
Затрону актуальную тему для всех, у кого сидячая работа, как у нас. Я уже не раз писал про мои эксперименты с работой стоя за соответствующим столом. Вот они: раз, два, и даже статья на сайте есть. Сейчас итог такой - работаю сидя, стол отдал сыну в качестве обычного сидячего стола. Рассказываю, почему так.
Я экспериментировал со стоячим столом примерно 3 года. Сразу скажу, что у меня подростковая травма позвоночника, которая после 30 лет стала сильно донимать во всех отделах позвоночника: протрузии, грыжи, s-образный сколиоз, высыхание межпозвоночных дисков. То есть у меня не типичная история среднестатистического сидячего человека, а скорее травмированного. Ситуация не совсем прям плохая, но в среднем хуже, чем у остальных. Постоянные занятия и аккуратная активность позволяют вести более менее нормальный образ жизни.
У меня по факту получилось так, что в долгосрочной перспективе что сидя, что стоя, долго работать всё равно нельзя. Поэтому я решил не морочиться с разными столами, а просто работаю сидя интервалами по 2-3 часа. Не сижу весь день за рабочим местом. А в таком режиме особой разницы нет, за каким столом ты работаешь. Так как у меня свободный рабочий график, то я могу себе позволить такой режим: по 2-3 интервала в день. В перерывах могу своими делами заниматься, куда-то съездить, позаниматься сходить и т.д.
Есть один вариант стола, который мне точно был бы полезен. Я даже со своим врачом обсуждал его. Он согласился, что вариант реально удобный без каких-то противопоказаний, типа полностью стоячего. Вот обзор стола:
https://habr.com/ru/companies/easyworkstation/articles/711434/
А вот сразу видео:
▶️ https://www.youtube.com/watch?v=7LXScZ2qZyA
Я очень хочу такое рабочее место, на сейчас мне его тупо некуда поставить. Надо много пространства. Работаю над решением этого вопроса. Ну и цена, конечно, кусается. Но тот, кто долго занимается проблемами со здоровьем, уже не экономит на этом, если есть возможность. Потом на лечение больше отдашь, чем на профилактику.
Ели же у вас в целом нет проблем со спиной, то комбинирование работы то сидя, то стоя (❗️) - хорошая идея. Я вспомнил про эту тему, когда недавно посмотрел на канале отзыв одного айтишника после того, как он купил себе удобный стоячий стол:
▶️ https://www.youtube.com/watch?v=ukWLBvEzoSk
Он прям в восторге. Я посмотрел цены на эти столы, они очень демократичные. Так что вполне можно приобрести. Не сильно дороже обычных. Даже если не понравится работать стоят, будет просто хороший стол. Мой, к примеру, так и служит, как самый обычный стол. При этом его и сидя можно подрегулировать под свой рост, что очень удобно для растущего ребёнка. Так что стол мой даром не пропал, а активно используется.
Если у вас есть свой опыт работы стоя, поделитесь.
#разное #здоровье
Я экспериментировал со стоячим столом примерно 3 года. Сразу скажу, что у меня подростковая травма позвоночника, которая после 30 лет стала сильно донимать во всех отделах позвоночника: протрузии, грыжи, s-образный сколиоз, высыхание межпозвоночных дисков. То есть у меня не типичная история среднестатистического сидячего человека, а скорее травмированного. Ситуация не совсем прям плохая, но в среднем хуже, чем у остальных. Постоянные занятия и аккуратная активность позволяют вести более менее нормальный образ жизни.
У меня по факту получилось так, что в долгосрочной перспективе что сидя, что стоя, долго работать всё равно нельзя. Поэтому я решил не морочиться с разными столами, а просто работаю сидя интервалами по 2-3 часа. Не сижу весь день за рабочим местом. А в таком режиме особой разницы нет, за каким столом ты работаешь. Так как у меня свободный рабочий график, то я могу себе позволить такой режим: по 2-3 интервала в день. В перерывах могу своими делами заниматься, куда-то съездить, позаниматься сходить и т.д.
Есть один вариант стола, который мне точно был бы полезен. Я даже со своим врачом обсуждал его. Он согласился, что вариант реально удобный без каких-то противопоказаний, типа полностью стоячего. Вот обзор стола:
https://habr.com/ru/companies/easyworkstation/articles/711434/
А вот сразу видео:
▶️ https://www.youtube.com/watch?v=7LXScZ2qZyA
Я очень хочу такое рабочее место, на сейчас мне его тупо некуда поставить. Надо много пространства. Работаю над решением этого вопроса. Ну и цена, конечно, кусается. Но тот, кто долго занимается проблемами со здоровьем, уже не экономит на этом, если есть возможность. Потом на лечение больше отдашь, чем на профилактику.
Ели же у вас в целом нет проблем со спиной, то комбинирование работы то сидя, то стоя (❗️) - хорошая идея. Я вспомнил про эту тему, когда недавно посмотрел на канале отзыв одного айтишника после того, как он купил себе удобный стоячий стол:
▶️ https://www.youtube.com/watch?v=ukWLBvEzoSk
Он прям в восторге. Я посмотрел цены на эти столы, они очень демократичные. Так что вполне можно приобрести. Не сильно дороже обычных. Даже если не понравится работать стоят, будет просто хороший стол. Мой, к примеру, так и служит, как самый обычный стол. При этом его и сидя можно подрегулировать под свой рост, что очень удобно для растущего ребёнка. Так что стол мой даром не пропал, а активно используется.
Если у вас есть свой опыт работы стоя, поделитесь.
#разное #здоровье
{kind=link}
Не забыли, какой сегодня день? Я не смог пропустить это знаменательное событие. К сожалению, не знаю, что тут можно придумать новое, поэтому повторяю свою же шутку двухлетней давности.
Предлагаю кострам рябин гореть вечно:
Я настрою cron — и снова третье сентября.
Юморнул, как умею 😁 Строго не судите. Мне кажется, это прикольный шуточный день, хоть и выглядит немного глупо.
#юмор
Предлагаю кострам рябин гореть вечно:
sudo echo "0 0 * * * root date 0903\`date +"%H%M"\`" >> /etc/crontabЯ настрою cron — и снова третье сентября.
Юморнул, как умею 😁 Строго не судите. Мне кажется, это прикольный шуточный день, хоть и выглядит немного глупо.
#юмор
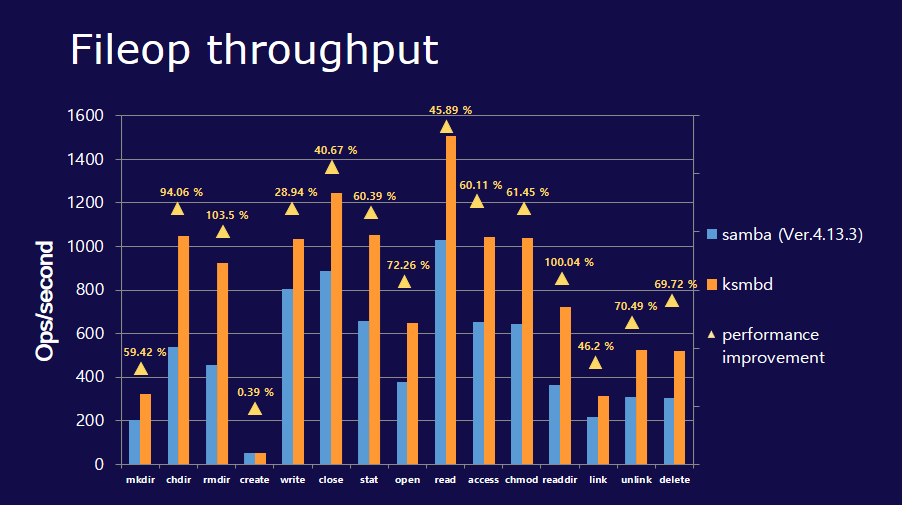
Некоторое время назад в ядро Linux завезли реализацию файлового сервера на базе протокола smb - ksmbd. Давно хотел его попробовать, но всё руки не доходили. А тут возникла потребность в простом файловом сервере для обмена файлами. Решил его попробовать.
Для поддержки ksmbd нужно относительно свежее ядро. В Ubuntu 22 и Debian 12 оно уже точно подходящей версии. Я как раз из анонсов Debian 12 про этот сервер и узнал. А вот в Debian 11 наверняка не знаю, надо уточнять, приехала ли туда поддержка ksmbd. Если нет, то лучше обойтись привычной самбой.
Настроить ksmbd реально очень просто и быстро. Показываю по шагам. Устанавливаем службу:
Рисуем конфиг
Ksmbd использует сопоставление с системным пользователем, так что добавляем его:
И сопоставляем с пользователем ksmbd:
После изменения конфигурации, необходимо перезапустить службу:
В автозагрузку она добавляется автоматически после установки.
После этого зашёл через свежий Windows Server 2022. Всё заработало сразу без танцев с бубнами, что бывает нередко, когда настраиваешь самбу. Не забудьте только права проверить, чтобы пользователи ksmbd имели доступ к директории, которую вы расшарили.
Погуглил немного настройки ksmbd. Хотел узнать, можно ли там, как в самбе, делать сразу в конфигурации ограничения на доступ не по пользователям, а по IP. Не увидел таких настроек. В принципе, они не сильно актуальны, так как сейчас почти во всех системах закрыт по умолчанию анонимный доступ по smb. Так что всё равно надо настраивать аутентификацию, а если надо ограничить доступ на уровне сети, использовать firewall.
Кстати, поддержка Win-ACL, Kerberos есть, судя по документации. Если верить тестам из репозитория разработчиков, то ksmbd работает заметно быстрее samba. Так что если для вас это критично, попробуйте.
#fileserver #linux #smb
Для поддержки ksmbd нужно относительно свежее ядро. В Ubuntu 22 и Debian 12 оно уже точно подходящей версии. Я как раз из анонсов Debian 12 про этот сервер и узнал. А вот в Debian 11 наверняка не знаю, надо уточнять, приехала ли туда поддержка ksmbd. Если нет, то лучше обойтись привычной самбой.
Настроить ksmbd реально очень просто и быстро. Показываю по шагам. Устанавливаем службу:
# apt install ksmbd-toolsРисуем конфиг
/etc/ksmbd/ksmbd.conf:[global] netbios name = 1cbackup map to guest = never[backup] comment = 1C_backup path = /mnt/backup writeable = yes users = ksmbduserKsmbd использует сопоставление с системным пользователем, так что добавляем его:
# useradd -s /sbin/nologin ksmbduserИ сопоставляем с пользователем ksmbd:
# ksmbd.adduser --add-user=ksmbduserПосле изменения конфигурации, необходимо перезапустить службу:
# systemctl restart ksmbdВ автозагрузку она добавляется автоматически после установки.
После этого зашёл через свежий Windows Server 2022. Всё заработало сразу без танцев с бубнами, что бывает нередко, когда настраиваешь самбу. Не забудьте только права проверить, чтобы пользователи ksmbd имели доступ к директории, которую вы расшарили.
Погуглил немного настройки ksmbd. Хотел узнать, можно ли там, как в самбе, делать сразу в конфигурации ограничения на доступ не по пользователям, а по IP. Не увидел таких настроек. В принципе, они не сильно актуальны, так как сейчас почти во всех системах закрыт по умолчанию анонимный доступ по smb. Так что всё равно надо настраивать аутентификацию, а если надо ограничить доступ на уровне сети, использовать firewall.
Кстати, поддержка Win-ACL, Kerberos есть, судя по документации. Если верить тестам из репозитория разработчиков, то ksmbd работает заметно быстрее samba. Так что если для вас это критично, попробуйте.
#fileserver #linux #smb
{kind=link}
Если вам внезапно захочется запустить кого-нибудь или самому зайти в консоль через web, то предлагаю очень простой и быстрый способ. Воспользуйтесь утилитой ttyd.
Достаточно её скачать из репозитория:
Переименовать и сделать исполняемой:
Запускаем bash через браузер:
В консоли увидите порт, на котором запустилась программа. Откройте этот порт в браузере: http://172.22.221.121:7681 и увидите свою консоль.
Таким образом можно открыть не только bash, но и любую другую программу. Например, можно очень просто и быстро вывести через браузер top:
или mc:
Если запустить ttyd без параметров, то увидите все доступные ключи. Можно указать используемый порт, забиндить на какой-то конкретный интерфейс, настроит basic аутентификацию, задать режим read-only и т.д. Там много интересных возмоностей.
Утилита простая и удобная. Люблю такие. Никаких заморочек с настройкой и установкой. Скорее всего прямо сейчас она вряд ли пригодится, но стоит запомнить, что есть такая возможность. Иногда это может быть полезным. Банально тот же top повесить на всеобщий обзор для каких-то целей отладки. Это быстрее, чем настраивать кому-то доступ по ssh.
#bash #terminal
Достаточно её скачать из репозитория:
# wget https://github.com/tsl0922/ttyd/releases/download/1.7.3/ttyd.i686Переименовать и сделать исполняемой:
# mv ttyd.i686 /usr/local/bin/ttyd# chmod +x /usr/local/bin/ttydЗапускаем bash через браузер:
# ttyd bashВ консоли увидите порт, на котором запустилась программа. Откройте этот порт в браузере: http://172.22.221.121:7681 и увидите свою консоль.
Таким образом можно открыть не только bash, но и любую другую программу. Например, можно очень просто и быстро вывести через браузер top:
# ttyd topили mc:
# ttyd mcЕсли запустить ttyd без параметров, то увидите все доступные ключи. Можно указать используемый порт, забиндить на какой-то конкретный интерфейс, настроит basic аутентификацию, задать режим read-only и т.д. Там много интересных возмоностей.
Утилита простая и удобная. Люблю такие. Никаких заморочек с настройкой и установкой. Скорее всего прямо сейчас она вряд ли пригодится, но стоит запомнить, что есть такая возможность. Иногда это может быть полезным. Банально тот же top повесить на всеобщий обзор для каких-то целей отладки. Это быстрее, чем настраивать кому-то доступ по ssh.
#bash #terminal
{kind=link}
Много раз в заметках упоминал про сервис по рисованию различных схем draw.io. Судя по отзывам, большая часть использует именно его в своей работе. Схемы из draw.io относительно легко можно наложить на мониторинг на базе Grafana. Если вы с ней работаете, то особых проблем не должно возникнуть. Если нет, то не скажу, что настройка будет простой. Но в целом, ничего особенного. Мне когда надо было, освоил Grafana за пару дней для простого мониторинга.
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
{kind=link}
Хочу предложить вашему вниманию bash скрипт по проверке статуса работы Nginx. Обращаю внимание именно на него, потому что он классно написан и его можно взять за основу для любой похожей задачи. Сейчас подробно расскажу, что там происходит.
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
{kind=link}
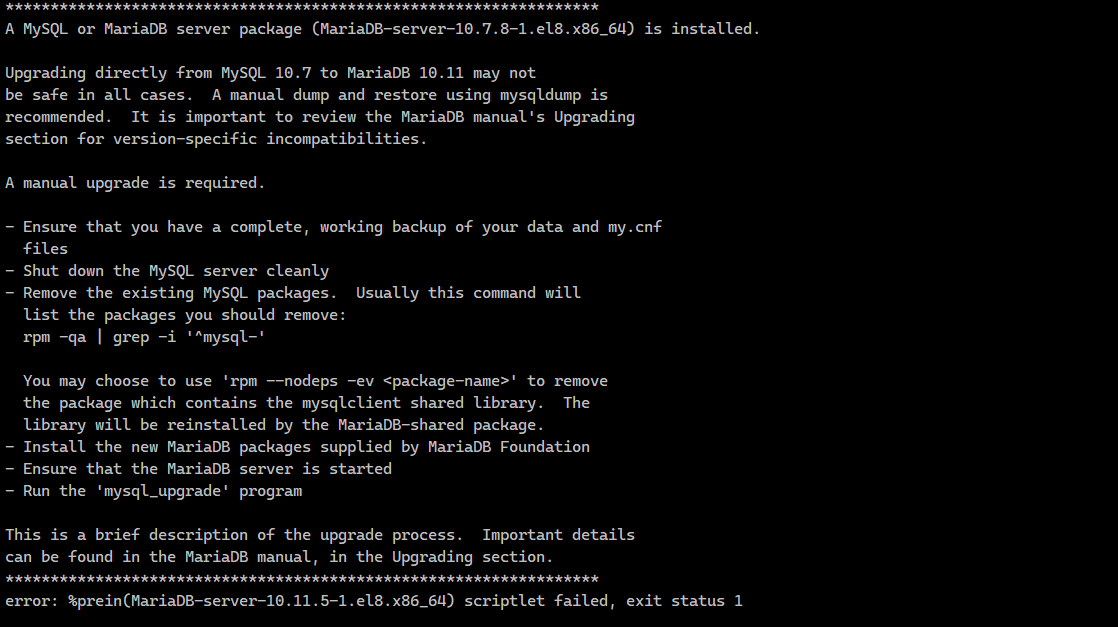
Нередко сталкиваюсь на относительно старых серверах ещё на форках RHEL (RockyLinux, Oracle Linux) при обновлении сервера ошибку доступа к репозиториям MariaDB. Они перестают существовать и отдают 404 ошибку. Сейчас уже не помню, то ли я сам выбирал установку последней на тот момент версии, не обращая внимание на время eol, то ли это скрипт автоматической установки реп от разработчиков подключал эти версии. Но смысл в том, что версии 10.7, 10.8, 10.9 уже не поддерживают и их репозитории на dlm.mariadb.com закрыты.
Привычка ставить mariadb из репозитория разработчиков появилась со времён использования Centos, так как там в базовых репозиториях всегда были очень старые версии. Сейчас так не делаю. В Debian ставлю из базовых реп, чтобы не заниматься вот этой работой.
Старые репозитории подключены примерно так:
Соответственно, когда версия снимается с поддержки, через некоторое время исчезает и репозиторий и отвечает 404-й ошибкой. Из-за этого обновление пакетов вообще не работает, пока не отключишь репозиторий или не исправишь на существующий.
На текущий момент свежая версия MariaDB 11.2. Скрипт автоматического подключения репозиториев от разработчиков подключит именно эту версию. Но лично мне нет нужды обновляться на 11-ю версию, так как у меня всё ещё работают Zabbix сервера 5-й версии, которая будет поддерживаться ещё два года.
Экспериментировать с новой версией на ровном месте нет никакого желания, поэтому использую по прежнему 10-ю версию. На текущий момент актуальная версия MariaDB-server-10.11. Соответственно, репозиторий с ней будет такой:
Это пример из Oracle Linux Server 8. У вас итоговая строка может быть другой в зависимости от дистрибутива. Главное, версию указать 10.11.
Отдельно упомяну процедуру обновления. В общем случае не рекомендуется обновлять наживую mariadb server на 10.11. Вы получите при обновлении пакета предупреждение, где будет сказано, что автоматическое обновление невозможно, сделайте дамп баз, обновите вручную и восстановите данные из дампа.
Я так понимаю, что это предостережение на всякий случай для каких-то пограничных ситуаций. В общем случае обновление проходит штатно по следующей процедуре:
1️⃣ Удаляем текущую версию mariadb-server (разумеется, делаем бэкап).
2️⃣ Подключаем новый репозиторий, ставим свежую версию из него.
3️⃣ Запускаем новую версию mariadb-server, не боимся страшных предупреждений.
4️⃣ После старта сервера, запускаем скрипт mysql_upgrade, указывая учётку СУБД root. Скрипт отработает и внесёт все необходимые изменения в старые базы.
5️⃣ После этого можно перезапустить mariadb сервер и убедиться, что всё в порядке с базами и данными в них.
#mariadb
Привычка ставить mariadb из репозитория разработчиков появилась со времён использования Centos, так как там в базовых репозиториях всегда были очень старые версии. Сейчас так не делаю. В Debian ставлю из базовых реп, чтобы не заниматься вот этой работой.
Старые репозитории подключены примерно так:
baseurl = https://dlm.mariadb.com/repo/mariadb-server/10.7/yum/rhel/8/x86_64Соответственно, когда версия снимается с поддержки, через некоторое время исчезает и репозиторий и отвечает 404-й ошибкой. Из-за этого обновление пакетов вообще не работает, пока не отключишь репозиторий или не исправишь на существующий.
На текущий момент свежая версия MariaDB 11.2. Скрипт автоматического подключения репозиториев от разработчиков подключит именно эту версию. Но лично мне нет нужды обновляться на 11-ю версию, так как у меня всё ещё работают Zabbix сервера 5-й версии, которая будет поддерживаться ещё два года.
Экспериментировать с новой версией на ровном месте нет никакого желания, поэтому использую по прежнему 10-ю версию. На текущий момент актуальная версия MariaDB-server-10.11. Соответственно, репозиторий с ней будет такой:
baseurl = https://dlm.mariadb.com/repo/mariadb-server/10.11/yum/rhel/8/x86_64Это пример из Oracle Linux Server 8. У вас итоговая строка может быть другой в зависимости от дистрибутива. Главное, версию указать 10.11.
Отдельно упомяну процедуру обновления. В общем случае не рекомендуется обновлять наживую mariadb server на 10.11. Вы получите при обновлении пакета предупреждение, где будет сказано, что автоматическое обновление невозможно, сделайте дамп баз, обновите вручную и восстановите данные из дампа.
Я так понимаю, что это предостережение на всякий случай для каких-то пограничных ситуаций. В общем случае обновление проходит штатно по следующей процедуре:
1️⃣ Удаляем текущую версию mariadb-server (разумеется, делаем бэкап).
2️⃣ Подключаем новый репозиторий, ставим свежую версию из него.
3️⃣ Запускаем новую версию mariadb-server, не боимся страшных предупреждений.
4️⃣ После старта сервера, запускаем скрипт mysql_upgrade, указывая учётку СУБД root. Скрипт отработает и внесёт все необходимые изменения в старые базы.
5️⃣ После этого можно перезапустить mariadb сервер и убедиться, что всё в порядке с базами и данными в них.
#mariadb
{kind=link}
Постоянно приходится заниматься вопросами сбора и анализа логов веб серверов. Решил сделать подборку инструментов для этих целей от самых навороченных, типа ELK, до одиночных консольных утилит.
✅ Сам я чаще всего использую именно ELK, потому что привык к нему, умею настраивать, есть все заготовки и понимание, как собрать необходимые дашборды. Минусов у этого решения два:
◽ELK очень прожорливый.
◽Порог входа довольно высокий. Но тем не менее, ничего запредельного там нет. У меня знакомый с нуля по моей статье за несколько дней во всём разобрался. Немного позадавал мне вопросов, чтобы побыстрее вникнуть в суть. А дальше сам. В итоге всю базу освоил, логи собрал, дашборды сделал. В общем, было бы желание, можно и без дорогих курсов разобраться с основами. Сразу плюс к резюме и будущей зарплате.
Про #elk я много писал как здесь, так и на сайте есть разные статьи.
🟢 Альтернатива ELK - Loki от Grafana. Сразу скажу, что опыта с ним у меня нет. Так и не собрался, нигде его не внедрил. Всё как-то лениво. Использую привычные и знакомые инструменты. Плюсы у Loki по сравнению с ELK существенные, а конкретно:
◽кушает меньше ресурсов;
◽проще настроить и разобраться.
Из минусов — меньше гибкости и возможностей по сравнению с ELK, но во многих случаях всего этого и не надо. Если бы сейчас мне нужно было собрать логи веб сервера и я бы выбирал из незнакомых инструментов, начал бы с Loki.
🟢 Ещё один вариант — облачный сервис axiom.co. У него есть бесплатный тарифный план, куда можно очень быстро настроить отправку и хранение логов общим объёмом до 500 ГБ!!! Зачастую этого хватает за глаза. В него можно отправить распарсенные grok фильтром логи, как в ELK и настроить простенькие дашборды, которых во многих случаях хватит для простого анализа. Мне понравился этот сервис, использую его как дубль некоторых других систем. Денег же не просит, почему бы не использовать.
Далее упомяну системы попроще, для одиночных серверов. Даже не системы, а утилиты, которых иногда может оказаться достаточно.
🟡 Классная бесплатная утилита goaccess, которая умеет показывать статистику логов веб сервера в режиме онлайн в консоли. Либо генерировать статические html страницы для просмотра статистики в браузере. Устанавливается и настраивается очень легко и быстро. Подробности есть в моей заметке. Интересная программа, рекомендую. Пример html страницы.
🟡 Ещё один вариант консольной программы — lnav. Он заточен не только под веб сервер, но понимает и его формат в виде базовых настроек access логов.
Перечислю ещё несколько решений по теме для полноты картины, с которыми я сам не работал, но знаю про них: Graylog, OpenSearch.
❗️Если забыл что-то известное, удобное, подходящее, дополните в комментариях.
#logs #webserver #подборка
✅ Сам я чаще всего использую именно ELK, потому что привык к нему, умею настраивать, есть все заготовки и понимание, как собрать необходимые дашборды. Минусов у этого решения два:
◽ELK очень прожорливый.
◽Порог входа довольно высокий. Но тем не менее, ничего запредельного там нет. У меня знакомый с нуля по моей статье за несколько дней во всём разобрался. Немного позадавал мне вопросов, чтобы побыстрее вникнуть в суть. А дальше сам. В итоге всю базу освоил, логи собрал, дашборды сделал. В общем, было бы желание, можно и без дорогих курсов разобраться с основами. Сразу плюс к резюме и будущей зарплате.
Про #elk я много писал как здесь, так и на сайте есть разные статьи.
🟢 Альтернатива ELK - Loki от Grafana. Сразу скажу, что опыта с ним у меня нет. Так и не собрался, нигде его не внедрил. Всё как-то лениво. Использую привычные и знакомые инструменты. Плюсы у Loki по сравнению с ELK существенные, а конкретно:
◽кушает меньше ресурсов;
◽проще настроить и разобраться.
Из минусов — меньше гибкости и возможностей по сравнению с ELK, но во многих случаях всего этого и не надо. Если бы сейчас мне нужно было собрать логи веб сервера и я бы выбирал из незнакомых инструментов, начал бы с Loki.
🟢 Ещё один вариант — облачный сервис axiom.co. У него есть бесплатный тарифный план, куда можно очень быстро настроить отправку и хранение логов общим объёмом до 500 ГБ!!! Зачастую этого хватает за глаза. В него можно отправить распарсенные grok фильтром логи, как в ELK и настроить простенькие дашборды, которых во многих случаях хватит для простого анализа. Мне понравился этот сервис, использую его как дубль некоторых других систем. Денег же не просит, почему бы не использовать.
Далее упомяну системы попроще, для одиночных серверов. Даже не системы, а утилиты, которых иногда может оказаться достаточно.
🟡 Классная бесплатная утилита goaccess, которая умеет показывать статистику логов веб сервера в режиме онлайн в консоли. Либо генерировать статические html страницы для просмотра статистики в браузере. Устанавливается и настраивается очень легко и быстро. Подробности есть в моей заметке. Интересная программа, рекомендую. Пример html страницы.
🟡 Ещё один вариант консольной программы — lnav. Он заточен не только под веб сервер, но понимает и его формат в виде базовых настроек access логов.
Перечислю ещё несколько решений по теме для полноты картины, с которыми я сам не работал, но знаю про них: Graylog, OpenSearch.
❗️Если забыл что-то известное, удобное, подходящее, дополните в комментариях.
#logs #webserver #подборка
{kind=link}
Давно не просматривал вакансии по подходящим мне направлениям. У меня отпала в этом нужда, так как работаю либо по старым знакомствам, либо меня люди сами находят. Раньше регулярно мониторил рынок труда, чтобы не проседать по доходам и понимать, сколько мои навыки сейчас стоят. Рекомендую всем, кто работает по найму, регулярно просматривать вакансии и подтягивать себя по зарплате и навыкам к реальности.
Решил посидеть на hh и своими глазами посмотреть картину. Немного удивился, так как ожидал увидеть спад по предложениям и зарплатам. Но не наблюдаю такого.
Первое и самое большое удивление. Искал вакансии по слову Devops и возможностью работать удалённо. Увидел 1133 вакансии (❗️). Думаю, может каких-то мёртвых много. Ставлю фильтр "за месяц" и количество почти не уменьшается. Я так понимаю, что спрос на специалистов с современным стеком технологий очень велик. Он неудовлетворён. Наблюдал там как крупные компании, так и небольшие, локальные и международные с зарплатой как в рублях, так и в долларах. Есть вакансии из Белоруссии, из Казахстана.
Если убрать в фильтре "удалённая работа", то вакансий будет 3000+. Немного полистал список, и понял, что сюда загрузили практически всё ИТ (девопсы, сисадмины, системные инженеры, руководители и т.д.). В основном все вакансии на уровень middle и выше. Junior есть, но объективно мало. То есть лёгкого старта не будет.
Я к чему решил это написать. Если у вас зарплата меньше 200 т.р., то есть все шансы её увеличить. И отговорки о том, что у вас депрессивный регион, где нет работы, абсолютно на канают. В России рынок труда ИТ специалистов не насыщен. Предложений полно, зарплаты хорошие, почти треть полная удалёнка.
За два года учёбы и плотной работы с базы в виде основ Linux можно дорасти до уровня, когда можно будет откликаться на вакансии 200+ т.р. Это вот прям вообще реально. Я вижу это по требованиям и понимаю, что и как нужно сделать, чтобы обучиться.
Сейчас уникальное время, когда неограниченные знания практически в руках у каждого. Есть платные курсы, есть бесплатные обучающие материалы, есть те же курсы на торрентах. В общем, всё есть, было бы желание. Не сидите на низких зарплатах, если чувствуете, что это не ваше место.
На картинке ниже пример вакансии на 2500$ на руки (~235 т.р.). Требования вполне лояльные, ничего запредельного. Обычный уверенный Linux админ. Смущает только groovy, даже не знаю, что это. Но, думаю, если bash и python на уровне, то groovy простят.
#разное
Решил посидеть на hh и своими глазами посмотреть картину. Немного удивился, так как ожидал увидеть спад по предложениям и зарплатам. Но не наблюдаю такого.
Первое и самое большое удивление. Искал вакансии по слову Devops и возможностью работать удалённо. Увидел 1133 вакансии (❗️). Думаю, может каких-то мёртвых много. Ставлю фильтр "за месяц" и количество почти не уменьшается. Я так понимаю, что спрос на специалистов с современным стеком технологий очень велик. Он неудовлетворён. Наблюдал там как крупные компании, так и небольшие, локальные и международные с зарплатой как в рублях, так и в долларах. Есть вакансии из Белоруссии, из Казахстана.
Если убрать в фильтре "удалённая работа", то вакансий будет 3000+. Немного полистал список, и понял, что сюда загрузили практически всё ИТ (девопсы, сисадмины, системные инженеры, руководители и т.д.). В основном все вакансии на уровень middle и выше. Junior есть, но объективно мало. То есть лёгкого старта не будет.
Я к чему решил это написать. Если у вас зарплата меньше 200 т.р., то есть все шансы её увеличить. И отговорки о том, что у вас депрессивный регион, где нет работы, абсолютно на канают. В России рынок труда ИТ специалистов не насыщен. Предложений полно, зарплаты хорошие, почти треть полная удалёнка.
За два года учёбы и плотной работы с базы в виде основ Linux можно дорасти до уровня, когда можно будет откликаться на вакансии 200+ т.р. Это вот прям вообще реально. Я вижу это по требованиям и понимаю, что и как нужно сделать, чтобы обучиться.
Сейчас уникальное время, когда неограниченные знания практически в руках у каждого. Есть платные курсы, есть бесплатные обучающие материалы, есть те же курсы на торрентах. В общем, всё есть, было бы желание. Не сидите на низких зарплатах, если чувствуете, что это не ваше место.
На картинке ниже пример вакансии на 2500$ на руки (~235 т.р.). Требования вполне лояльные, ничего запредельного. Обычный уверенный Linux админ. Смущает только groovy, даже не знаю, что это. Но, думаю, если bash и python на уровне, то groovy простят.
#разное
{kind=link}
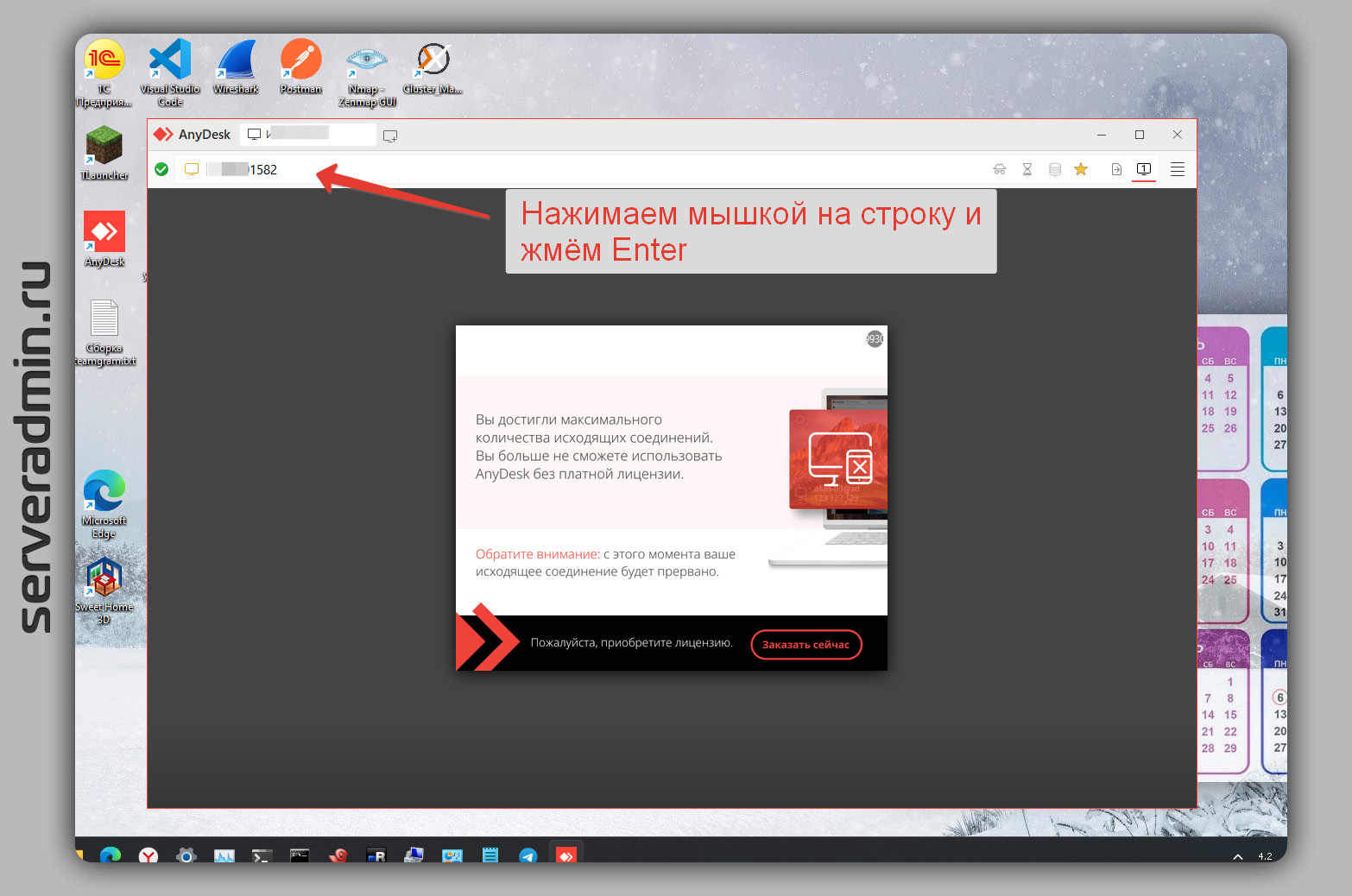
Очень простая и короткая заметка, которая наверняка будет полезна многим, кто пользуется AnyDesk. Для меня это было прям открытием и облегчением, когда узнал.
Если вы постоянно используете AnyDesk, то с высокой степенью вероятности вам будет предложено заплатить, чтобы нормально подключаться. В какой-то момент я стал постоянно получать такое предложение. Приходилось запускать AnyDesk в виртуалке и подключаться оттуда.
Где-то наверное год назад один человек подсказал, как спокойно продолжать использовать AnyDesk без всяких ограничений. С тех пор прошло много времени, способ всё ещё работает. Я много раз рассказывал о нём людям, которые не знали, что ограничение очень просто обойти. И таких людей немало.
Когда увидите табличку, где будет написано, что вы достигли максимального количества исходящих подключений, выделите мышкой строку с ID клиента и нажмите Enter. И вы успешно подключитесь без каких-либо ограничений.
#remote
Если вы постоянно используете AnyDesk, то с высокой степенью вероятности вам будет предложено заплатить, чтобы нормально подключаться. В какой-то момент я стал постоянно получать такое предложение. Приходилось запускать AnyDesk в виртуалке и подключаться оттуда.
Где-то наверное год назад один человек подсказал, как спокойно продолжать использовать AnyDesk без всяких ограничений. С тех пор прошло много времени, способ всё ещё работает. Я много раз рассказывал о нём людям, которые не знали, что ограничение очень просто обойти. И таких людей немало.
Когда увидите табличку, где будет написано, что вы достигли максимального количества исходящих подключений, выделите мышкой строку с ID клиента и нажмите Enter. И вы успешно подключитесь без каких-либо ограничений.
#remote
{kind=link}
На днях поднимал вопрос сбора логов веб сервера и забыл упомянуть одну систему, которую я знаю уже очень давно. Пользуюсь лет 8. Речь пойдёт про New Relic. Это очень мощная SaaS платформа по мониторингу и аналитике веб приложений и всего, что с ними связано, в том числе серверов. Я не раз уже писал о нём, но можно и ещё раз напомнить.
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
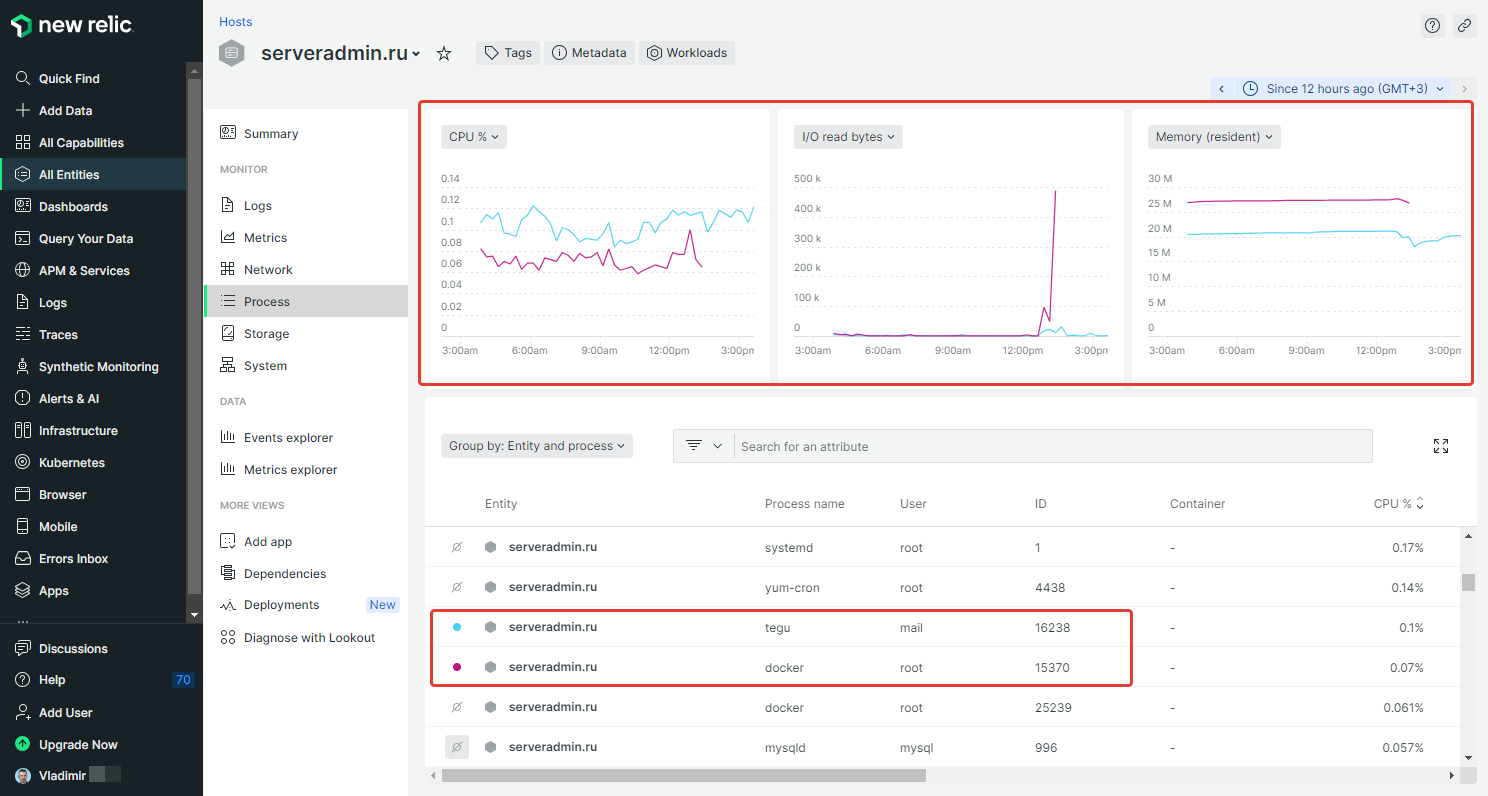
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Старая шутка вспомнилась про Кубернетис. Классно сделано, с душой.
В оригинале была семья. Кстати, этот вопрос, думаю, многих способен в тупик поставить. Как сами думаете? Но лично меня - нет. Я чётко знаю, зачем мне семья и почему я не хочу работать с Kubernetes.
#юмор
В оригинале была семья. Кстати, этот вопрос, думаю, многих способен в тупик поставить. Как сами думаете? Но лично меня - нет. Я чётко знаю, зачем мне семья и почему я не хочу работать с Kubernetes.
#юмор
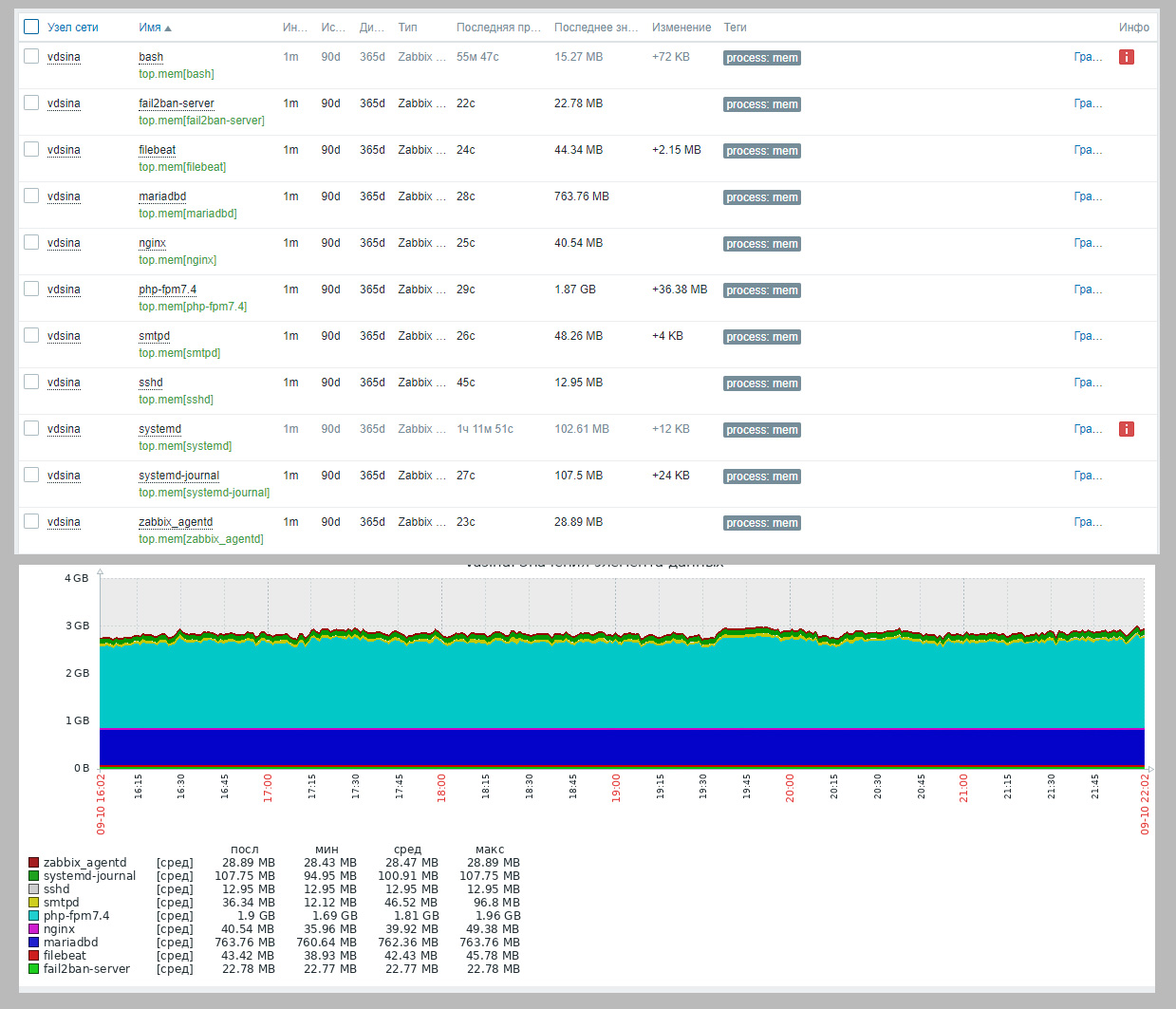
После публикации про мониторинг Newrelic, где можно наблюдать за каждым процессом в системе в отдельности, решил прикинуть, а как подобное реализовать в Zabbix. Итоговое решение по всем метрикам пока не созрело, но контроль использования памяти уже реализовал. Решил поделиться своими наработками. Может кто-то подскажет другие пути решения задачи.
Прикинул, как снимать метрики. Тут особо не пришлось ломать голову, так как сразу родилась идея с утилитами jc и jq, которые я давно знаю. Взял вывод ps, обернул его в json с помощью jc, отсортировал по метрике rss и вывел top 10:
Понравилось, как получилось. Закинул эти данные в отдельный айтем заббикса, но дальше тупик. Не понимаю, как это всё оформить в правила автообнаружения, чтобы автоматически создавались айтемы с именем процесса в названии, чтобы потом можно было для этих айтемов делать выборку с данными об rss из этого json.
Напомню, что у Zabbix свой определённый формат, иерархия и логика работы правил автообнаружения. Чтобы автоматически создавать айтемы, нужно подать на вход json следующего содержания:
Такую строку он сможет взять, на основе переданных значений
Взял вот такую конструкцию, которая анализирует вывод ps, формирует удобный список, который можно отсортировать с помощью sort и взять top 10 самых нагруженных по памяти процессов и в итоге вывести только их имена:
Далее обернул её в скрипт для формирования json для автообнаружения в Zabbix.
top_mem.discovery.sh:
На выходе получаем то, что нам надо:
Сразу же готовим второй скрипт, который будет принимать в качестве параметра имя процесса и отдавать его память (rss).
top_mem.sh:
Проверяем:
Добавляем в конфиг zabbix-agent:
Теперь идём на сервер, создаём шаблон, правило автообнаружения, прототип айтема, графика и сразу делаем панель.
Получилось удобно и функционально. Все нюансы не смог описать, так как лимит на длину поста. Нерешённый момент - особенности реализации LLD не позволяют автоматом закидывать все процессы на один график. Без API не знаю, как это сделать. Текущее решение придумал и опробовал за пару часов.
#zabbix
Прикинул, как снимать метрики. Тут особо не пришлось ломать голову, так как сразу родилась идея с утилитами jc и jq, которые я давно знаю. Взял вывод ps, обернул его в json с помощью jc, отсортировал по метрике rss и вывел top 10:
# ps axu | jc --ps -p | jq 'sort_by(.rss)' | jq .[-10:]..................................] { "user": "servera+", "pid": 1584266, "vsz": 348632, "rss": 109488, "tty": null, "stat": "S", "start": "19:41", "time": "0:28", "command": "php-fpm: pool serveradmin.ru", "cpu_percent": 0.5, "mem_percent": 2.7 }, { "user": "mysql", "pid": 853, "vsz": 2400700, "rss": 782060, "tty": null, "stat": "Ssl", "start": "Aug28", "time": "365:40", "command": "/usr/sbin/mariadbd", "cpu_percent": 1.8, "mem_percent": 19.4 }]..........................................Понравилось, как получилось. Закинул эти данные в отдельный айтем заббикса, но дальше тупик. Не понимаю, как это всё оформить в правила автообнаружения, чтобы автоматически создавались айтемы с именем процесса в названии, чтобы потом можно было для этих айтемов делать выборку с данными об rss из этого json.
Напомню, что у Zabbix свой определённый формат, иерархия и логика работы правил автообнаружения. Чтобы автоматически создавать айтемы, нужно подать на вход json следующего содержания:
[{"{#COMMAND}":"php-fpm7.4"},{"{#COMMAND}":"mariadbd"}.........,{"{#COMMAND}":"smtpd"}]Такую строку он сможет взять, на основе переданных значений
{#COMMAND} создать айтемы. Как мою json от ps приспособить под эти задачи, я не знал. Для этого можно было бы сделать обработку на javascript прямо в айтеме, но мне показалось это слишком сложным для меня путём. Решил всё сделать по старинке на bash.Взял вот такую конструкцию, которая анализирует вывод ps, формирует удобный список, который можно отсортировать с помощью sort и взять top 10 самых нагруженных по памяти процессов и в итоге вывести только их имена:
# ps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{print $2}'Далее обернул её в скрипт для формирования json для автообнаружения в Zabbix.
top_mem.discovery.sh:
#!/bin/bashTOPPROC=`ps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{print $2}'`JSON=$(for i in ${TOPPROC[@]}; do printf "{\"{#COMMAND}\":\"$i\"},"; done | sed 's/^\(.*\).$/\1/')printf "["printf "$JSON"printf "]"На выходе получаем то, что нам надо:
[{"{#COMMAND}":"php-fpm7.4"},........{"{#COMMAND}":"smtpd"}]Сразу же готовим второй скрипт, который будет принимать в качестве параметра имя процесса и отдавать его память (rss).
top_mem.sh:
#!/bin/bashps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | grep $1 | awk '{print $1}'Проверяем:
# ./top_mem.sh mariadbd780840Добавляем в конфиг zabbix-agent:
UserParameter=top.mem.discovery, /bin/bash /etc/zabbix/scripts/top_mem.discovery.shUserParameter=top.mem[*], /bin/bash /etc/zabbix/scripts/top_mem.sh $1Теперь идём на сервер, создаём шаблон, правило автообнаружения, прототип айтема, графика и сразу делаем панель.
Получилось удобно и функционально. Все нюансы не смог описать, так как лимит на длину поста. Нерешённый момент - особенности реализации LLD не позволяют автоматом закидывать все процессы на один график. Без API не знаю, как это сделать. Текущее решение придумал и опробовал за пару часов.
#zabbix
{kind=link}
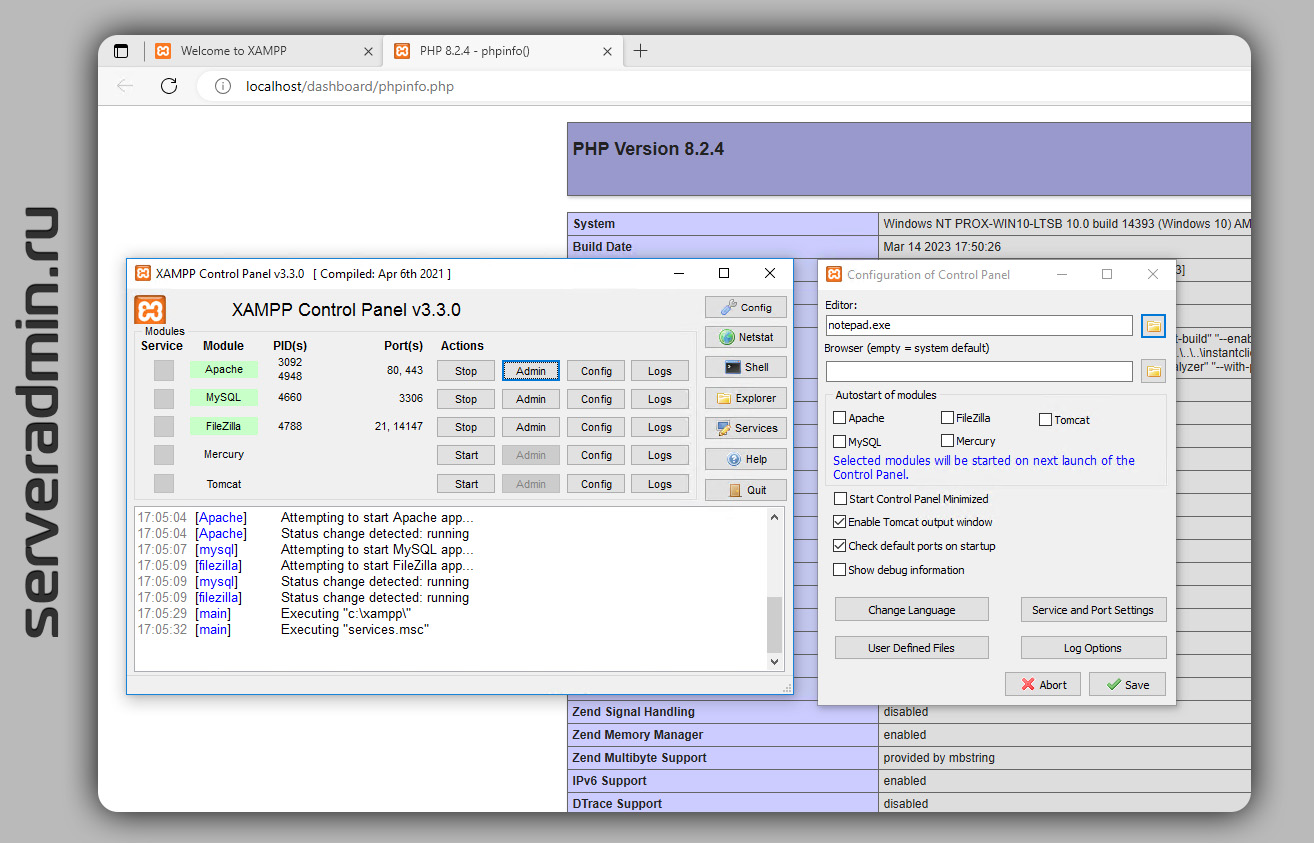
Увидел недавно в комментариях в ВК упоминание сборки XAMPP. Для тех, кто не в курсе, поясню, что это сборка локального веб-сервера, содержащая Apache, MariaDB, интерпретатор скриптов PHP, язык программирования Perl и большое количество дополнительных библиотек, позволяющих запустить полноценный веб-сервер. Подобные сборки были очень популярны лет 15-20 назад.
Среди подобных сборок наиболее популярны были Denver, позже появилась OSPanel, параллельно существовал и XAMPP. Я думал, что все эти панели уже отжили своё и исчезли. Оказывается, нет. Полностью устарел и давно не обновляется Denver. У OSPanel последнее обновление год назад, так что весь софт довольно свежий (PHP 8.1, MariaDB 10.8, MongoDB 6.0, Redis 7 и т.д.)
А живее всех живых оказался XAMPP. Он регулярно обновляется. Свежая версия на базе PHP 8.2.4. Удобство всех этих панелей в том, что не нужно разбираться с настройками серверной части. Запустил установщик и он всё сделал за тебя. То есть они ориентированы на разработчиков и служат только для локальной работы. Хотя некоторые не очень разумные люди использовали их и для прода.
Не знаю, кому сейчас это будет актуально. Все разработчики, кого я знаю последние 5-7 лет, худо бедно умеют настраивать локально или удалённо базовый стек веб сервера, с которым работают. Кто руками, кто скриптами, кто докером. Но раз уж справки навёл, поделился с вами. Может кому-то пригодится.
⇨ XAMPP: https://www.apachefriends.org (Windows, Linux, OSX)
⇨ OSPanel: https://ospanel.io (только Windows)
#webserver
Среди подобных сборок наиболее популярны были Denver, позже появилась OSPanel, параллельно существовал и XAMPP. Я думал, что все эти панели уже отжили своё и исчезли. Оказывается, нет. Полностью устарел и давно не обновляется Denver. У OSPanel последнее обновление год назад, так что весь софт довольно свежий (PHP 8.1, MariaDB 10.8, MongoDB 6.0, Redis 7 и т.д.)
А живее всех живых оказался XAMPP. Он регулярно обновляется. Свежая версия на базе PHP 8.2.4. Удобство всех этих панелей в том, что не нужно разбираться с настройками серверной части. Запустил установщик и он всё сделал за тебя. То есть они ориентированы на разработчиков и служат только для локальной работы. Хотя некоторые не очень разумные люди использовали их и для прода.
Не знаю, кому сейчас это будет актуально. Все разработчики, кого я знаю последние 5-7 лет, худо бедно умеют настраивать локально или удалённо базовый стек веб сервера, с которым работают. Кто руками, кто скриптами, кто докером. Но раз уж справки навёл, поделился с вами. Может кому-то пригодится.
⇨ XAMPP: https://www.apachefriends.org (Windows, Linux, OSX)
⇨ OSPanel: https://ospanel.io (только Windows)
#webserver
{kind=link}
Забавная история случилась с моим репозиторием для ELK Stack. Специально расположил его на VPS, арендованном в USA, чтобы было удобнее скачивать новые пакеты и обновлять репозитории. И вот на днях решил в очередной раз его обновить и очень удивился, когда не смог ничего скачать по свежим ссылкам. Получал
Пришлось через другой сервер качать и обновлять репозиторий. Теперь его можно и в Россию вернуть. Один фиг качать через прокладки придётся. Я там всю структуру переделал, добавив сразу Debian 11 и 12, чтобы удобнее было. Настроил всё с помощью aptly, так что сразу кратко все команды приведу, а то постоянно забываю и приходится каждый раз в документацию лезть, когда с ним работаешь.
Ставим:
Конфиг
Под репы выделил каталог
Добавляем туда пакеты:
Создаю gpg ключ для репозиториев:
Публикую репозитории:
В директории
Осталось положить ключ в публичную директорию:
На этом всё. Запускаем веб сервер и подключаем репозитории к системам:
Устанавливаем ключ:
На Debian 12 увидите предупреждение, что
Если нужно добавить пакеты, то делаем так:
Если надо удалить пакет:
Ещё полезные команды aptly:
#debian #elk #aptly
ERROR 403: Forbidden. Проверил на другом иностранном сервере, скачал без проблем. То есть мой VPS забанили. Не понятно, в рамках чего это было сделано. Кто-то стуканул или какая-то другая причина. Обновлял я в ручном режиме и запросами не спамил. IP (188.227.57.126) по всем базам сшашный. Пришлось через другой сервер качать и обновлять репозиторий. Теперь его можно и в Россию вернуть. Один фиг качать через прокладки придётся. Я там всю структуру переделал, добавив сразу Debian 11 и 12, чтобы удобнее было. Настроил всё с помощью aptly, так что сразу кратко все команды приведу, а то постоянно забываю и приходится каждый раз в документацию лезть, когда с ним работаешь.
Ставим:
# apt install aptlyКонфиг
/etc/aptly.conf:{ "rootDir": "/mnt/aptly", "downloadConcurrency": 4, "downloadSpeedLimit": 0, "architectures": [], "dependencyFollowSuggests": false, "dependencyFollowRecommends": false, "dependencyFollowAllVariants": false, "dependencyFollowSource": false, "dependencyVerboseResolve": false, "gpgDisableSign": false, "gpgDisableVerify": false, "gpgProvider": "gpg", "downloadSourcePackages": false, "skipLegacyPool": true, "ppaDistributorID": "elastic", "ppaCodename": "", "FileSystemPublishEndpoints": { "elastic": { "rootDir": "/mnt/aptly", "linkMethod": "symlink", "verifyMethod": "md5" } }, "enableMetricsEndpoint": false}Под репы выделил каталог
/mnt/aptly. Создаём 2 репозитория:# aptly repo create -comment="Elastic repo" -component="main" \-distribution="bullseye" -architectures="amd64" elastic-bullseye# aptly repo create -comment="Elastic repo" -component="main" \-distribution="bookworm" -architectures="amd64" elastic-bookwormДобавляем туда пакеты:
# aptly repo add elastic-bullseye elasticsearch-8.9.2-amd64.deb.......# aptly repo add elastic-bookworm elasticsearch-8.9.2-amd64.deb.......Создаю gpg ключ для репозиториев:
# gpg --default-new-key-algo rsa4096 --gen-key --keyring pubringПубликую репозитории:
# aptly publish repo elastic-bullseye# aptly publish repo elastic-bookwormВ директории
/mnt/aptly появляются две директории: db, public. Ту, что public, надо опубликовать через web сервер. Вот мой конфиг nginx:server { listen 80 default_server; server_name elasticrepo.serveradmin.ru; root /mnt/aptly/public/; access_log /var/log/nginx/aptly-access.log main; error_log /var/log/nginx/aptly-error.log; location / { autoindex on; }}Осталось положить ключ в публичную директорию:
# gpg --export --armor > /mnt/repo/public/elastic.ascНа этом всё. Запускаем веб сервер и подключаем репозитории к системам:
# echo "deb http://elasticrepo.serveradmin.ru bullseye main" \| tee /etc/apt/sources.list.d/elasticrepo.list# echo "deb http://elasticrepo.serveradmin.ru bookworm main" \| tee /etc/apt/sources.list.d/elasticrepo.listУстанавливаем ключ:
# wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -На Debian 12 увидите предупреждение, что
apt-key is deprecated, но это не критично. Теперь можно обновлять репозитории и устанавливать из них пакеты. Если нужно добавить пакеты, то делаем так:
# aptly repo add elastic-bullseye elasticsearch-9.0.0-amd64.deb# aptly publish update bullseyeЕсли надо удалить пакет:
# aptly repo remove elastic-bullseye elasticsearch_8.5.2_amd64# aptly publish update bullseyeЕщё полезные команды aptly:
# aptly repo list# aptly package search logstash# aptly repo show -with-packages elastic-bullseye#debian #elk #aptly
{kind=link}
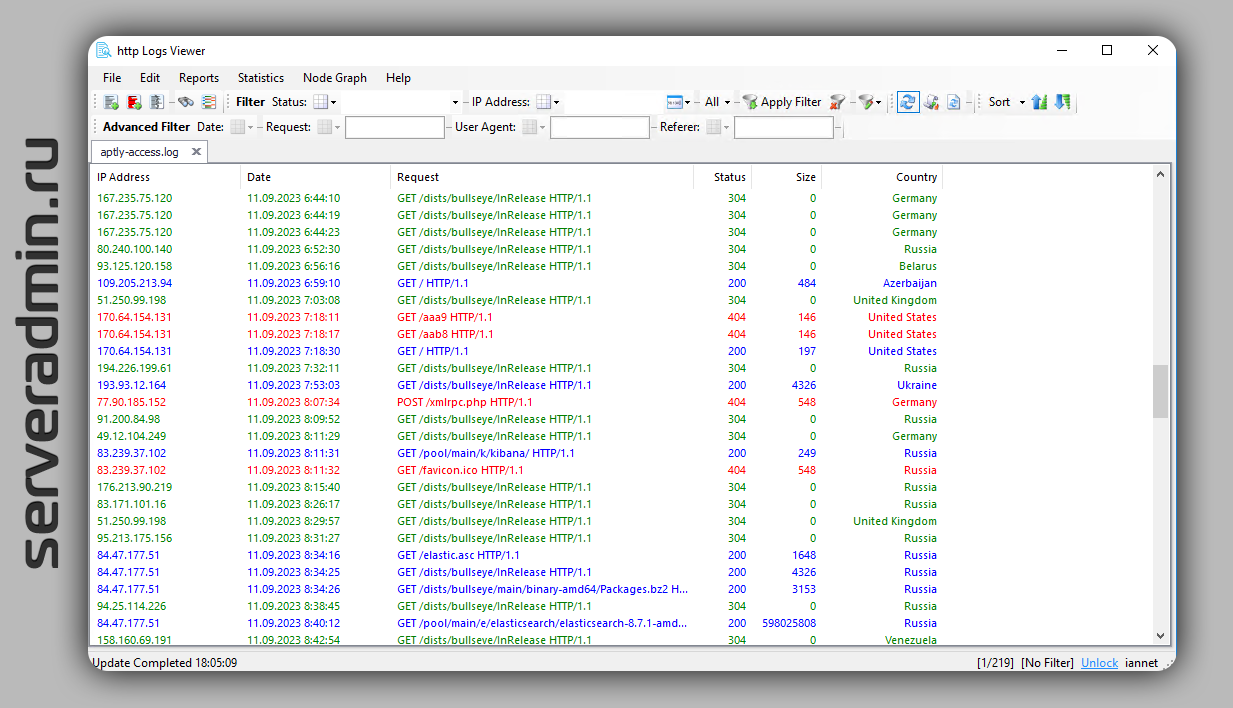
Если у вас есть желание максимально быстро и без лишних телодвижений проанализировать логи веб сервера, то можно воспользоваться типичной windows way программой http Logs Viewer. Скачиваете, устанавливаете, открываете в ней свой лог.
Программа платная, но базовые возможности доступны в бесплатной версии. После открытия лога она автоматом парсит значения из него в виде типовых полей: url, код ответа, IP адрес и т.д. Для IP адреса сразу же определяет страну. Можно тут же сделать сортировку по странам, кодам ответа, урлу и прочим записям в логе.
Если загрузить большой лог, то можно по всем распознанным значениям посмотреть статистику за разные промежутки времени. Тут уже начинается платная функциональность. Бесплатно доступен очень ограниченный набор отчётов.
Программа удобная и простая. Кто привык тыкать мышкой, а не грепать в консоли, будет прям кайфово. Нашёл, отсортировал, скопировал, выгрузил и т.д. Всё наглядно с привычным скролом для больших списков. И никаких вам ELK.
⇨ Сайт
#webserver #logs
Программа платная, но базовые возможности доступны в бесплатной версии. После открытия лога она автоматом парсит значения из него в виде типовых полей: url, код ответа, IP адрес и т.д. Для IP адреса сразу же определяет страну. Можно тут же сделать сортировку по странам, кодам ответа, урлу и прочим записям в логе.
Если загрузить большой лог, то можно по всем распознанным значениям посмотреть статистику за разные промежутки времени. Тут уже начинается платная функциональность. Бесплатно доступен очень ограниченный набор отчётов.
Программа удобная и простая. Кто привык тыкать мышкой, а не грепать в консоли, будет прям кайфово. Нашёл, отсортировал, скопировал, выгрузил и т.д. Всё наглядно с привычным скролом для больших списков. И никаких вам ELK.
⇨ Сайт
#webserver #logs
{kind=link}
Перенос VM с Hyper-V на Proxmox
На днях стояла задача перенести виртуальные машины Linux (Debian 11) с Hyper-V на KVM (Proxmox). Помучался изрядно, но в итоге всё получилось. Если VM первого поколения без EFI раздела, то проблем вообще никаких. Просто переносим диск виртуальной машины, конвертируем и подключаем к VM. Вообще ничего перенастраивать не надо, все имена дисков и сетевых адаптеров будут те же, что и на Hyper-V. А вот если машины второго поколения с загрузкой по EFI, то начинаются танцы с бубном. Причём у каждого свои, судя по информации из интернета.
Рассказываю, как в итоге сделал я, чтобы всё заработало. Перенос делал следующим образом:
1️⃣ Завершаю работу VM на Hyper-V.
2️⃣ Копирую файл диска vhdx на хост Proxmox.
3️⃣ Создаю в Proxmox новую виртуальную машину и обязательно указываю Bios: OVMF (UEFI), SCSI Controller: VirtIO SCSI. Остальное не принципиально. Диски можно никакие не добавлять. Но при этом у вас будет автоматически подключен EFI Disk, с какими-то своими параметрами, из которых я выбрал только формат - qcow2.
4️⃣ В консоли Proxmox конвертируем vhdx диск в диск виртуальной машины:
Формат команды следующий:
5️⃣ После импорта диск цепляется к VM в отключенном виде. Подключаем его как SCSI и настраиваем с него загрузку.
6️⃣ Загружаем VM с этого диска. Тут по многим руководствам из инета виртуалка уже запускается и нормально работает. Но не у меня. Я проваливался в uefi interactive shell v2.2 proxmox.
7️⃣ Заходим в bios этой виртуалки и отключаем там Secure Boot. Делается это в разделе Device Manager ⇨ Secure Boot Configuration. После этого у некоторых VM начинает загружаться, но опять не у меня.
8️⃣ Опять иду в bios, в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Add Boot Option. Выбираю импортированный диск VM. Там кроме него будет только CD-ROM, так что легко понять, что надо выбрать. Открывается обзор файловой системы EFI раздела от нашей системы. Перемещаемся там по директориям
А я сначала пробовал разные настройки VM, загружался с LiveCD и проверял разделы диска, загрузчик. Там всё ОК, данные нормально переезжают. Проблема именно в настройке загрузки через EFI раздел. Почему-то автоматом он не подхватывался. Может это была особенность Debian 11. Я переносил именно их.
❗️Сразу добавлю полезную информацию по поводу Centos 7. Может это будет актуально и для каких-то других система. Когда я переносил виртуалки с этой системой между гипервизорами, они не загружались, пока не пересоберёшь initramfs под конкретным гипервизором. Если просто перенести, то загрузка не ехала дальше из-за проблем с определением дисков на этапе загрузки. Пересборка initramfs решала эту проблему.
❗️И ещё один нюанс с переездами между гипервизорами, с которым сталкивался. Иногда система не грузится, потому что в fstab были прописаны имена дисков, которые на новом гипервизоре получили другие названия. Тогда грузимся с LiveCD и меняем диски в fstab и возможно в grub.
Тема переезда между разными типами гипервизоров непростая. Иногда проще воспользоваться какой-то системой, типа Veeam Agent For Linux или Rescuezilla. Так как я более ли менее теорию понимаю по этой теме, то переношу обычно вручную.
#linux #hyperv #виртуализация
На днях стояла задача перенести виртуальные машины Linux (Debian 11) с Hyper-V на KVM (Proxmox). Помучался изрядно, но в итоге всё получилось. Если VM первого поколения без EFI раздела, то проблем вообще никаких. Просто переносим диск виртуальной машины, конвертируем и подключаем к VM. Вообще ничего перенастраивать не надо, все имена дисков и сетевых адаптеров будут те же, что и на Hyper-V. А вот если машины второго поколения с загрузкой по EFI, то начинаются танцы с бубном. Причём у каждого свои, судя по информации из интернета.
Рассказываю, как в итоге сделал я, чтобы всё заработало. Перенос делал следующим образом:
1️⃣ Завершаю работу VM на Hyper-V.
2️⃣ Копирую файл диска vhdx на хост Proxmox.
3️⃣ Создаю в Proxmox новую виртуальную машину и обязательно указываю Bios: OVMF (UEFI), SCSI Controller: VirtIO SCSI. Остальное не принципиально. Диски можно никакие не добавлять. Но при этом у вас будет автоматически подключен EFI Disk, с какими-то своими параметрами, из которых я выбрал только формат - qcow2.
4️⃣ В консоли Proxmox конвертируем vhdx диск в диск виртуальной машины:
# qm importdisk 102 /mnt/500G/Debian11.vhdx local-500GФормат команды следующий:
# qm importdisk <vmid> <source> <storage>5️⃣ После импорта диск цепляется к VM в отключенном виде. Подключаем его как SCSI и настраиваем с него загрузку.
6️⃣ Загружаем VM с этого диска. Тут по многим руководствам из инета виртуалка уже запускается и нормально работает. Но не у меня. Я проваливался в uefi interactive shell v2.2 proxmox.
7️⃣ Заходим в bios этой виртуалки и отключаем там Secure Boot. Делается это в разделе Device Manager ⇨ Secure Boot Configuration. После этого у некоторых VM начинает загружаться, но опять не у меня.
8️⃣ Опять иду в bios, в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Add Boot Option. Выбираю импортированный диск VM. Там кроме него будет только CD-ROM, так что легко понять, что надо выбрать. Открывается обзор файловой системы EFI раздела от нашей системы. Перемещаемся там по директориям
/EFI/debian, выбираем файл grubx64.efi. То есть мы создаём новый вариант загрузки системы, выбрав этот файл. Там же пишем какое-то название для этой загрузки, чтобы отличить от остальных вариантов. Далее идём в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Change Boot Order и назначаем первым номером только что созданный вариант для загрузки. Сохраняем изменения и загружаемся. Теперь всё ОК, система загрузилась. А я сначала пробовал разные настройки VM, загружался с LiveCD и проверял разделы диска, загрузчик. Там всё ОК, данные нормально переезжают. Проблема именно в настройке загрузки через EFI раздел. Почему-то автоматом он не подхватывался. Может это была особенность Debian 11. Я переносил именно их.
❗️Сразу добавлю полезную информацию по поводу Centos 7. Может это будет актуально и для каких-то других система. Когда я переносил виртуалки с этой системой между гипервизорами, они не загружались, пока не пересоберёшь initramfs под конкретным гипервизором. Если просто перенести, то загрузка не ехала дальше из-за проблем с определением дисков на этапе загрузки. Пересборка initramfs решала эту проблему.
❗️И ещё один нюанс с переездами между гипервизорами, с которым сталкивался. Иногда система не грузится, потому что в fstab были прописаны имена дисков, которые на новом гипервизоре получили другие названия. Тогда грузимся с LiveCD и меняем диски в fstab и возможно в grub.
Тема переезда между разными типами гипервизоров непростая. Иногда проще воспользоваться какой-то системой, типа Veeam Agent For Linux или Rescuezilla. Так как я более ли менее теорию понимаю по этой теме, то переношу обычно вручную.
#linux #hyperv #виртуализация
{kind=link}
Мой первый настроенный мониторинг в роли системного администратора Linux был на базе rrd графиков, которые рисовались с помощью rrdtool и скриптов, которые забирали информацию с сенсоров и записывали в rrd базу. Было это ещё на Freebsd примерно в 2007-2008 году. Потом переехал на Zabbix версии 1.6 или 1.8, не помню точно.
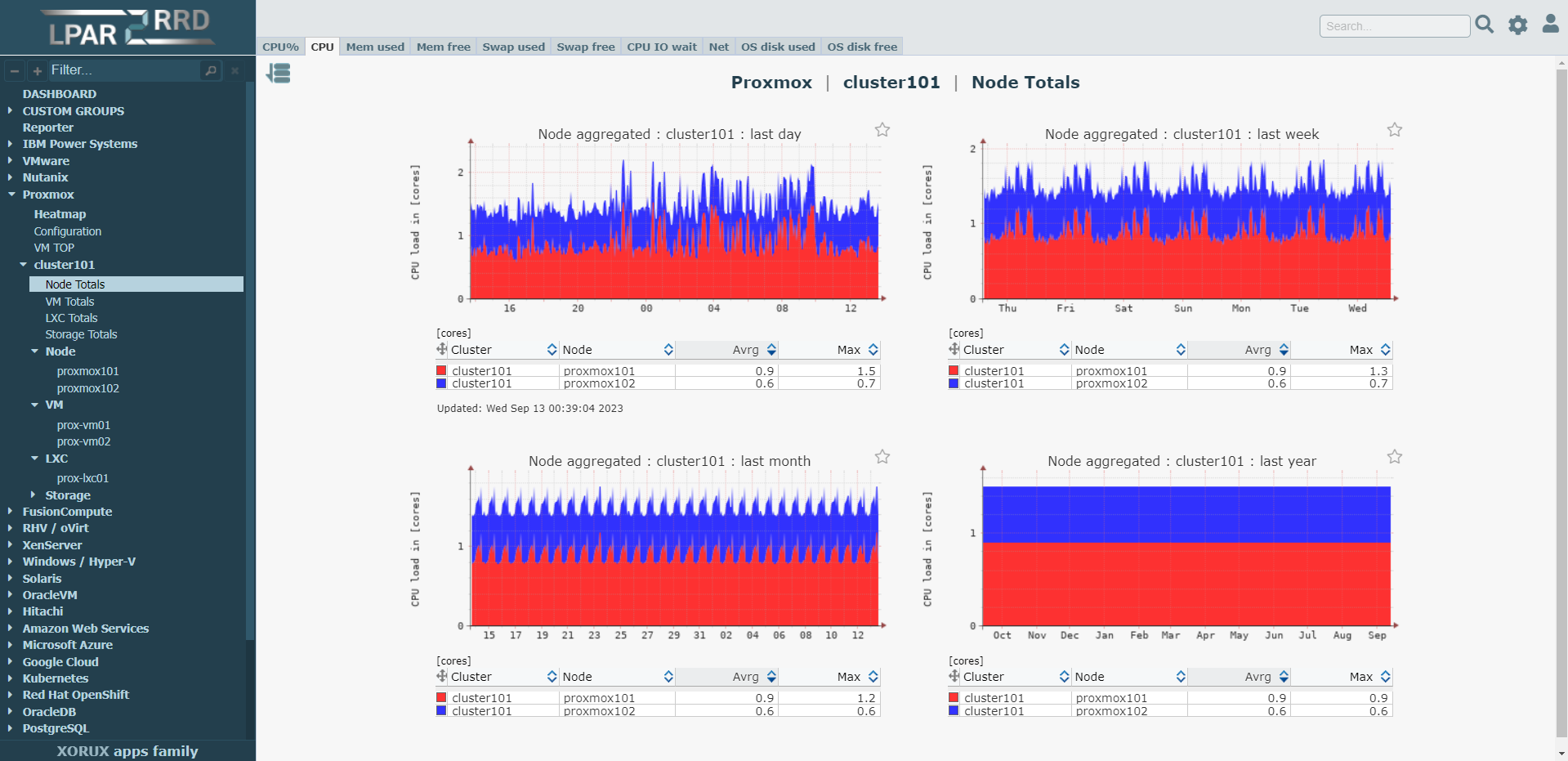
Сейчас rrd графики выглядят старомодно, хотя лично мне их стилистика нравится. Я к чему обо всём этом. Есть неплохой и вполне современный мониторинг LPAR2RRD, у которого все графики rrd. Это старый open source продукт, который монетизируется платной поддержкой этого и ещё одного своего продукта - STOR2RRD.
Отличает lpar2rrd простота установки и настройки. У него есть как свой агент, так и интеграция с популярными программными продуктами. Например, он умеет через API мониторить Proxmox. Просто делаете для lpar2rrd учётку с доступом на чтение к API и он автоматом забирает все необходимые метрики с определённой периодичностью. Другой пример интеграции - PostgreSQL. Тут то же самое. Делаете учётку с доступом на чтение, lpar2rrd забирает всю информацию вплоть до отдельной базы и рисует мониторинг.
Причём поддерживает lpar2rrd всех крупных современных вендоров, коммерческие и open source продукты, облачных провайдеров:
◽IBM Power Systems, VMware, Oracle Solaris, RHV, oVirt, XenServer, Citrix, Hyper-V
◽PostgreSQL, MSSQL, Oracle Database
◽Docker, Kubernetes, OpenShift
◽AWS, Google Cloud, Azure
Ну и обычные агенты под ОС Linux. Выше список не полный. Поддержка Windows тоже есть, но специфичная. Ставится агент на какую-то одну ОС, и он по WMI опрашивает все необходимые машины.
Посмотреть, как всё это выглядит, можно в публичном Demo, где очень удобно представлены все наиболее популярные системы. Можно увидеть в каком виде все метрики будут организованы в мониторинге. Если кто не знает, то временные интервалы задаются мышкой прям на самом графике. Сразу добавлю, что rrd ещё удобен тем, что из него легко картинки графиков автоматом забирать.
Мониторинг, конечно, выглядит простовато по сегодняшним меркам. Пригодится он может в основном тем, кому нужно что-то простое и обзорное, чтобы поставил и не морочился с настройкой и внедрением. И на этот вопрос он реально отвечает. Дал доступ к кластеру Proxmox и получил автоматом мониторинг вплоть до загрузки сетевого интерфейса отдельного lxc контейнера. А так как всё хранится в локальной rrd базе, ему даже полноценная СУБД не нужна.
Можно как дублирующий внешний контур для основного мониторинга использовать. Когда он ляжет, чтобы хоть примерно понимать, как у тебя обстановка.
⇨ Сайт / Demo / Установка
#мониторинг
Сейчас rrd графики выглядят старомодно, хотя лично мне их стилистика нравится. Я к чему обо всём этом. Есть неплохой и вполне современный мониторинг LPAR2RRD, у которого все графики rrd. Это старый open source продукт, который монетизируется платной поддержкой этого и ещё одного своего продукта - STOR2RRD.
Отличает lpar2rrd простота установки и настройки. У него есть как свой агент, так и интеграция с популярными программными продуктами. Например, он умеет через API мониторить Proxmox. Просто делаете для lpar2rrd учётку с доступом на чтение к API и он автоматом забирает все необходимые метрики с определённой периодичностью. Другой пример интеграции - PostgreSQL. Тут то же самое. Делаете учётку с доступом на чтение, lpar2rrd забирает всю информацию вплоть до отдельной базы и рисует мониторинг.
Причём поддерживает lpar2rrd всех крупных современных вендоров, коммерческие и open source продукты, облачных провайдеров:
◽IBM Power Systems, VMware, Oracle Solaris, RHV, oVirt, XenServer, Citrix, Hyper-V
◽PostgreSQL, MSSQL, Oracle Database
◽Docker, Kubernetes, OpenShift
◽AWS, Google Cloud, Azure
Ну и обычные агенты под ОС Linux. Выше список не полный. Поддержка Windows тоже есть, но специфичная. Ставится агент на какую-то одну ОС, и он по WMI опрашивает все необходимые машины.
Посмотреть, как всё это выглядит, можно в публичном Demo, где очень удобно представлены все наиболее популярные системы. Можно увидеть в каком виде все метрики будут организованы в мониторинге. Если кто не знает, то временные интервалы задаются мышкой прям на самом графике. Сразу добавлю, что rrd ещё удобен тем, что из него легко картинки графиков автоматом забирать.
Мониторинг, конечно, выглядит простовато по сегодняшним меркам. Пригодится он может в основном тем, кому нужно что-то простое и обзорное, чтобы поставил и не морочился с настройкой и внедрением. И на этот вопрос он реально отвечает. Дал доступ к кластеру Proxmox и получил автоматом мониторинг вплоть до загрузки сетевого интерфейса отдельного lxc контейнера. А так как всё хранится в локальной rrd базе, ему даже полноценная СУБД не нужна.
Можно как дублирующий внешний контур для основного мониторинга использовать. Когда он ляжет, чтобы хоть примерно понимать, как у тебя обстановка.
⇨ Сайт / Demo / Установка
#мониторинг
{kind=link}
Обратил внимание, что большинство прокомментировавших вчерашнюю заметку про перенос VM не уловили суть проблем, с которыми можно столкнуться при любом переносе системы на другое "железо". А смена типа гипервизора это по сути смена железа.
Причём система Windows, на удивление, гораздо лучше переживает переезд, чем Linux. Многие вещи она умеет делать автоматически при проблемах с загрузкой. Вообще не припоминаю с ней проблем, кроме установки драйверов virtio при переезде на KVM. А вот с Linux проблемы как раз бывают.
Всем спасибо за содержательные комментарии. В них упоминали несколько инструментов по конвертации дисков:
◽Starwind V2V
◽qemu-img convert
◽virt-p2v
Они все делают примерно одинаковые вещи - конвертируют формат дисков между форматами разных гипервизоров, либо из физической машины делают образ диска для виртуальной. Это только часть задачи по переносу VM и зачастую самая простая.
Проблема возникает именно в том, что на новом железе исходная система не работает, скопированная 1 в 1 в неизменном виде. То есть вам нужно либо перед конвертацией её подготовить к перемещению, либо потом по месту выполнять какие-то манипуляции, чтобы запустить.
Приведу самый простой пример подготовки. Я в своё время переносил много систем с гипервизора Xen, и там диски имели имена /dev/vdX, а при переезде на KVM - /dev/sdX. Если просто скопировать систему, то на новом гипервизоре она не запускалась. Надо было поправить grub и fstab. Можно было это делать предварительно, перед снятием образа системы, либо потом с помощью LiveCD на перенесённой системе.
Другой пример - Initramfs. Это файловая система, содержащая файлы, необходимые для загрузки системы Linux. Она запускается перед загрузкой основной системы. С её помощью, к примеру, монтируются разделы диска с основной системой. Соответственно, если Initramfs создавалась под одно железо, а потом переехала на другое, она может не определить, к примеру, диски, и основная система не загрузится. Это наиболее частая проблема при переезде.
Есть бесплатный Veeam Agent For Linux Free. Вот он как раз не просто делает образ диска для переноса, но и готовит загрузочный диск со списком оборудования вашей системы, чтобы в процессе восстановления на основании этого списка попытаться гарантированно запустить вашу систему. И чаще всего у него это получается.
То же самое делает Rear, я о ней писал и тестировал.
Сходу не могу припомнить ещё какие-то программы такого же класса, как Veeam Agent For Linux или Rear, которые не просто переносят данные, но и подготавливают системы. Если вы такие знаете, то поделитесь информацией.
Отдельным пунктом идут проблемы, связанные с EFI. Там тоже много своих нюансов. В итоге переезд виртуальных машин может выглядеть очень непростой задачей, но всегда решаемой. По крайней мере я ни разу не сталкивался с тем, что нельзя было перенести какую-то виртуалку. Если понимаешь теорию, то починить загрузку почти всегда получается. Надо идти последовательно по пути:
✅ EFI (в том числе настройки VM в гипервизоре) ⇨ GRUB ⇨ INITRAMFS ⇨ Настройки системы.
Ещё момент. Лично я до конца не понимаю, зачем виртулакам EFI. Он усложняет эксплуатацию, а какую проблему решает - не знаю, если только вы не используете для загрузки диск более 2ТБ, что для виртуалок нетипично. Если у вас повышенные требования к безопасности и используется Secure Boot, тогда понятно. Хотя опять же, при работе в виртуальной машине не факт, что эта защита эффективна. Во всех остальных случаях не вижу смысла его (EFI) использовать. Возможно, я ошибаюсь.
#виртуализация
Причём система Windows, на удивление, гораздо лучше переживает переезд, чем Linux. Многие вещи она умеет делать автоматически при проблемах с загрузкой. Вообще не припоминаю с ней проблем, кроме установки драйверов virtio при переезде на KVM. А вот с Linux проблемы как раз бывают.
Всем спасибо за содержательные комментарии. В них упоминали несколько инструментов по конвертации дисков:
◽Starwind V2V
◽qemu-img convert
◽virt-p2v
Они все делают примерно одинаковые вещи - конвертируют формат дисков между форматами разных гипервизоров, либо из физической машины делают образ диска для виртуальной. Это только часть задачи по переносу VM и зачастую самая простая.
Проблема возникает именно в том, что на новом железе исходная система не работает, скопированная 1 в 1 в неизменном виде. То есть вам нужно либо перед конвертацией её подготовить к перемещению, либо потом по месту выполнять какие-то манипуляции, чтобы запустить.
Приведу самый простой пример подготовки. Я в своё время переносил много систем с гипервизора Xen, и там диски имели имена /dev/vdX, а при переезде на KVM - /dev/sdX. Если просто скопировать систему, то на новом гипервизоре она не запускалась. Надо было поправить grub и fstab. Можно было это делать предварительно, перед снятием образа системы, либо потом с помощью LiveCD на перенесённой системе.
Другой пример - Initramfs. Это файловая система, содержащая файлы, необходимые для загрузки системы Linux. Она запускается перед загрузкой основной системы. С её помощью, к примеру, монтируются разделы диска с основной системой. Соответственно, если Initramfs создавалась под одно железо, а потом переехала на другое, она может не определить, к примеру, диски, и основная система не загрузится. Это наиболее частая проблема при переезде.
Есть бесплатный Veeam Agent For Linux Free. Вот он как раз не просто делает образ диска для переноса, но и готовит загрузочный диск со списком оборудования вашей системы, чтобы в процессе восстановления на основании этого списка попытаться гарантированно запустить вашу систему. И чаще всего у него это получается.
То же самое делает Rear, я о ней писал и тестировал.
Сходу не могу припомнить ещё какие-то программы такого же класса, как Veeam Agent For Linux или Rear, которые не просто переносят данные, но и подготавливают системы. Если вы такие знаете, то поделитесь информацией.
Отдельным пунктом идут проблемы, связанные с EFI. Там тоже много своих нюансов. В итоге переезд виртуальных машин может выглядеть очень непростой задачей, но всегда решаемой. По крайней мере я ни разу не сталкивался с тем, что нельзя было перенести какую-то виртуалку. Если понимаешь теорию, то починить загрузку почти всегда получается. Надо идти последовательно по пути:
✅ EFI (в том числе настройки VM в гипервизоре) ⇨ GRUB ⇨ INITRAMFS ⇨ Настройки системы.
Ещё момент. Лично я до конца не понимаю, зачем виртулакам EFI. Он усложняет эксплуатацию, а какую проблему решает - не знаю, если только вы не используете для загрузки диск более 2ТБ, что для виртуалок нетипично. Если у вас повышенные требования к безопасности и используется Secure Boot, тогда понятно. Хотя опять же, при работе в виртуальной машине не факт, что эта защита эффективна. Во всех остальных случаях не вижу смысла его (EFI) использовать. Возможно, я ошибаюсь.
#виртуализация
Telegram
ServerAdmin.ru
У меня на канале и на сайте много материалов по теме бэкапов и инструментов для их выполнения, так что найти что-то новое и полезное довольно трудно. Напомню, что материалы по бэкапам удобнее всего посмотреть по тэгу #backup, к нему можно добавить тэг #подборка…
Я периодически пользуюсь сайтом virustotal.com, чтобы проверить незнакомые файлы. Никогда не обращал внимания, что он умеет проверять ещё и сайты, хотя на главной есть возможность выбрать url, а не файл.
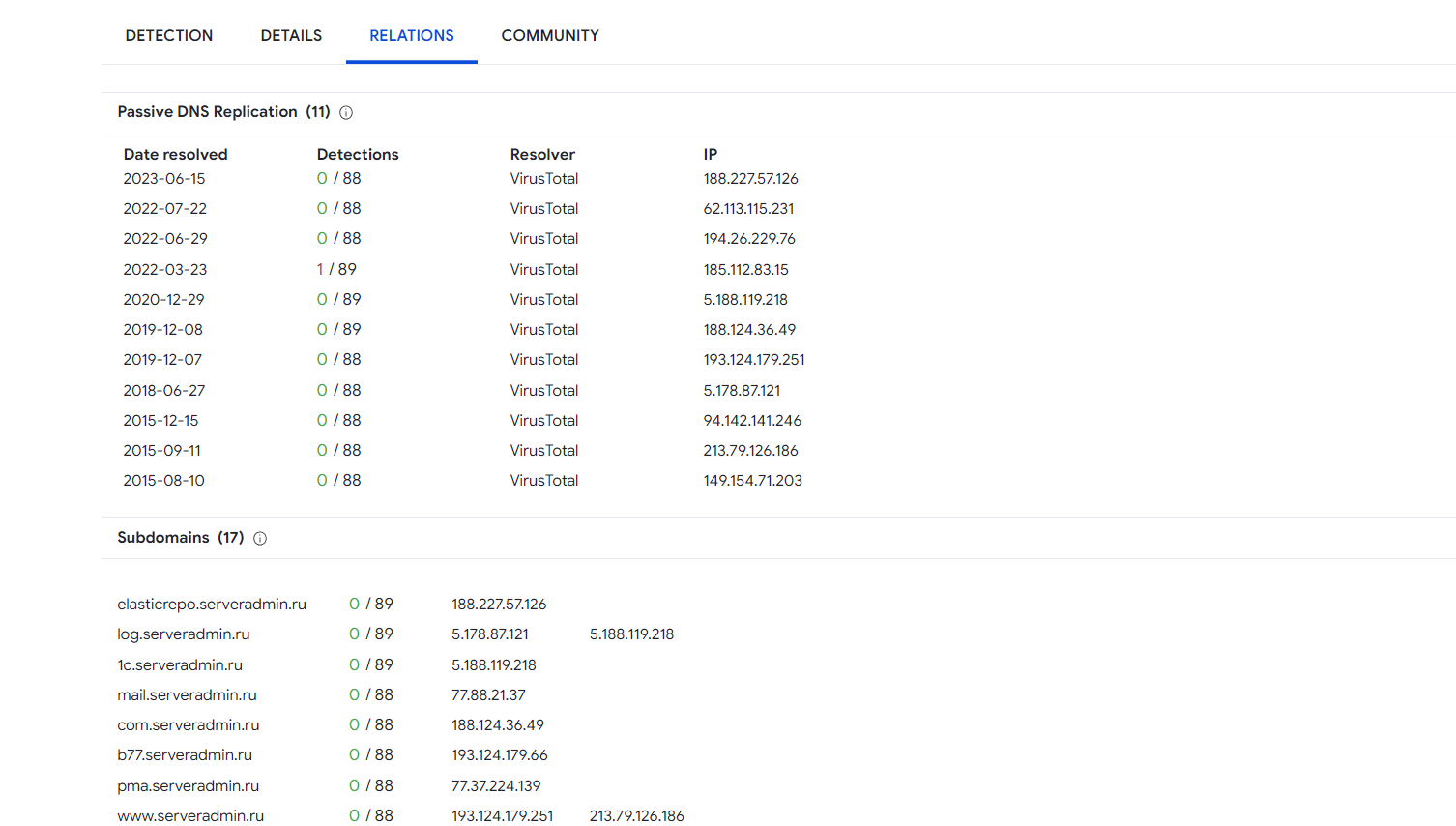
Оказывается, этот сервис не только на вирусы по базам пробивает сайт, но и выводит всю историю IP адресов сайта, плюс все засветившиеся поддомены и IP адреса к ним. Проверил свой домен. Он показывает даже краткосрочные изменения IP адреса в А записи. Летом менял на 12 часов адрес, он там тоже засветился. Не знаю, как технически отслеживают такие вещи. Кто-то эти базы ведёт?
Сделано удобно и информативно. Я знал и раньше, что подобные базы есть, но особо не пользовался. Только на поддомены проверял. Они светятся в том числе выпуском TLS сертификатов на них. А как A записи поддоменов отслеживают, хз. Они разве где-то в базе чьей-то хранятся?
❗️Проверьте свои поддомены на предмет того, не забыли ли вы что-то закрыть, что не должно быть в общем доступе.
В целом, полезная штука на базе известного сервиса. Можно пользоваться. Кстати, быстро проверять файлы можно с помощью бота. Я когда-то давно уже упоминал его, но отключил, потому что он периодически шлёт рекламу. Но если вы часто проверяете файлы, то может быть удобно: @VirusTotalAV_bot Он ещё просит подписываться на какие-то каналы. Можно этого не делать. Работает и так.
#сервис
Оказывается, этот сервис не только на вирусы по базам пробивает сайт, но и выводит всю историю IP адресов сайта, плюс все засветившиеся поддомены и IP адреса к ним. Проверил свой домен. Он показывает даже краткосрочные изменения IP адреса в А записи. Летом менял на 12 часов адрес, он там тоже засветился. Не знаю, как технически отслеживают такие вещи. Кто-то эти базы ведёт?
Сделано удобно и информативно. Я знал и раньше, что подобные базы есть, но особо не пользовался. Только на поддомены проверял. Они светятся в том числе выпуском TLS сертификатов на них. А как A записи поддоменов отслеживают, хз. Они разве где-то в базе чьей-то хранятся?
❗️Проверьте свои поддомены на предмет того, не забыли ли вы что-то закрыть, что не должно быть в общем доступе.
В целом, полезная штука на базе известного сервиса. Можно пользоваться. Кстати, быстро проверять файлы можно с помощью бота. Я когда-то давно уже упоминал его, но отключил, потому что он периодически шлёт рекламу. Но если вы часто проверяете файлы, то может быть удобно: @VirusTotalAV_bot Он ещё просит подписываться на какие-то каналы. Можно этого не делать. Работает и так.
#сервис
{kind=link}
Столкнулся с тем, что один IP адрес засветился в некоторых списках различных блокировок. Проверить удобно тут:
⇨ http://mail-blacklist-checker.online-domain-tools.com
Более полный список нигде не видел (советую в закладки забрать).
Суть в чём. Сам адрес неповинен. Его заблокировали кучей вместе с проштрафившейся подсеткой. Какой-то один адрес нагадил. Причём некоторые сервисы тупо просят заплатить, чтобы гарантированно не попасть в свой список на 24 месяца.
Я к чему это. Не используйте эти списки никогда в своих сервисах. Это полное днище. А говённый spamhaus до сих пор некоторые админы почтовых серверов используют. Да и не только они. Антивирусы тоже накидывают лишних баллов по этим спискам.
Как по мне, так все статические списки в наши дни должны быть ликвидированы. И тем более нельзя делать блокировки сразу подсетям.
У меня как-то раз адрес сайта залетел в один из таких списков и его некоторые антивирусы начали блокировать. Причём тоже не я был виноват, а заблокировали всю подсеть. В другой раз попал в список за то, что на сайте был выложен RDP Wrapper, который вирусом не является. Пришлось убрать. Это я уже сильно потом узнал и исправил. А до этого просто не мог понять, за что сижу в списках. Перепроверил всё по 10 раз. Ни взломов, ни спама с сайта не было.
#сервис
⇨ http://mail-blacklist-checker.online-domain-tools.com
Более полный список нигде не видел (советую в закладки забрать).
Суть в чём. Сам адрес неповинен. Его заблокировали кучей вместе с проштрафившейся подсеткой. Какой-то один адрес нагадил. Причём некоторые сервисы тупо просят заплатить, чтобы гарантированно не попасть в свой список на 24 месяца.
Я к чему это. Не используйте эти списки никогда в своих сервисах. Это полное днище. А говённый spamhaus до сих пор некоторые админы почтовых серверов используют. Да и не только они. Антивирусы тоже накидывают лишних баллов по этим спискам.
Как по мне, так все статические списки в наши дни должны быть ликвидированы. И тем более нельзя делать блокировки сразу подсетям.
У меня как-то раз адрес сайта залетел в один из таких списков и его некоторые антивирусы начали блокировать. Причём тоже не я был виноват, а заблокировали всю подсеть. В другой раз попал в список за то, что на сайте был выложен RDP Wrapper, который вирусом не является. Пришлось убрать. Это я уже сильно потом узнал и исправил. А до этого просто не мог понять, за что сижу в списках. Перепроверил всё по 10 раз. Ни взломов, ни спама с сайта не было.
#сервис
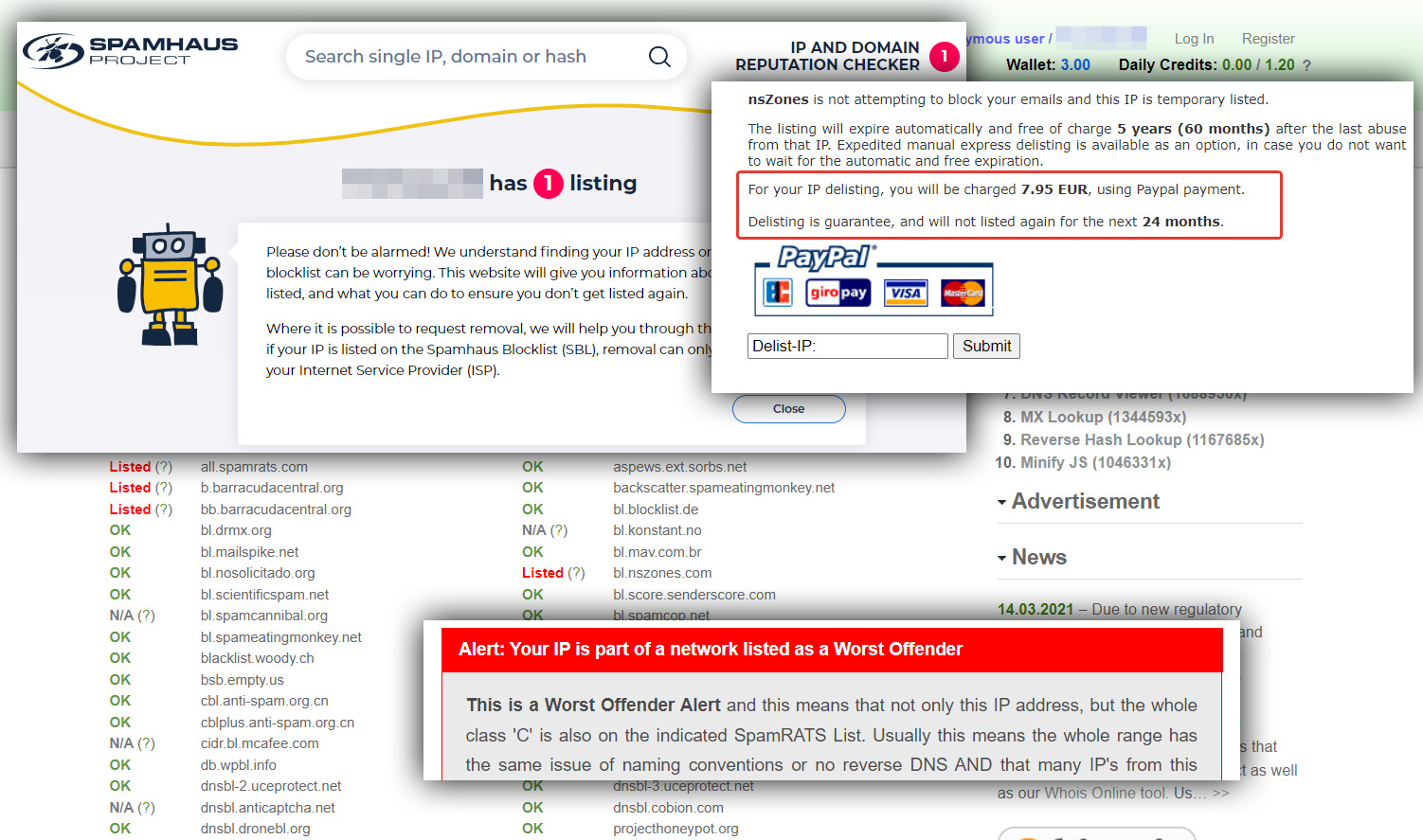{kind=link}