
На днях триггер в Zabbix сработал на то, что дамп Mysql базы не создался. Это бывает редко, давно его не видел. Решил по этому поводу рассказать, как у меня устроена проверка создания дампов с контролем этого процесса через Zabbix. Здесь будет только теория в общих словах. Пример реализации описан у меня в статье:
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Проверил таблицу, там всё в порядке:
Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
-- MySQL dump и в конце -- Dump completed. После создания дампа я банальным grep проверяю, что там эти строки есть. 2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
${BASE01} backup is OK, если хоть одной строки нет, то ${BASE01} backup is corrupted.3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
mysqldump: Error 2013: Lost connection to MySQL server during query when dumping table `b_stat_session_data` at row: 1479887Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Aborted connection 1290694 to db: 'db01' user: 'user01' host: 'localhost' (Got timeout writing communication packets)Проверил таблицу, там всё в порядке:
> check table b_stat_session_data;Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
Server Admin
Настройка mysqldump, проверка и мониторинг бэкапов mysql |...
Создание и проверка бэкапов MySQL с помощью mysqldump. Мониторинг бэкапов в Zabbix с уведомлением об ошибках создания.
В комментариях к заметке о Grav подсказали очень прикольный продукт, про который я раньше не слышал – docusaurus.io. Это генератор статических сайтов, который изначально написали в Facebook. С его помощью весь контент сайта можно держать в git в формате Markdown. Я хоть и написал, что это генератор сайтов, но по факту продукт был создан конкретно под ведение документации.
Docusaurus написан на Javascript, так что установка очень простая. Ставим сначала nodejs, потом через npm запускаем docusaurus:
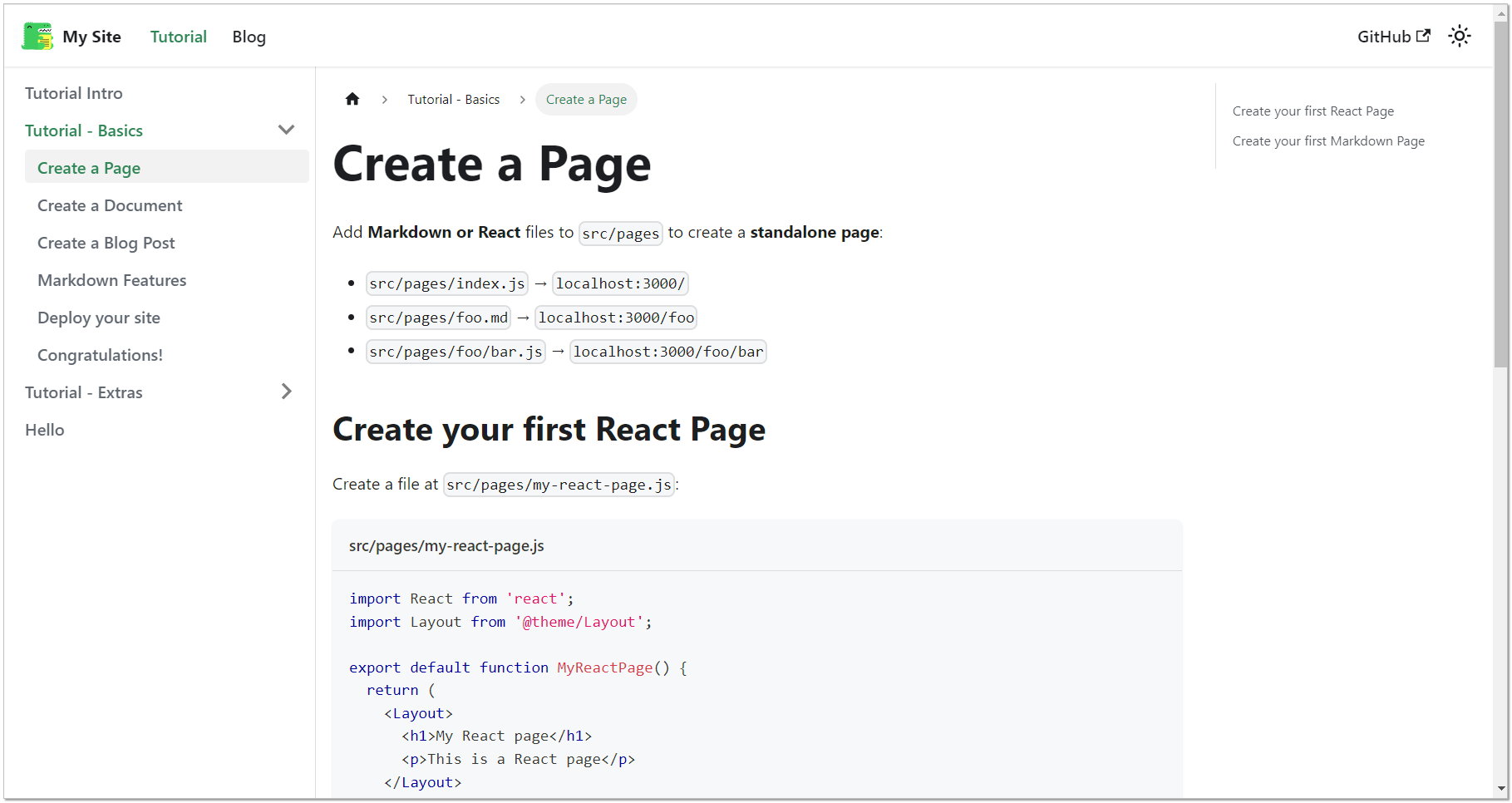
Всё, можно идти на 3000 порт сервера. На главной странице будут ссылки на обучение – Tutorial - Basics. Там самая база даётся с описанием того, как всё устроено. Например, если создать файл
Настройки сайта хранятся в js файлах. Чтобы их редактировать, знать js не обязательно. Если делать стандартный сайт, поменяв там иконки, цвета и т.д., то достаточно просто отредактировать существующие шаблоны.
Движок простой и удобный. Для постоянного использования нужно будет написать systemd юнит и проксировать запросы с какого-нибудь веб сервера, чтобы прикрутить TLS. Помимо документации в движке сразу реализована возможность вести блог и сделать страничку с какой-то общей информацией. То есть это может выступать как готовое решение для какого-то продукта, где есть его описание, документация и блог разработчиков. На выходе получается очень простой и быстрый html код, где ничего лишнего.
Функциональность Docusaurus расширяется плагинами. Для изменения внешнего вида есть множество готовых тем. Как я понял, это довольно популярный и зрелый продукт с большим сообществом. Так что если подбираете себе инструмент для ведения документации, обратите внимание. Его удобно загнать в git и там работать с исходниками.
⇨ Сайт / Исходники
#docs
Docusaurus написан на Javascript, так что установка очень простая. Ставим сначала nodejs, потом через npm запускаем docusaurus:
# apt install nodejs npm# npx create-docusaurus@latest my-docsite classic# cd my-docsite# npx docusaurus start --port 3000 --host 172.20.4.92Всё, можно идти на 3000 порт сервера. На главной странице будут ссылки на обучение – Tutorial - Basics. Там самая база даётся с описанием того, как всё устроено. Например, если создать файл
src/pages/page01.md, то он будет доступен по ссылке 172.20.4.92:3000/page01. То есть можно сразу писать контент. Это будет одиночная страница. В директории docs можно создавать связанные страницы с сайдбаром. Предлагаемая базовая документация как раз оформлена через docs.Настройки сайта хранятся в js файлах. Чтобы их редактировать, знать js не обязательно. Если делать стандартный сайт, поменяв там иконки, цвета и т.д., то достаточно просто отредактировать существующие шаблоны.
Движок простой и удобный. Для постоянного использования нужно будет написать systemd юнит и проксировать запросы с какого-нибудь веб сервера, чтобы прикрутить TLS. Помимо документации в движке сразу реализована возможность вести блог и сделать страничку с какой-то общей информацией. То есть это может выступать как готовое решение для какого-то продукта, где есть его описание, документация и блог разработчиков. На выходе получается очень простой и быстрый html код, где ничего лишнего.
Функциональность Docusaurus расширяется плагинами. Для изменения внешнего вида есть множество готовых тем. Как я понял, это довольно популярный и зрелый продукт с большим сообществом. Так что если подбираете себе инструмент для ведения документации, обратите внимание. Его удобно загнать в git и там работать с исходниками.
⇨ Сайт / Исходники
#docs
{kind=link}
В ОС на базе ядра Linux реализован механизм изоляции системных вызовов под названием namespace. С его помощью каждое приложение может быть изолировано от других средствами самого ядра, без сторонних инструментов. Попробую простыми словами рассказать, что это такое.
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
Теперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
Посмотреть существующие namespaces можно командой
Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
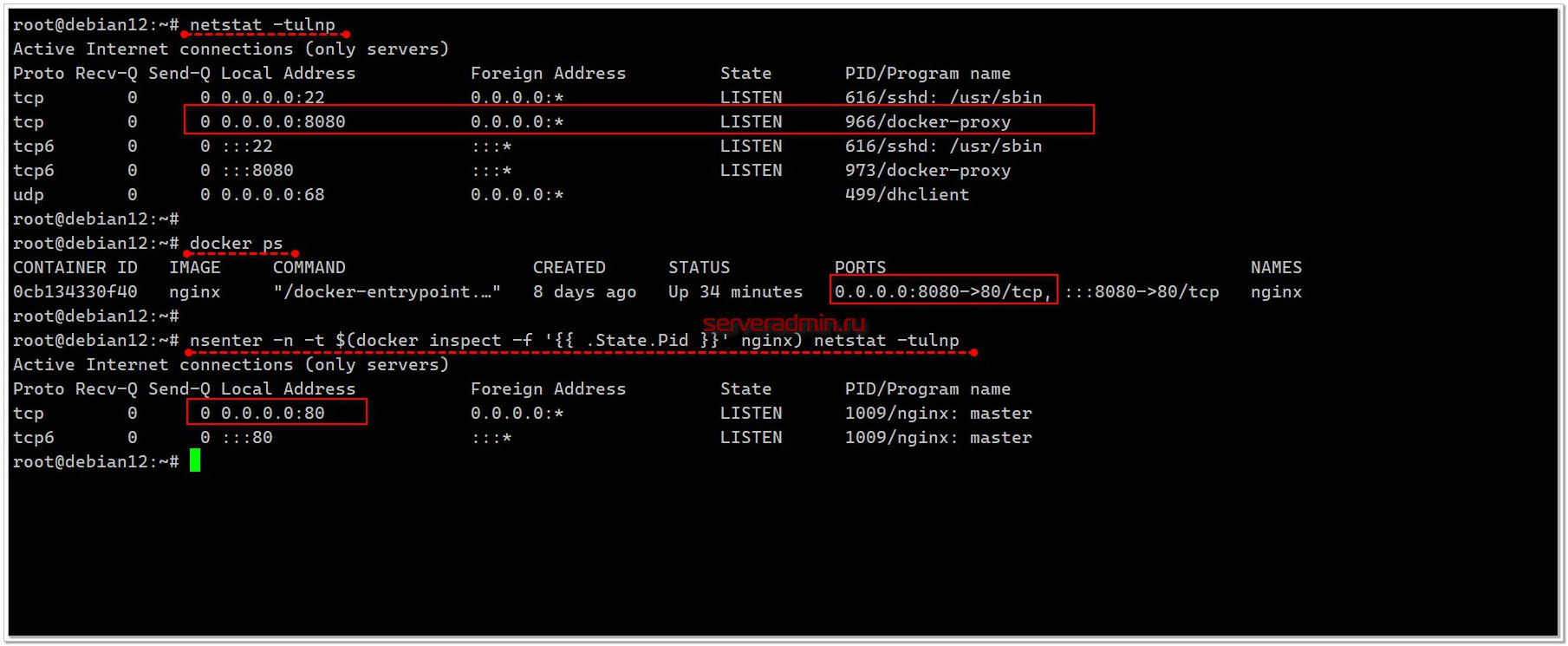
С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
#
Возвращаемся в консоль с unshare и смотрим список процессов:
Видим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
# unshare --pid --fork --mount-proc --mount /bin/bash# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 45 pts/0 R+ 0:00 ps axТеперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
# mkdir /tmp/dir1 /mnt/dir1# mount --bind /tmp/dir1 /mnt/dir1# mount | grep dir1/dev/sda2 on /mnt/dir1 type ext4 (rw,relatime,errors=remount-ro)При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
Посмотреть существующие namespaces можно командой
lsns:# lsns................................................4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash.................................................Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
lsns. С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
lsns узнаём pid процесса в ns pid и подцепляем к нему, к примеру, команду sleep.# lsns | grep /bin/bash4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash#
nsenter -t 854 -m -p sleep 60Возвращаемся в консоль с unshare и смотрим список процессов:
# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 50 pts/2 S+ 0:00 sleep 60 51 pts/0 R+ 0:00 ps axВидим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
{kind=link}
Я активно использую технологию wake on lan в личных целях. Запускаю разное железо дома, когда это нужно. Сам для этого использую Mikrotik и его функциональность в виде tool wol и встроенной системы скриптов. Скрипт выглядит вот так:
Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
Всё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
tool wol interface=ether1 mac=00:25:21:BC:39:42Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
# git clone https://github.com/seriousm4x/UpSnap# cd UpSnap# docker compose upВсё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
{kind=link}
Перебираю иногда старые публикации в поисках интересной и актуальной информации. Каналу уже много лет и что-то из старого не потеряло актуальность, а аудитория с тех пор выросла в разы. Нашёл утилиту bat, как аналог cat и less одновременно.
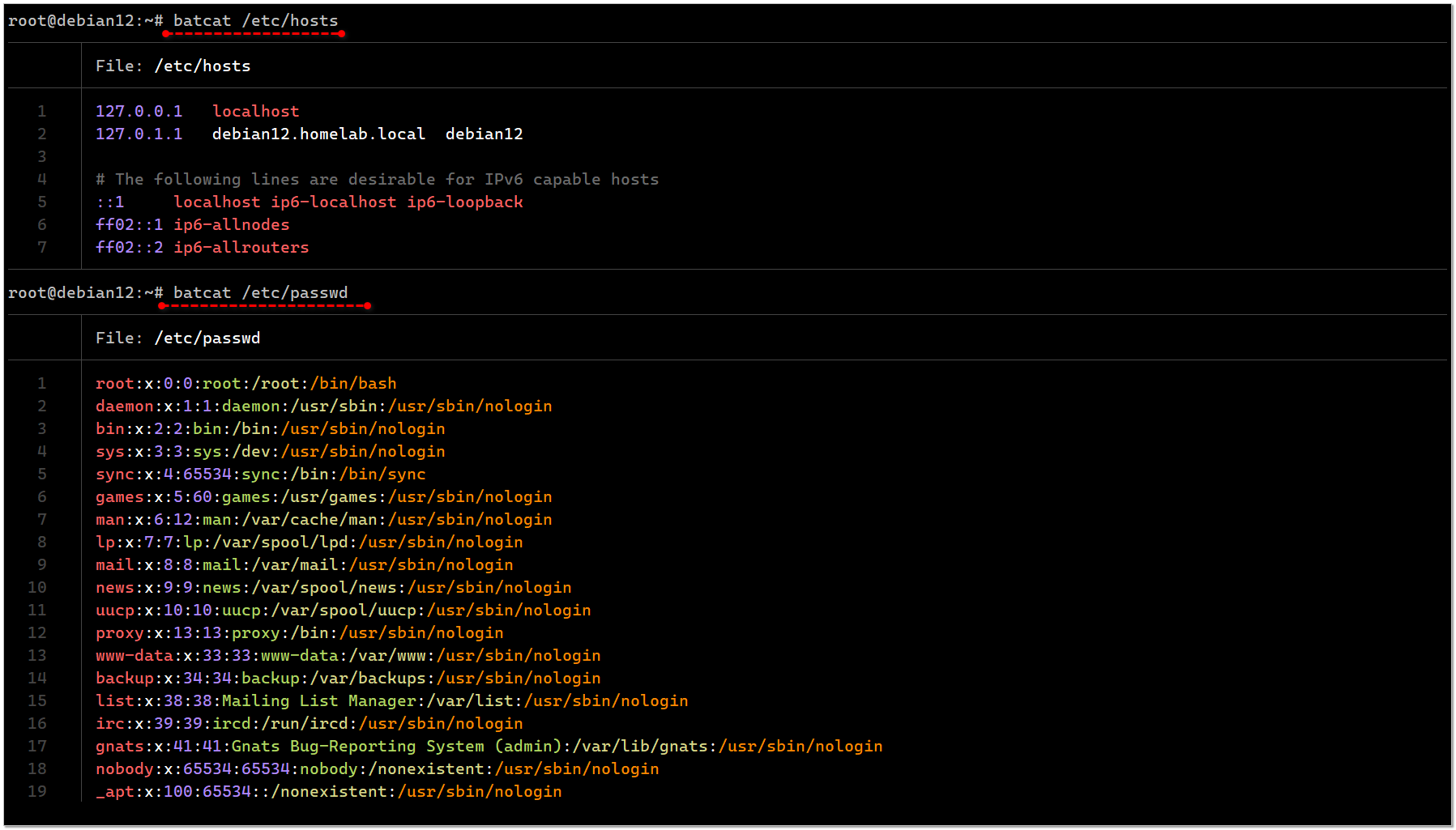
Со времён первого упоминания утилиты bat не было в базовых репозиториях Debian (была в sid) и ставить приходилось вручную бинарник. Очевидно, что это неудобно и не располагает к регулярному использованию. С тех пор ситуация изменилась и теперь эту удобную программу можно поставить из стандартного репозитория:
В системе она почему-то появится с именем не bat, хотя оно не занято, а batcat. Её удобно использовать как для просмотра небольших файлов, так и огромных.
Короткий файл она целиком выводит в терминал с подсветкой и нумерацией строк, а длинный, который не умещается на экран, подгружает по мере прокрутки вниз, как less. То есть по сути она заменяет две эти стандартные утилиты.
Благодаря тому, что bat по умолчанию (это поведение можно изменить) не подгружает сразу весь файл, с её помощью удобно смотреть большие логи. Нумерация строк слева помогает более наглядно воспринимать длинные записи с переносом на несколько строк.
При просмотре больших файлов, горячие клавиши такие же, как у less, так что привыкать не придётся:
▪️ Стрелка вверх – перемещение на одну строку вверх
▪️ Стрелка вниз – перемещение на одну строку вниз
▪️ Пробел или PgDn – перемещение на одну страницу вниз
▪️ b или PgUp – переместить на одну страницу вверх
▪️ g – переместить в начало файла
▪️ G – переместить в конец файла
▪️ ng – перейти на n-ю строку
Ещё bat умеет:
◽хранить свои настройки в файле конфигураций
◽интегрироваться с git
◽показывать непечатаемые символы (ключ -A или настройка в конфиге)
◽интегрироваться с разными утилитами (find, tail, man и другими)
◽использовать разные темы и подсветки синтаксиса
В общем, утилита удобная. Быстро набрала популярность, кучу звёзд на github, поэтому приехала в стандартные репозитории почти всех популярных дистрибутивов Linux. И даже во FreeBSD и Windows. Не нашёл только в RHEL и его форках. Единственный заметный минус - если нужно будет скопировать какую-то строку, то будет захватываться псевдографика с нумерацией строк. Так что для просмотра удобно, для копирования длинных строк - нет.
⇨ Исходники / Описание на русском
#terminal
Со времён первого упоминания утилиты bat не было в базовых репозиториях Debian (была в sid) и ставить приходилось вручную бинарник. Очевидно, что это неудобно и не располагает к регулярному использованию. С тех пор ситуация изменилась и теперь эту удобную программу можно поставить из стандартного репозитория:
# apt install batВ системе она почему-то появится с именем не bat, хотя оно не занято, а batcat. Её удобно использовать как для просмотра небольших файлов, так и огромных.
# batcat /etc/passwd# batcat /var/log/syslogКороткий файл она целиком выводит в терминал с подсветкой и нумерацией строк, а длинный, который не умещается на экран, подгружает по мере прокрутки вниз, как less. То есть по сути она заменяет две эти стандартные утилиты.
Благодаря тому, что bat по умолчанию (это поведение можно изменить) не подгружает сразу весь файл, с её помощью удобно смотреть большие логи. Нумерация строк слева помогает более наглядно воспринимать длинные записи с переносом на несколько строк.
При просмотре больших файлов, горячие клавиши такие же, как у less, так что привыкать не придётся:
▪️ Стрелка вверх – перемещение на одну строку вверх
▪️ Стрелка вниз – перемещение на одну строку вниз
▪️ Пробел или PgDn – перемещение на одну страницу вниз
▪️ b или PgUp – переместить на одну страницу вверх
▪️ g – переместить в начало файла
▪️ G – переместить в конец файла
▪️ ng – перейти на n-ю строку
Ещё bat умеет:
◽хранить свои настройки в файле конфигураций
◽интегрироваться с git
◽показывать непечатаемые символы (ключ -A или настройка в конфиге)
◽интегрироваться с разными утилитами (find, tail, man и другими)
◽использовать разные темы и подсветки синтаксиса
В общем, утилита удобная. Быстро набрала популярность, кучу звёзд на github, поэтому приехала в стандартные репозитории почти всех популярных дистрибутивов Linux. И даже во FreeBSD и Windows. Не нашёл только в RHEL и его форках. Единственный заметный минус - если нужно будет скопировать какую-то строку, то будет захватываться псевдографика с нумерацией строк. Так что для просмотра удобно, для копирования длинных строк - нет.
⇨ Исходники / Описание на русском
#terminal
{kind=link}
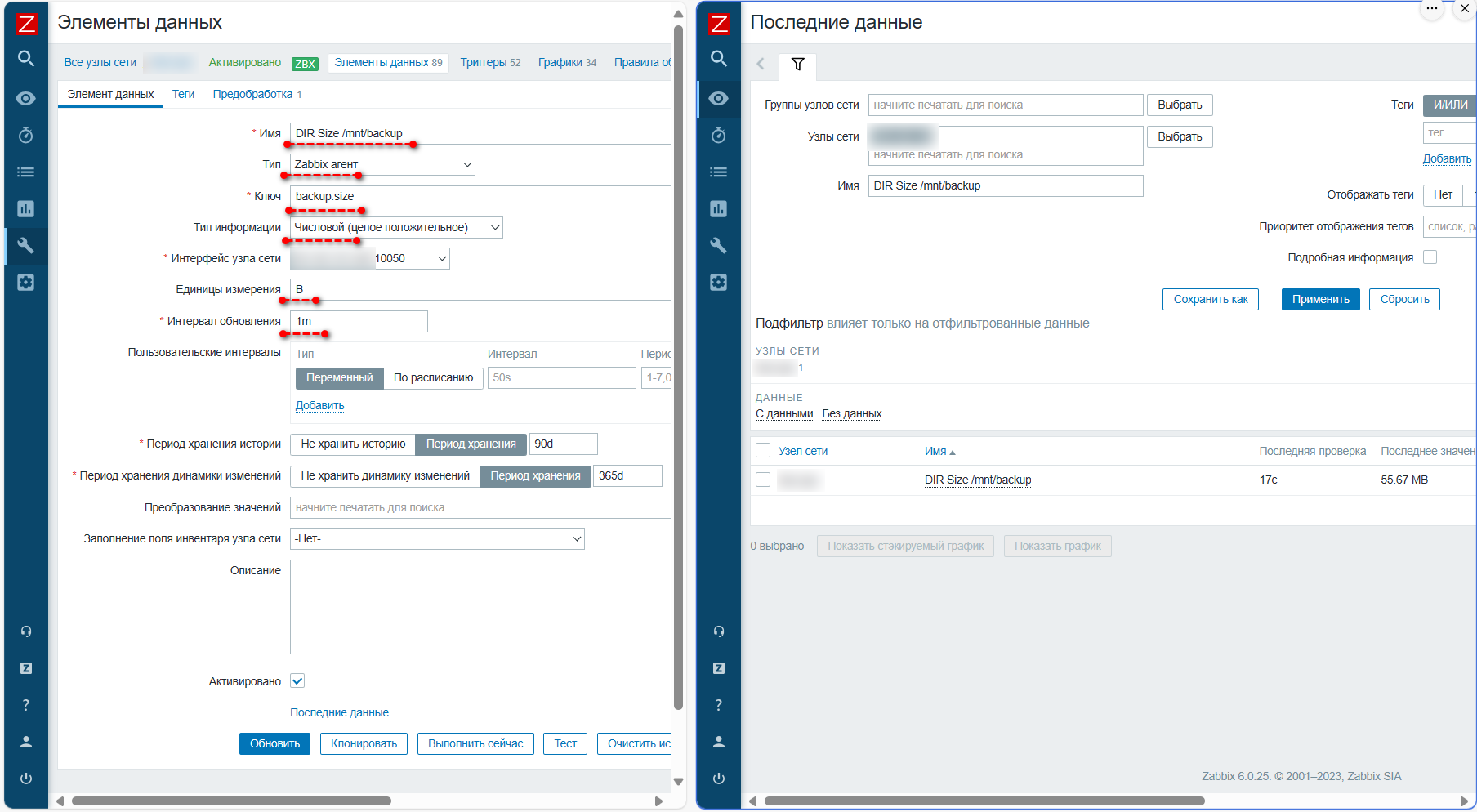
Расскажу про очень простой и быстрый способ мониторить размер какой-нибудь директории или файла на сервере с помощью Zabbix. Способов реализации может быть очень много. Предлагаю наиболее простой, который подойдёт для директорий, где проверку надо делать не часто, и она относительно быстро выполнится. В пределах настроенных таймаутов для агента.
Смотрим размер директории в килобайтах:
Эту цифру надо передать на Zabbix Server. Для этого открываем конфиг zabbix_agentd.conf и добавляем туда:
Перезапускаем агента и проверяем работу метрики:
Отлично, метрика работает. Идём на Zabbix Server, создаём новый шаблон или добавляем айтем напрямую в нужный хост (лучше всегда делать шаблоны). Указываем:
◽Имя: DIR Size /mnt/backup (указываете любое)
◽Тип: Zabbix agent
◽Ключ: backup.size
◽Тип информации: целое положительное
◽Единицы измерения: B (латинская B - байты)
Единица измерения байты указана для того, чтобы Zabbix понимал, что речь идёт о размере данных. Тогда он будет автоматически их переводить на графиках в килобайты, мегабайты, гигабайты, что удобно. Единственный нюанс, у нас данные приходят не в байтах, а килобайтах, поэтому нам нужно добавить множитель 1024. Для этого переходим в настройках айтема на вкладку Предобработка и добавляем шаг:
◽Пользовательский множитель: 1024
Сохраняем айтем. Теперь шаблон можно прикрепить к хосту, где настраивали агента и проверить, как работает. При необходимости можно сделать триггер на этот размер. Не знаю, за чем конкретно вам нужно будет следить, за превышением или наоборот за уменьшением размера, или за изменениями в день. В зависимости от этого настраивается триггер. Там всё интуитивно и по-русски, не трудно разобраться.
По аналогии можно следить за размером отдельного файла. Для этого достаточно указать именно его, а не директорию:
Ну и точно так же добавляем потом в UserParameter новый айтем, настраиваем его на сервере.
Если в UserParameter написать примерно так:
То в качестве имени файла можно передавать значения из ключа айтема, который настраивается на сервере. Примерно так будет выглядеть ключ:
Вот это значение из квадратных скобок приедет на агента вместо
Такой простой механизм передачи в Zabbix любых значений с сервера. Это открывает безграничные возможности для мониторинга всего, что только можно придумать.
Отдельно отмечу, что если директорий у вас много, там много файлов, и частота проверок приличная, то сажайте эти подсчёты на cron, записывайте результаты в файл, а в Zabbix забирайте уже из файла. Так будет надёжнее и проще для сервера мониторинга. Не будет его нагружать лишними соединениями и ожиданиями результата.
Если у кого-то есть вопросы по Zabbix, можете позадавать. Если что, подскажу. Особенно если надо придумать мониторинг какой-нибудь нестандартной метрики. Я чего только не мониторил с ним. От давления жидкости в контуре с контроллера по Modbus протоколу до числа подписчиков в Telegram группе.
#zabbix
Смотрим размер директории в килобайтах:
# du -s /mnt/backup | awk '{print $1}'57004Эту цифру надо передать на Zabbix Server. Для этого открываем конфиг zabbix_agentd.conf и добавляем туда:
UserParameter=backup.size, du -s /mnt/backup | awk '{print $1}'Перезапускаем агента и проверяем работу метрики:
# systemctl restart zabbix-agent# zabbix_agentd -t backup.sizebackup.size [t|57004]Отлично, метрика работает. Идём на Zabbix Server, создаём новый шаблон или добавляем айтем напрямую в нужный хост (лучше всегда делать шаблоны). Указываем:
◽Имя: DIR Size /mnt/backup (указываете любое)
◽Тип: Zabbix agent
◽Ключ: backup.size
◽Тип информации: целое положительное
◽Единицы измерения: B (латинская B - байты)
Единица измерения байты указана для того, чтобы Zabbix понимал, что речь идёт о размере данных. Тогда он будет автоматически их переводить на графиках в килобайты, мегабайты, гигабайты, что удобно. Единственный нюанс, у нас данные приходят не в байтах, а килобайтах, поэтому нам нужно добавить множитель 1024. Для этого переходим в настройках айтема на вкладку Предобработка и добавляем шаг:
◽Пользовательский множитель: 1024
Сохраняем айтем. Теперь шаблон можно прикрепить к хосту, где настраивали агента и проверить, как работает. При необходимости можно сделать триггер на этот размер. Не знаю, за чем конкретно вам нужно будет следить, за превышением или наоборот за уменьшением размера, или за изменениями в день. В зависимости от этого настраивается триггер. Там всё интуитивно и по-русски, не трудно разобраться.
По аналогии можно следить за размером отдельного файла. Для этого достаточно указать именно его, а не директорию:
# du -s /mnt/backup/daily/mysql/daily_mysql_2024-03-01_16h13m_Friday.sql.gz530004Ну и точно так же добавляем потом в UserParameter новый айтем, настраиваем его на сервере.
Если в UserParameter написать примерно так:
UserParameter=file.size[*], du -s $1 | awk '{print $1}'То в качестве имени файла можно передавать значения из ключа айтема, который настраивается на сервере. Примерно так будет выглядеть ключ:
file.size[/mnt/backup/daily/mysql/daily_mysql_2024-03-01_16h13m_Friday.sql.gz]Вот это значение из квадратных скобок приедет на агента вместо
* в квадратные скобки, и вместо $1 в консольную команду.. То есть не придётся для каждого файла настраивать UserParameter. Звёздочка будет разворачиваться в переданное значение.Такой простой механизм передачи в Zabbix любых значений с сервера. Это открывает безграничные возможности для мониторинга всего, что только можно придумать.
Отдельно отмечу, что если директорий у вас много, там много файлов, и частота проверок приличная, то сажайте эти подсчёты на cron, записывайте результаты в файл, а в Zabbix забирайте уже из файла. Так будет надёжнее и проще для сервера мониторинга. Не будет его нагружать лишними соединениями и ожиданиями результата.
Если у кого-то есть вопросы по Zabbix, можете позадавать. Если что, подскажу. Особенно если надо придумать мониторинг какой-нибудь нестандартной метрики. Я чего только не мониторил с ним. От давления жидкости в контуре с контроллера по Modbus протоколу до числа подписчиков в Telegram группе.
#zabbix
{kind=link}
Сейчас в большинстве популярных дистрибутивов на базе Linux в качестве файрвола по умолчанию используется nftables. Конкретно в Debian начиная с Debian 10 Buster. Я обычно делаю вот так в нём:
Но это не может продолжаться вечно. Для какого-нибудь одиночного сервера эти действия просто не нужны. Проще сразу настроить nftables. К тому же у него есть и явные преимущества, про которые я знаю:
◽️ единый конфиг для ipv4 и ipv6;
◽️ более короткий и наглядный синтаксис;
◽️ nftables умеет быстро работать с огромными списками, не нужен ipset;
◽️ экспорт правил в json, удобно для мониторинга.
Я точно помню, что когда-то писал набор стандартных правил для nftables, но благополучно его потерял. Пришлось заново составлять, поэтому и пишу сразу заметку, чтобы не потерять ещё раз. Правила будут для условного веб сервера, где разрешены на вход все соединения на 80 и 443 порты, на порт 10050 zabbix агента разрешены только с zabbix сервера, а на 22-й порт SSH только для списка IP адресов. Всё остальное закрыто на вход. Исходящие соединения сервера разрешены.
Начну с базы, нужной для управления правилами. Смотрим существующий список правил и таблиц:
Очистка правил:
Дальше сразу привожу готовый набор правил. Отдельно отмечу, что в nftables привычные таблицы и цепочки нужно создать отдельно. В iptables они были по умолчанию.
Вот и всё. Мы создали таблицу filter, добавили цепочку input, закинули туда нужные нам разрешающие правила и в конце изменили политику по умолчанию на drop. Так как никаких других правил нам сейчас не надо, остальные таблицы и цепочки можно не создавать. Осталось только сохранить эти правила и применить их после загрузки сервера.
У nftables есть служба, которая при запуске читает файл конфигурации
Можно перезагружаться и проверять автозагрузку правил. Ещё полезная команда, которая пригодится в процессе настройки. Удаление правила по номеру:
Добавление правила в конкретное место с номером в списке:
В целом, ничего сложного. Подобным образом настраиваются остальные цепочки output или forward, если нужно. Синтаксис удобнее, чем у iptables. Как-то более наглядно и логично, особенно со списками ip адресов и портов, если они небольшие.
Единственное, что не нашёл пока как делать - как подгружать очень большие списки с ip адресами. Вываливать их в список правил - плохая идея. Надо как-то подключать извне. По идее это описано в sets, но я пока не разбирался.
⇨ Документация
#nftables
# apt remove --auto-remove nftables# apt purge nftables# apt update# apt install iptablesНо это не может продолжаться вечно. Для какого-нибудь одиночного сервера эти действия просто не нужны. Проще сразу настроить nftables. К тому же у него есть и явные преимущества, про которые я знаю:
◽️ единый конфиг для ipv4 и ipv6;
◽️ более короткий и наглядный синтаксис;
◽️ nftables умеет быстро работать с огромными списками, не нужен ipset;
◽️ экспорт правил в json, удобно для мониторинга.
Я точно помню, что когда-то писал набор стандартных правил для nftables, но благополучно его потерял. Пришлось заново составлять, поэтому и пишу сразу заметку, чтобы не потерять ещё раз. Правила будут для условного веб сервера, где разрешены на вход все соединения на 80 и 443 порты, на порт 10050 zabbix агента разрешены только с zabbix сервера, а на 22-й порт SSH только для списка IP адресов. Всё остальное закрыто на вход. Исходящие соединения сервера разрешены.
Начну с базы, нужной для управления правилами. Смотрим существующий список правил и таблиц:
# nft -a list ruleset# nft list tablesОчистка правил:
# nft flush rulesetДальше сразу привожу готовый набор правил. Отдельно отмечу, что в nftables привычные таблицы и цепочки нужно создать отдельно. В iptables они были по умолчанию.
nft add table inet filternft add chain inet filter input { type filter hook input priority 0\; }nft add rule inet filter input ct state related,established counter acceptnft add rule inet filter input iifname "lo" counter acceptnft add rule inet filter input ip protocol icmp counter acceptnft add rule inet filter input tcp dport {80, 443} counter acceptnft add rule inet filter input ip saddr { 192.168.100.0/24, 172.20.0.0/24, 1.1.1.1/32 } tcp dport 22 counter acceptnft add rule inet filter input ip saddr 2.2.2.2/32 tcp dport 10050 counter acceptnft chain inet filter input { policy drop \; }Вот и всё. Мы создали таблицу filter, добавили цепочку input, закинули туда нужные нам разрешающие правила и в конце изменили политику по умолчанию на drop. Так как никаких других правил нам сейчас не надо, остальные таблицы и цепочки можно не создавать. Осталось только сохранить эти правила и применить их после загрузки сервера.
У nftables есть служба, которая при запуске читает файл конфигурации
/etc/nftables.conf. Запишем туда наш набор правил. Так как мы перезапишем существующую конфигурацию, где в начале стоит очистка всех правил, нам надо отдельно добавить её туда:# echo "flush ruleset" > /etc/nftables.conf# nft -s list ruleset >> /etc/nftables.conf# systemctl enable nftables.serviceМожно перезагружаться и проверять автозагрузку правил. Ещё полезная команда, которая пригодится в процессе настройки. Удаление правила по номеру:
# nft delete rule inet filter input handle 9Добавление правила в конкретное место с номером в списке:
# nft add rule inet filter input position 8 tcp dport 22 counter acceptВ целом, ничего сложного. Подобным образом настраиваются остальные цепочки output или forward, если нужно. Синтаксис удобнее, чем у iptables. Как-то более наглядно и логично, особенно со списками ip адресов и портов, если они небольшие.
Единственное, что не нашёл пока как делать - как подгружать очень большие списки с ip адресами. Вываливать их в список правил - плохая идея. Надо как-то подключать извне. По идее это описано в sets, но я пока не разбирался.
⇨ Документация
#nftables
{kind=link}
▶️ Очередная подборка авторских IT роликов, которые я лично посмотрел и посчитал интересными/полезными. Как раз к выходным.
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
YouTube
Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox | КАК ПРОЙТИ #DRIVE.HTB
Как решить машину DRIVE на HackTheBox?
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
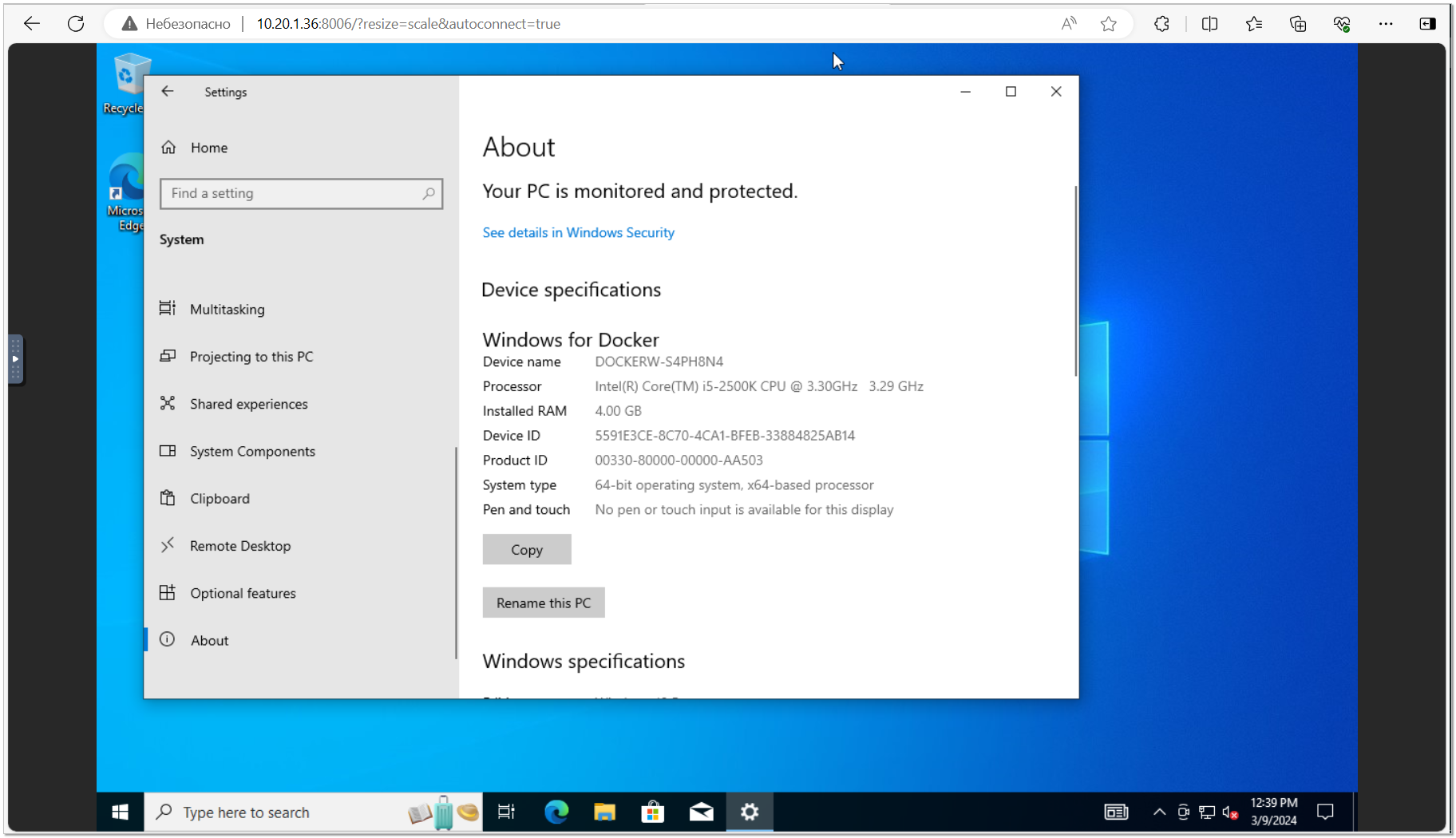
В пятницу рассказывал про ролик, где показан запуск системы Windows через Docker контейнер. Меня заинтересовала эта штука, так что решил сразу попробовать, как это работает. А работает неплохо, мне понравилось.
Есть репозиторий, где всё подробно описано:
⇨ https://github.com/dockur/windows
Я решил попробовать работу этого проекта на обычной виртуальной машине Proxmox, где включена вложенная виртуализация. Для виртуалки тип процессора установил host. Больше никаких особенных настроек не делал.
Скопировал себе репозиторий и запустил дефолтный docker compose:
Был создан и запущен контейнер с Windows 11. Ничего не заработало, так как контейнер не смог загрузить образ системы, о чём сообщил в консоли. Там же была информация о том, что с моего IP нельзя выполнить загрузку. Судя по всему это работает блокировка Microsoft. Можно скачать образ вручную и подсунуть его контейнеру. Мне не захотелось заморачиваться.
Я просто изменил систему на Windows 10, добавив в окружение переменную, как показано в репозитории.
И запустил ещё раз. На удивление, всё прошло успешно. Стартовал контейнер, загрузил образ системы, развернул его, выполнив стандартную установку. За процессом можно наблюдать через веб интерфейс, зайдя по ip адресу сервера, указав порт 8006. Участие не требуется, всё выполняется автоматически. Никаких ключей вводить не надо. На выходе будет неактивированная, полностью легальная система.
Длилось всё это минут 30. На хосте должно быть достаточно свободного места и ресурсов системы. По умолчанию контейнеру выделяется 2 CPU, 4 GB памяти и 64 GB диска. Эти настройки можно изменить через environment.
У меня первый раз не хватило места на диске, второй раз память закончилась. Тогда я всё же сходил в репозиторий и уточнил информацию по ресурсам, которые требуются.
После запуска системы, с ней можно работать через браузер, либо по RDP. Специально ничего настраивать не надо. По RDP можно подключиться, указать пользователя docker, пароль пустой.
Мне очень понравилось, как тут всё организовано. Для тестовых стендов отличный инструмент. Весь ручной труд сделан за нас. Достаточно просто запустить контейнер и на выходе получить готовую систему. Можно на одной виртуалке держать полный набор различных тестовых систем Windows и запускать по мере надобности.
Работает всё это на базе KVM. От Docker тут только автоматизация запуска и управления.
#windows #docker
Есть репозиторий, где всё подробно описано:
⇨ https://github.com/dockur/windows
Я решил попробовать работу этого проекта на обычной виртуальной машине Proxmox, где включена вложенная виртуализация. Для виртуалки тип процессора установил host. Больше никаких особенных настроек не делал.
Скопировал себе репозиторий и запустил дефолтный docker compose:
# git clone https://github.com/dockur/windows# cd windows# docker compose upБыл создан и запущен контейнер с Windows 11. Ничего не заработало, так как контейнер не смог загрузить образ системы, о чём сообщил в консоли. Там же была информация о том, что с моего IP нельзя выполнить загрузку. Судя по всему это работает блокировка Microsoft. Можно скачать образ вручную и подсунуть его контейнеру. Мне не захотелось заморачиваться.
Я просто изменил систему на Windows 10, добавив в окружение переменную, как показано в репозитории.
version: "3"services: windows:................................. environment: VERSION: "win10".................................И запустил ещё раз. На удивление, всё прошло успешно. Стартовал контейнер, загрузил образ системы, развернул его, выполнив стандартную установку. За процессом можно наблюдать через веб интерфейс, зайдя по ip адресу сервера, указав порт 8006. Участие не требуется, всё выполняется автоматически. Никаких ключей вводить не надо. На выходе будет неактивированная, полностью легальная система.
Длилось всё это минут 30. На хосте должно быть достаточно свободного места и ресурсов системы. По умолчанию контейнеру выделяется 2 CPU, 4 GB памяти и 64 GB диска. Эти настройки можно изменить через environment.
У меня первый раз не хватило места на диске, второй раз память закончилась. Тогда я всё же сходил в репозиторий и уточнил информацию по ресурсам, которые требуются.
После запуска системы, с ней можно работать через браузер, либо по RDP. Специально ничего настраивать не надо. По RDP можно подключиться, указать пользователя docker, пароль пустой.
Мне очень понравилось, как тут всё организовано. Для тестовых стендов отличный инструмент. Весь ручной труд сделан за нас. Достаточно просто запустить контейнер и на выходе получить готовую систему. Можно на одной виртуалке держать полный набор различных тестовых систем Windows и запускать по мере надобности.
Работает всё это на базе KVM. От Docker тут только автоматизация запуска и управления.
#windows #docker
{kind=link}
Небольшая заметка-напоминание по мотивам моих действий на одном из серверов. Пару месяцев назад обновлял почтовый сервер. Не помню точно, что там за нюансы были, но на всякий случай сделал контрольную точку виртуальной машине, чтобы можно было быстро откатиться в случае проблем.
Ну и благополучно забыл про неё, когда всё удачно завершилось. Заметил это в выходные случайно, когда просматривал сервера. Нужно будет заменить один старый сервер на новый и перераспределить виртуалки. Плюс, в виду завершения развития бесплатного Hyper-V, буду постепенно переводить все эти гипервизоры на Proxmox.
Возвращаясь к контрольной точке. Там сервер довольно крупный. За это время расхождение со снимком набежало почти на 150 Гб. Смержить это всё быстро не получится. Немного запереживал, так как сервер там в целом нагружен. Дождался позднего вечера, сделал бэкап и потушил машину. На выключенной виртуалке удалил контрольную точку. Слияние минут 15-20 длилось. Прошло успешно.
Не люблю такие моменты. Затяжное слияние контрольных точек потенциально небезопасная процедура, поэтому не рекомендуется накапливать большие расхождения. Сделал контрольную точку, накатил изменения, убедился, что всё в порядке, удаляй. Нельзя оставлять их надолго. В этот раз обошлось. Я уже не первый раз так забываю. Как то раз целый год у меня провисела контрольная точка. Тоже благополучно объединилась с основой.
Но я видел и проблемы, особенно когда по ошибке выстраивалась цепочка контрольных точек. Не у меня было, но меня просили помочь разобраться. В какой-то момент виртуалка повисла и перестала запускаться. Контрольные точки объединить не получилось. Пришлось восстанавливать виртуалку из бэкапов. А так как эти контрольные точки создавала программа для бэкапов, она в какой-то момент тоже стала глючить. В итоге часть данных потеряли, так как восстановились на бэкап недельной давности.
В общем, с контрольными точками надо быть аккуратным и без особой необходимости их не плодить. И следить, чтобы программы для бэкапа не оставляли контрольные точки. Часто именно они их создают и из-за глюков могут оставлять.
#виртуализация
Ну и благополучно забыл про неё, когда всё удачно завершилось. Заметил это в выходные случайно, когда просматривал сервера. Нужно будет заменить один старый сервер на новый и перераспределить виртуалки. Плюс, в виду завершения развития бесплатного Hyper-V, буду постепенно переводить все эти гипервизоры на Proxmox.
Возвращаясь к контрольной точке. Там сервер довольно крупный. За это время расхождение со снимком набежало почти на 150 Гб. Смержить это всё быстро не получится. Немного запереживал, так как сервер там в целом нагружен. Дождался позднего вечера, сделал бэкап и потушил машину. На выключенной виртуалке удалил контрольную точку. Слияние минут 15-20 длилось. Прошло успешно.
Не люблю такие моменты. Затяжное слияние контрольных точек потенциально небезопасная процедура, поэтому не рекомендуется накапливать большие расхождения. Сделал контрольную точку, накатил изменения, убедился, что всё в порядке, удаляй. Нельзя оставлять их надолго. В этот раз обошлось. Я уже не первый раз так забываю. Как то раз целый год у меня провисела контрольная точка. Тоже благополучно объединилась с основой.
Но я видел и проблемы, особенно когда по ошибке выстраивалась цепочка контрольных точек. Не у меня было, но меня просили помочь разобраться. В какой-то момент виртуалка повисла и перестала запускаться. Контрольные точки объединить не получилось. Пришлось восстанавливать виртуалку из бэкапов. А так как эти контрольные точки создавала программа для бэкапов, она в какой-то момент тоже стала глючить. В итоге часть данных потеряли, так как восстановились на бэкап недельной давности.
В общем, с контрольными точками надо быть аккуратным и без особой необходимости их не плодить. И следить, чтобы программы для бэкапа не оставляли контрольные точки. Часто именно они их создают и из-за глюков могут оставлять.
#виртуализация
Для тех, кто работает с 1С, могу порекомендовать сайт Кухара Богдана. Я давно его знаю, подписан на его ютуб канал, смотрю выпуски. Не могу сказать, что там прям что-то очень нужное и полезное. Обычная базовая информация для системного администратора. Много рекламы его курса, куда он выносит наиболее интересные моменты из своих материалов.
Привлекло моё внимание его небольшой bat скрипт для бэкапа файловых баз в Windows, который он недавно анонсировал. Я много раз настраивал различным заказчикам файловые базы где-то на выделенном сервере. Это хорошее и экономное решение для работы 2-3 человек с базой. Актуально для аутсорсеров, где каждый бухгалтер ведёт кучу баз клиентов, и при этом работает там в основной один или с помощником.
- Описание скрипта
- Видео обзор
Файловая база представляет из себя обычный файл на диске, но при этом внутри там полноценная база данных. Не всегда простым копированием можно получить рабочий бэкап. Если во время копирования с базой работали пользователи, база может оказаться битой. То же самое с выгрузкой в dt. Она не является полноценным бэкапом, так как нет 100% гарантии, что из неё получится развернуть базу.
Самым надёжным способом сделать бэкап файловой базы - выгнать всех пользователей, запретить им вход и базу и после этого скопировать файл 1Cv8.1CD. Именно это и делает указанный скрипт, и не только. Он умеет:
▪️ Выгонять всех пользователей из базы и завершать работу платформы.
▪️ Если платформа зависла и штатно не завершила работу, завершает её принудительно.
▪️ Если база опубликована через Apache 2.4 на этом же сервере, то завершает сеансы 1С в веб сервере.
▪️ Жать бэкап базы с помощью 7zip.
▪️ Вести лог файл своей работы.
▪️ Запускаться через планировщик Windows.
▪️ Автоматически удалять старые копии.
Для корректной работы скрипта путь до файловой базы должен быть только латинскими буквами. Получилось готовое рабочее решение, которое можно сразу поставить в планировщик и настроить мониторинг лог файла, чтобы понимать, как прошёл очередной бэкап.
Отдельно советую на сайте посмотреть раздел Администратору 1С. Там много полезных материалов, в том числе свежая инструкция:
⇨ PostgreSQL 16 + Cервер 1С x64 и 1С 8.3.23 на Ubuntu 22.04
#1С
Привлекло моё внимание его небольшой bat скрипт для бэкапа файловых баз в Windows, который он недавно анонсировал. Я много раз настраивал различным заказчикам файловые базы где-то на выделенном сервере. Это хорошее и экономное решение для работы 2-3 человек с базой. Актуально для аутсорсеров, где каждый бухгалтер ведёт кучу баз клиентов, и при этом работает там в основной один или с помощником.
- Описание скрипта
- Видео обзор
Файловая база представляет из себя обычный файл на диске, но при этом внутри там полноценная база данных. Не всегда простым копированием можно получить рабочий бэкап. Если во время копирования с базой работали пользователи, база может оказаться битой. То же самое с выгрузкой в dt. Она не является полноценным бэкапом, так как нет 100% гарантии, что из неё получится развернуть базу.
Самым надёжным способом сделать бэкап файловой базы - выгнать всех пользователей, запретить им вход и базу и после этого скопировать файл 1Cv8.1CD. Именно это и делает указанный скрипт, и не только. Он умеет:
▪️ Выгонять всех пользователей из базы и завершать работу платформы.
▪️ Если платформа зависла и штатно не завершила работу, завершает её принудительно.
▪️ Если база опубликована через Apache 2.4 на этом же сервере, то завершает сеансы 1С в веб сервере.
▪️ Жать бэкап базы с помощью 7zip.
▪️ Вести лог файл своей работы.
▪️ Запускаться через планировщик Windows.
▪️ Автоматически удалять старые копии.
Для корректной работы скрипта путь до файловой базы должен быть только латинскими буквами. Получилось готовое рабочее решение, которое можно сразу поставить в планировщик и настроить мониторинг лог файла, чтобы понимать, как прошёл очередной бэкап.
Отдельно советую на сайте посмотреть раздел Администратору 1С. Там много полезных материалов, в том числе свежая инструкция:
⇨ PostgreSQL 16 + Cервер 1С x64 и 1С 8.3.23 на Ubuntu 22.04
#1С
Kuharbogdan
Блог Кухара Богдана - Администрирование и программирование в 1С
Блог Кухара Богдана - Администрирование и программирование в 1С Предприятии Советы администраторам и программистам 1С, а также образовательные курсы
Я привык вместе с почтовыми серверами настраивать веб интерфейс на базе RoundCube. Простой и удобный интерфейс, написанный на php. Основной его минус - он почти не развивался последние лет 10. Недавно его под своё крыло взяла Nextcloud GmbH и пообещала добавить разработчиков, чтобы оживить панельку и вдохнуть в неё новую жизнь. Времени прошло немного, так что каких-то изменений пока нет. Выкатили один релиз с исправлением известных ошибок.
Много раз видел рекомендации на SnappyMail, это форк RainLoop, который больше не развивается. Решил посмотреть на SnappyMail и подключил к одному из почтовых серверов. Напишу то, на что обратил внимание сам по сравнению с RoundCube:
🔹SnappyMail имеет очень простой и быстрый веб интерфейс. Я, честно говоря, прям кайфую, когда вижу лёгкие и быстрые интерфейсы. Сейчас это редкость. Не сказать, что RoundCube тяжёлый, но SnappyMail легче и отзывчивее.
🔹Если вам не нужна общая адресная книга, то для работы SnappyMail не нужна СУБД. Она все настройки хранит в файлах. Написана тоже на php, так что для установки достаточно просто исходники положить в директорию веб сервера. Все дальнейшие настройки через веб интерфейс. Не нужно руками править конфиги. В RoundCube придётся по конфигам полазить, чтобы настроить.
🔹Как и RoundCube, SnappyMail поддерживает работу фильтров sieve. Из коробки стандартная тема поддерживает мобильные устройства.
🔹В SnappyMail по умолчанию любой пользователь может настраивать несколько почтовых ящиков, подключенных к его аккаунту.
🔹Для SnappyMail, как и RoundCube, есть много дополнительных плагинов. Но в отличие от круглого куба, в Snappy вся установка и настройка выполняется через веб интерфейс администратора. Не надо руками качать плагины и править конфиги. Это очень удобно. Набор плагинов тоже понравился.
🔹У SnappyMail есть готовые фильтры для Fail2ban, которые пресекают перебор учёток через веб интерфейс.
В общем и целом, ничего особенного у SnappyMail я не увидел, но по совокупности небольших улучшений он выглядит более простым и удобным в установке и настройке. Плюс, мне внешний вид темы по умолчанию понравился больше в SnappyMail. Он более минималистичный и компактный.
Единственное, что не понравилось - не увидел в SnappyMail плагин, который позволяет пользователю самостоятельно поставить отбойник, когда он уходит в отпуск. В RoundCube я в обязательном порядке его ставлю, пользователи активно используют. Можно это реализовывать с помощью фильтров, но отдельный плагин только под это дело удобнее.
❗️Если кто-то будет прямо сейчас пробовать, имейте ввиду, что в последних двух релизах есть баг, связанный с начальной настройкой, который уже исправили, но ещё не выпустили новый релиз с исправлением. Ставьте версию 2.35.0. Там ошибок нет.
#mailserver
Много раз видел рекомендации на SnappyMail, это форк RainLoop, который больше не развивается. Решил посмотреть на SnappyMail и подключил к одному из почтовых серверов. Напишу то, на что обратил внимание сам по сравнению с RoundCube:
🔹SnappyMail имеет очень простой и быстрый веб интерфейс. Я, честно говоря, прям кайфую, когда вижу лёгкие и быстрые интерфейсы. Сейчас это редкость. Не сказать, что RoundCube тяжёлый, но SnappyMail легче и отзывчивее.
🔹Если вам не нужна общая адресная книга, то для работы SnappyMail не нужна СУБД. Она все настройки хранит в файлах. Написана тоже на php, так что для установки достаточно просто исходники положить в директорию веб сервера. Все дальнейшие настройки через веб интерфейс. Не нужно руками править конфиги. В RoundCube придётся по конфигам полазить, чтобы настроить.
🔹Как и RoundCube, SnappyMail поддерживает работу фильтров sieve. Из коробки стандартная тема поддерживает мобильные устройства.
🔹В SnappyMail по умолчанию любой пользователь может настраивать несколько почтовых ящиков, подключенных к его аккаунту.
🔹Для SnappyMail, как и RoundCube, есть много дополнительных плагинов. Но в отличие от круглого куба, в Snappy вся установка и настройка выполняется через веб интерфейс администратора. Не надо руками качать плагины и править конфиги. Это очень удобно. Набор плагинов тоже понравился.
🔹У SnappyMail есть готовые фильтры для Fail2ban, которые пресекают перебор учёток через веб интерфейс.
В общем и целом, ничего особенного у SnappyMail я не увидел, но по совокупности небольших улучшений он выглядит более простым и удобным в установке и настройке. Плюс, мне внешний вид темы по умолчанию понравился больше в SnappyMail. Он более минималистичный и компактный.
Единственное, что не понравилось - не увидел в SnappyMail плагин, который позволяет пользователю самостоятельно поставить отбойник, когда он уходит в отпуск. В RoundCube я в обязательном порядке его ставлю, пользователи активно используют. Можно это реализовывать с помощью фильтров, но отдельный плагин только под это дело удобнее.
❗️Если кто-то будет прямо сейчас пробовать, имейте ввиду, что в последних двух релизах есть баг, связанный с начальной настройкой, который уже исправили, но ещё не выпустили новый релиз с исправлением. Ставьте версию 2.35.0. Там ошибок нет.
#mailserver
{kind=link}
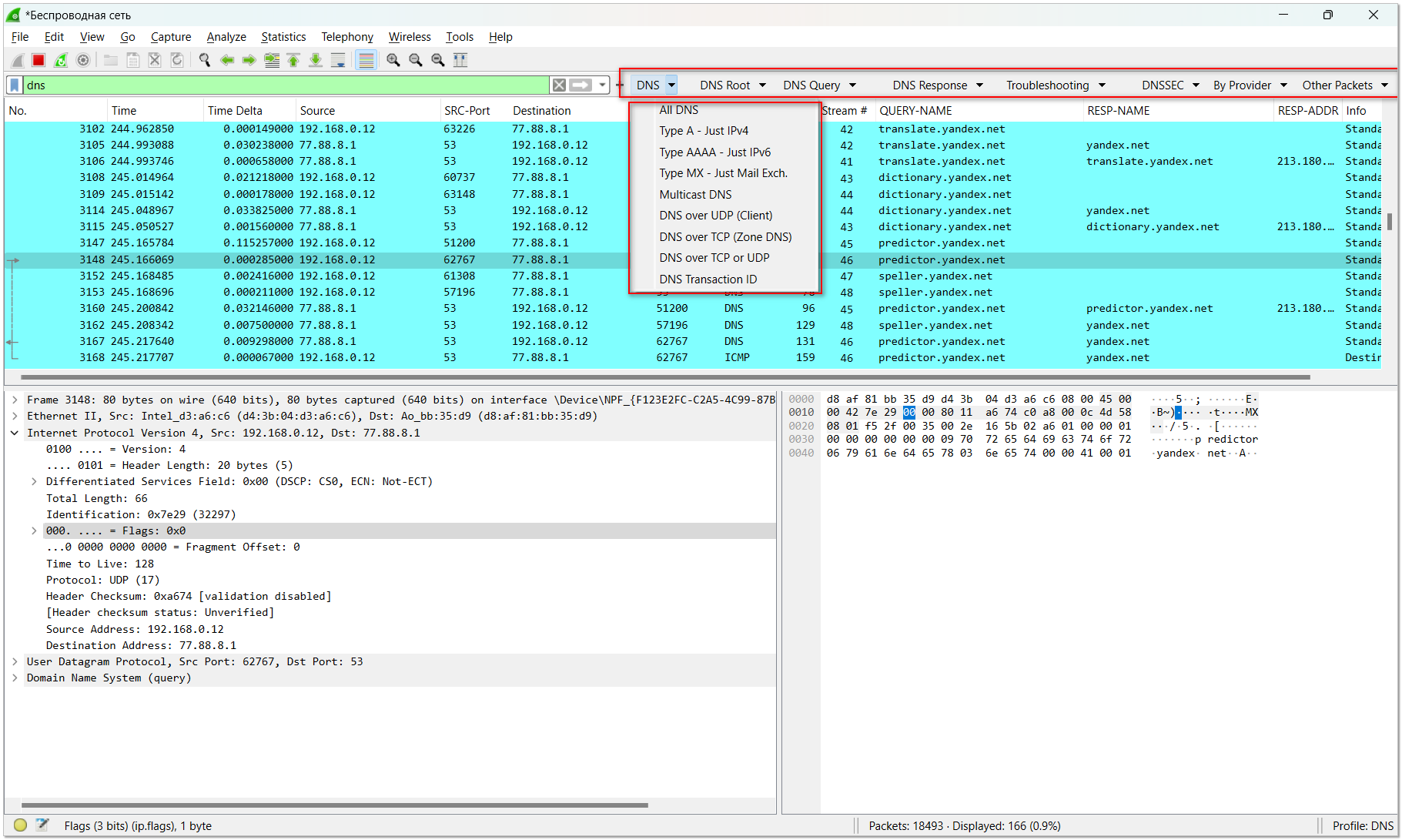
Если вам иногда приходится работать в Wireshark, а любому админу рано или поздно приходится это делать, то у меня для вас есть полезный репозиторий. Даже если он вам сейчас не нужен, сохраните его. Пригодится, когда расчехлите Wireshark.
⇨ https://github.com/amwalding/wireshark_profiles
Здесь собрано множество готовых профилей для анализа того или иного трафика. Рассказываю на пальцах, как им пользоваться.
1️⃣ Скачиваете из репозитория zip файл нужного вам профиля. Например, DNS.
2️⃣ В Wireshark идёте в раздел Edit ⇨ Configuration Profiles. Жмёте Import from zip files и импортируете скачанный профайл в zip файле. Выбираете его.
3️⃣ Выбираете сетевой интерфейс, с которого хотите собирать пакеты. Откроется основной интерфейс программы с готовыми настройками фильтров.
4️⃣ Потом загруженные фильтры можно быстро переключать в правом нижнем углу программы.
Ничего особенного тут нет, можно и самому набросать себе нужные фильтры. Но тут всё сделали за нас, упростив задачу. Как минимум, не помешают базовые фильтры на DNS, DHCP, HTTP, ARP, SMB, VLAN и т.д.
#network #wireshark
⇨ https://github.com/amwalding/wireshark_profiles
Здесь собрано множество готовых профилей для анализа того или иного трафика. Рассказываю на пальцах, как им пользоваться.
1️⃣ Скачиваете из репозитория zip файл нужного вам профиля. Например, DNS.
2️⃣ В Wireshark идёте в раздел Edit ⇨ Configuration Profiles. Жмёте Import from zip files и импортируете скачанный профайл в zip файле. Выбираете его.
3️⃣ Выбираете сетевой интерфейс, с которого хотите собирать пакеты. Откроется основной интерфейс программы с готовыми настройками фильтров.
4️⃣ Потом загруженные фильтры можно быстро переключать в правом нижнем углу программы.
Ничего особенного тут нет, можно и самому набросать себе нужные фильтры. Но тут всё сделали за нас, упростив задачу. Как минимум, не помешают базовые фильтры на DNS, DHCP, HTTP, ARP, SMB, VLAN и т.д.
#network #wireshark
{kind=link}
В Linux относительно просто назначить выполнение того или иного процесса на заданном количестве ядер процессора. Для этого используется утилита taskset. Она может "сажать" на указанные ядра как запущенный процесс, так и запустить новый с заданными параметрами.
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
Выбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
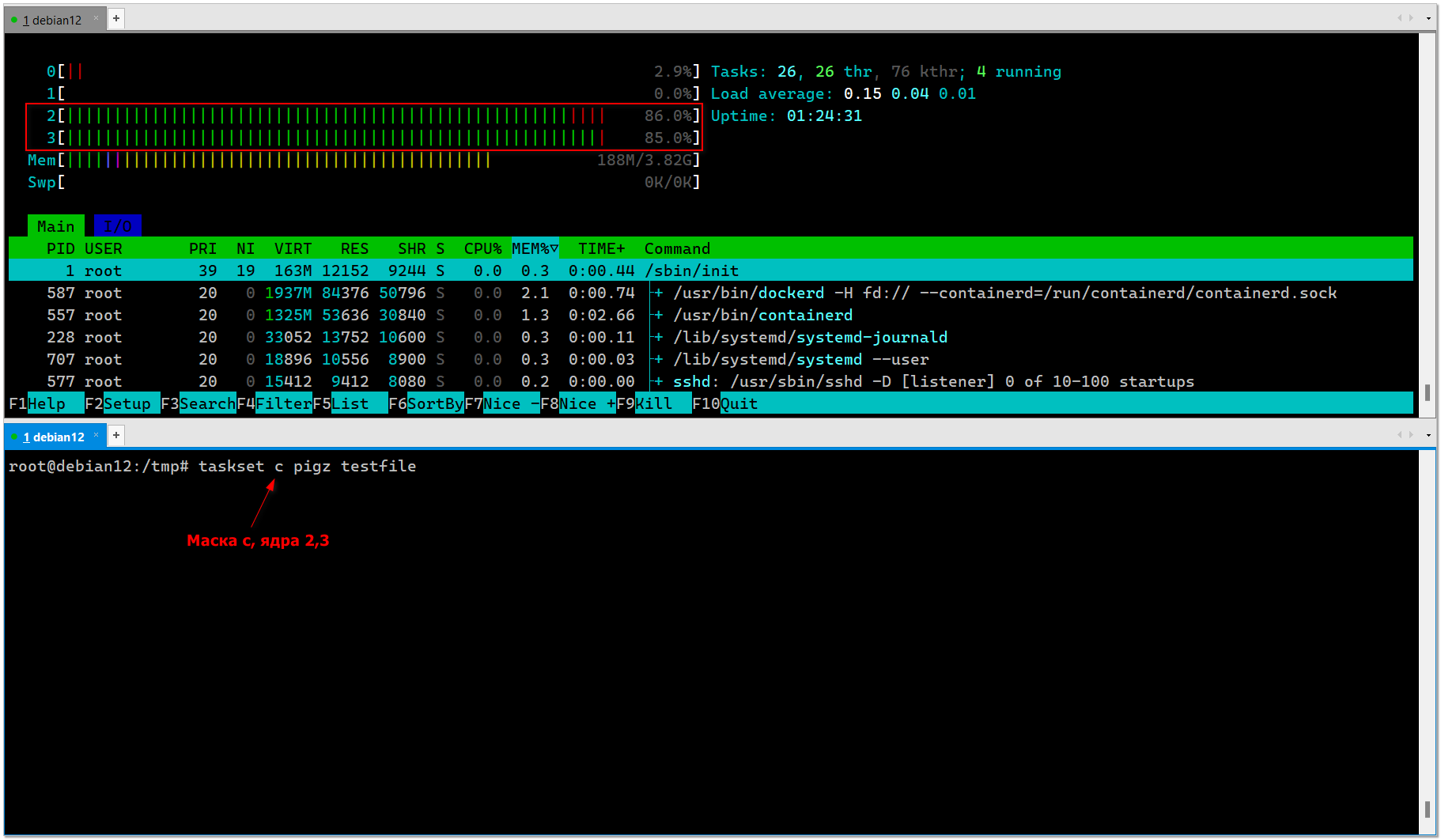
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
или просто
Pigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
Маска
Я взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
Список масок, которые имеют отношение к первым 4-м ядрам:
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
#linux #system
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
# ps ax | grep mc# ps -T -C mc | awk '{print $2}' | grep -E '[0-9]'# pidof mcВыбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
# lscpu | grep -i CPU\(s\)# lscpu | grep -i numaNUMA node(s): 1NUMA node0 CPU(s): 0-3Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
# taskset -pc 0-1 927pid 927's current affinity list: 0-3pid 927's new affinity list: 0,1Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
# taskset 0x00000001 pigz testfileили просто
# taskset 1 pigz testfilePigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
# taskset -pc 2-3 `pidof htop`pid 984's current affinity list: 0-3pid 984's new affinity list: 2,3Смотрим маску:# taskset -p `pidof htop`pid 984's current affinity mask: cМаска
c. Запускаем pigz с этой маской, чтобы он жал только на 2 и 3 ядрах, оставив первые два свободными:# taskset c pigz testfileЯ взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
# dd if=/dev/zero of=/tmp/testfile bs=1024 count=2000000# taskset 6 pigz testfileСписок масок, которые имеют отношение к первым 4-м ядрам:
◽
1 - ядро 0◽
2 - ядро 1◽
3 - ядра 0,1◽
4 - ядро 2◽
5 - ядра 0,2◽
6 - ядра 1,2◽
7 - ядра 1,2,3◽
8 - ядро 3◽
9 - ядра 0,3◽
a - ядра 1,3◽
b - ядра 0,1,3◽
с - ядра 2,3◽
d - ядра 0,2,3#linux #system
{kind=link}
Для бэкапа серверов под управлением Linux существует отличное бесплатное решение - Veeam Agent for Linux FREE. Я очень давно его знаю, но конкретно для Linux давно не пользовался. У меня есть статья по работе с ним:
⇨ Бэкап и перенос linux (centos, debian, ubuntu) сервера с помощью Veeam Agent for Linux
Она написана давно, поэтому я решил проверить, насколько актуален тот метод восстановления, что там описан. Забегая вперёд скажу, что актуален. Изменились некоторые детали, но в основном всё то же самое.
Я себе поставил задачу – перенести виртуальную машину от обычного хостера, где используется стандартная услуга VPS и больше ничего. То есть у вас система на одном жёстком диске заданного размера. Задача перенести её в исходном виде к себе на локальный гипервизор Proxmox. В итоге у меня всё получилось. Рассказываю по шагам, что делал.
1️⃣ Скачал с сайта Veeam файл с репозиторием для Debian veeam-release-deb_1.0.8_amd64.deb и загрузочный ISO для восстановления Veeam Linux Recovery Media. Для загрузки нужна регистрация.
2️⃣ Скопировал файл с репозиторием на целевой сервер и подключил его:
3️⃣ Установил veeam и дополнительные пакеты:
4️⃣ К сожалению, понадобилась перезагрузка сервера. Без перезагрузки не создавался бэкап. Veeam ругался, что не загружен модуль для снепшота диска. У меня так и не получилось его загрузить вручную. Вроде всё делал, что надо, но не заработало. Пришлось перезагрузиться и проблема ушла.
5️⃣ Так как на сервере у нас только один диск, мы не можем на него же класть бэкап, когда будем делать образ всей системы. Я решил использовать сетевой smb диск с другой виртуальной машины, которая запущена на целевом Proxmox, куда буду переносить систему. Для этого на ней поднял и настроил ksmbd, затем с помощью ssh настроил VPN туннель между машинами. Всё делал прям по инструкциям из указанных заметок. Заняло буквально 5-10 минут.
6️⃣ Запустил на целевой машине veeam:
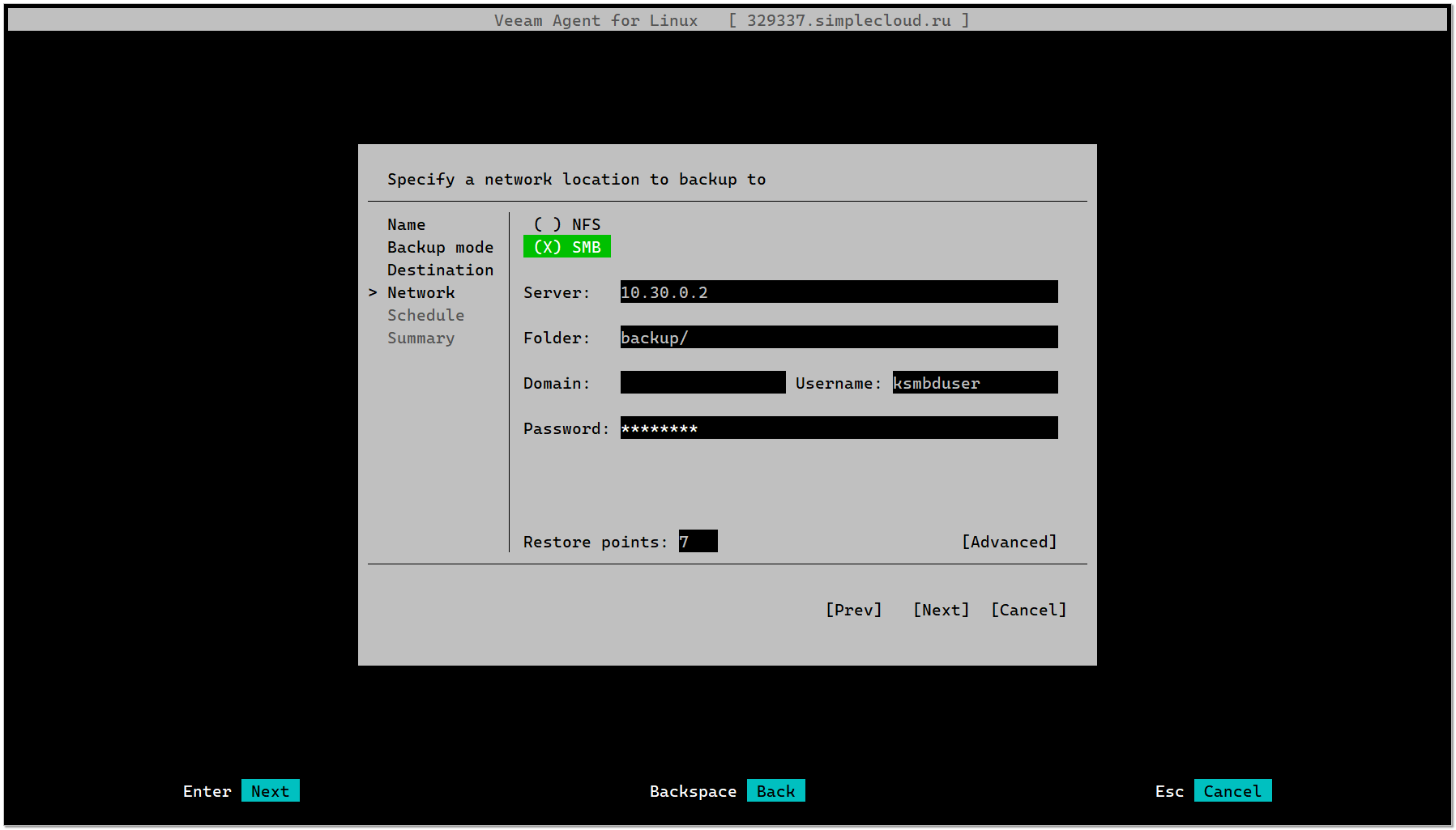
И с помощью псевдографического интерфейса настроил задание для бэкапа в сетевую папку smb. Там всё просто. Немного затупил с правильностью указания настроек для smb, так как не сразу понял формат, в котором надо записать путь к серверу (на картинке снизу скриншот правильных настроек). Но быстро разобрался. И ещё важный момент. На smb шару у вас должны быть права на запись. Если их нет, получите неинформативную ошибку. Я с этим проковырялся немного, пока не догадался проверить. Оказалось, что забыл дать права на запись в директорию, которая монтировалась по smb.
7️⃣ Запустил задание бэкапа и убедился, что он прошёл без ошибок.
8️⃣ Сделал на Proxmox новую виртуальную машину с диском, у которого размер не меньше исходной машины, которую бэкапили. Это важно. Даже если на диске занято очень мало места, перераспределить его при восстановлении на меньший диск не получится. Veeam просто не умеет этого делать.
9️⃣ Загрузил новую виртуалку с Veeam Linux Recovery Media, подключил туда по smb тот же сетевой диск, куда делал бэкап и успешно выполнил восстановление. Всё прошло без сучка и задоринки. Виртуалка сразу же загрузилась с восстановленного диска и заработала без каких-то дополнительных действий.
Такой вот полезный инструмент. Если локально ещё есть разные варианты, чем забэкапить машину, то с арендованными VPS всё не так просто. Veeam Agent for Linux позволяет из без проблем бэкапить и в случае необходимости восстанавливать локально.
#backup #veeam
⇨ Бэкап и перенос linux (centos, debian, ubuntu) сервера с помощью Veeam Agent for Linux
Она написана давно, поэтому я решил проверить, насколько актуален тот метод восстановления, что там описан. Забегая вперёд скажу, что актуален. Изменились некоторые детали, но в основном всё то же самое.
Я себе поставил задачу – перенести виртуальную машину от обычного хостера, где используется стандартная услуга VPS и больше ничего. То есть у вас система на одном жёстком диске заданного размера. Задача перенести её в исходном виде к себе на локальный гипервизор Proxmox. В итоге у меня всё получилось. Рассказываю по шагам, что делал.
1️⃣ Скачал с сайта Veeam файл с репозиторием для Debian veeam-release-deb_1.0.8_amd64.deb и загрузочный ISO для восстановления Veeam Linux Recovery Media. Для загрузки нужна регистрация.
2️⃣ Скопировал файл с репозиторием на целевой сервер и подключил его:
# dpkg -i veeam-release-deb_1.0.8_amd64.deb3️⃣ Установил veeam и дополнительные пакеты:
# apt install blksnap veeam cifs-utils4️⃣ К сожалению, понадобилась перезагрузка сервера. Без перезагрузки не создавался бэкап. Veeam ругался, что не загружен модуль для снепшота диска. У меня так и не получилось его загрузить вручную. Вроде всё делал, что надо, но не заработало. Пришлось перезагрузиться и проблема ушла.
5️⃣ Так как на сервере у нас только один диск, мы не можем на него же класть бэкап, когда будем делать образ всей системы. Я решил использовать сетевой smb диск с другой виртуальной машины, которая запущена на целевом Proxmox, куда буду переносить систему. Для этого на ней поднял и настроил ksmbd, затем с помощью ssh настроил VPN туннель между машинами. Всё делал прям по инструкциям из указанных заметок. Заняло буквально 5-10 минут.
6️⃣ Запустил на целевой машине veeam:
# veeamИ с помощью псевдографического интерфейса настроил задание для бэкапа в сетевую папку smb. Там всё просто. Немного затупил с правильностью указания настроек для smb, так как не сразу понял формат, в котором надо записать путь к серверу (на картинке снизу скриншот правильных настроек). Но быстро разобрался. И ещё важный момент. На smb шару у вас должны быть права на запись. Если их нет, получите неинформативную ошибку. Я с этим проковырялся немного, пока не догадался проверить. Оказалось, что забыл дать права на запись в директорию, которая монтировалась по smb.
7️⃣ Запустил задание бэкапа и убедился, что он прошёл без ошибок.
8️⃣ Сделал на Proxmox новую виртуальную машину с диском, у которого размер не меньше исходной машины, которую бэкапили. Это важно. Даже если на диске занято очень мало места, перераспределить его при восстановлении на меньший диск не получится. Veeam просто не умеет этого делать.
9️⃣ Загрузил новую виртуалку с Veeam Linux Recovery Media, подключил туда по smb тот же сетевой диск, куда делал бэкап и успешно выполнил восстановление. Всё прошло без сучка и задоринки. Виртуалка сразу же загрузилась с восстановленного диска и заработала без каких-то дополнительных действий.
Такой вот полезный инструмент. Если локально ещё есть разные варианты, чем забэкапить машину, то с арендованными VPS всё не так просто. Veeam Agent for Linux позволяет из без проблем бэкапить и в случае необходимости восстанавливать локально.
#backup #veeam
{kind=link}
Я одно время перепробовал кучу программ для ведения личных заметок. После этого собрал их все в одну публикацию (13 программ) и бросил это дело, потому что надоело. Таких программ море. Пробовать их, только время тратить. Сам сижу на Joplin + Singularity (недавно перешёл).
В закладках с тех пор остались некоторые варианты. Решил посмотреть кое-что и остановился на Memos. Эта штука мне прям понравилась. Покидал туда несколько заметок из Joplin. Формат один и тот же - Markdown, так что можно спокойно заметки переносить. Я где-то час погонял Memos, попробовал, почитал документацию.
Если кратко, то это минималистичное веб приложение с работой через браузер. Мобильного клиента нет, дизайн адаптивен, нормально смотрится на смартфонах. Опишу своими словами особенности, которые больше всего привлекли:
🟢 Сразу понравился дизайн и оформление. Это чистая субъективщина. Когда увидел, сразу захотелось попробовать, потому что понравился минималистичный дизайн и хороший отклик. Приложение написано на Go + React.js. Работает очень шустро.
🟢 Memos поддерживает многопользовательскую работу со свободной регистрацией. То есть в целом это инструмент командной работы. Есть поддержка SSO с готовыми шаблонами для Github, Gitlab, Google, либо свой сервис через OAUTH2. Также встроена поддержка Keycloak. К общим заметкам можно оставлять комментарии.
🟢 По умолчанию используется база SQLite. В большинстве случаев этого за глаза хватит для текстовых заметок. Если сильно захочется, можно в MySQL или PostgreSQL перенести. Вложения могут храниться в базе, в файловой системе или в S3. Настраивается очень просто в веб интерфейсе. Я сразу на файловую систему переключил.
🟢 Простая интеграция с Telegram. Делаете своего бота, подключаете к Memos и создаёте заметки обычными сообщениями в телеге.
🟢 Заметки могут быть личные, публичные для всех, либо открытые для каких-то групп пользователей.
🟢 Записи упорядочены либо тэгами, либо календарём. Разбивки по проектам нет. То есть вся навигация по тэгам и датам. Мне лично это не понравилось. Я привык к проектам. Но сразу скажу, что по тэгам навигация сделана удобно. Они как проекты всегда на виду с правой стороны в интерфейсе.
🟢 Ставится, как и переносится очень быстро и просто. Это обычный Docker контейнер с базой данных и вложениями в виде файлов.
Соответственно, достаточно бэкапить паочку .memos.
🟢 Memos умеет в один клик выгружать все заметки единым архивом в виде .md файлов. Это если куда-то перенести надо будет или сохранить бэкап.
🟢 Есть поддержка вебхуков, но я так и не понял, к каким событиям их можно привязать. В документации написано, что к созданию заметки, но я не понял, как это работает. Через хук передаётся создатель заметки, время и текст (это ихз документации).
🟢 Есть поддержка API с доступом по токенам. Правда в документации не увидел описание возможностей. По идее заметки можно создавать. Что там ещё делать.
В общем, на вид простой, но под капотом очень функциональный инструмент, которым можно пользоваться как одному, так и командой. Если подбираете себе что-то подобное, то рекомендую посмотреть. Мне в целом понравилось. Если бы ещё на проекты была разбивка, вообще было бы хорошо. Внешне кажется простоват, но внутри хорошие возможности командной работы.
⇨ Сайт / Исходники / Demo
#заметки
В закладках с тех пор остались некоторые варианты. Решил посмотреть кое-что и остановился на Memos. Эта штука мне прям понравилась. Покидал туда несколько заметок из Joplin. Формат один и тот же - Markdown, так что можно спокойно заметки переносить. Я где-то час погонял Memos, попробовал, почитал документацию.
Если кратко, то это минималистичное веб приложение с работой через браузер. Мобильного клиента нет, дизайн адаптивен, нормально смотрится на смартфонах. Опишу своими словами особенности, которые больше всего привлекли:
🟢 Сразу понравился дизайн и оформление. Это чистая субъективщина. Когда увидел, сразу захотелось попробовать, потому что понравился минималистичный дизайн и хороший отклик. Приложение написано на Go + React.js. Работает очень шустро.
🟢 Memos поддерживает многопользовательскую работу со свободной регистрацией. То есть в целом это инструмент командной работы. Есть поддержка SSO с готовыми шаблонами для Github, Gitlab, Google, либо свой сервис через OAUTH2. Также встроена поддержка Keycloak. К общим заметкам можно оставлять комментарии.
🟢 По умолчанию используется база SQLite. В большинстве случаев этого за глаза хватит для текстовых заметок. Если сильно захочется, можно в MySQL или PostgreSQL перенести. Вложения могут храниться в базе, в файловой системе или в S3. Настраивается очень просто в веб интерфейсе. Я сразу на файловую систему переключил.
🟢 Простая интеграция с Telegram. Делаете своего бота, подключаете к Memos и создаёте заметки обычными сообщениями в телеге.
🟢 Заметки могут быть личные, публичные для всех, либо открытые для каких-то групп пользователей.
🟢 Записи упорядочены либо тэгами, либо календарём. Разбивки по проектам нет. То есть вся навигация по тэгам и датам. Мне лично это не понравилось. Я привык к проектам. Но сразу скажу, что по тэгам навигация сделана удобно. Они как проекты всегда на виду с правой стороны в интерфейсе.
🟢 Ставится, как и переносится очень быстро и просто. Это обычный Docker контейнер с базой данных и вложениями в виде файлов.
# docker run -d --name memos -p 5230:5230 -v ~/.memos/:/var/opt/memos neosmemo/memos:stableСоответственно, достаточно бэкапить паочку .memos.
🟢 Memos умеет в один клик выгружать все заметки единым архивом в виде .md файлов. Это если куда-то перенести надо будет или сохранить бэкап.
🟢 Есть поддержка вебхуков, но я так и не понял, к каким событиям их можно привязать. В документации написано, что к созданию заметки, но я не понял, как это работает. Через хук передаётся создатель заметки, время и текст (это ихз документации).
🟢 Есть поддержка API с доступом по токенам. Правда в документации не увидел описание возможностей. По идее заметки можно создавать. Что там ещё делать.
В общем, на вид простой, но под капотом очень функциональный инструмент, которым можно пользоваться как одному, так и командой. Если подбираете себе что-то подобное, то рекомендую посмотреть. Мне в целом понравилось. Если бы ещё на проекты была разбивка, вообще было бы хорошо. Внешне кажется простоват, но внутри хорошие возможности командной работы.
⇨ Сайт / Исходники / Demo
#заметки
{kind=link}
Для администраторов Windows существует небольшая программа, написанная на каком-то стародавнем языке, потому что работает очень быстро и весит всего 4,2 Мб, которая помогает управлять терминальными серверами Windows. Хотя подойдёт не только для них, но и для любых серверов и рабочих станций, но писалась она именно для терминальников.
Называется Terminal Services Manager от компании LizardSystems. Это платная программа, но существует бесплатная версия без ограничений для персонального использования. Кто и как её в итоге использует – не проверяется. Лицензия получается автоматически через специальную форму на сайте. Заполняешь и сразу получаешь лицензионный ключ на почту. Я проверил, всё работает. Свою лицензию получил сразу же после отправки формы.
Terminal Services Manager умеет:
◽Просматривать информацию о пользователях: кто и когда подключался, кто сейчас подключен, кто отключился, но сессию не завершил и т.д.
◽Подключаться к активной терминальной сессии пользователя, завершать его работу, завершать работу всех пользователей.
◽Отправляться сообщения пользователям.
◽Просматривать базовые системные метрики производительности: память, процессор, диск.
◽Просматривать и управлять списком запущенных процессов.
◽Перезагружать и выключать удалённые машины.
◽Удалять профили пользователей.
◽Включать запрет на удалённые подключения.
Я попробовал подключаться в сессии пользователей. Всё без проблем работает. Очень удобно. Думаю, это основная фишка этой программы.
Основной недостаток, из-за которого я сначала не хотел про неё писать, так как не разобрался сходу – нет возможности указать пользователя, под которым можно подключиться к удалённой машине. Вы должны запустить программу локально под тем пользователем, у которого есть административный доступ к удалённым машинам. Это может быть либо доменная учётка, либо локальная, но тогда она должна быть точно такой же и на всех остальных компьютерах.
Я сначала подумал, что программа работает только в доменной сети, потому что не понимал, как она будет получать доступ к удалённым машинам. Потом сообразил попробовать с идентичными учётками на локальном и удалённом компе. В итоге всё заработало, когда запустил на одинаковых учётках. Не сказать, что большой минус. Придётся на все управляемые компы добавить одинаковую административную учётную запись, что и так чаще всего делают для удобства. По крайней мере я всегда делал.
Программа простая, удобная, разбираться с настройкой не надо. Всё интуитивно понятно, настраивается сходу. Можно считать, что она бесплатна, так как использование никто не проверяет. Авторы не из России. Так и не понял, откуда они. Плюс, у них есть неплохой набор бесплатных программ: LanSpy, LanWhois, Remote Shutdown (эту программу я когда-то использовал), LanLoad.
#windows
Называется Terminal Services Manager от компании LizardSystems. Это платная программа, но существует бесплатная версия без ограничений для персонального использования. Кто и как её в итоге использует – не проверяется. Лицензия получается автоматически через специальную форму на сайте. Заполняешь и сразу получаешь лицензионный ключ на почту. Я проверил, всё работает. Свою лицензию получил сразу же после отправки формы.
Terminal Services Manager умеет:
◽Просматривать информацию о пользователях: кто и когда подключался, кто сейчас подключен, кто отключился, но сессию не завершил и т.д.
◽Подключаться к активной терминальной сессии пользователя, завершать его работу, завершать работу всех пользователей.
◽Отправляться сообщения пользователям.
◽Просматривать базовые системные метрики производительности: память, процессор, диск.
◽Просматривать и управлять списком запущенных процессов.
◽Перезагружать и выключать удалённые машины.
◽Удалять профили пользователей.
◽Включать запрет на удалённые подключения.
Я попробовал подключаться в сессии пользователей. Всё без проблем работает. Очень удобно. Думаю, это основная фишка этой программы.
Основной недостаток, из-за которого я сначала не хотел про неё писать, так как не разобрался сходу – нет возможности указать пользователя, под которым можно подключиться к удалённой машине. Вы должны запустить программу локально под тем пользователем, у которого есть административный доступ к удалённым машинам. Это может быть либо доменная учётка, либо локальная, но тогда она должна быть точно такой же и на всех остальных компьютерах.
Я сначала подумал, что программа работает только в доменной сети, потому что не понимал, как она будет получать доступ к удалённым машинам. Потом сообразил попробовать с идентичными учётками на локальном и удалённом компе. В итоге всё заработало, когда запустил на одинаковых учётках. Не сказать, что большой минус. Придётся на все управляемые компы добавить одинаковую административную учётную запись, что и так чаще всего делают для удобства. По крайней мере я всегда делал.
Программа простая, удобная, разбираться с настройкой не надо. Всё интуитивно понятно, настраивается сходу. Можно считать, что она бесплатна, так как использование никто не проверяет. Авторы не из России. Так и не понял, откуда они. Плюс, у них есть неплохой набор бесплатных программ: LanSpy, LanWhois, Remote Shutdown (эту программу я когда-то использовал), LanLoad.
#windows
{kind=link}
Просматривал на днях на reddit r/Sysadminhumor, где встретил любопытный комикс. Сходил на сайт автора, а их там полно. Мне лично понравился формат и его какой-то душевный подход. Переведу для тех, кто не очень знает английский, то, что написано на комиксе выше. Он получился поучительный.
- Это Боб. Боб - обычный процесс в Linux.
- Как и большинство процессов, Боб имеет свои потоки, с которыми он делит контекст, общую память и любовь.
- Как и любой процесс, он рано или поздно будет уничтожен. Когда мы аккуратно завершаем процесс с помощью SIGTERM,
- мы даём ему шанс пообщаться с потомками об этом, так что они успевают завершить все свои дела
- и попрощаться друг с другом. Такова жизнь процесса.
- С другой стороны, когда мы прибиваем процесс через SIGKILL, мы не даём ему возможности закончить свои дела и попрощаться.
- И это ужасно.
- Так что, пожалуйста, не используйте SIGKILL. Позвольте потомкам спокойно завершить свою работу.
Мораль такова. Прибивайте процесс так:
а не так:
⇨ Сайт автора с комиксами: https://turnoff.us
#мем
- Это Боб. Боб - обычный процесс в Linux.
- Как и большинство процессов, Боб имеет свои потоки, с которыми он делит контекст, общую память и любовь.
- Как и любой процесс, он рано или поздно будет уничтожен. Когда мы аккуратно завершаем процесс с помощью SIGTERM,
- мы даём ему шанс пообщаться с потомками об этом, так что они успевают завершить все свои дела
- и попрощаться друг с другом. Такова жизнь процесса.
- С другой стороны, когда мы прибиваем процесс через SIGKILL, мы не даём ему возможности закончить свои дела и попрощаться.
- И это ужасно.
- Так что, пожалуйста, не используйте SIGKILL. Позвольте потомкам спокойно завершить свою работу.
Мораль такова. Прибивайте процесс так:
# kill <process_id>
а не так:
# kill -9 <process_id>
⇨ Сайт автора с комиксами: https://turnoff.us
#мем
🎓 Мне давно скидывали ссылку на небольшой курс по GIT на youtube для начинающих. Там с самых азов даётся инфа для тех, кто с GIT никогда не работал. Только сейчас дошли руки посмотреть. Вроде неплохо сделано, послушал введение. Комментарии хорошие, просмотров много. Весь материал разбит на небольшие ролики по 5-7 минут, где разбирается одна тема. Если вы совсем нулёвый по этой теме, то это для вас:
⇨ Базовый курс по Git
Заодно решил подбить всю эту тему с обучением GIT.
▪️ Обзорное видео по GIT от авторского ютуб канала Артема Матяшова - Git. Большой практический выпуск. Автор очень хорошо объясняет. Если прям ничего про GIT не знаете, рекомендую начать с него. Хороший монтаж, подача, оформление. Я почти все его видео с удовольствием смотрел. У него их немного.
🔥Очень прикольная визуальная обучалка по основам GIT - LearnGitBranching. Она поддерживается, регулярно обновляется. Качественно сделана. Есть русский язык.
▪️ Ещё одна игра по обучению GIT - Oh My Git! Она попроще learnGitBranching, но в целом тоже неплохая.
▪️ Бесплатный курс по основам от Слёрм - Git для начинающих.
▪️ Бесплатные курсы по основам GIT на Stepik: Основы работы с Git и Самоучитель по GIT.
▪️ Более продвинутый курс с погружением в нюансы, ориентированный на разработчиков - Git курс от сообщества javascript.ru.
▪️ Бесплатная книга на русском языке - Pro Git book.
В завершении добавлю мотивирующий текст, который я написал ещё 3 года назад здесь на канале, если вы всё ещё сомневаетесь, надо ли вам разбираться с GIT или нет:
Хочу посоветовать всем системным администраторам, кто это еще не сделал, обратить пристальное внимание на git. Сам я давно пользуюсь этой системой контроля версий, но только недавно дошел до того, что стал там хранить практически все текстовые данные.
Чистил свою тестовую лабу и удалил несколько виртуалок. И только потом вспомнил, что на одной из них были нужные скрипты, на написание которых ушло прилично времени. Все репозитории проверил, нигде не нашел копий. Их просто не было. Пришлось потратить несколько часов на восстановление.
Теперь всегда, прежде чем начать писать какой-то скрипт или более ли менее большой конфиг, создаю репозиторий под это дело и все пушу туда. Я обычно использую облачный gitlab и свой локальный для приватных данных. Gitlab - мое личное предпочтение. Вы можете использовать любой бесплатный сервис. Их сейчас полно развелось.
Мало того, что это удобный контроль изменений, так еще и мгновенный бэкап всей информации по одной команде. Плюс, можно быстро что-то отредактировать через веб интерфейс. В общем, удобно, рекомендую. Еще и к разработчикам приблизитесь, будете лучше разбираться в их кухне.
С тех пор я неизменно верен себе. Все нужные скрипты, конфиги в обязательном порядке хранятся в репозиториях git, как локально на ноуте, так и на удалённых сервисах.
#обучение #git #подборка
⇨ Базовый курс по Git
Заодно решил подбить всю эту тему с обучением GIT.
▪️ Обзорное видео по GIT от авторского ютуб канала Артема Матяшова - Git. Большой практический выпуск. Автор очень хорошо объясняет. Если прям ничего про GIT не знаете, рекомендую начать с него. Хороший монтаж, подача, оформление. Я почти все его видео с удовольствием смотрел. У него их немного.
🔥Очень прикольная визуальная обучалка по основам GIT - LearnGitBranching. Она поддерживается, регулярно обновляется. Качественно сделана. Есть русский язык.
▪️ Ещё одна игра по обучению GIT - Oh My Git! Она попроще learnGitBranching, но в целом тоже неплохая.
▪️ Бесплатный курс по основам от Слёрм - Git для начинающих.
▪️ Бесплатные курсы по основам GIT на Stepik: Основы работы с Git и Самоучитель по GIT.
▪️ Более продвинутый курс с погружением в нюансы, ориентированный на разработчиков - Git курс от сообщества javascript.ru.
▪️ Бесплатная книга на русском языке - Pro Git book.
В завершении добавлю мотивирующий текст, который я написал ещё 3 года назад здесь на канале, если вы всё ещё сомневаетесь, надо ли вам разбираться с GIT или нет:
Хочу посоветовать всем системным администраторам, кто это еще не сделал, обратить пристальное внимание на git. Сам я давно пользуюсь этой системой контроля версий, но только недавно дошел до того, что стал там хранить практически все текстовые данные.
Чистил свою тестовую лабу и удалил несколько виртуалок. И только потом вспомнил, что на одной из них были нужные скрипты, на написание которых ушло прилично времени. Все репозитории проверил, нигде не нашел копий. Их просто не было. Пришлось потратить несколько часов на восстановление.
Теперь всегда, прежде чем начать писать какой-то скрипт или более ли менее большой конфиг, создаю репозиторий под это дело и все пушу туда. Я обычно использую облачный gitlab и свой локальный для приватных данных. Gitlab - мое личное предпочтение. Вы можете использовать любой бесплатный сервис. Их сейчас полно развелось.
Мало того, что это удобный контроль изменений, так еще и мгновенный бэкап всей информации по одной команде. Плюс, можно быстро что-то отредактировать через веб интерфейс. В общем, удобно, рекомендую. Еще и к разработчикам приблизитесь, будете лучше разбираться в их кухне.
С тех пор я неизменно верен себе. Все нужные скрипты, конфиги в обязательном порядке хранятся в репозиториях git, как локально на ноуте, так и на удалённых сервисах.
#обучение #git #подборка
{kind=link}
Когда мне нужно было быстро поднять smb сервер, чтобы разово перекинуть какие-то файлы, раньше я устанавливал samba и делал для неё простейший конфиг.
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
Это довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
Подключаемся к настроенной шаре:
Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
# apt install python3-impacketЭто довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
# cd /usr/share/doc/python3-impacket/examples/# python3 smbserver.py share /mnt/share -smb2support◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
# python3 smbserver.py share /mnt/share -smb2support -username user -password 123Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
# smbclient -L 172.20.204.133 --user user --password=123Подключаемся к настроенной шаре:
# smbclient //172.20.204.133/share --user user --password=123Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
{kind=link}
Расскажу про необычный и полезный сервис, который позволяет создать зашифрованные HTML странички, которые могут быть расшифрованы полностью на стороне клиента за счёт возможностей современных браузеров и JavaScript. То есть это полностью client side шифрование. На веб сервере лежит обычная html страничка. Никакой поддержки шифрования со стороны сервера не требуется.
Это простой, удобный и надёжный способ зашифровать какую-то приватную информацию и положить её полностью в публичный доступ. Посмотреть информацию может только тот, кто знает пароль. Он заходит на публичную страничку, видит форму для ввода пароля. Указывает его и получает доступ к данным. При этом сам html код зашифрован. Он может лежать на любом публичном хостинге. Расшифровать информацию можно только зная пароль.
Исходники сервера открыты:
⇨ https://github.com/robinmoisson/staticrypt
Можно развернуть его у себя и шифровать странички через свой сервис. А можно воспользоваться уже готовым сервисом, который доступен для всех желающих:
⇨ https://robinmoisson.github.io/staticrypt/
Указываете пароль, загружаете html код и на выходе получаете зашифрованную html страничку. Можно её скачать и открыть через свой браузер. Убедиться, что всё работает. Дальше можно положить её на любой публичный хостинг.
Такой сервис удобно использовать для публикации какой-то инструкции с чувствительными данными. Можно положить её в открытый доступ, а пользователям рассылать пароль, чтобы они смогли прочитать информацию.
Вот пример зашифрованной странички, которую я создал с помощью этого сервиса: https://serveradmin.ru/files/encrypted.html Пароль - serveradmin. Можете скачать html код и посмотреть, что он из себя представляет. В репозитории проекта описан принцип работы по шифрованию и расшифровке.
Напомню, что ранее я рассказывал про сервис link-loc, который похожим образом шифрует не саму страницу, а ссылку на неё. В связке с этим сервисом получается вообще полное шифрование и ссылки, и самой страницы.
#security
Это простой, удобный и надёжный способ зашифровать какую-то приватную информацию и положить её полностью в публичный доступ. Посмотреть информацию может только тот, кто знает пароль. Он заходит на публичную страничку, видит форму для ввода пароля. Указывает его и получает доступ к данным. При этом сам html код зашифрован. Он может лежать на любом публичном хостинге. Расшифровать информацию можно только зная пароль.
Исходники сервера открыты:
⇨ https://github.com/robinmoisson/staticrypt
Можно развернуть его у себя и шифровать странички через свой сервис. А можно воспользоваться уже готовым сервисом, который доступен для всех желающих:
⇨ https://robinmoisson.github.io/staticrypt/
Указываете пароль, загружаете html код и на выходе получаете зашифрованную html страничку. Можно её скачать и открыть через свой браузер. Убедиться, что всё работает. Дальше можно положить её на любой публичный хостинг.
Такой сервис удобно использовать для публикации какой-то инструкции с чувствительными данными. Можно положить её в открытый доступ, а пользователям рассылать пароль, чтобы они смогли прочитать информацию.
Вот пример зашифрованной странички, которую я создал с помощью этого сервиса: https://serveradmin.ru/files/encrypted.html Пароль - serveradmin. Можете скачать html код и посмотреть, что он из себя представляет. В репозитории проекта описан принцип работы по шифрованию и расшифровке.
Напомню, что ранее я рассказывал про сервис link-loc, который похожим образом шифрует не саму страницу, а ссылку на неё. В связке с этим сервисом получается вообще полное шифрование и ссылки, и самой страницы.
#security
{kind=link}