FTP, CIFS (SMB), NFS, WebDAV.
🔹Уведомления по email, Telegram, Slack или любой webhook.
Теперь отдельно расскажу, что хорошего и полезного есть конкретно в этой программе, так как список возможностей типичный для подобных программ.
➕Простые конфиги в формате yaml для заданий + одиночный бинарник. Удобно масштабировать и использовать одни и те же настройки на различных проектах. Работает одинаково без зависимостей и пересборки практически на всех Linux.
➕Из предыдущего пункта вытекает удобство использования в контейнерах. В конфиги можно передавать переменные, что упрощает настройку и позволяет не хранить секреты в конфигах. Бонусом будет очень маленький образ с самим nxs-backup, если он будет запускаться отдельно.
➕Возможность гибкой настройки логов и уведомлений. Я сделал хранение полного лога в текстовом файле локально, который легко анализировать и куда-то в общее хранилище передавать. А оповещения об ошибках и предупреждениях отдельно отправляю в Telegram.
➕Бэкап на уровне файлов делается простым tar. На базе его же возможностей организованы инкрементные бэкапы. То есть файлы хранятся в исходном виде, а восстановление возможно самостоятельно без использования nxs-backup. Кому-то это покажется минусом, но лично я больше люблю хранение в таком виде. Да, нет дедупликации, но меньше шансов получить поврежденные данные в случае каких-то проблем.
➕В едином формате конфигов описываются задания для бэкапа файлов и баз. Закрываются базовые потребности одной программой. Не надо дампить или делать бинарные бэкапы каким-то отдельным инструментом.
➕Удобно настроить одновременно локальное хранение бэкапов и отправку в S3. Я обычно это сам костылю скриптами.
➕Есть Helm чарт для использования в Kubernetes.
☝ Сразу отмечу явные минусы:
➖Нет встроенного шифрования.
➖Не очень удобно мониторить. По сути есть только логи и уведомления.
➖Документация так себе. Пришлось поковыряться, хоть в итоге всё и получилось, как задумал.
В целом, получилось неплохо. Я потратил время и создал для себя универсальные конфиги, которые буду использовать. Для интегратора или аутсорсера, кто занимается поддержкой серверов, это удобное решение. Собственно, оно для этих целей и писалось, чтобы закрыть внутренние потребности.
Установка:
# curl -L https://github.com/nixys/nxs-backup/releases/latest/download/nxs-backup-amd64.tar.gz -o /tmp/nxs-backup.tar.gz# tar xf /tmp/nxs-backup.tar.gz -C /tmp# mv /tmp/nxs-backup /usr/sbin/nxs-backupПодготовка основного конфига в
/etc/nxs-backup/nxs-backup.conf:⇨ nxs-backup.conf
Конфиг с заданием для бэкапа файлов
/etc/nxs-backup/conf.d/site01-files.conf:⇨ site01-files.conf
Конфиг с заданием для бэкапа БД
/etc/nxs-backup/conf.d/site01-mysql.conf:⇨ site01-mysql.conf
Проверяем конфигурацию:
# nxs-backup -tЕсли есть ошибки, увидите их. Если нет, то запускаем бэкап:
# nxs-backup start allУ меня успешно создаётся локальный бэкап и одновременно с ним отправляется в S3 Селектела. Соответственно, политика хранения бэкапов указана. Nxs-backup будет автоматически складывать по указанной структуре бэкапы и удалять старые.
Продукт интересный. Кто занимается подобными вещами, рекомендую обратить внимание.
⇨ Сайт / Исходники
#backup
{kind=link}
▶️ Всем хороших тёплых весенних выходных. Как обычно, ниже те видео из моих подписок за последнее время, что мне показались интересными. Сегодня прям большой список получился.
⇨ HTTP в Wireshark | Компьютерные сети 2024 - 13
Очередной урок с курса по сетям от Созыкина Андрея.
⇨ 2FAuth: автономная веб-альтернатива генераторам одноразовых паролей (OTP) и установка на Synology
Интересная тема. Я раньше не слышал и не видел self-hosted решений для 2FAuth с помощью OTP. Автор разворачивает его на своём Synology.
⇨ Решаем "Тред Ариадны" | TINKOFF CTF 2024 | EASY
Очередной разбор задания от Mekan Bairyev на взлом с низкой сложностью, поэтому ролик относительно прошлых - очень короткий. Как обычно интересная тема и хорошая подача.
⇨ ВЗЛАМЫВАЕМ "Гипнолуч" | TINKOFF CTF 2024 | EASY WEB
Ещё одно относительно простое задание и ролик на 13 минут по нему. Он немного сложнее предыдущего.
⇨ Why pay for Adobe? You don't need it!
Пример установки и настройки self-hosted сервиса для работы через браузер с pdf документами Stirling-PDF. Объединение, разъединение, сжатие, вырезание страниц и вот это вот всё.
⇨ Top 5 Mini PCs for Home Server in early 2024
Обзор современных MiniPC для домашних лабораторий и не только. Некоторые из них вполне продаются в РФ. Например, вот сайт bee-link с minipc. Мне лично нравится такой формат компов для дома и офиса, если вам не нужна мощность.
⇨ Traefik 3 and FREE Wildcard Certificates with Docker
Очень подробный обзор HTTP прокси-сервера и балансировщик нагрузки Traefik. Разобраны все его особенности и удобства. Также показана настройка и реальная эксплуатация. Акцент на получении сертификатов и автоматическую настройку проксирования докер контейнеров.
⇨ Don’t run Proxmox without these settings!
Автор рассказывает о настройках Proxmox, которые он обязательно делает после установки гипервизора: обновления, уведомления, TLS сертификаты, сторейджи, бэкапы и т.д. В целом, ничего особенного. Стандартный чек-лист.
⇨ Proxmox. Templates для VM и LXC. Linked vs Full templates.
Небольшая теория и практика на тему шаблонов в Proxmox. Интересно будет тем, кто не знаком с темой.
⇨ Установка NUT в Proxmox
Пример настройки ИБП с Proxmox через NUT. Рассмотрена установка серверной части, которая корректно выключает сервер при пропадании питания и клиента к ней с веб интерфейсом. Я лично для этих целей предпочитаю apcupsd.
⇨ Настраиваем свой сервер пуш уведомлений Gotify вместе с Proxmox и Crowdsec
Установка и настройка своего сервера Gotify для отправки пуш уведомлений. Известный бесплатный self-hosted сервис с бесплатным мобильным приложением.
⇨ Diun - это вам не watchtower
Обзор программы Diun - маленькое консольное приложение, которое следит за актуальностью локальных docker images и уведомляет, когда вышло обновление. Про него будет скоро отдельная заметка.
⇨ Что такое CI/CD? // Зачем и как работает
Простыми словами о том, что такое CI/CD. Интересно будет тем, кто не знает или до конца не понимает, что это такое, как работает, как архитектурно устроено.
⇨ Экспресс обзор версии Truenas Scale 24 04 Dragonfish
Обзор очередного обновления известного файлового сервера Truenas Scale. По видео можно немного посмотреть на этот продукт изнутри для тех, кто про него не знает. Продукт функциональный с большой историей. Если не ошибаюсь, то Truenas я ставил в офис под файловый сервер с интеграцией в AD ещё лет 15 назад, когда он был на Freebsd.
#видео
⇨ HTTP в Wireshark | Компьютерные сети 2024 - 13
Очередной урок с курса по сетям от Созыкина Андрея.
⇨ 2FAuth: автономная веб-альтернатива генераторам одноразовых паролей (OTP) и установка на Synology
Интересная тема. Я раньше не слышал и не видел self-hosted решений для 2FAuth с помощью OTP. Автор разворачивает его на своём Synology.
⇨ Решаем "Тред Ариадны" | TINKOFF CTF 2024 | EASY
Очередной разбор задания от Mekan Bairyev на взлом с низкой сложностью, поэтому ролик относительно прошлых - очень короткий. Как обычно интересная тема и хорошая подача.
⇨ ВЗЛАМЫВАЕМ "Гипнолуч" | TINKOFF CTF 2024 | EASY WEB
Ещё одно относительно простое задание и ролик на 13 минут по нему. Он немного сложнее предыдущего.
⇨ Why pay for Adobe? You don't need it!
Пример установки и настройки self-hosted сервиса для работы через браузер с pdf документами Stirling-PDF. Объединение, разъединение, сжатие, вырезание страниц и вот это вот всё.
⇨ Top 5 Mini PCs for Home Server in early 2024
Обзор современных MiniPC для домашних лабораторий и не только. Некоторые из них вполне продаются в РФ. Например, вот сайт bee-link с minipc. Мне лично нравится такой формат компов для дома и офиса, если вам не нужна мощность.
⇨ Traefik 3 and FREE Wildcard Certificates with Docker
Очень подробный обзор HTTP прокси-сервера и балансировщик нагрузки Traefik. Разобраны все его особенности и удобства. Также показана настройка и реальная эксплуатация. Акцент на получении сертификатов и автоматическую настройку проксирования докер контейнеров.
⇨ Don’t run Proxmox without these settings!
Автор рассказывает о настройках Proxmox, которые он обязательно делает после установки гипервизора: обновления, уведомления, TLS сертификаты, сторейджи, бэкапы и т.д. В целом, ничего особенного. Стандартный чек-лист.
⇨ Proxmox. Templates для VM и LXC. Linked vs Full templates.
Небольшая теория и практика на тему шаблонов в Proxmox. Интересно будет тем, кто не знаком с темой.
⇨ Установка NUT в Proxmox
Пример настройки ИБП с Proxmox через NUT. Рассмотрена установка серверной части, которая корректно выключает сервер при пропадании питания и клиента к ней с веб интерфейсом. Я лично для этих целей предпочитаю apcupsd.
⇨ Настраиваем свой сервер пуш уведомлений Gotify вместе с Proxmox и Crowdsec
Установка и настройка своего сервера Gotify для отправки пуш уведомлений. Известный бесплатный self-hosted сервис с бесплатным мобильным приложением.
⇨ Diun - это вам не watchtower
Обзор программы Diun - маленькое консольное приложение, которое следит за актуальностью локальных docker images и уведомляет, когда вышло обновление. Про него будет скоро отдельная заметка.
⇨ Что такое CI/CD? // Зачем и как работает
Простыми словами о том, что такое CI/CD. Интересно будет тем, кто не знает или до конца не понимает, что это такое, как работает, как архитектурно устроено.
⇨ Экспресс обзор версии Truenas Scale 24 04 Dragonfish
Обзор очередного обновления известного файлового сервера Truenas Scale. По видео можно немного посмотреть на этот продукт изнутри для тех, кто про него не знает. Продукт функциональный с большой историей. Если не ошибаюсь, то Truenas я ставил в офис под файловый сервер с интеграцией в AD ещё лет 15 назад, когда он был на Freebsd.
#видео
YouTube
HTTP в Wireshark | Компьютерные сети 2024 - 13
Практика с разбором пакетов HTTP в Wireshark
Как поддержать курс:
- Boosty - https://boosty.to/asozykin
- Cloudtips - https://pay.cloudtips.ru/p/45a4055b
Заранее спасибо за помощь!
Текстовая версия видео - https://habr.com/ru/articles/813395/
Сайт курса…
Как поддержать курс:
- Boosty - https://boosty.to/asozykin
- Cloudtips - https://pay.cloudtips.ru/p/45a4055b
Заранее спасибо за помощь!
Текстовая версия видео - https://habr.com/ru/articles/813395/
Сайт курса…