
У меня печальные новости для тех, кто использует сервер 1С под Linux. До недавнего времени он для запуска не требовал серверную лицензию, если использовалось не больше 12-ти клиентских соединений.
Я эту возможность всегда использовал для дублирования основного сервера. Копию использовал для тестирования обновлений, для восстановления бэкапов, для проверки восстановленных баз, для выгрузки dt, для тестирования баз и т.д. В общем, для служебных нужд. Пользователей туда не пускал.
Сначала я увидел комментарий к своей статье на сайте, где автор говорит, что версия 8.3.23.1865 без серверной лицензии не запускается. Подумал, что автор что-то делает не так. Но на днях я один из серверов тоже обновил на новую платформу 8.3.23.1865. Сделал всё как обычно. Сначала проверил обновление на тестовом сервере. Запускаю его, пытаюсь подключиться клиентом и вижу отказ, так как не найдена серверная лицензия.
Если бы не увиденный мной комментарий, я бы подумал, что сам где-то ошибаюсь, потому что не смог найти никаких новостей или упоминаний где-то ещё в интернете по этому поводу. Но так как нас уже как минимум двое, значит какие-то изменения в свежей платформе появились.
Кто-то сталкивался уже с этим? Будет очень жаль, если работу Linux сервера без лицензии уберут совсем. Для тестовых целей это было очень удобно.
#1С
Я эту возможность всегда использовал для дублирования основного сервера. Копию использовал для тестирования обновлений, для восстановления бэкапов, для проверки восстановленных баз, для выгрузки dt, для тестирования баз и т.д. В общем, для служебных нужд. Пользователей туда не пускал.
Сначала я увидел комментарий к своей статье на сайте, где автор говорит, что версия 8.3.23.1865 без серверной лицензии не запускается. Подумал, что автор что-то делает не так. Но на днях я один из серверов тоже обновил на новую платформу 8.3.23.1865. Сделал всё как обычно. Сначала проверил обновление на тестовом сервере. Запускаю его, пытаюсь подключиться клиентом и вижу отказ, так как не найдена серверная лицензия.
Если бы не увиденный мной комментарий, я бы подумал, что сам где-то ошибаюсь, потому что не смог найти никаких новостей или упоминаний где-то ещё в интернете по этому поводу. Но так как нас уже как минимум двое, значит какие-то изменения в свежей платформе появились.
Кто-то сталкивался уже с этим? Будет очень жаль, если работу Linux сервера без лицензии уберут совсем. Для тестовых целей это было очень удобно.
#1С
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Немного актуальных новостей про Zabbix, которым я постоянно пользуюсь.
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
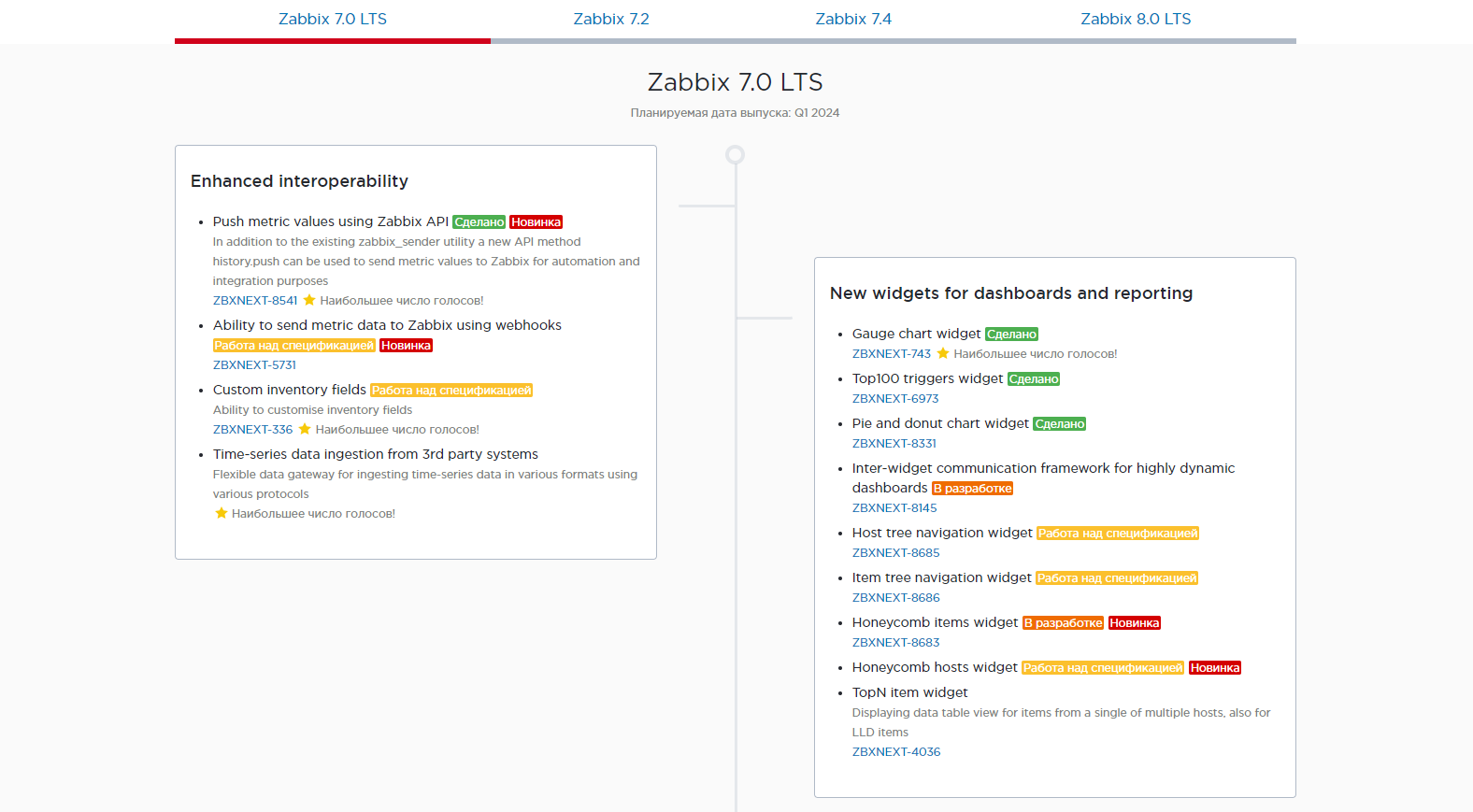
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
{kind=link}
Если хотите потренироваться и погонять бесплатно S3 хранилище, то у меня есть подходящий сервис для вас с бесплатным тарифным планом - tebi.io. Для регистрации требуется только email, карту не просят. Обещают Free Tier с ограничением на 25 GiB хранилища и 250 GiB исходящего трафика в месяц.
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
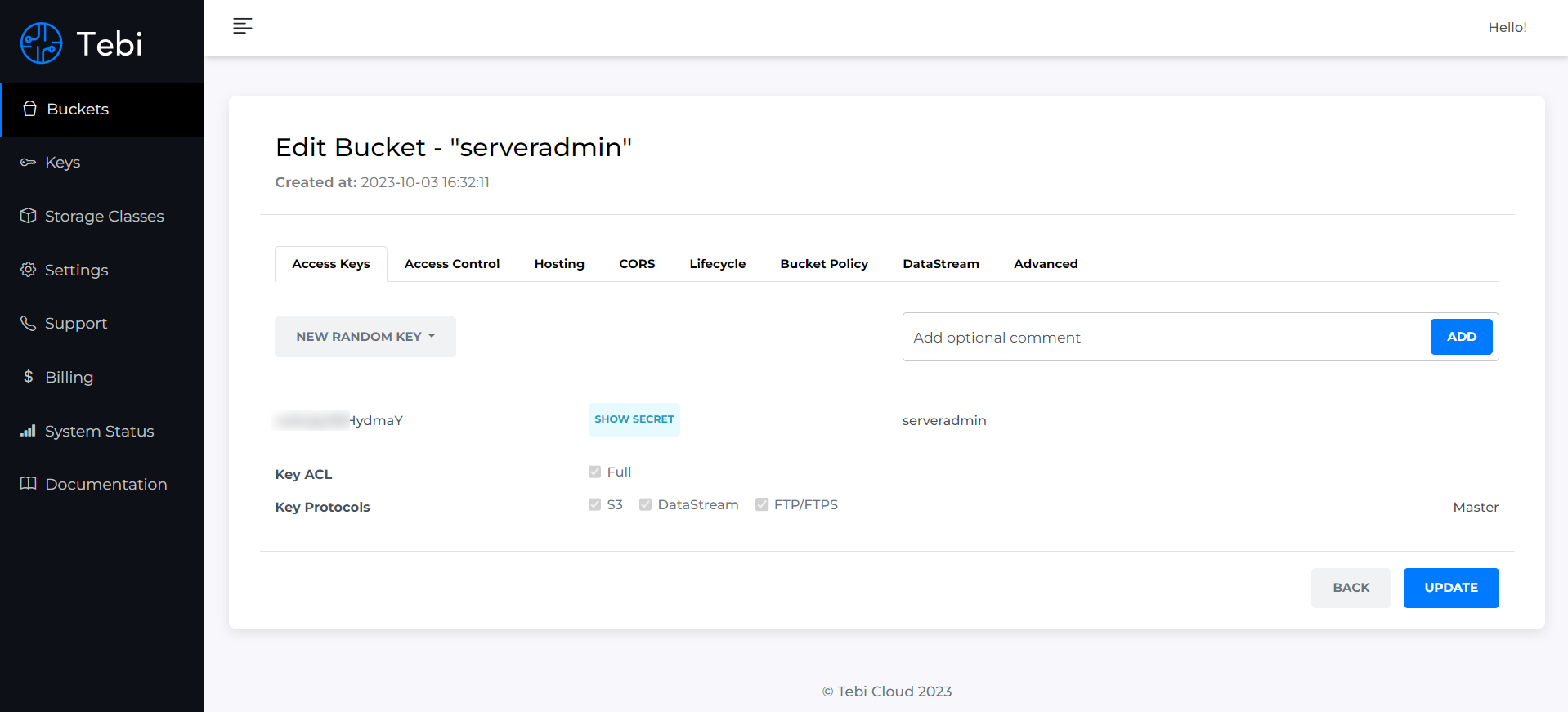
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
И можно грузить файлы или директории:
Для FTP нужны только эти данные:
Третий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
[tebi]type = s3provider = Otheraccess_key_id = uo5csfdErtydmaYsecret_access_key = vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmendpoint = https://s3.tebi.io/acl = privateИ можно грузить файлы или директории:
# rclone sync -i testfile.exe tebi:bucket_nameДля FTP нужны только эти данные:
server: ftp.tebi.ioport: 21login: uo5csfdErtydmaYpassword: vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmТретий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
{kind=link}
Немного поизучал тему self-hosted решений для S3 и понял, что аналогов MiniO по сути и нет. Всё, что есть, либо малофункционально, либо малоизвестно. Нет ни руководств, ни отзывов. Но в процессе заметил любопытный продукт от известной компании Zenko, которая специализируется на multi-cloud решениях.
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
Примеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
docker run -p 8000:8000 --name=cloudserver \ -v $(pwd)/config.json:/usr/src/app/config.json \ -v $(pwd)/locationConfig.json /usr/src/app/locationConfig.json \ -v $(pwd)/data:/usr/src/app/localData \ -v $(pwd)/metadata:/usr/src/app/localMetadata \ -e REMOTE_MANAGEMENT_DISABLE=1 -d zenko/cloudserverПримеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
[remote]type = s3env_auth = falseaccess_key_id = accessKey1secret_access_key = verySecretKey1region = other-v2-signatureendpoint = http://localhost:8000location_constraint =acl = privateserver_side_encryption =storage_class =Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
{kind=link}
Я не так давно рассказывал про сервис рисования схем excalidraw.com. Тогда впервые о нём узнал, и он мне очень понравился. В комментариях кто-то упомянул, что у него есть плагин для VSCode, но я не придал значения.
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
YouTube
Рисуем документацию прямо внутри IDE - excalidraw
Рассмотрим: интеграцию рисовалки для документации в вашем любимом vscode (phpstorm)
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru
«Главная проблема цитат в интернете в том, что люди сразу верят в их подлинность», - Владимир Ленин.
Просматривал недавно общение в какой-то заметке с комментариями, а там подняли тему Fail2Ban и SSH, и в голове всплыла выдуманная цитата, приписываемая Салтыкову-Щедрину, хотя он её никогда не произносил: «Если я усну и проснусь через сто лет и меня спросят, что сейчас происходит в России, я отвечу: пьют и воруют». Она на самом деле новодел 90-х годов. Ни один из классиков её никогда не произносил, а в голове у меня она каким-то образом оказалась.
А вспомнил я её, потому что на все эти блокировки SSH у меня родился свой аналог этого выражения:
«Если я усну и проснусь через сто лет и меня спросят, что сейчас настраивают системные администраторы Linux, я отвечу: блокировку SSH с помощью Fail2Ban».
Я не знаю, зачем об этом до сих пор кто-то вспоминает, рекомендует или сам настраивает. Это было неактуально уже тогда, когда я сам начал изучать Linux.
Сервис SSH давно уже не брутится, потому что повсеместно распространены сертификаты, либо можно применить другие существующие настройки sshd: MaxAuthTries, MaxSessions, MaxStartups, которые делают брут фактически невозможным. Наверное стоит посвятить этому отдельную заметку. И никакой Fail2Ban тут не нужен. Я сам его использую, но не для SSH.
#ssh #fail2ban
Просматривал недавно общение в какой-то заметке с комментариями, а там подняли тему Fail2Ban и SSH, и в голове всплыла выдуманная цитата, приписываемая Салтыкову-Щедрину, хотя он её никогда не произносил: «Если я усну и проснусь через сто лет и меня спросят, что сейчас происходит в России, я отвечу: пьют и воруют». Она на самом деле новодел 90-х годов. Ни один из классиков её никогда не произносил, а в голове у меня она каким-то образом оказалась.
А вспомнил я её, потому что на все эти блокировки SSH у меня родился свой аналог этого выражения:
«Если я усну и проснусь через сто лет и меня спросят, что сейчас настраивают системные администраторы Linux, я отвечу: блокировку SSH с помощью Fail2Ban».
Я не знаю, зачем об этом до сих пор кто-то вспоминает, рекомендует или сам настраивает. Это было неактуально уже тогда, когда я сам начал изучать Linux.
Сервис SSH давно уже не брутится, потому что повсеместно распространены сертификаты, либо можно применить другие существующие настройки sshd: MaxAuthTries, MaxSessions, MaxStartups, которые делают брут фактически невозможным. Наверное стоит посвятить этому отдельную заметку. И никакой Fail2Ban тут не нужен. Я сам его использую, но не для SSH.
#ssh #fail2ban
🎓 На прошлой неделе я рассказывал про репозиторий с обучающими TUI программами с популярными консольными утилитами. Хочу обратить внимание на тренажёр по awk. Я там увидел много полезных примеров с возможностями awk, про которые я даже не знал.
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
Команды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
Тут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
Я не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
Это хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
Закомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
# grep 'word' file.txt# awk '/word/' file.txtКоманды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
# grep 'word' file.txt | awk '{print $1}'# awk '/word/{print $1}' file.txtТут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
# awk '{print $0 "."}' file.txtЯ не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
# awk '{print "#" $0}' file.txtЭто хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
# awk '/word/{print "#" $0}' file.txtЗакомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
{kind=link}
Забавная история произошла. На днях постучался человек в личку и спросил, куда лучше задать вопрос по поводу статьи, сюда или на сайте. Я ответил, что на сайте.
На следующий день появляется вопрос на сайте и через минуту у меня в личке. Содержание на картинке. У человека терпения хватило на минуту.
Я без негатива, просто забавно вышло. На вопрос ответил ссылкой из гугла.
#мем
На следующий день появляется вопрос на сайте и через минуту у меня в личке. Содержание на картинке. У человека терпения хватило на минуту.
Я без негатива, просто забавно вышло. На вопрос ответил ссылкой из гугла.
#мем
У меня написаны заметки по всем более ли менее популярным бесплатным системам мониторинга. И только одну очень старую систему я всегда обходил стороной, за что неоднократно получал комментарии на эту тему. Надо это исправить и дополнить мою статью с обзором систем мониторинга (20 штук).
Речь пойдёт про старичка Cacti, он же Кактус, который хранит данные и рисует графики с помощью очень старой TSDB — RRDTool. Работает Cacti на базе стандартного LAMP стэка, так как написан на PHP, настройки хранит в MySQL. Поднять сервер можно даже на Windows под IIS. Сбор метрик крутится в основном вокруг SNMP, но можно их собирать и другими способами на базе собственных Data Collectors, в качестве которых могут выступать и обычные скрипты. Кактус ориентирован в основном на мониторинг сетевых устройств.
Cacti поддерживает шаблоны, правила автообнаружения, расширяет свои возможности через плагины, имеет разные механизмы аутентификации пользователей, в том числе через LDAP. То есть там полный набор полноценной системы мониторинга. Система очень старая, из 2001 (😎) года, но поддерживается и развивается до сих пор.
Это такая самобытная, добротная, с приятным интерфейсом система мониторинга. Если честно, я не знаю, что может заставить её использовать сейчас. Разве что её интерфейс дашборды. Сказать, что она легко и быстро разворачивается не могу. Чего-то особенного в ней тоже нет. Используется мало где, и мало кому нужна. Не знаю ни одного аргумента, который бы оправдал её использование вместо того же Zabbix или более современных систем.
Если в каких-то других системах мониторинга я могу увидеть простоту установки и настройки, необычный внешний вид или удобные дашборды, то тут ничего такого нет. Настраивать придётся вручную, изучать сбор метрик и принцип работы, разбираться. Материалов не так много, все в основном старые. Это скорее система для тех, кто с ней знаком и работал раньше. Сейчас её изучать смысла не вижу.
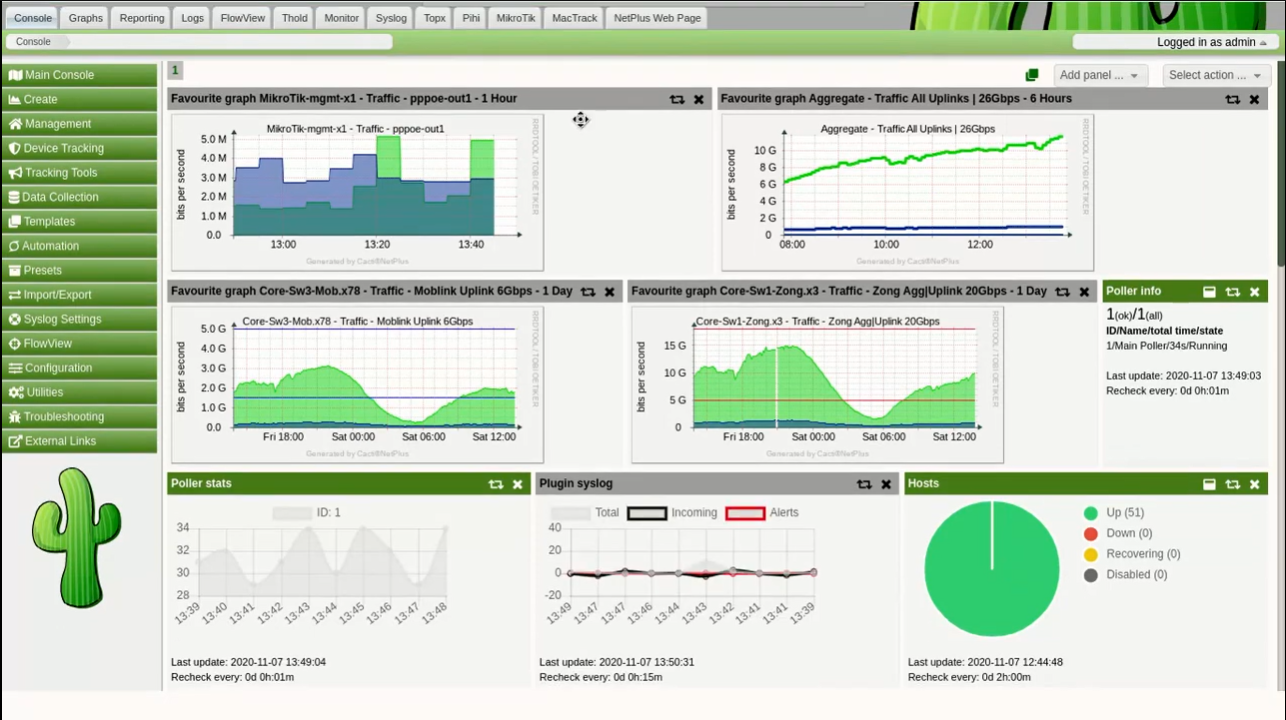
Посмотреть внешний вид и основные возможности можно вот в этом обзорном видео: ▶️ https://www.youtube.com/watch?v=Xww5y9V1ikI Возможно вас эта система чем-то зацепит. Как я уже сказал, она самобытная с необычным интерфейсом и дашбордами. Выглядит неплохо. Мне, к примеру, RRD графики нравятся больше чем то, что сейчас есть в Zabbix.
Отдельно отмечу, что у Cacti есть плагин для NetFlow. Можно собирать информацию о трафике с сетевых устройств и смотреть в Кактусе. Пример того, как это может выглядеть в связке с Mikrotik, можно посмотреть в видео. Хотя лично я считаю, что лучше отдельную систему под это, так как это не совсем мониторинг.
В Debian Cacti есть в базовых репах и ставится автоматически весь стек:
После этого идёте в веб интерфейс по адресу http://172.17.196.25/cacti/. Учётка admin / cacti. Для теста можете поставить локально службу snmpd и добавить хост localhost в систему мониторинга.
⇨ Сайт / Исходники / Видеоинструкции
#мониторинг
Речь пойдёт про старичка Cacti, он же Кактус, который хранит данные и рисует графики с помощью очень старой TSDB — RRDTool. Работает Cacti на базе стандартного LAMP стэка, так как написан на PHP, настройки хранит в MySQL. Поднять сервер можно даже на Windows под IIS. Сбор метрик крутится в основном вокруг SNMP, но можно их собирать и другими способами на базе собственных Data Collectors, в качестве которых могут выступать и обычные скрипты. Кактус ориентирован в основном на мониторинг сетевых устройств.
Cacti поддерживает шаблоны, правила автообнаружения, расширяет свои возможности через плагины, имеет разные механизмы аутентификации пользователей, в том числе через LDAP. То есть там полный набор полноценной системы мониторинга. Система очень старая, из 2001 (😎) года, но поддерживается и развивается до сих пор.
Это такая самобытная, добротная, с приятным интерфейсом система мониторинга. Если честно, я не знаю, что может заставить её использовать сейчас. Разве что её интерфейс дашборды. Сказать, что она легко и быстро разворачивается не могу. Чего-то особенного в ней тоже нет. Используется мало где, и мало кому нужна. Не знаю ни одного аргумента, который бы оправдал её использование вместо того же Zabbix или более современных систем.
Если в каких-то других системах мониторинга я могу увидеть простоту установки и настройки, необычный внешний вид или удобные дашборды, то тут ничего такого нет. Настраивать придётся вручную, изучать сбор метрик и принцип работы, разбираться. Материалов не так много, все в основном старые. Это скорее система для тех, кто с ней знаком и работал раньше. Сейчас её изучать смысла не вижу.
Посмотреть внешний вид и основные возможности можно вот в этом обзорном видео: ▶️ https://www.youtube.com/watch?v=Xww5y9V1ikI Возможно вас эта система чем-то зацепит. Как я уже сказал, она самобытная с необычным интерфейсом и дашбордами. Выглядит неплохо. Мне, к примеру, RRD графики нравятся больше чем то, что сейчас есть в Zabbix.
Отдельно отмечу, что у Cacti есть плагин для NetFlow. Можно собирать информацию о трафике с сетевых устройств и смотреть в Кактусе. Пример того, как это может выглядеть в связке с Mikrotik, можно посмотреть в видео. Хотя лично я считаю, что лучше отдельную систему под это, так как это не совсем мониторинг.
В Debian Cacti есть в базовых репах и ставится автоматически весь стек:
# apt install cactiПосле этого идёте в веб интерфейс по адресу http://172.17.196.25/cacti/. Учётка admin / cacti. Для теста можете поставить локально службу snmpd и добавить хост localhost в систему мониторинга.
⇨ Сайт / Исходники / Видеоинструкции
#мониторинг
{kind=link}
Решил сделать подборку self-hosted решений хранения большого количества фотографий для совместной работы с ними и просмотра. Я одно время заморочился и перетащил весь семейный фотоархив во встроенное приложение в Synology. Но со временем надоело туда вносить правки, всё устарело и потеряло актуальность. Сейчас решил возобновить эту тему, но без привязки к какому-то вендору, на базе open source.
Если кто-то пользуется чем-то и ему оно нравится, то поделитесь своим продуктом. Я и на работе не раз видел потребность в каких-то общих галереях. Например, для выездных специалистов, которые фотографируют объекты. Или просто перетащить куда-то в одно место фотки с корпоративов, которые забивают общие сетевые диски и расползаются по личным папкам пользователей, занимая огромные объёмы. Практически везде с этим сталкивался.
Вот подборка, которую я собрал:
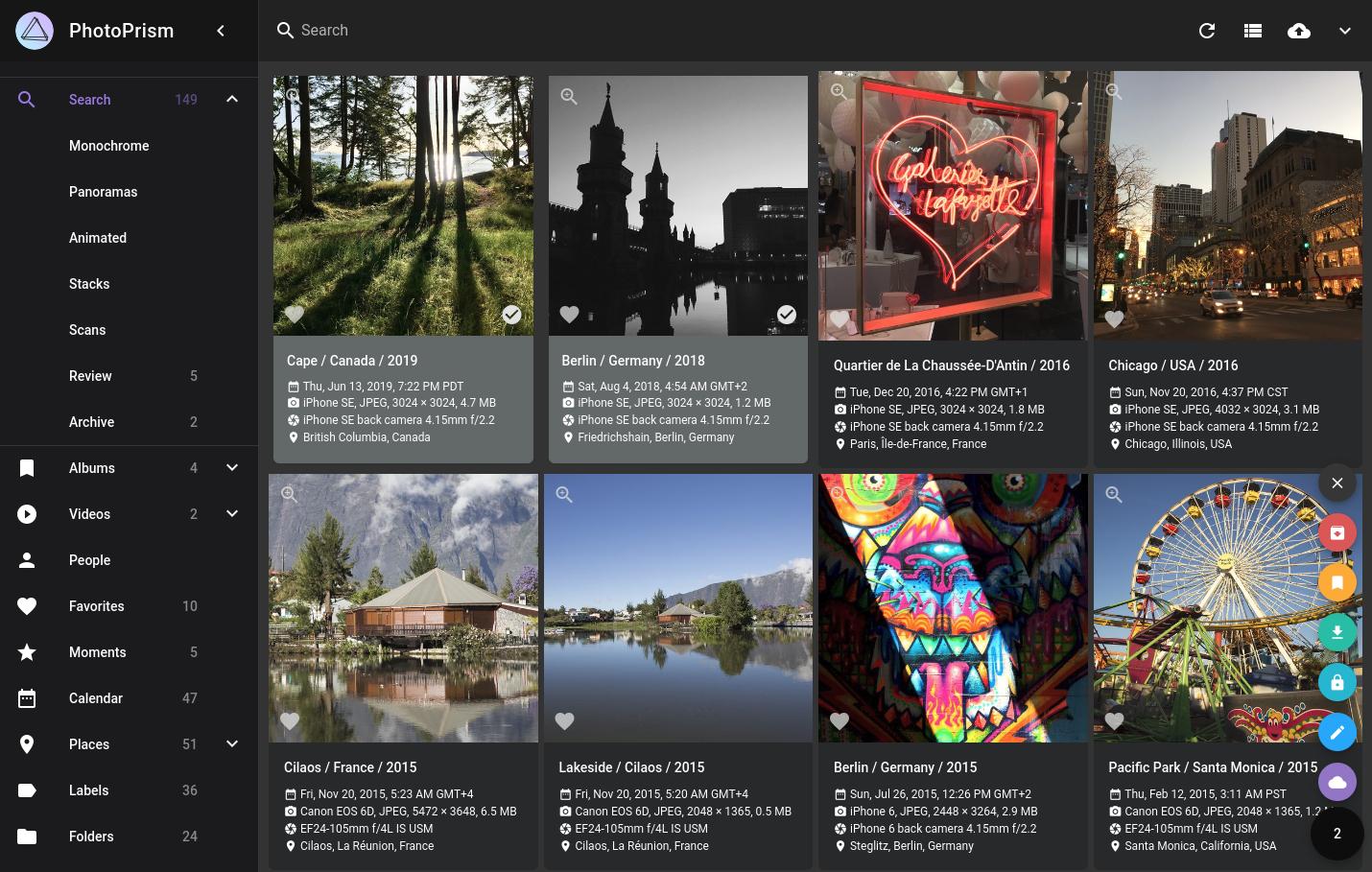
◽Photoprism - самый масштабный и известный продукт. Выглядит монструозно и функционально. Умеет распознавать лица, классифицировать фотографии по содержанию и координатам. Запустить можно быстро через Docker. Написан на Go. Есть мобильное приложение. На первый взгляд хороший вариант.
◽Lychee в противовес предыдущей галерее предлагает более простую функциональность базе PHP фреймворка Laravel, который работает на стандартном стэке LAMP, настройки хранит в MySQL/MariaDB, PostgreSQL или SQLite базе. Каких-то особых фишек нет, просто публичные, либо закрытые альбомы. Если не нужны навороты, то неплохой вариант. Мне нравится Laravel, на его базе получаются простые и шустрые приложения.
◽Librephotos - эта галерея написана на Python. Есть распознавание и классификация лиц, анализ и группировка по гео меткам, анализ сцены, объектов в фотках. В репе есть ссылки на все open source продукты, что используются для распознавания. На вид ничего особенного, интерфейс посмотрел. Но количество звёзд на гитхабе очень много.
◽Photoview на вид простая и лаконичная галерея. Минималистичный, но удобный для своих задач дизайн. Написан на Go и JavaScript примерно в равных пропорциях. Из анализа содержимого заявлено только распознавание лиц. Есть мобильное приложение, но только под iOS. На вид выглядит как середнячок на современном стэке с простой функциональностью.
◽Piwigo - ещё одна галерея на PHP под LAMP. Старичок из далёкого 2002 года, который развивается до сих пор. Есть темы и плагины, API, развитая система управления пользователями и их правами. За время существования проекта накопилось огромное количество плагинов. Я немного полистал список, чего там только нет. Например, плагин аутентификации пользователей через LDAP каталог.
Как я уже написал, лидером выглядит Photoprism, но лично мне, судя по всему, больше подойдёт Photoview, так как распознавания лиц мне будет достаточно.
#fileserver #подборка
Если кто-то пользуется чем-то и ему оно нравится, то поделитесь своим продуктом. Я и на работе не раз видел потребность в каких-то общих галереях. Например, для выездных специалистов, которые фотографируют объекты. Или просто перетащить куда-то в одно место фотки с корпоративов, которые забивают общие сетевые диски и расползаются по личным папкам пользователей, занимая огромные объёмы. Практически везде с этим сталкивался.
Вот подборка, которую я собрал:
◽Photoprism - самый масштабный и известный продукт. Выглядит монструозно и функционально. Умеет распознавать лица, классифицировать фотографии по содержанию и координатам. Запустить можно быстро через Docker. Написан на Go. Есть мобильное приложение. На первый взгляд хороший вариант.
◽Lychee в противовес предыдущей галерее предлагает более простую функциональность базе PHP фреймворка Laravel, который работает на стандартном стэке LAMP, настройки хранит в MySQL/MariaDB, PostgreSQL или SQLite базе. Каких-то особых фишек нет, просто публичные, либо закрытые альбомы. Если не нужны навороты, то неплохой вариант. Мне нравится Laravel, на его базе получаются простые и шустрые приложения.
◽Librephotos - эта галерея написана на Python. Есть распознавание и классификация лиц, анализ и группировка по гео меткам, анализ сцены, объектов в фотках. В репе есть ссылки на все open source продукты, что используются для распознавания. На вид ничего особенного, интерфейс посмотрел. Но количество звёзд на гитхабе очень много.
◽Photoview на вид простая и лаконичная галерея. Минималистичный, но удобный для своих задач дизайн. Написан на Go и JavaScript примерно в равных пропорциях. Из анализа содержимого заявлено только распознавание лиц. Есть мобильное приложение, но только под iOS. На вид выглядит как середнячок на современном стэке с простой функциональностью.
◽Piwigo - ещё одна галерея на PHP под LAMP. Старичок из далёкого 2002 года, который развивается до сих пор. Есть темы и плагины, API, развитая система управления пользователями и их правами. За время существования проекта накопилось огромное количество плагинов. Я немного полистал список, чего там только нет. Например, плагин аутентификации пользователей через LDAP каталог.
Как я уже написал, лидером выглядит Photoprism, но лично мне, судя по всему, больше подойдёт Photoview, так как распознавания лиц мне будет достаточно.
#fileserver #подборка
{kind=link}
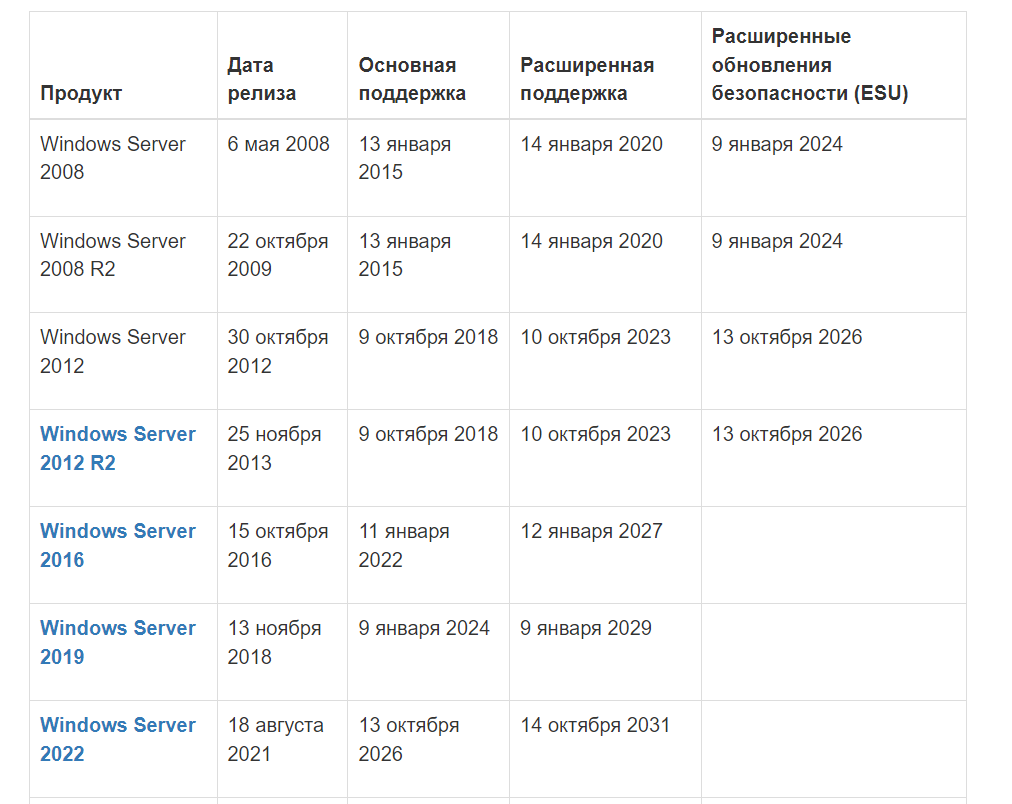
Сижу вчера вечером, готовлю публикации на ближайшее время. И тут в голове непонятно почему проскакивает мысль проверить, когда заканчивается поддержка Windows Server 2012 и 2012 R2. У меня много таких серверов и когда-то давно я видел информацию, что этой осенью поддержка кончится. И вот сложились какие-то переменные вселенной, что мысль сама пришла именно накануне нужной даты. Никаких новостей и заметок по этой теме я не видел в ближайшие месяцы. Можно подумать, что совпадение, но я уверен, что нет. Но подобные "совпадения" не тема моего канала.
Я ещё где-то пару лет назад пробовал обновлять Windows Server 2012 R2 до Windows Server 2016. Процедура там простая. Вставляем установочный диск более старшей версии сервера и при загрузке с него выбираем "Обновление", а не установку. Всё прошло не очень гладко, это был одиночный сервер, но в итоге решил проблемы. А предстоит обновлять рабочие сервера с полезной нагрузкой. И больше всего я переживаю за AD.
Кто-нибудь уже проводил такие обновления? Были ли какие-то проблемы? Особенно интересует AD. Его по идее надо не обновлять, а устанавливать новые сервера, реплицировать каталог и выводить старые из работы. А это мощности надо выделать дополнительные, системы разворачивать.
За всё остальное как-то не очень переживаю, хотя тоже не знаю, что лучше сделать. Установить новые серверы и перенести туда сервисы или всё же рискнуть обновить текущие. Если переносить сервисы, то это очень много работы в неурочное время. Программные лицензии 1С наверное послетают.
У админа такая работа, как миграция, хоть увольняйся 😄 Когда вообще планируете обновляться?
Вот видео по теме:
▶️ Active Directory InPlace Upgrade from Windows Server 2012 R2 to 2016 Step by step
#windows
Я ещё где-то пару лет назад пробовал обновлять Windows Server 2012 R2 до Windows Server 2016. Процедура там простая. Вставляем установочный диск более старшей версии сервера и при загрузке с него выбираем "Обновление", а не установку. Всё прошло не очень гладко, это был одиночный сервер, но в итоге решил проблемы. А предстоит обновлять рабочие сервера с полезной нагрузкой. И больше всего я переживаю за AD.
Кто-нибудь уже проводил такие обновления? Были ли какие-то проблемы? Особенно интересует AD. Его по идее надо не обновлять, а устанавливать новые сервера, реплицировать каталог и выводить старые из работы. А это мощности надо выделать дополнительные, системы разворачивать.
За всё остальное как-то не очень переживаю, хотя тоже не знаю, что лучше сделать. Установить новые серверы и перенести туда сервисы или всё же рискнуть обновить текущие. Если переносить сервисы, то это очень много работы в неурочное время. Программные лицензии 1С наверное послетают.
У админа такая работа, как миграция, хоть увольняйся 😄 Когда вообще планируете обновляться?
Вот видео по теме:
▶️ Active Directory InPlace Upgrade from Windows Server 2012 R2 to 2016 Step by step
#windows
{kind=link}
Делюсь с вами очень классным скриптом для Linux, с помощью которого можно быстро и в удобном виде посмотреть использование оперативной памяти программами (не процессами!). Я изначально нашёл только скрипт на Python и использовал его, а потом понял, что этот же скрипт есть и в стандартных репозиториях некоторых дистрибутивов.
Например в Centos или форках RHEL:
В deb дистрибутивах нет, но можно поставить через pip:
Либо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
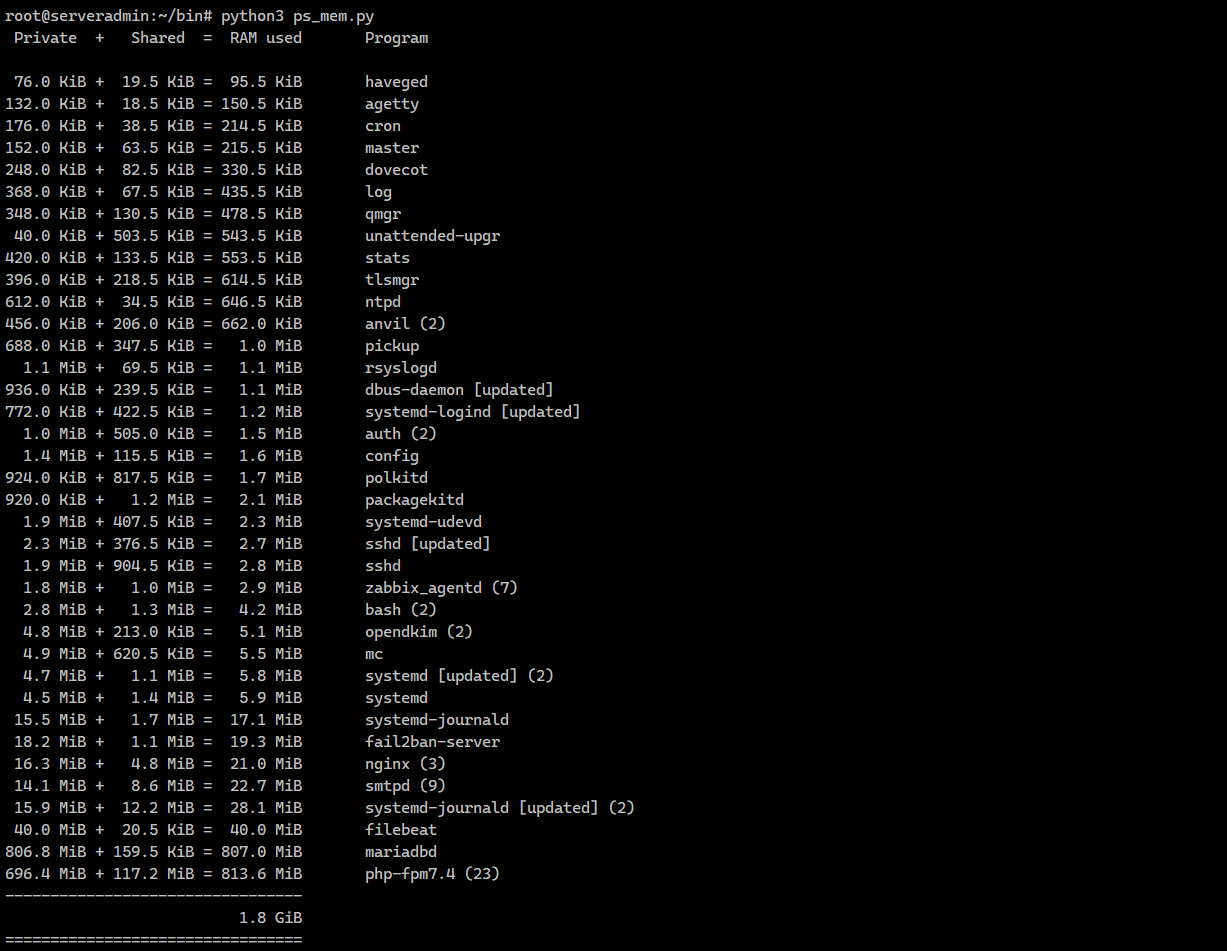
Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
Например в Centos или форках RHEL:
# yum/dnf install ps_memВ deb дистрибутивах нет, но можно поставить через pip:
# pip install ps_memЛибо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
# python3 ps_mem.py Private + Shared = RAM used Program 18.2 MiB + 1.1 MiB = 19.2 MiB fail2ban-server 16.3 MiB + 4.7 MiB = 21.0 MiB nginx (3) 17.5 MiB + 5.5 MiB = 23.0 MiB smtpd (11) 15.5 MiB + 10.3 MiB = 25.8 MiB systemd-journald [updated] (2) 39.2 MiB + 18.5 KiB = 39.2 MiB filebeat806.8 MiB + 145.5 KiB = 806.9 MiB mariadbd709.4 MiB + 120.2 MiB = 829.5 MiB php-fpm7.4 (23)Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
{kind=link}
Тема мониторинга imap сервера Dovecot всегда обходила меня стороной. Я даже и не знал, что там есть встроенный модуль, который умеет отдавать кучу своих метрик. Не видел особой надобности. Я всегда настраивал fail2ban на перебор учёток Dovecot и мониторинг доступности TCP портов службы. В общем случае мне этого достаточно.
На днях читал новость про обновления в очередной новой версии Dovecot и увидел там изменения в модуле статистики. Заинтересовался и решил изучить его. Оказалось, там всё не так просто, как думалось на первый взгляд. Ожидал там увидеть что-то типа того, что есть в статистике Nginx или Php-fpm. А на самом деле в Dovecot очень много всевозможных метрик и их представлений: в линейных, логарифмических, средних, перцинтильных видах. Плюс фильтры, наборы метрик и т.д. Постараюсь кратко саму суть рассказать. А позже, скорее всего, сделаю небольшой шаблон для Zabbix и настрою мониторинг.
Включаем мониторинг и добавляем некоторый набор метрик, который описывает документация, как пример. Добавляем в конфиг Dovecot:
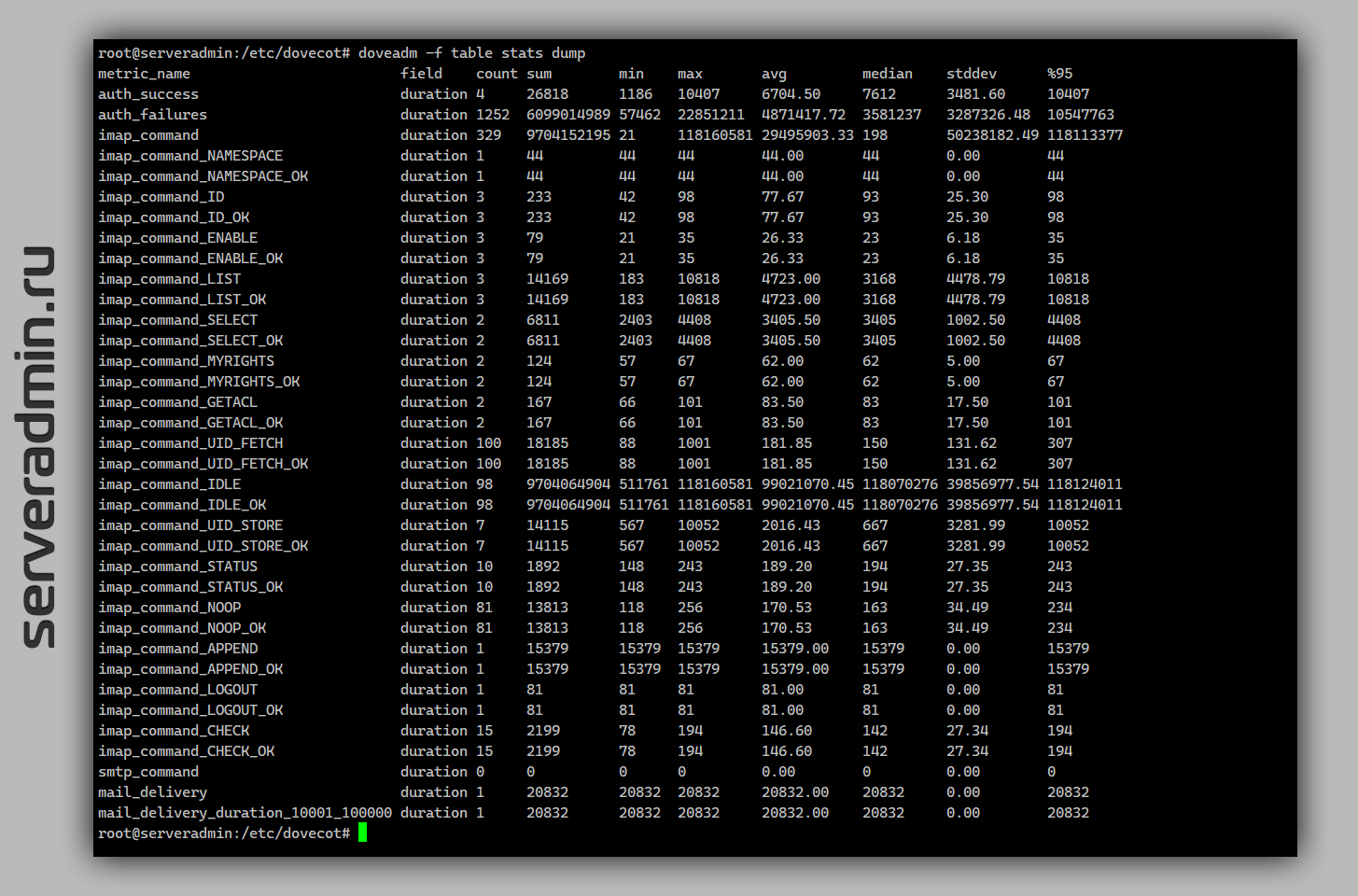
Перезапускаем Dovecot. Метрики можно увидеть по HTTP на порту сервера 9900 (не забудьте настроить ограничение на firewall) или в консоли:
Описание увиденных полей смотрите в документации, в разделе listing-statistic. Все метрики, что не count, выводятся в микросекундах. Я долго не мог понять, что это за огромные числа и зачем они нужны, пока не нашёл описание в документации.
В данном примере мы вывели статистику по успешным и неуспешным аутентификациям, по всем imap и smtp (не понял, что это за smtp метрики, у меня они по нулям) командам, и по успешным доставкам почты в ящики. Полный список событий, которые можно выводить, смотрите в разделе Events. А возможности фильтрации в Event Filtering. В принципе, тут будет вся информация по поводу метрик и их вывода.
Я посмотрел все возможные метрики и прикинул, что реально полезных, за которыми стоит следить, не так много. Перечислю их:
1️⃣ Uptime сервера. Выводится по умолчанию, отдельно настраивать эту метрику не надо. Соответственно, можно делать триггер на перезапуск сервера.
2️⃣ Количество успешных и неудачных аутентификаций. Причём интересны не абсолютные значения, а изменение в минуту. Сделать триггер на превышение среднего значения, например, в 1,5-2 раза. Если у вас резко выросли аутентификации, то, возможно, кто-то наплодил ящиков и заходит в них. А если много неудачных попыток, то, возможно, fail2ban сломался и начался подбор паролей.
3️⃣ Число успешных доставок почты. Если резво выросло число доставленных писем на каком-то большой интервале, то это повод обратить внимание. Интервал надо брать побольше, чем минута, иначе на какие-то легитимные рассылки будет реакция. Взять, думаю, надо интервал 30-60 минут и сравнивать изменения на нём. Можно и накопительную метрику сделать за сутки, чтобы быстро оценить количество входящей почты.
Вот, в принципе, и всё. Остальные метрики это уже тонкая настройка отдельных служб или слежение за производительностью. Dovecot умеет считать выполнение в микросекундах каждой своей команды и выводить min, max, avg, median, персинтили. Можно очень гибко следить за производительностью в разрезе отдельной imap команды, если для вас это важно.
#dovecot #mailserver #мониторинг
На днях читал новость про обновления в очередной новой версии Dovecot и увидел там изменения в модуле статистики. Заинтересовался и решил изучить его. Оказалось, там всё не так просто, как думалось на первый взгляд. Ожидал там увидеть что-то типа того, что есть в статистике Nginx или Php-fpm. А на самом деле в Dovecot очень много всевозможных метрик и их представлений: в линейных, логарифмических, средних, перцинтильных видах. Плюс фильтры, наборы метрик и т.д. Постараюсь кратко саму суть рассказать. А позже, скорее всего, сделаю небольшой шаблон для Zabbix и настрою мониторинг.
Включаем мониторинг и добавляем некоторый набор метрик, который описывает документация, как пример. Добавляем в конфиг Dovecot:
service stats { inet_listener http { port = 9900 }}metric auth_success { filter = event=auth_request_finished AND success=yes}metric auth_failures { filter = event=auth_request_finished AND NOT success=yes}metric imap_command { filter = event=imap_command_finished group_by = cmd_name tagged_reply_state}metric smtp_command { filter = event=smtp_server_command_finished group_by = cmd_name status_code duration:exponential:1:5:10}metric mail_delivery { filter = event=mail_delivery_finished group_by = duration:exponential:1:5:10}Перезапускаем Dovecot. Метрики можно увидеть по HTTP на порту сервера 9900 (не забудьте настроить ограничение на firewall) или в консоли:
# doveadm -f table stats dumpОписание увиденных полей смотрите в документации, в разделе listing-statistic. Все метрики, что не count, выводятся в микросекундах. Я долго не мог понять, что это за огромные числа и зачем они нужны, пока не нашёл описание в документации.
В данном примере мы вывели статистику по успешным и неуспешным аутентификациям, по всем imap и smtp (не понял, что это за smtp метрики, у меня они по нулям) командам, и по успешным доставкам почты в ящики. Полный список событий, которые можно выводить, смотрите в разделе Events. А возможности фильтрации в Event Filtering. В принципе, тут будет вся информация по поводу метрик и их вывода.
Я посмотрел все возможные метрики и прикинул, что реально полезных, за которыми стоит следить, не так много. Перечислю их:
1️⃣ Uptime сервера. Выводится по умолчанию, отдельно настраивать эту метрику не надо. Соответственно, можно делать триггер на перезапуск сервера.
2️⃣ Количество успешных и неудачных аутентификаций. Причём интересны не абсолютные значения, а изменение в минуту. Сделать триггер на превышение среднего значения, например, в 1,5-2 раза. Если у вас резко выросли аутентификации, то, возможно, кто-то наплодил ящиков и заходит в них. А если много неудачных попыток, то, возможно, fail2ban сломался и начался подбор паролей.
3️⃣ Число успешных доставок почты. Если резво выросло число доставленных писем на каком-то большой интервале, то это повод обратить внимание. Интервал надо брать побольше, чем минута, иначе на какие-то легитимные рассылки будет реакция. Взять, думаю, надо интервал 30-60 минут и сравнивать изменения на нём. Можно и накопительную метрику сделать за сутки, чтобы быстро оценить количество входящей почты.
Вот, в принципе, и всё. Остальные метрики это уже тонкая настройка отдельных служб или слежение за производительностью. Dovecot умеет считать выполнение в микросекундах каждой своей команды и выводить min, max, avg, median, персинтили. Можно очень гибко следить за производительностью в разрезе отдельной imap команды, если для вас это важно.
#dovecot #mailserver #мониторинг
{kind=link}
На днях проходил очередной масштабный Zabbix Summit 2023 на английском языке. Сейчас уже выложили полную информацию по нему, в том числе видеозаписи и презентации докладов. Всё это на отдельной странице:
⇨ https://www.zabbix.com/ru/events/zabbix_summit_2023
Было много всяких событий, даже не знаю, о чём конкретно рассказать. В принципе, вы можете сами по программе мероприятия посмотреть то, что вам больше всего интересно и перейти на запись выступления или посмотреть презентацию.
Приведу некоторые интересные факты из выступления основателя компании Алексея Владышева:
🔹Компания Zabbix непрерывно растёт. Сейчас это 150 сотрудников в компании и 250 партнёрских компаний по всему миру.
🔹Zabbix старается покрывать все уровни инфраструктуры от железа до бизнес метрик.
🔹Zabbix следует современным требованиям к безопасности: интеграция с hashicorp vault, 2FA, SSO, Токены к API, работа агентов без прав root и т.д.
🔹Анонсировал изменение в 7-й версии, про которое я не слышал ранее. Раньше было одно соединение на один poller, теперь pollers будут поддерживать множественные соединения, буквально тысячи на каждый poller. Также рассказал про другие нововведения:
◽Хранение метрик для увеличения быстродействия в памяти zabbix-proxy, а не в только в базе, как сейчас.
◽Новые айтемы будут сразу же забирать метрики после создания, в течении минуты, а не через настроенные в них интервалы. Если интервал был час, то час и нужно было ждать до первого обновления, если не сделать его принудительно.
🔹В выступлении Алексей упомянул, что сейчас Zabbix не поддерживает OpenTelemetry, Tracing, полноценный сбор логов. В конце этого блока он сказал, что они будут это исправлять. Было бы неплохо, но хз когда всё это появится.
В целом, мне кажется, что Zabbix как-то забуксовал в развитии. Сейчас в продуктах упор идёт на простоту и скорость настройки. Берём Prometheus, ставим на хост Exporter, забираем все метрики, идём в Grafana, берём готовый дашборд, коих масса под все популярные продукты. И в течении 10 минут у нас всё готово. С Zabbix так не получится. Коллекции публичных дашбордов вообще нет. Мне прям грустно становится, когда настраиваешь какой-то мониторинг и приходится самому вручную собирать дашборд. Это небыстрое занятие.
Графики с виджетами как-то коряво и разномастно смотрятся, даже новые. Нет единства стиля. В дашбордах одни графики через виджеты, в панелях и просто графиках другие. Надо всё это как-то к единообразию привести и дать возможность импорта и экспорта всех этих сущностей, а не только полных шаблонов. Шаблоны это больше про метрики, а визуализации могут быть совсем разные в зависимости от задач. Надо их разделить и создать на сайте раздел с дашбордами, как это есть у Grafana.
Что ещё было интересно из саммита:
🟢 Internal Changes and Improvements in Zabbix 7.0 - Внутренние изменения в работе Zabbix, которые будут в 7-й версии.
🟢 Monitoring Kubernetes Cluster with an External Zabbix Server - Про то, как заббиксом мониторят Kubernetes.
🟢 Logs Go LLD - тут знатные костыли автообнаружения на bash и regex, приправленное перлом.
🟢 Tips and Tricks on using useful features of Zabbix in large scale environments - много интересных примеров и конкретики при построении мониторинга в большой распределённой инфраструктуре.
🟢 Implementing TimescaleDB on large Zabbix without downtime - миграция очень большой базы Zabbix с обычного формата на TimescaleDB без остановки на обслуживание и перенос, и без потери метрик.
#zabbix
⇨ https://www.zabbix.com/ru/events/zabbix_summit_2023
Было много всяких событий, даже не знаю, о чём конкретно рассказать. В принципе, вы можете сами по программе мероприятия посмотреть то, что вам больше всего интересно и перейти на запись выступления или посмотреть презентацию.
Приведу некоторые интересные факты из выступления основателя компании Алексея Владышева:
🔹Компания Zabbix непрерывно растёт. Сейчас это 150 сотрудников в компании и 250 партнёрских компаний по всему миру.
🔹Zabbix старается покрывать все уровни инфраструктуры от железа до бизнес метрик.
🔹Zabbix следует современным требованиям к безопасности: интеграция с hashicorp vault, 2FA, SSO, Токены к API, работа агентов без прав root и т.д.
🔹Анонсировал изменение в 7-й версии, про которое я не слышал ранее. Раньше было одно соединение на один poller, теперь pollers будут поддерживать множественные соединения, буквально тысячи на каждый poller. Также рассказал про другие нововведения:
◽Хранение метрик для увеличения быстродействия в памяти zabbix-proxy, а не в только в базе, как сейчас.
◽Новые айтемы будут сразу же забирать метрики после создания, в течении минуты, а не через настроенные в них интервалы. Если интервал был час, то час и нужно было ждать до первого обновления, если не сделать его принудительно.
🔹В выступлении Алексей упомянул, что сейчас Zabbix не поддерживает OpenTelemetry, Tracing, полноценный сбор логов. В конце этого блока он сказал, что они будут это исправлять. Было бы неплохо, но хз когда всё это появится.
В целом, мне кажется, что Zabbix как-то забуксовал в развитии. Сейчас в продуктах упор идёт на простоту и скорость настройки. Берём Prometheus, ставим на хост Exporter, забираем все метрики, идём в Grafana, берём готовый дашборд, коих масса под все популярные продукты. И в течении 10 минут у нас всё готово. С Zabbix так не получится. Коллекции публичных дашбордов вообще нет. Мне прям грустно становится, когда настраиваешь какой-то мониторинг и приходится самому вручную собирать дашборд. Это небыстрое занятие.
Графики с виджетами как-то коряво и разномастно смотрятся, даже новые. Нет единства стиля. В дашбордах одни графики через виджеты, в панелях и просто графиках другие. Надо всё это как-то к единообразию привести и дать возможность импорта и экспорта всех этих сущностей, а не только полных шаблонов. Шаблоны это больше про метрики, а визуализации могут быть совсем разные в зависимости от задач. Надо их разделить и создать на сайте раздел с дашбордами, как это есть у Grafana.
Что ещё было интересно из саммита:
🟢 Internal Changes and Improvements in Zabbix 7.0 - Внутренние изменения в работе Zabbix, которые будут в 7-й версии.
🟢 Monitoring Kubernetes Cluster with an External Zabbix Server - Про то, как заббиксом мониторят Kubernetes.
🟢 Logs Go LLD - тут знатные костыли автообнаружения на bash и regex, приправленное перлом.
🟢 Tips and Tricks on using useful features of Zabbix in large scale environments - много интересных примеров и конкретики при построении мониторинга в большой распределённой инфраструктуре.
🟢 Implementing TimescaleDB on large Zabbix without downtime - миграция очень большой базы Zabbix с обычного формата на TimescaleDB без остановки на обслуживание и перенос, и без потери метрик.
#zabbix
{kind=link}
Как вы думаете, почему за столько лет пакетный менеджер для Debian и Ubuntu, тот, который сначала был apt-get, а сейчас просто apt, не стал удобным? Чтобы понять о чём идёт речь, посмотрите внизу картинку сравнения работы apt и dnf.
Когда появился apt, я подумал, что теперь и в Debian будет так же удобно и красиво, как в Centos. Ведь что сложного в том, чтобы отформатировать информацию о выводимых пакетах? Но увы, apt как был неудобен, так и остался.
Если нужно обновить старую систему или установить что-то объёмное, apt вываливает длиннющую трудночитаемую лапшу названий пакетов, в которой трудно разглядеть полезную информацию. И в противовес этому yum/dnf, которые выводят список в алфавитном порядке, каждый пакет в отдельной строке, видно версию, размер пакета, репозиторий, откуда он будет установлен. Всё четко и понятно.
В apt можно добавить ключ -V и будет немного лучше:
Но об этом мало кто знает и использует. Я и сам узнал только тогда, когда написал похожий пост тут на канале. На днях просто работал с dnf и опять вспомнил про эту тему. Уже когда сел писать заметку понял, что я её уже писал когда-то. Этот ключ стоило бы по умолчанию добавлять в стандартный вывод. С ним ведь всяко удобнее.
Ну а если хочется так же красиво и удобно, как в dnf, можно поставить Nala. К сожалению, она живёт только в Testing/Sid, в основные репы почему-то не переводят. Можно поставить из репы разработчика:
И будет красота, как в dnf, даже чуть лучше.
#debian
Когда появился apt, я подумал, что теперь и в Debian будет так же удобно и красиво, как в Centos. Ведь что сложного в том, чтобы отформатировать информацию о выводимых пакетах? Но увы, apt как был неудобен, так и остался.
Если нужно обновить старую систему или установить что-то объёмное, apt вываливает длиннющую трудночитаемую лапшу названий пакетов, в которой трудно разглядеть полезную информацию. И в противовес этому yum/dnf, которые выводят список в алфавитном порядке, каждый пакет в отдельной строке, видно версию, размер пакета, репозиторий, откуда он будет установлен. Всё четко и понятно.
В apt можно добавить ключ -V и будет немного лучше:
# apt -V upgradeНо об этом мало кто знает и использует. Я и сам узнал только тогда, когда написал похожий пост тут на канале. На днях просто работал с dnf и опять вспомнил про эту тему. Уже когда сел писать заметку понял, что я её уже писал когда-то. Этот ключ стоило бы по умолчанию добавлять в стандартный вывод. С ним ведь всяко удобнее.
Ну а если хочется так же красиво и удобно, как в dnf, можно поставить Nala. К сожалению, она живёт только в Testing/Sid, в основные репы почему-то не переводят. Можно поставить из репы разработчика:
# echo "deb https://deb.volian.org/volian/ scar main" \| sudo tee -a /etc/apt/sources.list.d/volian-archive-scar-unstable.list# wget -qO - https://deb.volian.org/volian/scar.key | apt-key add -# apt update && apt install nalaИ будет красота, как в dnf, даже чуть лучше.
#debian
{kind=link}
Некоторое время назад у меня к статье про обновление Debian с 11 на 12 появился комментарий, на тему того, что зачем такие статьи. Debian и так автоматически обновляется с выходом нового релиза. Я как-то особо не обратил внимание, потому что знаю, что система сама собой на новый релиз не обновится, если не предпринять явных действий для этого.
А на днях другой человек предположил, что скорее всего в репозиториях у автора коммента был указан релиз в виде stable, а не конкретной версии bullseye или bookworm. И тогда стало понятно, почему у кого-то система может обновиться автоматически. Я поясню этот момент, потому что он важный и неочевидный. Поначалу, когда начинал работать с Debian, тоже не понимал этот момент.
В Debian для именования выпусков используются как псевдонимы в виде имён персонажей мультфильма «История игрушек»: Wheezy, Jessie, Stretch, Buster, Bullseye, Bookworm, так и классы релизов: Stable, Oldstable, Testing, Unstable, Experimental, Backports.
🔹Stable - стабильная ветка официального текущего релиза Debian. То есть это самая свежая и актуальная версия, которую рекомендуется использовать.
🔹Oldstable - кодовое имя предыдущего stable выпуска.
🔹Testing - содержит в себе текущее состояние разработки нового стабильного релиза. После его выхода, testing становится stable. Пакеты в testing попадают из репы unstable.
🔹Unstable (sid) - репозиторий с самым свежим программных обеспечением. Оно еще не протестировано достаточным образом для использования. Если вы точно уверены, что вам нужен новый софт, и он не сломает вам систему, можете поставить его из unstable репозитория. Но в общем случае, делать это не рекомендуется. Даже если софт из unstable не повредит работе системы, он может нарушить зависимости пакетов, так что потом может быть затруднительно вернуться на stable ветку.
Исходя из этой информации, если у вас по какой-то причине описание репозитория в
То система будет автоматически обновляться до нового стабильного релиза в соответствии с правилами формирования ветки Stable. Выполнив после обновления релиза:
Вы получите новый стабильный выпуск. Или не получите, если что-то пойдёт не так.
В общем случае менять имя конкретного релиза на какую-то ветку типа Stable не рекомендуется. Обновление релиза потенциально опасная процедура и лучше её делать планового, а не когда это случится из-за выхода новой версии.
При установке системы из стандартных iso образов Debian, релиз всегда прописан конкретным кодовым именем дистрибутива, а не веткой. Так что автоматически Debian не обновится без вашего участия, если вы сами не выполните соответствующие настройки.
Подробно о репозиториях в Debian можно почитать в моей обзорной статье.
#debian
А на днях другой человек предположил, что скорее всего в репозиториях у автора коммента был указан релиз в виде stable, а не конкретной версии bullseye или bookworm. И тогда стало понятно, почему у кого-то система может обновиться автоматически. Я поясню этот момент, потому что он важный и неочевидный. Поначалу, когда начинал работать с Debian, тоже не понимал этот момент.
В Debian для именования выпусков используются как псевдонимы в виде имён персонажей мультфильма «История игрушек»: Wheezy, Jessie, Stretch, Buster, Bullseye, Bookworm, так и классы релизов: Stable, Oldstable, Testing, Unstable, Experimental, Backports.
🔹Stable - стабильная ветка официального текущего релиза Debian. То есть это самая свежая и актуальная версия, которую рекомендуется использовать.
🔹Oldstable - кодовое имя предыдущего stable выпуска.
🔹Testing - содержит в себе текущее состояние разработки нового стабильного релиза. После его выхода, testing становится stable. Пакеты в testing попадают из репы unstable.
🔹Unstable (sid) - репозиторий с самым свежим программных обеспечением. Оно еще не протестировано достаточным образом для использования. Если вы точно уверены, что вам нужен новый софт, и он не сломает вам систему, можете поставить его из unstable репозитория. Но в общем случае, делать это не рекомендуется. Даже если софт из unstable не повредит работе системы, он может нарушить зависимости пакетов, так что потом может быть затруднительно вернуться на stable ветку.
Исходя из этой информации, если у вас по какой-то причине описание репозитория в
sources.list будет в таком виде:deb http://ftp.debian.org/debian stable main contribТо система будет автоматически обновляться до нового стабильного релиза в соответствии с правилами формирования ветки Stable. Выполнив после обновления релиза:
# apt update && apt dist-upgradeВы получите новый стабильный выпуск. Или не получите, если что-то пойдёт не так.
В общем случае менять имя конкретного релиза на какую-то ветку типа Stable не рекомендуется. Обновление релиза потенциально опасная процедура и лучше её делать планового, а не когда это случится из-за выхода новой версии.
При установке системы из стандартных iso образов Debian, релиз всегда прописан конкретным кодовым именем дистрибутива, а не веткой. Так что автоматически Debian не обновится без вашего участия, если вы сами не выполните соответствующие настройки.
Подробно о репозиториях в Debian можно почитать в моей обзорной статье.
#debian
Server Admin
Настройка репозиториев в Debian | serveradmin.ru
Подробное описание настройки, подключения, обновления и удаления репозиториев в Debian. Все настройки показаны на конкретных примерах.
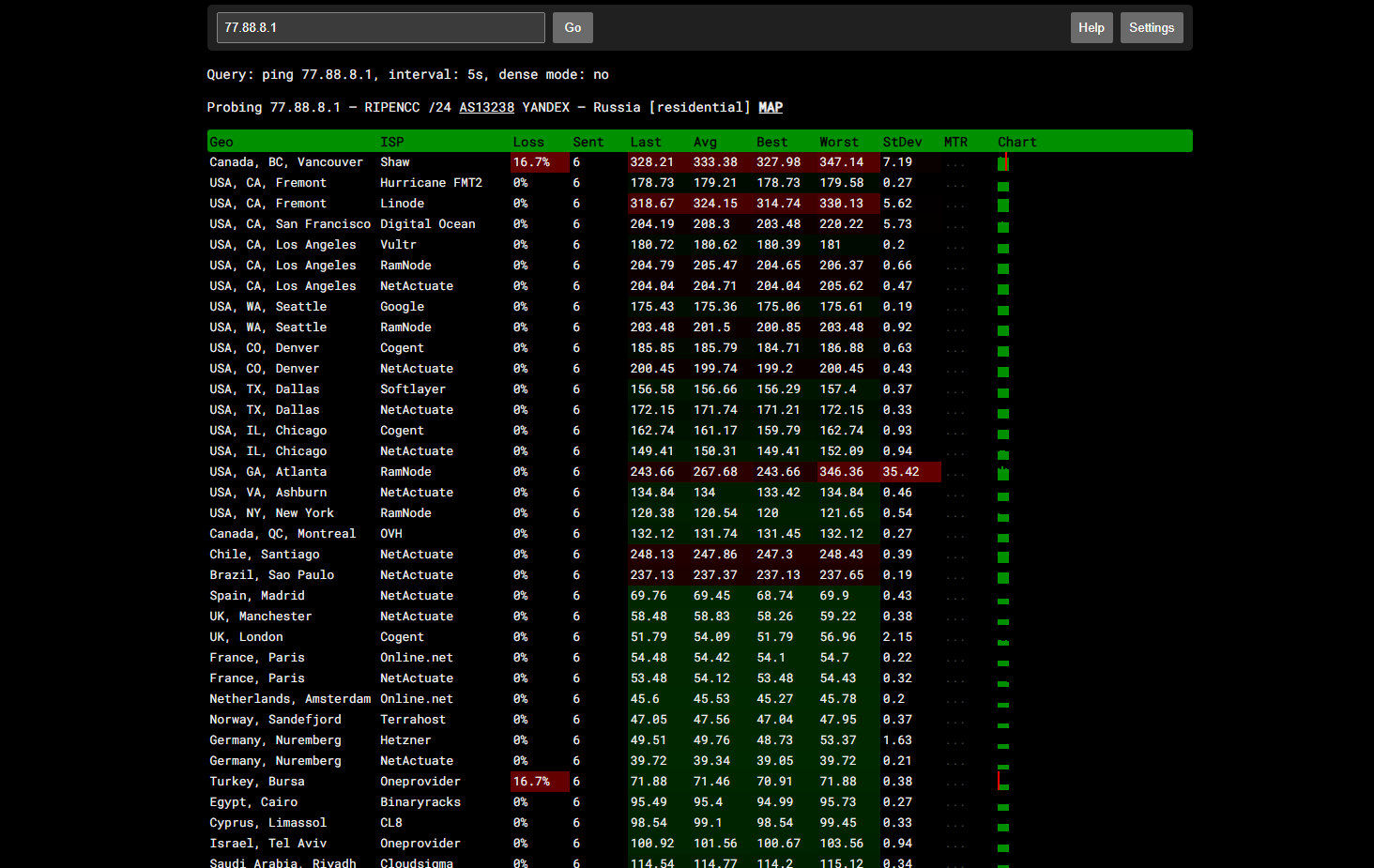
Рекомендую вам полезный сервис-пинговалку в режиме реального времени ping.pe. Он удобен тем, что имеет по несколько точек в разных концах планеты.
Простой пример того, как он может быть полезен. У меня есть пару сайтов, закрытых бесплатным тарифом cloudflare. Этот сервис работает как и раньше без всяких ограничений. У него был датацентр в Москве, но, судя по всему, больше не работает. Узнать, какой именно датацентр отдаёт контент сайта, нельзя, либо я не знаю, как это сделать.
Cloudflare использует пул IP адресов, которые определяются как американские, но на самом деле запрос к этому адресу переадресуется ближайшему серверу из его сети. Если не ошибаюсь, то используется технология маршрутизации anycast, как в тех же публичных dns серверах 1.1.1.1 или 8.8.8.8.
Я пингую один из своих сайтов и вижу, что отклик в районе 40-50 мс, что соответствует ответу примерно из центральной или западной Европы. Судя по всему, отвечает один из датацентров оттуда. Хотя на сайте cloudflarestatus статус московского датацентра Operational, но занят он видимо чем-то другим.
Я потестировал эту пинговалку с серверами, которые у меня есть за рубежом, чтобы сопоставить результаты. По времени отклика примерно можно понять, где сервер. Например, пингую через сервис сервер в Москве и вижу отклик из New York в районе 110 мс. Пингую от себя свой же арендованный сервер на западном побережье США, получаю те же 110 мс. То есть данные плюс-минус верные.
Если нет каких-то глобальных сетевых проблем, то с помощью этой пинговалки можно примерно понимать, где находится удалённый сервер, с которого приходит ответ. Да и просто удобно проверить кого-то с точек по всему миру и оценить результат. Сервис умеет не только пинговать, но и выполнять кучу других действий. Запросы можно прямо в поле ввода писать:
Проверка доступа порта особенно удобна, если используете GEO фильтры. Можно быстро проверить, из каких стран есть доступ, а где закрыт.
#сервис
Простой пример того, как он может быть полезен. У меня есть пару сайтов, закрытых бесплатным тарифом cloudflare. Этот сервис работает как и раньше без всяких ограничений. У него был датацентр в Москве, но, судя по всему, больше не работает. Узнать, какой именно датацентр отдаёт контент сайта, нельзя, либо я не знаю, как это сделать.
Cloudflare использует пул IP адресов, которые определяются как американские, но на самом деле запрос к этому адресу переадресуется ближайшему серверу из его сети. Если не ошибаюсь, то используется технология маршрутизации anycast, как в тех же публичных dns серверах 1.1.1.1 или 8.8.8.8.
Я пингую один из своих сайтов и вижу, что отклик в районе 40-50 мс, что соответствует ответу примерно из центральной или западной Европы. Судя по всему, отвечает один из датацентров оттуда. Хотя на сайте cloudflarestatus статус московского датацентра Operational, но занят он видимо чем-то другим.
Я потестировал эту пинговалку с серверами, которые у меня есть за рубежом, чтобы сопоставить результаты. По времени отклика примерно можно понять, где сервер. Например, пингую через сервис сервер в Москве и вижу отклик из New York в районе 110 мс. Пингую от себя свой же арендованный сервер на западном побережье США, получаю те же 110 мс. То есть данные плюс-минус верные.
Если нет каких-то глобальных сетевых проблем, то с помощью этой пинговалки можно примерно понимать, где находится удалённый сервер, с которого приходит ответ. Да и просто удобно проверить кого-то с точек по всему миру и оценить результат. Сервис умеет не только пинговать, но и выполнять кучу других действий. Запросы можно прямо в поле ввода писать:
mtr IP, chart IP, tcp IP:PORT, dig HOST:TYPE:NAMESERVER.Проверка доступа порта особенно удобна, если используете GEO фильтры. Можно быстро проверить, из каких стран есть доступ, а где закрыт.
#сервис
{kind=link}
Бэкап Шрёдингера
☝ Состояние любого бэкапа остаётся неизвестным до того, как его попробуют восстановить.
Услышал прикольную шутку. Даже любопытно стало почитать подробности оригинального мысленного эксперимента Шрёдингера с котом. Проникся. Для бэкапов этот эксперимент очень актуален. Бэкапы реально находятся в состоянии Шрёдингера до тех пор, пока не попытаешься выполнить восстановление. До этого они существуют и не существуют одновременно, так как если восстановить данные не получится, то это и не бэкап был.
Провели мысленный эксперимент со своими бэкапами?
#мем
☝ Состояние любого бэкапа остаётся неизвестным до того, как его попробуют восстановить.
Услышал прикольную шутку. Даже любопытно стало почитать подробности оригинального мысленного эксперимента Шрёдингера с котом. Проникся. Для бэкапов этот эксперимент очень актуален. Бэкапы реально находятся в состоянии Шрёдингера до тех пор, пока не попытаешься выполнить восстановление. До этого они существуют и не существуют одновременно, так как если восстановить данные не получится, то это и не бэкап был.
Провели мысленный эксперимент со своими бэкапами?
#мем
{kind=link}
Для тех, кто не знает, расскажу, что у меня на сайте есть статьи, где в одном месте собраны заметки по различным темам: бэкапы, мониторинг и т.д. Я наконец-то сделал отдельный раздел для них. А также полностью актуализировал, добавив свежие заметки за последний год.
▪ Топ бесплатных программ для бэкапа
▪ Топ бесплатных систем мониторинга
▪ Топ бесплатных HelpDesk систем
▪ Топ программ для инвентаризации оборудования
▪ Топ бесплатных программ для удалённого доступа
▪ Хостеры, личная рекомендация
Когда изначально делал подборки, не учёл, что буду их обновлять, поэтому цифры в названиях топа неактуальны. Программ стало значительно больше.
Подобные списки удобны, если первый раз подбираете продукт. Можно быстро оценить основные различия, посмотреть скриншоты программ. Плюс, к каждому описанию есть ссылка на заметку в канале с обсуждением, где много содержательных комментариев по теме.
#подборка
▪ Топ бесплатных программ для бэкапа
▪ Топ бесплатных систем мониторинга
▪ Топ бесплатных HelpDesk систем
▪ Топ программ для инвентаризации оборудования
▪ Топ бесплатных программ для удалённого доступа
▪ Хостеры, личная рекомендация
Когда изначально делал подборки, не учёл, что буду их обновлять, поэтому цифры в названиях топа неактуальны. Программ стало значительно больше.
Подобные списки удобны, если первый раз подбираете продукт. Можно быстро оценить основные различия, посмотреть скриншоты программ. Плюс, к каждому описанию есть ссылка на заметку в канале с обсуждением, где много содержательных комментариев по теме.
#подборка
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
Расскажу про известный сервис Cloudflare, который несмотря на все санкции, Россию не покинул, а продолжает оказывать услуги. Не знаю, что там с платными тарифами, и каким образом можно произвести оплату. Я использую бесплатный тариф, который у него не меняется уже много лет. Как-то серьезно привязываться к этому сервису не рекомендую в силу очевидных рисков, так как это американская компания. Но где-то по мелочи можно закрыть некоторые потребности, так как сервис удобный.
Я не буду его подробно описывать, так как специально не разбирался в его возможностях. Расскажу, как и для чего я его использую сам в одном из проектов.
С помощью бесплатного тарифа Cloudflare можно использовать:
1️⃣ Бесплатные DNS сервера. Вы можете перенести управление своими доменами на DNS серверы Cloudflare.
2️⃣ DDOS защиту. Я не знаю, до какого масштаба ддоса можно пользоваться бесплатным тарифом, но от всех видов атак, с которыми сталкивался я, Cloudflare помогал. Но это были местечковые сайты, которые возможно случайно или без особого умысла ддосили.
3️⃣ Бесплатные TLS сертификаты. Включая ddos защиту для сайта, вы автоматически получаете TLS сертификаты, которые вообще не надо настраивать. Cloudflare всё делает сам.
4️⃣ Web Application Firewall (WAF). Бесплатный тарифный план также включает в себя некоторые возможности WAF.
В итоге получается вот что. У меня есть несколько старых сайтов, которые давно никто не обновляет и не обслуживает. Они располагаются на веб сервере организации, где на тех же IP адресах живут другие сервисы. Всё это не хочется светить в интернете.
Я для них подключил DDOS защиту, скрыл их реальные IP адреса. С помощью бесплатного тарифного плана можно скрыть связность сайтов, живущих на одном и том же сервере, так как Cloudflare скрывает реальные IP адреса, на которых хостятся сайты. На веб сервере запросы на 80-й порт разрешены только с серверов Cloudflare. Весь входящий трафик приходит на Cloudflare, где активны бесплатные TLS сертификаты. Настраивать их и как-то следить за актуальностью не надо. Сервис всё это делает сам.
Плюс Cloudflare защищает с помощью WAF от многих типовых и массовых атак, которые могут осуществляться по известным уязвимостям. На выходе я имею старый веб сервер со старыми сайтами на древней версии php. Веб сервер полностью скрыт от интернета, трафик к нему фильтруется и приходит чистым от ddos и многих уязвимостей. Для надёжности на входящей стороне у меня стоит сначала Nginx свежих версий, который регулярно обновляется, а потом уже старый веб сервер, который обновить нельзя из-за древних версий php.
В сумме получается удобно. Тут тебе и DNS, и TLS, и Antiddos, и всё в одном месте, и настраивать не надо. Достаточно через настройки DNS направить весь трафик в CF, а всё остальное сделать через веб интерфейс.
❗️Почти на 100% уверен, что Cloudflare шпионит за сайтами, пользователями и собирает биг дату, иначе зачем ему устраивать аттракцион такой щедрости. Так что имейте это ввиду и принимайте решение об использовании с учётом этого нюанса.
#сервис #бесплатно
Я не буду его подробно описывать, так как специально не разбирался в его возможностях. Расскажу, как и для чего я его использую сам в одном из проектов.
С помощью бесплатного тарифа Cloudflare можно использовать:
1️⃣ Бесплатные DNS сервера. Вы можете перенести управление своими доменами на DNS серверы Cloudflare.
2️⃣ DDOS защиту. Я не знаю, до какого масштаба ддоса можно пользоваться бесплатным тарифом, но от всех видов атак, с которыми сталкивался я, Cloudflare помогал. Но это были местечковые сайты, которые возможно случайно или без особого умысла ддосили.
3️⃣ Бесплатные TLS сертификаты. Включая ddos защиту для сайта, вы автоматически получаете TLS сертификаты, которые вообще не надо настраивать. Cloudflare всё делает сам.
4️⃣ Web Application Firewall (WAF). Бесплатный тарифный план также включает в себя некоторые возможности WAF.
В итоге получается вот что. У меня есть несколько старых сайтов, которые давно никто не обновляет и не обслуживает. Они располагаются на веб сервере организации, где на тех же IP адресах живут другие сервисы. Всё это не хочется светить в интернете.
Я для них подключил DDOS защиту, скрыл их реальные IP адреса. С помощью бесплатного тарифного плана можно скрыть связность сайтов, живущих на одном и том же сервере, так как Cloudflare скрывает реальные IP адреса, на которых хостятся сайты. На веб сервере запросы на 80-й порт разрешены только с серверов Cloudflare. Весь входящий трафик приходит на Cloudflare, где активны бесплатные TLS сертификаты. Настраивать их и как-то следить за актуальностью не надо. Сервис всё это делает сам.
Плюс Cloudflare защищает с помощью WAF от многих типовых и массовых атак, которые могут осуществляться по известным уязвимостям. На выходе я имею старый веб сервер со старыми сайтами на древней версии php. Веб сервер полностью скрыт от интернета, трафик к нему фильтруется и приходит чистым от ddos и многих уязвимостей. Для надёжности на входящей стороне у меня стоит сначала Nginx свежих версий, который регулярно обновляется, а потом уже старый веб сервер, который обновить нельзя из-за древних версий php.
В сумме получается удобно. Тут тебе и DNS, и TLS, и Antiddos, и всё в одном месте, и настраивать не надо. Достаточно через настройки DNS направить весь трафик в CF, а всё остальное сделать через веб интерфейс.
❗️Почти на 100% уверен, что Cloudflare шпионит за сайтами, пользователями и собирает биг дату, иначе зачем ему устраивать аттракцион такой щедрости. Так что имейте это ввиду и принимайте решение об использовании с учётом этого нюанса.
#сервис #бесплатно
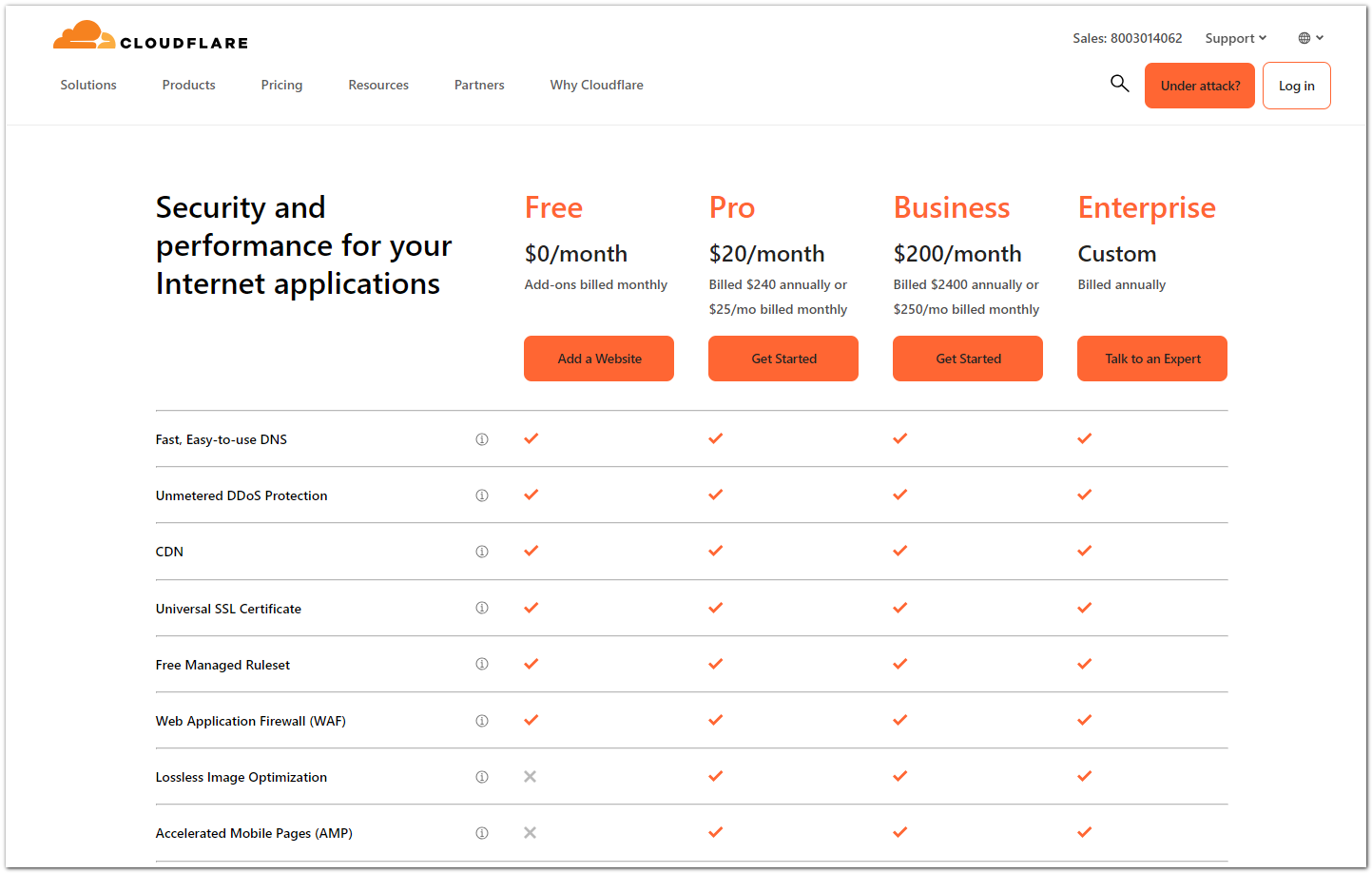{kind=link}