
Недавно один человек у меня попросил совета по поводу программы для бэкапов в Linux на базе rsync, но только чтобы была полноценная поддержка инкрементных архивов, чтобы можно было вернуться назад на заданный день. Я знаю, что базовыми возможностями rsync без костылей и скриптов такое не сделать, поэтому сразу вспомнил про программу rdiff-backup. Хотел скинуть ссылку на свою заметку, но с удивлением обнаружил, что я вообще ни разу про неё не писал, хотя сам лично использовал.
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
Если надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
Добавляя ключи
Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
Вы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
Или посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
Ну и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
Программа простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
# apt install rdiff-backupЕсли надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
# rdiff-backup /var/www/site.ru/ /backup/site.ru/Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
# rdiff-backup user@hostname::/remote-dir local-dirДобавляя ключи
-v5 и --print-statistics вы можете получать подробную информацию о процессе бэкапа, которую потом удобно парсить, отправлять на хранение, мониторить. Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
local-dir будет лежать самая последняя копия файлов. А кроме этого в ней же будет находиться директория rdiff-backup-data, которая будет содержать информацию и логи о проводимых бэкапах, а также инкременты, необходимые для отката на любой прошлый выполненный бэкап. Посмотреть инкременты можно вот так:# rdiff-backup -l local-dirВы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
# rdiff-backup list files --changed-since 5D local-dirИли посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
# rdiff-backup list files --at 5D local-dirНу и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
# rdiff-backup restore \local-dir/rdiff-backup-data/increments.2023-10-29T21:03:37+03:00.dir \/tmp/restoreПрограмма простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
{kind=link}
Для Linux есть замечательный локальный веб сервер, который можно запустить с помощью python:
Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
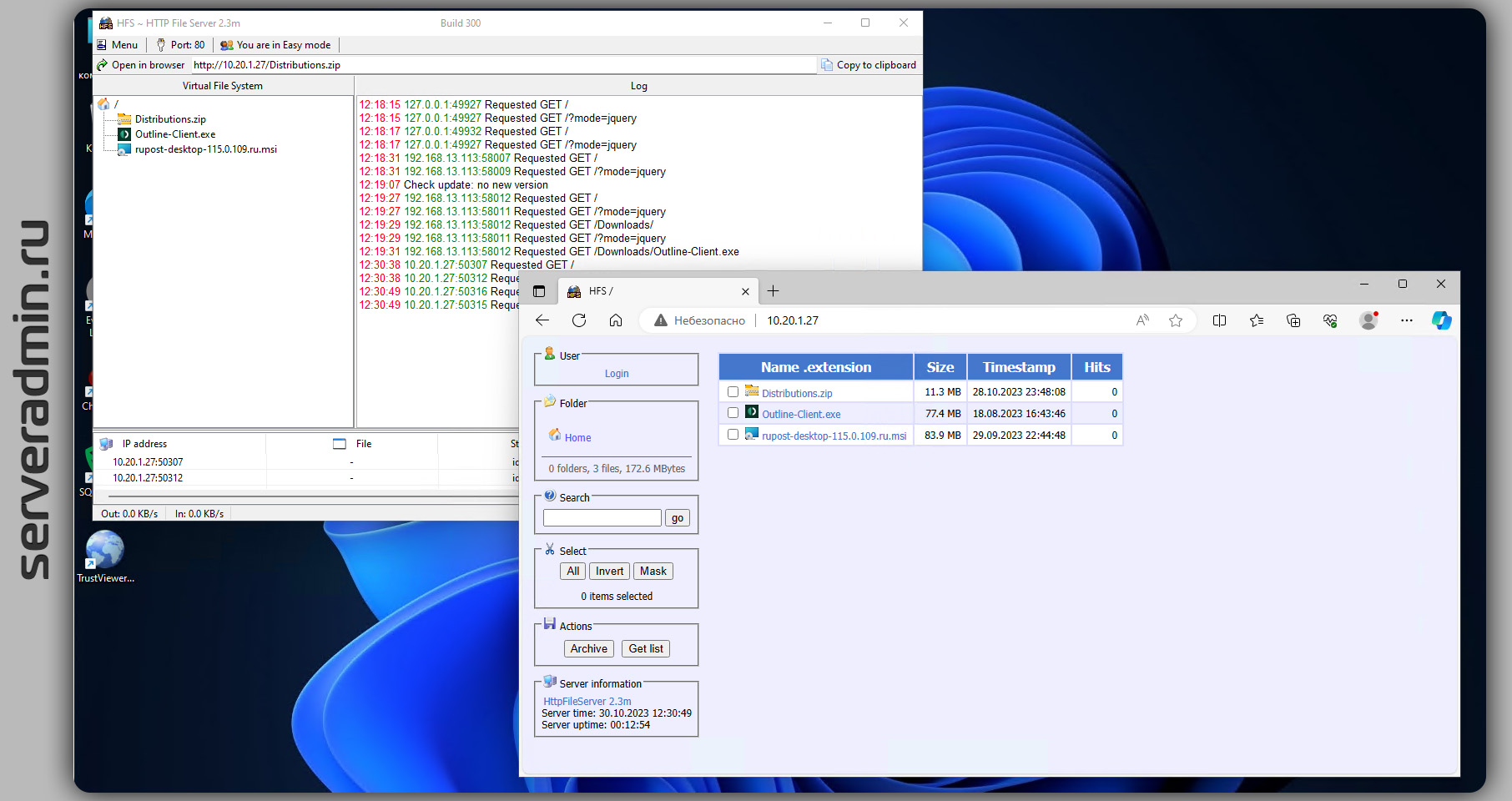
Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
# cd /var/log# python3 -m http.server 8181Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
/var/log. Когда скачали, завершаем работу. Это очень простой способ быстро передать файлы, когда не хочется ничего настраивать. Я регулярно им пользуюсь. Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
{kind=link}
Попереживал тут на днях из-за своей неаккуратности. Настроил сервер 1С примерно так же, как описано у меня в статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
3️⃣ Проверяю, создалась ли база:
4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
# sudo -u postgres /usr/bin/createdb -U postgres -T template0 base1C-restored3️⃣ Проверяю, создалась ли база:
# sudo -u postgres /usr/bin/psql -U postgres -l4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
# sudo -u postgres /usr/bin/psql -U postgres base1C-restored < /tmp/backup.sql5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Погрузитесь в мир 🐳 DevOps и станьте devops-инженером за рекордные 4 месяца с курсом от Merion Academy!
Все, кому интересно, получат 🚀 2 бесплатных урока, где расскажут, кто такой DevOps-инженер, какие инструменты использует, куда и как развивает карьеру. Познакомитесь с Docker и контейнирезацией и закрепите знания.
🎁 Бонус – интенсив по развитию карьеры, где HR-эксперты расскажут как создавать сильные резюме и проходить собеседования.
📜 Плюс гайд по командам Docker.
🕺У ребят одна из самых доступных цен, которая в разы ниже, чем в других онлайн-школах, а еще есть рассрочка для тех, кто хочет учиться сейчас и платить по чуть-чуть ежемесячно.
👉 Регистрируйтесь по ссылке чтобы забирать бесплатные уроки, интенсив по карьере и гайд.
Merion Academy – это экосистема доступного образования, которая включает в себя:
📍IT-базу знаний с полезными статьями.
📍Youtube-канал ,где простыми словами говорят о сложных вещах.
📍 IT-академию, где обучат востребованным направлениям по самым доступным ценам.
#реклама
Все, кому интересно, получат 🚀 2 бесплатных урока, где расскажут, кто такой DevOps-инженер, какие инструменты использует, куда и как развивает карьеру. Познакомитесь с Docker и контейнирезацией и закрепите знания.
🎁 Бонус – интенсив по развитию карьеры, где HR-эксперты расскажут как создавать сильные резюме и проходить собеседования.
📜 Плюс гайд по командам Docker.
🕺У ребят одна из самых доступных цен, которая в разы ниже, чем в других онлайн-школах, а еще есть рассрочка для тех, кто хочет учиться сейчас и платить по чуть-чуть ежемесячно.
👉 Регистрируйтесь по ссылке чтобы забирать бесплатные уроки, интенсив по карьере и гайд.
Merion Academy – это экосистема доступного образования, которая включает в себя:
📍IT-базу знаний с полезными статьями.
📍Youtube-канал ,где простыми словами говорят о сложных вещах.
📍 IT-академию, где обучат востребованным направлениям по самым доступным ценам.
#реклама
Протестировал новый для себя инструмент, с которым раньше не был знаком. Он очень понравился и показался удобнее аналогичных, про которые знал и использовал раньше. Речь пойдёт про систему планирования и управления задачами серверов Cronicle. Условно его можно назвать продвинутым Cron с веб интерфейсом. Очень похож на Rundeck, про который когда-то писал.
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
Теперь ставим сам Cronicle. Для этого есть готовый скрипт:
Установка будет выполнена в директорию
А потом запустите:
Теперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
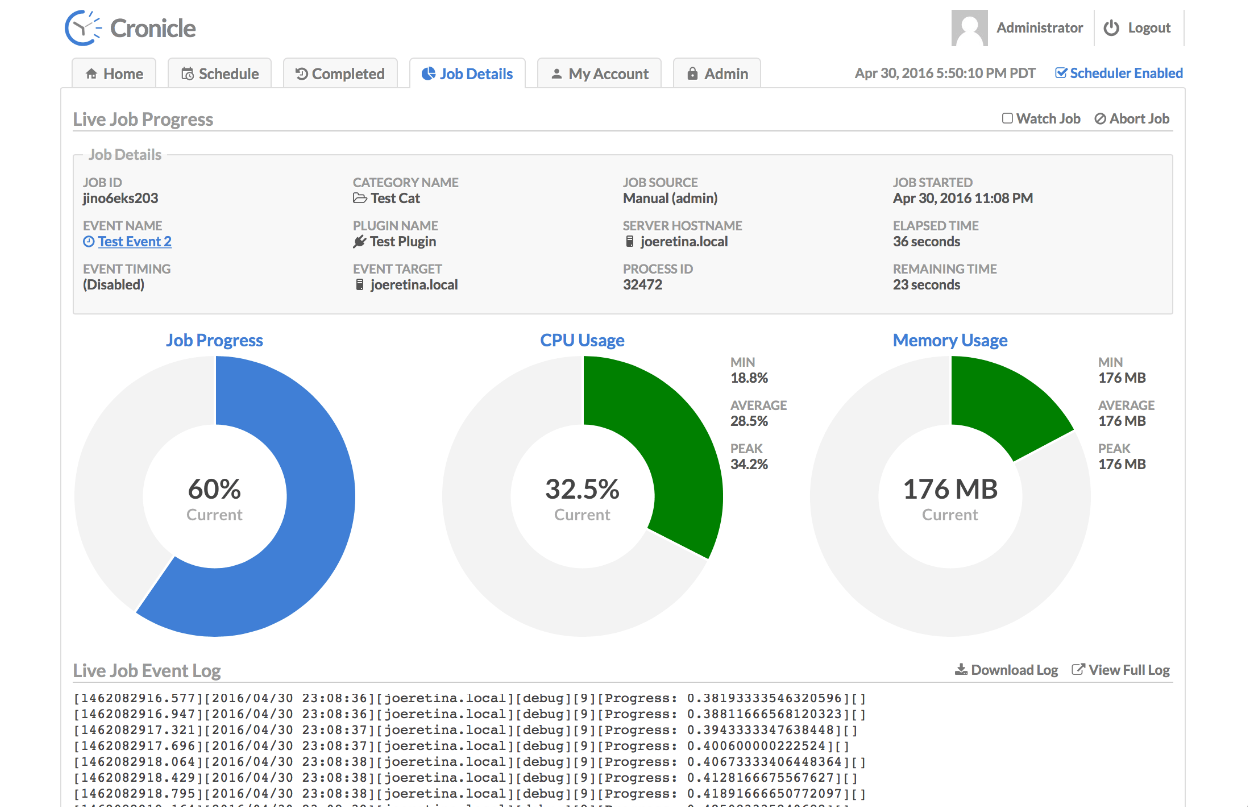
В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
# apt update# apt install ca-certificates curl gnupg# mkdir -p /etc/apt/keyrings# curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key \| gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg# NODE_MAJOR=20# echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" \| tee /etc/apt/sources.list.d/nodesource.list# apt update# apt install nodejsТеперь ставим сам Cronicle. Для этого есть готовый скрипт:
# curl -s https://raw.githubusercontent.com/jhuckaby/Cronicle/master/bin/install.js \| nodeУстановка будет выполнена в директорию
/opt/cronicle. Если ставите master сервер, то после установки выполните setup:# /opt/cronicle/bin/control.sh setupА потом запустите:
# /opt/cronicle/bin/control.sh startТеперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
/opt/cronicle/conf/config.json с master сервера. Там прописаны ключи, которые должны везде быть одинаковые. В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
{kind=link}
🔝 Очередной ТОП постов за прошедший месяц. Для тех, кто недавно присоединился к каналу, напомню, что он выходит регулярно уже более года. Все самые популярные публикации можно почитать со соответствующему хэштэгу #топ
📌 Больше всего просмотров:
◽️Мем про бэкап Шрёдингера (10984)
◽️Сервис-пинговалка ping.pe (9147)
◽️Заметка про ownCloud Infinite Scale 4.0 (9097)
📌 Больше всего комментариев:
◽️Отмена бесплатных лицензий 1C сервера на Linux (106)
◽️Почтовый сервер RuPost (104)
◽️Обновление Windows Server 2012 и 2012 R2 (95)
📌 Больше всего пересылок:
◽️Скрипт ps_mem для просмотра памяти приложений (371)
◽️Заметка про rdiff-backup (307)
◽️Нейронка для составления консольных команд (296)
📌 Больше всего реакций:
◽️Заметка про утилиту column (212)
◽️Мем про бэкап Шрёдингера (167)
◽️Как я делал rm -rf / (164)
◽️Заметка про увод Telegram каналов (152)
#топ
📌 Больше всего просмотров:
◽️Мем про бэкап Шрёдингера (10984)
◽️Сервис-пинговалка ping.pe (9147)
◽️Заметка про ownCloud Infinite Scale 4.0 (9097)
📌 Больше всего комментариев:
◽️Отмена бесплатных лицензий 1C сервера на Linux (106)
◽️Почтовый сервер RuPost (104)
◽️Обновление Windows Server 2012 и 2012 R2 (95)
📌 Больше всего пересылок:
◽️Скрипт ps_mem для просмотра памяти приложений (371)
◽️Заметка про rdiff-backup (307)
◽️Нейронка для составления консольных команд (296)
📌 Больше всего реакций:
◽️Заметка про утилиту column (212)
◽️Мем про бэкап Шрёдингера (167)
◽️Как я делал rm -rf / (164)
◽️Заметка про увод Telegram каналов (152)
#топ
Столкнулся на днях с историей, когда не заработал LXC контейнер в Proxmox 7.4. Попросили развернуть один свежий сайт на Bitrix из бэкапа для дальнейшей разработки. У Bitrix в этом плане удобно сделано. Разворачиваешь в пару действий их окружение BitrixENV (набор скриптов, плейбуков и костылей для поднятия LAMP и других сервисов), закидываешь бэкап в корень сайта и дальше всё само происходит, а на выходе получаешь рабочую копию сайта.
Но есть одна значительная проблема. BitrixENV до сих пор работает на Centos 7. И я нигде не видел информации, что они с этим собираются делать. Поддержка этой системы скоро закончится, но уже сейчас возникают проблемы с её использованием.
В Proxmox 7 и 8 запустить Centos 7, как и Ubuntu 16 в LXC не получится. Начиная с 7-й версии Proxmox, обновился механизм контейнеризации до cgroupv2. Указанные системы его не поддерживают. Подробнее об этом можно почитать тут:
⇨ CGroup Version Compatibility
⇨ Old Container and CGroupv2
Пришлось разворачивать виртуалку и запускать сайт там. Если у кого-то есть информация, как разработчики Bitrix собираются решать вопрос с Centos 7, дайте знать. Меня очень напрягает этот момент. Переносить сайты на другую систему очень не хочется. С BitrixENV реально удобно.
Я всегда использовал это окружение, в первую очередь из-за того, что упрощается взаимодействие с разработчиками. Все работают в одной и той же среде. Она легко переносится, настраивается. Да и пользоваться ей удобно. Разработчик пилит сайт на своём компе или сервере с этим окружением и потом без проблем отдаёт его заказчикам, где они его разворачивают.
У меня так и было с этим сайтом. Разработчики дали доступ к админке сайта. Я зашёл, сделал бэкап, получил там же на него прямую ссылку. Установил Centos 7, развернул BitrixENV, добавил через менюшку новый сайт, зашёл на него браузером, запустил режим восстановления из бэкапа, указал ссылку на бэкап с сайта разработчиков. Ну и всё. Получил копию сайта на своём сервере. Даже в консоль сервера разработчиков идти не пришлось. Да и они сами ничего не делали.
Удобный механизм. Несмотря на все недостатки Битркса, в нём очень много преимуществ. Надеюсь, разработчики как-то решат вопрос со своим окружением и устаревшей Centos 7. Интересно, какую систему выберут и сохранят ли вообще это окружение.
#bitrix
Но есть одна значительная проблема. BitrixENV до сих пор работает на Centos 7. И я нигде не видел информации, что они с этим собираются делать. Поддержка этой системы скоро закончится, но уже сейчас возникают проблемы с её использованием.
В Proxmox 7 и 8 запустить Centos 7, как и Ubuntu 16 в LXC не получится. Начиная с 7-й версии Proxmox, обновился механизм контейнеризации до cgroupv2. Указанные системы его не поддерживают. Подробнее об этом можно почитать тут:
⇨ CGroup Version Compatibility
⇨ Old Container and CGroupv2
Пришлось разворачивать виртуалку и запускать сайт там. Если у кого-то есть информация, как разработчики Bitrix собираются решать вопрос с Centos 7, дайте знать. Меня очень напрягает этот момент. Переносить сайты на другую систему очень не хочется. С BitrixENV реально удобно.
Я всегда использовал это окружение, в первую очередь из-за того, что упрощается взаимодействие с разработчиками. Все работают в одной и той же среде. Она легко переносится, настраивается. Да и пользоваться ей удобно. Разработчик пилит сайт на своём компе или сервере с этим окружением и потом без проблем отдаёт его заказчикам, где они его разворачивают.
У меня так и было с этим сайтом. Разработчики дали доступ к админке сайта. Я зашёл, сделал бэкап, получил там же на него прямую ссылку. Установил Centos 7, развернул BitrixENV, добавил через менюшку новый сайт, зашёл на него браузером, запустил режим восстановления из бэкапа, указал ссылку на бэкап с сайта разработчиков. Ну и всё. Получил копию сайта на своём сервере. Даже в консоль сервера разработчиков идти не пришлось. Да и они сами ничего не делали.
Удобный механизм. Несмотря на все недостатки Битркса, в нём очень много преимуществ. Надеюсь, разработчики как-то решат вопрос со своим окружением и устаревшей Centos 7. Интересно, какую систему выберут и сохранят ли вообще это окружение.
#bitrix
{kind=link}
Я написал большую обзорную статью про отечественный программный продукт для удалённого управления компьютерами TrustViewerPro:
⇨ Установка и настройка TrustViewerPro
Этот софт существует в нескольких редакциях:
◽ TrustViewer — некоммерческая версия, которая полностью бесплатна. Не требует установки и регистрации. Её можно просто скачать, запустить, получить ID код для подключения к компьютеру через публичные сервера разработчиков.
◽ TrustViewerPro — коммерческая версия, которая в том числе имеет бесплатный тарифный план, который позволяет развернуть у себя собственный сервер TrustServer и использовать до 10-ти подключенных к нему устройств.
Продукт предназначен как для работы через интернет, так и в закрытой локальной сети, а также в смешанных сетях. Функциональность очень обширная, помимо стандартных для таких программ функций.
Особенность TrustViewerPro в том, что у него очень много настроек управления пользователями и правами. Кому-то можно дать права только на просмотр экрана, кому-то на трансляцию экрана своего компа группе компов, кому-то только на загрузку файлов на группу компьютеров, кому-то на просмотр записей прошедших сессий. Возможности очень гибкие. Плюс, все действия логируются. Архитектурно система готова на установку в масштабные разветвлённые структуры.
Сервер устанавливается и на Windows, и на Linux, на выбор. Я ставил и туда, и туда. Установка очень простая, как и настройка. Сложностей нет. В статье подробно показано. Сервер весит 1 Мб, клиент 2 Мб 😱 Клиенты тоже под обе системы.
TrustViewerPro очень необычный самобытный продукт. Мне реально понравился. Я так понимаю, там всё самостоятельно запрограммировано, ничего готового не используется. Как-то непривычно было устанавливать сервер с управлением через веб, с встроенным веб сервером, который весит 826 КБ под виндой и 1061 КБ под линуксом.
Цены все открыты, можно посмотреть, сравнить.
#remote #отечественное
⇨ Установка и настройка TrustViewerPro
Этот софт существует в нескольких редакциях:
◽ TrustViewer — некоммерческая версия, которая полностью бесплатна. Не требует установки и регистрации. Её можно просто скачать, запустить, получить ID код для подключения к компьютеру через публичные сервера разработчиков.
◽ TrustViewerPro — коммерческая версия, которая в том числе имеет бесплатный тарифный план, который позволяет развернуть у себя собственный сервер TrustServer и использовать до 10-ти подключенных к нему устройств.
Продукт предназначен как для работы через интернет, так и в закрытой локальной сети, а также в смешанных сетях. Функциональность очень обширная, помимо стандартных для таких программ функций.
Особенность TrustViewerPro в том, что у него очень много настроек управления пользователями и правами. Кому-то можно дать права только на просмотр экрана, кому-то на трансляцию экрана своего компа группе компов, кому-то только на загрузку файлов на группу компьютеров, кому-то на просмотр записей прошедших сессий. Возможности очень гибкие. Плюс, все действия логируются. Архитектурно система готова на установку в масштабные разветвлённые структуры.
Сервер устанавливается и на Windows, и на Linux, на выбор. Я ставил и туда, и туда. Установка очень простая, как и настройка. Сложностей нет. В статье подробно показано. Сервер весит 1 Мб, клиент 2 Мб 😱 Клиенты тоже под обе системы.
TrustViewerPro очень необычный самобытный продукт. Мне реально понравился. Я так понимаю, там всё самостоятельно запрограммировано, ничего готового не используется. Как-то непривычно было устанавливать сервер с управлением через веб, с встроенным веб сервером, который весит 826 КБ под виндой и 1061 КБ под линуксом.
Цены все открыты, можно посмотреть, сравнить.
#remote #отечественное
Server Admin
Установка и настройка TrustViewerPro — ПО для удалённого...
Подробная установка и настройка российского ПО TrustViewerPro для удалённого управления компьютерами и поддержки пользователей.
Думаю, многие, если не все, знают всемирно известный сервис web.archive.org. С его помощью можно посмотреть архивные копии сайтов, в том числе уже закрытых. Существует известный и функциональный сервис с похожими возможностями, который можно развернуть у себя — ArchiveBox. Я
это сделал и попробовал его в работе.
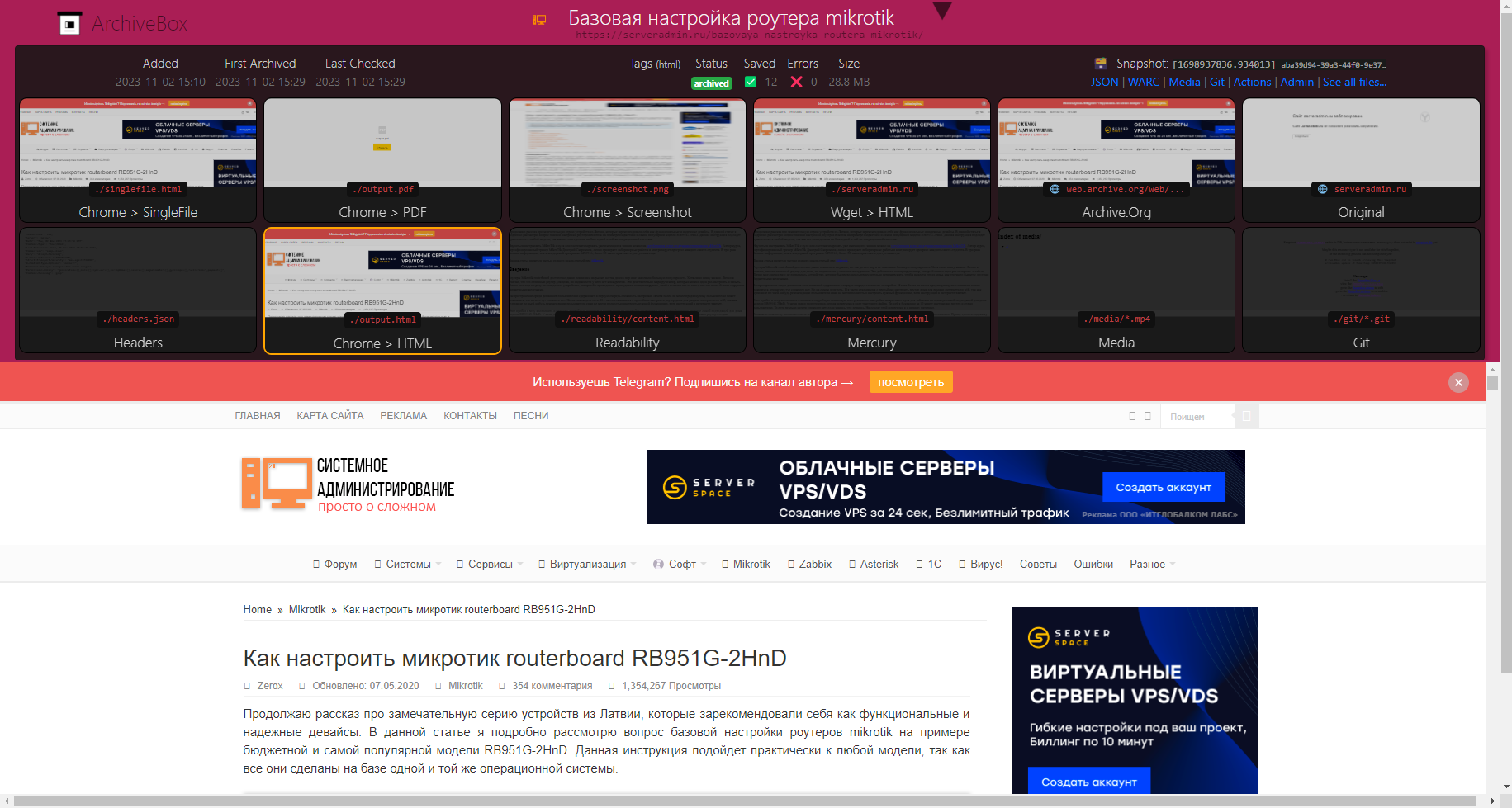
Сервис простой и функциональный. С установкой нет никаких проблем, так как есть и Docker образы, и готовый docker-compose.yaml, и bash скрипты, и готовые пакеты, в том числе под Freebsd. Я установил через compose:
Теперь идём на порт 8000 сервера и проходим аутентификацию с использованием учётной записи, которую создали в процессе инициализации. ArchiveBox может работать как приватное хранилище сайтов, так и публичное. Можно открывать публичный доступ без аутентификации. Как это работает, можно посмотреть в публичном demo:
⇨ https://demo.archivebox.io/public
Сервис работает следующим образом. Добавляете сайт на загрузку, указав некоторые параметры. Причём делать это можно как через браузер, так и CLI. То есть нет проблем с автоматизацией. Затем вы либо разово запускаете загрузку сайта, либо настраиваете расписание, по которому он будет регулярно обновляться.
После того, как сайт будет загружен, вы можете его просматривать через веб интерфейс, который расширен дополнительными возможностями. Вы можете смотреть копию из своего архива, можете обратиться к этой же странице, хранящейся в web.archive.org, можно посмотреть скриншот страницы, либо загрузить её в формате pdf.
❗️Есть отдельный плагин для браузера, чтобы удобно было добавлять сайты на загрузку в свой сервер.
Выглядит всё это классно и удобно. Если вам необходима подобная функциональность, то пользуйтесь. Когда я учился администрированию и занимался самообразованием, сохранял много html страниц с полезной информацией и инструкциями. Они хранятся до сих пор. Сейчас лично для меня отпал в этом смысл, так как чаще всего я всё могу сам настроить, открыв документацию. А если надо что-то автоматизировать и упростить установку, то сразу пишу небольшую инструкцию для себя в простом текстовом виде. Что-то переходит в статьи, но последнее время крайне редко, потому что не остаётся на это времени.
⇨ Сайт / Исходники
#сервис
это сделал и попробовал его в работе.
Сервис простой и функциональный. С установкой нет никаких проблем, так как есть и Docker образы, и готовый docker-compose.yaml, и bash скрипты, и готовые пакеты, в том числе под Freebsd. Я установил через compose:
# mkdir ~/archivebox && cd ~/archivebox# curl -O 'https://raw.githubusercontent.com/ArchiveBox/ArchiveBox/dev/docker-compose.yml'# docker compose run archivebox init --setup# docker compose upТеперь идём на порт 8000 сервера и проходим аутентификацию с использованием учётной записи, которую создали в процессе инициализации. ArchiveBox может работать как приватное хранилище сайтов, так и публичное. Можно открывать публичный доступ без аутентификации. Как это работает, можно посмотреть в публичном demo:
⇨ https://demo.archivebox.io/public
Сервис работает следующим образом. Добавляете сайт на загрузку, указав некоторые параметры. Причём делать это можно как через браузер, так и CLI. То есть нет проблем с автоматизацией. Затем вы либо разово запускаете загрузку сайта, либо настраиваете расписание, по которому он будет регулярно обновляться.
После того, как сайт будет загружен, вы можете его просматривать через веб интерфейс, который расширен дополнительными возможностями. Вы можете смотреть копию из своего архива, можете обратиться к этой же странице, хранящейся в web.archive.org, можно посмотреть скриншот страницы, либо загрузить её в формате pdf.
❗️Есть отдельный плагин для браузера, чтобы удобно было добавлять сайты на загрузку в свой сервер.
Выглядит всё это классно и удобно. Если вам необходима подобная функциональность, то пользуйтесь. Когда я учился администрированию и занимался самообразованием, сохранял много html страниц с полезной информацией и инструкциями. Они хранятся до сих пор. Сейчас лично для меня отпал в этом смысл, так как чаще всего я всё могу сам настроить, открыв документацию. А если надо что-то автоматизировать и упростить установку, то сразу пишу небольшую инструкцию для себя в простом текстовом виде. Что-то переходит в статьи, но последнее время крайне редко, потому что не остаётся на это времени.
⇨ Сайт / Исходники
#сервис
{kind=link}
В современном интернете очень активно используется протокол шифрования TLS. Чаще всего с ним сталкиваешься в HTTPS, VPN, STARTTLS (imap и smtp в основном). В Linux (и Unix в целом) этот протокол в основном реализован посредством OpenSSL. Это библиотека libssl и утилита командной строки openssl. Работа с этой утилитой настоящий вынос мозга. Там море всяких ключей, длиннющих конструкций и команд. Сталкиваться с этим напрямую приходится, например, при настройке своего OpenVPN сервера.
Чтобы упростить задачу управления сертификатами с помощью OpenSSL, придумали набор скриптов EasyRSA, которые даже в винду портировали. Именно с ними я всегда взаимодействовал, когда нужно было создать CA, серверные и клиентские ключи для OpenVPN (вот пример из моей статьи). Да и не только. Для всех подобных задач использовал EasyRSA и не знал, что есть инструменты проще.
В одном из комментариев увидел информацию, что есть CFSSL. Это утилита от cloudflare, с помощью которой можно создать и управлять CA, только без лишних костылей и подпорок. У неё вполне простой и понятный CLI, которым пользоваться в разы удобнее и проще, чем у openssl. Покажу сразу на примере создания CA и выпуска сертификатов для нужд OpenVPN сервера. Использую потом эту заметку при очередном обновлении статьи (уже назрело).
CFSSL это просто бинарник, скомпилированный из исходников на GO. В репозиториях Debian 12 он живёт под названием
Версия почему-то очень древнючая - 1.2.0, когда в репе уже 1.6.4 есть. Можно вручную скачать свежий бинарник.
Для cfssl нужно готовить конфиги в формате json. Сделать это нужно будет 1 раз. Интерактивного ввода, как у easyrsa, как я понял, нет. Готовим простой конфиг для выпуска СА:
Сохранили с именем
Генерируем ключ для CA:
Получили 3 файла:
▪ ca-key.pem - приватный ключ для подписи сертификатов
▪ ca.pem - сам сертификат удостоверяющего центра
▪ ca.csr - запрос на сертификат
Подготовим конфиг профилей, которые нужны будут для сертификата сервера и клиентов:
Сохранили с именем ca.json. И делаем конфиг для запроса, такой же как для CA, только секцию с CA убираем:
Сохранили с именем csr.json. Выпускаем сертификат сервера:
Получили 3 файла:
Выпускаем сертификат для клиента:
Проверяем:
Вот и всё. Подготовили удостоверяющий центр и выпустили сертификаты клиента и сервера. Выглядит действительно удобнее и проще EasyRSA.
#security #openvpn
Чтобы упростить задачу управления сертификатами с помощью OpenSSL, придумали набор скриптов EasyRSA, которые даже в винду портировали. Именно с ними я всегда взаимодействовал, когда нужно было создать CA, серверные и клиентские ключи для OpenVPN (вот пример из моей статьи). Да и не только. Для всех подобных задач использовал EasyRSA и не знал, что есть инструменты проще.
В одном из комментариев увидел информацию, что есть CFSSL. Это утилита от cloudflare, с помощью которой можно создать и управлять CA, только без лишних костылей и подпорок. У неё вполне простой и понятный CLI, которым пользоваться в разы удобнее и проще, чем у openssl. Покажу сразу на примере создания CA и выпуска сертификатов для нужд OpenVPN сервера. Использую потом эту заметку при очередном обновлении статьи (уже назрело).
CFSSL это просто бинарник, скомпилированный из исходников на GO. В репозиториях Debian 12 он живёт под названием
golang-cfssl:# apt install golang-cfsslВерсия почему-то очень древнючая - 1.2.0, когда в репе уже 1.6.4 есть. Можно вручную скачать свежий бинарник.
Для cfssl нужно готовить конфиги в формате json. Сделать это нужно будет 1 раз. Интерактивного ввода, как у easyrsa, как я понял, нет. Готовим простой конфиг для выпуска СА:
{ "CN": "My Root CA", "key": { "algo": "rsa", "size": 2048 }, "ca": { "expiry": "87600h" }, "names": [ { "C": "RU", "L": "Moscow", "O": "Serveradmin Company", "OU": "OpenVPN", "ST": "Moscow" } ]}Сохранили с именем
ca-csr.json. Тут срок действия стоит 10 лет. Кажется, что много. Но на самом деле у меня лично был случай, когда 10-ти летний CA протух.Генерируем ключ для CA:
# mkdir keys && cd keys# cfssl gencert -initca ca-csr.json | cfssljson -bare caПолучили 3 файла:
▪ ca-key.pem - приватный ключ для подписи сертификатов
▪ ca.pem - сам сертификат удостоверяющего центра
▪ ca.csr - запрос на сертификат
Подготовим конфиг профилей, которые нужны будут для сертификата сервера и клиентов:
{ "signing": { "profiles": { "server": { "expiry": "87600h", "usages": [ "digital signature", "key encipherment", "server auth" ] }, "client": { "expiry": "87600h", "usages": [ "signing", "client auth" ] } } }}Сохранили с именем ca.json. И делаем конфиг для запроса, такой же как для CA, только секцию с CA убираем:
{ "CN": "My Root CA", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "RU", "L": "Moscow", "O": "Serveradmin Company", "OU": "OpenVPN", "ST": "Moscow" } ]}Сохранили с именем csr.json. Выпускаем сертификат сервера:
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \-config=ca.json -profile="server" \-cn="openvpn.server.local" -hostname="openvpn" \csr.json | cfssljson -bare serverПолучили 3 файла:
# ls | grep serverserver.csrserver-key.pemserver.pemВыпускаем сертификат для клиента:
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \-config=ca.json -profile="client" \-cn="client01" -hostname="User 01" \csr.json | cfssljson -bare client01Проверяем:
# ls | grep client01client01.csrclient01-key.pemclient01.pemВот и всё. Подготовили удостоверяющий центр и выпустили сертификаты клиента и сервера. Выглядит действительно удобнее и проще EasyRSA.
#security #openvpn
{kind=link}
Запомнился один момент с недавней конференции, где я присутствовал. Выступающий рассказывал, если не ошибаюсь, про технологию VDI и оптимизацию полосы пропускания, что позволяет комфортно общаться по видеосвязи. В подтверждение своих слов с цифрами показал картинку, где справа окно терминала.
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Всегда составляю список дел на день. Сегодня день расписан, как будний, в том числе по плану публикаций, а по факту нынче выходной. Когда работаешь в свободном графике, а доход зависит напрямую от сделанного, часто забываешь такие дни. Это для кого-то плюс, для кого-то минус. Кстати, на эту тему я как-то написал цикл заметок, который очень зашёл. Кто не читал, рекомендую:
🟢 Про работу
🟢 Про выбор профессии
🟢 Плюсы и минусы моего режима труда
А сегодня, раз уж выходной день, расскажу про одно произведение, которое недавно прочитал:
people > /dev/null
⇨ https://author.today/work/49584
Автор, судя по всему, программист, либо какой-то другой специальности, но точно умеет программировать. Произведение необычное и самобытное. Небольшое. Прочитал за вечер и мне понравилось. Сюжет рассказывать не буду, чтобы интерес не пропал. Приведу только немного фрагментов из текста.
Наверное, мне стоит вам пояснить, чем отличаются староверы от нововеров. Программисты староверы избирательны — они воруют чужой код двумя комбинациями клавиш: Ctrl+C, Ctrl+V. Нововер ворует тремя: Ctrl+A, Ctrl+C, Ctrl+V — истребляя в себе духовность на корню.
— …еще в колтехе мы вырубали датчики при помощи микроволновок…
Слушая их предложения, я приходил к выводу, что ни один хакер по объёму ущерба, причинённого компании, не сравнится с сотрудниками этой компании. Особенно по степени изощрённости нанесения вреда.
— На суппорт-форумах я прикрепляю битые ссылки с пометкой — вот вариант решения вашей проблемы! — Признавался Питер Ли Честер.
— А я оставляю на форумах вопросы, — подхватил эстафету Карим, — После чего закрываю беседу, заявляя, что сам во всём разобрался.
— При всём уважении, — перебил их Бенджамин, — Уверен, в аду для вас обоих припасён отдельный котёл.
Необходимо решать прямо сейчас. Это как горячая замена диска в массиве, ты уверен, что всё пройдёт гладко, но страх развалить RAID тягостно дышит тебе в спину.
Про рейд мне особенно срезонировало. Каждый раз меняя диск в рейде, я мысленно представляю, что я буду делать, если сейчас по неведомой причине всё развалится. Особенно, если тебе меняют диск в дата-центре по заявке. Однажды мне заменили не тот диск и всё упало.
#разное
🟢 Про работу
🟢 Про выбор профессии
🟢 Плюсы и минусы моего режима труда
А сегодня, раз уж выходной день, расскажу про одно произведение, которое недавно прочитал:
people > /dev/null
⇨ https://author.today/work/49584
Автор, судя по всему, программист, либо какой-то другой специальности, но точно умеет программировать. Произведение необычное и самобытное. Небольшое. Прочитал за вечер и мне понравилось. Сюжет рассказывать не буду, чтобы интерес не пропал. Приведу только немного фрагментов из текста.
Наверное, мне стоит вам пояснить, чем отличаются староверы от нововеров. Программисты староверы избирательны — они воруют чужой код двумя комбинациями клавиш: Ctrl+C, Ctrl+V. Нововер ворует тремя: Ctrl+A, Ctrl+C, Ctrl+V — истребляя в себе духовность на корню.
— …еще в колтехе мы вырубали датчики при помощи микроволновок…
Слушая их предложения, я приходил к выводу, что ни один хакер по объёму ущерба, причинённого компании, не сравнится с сотрудниками этой компании. Особенно по степени изощрённости нанесения вреда.
— На суппорт-форумах я прикрепляю битые ссылки с пометкой — вот вариант решения вашей проблемы! — Признавался Питер Ли Честер.
— А я оставляю на форумах вопросы, — подхватил эстафету Карим, — После чего закрываю беседу, заявляя, что сам во всём разобрался.
— При всём уважении, — перебил их Бенджамин, — Уверен, в аду для вас обоих припасён отдельный котёл.
Необходимо решать прямо сейчас. Это как горячая замена диска в массиве, ты уверен, что всё пройдёт гладко, но страх развалить RAID тягостно дышит тебе в спину.
Про рейд мне особенно срезонировало. Каждый раз меняя диск в рейде, я мысленно представляю, что я буду делать, если сейчас по неведомой причине всё развалится. Особенно, если тебе меняют диск в дата-центре по заявке. Однажды мне заменили не тот диск и всё упало.
#разное
{kind=link}
2 полезных канала для системных администраторов:
📚 @it_secur — редкая литература, курсы и уникальные мануалы для сетевиков и ИБ специалистов любого уровня и направления. Читайте, развивайтесь, практикуйте.
👨🏻💻 @infosecurity — авторский Telegram канал, посвященный информационной безопасности, OSINT и социальной инженерии.
#реклама
📚 @it_secur — редкая литература, курсы и уникальные мануалы для сетевиков и ИБ специалистов любого уровня и направления. Читайте, развивайтесь, практикуйте.
👨🏻💻 @infosecurity — авторский Telegram канал, посвященный информационной безопасности, OSINT и социальной инженерии.
#реклама
Давно ничего бесплатного не было. Мне самому особо не надо, а чего-то прям реально удобного и полезного, типа бесплатных виртуалок от Oracle, не попадалось. Но в этот раз тема нормальная будет. Речь пойдёт про бесплатный php хостинг InfinityFree:
⇨ https://www.infinityfree.com
Я не знаю, зачем подобные хостинги делают бесплатные тарифы, но тут по факту он существует, причём полнофункциональный. Возможно за счёт баннеров в админке монетизируют. Я их сначала не увидел даже без блокировщика рекламы. А потом пока тестировал, зашёл в админку через VPN и увидел баннеры AdSense. С адресов РФ они не отображаются.
Для регистрации достаточно только email. После регистрации создаёте себе аккаунт, выбираете доменное имя, либо на бесплатном поддомене, либо свой домен указываете и привязываете через DNS.
После создания сайта автоматически получаете учётку FTP и базу данных MySQL. Я проверил, всё работает, в том числе бесплатный сертификат от Let's Encrypt. Денег нигде не просили. Дают 5 гигов диска, 30019 inodes. Больше никаких ограничений не заявлено.
В качестве управления хостингом используется VistaPanel. Первый раз её увидел. Толком не понял, что это такое. Хотел почитать про неё, но даже через поиск не нашёл официального сайта или какого-то внятного описания. Судя по всему, это что-то уже умершее. То ли это какой-то ребрендинг cPanel. Выглядит она похоже.
#бесплатно #хостинг
⇨ https://www.infinityfree.com
Я не знаю, зачем подобные хостинги делают бесплатные тарифы, но тут по факту он существует, причём полнофункциональный. Возможно за счёт баннеров в админке монетизируют. Я их сначала не увидел даже без блокировщика рекламы. А потом пока тестировал, зашёл в админку через VPN и увидел баннеры AdSense. С адресов РФ они не отображаются.
Для регистрации достаточно только email. После регистрации создаёте себе аккаунт, выбираете доменное имя, либо на бесплатном поддомене, либо свой домен указываете и привязываете через DNS.
После создания сайта автоматически получаете учётку FTP и базу данных MySQL. Я проверил, всё работает, в том числе бесплатный сертификат от Let's Encrypt. Денег нигде не просили. Дают 5 гигов диска, 30019 inodes. Больше никаких ограничений не заявлено.
В качестве управления хостингом используется VistaPanel. Первый раз её увидел. Толком не понял, что это такое. Хотел почитать про неё, но даже через поиск не нашёл официального сайта или какого-то внятного описания. Судя по всему, это что-то уже умершее. То ли это какой-то ребрендинг cPanel. Выглядит она похоже.
#бесплатно #хостинг
{kind=link}
Для Linux существует не так много антивирусов, особенно бесплатных. Я знаю только один - clamav. Чаще всего именно он используется в различных open source продуктах. С марта 2022 года разработчик запретил доступ ко всему своему сайту, включая обновления, для российских IP-адресов. Обновление антивирусных баз возможно с альтернативных зеркал, репозиториев.
Я решил поискать, а есть ли какие-то альтернативы. Нашёл тоже open source антивирус, который в том числе умеет использовать сигнатуры clamav - Linux Malware Detection (LMD). Решил его установить и потестировать. В первую очередь для сканирования сайтов, поэтому проверять его буду на некоторых известных шеллах.
Установка Linux Malware Detection (LMD):
Антивирус будет установлен в директорию
❗️Сделаю важное уточнение. По умолчанию, антивирус не проверяет файлы, которые принадлежат пользователю root. Сделано это, чтобы ненароком не навредить системе. Так что во всех дальнейших тестах учитывайте это.
Для начала проверим антивирус на стандартном тестовом файле для антивирусов от EICAR:
В консоли увидите команду на просмотр отчёта. Там будет видно, что антивирус отреагировал на тестовый файл с образцом вируса.
Проверим теперь на реальном шелле. Например, отсюда. Скачал и распаковал php shell - r57shell.rar. Скопировал в директорию, изменил владельца и запустил тест. Антивирус обнаружил shell:
Решил ещё одну проверку сделать, взяв несколько php-shells с сайта https://www.r57shell.net/php-shells.php, которых нету в репозитории выше. На ZeroByte PHP Shell, AnonGhost Bypass Shell, TurkShell Bypass Php shell не отреагировал. Дальше не стал проверять. Обратил внимание, что они все закодированы в base64. Думаю, что-то тут не так. Полез в настройки и увидел там параметр:
Значение было 0, я изменил на 1. Он отвечает за анализ обфусцированных строк. После этого все шеллы, кроме ZeroByte, были обнаружены:
Такой вот антивирус. В условиях отсутствия других вариантов выглядит не так плохо. Можно использовать для проверки сайтов и помощи в лечении. Хотя, конечно, лучше бэкапов тут никто не поможет. Но не всегда есть возможность их использовать. Недавно активно атаковали сайты на Битриксах. Так вирус сидел несколько месяцев в исходниках, прежде чем начал вредоносную деятельность. В итоге у многих бэкапы оказались заражены.
Под конец проверок решил поставить clamav, залил туда вручную базы от 29 июля, которые нашёл. Он шеллы в base64 тоже не обнаружил. Настройки бегло глянул, не понял, что там подкрутить надо. Скорее всего есть какая-то отдельная с signatures под эти вещи.
⇨ Сайт / Исходники
Если работаете с сайтами, скажите, чем и как сейчас их проверяете в случае проблем.
#security #antivirus #linux
Я решил поискать, а есть ли какие-то альтернативы. Нашёл тоже open source антивирус, который в том числе умеет использовать сигнатуры clamav - Linux Malware Detection (LMD). Решил его установить и потестировать. В первую очередь для сканирования сайтов, поэтому проверять его буду на некоторых известных шеллах.
Установка Linux Malware Detection (LMD):
# wget http://www.rfxn.com/downloads/maldetect-current.tar.gz# tar -xvf maldetect-current.tar.gz# cd maldetect-*/# ./install.shАнтивирус будет установлен в директорию
/usr/local/maldetect/, там же будет его конфиг conf.maldet. Я не буду останавливаться на настройке, так как во-первых, файл хорошо прокомментирован, сможете сами разобраться. Во-вторых, в сети много руководств по этой теме. ❗️Сделаю важное уточнение. По умолчанию, антивирус не проверяет файлы, которые принадлежат пользователю root. Сделано это, чтобы ненароком не навредить системе. Так что во всех дальнейших тестах учитывайте это.
Для начала проверим антивирус на стандартном тестовом файле для антивирусов от EICAR:
# mkdir /tmp/shells && cd /tmp/shells# wget http://www.eicar.org/download/eicar.com# chown -R www-data:www-data /tmp/shells# maldet --scan-all /tmp/shellsВ консоли увидите команду на просмотр отчёта. Там будет видно, что антивирус отреагировал на тестовый файл с образцом вируса.
Проверим теперь на реальном шелле. Например, отсюда. Скачал и распаковал php shell - r57shell.rar. Скопировал в директорию, изменил владельца и запустил тест. Антивирус обнаружил shell:
{HEX}php.cmdshell.mic22.316 : /tmp/shells/r57.phpРешил ещё одну проверку сделать, взяв несколько php-shells с сайта https://www.r57shell.net/php-shells.php, которых нету в репозитории выше. На ZeroByte PHP Shell, AnonGhost Bypass Shell, TurkShell Bypass Php shell не отреагировал. Дальше не стал проверять. Обратил внимание, что они все закодированы в base64. Думаю, что-то тут не так. Полез в настройки и увидел там параметр:
string_length_scan="1"Значение было 0, я изменил на 1. Он отвечает за анализ обфусцированных строк. После этого все шеллы, кроме ZeroByte, были обнаружены:
{SA}stat.strlength : /tmp/shells/turkshell.php{MD5}EICAR.TEST.3.62 : /tmp/shells/eicar.com{SA}stat.strlength : /tmp/shells/anonghost.php{HEX}php.cmdshell.mic22.316 : /tmp/shells/r57.phpТакой вот антивирус. В условиях отсутствия других вариантов выглядит не так плохо. Можно использовать для проверки сайтов и помощи в лечении. Хотя, конечно, лучше бэкапов тут никто не поможет. Но не всегда есть возможность их использовать. Недавно активно атаковали сайты на Битриксах. Так вирус сидел несколько месяцев в исходниках, прежде чем начал вредоносную деятельность. В итоге у многих бэкапы оказались заражены.
Под конец проверок решил поставить clamav, залил туда вручную базы от 29 июля, которые нашёл. Он шеллы в base64 тоже не обнаружил. Настройки бегло глянул, не понял, что там подкрутить надо. Скорее всего есть какая-то отдельная с signatures под эти вещи.
⇨ Сайт / Исходники
Если работаете с сайтами, скажите, чем и как сейчас их проверяете в случае проблем.
#security #antivirus #linux
{kind=link}
В процессе подготовки утренней публикации с антивирусами, пришлось работать с rar архивами. Казалось бы, что может быть проще установки архиватора rar в Debian. Я точно знаю, что он там есть, потому что ранее уже пользовался им.
Помню, что у него имя пакета не просто rar, а что-то ещё добавляется. Нет проблем, воспользуемся поиском:
На экран вываливается тонна пакетов. Такое ощущение, что тут весь список стандартного репозитория. Мотая экран вверх, я даже до буквы R не дошёл, буфер кончился. Читаю описание пакетов из списка, и не понимаю, почему они тут. Никакого rar там нет.
Запускаю другой поиск:
Тут то же самое. Огромный список. Становится понятно, что сюда попали все пакеты, в которых где-то в названии или описании есть rar в составе. То есть все пакеты, где в описании есть слово library, тоже в этом списке. Но не только они. Даже если нигде не видно rar, всё равно где-то в спецификации пакета он есть и пакет выведен в результаты поиска.
Тут мне уже надоело и я тупо загуглил нужный пакет. Он оказался unrar. Ну наконец-то. Ставлю и распаковываю:
Опять какая-то ерунда. Скачиваю этот же архив к себе на комп, нормально открывается с помощью 7zip. То есть архив рабочий, самый обычный. Смотрю версию unrar. Смущает, что она от 2004 года. Полез опять в поиск.
Оказывается, нормальная версия unrar есть в репозитории non-free. Подключаю его, добавляя в sources.list:
Обновляю репы и пакет:
Теперь всё нормально работает.
Я давно знаю, что поиск пакетов через apt или apt-cache работает неудобно. По нему зачастую трудно что-то найти, если название пакета короткое и много где может встречаться в описании. Если знаете какие-то способы, что с этим делать, то поделитесь. Я так всегда и ищу. Если не нахожу, то иду в веб поиск и ищу там. Зачастую это получается быстрее.
Можно немного упростить себе задачу и искать только по названию пакета:
Search в том числе поддерживает регулярки, так что по идее можно ими себе помогать. Но конкретно с rar я не очень понимаю, как могла бы выглядеть регулярка, так как нужен unrar. А если искать обычный rar, то вот так проще всего найти:
А вообще, с rar очень редко приходится иметь дела в Linux. Как-то он тут не прижился. Лично я либо gzip, либо pigz использую, если нужна многопоточность. Что-то другое крайне редко. Даже не припомню, использовал ли какие-то другие архиваторы. Хотя, по идее, сейчас оптимальный алгоритм сжатия - zstd, который используется в том числе в proxmox для создания бэкапов. Да и много где ещё. Он и жмёт хорошо, и самое главное - быстро.
#linux
Помню, что у него имя пакета не просто rar, а что-то ещё добавляется. Нет проблем, воспользуемся поиском:
# apt search rarНа экран вываливается тонна пакетов. Такое ощущение, что тут весь список стандартного репозитория. Мотая экран вверх, я даже до буквы R не дошёл, буфер кончился. Читаю описание пакетов из списка, и не понимаю, почему они тут. Никакого rar там нет.
Запускаю другой поиск:
# apt-cache search rarТут то же самое. Огромный список. Становится понятно, что сюда попали все пакеты, в которых где-то в названии или описании есть rar в составе. То есть все пакеты, где в описании есть слово library, тоже в этом списке. Но не только они. Даже если нигде не видно rar, всё равно где-то в спецификации пакета он есть и пакет выведен в результаты поиска.
Тут мне уже надоело и я тупо загуглил нужный пакет. Он оказался unrar. Ну наконец-то. Ставлю и распаковываю:
# apt install unrar# unrar e anonghost.rarunknown archive type, only plain RAR 2.0 supported(normal and solid archives), SFX and Volumes are NOT supported!Опять какая-то ерунда. Скачиваю этот же архив к себе на комп, нормально открывается с помощью 7zip. То есть архив рабочий, самый обычный. Смотрю версию unrar. Смущает, что она от 2004 года. Полез опять в поиск.
Оказывается, нормальная версия unrar есть в репозитории non-free. Подключаю его, добавляя в sources.list:
deb http://deb.debian.org/debian/ bullseye main non-freeОбновляю репы и пакет:
# apt update# apt upgrade unrarТеперь всё нормально работает.
Я давно знаю, что поиск пакетов через apt или apt-cache работает неудобно. По нему зачастую трудно что-то найти, если название пакета короткое и много где может встречаться в описании. Если знаете какие-то способы, что с этим делать, то поделитесь. Я так всегда и ищу. Если не нахожу, то иду в веб поиск и ищу там. Зачастую это получается быстрее.
Можно немного упростить себе задачу и искать только по названию пакета:
# apt search --names-only rarSearch в том числе поддерживает регулярки, так что по идее можно ими себе помогать. Но конкретно с rar я не очень понимаю, как могла бы выглядеть регулярка, так как нужен unrar. А если искать обычный rar, то вот так проще всего найти:
# apt search ^rar А вообще, с rar очень редко приходится иметь дела в Linux. Как-то он тут не прижился. Лично я либо gzip, либо pigz использую, если нужна многопоточность. Что-то другое крайне редко. Даже не припомню, использовал ли какие-то другие архиваторы. Хотя, по идее, сейчас оптимальный алгоритм сжатия - zstd, который используется в том числе в proxmox для создания бэкапов. Да и много где ещё. Он и жмёт хорошо, и самое главное - быстро.
#linux
Несмотря на то, что Микротики стало сложнее купить, да и стоить они стали больше, особых альтернатив так и не просматривается. Я сам постоянно ими пользуюсь, управляю, как в личных целях, так и на работе. Мне нравятся эти устройства. Очень хочется продолжать ими пользоваться. У меня и дома, и на даче, и у родителей и много где ещё стоят Микротики.
Я когда-то писал про полезный ресурс для Mikrotik - https://buananetpbun.github.io. Там была куча скриптов, утилит, генераторов конфигов для различных настроек. Я им иногда пользовался. Там сначала дизайн поменялся, стало удобнее, появились запросы доната. На днях зашёл, смотрю, а там всё платное стало. Из открытого доступа почти всё исчезло.
Сначала решил через web.archive.org зайти, посмотреть, что там можно достать из полезного контента. Перед этим попробовал поискать по некоторым ключевым словам похожие ресурсы. И не ошибся. Сразу же нашёл копию сайта, когда он был ещё бесплатным. Так что теперь можно пользоваться им:
⇨ https://mikrotiktool.github.io
Основное там - большая структурированная база скриптов для RouterOS. Помимо прям больших и сложных скриптов, там много и простых примеров по типу блокировки сайтов с помощью блокировки DNS запросов, с помощью Layer 7, блокировка торрентов и т.д.
Помимо скриптов там есть генераторы конфигов, которые помогут выполнить настройку устройства. Например:
◽MikroTik Burst Limit Calculator - помогает рассчитать параметры burst при настройке простыл очередей.
◽Port Knocking Generator with (ping) ICMP + Packet Size - простенький генератор правил firewall для настройки Port Knocking.
◽Simple Queue Script Generator - генератор конфигурации для простых очередей.
В общем, там много всего интересного. Если настраиваете Микротики, покопайтесь. Можете найти для себя что-то полезное.
#mikrotik
Я когда-то писал про полезный ресурс для Mikrotik - https://buananetpbun.github.io. Там была куча скриптов, утилит, генераторов конфигов для различных настроек. Я им иногда пользовался. Там сначала дизайн поменялся, стало удобнее, появились запросы доната. На днях зашёл, смотрю, а там всё платное стало. Из открытого доступа почти всё исчезло.
Сначала решил через web.archive.org зайти, посмотреть, что там можно достать из полезного контента. Перед этим попробовал поискать по некоторым ключевым словам похожие ресурсы. И не ошибся. Сразу же нашёл копию сайта, когда он был ещё бесплатным. Так что теперь можно пользоваться им:
⇨ https://mikrotiktool.github.io
Основное там - большая структурированная база скриптов для RouterOS. Помимо прям больших и сложных скриптов, там много и простых примеров по типу блокировки сайтов с помощью блокировки DNS запросов, с помощью Layer 7, блокировка торрентов и т.д.
Помимо скриптов там есть генераторы конфигов, которые помогут выполнить настройку устройства. Например:
◽MikroTik Burst Limit Calculator - помогает рассчитать параметры burst при настройке простыл очередей.
◽Port Knocking Generator with (ping) ICMP + Packet Size - простенький генератор правил firewall для настройки Port Knocking.
◽Simple Queue Script Generator - генератор конфигурации для простых очередей.
В общем, там много всего интересного. Если настраиваете Микротики, покопайтесь. Можете найти для себя что-то полезное.
#mikrotik
{kind=link}
▶️ Вчера посмотрел видео про обзор российских дистрибутивов. Сделано качественно и информативно, так что если вам интересна тема, то рекомендую посмотреть. Я узнал некоторые факты и подробности, про которые не слышал, либо не интересовался.
⇨ https://www.youtube.com/watch?v=ZMHUBc_4Zbw
Добавлю краткие выжимки и приведу список описанных дистрибутивов:
🟢 Astra Linux - сделана на базе Debian. Ориентация в основном на госсектор с повышенными требованиями к безопасности. Куча сертификатов самого высокого уровня доверия. Для многих секторов безальтернативный вариант. На текущий момент лидер рынка российских ОС.
🟢 ALT Linux - старейший дистрибутив из 2000 года, в основу была взята Mandriva. Сейчас это полностью самобытный и самостоятельный дистрибутив с самым большим сообществом в РФ. Дистрибутив ориентирован и на госсектор, и на коммерческие организации. Есть отдельный фокус на продукты в сфере образования. Для домашнего использования почти всё бесплатно.
🟢 Calculate Linux - в основе Gentoo. Относительно старый дистрибутив, разработка начата в 2007 году. Имеет стабильное сообщество, неплохие отзывы и в целом выглядит самобытно. Есть своя экосистема программных продуктов, своя целевая аудитория в виде малого и среднего бизнеса.
🟢 ROSA - в основе Mandriva, используются rpm пакеты, установщик - dnf. Примечательна тем, что разрабатывает свою ОС для смартфонов - РОСА Мобайл. Обещают презентацию уже 14 декабря 2023. Ориентация в основном на госсектор. Есть сертификаты ФСТЭК и Министерства обороны РФ. Тем не менее, предлагает широкую линейку продуктов, где есть в том числе РОСА ФРЕШ - полностью бесплатный продукт для дома.
🟢 RedOS - в основе rpm дистрибутивы, изначально - CentOS. Была сделана под конкретный гос. заказ, который был признан успешным, так что система получила развитие. Чего-то примечательного в этой системе не замечено, похоже просто на переупаковку rpm дистра для получение статуса отечественного.
#linux #отечественное
⇨ https://www.youtube.com/watch?v=ZMHUBc_4Zbw
Добавлю краткие выжимки и приведу список описанных дистрибутивов:
🟢 Astra Linux - сделана на базе Debian. Ориентация в основном на госсектор с повышенными требованиями к безопасности. Куча сертификатов самого высокого уровня доверия. Для многих секторов безальтернативный вариант. На текущий момент лидер рынка российских ОС.
🟢 ALT Linux - старейший дистрибутив из 2000 года, в основу была взята Mandriva. Сейчас это полностью самобытный и самостоятельный дистрибутив с самым большим сообществом в РФ. Дистрибутив ориентирован и на госсектор, и на коммерческие организации. Есть отдельный фокус на продукты в сфере образования. Для домашнего использования почти всё бесплатно.
🟢 Calculate Linux - в основе Gentoo. Относительно старый дистрибутив, разработка начата в 2007 году. Имеет стабильное сообщество, неплохие отзывы и в целом выглядит самобытно. Есть своя экосистема программных продуктов, своя целевая аудитория в виде малого и среднего бизнеса.
🟢 ROSA - в основе Mandriva, используются rpm пакеты, установщик - dnf. Примечательна тем, что разрабатывает свою ОС для смартфонов - РОСА Мобайл. Обещают презентацию уже 14 декабря 2023. Ориентация в основном на госсектор. Есть сертификаты ФСТЭК и Министерства обороны РФ. Тем не менее, предлагает широкую линейку продуктов, где есть в том числе РОСА ФРЕШ - полностью бесплатный продукт для дома.
🟢 RedOS - в основе rpm дистрибутивы, изначально - CentOS. Была сделана под конкретный гос. заказ, который был признан успешным, так что система получила развитие. Чего-то примечательного в этой системе не замечено, похоже просто на переупаковку rpm дистра для получение статуса отечественного.
#linux #отечественное
YouTube
ВСЁ О РУССКИХ ЛИНУКСАХ (2023)
Как много ты знаешь об отечественных вариантах Линукса? В этом видео разберём самые популярные российские дистрибутивы на базе ядра линукс и соберём весь пазл воедино! Приятного просмотра!
Гайд ALT Zero: https://plafon.gitbook.io/alt-zero/alt-zero/start…
Гайд ALT Zero: https://plafon.gitbook.io/alt-zero/alt-zero/start…
Ко мне как то раз обратился человек за помощью в настройке веб сервера. Суть была вот в чём. У него есть контентный сайт, где он пишет хайповые статьи для сбора ситуативного трафика. Монетизируется, соответственно, показами различной рекламы. Чем больше показов, тем больше доход.
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
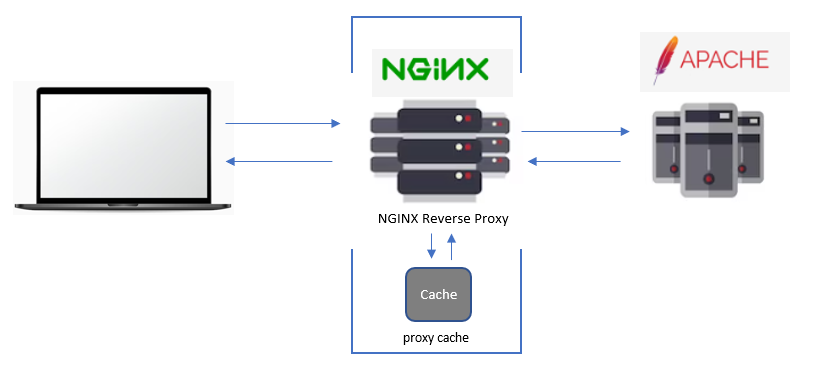
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
Создаём директорию
Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
http { ... proxy_cache_path /var/cache/nginx keys_zone=my_cache:10m inactive=1w max_size=1G; ...}Создаём директорию
/var/cache/nginx и делаем владельцем пользователя, под которым работает веб сервер. Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
server { ... proxy_cache my_cache; ... location / { proxy_set_header Host $host; proxy_pass http://10.20.1.36:81; proxy_cache_key $scheme://$host$uri$is_args$query_string; proxy_cache_valid 200 30m; proxy_cache_bypass $arg_bypass_cache; proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_429; }}Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
/var/cache/nginx, можете сходить туда и убедиться. Если используется gzip, то там будут сжатые файлы. Теперь, даже если веб сервер 10.20.1.36:81 умрёт, прокси сервер всё равно будет отдавать статические страницы. Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
/var/cache/nginx появились эти страницы. Отключил контейнер с Wordpress, сайт продолжил работать в виде закэшированной статики на прокси. Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
{kind=link}
❗️Сразу важное предупреждение перед непосредственно содержательной частью. Всё, что дальше будет изложено, не призыв к действию. Пишу только в качестве информации, с которой каждый сам решает, как поступать. Сразу акцентирую на этом внимание, потому что ко всем подобным заметкам постоянно пишут комментарии на тему того, что бесплатный сыр бывает только в мышеловке, свои данные нельзя ни в какие облака загружать, всё, что в облаке, принадлежит не вам и т.д.
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
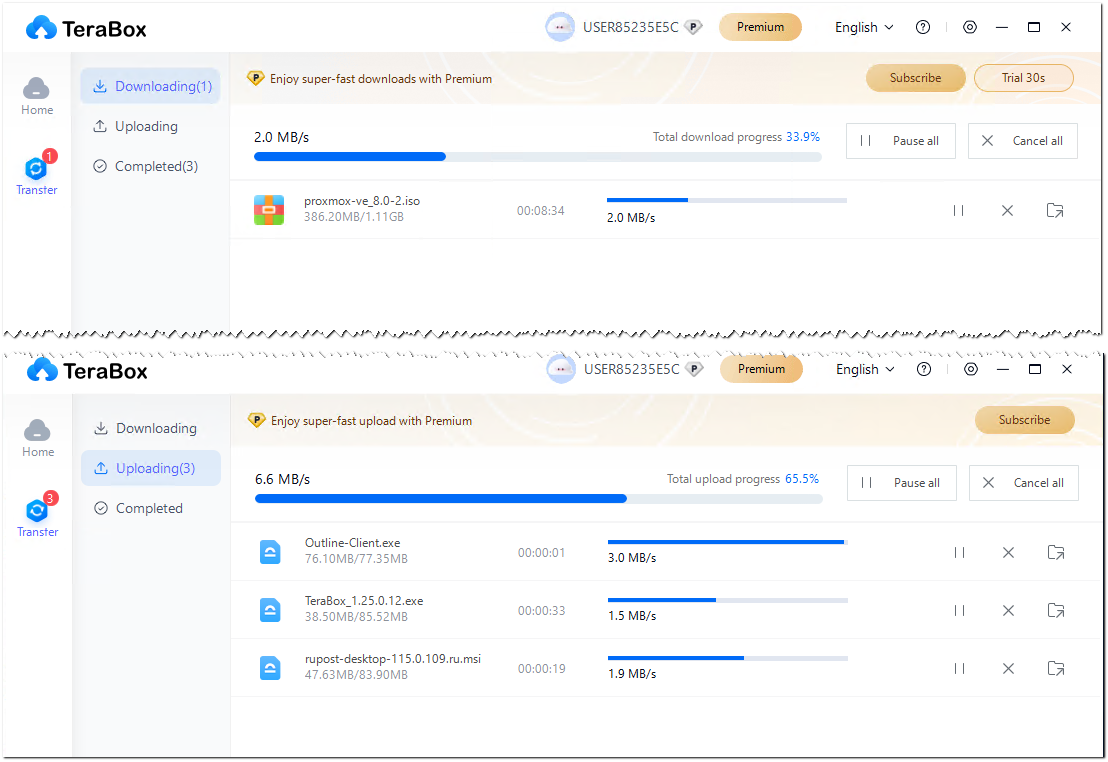{kind=link}
Расскажу про систему построения отказоустойчивого сервиса из подручных средств по цене аренды железа. Я её когда-то придумал, протестировал и использовал некоторое время для одного сайта. Не могу сказать, что мне понравилось, как всё это работало, но там были частности в виде репликации СУБД, у которой может быть разное решение, которое на саму схему не влияет.
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
{kind=link}