
Сегодня вышло крупное обновление веб сервера Angie 1.3.0. Кто не читал, посмотрите две мои предыдущие заметки про него (1, 2). Изменения затронули open source версию, так что попробовать и оценить их сможет каждый.
Перечислю наиболее заметные нововведения.
1️⃣ В конфигурации location теперь можно использовать одновременно несколько шаблонов uri. Это упрощает конфигурацию location с одинаковыми настройками. То есть можно сделать примерно вот так:
Сейчас у меня то же самое записано вот так:
Там есть нюанс, что между модификатором и uri не допускается пробел. Немного синтаксис другой получается, не как у одиночных шаблонов. Я возможно что-то с синтаксисом напутал, но идею, думаю, вы поняли. Чуть позже обновится документация и можно будет уже точно смотреть, как это настраивается.
2️⃣ Angie научился самостоятельно экспортировать свою статистику в формате Prometheus, что явно упростит настройку мониторинга. Не нужен отдельный exporter для этих целей. Было бы неплохо сразу и шаблон для Zabbix сделать, не дожидаясь, пока кто-то из энтузиастов это реализует. Достаточно распарсить вывод для Prometheus.
3️⃣ Отдельной настройкой можно включить возможность экспорта содержимого конфигурационных файлов запущенной версии веб сервера через API.
Остальные изменения:
◽детальная информация и метрики по группам проксируемых stream-серверов в интерфейсе статистики, предоставляемом директивой "api"
◽опция "resolve" директивы "server" в блоке "upstream" модуля "stream", позволяющая отслеживать изменения списка IP-адресов, соответствующего доменному имени, и автоматически обновлять его без перезагрузки конфигурации
◽опция "service" директивы "server" в блоке "upstream" модуля "stream", позволяющая получать списки адресов из DNS-записей SRV, с базовой поддержкой приоритета
◽отображение номера поколения конфигурации в именах процессов, что позволяет с помощью утилиты "ps" отслеживать успех перезагрузок конфигурации и количество поколений рабочих процессов с предыдущими версиями конфигурации.
Согласитесь, изменения существенные, которые повышают удобство использования веб сервера. История с мониторингом особенно нравится. Плюс, не забываем, про готовые собранные наиболее популярные модули для веб сервера, которые можно ставить из собранных пакетов разработчиков и подключать в конфигурации. В бесплатной версии Nginx всего этого нет, что требует дополнительные телодвижения при настройке.
#webserver #angie
Перечислю наиболее заметные нововведения.
1️⃣ В конфигурации location теперь можно использовать одновременно несколько шаблонов uri. Это упрощает конфигурацию location с одинаковыми настройками. То есть можно сделать примерно вот так:
location =~/.git ~*^/(\.ht|xmlrpc\.php)${ return 404;}Сейчас у меня то же самое записано вот так:
location ~ /.git {return 404;}location ~* ^/(\.ht|xmlrpc\.php)$ { return 404;}Там есть нюанс, что между модификатором и uri не допускается пробел. Немного синтаксис другой получается, не как у одиночных шаблонов. Я возможно что-то с синтаксисом напутал, но идею, думаю, вы поняли. Чуть позже обновится документация и можно будет уже точно смотреть, как это настраивается.
2️⃣ Angie научился самостоятельно экспортировать свою статистику в формате Prometheus, что явно упростит настройку мониторинга. Не нужен отдельный exporter для этих целей. Было бы неплохо сразу и шаблон для Zabbix сделать, не дожидаясь, пока кто-то из энтузиастов это реализует. Достаточно распарсить вывод для Prometheus.
3️⃣ Отдельной настройкой можно включить возможность экспорта содержимого конфигурационных файлов запущенной версии веб сервера через API.
Остальные изменения:
◽детальная информация и метрики по группам проксируемых stream-серверов в интерфейсе статистики, предоставляемом директивой "api"
◽опция "resolve" директивы "server" в блоке "upstream" модуля "stream", позволяющая отслеживать изменения списка IP-адресов, соответствующего доменному имени, и автоматически обновлять его без перезагрузки конфигурации
◽опция "service" директивы "server" в блоке "upstream" модуля "stream", позволяющая получать списки адресов из DNS-записей SRV, с базовой поддержкой приоритета
◽отображение номера поколения конфигурации в именах процессов, что позволяет с помощью утилиты "ps" отслеживать успех перезагрузок конфигурации и количество поколений рабочих процессов с предыдущими версиями конфигурации.
Согласитесь, изменения существенные, которые повышают удобство использования веб сервера. История с мониторингом особенно нравится. Плюс, не забываем, про готовые собранные наиболее популярные модули для веб сервера, которые можно ставить из собранных пакетов разработчиков и подключать в конфигурации. В бесплатной версии Nginx всего этого нет, что требует дополнительные телодвижения при настройке.
#webserver #angie
{kind=link}
В Telegram огромное количество всевозможных ботов в том числе IT тематики. Я мало их знаю и использую, но кое-что есть. Поделюсь с вами тем, что использую сам, а также очень рассчитываю на то, что кто-то поделится чем-то полезным, что использует он. Тогда можно будет составить более полный список.
📌 Два качественных бота от @kiriharu:
▪ @unicheckbot - пинговалка ip адресов, сайтов, whois, а также проверялка TCP портов.
▪ @boxtoolbot - полный набор всевозможных проверок: информация об IP адресе, информация о технологиях, используемых на сайте, информация по MAC адресу и многое другое, в том числе не относящееся к IT.
📌 @SiteKnockerBot - мониторинг доступности сайтов. Долго им пользовался как одним из резервных мониторингов, но в какой-то момент было много ложных срабатываний, отключил.
📌 @VirusTotalAV_bot - проверяет файлы на вирусы через virustotal. Надоедает рекламой, поэтому постоянно пользоваться на основном аккаунте невозможно, но лучше вариант не нашёл.
📌 @DrWebBot - проверка на вирусы от DrWeb. Тут никакой рекламы и спама.
📌 @SaveYoutubeBot - этот бот качает видео с ютуба. Привык им пользоваться вместо vanced, который умер. С аналогами не захотелось связываться. С ботом в целом удобно скачать и слушать в фоне. Бот показывает много рекламы, так что на основном акке пользоваться не получится, задолбает.
📌 @creationdatebot - бот показывает дату создания аккакунта в Telegram. Иногда бывает полезно посмотреть, с кем общаешься.
📌 @GmailBot - очень давно пользуюсь для второстепенных ящиков. Это самый простой способ получить уведомления от мониторинга в Telegram. Настраиваем его на почтовый ящик и подключаем бота.
Это то, что я знаю сам и хоть немного использовал. Пользовался одно время удобным ботом для временной почты, но он помер. Замена не попадалась на глаза, специально не искал.
Кстати, написание бота — отличный способ начать изучение Python. Я одно время занимался этим, даже бота в итоге написал, который работал. Но всё забросил, потому что нет времени осваивать ещё одно направление. Для изучения программирования нужно прилично погружаться в тематику. Но в целом, там ничего сложно. С помощью небольшого бесплатного курса я оказался в состоянии сам программировать простейшие вещи. А дальше уже дело техники, главное начать и увлечься. У Python порог входа очень низкий.
#подборка #tg_bots
📌 Два качественных бота от @kiriharu:
▪ @unicheckbot - пинговалка ip адресов, сайтов, whois, а также проверялка TCP портов.
▪ @boxtoolbot - полный набор всевозможных проверок: информация об IP адресе, информация о технологиях, используемых на сайте, информация по MAC адресу и многое другое, в том числе не относящееся к IT.
📌 @SiteKnockerBot - мониторинг доступности сайтов. Долго им пользовался как одним из резервных мониторингов, но в какой-то момент было много ложных срабатываний, отключил.
📌 @VirusTotalAV_bot - проверяет файлы на вирусы через virustotal. Надоедает рекламой, поэтому постоянно пользоваться на основном аккаунте невозможно, но лучше вариант не нашёл.
📌 @DrWebBot - проверка на вирусы от DrWeb. Тут никакой рекламы и спама.
📌 @SaveYoutubeBot - этот бот качает видео с ютуба. Привык им пользоваться вместо vanced, который умер. С аналогами не захотелось связываться. С ботом в целом удобно скачать и слушать в фоне. Бот показывает много рекламы, так что на основном акке пользоваться не получится, задолбает.
📌 @creationdatebot - бот показывает дату создания аккакунта в Telegram. Иногда бывает полезно посмотреть, с кем общаешься.
📌 @GmailBot - очень давно пользуюсь для второстепенных ящиков. Это самый простой способ получить уведомления от мониторинга в Telegram. Настраиваем его на почтовый ящик и подключаем бота.
Это то, что я знаю сам и хоть немного использовал. Пользовался одно время удобным ботом для временной почты, но он помер. Замена не попадалась на глаза, специально не искал.
Кстати, написание бота — отличный способ начать изучение Python. Я одно время занимался этим, даже бота в итоге написал, который работал. Но всё забросил, потому что нет времени осваивать ещё одно направление. Для изучения программирования нужно прилично погружаться в тематику. Но в целом, там ничего сложно. С помощью небольшого бесплатного курса я оказался в состоянии сам программировать простейшие вещи. А дальше уже дело техники, главное начать и увлечься. У Python порог входа очень низкий.
#подборка #tg_bots
▶️ Посмотрел на днях видео, которое меня привлекло в первую очередь своим названием:
⇨ Голосовое управление оборудованием Mikrotik: от фантазий к реальности
Не могу сказать, что мне это было сильно интересно или полезно, но для общего развития знать не помешает, насколько сейчас продвинулись технологии голосового управления.
А подвинулись они до такой степени, что сейчас практически любой, кто умеет работать с Linux, может настроить распознавание голосовых команд и выполнять какие-то действия. Это в случае использования чьих-то наработок. Если строить свою логику, то придётся немного программировать на одном из популярных языков программирования. Bash тоже сойдёт, если что.
В выступлении автор рассказывает, как он с помощью колонки Алиса, сервиса Яндекса (если я правильно понял, то он бесплатен, если у тебя колонка) настроил выполнение некоторых команд на домашнем Mikrotik: включение гостевой wifi сети, отключение интернета детям и другие штуки.
В данном случае Микротик здесь постольку-поскольку, потому что реально выполняется подключение по SSH и выполняется заскриптованная команда. То есть это универсальный вариант запуска любых команд по SSH.
Я сам не фанат какой-то автоматизации в доме. Ничего умнее термостата тёплого пола и gsm модуля для управления котлом у меня нет. Все кнопки физические, везде протянуты провода. Я даже wifi не планирую использовать, так как у всех и так море интернета в смартфонах, а все рабочие места проводные. Пока необходимости в wifi в новом доме не возникло ни разу.
С использованием описанной технологии Яндекса вы умный дом можете себе настроить самостоятельно. Причём довольно просто. Берём колонку, некий контроллер, который можно дёргать удалёнными командами и реализуем свои фантазии. Главное, не забыть продублировать всё физически, чтобы при отсутствии интернета дом не превратился в тыкву.
#видео #mikrotik
⇨ Голосовое управление оборудованием Mikrotik: от фантазий к реальности
Не могу сказать, что мне это было сильно интересно или полезно, но для общего развития знать не помешает, насколько сейчас продвинулись технологии голосового управления.
А подвинулись они до такой степени, что сейчас практически любой, кто умеет работать с Linux, может настроить распознавание голосовых команд и выполнять какие-то действия. Это в случае использования чьих-то наработок. Если строить свою логику, то придётся немного программировать на одном из популярных языков программирования. Bash тоже сойдёт, если что.
В выступлении автор рассказывает, как он с помощью колонки Алиса, сервиса Яндекса (если я правильно понял, то он бесплатен, если у тебя колонка) настроил выполнение некоторых команд на домашнем Mikrotik: включение гостевой wifi сети, отключение интернета детям и другие штуки.
В данном случае Микротик здесь постольку-поскольку, потому что реально выполняется подключение по SSH и выполняется заскриптованная команда. То есть это универсальный вариант запуска любых команд по SSH.
Я сам не фанат какой-то автоматизации в доме. Ничего умнее термостата тёплого пола и gsm модуля для управления котлом у меня нет. Все кнопки физические, везде протянуты провода. Я даже wifi не планирую использовать, так как у всех и так море интернета в смартфонах, а все рабочие места проводные. Пока необходимости в wifi в новом доме не возникло ни разу.
С использованием описанной технологии Яндекса вы умный дом можете себе настроить самостоятельно. Причём довольно просто. Берём колонку, некий контроллер, который можно дёргать удалёнными командами и реализуем свои фантазии. Главное, не забыть продублировать всё физически, чтобы при отсутствии интернета дом не превратился в тыкву.
#видео #mikrotik
YouTube
Голосовое управление оборудованием Mikrotik: от фантазий к реальности
AsterConf'23 - конфа для спецов по Asterisk и VoIP: https://asterconf.ru
Помогаем в Telegram: https://t.me/MikTrain
На докладе вы узнаете, какие есть возможности интеграции системы умного дома Яндекс и Mikrotik, как его можно использовать, и с чего начать…
Помогаем в Telegram: https://t.me/MikTrain
На докладе вы узнаете, какие есть возможности интеграции системы умного дома Яндекс и Mikrotik, как его можно использовать, и с чего начать…
На одном из почтовых серверов попросили увеличить лимит на размер вложений. Сказали, что 10 Мб им не хватает. Немного удивился, потому что по умолчанию ставлю лимит на размер письма 20 Мб. Считаю это универсальным размером. Разрешение пересылки больших файлов без квот на почтовые ящики очень быстро приводит к разрастанию почтовой базы. Особенно, когда кто-то начинает макеты, презентации и прочие большие файлы по почте ежедневно гонять.
Сходил, проверил. Ограничение действительно стояло 20 Мб. Смысл тут в том, что итоговый размер письма может быть существенно больше, чем объём вложения. Всё дело в кодировании вложений для пересылки в письме. Они передаются как часть письма в виде печатных символов стандартной кодовой таблицы ASCII.
Для кодирования вложений в электронной почте обычно используют методы base64 и quoted-printable, описанные в стандарте MIME. Их там больше представлено, но насколько я знаю, в современной почте используют именно эти два. При кодировании по методу base64, а чаще всего используется именно он, получается в среднем увеличение размера вложения в 1,3 раза. Но бывает и значительно больше. Это зависит от особенностей исходного файла и метода кодирования. При использовании quoted-printable увеличение размера может доходить до 3-х раз.
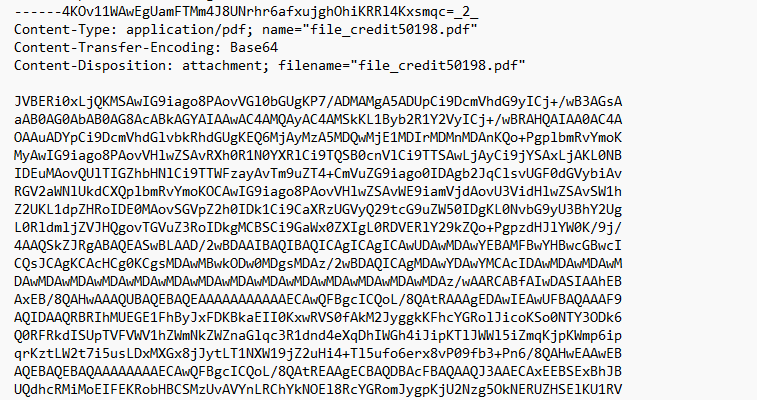
Посмотреть информацию о вложении и методе кодирования можно, сохранив письмо и открыв любым текстовым редактором. Там будут примерно такие заголовки:
Это кодированный pdf файл, который в исходном тексте письма представлен в виде ASCII символов.
Так что когда ставите ограничение на размер письма, имейте ввиду, что этот размер может существенно отличаться от итогового размера вложения, которое сможет пролезть в этот лимит.
#mailserver
Сходил, проверил. Ограничение действительно стояло 20 Мб. Смысл тут в том, что итоговый размер письма может быть существенно больше, чем объём вложения. Всё дело в кодировании вложений для пересылки в письме. Они передаются как часть письма в виде печатных символов стандартной кодовой таблицы ASCII.
Для кодирования вложений в электронной почте обычно используют методы base64 и quoted-printable, описанные в стандарте MIME. Их там больше представлено, но насколько я знаю, в современной почте используют именно эти два. При кодировании по методу base64, а чаще всего используется именно он, получается в среднем увеличение размера вложения в 1,3 раза. Но бывает и значительно больше. Это зависит от особенностей исходного файла и метода кодирования. При использовании quoted-printable увеличение размера может доходить до 3-х раз.
Посмотреть информацию о вложении и методе кодирования можно, сохранив письмо и открыв любым текстовым редактором. Там будут примерно такие заголовки:
Mime-Version: 1.0Content-Type: application/pdf; name="file_credit50198.pdf"Content-Transfer-Encoding: Base64Content-Disposition: attachment; filename="file_credit50198.pdf"Это кодированный pdf файл, который в исходном тексте письма представлен в виде ASCII символов.
Так что когда ставите ограничение на размер письма, имейте ввиду, что этот размер может существенно отличаться от итогового размера вложения, которое сможет пролезть в этот лимит.
#mailserver
{kind=link}
Один подписчик поделился полезным сервисом, про который я ранее не слышал:
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
{kind=link}
Для бэкапа баз PostgreSQL существует много различных подходов и решений. Я вам хочу предложить ещё одно, отметив его особенности и преимущества. Да и в целом это одна из самых известных программ для этих целей. А в конце приведу список того, чем ещё можно бэкапить PostgreSQL.
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
Дальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
# apt install pgbackrestДальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
{kind=link}
Вспомнился старый мем с колонками. Дело в том, что у меня примерно такие же работают до сих пор. Даже не знаю, сколько им лет. 20 примерно, работают исправно.
И вот в какой-то момент они начали трещать. У меня прям флешбэки из прошлого пошли. Не хватало только треска модема. Долго не мог понять, почему колонки снова стали трещать. А потом нашёл объяснение.
Сыну купил часы-браслет с возможностью звонить через них, чтобы он в школе был на связи без смартфона. А браслет этот работает только через 2G. Пришлось купить симку не Tele2, которым вся семья пользуется, так как он в Москве не поддерживает 2G.
Если положить этот браслет рядом, начинают трещать колонки в момент обмена информацией с базовыми станциями. Современные сотовые телефоны на 4G такого эффекта не дают.
Кстати, браслет - удобная шутка. Хороший вариант для младшеклассников оставаться на связи без смартфона, который им в школе не нужен.
#мем
И вот в какой-то момент они начали трещать. У меня прям флешбэки из прошлого пошли. Не хватало только треска модема. Долго не мог понять, почему колонки снова стали трещать. А потом нашёл объяснение.
Сыну купил часы-браслет с возможностью звонить через них, чтобы он в школе был на связи без смартфона. А браслет этот работает только через 2G. Пришлось купить симку не Tele2, которым вся семья пользуется, так как он в Москве не поддерживает 2G.
Если положить этот браслет рядом, начинают трещать колонки в момент обмена информацией с базовыми станциями. Современные сотовые телефоны на 4G такого эффекта не дают.
Кстати, браслет - удобная шутка. Хороший вариант для младшеклассников оставаться на связи без смартфона, который им в школе не нужен.
#мем
Давно не затрагивал игровые или детские темы. Решил немного посмотреть, не появилось ли чего-то нового. А оно появилось. Я уже рассказывал про компанию Luden.io, у которой очень классные игры для детей на русском языке с уклоном в обучение программированию. Да и не только для детей. Игры реально классные, красочные, увлекательные. Прочитайте мою заметку, там много информации.
У них появилась новая игра Craftomation 101. Она ещё не полностью доделана, но вполне играбельна. Можно бесплатно скачать и поиграть. По ссылке в конце дистрибутив под Windows, Linux, Mac. На винду установка не требуется. Просто скачиваете и играете. Можно выбрать русский язык в настройках. Перевод качественный, так как создатели русскоязычные.
Я немного поиграл, примерно час. Дошёл до появления роботов и их программирования. Запрограммировал их на выполнения некоторых действий. Игра реально красивая и увлекательная. Интересно и самому поиграть. Показал сыну (9 лет), сразу заинтересовался. Поиграл немного, научился роботов программировать. Сразу всех задействовал, автоматизировал рутину. В общем, ничего так игра, рекомендую.
Напомню, что у меня есть подборка обучающих материалов для детей, которую я собрал на основе ваших отзывов.
#игра #обучение #дети
У них появилась новая игра Craftomation 101. Она ещё не полностью доделана, но вполне играбельна. Можно бесплатно скачать и поиграть. По ссылке в конце дистрибутив под Windows, Linux, Mac. На винду установка не требуется. Просто скачиваете и играете. Можно выбрать русский язык в настройках. Перевод качественный, так как создатели русскоязычные.
Я немного поиграл, примерно час. Дошёл до появления роботов и их программирования. Запрограммировал их на выполнения некоторых действий. Игра реально красивая и увлекательная. Интересно и самому поиграть. Показал сыну (9 лет), сразу заинтересовался. Поиграл немного, научился роботов программировать. Сразу всех задействовал, автоматизировал рутину. В общем, ничего так игра, рекомендую.
Напомню, что у меня есть подборка обучающих материалов для детей, которую я собрал на основе ваших отзывов.
#игра #обучение #дети
{kind=link}
🎓 На днях на хабре был анонс на вид очень неплохого учебника для тестировщика под названием "The 100-Year QA-Textbook". Он собрал много просмотров, так что возможно многие из вас про него уже знают. К тому же предварительный релиз этого обучающего материала был давно, а сейчас вышло очередное обновление.
Вот информация о курсе от создателей:
⇨ Зачем появился бесплатный интерактивный «100-Year QA-textbook» на 700+ страниц для обучающихся тестированию
⇨ Полный релиз бесплатного интерактивного 700-страничного учебника по тестированию
На вид материал выглядит качественным. Несмотря на то, что он анонсирован для тестировщиков, 2/3 курса это база, которая подойдёт для любой специальности в IT. Судя по содержанию это так и есть, потому что там разбирают:
◽СУБД и SQL запросы
◽База по ОС Linux (файловые системы, пользователи, процессы и т.д.)
◽Работа с сетью
◽Архитектура серверного ПО
◽Rest API, HTTP
◽Docker, GIT
К сожалению, не смог посмотреть раздел по Linux, потому что курс даёт возможность проходить материал последовательно. Пока не пройдёшь тест за предыдущий раздел, к следующему доступа нет.
Как я понял, курс сделан на базе онлайн школы тестировщиков. У меня есть любопытная история на этот счёт и общее мнение насчёт тестировщиков. Но чтобы не смешивать тематику, это будет вечером в отдельной публикации.
#обучение #бесплатно
Вот информация о курсе от создателей:
⇨ Зачем появился бесплатный интерактивный «100-Year QA-textbook» на 700+ страниц для обучающихся тестированию
⇨ Полный релиз бесплатного интерактивного 700-страничного учебника по тестированию
На вид материал выглядит качественным. Несмотря на то, что он анонсирован для тестировщиков, 2/3 курса это база, которая подойдёт для любой специальности в IT. Судя по содержанию это так и есть, потому что там разбирают:
◽СУБД и SQL запросы
◽База по ОС Linux (файловые системы, пользователи, процессы и т.д.)
◽Работа с сетью
◽Архитектура серверного ПО
◽Rest API, HTTP
◽Docker, GIT
К сожалению, не смог посмотреть раздел по Linux, потому что курс даёт возможность проходить материал последовательно. Пока не пройдёшь тест за предыдущий раздел, к следующему доступа нет.
Как я понял, курс сделан на базе онлайн школы тестировщиков. У меня есть любопытная история на этот счёт и общее мнение насчёт тестировщиков. Но чтобы не смешивать тематику, это будет вечером в отдельной публикации.
#обучение #бесплатно
{kind=link}
История насчёт тестировщика. Есть у меня знакомый дальнобойщик. Ну как знакомый. Я с ним специально не общаюсь, но иногда пересекался на одном объекте. Он молодой мужчина лет 30-ти. И вот он мне как-то раз сказал, что решил стать тестировщиком, чем очень меня удивил. Я попросил подробностей.
Оказалось, есть какой-то человек, который собирает группу людей, вообще не связанных с IT, и по какой-то специальной программе обучает людей некой базе по тестированию. А самое главное, что учит успешно проходить собеседования и гарантированно получать работу. Метода, якобы, работает на 100%.
Сказать, что я удивился, это ничего не сказать. Никакие мои доводы на то, что это развод, приняты не были. Человек вёл себя так, как будто его загипнотизировали и вовлекли в секту будущих QA. Все доводы отмёл, сказал, что уже сделана предоплата, а тема верная. Обучение будет удалённое по интернету, так что даже ездить никуда не надо.
Этот дальнобой уволился и больше я его не видел. Так бы обязательно спросил про обучение. Знаю только, что тестировщиком он не стал, продолжает работать водителем в Москве. Вспомнил сейчас эту историю и попробую всё-таки навести справки и связаться с ним. Стало интересно, что же в итоге за обучение было и было ли вообще.
Насчёт тестировщиков есть реальное умопомешательство у некоторых, вызванное агрессивной промывкой мозгов на тему того, что стать тестировщиком относительно просто, а зарплаты хорошие. Это же IT. Раз уже до дальнобойщиков дошло.
По моим представлениям, сейчас тестировщиком с нуля невозможно никуда устроиться. Вас просто не возьмут, потому что существуют тысячи выпускников курсов, которые долбят вакансии сотнями откликов. Реально стать QA, перейдя из какого-то другого направления. Например, будучи сисадмином или разработчиком. Не всем же вовлечённым нравится эта деятельность. Можно попробовать себя тестировщиком. Вся база уже есть. Мне кажется, что вакансии закрывают именно такие люди. А все, кто пытаются с нуля стать тестировщиком, только тратят своё время и деньги на пустые обучения.
❗️Кстати, если среди читателей есть тестировщики, расскажите свою историю, как туда попали, где учились, откуда пришли. У меня нет ни одного знакомого тестировщика. Ни разу с ними не общался и не контактировал.
#мысли #разное
Оказалось, есть какой-то человек, который собирает группу людей, вообще не связанных с IT, и по какой-то специальной программе обучает людей некой базе по тестированию. А самое главное, что учит успешно проходить собеседования и гарантированно получать работу. Метода, якобы, работает на 100%.
Сказать, что я удивился, это ничего не сказать. Никакие мои доводы на то, что это развод, приняты не были. Человек вёл себя так, как будто его загипнотизировали и вовлекли в секту будущих QA. Все доводы отмёл, сказал, что уже сделана предоплата, а тема верная. Обучение будет удалённое по интернету, так что даже ездить никуда не надо.
Этот дальнобой уволился и больше я его не видел. Так бы обязательно спросил про обучение. Знаю только, что тестировщиком он не стал, продолжает работать водителем в Москве. Вспомнил сейчас эту историю и попробую всё-таки навести справки и связаться с ним. Стало интересно, что же в итоге за обучение было и было ли вообще.
Насчёт тестировщиков есть реальное умопомешательство у некоторых, вызванное агрессивной промывкой мозгов на тему того, что стать тестировщиком относительно просто, а зарплаты хорошие. Это же IT. Раз уже до дальнобойщиков дошло.
По моим представлениям, сейчас тестировщиком с нуля невозможно никуда устроиться. Вас просто не возьмут, потому что существуют тысячи выпускников курсов, которые долбят вакансии сотнями откликов. Реально стать QA, перейдя из какого-то другого направления. Например, будучи сисадмином или разработчиком. Не всем же вовлечённым нравится эта деятельность. Можно попробовать себя тестировщиком. Вся база уже есть. Мне кажется, что вакансии закрывают именно такие люди. А все, кто пытаются с нуля стать тестировщиком, только тратят своё время и деньги на пустые обучения.
❗️Кстати, если среди читателей есть тестировщики, расскажите свою историю, как туда попали, где учились, откуда пришли. У меня нет ни одного знакомого тестировщика. Ни разу с ними не общался и не контактировал.
#мысли #разное
{kind=link}
В современных дистрибутивах Linux почти везде вместо традиционных текстовых логов средствами syslog используются бинарные логи journald. Они также, как и текстовые логи, иногда разрастаются до больших размеров, так что необходимо заниматься чисткой. Вот об этом и будет заметка. На днях пришлось на одном сервере этим заняться, поэтому решил сразу оформить заметку. Написана она будет по мотивам Debian 11.
Смотрим, сколько логи занимают места:
Обычно они хранятся в директории
Настройки ротации логов могут быть заданы в файле
Параметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
Так же вы можете обрезать логи в режиме реального времени. Примерно так:
В первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
Добавляем:
Создаём в директории
Перезапускаем службу:
Смотрим его логи отдельно:
Я, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
Смотрим, сколько логи занимают места:
# journalctl --disk-usageОбычно они хранятся в директории
/var/log/journal. Настройки ротации логов могут быть заданы в файле
/etc/systemd/journald.conf. Управляются они следующими параметрами:[Journal]SystemMaxUse=1024MSystemMaxFileSize=50MПараметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
# systemctl restart systemd-journald.serviceТак же вы можете обрезать логи в режиме реального времени. Примерно так:
# journalctl --vacuum-size=1024M# journalctl --vacuum-time=7dВ первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
[Service] добавьте отдельное пространство логов. Покажу на примере ssh. Запускаем редактирования юнита. # systemctl edit sshДобавляем:
[Service]LogNamespace=sshСоздаём в директории
/etc/systemd/ отдельный конфиг для этого namespace journald@ssh.conf со своими параметрами:[Journal]SystemMaxUse=20MПерезапускаем службу:
# systemctl restart sshСмотрим его логи отдельно:
# journalctl --namespace sshЯ, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
Когда-то давно на одном из обучений услышал необычное сравнение работы классических сисадминов и девопсов, как разницу между домашними животными и крупным рогатым скотом - pet vs cattle. Многие, наверное, уже знают, о чём тут речь. Напишу для тех, кто, возможно, об этом не слышал.
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
{kind=link}
В systemd есть все необходимые инструменты для централизованного сбора логов. Вот они:
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
После этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
Заменили ключ
Служба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
Запускаем службу и проверяем, что она успешно начала отправку логов:
Если ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
Сами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
Или только сообщения ядра:
Если я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
systemd-journal-remote. # apt install systemd-journal-remoteПосле этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
/etc/systemd/system и меняем параметр ExecStart:# cp /lib/systemd/system/systemd-journal-remote.service \/etc/systemd/system/systemd-journal-remote.service[Service]ExecStart=/lib/systemd/systemd-journal-remote --listen-http=-3 --output=/var/log/journal/remote/Заменили ключ
--listen-https на --listen-http. Если захотите использовать https, то сертификат надо будет прописать в /etc/systemd/journal-remote.conf. Далее достаточно создать необходимую директорию, назначить права и запустить службу:# mkdir -p /var/log/journal/remote# chown systemd-journal-remote:systemd-journal-remote /var/log/journal/remote# systemctl daemon-reload# systemctl start systemd-journal-remoteСлужба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
/etc/systemd/journal-upload.conf и добавляем туда путь к серверу:[Upload]URL=http://10.20.1.36:19532Запускаем службу и проверяем, что она успешно начала отправку логов:
# systemctl start systemd-journal-upload# systemctl status systemd-journal-uploadЕсли ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
# journalctl -D /var/log/journal/remote -fСами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
remote-10.20.1.56.journal. Можно посмотреть конкретный файл:# journalctl --file=remote-10.20.1.56.journal -n 100Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
# journalctl --file=remote-10.20.1.56.journal -u sshИли только сообщения ядра:
# journalctl --file=remote-10.20.1.56.journal -kЕсли я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
Информация с канала руководителя одного из направлений разработки в RUTUBE. Так что сейчас, как никогда, актуальные старые русские поговорки:
◽"Слово не воробей, вылетит не поймаешь"
◽"Береги честь смолоду"
Я уже давно понял, что в публичной плоскости надо очень аккуратно выражаться. Некоторые свои старые записи убрал (не в этом канале).
Политические срачи прошу не разводить, буду банить за это. Просто лишний раз решил всем напомнить, что сейчас вот так. Причём во всём мире. За неаккуратное слово даже нобелевской премии в 90 лет лишиться можно. Что уж говорить о приёме на работу.
Сам смотрел соцсети кандидатов, когда наймом занимался. Иногда это хорошо характеризует человека. Если вы идейный протестун, старайтесь это не сильно афишировать. Работе может помешать. Я сам иногда бываю несдержан в критике. Получал предупреждения от мудрых знакомых, что иногда пишу лишнее публично, в основном в ВК. Стараюсь следить за собой.
#разное
◽"Слово не воробей, вылетит не поймаешь"
◽"Береги честь смолоду"
Я уже давно понял, что в публичной плоскости надо очень аккуратно выражаться. Некоторые свои старые записи убрал (не в этом канале).
Политические срачи прошу не разводить, буду банить за это. Просто лишний раз решил всем напомнить, что сейчас вот так. Причём во всём мире. За неаккуратное слово даже нобелевской премии в 90 лет лишиться можно. Что уж говорить о приёме на работу.
Сам смотрел соцсети кандидатов, когда наймом занимался. Иногда это хорошо характеризует человека. Если вы идейный протестун, старайтесь это не сильно афишировать. Работе может помешать. Я сам иногда бываю несдержан в критике. Получал предупреждения от мудрых знакомых, что иногда пишу лишнее публично, в основном в ВК. Стараюсь следить за собой.
#разное
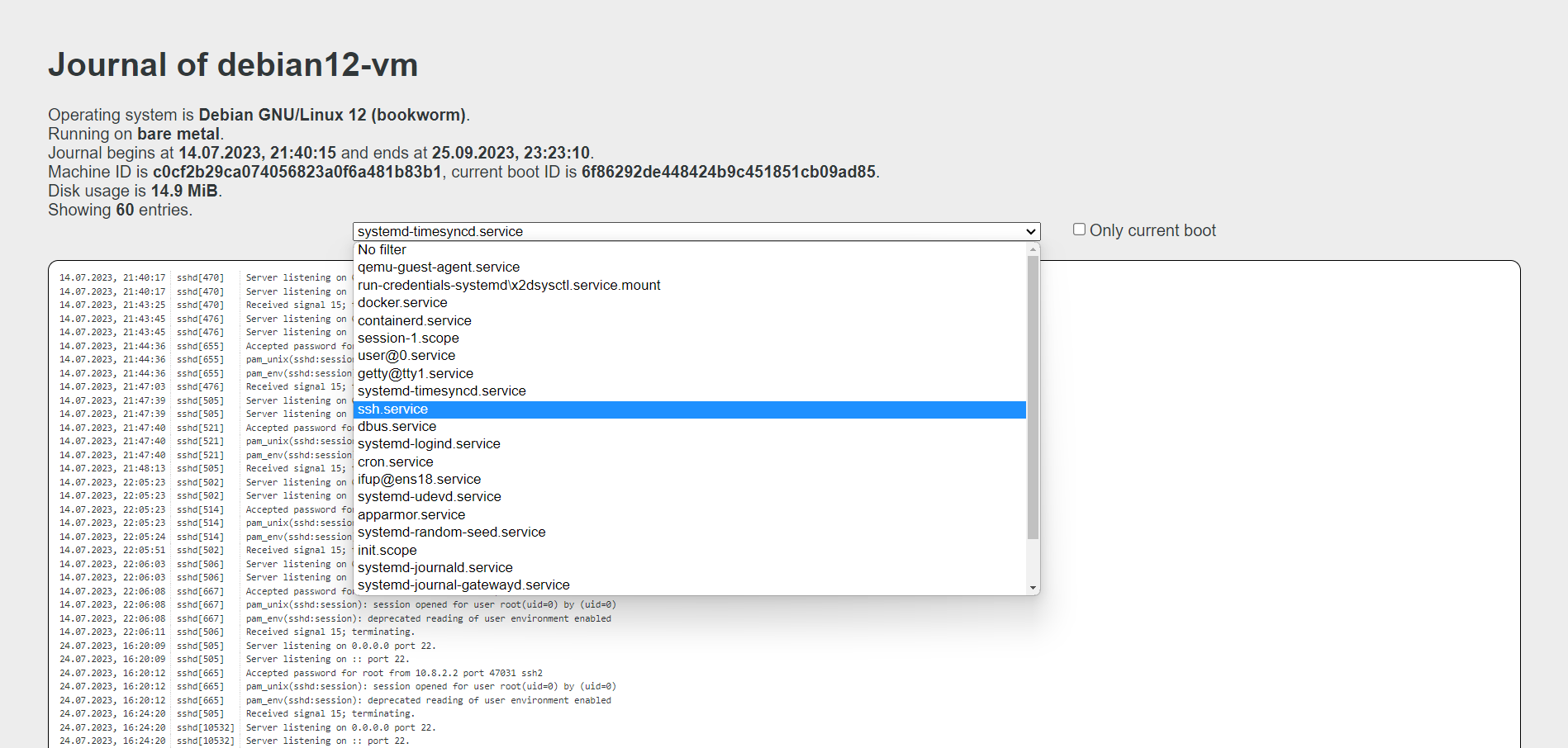
Ещё одна заметка про systemd и его встроенные инструменты для работы с логами. Есть служба systemd-journal-gatewayd, с помощью которой можно смотреть логи systemd через браузер. Причём настраивается она максимально просто, буквально в пару действий. Показываю на примере Debian.
Устанавливаем пакет systemd-journal-remote:
Запускаем службу:
Порт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
#linux #logs #systemd #journal
Устанавливаем пакет systemd-journal-remote:
# apt install systemd-journal-remoteЗапускаем службу:
# systemctl start systemd-journal-gatewayd.serviceПорт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
# curl --silent -H 'Accept: application/json' \ 'http://10.20.1.36:19531/entries?UNIT=ssh.service'Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
-D DIR, --directory=DIR.#linux #logs #systemd #journal
{kind=link}
⚠ Почему я не люблю работать с железом
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Ещё одну историю про железо расскажу. Как-то кучно было на прошлой неделе. В одном сервере для бэкапов вылетел диск из рейд массива. Он сначала помигал параметром SMART Current_Pending_Sector. То появлялся, то исчезал. В принципе, это не критично. Я видел много дисков, которые годами работают в массивах с этими метриками, и с ними в целом всё в порядке. Главное, чтобы всё стабильно было, не прыгало туда сюда в значениях.
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
Важно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
Если боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
# sgdisk -R /dev/sdb /dev/sdaВажно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
# sgdisk -G /dev/sdbЕсли боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
В Linux есть любопытный бинарник
Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
Код выхода у неё ошибочный, то есть 1.
Узнал про
Вообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
/bin/true, про который я узнал случайно. Стал искать подробности и наткнулся на интересную информацию про него. Сначала про него расскажу, а потом как я на него наткнулся. Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
# Copyright (c) 1984 AT&T # All Rights Reserved # THIS IS UNPUBLISHED PROPRIETARY SOURCE CODE OF AT&T # The copyright notice above does not evidence any # actual or intended publication of such source code. #ident "@(#)cmd/true.sh 50.1"По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
/bin/false:# /bin/false# echo $?1Код выхода у неё ошибочный, то есть 1.
Узнал про
/bin/true я случайно, когда в Debian смотрел systemd unit от postfix /lib/systemd/system/postfix.service. Открываю, а там такое:[Unit]Description=Postfix Mail Transport AgentConflicts=sendmail.service exim4.serviceConditionPathExists=/etc/postfix/main.cf[Service]Type=oneshotRemainAfterExit=yesExecStart=/bin/trueExecReload=/bin/true[Install]WantedBy=multi-user.targetВообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
postfix@.service, где уже описаны все параметры запуска конкретного экземпляра почтового сервера. При этом в /etc/systemd/system/multi-user.target.wants есть символьная ссылка только на postfix.service, поэтому сразу не очевидно, что там зависимые юниты есть.В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
🎓 Сегодня пятница, а пятница — это почти выходной, когда уже не хочется заниматься делами. Лучше это время потратить с пользой и заняться самообразованием. А в этом нам может помочь набор TUI программ для обучения в консоли.
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
Запускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
Ответ правильный и мне предлагают ещё вариант:
С sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
Я ошибся и срезал только 4 строки. Поправился:
Утилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
Тоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
#обучение #terminal #bash
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
# python3 -m venv textual_apps# cd textual_apps# source bin/activate# pip install cliexercises# cliexercisesЗапускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
head -n 5 ip.txtОтвет правильный и мне предлагают ещё вариант:
sed '5q' ip.txtС sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
tail -n +5 blocks.txt Я ошибся и срезал только 4 строки. Поправился:
tail -n +6 blocks.txtУтилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
sed '1,5d' blocks.txtТоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
awk 'NR>5' blocks.txt Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
%=%=, надо вывести 3-й блок. Для меня это уже сложно, чтобы что-то сходу придумать. Вот решение:awk '$0 == \"%=%=\"{c++} c==3' blocks.txt#обучение #terminal #bash
{kind=link}
🔝Топ постов за прошедший месяц. Пробивка инфы СБ при приёме на работу породила активное обсуждение всего, что только можно и продолжалась даже вчера. В заметке не была затронута и не подразумевалась политическая подоплёка, но в результате некоторые дошли до политики Ленина и обсуждают это до сих пор. Хотя в заметке была речь о СБ коммерческой организации.
📌 Больше всего просмотров:
◽️Обход блокировки бесплатной версии Anydesk (10644)
◽️Шутка про Kubernetes (10045)
◽️Заморозка списка процессов в диспетчере задач (9393)
📌 Больше всего комментариев:
◽️Пробивка публичной инфы при приёме на работу (248)
◽️Проблемы со спиной при сидячей работе (209)
◽️Информация по вакансиям в IT (199)
📌 Больше всего пересылок:
◽️Бесплатные уроки от RedHat (423)
◽️Сервис CMD Generator (387)
◽️Обход блокировки бесплатной версии Anydesk (353)
◽️Ttyd для шаринга консоли сервера (327)
📌 Больше всего реакций:
◽️Заморозка списка процессов в диспетчере задач (281)
◽️Обход блокировки бесплатной версии Anydesk (188)
◽️Подход pet vs cattle (177)
◽️Перенос VM с Hyper-V на Proxmox (169)
#топ
📌 Больше всего просмотров:
◽️Обход блокировки бесплатной версии Anydesk (10644)
◽️Шутка про Kubernetes (10045)
◽️Заморозка списка процессов в диспетчере задач (9393)
📌 Больше всего комментариев:
◽️Пробивка публичной инфы при приёме на работу (248)
◽️Проблемы со спиной при сидячей работе (209)
◽️Информация по вакансиям в IT (199)
📌 Больше всего пересылок:
◽️Бесплатные уроки от RedHat (423)
◽️Сервис CMD Generator (387)
◽️Обход блокировки бесплатной версии Anydesk (353)
◽️Ttyd для шаринга консоли сервера (327)
📌 Больше всего реакций:
◽️Заморозка списка процессов в диспетчере задач (281)
◽️Обход блокировки бесплатной версии Anydesk (188)
◽️Подход pet vs cattle (177)
◽️Перенос VM с Hyper-V на Proxmox (169)
#топ
Настраивал на днях на Proxmox Backup Server отправку email уведомлений. Использовал для этого почту Яндекса. Расскажу, как это сделал, так как там есть нюансы.
Ставим утилиты, которые нам понадобятся для настройки и диагностики:
В почтовом ящике Яндекса создаём пароль для приложения. Без него не работает smtp аутентификация в сторонних приложениях. После этого создаём файл
Формат такой: имя сервера, логин, пароль приложения.
Дальше создадим ещё один файл
Содержимое файла
Заменили локальный ящик на ящик Яндекса.
Назначаем права и формируем хэш файлы:
Редактируем конфигурационный файл postfix -
До пустой строки то, что было по умолчанию, после - то, что добавил я. Пустое значение
Перечитываем конфигурацию postfix:
И пробуем отправить тестовое письмо через консоль:
В логе
Письмо успешно доставлено. Теперь надо указать почтовый ящик для локального пользователя root@pam, чтобы почта отправлялась на внешний ящик, а не локальный
Инструкция будет актуальна и для PVE, только замену адреса отправителя можно не настраивать через консоль, так как в веб интерфейсе есть настройка для этого: Datacenter ⇨ Options ⇨ Email from address.
#proxmox
Ставим утилиты, которые нам понадобятся для настройки и диагностики:
# apt install -y libsasl2-modules mailutilsВ почтовом ящике Яндекса создаём пароль для приложения. Без него не работает smtp аутентификация в сторонних приложениях. После этого создаём файл
/etc/postfix/sasl_passwd следующего содержания:smtp.yandex.ru mailbox@yandex.ru:sjmprudhjgfmrdsФормат такой: имя сервера, логин, пароль приложения.
Дальше создадим ещё один файл
/etc/postfix/generic. Он нам нужен для того, чтобы заменять адрес отправителя. Яндекс разрешает отправлять только тому отправителю, кто является владельцем ящика. В нашем случае mailbox@yandex.ru, а pbs будет пытаться отправлять почту от системного пользователя root@servername.ru. Точно узнать почтовый адрес системного пользователя можно в лог файле postfix - /var/log/mail.log. Там вы увидите попытки отправки, где отправитель будет указан примерно так: 9D8CC3C81DE4: from=<root@pbs.servername.ru>.Содержимое файла
/etc/postfix/generic следующее:root@pbs.servername.ru mailbox@yandex.ruЗаменили локальный ящик на ящик Яндекса.
Назначаем права и формируем хэш файлы:
# postmap hash:/etc/postfix/sasl_passwd hash:/etc/postfix/generic# chmod 600 /etc/postfix/sasl_passwd /etc/postfix/genericРедактируем конфигурационный файл postfix -
/etc/postfix/main.cf. Приводим его к виду:myhostname=pbs.servername.rusmtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)biff = noappend_dot_mydomain = noalias_maps = hash:/etc/aliasesalias_database = hash:/etc/aliasesmydestination = $myhostname, localhost.$mydomain, localhostmynetworks = 127.0.0.0/8inet_interfaces = loopback-onlyrecipient_delimiter = +compatibility_level = 2relayhost = smtp.yandex.ru:465smtp_use_tls = yessmtp_sasl_auth_enable = yessmtp_sasl_security_options =smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwdsmtp_tls_CAfile = /etc/ssl/certs/Entrust_Root_Certification_Authority.pemsmtp_tls_session_cache_database = btree:/var/lib/postfix/smtp_tls_session_cachesmtp_tls_session_cache_timeout = 3600ssmtp_tls_wrappermode = yessmtp_tls_security_level = encryptsmtp_generic_maps = hash:/etc/postfix/genericДо пустой строки то, что было по умолчанию, после - то, что добавил я. Пустое значение
relayhost =, что было по умолчанию, я удалил. Перечитываем конфигурацию postfix:
# postfix reloadИ пробуем отправить тестовое письмо через консоль:
# echo "Message for test" | mail -s "Test subject" zeroxzed@gmail.comВ логе
/var/log/mail.info должно быть примерно следующее:Sep 29 21:47:24 pbs postfix/pickup[640930]: E282E3C820D6: uid=0 from=<root@pbs.servername.ru>Sep 29 21:47:25 pbs postfix/cleanup[640993]: E282E3C820D6: message-id=<20230929184724.E282E3C820D6@pbs.servername.ru>Sep 29 21:47:25 pbs postfix/qmgr[640929]: E282E3C820D6: from=<root@pbs.servername.ru>, size=348, nrcpt=1 (queue active)Sep 29 21:47:25 pbs postfix/smtp[640994]: E282E3C820D6: to=<zeroxzed@gmail.com>, relay=smtp.yandex.ru[77.88.21.158]:465, delay=1.1, delays=0.34/0.01/0.51/0.2, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued on mail-nwsmtp-smtp-production-main-84.vla.yp-c.yandex.net 1696013245-PlXVUC7DXqM0-wnVoD1Uo)Sep 29 21:47:25 pbs postfix/qmgr[640929]: E282E3C820D6: removedПисьмо успешно доставлено. Теперь надо указать почтовый ящик для локального пользователя root@pam, чтобы почта отправлялась на внешний ящик, а не локальный
/var/spool/mail/root. Сделать это можно через web интерфейс в разделе Configuration ⇨ Access Control. Выбираем пользователя root и в свойствах указываем его ящик. Теперь вся почта, что настроена в PBS для пользователя root@pam будет попадать во внешний ящик. Инструкция будет актуальна и для PVE, только замену адреса отправителя можно не настраивать через консоль, так как в веб интерфейсе есть настройка для этого: Datacenter ⇨ Options ⇨ Email from address.
#proxmox