
🎓 На днях на хабре был анонс на вид очень неплохого учебника для тестировщика под названием "The 100-Year QA-Textbook". Он собрал много просмотров, так что возможно многие из вас про него уже знают. К тому же предварительный релиз этого обучающего материала был давно, а сейчас вышло очередное обновление.
Вот информация о курсе от создателей:
⇨ Зачем появился бесплатный интерактивный «100-Year QA-textbook» на 700+ страниц для обучающихся тестированию
⇨ Полный релиз бесплатного интерактивного 700-страничного учебника по тестированию
На вид материал выглядит качественным. Несмотря на то, что он анонсирован для тестировщиков, 2/3 курса это база, которая подойдёт для любой специальности в IT. Судя по содержанию это так и есть, потому что там разбирают:
◽СУБД и SQL запросы
◽База по ОС Linux (файловые системы, пользователи, процессы и т.д.)
◽Работа с сетью
◽Архитектура серверного ПО
◽Rest API, HTTP
◽Docker, GIT
К сожалению, не смог посмотреть раздел по Linux, потому что курс даёт возможность проходить материал последовательно. Пока не пройдёшь тест за предыдущий раздел, к следующему доступа нет.
Как я понял, курс сделан на базе онлайн школы тестировщиков. У меня есть любопытная история на этот счёт и общее мнение насчёт тестировщиков. Но чтобы не смешивать тематику, это будет вечером в отдельной публикации.
#обучение #бесплатно
Вот информация о курсе от создателей:
⇨ Зачем появился бесплатный интерактивный «100-Year QA-textbook» на 700+ страниц для обучающихся тестированию
⇨ Полный релиз бесплатного интерактивного 700-страничного учебника по тестированию
На вид материал выглядит качественным. Несмотря на то, что он анонсирован для тестировщиков, 2/3 курса это база, которая подойдёт для любой специальности в IT. Судя по содержанию это так и есть, потому что там разбирают:
◽СУБД и SQL запросы
◽База по ОС Linux (файловые системы, пользователи, процессы и т.д.)
◽Работа с сетью
◽Архитектура серверного ПО
◽Rest API, HTTP
◽Docker, GIT
К сожалению, не смог посмотреть раздел по Linux, потому что курс даёт возможность проходить материал последовательно. Пока не пройдёшь тест за предыдущий раздел, к следующему доступа нет.
Как я понял, курс сделан на базе онлайн школы тестировщиков. У меня есть любопытная история на этот счёт и общее мнение насчёт тестировщиков. Но чтобы не смешивать тематику, это будет вечером в отдельной публикации.
#обучение #бесплатно
{kind=link}
История насчёт тестировщика. Есть у меня знакомый дальнобойщик. Ну как знакомый. Я с ним специально не общаюсь, но иногда пересекался на одном объекте. Он молодой мужчина лет 30-ти. И вот он мне как-то раз сказал, что решил стать тестировщиком, чем очень меня удивил. Я попросил подробностей.
Оказалось, есть какой-то человек, который собирает группу людей, вообще не связанных с IT, и по какой-то специальной программе обучает людей некой базе по тестированию. А самое главное, что учит успешно проходить собеседования и гарантированно получать работу. Метода, якобы, работает на 100%.
Сказать, что я удивился, это ничего не сказать. Никакие мои доводы на то, что это развод, приняты не были. Человек вёл себя так, как будто его загипнотизировали и вовлекли в секту будущих QA. Все доводы отмёл, сказал, что уже сделана предоплата, а тема верная. Обучение будет удалённое по интернету, так что даже ездить никуда не надо.
Этот дальнобой уволился и больше я его не видел. Так бы обязательно спросил про обучение. Знаю только, что тестировщиком он не стал, продолжает работать водителем в Москве. Вспомнил сейчас эту историю и попробую всё-таки навести справки и связаться с ним. Стало интересно, что же в итоге за обучение было и было ли вообще.
Насчёт тестировщиков есть реальное умопомешательство у некоторых, вызванное агрессивной промывкой мозгов на тему того, что стать тестировщиком относительно просто, а зарплаты хорошие. Это же IT. Раз уже до дальнобойщиков дошло.
По моим представлениям, сейчас тестировщиком с нуля невозможно никуда устроиться. Вас просто не возьмут, потому что существуют тысячи выпускников курсов, которые долбят вакансии сотнями откликов. Реально стать QA, перейдя из какого-то другого направления. Например, будучи сисадмином или разработчиком. Не всем же вовлечённым нравится эта деятельность. Можно попробовать себя тестировщиком. Вся база уже есть. Мне кажется, что вакансии закрывают именно такие люди. А все, кто пытаются с нуля стать тестировщиком, только тратят своё время и деньги на пустые обучения.
❗️Кстати, если среди читателей есть тестировщики, расскажите свою историю, как туда попали, где учились, откуда пришли. У меня нет ни одного знакомого тестировщика. Ни разу с ними не общался и не контактировал.
#мысли #разное
Оказалось, есть какой-то человек, который собирает группу людей, вообще не связанных с IT, и по какой-то специальной программе обучает людей некой базе по тестированию. А самое главное, что учит успешно проходить собеседования и гарантированно получать работу. Метода, якобы, работает на 100%.
Сказать, что я удивился, это ничего не сказать. Никакие мои доводы на то, что это развод, приняты не были. Человек вёл себя так, как будто его загипнотизировали и вовлекли в секту будущих QA. Все доводы отмёл, сказал, что уже сделана предоплата, а тема верная. Обучение будет удалённое по интернету, так что даже ездить никуда не надо.
Этот дальнобой уволился и больше я его не видел. Так бы обязательно спросил про обучение. Знаю только, что тестировщиком он не стал, продолжает работать водителем в Москве. Вспомнил сейчас эту историю и попробую всё-таки навести справки и связаться с ним. Стало интересно, что же в итоге за обучение было и было ли вообще.
Насчёт тестировщиков есть реальное умопомешательство у некоторых, вызванное агрессивной промывкой мозгов на тему того, что стать тестировщиком относительно просто, а зарплаты хорошие. Это же IT. Раз уже до дальнобойщиков дошло.
По моим представлениям, сейчас тестировщиком с нуля невозможно никуда устроиться. Вас просто не возьмут, потому что существуют тысячи выпускников курсов, которые долбят вакансии сотнями откликов. Реально стать QA, перейдя из какого-то другого направления. Например, будучи сисадмином или разработчиком. Не всем же вовлечённым нравится эта деятельность. Можно попробовать себя тестировщиком. Вся база уже есть. Мне кажется, что вакансии закрывают именно такие люди. А все, кто пытаются с нуля стать тестировщиком, только тратят своё время и деньги на пустые обучения.
❗️Кстати, если среди читателей есть тестировщики, расскажите свою историю, как туда попали, где учились, откуда пришли. У меня нет ни одного знакомого тестировщика. Ни разу с ними не общался и не контактировал.
#мысли #разное
{kind=link}
В современных дистрибутивах Linux почти везде вместо традиционных текстовых логов средствами syslog используются бинарные логи journald. Они также, как и текстовые логи, иногда разрастаются до больших размеров, так что необходимо заниматься чисткой. Вот об этом и будет заметка. На днях пришлось на одном сервере этим заняться, поэтому решил сразу оформить заметку. Написана она будет по мотивам Debian 11.
Смотрим, сколько логи занимают места:
Обычно они хранятся в директории
Настройки ротации логов могут быть заданы в файле
Параметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
Так же вы можете обрезать логи в режиме реального времени. Примерно так:
В первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
Добавляем:
Создаём в директории
Перезапускаем службу:
Смотрим его логи отдельно:
Я, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
Смотрим, сколько логи занимают места:
# journalctl --disk-usageОбычно они хранятся в директории
/var/log/journal. Настройки ротации логов могут быть заданы в файле
/etc/systemd/journald.conf. Управляются они следующими параметрами:[Journal]SystemMaxUse=1024MSystemMaxFileSize=50MПараметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
# systemctl restart systemd-journald.serviceТак же вы можете обрезать логи в режиме реального времени. Примерно так:
# journalctl --vacuum-size=1024M# journalctl --vacuum-time=7dВ первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
[Service] добавьте отдельное пространство логов. Покажу на примере ssh. Запускаем редактирования юнита. # systemctl edit sshДобавляем:
[Service]LogNamespace=sshСоздаём в директории
/etc/systemd/ отдельный конфиг для этого namespace journald@ssh.conf со своими параметрами:[Journal]SystemMaxUse=20MПерезапускаем службу:
# systemctl restart sshСмотрим его логи отдельно:
# journalctl --namespace sshЯ, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
Когда-то давно на одном из обучений услышал необычное сравнение работы классических сисадминов и девопсов, как разницу между домашними животными и крупным рогатым скотом - pet vs cattle. Многие, наверное, уже знают, о чём тут речь. Напишу для тех, кто, возможно, об этом не слышал.
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
{kind=link}
В systemd есть все необходимые инструменты для централизованного сбора логов. Вот они:
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
После этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
Заменили ключ
Служба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
Запускаем службу и проверяем, что она успешно начала отправку логов:
Если ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
Сами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
Или только сообщения ядра:
Если я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
systemd-journal-remote. # apt install systemd-journal-remoteПосле этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
/etc/systemd/system и меняем параметр ExecStart:# cp /lib/systemd/system/systemd-journal-remote.service \/etc/systemd/system/systemd-journal-remote.service[Service]ExecStart=/lib/systemd/systemd-journal-remote --listen-http=-3 --output=/var/log/journal/remote/Заменили ключ
--listen-https на --listen-http. Если захотите использовать https, то сертификат надо будет прописать в /etc/systemd/journal-remote.conf. Далее достаточно создать необходимую директорию, назначить права и запустить службу:# mkdir -p /var/log/journal/remote# chown systemd-journal-remote:systemd-journal-remote /var/log/journal/remote# systemctl daemon-reload# systemctl start systemd-journal-remoteСлужба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
/etc/systemd/journal-upload.conf и добавляем туда путь к серверу:[Upload]URL=http://10.20.1.36:19532Запускаем службу и проверяем, что она успешно начала отправку логов:
# systemctl start systemd-journal-upload# systemctl status systemd-journal-uploadЕсли ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
# journalctl -D /var/log/journal/remote -fСами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
remote-10.20.1.56.journal. Можно посмотреть конкретный файл:# journalctl --file=remote-10.20.1.56.journal -n 100Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
# journalctl --file=remote-10.20.1.56.journal -u sshИли только сообщения ядра:
# journalctl --file=remote-10.20.1.56.journal -kЕсли я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
Информация с канала руководителя одного из направлений разработки в RUTUBE. Так что сейчас, как никогда, актуальные старые русские поговорки:
◽"Слово не воробей, вылетит не поймаешь"
◽"Береги честь смолоду"
Я уже давно понял, что в публичной плоскости надо очень аккуратно выражаться. Некоторые свои старые записи убрал (не в этом канале).
Политические срачи прошу не разводить, буду банить за это. Просто лишний раз решил всем напомнить, что сейчас вот так. Причём во всём мире. За неаккуратное слово даже нобелевской премии в 90 лет лишиться можно. Что уж говорить о приёме на работу.
Сам смотрел соцсети кандидатов, когда наймом занимался. Иногда это хорошо характеризует человека. Если вы идейный протестун, старайтесь это не сильно афишировать. Работе может помешать. Я сам иногда бываю несдержан в критике. Получал предупреждения от мудрых знакомых, что иногда пишу лишнее публично, в основном в ВК. Стараюсь следить за собой.
#разное
◽"Слово не воробей, вылетит не поймаешь"
◽"Береги честь смолоду"
Я уже давно понял, что в публичной плоскости надо очень аккуратно выражаться. Некоторые свои старые записи убрал (не в этом канале).
Политические срачи прошу не разводить, буду банить за это. Просто лишний раз решил всем напомнить, что сейчас вот так. Причём во всём мире. За неаккуратное слово даже нобелевской премии в 90 лет лишиться можно. Что уж говорить о приёме на работу.
Сам смотрел соцсети кандидатов, когда наймом занимался. Иногда это хорошо характеризует человека. Если вы идейный протестун, старайтесь это не сильно афишировать. Работе может помешать. Я сам иногда бываю несдержан в критике. Получал предупреждения от мудрых знакомых, что иногда пишу лишнее публично, в основном в ВК. Стараюсь следить за собой.
#разное
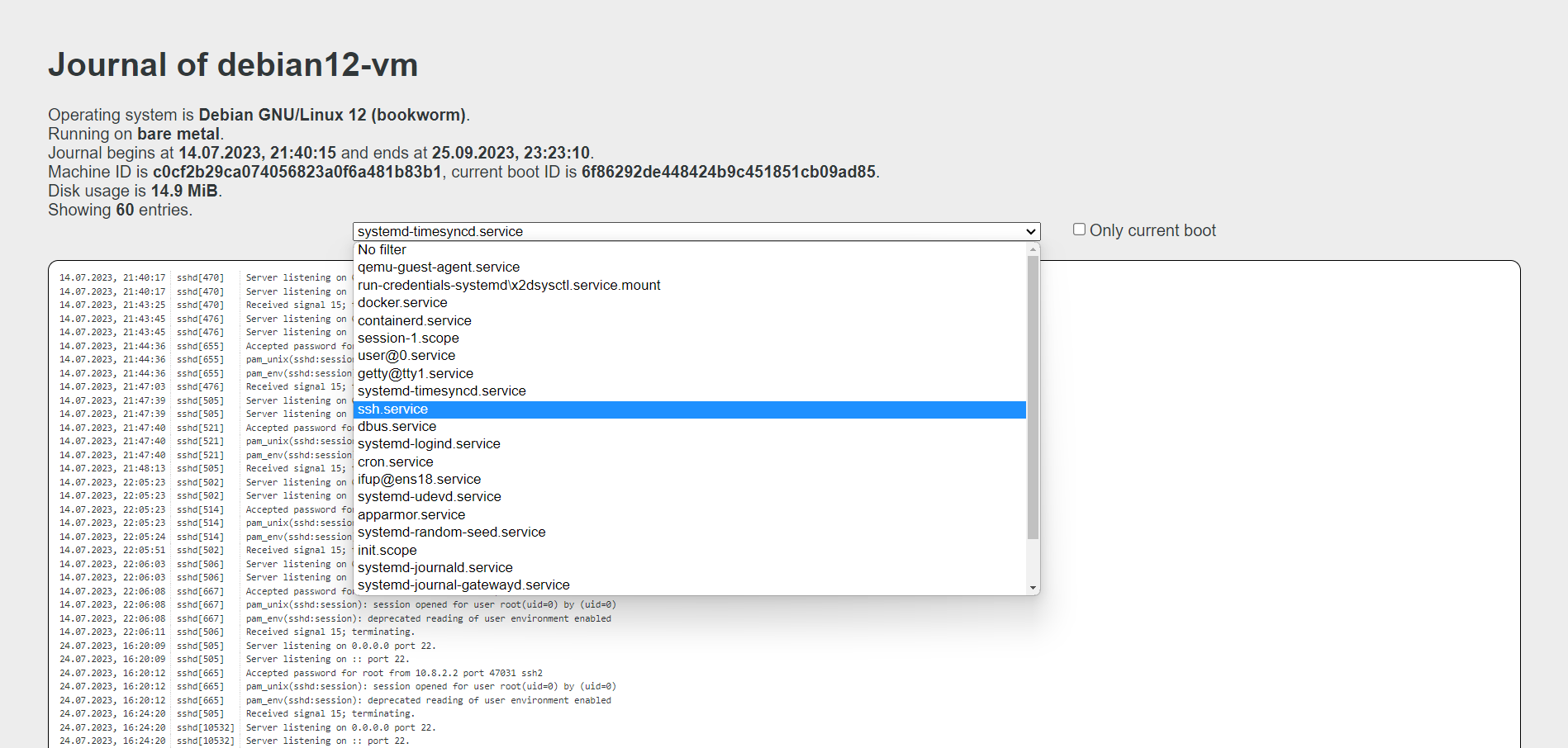
Ещё одна заметка про systemd и его встроенные инструменты для работы с логами. Есть служба systemd-journal-gatewayd, с помощью которой можно смотреть логи systemd через браузер. Причём настраивается она максимально просто, буквально в пару действий. Показываю на примере Debian.
Устанавливаем пакет systemd-journal-remote:
Запускаем службу:
Порт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
#linux #logs #systemd #journal
Устанавливаем пакет systemd-journal-remote:
# apt install systemd-journal-remoteЗапускаем службу:
# systemctl start systemd-journal-gatewayd.serviceПорт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
# curl --silent -H 'Accept: application/json' \ 'http://10.20.1.36:19531/entries?UNIT=ssh.service'Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
-D DIR, --directory=DIR.#linux #logs #systemd #journal
{kind=link}
⚠ Почему я не люблю работать с железом
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Ещё одну историю про железо расскажу. Как-то кучно было на прошлой неделе. В одном сервере для бэкапов вылетел диск из рейд массива. Он сначала помигал параметром SMART Current_Pending_Sector. То появлялся, то исчезал. В принципе, это не критично. Я видел много дисков, которые годами работают в массивах с этими метриками, и с ними в целом всё в порядке. Главное, чтобы всё стабильно было, не прыгало туда сюда в значениях.
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
Важно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
Если боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
# sgdisk -R /dev/sdb /dev/sdaВажно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
# sgdisk -G /dev/sdbЕсли боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
В Linux есть любопытный бинарник
Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
Код выхода у неё ошибочный, то есть 1.
Узнал про
Вообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
/bin/true, про который я узнал случайно. Стал искать подробности и наткнулся на интересную информацию про него. Сначала про него расскажу, а потом как я на него наткнулся. Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
# Copyright (c) 1984 AT&T # All Rights Reserved # THIS IS UNPUBLISHED PROPRIETARY SOURCE CODE OF AT&T # The copyright notice above does not evidence any # actual or intended publication of such source code. #ident "@(#)cmd/true.sh 50.1"По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
/bin/false:# /bin/false# echo $?1Код выхода у неё ошибочный, то есть 1.
Узнал про
/bin/true я случайно, когда в Debian смотрел systemd unit от postfix /lib/systemd/system/postfix.service. Открываю, а там такое:[Unit]Description=Postfix Mail Transport AgentConflicts=sendmail.service exim4.serviceConditionPathExists=/etc/postfix/main.cf[Service]Type=oneshotRemainAfterExit=yesExecStart=/bin/trueExecReload=/bin/true[Install]WantedBy=multi-user.targetВообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
postfix@.service, где уже описаны все параметры запуска конкретного экземпляра почтового сервера. При этом в /etc/systemd/system/multi-user.target.wants есть символьная ссылка только на postfix.service, поэтому сразу не очевидно, что там зависимые юниты есть.В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
🎓 Сегодня пятница, а пятница — это почти выходной, когда уже не хочется заниматься делами. Лучше это время потратить с пользой и заняться самообразованием. А в этом нам может помочь набор TUI программ для обучения в консоли.
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
Запускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
Ответ правильный и мне предлагают ещё вариант:
С sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
Я ошибся и срезал только 4 строки. Поправился:
Утилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
Тоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
#обучение #terminal #bash
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
# python3 -m venv textual_apps# cd textual_apps# source bin/activate# pip install cliexercises# cliexercisesЗапускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
head -n 5 ip.txtОтвет правильный и мне предлагают ещё вариант:
sed '5q' ip.txtС sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
tail -n +5 blocks.txt Я ошибся и срезал только 4 строки. Поправился:
tail -n +6 blocks.txtУтилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
sed '1,5d' blocks.txtТоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
awk 'NR>5' blocks.txt Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
%=%=, надо вывести 3-й блок. Для меня это уже сложно, чтобы что-то сходу придумать. Вот решение:awk '$0 == \"%=%=\"{c++} c==3' blocks.txt#обучение #terminal #bash
{kind=link}
🔝Топ постов за прошедший месяц. Пробивка инфы СБ при приёме на работу породила активное обсуждение всего, что только можно и продолжалась даже вчера. В заметке не была затронута и не подразумевалась политическая подоплёка, но в результате некоторые дошли до политики Ленина и обсуждают это до сих пор. Хотя в заметке была речь о СБ коммерческой организации.
📌 Больше всего просмотров:
◽️Обход блокировки бесплатной версии Anydesk (10644)
◽️Шутка про Kubernetes (10045)
◽️Заморозка списка процессов в диспетчере задач (9393)
📌 Больше всего комментариев:
◽️Пробивка публичной инфы при приёме на работу (248)
◽️Проблемы со спиной при сидячей работе (209)
◽️Информация по вакансиям в IT (199)
📌 Больше всего пересылок:
◽️Бесплатные уроки от RedHat (423)
◽️Сервис CMD Generator (387)
◽️Обход блокировки бесплатной версии Anydesk (353)
◽️Ttyd для шаринга консоли сервера (327)
📌 Больше всего реакций:
◽️Заморозка списка процессов в диспетчере задач (281)
◽️Обход блокировки бесплатной версии Anydesk (188)
◽️Подход pet vs cattle (177)
◽️Перенос VM с Hyper-V на Proxmox (169)
#топ
📌 Больше всего просмотров:
◽️Обход блокировки бесплатной версии Anydesk (10644)
◽️Шутка про Kubernetes (10045)
◽️Заморозка списка процессов в диспетчере задач (9393)
📌 Больше всего комментариев:
◽️Пробивка публичной инфы при приёме на работу (248)
◽️Проблемы со спиной при сидячей работе (209)
◽️Информация по вакансиям в IT (199)
📌 Больше всего пересылок:
◽️Бесплатные уроки от RedHat (423)
◽️Сервис CMD Generator (387)
◽️Обход блокировки бесплатной версии Anydesk (353)
◽️Ttyd для шаринга консоли сервера (327)
📌 Больше всего реакций:
◽️Заморозка списка процессов в диспетчере задач (281)
◽️Обход блокировки бесплатной версии Anydesk (188)
◽️Подход pet vs cattle (177)
◽️Перенос VM с Hyper-V на Proxmox (169)
#топ
Настраивал на днях на Proxmox Backup Server отправку email уведомлений. Использовал для этого почту Яндекса. Расскажу, как это сделал, так как там есть нюансы.
Ставим утилиты, которые нам понадобятся для настройки и диагностики:
В почтовом ящике Яндекса создаём пароль для приложения. Без него не работает smtp аутентификация в сторонних приложениях. После этого создаём файл
Формат такой: имя сервера, логин, пароль приложения.
Дальше создадим ещё один файл
Содержимое файла
Заменили локальный ящик на ящик Яндекса.
Назначаем права и формируем хэш файлы:
Редактируем конфигурационный файл postfix -
До пустой строки то, что было по умолчанию, после - то, что добавил я. Пустое значение
Перечитываем конфигурацию postfix:
И пробуем отправить тестовое письмо через консоль:
В логе
Письмо успешно доставлено. Теперь надо указать почтовый ящик для локального пользователя root@pam, чтобы почта отправлялась на внешний ящик, а не локальный
Инструкция будет актуальна и для PVE, только замену адреса отправителя можно не настраивать через консоль, так как в веб интерфейсе есть настройка для этого: Datacenter ⇨ Options ⇨ Email from address.
#proxmox
Ставим утилиты, которые нам понадобятся для настройки и диагностики:
# apt install -y libsasl2-modules mailutilsВ почтовом ящике Яндекса создаём пароль для приложения. Без него не работает smtp аутентификация в сторонних приложениях. После этого создаём файл
/etc/postfix/sasl_passwd следующего содержания:smtp.yandex.ru mailbox@yandex.ru:sjmprudhjgfmrdsФормат такой: имя сервера, логин, пароль приложения.
Дальше создадим ещё один файл
/etc/postfix/generic. Он нам нужен для того, чтобы заменять адрес отправителя. Яндекс разрешает отправлять только тому отправителю, кто является владельцем ящика. В нашем случае mailbox@yandex.ru, а pbs будет пытаться отправлять почту от системного пользователя root@servername.ru. Точно узнать почтовый адрес системного пользователя можно в лог файле postfix - /var/log/mail.log. Там вы увидите попытки отправки, где отправитель будет указан примерно так: 9D8CC3C81DE4: from=<root@pbs.servername.ru>.Содержимое файла
/etc/postfix/generic следующее:root@pbs.servername.ru mailbox@yandex.ruЗаменили локальный ящик на ящик Яндекса.
Назначаем права и формируем хэш файлы:
# postmap hash:/etc/postfix/sasl_passwd hash:/etc/postfix/generic# chmod 600 /etc/postfix/sasl_passwd /etc/postfix/genericРедактируем конфигурационный файл postfix -
/etc/postfix/main.cf. Приводим его к виду:myhostname=pbs.servername.rusmtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)biff = noappend_dot_mydomain = noalias_maps = hash:/etc/aliasesalias_database = hash:/etc/aliasesmydestination = $myhostname, localhost.$mydomain, localhostmynetworks = 127.0.0.0/8inet_interfaces = loopback-onlyrecipient_delimiter = +compatibility_level = 2relayhost = smtp.yandex.ru:465smtp_use_tls = yessmtp_sasl_auth_enable = yessmtp_sasl_security_options =smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwdsmtp_tls_CAfile = /etc/ssl/certs/Entrust_Root_Certification_Authority.pemsmtp_tls_session_cache_database = btree:/var/lib/postfix/smtp_tls_session_cachesmtp_tls_session_cache_timeout = 3600ssmtp_tls_wrappermode = yessmtp_tls_security_level = encryptsmtp_generic_maps = hash:/etc/postfix/genericДо пустой строки то, что было по умолчанию, после - то, что добавил я. Пустое значение
relayhost =, что было по умолчанию, я удалил. Перечитываем конфигурацию postfix:
# postfix reloadИ пробуем отправить тестовое письмо через консоль:
# echo "Message for test" | mail -s "Test subject" zeroxzed@gmail.comВ логе
/var/log/mail.info должно быть примерно следующее:Sep 29 21:47:24 pbs postfix/pickup[640930]: E282E3C820D6: uid=0 from=<root@pbs.servername.ru>Sep 29 21:47:25 pbs postfix/cleanup[640993]: E282E3C820D6: message-id=<20230929184724.E282E3C820D6@pbs.servername.ru>Sep 29 21:47:25 pbs postfix/qmgr[640929]: E282E3C820D6: from=<root@pbs.servername.ru>, size=348, nrcpt=1 (queue active)Sep 29 21:47:25 pbs postfix/smtp[640994]: E282E3C820D6: to=<zeroxzed@gmail.com>, relay=smtp.yandex.ru[77.88.21.158]:465, delay=1.1, delays=0.34/0.01/0.51/0.2, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued on mail-nwsmtp-smtp-production-main-84.vla.yp-c.yandex.net 1696013245-PlXVUC7DXqM0-wnVoD1Uo)Sep 29 21:47:25 pbs postfix/qmgr[640929]: E282E3C820D6: removedПисьмо успешно доставлено. Теперь надо указать почтовый ящик для локального пользователя root@pam, чтобы почта отправлялась на внешний ящик, а не локальный
/var/spool/mail/root. Сделать это можно через web интерфейс в разделе Configuration ⇨ Access Control. Выбираем пользователя root и в свойствах указываем его ящик. Теперь вся почта, что настроена в PBS для пользователя root@pam будет попадать во внешний ящик. Инструкция будет актуальна и для PVE, только замену адреса отправителя можно не настраивать через консоль, так как в веб интерфейсе есть настройка для этого: Datacenter ⇨ Options ⇨ Email from address.
#proxmox
Последнее время кучно пошли поломки железа. Расскажу про ещё один случай, но уже с арендованным сервером в Selectel. У заказчика арендован уже несколько лет сервер CL21-SSD (Intel Core i7-8700: 6 × 3.2ГГц, 32 ГБ DDR4, 2 × 480 ГБ SSD SATA). Сейчас его стоимость 5450 р. в месяц.
Он был заказан сразу с предустановленным Proxmox на софтовом рейде mdadm. Очень удобно. Ничего не надо самому колхозить. Заказал и сразу получил настроенный гипервизор. Единственное, сразу отмечу, что на всякий случай проверяйте, установлен ли загрузчик на оба диска. У меня были случаи, когда загрузчик стоял только на sda. Похоже не учли этот момент создатели шаблона. Сейчас может уже исправили.
На этом сервере крутятся 5 виртуалок. Три виртуалки с веб серверами. Они сильно разные по стекам, поэтому пришлось разнести. Один сайт на Bitrix довольно тяжёлый и нагруженный. Одна виртуалка с Zabbix, который мониторит всю инфраструктуру. И ещё одна виртуалка с WinSrv и файловыми базами 1С, которые опубликованы через HTTP. Работают примерно 5 человек. И вот этот дешёвый дедик без проблем тянет всё это хозяйство и каждая отдельная виртуалка работает значительно быстрее, чем то же самое было бы при аренде по отдельности виртуальных машин.
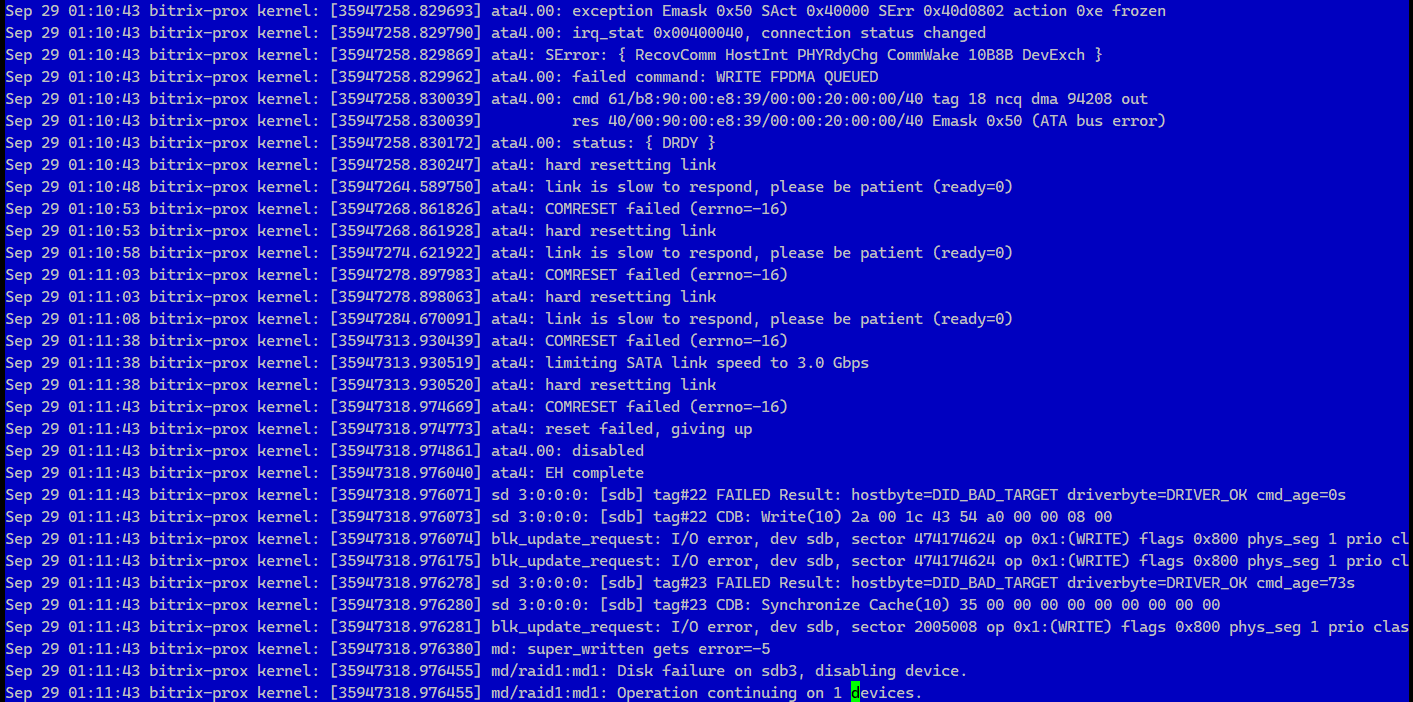
Из массива выпал один диск. Узнал из мониторинга. В нём же посмотрел информацию о дисках. На сервере стояли идентичные диски Patriot Burst. Насколько я понимаю, это самый дешман. Но даже он без проблем отработал 5 лет на этом сервере. Информация тоже из мониторинга. Там же видно по показателям SMART, что у одного диска осталось 19% ресурса, а у второго, который вышел из строя - 25%. Толку от этого SMART никакого нет.
Пишу в тот же день в техподдержку информацию о том, что диск сломан, выпал из массива. Прикладываю кусок лога из
Вечером актуализировал бэкапы данных, снял бэкапы виртуалок, потушил сервер, написал в техподдержку, что можно менять. Буквально за 10 минут заменили диск, включили сервер. Я зашёл по SSH, убедился, что всё ОК, увидел, что диск заменили на KINGSTON SA400S37480G того же объёма. Запустил ребилд массива. Первые несколько минут он ребилдился со скоростью 200 МБ в секунду, потом со 100 МБ/c. Судя по всему кэш забился. Скорость записи очень низкая, диски дешёвые. Но при этом явно видна вся прелесть SSD. Несмотря на дешивизну, они вполне функциональны и тянут типовую нагрузку, где преимущественно чтение данных. В конце не забыл установить загрузчик на новый диск, так как очевидно, что скоро второй старый тоже выйдет из строя.
Написал заметку в таком ключе, чтобы продемонстрировать удобство и дешевизну бюджетных серверов с SSD. Они стоят очень мало по сравнению с полноценными брендовыми серверами, но типовую нагрузку спокойно тянут. Они намного выгоднее по деньгам аренды VPS, и при этом имеют вполне приемлемую отказоустойчивость на уровне дисков. Само железо у меня ни разу не выходило из строя в Selectel, а диски регулярно.
Я всем заказчикам арендую сервера в Selectel, потому что нравится соотношение цены и качества железа, а так же уровень техподдержки. Плохо только, что конфигурации только с двумя дисками, либо SSD, либо HDD. Очень не хватает серверов с 4-мя дисками, чтобы можно было миксовать SSD и большой объём HDD. Раньше у них такие сервера были и они до сих пор есть у меня в управлении. Но больше их не будет. Специально интересовался. Все платформы бюджетных серверов теперь поддерживают только 2 диска.
Если будете пробовать Selectel, зарегистрируйтесь через мою реф. ссылку. Вам всё равно, а мне приятно. Из услуг я там использую ещё S3 хранилища и бесплатный DNS хостинг. Больше ничего.
#железо #хостинг
Он был заказан сразу с предустановленным Proxmox на софтовом рейде mdadm. Очень удобно. Ничего не надо самому колхозить. Заказал и сразу получил настроенный гипервизор. Единственное, сразу отмечу, что на всякий случай проверяйте, установлен ли загрузчик на оба диска. У меня были случаи, когда загрузчик стоял только на sda. Похоже не учли этот момент создатели шаблона. Сейчас может уже исправили.
На этом сервере крутятся 5 виртуалок. Три виртуалки с веб серверами. Они сильно разные по стекам, поэтому пришлось разнести. Один сайт на Bitrix довольно тяжёлый и нагруженный. Одна виртуалка с Zabbix, который мониторит всю инфраструктуру. И ещё одна виртуалка с WinSrv и файловыми базами 1С, которые опубликованы через HTTP. Работают примерно 5 человек. И вот этот дешёвый дедик без проблем тянет всё это хозяйство и каждая отдельная виртуалка работает значительно быстрее, чем то же самое было бы при аренде по отдельности виртуальных машин.
Из массива выпал один диск. Узнал из мониторинга. В нём же посмотрел информацию о дисках. На сервере стояли идентичные диски Patriot Burst. Насколько я понимаю, это самый дешман. Но даже он без проблем отработал 5 лет на этом сервере. Информация тоже из мониторинга. Там же видно по показателям SMART, что у одного диска осталось 19% ресурса, а у второго, который вышел из строя - 25%. Толку от этого SMART никакого нет.
Пишу в тот же день в техподдержку информацию о том, что диск сломан, выпал из массива. Прикладываю кусок лога из
/var/log/syslog с ошибками диска и скрин из мониторинга с информацией об износе и серийном номере диска. Техподдержка подтверждает, что готова заменить диск, просит погасить сервер и написать, когда можно начинать замену. Вечером актуализировал бэкапы данных, снял бэкапы виртуалок, потушил сервер, написал в техподдержку, что можно менять. Буквально за 10 минут заменили диск, включили сервер. Я зашёл по SSH, убедился, что всё ОК, увидел, что диск заменили на KINGSTON SA400S37480G того же объёма. Запустил ребилд массива. Первые несколько минут он ребилдился со скоростью 200 МБ в секунду, потом со 100 МБ/c. Судя по всему кэш забился. Скорость записи очень низкая, диски дешёвые. Но при этом явно видна вся прелесть SSD. Несмотря на дешивизну, они вполне функциональны и тянут типовую нагрузку, где преимущественно чтение данных. В конце не забыл установить загрузчик на новый диск, так как очевидно, что скоро второй старый тоже выйдет из строя.
Написал заметку в таком ключе, чтобы продемонстрировать удобство и дешевизну бюджетных серверов с SSD. Они стоят очень мало по сравнению с полноценными брендовыми серверами, но типовую нагрузку спокойно тянут. Они намного выгоднее по деньгам аренды VPS, и при этом имеют вполне приемлемую отказоустойчивость на уровне дисков. Само железо у меня ни разу не выходило из строя в Selectel, а диски регулярно.
Я всем заказчикам арендую сервера в Selectel, потому что нравится соотношение цены и качества железа, а так же уровень техподдержки. Плохо только, что конфигурации только с двумя дисками, либо SSD, либо HDD. Очень не хватает серверов с 4-мя дисками, чтобы можно было миксовать SSD и большой объём HDD. Раньше у них такие сервера были и они до сих пор есть у меня в управлении. Но больше их не будет. Специально интересовался. Все платформы бюджетных серверов теперь поддерживают только 2 диска.
Если будете пробовать Selectel, зарегистрируйтесь через мою реф. ссылку. Вам всё равно, а мне приятно. Из услуг я там использую ещё S3 хранилища и бесплатный DNS хостинг. Больше ничего.
#железо #хостинг
{kind=link}
Провёл аудит своих систем мониторинга Zabbix в связке с Grafana. У меня работают версии LTS 5.0 и 6.0. Промежуточные обычно только для теста ставлю где-то в одном месте. Разбирался в первую очередь с базовым шаблоном для Linux серверов.
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
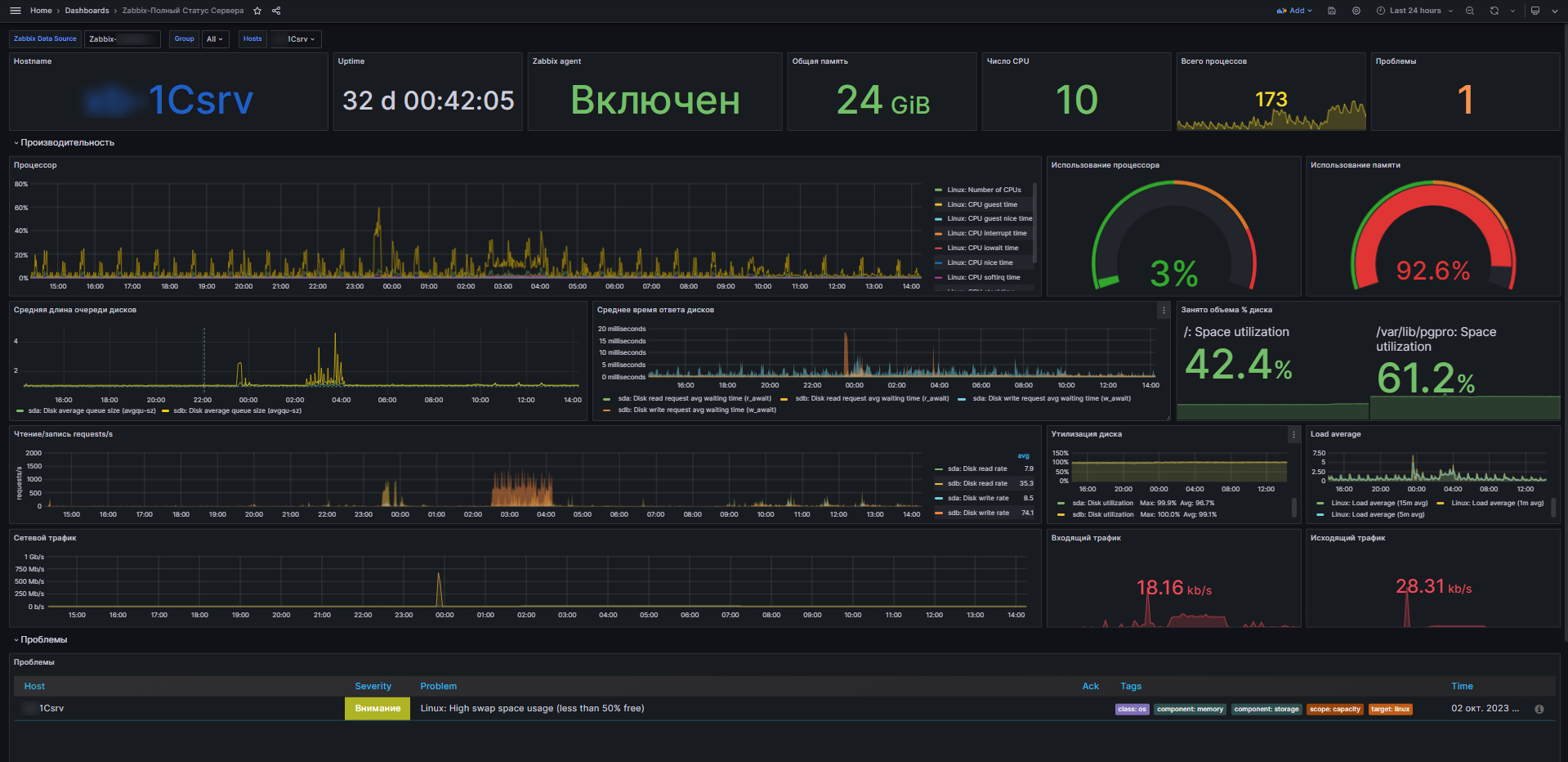
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
{kind=link}
В процессе актуализации мониторинга обновил также и Grafana до последней 10-й версии. Расскажу, как это делаю я. Это не руководство к действию для вас, а только мой персональный опыт, основанный на том, что у меня немного дашбордов и Data sources.
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
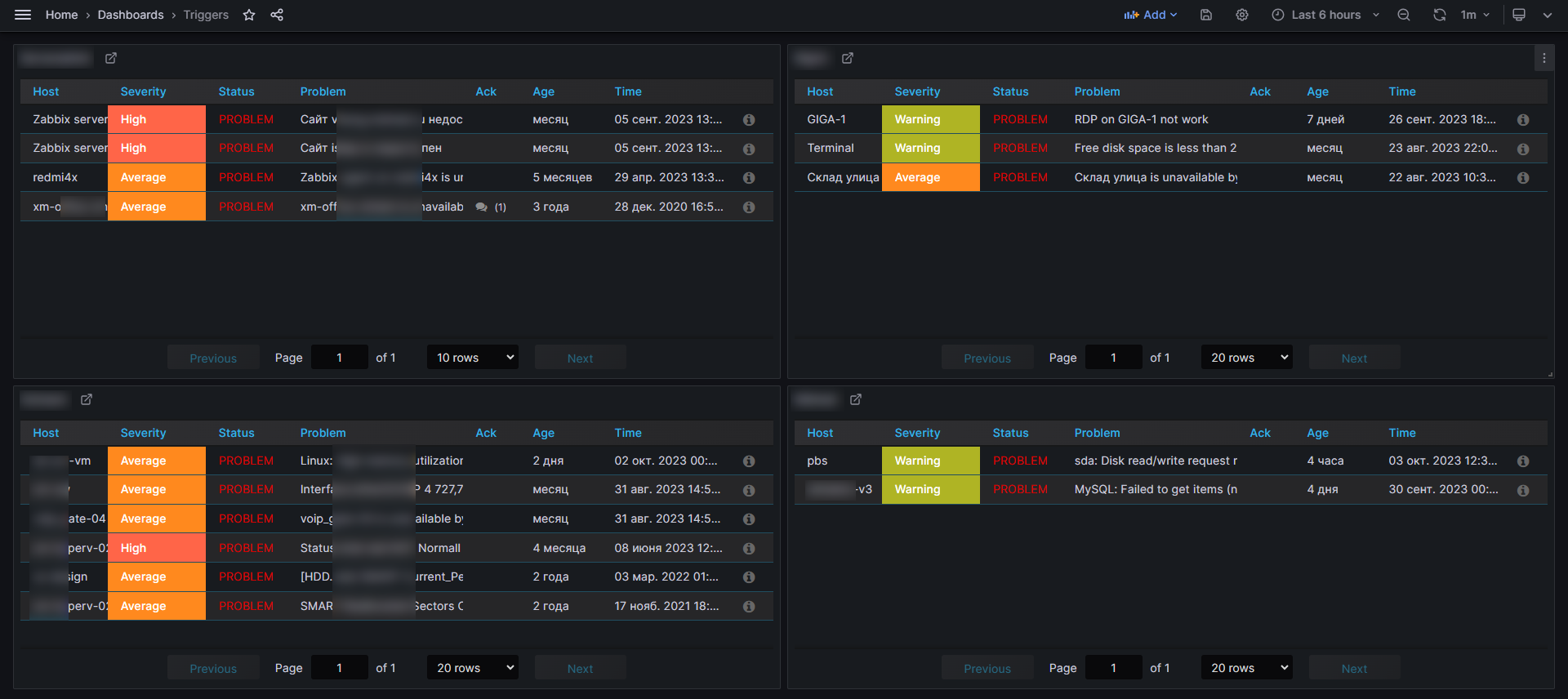
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
{kind=link}
У меня печальные новости для тех, кто использует сервер 1С под Linux. До недавнего времени он для запуска не требовал серверную лицензию, если использовалось не больше 12-ти клиентских соединений.
Я эту возможность всегда использовал для дублирования основного сервера. Копию использовал для тестирования обновлений, для восстановления бэкапов, для проверки восстановленных баз, для выгрузки dt, для тестирования баз и т.д. В общем, для служебных нужд. Пользователей туда не пускал.
Сначала я увидел комментарий к своей статье на сайте, где автор говорит, что версия 8.3.23.1865 без серверной лицензии не запускается. Подумал, что автор что-то делает не так. Но на днях я один из серверов тоже обновил на новую платформу 8.3.23.1865. Сделал всё как обычно. Сначала проверил обновление на тестовом сервере. Запускаю его, пытаюсь подключиться клиентом и вижу отказ, так как не найдена серверная лицензия.
Если бы не увиденный мной комментарий, я бы подумал, что сам где-то ошибаюсь, потому что не смог найти никаких новостей или упоминаний где-то ещё в интернете по этому поводу. Но так как нас уже как минимум двое, значит какие-то изменения в свежей платформе появились.
Кто-то сталкивался уже с этим? Будет очень жаль, если работу Linux сервера без лицензии уберут совсем. Для тестовых целей это было очень удобно.
#1С
Я эту возможность всегда использовал для дублирования основного сервера. Копию использовал для тестирования обновлений, для восстановления бэкапов, для проверки восстановленных баз, для выгрузки dt, для тестирования баз и т.д. В общем, для служебных нужд. Пользователей туда не пускал.
Сначала я увидел комментарий к своей статье на сайте, где автор говорит, что версия 8.3.23.1865 без серверной лицензии не запускается. Подумал, что автор что-то делает не так. Но на днях я один из серверов тоже обновил на новую платформу 8.3.23.1865. Сделал всё как обычно. Сначала проверил обновление на тестовом сервере. Запускаю его, пытаюсь подключиться клиентом и вижу отказ, так как не найдена серверная лицензия.
Если бы не увиденный мной комментарий, я бы подумал, что сам где-то ошибаюсь, потому что не смог найти никаких новостей или упоминаний где-то ещё в интернете по этому поводу. Но так как нас уже как минимум двое, значит какие-то изменения в свежей платформе появились.
Кто-то сталкивался уже с этим? Будет очень жаль, если работу Linux сервера без лицензии уберут совсем. Для тестовых целей это было очень удобно.
#1С
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Немного актуальных новостей про Zabbix, которым я постоянно пользуюсь.
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
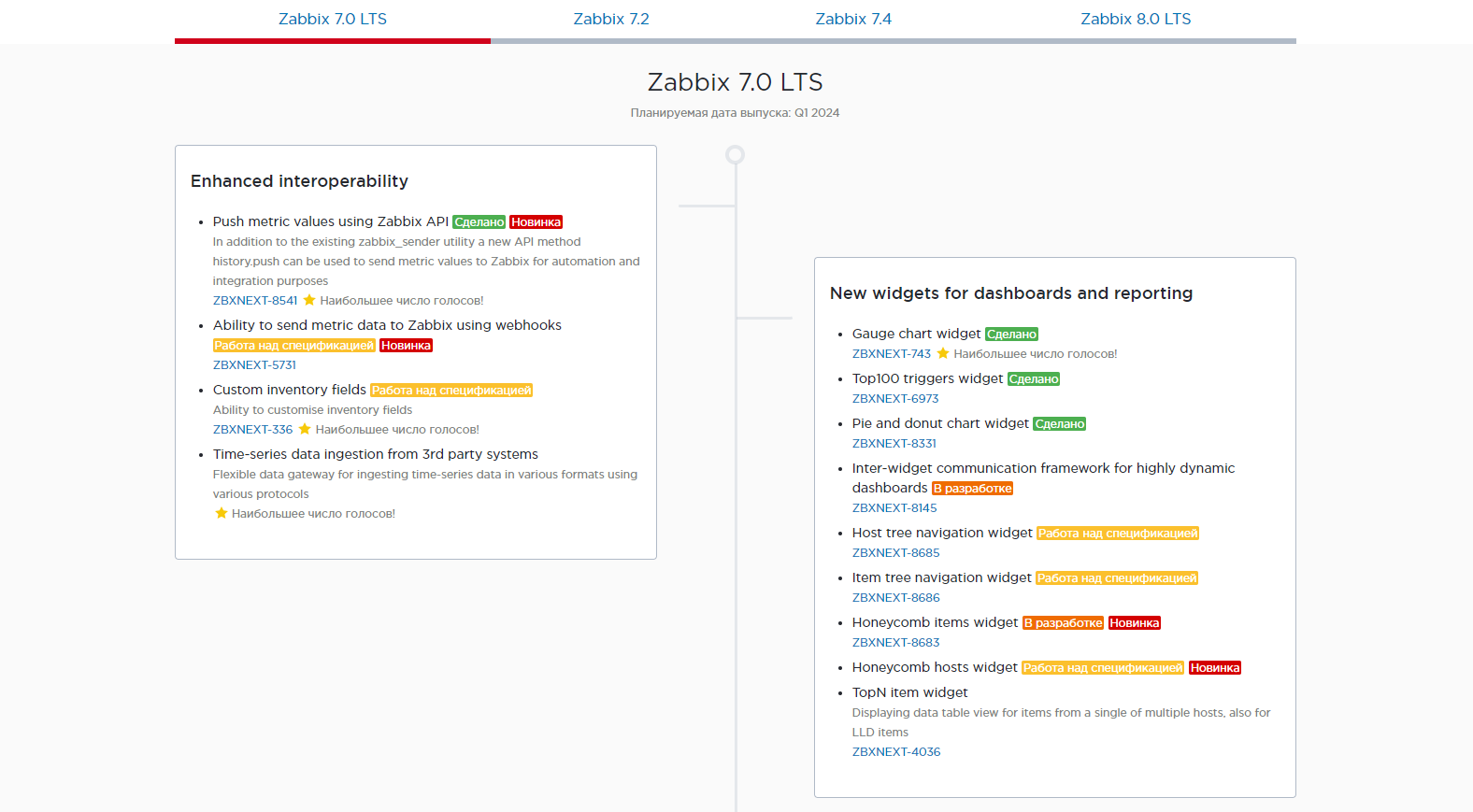
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
{kind=link}
Если хотите потренироваться и погонять бесплатно S3 хранилище, то у меня есть подходящий сервис для вас с бесплатным тарифным планом - tebi.io. Для регистрации требуется только email, карту не просят. Обещают Free Tier с ограничением на 25 GiB хранилища и 250 GiB исходящего трафика в месяц.
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
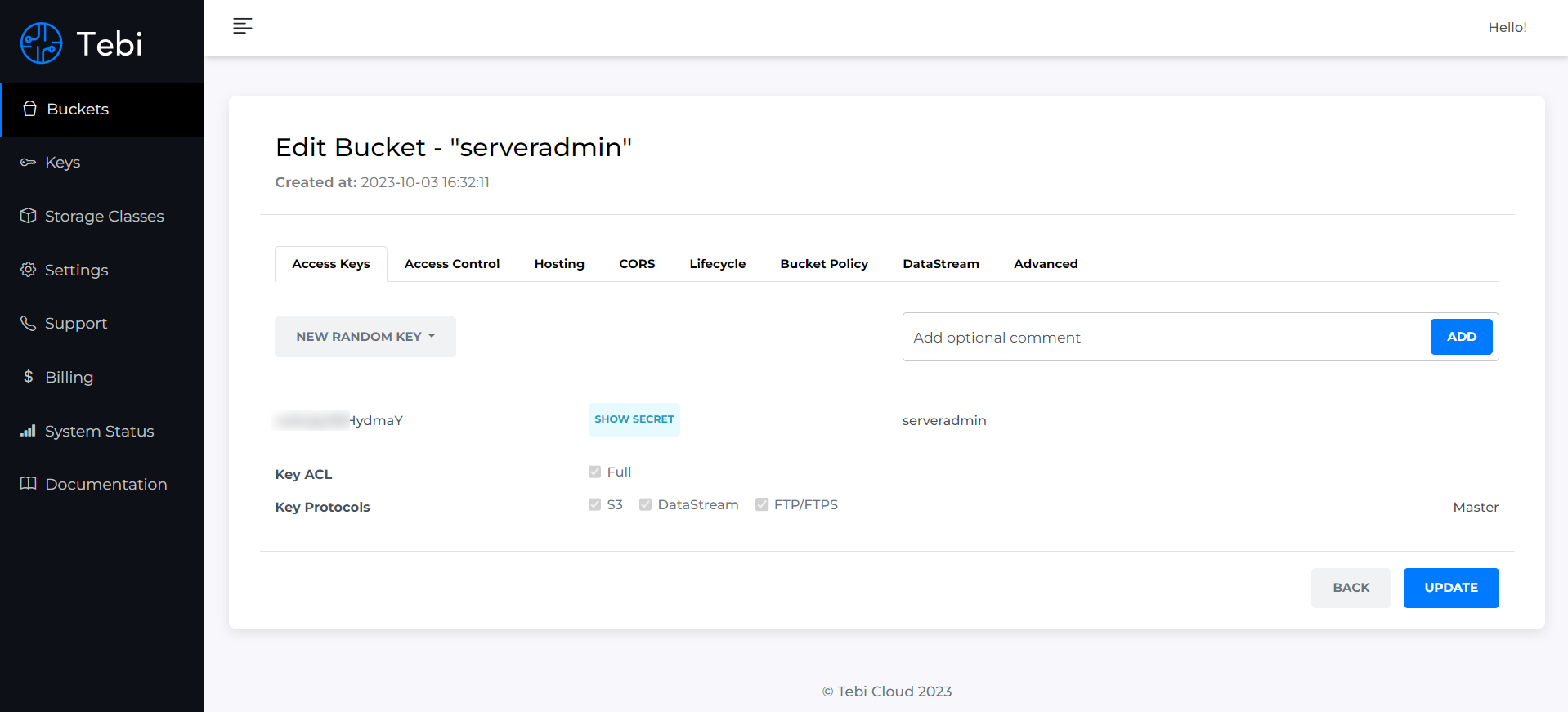
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
И можно грузить файлы или директории:
Для FTP нужны только эти данные:
Третий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
[tebi]type = s3provider = Otheraccess_key_id = uo5csfdErtydmaYsecret_access_key = vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmendpoint = https://s3.tebi.io/acl = privateИ можно грузить файлы или директории:
# rclone sync -i testfile.exe tebi:bucket_nameДля FTP нужны только эти данные:
server: ftp.tebi.ioport: 21login: uo5csfdErtydmaYpassword: vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmТретий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
{kind=link}
Немного поизучал тему self-hosted решений для S3 и понял, что аналогов MiniO по сути и нет. Всё, что есть, либо малофункционально, либо малоизвестно. Нет ни руководств, ни отзывов. Но в процессе заметил любопытный продукт от известной компании Zenko, которая специализируется на multi-cloud решениях.
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
Примеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
docker run -p 8000:8000 --name=cloudserver \ -v $(pwd)/config.json:/usr/src/app/config.json \ -v $(pwd)/locationConfig.json /usr/src/app/locationConfig.json \ -v $(pwd)/data:/usr/src/app/localData \ -v $(pwd)/metadata:/usr/src/app/localMetadata \ -e REMOTE_MANAGEMENT_DISABLE=1 -d zenko/cloudserverПримеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
[remote]type = s3env_auth = falseaccess_key_id = accessKey1secret_access_key = verySecretKey1region = other-v2-signatureendpoint = http://localhost:8000location_constraint =acl = privateserver_side_encryption =storage_class =Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
{kind=link}
Я не так давно рассказывал про сервис рисования схем excalidraw.com. Тогда впервые о нём узнал, и он мне очень понравился. В комментариях кто-то упомянул, что у него есть плагин для VSCode, но я не придал значения.
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
YouTube
Рисуем документацию прямо внутри IDE - excalidraw
Рассмотрим: интеграцию рисовалки для документации в вашем любимом vscode (phpstorm)
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru